Improved Estimations of Nitrate and Sediment Concentrations Based on SWAT Simulations and Annual Updated Land Cover Products from a Deep Learning Classification Algorithm


Abstract
:1. Introduction
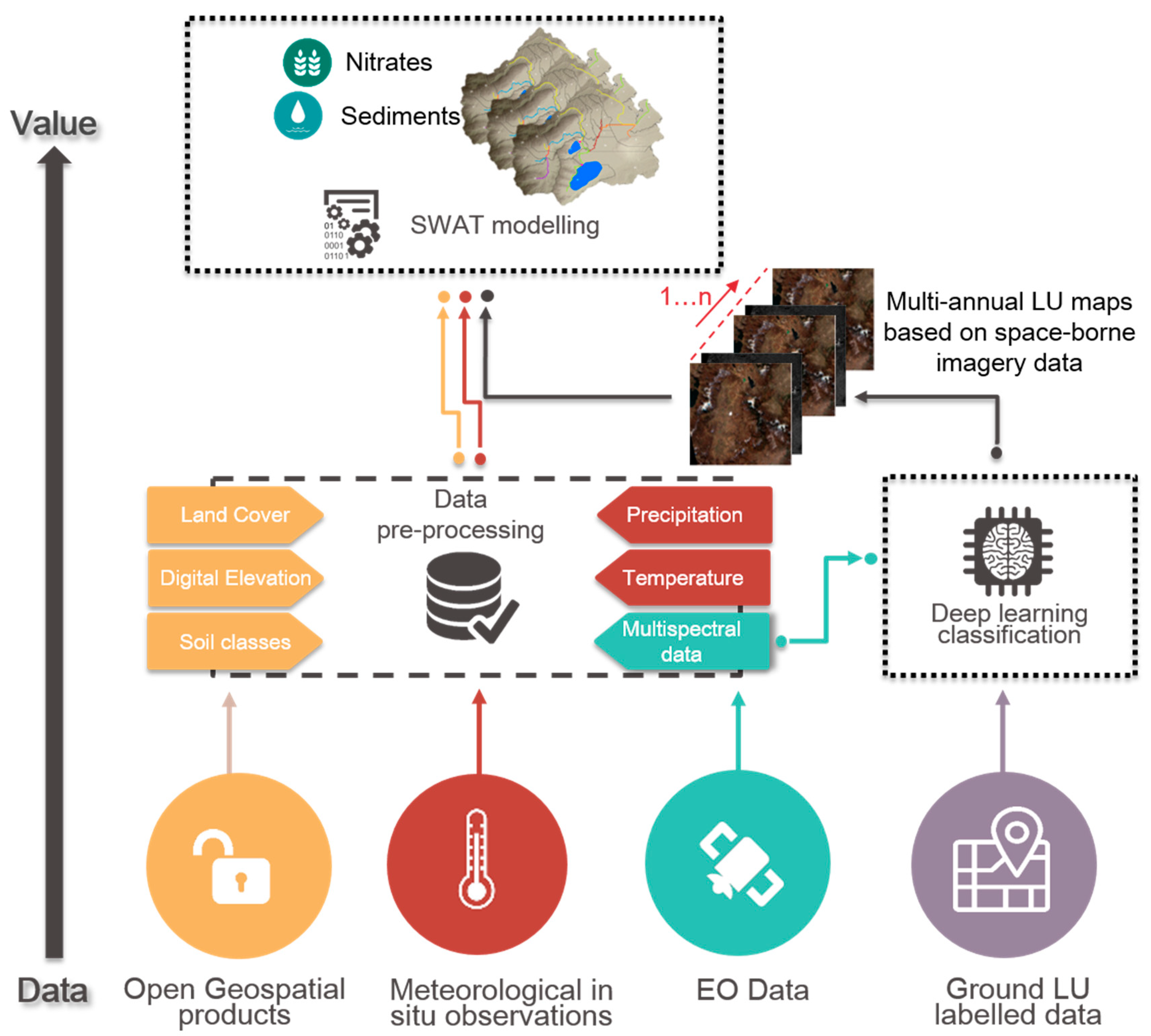
2. Materials and Methods
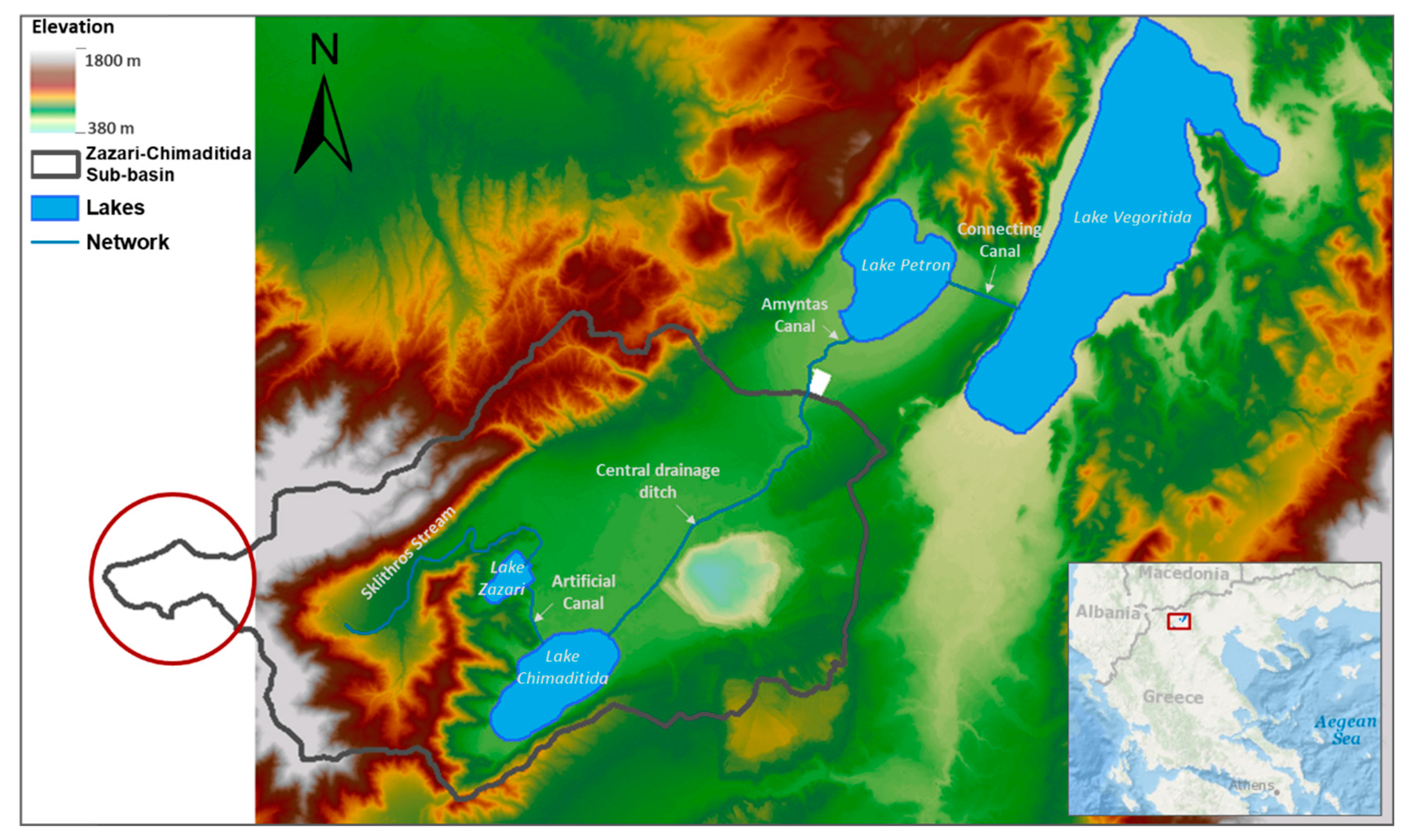
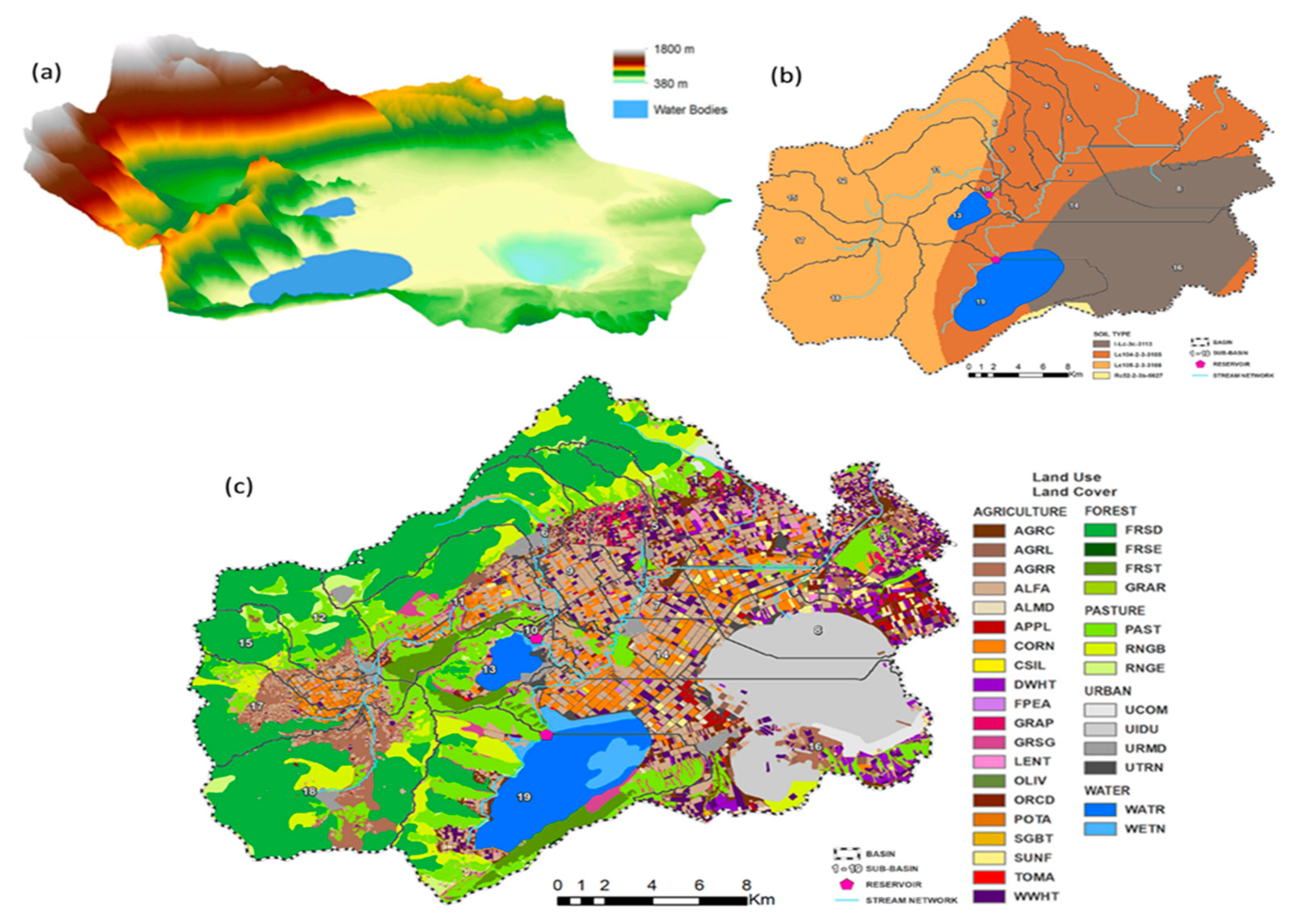
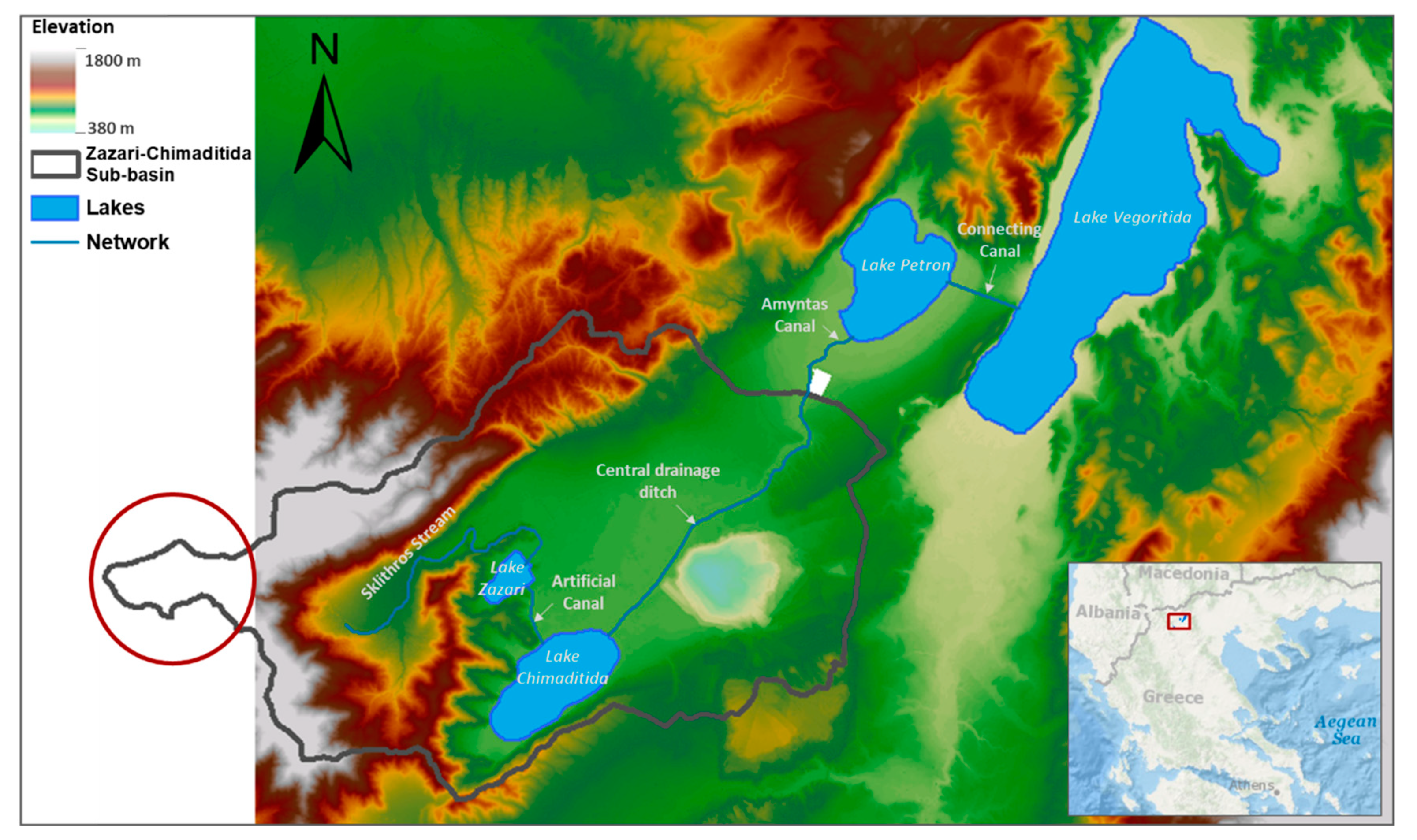
2.1. Description of the Study Area
2.2. Data Collection and Analysis
2.2.1. In Situ Information Procurement
2.2.2. Spatially Explicit Data
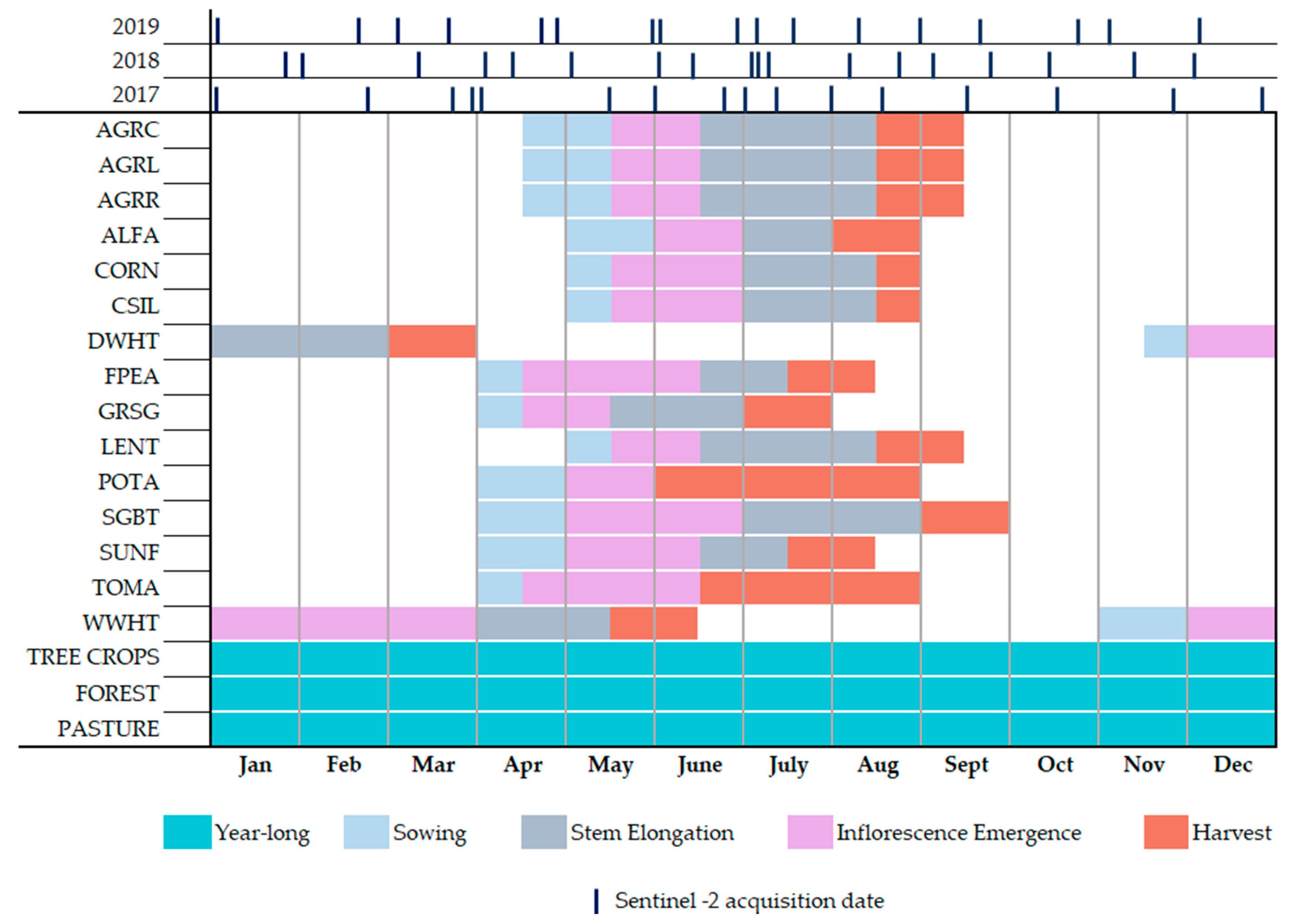
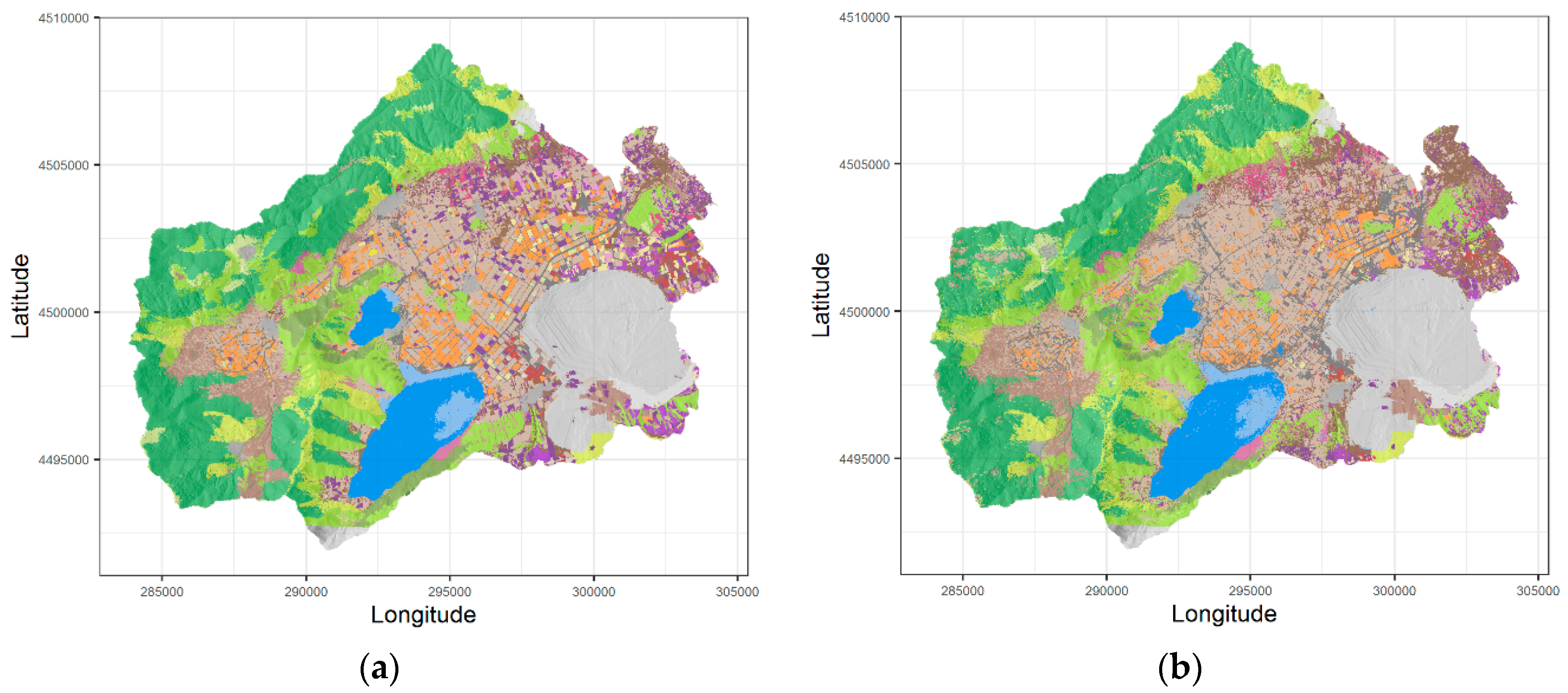
2.3. Generation of Annual Land Cover Dynamic Maps
2.4. The SWAT Model
2.4.1. SWAT Model Set Up
2.4.2. Sensitivity Analysis, Calibration and Validation
2.4.3. Validation of the Results
2.4.4. Improvement in SWAT Predictions
2.5. Implementation
3. Results and Discussion
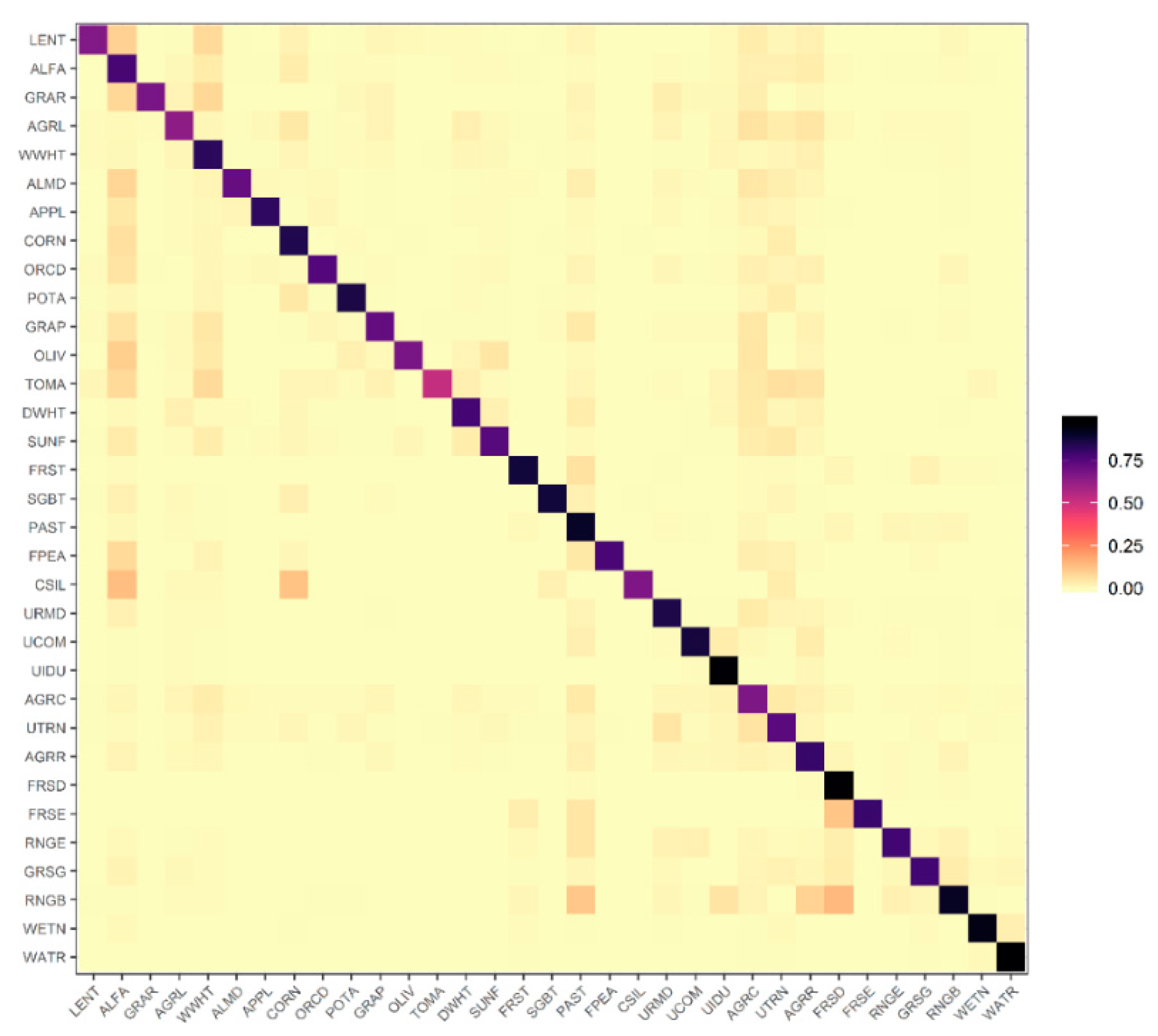
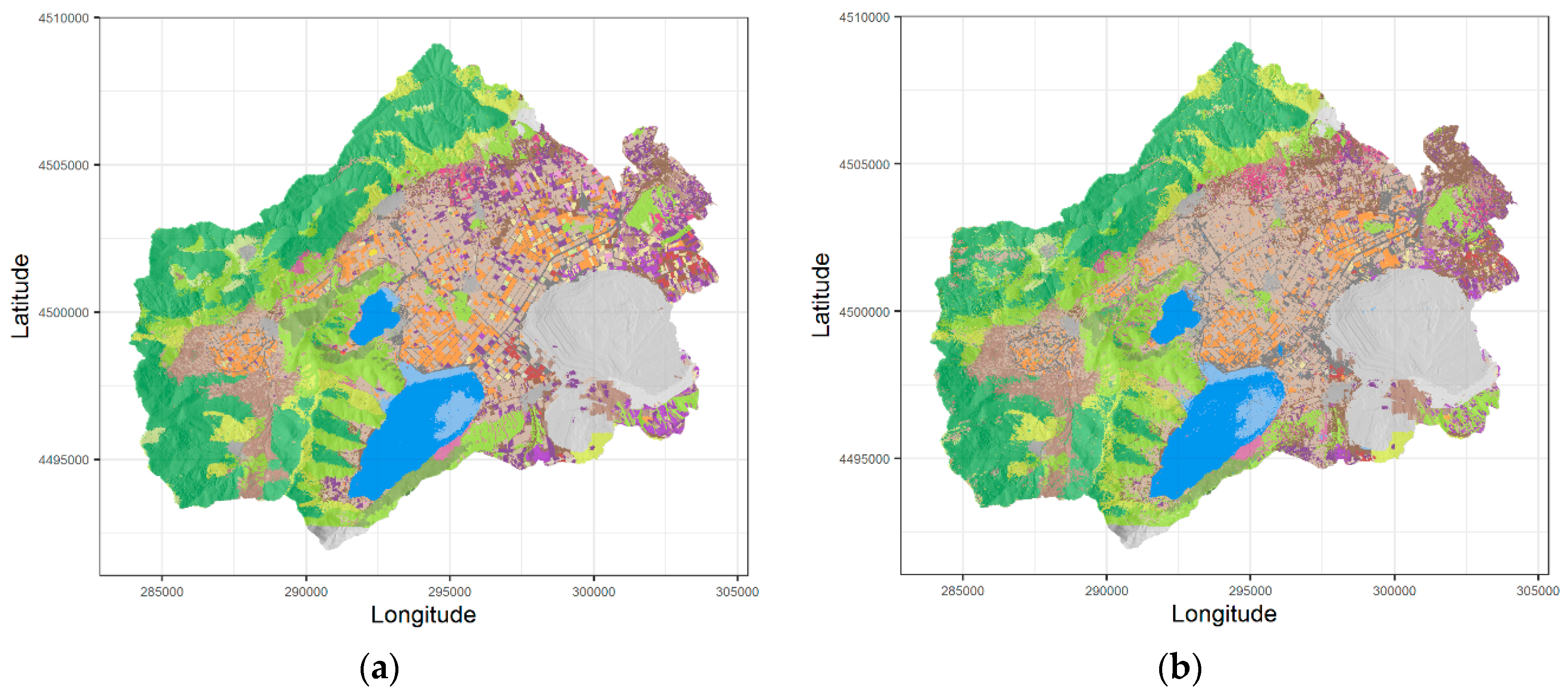
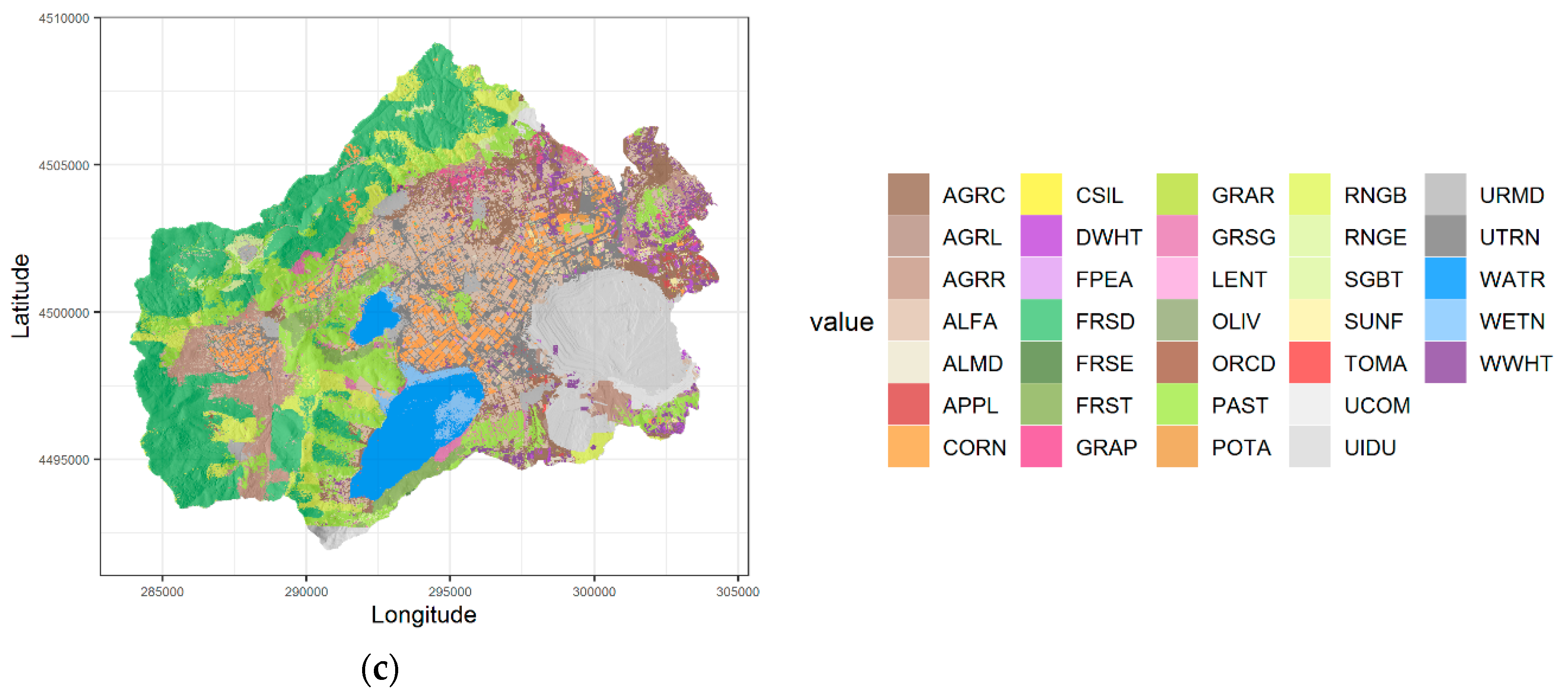
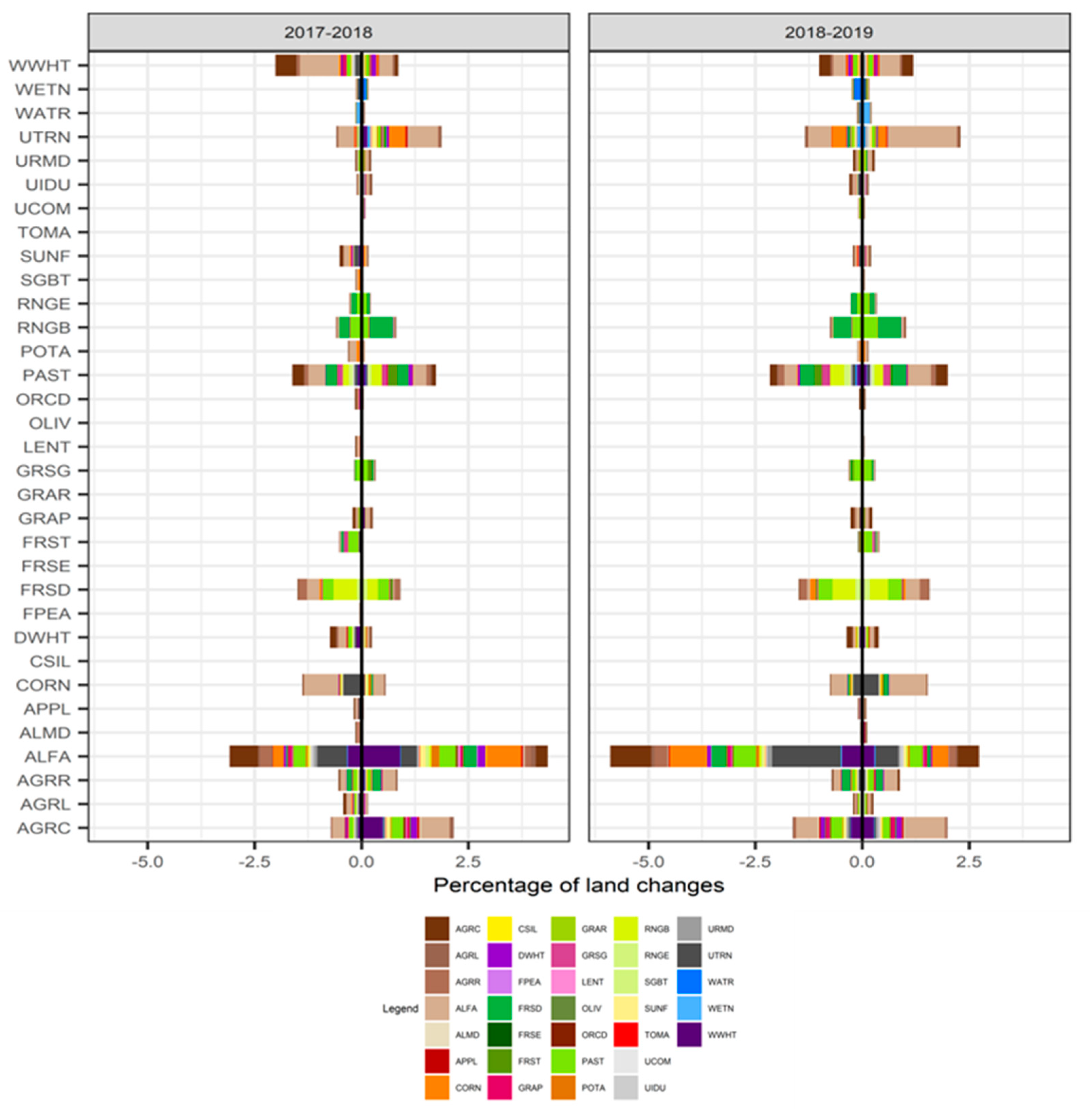
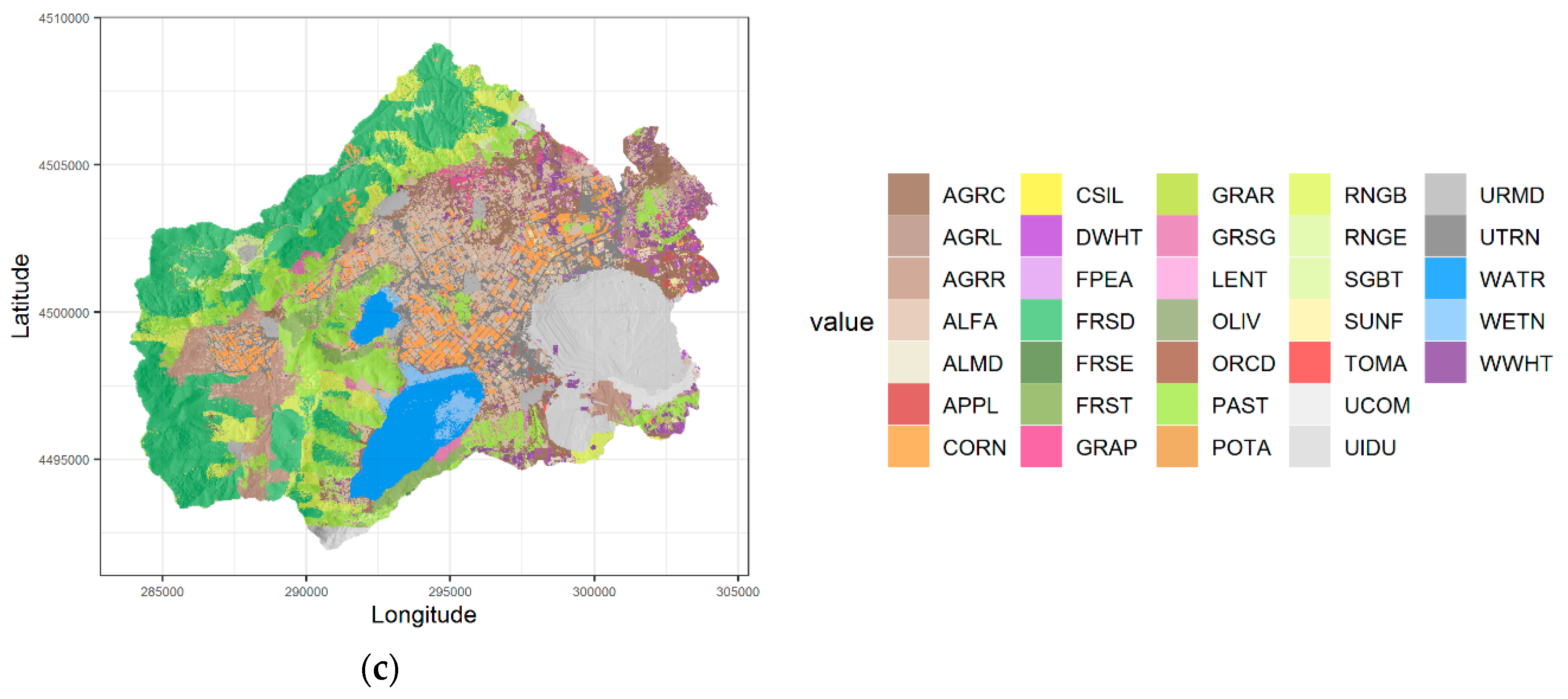
3.1. Remote Sensing Land Use and Land Cover Classification Results
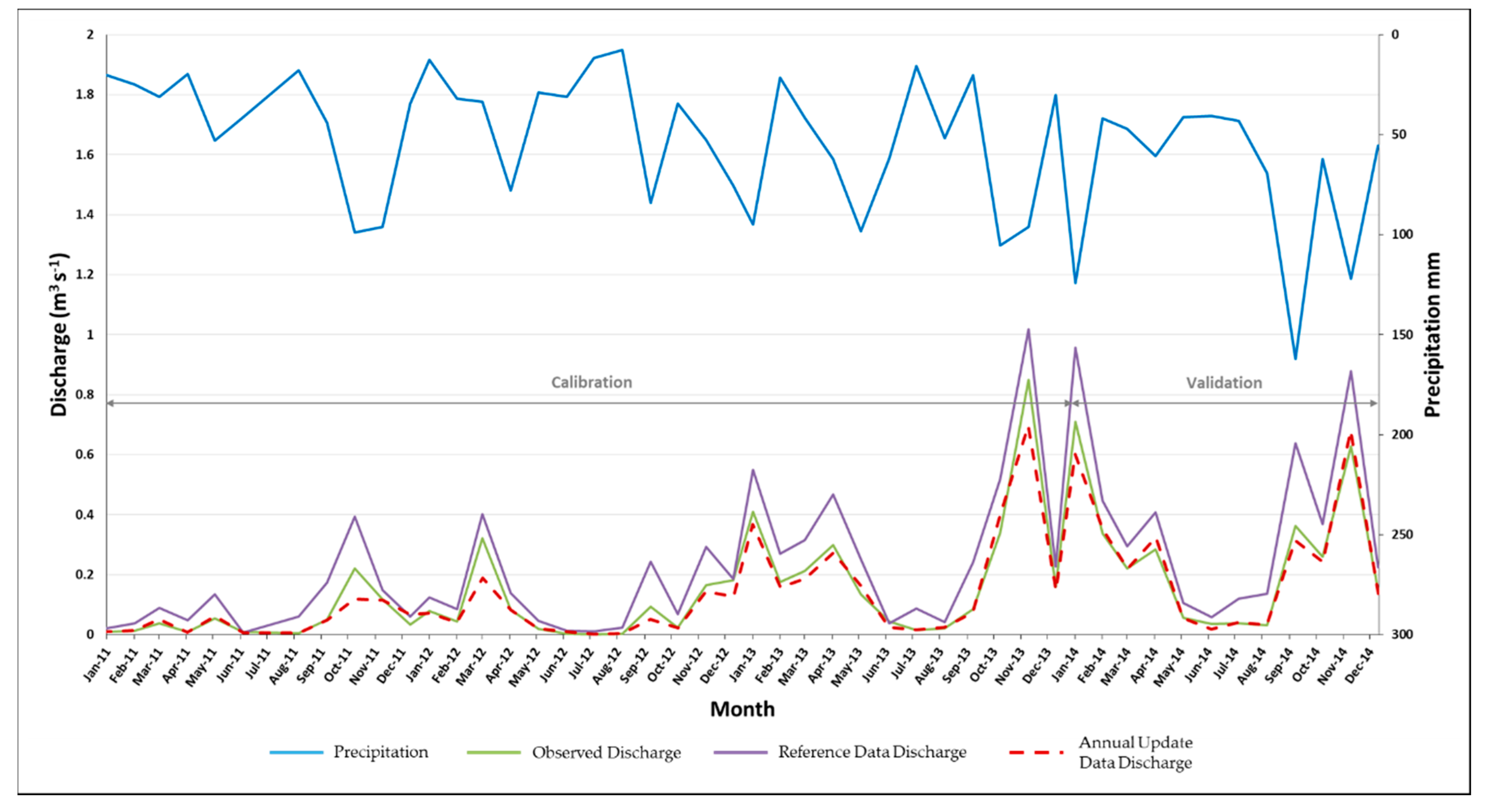
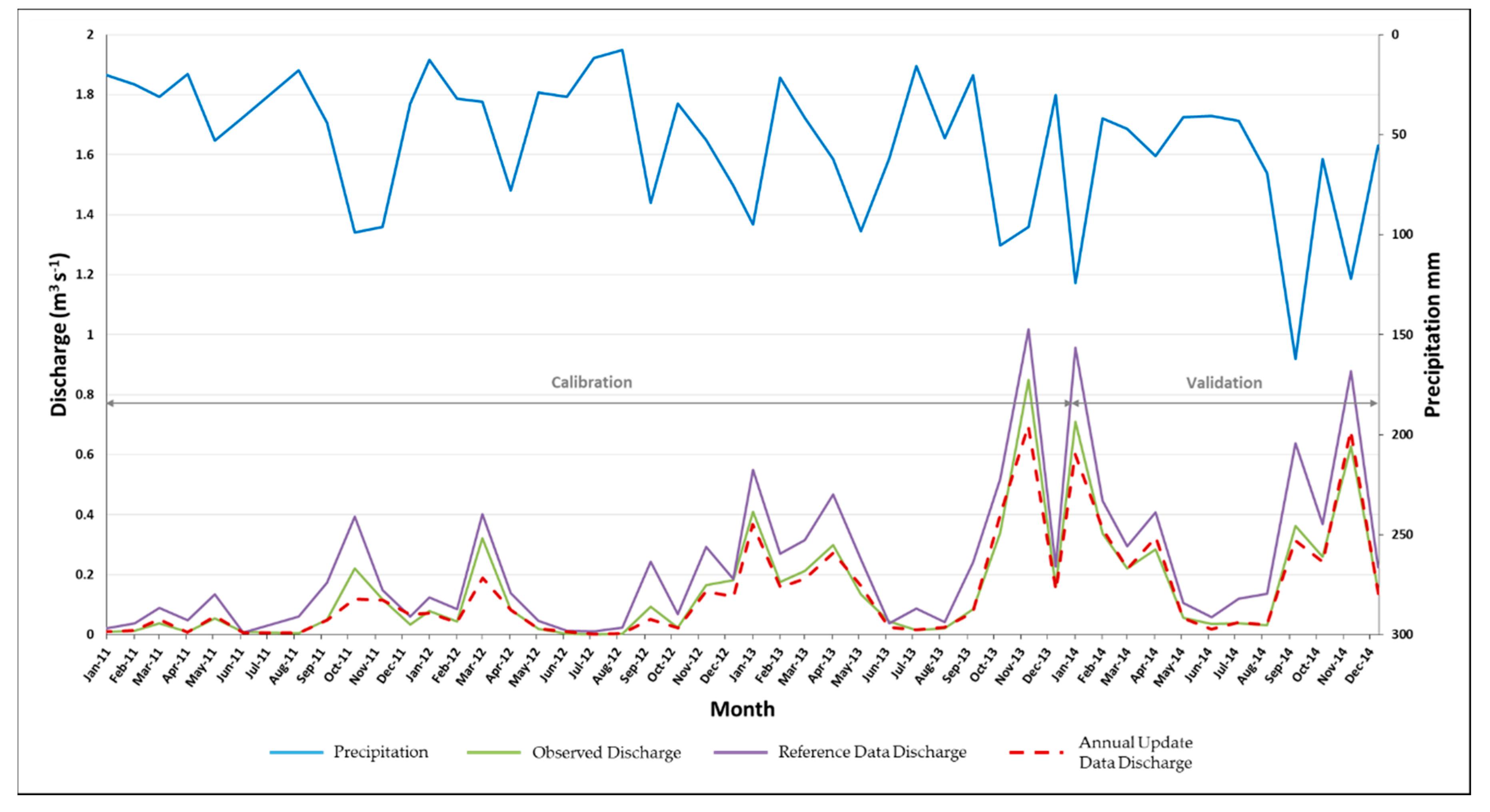
3.2. SWAT Calibration and Validation
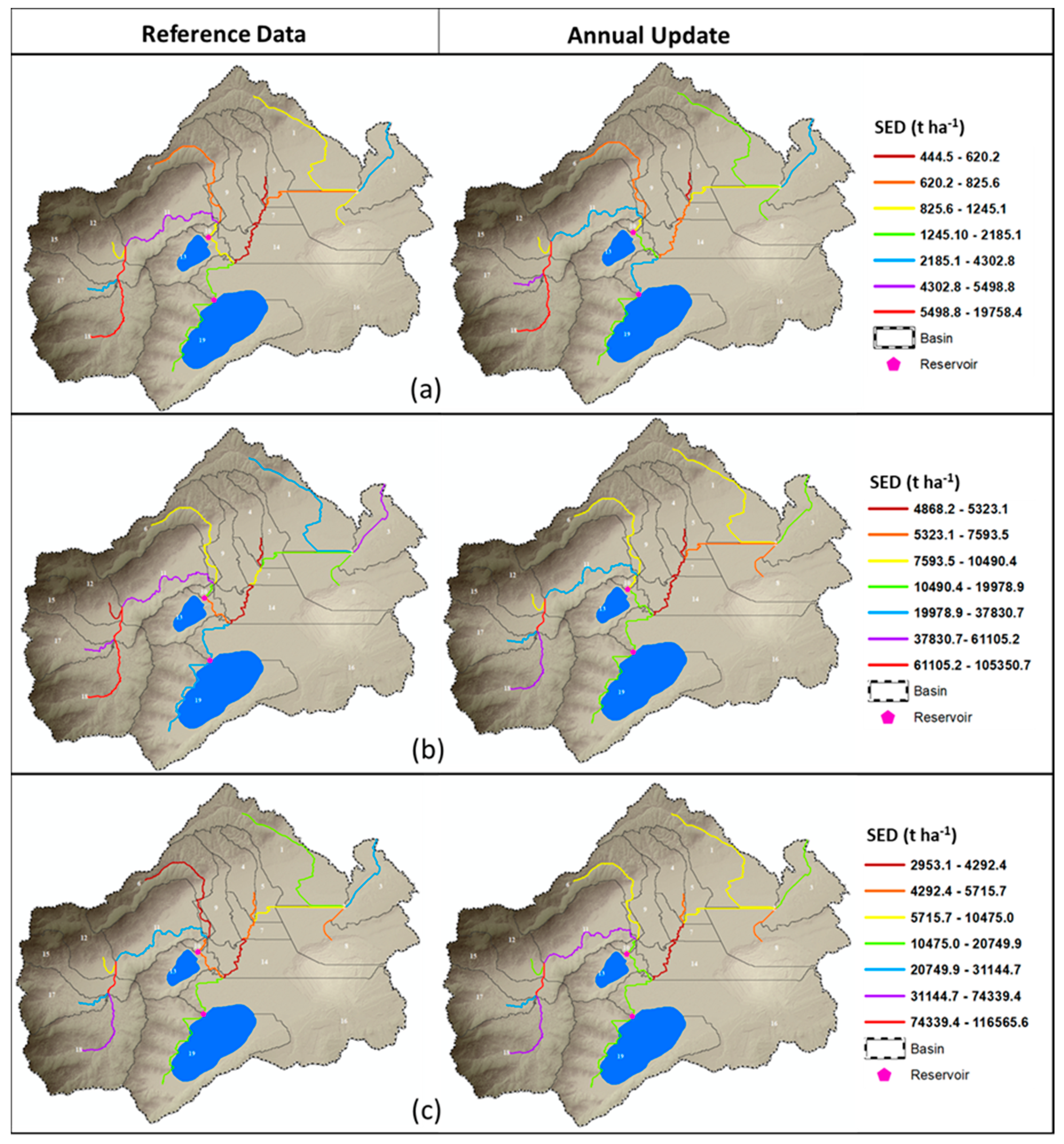
3.3. SWAT Model Simulation Results
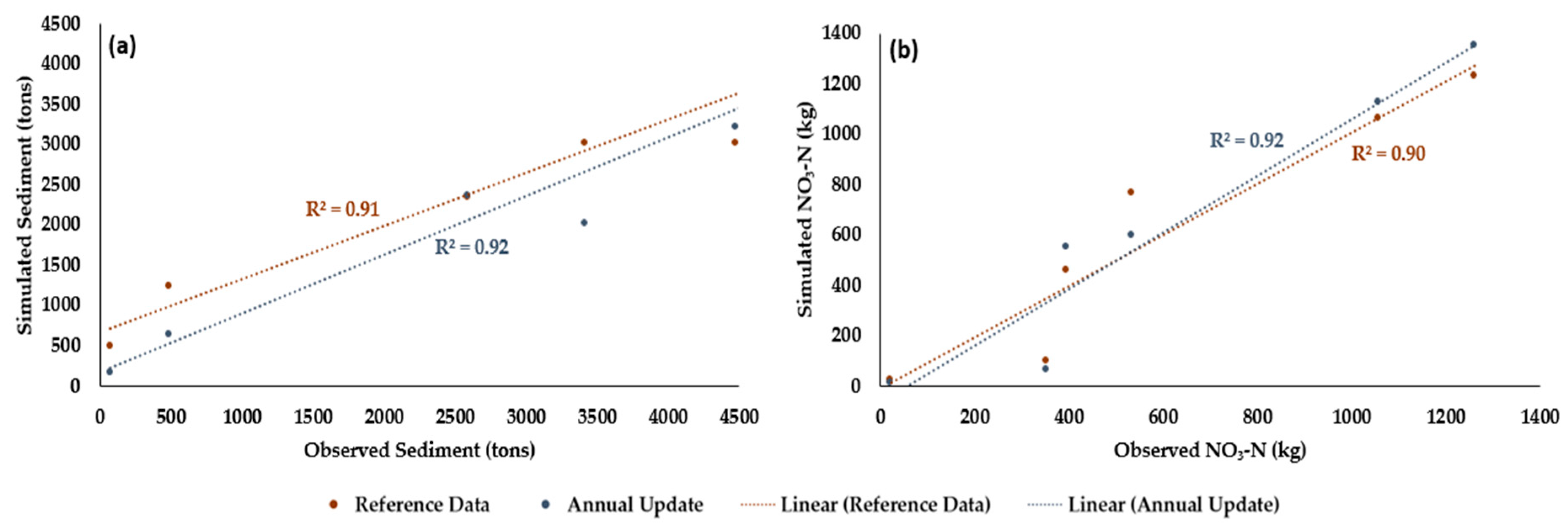
3.4. Source of the Improvement in Predictions
4. Conclusions and Outlook
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | SWAT Code | Label | Number of Pixels | Number of Pixels for Validation |
|---|---|---|---|---|
| Agricultural | ||||
| 0 | LENT | Lentils | 5501 | 491 |
| 1 | ALFA | Alfalfa | 320,917 | 20,592 |
| 2 | AGRL | Agricultural Land-Generic | 21,397 | 1625 |
| 3 | WWHT | Winter Wheat | 90,055 | 5728 |
| 4 | CORN | Corn | 89,190 | 6205 |
| 5 | POTA | Potatoe | 12,579 | 1049 |
