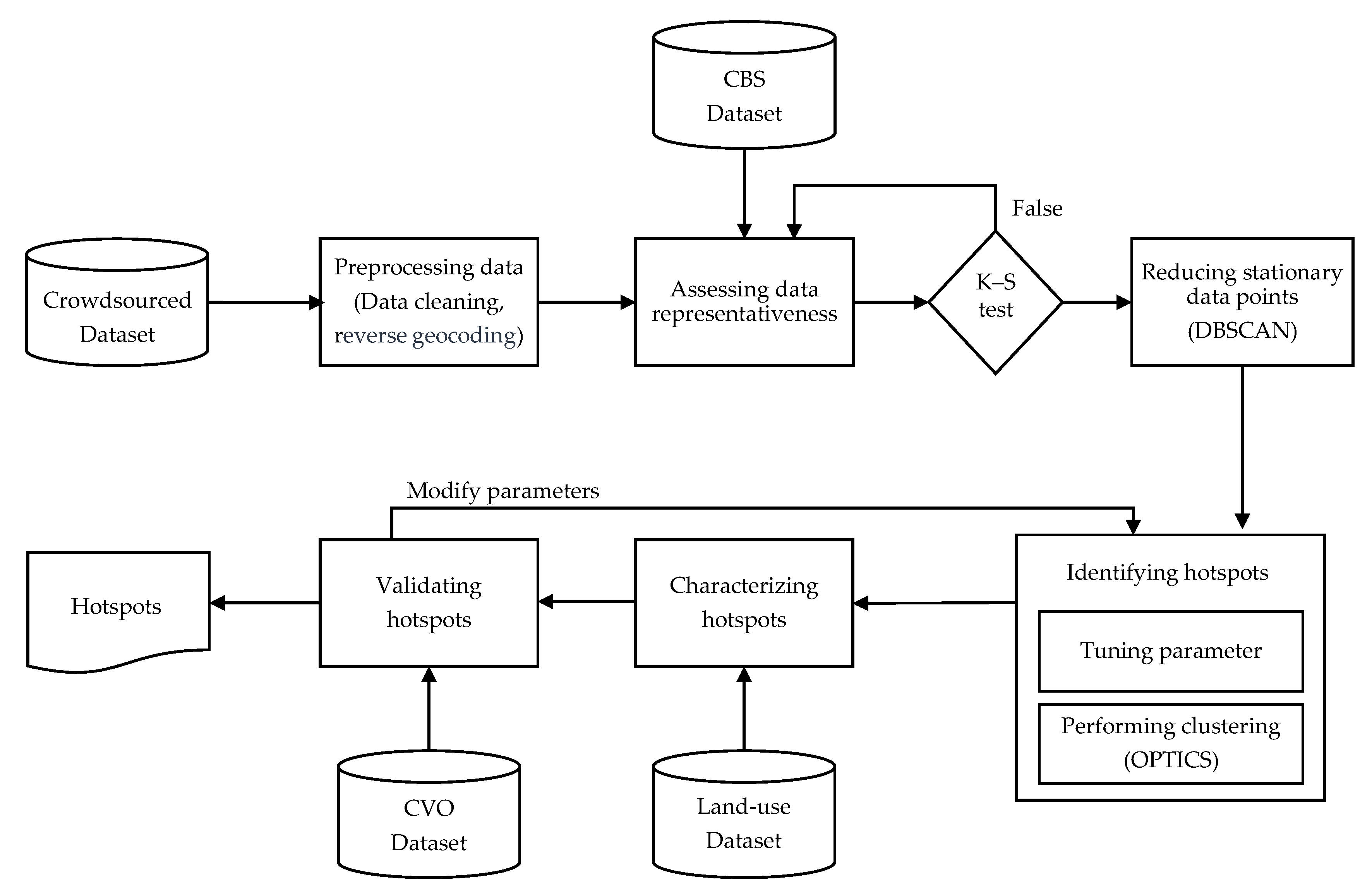
2.3.3. Clustering Analysis
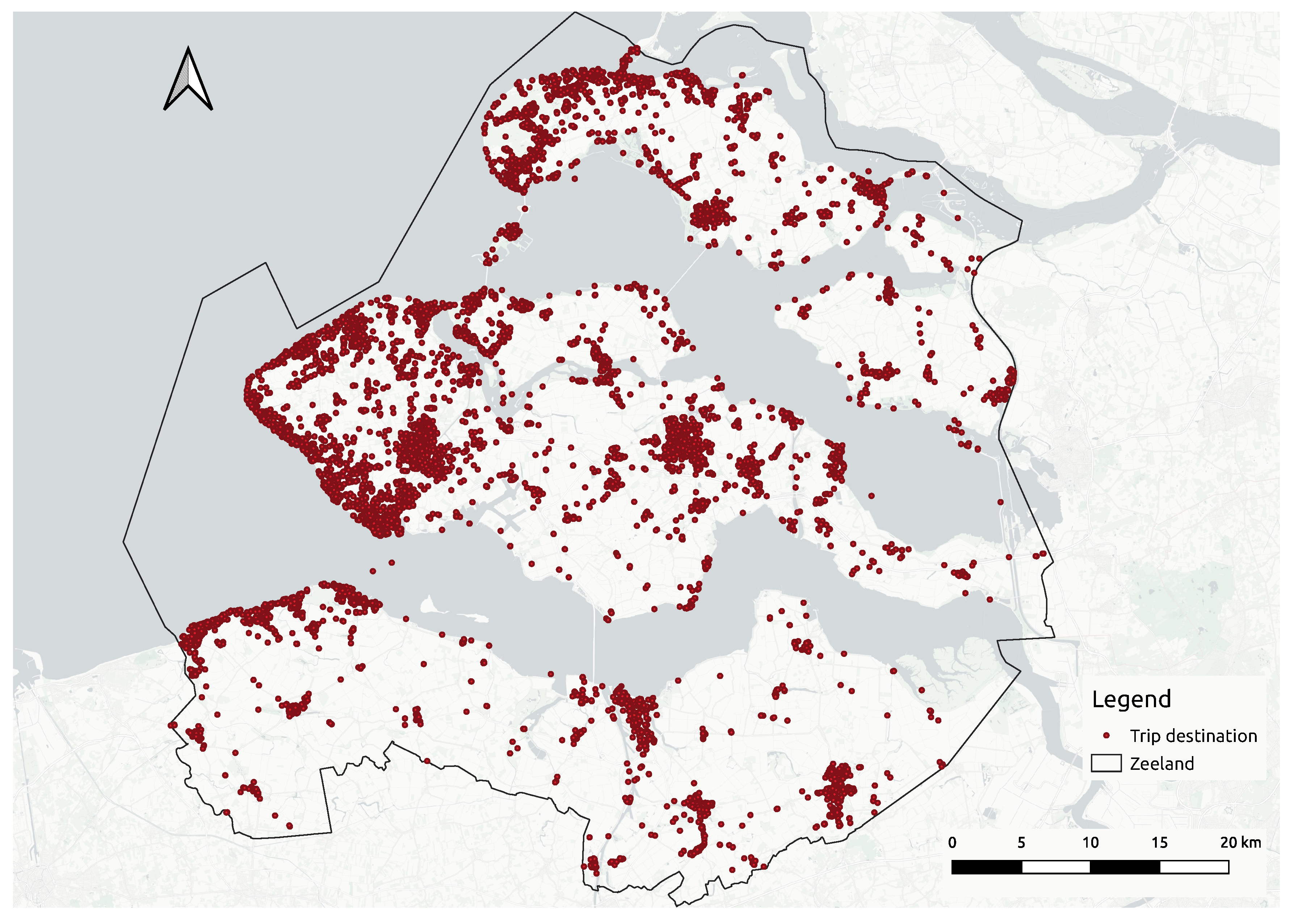
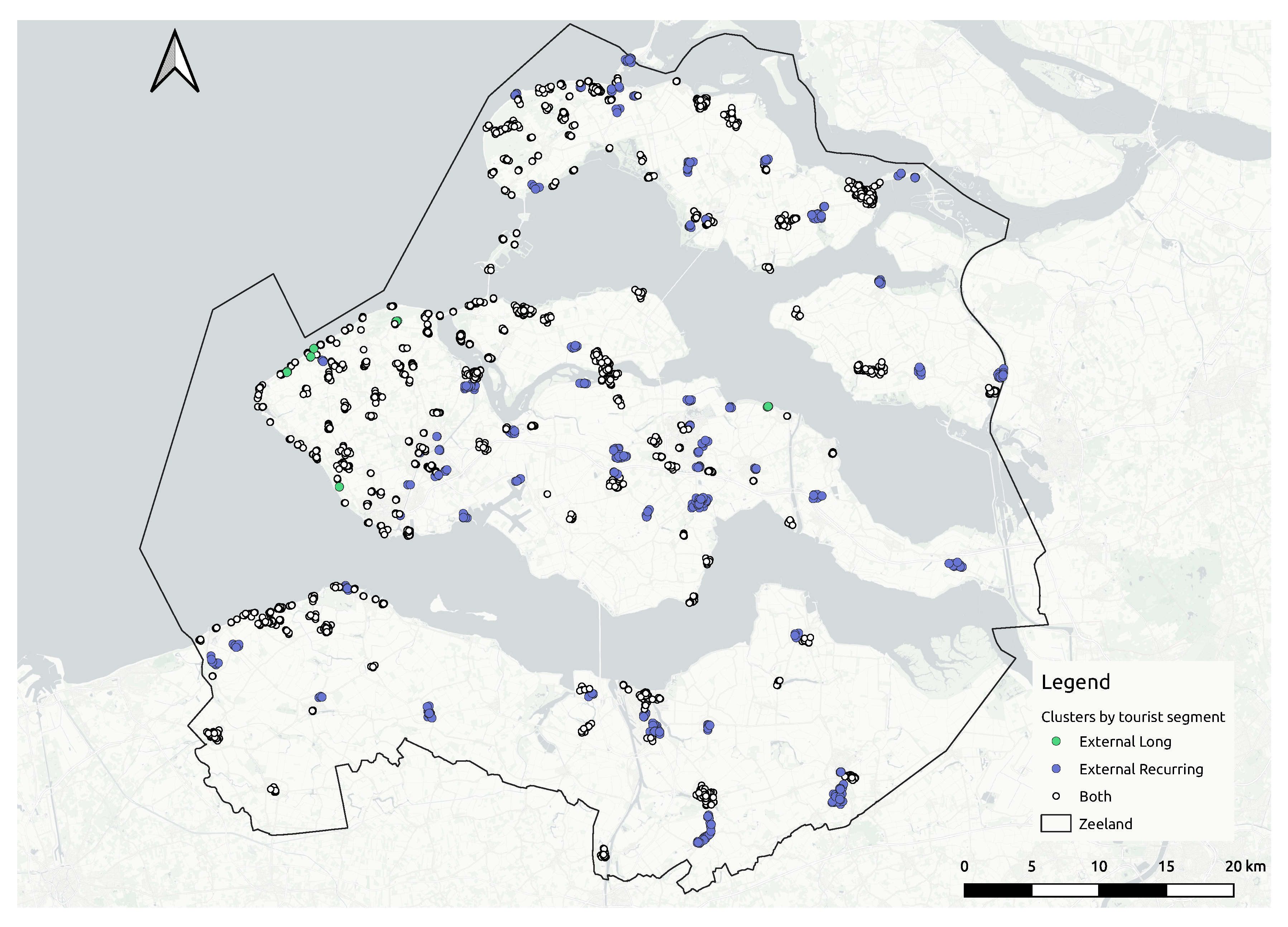
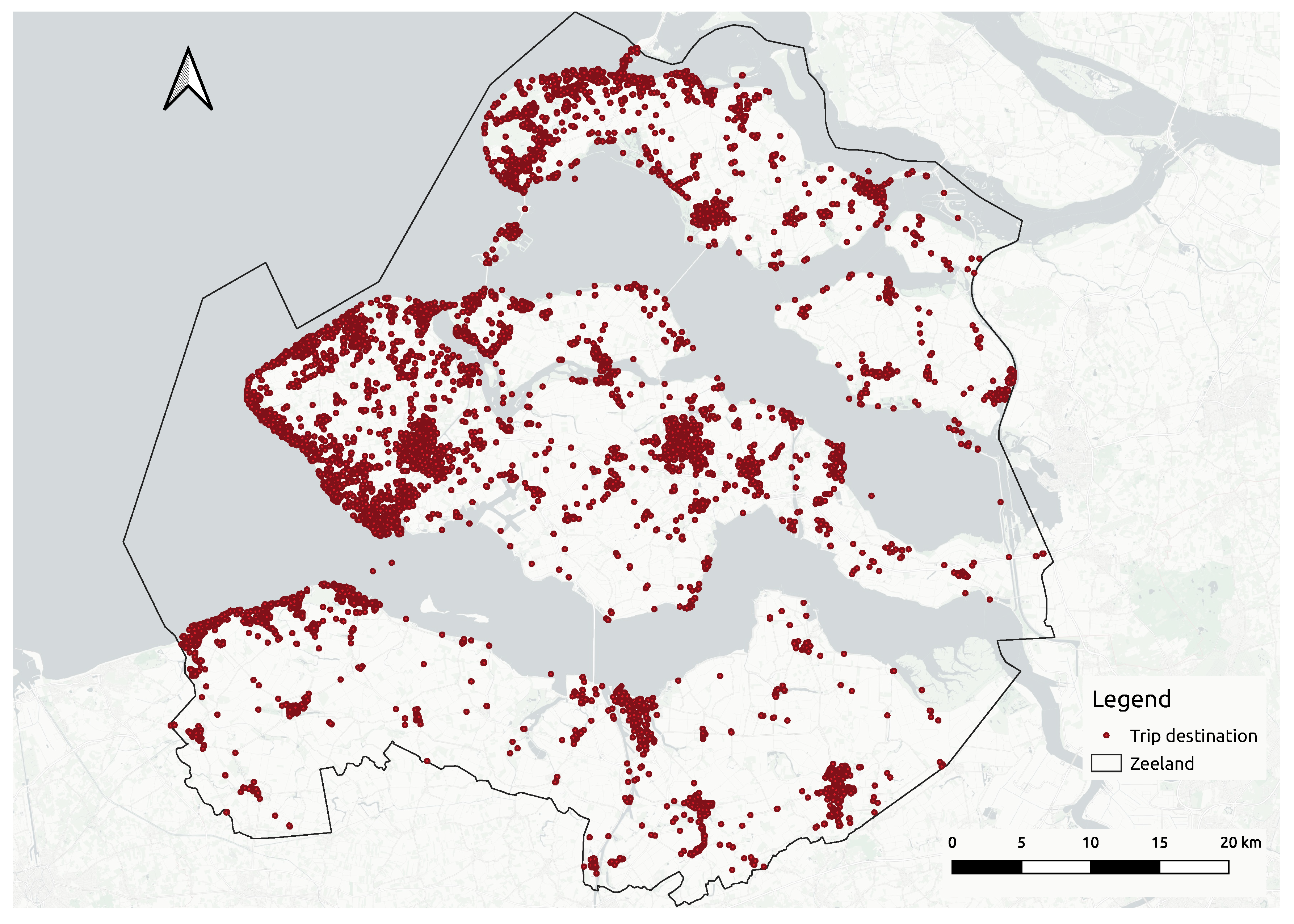
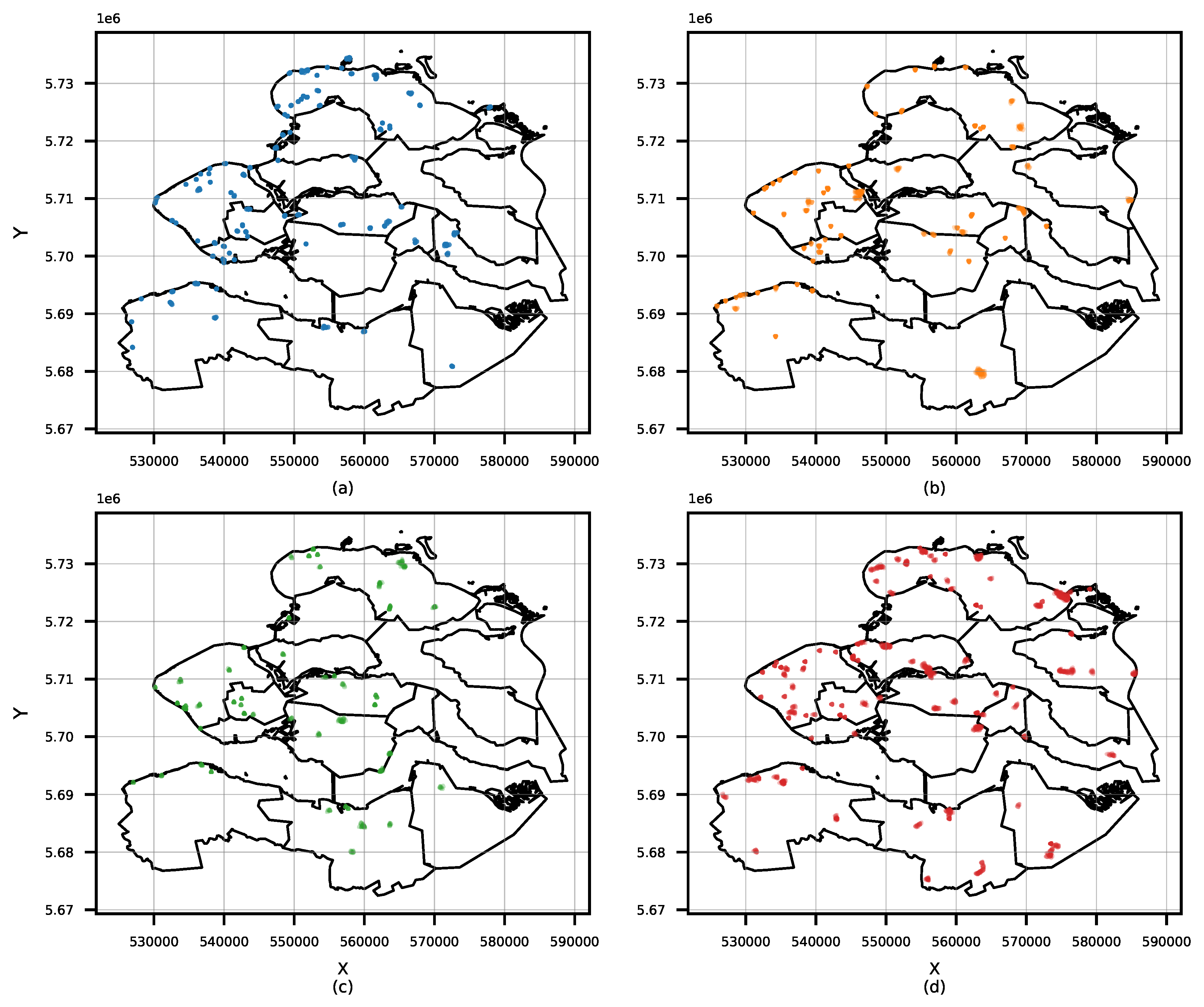
In this study, the aim is to identify hotspots visited by Zeeland tourists by using clustering, an unsupervised learning technique to explore data structures in order to extract meaningful information. A density-based clustering algorithm uses the concept of density which can be defined as the number of data points per unit volume of the feature space [
27]. A data point is made from variables shown in
Table 5. A region from the feature space is identified as a high-density or low-density area according to the occurrence of data points that are packed closely together. Then, clusters are identified by partitioning and learning patterns from high-density regions.
