Assessing the Intensity of the Population Affected by a Complex Natural Disaster Using Social Media Data

 and
and
Abstract
:
1. Introduction
2. Related Work
2.1. Traditional Approaches to Assessing Affected Population
2.2. Social Media-Based Approach for Disaster Situational Awareness
3. A Social Media-Based Approach to Assess the Disaster-Affected Population
3.1. Tweet Collection and Preprocessing
- Step 1: The tweets and hashtags located in the disaster area were extracted from the Internet Archive database, which contains 1% of Twitter;
- Step 2: The hashtags that appeared only once were filtered out;
- Step 3: The hashtags that appeared before the disaster warning were filtered out;
- Step 5: Expert knowledge can also be used to further improve the accuracy of the obtained disaster-related hashtags by removing irrelevant ones. However, this step is not always necessary.
3.2. The Proxy Index of the Affected Population Intensity
4. Case Study and Dataset
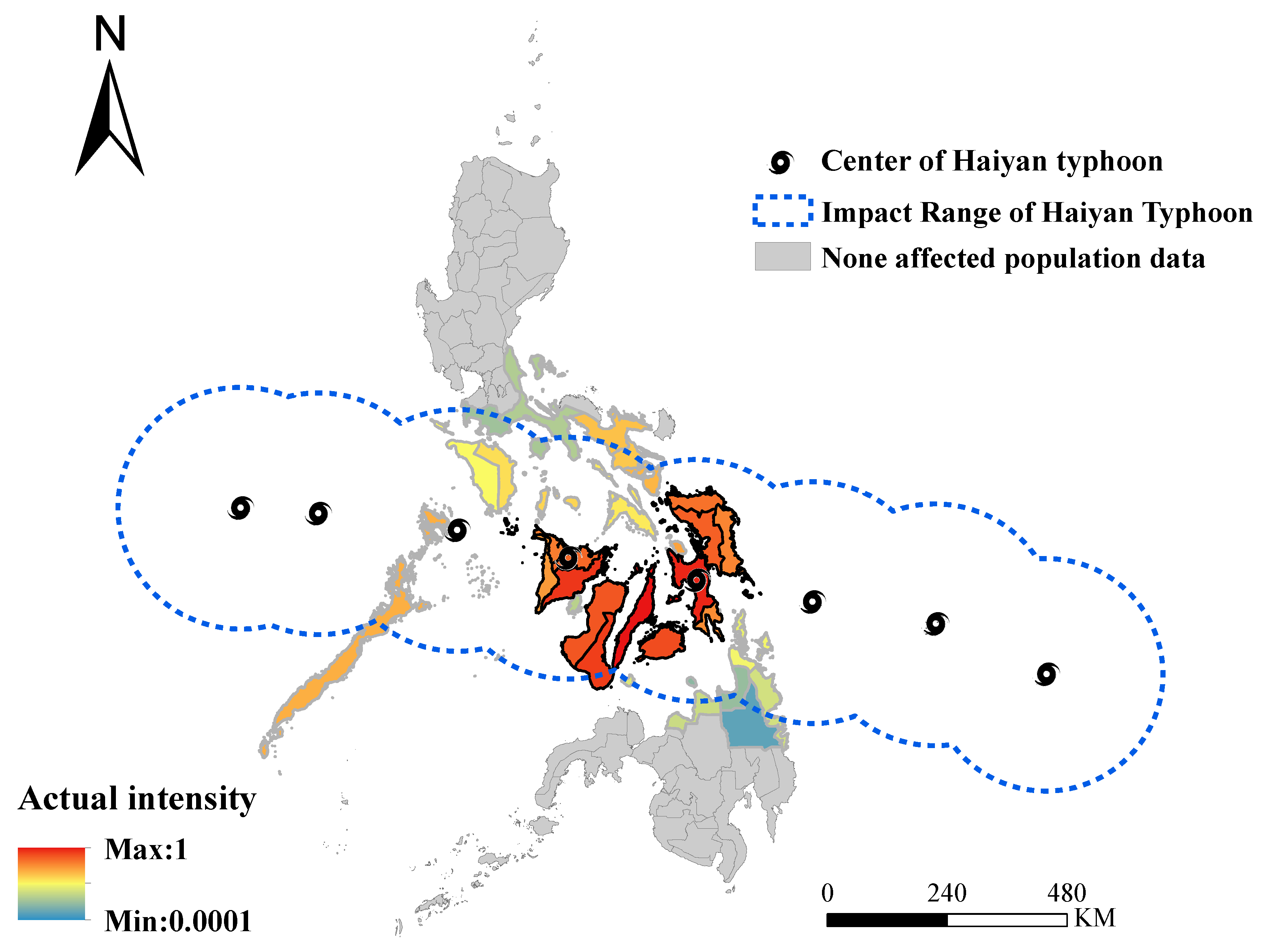
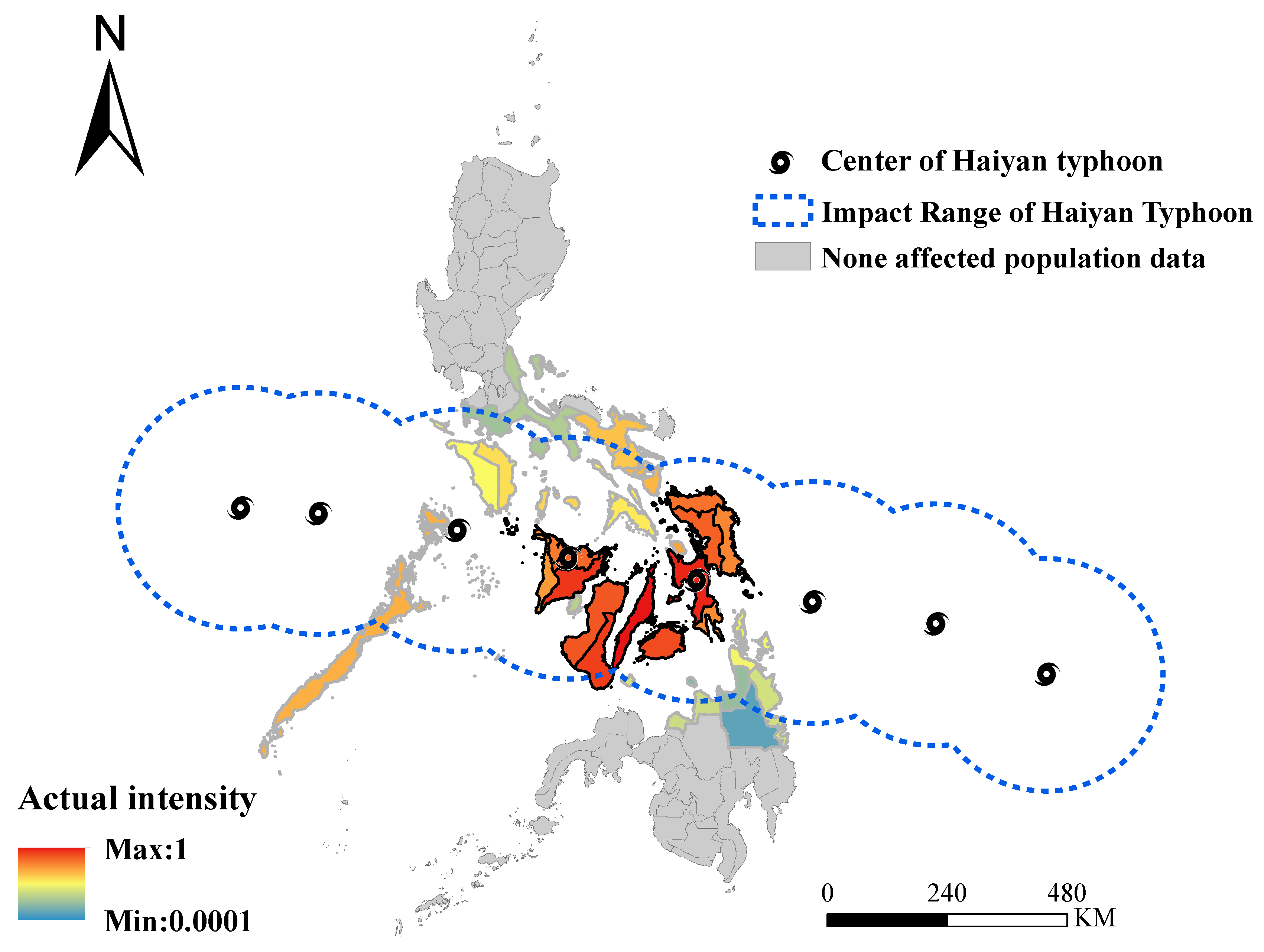
4.1. Typhoon Haiyan in 2013
4.2. Datasets
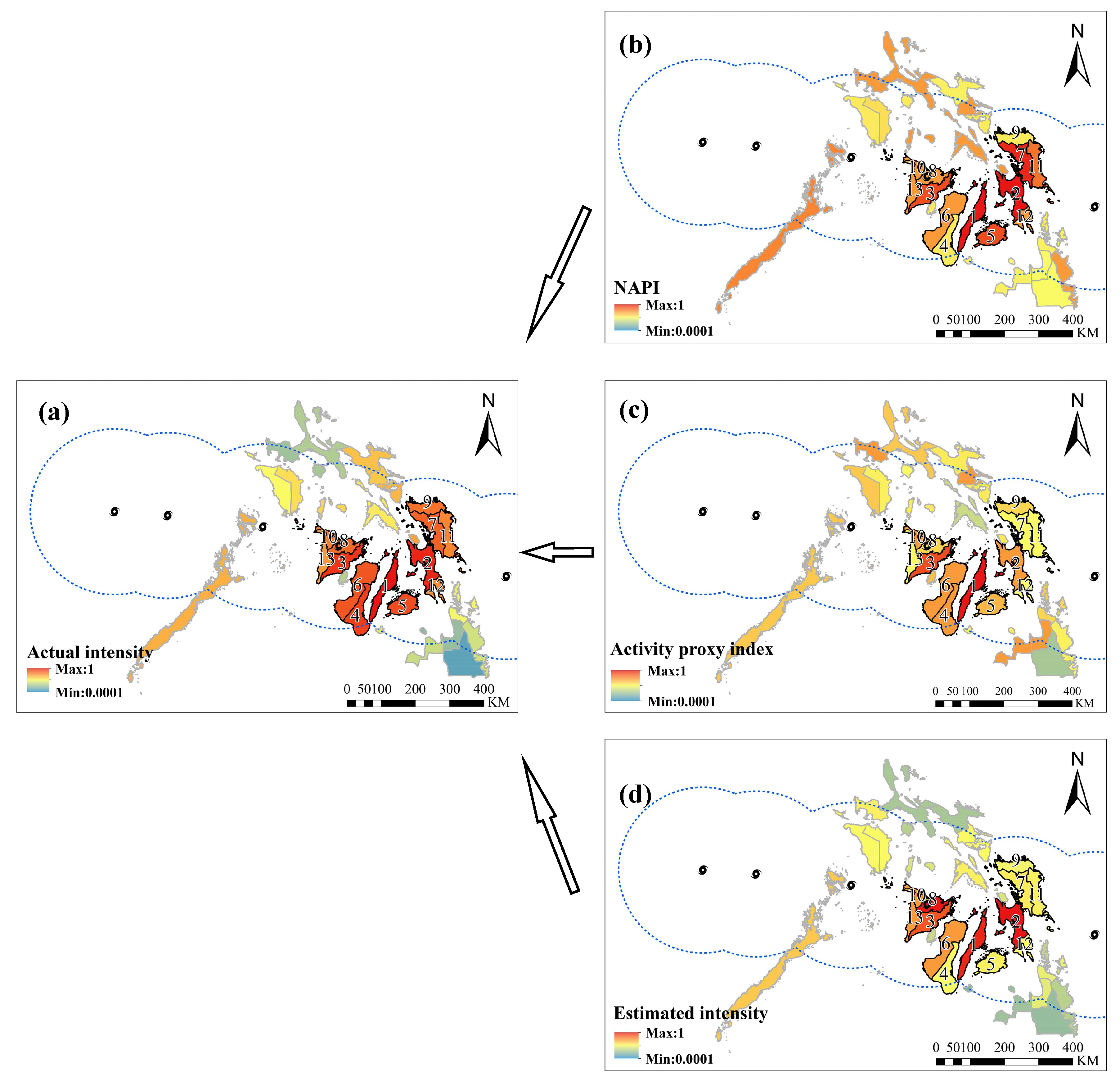
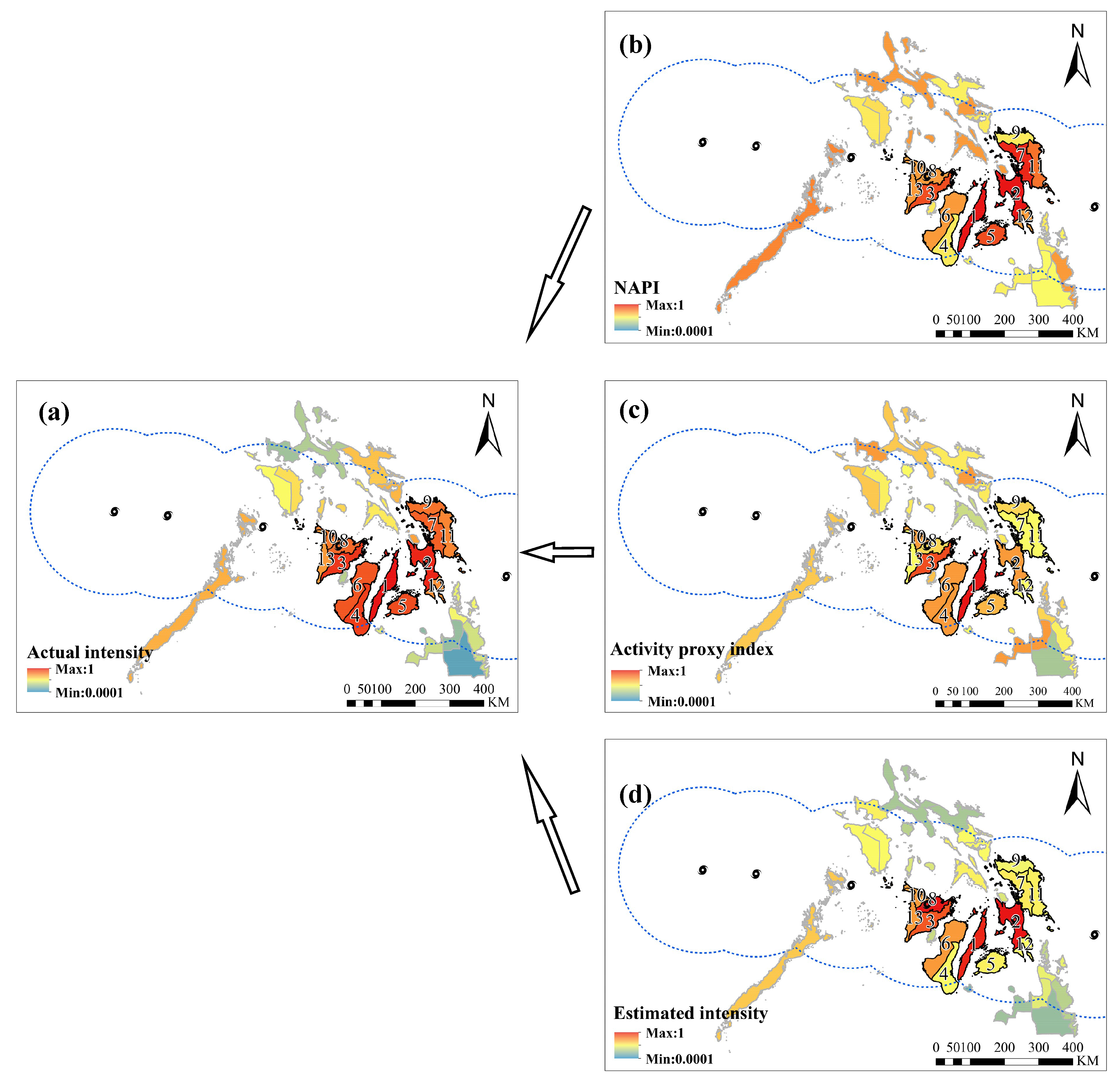
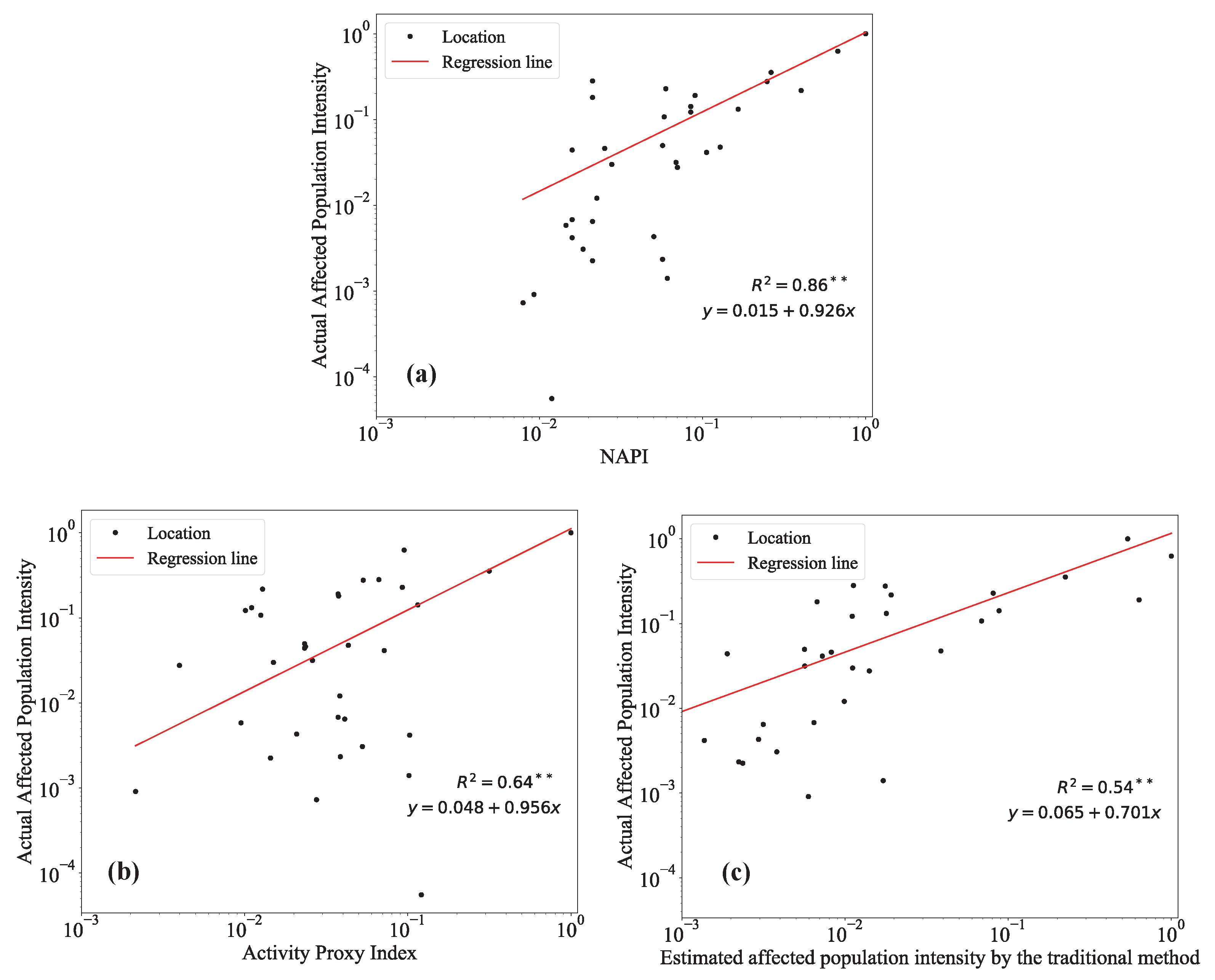
5. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| NAPI | Normalized Affected Population Index |
| LDA | Latent Dirichlet Allocation |
| SVM | Support Vector Machine |
| GIS | Geographic Information System |
References
