Quality of GNSS Traces from VGI: A Data Cleaning Method Based on Activity Type and User Experience


Abstract
:1. Introduction
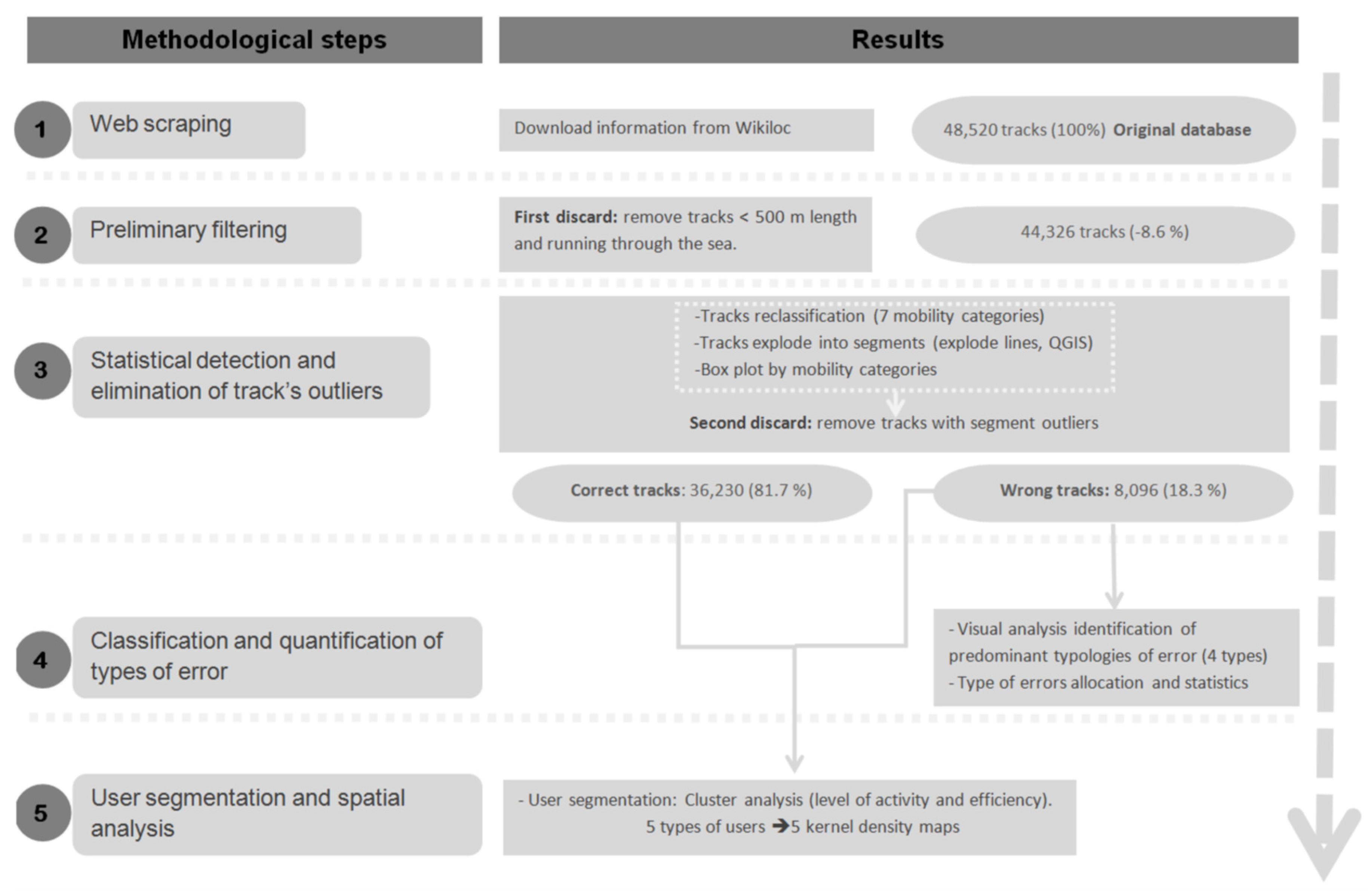
2. Materials and Methods
2.1. Source, Web Scraping, and Database Characteristics
2.2. Preliminary Filtering
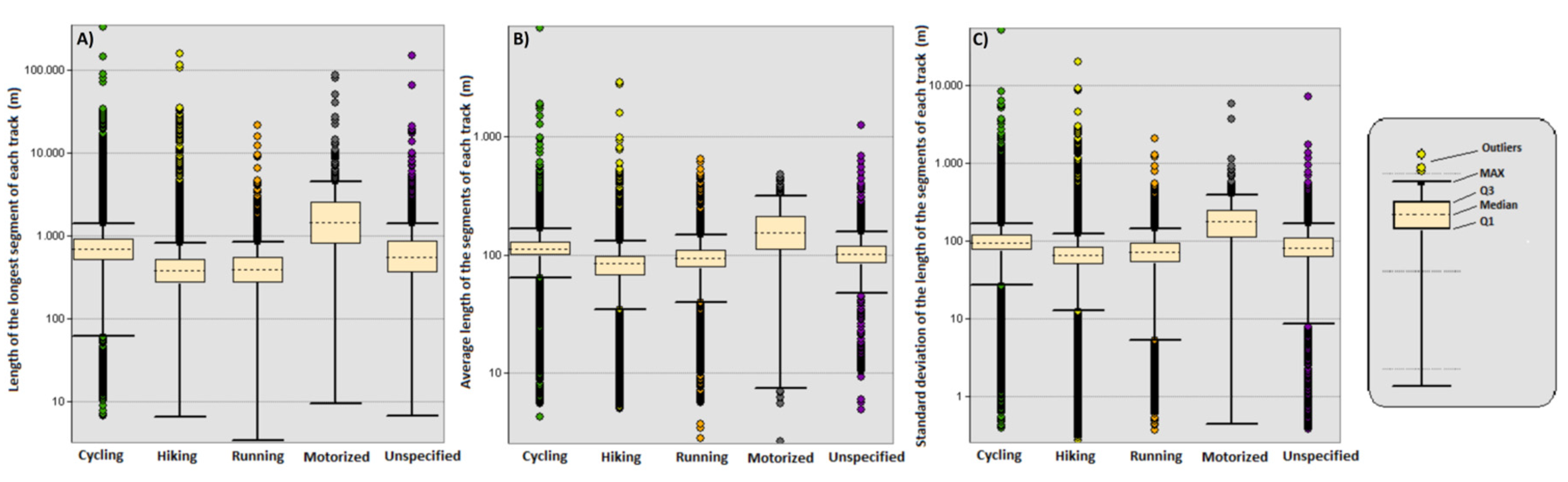
2.3. Statistical Analysis for the Detection and Removal of Outliers
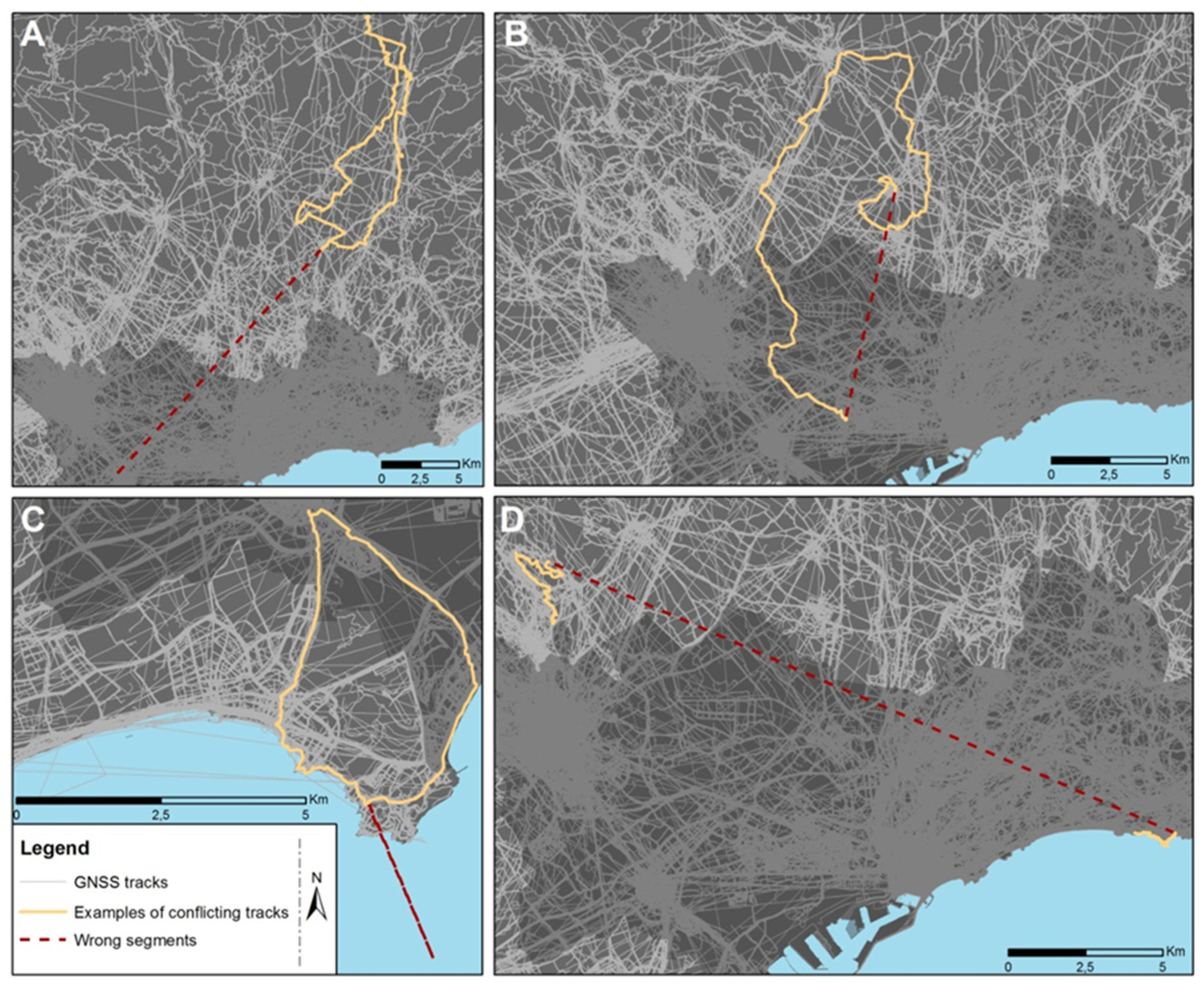
2.4. Visual Analysis for the Characterization of Errors and Identification and Allocation of Error Types on Discarded Tracks
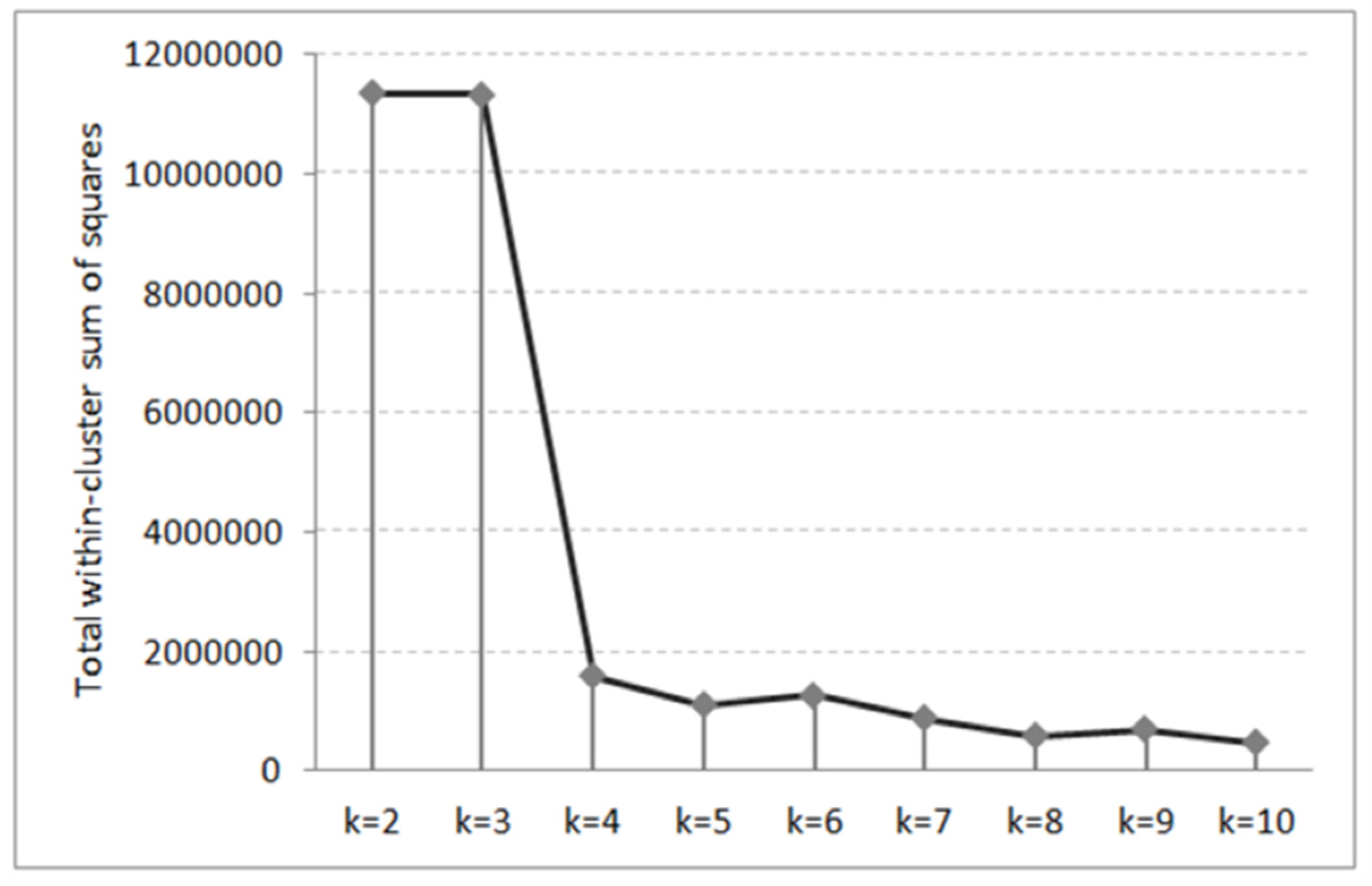
2.5. Segmentation of Users and Spatial Analysis
2.6. Study Area
3. Results
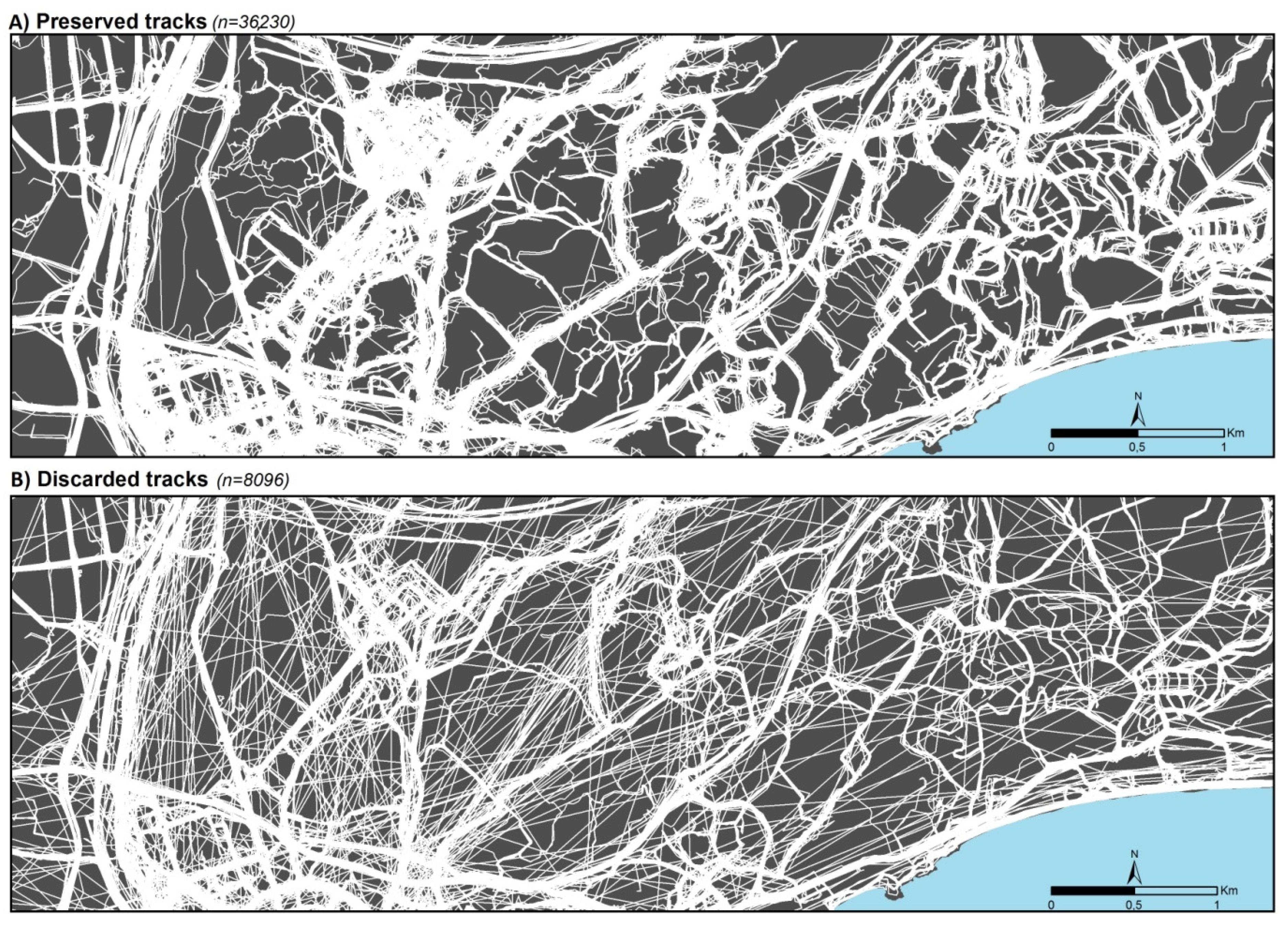
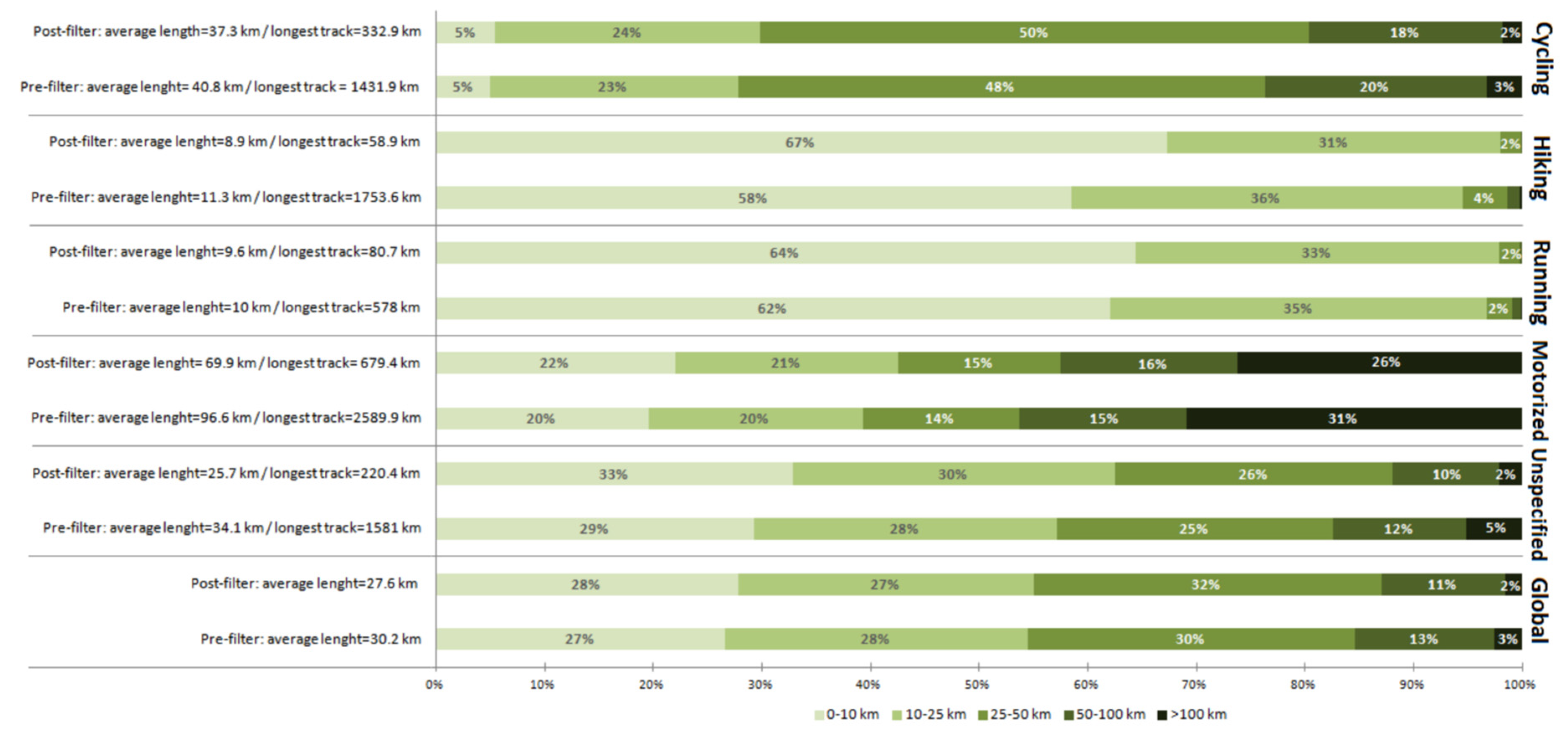
3.1. Pre-Processing and Filtering: Characteristics of Discarded and Preserved Tracks According to Mobility Type
3.2. Types of Errors on Tracks
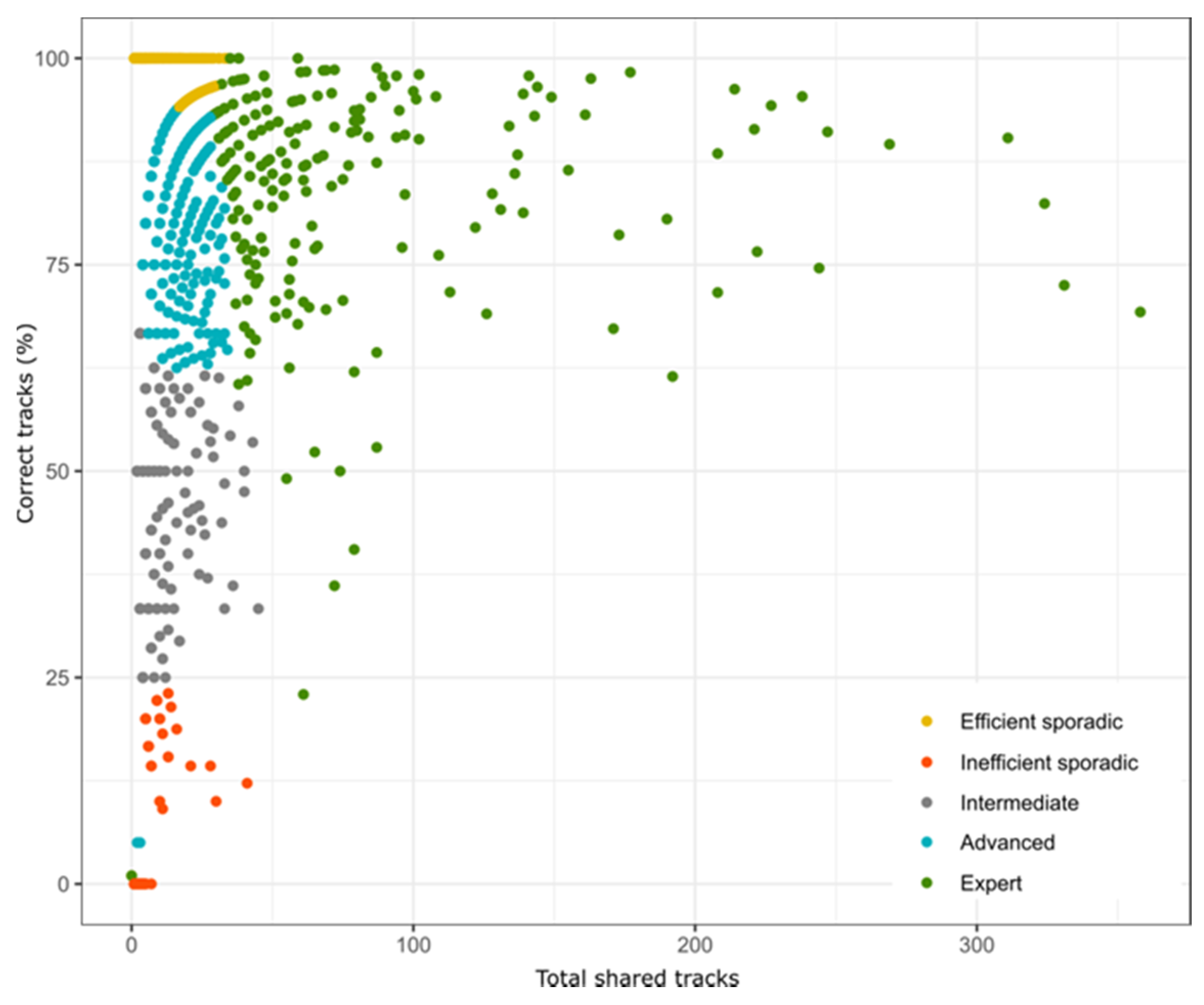
3.3. Reliability of Users
3.4. Spatial Behavior of Users According to Their Level of Efficiency, Expertise, or Reliability
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef] [Green Version]
- García-Palomares, J.C.; Gutiérrez, J.; Mínguez, C. Identification of tourist hot spots based on social networks: A comparative analysis of European metropolises using photo-sharing services and GIS. Appl. Geogr. 2015, 63, 408–417. [Google Scholar] [CrossRef]
- Norman, P.; Pickering, C.M. Using volunteered geographic information to assess park visitation: Comparing three on-line platforms. Appl. Geogr. 2017, 89, 163–172. [Google Scholar] [CrossRef]
- Palacio, A.B.; Pérez, A.M.Y.; Serrano, G.D. PPGIS and public use in protected areas: A case study in the Ebro Delta Natural Park, Spain. ISPRS Int. J. Geo Inf. 2019, 8, 244. [Google Scholar] [CrossRef] [Green Version]
