3.1. -LCA Algorithm
The basic idea of the first proposed algorithm (-LCA) is that the simplification of AF is performed after every edge relaxation (the operation combination). The degree of the simplification is directed by Theorem 2.
The
-LCA computes AF with the maximum relative error
assuming that
where
is the maximum slope of AF
. The slope
must be bounded because Theorem 2 is used in the
-LCA and the theorem needs this assumption.
The
-LCA differs from the exact LCA only in the computation of
. The AF
in the line 8 in Algorithm 1 is simplified with the maximum absolute error
(according to Theorem 2), so the line 8 is replaced by two lines
where
is the maximum slope of
in the interval
. The simplification was performed using Douglas–Peucker algorithm (DP) or Imai and Iri algorithm (II) [
13].
The main problem of
-LCA is that if the assumption (
2) is not complied,
and the algorithm cannot ensure the given relative error
. This occurs when the maximum slope
is too large. This issue is resolved using the second algorithm that is described in the upcoming section.
3.2. -LCA-BS Algorithm
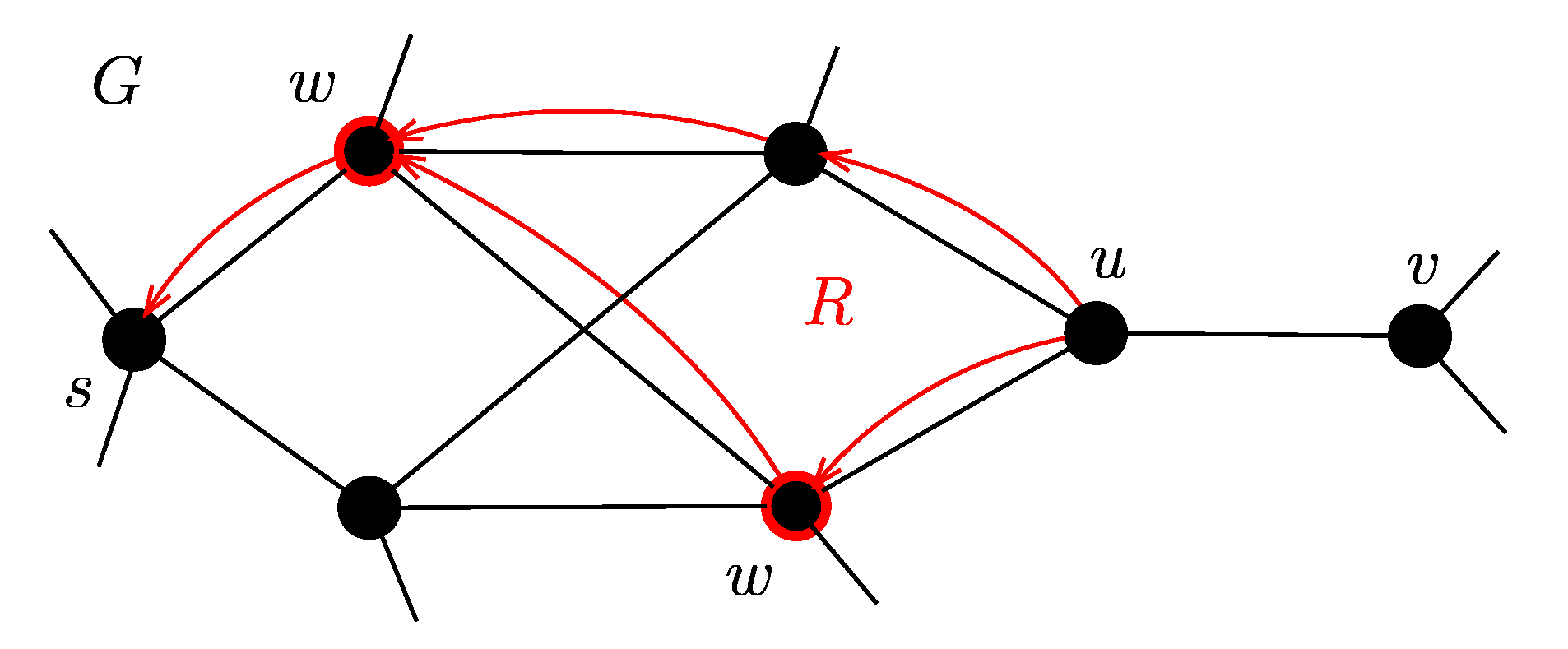
The second proposed algorithm (-LCA-BS) is based on backsearch. It has no limitations for the slope . The pseudo-code of the -LCA-BS is in Algorithm 2. The basic idea is that if the algorithm finds an edge where is too big in some departure time interval (), it determines in again with a higher accuracy (lines 11–15 of the Algorithm 2). The algorithm returns back to the point such that the edge can be reached from this point with sufficient precision using the exact LCA.
