Spatial Paradigms in Road Networks and Their Delimitation of Urban Boundaries Based on KDE

Abstract
:1. Introduction
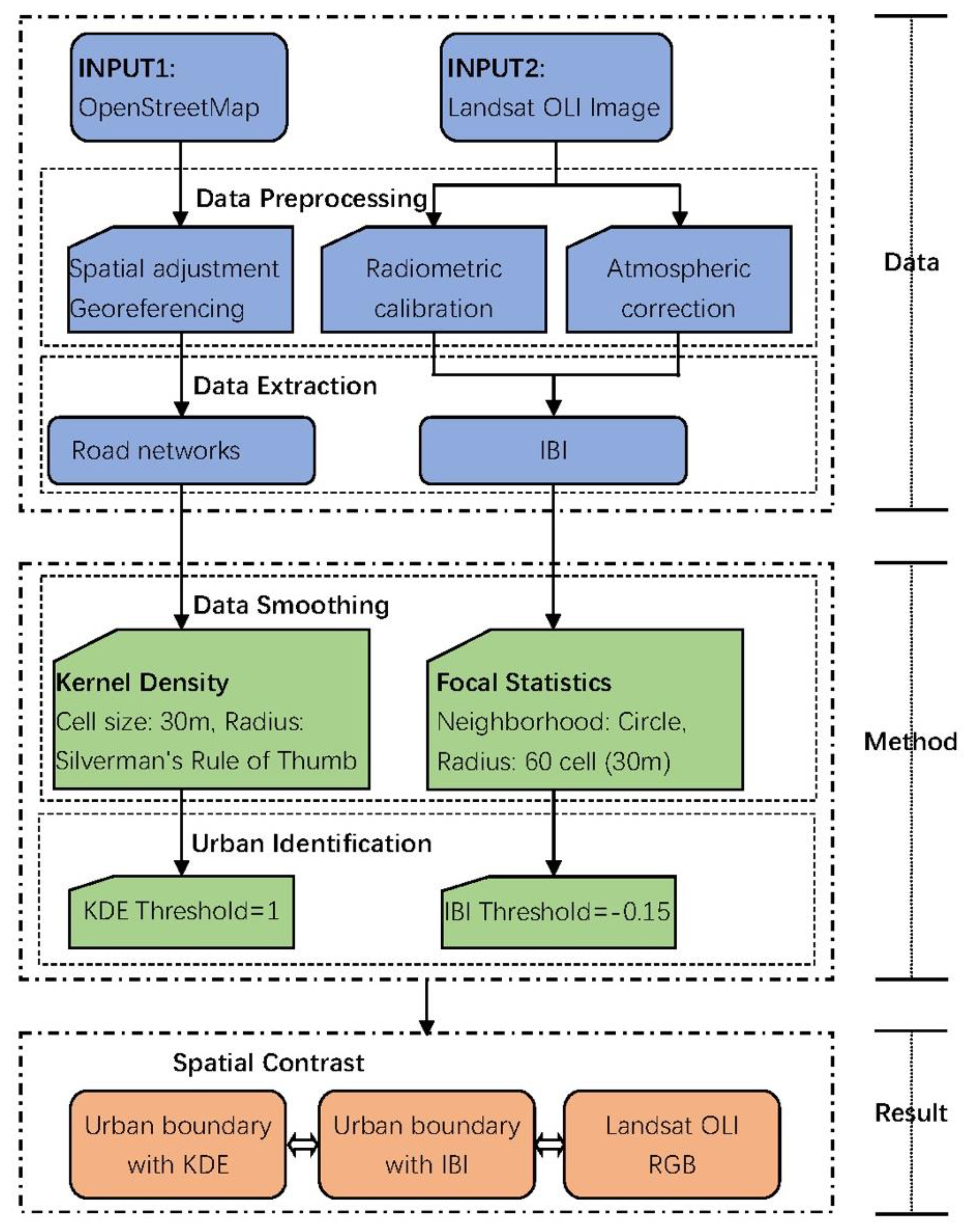
2. Materials and Methods
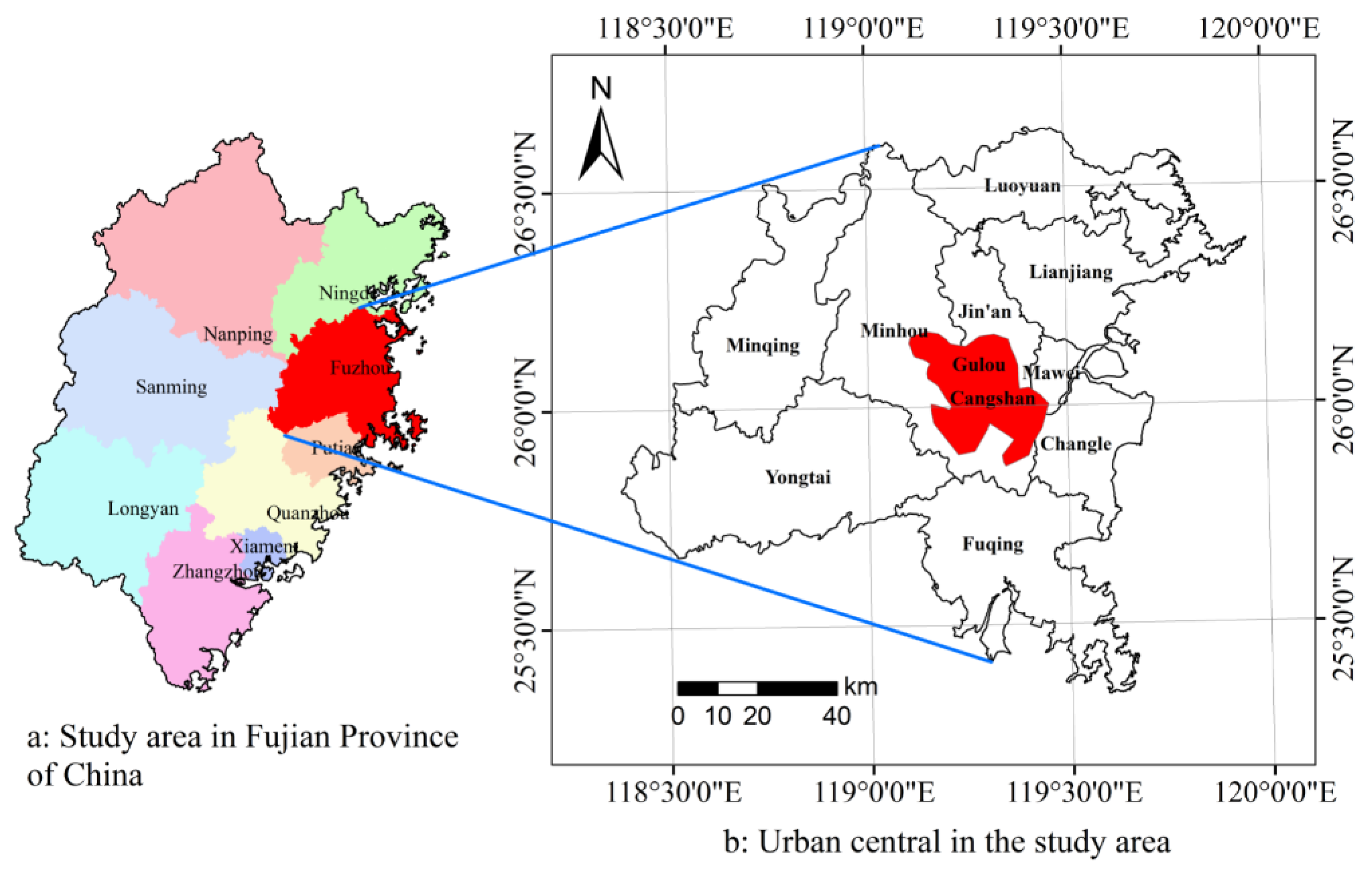
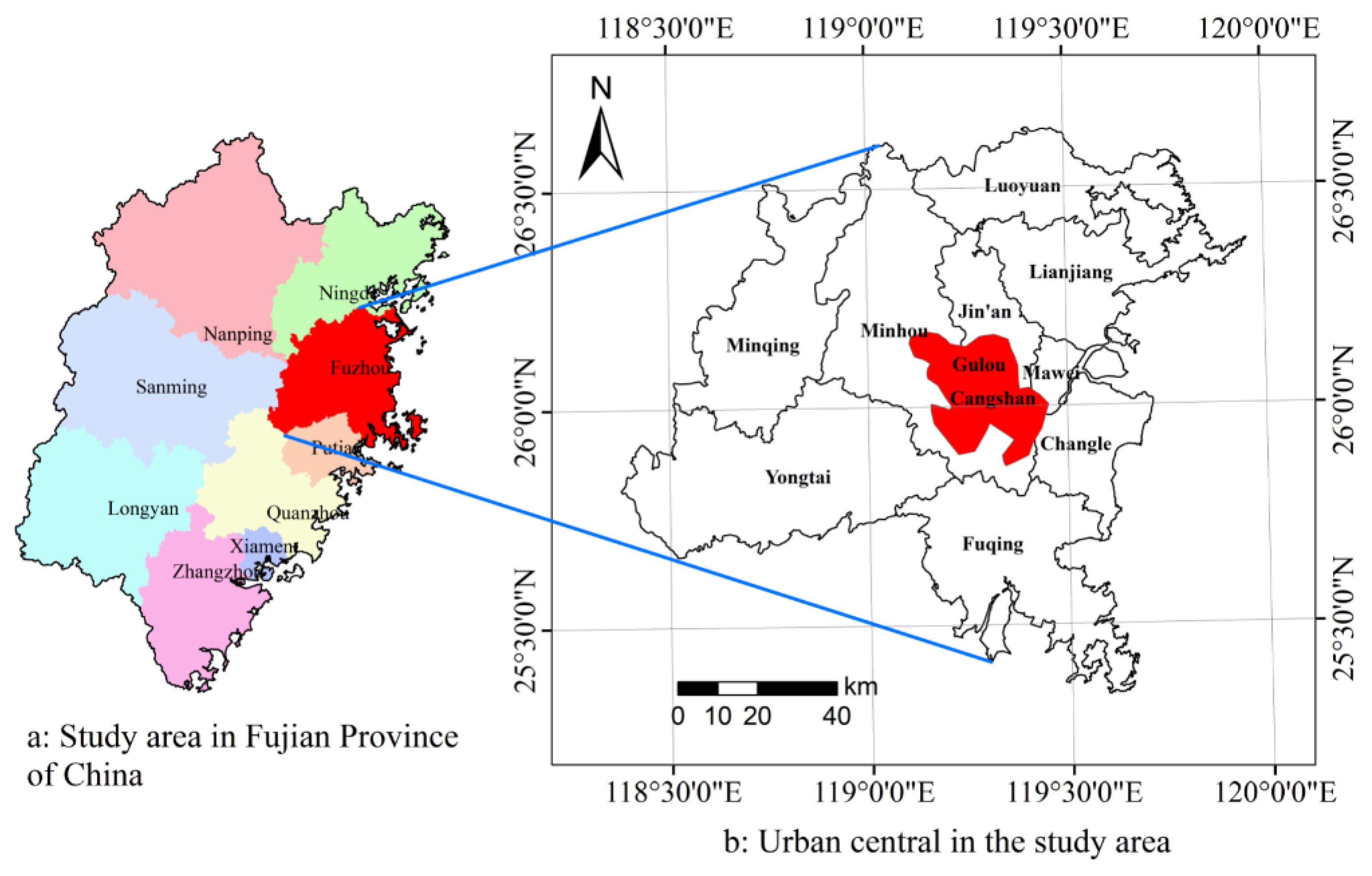
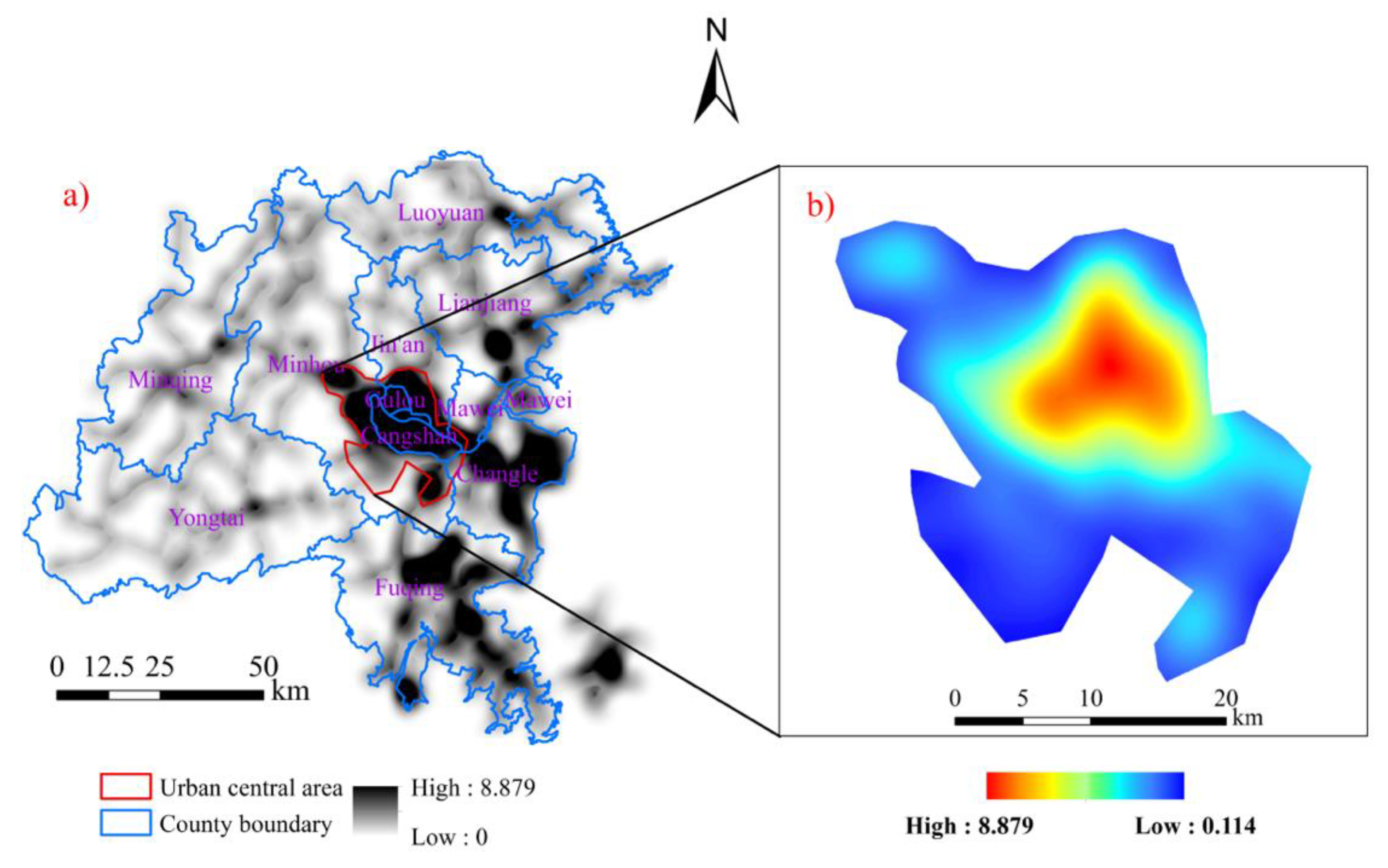
2.1. Study Area
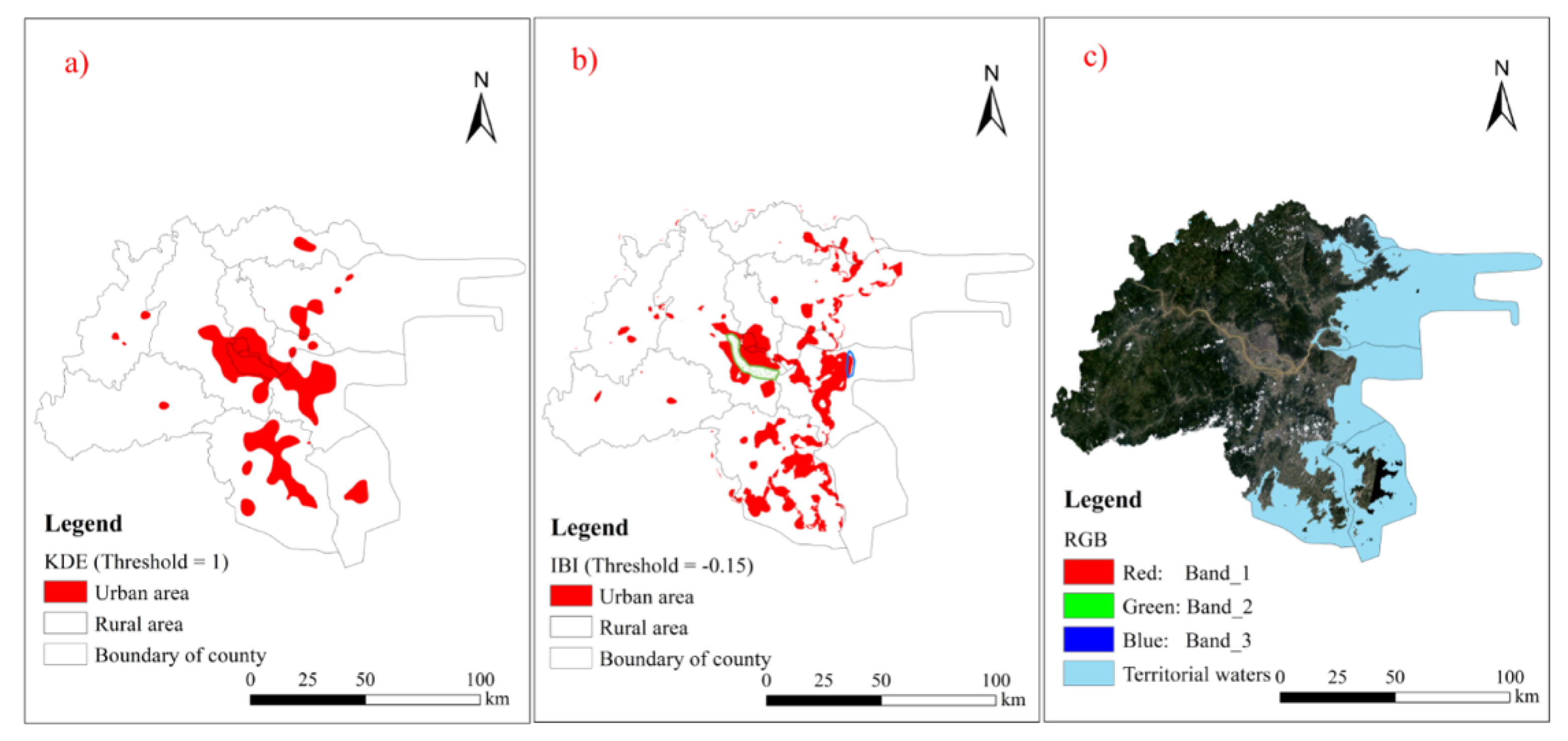
2.2. Identification of Urban Boundary
2.3. Data Sources and Pre-Processing
2.4. Kernel Density Estimation
2.5. Index-Based Built-Up Index
+[BNIR/(BNIR+BRed)+BBlue/(BBlue+BSWI1)}
2.6. Geographical Variation Analysis
2.6.1. Spatial Autocorrelation Analysis
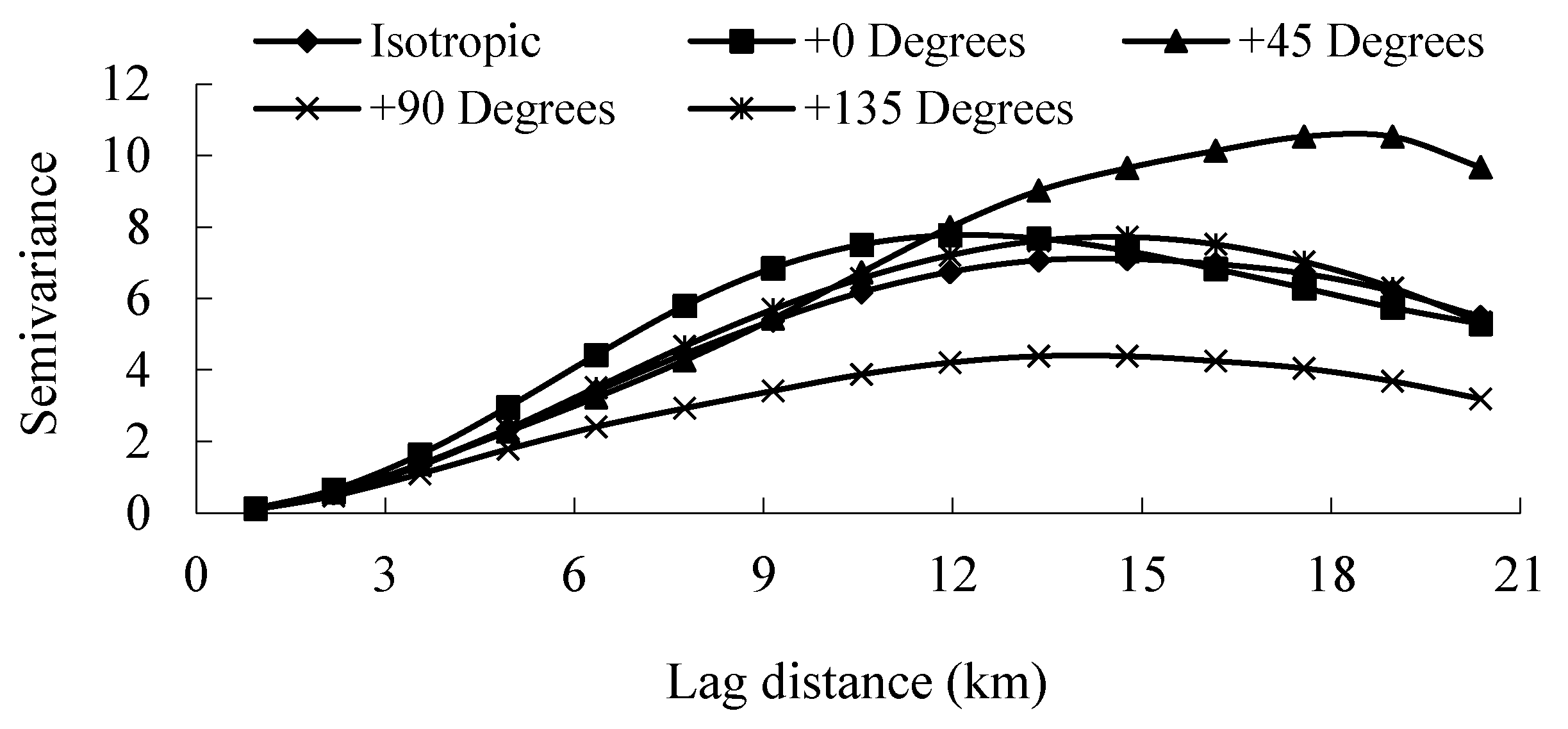
2.6.2. Semivariance Analysis
2.7. Sampling Strategies
3. Results and Discussion
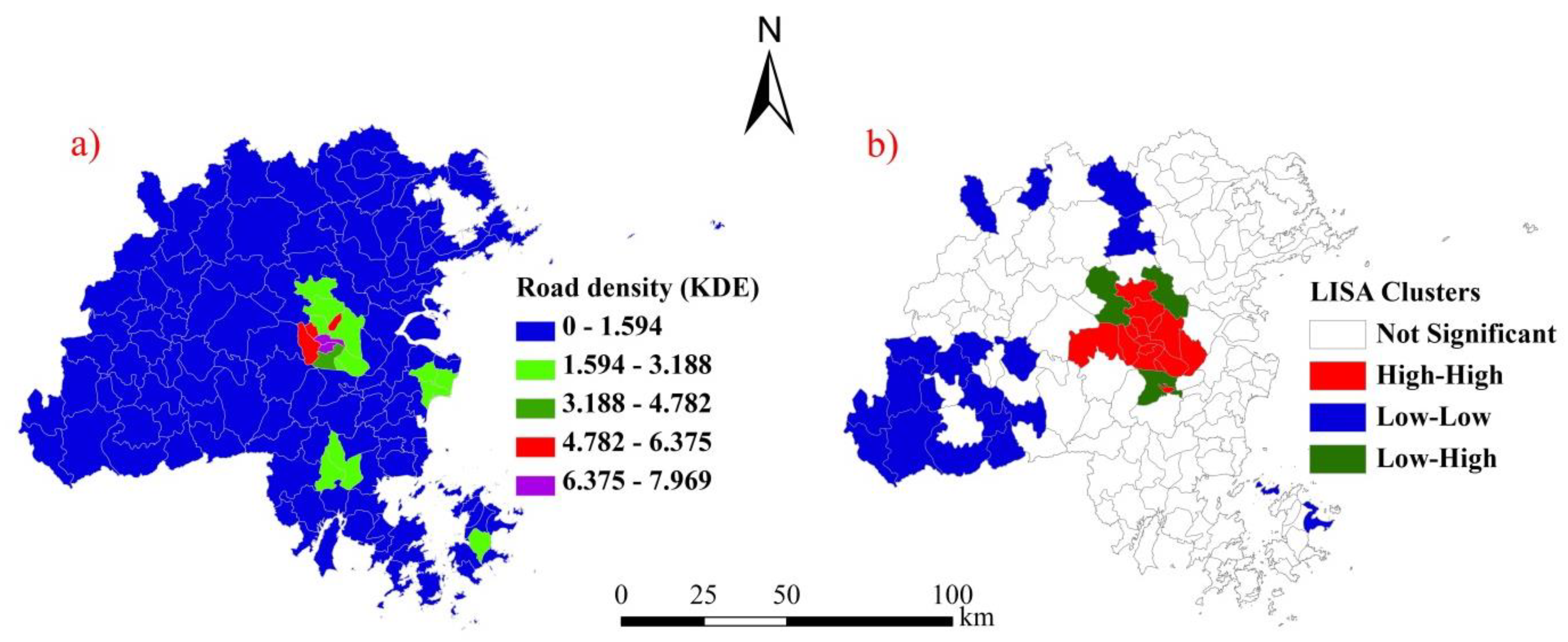
3.1. Spatial Patterns of the Road Density at Different Levels
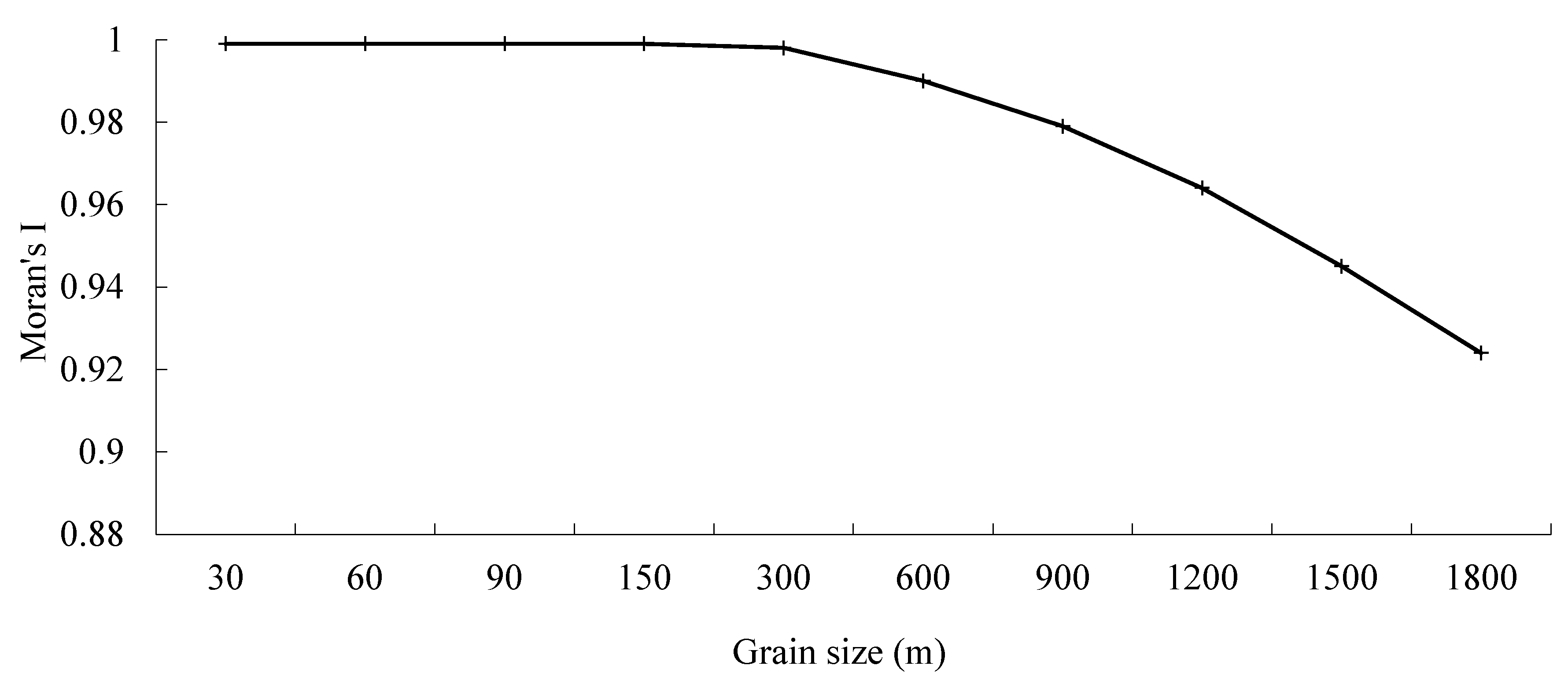
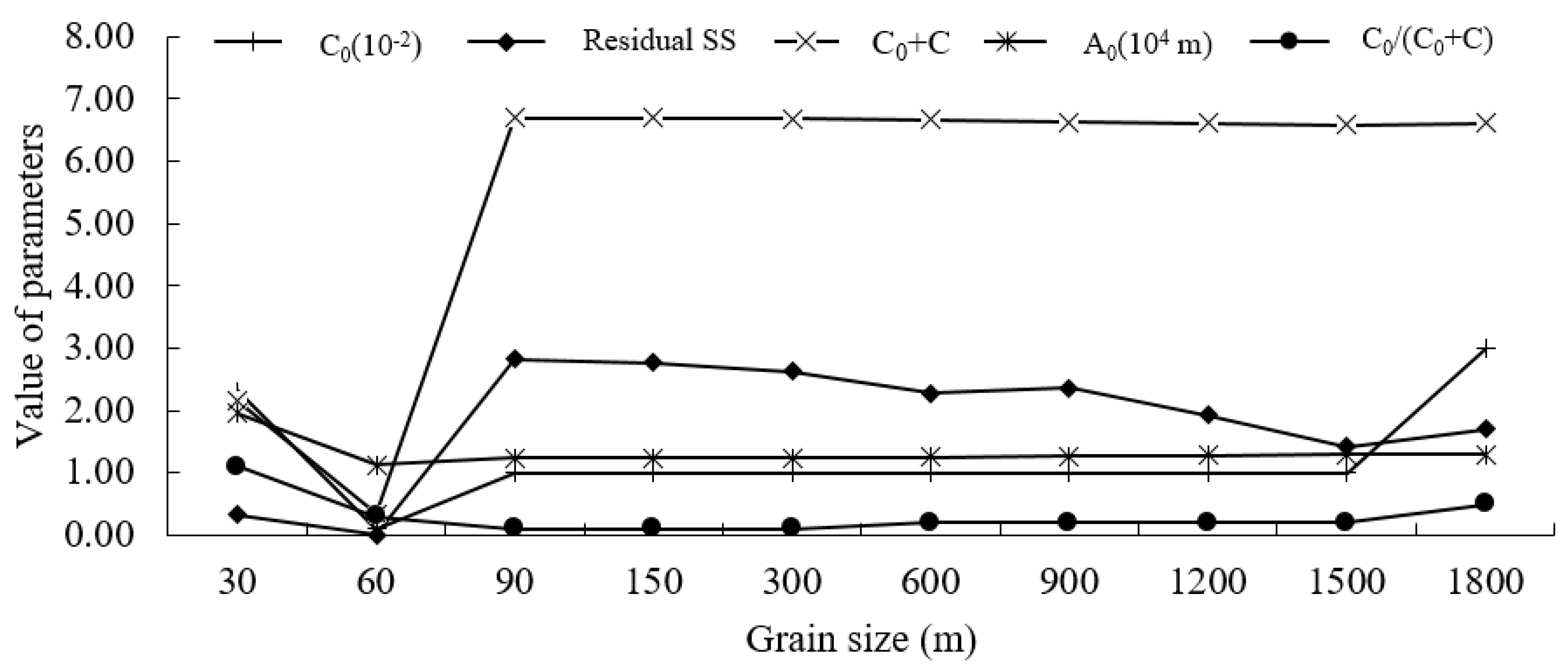
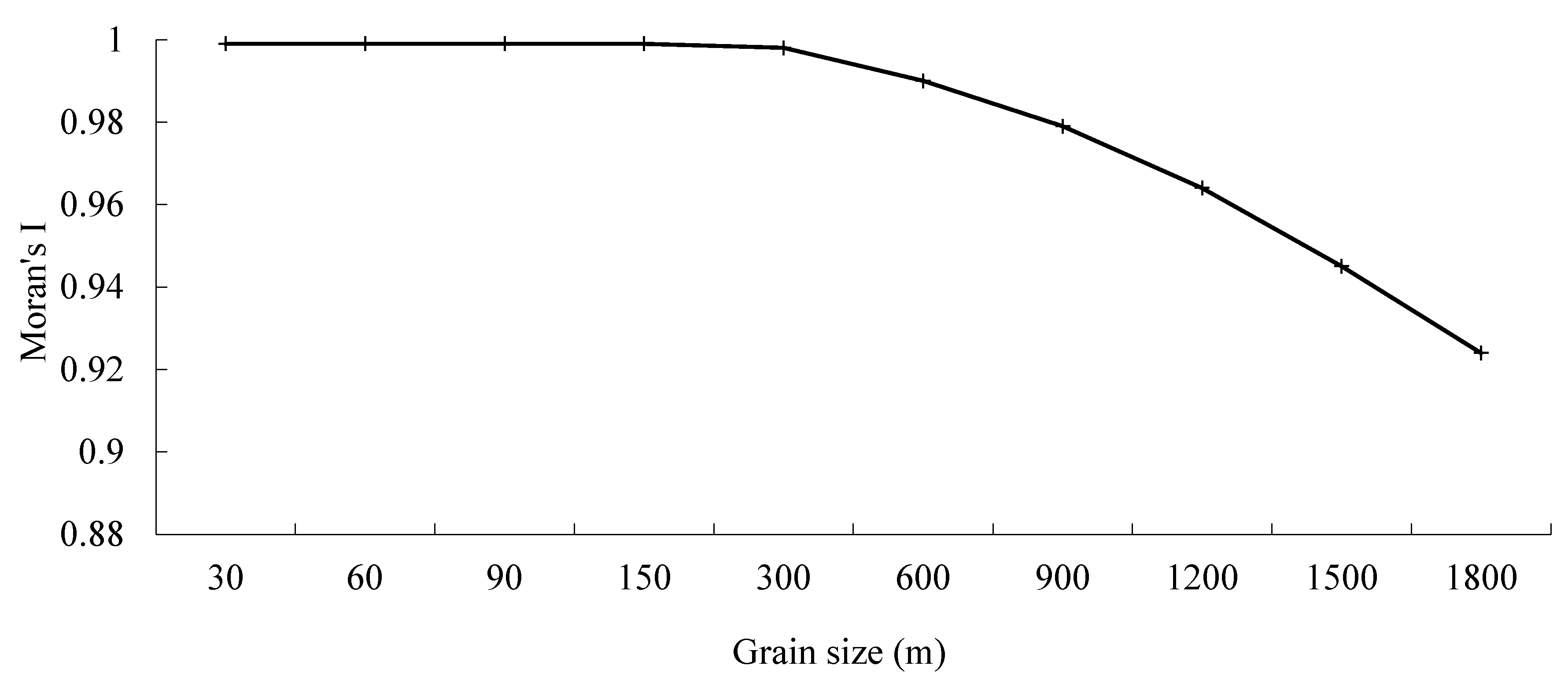
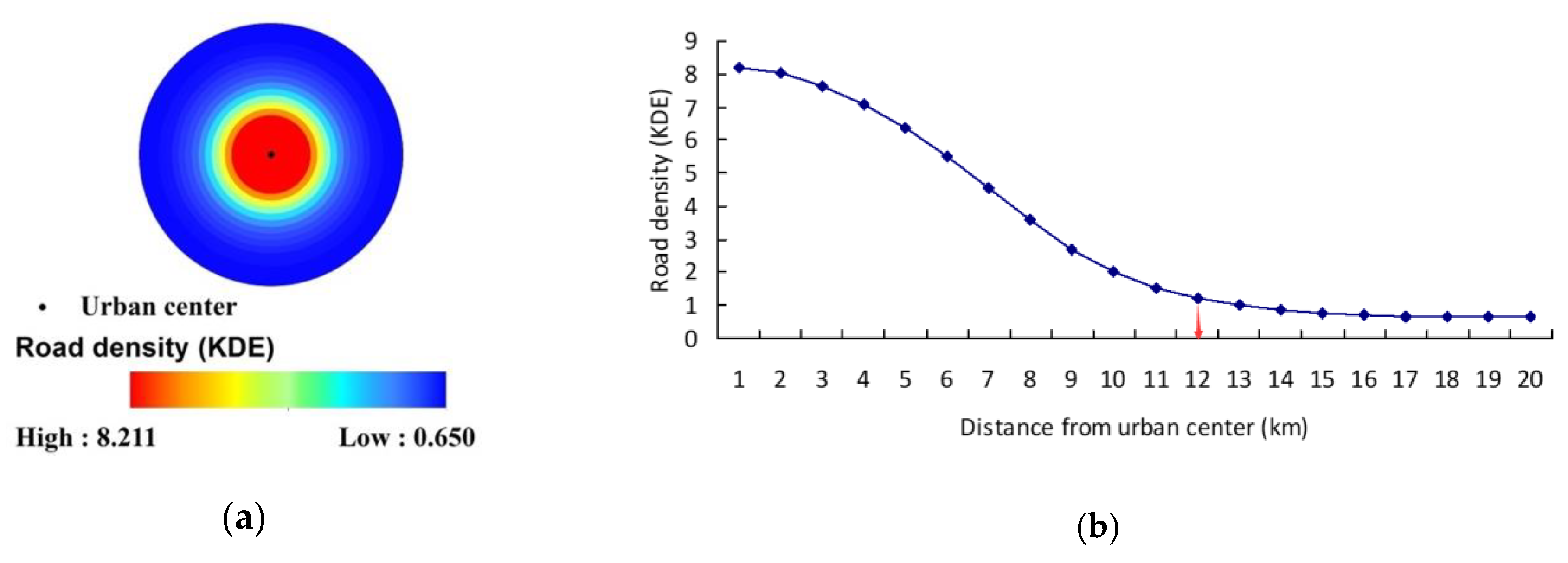
3.2. Scale Effect of Spatial Patterns in Road Density in the Downtown Area
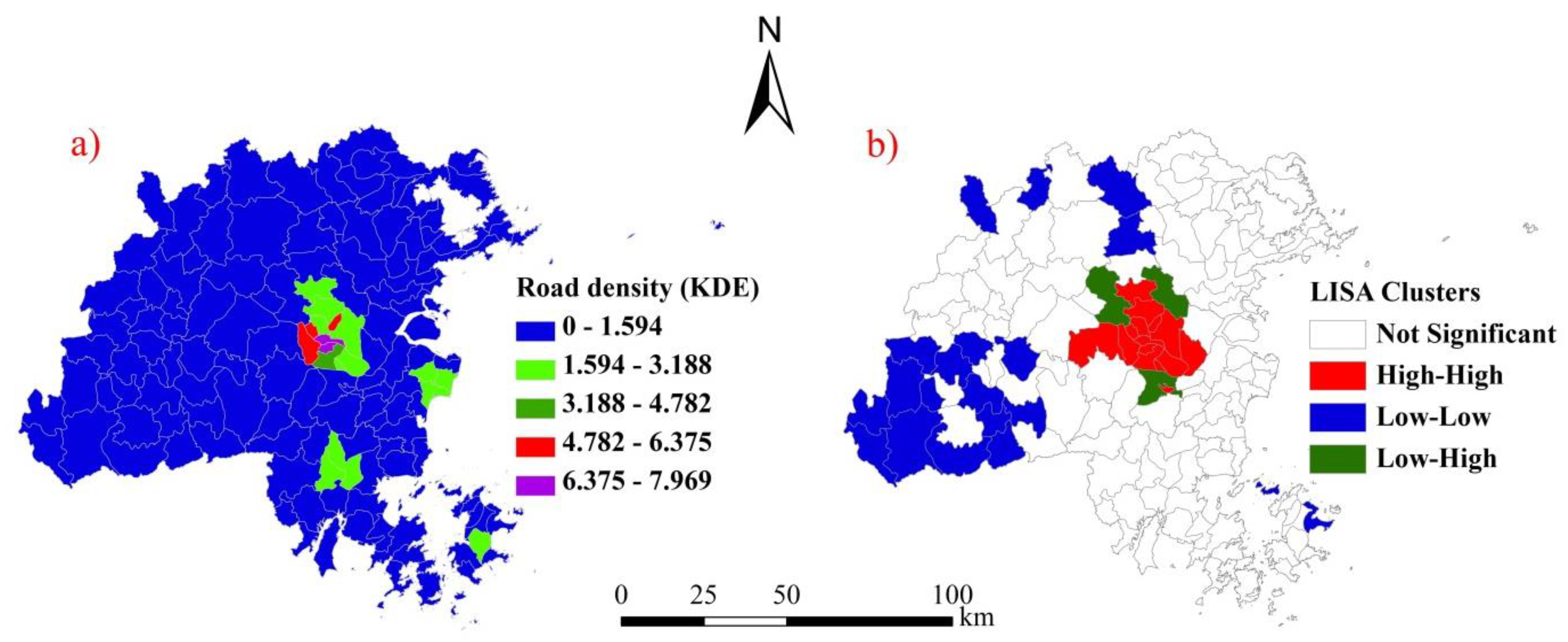
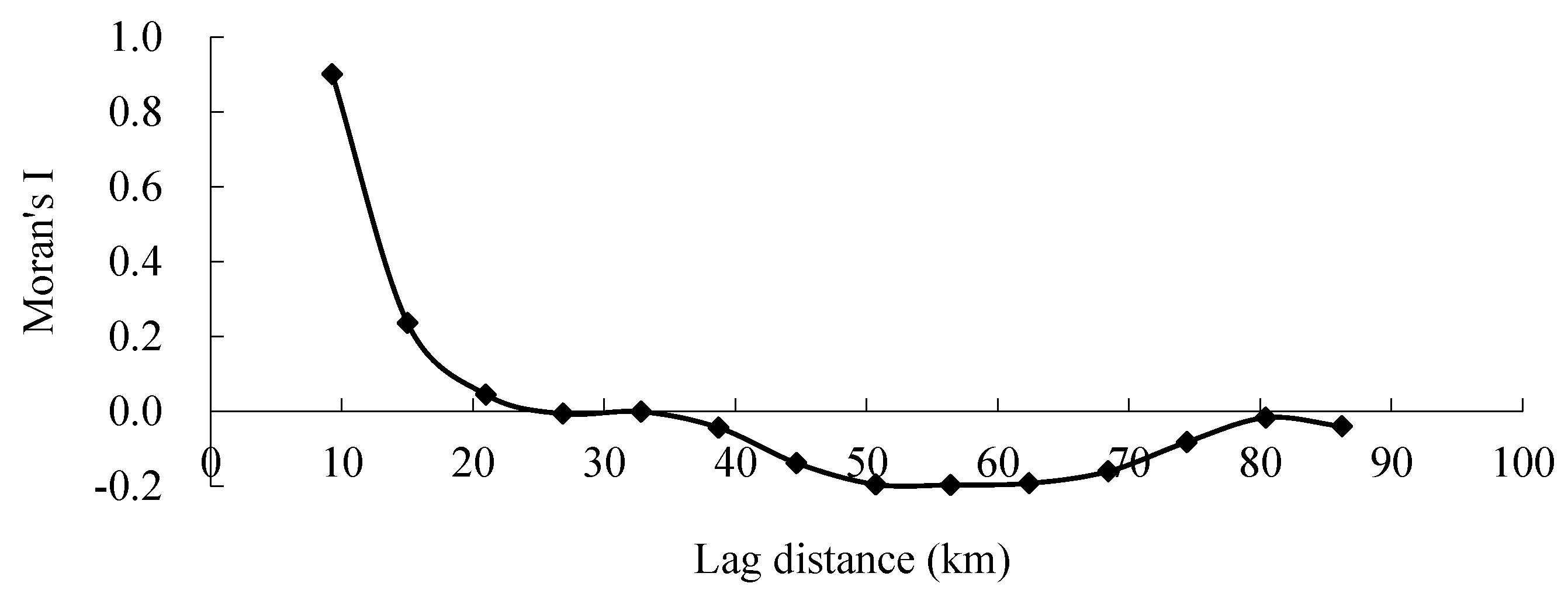
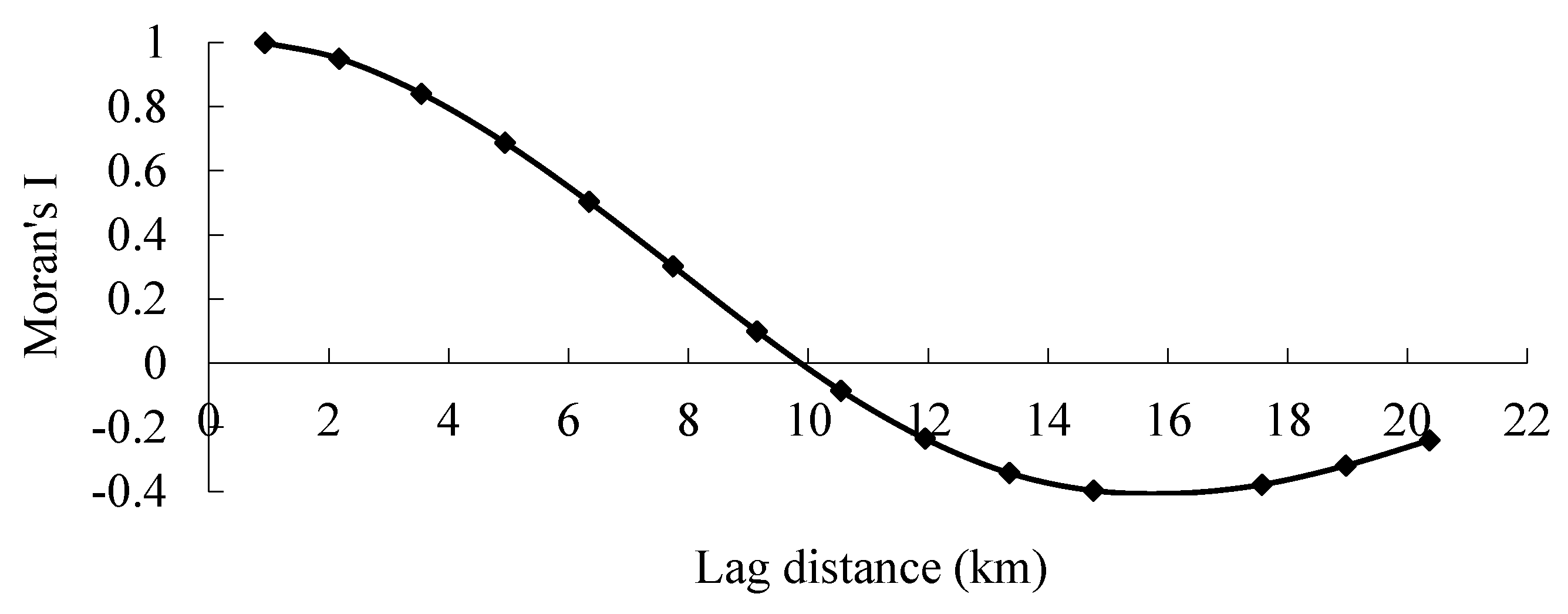
3.3. Characteristics of Spatial Heterogeneity in the Road Density in the Downtown Area
3.4. Delimitation of the Urban Boundary
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mcdonald, R.I.; Green, P.; Balk, D.; Fekete, B.M.; Revenga, C.; Todd, M.; Montgomery, M. Urban growth, climate change, and freshwater availability. Proc. Natl. Acad. Sci. USA 2011, 108, 6312–6317. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gong, P.; Li, X.; Zhang, W. 40-Year (1978–2017) human settlement changes in China reflected by impervious surfaces from satellite remote sensing. Sci. Bull. 2019, 64, 756–763. [Google Scholar] [CrossRef] [Green Version]
