New Tools for the Classification and Filtering of Historical Maps

 , ,
, ,  , , and
, , and
Abstract
:
1. Introduction
2. Test Maps
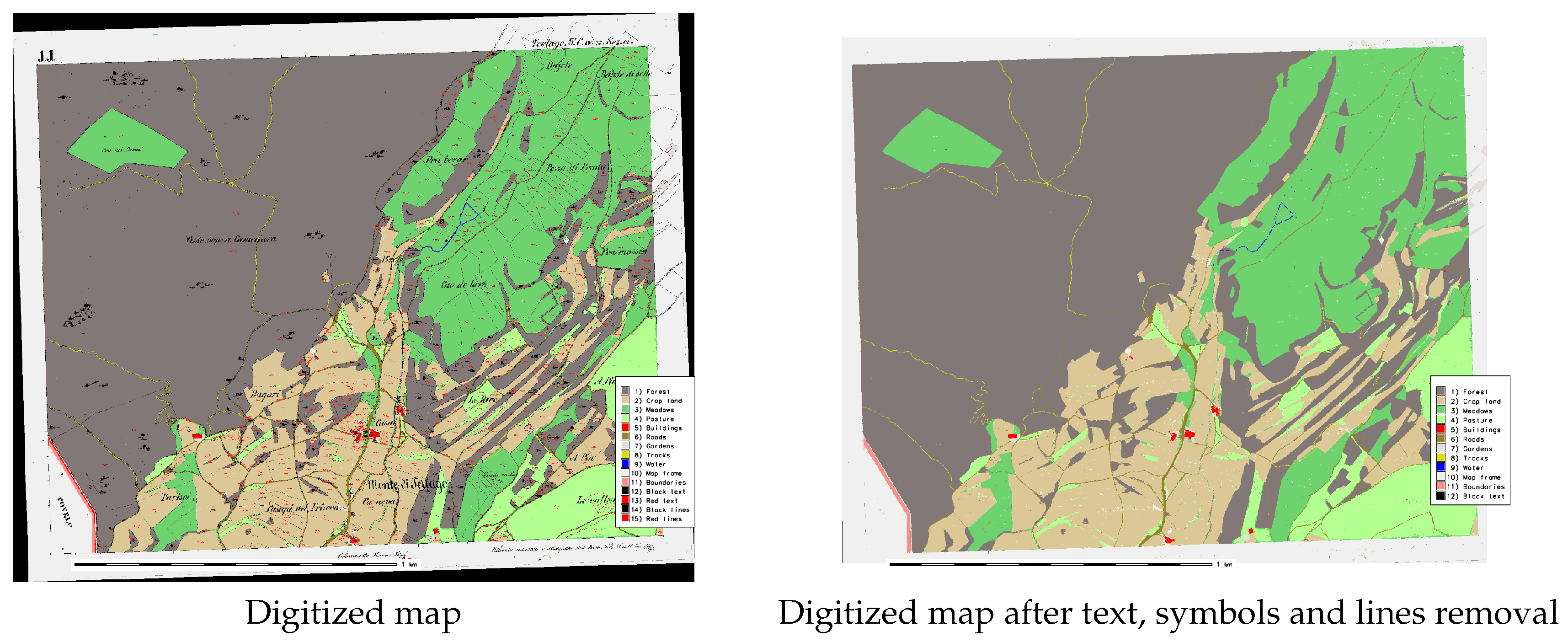
3. Historical Map Digitalization
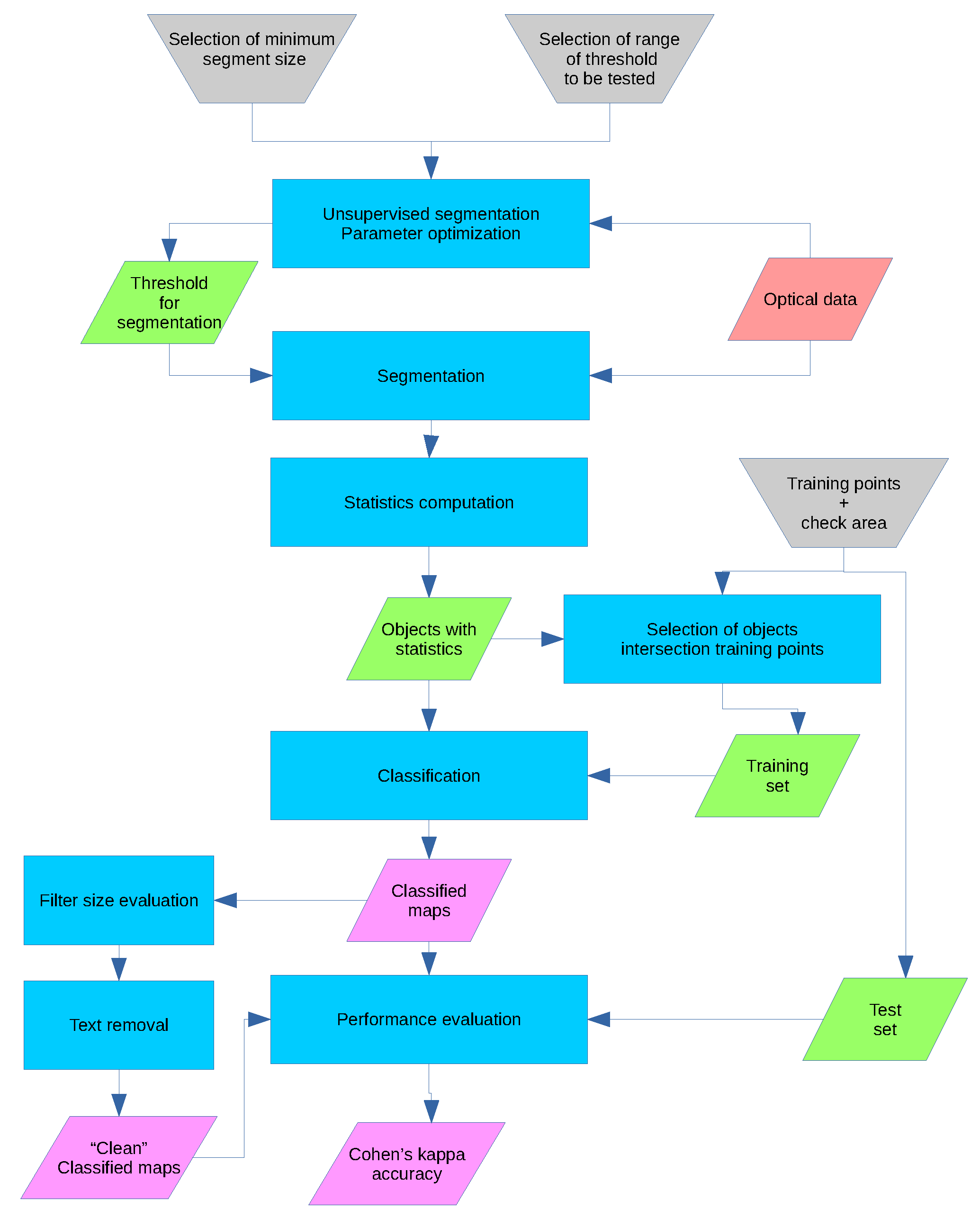
4. Segmentation
- Pixelwise, an algorithm classifies every single pixel of the image in an LULC category, using its spectral signature;
- Object oriented, an algorithm creates “objects”, or cluster of adjacent pixels with a similar spectral response, and then classifies the objects using their geometric and spectral features.
5. Classification
- Simple Majority Vote (SMV): all the classifiers have the same authority and the decision on the LULC class of an object is determined by a majority vote;
- Simple Weighted Vote (SWV): the weight of the vote of each classifier in the decision process is proportional to its accuracy in the identification of the class of the training areas;
- Best-Worst Weighted Vote (BWWV): as in the SWV process, all the classifiers are ranked according to their accuracy; the worst voter is excluded from the voting process;
- Quadratic Best-Worst Weighted Vote (QBWWV): as in BWWV, but the weights of the best voters are squared in order to give them more authority.
