1. Introduction
Big data has become a very common subject in technical, academic, and scientific publications in recent years. There is still no accurate and generally accepted definition of the term. As a popular buzzword and objective topic of research, there are several approaches and perspectives on Big data and several ways of interpreting it that differ according to different fields of study, including geographical information science (GISci). As both GISci and Big data are based on visualizations, combining the fields has potential. In general, Big data can be considered bulky structured or unstructured datasets that cannot be easily stored, managed, or analyzed using conventional methods in a reasonable amount of time [
1]. Today, several technologies used for Big data processing already exist and are being continually improved. Most of these technologies are generally available as a cheap solution. Many of them also have open source code, typically represented by the Apache Hadoop framework, which is the most widely used technology in Big data for GISci [
2]. It combines commonly-available hardware with open source software, and its development is supported by several large companies such as Google, Amazon, Microsoft, Facebook, and Twitter [
3], which are looking at options for the (future) development of internet Big data tasks.
The aim of this paper is to analyze Big data paradigms in GISci, specifically with regard to visualization possibilities on the web platform. Currently, most web mapping libraries are based on JavaScript technology [
4]. The paper; therefore, compares popular JavaScript mapping libraries such as Leaflet and OpenLayers. The article specifies, verifies, and compares the options in cartographic visualization both theoretically and practically. Several pilot studies on real data describe specific methods, technologies, and procedures for Big data with a spatial aspect. The main results of the article are comparative testing and analysis of loading and performance.
The main research questions were:
To find out optimal workflow and technology required for visualizing a large amount of point spatial data on an Internet platform?
Are there limits of point data visualization?
Is there any limiting threshold for implementation without a noticeable slowdown in performance?
2. Big Data and Geographical Information Science
Big data is a term describing very large data sets that are difficult to store, manage, share, analyze, and visualize using common tools. The huge increase in the amount of data in the past few decades has been a result of decreasing costs in computing and information technology. Technologies and the possibilities to process Big data are growing with the rise in popularity of Big data. The term “Big data” was firstly mentioned by NASA (National Aeronautics and Space Administration) scientists at the eighth IEEE (Institute of Electrical and Electronics Engineers) Visualization Conference in 1997 in relation to data visualization, referring to data so large that it exceeded memory capacity [
5]. Big data was originally characterized by the so-called “3V”, which was first used by Gartner analyst Doug Laney [
6]. The first research report on these characteristics was developed in 2000 and then released in February 2001 under the name 3D Data Management—Controlling Data Volume, Velocity, and Variety. According to Laney [
6], it is volume, velocity, and variety:
Volume—the size of the data or number of records that the dataset contains.
Velocity—represents how fast data are generated and processed. Unstructured data grows faster than structured data and generates about 90% of all data. Therefore, choosing different ways of processing Big data is necessary.
Variety—Big data differs in structure and formats and includes semi-structured (e.g., documents in CSV (Comma-separated values), XML (Extensible Markup Language) or JSON (JavaScript Object Notation) formats) or totally unstructured (e.g., multimedia) available data. These basic characteristics were later expanded by some authors and companies. According to [
2,
3,
6], Big data has five dimensions (5V): volume, velocity, variety, value, and veracity, which expresses the uncertainty in data. Low veracity corresponds to the changed uncertainty and the large-scale missing values of Big data. Sometimes, along with the growing size of datasets, the uncertainty of data itself often changes sharply, which makes the traditional processing tools unavailable. One of the possible ways to cope with uncertainty is via visualization techniques [
7].
Microsoft has extended the original characteristics by two more dimensions: variability (which, in contrast to diversity, expresses the number of variables in the dataset) and visibility [
8]. Other characteristics are often added. Some authors supplement the value that data represent to a company (value), validity period (validity), temporary period of necessary data storage (volatility), etc. [
9]. Today, there are many technologies that are being continually improved to process such data. Most of these technologies are inexpensive data processing solutions, and many have open source code. An example is the Apache Hadoop framework, which is one of the most widely used technologies combining common hardware with open source software [
8].
In 2010, Teradata’s Chief Technology Officer Stephen Brobst predicted that social networks would not be the largest source of unstructured data within three to five years but would be data captured from sensors and sensor networks [
10]. Typically, a large source of 2D spatial data is represented by spatial data and satellite/aerial imagery. On 1 January 2015, there were 5,532,454 Landsat images of 4.134 PB in total [
11] in the USGS (United States Geological Survey) archive. NASA receives approximately 5 TB per day of remote sensing data [
12]. Another extensive source is 3D data obtained using LIDAR (Light Detection And Ranging) technology for object detection and distance measurement using laser radiation. A user can therefore easily obtain millions of points in a selected area of interest. These spot clouds can then be used to create 3D models of scanned objects, such as digital elevation models. Sharing, analyzing, and visualizing spatial dynamic information is the fundamental purpose of GISci and web cartography. As digital transformation relocates from desktop platforms to the internet environment, new technologies in field of Web cartography and WebGIS (Web Geographic Information System) are rapidly emerging [
4]. Mobile technologies, social networks, real-time technologies, and sensor networks provide an enormous amount of spatial data. However, the results of any spatial analysis cannot be interpreted and discussed without visualizing data. While numerous articles focus on Big data distribution and processing rather than visualization [
13], our paper focuses only on implementing interactive map outputs.
3. Spatial Data Formats for Point Data
The paper is focused on point data visualization by JavaScript libraries visualization via an Internet platform. Our research concentrated on 2D point data. The libraries tested during our research were primarily developed for visualizing 2D spatial data. 3D data in the form of point clouds (e.g., LIDAR, photogrammetry, etc.), which can also be considered as Big data, were not examined.
A common database solution such as NoSQL (Non Structured Query Language), distributed, or cloud storage was; therefore, not applied. Several spatial-friendly formats are compatible with JavaScript for interactive web map applications, for example, GeoJSON, TopoJSON, XML, GML (Geography Markup Language), KML (Keyhole Markup Language), CSV, etc. We mainly applied GeoJSON, which is currently the most supported format for web visualizations.
GeoJSON is an interoperable geospatial format based on the JSON data format. It defines several types of JSON objects and how they are combined to represent geographic features (point, line, polygon, multipoint, multiline, multipolygon), their properties and spatial scope. The JSON (JavaScript Object Notation) format was originally designed to pass data between the server side and client side of a web application. JSON has become a widespread data format, and libraries for its use exist in all programming languages. The use of JSON in applications is very straightforward, as JSON can be easily mapped to objects of the given language [
9].
GeoJSON uses the WGS84 (World Geodetic System 1984) coordinate system and decimal degrees. GeoJSON is widely used in web services for its small volume and simplicity. It is less processing-intensive, which is especially useful for web browsers [
14]. Currently, GeoJSON is considered the de-facto standard and is quite popular for web mapping solutions. Another format derived from JSON is TopoJSON. The main goal is to minimize data flow between the web server and client. Therefore, TopoJSON is based on topology.
4. Visualization Methods
Conventional cartographical methods for point layers are not suitable for visualizing Big data because of the extreme amount of data. Standardized representations of point features with icons (map pins) will cover an entire map area, making each feature impossible to identify, and the map background (basemap) will be fully covered, which prevents orientation and movement over the map. For these reasons, more sophisticated methods applied especially to Big data were introduced. Our study uses marker clustering and heatmaps. Another method is spatial binning.
