Conciliating Perspectives from Mapping Agencies and Web of Data on Successful European SDIs: Toward a European Geographic Knowledge Graph

 , , ,
, , , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. European Spatial Data Infrastructures: Stakes and Challenges
- More automation in data integration preserving different semantics, for example, extracting evolution of land use from data at different dates with different conceptual schema.
- More automation in the generation of consistent views at different scales, for example, automatic filtering of the most important place names to show in a map at small scales.
- Designing user-oriented catalogues, for example, supporting a scientist working on urban climate to retrieve every datum required to describe building behavior with respect to heat and moisture flux.
- Documenting the different uncertainties (including semantic ones) of a multisource product, for example, a multisource land-cover product where networks are provided by different authorities, and possibly by non authoritative sources.
- Knowledge management solutions when designing SDIs adapted to thematic applications, for example, to identify if the water-related concepts (lakes, rivers, and wetlands) referenced by the biodiversity community are the very same as topographic features maintained by mapping agencies.
1.2. Objectives and Approach of This Work
2. Why Is Collaboration between Both Communities Needed and Yet So Difficult?
2.1. Expertise and Theories Related to the Provision of Reusable Geographical Data, Grounding Critical Decisions: Mapping Agencies and Geographic Information Science
2.2. The Semantic Web and Linked Data
- −
- “How best to provide access to data so it can be most easily reused?”
- −
- “How to enable the discovery of relevant data within the multitude of available data sets?”
- −
- “How to enable applications to integrate data from large numbers of formerly unknown data sources?”
2.3. Different Perspectives on Uncertainty, Authorities, and Context
2.4. Closed-World Assumption vs. Open-World Assumption
3. Advancing Ontologies and Knowledge Graph Technologies for European SDIs
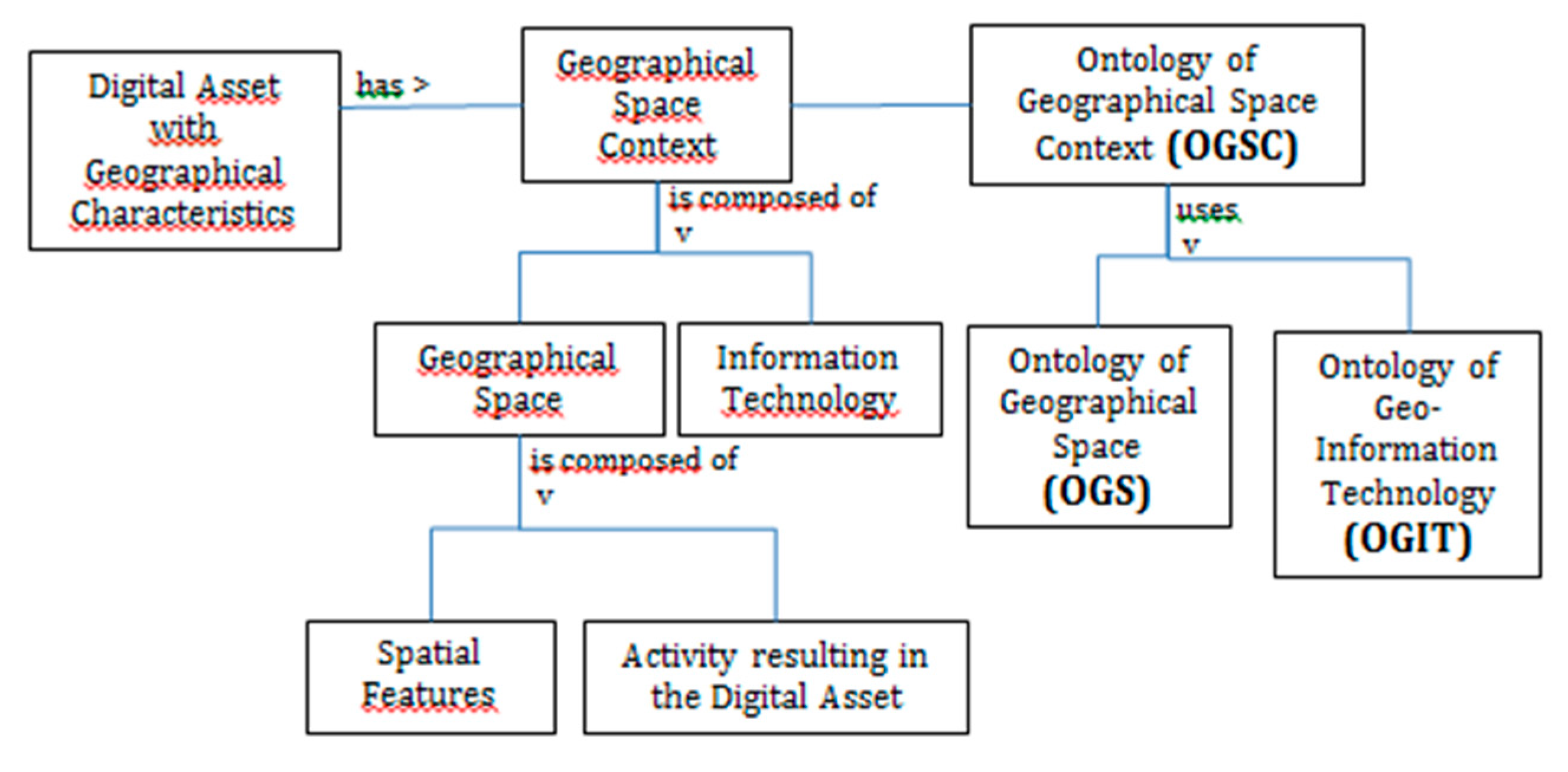
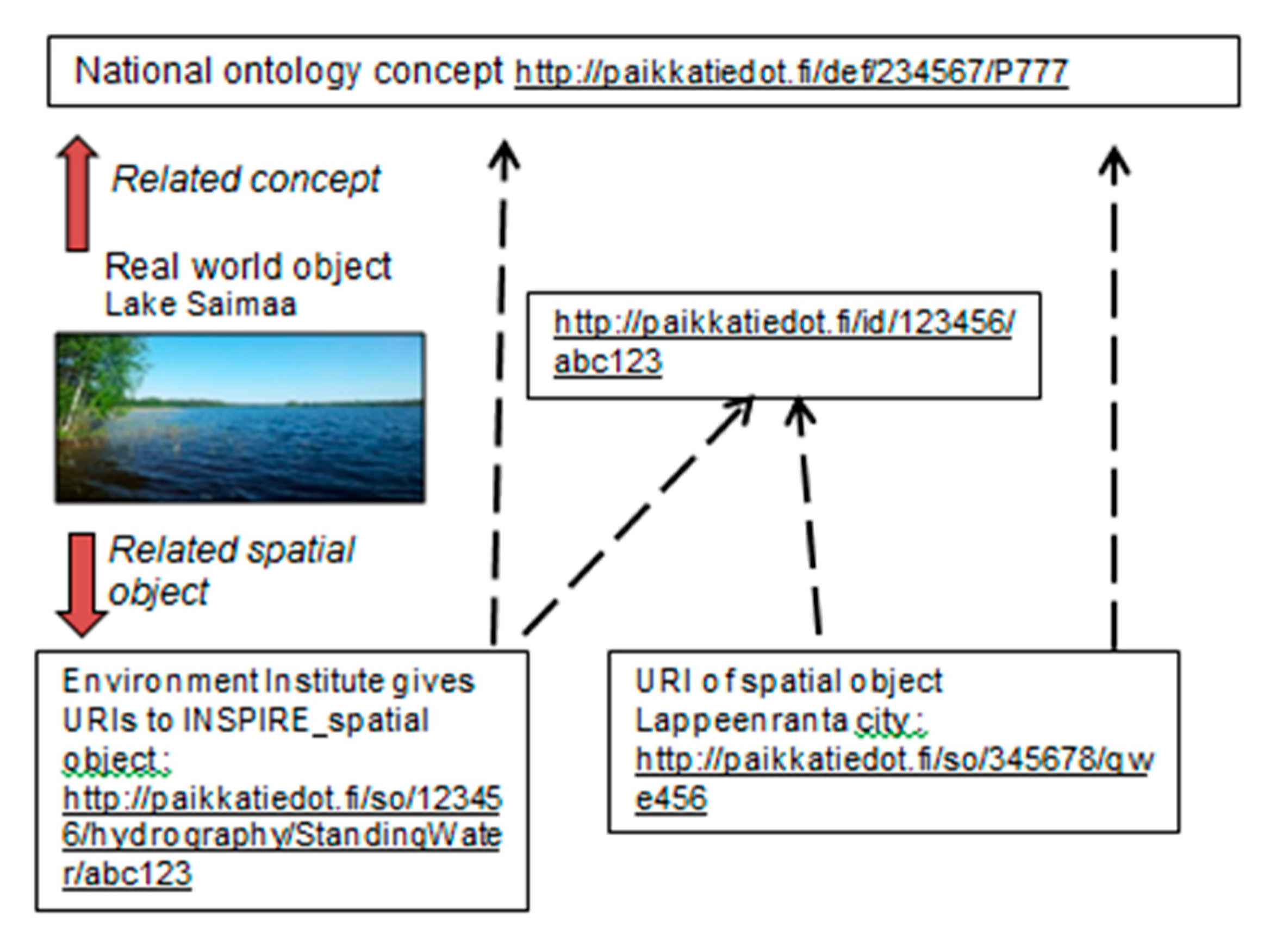
3.1. A Referencing Framework to Align and Compare Geographical Data: The Ontology Geographical Space Context (OGSC)
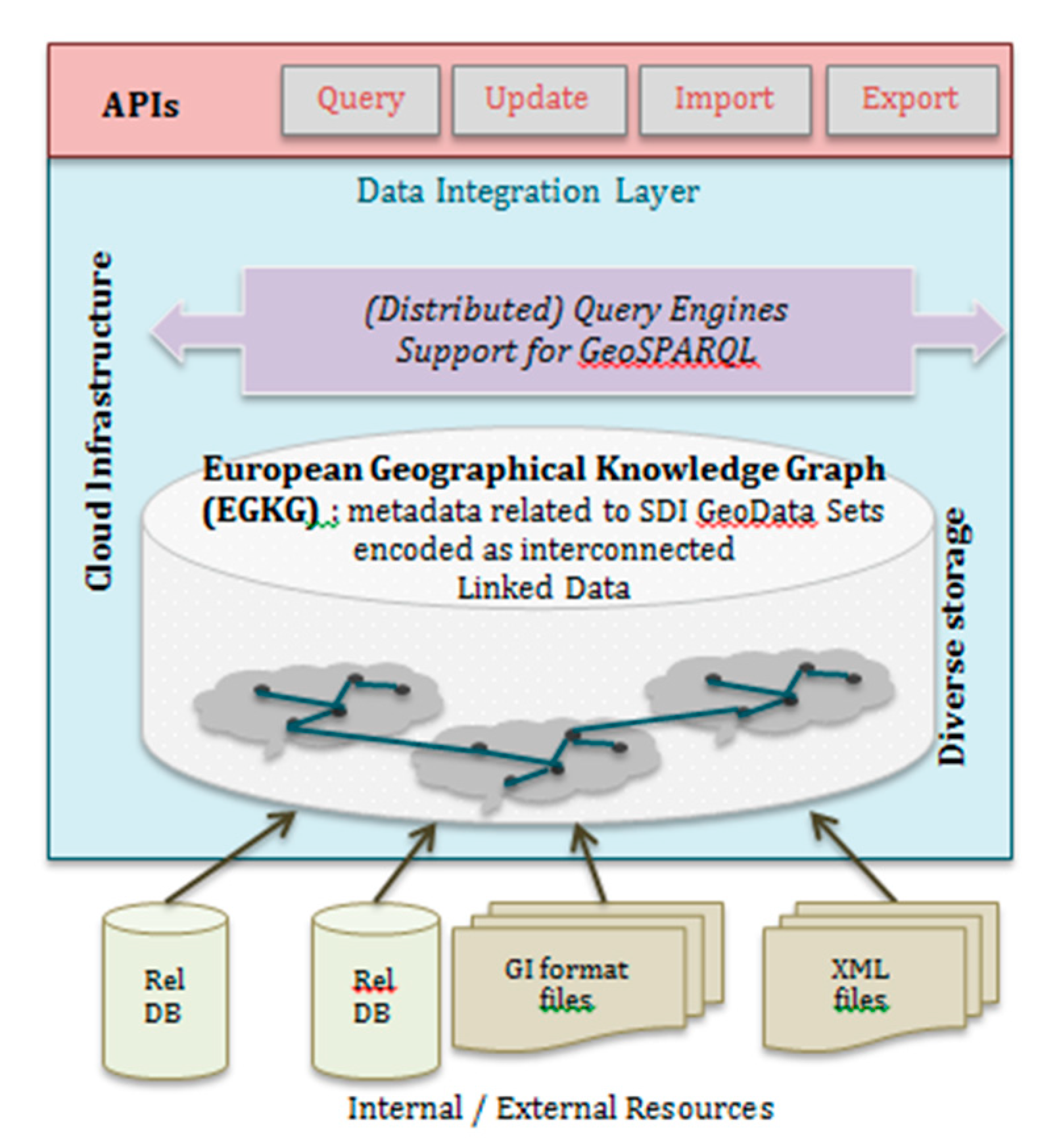
3.2. A European Geographical Knowledge Graph
4. Evolving toward Open SDIs