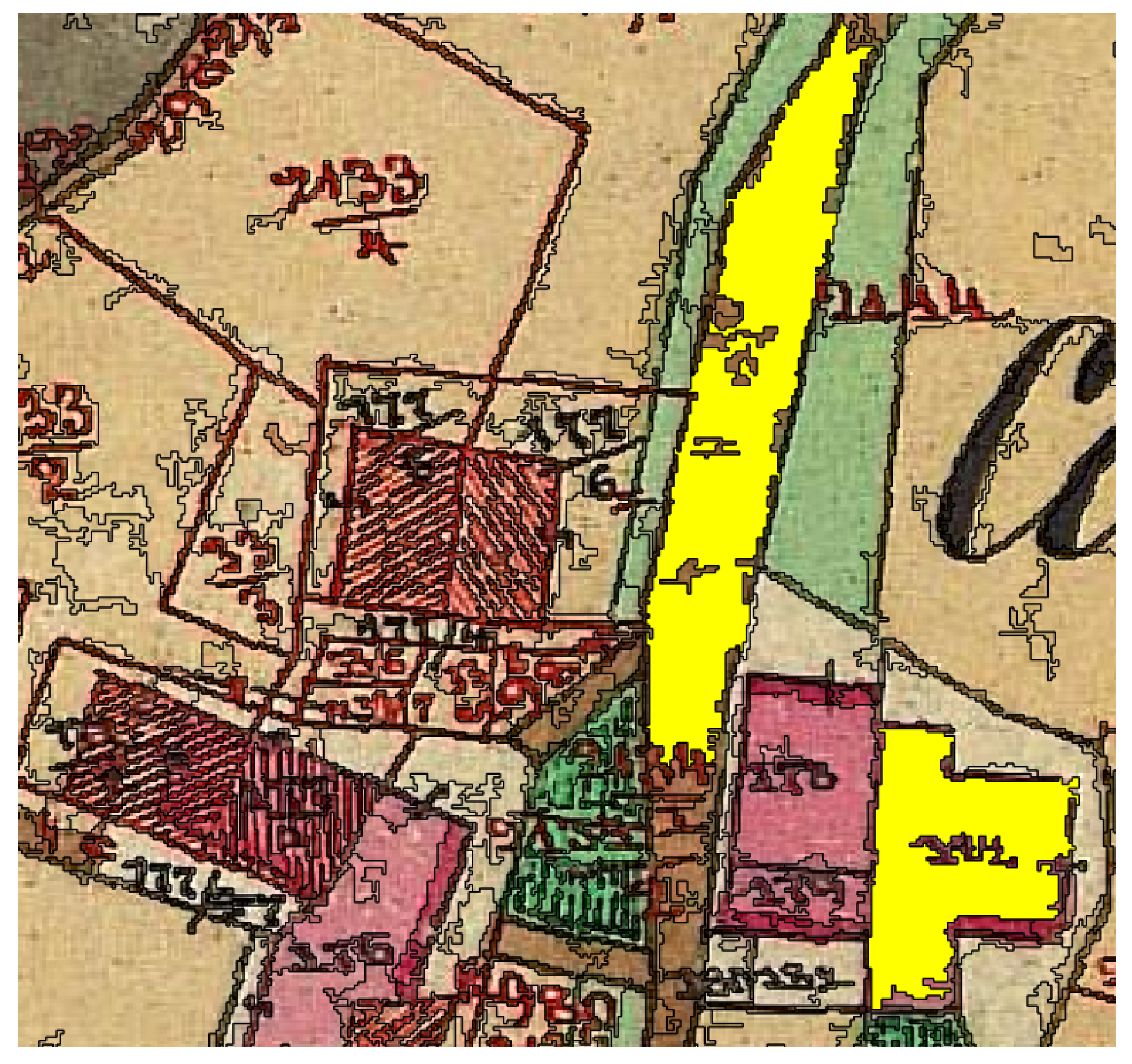
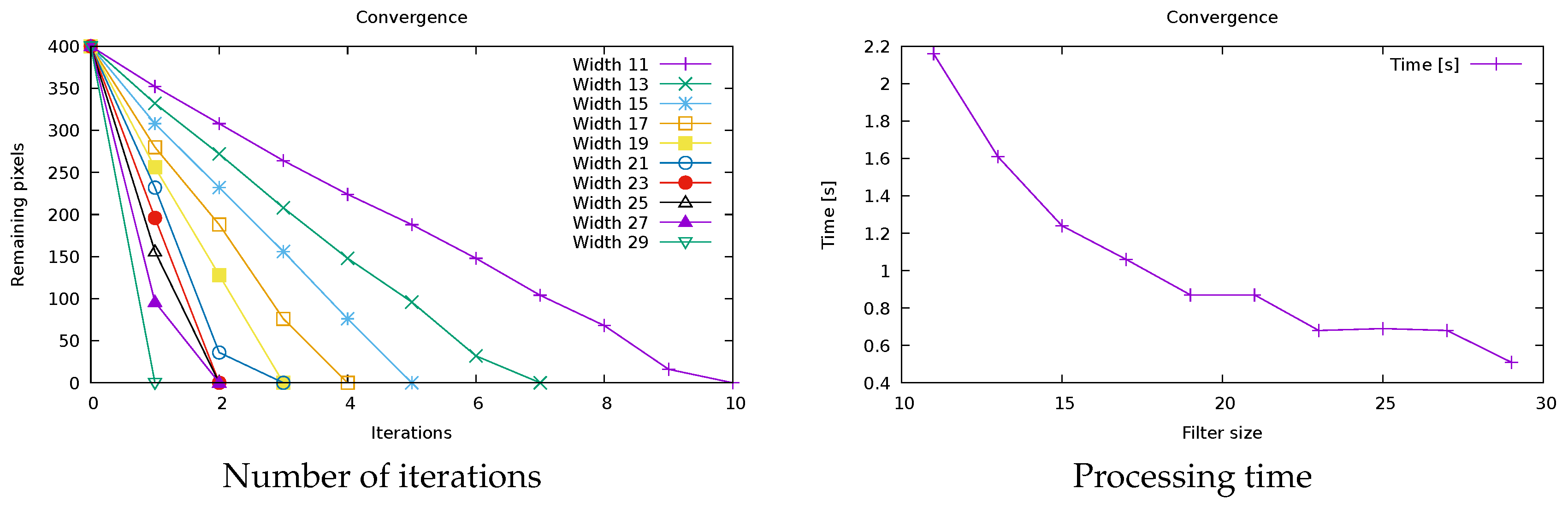
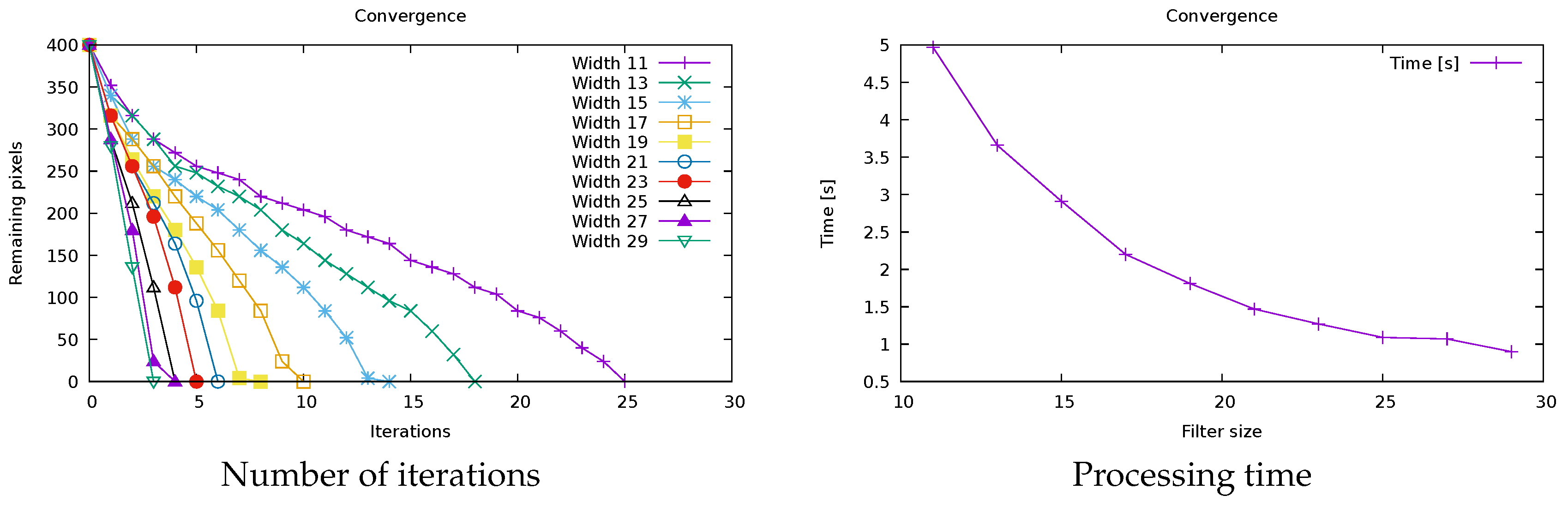
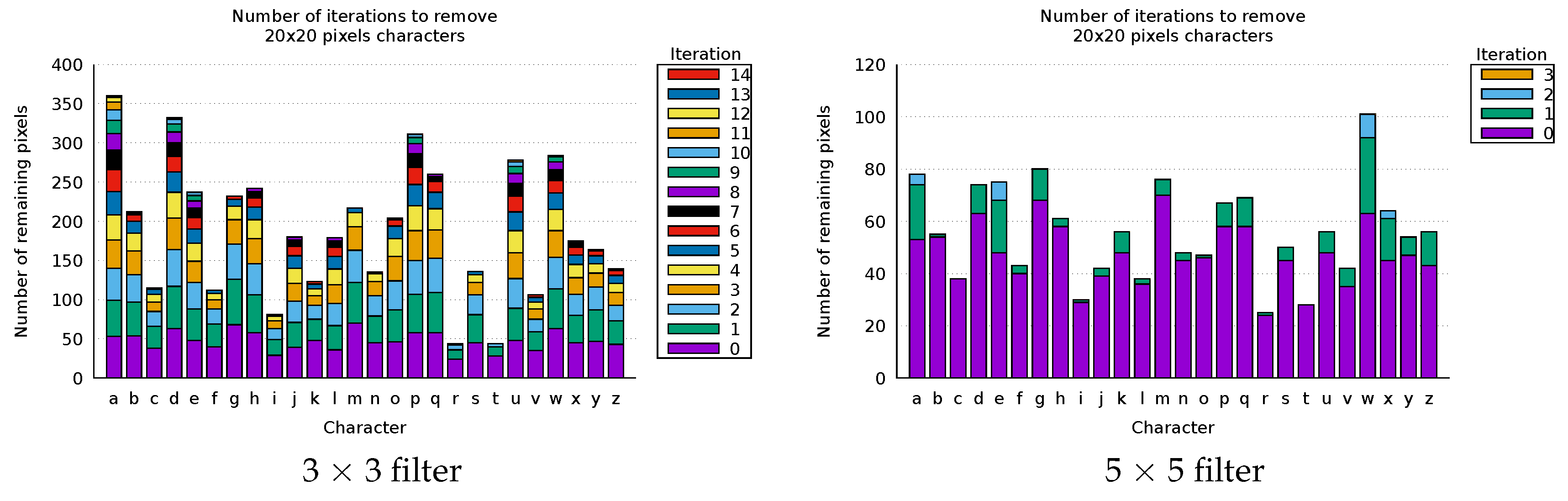
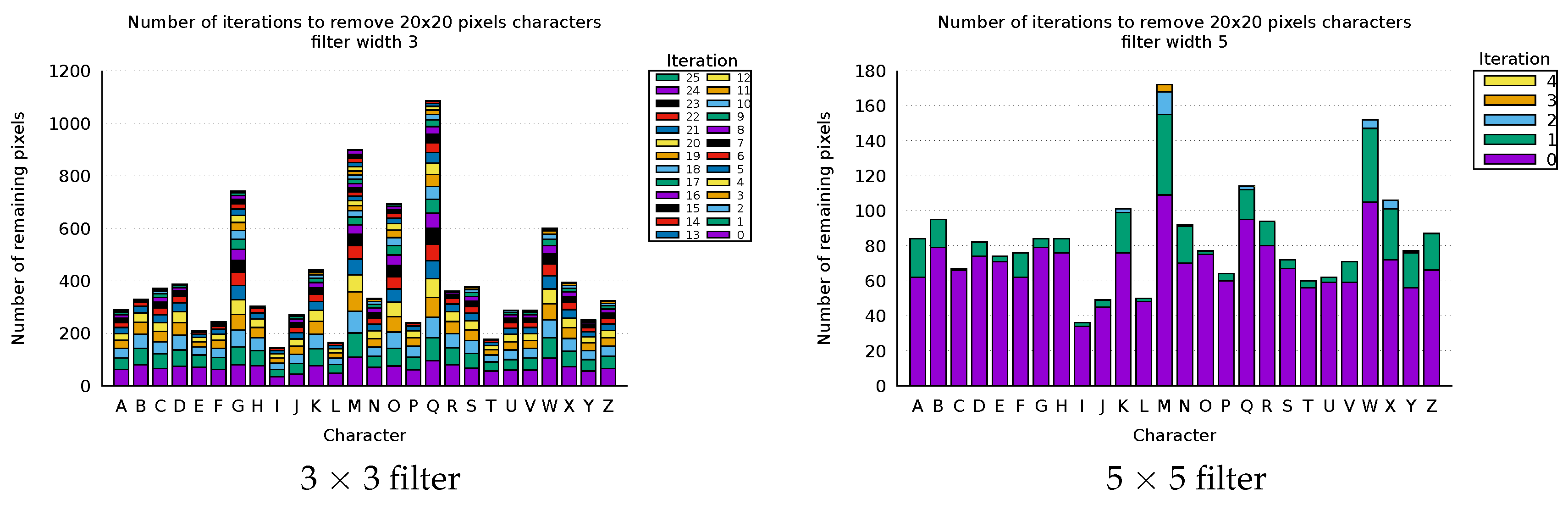
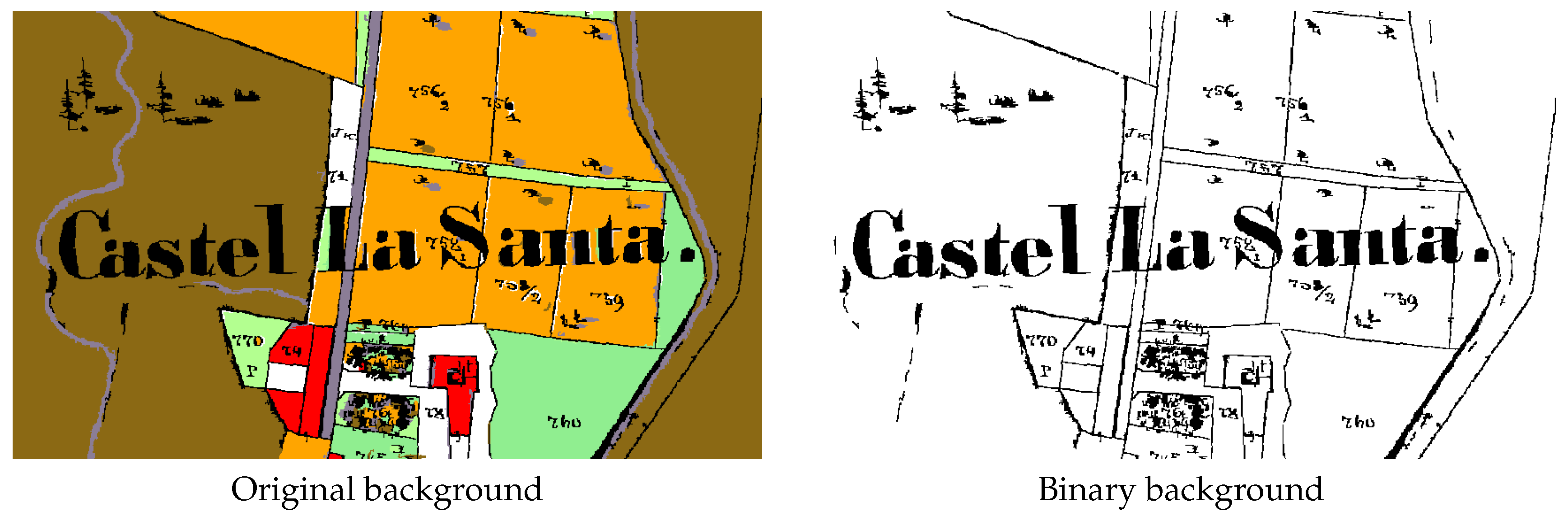
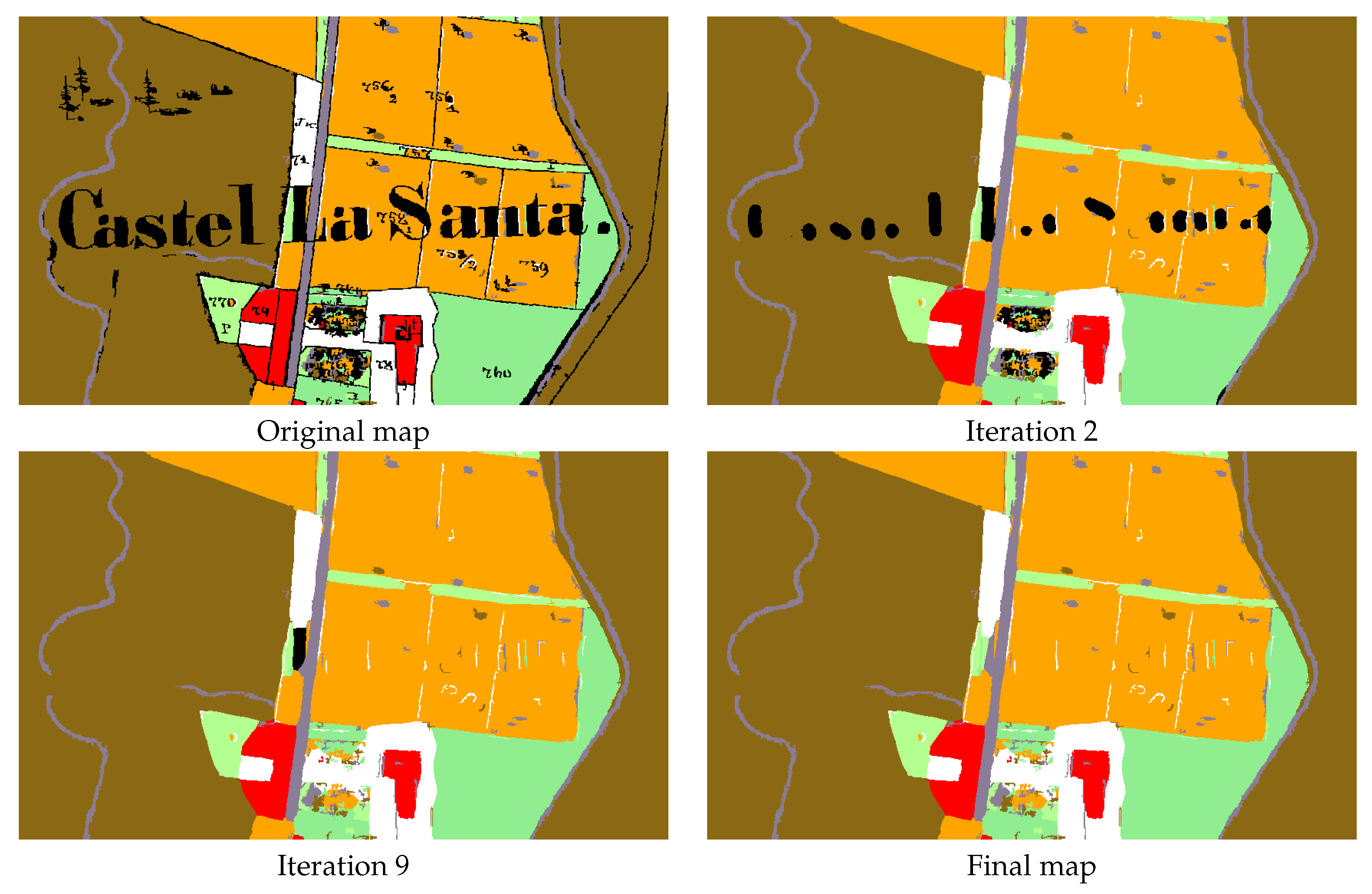
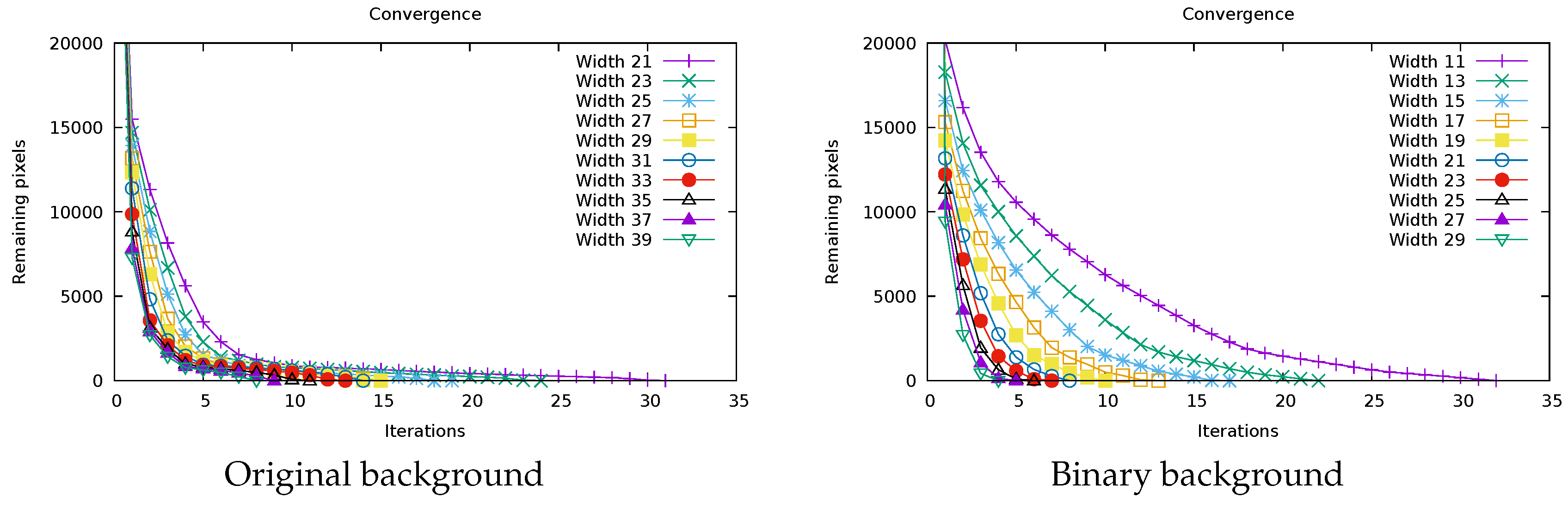
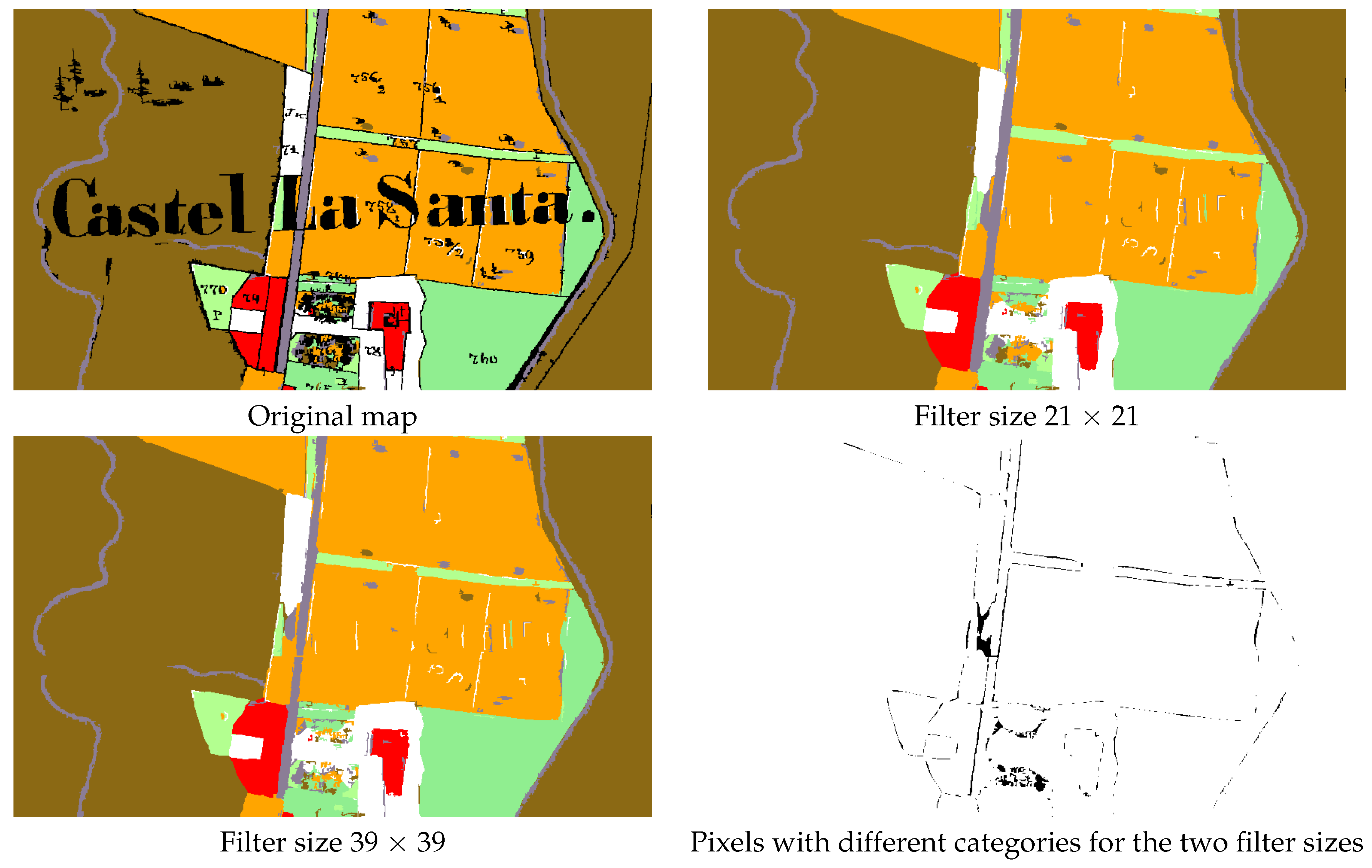
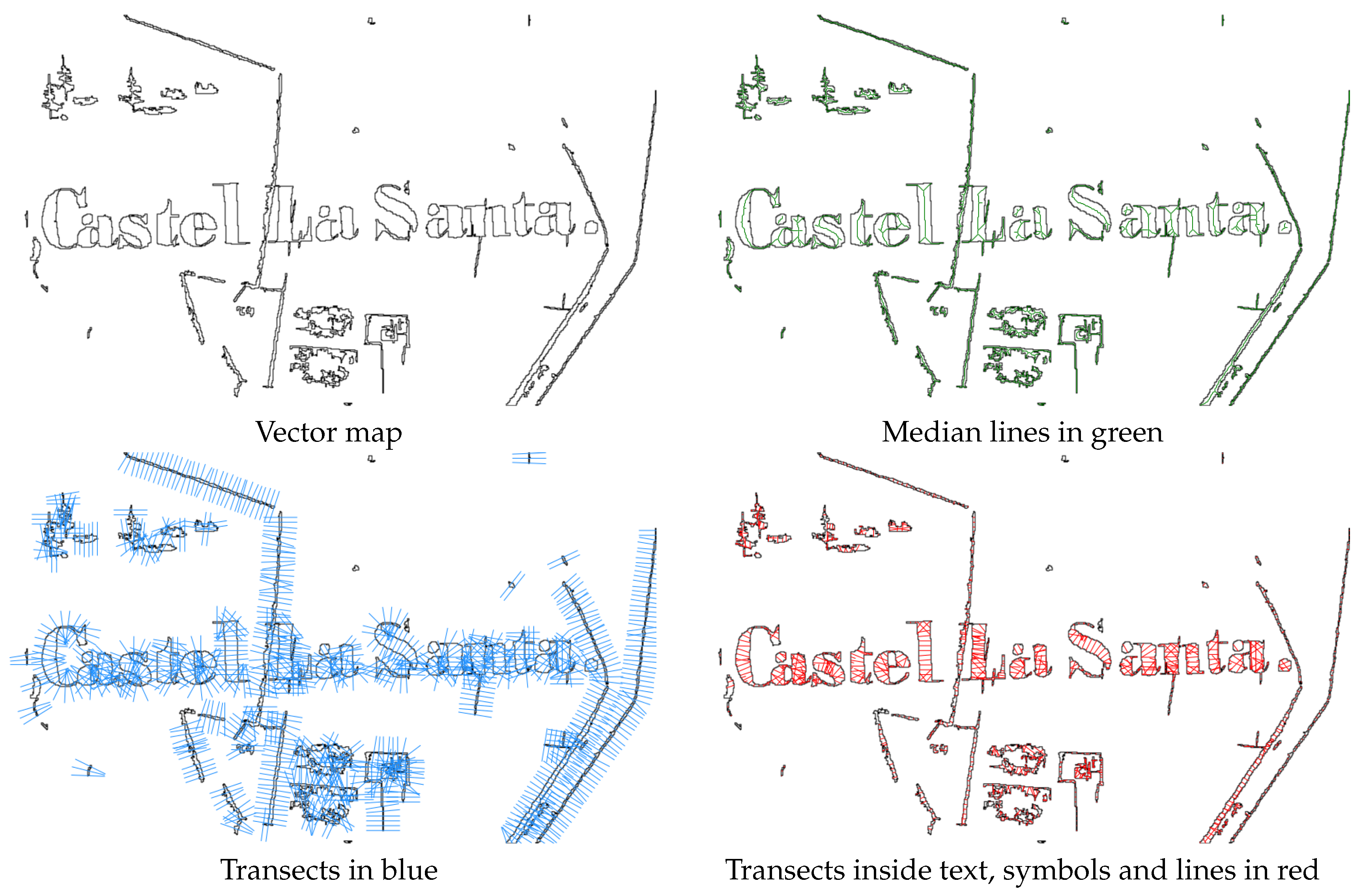
6. Text and Symbol Removal
7. Results
8. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| BWWV | Best-Worst Weighted Vote |
| CC | Compact Circle |
| CS | Compact Square |
| DPI | Digit Per Inch |
| DT | Decision Tree |
| EPSG | European Petroleum Survey Group (EPSG Geodetic Parameter Set) |
| FD | Fractal Dimension |
| GCP | Ground Control Point |
| GIS | Geographic Information System |
| GPL | Gnu Public License |
| FOSS | Free and Open Source Software |
| IGMI | Istituto Geografico Militare Italiano (Italian Military Geografic Institute) |
| IKFM | Italian Kingdom Forest Map |
| k-NN | k-Nearest-Neighbor classifier |
| LULC | Land Use/Land Cover |
| MLP | Multi-Layer Perceptron |
| MPLFT | Map of the Potential Limit of the Forest in Trentino |
| NB | Naive Bayesian classifier |
| OBIA | Object-Based Image Analysis |
| OCR | Optical Character Recognition |
| QBS | Query-By-String |
| QBWWV | Quadratic Best-Worst Weighted Vote |
| SA | Spatial Autocorrelation |
| SMV | Simple Majority Vote |
| SVM | Support Vector Machine |
| SWV | Simple Weighted Vote |
| USPO | Unsupervised Segment Parameter Optimization |
| VW | intra-object Variance Weighted by object size |
References
- Loran, C.; Haegi, S.; Ginzler, C. Comparing historical and contemporary maps - a methodological framework for a cartographic map comparison applied to Swiss maps. Int. J. Geogr. Inf. Sci. 2018, 32, 2123–2139. [Google Scholar] [CrossRef]
- Ciolli, M.; Bezzi, M.; Comunello, G.; Laitempergher, G.; Gobbi, S.; Tattoni, C.; Cantiani, M. Integrating dendrochronology and geomatics to monitor natural hazards and landscape changes. Appl. Geomat. 2019, 11, 39–52. [Google Scholar] [CrossRef]