- Serrano, G.D.; Pérez, A.M.Y.; Àvila, C.A.; Jurado, R.J. Dataset on georeferenced and tagged photographs for ecosystem services assessment, Ebro Delta, N-E Spain. Data Brief 2020, 29, 105178. [Google Scholar] [CrossRef] [PubMed]
- Jurado, R.J.; Pérez, A.M.Y.; Serrano, G.D. Visitor monitoring in protected areas: An approach to Natura 2000 sites using Volunteered Geographic Information (VGI). Geogr. Tidsskr. 2019, 119, 69–83. [Google Scholar] [CrossRef]
- Barros, C.; Moya-Gómez, B.; Gutiérrez, J. Using geotagged photographs and GPS tracks from social networks to analyse visitor behaviour in national parks. Curr. Issues Tour. 2019, 23, 1291–1310. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Li, L. Assuring the quality of volunteered geographic information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Flanagin, A.J.; Metzger, M.J. The credibility of volunteered geographic information. GeoJournal 2008, 72, 137–148. [Google Scholar] [CrossRef]
- Mooney, P.; Minghini, M.; Laakso, M.; Antoniou, V.; Olteanu-Raimond, A.-M.; Skopeliti, A. Towards a protocol for the collection of VGI vector data. ISPRS Int. J. Geo Inf. 2016, 5, 217. [Google Scholar] [CrossRef] [Green Version]
- Gil de la Vega, P.; Ariza-López, F.J.; Mozas-Calvache, A.T. Problemas que presentan las trazas GNSS procedentes de VGI. Geofocus 2016, 17, 161–184. [Google Scholar]
- Ivanović, S.S.; Raimond, A.-M.O.; Mustière, S.; Devogele, T. Detection of outliers in crowdsourced GPS traces. In Proceedings of the Spatial Accuracy 2016 Symposium, Montpellier, France, 5–8 July 2016. [Google Scholar]