4.1. Fostering Adoption of SW and of EGKG from NMAs
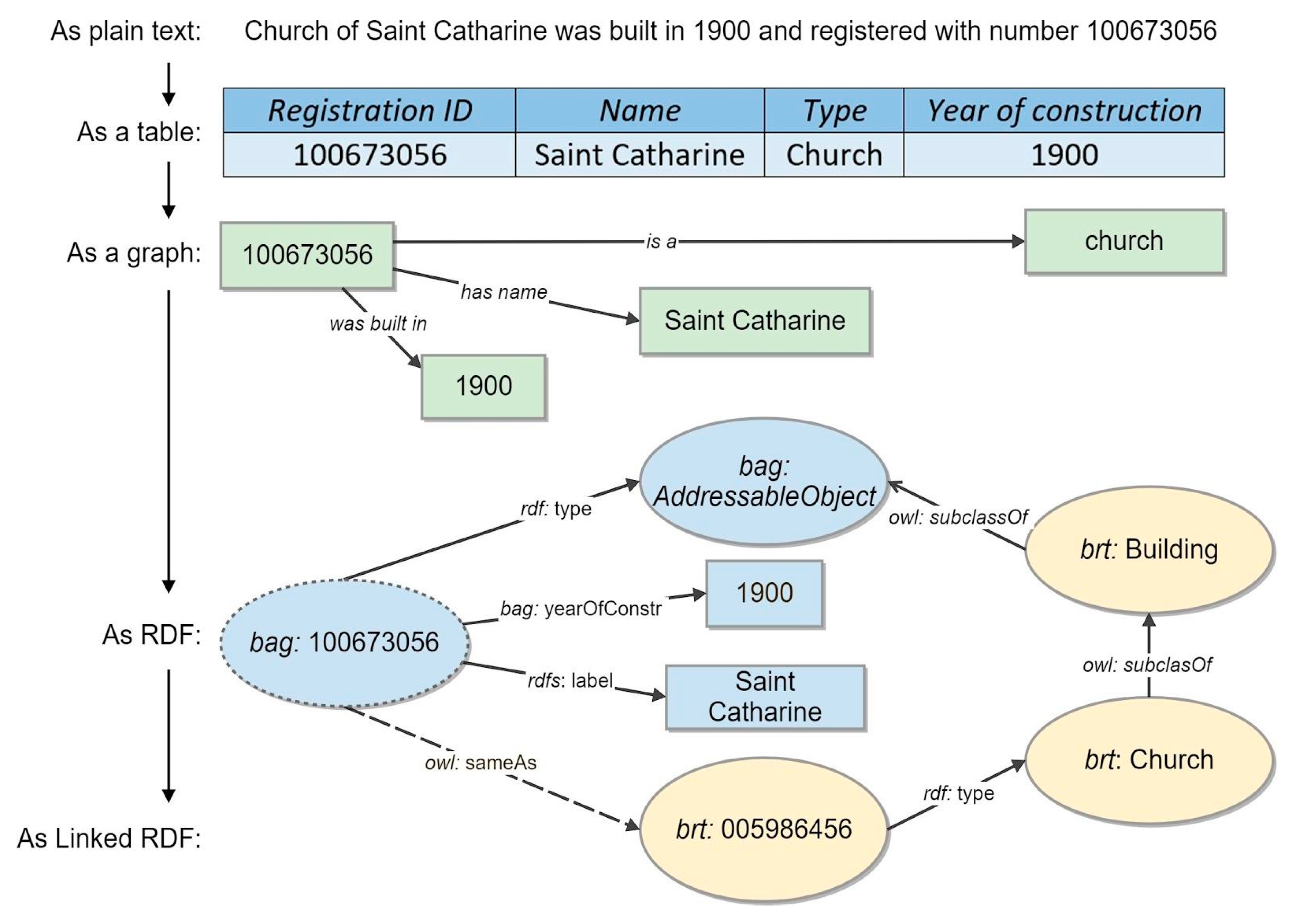
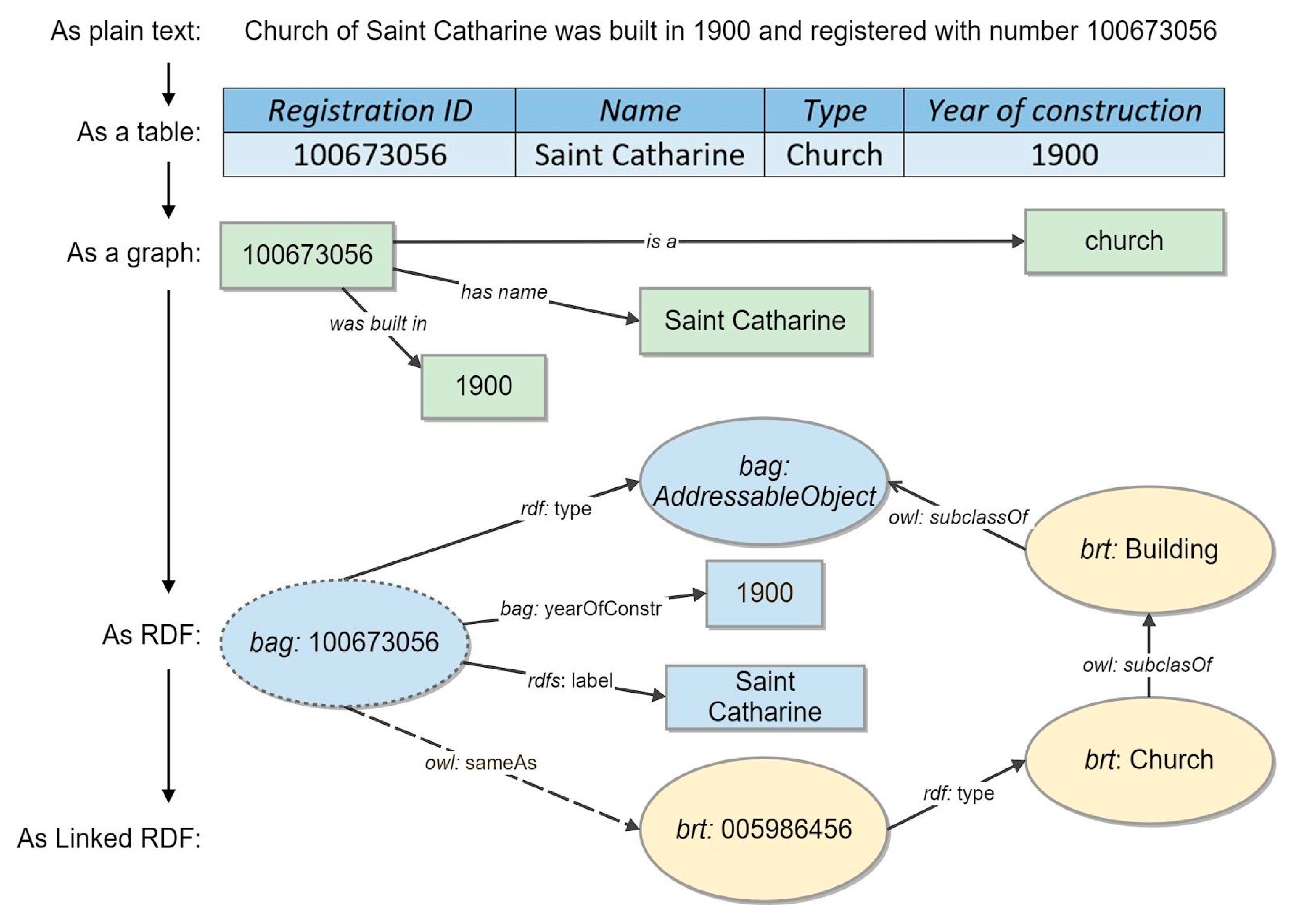
4.1.1. Annotating NMA Registries with Linked Data and Shared Ontologies
4.1.2. Supporting Feature-Centered Discovery and Exploration of NMAs Datasets
4.1.3. Generating Geographical Data Cards
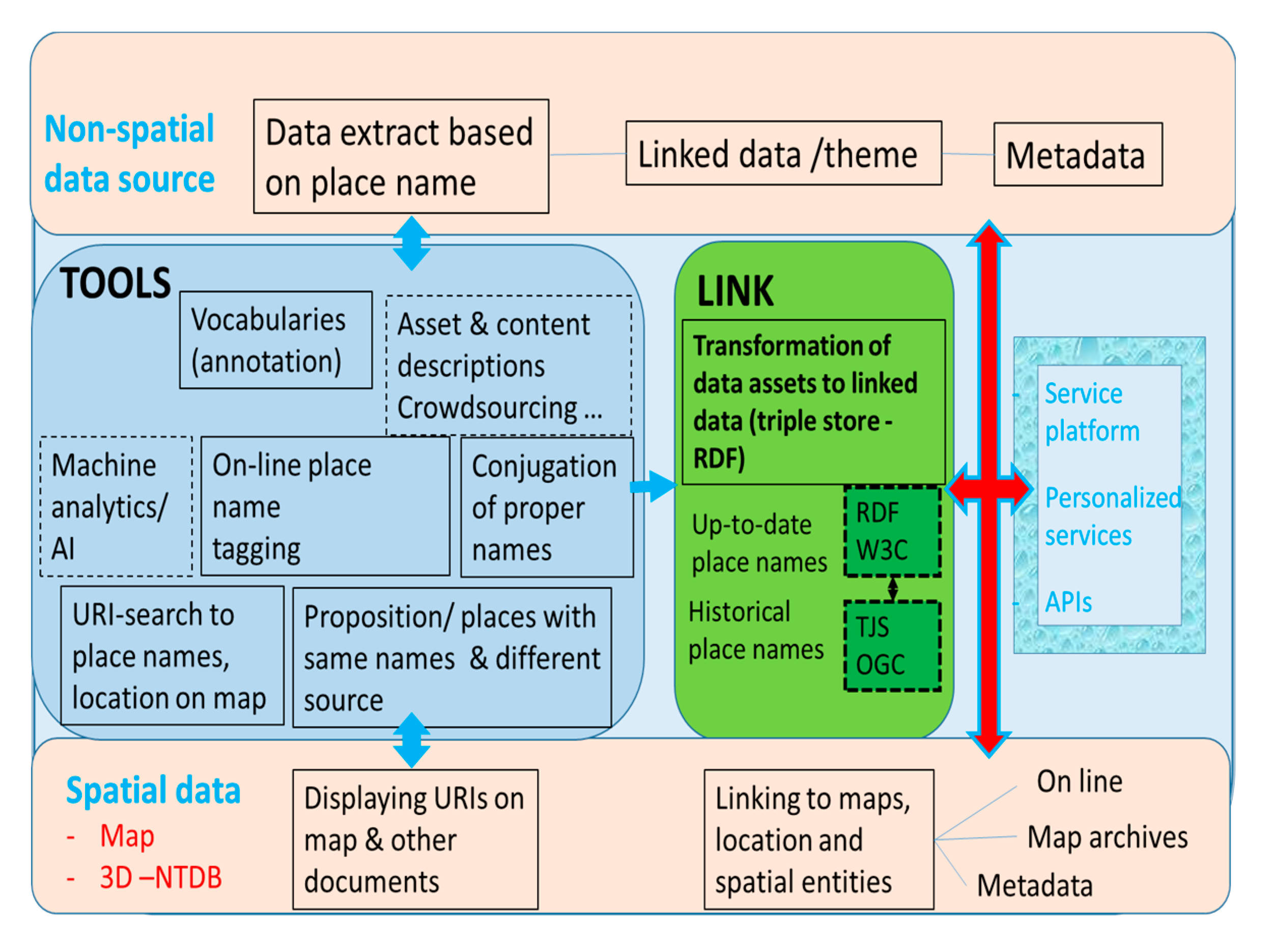
4.2. Designing New Technology Spheres for Spatial Data Infrastructures
- ·
- Data distribution: Distributing graph modeled data, like Linked Open Data (LOD), on the cloud is a hard problem, due to interdependencies among the different parts of the dataset.
- ·
- RDF/Semantic Data processing and querying: It usually requires large amounts of memory in order to materialize transitive closures for the whole or parts of the graph. This is not always available in cloud computing nodes, so additional distribution might be necessary to support this.
- ·
- Geodata analytics: These are highly based on using spatial correlations while data distribution on the cloud is usually oblivious to the actual geo-location of the data, so more elaborate methods should be used.
4.3. Collaborative Metadata Curation: Infolabs
5. Conclusions and Perspectives
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- European Parliament; Council of European Union. Directive 2007/2/EC Establishing an Infrastructure for Spatial Information in the European Community (INSPIRE); OJL 108, 25.4.2007; European Parliament & Council of European Union: Brussels, Belgium, 2007; pp. 1–14. Available online: http://data.europa.eu/eli/dir/2007/2/oj (accessed on 20 January 2020).