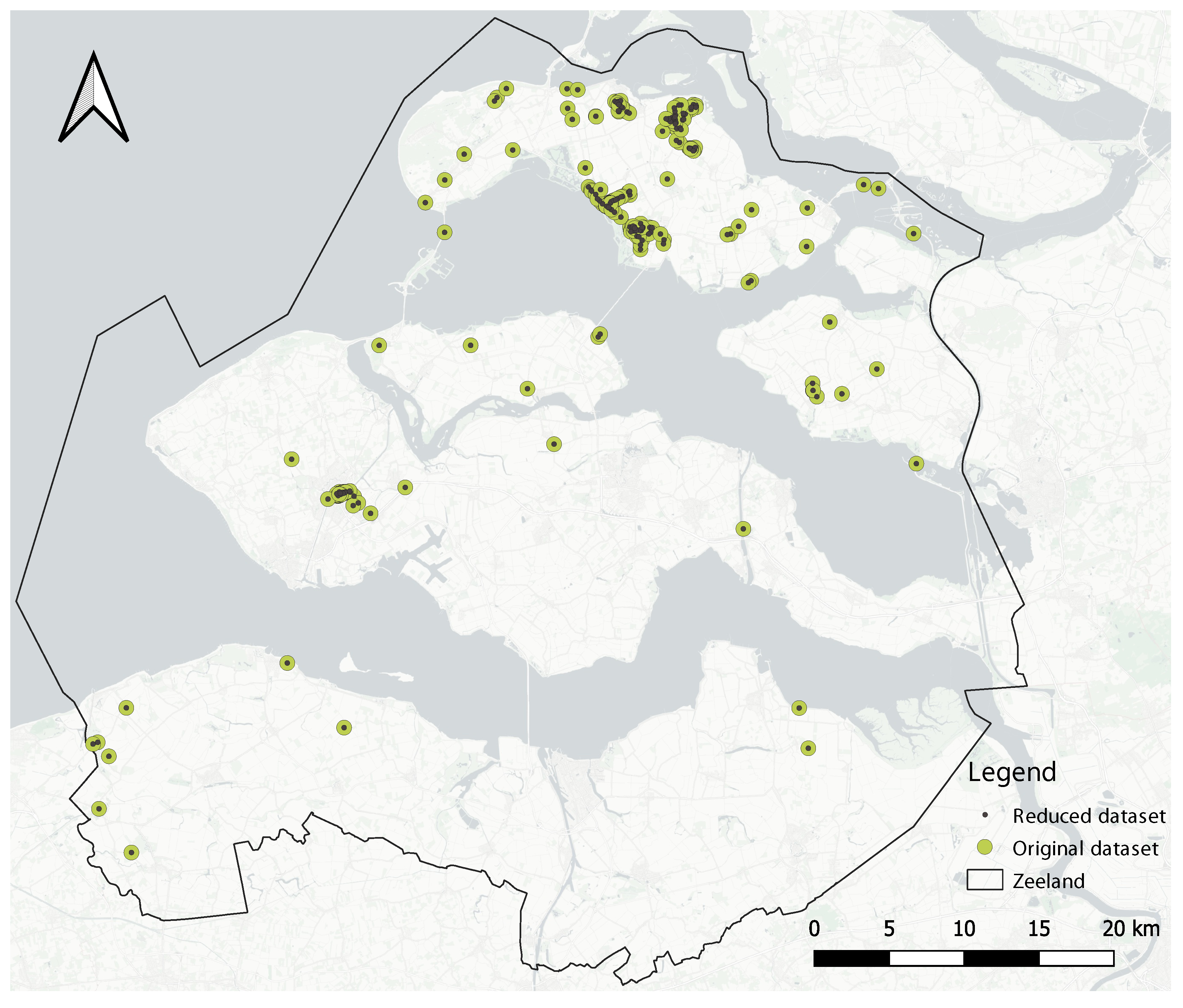
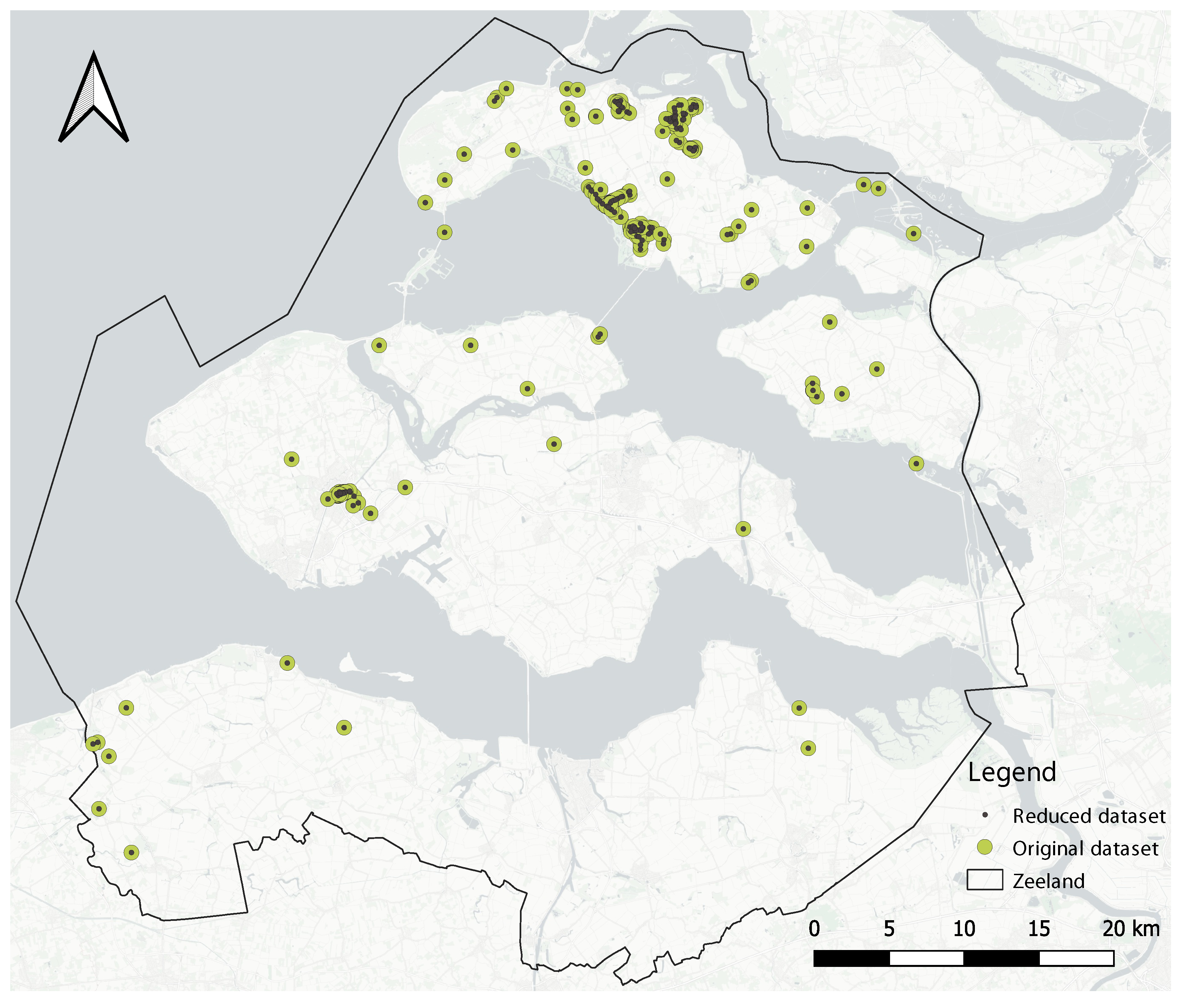
In this stage, the first aim is to reduce the number of data points generated by an individual tourist to then look for clusters with heterogeneous density. In general, the clustering algorithms do not consider the ownership of the data points, so a spot could be wrongly classified as a hotspot just because of the high number of visits registered by one single user. To handle this problem, the
Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm [
28] is selected as it finds places visited by a tourist regardless of how many times they were visited, i.e., clusters with any shape regardless their density, and because of DBSCAN’s ability to process very large datasets [
29]. To handle the heterogeneous cluster density problem, the
Ordering Points To Identify the Clustering Structure (OPTICS) algorithm [
30] is used. The main advantage of OPTICS is that it can find clusters of varying density. To the best of our knowledge, density-based algorithms that handle both finding clusters with data points of different users and heterogeneous cluster density conditions do not exist. For example, the Reverse Nearest Neighbor-DBSCAN [
31] that is an algorithm based on DBSCAN only handles the search for clusters with heterogeneous density. Photo-DBSCAN [
32] finds clusters that contain data points of different users, but it does not guarantee that it can identify clusters with different densities.
