Road Extraction from Very High Resolution Images Using Weakly labeled OpenStreetMap Centerline


Abstract
:1. Introduction
- A novel deep learning approach based on revised ResUNet with hybrid loss is proposed for road extraction, which can only be supervised by weakly labeled OSM centerline instead of carefully notated pixel-wise road width information.
- In order to improve the performance of the proposed model furtherly, a novel multi-dilation network with learnable parameters is added to conventional ResUnet. The multi-dilation network, which employs non-linear dilated convolution, can exchange information with various corresponding layers of ResUnet and expand the receptive field of convolution operations in ResUnet. The experiment results show that compared to conventional ResUnet, the multi-dilation ResUnet can work better in weakly supervised learning.
- To validate the proposed methods, we conducted experiments on two different datasets. The experiment results show that the proposed road extraction approach achieves promising performance close to fully supervised methods using a high quality pixel-wise training dataset.
2. Related Work
2.1. Road Extraction
2.2. Weakly Supervised Learning
3. Methodology for Weakly Supervised Road Extraction
3.1. Initial Road Annotation Inference
3.2. Regularized Semi-Supervised Loss
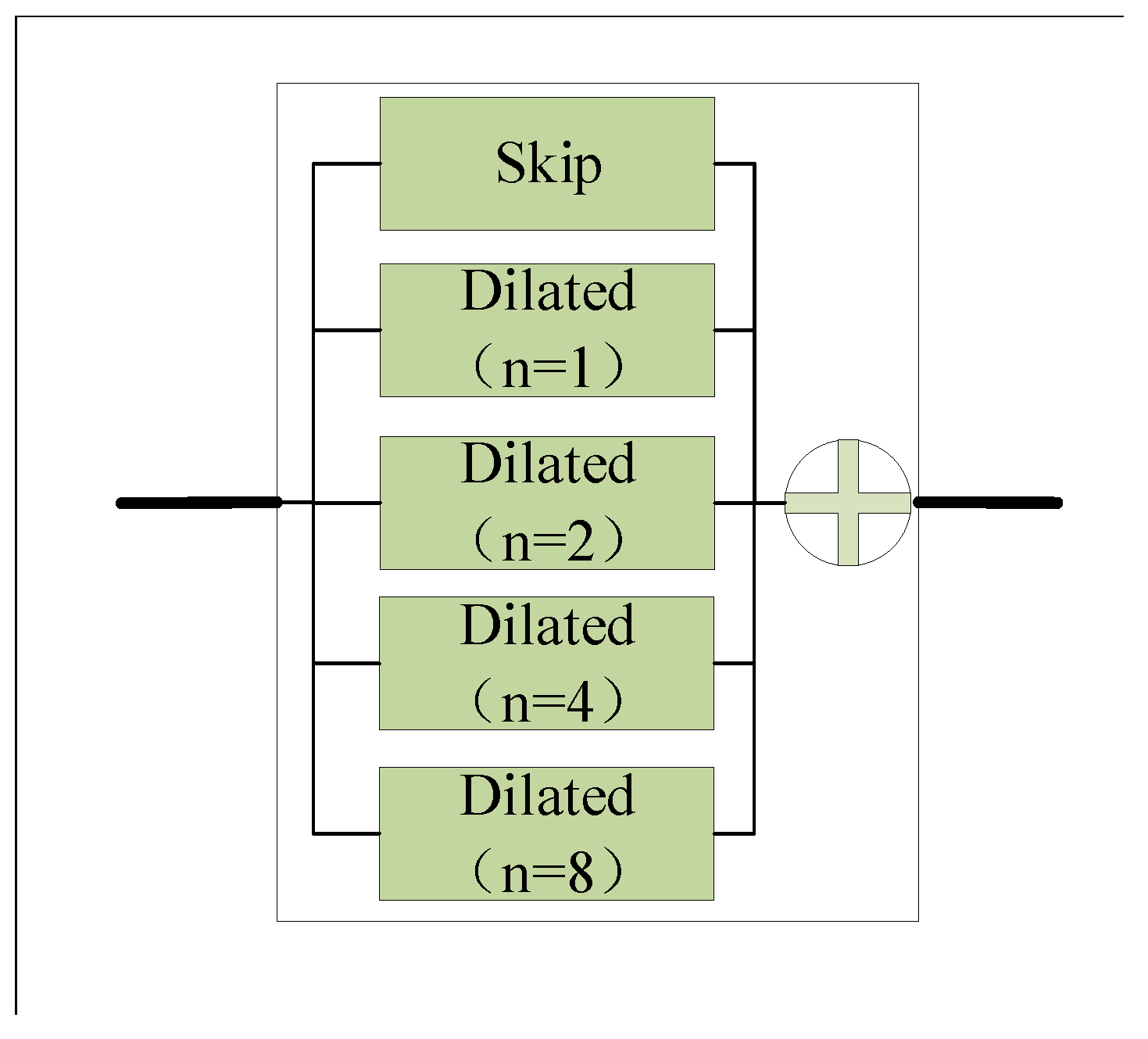
3.3. Road Extraction Using Multi-Dilated ResUNET
3.4. Training Algorithm
| Algorithm 1: Training the MD-ResUNet |
| input: The input VHR images The annotation inferenced by the OSM centerlines The parameter of the normalized cur weight The parameter of the learning rate The parameter of the max iteration times for partial supervised learning The parameter of the max iteration times for the whole learning output: The model parameters 1 randomly initialize the model parameter ; 2 3 for : 4 5 6 7 8 9 10 |
4. Experiment
4.1. Dataset Description
4.2. Data Processing
4.3. Results Comparison
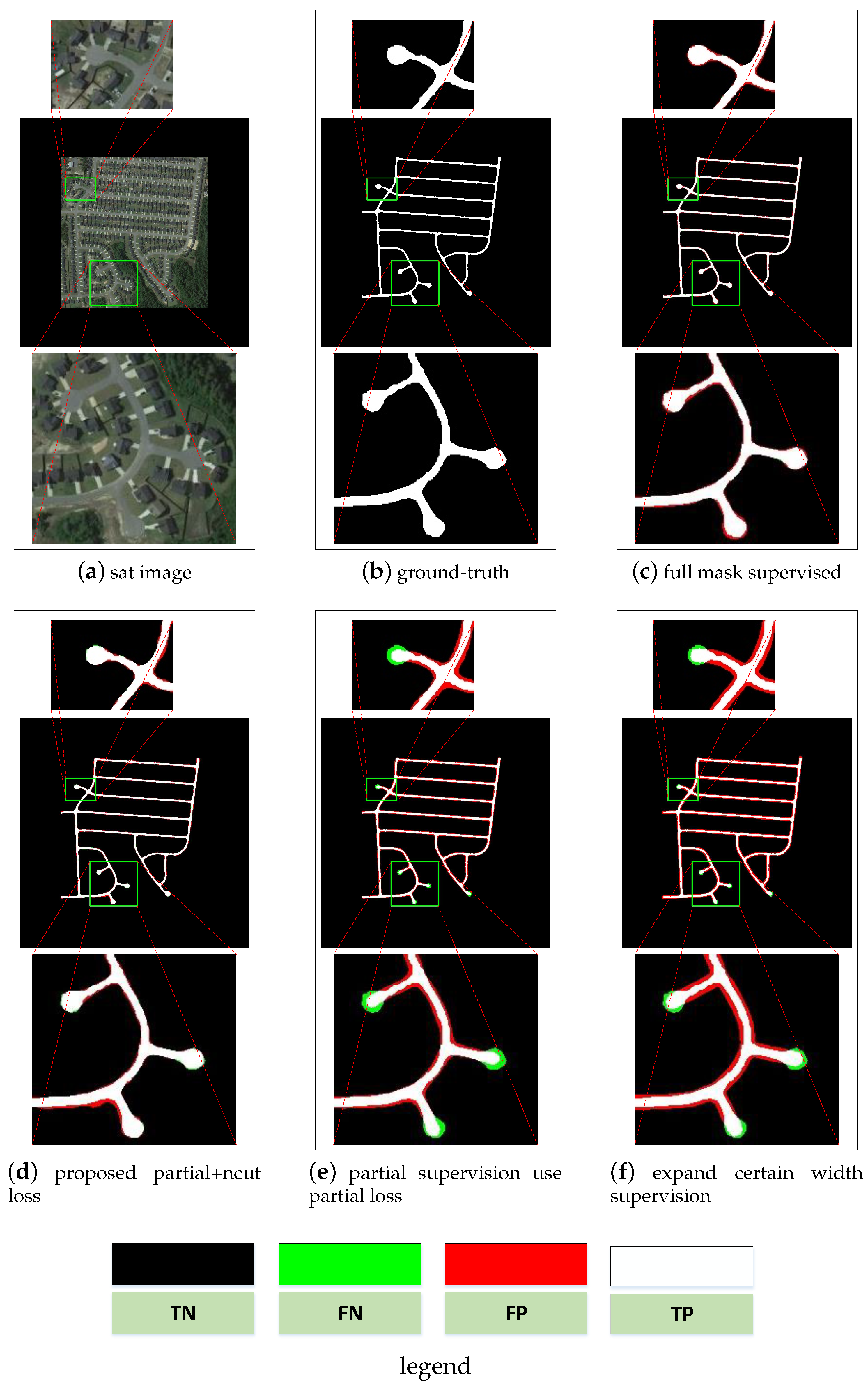
4.3.1. Evaluation the Partial Loss Performance of the Road Extraction