- The White House. Office of Management and Budget (2002) Circular No. A-16 Revised; The White House: Washington, DC, USA, 2002. [Google Scholar]
- UN-GGIM: Europe Work Group on Data Integration. Report on the Territorial Dimension in SDG Indicators: Geospatial Data Analysis and Its Integration with Statistical Data; v1.4; Europe Work Group on Data Integration, Instituto Nacional de Estatística: Lisboa, Portugal, 2019. [Google Scholar]
- Crompvoet, J.; Rajabifard, A.; Bregt, A.; Williamson, I. Assessing the Worldwide developments of National Spatial Data Clearinghouses. Int. J. Geogr. Inf. Sci. 2004, 18, 665–689. [Google Scholar] [CrossRef]
- Masser, I. All shapes and sizes: The first generation of national spatial data infrastructures. Int. J. Geogr. Inf. Sci. 1999, 13, 67–84. [Google Scholar] [CrossRef]
- Masser, I.; Crompvoets, J. Building European Spatial Data Infrastructures; Esri Press: Redlands, CA, USA, 2015. [Google Scholar]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The Semantic Web. Sci. Am. 2001, 284, 34–43. [Google Scholar] [CrossRef]
- Noy, N. Industry-scale Knowledge Graphs: Lessons and Challenges. Queue 2019, 17, 48–75. [Google Scholar] [CrossRef] [Green Version]
- Goodwin, J.; Dolbear, C.; Hart, G. Geographical linked data: The administrative geography of Great Britain on the semantic web. Trans. GIS 2008, 12, 19–30. [Google Scholar] [CrossRef]
- Scharffe, F.; Atemezing, G.; Troncy, R.; Gandon, F.; Villata, S.; Bucher, B.; Hamdi, F.; Bihanic, L.; Képéklian, G.; Cotton, F.; et al. Enabling Linked Data Publication with the Datalift Platform. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]
- Hamdi, F.; Abadie, N.; Bucher, B.; Feliachi, A. GeomRDF: A geodata converter with a Fine-Grained Structured Representation of Geometry in the Web. arXiv 2015, arXiv:1503.04864. [Google Scholar]
- Debruyne, C.; Meehan, A.; Clinton, É.; McNerney, L.; Nautiyal, A.; Lavin, P.; O’Sullivan, D. Ireland’s Authoritative Geospatial Linked Data. In Proceedings of the 16th International Semantic Web Conference, Vienna, Austria, 21–25 October 2017; Springer: Cham, Switzerland, 2017; pp. 66–74. [Google Scholar]
- Ronzhin, S.; Folmer, E.; Maria, P.; Brattinga, M.; Beek, W.; Lemmens, R.; van’t Veer, R. Kadaster Knowledge Graph: Beyond the Fifth Star of Open Data. Information 2019, 10, 310. [Google Scholar] [CrossRef] [Green Version]
- Platform Linked Data Netherlands. Available online: http://platformlinkeddata.nl (accessed on 20 January 2020).
- Use Of INSPIRE Data Workshop. Available online: https://eurogeographics.org/calendar-event/use-of-inspire-data-past-experiences-and-scenarios-for-the-future/ (accessed on 20 January 2020).
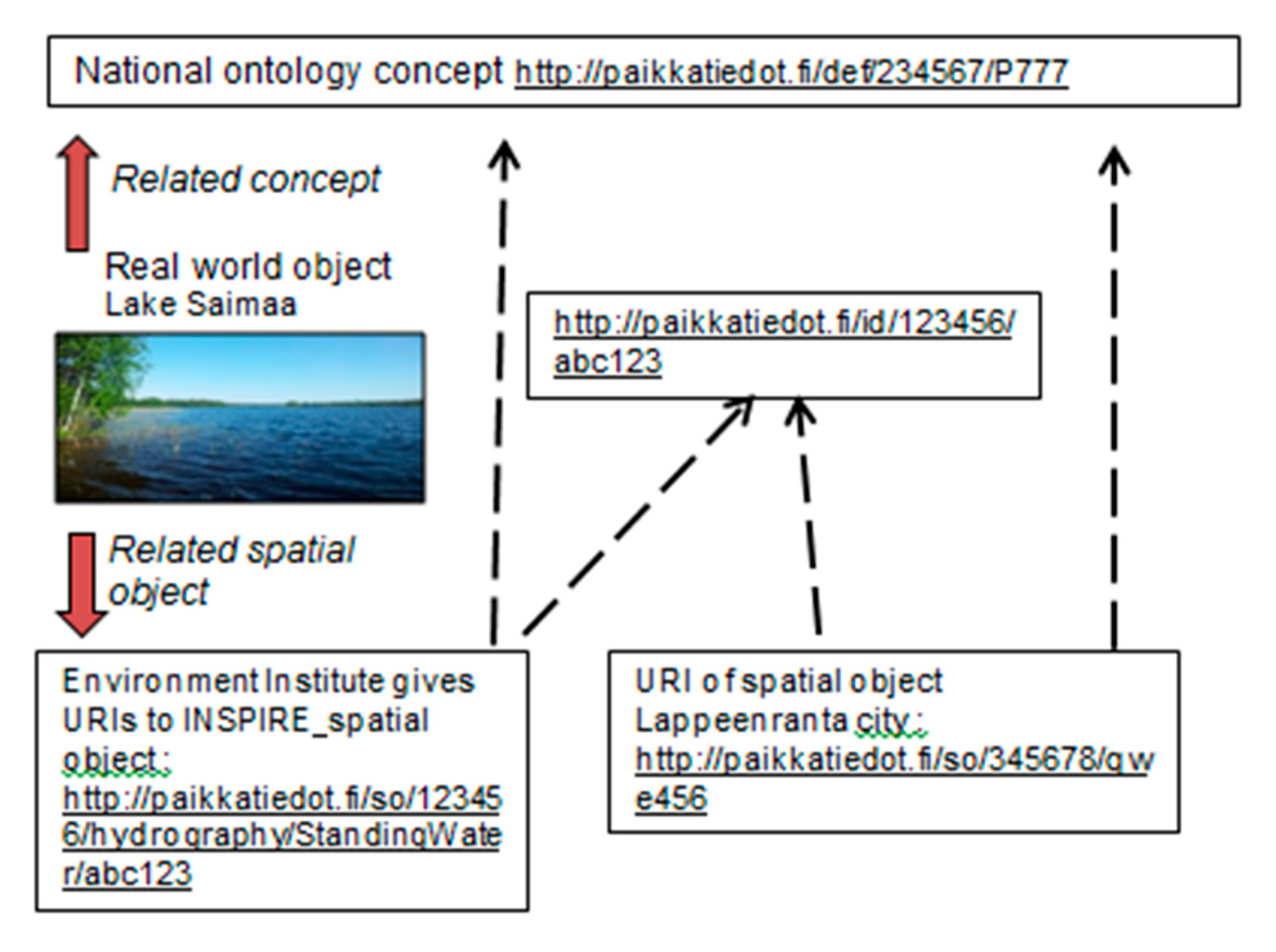
- Bucher, B.; Tiainen, E.; Ellett, T.; Acheson, E.; Laurent, D.; Boissel, S. Data Linking by Indirect Spatial Referencing Systems. In Proceedings of the EuroSDR-Eurogeographics Workshop Report, Paris, France, 5–6 September 2018. [Google Scholar]
- Bucher, B.; Laurent, D.; Jansen, P. Preserving Semantics, Tractability and Evolution on a Multi-Scale Geographic Information Infrastructure: Cases for Extending INSPIRE Data Specifications. In Proceedings of the Report of Eurogeographics-EuroSDR workshop on INSPIRE Data Extension, Warsaw, Poland, 27–28 November 2018. [Google Scholar]
- The General Finnish Ontology YSO. Available online: https://finto.fi/en/ (accessed on 20 January 2020).