DBSCAN has two parameters: the minimum number of data points to form a dense region (
minPts) and ε (
epsilon) that represents the maximum distance, expressed in units of the feature space, between two data points for one to be considered as in the neighborhood of the other. According to the literature, the number of dimensions (
dim) of a dataset can be used to determine the hyperparameter
minPts value. In many cases of a two-dimensional dataset, this can be kept at the default value of
minPts = 4 [
28], while in cases of large and high-dimensional datasets it can be set up
minPts = 2*
dim [
33]. In some studies, a single absolute value is not suitable, so they have set it up based on a percentage of the data point ownership [
34], using a heuristic approach based on the size of the dataset [
35] or perform its value estimation using an objective function [
36]. In general, larger values of
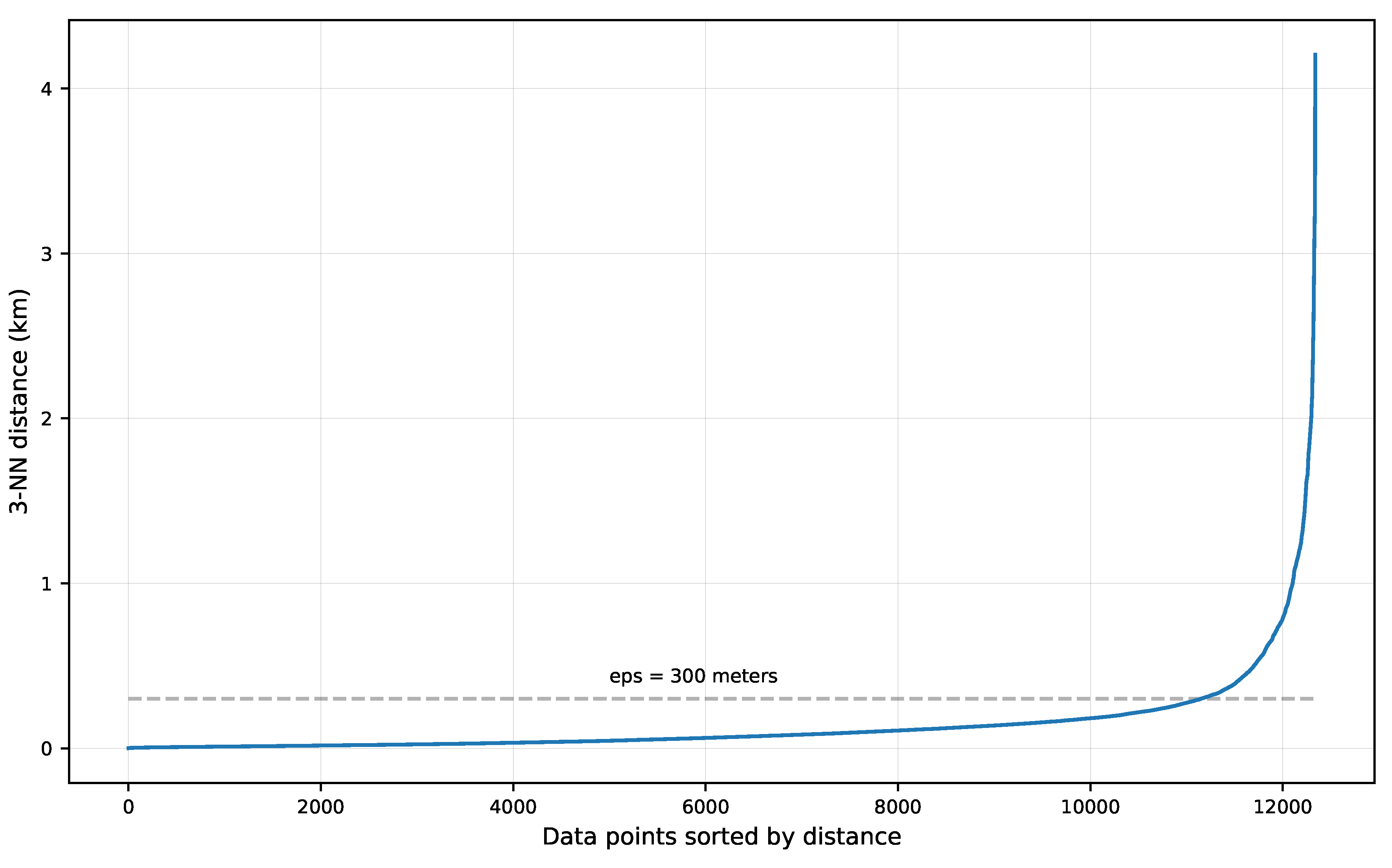
minPts are considered more robust to noise and produce more significant clusters. However, it is sought to represent the multiple visits made by a user to the same place with one single data point while places visited just once have to be kept, so non-data points should be classified as noise. The ε hyperparameter that represents the maximum distance of the search radius must be set up with the smallest possible value. This hyperparameter has also been tuned in many studies using the k-NN distance (i.e., 25 to 550 m) or considering the application domain and knowledge of the study area [
33,
36,
37].
The algorithm starts by selecting a random data point p from the dataset D. Then, it looks for data points in the ε-neighborhood of p. If there are at least minPts data points (including it), p is marked as a core point representing the start of a cluster and all data points within its ε-neighborhood are added to its cluster. Otherwise, the data point p is labeled as noise; however, p might later be part of the ε-neighborhood of another core point and hence be made part of a cluster. The algorithm then visits each data point of the new cluster to perform the same task. If a point q from ε-neighborhood of p is a core point, these data points are said to be directly density connected and reachable from each other. The network made by these density-connected data points is considered a cluster. The algorithm searches recursively through the density connections from core points. It stops when a data point is reachable from a core point, but it is not a core point. This data point is considered a border point. Then, the algorithm continues by selecting an unvisited data point to repeat the process.
In DBSCAN, the default distance metric used for neighborhood computation is the Euclidean distance between two data points (Equation (
3)). This is defined as follows:
where
i = (
,
, …,
xin) and
j = (
,
, …,
xjn) represent two data points described by
n numeric attributes. Once DBSCAN is evaluated with the data points of a tourist, for each resulting cluster, its centermost data point is extracted, and the “stay time” feature is updated with the average of “stay time” from the data points in the cluster. This feature will be used during the data-driven characterization stage. This procedure is applied for every (non-filtered) tourist in the dataset to generate a new dataset made of the extracted centermost points.
Then, the
Ordering Points To Identify the Clustering Structure (OPTICS) [
30] is used to assign cluster membership over the reduced dataset. OPTICS was selected because of its capability to find clusters of varying density. This algorithm uses the same parameters as DBSCAN. However, the only mandatory hyperparameter is the
minPts. The search radius (ε) around a data point is optional. It is not fixed and increases while there are not at least
minPts data points within which allow OPTICS to identify regions with different density. High density regions will have a small ε while low density regions will have a large ε. Therefore, ε is used to restrict the number of data points considered in the neighborhood search to reduce the computational complexity.
The smallest distance away from a data point that includes
minPts other data points is called the core distance (Equation (
5)). The distance between a core point
p and a core point
q within its ε, which cannot be less than the
core distance, is the
rechability-distance (Equation (
5)). The core-distance and
reachability-distance were defined in OPTICS [
30] as:
where
minPts-dist(
p) is the distance to the
minPts nearest neighbor of
p,
is the cardinality of a subset of the dataset
D contained in the ε-neighborhood of a data point
p,
is the ε-neighborhood of a data point
q, and
dist(
q,
p) is the Euclidean distance between
p and
q.