4.1. Marker Clustering
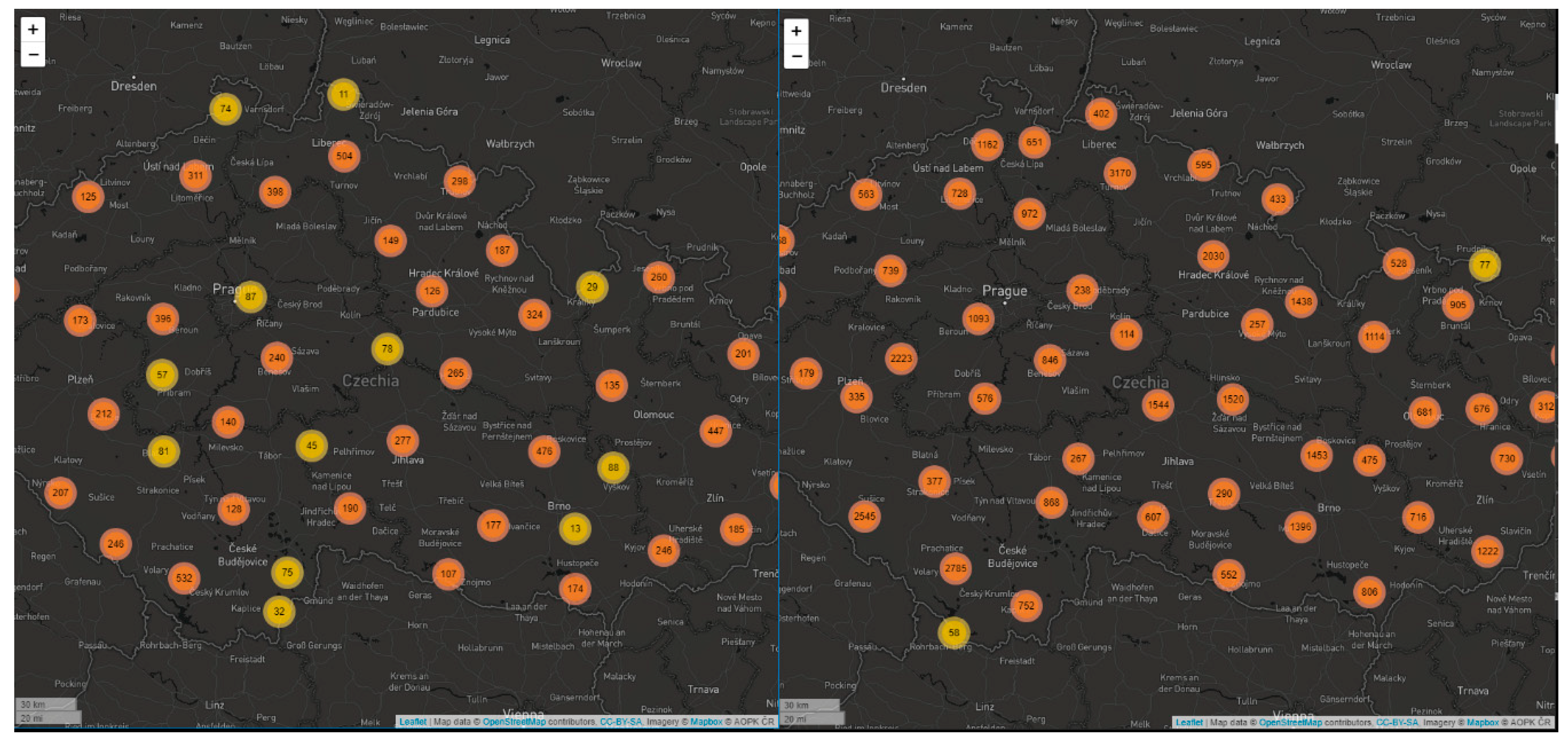
Marker clustering represents a visualization technique where individual points on a web map are grouped into clusters according to a specific algorithm based on the radius of clusters. Grouped points are then represented on a map by a “new” symbol, with the number of points included in the cluster. The created clusters can be modified with a set of symbols according to the number of points they contain (e.g., color, size). Marker clustering is a dynamic method strictly dependent on changes at each zoom level (map scale). When zooming in, the clusters then shrink, and individual points are displayed. Clustering eliminates overlapping points and makes the web map clearer. More technical details are available at
https://developers.google.com/maps/documentation/javascript/marker-clustering.
4.2. Heatmaps
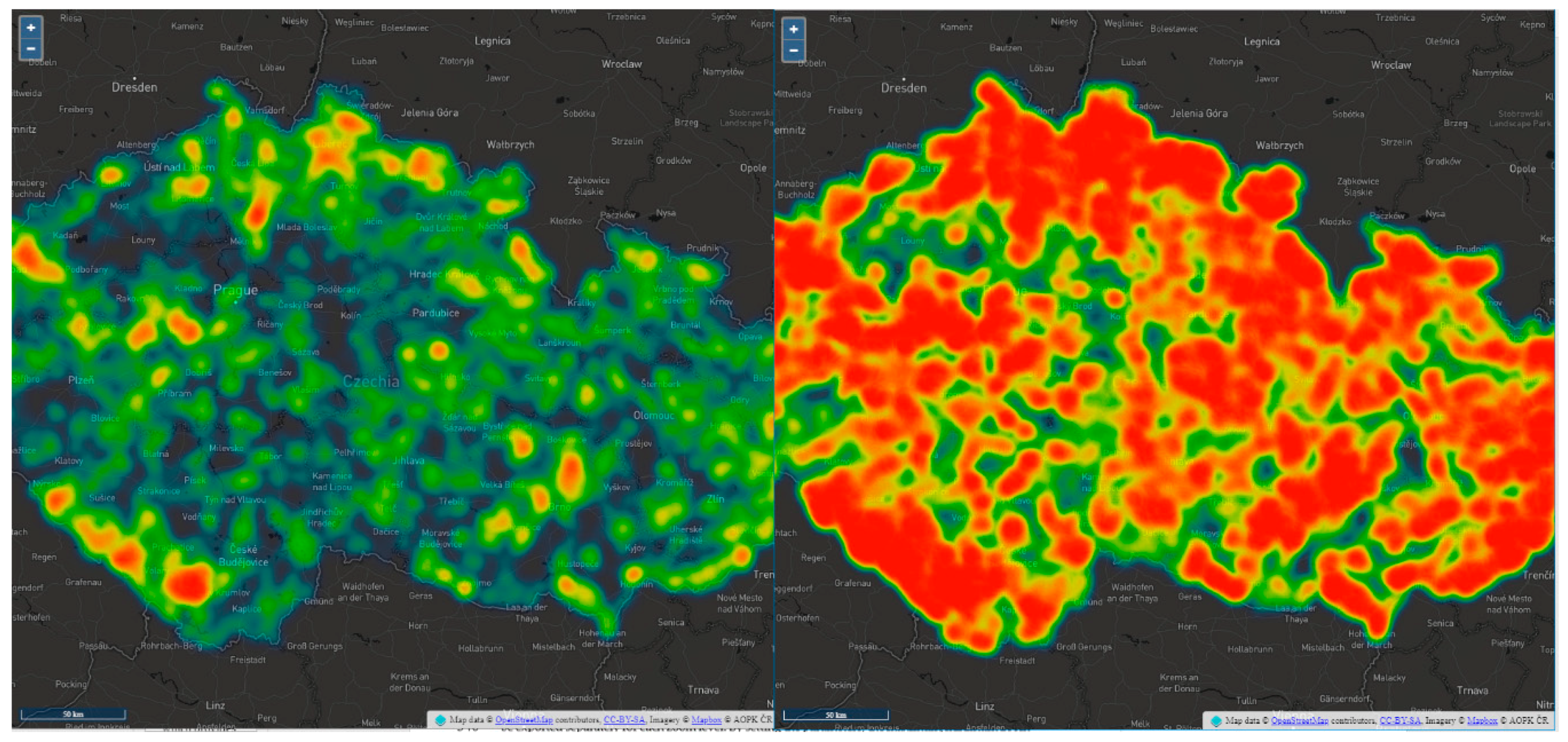
Heatmaps are one of the most popular methods for visualizing extensive point datasets. This method makes it easy to continuously visualize and analyze large data sets and identify clusters [
15]. However, it cannot be determined whether these clusters are statistically significant [
16]). Points are represented as a color gradient depicting the area and strength of each point’s influence [
17]. In the case of overlaps, the effects of these points are cumulative.