| 6 | GRAP | Vineyard | 12,526 | 1001 |
| 7 | TOMA | Tomato | 1427 | 174 |
| 8 | DWHT | Durum Wheat | 33,361 | 2118 |
| 9 | SUNF | Sunflower | 21,145 | 1662 |
| 10 | SGBT | Sugarbeet | 5055 | 408 |
| 11 | FPEA | Field Peas | 1546 | 158 |
| 12 | CSIL | Corn Silage | 1112 | 120 |
| 13 | AGRC | Agricultural Land-Close-grown | 72,529 | 3613 |
| 14 | AGRR | Agricultural Land-Row Crops | 80,600 | 4778 |
| 15 | ALMD | Almonds | 5843 | 584 |
| 16 | APPL | Apple | 9588 | 715 |
| 17 | ORCD | Orchard | 6969 | 613 |
| 18 | OLIV | Olives | 1242 | 122 |
| 19 | GRSG | Grain Sorghum | 15,209 | 1017 |
| Forest | ||||
| 20 | FRST | Forest-Mixed | 44,676 | 3128 |
| 21 | FRSE | Forest-evergreen | 730 | 100 |
| 22 | GRAR | Grarigue | 323 | 100 |
| 23 | FRSD | Forest-deciduous | 467,909 | 30,295 |
| Pasture | ||||
| 24 | PAST | Pasture | 269,435 | 16,740 |
| 25 | RNGE | Range-Grasses | 22,211 | 1620 |
| 26 | RNGB | Range-brush | 97,858 | 5918 |
| Urban | ||||
| 27 | URMD | Urban Residential-Medium Density | 26,036 | 1883 |
| 28 | UCOM | Urban Commercial | 18,887 | 1294 |
| 29 | UIDU | Urban Industrial | 206,224 | 14,168 |
| 30 | UTRN | Urban Transportation | 63,571 | 3584 |
| Water | ||||
| 31 | WETN | Wetlands-Non-Forested | 26,770 | 1856 |
| 32 | WATR | Water | 105,905 | 7230 |
References
- Simpson, G.B.; Jewitt, G.P.W. The Development of the Water-Energy-Food Nexus as a Framework for Achieving Resource Security: A Review. Front. Environ. Sci. 2019, 7, 8. [Google Scholar] [CrossRef] [Green Version]
- Giuliani, G.; Chatenoux, B.; Benvenuti, A.; Lacroix, P.; Santoro, M.; Mazzetti, P. Monitoring land degradation at national level using satellite Earth Observation time-series data to support SDG15 – exploring the potential of data cube. Big Earth Data 2020, 4, 3–22. [Google Scholar] [CrossRef] [Green Version]
