
A High Performance, Spatiotemporal Statistical Analysis System Based on a Spatiotemporal Cloud Platform

Abstract
:1. Introduction
2. Related Work
3. Methodology
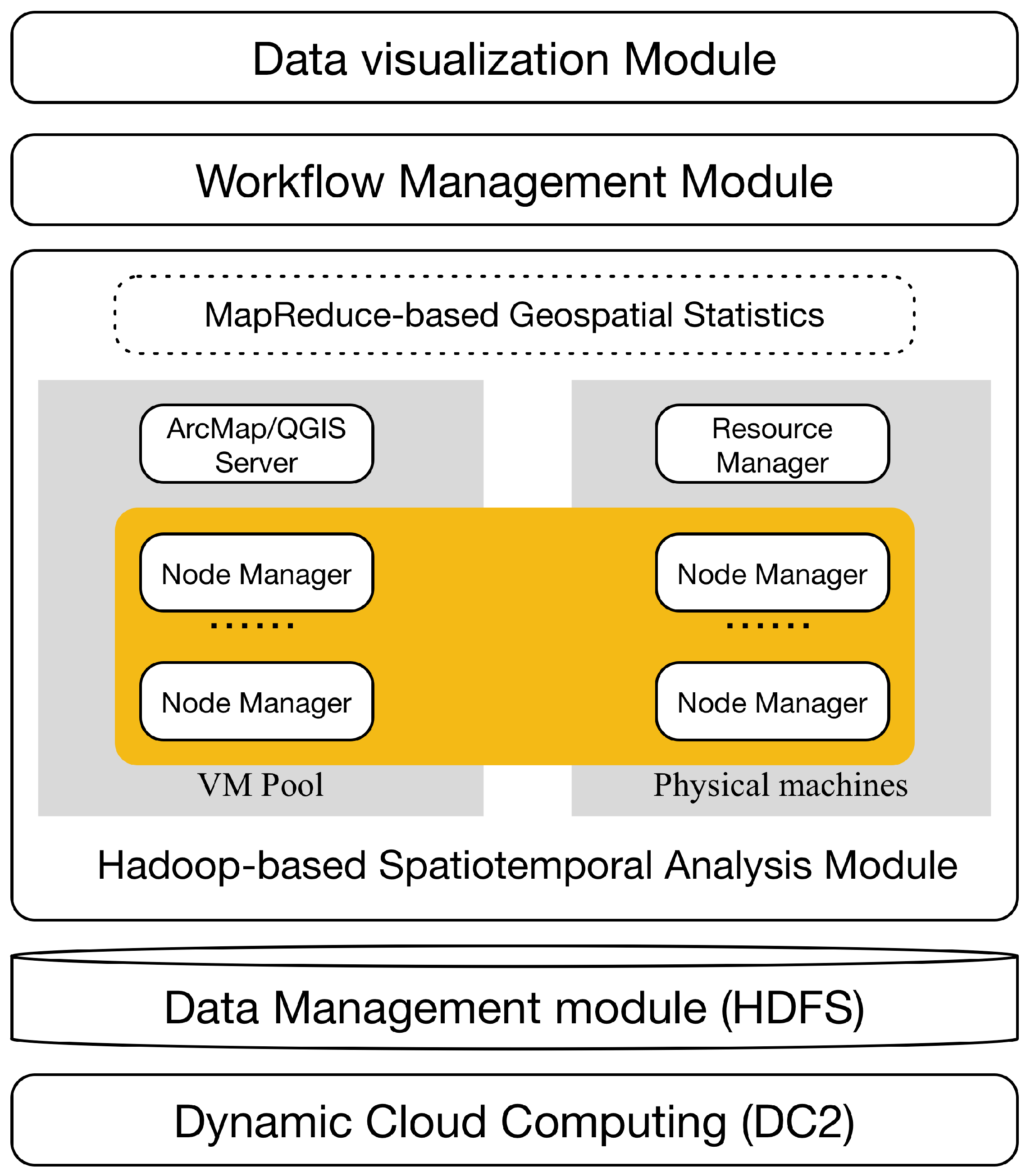
3.1. The Architecture of GeoStatistics-Hadoop
- The dynamic cloud computing system (DC2) is a private cloud environment built using Eucalyptus, which is a free and open-source computer software used for deploying Amazon Web Services (AWS)-compatible private and hybrid cloud computing systems. With an elastic utility computing architecture, DC2 can dynamically scale computing, storage, and network resources as the spatiotemporal statistical analytics workloads change. It provides a cost-efficient and fast way for the proposed Geostatistics-Hadoop system to better utilize computing and storage resources. The Hadoop cluster, including MapReduce, Apache Oozie, and the QGIS/Arcmap server can be deployed on the virtual resources supplied by DC2, which provides on-demand computing and storage resources for geospatial data processing.
- The data management module is a geospatial data management engine. The Hadoop distributed file system is adopted to store geospatial data in a distributed and scalable environment to meet the challenges of the unprecedented growth of big geospatial data. Since HDFS is not a fully POSIX-compliant file-system, existing GIS libraries do not effectively work on HDFS to read or write data stored in binary formats (e.g., shapefile). Accordingly, the proposed system utilizes the GeoJSON data format, a plain-text format supported by HDFS, to encode geographical objects (e.g., points, polylines, and polygons) and store their associated properties. As a standard geospatial data interchange format, GeoJSON is supported by much open source software and libraries and is easy to implement and customize. In the proposed implementation, the GeoJSON library for Hadoop developed by Esri to convert, read, and write vector data as GeoJSON on HDFS is adopted. All geospatial vector data will be archived in GeoJSON and stored in HDFS.