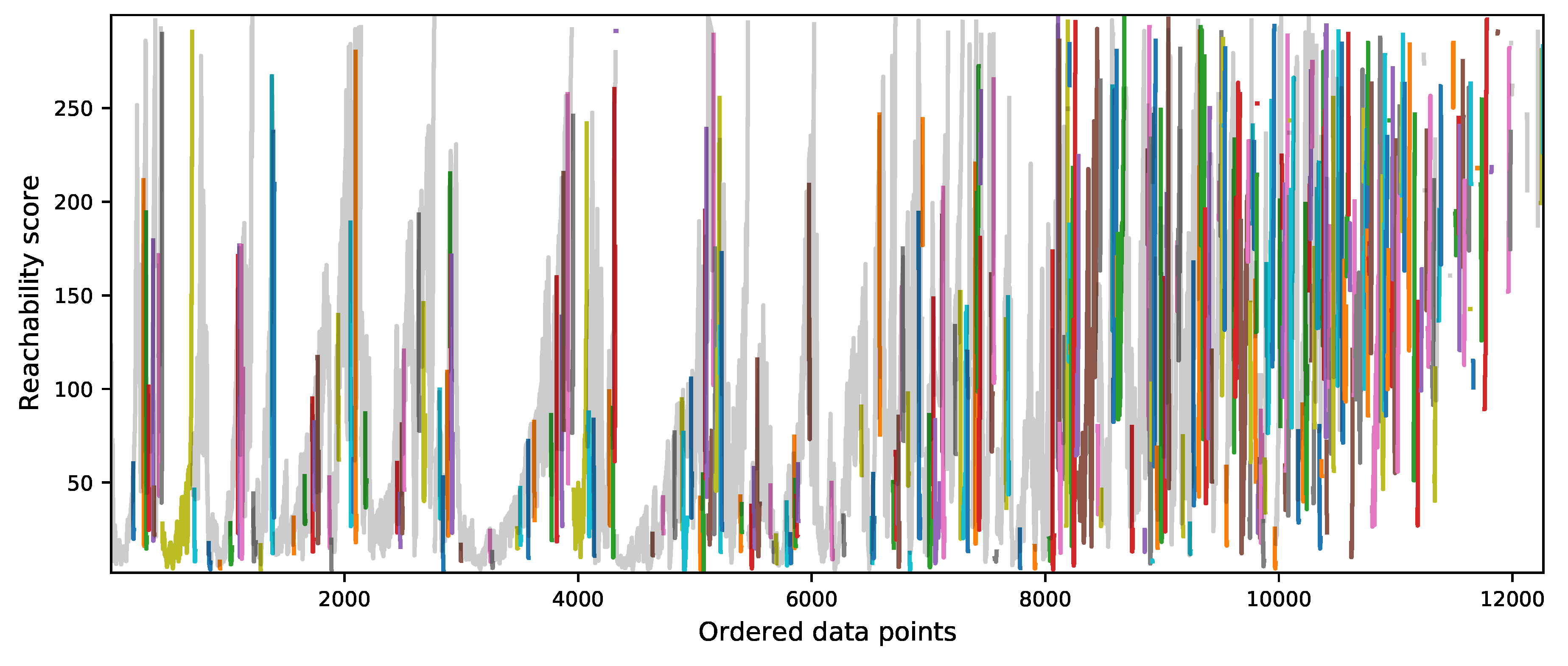
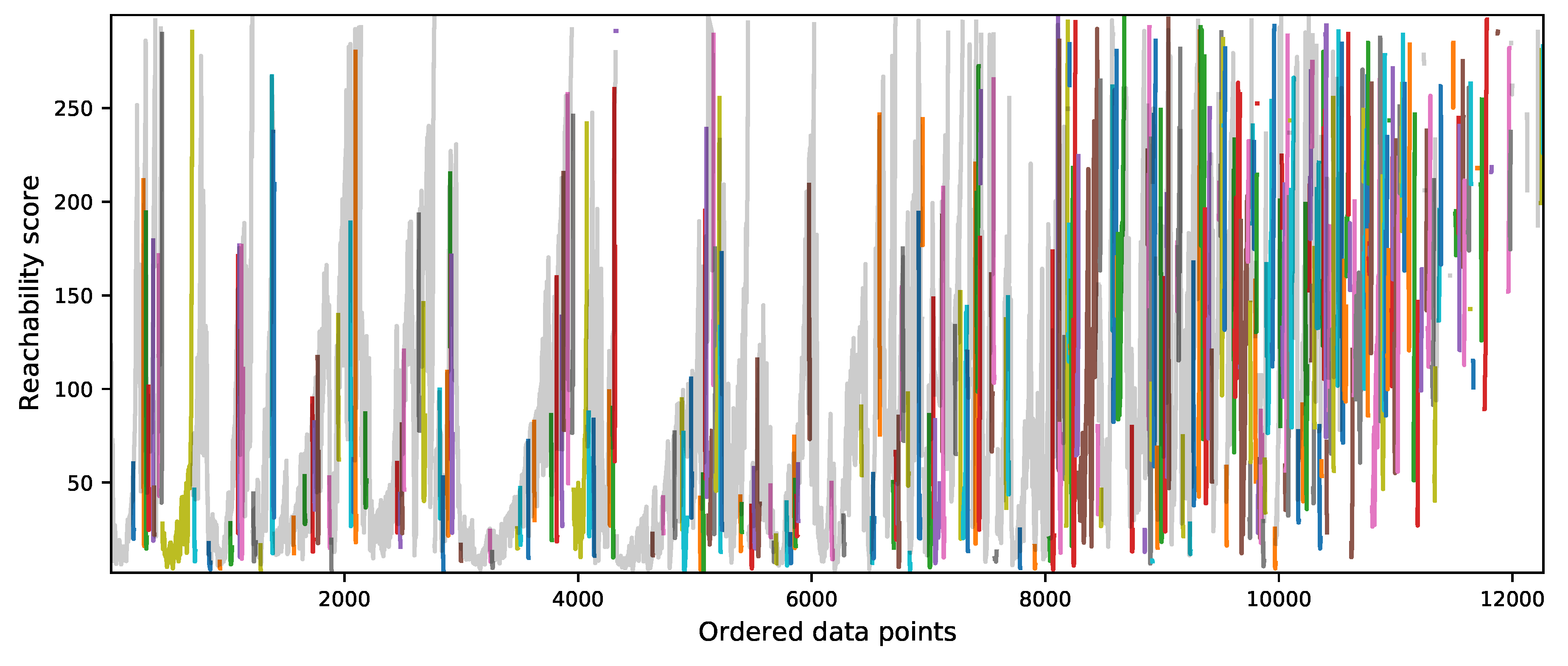
The algorithm starts visiting each data point of the dataset to identify and mark core points. For each point, some computations are performed. First, the core distance and the reachability distance are computed. Second, the reachability score that is defined as the larger of its core distance or its smallest reachability distance is computed. Finally, the sequence of data points that the algorithm is going to visit next is updated based on the reachability distance to the current data point. This means that the next core point to visit is the one with the smallest reachability distance with respect to the current point. Once the algorithm visits all the points, it returns both the order in which each data point was visited and the reachability score of each case.