- Arnold, J.G.; Fohrer, N. SWAT2000: Current capabilities and research opportunities in applied watershed modelling. Hydrol. Process. 2005, 19, 563–572. [Google Scholar] [CrossRef]
- Pandey, A.; Himanshu, S.K.; Mishra, S.K.; Singh, V.P. Physically based soil erosion and sediment yield models revisited. Catena 2016, 147, 595–620. [Google Scholar] [CrossRef]
- Abbaspour, K.C.; Rouholahnejad, E.; Vaghefi, S.; Srinivasan, R.; Yang, H.; Kløve, B. A continental-scale hydrology and water quality model for Europe: Calibration and uncertainty of a high-resolution large-scale SWAT model. J. Hydrol. 2015, 524, 733–752. [Google Scholar] [CrossRef] [Green Version]
- Garg, K.K.; Bharati, L.; Gaur, A.; George, B.; Acharya, S.; Jella, K.; Narasimhan, B. Spatial mapping of agricultural water productivity using the swat model in Upper Bhima catchment, India. Irrig. Drain. 2012, 61, 60–79. [Google Scholar] [CrossRef] [Green Version]
- Cai, T.; Li, Q.; Yu, M.; Lu, G.; Cheng, L.; Wei, X. Investigation into the impacts of land-use change on sediment yield characteristics in the upper Huaihe River basin, China. Phys. Chem. Earth 2012, 53–54, 1–9. [Google Scholar] [CrossRef]
- Memarian, H.; Balasundram, S.K.; Abbaspour, K.C.; Talib, J.B.; Boon Sung, C.T.; Sood, A.M. SWAT-based hydrological modelling of tropical land-use scenarios. Hydrol. Sci. J. 2014, 59, 1808–1829. [Google Scholar] [CrossRef]
- Chaplot, V.; Saleh, A.; Jaynes, D.B. Effect of the accuracy of spatial rainfall information on the modeling of water, sediment, and NO3-N loads at the watershed level. J. Hydrol. 2005, 312, 223–234. [Google Scholar] [CrossRef]
- Sorando, R.; Comín, F.A.; Jiménez, J.J.; Sánchez-Pérez, J.M.; Sauvage, S. Water resources and nitrate discharges in relation to agricultural land uses in an intensively irrigated watershed. Sci. Total Environ. 2019, 659, 1293–1306. [Google Scholar] [CrossRef] [PubMed]