- Ferretti, F.; Sboarina, C.; Tattoni, C.; Vitti, A.; Zatelli, P.; Geri, F.; Pompei, E.; Ciolli, M. The 1936 Italian Kingdom Forest Map reviewed: A dataset for landscape and ecological research. Ann. Silvic. Res. 2018, 42, 3–19. [Google Scholar] [CrossRef]
- Tattoni, C.; Ciolli, M.; Ferretti, F. The fate of priority areas for conservation in protected areas: A fine-scale markov chain approach. Environ. Manag. 2011, 47, 263–278. [Google Scholar] [CrossRef] [PubMed]
- Sitzia, T.; Semenzato, P.; Trentanovi, G. Natural reforestation is changing spatial patterns of rural mountain and hill landscapes: A global overview. For. Ecol. Manag. 2010, 259, 1354–1362. [Google Scholar] [CrossRef]
- Senapathi, D.; Carvalheiro, L.; Biesmeijer, J.; Dodson, C.A.; Evans, R.; McKerchar, M.; Morton, D.; Moss, E.; Roberts, S.; Kunin, W.; et al. The impact of over 80 years of land cover changes on bee and wasp pollinator communities in England. Proc. R. Soc. B Biol. Sci. 2015, 282. [Google Scholar] [CrossRef]
- Cousins, S.; Auffret, A.; Lindgren, J.; Tränk, L. Regional-scale land-cover change during the 20th century and its consequences for biodiversity. Ambio 2015, 44, 17–27. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feurdean, A.; Munteanu, C.; Kuemmerle, T.; Nielsen, A.; Hutchinson, S.; Ruprecht, E.; Parr, C.; Perşoiu, A.; Hickler, T. Long-term land-cover/use change in a traditional farming landscape in Romania inferred from pollen data, historical maps and satellite images. Reg. Environ. Chang. 2017, 17, 2193–2207. [Google Scholar] [CrossRef]
- Auffret, A.; Kimberley, A.; Plue, J.; Skånes, H.; Jakobsson, S.; Waldén, E.; Wennbom, M.; Wood, H.; Bullock, J.; Cousins, S.; et al. HistMapR: Rapid digitization of historical land-use maps in R. Methods Ecol. Evol. 2017, 8, 1453–1457. [Google Scholar] [CrossRef]
- Tattoni, C.; Ianni, E.; Geneletti, D.; Zatelli, P.; Ciolli, M. Landscape changes, traditional ecological knowledge and future scenarios in the Alps: A holistic ecological approach. Sci. Total Environ. 2017, 579, 27–36. [Google Scholar] [CrossRef]