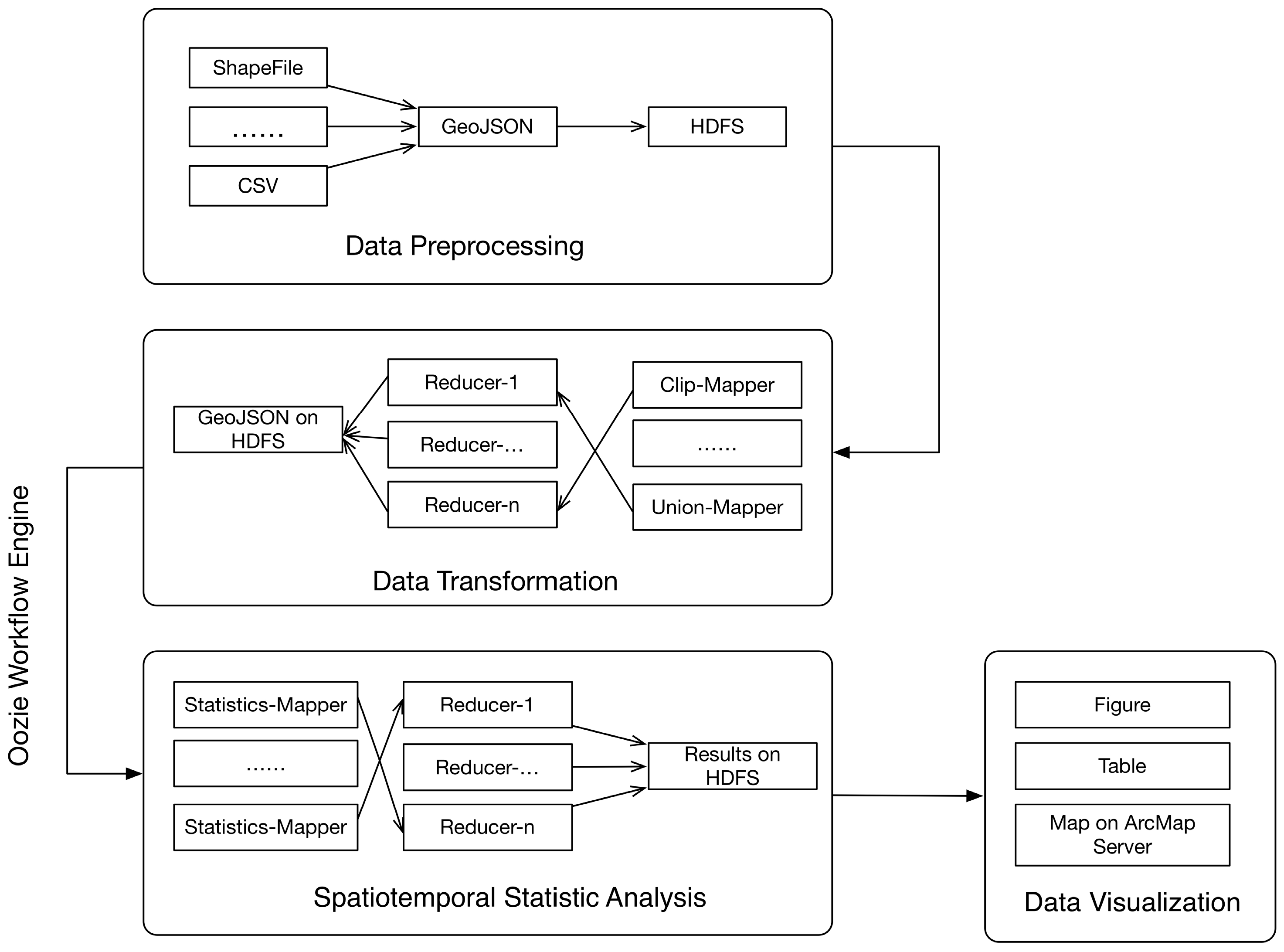
- The Hadoop-based spatiotemporal analysis module supports parallelized spatial analysis using MapReduce for points, polylines and polygons. Currently, a number of basic spatial analysis algorithms are implemented for computing distance, area, and performing basic operations (e.g., clip, intersect, buffer, contain, and overlap). If the input data size fits a single virtual machine’s (VM) capacity, the QGIS/ArcMap server can be used to conduct the spatial analysis jobs. Based on these basic geospatial operations and statistical methods, users can develop their own statistics algorithms in the Map-Reduce style.