5. Research Design and Data
The main goal of the paper is to find and set the limits of JavaScript libraries for point data visualization via an Internet platform from the point of its quantity, size, and number of records. For this reason, we do not consider the conventional Big data storage approaches. We want to visualize the point data by rendering directly in the browser to find limitations and benefits. This different strategy requires different data and visualization methods than common Big data-oriented database (such as MongoDB (Mongo Database), NoSQL, etc.) described in many scientific and popular papers. The minor goal of the paper is to define the situation when point data can be considered as Big data and especially when technical limits occur. We can also define the restrictions on the side of the mapping library (e.g., when the data are no longer displayed).
Several data sets are suitable for Big data processing technologies. Open data, contracted data, data retrieved using publicly available APIs, or methods such as data mining or web crawling may be encountered. As a primary data source for our study, data concerning nature conservation was selected. This data was exported from the NDOP (Nálezová databáze ochrany přírody - Nature Conservation Database of the Czech Republic) provided by the Landscape and Nature Protection Agency of the Czech Republic (AOPK).
The Nature Conservation Database is a national source of data that records species diversity in the Czech Republic. It summarizes all the available data on the distribution of species in the Czech Republic. The database is general and interdisciplinary, focusing on plants, animals, mushrooms, and lichens. The database is continuously updated using the NDOP application (available at ndop.nature.cz [
18]), which is used for data editing. The data discovery filter (FiND) allows the available data to be viewed under license agreements. The Nature Conservation Database currently contains over 22 million findings.
The database not only contains data about flora and fauna in the wild, but also information about specimens from collections and herbaria and published or unpublished records of the occurrence of a species in the Czech Republic. The database is not limited to a group, and data is collected on all kinds of species. It primarily concentrates on endangered species, although the database also contains many records of common species. Data are provided for research purposes under contract in SHP (Shapefile) and CSV format [
18]. Records contain an ID, the taxonomy, author of the finding, localization, date of the finding, abundance of the taxonomy, coordinates of the point in the S-JTSK coordinate system (local coordinate system used in the Czech and Slovak Republics; EPSG:5514) and notes.
In total, nine data samples with a different number of records (
Table 1) were created for testing purposes. These data sets were exported from the Nature Conservation Database. All thematic attributes (taxonomy, etc.) except coordinates were removed, as they were irrelevant to the testing. Finally, a GeoJSON sample with 10,000, 25,000, 50,000, 100,000, 250,000, 500,000, 1,000,000, 1,500,000, and 3,127,866 points/records of specimens were generated (
Table 1). Since PruneCluster does not support GeoJSON, the same samples were also generated as JSON data. Testing was primarily focused on loading and rendering speed. Loading the entire web map was tested ten times for each data sample. The arithmetic mean and median were calculated from the measured values. The obtained results are described in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8 (all values are in milliseconds). All web applications with samples for clustering and heatmap creation are available at
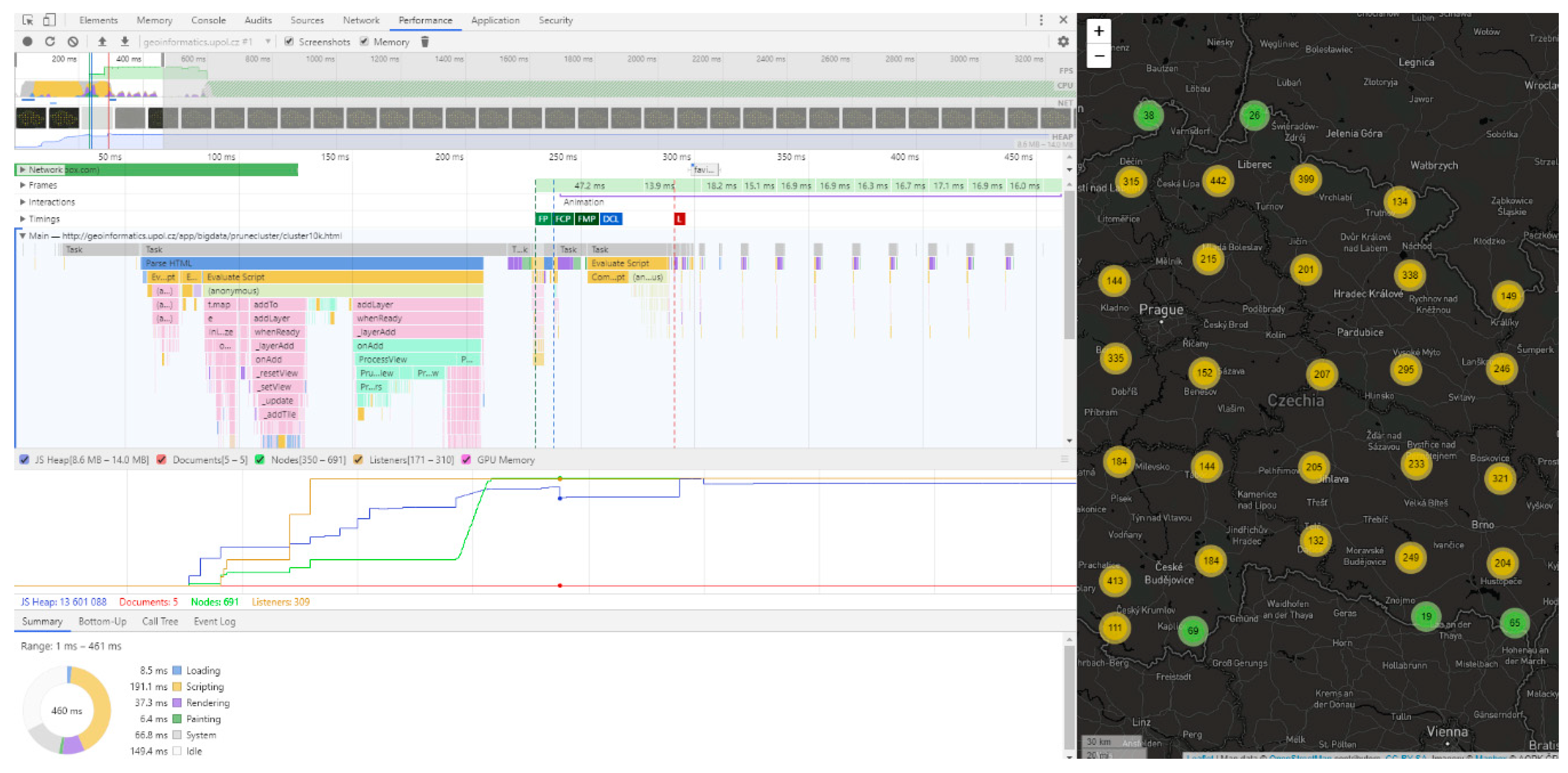
http://geoinformatics.upol.cz/app/bigdata (see
Figure 1).