- Himanshu, S.K.; Pandey, A.; Yadav, B.; Gupta, A. Evaluation of best management practices for sediment and nutrient loss control using SWAT model. Soil Tillage Res. 2019, 192, 42–58. [Google Scholar] [CrossRef]
- Buchhorn, M.; Lesiv, M.; Tsendbazar, N.-E.; Herold, M.; Bertels, L.; Smets, B. Copernicus Global Land Cover Layers—Collection 2. Remote Sens. 2020, 12, 1044. [Google Scholar] [CrossRef] [Green Version]
- Interdonato, R.; Ienco, D.; Gaetano, R.; Ose, K. DuPLO: A DUal view Point deep Learning architecture for time series classificatiOn. ISPRS J. Photogramm. Remote Sens. 2019, 149, 91–104. [Google Scholar] [CrossRef] [Green Version]
- Ienco, D.; Interdonato, R.; Gaetano, R.; Ho Tong Minh, D. Combining Sentinel-1 and Sentinel-2 Satellite Image Time Series for land cover mapping via a multi-source deep learning architecture. ISPRS J. Photogramm. Remote Sens. 2019, 158, 11–22. [Google Scholar] [CrossRef]
- Fisher, J.R.B.; Acosta, E.A.; Dennedy-Frank, P.J.; Kroeger, T.; Boucher, T.M. Impact of satellite imagery spatial resolution on land use classification accuracy and modeled water quality. Remote Sens. Ecol. Conserv. 2018, 4, 137–149. [Google Scholar] [CrossRef]
- Foteh, R.; Garg, V.; Nikam, B.R.; Khadatare, M.Y.; Aggarwal, S.P.; Kumar, A.S. Reservoir Sedimentation Assessment Through Remote Sensing and Hydrological Modelling. J. Indian Soc. Remote Sens. 2018, 46, 1893–1905. [Google Scholar] [CrossRef]
- Azimi, S.; Dariane, A.B.; Modanesi, S.; Bauer-Marschallinger, B.; Bindlish, R.; Wagner, W.; Massari, C. Assimilation of Sentinel 1 and SMAP – based satellite soil moisture retrievals into SWAT hydrological model: The impact of satellite revisit time and product spatial resolution on flood simulations in small basins. J. Hydrol. 2020, 581, 124–367. [Google Scholar] [CrossRef]