- Qi, F.; Du, F. Tracking and visualization of space-time activities for a micro-scale flu transmission study. Int. J. Health Geogr. 2013, 12, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qi, F.; Du, F. Trajectory data analyses for pedestrian space-time activity study. J. Vis. Exp. 2013, 72, e50130. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ariza-López, F.J.; Rodríguez-Avi, J.; Reinoso-Gordo, J.F. An approximation to outliers in GNSS traces. In Proceedings of the 11th International Symposium on Spatial Accuracy Assessment in Natural Resources and Environmental Sciences, East Lansing, MI, USA, 8–11 July 2014. [Google Scholar]
- Ivanovic, S.S.; Olteanu-Raimond, A.-M.; Mustière, S.; Devogele, T. A filtering-based approach for improving crowdsourced GNSS traces in a data update context. ISPRS Int. J. Geo Inf. 2019, 8, 380. [Google Scholar] [CrossRef] [Green Version]
- Ames, M.; Naaman, M. Why we tag: Motivations for annotation in mobile and online media. In Proceedings of the 25th SIGCHI Conference on Human Factors in Computing Systems, San José, CA, USA, 28 April–3 May 2007; pp. 971–980. [Google Scholar] [CrossRef]
- Àvila, C.A.; Pérez, A.M.Y.; Jurado, R.J.; Serrano, G.D. Landscape characterization using photographs from crowdsourced platforms: Content analysis of social media photographs. Open Geosci. 2019, 11, 558–571. [Google Scholar] [CrossRef]
- Korpilo, S.; Virtanen, T.; Lehvävirta, S. Smartphone GPS tracking—Inexpensive and efficient data collection on recreational movement. Landsc. Urban Plan. 2017, 157, 608–617. [Google Scholar] [CrossRef] [Green Version]
- Nuviala, A.; Gómez-López, M.; Grao-Cruces, A.; Granero-Gallegos, A.; Nuviala, R. Perfiles motivacionales de usuarios de servicios deportivos públicos y privados. Univ. Psychol. 2013, 12, 421–431. [Google Scholar] [CrossRef] [Green Version]