- Geri, F.; La Porta, N.; Zottele, F.; Ciolli, M. Mapping historical data: Recovering a forgotten floristic and vegetation database for biodiversity monitoring. ISPRS Int. J. Geo-Inf. 2016, 5. [Google Scholar] [CrossRef]
- Spooner, P.; Shoard, J. Using historic maps and citizen science to investigate the abundance and condition of survey reference ’blaze’ trees. Aust. J. Bot. 2016, 64, 377–388. [Google Scholar] [CrossRef]
- Alberico, I.; Cavuoto, G.; Di Fiore, V.; Punzo, M.; Tarallo, D.; Pelosi, N.; Ferraro, L.; Marsella, E. Historical maps and satellite images as tools for shoreline variations and territorial changes assessment: The case study of Volturno Coastal Plain (Southern Italy). J. Coast. Conserv. 2018, 22, 919–937. [Google Scholar] [CrossRef]
- Tortora, A.; Statuto, D.; Picuno, P. Rural landscape planning through spatial modelling and image processing of historical maps. Land Use Policy 2015, 42, 71–82. [Google Scholar] [CrossRef]
- Gabriel, N. Mapping urban space: The production, division and reconfiguration of natures and economies. City 2013, 17, 325–342. [Google Scholar] [CrossRef]
- Gretter, A.; Ciolli, M.; Scolozzi, R. Governing mountain landscapes collectively: Local responses to emerging challenges within a systems thinking perspective. Landsc. Res. 2018, 43, 1117–1130. [Google Scholar] [CrossRef]
- Svenningsen, S.; Levin, G.; Perner, M. Military land use and the impact on landscape: A study of land use history on Danish Defence sites. Land Use Policy 2019, 84, 114–126. [Google Scholar] [CrossRef]
- Ciolli, M.; Tattoni, C.; Ferretti, F. Understanding forest changes to support planning: A fine-scale Markov chain approach. Dev. Environ. Model. 2012, 25, 355–373. [Google Scholar] [CrossRef]
- Willcock, S.; Phillips, O.; Platts, P.; Swetnam, R.; Balmford, A.; Burgess, N.; Ahrends, A.; Bayliss, J.; Doggart, N.; Doody, K.; et al. Land cover change and carbon emissions over 100 years in an African biodiversity hotspot. Glob. Chang. Biol. 2016, 22, 2787–2800. [Google Scholar] [CrossRef] [Green Version]
