High-Resolution Remote Sensing Image Integrity Authentication Method Considering Both Global and Local Features


Abstract
:1. Introduction
- The process of watermark embedding is a modification of the original data, which is not allowed in some fields, especially in the high-fidelity field.
- Watermark-based authentication is essentially a carrier-based authentication. If format conversion is applied to the data without modifying the content, the watermark information may also change greatly.
- Most of the existing HRRS perceptual hashing algorithms are based on one feature for authentication. Remote sensing images have the characteristics of data magnanimity, and generally there is no clear subject information, so the authentication results based on a single feature are not convincing.
- Existing algorithms are essentially a process of binary decision-making; that is, there are only two results: to pass the integrity authentication and to not pass the integrity authentication. A further interpretable information cannot be given by these algorithms.
2. Related Works
2.1. Perceptual Hashing
- One-way: hash sequence can be generated from the image, but the image information cannot be generated from hash sequence.
- Collision resistance: different images generate completely different hash sequence.
- Perceptual robustness: hash sequence does not change significantly after content retention operations.
- Tampering sensitivity: after content tampering operations, the value of the hash sequence can change greatly.
2.2. High-Resolution Remote Sensing Image
- Micro tamper identification capability: by setting the protection level, micro tamper higher than the protection level can be detected.
- Tampering localization capability: the remote sensing image size is usually large, and good algorithms should be able to provide specific tampering locations.
- The computation efficiency and authentication accuracy should be balanced.
- The method of grid division is introduced to extract the data features of HRRS images in a more detailed way comparing with existing image perceptual hashing algorithms, which satisfied the accuracy requirements of HRRS images.
- A comprehensive description of the image content is made by combining global features and local features, which satisfied the diversity and ambiguity characteristics of HRRS images. After all, a single feature can hardly reflect all the main information of an image.
- In consideration of the computational efficiency, the FAST algorithm is adopted to extract local features. Compared with the existing digital image perceptual hash algorithm, the computational efficiency is greatly improved.
2.3. Zernike Moments
2.4. FAST Key Point Detection
2.4.1. Analysis Window Creation
2.4.2. Subset Partitioning
2.4.3. Non-Maximal Suppression
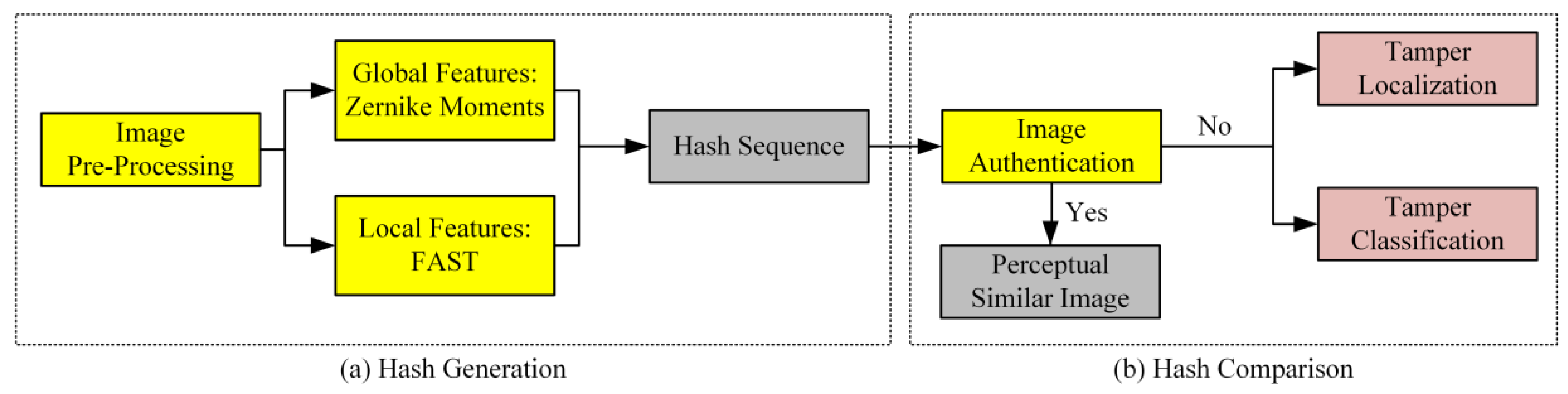
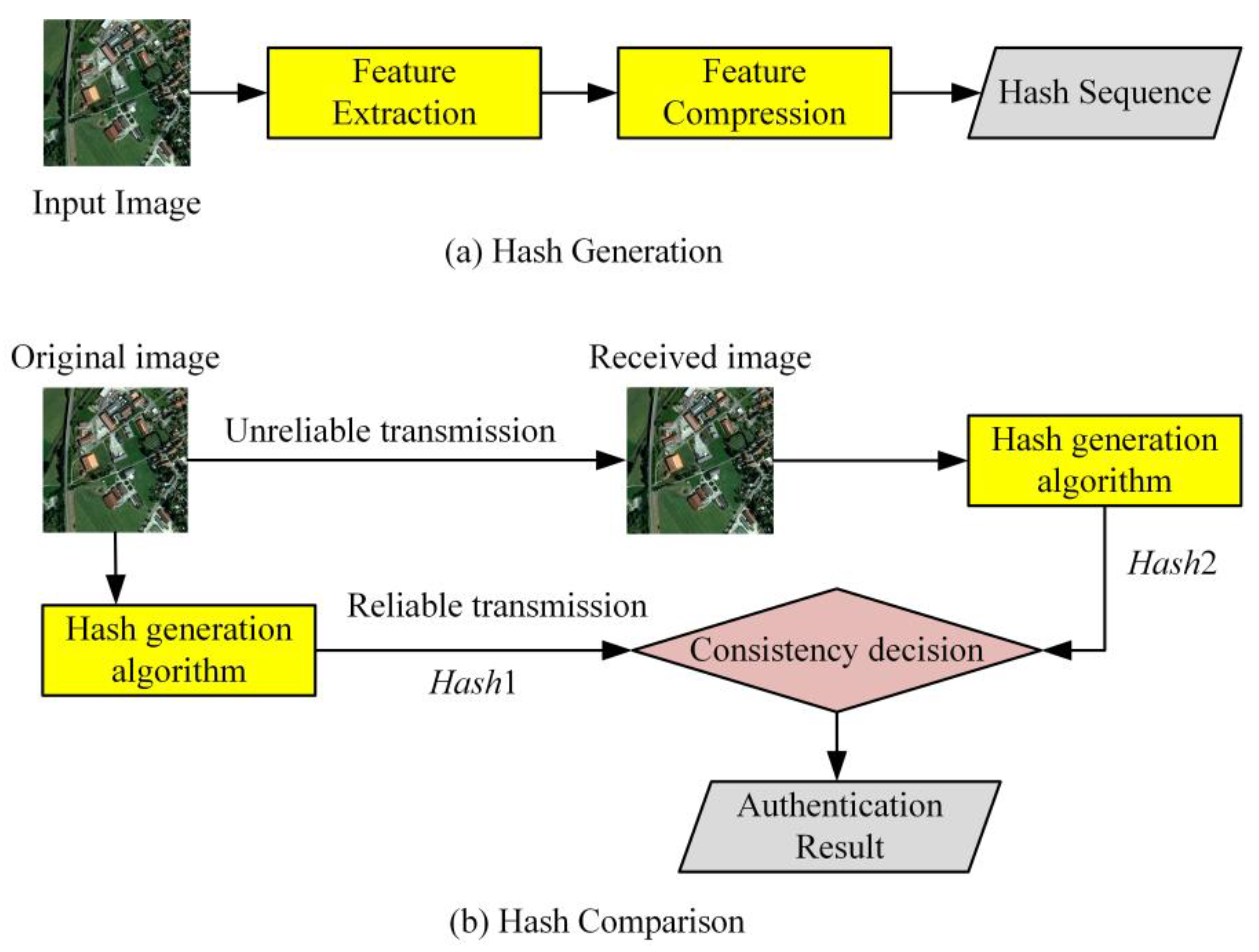
3. Perceptual Hashing Algorithm Combining Zernike Moments and FAST
3.1. HRRS Images Pre-Processing
3.2. HRRS Image Hash Generation
3.2.1. Global Features Extraction
3.2.2. Local Features Extraction
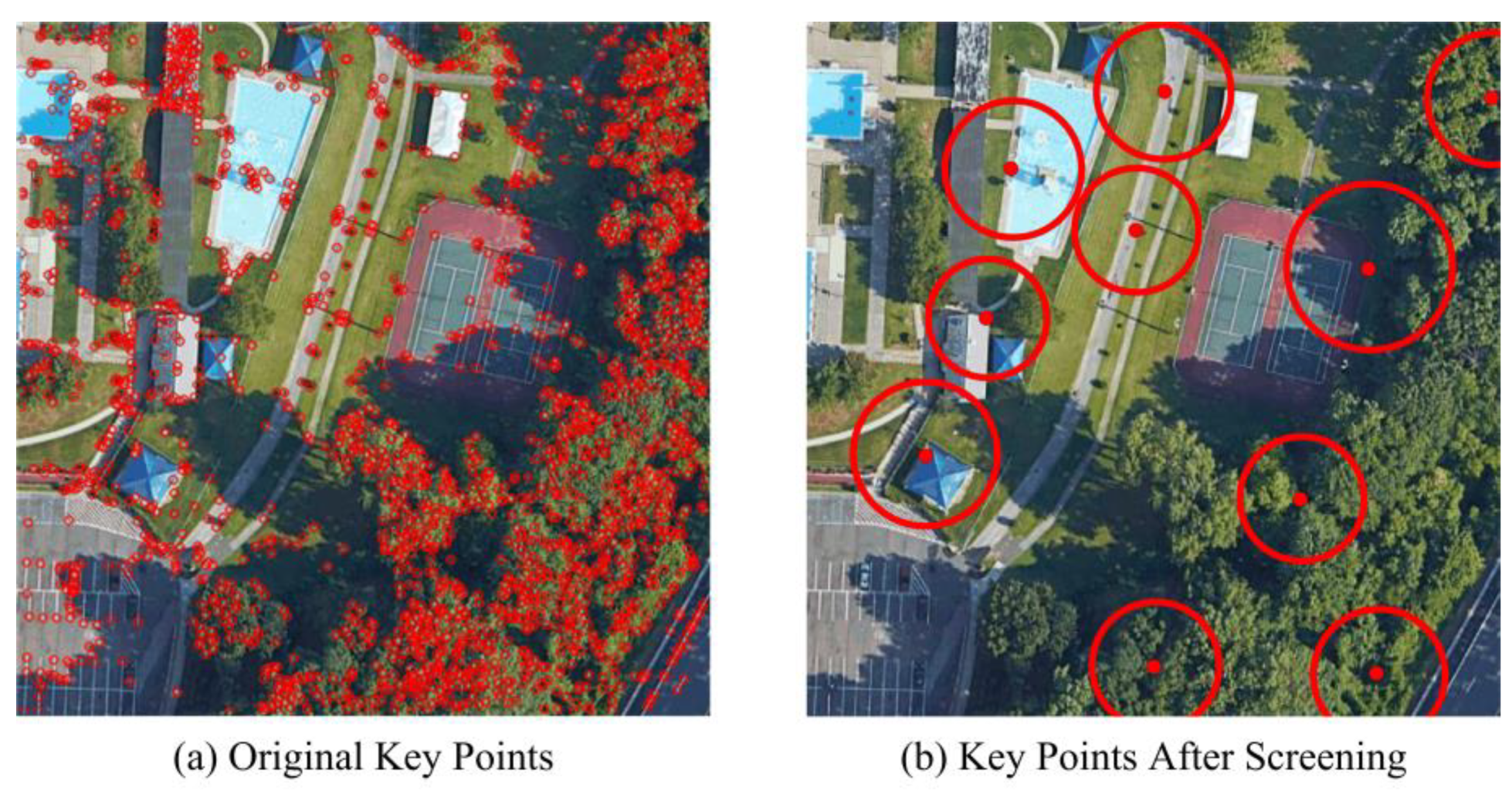
- Sort all the feature points from large to small according to the response , and define the sorted feature point set as . A new key point set is defined as , and an auxiliary circle set is defined.