- Sauvageot, N.; Schritz, A.; Leite, S.; Alkerwi, A.; Stranges, S.; Zannad, F.; Guillaume, M. Stability-based validation of dietary patterns obtained by cluster analysis. Nutr. J. 2017, 16, 4. [Google Scholar] [CrossRef] [Green Version]
- Bulut, Z.A.; Doğan, O. The ABCD typology: Profile and motivations of Turkish social network sites users. Comput. Hum. Behav. 2017, 67, 73–83. [Google Scholar] [CrossRef]
- Kakalejcik, L.; Bacik, R.; Gavurova, B. Diverse groups of smartphone users and their shopping activities. Sci. Pap. Univ. Pardubic. Ser. Fac. Econ. Adm. 2018, 26, 5–16. [Google Scholar]
- Gusmini, M.; Jabeur, N.; Karam, R.; Melchiori, M.; Renso, C. Reputation evaluation of georeferenced data for crowd-sensed applications. In Proceedings of the 8th International Conference on Ambient Systems, Networks and Technologies and the 7th International Conference on Sustainable Energy Information Technology, Madeira, Portugal, 16–19 May 2017; Volume 109, pp. 656–663. [Google Scholar] [CrossRef] [Green Version]
- Fogliaroni, P.; D’Antonio, F.; Clementini, E. Data trustworthiness and user reputation as indicators of VGI quality. Geo. Spat. Inf. Sci. 2018, 21, 213–233. [Google Scholar] [CrossRef] [Green Version]
- Wikiloc. Available online: https://es.wikiloc.com/ (accessed on 1 July 2019).
- Leiva-Valdebenito, S.A.; Torres-Avilés, F.J. A review of the most common partition algorithms in cluster analysis: A comparative study. Rev. Colomb. Estad. 2010, 33, 321–339. [Google Scholar]
- Zhang, Y.; Moges, S.; Block, P. Optimal cluster analysis for objective regionalization of seasonal precipitation in regions of high spatial-temporal variability: Application to Western Ethiopia. J. Clim. 2016, 29, 3697–3717. [Google Scholar] [CrossRef]