4.3.2. Evaluation Road Extraction Using Normalized Cut Loss Combined With Partial Losses
- The proposed MD-ResUNet achieves better performance than the state-of-the-art methods ResUNet and D-Linknet in VHR images road extraction, especially for the partial supervised dataset.
- Compared with those methods supervised by full annotation, our proposed method supervised by partial centerline annotation achieves close performance.
- The normalized cut loss promotes the road extraction performance because it can extract more details of the VHR images.
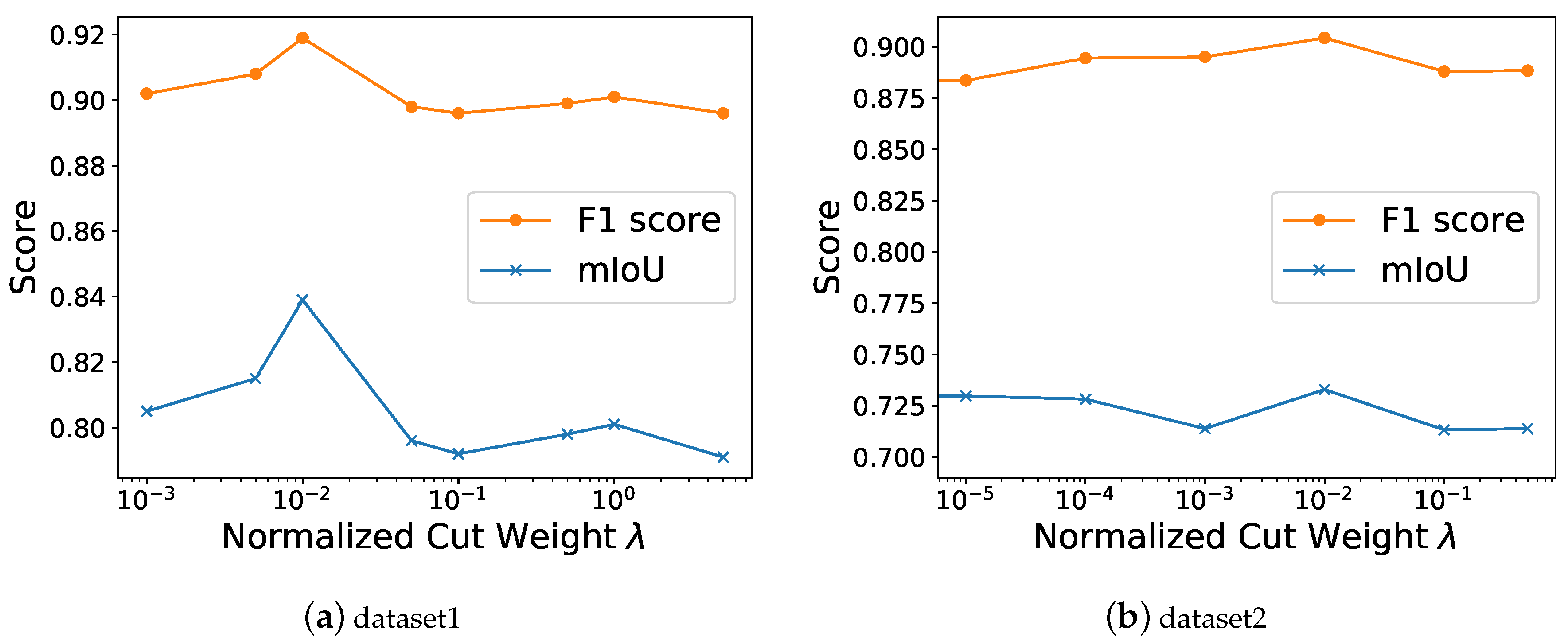
4.4. The Influence of the Parameter to the Weakly Supervised Road Extraction
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Peng, T.; Jermyn, I.H.; Prinet, V.; Zerubia, J. Incorporating Generic and Specific Prior Knowledge in a Multiscale Phase Field Model for Road Extraction From VHR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2008, 1, 139–146. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef]
- Guo, Z.; Du, S. Mining parameter information for building extraction and change detection with very high-resolution imagery and GIS data. GIscience Remote Sens. 2017, 54, 38–63. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Zhu, C.; Shi, W.; Pesaresi, M.; Liu, L.; Chen, X.; King, B. The recognition of road network from high-resolution satellite remotely sensed data using image morphological characteristics. Int. J. Remote Sens. 2005, 26, 5493–5508. [Google Scholar] [CrossRef]
- Shi, W.; Miao, Z.; Debayle, J. An integrated method for urban main-road centerline extraction from optical remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2013, 52, 3359–3372. [Google Scholar] [CrossRef]
- Wang, J.; Song, J.; Chen, M.; Yang, Z. Road network extraction: A neural-dynamic framework based on deep learning and a finite state machine. Int. J. Remote Sens. 2015, 36, 3144–3169. [Google Scholar] [CrossRef]
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. 2016, 3, 271–282. [Google Scholar] [CrossRef] [Green Version]
- OpenStreetMap. Available online: https://www.openstreetmap.org/ (accessed on 22 April 2019).