- Fallatah, O.A.; Ahmed, M.; Cardace, D.; Boving, T.; Akanda, A.S. Assessment of modern recharge to arid region aquifers using an integrated geophysical, geochemical, and remote sensing approach. J. Hydrol. 2019, 569, 600–611. [Google Scholar] [CrossRef]
- Kottek, M.; Grieser, J.; Beck, C.; Rudolf, B.; Rubel, F. World Map of the Köppen-Geiger climate classification updated. Meteorol. Zeitschrift 2006, 15, 259–263. [Google Scholar] [CrossRef]
- Christophoridis, C.; Zervou, S.-K.; Manolidi, K.; Katsiapi, M.; Moustaka-Gouni, M.; Kaloudis, T.; Triantis, T.M.; Hiskia, A. Occurrence and diversity of cyanotoxins in Greek lakes. Sci. Rep. 2018, 8, 17877. [Google Scholar] [CrossRef] [Green Version]
- Sitokonstantinou, V.; Papoutsis, I.; Kontoes, C.; Lafarga Arnal, A.; Armesto Andrés, A.P.; Garraza Zurbano, J.A. Scalable Parcel-Based Crop Identification Scheme Using Sentinel-2 Data Time-Series for the Monitoring of the Common Agricultural Policy. Remote Sens. 2018, 10, 911. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Zhao, X.; Zhang, X.; Wu, D.; Du, X. Long Time Series Land Cover Classification in China from 1982 to 2015 Based on Bi-LSTM Deep Learning. Remote Sens. 2019, 11, 1639. [Google Scholar] [CrossRef] [Green Version]
- Arnold, J.G.; Srinivasan, R.; Muttiah, R.S.; Williams, J.R. Large area hydrologic modeling and assessment part I: Model development. J. Am. Water Resour. Assoc. 1998, 34, 73–89. [Google Scholar] [CrossRef]
- Tripathi, M.P.; Panda, R.K.; Raghuwanshi, N.S. Identification and prioritisation of critical sub-watersheds for soil conservation management using the SWAT model. Biosyst. Eng. 2003, 85, 365–379. [Google Scholar] [CrossRef]
- Williams, J.R. Sediment-Yield Prediction with Universal Equation Using Runoff Energy Factor. In Present and Prospective Technology for Predicting Sediment Yields and Sources: Proceedings of the Sediment-Yield Workshop; USDA Sedimentation Lab.: Oxford, MS, USA; Oxford, UK, 1975. [Google Scholar]