- Clayman, C.L.; Clayman, S.N.; Mukherjee, P. Clustering analysis of brain protein expression levels in trisomic and control mice. In Proceedings of the 3rd International Conference on Information System and Data Mining, University of, Houston, Houston, TX, USA, 6–8 April 2019; pp. 114–118. [Google Scholar] [CrossRef]
- Thorndike, R.L. Who belongs in the family? Psychometrika 1953, 18, 267–276. [Google Scholar] [CrossRef]
- Marutho, D.; Hendra Handaka, S.; Wijaya, E.; Muljono. The Determination of Cluster Number at k-Mean Using Elbow Method and Purity Evaluation on Headline News. In Proceedings of the International Seminar on Application for Technology of Information and Communication: Creative Technology for Human Life, Universitas Dian Nuswantoro, Semarang, Indonesia, 21–22 September 2018; pp. 533–538. [Google Scholar] [CrossRef]
- Yu, L.; Zhou, C. Determining the Best Clustering Number of K-Means Based on Bootstrap Sampling. In Proceedings of the 2nd Annual International Conference on Data Science and Business Analytics, ChangSha, Hunan, China, 24 December 2018; pp. 78–83. [Google Scholar] [CrossRef]
- Idescat. Available online: https://www.idescat.cat/?lang=es (accessed on 5 February 2020).
- Saladié Gil, S. El catálogo de paisaje del Camp de Tarragona como instrumento para la ordenación y gestión del paisaje periurbano de Reus-Tarragona. In Ciudad, Territorio y Paisaje: Reflexiones Para un Debate Multidiciplinar; CSIC: Madrid, Spain, 2010; pp. 421–436. [Google Scholar]