- The screening algorithm is executed from . Let the current point be , draw a circle with the coordinates of as the center, and the response as the radius. If does not intersect any circle in , then is added to , and is added to .
- Step 2 is performed in sequence until there are 10 points in , and the screening is completed.
- For each point in , the average luminance feature is added to the key point description. The average luminance A is defined as the mean value of the pixel in the square with response as the side length and the key point coordinate as the center.
3.2.3. Hash Construction
3.3. Hash Comparison
3.3.1. Global Features Discrimination
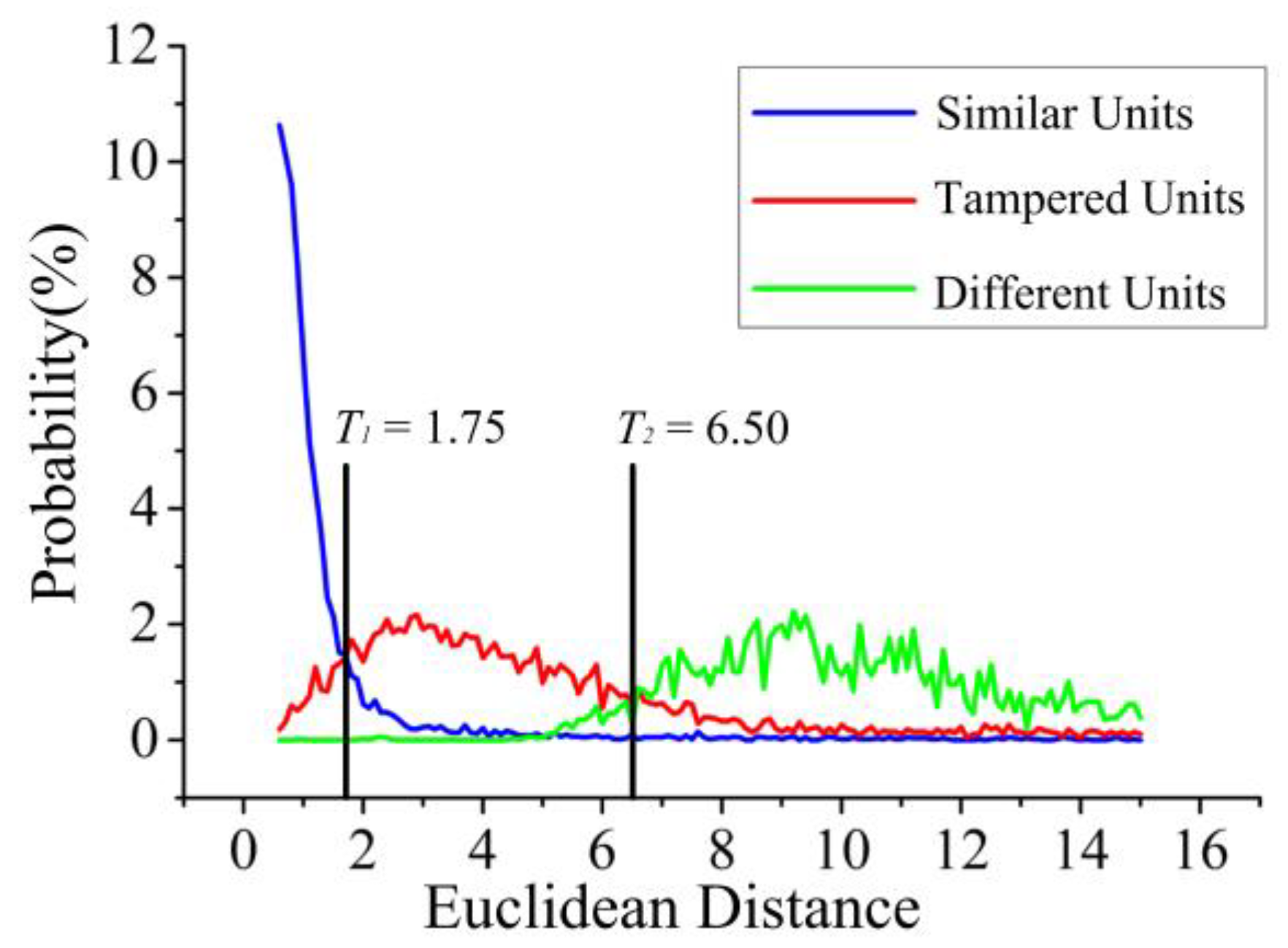
- : Group 1, consistent with original data perception and passed authentication;
- : Group 2, the grid unit has been tampered and does not pass the authentication, which needs to be tamper-localized;
- : Group 3, there are totally different content data in the grid unit, which cannot pass the authentication. The whole grid unit is marked as tampered.