- The workflow management module utilizes Apache Oozie to manage the analytic services developed in the Hadoop-based spatiotemporal analysis module. Users can reuse the analytical services that exist in this platform, or are shared by other users in a drag-dropping mode, as well as chain the existing basic services together to build a more powerful workflow to be submitted to the Hadoop cluster and executed in parallel. It avoids duplicated development, and supports service/workflow sharing.
- The data visualization module uses a virtual machine with QGIS/ArcMap to visualize spatiotemporal statistical results fetched from the HDFS.
3.2. Parallel Spatiotemporal Statistics Using MapReduce
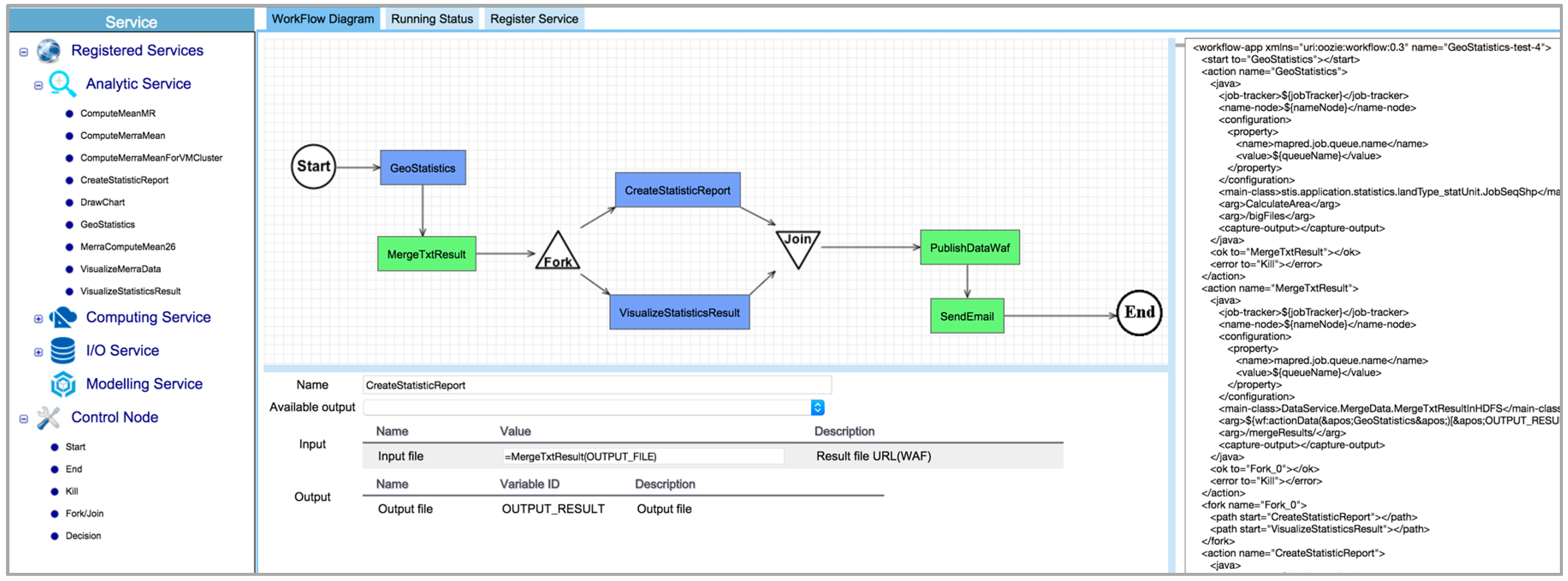
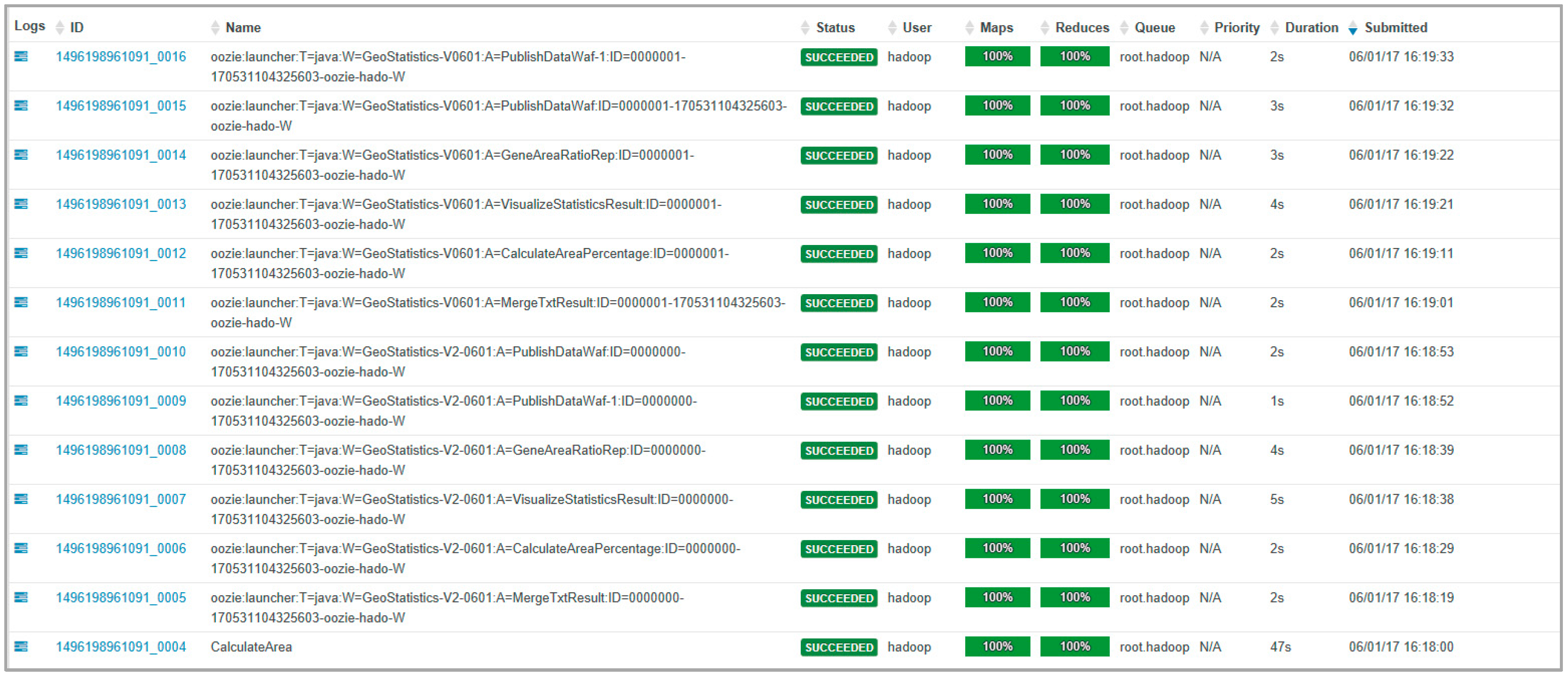
3.3. Oozie-Based Workflow System
4. Results and Evaluation
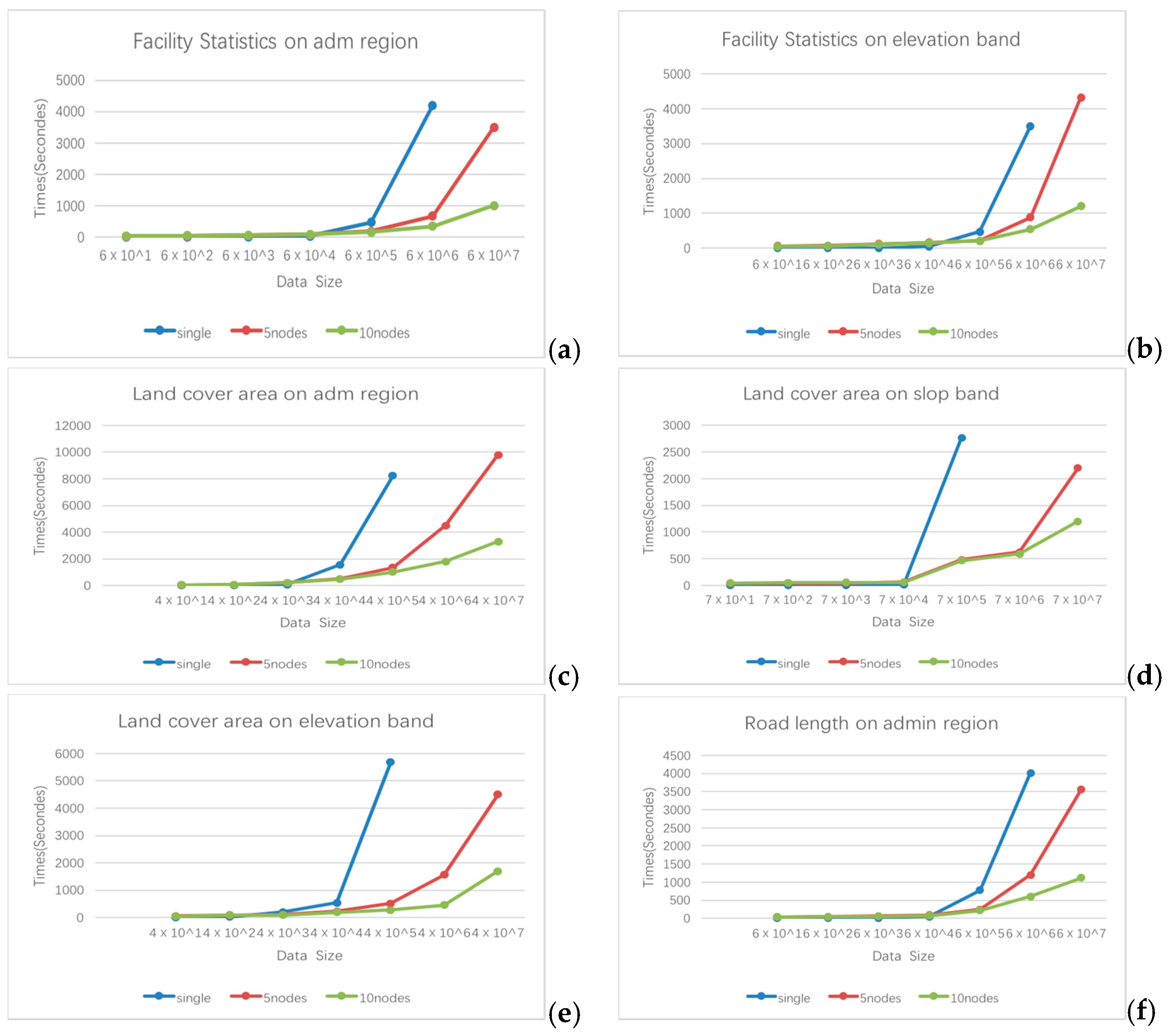
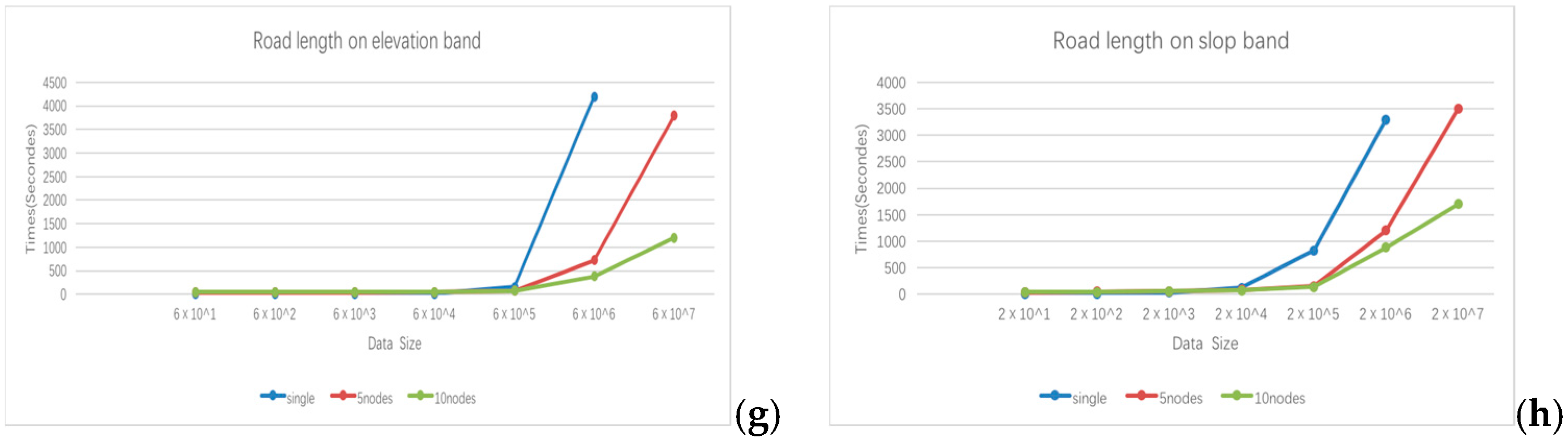
4.1. Experimental Design
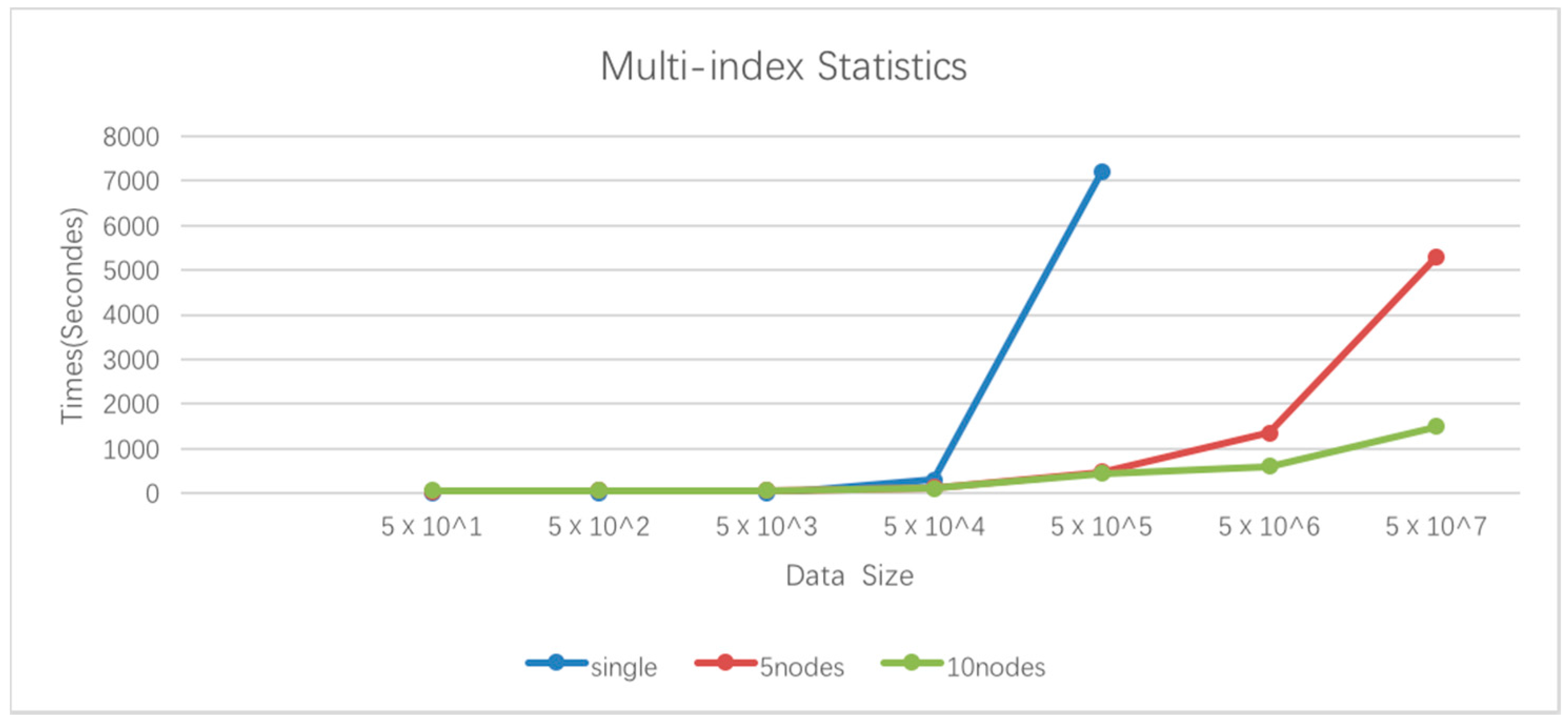
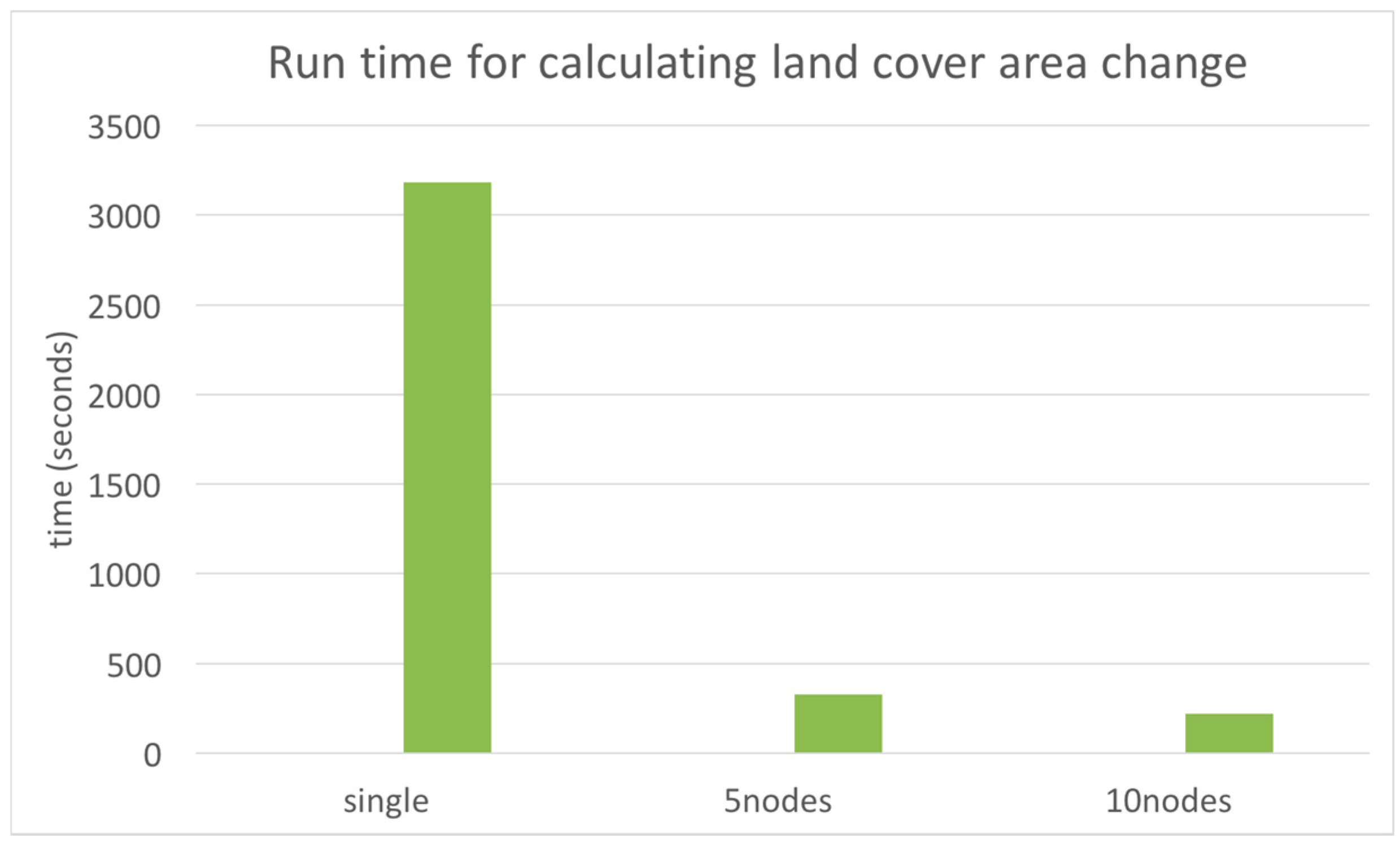
4.2. Experimental Results and Discussion
5. Conclusions
- A methodology integrating GIS tools with the Hadoop ecosystem to enable spatiotemporal data processing and geospatial analysis in parallel to address the computing-intensive issues in geospatial data processing of big data;
- A methodology providing Hadoop-based workflow services capable of being customized, shared and executed concurrently to simplify the data analytic process;
- A system built on the virtual environment of a cloud platform and a Hadoop cluster that leverages the cloud platform to rapidly provide on-demand computing and storage resources.