When the label at the node
v (AF
) is updated (the condition at the line 16 is fulfilled), the edge
is added to the predecessor list
of the node
v (lines 17–20). The set of predecessors form a graph
(red color in
Figure 2). We assume that the graph
R is acyclic. In general, the graph
R may not be acyclic, but in real case it is very unlikely.
We want to find nodes
w such that if the exact LCA is performed from these nodes
w, the AF
is an
-approximation. The nodes
w have to satisfy the following inequalities in the interval
:
where
is the set of all paths from
v to
w in the graph
R (the paths must contain the edge
) and
represents the maximum slope of AF
corresponding with the edge
e. The set
W is the set of all nodes
w that meet the condition (
4) and there is a path
that does not contain any other node from the set
W (
W is the smallest possible).
| Algorithm 2:-LCA-BS. |
![Ijgi 08 00538 i002]() |
These nodes
w can be found using a topological ordering of
(Algorithm 3). The node labels
correspond to the left side of the inequalities (
4), so the algorithm finds maximal paths in
R. First, the labels are set to negative infinity (the line 2) and the label at
u is set to
(the line 3). The lines 4–5 ensure a topological ordering. If the condition (
4) in line 6 is fulfilled,
b is added to the
W. The lines 9–12 ensure updating of the node labels. The part of
in the interval
is substituted by a more accurate result of the exact LCA with the initial priority queue PQ that is created by adding all
(the lines 13–16).
In
Figure 2 there is an example of backsearch. The black color represents the original graph
G and the red color represents the acyclic graph
R. The edge
violates the condition (
2). Then the algorithm starts
backSearch procedure and finds the set
W (red nodes) using the graph
R.
| Algorithm 3: backSearch. |
![Ijgi 08 00538 i003]() |
When the graph R is not acyclic, it is necessary to modify the algorithm for searching the set W.
If the condition (
2) is fulfilled, the
-LCA-BS is reduced to
-LCA, because the algorithm then does not perform any
backSearch procedure.
The
-LCA-BS has one main disadvantage. If there are a lot of edges with the arrival function where the maximum slope is too big, the algorithm will perform a lot of
backSearch procedures (Algorithm 3). The
backSearch procedure is time-consuming so the whole algorithm will be slow in such a case. But, in a real road network, the maximum slopes of AFs are not too steep [
9,
14]. Therefore, the main disadvantage is not a too big problem.
3.3. Heuristic Improvement
The proposed solution can be further accelerated on the basis of departure time interval decomposition as follows. The profile search problem on the departure time interval
can be decomposed in time to two subproblems on intervals
and
and these subproblems are independent [
15]. It follows that the problem can be split into
N independent computation parts. This property enables effective parallelization and distribution of the computation.
A surprising property is that the splitting of the problem often saves total computation time in the serial case, too. The -LCA-BS runtime on the interval is often higher than the sum of runtimes on the intervals and . In the following text, the reasons why the decomposition is faster than the original problem are presented. Some splitting strategies are also discussed.
The number of relaxations
K (the number of iterations of the main loop) of
-LCA-BS is greater than or equal to the number of relaxations of the Dijkstra’s algorithm [
2]. The aim is to approach as close to the Dijkstra’s algorithm as possible. The condition at line 16 in Algorithm 2 controls adding to the priority queue (PQ) and thereby controls the number of iterations. The condition compares two AFs. The small piece of the
under
is enough for adding to the PQ. It follows that a more fluctuating TTF indicates a higher
K.