- Chiang, Y.Y.; Leyk, S.; Knoblock, C.A. A Survey of Digital Map Processing Techniques. ACM Comput. Surv. 2014, 47, 1–44. [Google Scholar] [CrossRef]
- Liu, T.; Xu, P.; Zhang, S. A review of recent advances in scanned topographic map processing. Neurocomputing 2019, 328, 75–87. [Google Scholar] [CrossRef]
- Herrault, P.A.; Sheeren, D.; Fauvel, M.; Paegelow, M. Automatic extraction of forests from historical maps based on unsupervised classification in the CIELab color space. In Lecture Notes in Geoinformation and Cartography; Springer: Cham, Switzerland, 2013; pp. 95–112. [Google Scholar] [CrossRef]
- Gobbi, S.; Maimeri, G.; Tattoni, C.; Cantiani, M.; Rocchini, D.; La Porta, N.; Ciolli, M.; Zatelli, P. Orthorectification of a large dataset of historical aerial images: Procedure and precision assessment in an open source environment. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences—ISPRS Archives, Dar es Salaam, Tanzania, 29–31 August 2018; pp. 53–59. [Google Scholar] [CrossRef]
- Gobbi, S.; Cantiani, M.; Rocchini, D.; Zatelli, P.; Tattoni, C.; Ciolli, M.; La Porta, N. Fine spatial scale modelling of Trentino past forest landscape (Trentinoland): A case study of FOSS application. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences—ISPRS Archives, Bucharest, Romania, 26–30 August 2019; pp. 71–78. [Google Scholar] [CrossRef]
- Bhowmik, S.; Sarkar, R.; Nasipuri, M.; Doermann, D. Text and non-text separation in offline document images: A survey. Int. J. Doc. Anal. Recognit. 2018, 21. [Google Scholar] [CrossRef]
- GRASS Development Team. Geographic Resources Analysis Support System (GRASS) Software. Open Source Geospatial Foundation. Available online: grass.osgeo.org (accessed on 20 September 2017).
- Ciolli, M.; Federici, B.; Ferrando, I.; Marzocchi, R.; Sguerso, D.; Tattoni, C.; Vitti, A.; Zatelli, P. FOSS tools and applications for education in geospatial sciences. ISPRS Int. J. Geo-Inf. 2017, 6. [Google Scholar] [CrossRef]