- More complicated spatiotemporal statistical analytical services (e.g., Kriging, SVM, Markov chain, and land use classification) based on MapReduce and a spatiotemporal cloud platform to meet near real-time demands by China’s national geographic condition monitoring; and
- I/O middleware for the raster data stored in HDFS or other cloud storage systems, and raster data processing and analysis algorithms; and
- Based on these complicated analytical tools, the development of a geospatial real-time monitoring and simulation system to facilitate public decision-making.
- Based on the pros and cons of a single-node computing paradigm and the Hadoop cluster computing paradigm, a computing scheduling strategy will be designed for different kinds of computing jobs by considering both the run-time and cost.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Keller, M.; Schimel, D.S.; Hargrove, W.W.; Hoffman, F.M. A continental strategy for the National Ecological Observatory Network. Front. Ecol. Environ. 2008, 6, 282–284. [Google Scholar] [CrossRef]
- Goodman, K.J.; Parker, S.M.; Edmonds, J.W.; Zeglin, L.H. Expanding the scale of aquatic sciences: The role of the National Ecological Observatory Network (NEON). Freshwater Sci. 2015, 34, 377–385. [Google Scholar] [CrossRef]
- Findley, J. Geographic analysis and monitoring at the United States Geological Survey. Cartogr. Geogr. Inform. Sci. 2003, 30, 203–210. [Google Scholar] [CrossRef]
- Yang, C.; Wu, H.; Huang, Q.; Li, Z.; Li, J. Using spatial principles to optimize distributed computing for enabling the physical science discoveries. Proc. Natl. Acad. Sci. USA 2011, 108, 5498–5503. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Sun, M.; Liu, K.; Huang, Q.; Li, Z.; Gui, Z.; Jiang, Y.; Xia, J.; Yu, M.; Xu, C.; et al. Contemporary computing technologies for processing big spatiotemporal data. In Space-Time Integration in Geography and GIScience; Springer: Berlin, Germany, 2014; pp. 327–351. [Google Scholar]
- Getis, A.; Ord, J.K. Local spatial statistics: An overview. In Spatial Analysis: Modelling in a GIS Environment; John Wiley and Sons: New York, NY, USA, 1996. [Google Scholar]
- Ripley, B.D. Spatial Statistics; John Wiley & Sons: New York, NY, USA, 2005; Volume 575. [Google Scholar]
- Dolores Ugarte, M. Statistical Methods for Spatio-Temporal Systems. J. R. Stat. Soc. Series A 2007. [Google Scholar] [CrossRef]
- Cressie, N.; Wikle, C.K. Statistics for Spatio-Temporal Data; John Wiley and Sons: New York, NY, USA, 2011. [Google Scholar]
- Kaihatu, J.M.; Handler, R.A.; Marmorino, G.O.; Shay, L.K. Empirical Orthogonal Function Analysis of Ocean Surface Currents Using Complex and Real-Vector Methods. J. Atmos. Ocean. Technol. 1998, 15, 927–941. [Google Scholar] [CrossRef]
- Yang, X.; Zheng, X.Q.; Lv, L.N. A spatiotemporal model of land use change based on ant colony optimization, Markov chain and cellular automata. Ecol. Model. 2012, 233, 11–19. [Google Scholar] [CrossRef]
- Miller, S.M.; Luark, R.D. Spatial simulation of rock strength properties using a Markov-Bayes method. Int. J. Rock Mech. Min. Sci. Geomech. Abstr. 1993, 30, 1631–1637. [Google Scholar] [CrossRef]
- Kyriakidis, P.C.; Journel, A.G. Geostatistical space—time models: A review. Math. Geol. 1999, 31, 651–684. [Google Scholar] [CrossRef]
- Li, S.H.; Jin, B.X.; Wei, X.Y.; Jiang, Y.Y.; Wang, J.L. Using Ca-Markov Model to Model the spatiotemporal change of land use/cover in Fuxian Lake for decision support. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, II-4/W2, 163–168. [Google Scholar] [CrossRef]
- Ji, C.; Li, Y.; Qiu, W.; Awada, U.; Li, K. Big data processing in cloud computing environments. In Proceedings of the 2012 12th International Symposium on Pervasive Systems, Algorithms and Networks, Washington, DC, USA, 13–15 December 2012; pp. 17–23. [Google Scholar]
- Yang, C.; Huang, Q. Spatial Cloud Computing: A Practical Approach; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Mell, P.; Grance, T. The NIST Definition of Cloud Computing. 2011. Available online: http://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-145.pdf (accessed on 28 September 2016).