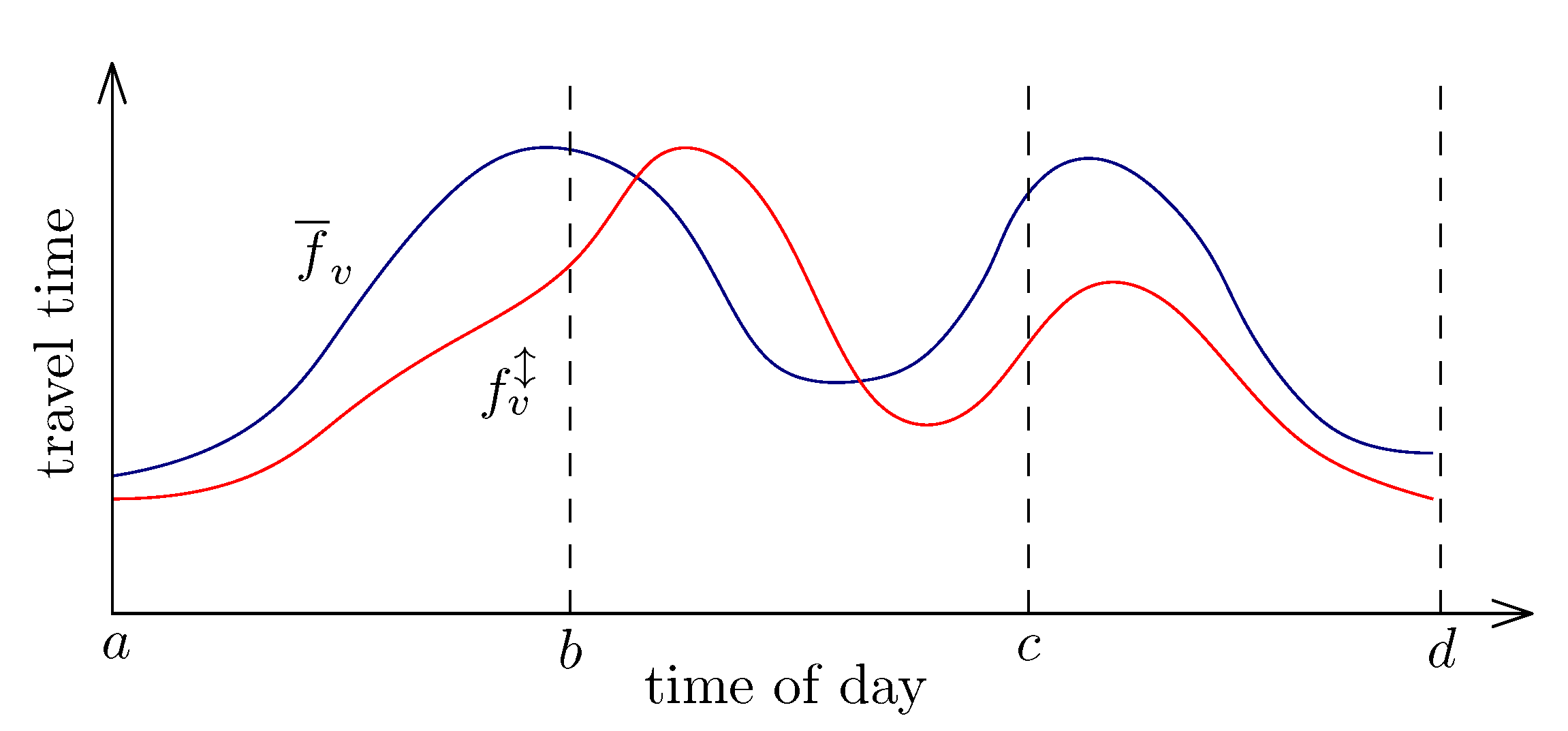
The fluctuation of the TTFs can be reduced by splitting the function to intervals. The function on a shorter interval has a smaller or equal difference between its maximum and minimum. It means that in more cases the condition
is false. In
Figure 3 there is an example of splitting. The original function
on the interval
is divided into three intervals
,
and
. As you can see, for the intervals
and
the condition at line 16 in Algorithm 2 is false. Thus, the node will not be added to the PQ and
K is reduced.