- Heintzman, L.J.; McIntyre, N.E. Quantifying the effects of projected urban growth on connectivity among wetlands in the Great Plains (USA). Landsc. Urban Plan. 2019, 186, 1–12. [Google Scholar] [CrossRef]
- Liu, X.; Hu, G.; Chen, Y.; Li, X.; Xu, X.; Li, S.; Pei, F.; Wang, S. High-resolution multi-temporal mapping of global urban land using Landsat images based on the Google Earth Engine Platform. Remote Sens. Environ. 2018, 209, 227–239. [Google Scholar] [CrossRef]
- Barnosky, A.D.; Hadly, E.A.; Bascompte, J.; Berlow, E.L.; Brown, J.H.; Fortelius, M.; Getz, W.M.; Harte, J.; Hastings, A.; Marquet, P.A.; et al. Approaching a state shift in Earth’s biosphere. Nature 2012, 486, 52–58. [Google Scholar] [CrossRef]
- Schmidt, C.; Domaratzki, M.; Kinnunen, R.P.; Bowman, J.; Garroway, C.J. Continent-wide effects of urbanization on bird and mammal genetic diversity. Proc. R. Soc. B 2020, 287, 20192497. [Google Scholar] [CrossRef]
- Shi, Y.; Ren, C.; Lau, K.K.; Ng, E. Investigating the influence of urban land use and landscape pattern on PM2.5 spatial variation using mobile monitoring and wudapt. Landsc. Urban Plan. 2019, 189, 15–26. [Google Scholar] [CrossRef]
- Ramalho, C.E.; Hobbs, R.J. Time for a change: Dynamic urban ecology. Trends Ecol. Evol. 2012, 27, 179–188. [Google Scholar] [CrossRef]
- Turner, B.L.; Lambin, E.F.; Anette, R. The emergence of land change science for global environmental change and sustainability. Proc. Natl. Acad. Sci. USA 2007, 104, 20666–20671. [Google Scholar] [CrossRef] [Green Version]
- Forman, R.T.T. Road ecology: A solution for the giant embracing us. Landsc. Ecol. 1998, 13, III–V. [Google Scholar] [CrossRef]
- Wei, W.; Shi, P.J.; Zhou, J.J.; Xie, B.B. The Road Network Density and Spatial Dependence Analysis Based on Basin Scale—A Case Study on Shiyang River Basin. Appl. Mech. Mater. 2014, 505, 750–754. [Google Scholar] [CrossRef]
- Barthelemy, M. Spatial Networks. Phys. Rep. 2010, 499, 1–101. [Google Scholar] [CrossRef] [Green Version]