3.3.2. Local Features Discrimination
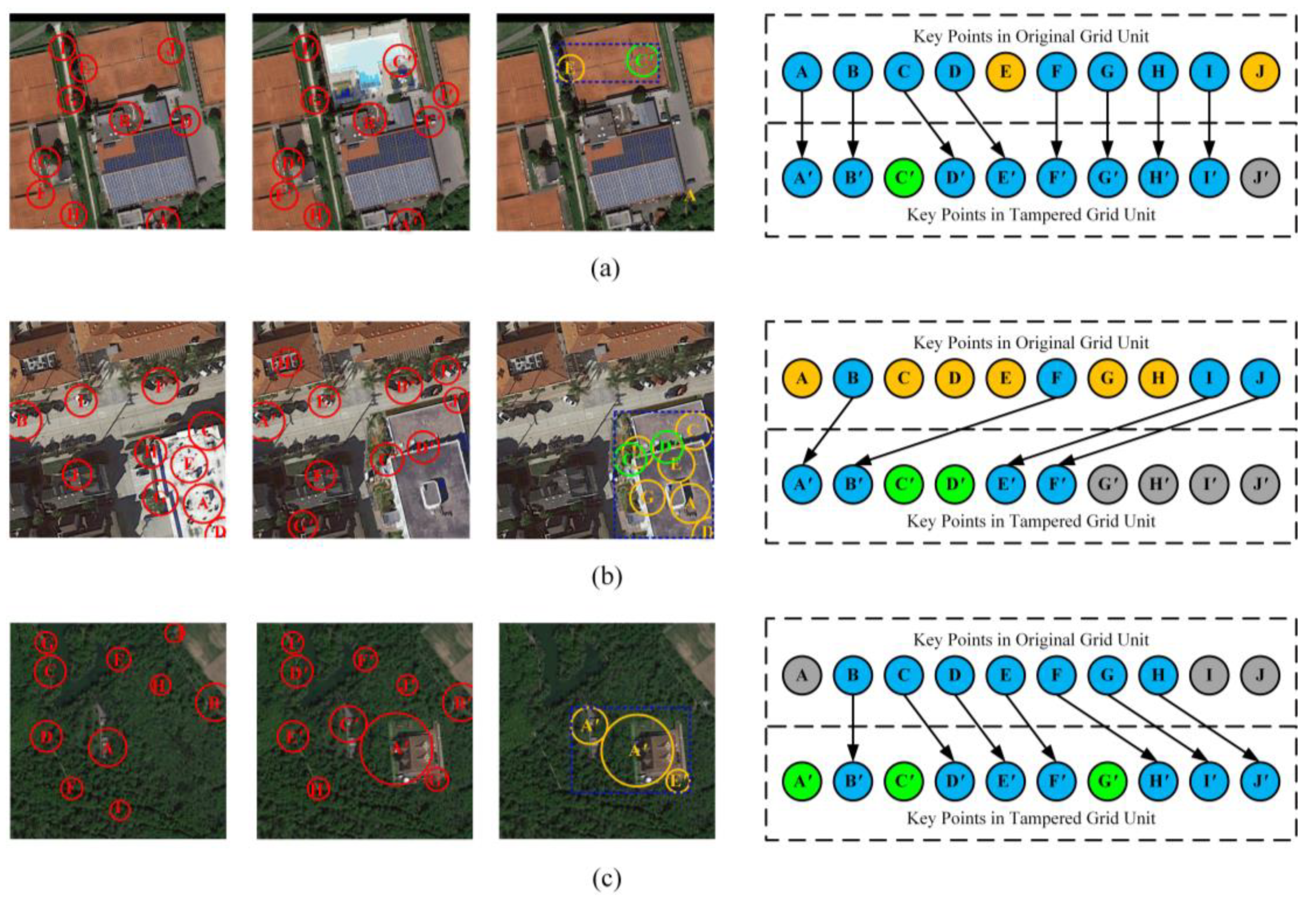
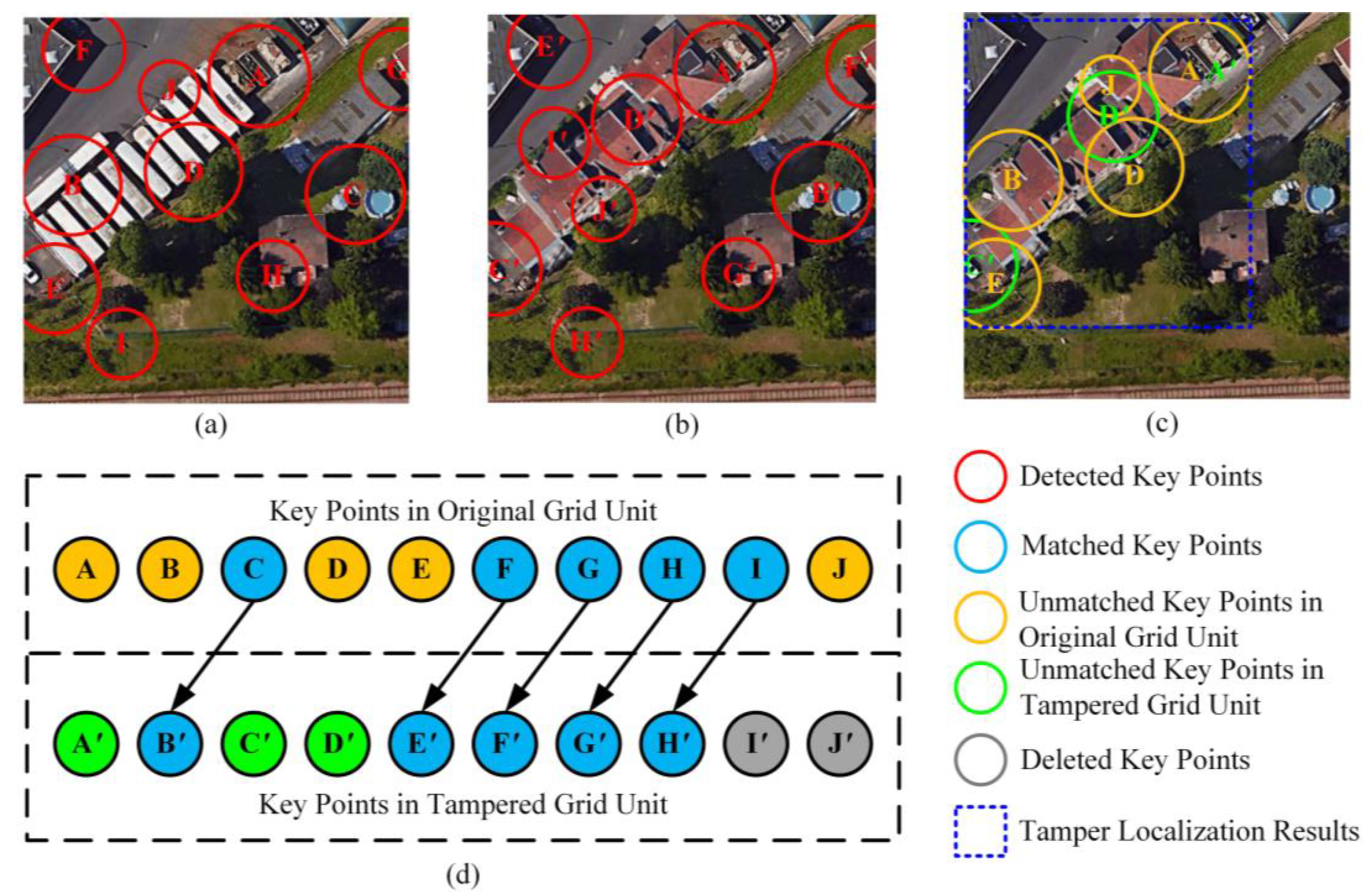
- Using the Fast Library for Approximate Nearest Neighbors (FLANN) method for the key points set of the original grid unit and the feature point set for the unit to be authenticated to making a match. FLANN is an efficient key point matching method, which needs to consider the matching threshold. We set the matching threshold to 0.8, which is the threshold recommended by Muja [46] in his paper. As shown in Figure 7d, the blue points are the five pairs of key points that were successfully matched.
- Delete the points whose average luminance has not changed significantly. For the unmatched key points in original grid units, if their average luminance does not change significantly compared with the tampered grid unit, they should be deleted. Otherwise, the key points should be retained. Since the average luminance of the key points in the original grid unit is known, the average luminance of the tampered grid unit can be calculated at the same position, so the average luminance change of these key points can be obtained. Which means, when:
- Delete the point. To enhance robustness, the average brightness threshold is set to . As shown in Figure 7c, the points “A”, “B”, “D”, “E”, and “J” are all retained because the average brightness around them has changed. Delete unmatched key points at the end of each sets. After matching, if there is still an unmatched key point at the end of and , remove it. However, if any of these points are determined to have changed in average luminance in the previous step, they will not be deleted. Since the number of a key points set is fixed at 10, a point at the end that is not matched does not mean that it has been tampered with, but that its corresponding matching point may be ranked after the 10th place of another set. For instance, “I′” and “J′” are deleted in this example. We can find that although they are not matched, their regions have not been tampered with.
- For the circle formed by all remaining feature points, the minimum external rectangle is constructed, which is the tamper region. As shown in Figure 7c, the remaining key points are “A”, “B”, “D”, “E”, “J”, “A′”, “C′”, and “D′”, and the blue rectangle is the tamper localization result.
- Three special cases are considered: If all the key points are not matched successfully it means that the grid unit is mistakenly divided into “Group 2”. Thus, this grid unit should be re-divided into “Group 3”, since all the key points have been tampered with. If all the key points are matched successfully, it means that the micro-tamper was not detected. In extreme cases, if the number of key points after screening is less than 10, the above method can still be used for key points matching and tamper localization—certainly with a lower accuracy.
4. Experiment and Analysis
4.1. Grid Unit Size Sensitivity Analysis
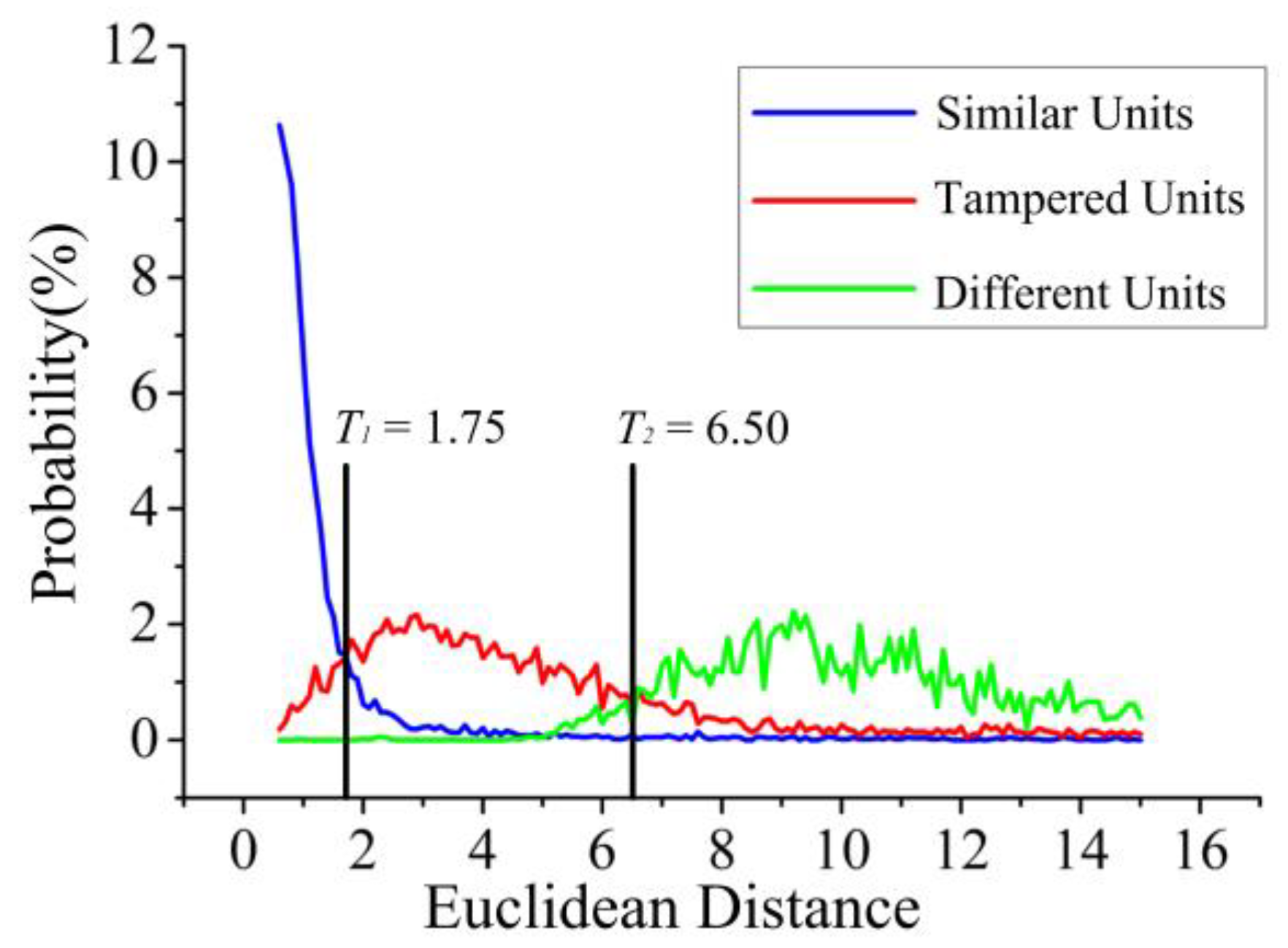
4.2. Global Features Threshold Analysis
4.3. Robustness Tests
4.4. Tamper Localization Tests
4.4.1. Tamper Localization Tests in Grid Units
4.4.2. Tamper Localization Tests in Whole Images
4.5. Algorithm Security Analysis
4.6. Comparison with Existing Algorithms
5. Conclusions
