Analysis of Tourism Hotspot Behaviour Based on Geolocated Travel Blog Data: The Case of Qyer


Abstract
:1. Introduction
2. Literature Review
2.1. Data Science and Big Data for Social Science Research
2.2. Social Media Mining for Tourism Research
2.3. Geolocated Data Mining for Tourist Behaviour Analysis
3. Method
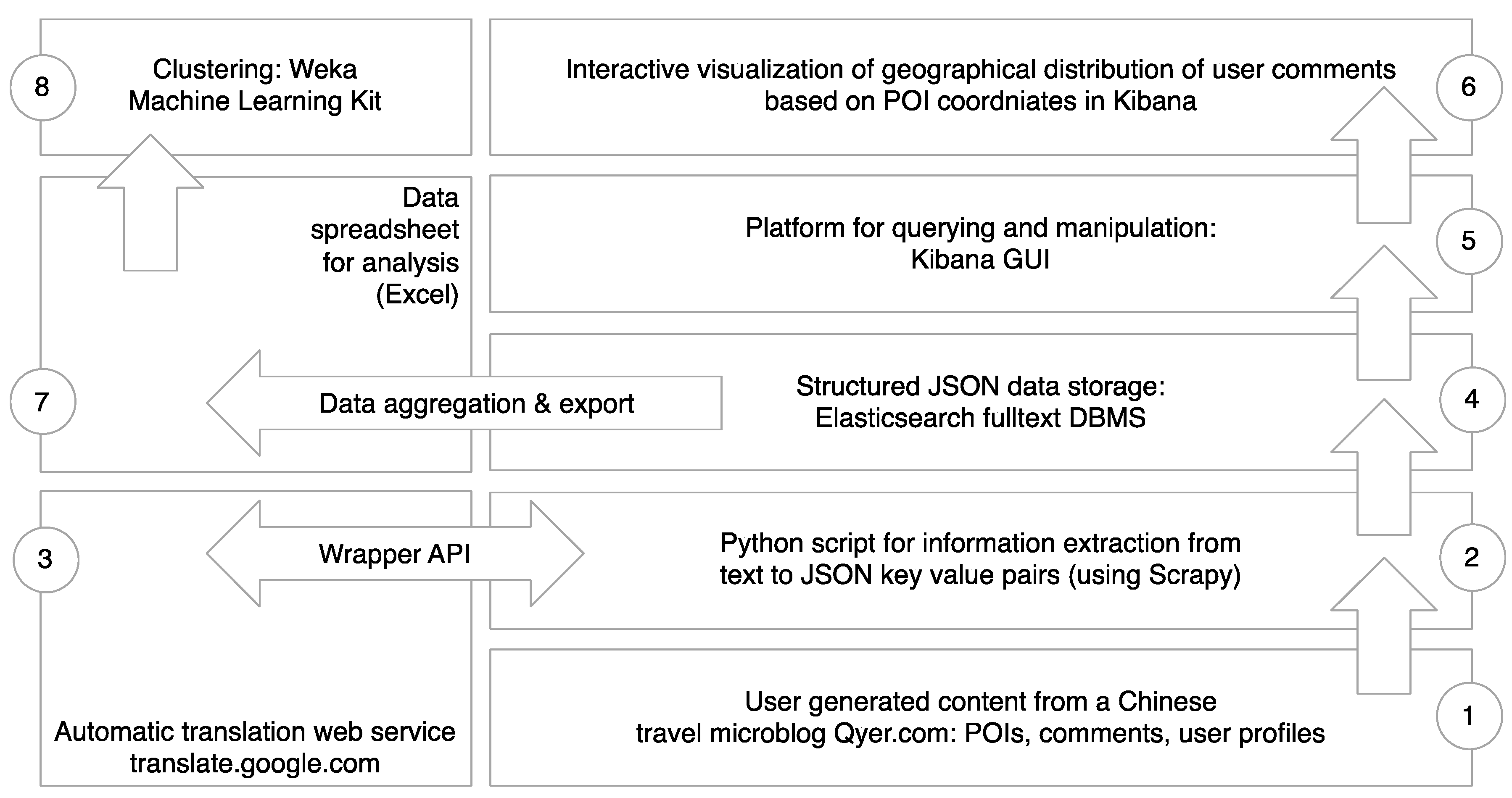
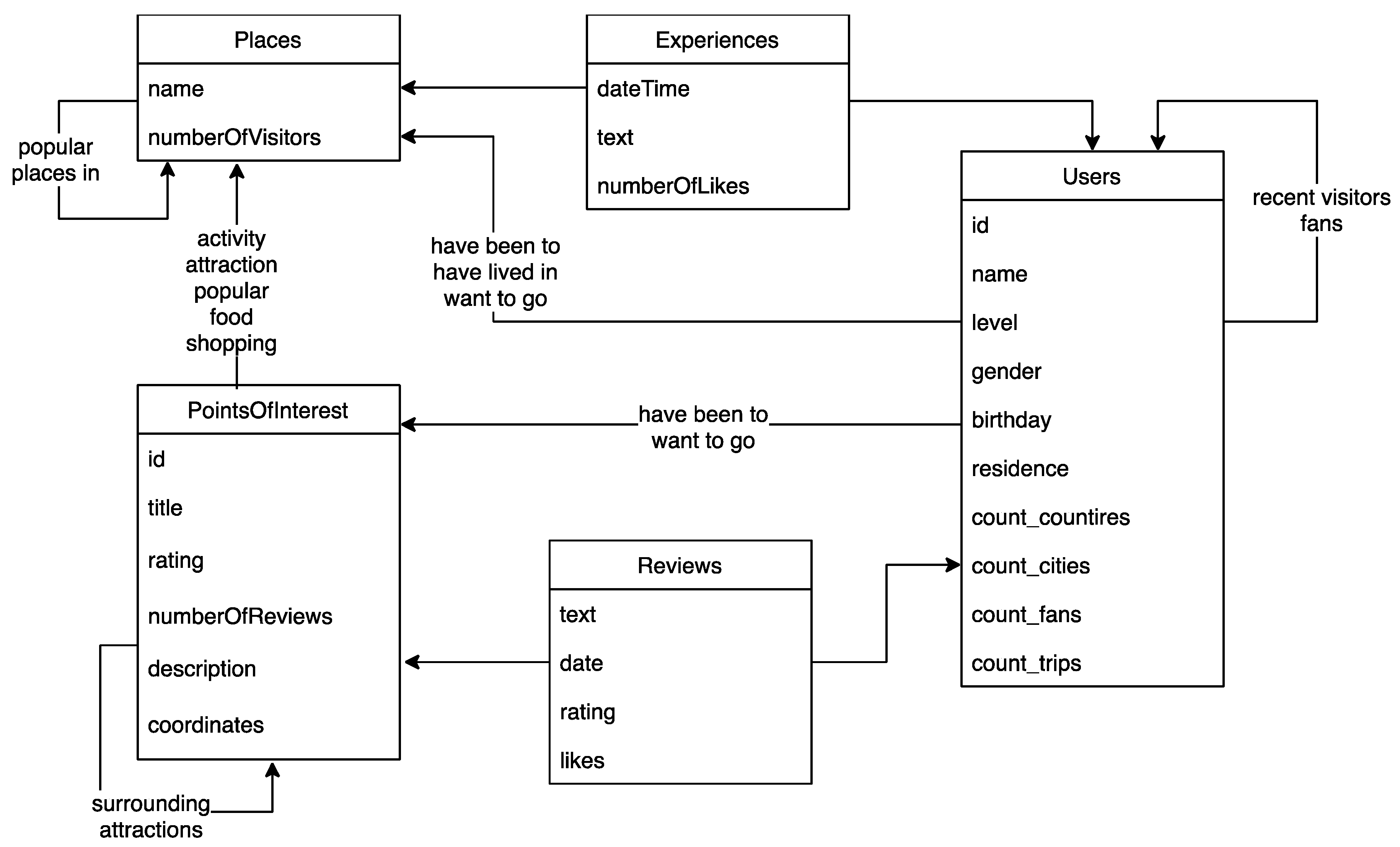
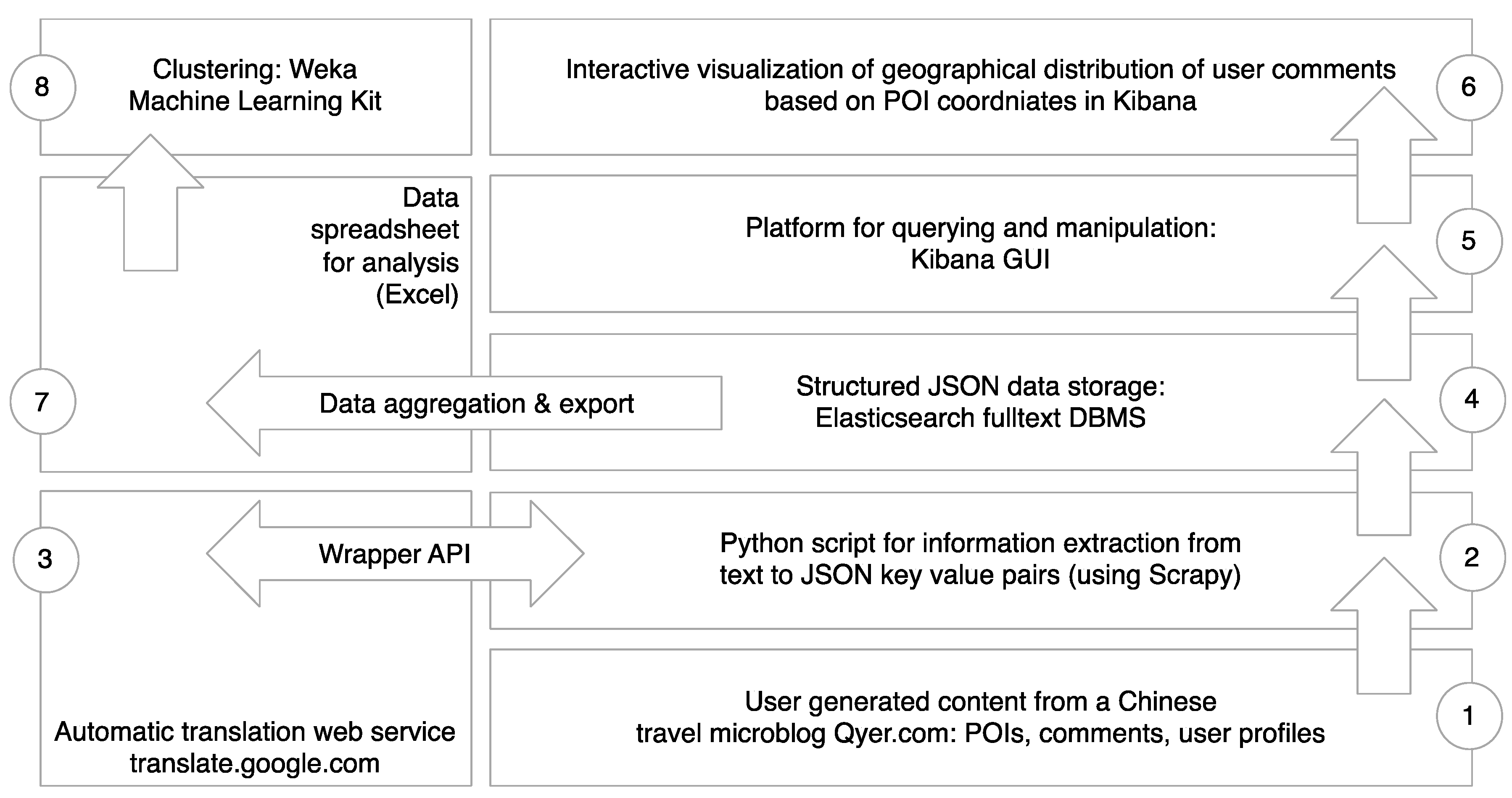
3.1. System Design for Data Collection: The Case of Qyer.com
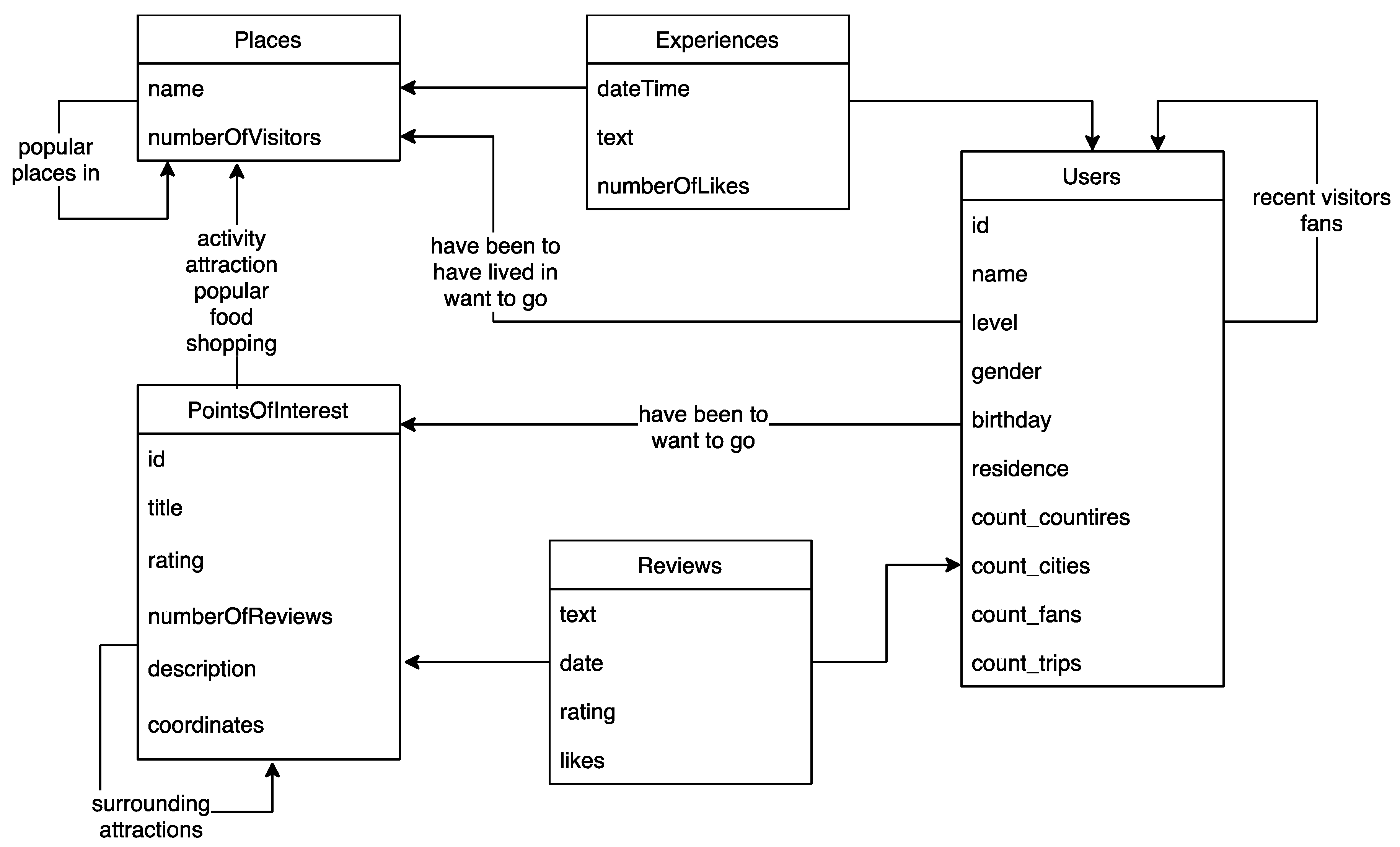
3.2. Theorizing and Generalization: Formal Methodology
- is a set of comments (posts, reviews) by users about locations interesting for tourism;