- Lämmer, S.; Gehlsen, B.; Helbing, D. Scaling laws in the spatial structure of urban road networks. Phys. Stat. Mech. Appl. 2006, 363, 89–95. [Google Scholar] [CrossRef] [Green Version]
- Borruso, G. Network Density and the Delimitation of Urban Areas. Trans. GIS 2010, 7, 177–191. [Google Scholar] [CrossRef]
- Su, Q. The effect of population density, road network density, and congestion on household gasoline consumption in U.S. urban areas. Energy Econ. 2011, 33, 445–452. [Google Scholar] [CrossRef]
- Quinn, P. Road density as a proxy for population density in regional-scale risk modeling. Nat. Hazards J. Int. Soc. Prev. Mitig. Nat. Hazards 2013, 65, 1227–1248. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, J.; Peng, X.; Gong, P.; Shi, P. Urban built-up land change detection with road density and spectral information from multi-temporal Landsat TM data. Int. J. Remote Sens. 2002, 23, 3057–3078. [Google Scholar] [CrossRef]
- Strano, E.; Nicosia, V.; Latora, V.; Porta, S.; Barthélemy, M. Elementary processes governing the evolution of road networks. Sci. Rep. UK 2012, 2, 296. [Google Scholar] [CrossRef] [Green Version]
- Hu, X.; Zhang, L.; Ye, L.; Lin, Y.; Qiu, R. Locating spatial variation in the association between road network and forest biomass carbon accumulation. Ecol. Indic. 2017, 73, 214–223. [Google Scholar] [CrossRef]
- Garrison, W.L. Connectivity of the Interstate Highway System. Pap. Reg. Sci. 2010, 6, 121–137. [Google Scholar] [CrossRef]
- Barabási, A.L.; Bonabeau, E. Scale-free networks. Sci. Am. 2003, 288, 60. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.S.; Wu, C.Z.; Wang, J.K.; Qiu, R.Z. Identification of spatial variation in road network and its driving patterns: Economy and population. Reg. Sci. Urban Econ. 2018, 71, 37–45. [Google Scholar] [CrossRef]