- Haklay, M.; Weber, P. OpenStreetMap: User-Generated Street Maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- Haklay, M. How good is volunteered geographical information? A comparative study of OpenStreetMap and Ordnance Survey datasets. Environ. Plan. Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Girres, J.F.; Touya, G. Quality Assessment of the French OpenStreetMap Dataset. Trans. Gis 2010, 14, 435–459. [Google Scholar] [CrossRef]
- Pathak, D.; Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional multi-class multiple instance learning. arXiv 2014, arXiv:1412.7144. [Google Scholar]
- Papandreou, G.; Chen, L.C.; Murphy, K.; Yuille, A.L. Weakly- and Semi-Supervised Learning of a DCNN for Semantic Image Segmentation. arXiv 2015, arXiv:1502.02734. [Google Scholar]
- Dai, J.; He, K.; Sun, J. BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation. arXiv 2015, arXiv:1503.01640. [Google Scholar]
- Bearman, A.; Russakovsky, O.; Ferrari, V.; Fei-Fei, L. What’s the Point: Semantic Segmentation with Point Supervision. arXiv 2015, arXiv:1506.02106. [Google Scholar]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3159–3167. [Google Scholar]
- Xu, J.; Schwing, A.G.; Urtasun, R. Learning to segment under various forms of weak supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3781–3790. [Google Scholar]
- Khoreva, A.; Benenson, R.; Hosang, J.; Hein, M.; Schiele, B. Simple does it: Weakly supervised instance and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 876–885. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Yang, C.; Duraiswami, R.; DeMenthon, D.; Davis, L. Mean-shift analysis using quasinewton methods. In Proceedings of the 2003 International Conference on Image Processing (Cat. No. 03CH37429), Barcelona, Spain, 14–17 September 2003; Volume 2. [Google Scholar]
- Miao, Z.; Wang, B.; Shi, W.; Zhang, H. A semi-automatic method for road centerline extraction from VHR images. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1856–1860. [Google Scholar] [CrossRef]
- Unsalan, C.; Sirmacek, B. Road network detection using probabilistic and graph theoretical methods. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4441–4453. [Google Scholar] [CrossRef]
- Pawar, V.; Zaveri, M. Graph based K-nearest neighbor minutiae clustering for fingerprint recognition. In Proceedings of the 2014 10th International Conference on Natural Computation (ICNC), Xiamen, China, 19–21 August 2014; pp. 675–680. [Google Scholar]
- Kirthika, A.; Mookambiga, A. Automated road network extraction using artificial neural network. In Proceedings of the 2011 International Conference on Recent Trends in Information Technology (ICRTIT), Chennai, Tamil Nadu, India, 3–5 June 2011; pp. 1061–1065. [Google Scholar]
- George, J.; Mary, L.; Riyas, K. Vehicle detection and classification from acoustic signal using ANN and KNN. In Proceedings of the 2013 International Conference on Control Communication and Computing (ICCC), Thiruvananthapuram, India, 13–15 December 2013; pp. 436–439. [Google Scholar]
- Simler, C. An improved road and building detector on VHR images. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium, Vancouver, BC, Canada, 24–29 July 2011; pp. 507–510. [Google Scholar]
- Zhu, D.M.; Wen, X.; Ling, C.L. Road extraction based on the algorithms of MRF and hybrid model of SVM and FCM. In Proceedings of the 2011 International Symposium on Image and Data Fusion, Tengchong, China, 9–11 August 2011; pp. 1–4. [Google Scholar]
- Zhou, J.; Bischof, W.F.; Caelli, T. Road tracking in aerial images based on human–computer interaction and Bayesian filtering. ISPRS J. Photogramm. Remote Sens. 2006, 61, 108–124. [Google Scholar] [CrossRef]