- By applying the idea of multi-feature combination to the authentication of HRRS images has enhanced reliability compared to existing HRRS image authentication algorithms.
- Compared with the existing digital image perceptual hashing algorithms, the introduction of the FAST algorithm greatly improves the extraction efficiency of key points. This would be more practical for HRRS images with a large image size.
- A series of databases were constructed to analyze the judgment threshold. Compared with the existing algorithms, the judgment is based on experimental threshold, which improves the interpretability and accuracy.
Author Contributions
Funding
Conflicts of Interest
Appendix A
- Hash1: (32, 5, 64, 0, 0, 2, 37, 0, 3, 1, 1, 0), (156, 38, 33, 105), (31, 111, 33, 144), (220, 117, 32, 80), (112.5, 102, 32, 101), (20.5, 179, 29, 89), (40, 21, 27, 62), (250, 34, 26, 90), (165, 171, 23, 54), (65, 216, 22, 78), (96, 48, 19, 126)
- Hash2: (32, 5, 63, 0, 2, 1, 34, 2, 3, 5, 2, 0), (156, 38, 33, 98), (220, 117, 32, 96), (4.5, 167, 30, 96), (98, 69, 29, 83), (40, 21, 27, 89), (250, 34, 26, 62), (165, 171, 23, 90), (43, 84, 22, 54), (65, 216, 22, 78), (76, 128)
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Threshold | Symbol | Value |
|---|---|---|
| Key points Extraction Threshold (Response of FAST Key points) | 10 | |
| Global Feature Threshold (Euclidean Distance of Zernike Moments) | , | 1.75, 6.50 |
| Key points Matching Threshold (FLANN Threshold) | 0.8 | |
| Key points Screening Threshold (Average Luminance) | 2 |
References
- Meng-Dawn, C.; Edwin, C. A study of extractive and remote-sensing sampling and measurement of emissions from military aircraft engines. Atmos. Environ. 2010, 44, 4867–4878. [Google Scholar]
- Sawaya, K.E.; Olmanson, L.G.; Heinert, N.J.; Brezonik, P.L.; Bauer, M.E. Extending satellite remote sensing to local scales: Land and water resource monitoring using high-resolution imagery. Remote Sens. Environ. 2003, 88, 144–156. [Google Scholar] [CrossRef]
- Yamazaki, F.; Matsuoka, M. Remote sensing technologies in post-disaster damage assessment. J. Earthq. Tsunami 2007, 1, 193–210. [Google Scholar] [CrossRef] [Green Version]
- Bio, A.; Gonçalves, J.A.; Magalhães, A.; Pinheiro, J.; Bastos, L. Combining Low-Cost Sonar and High-Precision Global Navigation Satellite System for Shallow Water Bathymetry. Estuaries Coasts 2020, 1–12. [Google Scholar] [CrossRef]
- Ding, K. Perceptual Hashing Based Authentication Algorithm Research for Remote Sensing Image. Ph.D. Thesis, Nanjing Normal University, Nanjing, China, 2013. [Google Scholar]
- Hambouz, A.; Shaheen, Y.; Manna, A.; Al-Fayoumi, M.; Tedmori, S. Achieving Data Integrity and Confidentiality Using Image Steganography and Hashing Techniques. In Proceedings of the 2nd International Conference on new Trends in Computing Sciences (ICTCS), Amman, Jordan, 9–11 October 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Iqbal, S. Digital Signature Based on Matrix Power Function. Ph.D. Thesis, Capital University, Columbus, OH, USA, 2019. [Google Scholar]
- Mohanarathinam, A.; Kamalraj, S.; Venkatesan, G.P.; Ravi, R.V.; Manikandababu, C.S. Digital watermarking techniques for image security: A review. J. Ambient Intell. Humaniz. Comput. 2019, 1–9. [Google Scholar] [CrossRef]
- Du, L.; Ho, A.T.; Cong, R. Perceptual hashing for image authentication: A survey. Signal Process. Image Commun. 2020, 81, 115713. [Google Scholar] [CrossRef]