- Abbaspour, K.C. SWAT-CUP 2012: SWAT Calibration and Uncertainty Programs—A User Manual. Sci. Technol. 2014. [Google Scholar] [CrossRef]
- Saltelli, A.; Tarantola, S.; Campolongo, F. Sensitivity analysis as an ingredient of modeling. Stat. Sci. 2000, 15, 377–395. [Google Scholar] [CrossRef]
- Abbaspour, K.C.; Vejdani, M.; Haghighat, S. SWAT-CUP calibration and uncertainty programs for SWAT. In MODSIM07-Land, Water and Environmental Management: Integrated Systems for Sustainability, Proceedings; SWAT: Christchurch, New Zealand, 2007. [Google Scholar]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Veith Model Evaluation Guidelines for Systematic Quantification of Accuracy in Watershed Simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Santhi, C.; Arnold, J.G.; Williams, J.R.; Dugas, W.A.; Srinivasan, R.; Hauck, L.M. Validation of the SWAT model on a large river basin with point and nonpoint sources. J. Am. Water Resour. Assoc. 2001, 37, 1169–1188. [Google Scholar] [CrossRef]
- Van Liew, M.W.; Arnold, J.G.; Garbrecht, J.D. Hydrologic simulation on agricultural watersheds: Choosing between two models. Trans. Am. Soc. Agric. Eng. 2003, 46, 1539–1551. [Google Scholar] [CrossRef]
- Hernandez, A.J.; Healey, S.P.; Huang, H.; Ramsey, R.D. Improved prediction of stream flow based on updating land cover maps with remotely sensed forest change detection. Forests 2018, 9, 317. [Google Scholar] [CrossRef] [Green Version]
- Killough, B. Overview of the open data cube initiative. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; pp. 8629–8632. [Google Scholar]
- Giuliani, G.; Camara, G.; Killough, B.; Minchin, S. Earth observation open science: Enhancing reproducible science using data cubes. Data 2019, 4, 147. [Google Scholar] [CrossRef] [Green Version]