- Shen, S.; Cheng, C.; Song, C.; Yang, J.; Yang, S.; Su, K.; Yuan, L.; Chen, X. Spatial distribution patterns of global natural disasters based on biclustering. Nat. Hazards 2018, 92, 1809. [Google Scholar] [CrossRef]
- Ho, H.C.; Knudby, A.; Chi, G.; Aminipouri, M.; Lai, D.Y.F. Spatiotemporal analysis of regional socio-economic vulnerability change associated with heat risks in Canada. Appl. Geogr. 2018, 95, 61–70. [Google Scholar] [CrossRef] [PubMed]
- Ho, H.C.; Wong, M.S.; Yang, L.; Chan, T.C.; Bilal, M. Influences of socioeconomic vulnerability and intra-urban air pollution exposure on short-term mortality during extreme dust events. Environ. Pollut. 2018, 235, 155–162. [Google Scholar] [CrossRef] [PubMed]
- Goodchild, M.F.; Glennon, J.A. Crowdsourcing geographic information for disaster response: A research frontier. Int. J. Digit. Earth 2010, 3, 231–241. [Google Scholar] [CrossRef]
- Shan, S.; Zhao, F.; Wei, Y.; Liu, M. Disaster management 2.0: A real–time disaster damage assessment model based on mobile social media data—A case study of Weibo (Chinese Twitter). Saf. Sci. 2019, 115, 393–413. [Google Scholar] [CrossRef]
- Heir, T.; Rosendal, S.; Bergh-Johannesson, K.; Michel, P.; Mortensen, E.L.; Weisæth, L.; Andersen, H.S.; Hultman, C.M. Tsunami-affected Scandinavian tourists: Disaster exposure and post-traumatic stress symptoms. Nord. J. Psychiatry 2011, 65, 9–15. [Google Scholar] [CrossRef] [PubMed]
- Resch, B.; Usländer, F.; Havas, C. Combining machine-learning topic models and spatiotemporal analysis of social media data for disaster footprint and damage assessment. Cartogr. Geogr. Inf. Sci. 2018, 45, 362–376. [Google Scholar] [CrossRef]