- Long, S. A Comparative Analysis of the Application of Hashing Encryption Algorithms for MD5, SHA-1, and SHA-512. J. Phys. Conf. Ser. 2019, 1314. [Google Scholar] [CrossRef]
- Li, L.; Zhang, C.; Li, D. Remote sensing image anti-modification in land consolidation based on XOR LSB algorithm. Trans. Case 2008, 24, 97–101. [Google Scholar]
- Serra-Ruiz, J.; Megías, D. A novel semi-fragile forensic watermarking scheme for remote sensing images. Int. J. Remote Sens. 2011, 32, 5583–5606. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X. Research on Integrity Authentication Algorithm of Remote Sensing Image Based on Fragile Watermarking. Master’s Thesis, Nanjing Normal University, Nanjing, China, 2014. [Google Scholar]
- Qin, Q.; Wang, W.; Chen, S.; Chen, D.; Fu, W. Research of digital semi-fragile watermarking of remote sensing image based on wavelet analysis. In Proceedings of the 2004 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Anchorage, AK, USA, 20–24 September 2004; IEEE: New York, NY, USA, 2004; Volume 4, pp. 2542–2545. [Google Scholar]
- Serra-Ruiz, J.; Megías, D. DWT and TSVQ-based semi-fragile watermarking scheme for tampering detection in remote sensing images. In Proceedings of the 2010 Fourth Pacific-Rim Symposium on Image and Video Technology, Washington, DC, USA, 14–17 November 2010; IEEE: New York, NY, USA, 2010; pp. 331–336. [Google Scholar]
- Tong, D.; Ren, N.; Zhu, C. Secure and robust watermarking algorithm for remote sensing images based on compressive sensing. Multimed. Tools Appl. 2019, 78, 16053–16076. [Google Scholar] [CrossRef]
- Niu, X.M.; Jiao, Y.H. An overview of perceptual hashing. Acta Electron. Sin. 2008, 36, 1405–1411. [Google Scholar]
- Sarohi, H.K.; Khan, F.U. Image retrieval using perceptual hashing. IOSR-JCE 2013, 9. [Google Scholar] [CrossRef]
- Nagarajan, S.K.; Saravanan, S. Content-based medical image annotation and retrieval using perceptual hashing algorithm. IOSR J. Eng. 2012, 2, 814–818. [Google Scholar] [CrossRef]
- He, S.; Zhao, H. A retrieval algorithm of encrypted speech based on syllable-level perceptual hashing. Comput. Sci. Inf. Syst. 2017, 14, 703–718. [Google Scholar] [CrossRef]
- Zhang, Q.Y.; Xing, P.F.; Huang, Y.B.; Dong, R.H.; Yang, Z.P. An efficient speech perceptual hashing authentication algorithm based on wavelet packet decomposition. J. Inf. Hiding Multimed. Signal Proc. 2015, 6, 311–322. [Google Scholar]
- Wang, H.; Yin, B. Perceptual hashing-based robust image authentication scheme for wireless multimedia sensor networks. Int. J. Distrib. Sens. Netw. 2013, 9, 791814. [Google Scholar] [CrossRef]
- Renza, D.; Vargas, J.; Ballesteros, D.M. Robust Speech Hashing for Digital Audio Forensics. Appl. Sci. 2020, 10, 249. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, M.; Siddiqui, J.; Ali, M.A. A Review of Hashing based Image Copy Detection Techniques. Cybernet. Inf. Tech. 2019, 19, 3–27. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Huang, Z. Efficient Image Hashing with Geometric Invariant Vector Distance for Copy Detection. ACM Trans. Multim. Comput. 2019, 15, 1–22. [Google Scholar] [CrossRef]
- Liu, C.; Ma, J.; Tang, X.; Zhang, X.; Jiao, L. Adversarial Hash-Code Learning for Remote Sensing Image Retrieval. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Yokohama, Japan, 28 July–2 August 2019; IEEE: New York, NY, USA, 2019; pp. 4324–4327. [Google Scholar]