6. Testing and Results
Five diverse JavaScript libraries were tested as a comparable study to visualize data via a web platform. Libraries tested for the clustering visualization method were Leaflet.markercluster, OpenLayers, Supercluster, MapBox GL JS (Graphics Library JavaScript), and PruneCluster. Libraries tested for the heatmap method were Leaflet and OpenLayers. Comparison of the JavaScript libraries was conducted on a common PC with the following specifications: Intel
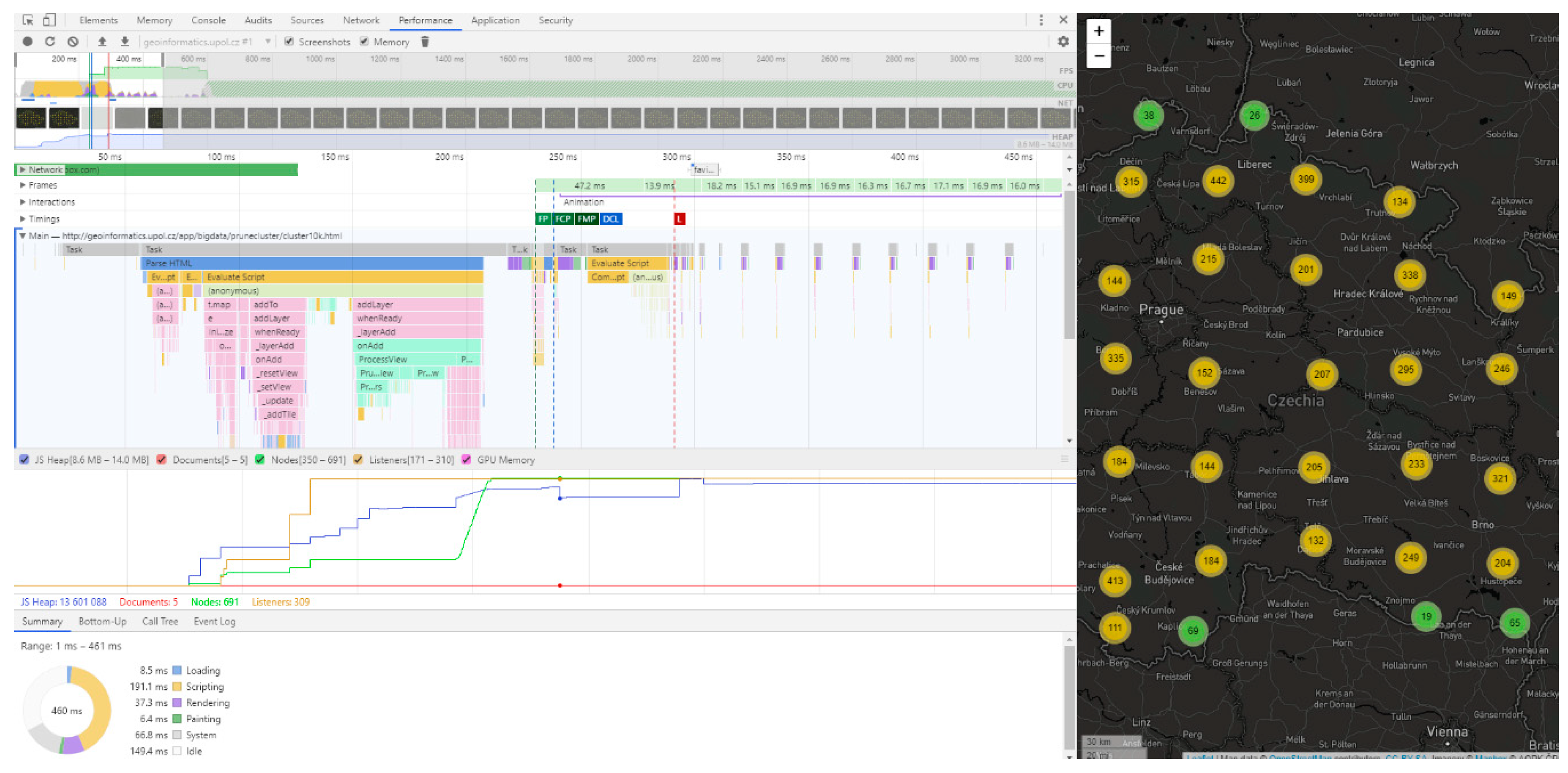
® Core™ i5-6200U (2.30 GHz), 8 GB RAM, NVIDIA GeForce 210, 22” monitor with resolution 1920 × 937 px. Google Chrome version 65.0.3325.181 was deployed as the browser. Google Chrome’s built-in developer tools (performance tab) were used to measure map rendering time (loading time). These tools allow page processing to be accurately tracked from initial loading through to scripting and full loading (see
Figure 2). Testing was performed on a local web server Apache HTTP (Hypertext Transfer Protocol) Server 2.4.29
6.1. Marker Clustering
6.1.1. Leaflet.markercluster (v1.4.1)
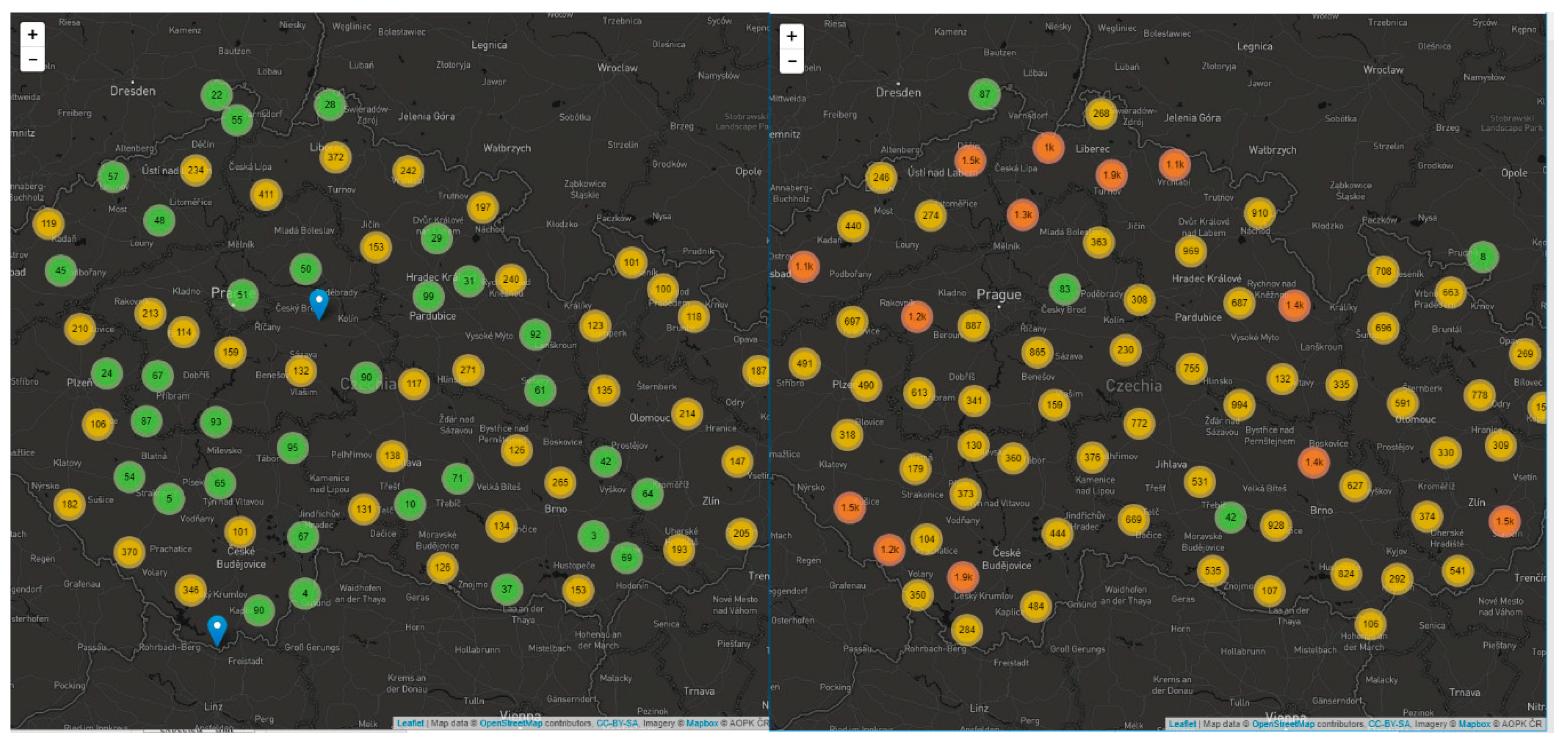
The first tested JavaScript library was the Leaflet.markercluster plugin for Leaflet (see
Figure 3). Leaflet is one of the most well-known open source solutions under the FreeBSD (Berkeley Software Distribution) license. Created by Vladimir Agafonkin, it is essentially a JavaScript library for interactive web maps [
19]. The first version 0.1 was released in 2011, and currently Leaflet is available in version 1.3.1. By default, it is designed to contain only basic functionality (as opposed to, for example, OpenLayers) and could be enhanced by additional plugins. Leaflet works on all major desktop and mobile platforms and uses HTML5 (Hypertext Markup Language) and CSS3 (Cascading Style Sheets) for functionality. The Leaflet.markercluster plugin was released in 2012, and the current version is 1.3.0 from January 2018, created by Dave Leaver [
19].