- Imran, M.; Castillo, C.; Diaz, F.; Vieweg, S. Processing social media messages in mass emergency: A survey. ACM Comput. Surv. 2015, 47, 1–38. [Google Scholar] [CrossRef]
- Yuan, F.; Liu, R. Feasibility study of using crowdsourcing to identify critical affected areas for rapid damage assessment: Hurricane Matthew case study. Int. J. Disaster Risk Reduct. 2018, 28, 758–767. [Google Scholar] [CrossRef]
- Gao, H.; Barbier, G.; Goolsby, R. Harnessing the Crowdsourcing Power of Social Media for Disaster Relief. IEEE Intell. Syst. 2011, 26, 10–14. [Google Scholar] [CrossRef]
- Kryvasheyeu, Y.; Chen, H.; Obradovich, N.; Moro, E.; Van Hentenryck, P.; Fowler, J.; Cebrian, M. Rapid assessment of disaster damage using social media activity. Sci. Adv. 2016, 2, e1500779. [Google Scholar] [CrossRef] [PubMed]
- Tkachenko, N.; Jarvis, S.; Procter, R. Predicting floods with Flickr tags. PLoS ONE 2017, 12, e0172870. [Google Scholar] [CrossRef] [PubMed]
- Mendoza, M.; Poblete, B. Valderrama, I. Nowcasting earthquake damages with Twitter. EPJ Data Sci. 2019, 8, 3. [Google Scholar] [CrossRef]
- Barrington, L.; Ghosh, S.; Greene, M.; Har-Noy, S.; Berger, J.; Gill, S.; Lin, A.Y.; Huyck, C. Crowdsourcing earthquake damage assessment using remote sensing. Ann. Geophys. 2012, 54. [Google Scholar] [CrossRef]
- De Albuquerque, J.; Herfort, B.; Brenning, A.; Zipf, A. A geographic approach for combining social media and authoritative data towards identifying useful information for disaster management. Int. J. Geogr. Inf. Sci. 2015, 8816, 1–23. [Google Scholar] [CrossRef]