- R Development Core Team. R: A Language and Environment for Statistical Computing. Available online: http://cran.univ-paris1.fr/web/packages/dplR/vignettes/intro-dplR.pdf (accessed on 4 July 2020).
- Abbaspour, K.C.; Vaghefi, S.A.; Srinivasan, R. A guideline for successful calibration and uncertainty analysis for soil and water assessment: A review of papers from the 2016 international SWAT conference. Water 2017, 10, 6. [Google Scholar] [CrossRef] [Green Version]
- Hallouz, F.; Meddi, M.; Mahé, G.; Alirahmani, S.; Keddar, A. Modeling of discharge and sediment transport through the SWAT model in the basin of Harraza (Northwest of Algeria). Water Sci. 2018, 32, 79–88. [Google Scholar] [CrossRef] [Green Version]
- Querner, E.P.; Zanen, M.V. Modelling water quantity and quality using SWAT. Alterra Wageningen UR Wageningen 2013, 1, 1–73. [Google Scholar]
- Bosch, D.D.; Sheridan, J.M.; Batten, H.L.; Arnold, J.G. Evaluation of the SWAT model on a coastal plain agricultural watershed. Trans. Am. Soc. Agric. Eng. 2004, 47, 1493–1506. [Google Scholar] [CrossRef]
- Cotter, A.S.; Chaubey, I.; Costello, T.A.; Soerens, T.S.; Nelson, M.A. Water quality model output uncertainty as affected by spatial resolution of input data. J. Am. Water Resour. Assoc. 2003, 39, 977–986. [Google Scholar] [CrossRef]
- Di Luzio, M.; Arnold, J.G.; Srinivasan, R. Effect of GIS data quality on small watershed stream flow and sediment simulations. Hydrol. Process. 2005, 19, 629–650. [Google Scholar] [CrossRef]






| Meteorological Data (2006–2019) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Temperature °C | Rainfall mm | Other | |||||||
| Max | Min | Max | Mean Annual | Min | Driest Month | Wettest Month | Wind speed | Relative Humidity | Solar Radiation |
| 41.12 | −14.6 | 857 | 615.3 | 374 | 30 mm | 90 mm | Light breeze | Moderate to high | Moderate to high |
| Parameter SWAT Code | Description | Statistical Indices | Range | Fitted Value | ||