Testing shows that the solution provided by the Leaflet.markercluster plugin is the slowest one. The 10,000-point sample achieved a comparable time (1572 ms) with OpenLayers (1388 ms). However, from 50,000 points onwards, rendering time (11,612 ms) rapidly increased, and increased latency was seen between redrawing levels, especially when moving from larger levels to lower levels. A possible reason may have been the use of re-draw animation at the expense of speed. The limit for this library was a 100,000-point data set drawn at 47,154 ms on average. For larger datasets, testing could not be completed because the browser froze or crashed. See
Table 2 for complete results.
6.1.2. OpenLayers (v4.6.4)
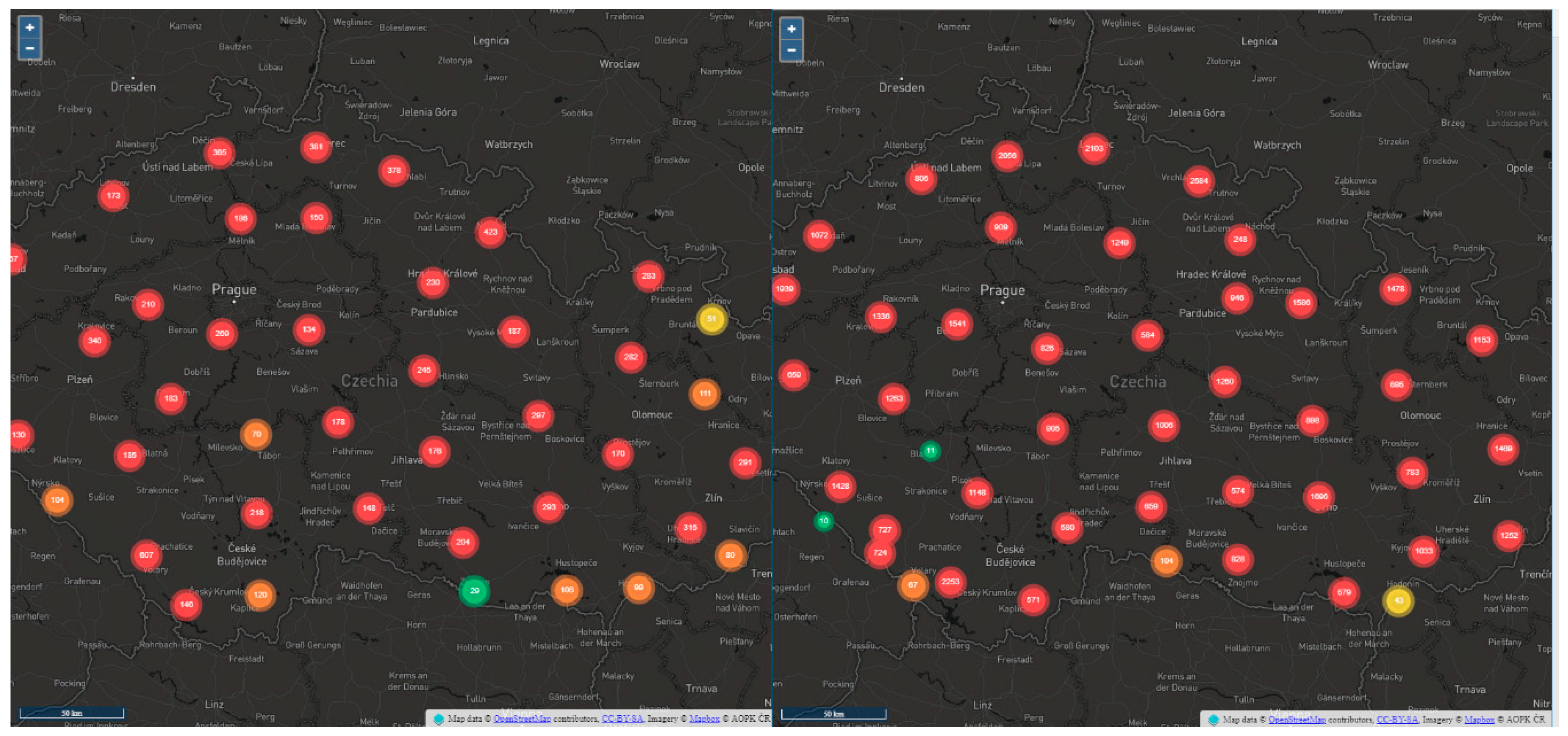
The second tested library was OpenLayers (see
Figure 4). The OpenLayers project is a direct competition to the Leaflet project, with similar characteristics—it is open source and licensed under the FreeBSD license. The first version was developed by MetaCarta and released in 2006 [
20]. OpenLayers natively supports point clustering, and no other plugins need be used. However, some additional plugins are available and expand native clustering behavior, for example, for animated transitions between zoom levels, similar to Leaflet (OL-ext, OL3-AnimatedCluster). Clustering in OpenLayers achieves good results. When testing on a 250,000-point dataset, the average plot time was 8061 ms. When tested on a 500,000-point dataset, the plot time increased by three times (average 24,455 ms). The OpenLayers library could not plot datasets larger than 500,000, and all attempts ended with the browser crashing or freezing. See
Table 3 for complete results.