- Wu, D.; Cui, Y. Disaster early warning and damage assessment analysis using social media data and geo–location information. Decis. Support Syst. 2018, 111, 48–59. [Google Scholar] [CrossRef]
- Schnebele, E.; Cervone, G. Improving remote sensing flood assessment using volunteered geographical data. Nat. Hazards Earth Syst. Sci. 2013, 13, 669–677. [Google Scholar] [CrossRef] [Green Version]
- Middleton, S.E.; Middleton, L.; Modafferi, S. Real-Time Crisis Mapping of Natural Disasters Using Social Media. IEEE Intell. Syst. 2014, 29, 9–17. [Google Scholar] [CrossRef]
- Yin, J.; Lampert, A.; Cameron, M.; Robinson, B.; Power, R. Using Social Media to Enhance Emergency Situation Awareness. IEEE Intell. Syst. 2012, 27, 52–59. [Google Scholar] [CrossRef]
- Huang, Q.; Xiao, Y. Geographic Situational Awareness: Mining Tweets for Disaster Preparedness, Emergency Response, Impact, and Recovery. ISPRS Int. J. Geo-Inf. 2015, 4, 1549. [Google Scholar] [CrossRef]
- Avvenuti, M.; Cresci, S.; Del Vigna, F.; Fagni, T.; Tesconi, M. CrisMap: A big data crisis mapping system based on damage detection and geoparsing. Inf. Syst. Front. 2018, 20, 993. [Google Scholar] [CrossRef]
- Murzintcev, N.; Cheng, C. Disaster Hashtags in Social Media. ISPRS Int. J. Geo-Inf. 2017, 6, 204. [Google Scholar] [CrossRef]
- Shen, S.; Murzintcev, N.; Song, C.; Cheng, C. Information retrieval of a disaster event from cross-platform social media. Inf. Discov. Deliv. 2017, 45, 220–226. [Google Scholar] [CrossRef]