- Huang, Q.; Xia, J.; Yang, C.; Liu, K.; Li, J.; Gui, Z.; Hassan, M.; Chen, S. An experimental study of open-source cloud platforms for dust storm forecasting. In Proceedings of the 20th International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 6–9 November 2012; pp. 534–537. [Google Scholar]
- Liu, Y.; Sun, A.Y.; Nelson, K.; Hipke, W.E. Cloud computing for integrated stochastic groundwater uncertainty analysis. Int.J. Digit. Earth 2013, 6, 313–337. [Google Scholar] [CrossRef]
- Sun, A. Enabling collaborative decision-making in watershed management using cloud-computing services. Environ. Model. Softw. 2013, 41, 93–97. [Google Scholar] [CrossRef]
- Yang, C.; Xu, Y.; Nebert, D. Redefining the possibility of digital Earth and geosciences with spatial cloud computing. Int. J. Digit. Earth 2013, 6, 297–312. [Google Scholar] [CrossRef]
- Ghoting, A.; Krishnamurthy, R.; Pednault, E.; Reinwald, B.; Sindhwani, V.; Tatikonda, S.; Tian, Y.; Vaithyanathan, S. SystemML: Declarative machine learning on MapReduce. In Proceedings of the 2011 IEEE 27th International Conference on Data Engineering, Hannover, Germany, 11–16 April 2011; pp. 231–242. [Google Scholar]
- Eldawy, A.; Mokbel, M.F. Spatialhadoop: A mapreduce framework for spatial data. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 1352–1363. [Google Scholar]
- Aji, A.; Wang, F.; Vo, H.; Lee, R.; Liu, Q.; Zhang, X.; Saltz, J. Hadoop GIS: a high performance spatial data warehousing system over mapreduce. In Proceedings of the VLDB Endowment, Riva del Garda, Italy, 26–30 August 2013; pp. 1009–1020. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
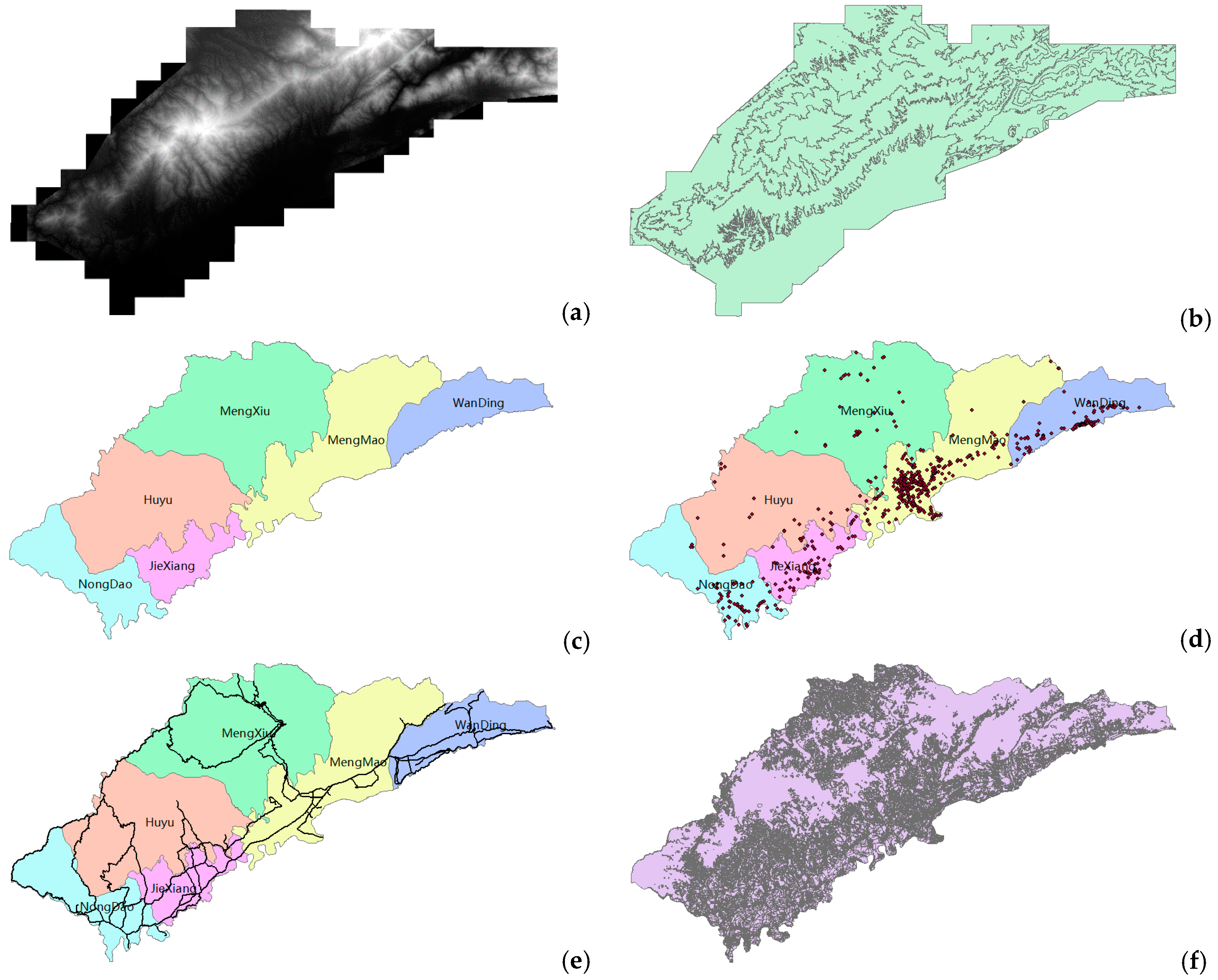
| Statistical Object | Statistical Unit | Statistical Index | Data Volume (Number of Geometry) |
|---|---|---|---|
| Land cover | county | area | 39387 (2.6 MB) |
| elevation zone | area | ||
| slope zone | area | ||
| Road | county | length | 588 (0.26 MB) |
| elevation zone | length | ||
| slope zone | length | ||
| Facility/resident | county | number | 600 (0.07 MB) |
| Number | Configuration | Cluster | Yarn Roles | HDFS Roles |
|---|---|---|---|---|
| 1 | CPU 3.2GHz 24 core | Hadoop2.5 | resource manager, node manager | Namenode, Datanode |
| RAM 128GB; | ||||
| DISK 6TB | ||||
| 2 | CPU 3.2GHz 24 core | Hadoop2.5 | node manager | Secondary Namenode, Datanode |
| RAM 128GB; | ||||
| DISK 6TB | ||||
| 3 | CPU 3.2GHz 24 core | Hadoop2.5 | node manager | Datanode |
| RAM 128GB; | ||||
| DISK 6TB |
| System | CPU | Disk | RAM | Software |
|---|---|---|---|---|
| Windows 8.1 Enterprise x64 | CPU 3.2GHz 24 core | SSD 2 TB SATA 20TB | 128 GB | ArcGIS 10.1; Python 2.6 |