- is a set of locations (sights, places) the users comment on and thus show their interest in. These locations possibly have a nested granular structure, such as places that contain POIs These locations are the object of travel hotspot detection;
- is a set of users who post these comments; these users are the object of tourist segmentation;
- is a mapping indicating the location that a comment is about;
- is the inverse function mapping a location to a set of comments that are about that location;
- is a mapping indicating the user who is the author of a comment;
- is a mapping indicating the set of users who commented on a location;
- is a mapping indicating, for each user, the set of users who follow them on the social network (i.e., subscribe to their content);
- is a set of analytic variables that represent data about the users. These features are candidates for classification predicates to segment the user base of the travel blog.
4. Results
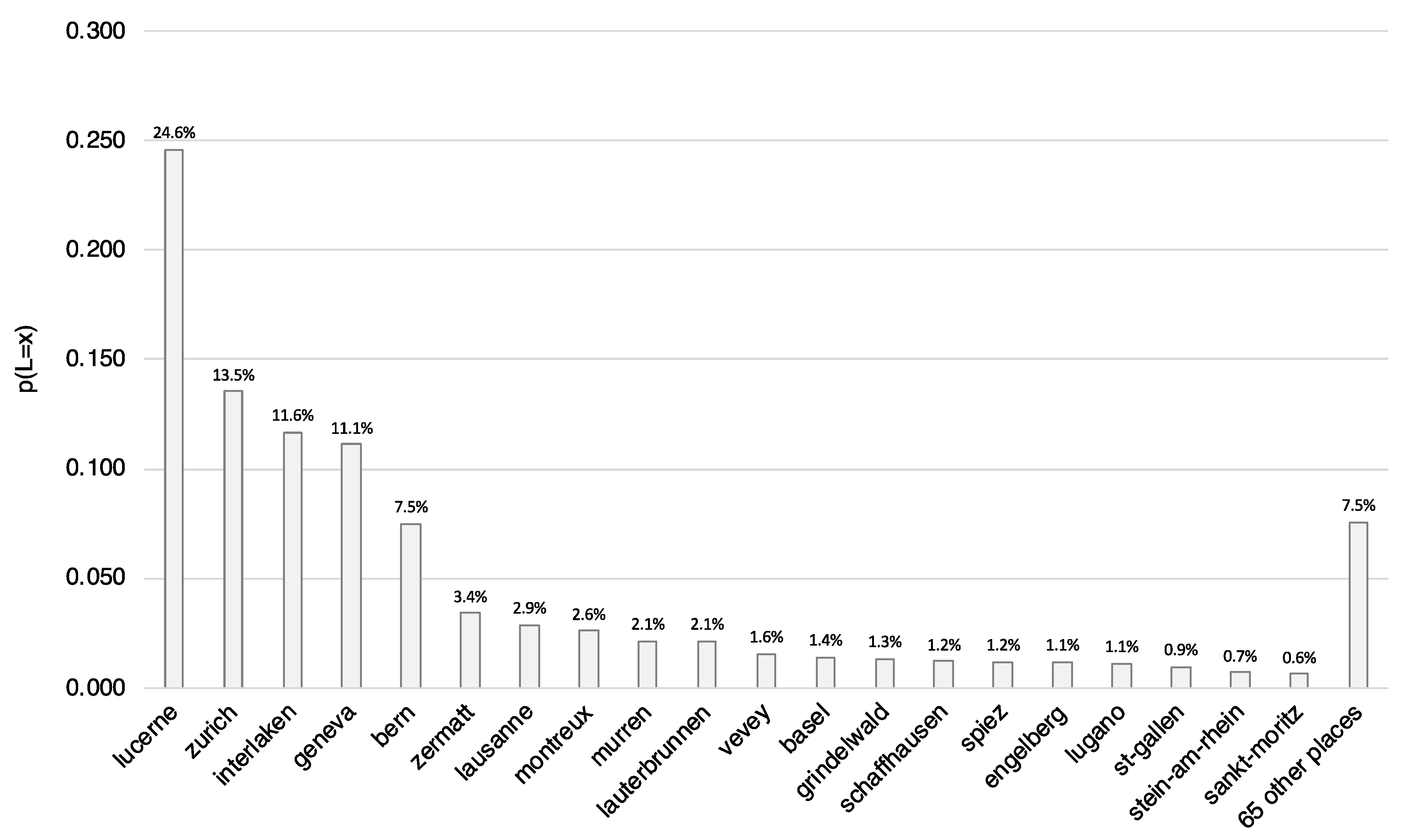
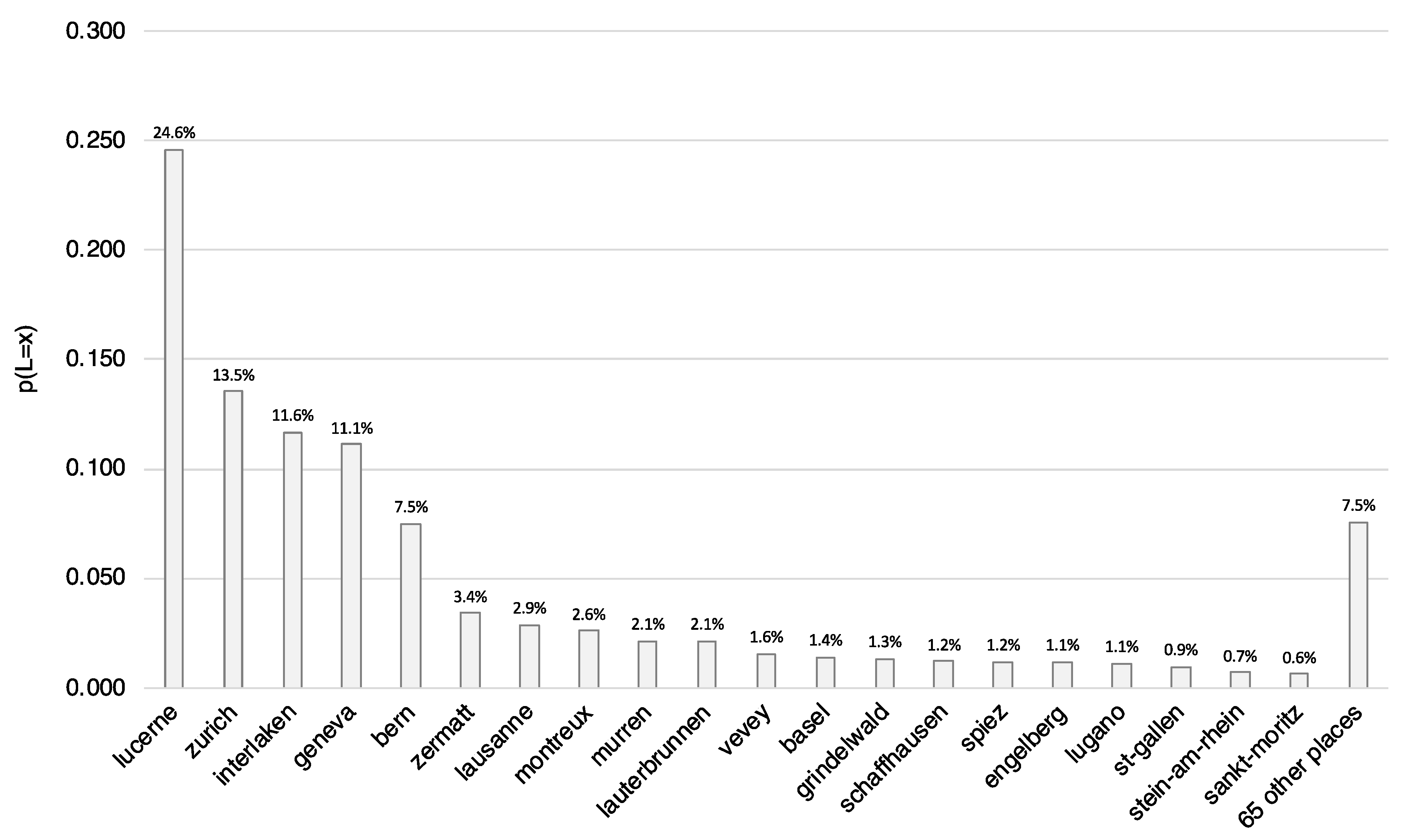
4.1. Tourist Hotspots: Geographical Distribution of Geolocated Blog Posts on Qyer
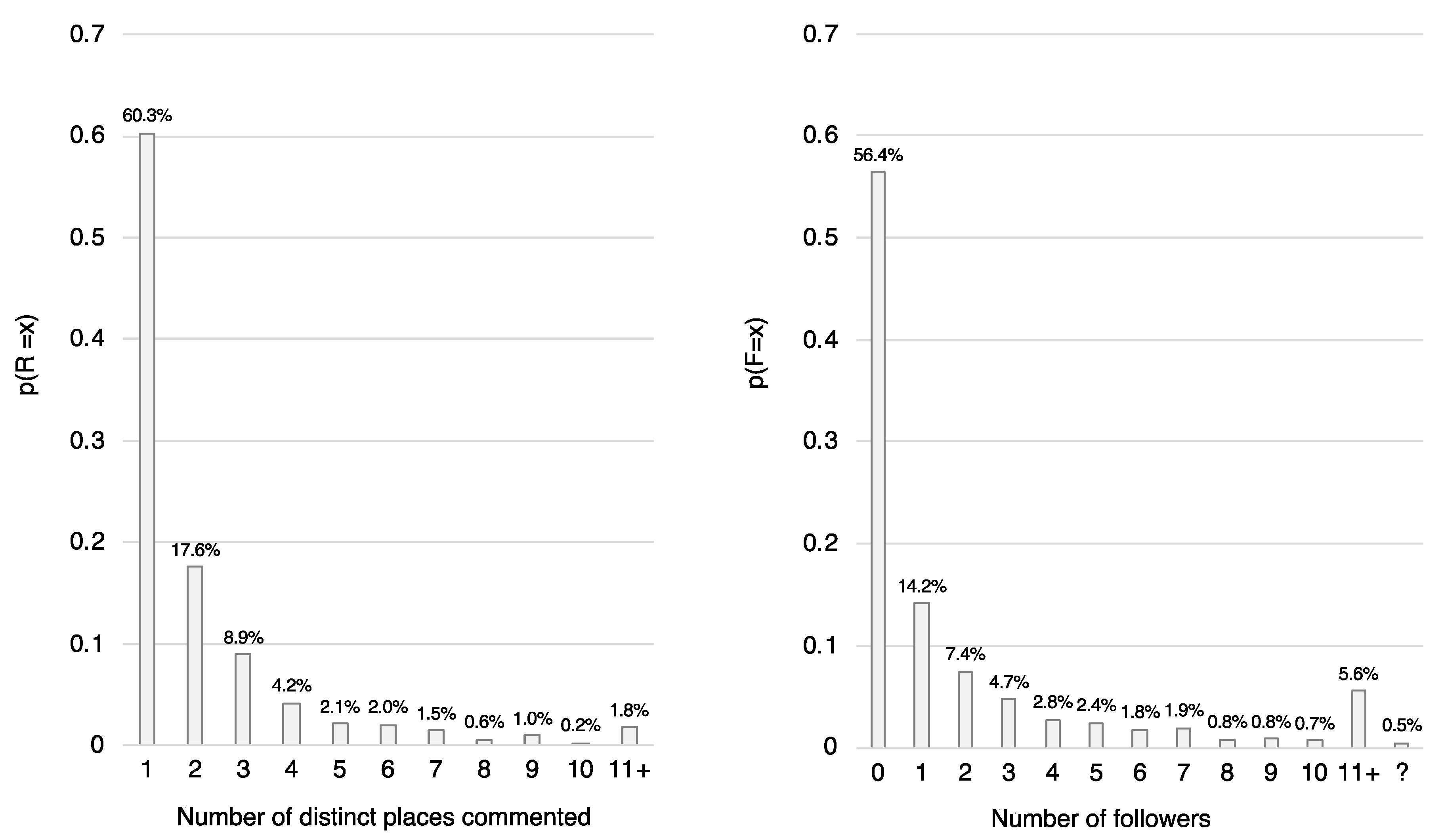
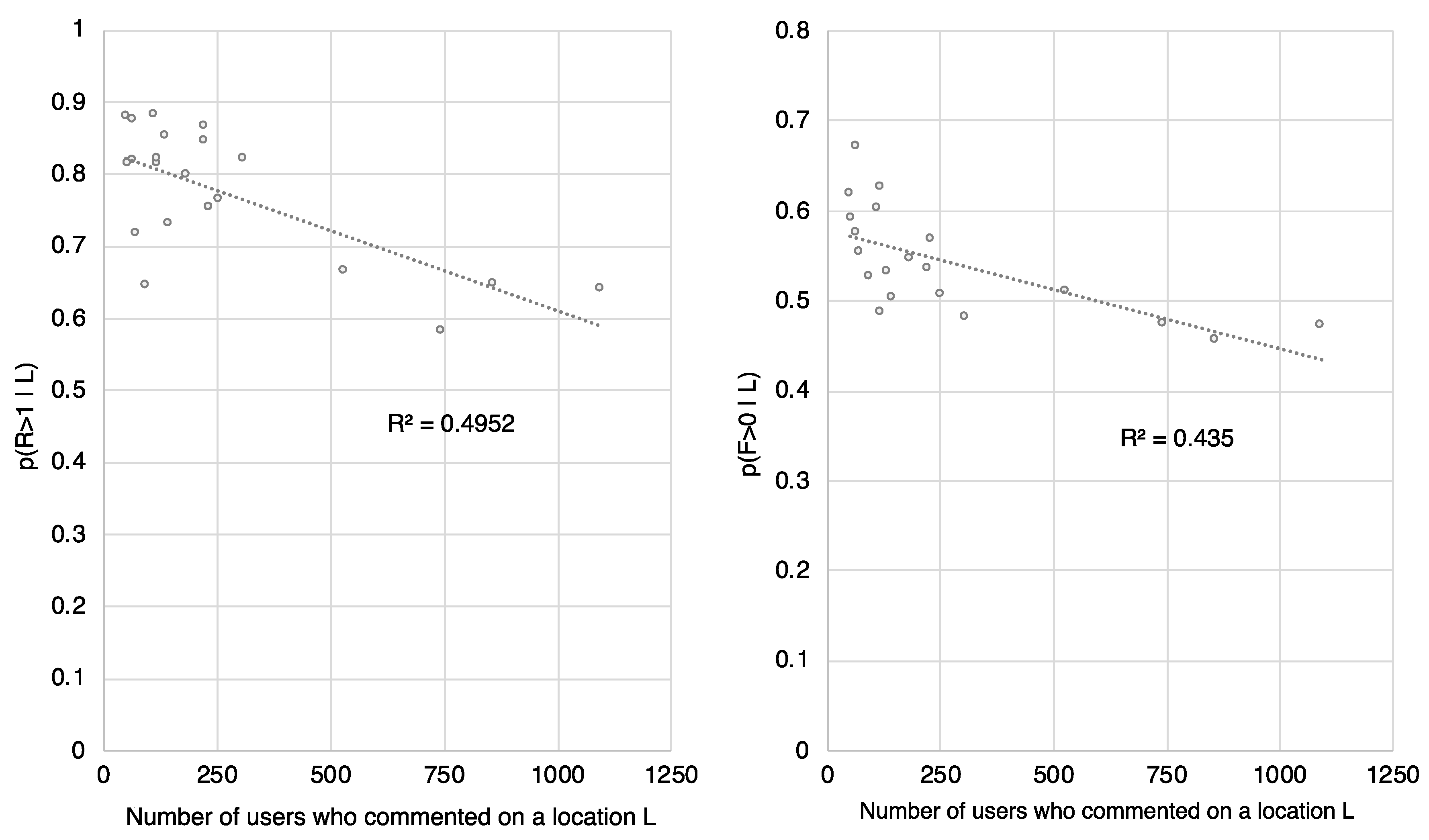
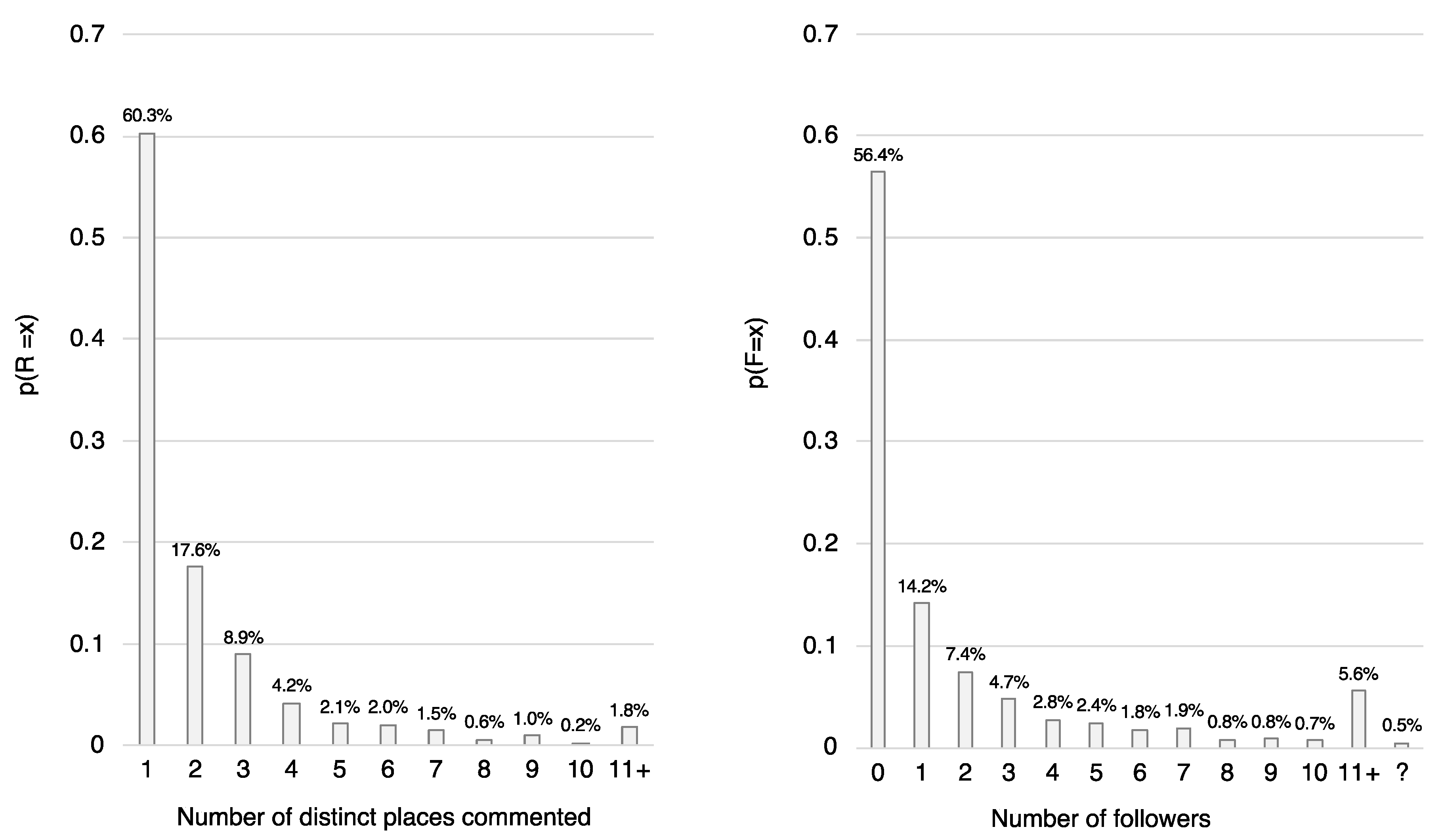
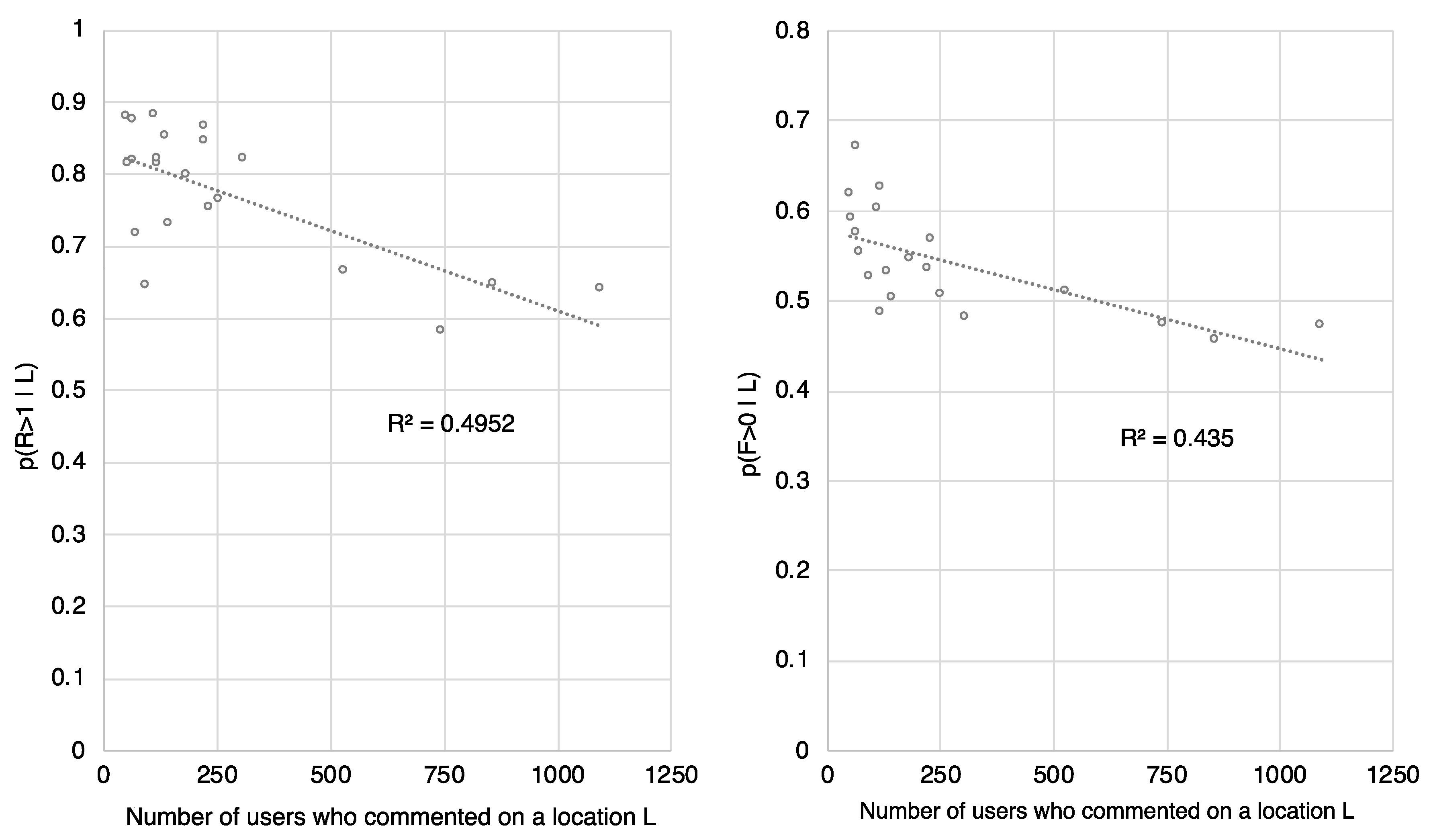
4.2. Tourist Segmentation Regarding Hotspot Interest Using Social Media Activity Features
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bauder, M. Engage! A Research Agenda for Big Data in Tourism Geography. In A Research Agenda for Tourism Geographies; Müller, D., Ed.; Edward Elgar Publishing Limited: Cheltenham, UK, 2019; pp. 149–157. Available online: https://www.elgaronline.com/view/edcoll/9781786439307/9781786439307.00023.xml (accessed on 28 October 2019).
- Riganti, P.; Nijkamp, P. Congestion in popular tourist areas: A multi attribute experimental choice analysis of willingness-to-wait in Amsterdam. Tour. Econ. 2008, 14, 25–44. [Google Scholar] [CrossRef]
- Orsi, F.; Geneletti, D. Using geotagged photographs and GIS analysis to estimate visitor flows in natural areas. J. Nat. Conversat. 2013, 21, 359–368. [Google Scholar] [CrossRef]
- Kerourio, P. Overtourism: The necessary regulation of tourist activity. Espaces Tour. Loisirs 2018, 344, 118–127. [Google Scholar]
- Miah, S.J.; Vu, H.Q.; Gammack, J.; McGrath, M. A big data analytics method for tourist behaviour analysis. Inf. Manag. 2016, 54, 771–785. [Google Scholar] [CrossRef]
- Vu, H.Q.; Li, G.; Law, R.; Ye, B.H. Exploring the travel behaviors of inbound tourists to Hong Kong using geotagged photos. Tour. Manag. 2015, 46, 222–232. [Google Scholar] [CrossRef]
- Garcìa-Palomares, J.C.; Gutiérrez, J.; Mìnguez, C. Identification of tourist hot spots based on social networks: A comparative analysis of European metropolises using photo-sharing services and GIS. Appl. Geogr. 2015, 63, 408–417. [Google Scholar] [CrossRef]
- Provost, F.; Fawcett, T. Data science and its relationship to Big Data and data-driven decision making. Big Data 2013, 1, 51–59. [Google Scholar] [CrossRef]
- Wheeler, G. Machine Epistemology and Big Data. In The Routledge Companion to Philosophy of Social Science; McIntyre, L., Rosenberg, A., Eds.; Routledge: Abingdon, UK, 2017. [Google Scholar]
- Demchenko, Y.; Grosso, P.; de Laat, C.; Membrey, P. Addressing big data issues in Scientific Data Infrastructure. In Proceedings of the 2013 International Conference on Collaboration Technologies and Systems (CTS), San Diego, CA, USA, 20–24 May 2013; pp. 48–55. [Google Scholar] [CrossRef]
- Kitchin, R.; McArdle, G. What makes Big Data, Big Data? Exploring the ontological characteristics of 26 datasets. Big Data Soc. 2016, 3. [Google Scholar] [CrossRef]
- Chang, W.L. NIST Big Data Interoperability Framework: Volume 1, Definitions. Available online: http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.1500-1.pdf (accessed on 20 October 2019).