- Jaiswal, K.; Wald, D. An Empirical Model for Global Earthquake Fatality Estimation. Earthq. Spectra 2010, 26, 1017–1037. [Google Scholar] [CrossRef] [Green Version]
- Aghamohammadi, H.; Mesgari, M.S.; Mansourian, A.; Molaei, D. Seismic human loss estimation for an earthquake disaster using neural network. Int. J. Environ. Sci. Technol. 2013, 10, 931–939. [Google Scholar] [CrossRef] [Green Version]
- Bhatt, C.M.; Srinivasa Rao, G.; Asiya, B.; Manjusree, P.; Sharma, S.V.S.P.; Prasanna, L.; Bhanumurthy, V. Satellite images for extraction of flood disaster footprints and assessing the disaster impact: Brahmaputra floods of June–July 2012, Assam, India. Curr. Sci. 2013, 104, 1692–1700. [Google Scholar]
- Raza, S.F.; Ahsan, M.S.; Ahmad, S.R. Rapid assessment of a flood-affected population through a spatial data model. J. Flood Risk Manag. 2017, 10, 219–225. [Google Scholar] [CrossRef]
- Ozcelik, C.; Gorokhovich, Y.; Doocy, S. Storm surge modelling with geographic information systems: Estimating areas and population affected by cyclone Nargis. Int. J. Climatol. 2012, 32, 95–107. [Google Scholar] [CrossRef]
- Roick, O.; Heuser, S. Location Based Social NetworksDefinition, Current State of the Art and Research Agenda. Trans. GIS 2013, 17, 763–784. [Google Scholar]
- Cervone, G.; Sava, E.; Huang, Q.; Schnebele, E.; Harrison, J.; Waters, N. Using Twitter for tasking remote-sensing data collection and damage assessment: 2013 Boulder flood case study. Int. J. Remote Sens. 2016, 37, 100–124. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake Shakes Twitter Users: Real–time Event Detection by Social Sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 851–860. [Google Scholar]