- Usyukov, V. Methodology for identifying activities from GPS data streams. In Proceedings of the 8th International Conference on Ambient Systems, Networks and Technologies and the 7th International Conference on Sustainable Energy Information Technology, Madeira, Portugal, 16–19 May 2017; Volume 109, pp. 10–17. [Google Scholar] [CrossRef]
- Bergman, C.; Oksanen, J. Conflation of OpenStreetMap and Mobile Sports Tracking Data for Automatic Bicycle Routing. Trans. GIS 2016, 20, 848–868. [Google Scholar] [CrossRef] [Green Version]
- Hernández, C.; Rodríguez, J. Structured Data Preprocessing. Revista Vínculos 2008, 4, 27–48. [Google Scholar] [CrossRef]
- Czaja, S.J.; Lee, C.C. The impact of aging on access to technology. Univers. Access Inf. Soc. 2007, 5, 341–349. [Google Scholar] [CrossRef]
- Gottwald, S.; Laatikainen, T.E.; Kyttä, M. Exploring the usability of PPGIS among older adults: Challenges and opportunities. Int. J. Geogr. Inf. Sci. 2016, 30, 2321–2338. [Google Scholar] [CrossRef]
- Poplin, A. How user-friendly are online interactive maps? Survey based on experiments with heterogeneous users. Cartogr. Geogr. Inf. Sci. 2015, 42, 358–376. [Google Scholar] [CrossRef]
- Rzeszewski, M.; Kotus, J. Usability and usefulness of internet mapping platforms in participatory spatial planning. Appl. Geogr. 2019, 103, 56–69. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Activity in Wikiloc (Old Category) | Type of Mobility (New Category) | Type of Activity in Wikiloc (Old Category) | Type of Mobility (New Category) |
|---|---|---|---|
| Cycling (unspecified) | Cycling | Car | Motorized |
| Mountain bike | Motorcycle | ||
| Bicycle touring | Quadricycle | ||
| Trail bike | Recreational Vehicle | ||
| Gravel bike | Trial motorcycle | ||
| Enduro | Skating (unspecified) | Skating | |
| Downhill mountain biking | Skating (line skates) | ||
| eBike | Electric scooter | ||