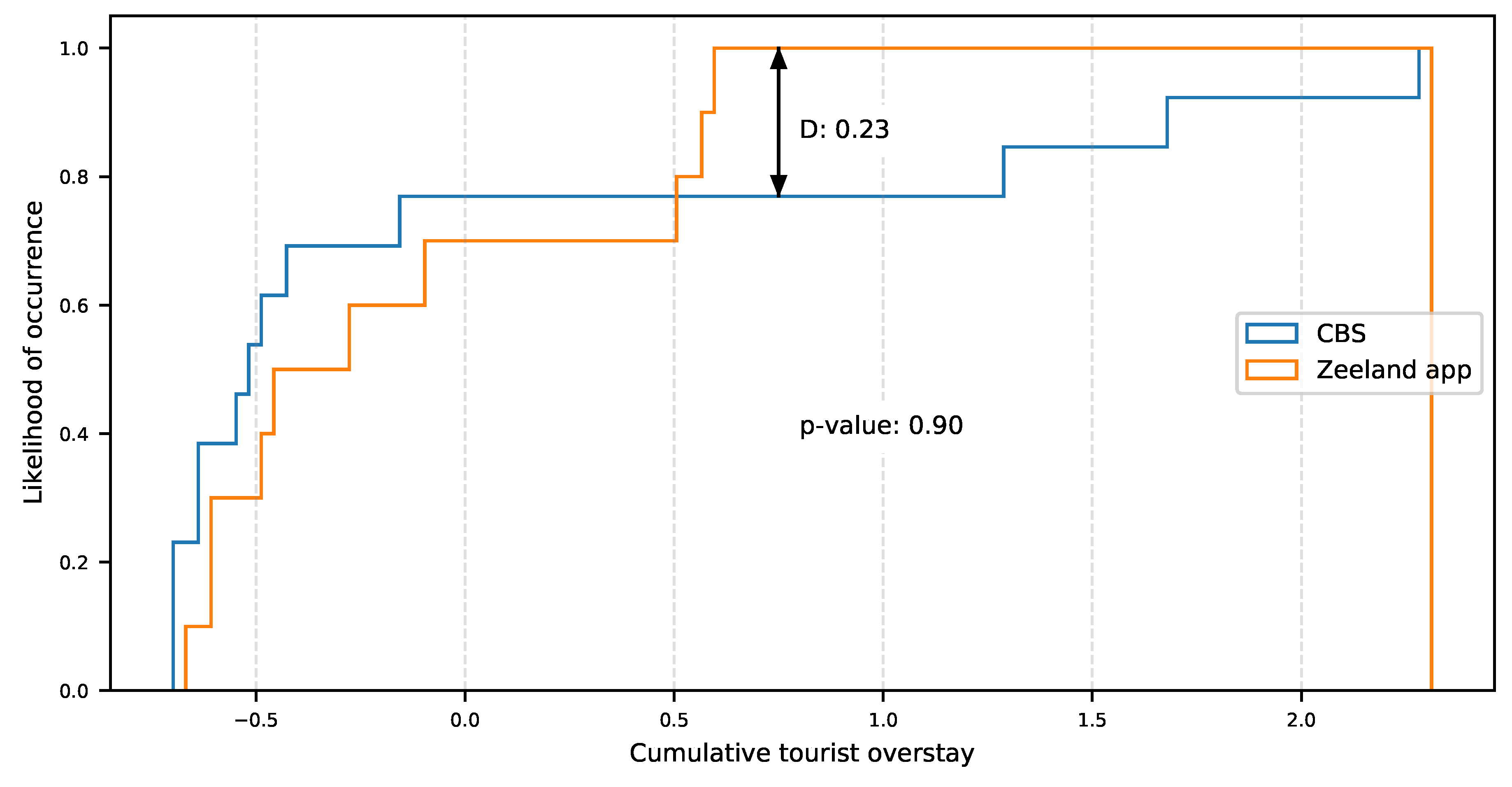
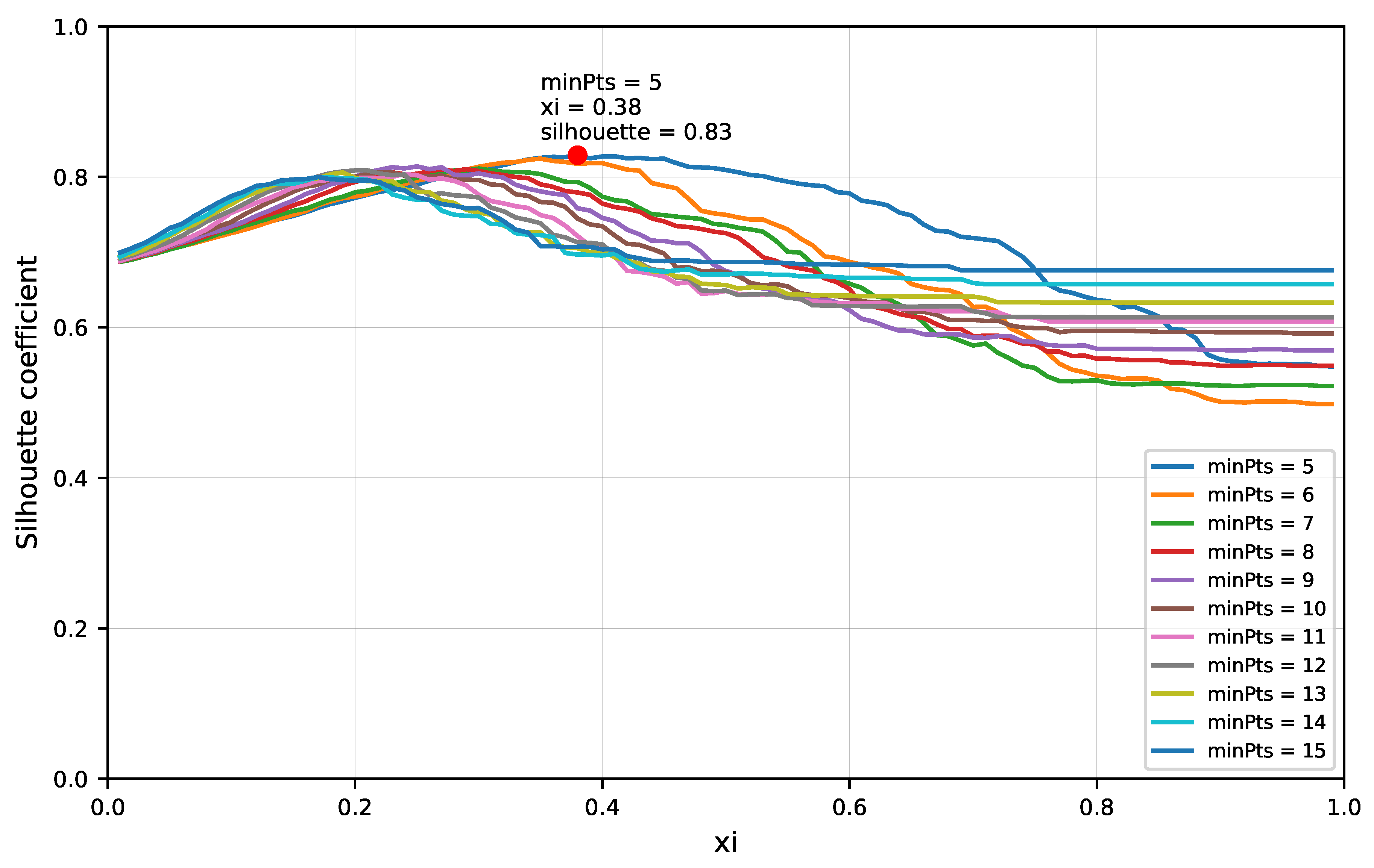
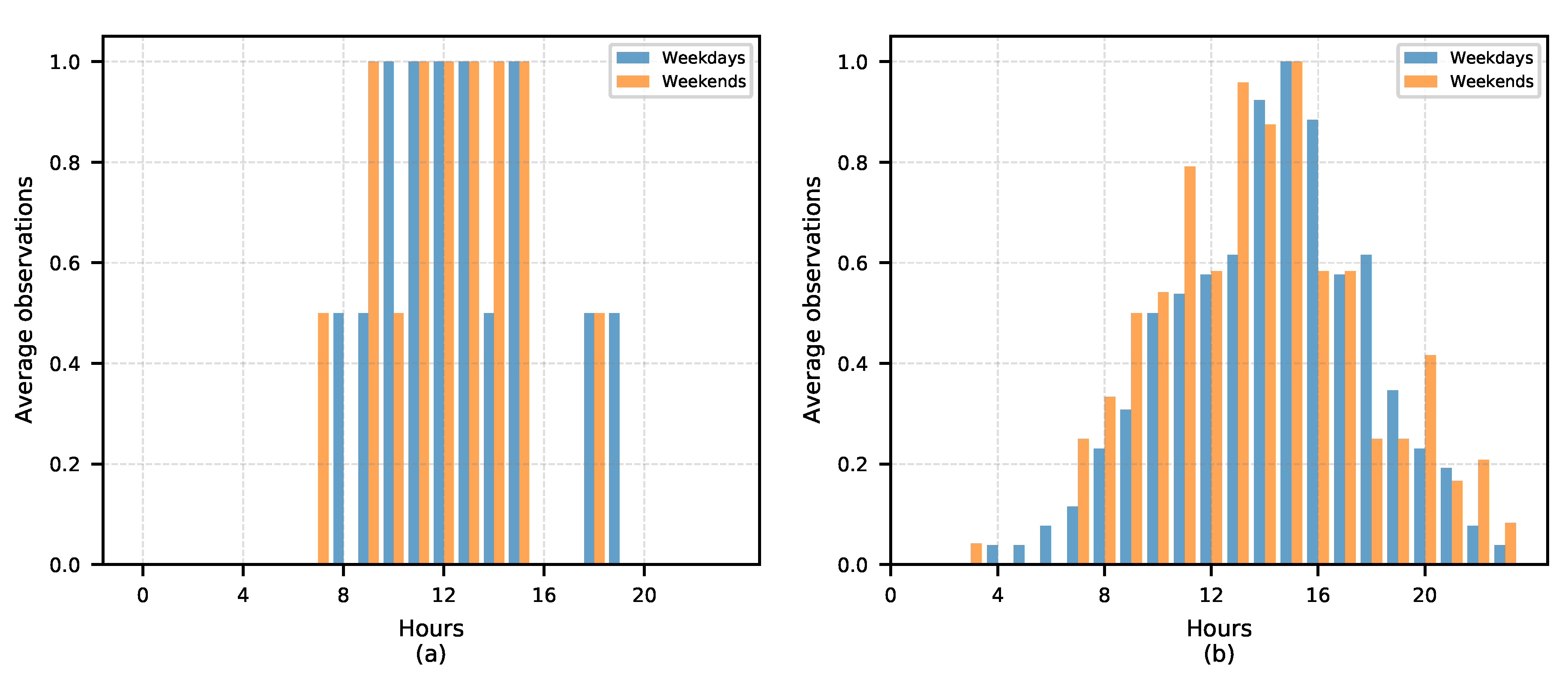
The clustering extraction process is performed using the Reachability plot. There are two methods to perform the clustering detection. The first method consists of selecting some reachability score to draw a horizontal line across the reachability plot. When the plot dips below the horizontal line, the starting point of a cluster is identified while, if the plot is back above the line, the end of the cluster is identified. Then, any cases above the horizontal line could be classified as noise. The second is the ξ(xi) method which uses the steepness concept defined as 1 − ξ. Here, the start and end of a cluster in the Reachability plot occurs when the reachability of two successive data points change by a factor of 1 − ξ. A downward slope of at least the selected steepness value establishes the start of a cluster while an upward slope of at least the selected steepness value marks its end. In this research, this method is used because of its capabilities to find clusters of different density and also hierarchies among them. However, a clustering algorithm only identifies clusters in the data points, but it does not establish how good or bad they are.