- Ding, K.; Zhu, Y.; Zhu, C. A Perceptual Hash Algorithm Based on Gabor Filter Bank and DWT for Remote Sensing Image Authenticaton. J. Chi. Rail Soci. 2016, 7, 70–76. [Google Scholar]
- Ding, K.; Meng, F.; Liu, Y.; Xu, N.; Chen, W. Perceptual Hashing Based Forensics Scheme for the Integrity Authentication of High-Resolution Remote Sensing Image. Information 2019, 9, 229. [Google Scholar] [CrossRef] [Green Version]
- Ding, K.; Yang, Z.; Wang, Y.; Liu, Y. An improved perceptual hash algorithm based on u-net for the authentication of high-resolution remote sensing image. Appl. Sci. 2019, 9, 2972. [Google Scholar] [CrossRef] [Green Version]
- Haitsma, J.; Kalker, T.; Oostveen, J. Robust audio hashing for content identification. In International Workshop on Content-Based Multimedia Indexing; University of Brescia: Brescia, Italy, 2001; Volume 4, pp. 117–124. [Google Scholar]
- Ouyang, J.; Liu, Y.; Shu, H. Robust hashing for image authentication using SIFT feature and quaternion Zernike moments. Multimed. Tools Appl. 2017, 76, 2609–2626. [Google Scholar] [CrossRef]
- Yang, G.; Chen, N.; Jiang, Q. A robust hashing algorithm based on SURF for video copy detection. Comput. Secur. 2012, 31, 33–39. [Google Scholar] [CrossRef]
- Sengar, S.S.; Mukhopadhyay, S. Moving object tracking using Laplacian-DCT based perceptual hash. In Proceedings of the 2016 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 23–25 March 2016; IEEE: New York, NY, USA, 2019; pp. 2345–2349. [Google Scholar]
- Li, Y.J.; Li, J.B. DCT and perceptual hashing based to identify texture anti-counterfeiting tag. Appl. Res. Comput. 2014, 31, 3734–3737. [Google Scholar]
- Hu, M.K. Visual pattern recognition by moment invariants. IEEE Trans. Inf. Theory 1962, 8, 179–187. [Google Scholar]
- Govindaraj, P.; Sandeep, R. Ring partition and dwt based perceptual image hashing with application to indexing and retrieval of near-identical images. In Proceedings of the 2015 Fifth International Conference on Advances in Computing and Communications (ICACC), Manipal, Karnataka, India, 2–4 September 2015; IEEE: New York, NY, USA, 2019; pp. 421–425. [Google Scholar]
- Zhao, Y.; Wang, S.; Feng, G.; Tang, Z. A robust image hashing method based on Zernike moments. J. Comput. Inf. Syst. 2010, 6, 717–725. [Google Scholar]
- Khotanzad, A.; Hong, Y.H. Invariant image recognition by Zernike moments. IEEE Trans Pattern Anal. 1990, 12, 489–497. [Google Scholar] [CrossRef] [Green Version]
- Harris, C.G.; Stephens, M. A combined corner and edge detector. In Proceedings of the 4th Alvey Vision Conference; Alvey: Manchester, UK, 1988; Volume 15, pp. 10–5244. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rosten, E.; Tom, D. Machine learning for high-speed corner detection. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 430–443. [Google Scholar]
- Bresenham, J. A linear algorithm for incremental digital display of circular arcs. Commun. ACM 1977, 20, 100–106. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, S.; Zhang, X.; Yao, H. Robust hashing for image authentication using Zernike moments and local features. IEEE Trans. Inf. Forensics Secur. 2012, 8, 55–63. [Google Scholar] [CrossRef]