- Earle, P.S.; Bowden, D.C.; Guy, M. Twitter earthquake detection: Earthquake monitoring in a social world. Ann. Geophys. 2011, 54, 708–715. [Google Scholar]
- Crooks, A.; Croitoru, A.; Stefanidis, A.; Radzikowski, J. #Earthquake: Twitter as a Distributed Sensor System. Trans. GIS 2013, 17, 124–147. [Google Scholar]
- Kent, J.D.; Capello, H.T. Spatial patterns and demographic indicators of effective social media content during theHorsethief Canyon fire of 2012. Cartogr. Geogr. Inf. Sci. 2013, 40, 78–89. [Google Scholar] [CrossRef]
- Yang, J.; Yu, M.; Qin, H.; Lu, M.; Yang, C. A Twitter Data Credibility Framework–Hurricane Harvey as a Use Case. ISPRS Int. J. Geo-Inf. 2019, 8, 111. [Google Scholar] [CrossRef]
- Ragini, J.R.; Rubesh, A.P.M.; Vidhyacharan, B. Mining crisis information: A strategic approach for detection of people at risk through social media analysis. Int. J. Disaster Risk Reduct. 2018, 27, 556–566. [Google Scholar] [CrossRef]
- Fang, J.; Hu, J.; Shi, X.; Zhao, L. Assessing disaster impacts and response using social media data in China: A case study of 2016 Wuhan rainstorm. Int. J. Disaster Risk Reduct. 2019, 34, 275–282. [Google Scholar] [CrossRef]
- Chang, J.; Boyd-Graber, J.; Gerrish, S.; Wang, C.; Blei, D.M. Reading tea leaves: How humans interpret topic models. In Proceedings of the 22nd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; Curran Associates Inc.: Vancouver, BC, Canada, 2009; pp. 288–296. [Google Scholar]