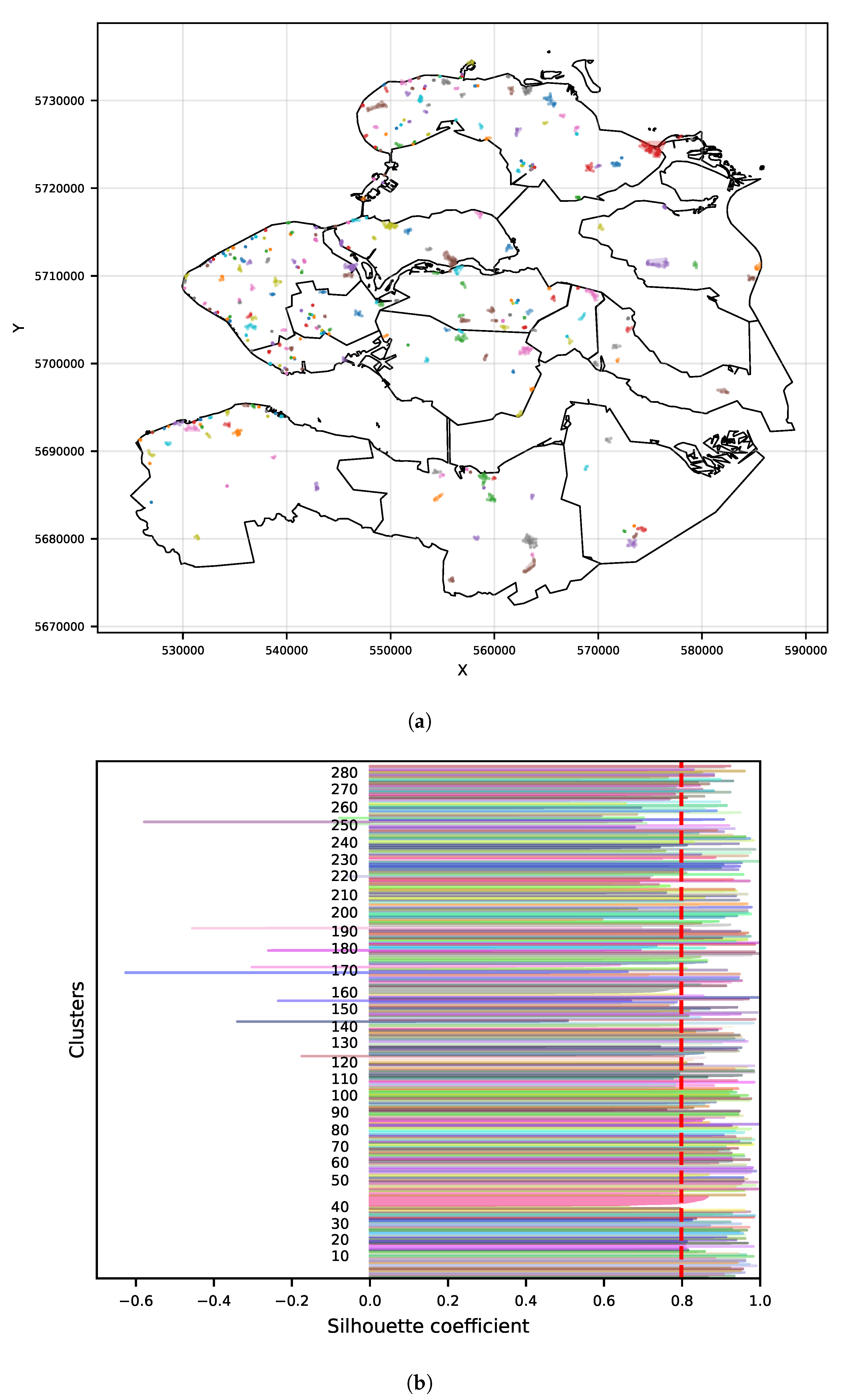
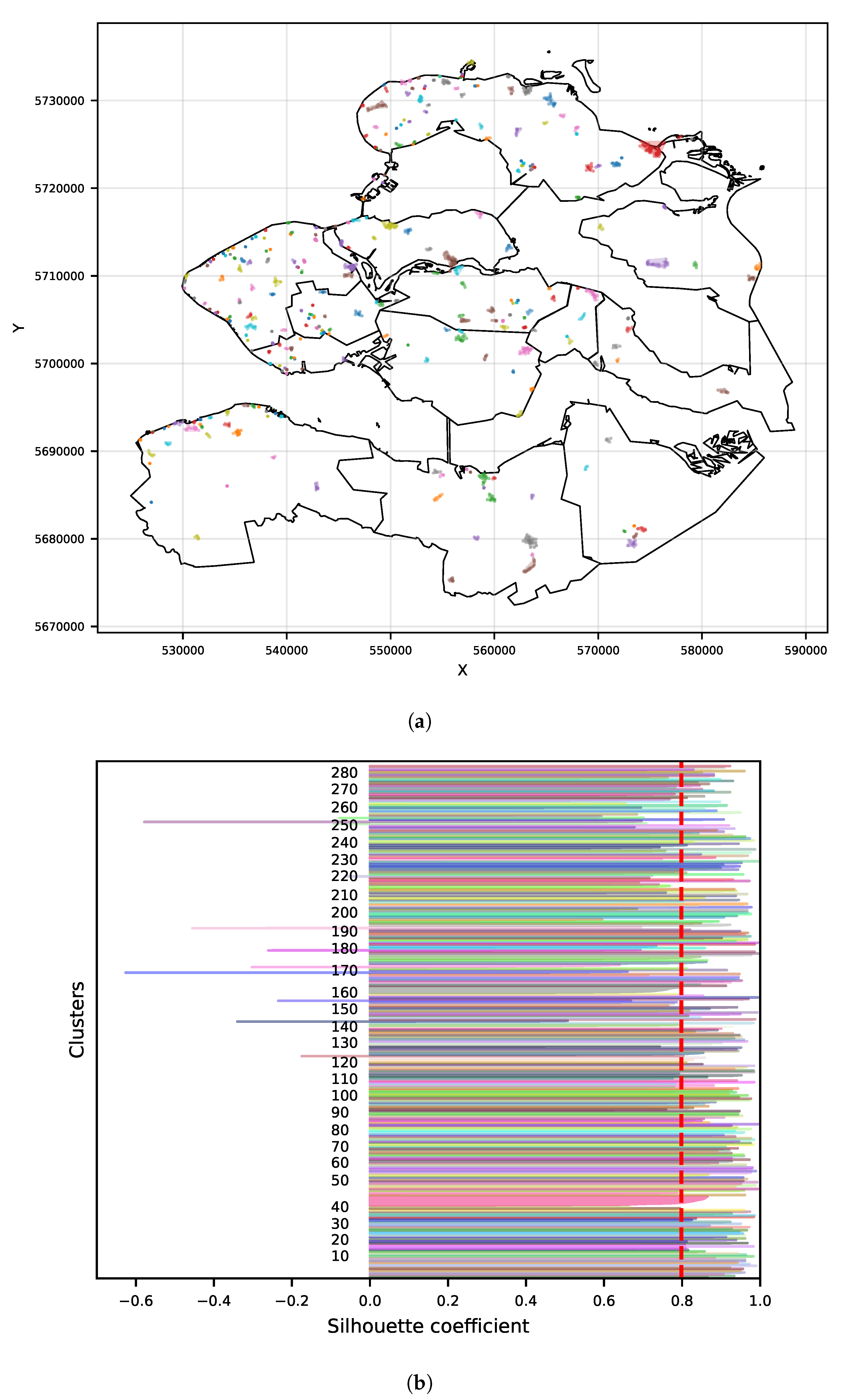
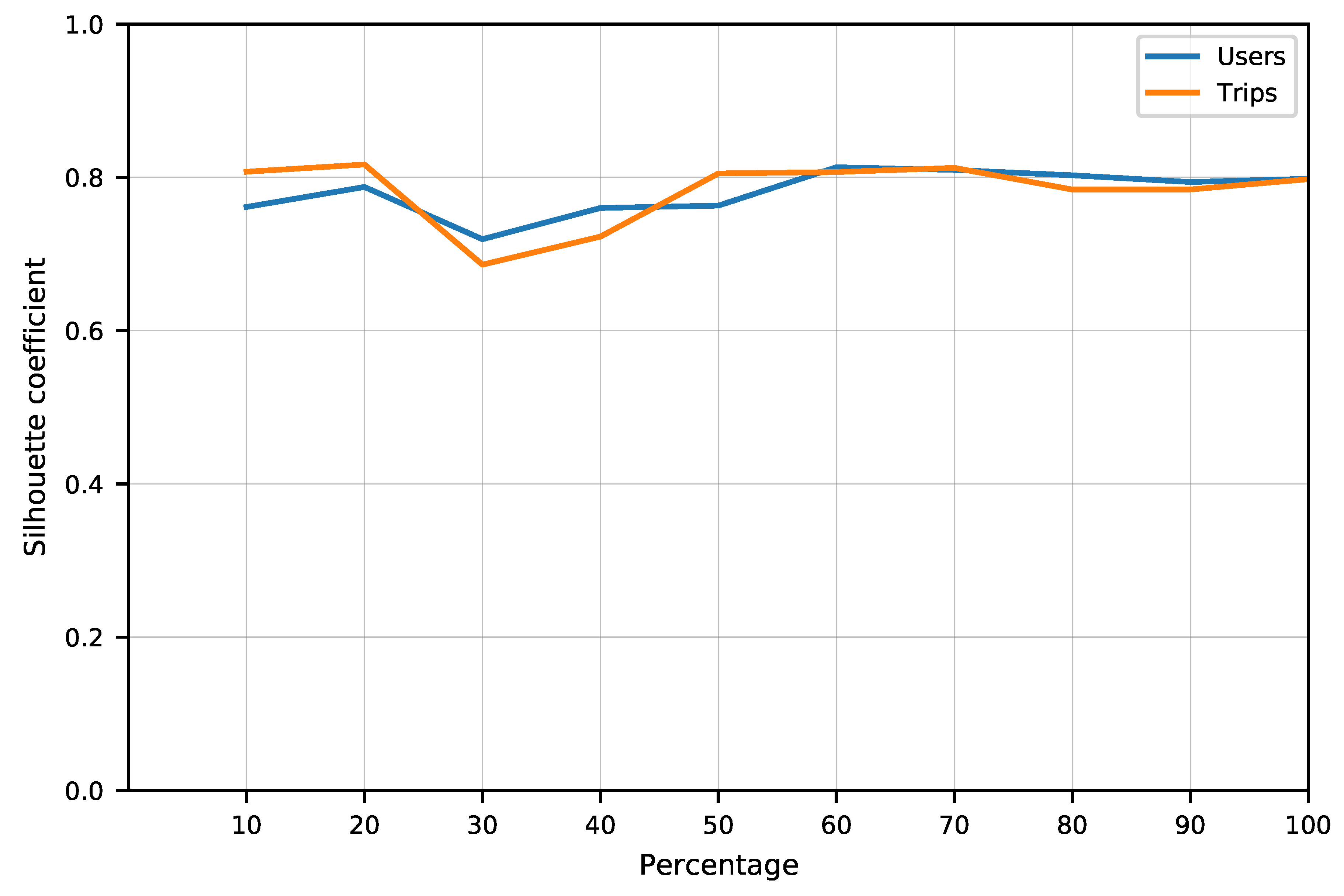
A clustering algorithm computed with different hyperparameters configuration might produce a different clustering result. Therefore, a clustering metric evaluation is used to be able to compare computations of the OPTICS algorithm with different hyperparameter values in order to determine the optimal values where the metric is the best. In this research, the Silhouette Coefficient [
38] is used as a metric to evaluate the clustering quality. This metric is used when the ground truth labels are not known. A clustering outcome can be assessed by four criteria: compactness, isolation, global fit, and intrinsic dimensionality [