- Maxwell, A.E. The logistic transformation in the analysis of paired-comparison data. Brit. J. Math. Stat. Psychol. 1974, 27, 62–71. [Google Scholar] [CrossRef]
- Muja, M.; Lowe, D.G. Fast approximate nearest neighbors with automatic algorithm configuration. VISAPP 2009, 2, 331–340. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]







| Order | Zernike Moments | Number of the Moments |
|---|---|---|
| 0 | Z0,0 | 1 |
| 1 | Z1,1, | 1 |
| 2 | Z2,0, Z2,2 | 2 |
| 3 | Z3,1, Z3,3 | 2 |
| 4 | Z4,0, Z4,2, Z4,4 | 3 |
| 5 | Z5,1, Z5,3, Z5,5 | 3 |
| Grid Size (pixel) | Calculation Time (s) | Euclidean Distance of Different Grid Units | Euclidean Distance of Similar Grid Units |
|---|---|---|---|
| 512 | 3.51 | 3.35 | 0.02 |
| 256 | 5.03 | 8.62 | 0.02 |
| 128 | 10.07 | 8.73 | 0.01 |
| Content Retention Operation. | Accuracy (%) |
|---|---|
| LSB Watermark Embedding | 99.99 |
| Format Conversion to BMP | 100.00 |
| Format Conversion to PNG | 100.00 |
| JPEG Compression () | 99.96 |
| JPEG Compression () | 99.93 |
| Gaussian Filtering () | 100.00 |
| Gaussian Filtering () | 83.81 |
| Predicted Value. | Real Value | ||
|---|---|---|---|
| Similar Unit | Tampered Unit | Different Unit | |
| Similar Unit | 43,463 | 356 | 49 |
| Tampered Unit | 732 | 4382 | 1149 |
| Different Unit | 164 | 1599 | 5139 |
| Evaluation Index | Dataset | ||
|---|---|---|---|
| Similar Dataset | Tampered Dataset | Different Dataset | |
| TPR | 97.98% (TPRS) | 69.15% (TPRT) | 81.09% (TPRD) |
| FPR | 3.19% (FPRS) | 3.37% (FPRT) | 3.47% (FPRD) |
| Image Size. | Division Granularity | Original Data | Tampered Data | Tamper Localization |
|---|---|---|---|---|
| 4020 × 2444 | 16 × 10 |  |  |  |
| 3004 × 2987 | 12 × 12 |  |  |  |
| 1703 × 1880 | 7 × 8 |  |  |  |
| 1954 × 1818 | 8 × 8 |  |  |  |
| 1945 × 1948 | 8 × 8 |  |  |  |
| 2098 × 1642 | 9 × 7 |  |  |  |
| Algorithm | DCT Based [33,34] | DWT Based [35,36] | Zernike Moments Based [37] | SIFT Based [31] | Canny Based [28] | U-Net Based [29] | Proposed Method |
|---|---|---|---|---|---|---|---|
| Feature Used | Global | Global | Global | Local | Local | Local | Global and Local |
| Time Cost of Feature Extraction | 0.016 | 0.484 | 0.336 | 2.281 | 0.482 | / | 0.347 |
| Robust Against Content Retention Options | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Tamper Identification | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Tamper Localization | No | No | No | Yes | Yes | Yes | Yes |
| Tamper Localization Granularity | / | / | / | Rectangle | Grid | Grid | Sub-Grid |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Yan, H.; Zhang, L.; Wang, H. High-Resolution Remote Sensing Image Integrity Authentication Method Considering Both Global and Local Features. ISPRS Int. J. Geo-Inf. 2020, 9, 254. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9040254
Zhang X, Yan H, Zhang L, Wang H. High-Resolution Remote Sensing Image Integrity Authentication Method Considering Both Global and Local Features. ISPRS International Journal of Geo-Information. 2020; 9(4):254. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9040254
Chicago/Turabian StyleZhang, Xingang, Haowen Yan, Liming Zhang, and Hao Wang. 2020. "High-Resolution Remote Sensing Image Integrity Authentication Method Considering Both Global and Local Features" ISPRS International Journal of Geo-Information 9, no. 4: 254. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9040254