|---|---|---|---|---|---|---|
| t-Stat | p-Value | Min | Max | |||
| CN2 | Soil conservation service (SCS) runoff curve number | −2.9339 | 0.0324 | 35 | 98 | 64 |
| ALPHA_BF | Base flow recession constant | −0.5717 | 0.5922 | 0 | 1 | 1 |
| GWQMN | Threshold depth for return flow of water in the shallow aquifer | 3.5081 | 0.0171 | 0 | 5000 | 1150 |
| GW_DELAY | Groundwater delay in days | 4.3518 | 0.0073 | 0 | 500 | 14 |
| GW_REVAP | Groundwater revap coefficient | 1.0249 | 0.3633 | 0.02 | 0.2 | 0.2 |
| Evaluation Statistics | Calibration | Validation | ||
|---|---|---|---|---|
| Reference Data | Annual Update | Reference Data | Annual Update | |
| R2 | 0.89 | 0.95 | 0.90 | 0.91 |
| NSE | −0.56 | 0.31 | −0.76 | 0.30 |
| PBIAS | −58.65 | 14.2 | −48.80 | 13.5 |
| RSR | 1.61 | 0.70 | 1.03 | 0.63 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samarinas, N.; Tziolas, N.; Zalidis, G. Improved Estimations of Nitrate and Sediment Concentrations Based on SWAT Simulations and Annual Updated Land Cover Products from a Deep Learning Classification Algorithm. ISPRS Int. J. Geo-Inf. 2020, 9, 576. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9100576
Samarinas N, Tziolas N, Zalidis G. Improved Estimations of Nitrate and Sediment Concentrations Based on SWAT Simulations and Annual Updated Land Cover Products from a Deep Learning Classification Algorithm. ISPRS International Journal of Geo-Information. 2020; 9(10):576. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9100576
Chicago/Turabian StyleSamarinas, Nikiforos, Nikolaos Tziolas, and George Zalidis. 2020. "Improved Estimations of Nitrate and Sediment Concentrations Based on SWAT Simulations and Annual Updated Land Cover Products from a Deep Learning Classification Algorithm" ISPRS International Journal of Geo-Information 9, no. 10: 576. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9100576