- Simeoni, L.; Zatelli, P.; Floretta, C. Field measurements in river embankments: Validation and management with spatial database and webGIS. Nat. Hazards 2014, 71, 1453–1473. [Google Scholar] [CrossRef]
- Preatoni, D.; Tattoni, C.; Bisi, F.; Masseroni, E.; D’Acunto, D.; Lunardi, S.; Grimod, I.; Martinoli, A.; Tosi, G. Open source evaluation of kilometric indexes of abundance. Ecol. Inform. 2012, 7, 35–40. [Google Scholar] [CrossRef] [Green Version]
- Federici, B.; Giacomelli, D.; Sguerso, D.; Vitti, A.; Zatelli, P. A web processing service for GNSS realistic planning. Appl. Geomat. 2013, 5, 45–57. [Google Scholar] [CrossRef]
- Timár, G. System of the 1:28 800 scale sheets of the Second Military Survey in Tyrol and Salzburg. Acta Geod. Et Geophys. Hung. 2009, 44, 95–104. [Google Scholar] [CrossRef] [Green Version]
- von Nischer-Falkenhof, E. The Survey by the Austrian General Staff under the Empress Maria Theresa and the Emperor Joseph II., and the Subsequent Initial Surveys of Neighbouring Territories during the Years 1749–1854. Imago Mundi 1937, 2, 83–88. [Google Scholar] [CrossRef]
- Buffoni, D.; Girardi, S.; Revolti, R.; Cortese, G.; Mastronunzio, M. HISTORICALKat. La documentazione catastale trentina d’impianto è Open Data. In Proceedings of the XX Conferenza Nazionale ASITA, Trieste, Italy, 12–14 November 2019; pp. 112–117. [Google Scholar]
- Servizio Catasto della Provincia Autonoma di Trento. HistoricalKat, Documentation of the Trentino Cadastral Archive. Available online: http://historicalkat.provincia.tn.it (accessed on 29 April 2019).
- Servizio Catasto della Provincia Autonoma di Trento. Mappe storiche di impianto (Urmappe). Available online: https://www.catastotn.it/mappeStoriche.html (accessed on 29 April 2019).
- OPENdata Trentino. Historical Cadaster Map of the Trentino Region Metadata. Available online: https://dati.trentino.it/dataset/mappe-storiche-d-impianto (accessed on 29 April 2019).
- Revolti, R. Produzione e restauro della cartografia catastale in Trentino. Available online: https://drive.google.com/file/d/0B0abPZ1IrxqdcnUwXzB1T2RvV0E/view (accessed on 29 April 2019).