- Cai, X.; Wu, Z.; Cheng, J. Using kernel density estimation to assess the spatial pattern of road density and its impact on landscape fragmentation. Int. J. Geogr. Inf. Sci. 2013, 27, 222–230. [Google Scholar] [CrossRef]
- Mo, W.; Wang, Y.; Zhang, Y.; Zhuang, D. Impacts of road network expansion on landscape ecological risk in a megacity, China: A case study of Beijing. Sci. Total Environ. 2017, 574, 1000–1011. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, Y.; Hu, X.; Zheng, X.; Hou, X.; Zhang, Z.; Zhou, X.; Qiu, R.; Lin, J. Spatial variations in the relationships between road network and landscape ecological risks in the highest forest coverage region of China. Ecol. Indic. 2019, 96, 392–403. [Google Scholar] [CrossRef]
- Hawbaker, T.J.; Radeloff, V.C.; Hammer, R.B.; Clayton, M.K. Road Density and Landscape Pattern in Relation to Housing Density, and Ownership, Land Cover, and Soils. Landsc. Ecol. 2005, 20, 609–625. [Google Scholar] [CrossRef]
- Zhang, Z.; Tan, S.; Tang, W. A GIS-based Spatial Analysis of Housing Price and Road Density in Proximity to Urban Lakes in Wuhan City, China. Chin. Geogr. Sci. 2015, 25, 775–790. [Google Scholar] [CrossRef] [Green Version]
- Miller, J.R.; Joyce, L.A.; Knight, R.L.; King, R.M. Forest roads and landscape structure in the southern Rocky Mountains. Landsc. Ecol. 1996, 11, 115–127. [Google Scholar] [CrossRef]
- Gatrell, A.C.; Bailey, T.C.; Diggle, P.J.; Rowlingson, B.S. Spatial Point Pattern Analysis and Its Application in Geographical Epidemiology. Trans. Inst. Br. Geogr. 1996, 21, 256–274. [Google Scholar] [CrossRef]
- Coffin, A.W. From roadkill to road ecology: A review of the ecological effects of roads. J. Transp. Geogr. 2007, 15, 396–406. [Google Scholar] [CrossRef]
- Li, T.; Li, W.; Qian, Z. Variations in ecosystem service value in response to land use changes in Shenzhen. Ecol. Econ. 2010, 69, 1427–1435. [Google Scholar]