- Li, J.; Chen, M. On-road multiple obstacles detection in dynamical background. In Proceedings of the 2014 Sixth International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2014; Volume 1, pp. 102–105. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; The Pennsylvania State University: State College, PA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Costea, D.; Marcu, A.; Leordeanu, M.; Slusanschi, E. Creating Roadmaps in Aerial Images with Generative Adversarial Networks and Smoothing-Based Optimization. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Venice, Italy, 22–29 Octover 2017. [Google Scholar]
- Wei, Y.; Wang, Z.; Xu, M. Road structure refined CNN for road extraction in aerial image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road Extraction from High-Resolution Remote Sensing Imagery Using Deep Learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wu, Z.; Gao, Y.; Li, L.; Xue, J.; Li, Y. Semantic segmentation of high-resolution remote sensing images using fully convolutional network with adaptive threshold. Connect. Sci. 2018, 31, 169–184. [Google Scholar] [CrossRef]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth Through Satellite Images. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Aich, S.; van der Kamp, W.; Stavness, I. Semantic Binary Segmentation using Convolutional Networks without Decoders. arXiv 2018, arXiv:1805.00138. [Google Scholar]
- Sun, T.; Chen, Z.; Yang, W.; Wang, Y. Stacked U-Nets With Multi-Output for Road Extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 202–206. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-linknet: Linknet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar]
- Sun, T.; Di, Z.; Che, P.; Liu, C.; Wang, Y. Leveraging Crowdsourced GPS Data for Road Extraction from Aerial Imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Tang, M.; Djelouah, A.; Perazzi, F.; Boykov, Y.; Schroers, C. Normalized cut loss for weakly-supervised CNN segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1818–1827. [Google Scholar]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Tang, M.; Marin, D.; Ayed, I.B.; Boykov, Y. Kernel Cuts: MRF meets kernel and spectral clustering. arXiv 2015, arXiv:1506.07439. [Google Scholar]
- Tang, M.; Marin, D.; Ayed, I.B.; Boykov, Y. Normalized cut meets MRF. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 748–765. [Google Scholar]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On spectral clustering: Analysis and an algorithm. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2002; pp. 849–856. [Google Scholar]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps for dimensionality reduction and data representation. Neural Comput. 2003, 15, 1373–1396. [Google Scholar] [CrossRef]
- Adams, A.; Gelfand, N.; Dolson, J.; Levoy, M. Gaussian kd-trees for fast high-dimensional filtering. In ACM Transactions on Graphics (ToG); ACM: New York, NY, USA, 2009; Volume 28, p. 21. [Google Scholar]
- Adams, A.; Baek, J.; Davis, M.A. Fast high-dimensional filtering using the permutohedral lattice. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2010; Volume 29, pp. 753–762. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Jian, S. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; Volume 1, p. 6. [Google Scholar]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic road detection and centerline extraction via cascaded end-to-end convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Martin, D.R.; Fowlkes, C.C.; Malik, J. Learning to detect natural image boundaries using local brightness, color, and texture cues. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 55, 530–549. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DataSet | Resolution | Area | Train | Test | Image Origin | Mask | Centerline |
|---|---|---|---|---|---|---|---|
| dataset1 | 1 m | America | 224 | 30 | Google Earth | muannual | muannual |
| dataset2 | 1.2 m | Seat | 285 | 30 | Google Earth | muannual | OSM |
| Annotation Dataset | Description |
|---|---|
| expand | directly inference by the centerline with certain road width |
| partial | inferenced by the centerline with certain width |