- Brengola, A. La carta Forestale d’Italia. [The Italian Forest Map]. In Rivista Forestale Italiana. Milizia Nazionale Forestale; Comando Centrale: Rome, Italy, 1939; pp. 1–10. [Google Scholar]
- Piussi, P. Carta del limite potenziale del bosco in Trentino; Technical Report; Servizio Foreste Caccia e Pesca: Provincia Autonoma di Trento, Italy, 1992. [Google Scholar]
- Liu, Y.; Guo, J.; Lee, J. Halftone Image Classification Using LMS Algorithm and Naive Bayes. IEEE Trans. Image Process. 2011, 20, 2837–2847. [Google Scholar] [CrossRef]
- Hackeloeer, A.; Klasing, K.; Krisp, J.; Meng, L. Georeferencing: A review of methods and applications. Ann. GIS 2014, 20, 61–69. [Google Scholar] [CrossRef]
- Zitová, B.; Flusser, J. Image registration methods: A survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef]
- Jenny, B.; Hurni, L. Studying cartographic heritage: Analysis and visualization of geometric distortions. Comput. Graph. 2011, 35, 402–411. [Google Scholar] [CrossRef]
- Yu, H.; Yang, Z.; Tan, L.; Wang, Y.; Sun, W.; Sun, M.; Tang, Y. Methods and datasets on semantic segmentation: A review. Neurocomputing 2018, 304, 82–103. [Google Scholar] [CrossRef]
- Vaithiyanathan, V.; Rajappa, U. A review on clustering techniques in image segmentation. Int. J. Appl. Eng. Res. 2013, 8, 2685–2688. [Google Scholar]
- Belgiu, M.; Drăgut, L. Comparing supervised and unsupervised multiresolution segmentation approaches for extracting buildings from very high resolution imagery. Int. J. Remote Sens. 2014, 96, 67–75. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, Y.; Mas, J. A comparison of the performance of pixel based and object based classifications over images with various spatial resolutions. Online J. Earth Sci. 2008, 2, 27–35. [Google Scholar]
- Zatelli, P.; Gobbi, S.; Tattoni, C.; La Porta, N.; Ciolli, M. Object-based image analysis for historic maps classification. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences—ISPRS Archives, Bucharest, Romania, 26–30 August 2019; pp. 247–254. [Google Scholar] [CrossRef]
- Momsen, E.; Metz, M. GRASS Development Team i.segment. Geographic Resources Analysis Support System (GRASS) Software, Version 7.6. 2016. Available online: https://grass.osgeo.org/grass76/manuals/i.segment.html (accessed on 25 July 2019).
- Peng, Q. An image segmentation algorithm research based on region growth. J. Softw. Eng. 2015, 9, 673–679. [Google Scholar]
- Grippa, T.; Lennert, M.; Beaumont, B.; Vanhuysse, S.; Stephenne, N.; Wolff, E. An open-source semi-automated processing chain for urban object-based classification. Remote Sens. 2017, 9. [Google Scholar] [CrossRef]
- Lennert, M. GRASS Development Team Addon i.segment.uspo. Geographic Resources Analysis Support System (GRASS) Software, Version 7.6. 2016. Available online: https://grass.osgeo.org/grass72/manuals/addons/i.segment.uspo.html (accessed on 25 July 2019).
- Espindola, G.; Camara, G.; Reis, I.; Bins, L.; Monteiro, A. Parameter selection for region-growing image segmentation algorithms using spatial autocorrelation. Int. J. Remote Sens. 2006, 27, 3035–3040. [Google Scholar] [CrossRef]
- Johnson, B.; Bragais, M.; Endo, I.; Magcale-Macandog, D.; Macandog, P. Image segmentation parameter optimization considering within-and between-segment heterogeneity at multiple scale levels: Test case for mapping residential areas using landsat imagery. ISPRS Int. J. Geo-Inf. 2015, 4, 2292–2305. [Google Scholar] [CrossRef]
- Schiewe, J. Segmentation of high-resolution remotely sensed data-concepts, applications and problems. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences—ISPRS Archives, Volume XXXIV, Part 4, Ottawa, QC, Canada, 9–12 July 2002; pp. 380–385. [Google Scholar]
- Carleer, A.; Debeir, O.; Wolff, E. Assessment of very high spatial resolution satellite image segmentations. Photogramm. Eng. Remote Sens. 2005, 1285–1294. [Google Scholar] [CrossRef]
- Metz, M.; Lennert, M. GRASS Development Team Addon i.segment.stats. Geographic Resources Analysis Support System (GRASS) Software, Version 7.6. 2016. Available online: https://grass.osgeo.org/grass76/manuals/addons/i.segment.stats.html (accessed on 25 July 2019).
- Metz, M.; Lennert, M. GRASS Development Team Addon r.object.geometry. Geographic Resources Analysis Support System (GRASS) Software, Version 7.6. 2016. Available online: https://grass.osgeo.org/grass72/manuals/addons/r.object.geometry.html (accessed on 25 July 2019).
- Kuhn, M. The R Caret Library. 2019. Available online: https://topepo.github.io/caret/ (accessed on 25 July 2019).
- Moreno-seco, F. Structural, Syntactic, and Statistical Pattern Recognition. Struct. Syntactic Stat. Pattern Recognit. 2006. [Google Scholar] [CrossRef]
- Fletcher, L.A.; Kasturi, R. A Robust Algorithm for Text String Separation from Mixed Text/Graphics Images. IEEE Trans. Pattern Anal. Mach. Intell. 1988, 10, 910–918. [Google Scholar] [CrossRef]
- Mhiri, M.; Desrosiers, C.; Cheriet, M. Word spotting and recognition via a joint deep embedding of image and text. Pattern Recognit. 2019, 88, 312–320. [Google Scholar] [CrossRef]
- Ye, Q.; Doermann, D. Text Detection and Recognition in Imagery: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1480–1500. [Google Scholar] [CrossRef] [PubMed]
- Moreno-García, C.F.; Elyan, E.; Jayne, C. New trends on digitisation of complex engineering drawings. Neural Comput. Appl. 2019, 31, 1695–1712. [Google Scholar] [CrossRef]
- Kang, S.O.; Lee, E.B.; Baek, H.K. A Digitization and Conversion Tool for Imaged Drawings to Intelligent Piping and Instrumentation Diagrams (P&ID). Energies 2019, 12. [Google Scholar] [CrossRef]
- Chiang, Y.Y.; Knoblock, C.A. An approach for recognizing text labels in raster maps. In Proceedings of the International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3199–3202. [Google Scholar] [CrossRef]
- Rokon, M.O.F.; Masud, M.R.; Islam, M.M. An iterative approach to detect region boundary eliminating texts from scanned land map images. In Proceedings of the 3rd International Conference on Electrical Information and Communication Technology, EICT 2017, Khulna, Bangladesh, 7–9 December 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Pouderoux, J.; Gonzato, J.; Pereira, A.; Guitton, P. Toponym Recognition in Scanned Color Topographic Maps. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Washington, DC, USA, 23–26 September 2007; Volume 1, pp. 531–535. [Google Scholar] [CrossRef]
- Roy, P.P.; Llados, J.; Pal, U. Text/Graphics Separation in Color Maps. In Proceedings of the 2007 International Conference on Computing: Theory and Applications (ICCTA’07), Kolkata, India, 5–7 March 2007; pp. 545–551. [Google Scholar] [CrossRef]
- Chiang, Y.Y.; Leyk, S.; Honarvar Nazari, N.; Moghaddam, S.; Tan, T.X. Assessing the impact of graphical quality on automatic text recognition in digital maps. Comput. Geosci. 2016, 93, 21–35. [Google Scholar] [CrossRef]
- Naidu, P.S.; Mathew, M. (Eds.) Chapter 4 Digital filtering of maps I. In Analysis of Geophysical Potential Fields; Elsevier: Amsterdam, The Netherlands, 1998; Volume 5, Advances in Exploration Geophysics; pp. 145–221. [Google Scholar] [CrossRef]
- Gobbi, S.; Zatelli, P. GRASS Development Team Addon r.fill.category. Geographic Resources Analysis Support System (GRASS) Software, Version 7.6. 2019. Available online: https://grass.osgeo.org/grass76/manuals/addons/r.fill.category.html (accessed on 25 July 2019).
- Zatelli, P. GRASS Development Team Addon r.object.thickness. Geographic Resources Analysis Support System (GRASS) Software, Version 7.6. 2019. Available online: https://grass.osgeo.org/grass76/manuals/addons/r.object.thickness.html (accessed on 25 July 2019).