- Atzemoglou, A.; Roussakis, Y.; Kritikos, K.; Lappas, Y.; Grinias, E.; Kotzinos, D. Transforming Geological and Hydrogeological Data to Linked (Open) Data for Groundwater Management. In Proceedings of the 10th International Hydrogeological Congress, Thessaloniki, Greece, 8–10 October 2014. [Google Scholar]
- Atzemoglou, A.; Kotzinos, D.; Grinias, E.; Spanou, N.; Pappas, C. Transforming Geological and Landslide Susceptibility Mapping Data to Linked (Open) Data for Hazard Management. Bull. Geol. Soc. Greece 2016, 50, 1683–1692. [Google Scholar] [CrossRef] [Green Version]
- Frank, A.U. Tiers of ontology and consistency constraints in geographical information systems. Int. J. Geogr. Inf. Sci. 2001, 15, 667–678. [Google Scholar] [CrossRef]
- Kuhn, W. Semantic reference systems. Int. J. Geogr. Inf. Sci. 2003, 17, 405–409. [Google Scholar] [CrossRef]
- Ceh, M.; Podobnikar, T.; Smole, D. Semantic similarity measures within the semantic framework of the universal ontology of geographical space. In Progress in Spatial Data Handling, Proceedings of the 12th International Symposium on Spatial Data Handling, Vienna, Austria, 12–14 July 2006; Riedl, A., Kainz, W., Elmes, G., Eds.; Springer: Berlin, Germany, 2006; pp. 417–434. [Google Scholar]
- Fonseca, G.; Câmara, A.; Miguel, M. A Framework for Measuring the Interoperability of Geo-Ontologies. Spat. Cognit. Comput. 2006, 6, 309–331. [Google Scholar] [CrossRef]
- Tambassi, T. The Philosophy of Geo-Ontologies; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Probst, F.; Lutz, C. Giving Meaning to GI Web Service Descriptions. In Proceedings of the 7th AGILE Conference on Geograpic Infirmation Science, Heraklion, Crete, 29 April–1 May 2004. [Google Scholar]
- Kuhn, W.; Raubal, M. Implementing Semantic Reference Systems; AGILE: Lyon, France, 2003. [Google Scholar]
- Heath, T.; Bizer, C. Linked Data: Evolving the Web into a Global Data Space. In Synthesis Lectures on the Semantic Web: Theory and Technology, 1st ed.; Morgan & Claypool: Burlington, MA, USA, 2011; pp. 1–136. [Google Scholar]
- Berners-Lee, T. Linked Data. Available online: http://www.w3.org/DesignIssues/LinkedData.html (accessed on 20 January 2020).
- Ronzhin, S.; Folmer, E.; Lemmens, R. Technological Aspects of (Linked) Open Data. In Open Data Exposed; van Loenen, B., Vancauwenberghe, G., Crompvoets, J., Eds.; T.M.C. Asser Press: The Hague, The Netherlands, 2018; pp. 173–193. [Google Scholar] [CrossRef]
- Osterwalder, A.; Pigneur, Y. Business Model Generation: A Handbook for Visionaries, Game Changers, and Challengers; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Archer, P.; Dekkers, M.; Goedertier, S.; Loutas, N. Study on Business Models for Linked Open Government Data; ISA Programme by PwC EU Services. European Union: Brussels, Belgium. Available online: https://ec.europa.eu/isa2/sites/isa/files/study-on-business-models-open-government_en.pdf (accessed on 20 January 2020).
- Kobilarov, G.; Scott, T.; Raimond, Y.; Sizemore, C.; Smethurst, M.; Bizer, C.; Lee, R. Media Meets Semantic Web—How the BBC Uses DBpedia and Linked Data to Make Connections. In Proceedings of the European Semantic Web Conference, Heraklion, Greece, 31 May–4 June 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 723–737. Available online: https://0-link-springer-com.brum.beds.ac.uk/content/pdf/10.1007/978-3-642-02121-3_53.pdf (accessed on 17 September 2018).