- Frické, M. Big data and its epistemology. J. Assoc. Inf. Sci. Technol. 2015, 66, 651–661. [Google Scholar] [CrossRef]
- Oswald, F.L.; Putka, D.J. Big data methods in the social sciences. Curr. Opin. Behav. Sci. 2017, 18, 103–106. [Google Scholar] [CrossRef]
- Kitchin, R. Big Data, new epistemologies and paradigm shifts. Big Data Soc. 2014, 1, 2053951714528481. [Google Scholar] [CrossRef]
- Floridi, L. Big data and their epistemological challenge. Philos. Technol. 2012, 25, 435–437. [Google Scholar] [CrossRef]
- Shah, D.V.; Cappella, J.N.; Neuman, W.R. Big Data, digital media, and computational social science: Possibilities and perils. Am. Acad. Polit. Soc. Sci. 2015, 659, 6–13. [Google Scholar] [CrossRef]
- Ghani, N.A.; Hamid, S.; Targio Hashem, I.A.; Ahmed, E. Social media big data analytics: A survey. Comput. Hum. Behav. 2018, 101, 417–428. [Google Scholar] [CrossRef]
- Lin, P.-J.; Jones, E.; Westwood, S. Perceived risk and risk-relievers in online travel purchase intentions. J. Hosp. Mark. Manag. 2009, 18, 782–810. [Google Scholar] [CrossRef]
- Fakharyan, M. The influence of online word of mouth communications on tourists’ attitudes toward Islamic destinations and travel intention: Evidence from Iran. Afr. J. Bus. Manag. 2012, 6, 10381–10388. [Google Scholar] [CrossRef]
- Lin, T.M.Y.; Fang, C.-H. The effects of perceived risk on the world-of-mouth communication dyad. Soc. Behav. Personal. Int. J. 2006, 34, 1207–1216. [Google Scholar] [CrossRef]
- Marchiori, E.; Cantoni, L. The role of prior experience in the perception of a tourism destination in user-generated content. J. Destin. Mark. Manag. 2015, 4, 194–201. [Google Scholar] [CrossRef]
- Mendes-Filho, L.; Mills, A.M.; Tan, F.B.; Milne, S. Empowering the traveler: An examination of the impact of user-generated content on travel planning. J. Travel Tour. Mark. 2018, 35, 425–436. [Google Scholar] [CrossRef]
- Ayeh, J.K.; Au, N.; Law, R. Investigating cross-national heterogeneity in the adoption of online hotel reviews. Int. J. Hosp. Manag. 2016, 55, 142–153. [Google Scholar] [CrossRef]
- Mauri, A.G.; Minazzi, R. Web reviews influence on expectations and purchasing intentions of hotel potential customers. Int. J. Hosp. Manag. 2013, 34, 99–107. [Google Scholar] [CrossRef]
- Pan, B.; MacLaurin, T.; Crotts, J.C. Travel blogs and the implications for destination marketing. J. Travel Res. 2007, 46, 35–45. [Google Scholar] [CrossRef]
- Jani, D.; Hwang, Y.-H. User-generated destination image through weblogs: A comparison of pre- and post-visit images. Asia Pac. J. Tour. Res. 2011, 16, 339–356. [Google Scholar] [CrossRef]
- Oliveira, E.; Panyik, E. Content, context and co-creation: Digital challenges in destination branding with references to Portugal as a tourist destination. J. Vacat. Mark. 2015, 21, 53–74. [Google Scholar] [CrossRef]
- Tse, T.S.; Zhang, E.Y. Analysis of blogs and microblogs: A case study of Chinese bloggers sharing their Hong Kong travel experiences. Asia Pac. J. Tour. Res. 2013, 18, 314–329. [Google Scholar] [CrossRef]
- Stepchenkova, S.; Zhan, F. Visual destination images of Peru: Comparative content analysis of DMO and user-generated photography. Tour. Manag. 2013, 36, 590–601. [Google Scholar] [CrossRef]
- Schweidel, D.A.; Moe, W.W. Listening in on social media: A joint model of sentiment and venue format choice. J. Mark. Res. 2014, 51, 387–402. [Google Scholar] [CrossRef]
- Tilly, R.; Fischbach, K.; Schoder, D. Mineable or messy? Assessing the quality of macro-level tourism information derived from social media. Electr. Mark. 2015, 25, 227–241. [Google Scholar] [CrossRef]
- Xiang, Y. The characteristics of independent Chinese outbound tourists. Tour. Plan. Dev. 2013, 10, 134–148. [Google Scholar] [CrossRef]
- Pearce, P.L.; Wu, M.-Y.; Chen, T. The spectacular and the mundane: Chinese tourists’ online representations of an iconic landscape journey. J. Destin. Mark. Manag. 2015, 4, 24–35. [Google Scholar] [CrossRef]
- Cheng, M.; Edwards, D. Social media in tourism: A visual analytic approach. Curr. Issues Tour. 2015, 18, 1080–1087. [Google Scholar] [CrossRef]
- Chen, F.W.; Plaza, A.G.; Urbistondo, P.A. Automatically extracting tourism-related opinion from Chinese social media. Curr. Issues Tour. 2017, 20, 1070–1087. [Google Scholar] [CrossRef]
- Liu, Z.; Shan, J.; Glassey Balet, N.; Fang, G. Semantic social media analysis of Chinese tourists in Switzerland. Inf. Technol. Tour. 2017, 17, 183–202. [Google Scholar] [CrossRef]
- Salas-Olmedo, M.H.; Moya-Gómez, B.; García-Palomares, J.C.; Gutiérrez, J. Tourists’ digital footprint in cities: Comparing Big Data sources. Tour. Manag. 2018, 66, 13–25. [Google Scholar] [CrossRef]
- Hale, B.W. Mapping potential environmental impacts from tourists using data from social media: A case study in the Westfjords of Iceland. Environ. Manag. 2018, 62, 446–457. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, C.; Lee, D.K.; Lee, H.; Andrada, R.I.T. Quantifying nature-based tourism in protected areas in developing countries by using social big data. Tour. Manag. 2019, 72, 249–256. [Google Scholar] [CrossRef]
- Brand, T.; Bendler, J.; Neumann, D. Social media analytics and value creation in urban smart tourism ecosystems. Inf. Manag. 2017, 54, 703–713. [Google Scholar] [CrossRef]
- Girardin, F.; Calabrese, F.D.; Fiore, C.; Ratti, J. Digital footprinting: Uncovering tourists with user-Generated content. IEEE Pervasive Comput. 2008, 7, 36–43. [Google Scholar] [CrossRef]