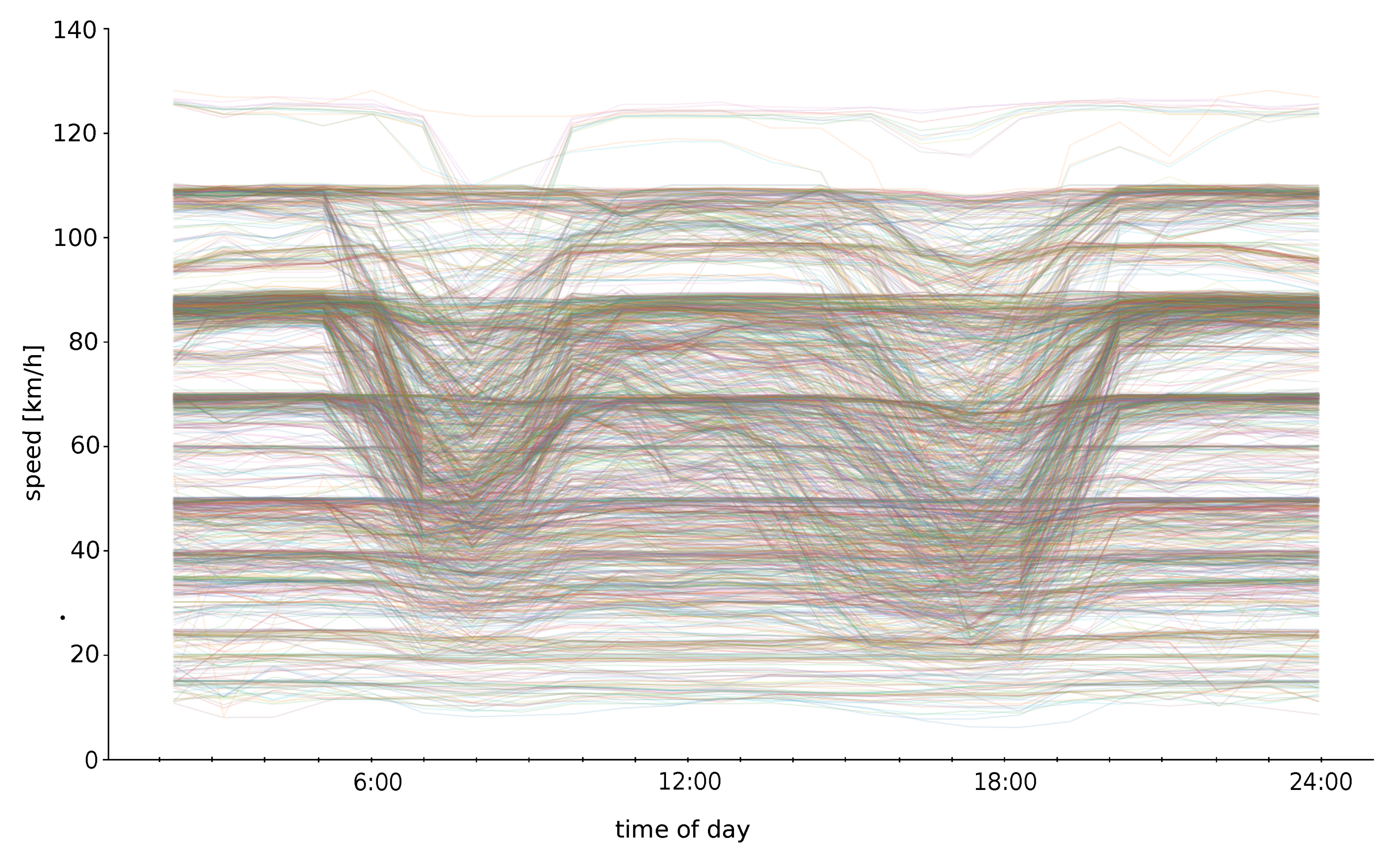
The question is how to split the departure time interval so that the computation is the most effective. In
Figure 4 there is a visualization of speed profiles for the testing dataset. The x-axis represents a time of day and the y-axis displays the average speed in time on edges. In the visualization, all speed profiles from the tested dataset are rendered in various colors. As you can see, the fluctuation in the night time (the first part and the last part) is small. There are two main concepts for splitting:
Split the origin interval into equal subintervals.
Split the origin interval into inhomogeneous subintervals (e.g., longer at night and shorter by day).
Which of these concepts is better strongly depends on the TTFs shape, as further presented in experiments.
The splitting into intervals enables a very simple parallelization. Due to the independence in the departure time intervals, we can set one interval equal to one thread.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}