- Ehrlinger, L.; Wöß, W. Towards a Definition of Knowledge Graphs. In Proceedings of the Posters and Demos Track of 12th International Conference on Semantic Systems, SEMANTICS 2016, Leipzig, Germany, 12–15 September 2016. [Google Scholar]
- Wilcke, X.; Bloem, P.; De Boer, V. The knowledge graph as the default data model for learning on heterogeneous knowledge. Data Sci. 2017, 1, 39–57. [Google Scholar] [CrossRef] [Green Version]
- Paulheim, H. Knowledge graph refinement: A survey of approaches and evaluation methods. Semant. Web 2017, 8, 489–508. [Google Scholar] [CrossRef] [Green Version]
- Ballatore, A.; Bertolotto, M.; Wilson, D. A structural-lexical measure of semantic similarity for geo-knowledge graphs. ISPRS Int. J. Geo Inf. 2015, 4, 471–492. [Google Scholar] [CrossRef] [Green Version]
- Brickley, D.; Burgess, M.; Noy, N. Google Dataset Search: Building a Search Engine for Datasets in an Open Web Ecosystem. In Proceedings of the Web Conference, San Francisco, CA, USA, 13–17 May 2019; ACM: New York, NY, USA, 2019; pp. 1365–1375. [Google Scholar]
- Keet, C.M. Open World Assumption. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013. [Google Scholar]
- Shapes Constraint Language (SHACL). Holger Knublauch; Dimitris Kontokostas. W3C. 20 July 2017. W3C Recommendation. Available online: https://www.w3.org/TR/shacl/ (accessed on 20 January 2020).
- Brink van den, L.; Janssen, P.; Quak, W.; Stoter, J. Linking spatial data: Automated conversion of geo-information models and GML data to RDF. Int. J. Spat. Data Infrastruct. Res. 2014, 9, 59–85. [Google Scholar]
- Smole, D.; Ceh, M.; Podobnikar, T. Evaluation of inductive logic programming for information extraction from natural language texts to support spatial data recommendation services. Int. J. Geogr. Inf. Sci. 2011, 25, 1809–1827. [Google Scholar] [CrossRef]
- Tiainen, E. Georef—Linked Data Deployment for Spatial Data. Finnish Initiative, FIG Working Week, Helsinki, Oral Presentation. Available online: http://www.fig.net/resources/proceedings/fig_proceedings/fig2017/ppt/ts02e/TS02E_tiainen_8781_ppt.pdf (accessed on 20 January 2020).
- Kritikos, K.; Roussakis, Y.; Kotzinos, D. A Cloud-Based, Geospatial Linked Data Management System. In Transactions on Large-Scale Data- and Knowledge-Centered Systems XX, Special Issue on Advanced Techniques for Big Data Management; Hameurlain, A., Küng, J., Wagner, R., Sakr, S., Wang, L., Zomaya, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume XX, pp. 59–89. [Google Scholar]
- Semic Interoperability Community. The Linked Data Showcase (LDS) Pilot: The Value of Interlinking Data. Available online: https://joinup.ec.europa.eu/collection/semantic-interoperability-community-semic/linked-data-showcase-lds-pilot-value-interlinking-data (accessed on 20 January 2020).
- Ronzhin, S.; Folmer, E.; Mellum, R.; Ellett von Brasch, T.; Martin, E.; Lopez Romero, E.; Kytö, S.; Hietanen, E.; Latvala, P. Next Generation of Spatial Data Infrastructure: Lessons from Linked Data Implementations across Europe. Available online: https://openels.eu/wp-content/uploads/2019/04/V2_Next_Generation_SDI_Lessons-from-LD-implementations-across-Europe_1.pdf (accessed on 20 January 2020).
- Bereta, K.; Stamoulis, G. Representation, Querying and Visualisation of Linked Geospatial Data. Available online: http://www.lirmm.fr/rod/slidesRoD04102018/RoD2018-tutorial.pdf (accessed on 20 January 2020).
- Bucher, B.; Van Damme, M.-D. URCLIM Deliverable D2.1-1, URCLIM Infolab. Project Report, Paris, France. 2018. Available online: https://eurogeographics.org/wp-content/uploads/2018/07/08_BBucher.pdf (accessed on 20 January 2020).
- Masson, V.W.; Heldens, E.; Bocher, M.; Bonhomme, B.; Bucher, C.; Burmeister, C.; de Munck, T.; Esch, J.; Hidalgo, F.; Kanani-Sühring, Y.-T. City-descriptive input data for urban climate models: Model requirements, data sources and challenges. Urban Clim. 2019, 31. [Google Scholar] [CrossRef]




© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bucher, B.; Tiainen, E.; Ellett von Brasch, T.; Janssen, P.; Kotzinos, D.; Čeh, M.; Rijsdijk, M.; Folmer, E.; Van Damme, M.-D.; Zhral, M. Conciliating Perspectives from Mapping Agencies and Web of Data on Successful European SDIs: Toward a European Geographic Knowledge Graph. ISPRS Int. J. Geo-Inf. 2020, 9, 62. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9020062
Bucher B, Tiainen E, Ellett von Brasch T, Janssen P, Kotzinos D, Čeh M, Rijsdijk M, Folmer E, Van Damme M-D, Zhral M. Conciliating Perspectives from Mapping Agencies and Web of Data on Successful European SDIs: Toward a European Geographic Knowledge Graph. ISPRS International Journal of Geo-Information. 2020; 9(2):62. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9020062
Chicago/Turabian StyleBucher, Bénédicte, Esa Tiainen, Thomas Ellett von Brasch, Paul Janssen, Dimitris Kotzinos, Marjan Čeh, Martijn Rijsdijk, Erwin Folmer, Marie-Dominique Van Damme, and Mehdi Zhral. 2020. "Conciliating Perspectives from Mapping Agencies and Web of Data on Successful European SDIs: Toward a European Geographic Knowledge Graph" ISPRS International Journal of Geo-Information 9, no. 2: 62. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9020062