| Trailer bike | Horseback riding trail | ||
| Trekking/hiking (unspecified) | Hiking | Mountaineering | Others |
| Nordic walking | Training | ||
| Orienteering races | Multisport | ||
| Via ferrata | Spelunking | ||
| Hiking (with baby stroller) | Birdwatching | ||
| Canyoning | Unspecified | Unspecified | |
| Running (unspecified) | Running | ||
| Running (on trails) | |||
| Canicross |
| Activities | A: Length of the Longest Segment of Each Track | B: Average Length of the Segments of Each Track | C: Sd of the Length of the Segments of Each Track |
|---|---|---|---|
| Max Value (m) | Max Value (m) | Max Value (m) | |
| Cycling | 1395.09 | 166.44 | 169.41 |
| Hiking | 495.15 | 131.64 | 122.93 |
| Running | 853.30 | 149.03 | 143.27 |
| Unspecified | 1411.31 | 157.78 | 165.65 |
| Motorized | 4508.78 | 315.70 | 394.77 |
| Activities | Tracks Pre-Filter | Tracks Pre-Filter (%) | Type of Selection of the Correct Tracks | Preserved Tracks | Discarded Tracks | Discarded Tracks (%) |
|---|---|---|---|---|---|---|
| Cycling | 25,310 | 57.10 | Selection algorithm | 21,611 | 3699 | 8.34 |
| Hiking | 10,644 | 24.01 | Selection algorithm | 7348 | 3296 | 7.44 |
| Running | 5889 | 13.29 | Selection algorithm | 5145 | 744 | 1.68 |
| Unspecified | 1675 | 3.78 | Selection algorithm | 1415 | 260 | 0.59 |
| Motorized | 680 | 1.53 | Selection algorithm | 590 | 90 | 0.20 |
| Skating | 67 | 0.15 | Visual check and manual selection | 63 | 4 | 0.01 |
| Others | 61 | 0.14 | Visual check and manual selection | 58 | 3 | 0.01 |
| Total | 44,326 | 100 | - | 36,230 | 8096 | 18.26 |
| Clusters | Total Shared Tracks (n) | Correct Tracks (%) | Activity Level | Efficiency Level | User Type |
|---|---|---|---|---|---|