- Qiu, G.Y.; Zou, Z.D.; Li, X.Z.; Li, H.Y.; Guo, Q.P.; Yan, C.H.; Tan, S.L. Experimental studies on the effects of green space and evapotranspiration on urban heat island in a subtropical megacity in China. Habitat Int. 2017, 68, 30–42. [Google Scholar] [CrossRef]
- Peng, J.; Lin, H.; Chen, Y.; Blaschke, T.; Luo, L.; Xu, Z.; Hu, Y.; Zhao, M.; Wu, J. Spatiotemporal evolution of urban agglomerations in China during 2000–2012: A nighttime light approach. Landsc. Ecol. 2020, 35, 421–434. [Google Scholar] [CrossRef]
- Zhou, W.Q.; Huang, G.L.; Pickett, S.T.A.; Cadenasso, M.L. 90 years of forest cover change in an urbanizing watershed: Spatial and temporal dynamics. Landsc. Ecol. 2011, 26, 645–659. [Google Scholar] [CrossRef]
- Kuang, W.H.; Liu, J.Y.; Dong, J.W.; Chi, W.F.; Zhang, C. The rapid and massive urban and industrial land expansions in China between 1990 and 2010: A CLUD-based analysis of their trajectories, patterns, and drivers. Landsc. Urban Plan. 2016, 145, 21–33. [Google Scholar] [CrossRef]
- Fenta, A.A.; Yasuda, H.; Haregeweyn, N.; Belay, A.S.; Hadush, Z.; Gebremedhin, M.A.; Mekonnen, G. The dynamics of urban expansion and land use/land cover changes using remote sensing and spatial metrics: The case of Mekelle City of northern Ethiopia. Int. J. Remote Sens. 2017, 38, 4107–4129. [Google Scholar] [CrossRef]
- Liu, Y.Q.; Song, W.; Deng, X.Z. Understanding the spatiotemporal variation of urban land expansion in oasis cities by integrating remote sensing and multi-dimensional DPSIR-based indicators. Ecol. Indic. 2019, 96, 23–37. [Google Scholar] [CrossRef]
- Xu, H.; Huang, S.; Zhang, T. Built-up land mapping capabilities of the ASTER and Landsat ETM+ sensors in coastal areas of southeastern China. Adv. Space Res. 2013, 52, 1437–1449. [Google Scholar] [CrossRef]
- Xian, G.; Crane, M.; McMahon, C. Quantifying multi-temporal urban development characteristics in Las Vegas from Landsat and ASTER data. Photogramm. Eng. Remote Sens. 2008, 74, 473–481. [Google Scholar] [CrossRef]