- Spence, P.R.; Lachlan, K.A.; Rainear, A.M. Social media and crisis research: Data collection and directions. Comput. Hum. Behav. 2016, 54, 667–672. [Google Scholar] [CrossRef] [Green Version]
- Olteanu, A.; Castillo, C.; Diaz, F.; Vieweg, S. CrisisLex: A lexicon for collecting and filtering Microblogged communications in crises. In Proceedings of the 8th International Conference on Weblogs and Social Media, ICWSM 2014, Ann Arbor, MI, USA, 1–4 June 2014; pp. 376–385. [Google Scholar]
- Olteanu, A.; Vieweg, S.; Castillo, C. What to expect when the unexpected happens: Social media communications across crises. In Proceedings of the 2015 ACM International Conference on Computer-Supported Cooperative Work and Social Computing, Vancouver, BC, Canada, 14–18 March 2015; ACM: New York, NY, USA, 2015; pp. 994–1009. [Google Scholar]
- Imran, M.; Castillo, C.; Lucas, J.; Meier, P.; Vieweg, S. AIDR: Artificial intelligence for disaster response. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; ACM: New York, NY, USA, 2014; pp. 159–162. [Google Scholar]
- Avvenuti, M.; Cresci, S.; Nizzoli, L.; Tesconi, M. Gsp (Geo-Semantic-Parsing): Geoparsing and Geotagging with Machine Learning on Top of Linked Data. In European Semantic Web Conference (ESWC 2018); Springer: Cham, Switzerland, 2018. [Google Scholar]
- National Disaster Risk Reduction and Management Council (NDRRMC). Final Report Effects of Typhoon Yolanda (Haiyan); NDRRMC: Quezon City, Philippines, 2014.