39]. The evaluation of clustering compactness and isolation with this metric is performed for each model generated by each hyperparameter’s combination. The silhouette coefficient is defined as follows:
where
represents the cluster compactness that is calculated as the average distance between a sample
and all other data points in the same cluster, and
represents the cluster isolation that is calculated as the average distance between the sample
and all samples in the nearest cluster. The Silhouette Coefficient is bounded between –1 for incorrect clustering and +1 for highly dense clustering. Scores around zero indicate overlapping clusters. The experiments for tuning the OPTICS hyperparameters
minPts and ξ are described in
Section 3.2.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
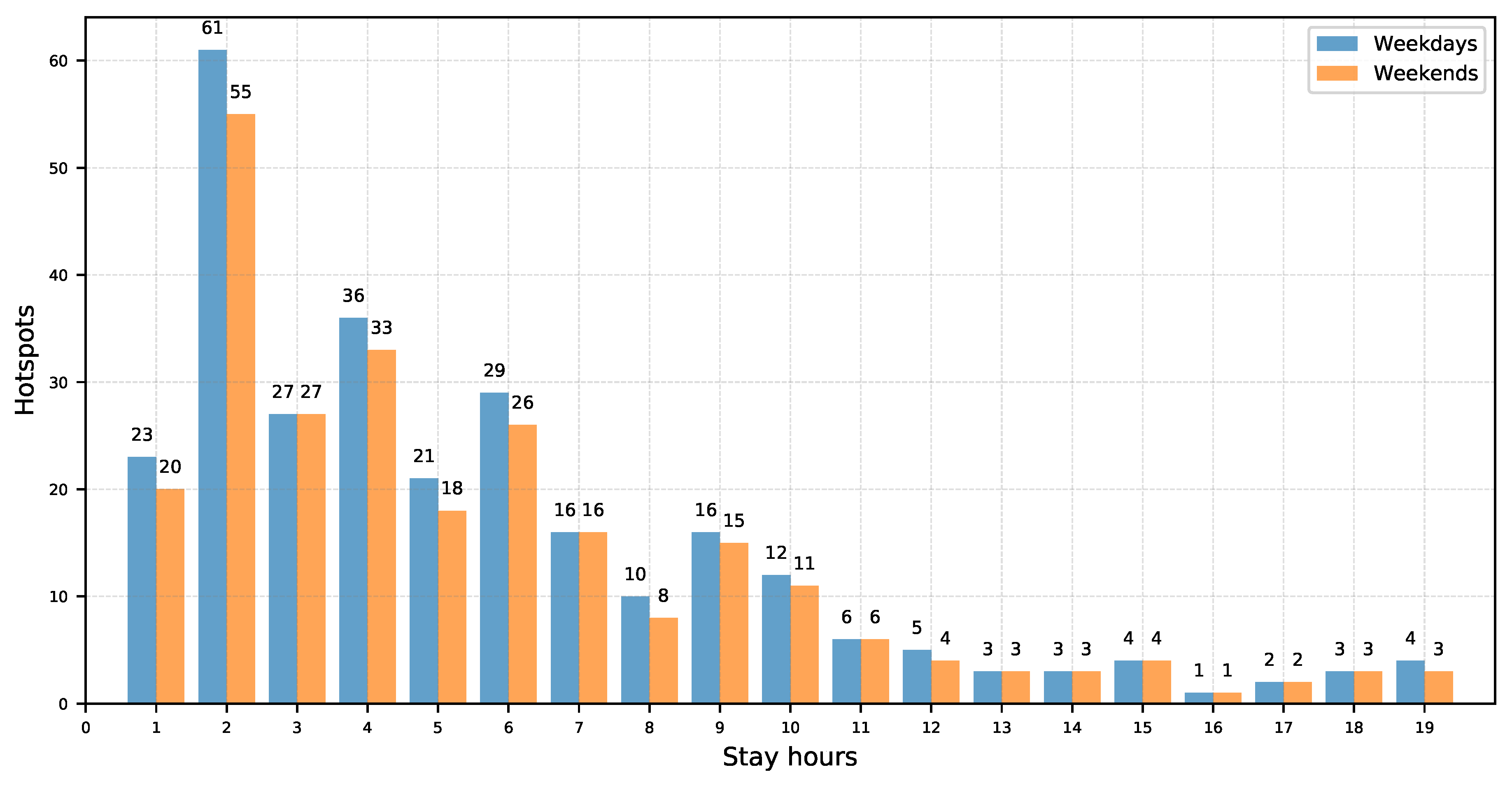{kind=link}
{kind=link}
{kind=link}
{kind=link}