- Zha, Y.; Gao, J.; Ni, S. Use of normalized difference built-up index in automatically mapping urban areas from TM imagery. Int. J. Remote Sens. 2003, 24, 583–594. [Google Scholar] [CrossRef]
- Xu, Y.Y.; Xie, Z.; Wu, L.; Chen, Z.L. Multilane roads extracted from the OpenStreetMap urban road network using random forests. Trans. GIS 2019, 23, 224–240. [Google Scholar] [CrossRef]
- Brovelli, M.A.; Minghini, M.; Molinari, M.; Mooney, P. Towards an Automated Comparison of OpenStreetMap with Authoritative Road Datasets. Trans. GIS 2017, 21, 191–206. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.B.; Du, C.; Chen, H.; Xu, Y.X.; Guo, N.; Jing, N. Road Extraction from Very High Resolution Images Using Weakly labeled OpenStreetMap Centerline. ISPRS Int. J. Geo-Inf. 2019, 8, 478. [Google Scholar] [CrossRef] [Green Version]
- Yang, D. Mapping Regional Landscape by Using OpenstreetMap (OSM): A Case Study to Understand Forest Patterns in Maya Zone, Mexico; IGI Global: Hershey, PA, USA, 2019. [Google Scholar]
- Hong, Y.; Yao, Y. Hierarchical community detection and functional area identification with OSM roads and complex graph theory. Int. J. Geogr. Inf. Sci. 2019, 33, 1569–1587. [Google Scholar] [CrossRef]
- Xu, H.; Feng, D.; Wen, X. Urban Expansion and Heat Island Dynamics in the Quanzhou Region, China. IEEE J. Select. Top. Appl. Earth Obs. Remote Sens. 2009, 2, 74–79. [Google Scholar] [CrossRef]
- Wang, J. Application of the linear feature detection system—LINDA to image segmentation from remotely sensed data. Remote Sens. Rev. 2009, 13, 49–66. [Google Scholar] [CrossRef]
- Airey, T. The impact of road construction on the spatial characteristics of hospital utilization in the Meru district of Kenya. Soc. Sci. Med. 1992, 34, 1135–1146. [Google Scholar] [CrossRef]