- Center for International Earth Science Information Network—CIESIN—Columbia University. Gridded Population of the World, Version 4 (GPWv4): Administrative Unit Center Points with Population Estimates, Revision 11; CIESIN: Palisades, NY, USA, 2018. [Google Scholar]
- Knapp, K.R.; Kruk, M.C.; Levinson, D.H.; Diamond, H.J.; Neumann, C.J. The International Best Track Archive for Climate Stewardship (IBTrACS). Bull. Am. Meteorol. Soc. 2016, 91, 363–376. [Google Scholar] [CrossRef]
- Cushman, S.A. Calculating the configurational entropy of a landscape mosaic. Landsc. Ecol. 2016, 31, 481–489. [Google Scholar] [CrossRef]
- Cushman, S.A. Thermodynamics in landscape ecology: The importance of integrating measurement and modeling of landscape entropy. Landsc. Ecol. 2015, 30, 7–10. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N of Tweets Related to Typhoon Haiyan | N of Tweets from the Philippines | Province | N of Tweets Mentioned the Province |
|---|---|---|---|
| 411,738 | 32,048 | Cebu | 756 |
| Leyte | 510 | ||
| Samar | 304 | ||
| Iloilo | 199 | ||
| Bohol | 188 | ||
| Eastern Samar | 125 | ||
| Palawan | 97 | ||
| Albay | 80 | ||
| Capiz | 68 | ||
| Aklan | 64 | ||
| Southern Leyte | 64 | ||
| Masbate | 53 | ||
| Romblon | 52 | ||
| Batangas | 46 | ||
| Negros Occidental | 45 | ||
| Antique | 44 | ||
| Biliran | 43 | ||
| Quezon | 43 | ||
| Surigao del Sur | 38 | ||
| Oriental Mindoro | 21 | ||
| Sorsogon | 19 | ||
| Occidental Mindoro | 17 | ||
| Dinagat Islands | 16 | ||
| Marinduque | 16 | ||
| Negros Oriental | 16 | ||
| Northern Samar | 16 | ||
| Guimaras | 14 | ||
| Camarines Sur | 12 | ||
| Misamis Oriental | 12 | ||
| Surigao del Norte | 12 | ||
| Siquijor | 11 | ||
| Agusan del Sur | 9 | ||
| Agusan del Norte | 7 | ||
| Camiguin | 6 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, C.; Zhang, T.; Su, K.; Gao, P.; Shen, S. Assessing the Intensity of the Population Affected by a Complex Natural Disaster Using Social Media Data. ISPRS Int. J. Geo-Inf. 2019, 8, 358. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8080358
Cheng C, Zhang T, Su K, Gao P, Shen S. Assessing the Intensity of the Population Affected by a Complex Natural Disaster Using Social Media Data. ISPRS International Journal of Geo-Information. 2019; 8(8):358. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8080358
Chicago/Turabian StyleCheng, Changxiu, Ting Zhang, Kai Su, Peichao Gao, and Shi Shen. 2019. "Assessing the Intensity of the Population Affected by a Complex Natural Disaster Using Social Media Data" ISPRS International Journal of Geo-Information 8, no. 8: 358. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8080358