| Cluster Centroid (Median) | Cluster Centroid (Median) | ||||
| k1 | 1 | 100 | Very low | Very high | Efficient sporadic |
| k2 | 1 | 0 | Very low | Very low | Inefficient sporadic |
| k3 | 3 | 50 | Low | Medium | Intermediate |
| k4 | 9 | 80 | Medium | High | Advanced |
| k5 | 56 | 88 | Very high | Very high | Expert |
| User Type | Users | Tracks | |||||
|---|---|---|---|---|---|---|---|
| n | % | n | % | Preserved | Discarded | % Correct | |
| Efficient Sporadic | 4814 | 62.00 | 12,115 | 27.34 | 12,071 | 44 | 99.64 |
| Inefficient Sporadic | 1013 | 13.05 | 1553 | 3.50 | 59 | 1494 | 3.80 |
| Intermediate | 850 | 10.95 | 4224 | 9.53 | 2124 | 2100 | 50.28 |
| Advanced | 872 | 11.23 | 9800 | 22.11 | 7912 | 1888 | 80.73 |
| Expert | 216 | 2.78 | 16,627 | 37.52 | 14,056 | 2572 | 84.54 |
| Total | 7765 | 100 | 44,319 | 100 | 36,222 | 8098 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Àvila Callau, A.; Pérez-Albert, Y.; Serrano Giné, D. Quality of GNSS Traces from VGI: A Data Cleaning Method Based on Activity Type and User Experience. ISPRS Int. J. Geo-Inf. 2020, 9, 727. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9120727
Àvila Callau A, Pérez-Albert Y, Serrano Giné D. Quality of GNSS Traces from VGI: A Data Cleaning Method Based on Activity Type and User Experience. ISPRS International Journal of Geo-Information. 2020; 9(12):727. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9120727
Chicago/Turabian StyleÀvila Callau, Aitor, Yolanda Pérez-Albert, and David Serrano Giné. 2020. "Quality of GNSS Traces from VGI: A Data Cleaning Method Based on Activity Type and User Experience" ISPRS International Journal of Geo-Information 9, no. 12: 727. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9120727