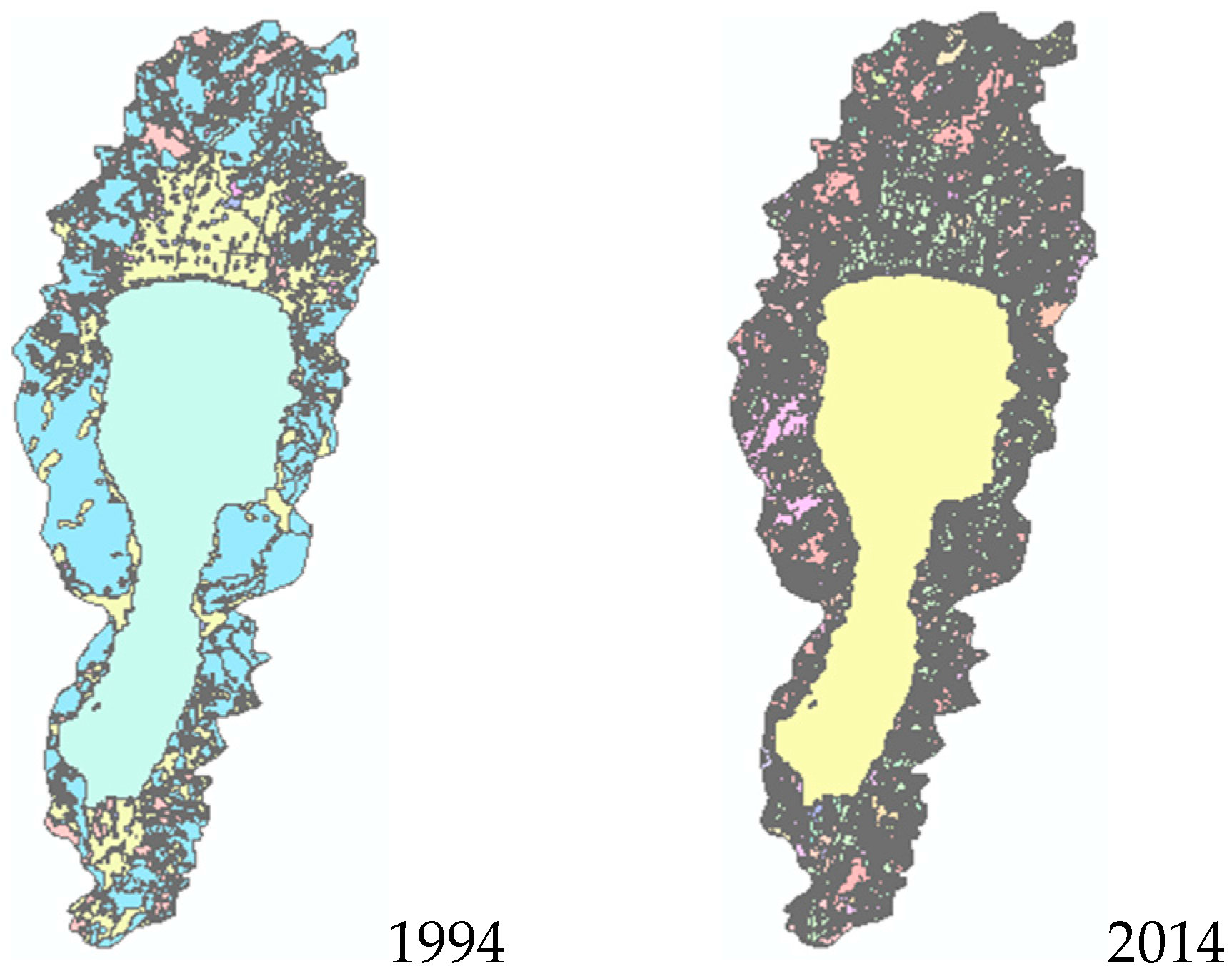
| 2014 | Developed | Cultivated | Commercial | Residential | Forest | Water | Farm Areas | Grassland | Road | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1994 | Area(m2) | Ratio(%) | Area(m2) | Ratio(%) | Area(m2) | Ratio(%) | Area(m2) | Ratio(%) | Area(m2) | Ratio(%) | Area(m2) | Ratio(%) | Area(m2) | Ratio(%) | Area(m2) | Ratio(%) | Area(m2) | Ratio(%) |
| Developed | 8.37 × 108 | 57.21 | 0 | 0.00 | 1.19 × 108 | 8.11 | 3.90 × 107 | 2.67 | 0 | 0.00 | 4.32 × 107 | 2.95 | 1.28 × 108 | 8.73 | 2.98 × 108 | 20.33 | 0 | 0.00 |
| Cultivated | 0 | 0.00 | 2.62 × 108 | 65.02 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 1.37 × 108 | 34.06 | 3.71 × 106 | 0.92 | 0 | 0.00 |
| Commercial | 0 | 0.00 | 0 | 0.00 | 1.49 × 108 | 100.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 |
| Residential | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 1.94 × 108 | 100.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 |
| Forest | 0 | 0.00 | 0 | 0.00 | 9.79 × 106 | 0.05 | 0 | 0.00 | 1.91 × 1010 | 94.64 | 1.62 × 108 | 0.80 | 1.50 × 108 | 0.74 | 5.88 × 108 | 2.91 | 1.73 × 108 | 0.86 |
| Water | 0 | 0.00 | 0 | 0.00 | 3.32 × 105 | 0.18 | 0 | 0.00 | 5.07 × 106 | 2.82 | 8.83 × 107 | 49.12 | 5.53 × 106 | 3.08 | 8.06 × 107 | 44.80 | 0 | 0.00 |
| Farm areas | 0 | 0.00 | 0 | 0.00 | 3.57 × 107 | 0.43 | 4.47 × 107 | 0.53 | 5.42 × 107 | 0.65 | 1.42 × 108 | 1.70 | 6.86 × 109 | 81.84 | 1.18 × 109 | 14.03 | 6.99 × 107 | 0.83 |
| Grassland | 0 | 0.00 | 0 | 0.00 | 7.10 × 106 | 0.28 | 0 | 0.00 | 1.60 × 107 | 0.62 | 2.05 × 106 | 0.08 | 1.03 × 108 | 4.04 | 2.42 × 109 | 94.47 | 1.29 × 107 | 0.50 |
| Road | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 2.50 × 108 | 100.00 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, B.; Song, W.; Zhao, K.; Wei, X.; Hu, F.; Jiang, Y. A High Performance, Spatiotemporal Statistical Analysis System Based on a Spatiotemporal Cloud Platform. ISPRS Int. J. Geo-Inf. 2017, 6, 165. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi6060165
Jin B, Song W, Zhao K, Wei X, Hu F, Jiang Y. A High Performance, Spatiotemporal Statistical Analysis System Based on a Spatiotemporal Cloud Platform. ISPRS International Journal of Geo-Information. 2017; 6(6):165. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi6060165
Chicago/Turabian StyleJin, Baoxuan, Weiwei Song, Kang Zhao, Xiaoyan Wei, Fei Hu, and Yongyao Jiang. 2017. "A High Performance, Spatiotemporal Statistical Analysis System Based on a Spatiotemporal Cloud Platform" ISPRS International Journal of Geo-Information 6, no. 6: 165. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi6060165