6.1.3. Supercluster (v5.0.0)
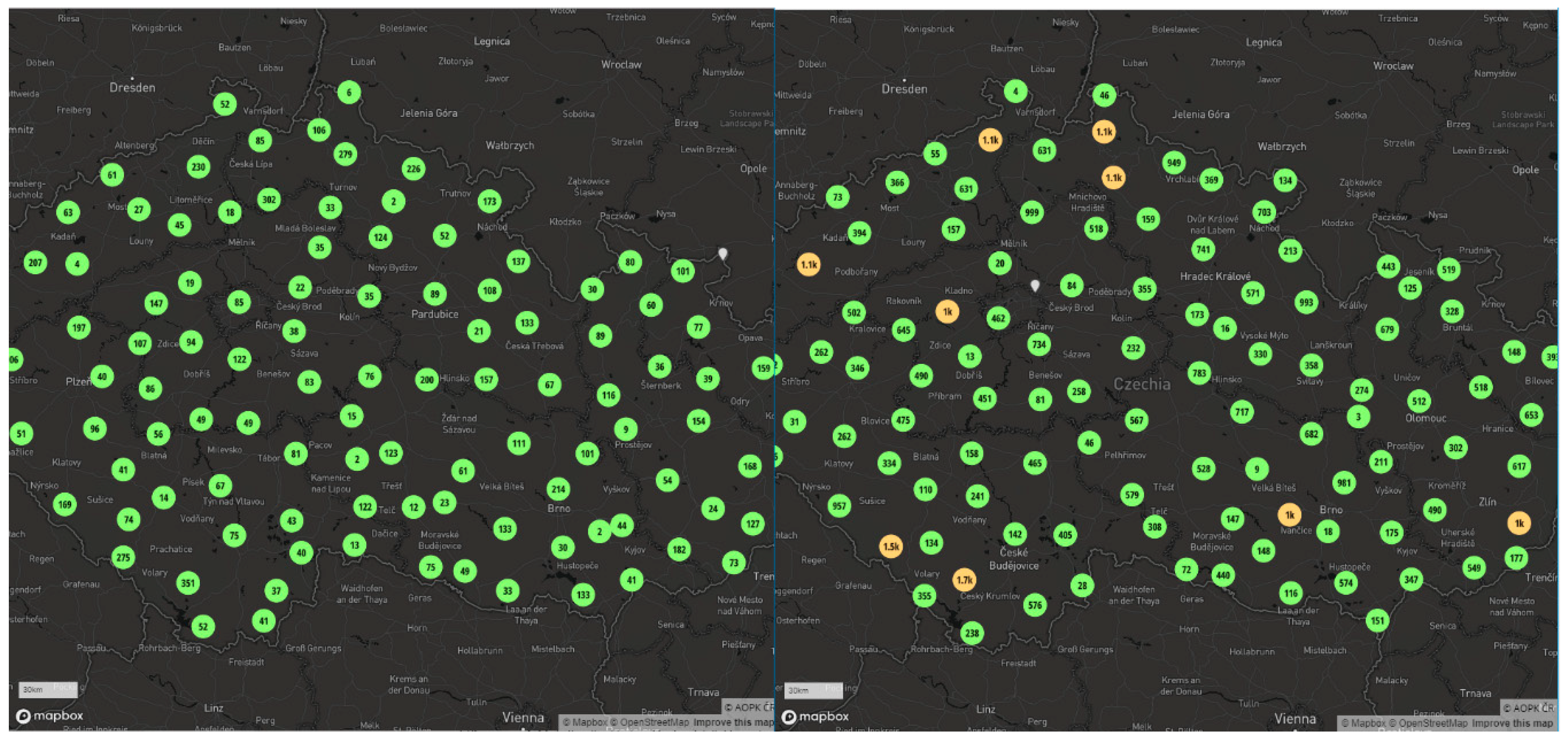
The third tested library was Supercluster (see
Figure 5). Its author is Vladimir Agafonkin, the same author as the Leaflet library. Supercluster is a standalone library that can be used in combination with any other JavaScript library for creating web maps. In this case, its speed was tested in conjunction with the Leaflet and OpenLayers libraries without significant difference. This clustering library uses a “hierarchical greedy clustering” method [
21]. Creating a cluster begins by selecting a point from the dataset. All points within the selected radius are merged and a new cluster is created. Creating another cluster begins by selecting a point that is not a part of any cluster. This method is also employed by the previously mentioned Leaflet.markercluster plugin for Leaflet. In Supercluster; however, this method was expanded to include a spatial index, processing points only once into a special data structure that is then available for immediate use in later queries and larger datasets [
21].
A sample of 1.5 million points was rendered by the Supercluster library in 23,911 ms (OpenLayers could only render half the points in approximately the same time in 24,455 ms). Supercluster rendered the map in 71,776 ms without any problems, even when the entire datasets with more than 3 million points were used. See
Table 4 for complete results. The transitions between zoom levels were quick, but definitely did not achieve the fluency of the Mapbox GL JS library.
6.1.4. Mapbox GL JS (v0.44.1)
Mapbox GL JS library (see
Figure 6) uses the Supercluster library mentioned above for clustering, though for rendering it uses WebGL technology based on GPUs. It would be expected that the Mapbox GL JS library achieves similar results to the Supercluster library in combination with the Leaflet library.
However, this solution was worse than the Supercluster library when combined with the Leaflet library up to 100,000 points. The difference decreased with the use of larger data sets. When tested with a sample of 250,000 points, the plot rate was comparable with only 168 ms difference. When sample with 500,000 records was used, the Mapbox GL JS library was 4330 ms faster than Supercluster. The entire dataset could be rendered on average in 34,224 ms (compared to 71,775 ms achieved by Supercluster with Leaflet). See
Table 5 for complete results. This library was definitely the smoothest, and the re-drawing of zoom levels was immediate, even when the entire dataset was drawn.