| full mask | pixel-wise annotation |
| Supervised | Loss-Function | Model | mIoU | P | |
|---|---|---|---|---|---|
| partial | partial loss | ResUnet | 0.87653086 | 0.75306173 | 0.89570851 |
| D-LinkNet | 0.87563359 | 0.75126717 | 0.92245609 | ||
| MD-ResUNet | 0.89013831 | 0.78027661 | 0.92865744 | ||
| expand | BCE+Dice loss | ResUnet | 0.86819215 | 0.73638429 | 0.93281329 |
| D-LinkNet | 0.86561087 | 0.73122173 | 0.93385345 | ||
| MD-ResUNet | 0.87207447 | 0.74414894 | 0.94288713 |
| Supervised | Loss-Function | Model | mIoU | P | |
|---|---|---|---|---|---|
| partial | partial loss | ResUnet | 0.84706692 | 0.69413384 | 0.80269701 |
| D-LinkNet | 0.84848621 | 0.69697242 | 0.82086524 | ||
| MD-ResUNet | 0.85499718 | 0.70999437 | 0.82653416 | ||
| expand | BCE+Dice loss | ResUnet | 0.8246249 | 0.6492498 | 0.7020651 |
| D-LinkNet | 0.82397769 | 0.6479554 | 0.7026635 | ||
| MD-ResUNet | 0.83285842 | 0.6657168 | 0.7195871 |
| Supervised | Loss-Function | Model | mIoU | P | |
|---|---|---|---|---|---|
| partial | partial loss | ResUnet | 0.87653086 | 0.75306173 | 0.89570851 |
| D-LinkNet | 0.87563359 | 0.75126717 | 0.92245609 | ||
| MD-ResUNet | 0.89013831 | 0.78027661 | 0.92865744 | ||
| partial+Ncut | ResUnet | 0.88004242 | 0.76008483 | 0.96818677 | |
| D-LinkNet | 0.89228412 | 0.78456824 | 0.96587194 | ||
| MD-ResUNet | 0.91944608 | 0.83889217 | 0.96507713 | ||
| expand | BCE +Dice loss | ResUnet | 0.86819215 | 0.73638429 | 0.93281329 |
| D-LinkNet | 0.86561087 | 0.73122173 | 0.93385345 | ||
| MD-ResUNet | 0.87207447 | 0.74414894 | 0.94288713 | ||
| full mask | BCE+Dice loss | ResUnet | 0.91902045 | 0.8380409 | 0.97072665 |
| D-LinkNet | 0.92372486 | 0.84744971 | 0.96415442 | ||
| MD-ResUNet | 0.92982933 | 0.85965865 | 0.97936734 |
| Supervised | Loss-Function | Model | mIoU | P | |
|---|---|---|---|---|---|
| partial | partial loss | ResUnet | 0.84706692 | 0.6941338 | 0.8026970 |
| D-LinkNet | 0.84848621 | 0.6969724 | 0.8208652 | ||
| MD-ResUNet | 0.85499718 | 0.7099944 | 0.8265342 | ||
| partial+Ncut | ResUnet | 0.85568974 | 0.71096308 | 0.83879415 | |
| D-LinkNet | 0.8514525 | 0.70309051 | 0.84594471 | ||
| MD-ResUNet | 0.88389762 | 0.7677952 | 0.8792988 | ||
| expand | BCE + Dice loss | ResUnet | 0.8246249 | 0.6492498 | 0.6820651 |
| D-LinkNet | 0.82397769 | 0.6479554 | 0.7026635 | ||
| MD-ResUNet | 0.83285842 | 0.6657168 | 0.6995871 | ||
| full mask | BCE+ Dice loss | ResUnet | 0.88128277 | 0.7625655 | 0.8658043 |
| D-LinkNet | 0.88294264 | 0.7658853 | 0.8762808 | ||
| MD-ResUNet | 0.89268734 | 0.7853747 | 0.9043937 |
| 0.001 | 0.005 | 0.01 | 0.05 | 0.1 | 0.5 | 1 | 5 | |
|---|---|---|---|---|---|---|---|---|
| mIoU | 0.805 | 0.815 | 0.839 | 0.796 | 0.792 | 0.798 | 0.801 | 0.791 |
| 0.902 | 0.908 | 0.919 | 0.898 | 0.896 | 0.899 | 0.901 | 0.896 |
| 0 | 0.00001 | 0.0001 | 0.001 | 0.01 | 0.1 | 0.5 | |
|---|---|---|---|---|---|---|---|
| mIoU | 0.699994 | 0.729759 | 0.72825 | 0.71389 | 0.732915 | 0.713298 | 0.713852 |
| 0.849997 | 0.864879 | 0.864125 | 0.856945 | 0.866458 | 0.856649 | 0.856926 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, S.; Du, C.; Chen, H.; Xu, Y.; Guo, N.; Jing, N. Road Extraction from Very High Resolution Images Using Weakly labeled OpenStreetMap Centerline. ISPRS Int. J. Geo-Inf. 2019, 8, 478. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8110478
Wu S, Du C, Chen H, Xu Y, Guo N, Jing N. Road Extraction from Very High Resolution Images Using Weakly labeled OpenStreetMap Centerline. ISPRS International Journal of Geo-Information. 2019; 8(11):478. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8110478
Chicago/Turabian StyleWu, Songbing, Chun Du, Hao Chen, Yingxiao Xu, Ning Guo, and Ning Jing. 2019. "Road Extraction from Very High Resolution Images Using Weakly labeled OpenStreetMap Centerline" ISPRS International Journal of Geo-Information 8, no. 11: 478. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8110478