- Giotis, A.; Sfikas, G.; Gatos, B.; Nikou, C. A survey of document image word spotting techniques. Pattern Recognit. 2017, 68, 310–332. [Google Scholar] [CrossRef]
- Krishnan, P.; Dutta, K.; Jawahar, C. Word spotting and recognition using deep embedding. In Proceedings of the 13th IAPR International Workshop on Document Analysis Systems, Vienna, Austria, 24–27 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Roy, P.; Pal, U.; Lladós, J. Query driven word retrieval in graphical documents. In Proceedings of the ACM International Conference Proceeding Series, Boston, MA, USA, 9–11 June 2010; pp. 191–198. [Google Scholar] [CrossRef]
- Tarafdar, A.; Pal, U.; Roy, P.; Ragot, N.; Ramel, J.Y. A two-stage approach for word spotting in graphical documents. In Proceedings of the International Conference on Document Analysis and Recognition, ICDAR, Washington, DC, USA, 25–28 August 2013; pp. 319–323. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Xu, P.; Miao, Q.; Liu, T.; Chen, X.; Nie, W. Graphic-based character grouping in topographic maps. Neurocomputing 2016, 189, 160–170. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
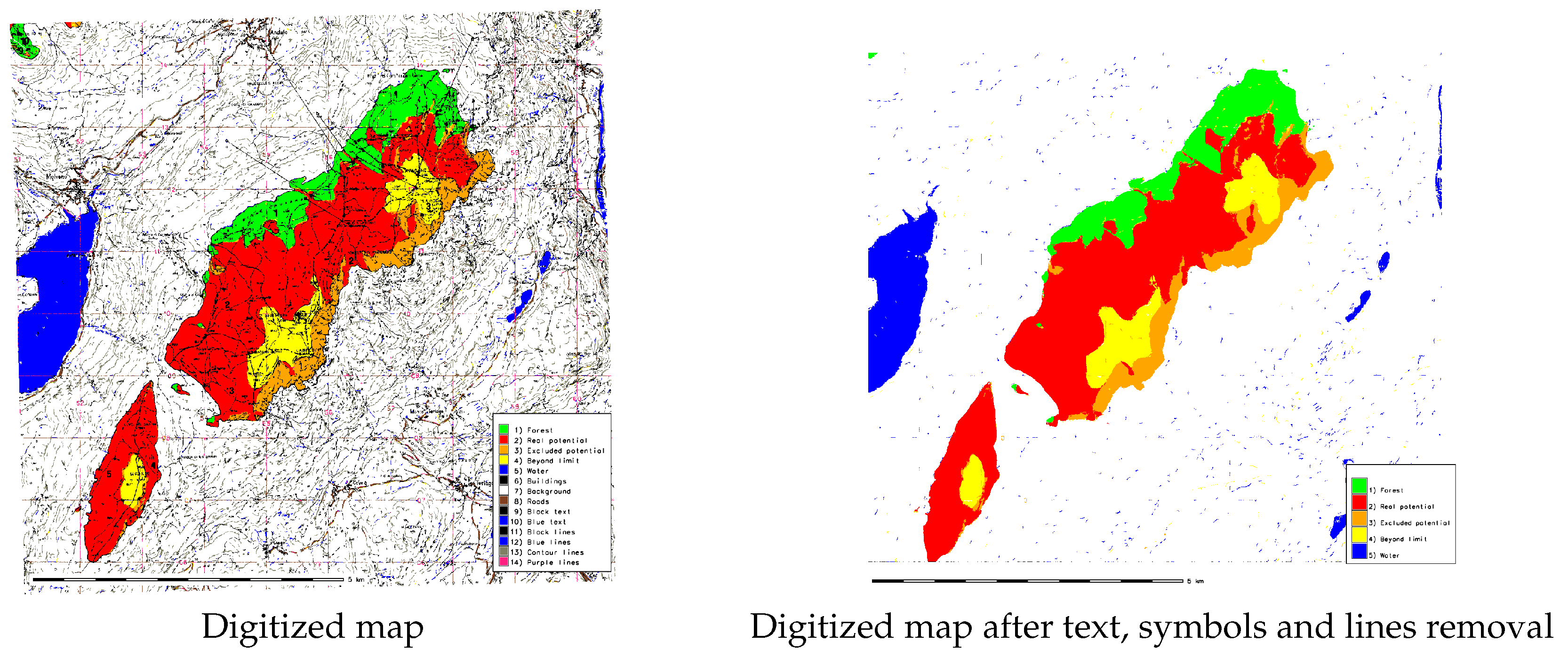{kind=link}
| Map | Threshold | Minsize | Optimization Criteria |
|---|---|---|---|
| Cadaster | 0.06 | 20 | 1.283 |
| IKFM | 0.03 | 20 | 1.077 |
| MPLFT | 0.03 | 60 | 1.340 |
| (a) Cadaster | |
|---|---|
| Class | Description |
| 1 | Forest |
| 2 | Crop land |
| 3 | Meadows |
| 4 | Pasture |
| 5 | Buildings |
| 6 | Roads |
| 7 | Gardens |
| 8 | Tracks |
| 9 | Water bodies |
| 10 | Map frame |
| 11 | Boundaries |
| 12 | Black text |
| 13 | Red text |
| 14 | Black lines |
| 15 | Red lines |
| (b) IKFM | |
| Class | Description |
| 1 | Conifers |
| 8 | Beech tree |
| 20 | Chestnut |
| 23 | Other species |
| 24 | Degraded forest |
| 30 | Background |
| 31 | City blocks |
| 32 | Brown text |
| 33 | Black symbols |
| 34 | Brown lines |
| 35 | Contour lines |
| 36 | Blue lines |
| 37 | Purple lines |
| (c) MPLFT | |
| Class | Description |
| 1 | Forest |
| 2 | Real potential [forest] |
| 3 | Excluded potential [forest] |
| 4 | Beyond [forest] limit |
| 5 | Water |
| 6 | Buildings |
| 7 | Background |
| 8 | Roads |
| 9 | Black text |
| 10 | Blue text |
| 11 | Black lines |
| 12 | Blue lines |
| 13 | Contour lines |
| 14 | Purple lines |
| Map | Min | Mean | Max | Filter Size | |
|---|---|---|---|---|---|
| Cadaster | [m] | 0.004318 | 1.625650 | 32.705302 | |
| [pixel] | 0.013467 | 5.070013 | 101.999999 | 53 | |
| IKFM | [m] | 0.004409 | 59.438563 | 1249.561948 | |
| [pixel] | 0.000678 | 9.135900 | 192.061727 | 97 | |
| MPLFT | [m] | 0.004493 | 10.868955 | 276.521482 | |
| [pixel] | 0.002118 | 5.122713 | 130.329011 | 67 |
| SMV | SWV | BWWV | QBWWV | |||||
|---|---|---|---|---|---|---|---|---|
| Map | Kappa | Accuracy | Kappa | Accuracy | Kappa | Accuracy | Kappa | Accuracy |
| Cadaster | 0.945367 | 96.706618 | 0.952895 | 97.156840 | 0.949426 | 96.944917 | 0.949426 | 96.944917 |
| Cadaster post | 0.961574 | 97.727262 | 0.969815 | 98.212840 | 0.967224 | 98.058683 | 0.967224 | 98.058683 |
| IKFM | 0.552870 | 67.439228 | 0.551012 | 67.237156 | 0.553261 | 67.442162 | 0.553261 | 67.442162 |
| IKFM post | 0.887051 | 93.064664 | 0.892390 | 93.399099 | 0.892722 | 93.422756 | 0.892722 | 93.422756 |
| MPLFT | 0.727045 | 82.038126 | 0.745224 | 83.390072 | 0.745680 | 83.420707 | 0.745680 | 83.420707 |
| MPLFT post | 0.935200 | 96.101119 | 0.936114 | 96.152864 | 0.937423 | 96.264055 | 0.936315 | 96.165954 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gobbi, S.; Ciolli, M.; La Porta, N.; Rocchini, D.; Tattoni, C.; Zatelli, P. New Tools for the Classification and Filtering of Historical Maps. ISPRS Int. J. Geo-Inf. 2019, 8, 455. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8100455
Gobbi S, Ciolli M, La Porta N, Rocchini D, Tattoni C, Zatelli P. New Tools for the Classification and Filtering of Historical Maps. ISPRS International Journal of Geo-Information. 2019; 8(10):455. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8100455
Chicago/Turabian StyleGobbi, Stefano, Marco Ciolli, Nicola La Porta, Duccio Rocchini, Clara Tattoni, and Paolo Zatelli. 2019. "New Tools for the Classification and Filtering of Historical Maps" ISPRS International Journal of Geo-Information 8, no. 10: 455. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8100455