6.1.5. PruneCluster (v2.1.0)
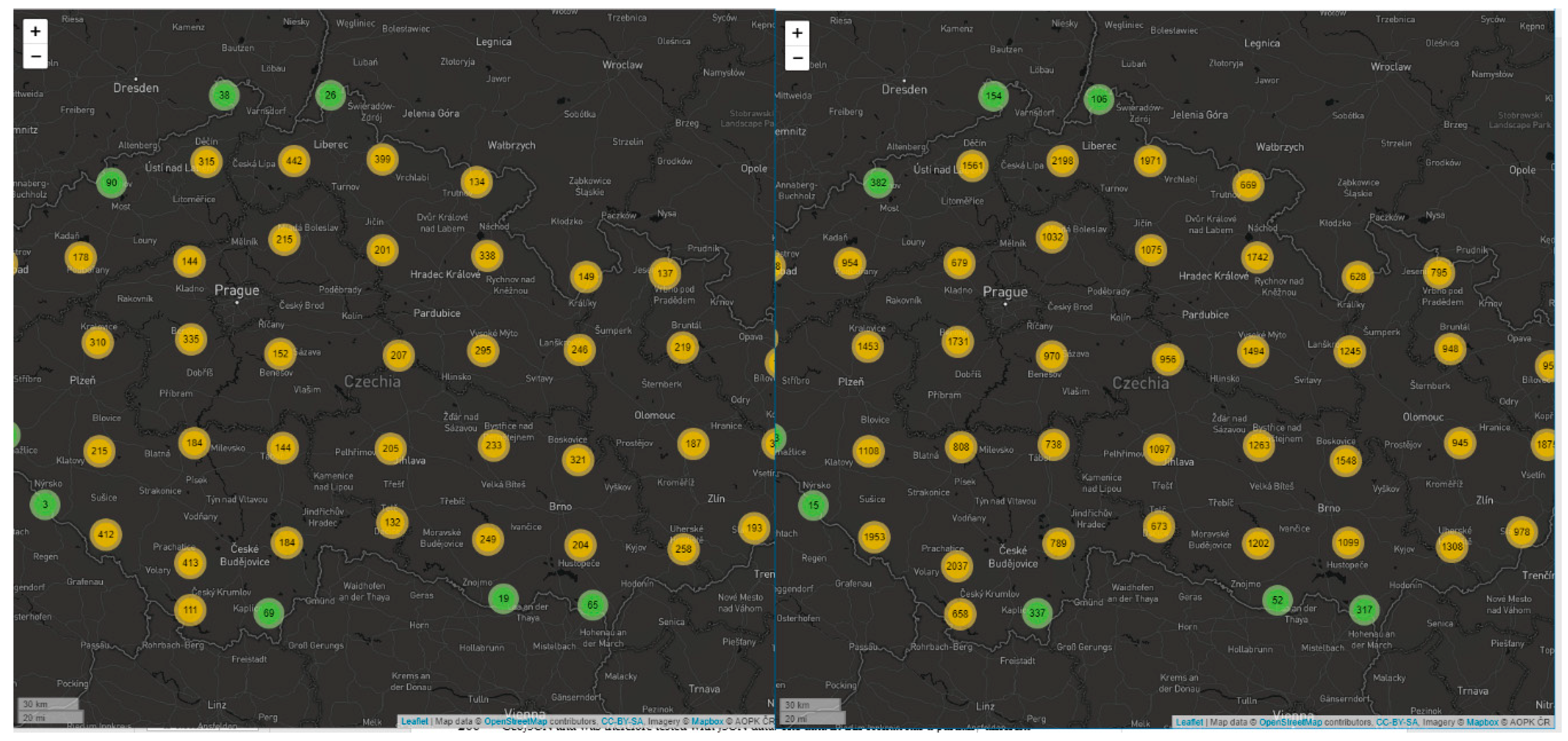
The latest tested solution is called PruneCluster (see
Figure 7), a project by Norwegian organization SINTEF (Stiftelsen for industriell og teknisk forskning). Technically, it is another plugin for Leaflet. The authors are Antoine Pultier and Aslak Wegner Eide, and it provides an effective solution for clustering points in web mapping applications [
22]. The authors developed a new algorithm for clustering and updating points in real time. They were inspired by algorithms for detecting collisions between two objects. According to testing by the authors [
22], the algorithm demonstrated significant improvement over other available solutions. This makes the library suitable for visualizing large datasets, even in real time. Its advantages include the option to categorize individual points and display their representation in the cluster (SINTEF, 2018). The PruneCluster library does not support GeoJSON and was; therefore, tested with JSON data. The data in this format has a partially different structure, but a significantly smaller size (72.1 MB compared to 362.1 MB for the entire dataset). PruneCluster; therefore, cannot be directly compared to other tested libraries. However, it uses a different algorithm for clustering, and it was included in testing.
PruneCluster reached the lowest times of all the tested libraries. Half a million points were loaded in 3202 ms. The entire dataset was drawn on average in 23,111 ms. It can be assumed from the test results that by using the GeoJSON format, the Mapbox GL JS library would probably provide the fastest rendering time (23,111 ms vs. 34,224 ms). See
Table 6 for complete results. As with Leaflet.markercluster, the PruneCluster library uses animations between zoom level. When smaller data samples were used, the re-draw response was acceptable, but larger samples (250,000 points or more) adversely affected the animation’s loading time.
6.2. Heatmap
Ježek et al. [
23] compared the rendering time of heatmaps with four JavaScript solutions: Google Maps API, Leaflet.heat plugin for Leaflet, ArcGIS online, and WebGLayer (the University of West Bohemia’s own developed WebGL solution). The latter solution achieved much lower rendering times than the previous: 100 ms for a 1,492,475-point dataset. Because of their general availability, two libraries were tested for heatmap rendering in this study. The first was the Leaflet.heat plugin (version 0.2.0 for the Leaflet library based on the simpleheat.js library). The second was OpenLayers, which supports creating heatmaps natively. For both tested libraries, a heatmap was rendered to an HTML canvas. A radius parameter could be set for any heatmap [
17]. According to Ježek et al. [
23], these parameters affect the resulting rendering and loading times of the heatmap while rendering on the GPU. Heitzel et al. [
24] confirm that algorithms executed on a GPU “allow the data size for analyzing complex simulations to be significantly reduced when certain datasets are generated only for the purpose of visual analysis” [
24]. However, not only the number of points but also the screen size affected rendering time. We also created a testing cycle for different monitors (22″/1920 × 937 px vs. 13.3″/1280 × 657 px). The generating time was around 180 ms faster on average on the smaller display.
6.2.1. Leaflet.heat (v0.2.0)
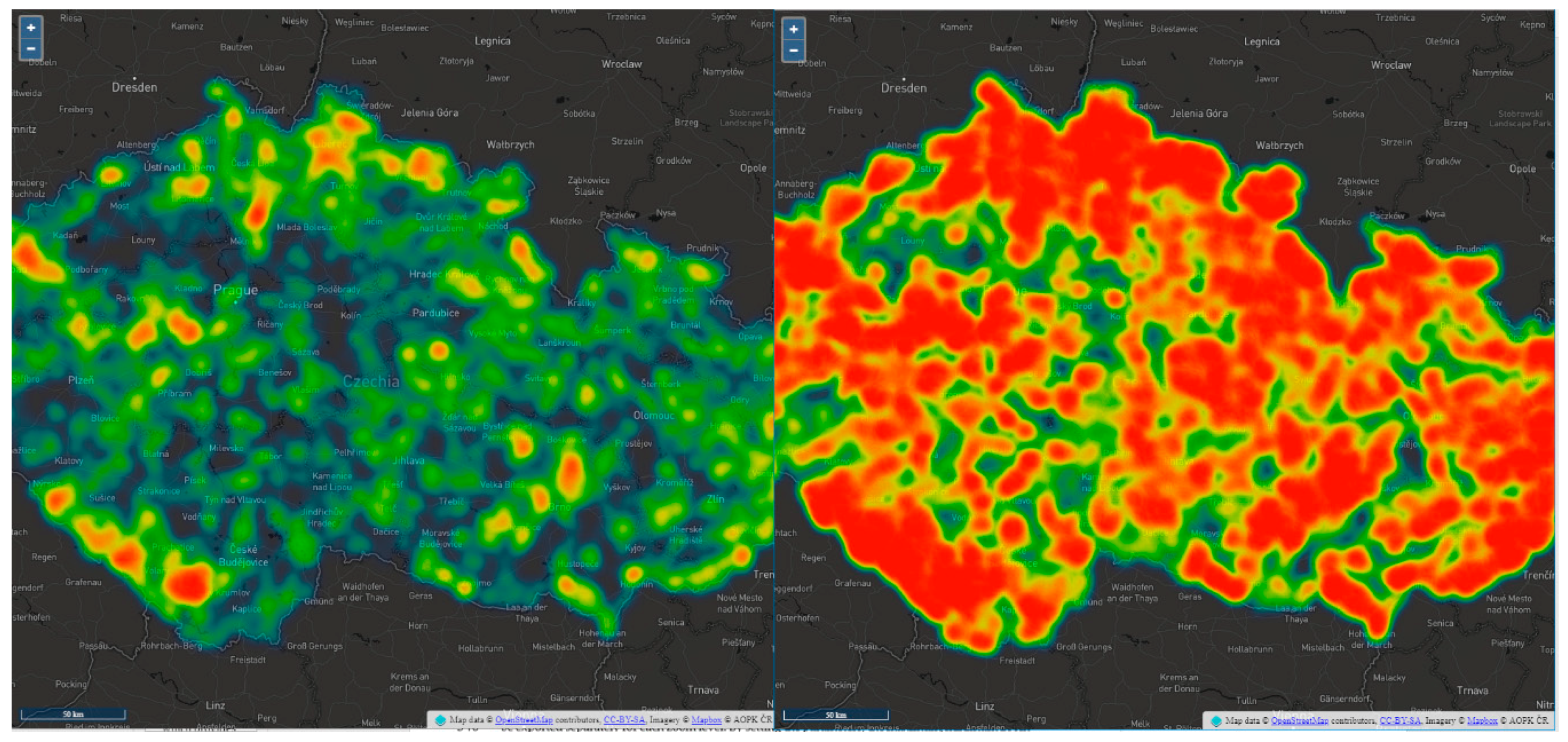
Leaflet.heat (see
Figure 8) is a lightweight heatmap plugin for Leaflet. It uses a “simpleheat” algorithm combined with clustering points to form a performance grid. Simpleheat is a super-tiny JavaScript library for drawing heatmaps on a canvas focusing on simplicity and performance [
25] and was developed by Vladimir Agafonkin. According to [
25], it creates an object given a canvas reference according to an [x, y, value] data format. Users can set the point radius, blur radius and gradient colors. When rendering, simpleheat draws a raster output with an optional minimum point opacity. With additional testing, we verified that the change of radius or blur only fluctuates in milliseconds—it is not a significant parameter.