- Ahmad, J.; Malik, A.S.; Xia, L. Effective techniques for vegetation monitoring of transmission lines right-of-ways. In Proceedings of the IEEE International Conference on Imaging Systems and Techniques, Penang, Malaysia, 17–18 May 2011. [Google Scholar]
- Kilic, A.; Allen, R.; Trezza, R.; Ratcliffe, I.; Kamble, B.; Robison, C.; Ozturk, D. Sensitivity of evapotranspiration retrievals from the METRIC processing algorithm to improved radiometric resolution of Landsat 8 thermal data and to calibration bias in Landsat 7 and 8 surface temperature. Remote Sens. Environ. 2016, 185, 198–209. [Google Scholar] [CrossRef] [Green Version]
- Essa, W.; Verbeiren, B.; van der Kwast, J.; Van de Voorde, T.; Batelaan, O. Evaluation of the DisTrad thermal sharpening methodology for urban areas. Int. J. Appl. Earth Obs. Geoinfor. 2012, 19, 163–172. [Google Scholar] [CrossRef]
- Yang, Y.; Wong, K.K.F. Spatial Distribution of Tourist Flows to China’s Cities. Tour. Geogr. 2013, 15, 338–363. [Google Scholar] [CrossRef]
- Hu, X.; Hong, W.; Qiu, R.; Hong, T.; Chen, C.; Wu, C. Geographic variations of ecosystem service intensity in Fuzhou City, China. Sci. Total Environ. 2015, 512, 215–226. [Google Scholar] [CrossRef] [PubMed]
- Łukaszyk, S. A new concept of probability metric and its applications in approximation of scattered data sets. Comput. Mech. 2004, 33, 299–304. [Google Scholar] [CrossRef]
- Tobler, W.R. A computer model simulation of urban growth in the Detroit region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Davis, J.C. Statistics and Data Analysis in Geology, 3rd ed.; John Wiley and Sons: Hoboken, NJ, USA, 1986. [Google Scholar]
- Wu, J.G. Effects of changing scale on landscape pattern analysis: Scaling relations. Landsc. Ecol. 2004, 19, 125–138. [Google Scholar] [CrossRef]
- Goodchild, M.F. The fundamental laws of GIScience. In Proceedings of the Paper presented at the Summer Assembly of the University Consortium for Geographic Information Science, Pacific Grove, CA, USA, 3 June 2003. [Google Scholar]