- Shi, Y.; Serdyukov, P.; Hanjalic, A.; Larson, M. Personalized landmark recommendation based on geotags from photo sharing sites. In Proceedings of the 5th AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; pp. 622–625. [Google Scholar] [CrossRef]
- Chareyron, G.; Rugna, J.D.; Cousin, S. Smart travel guide: From internet image database to intelligent system. In Multimedia on Mobile Devices 2011; and Multimedia Content Access: Algorithms and Systems V, Proceedings of the IS&T/SPIE Electronic Imaging, San Francisco Airport, California, United States 23–27 January 2011; SPIE: Bellingham, WA, USA, 2011. [Google Scholar] [CrossRef]
- Hu, F.; Li, Z.; Yang, C.; Jiang, Y. A graph-based approach to detecting tourist movement patterns using social media data. Cartogr. Geogr. Inf. Sci. 2019, 46, 368–382. [Google Scholar] [CrossRef]
- Chen, S.; Zhu, J.; Xie, Q.; Huang, W.; Huang, Y. Understanding airline passenger behavior through PNR, SOW and webtrends data analysis. In Proceedings of the 2015 IEEE First International Conference on Big Data Computing Service and Applications, Redwood City, CA, USA, 30 March–2 April 2015; pp. 323–328. [Google Scholar] [CrossRef]
- Kim, D.-Y.; Lehto, X.Y.; Morrison, A.M. Gender differences in online travel information search: Implications for marketing communications on the internet. Tour. Manag. 2007, 28, 423–433. [Google Scholar] [CrossRef]
- Park, S.Y.; Pan, B. Identifying the next non-stop flying market with a big data approach. Tour. Manag. 2018, 66, 411–421. [Google Scholar] [CrossRef]
- Karagiorgou, S.; Pfoser, D.; Skoutas, D. Geosemantic network-of-interest construction using social media data. In Proceedings of the Eighth International Conference on Geographic Information Science, Vienna, Austria, 24–26 September 2014; pp. 109–125. [Google Scholar]
- Kladou, S.; Mavragani, E. Assessing destination image: An online marketing approach and the case of TripAdvisor. J. Destin. Mark. Manag. 2015, 4, 187–193. [Google Scholar] [CrossRef] [Green Version]
- Wein, J. A Deep Dive into Ctrip And the China Online Travel Market. Available online: https://research.skift.com/reports/deep-dive-ctrip-china-online-travel-market-2017/ (accessed on 31 October 2019).
- Ge, J.; Gretzel, U. A new cultural revolution: Chinese consumers’ internet and social media use. In Advances in Social Media for Travel, Tourism Advances in Social Media for Travel, Tourism and Hospitality: New Perspectives, Practice and Cases; Sigala, M., Gretzel, U., Eds.; Routledge: New York, NY, USA, 2018. [Google Scholar]
- Shen, H.; Xing, L. Application of social media among chinese outbound tourists: Platforms and behaviors. In Advances in Hospitality and Tourism. Chinese Outbound Tourism 2.0; Li, X., Ed.; Apple Academic Press: Burlington, ON, Canada, 2016; pp. 260–271. [Google Scholar]
- Fugmann, R.; Aceves, B. Under control: Performing Chinese outbound tourism to germany. Tour. Plan. Dev. 2013, 10, 159–168. [Google Scholar] [CrossRef]
- Wu, M.-Y.; Pearce, P.L. Tourism blogging motivations. J. Travel Res. 2016, 55, 537–549. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar] [CrossRef]
- Swiss Federal Statistical Office (BfS). Tourist Accommodation Statistics. Available online: https://www.bfs.admin.ch/bfs/en/home/statistics/tourism/tourist-accommodation.html (accessed on 17 January 2019).
- Bai, B.; Jang, S.S.; Cai, L.A.; O’leary, J.T. Determinants of travel mode choice of senior travelers to the United States. J. Hosp. Leis. Mark. 2001, 8, 147–168. [Google Scholar] [CrossRef]
- Bilgihan, A.; Barreda, A.; Okumus, F.; Nusair, K. Consumer perception of knowledge-sharing in travel-related online social networks. Tour. Manag. 2016, 52, 287–296. [Google Scholar] [CrossRef]
- Juhàsz, L.; Hochmair, H. Comparing the spatial and temporal activity patterns between Snapchat, Twitter and Flickr in Florida. Giforum 2019, 1, 134–147. [Google Scholar] [CrossRef]
- Norman, P.; Pickering, C.M. Using volunteered geographic information to assess park visitation: Comparing three on-line platforms. Appl. Geogr. 2017, 89, 163–172. [Google Scholar] [CrossRef]
- Liu, X.; Li, J.J.; Yang, Y. Travel arrangement as a moderator in image–satisfaction–behavior relations. J. Vacat. Mark. 2015, 21, 225–236. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ri > 1 | Ri = 1 | Σ | |
|---|---|---|---|
| Fi > 0 | 587 | 674 | 1261 |
| Fi = 0 | 563 | 1070 | 1633 |
| Σ | 1150 | 1744 | 2894 |
| i ∈ S | i ∉ S | Σ | |
|---|---|---|---|
| reviewed alternative destinations | 477 | 982 | 1459 |
| reviewed only hotspots | 110 | 1325 | 1435 |
| Σ | 587 | 2307 | 2894 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaufmann, M.; Siegfried, P.; Huck, L.; Stettler, J. Analysis of Tourism Hotspot Behaviour Based on Geolocated Travel Blog Data: The Case of Qyer. ISPRS Int. J. Geo-Inf. 2019, 8, 493. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8110493
Kaufmann M, Siegfried P, Huck L, Stettler J. Analysis of Tourism Hotspot Behaviour Based on Geolocated Travel Blog Data: The Case of Qyer. ISPRS International Journal of Geo-Information. 2019; 8(11):493. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8110493
Chicago/Turabian StyleKaufmann, Michael, Patrick Siegfried, Lukas Huck, and Jürg Stettler. 2019. "Analysis of Tourism Hotspot Behaviour Based on Geolocated Travel Blog Data: The Case of Qyer" ISPRS International Journal of Geo-Information 8, no. 11: 493. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8110493