It was able to render all test samples. Compared to the OpenLayers library, Leaflet.heat rendered ten times more points in a comparable time: on average 1217 ms for 100,000 points using Leaflet.heat vs. 1276 ms for 10,000 points using OpenLayers. The entire datasets with more than 3,000,000 points were rendered on average in 16,313 ms. See
Table 7 for complete results.
6.2.2. OpenLayers (v4.6.4)
OpenLayers provides native heatmap functionality by default (see
Figure 9). It is also rendered on a canvas, but provides more options: opacity, visibility, extent (the layer is not rendered outside a defined extent), zIndex, min/max resolution, gradient, radius, blur, shadow, weight (the feature attribute used for the weight or a function to return a weight from a feature), and render mode (vector or image format of output). In this case, only render mode could determine the rendering time. Surprisingly, the fluctuation was only 260 ms for a 10,000 dataset during an additional test cycle. A raster format was used for performance testing in order to compare with the previous example. With additional testing, we verified that the change of radius or blur only fluctuates in milliseconds—it is not a significant parameter.
The OpenLayers library rendered a maximum of 250,000 points as a heatmap in 10,846 ms on average. With larger data samples, the map did not work, and all other tests resulted in the web browser freezing or crashing. Even when using the smallest test sample of 10,000 points, user interactivity of the web application deteriorated, and map manipulation was not smooth. See
Table 8 for complete results.
6.3. Vector Tiles
Another option for visualization is to display the whole dataset using a vector tile concept. Entire large data sets could be effectively displayed, including interactivity and accessibility to attributes. Vector tiles can be generated from JSON, GeoJSON, CSV, or Geobuf formats using various software, such as tippecanoe, MapTiler, or ArcGIS Pro. The output is an MBTiles (MapBox Tiles) file that contains the resulting vector tiles. Technically, it is an SQLite (Structured Query Lite) database for storing vector or raster tiles. Vector tiles can also be exported separately for each zoom level. By setting the parameters, the maximum/minimum zoom levels or level of generalization can be affected. As a result, individual vector tiles in Protocol (buffer binary format) will be generated. For visualization purposes, vector tiles can then be uploaded to storage provided by Mapbox and visualized using the JavaScript library Mapbox GL JS. Another means of hosting the resulting vector tile is to use TileServer to run your own server.
7. Conclusions
The aim of the article was to specify, test, and compare the possibilities of visualizing Big data in JavaScript mapping libraries. Nine datasets containing 10,000 to 3,000,000 points were generated from the Nature Conservation Database. Five libraries for marker clustering and two libraries for heatmap visualization was analyzed, and quantitative limit was set. Loading time and the ability to visualize large data sets were compared for each dataset and each library. Testing was conducted on a common PC configuration (2.30 GHz, 8 GB RAM, 22” monitor) on a local Apache HTTP Server. All testing studies were conducted using the Google Chrome web browser.
The Leaflet.markercluster and OpenLayers solutions were evaluated as unsuitable. The Leaflet.markercluster library rendered a maximum of 100,000 points in 47 s. Larger samples were not possible to render. This was the slowest library in the comparison. The OpenLayers solution rendered a maximum of 250,000 points in 24.5 s using the clustering method and only 250,000 points in approximately 11 s using the heatmap method. It supports clustering natively and could render a maximum of 500,000 points. Testing on other samples was not successful. Combined with Leaflet, the Supercluster library was already able to render the entire dataset of more than 3,000,000 points in approximately 7 s. Redrawing when changing levels was quick, but not as smooth as with Mapbox GL JS. Mapbox GL JS was the smoothest of all samples because of WebGL technology used with GPU rendering. The benefits of Mapbox GL JS were also corroborated by testing heatmap rendering and loading times, rendering using WebGL being almost immediate. The final library tested for clustering was the PruneCluster library. It does not support GeoJSON; therefore, it was tested with JSON samples. The entire export was done in approximately 23 s. When GeoJSON data was used, rendering time increased significantly because of the dependency on file size (GeoJSON 362.1 MB; JSON 75.1 MB).
The Leaflet.heat library and native OpenLayers library were compared for loading heatmaps. The former rendered a heatmap of the entire dataset in approximately 16 s. The OpenLayers library could not render a sample of more than 250,000 points, which was rendered in approximately 10 s. Even with the smallest sample, OpenLayers demonstrated an increased response. All web applications with samples for clustering and heatmap creation are available on
http://geoinformatics.upol.cz/app/bigdata. Rendering such large data sets can also be accelerated by using vector tiles, even when combined with the marker clustering method.
The diverse results in point rendering has two explanations. The first is the “cluster points matrix” computing algorithm. While some libraries re-compute the matrix randomly, other libraries use sophisticated algorithms such as k-means, greedy clustering [
21], or detecting collisions [
22]. For example, a matrix calculated with PruneCluster approaches a regular grid. The second reason is the overall performance of the core library. Mapbox GL JS provides best results, because it is based on different technology and is a live project. The best-evaluated libraries were observed on “fresh” versions—they benefitted from community developments and updates—while the worst evaluated library Leaflet.markercluster was based on a solution more than a year old. Future research will certainly include diverse algorithms. In our study, the most recent (major) version of libraries available at the beginning of 2019 was implemented. Future updates may cause differences in loading time. Technically, updates available for core libraries (Leaflet, OpenLayers, Mapbox GL JS) and updates for the heatmap/clustering method should be separated, the most fundamental aspect being compatibility between them. In our pre-testing, different minor versions of the core library did not affect loading time. The different major version required a different clustering library version, but even then it did not significantly affect loading time (Leaflet.markercluster on 50,000 points in v1.0, v0.7, and v0.5 = a loading difference of approximately 150 to 200 ms; PruneCluster on 50,000 points in v2.1.0 and v1.0.0 = a loading difference of approximately 100 ms). This means that not all versions of clustering library are compatible with the Leaflet core library and vice versa. Since a new major library version such as Leaflet or OpenLayers is not released every few weeks or months but years, the results of this paper may be relevant for some time, especially until a new version with an essential change in the source code is released.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}