- He, Z.; Zhao, W.; Chang, X. The modifiable areal unit problem of spatial heterogeneity of plant community in the transitional zone between oasis and desert using semivariance analysis. Landsc. Ecol. 2007, 22, 95–104. [Google Scholar] [CrossRef]
- Hu, X.S.; Xu, H.Q. A new remote sensing index for assessing the spatial heterogeneity in urban ecological quality: A case from Fuzhou City, China. Ecol. Indic. 2018, 89, 11–21. [Google Scholar] [CrossRef]
- Hosking, P.L. Network Analysis in Geography. N. Z. Geogr. 2010, 28, 102–103. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Isotropic | Anisotropic | ||||
|---|---|---|---|---|---|
| Model | Gaussian | Exponential | |||
| 0 | 45 | 90 | 135 | ||
| C0 | 0.010 | 0.010 | |||
| C | 6.683 | 10.449 | |||
| C0+C | 6.693 | 10.549 | |||
| A0 | 12384 | 11440–18660 | |||
| C0/(C0+C) | 0.001 | 0.001 | |||
| Dimension (D) | 1.365 | 1.400 | 1.282 | 1.440 | 1.344 |
| R2 | 0.968 | 0.849 | 0.976 | 0.885 | 0.905 |
| Residual Sum of Squares (RSS) | 2.770 | - | |||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.; Hu, X.; Lin, M.; Qiu, R.; Lin, J.; Li, B. Spatial Paradigms in Road Networks and Their Delimitation of Urban Boundaries Based on KDE. ISPRS Int. J. Geo-Inf. 2020, 9, 204. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9040204
Lin Y, Hu X, Lin M, Qiu R, Lin J, Li B. Spatial Paradigms in Road Networks and Their Delimitation of Urban Boundaries Based on KDE. ISPRS International Journal of Geo-Information. 2020; 9(4):204. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9040204
Chicago/Turabian StyleLin, Yuying, Xisheng Hu, Mingshui Lin, Rongzu Qiu, Jinguo Lin, and Baoyin Li. 2020. "Spatial Paradigms in Road Networks and Their Delimitation of Urban Boundaries Based on KDE" ISPRS International Journal of Geo-Information 9, no. 4: 204. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9040204