Comparing Machine Learning Models and Hybrid Geostatistical Methods Using Environmental and Soil Covariates for Soil pH Prediction

 ,
,  ,
, 
_Doukas.jpg)
Abstract
:1. Introduction
2. Materials and Methods
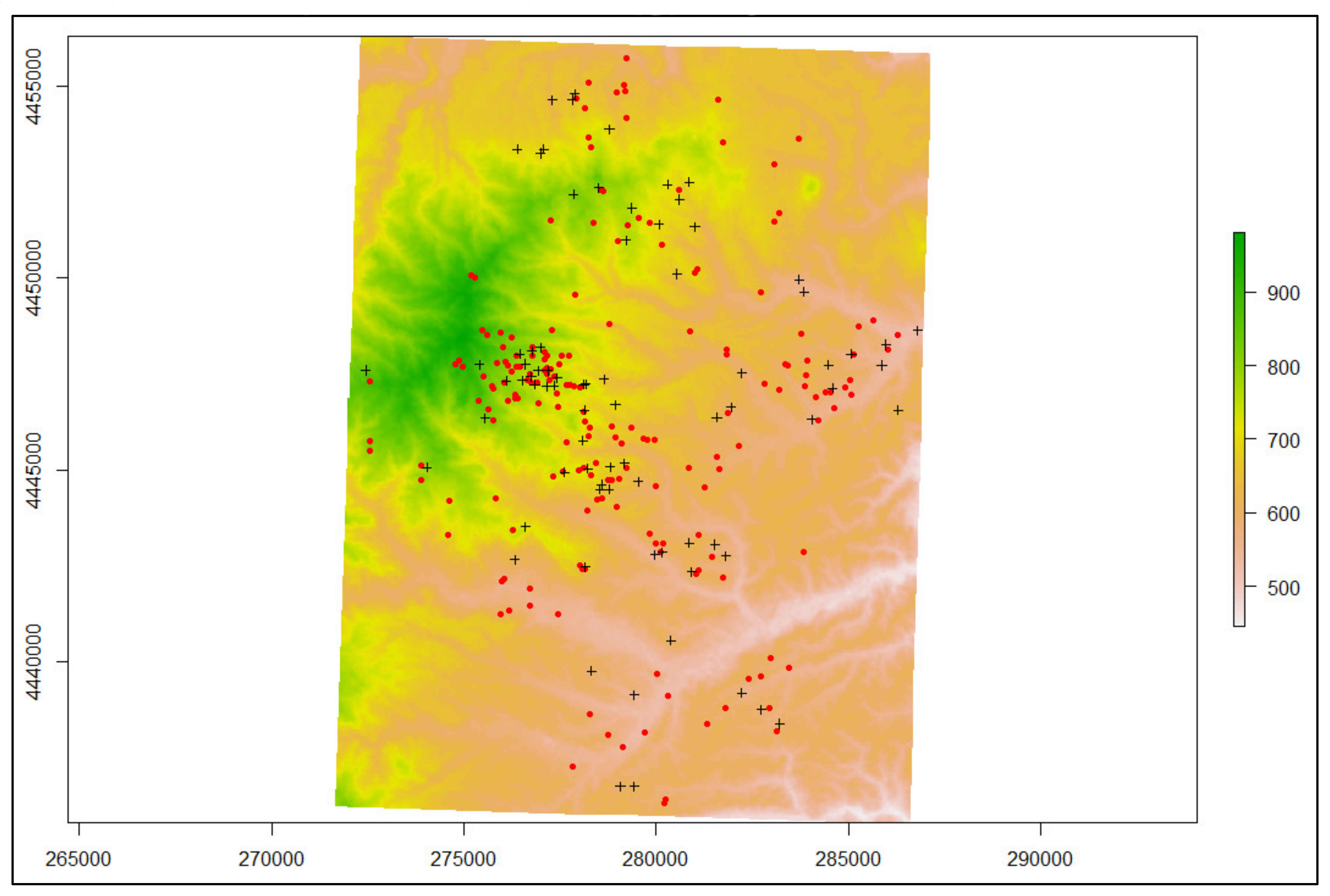
2.1. Soil Data and Environmental Covariates Collection
2.2. Software
2.3. Regression Kriging
2.4. Random Forests Kriging
2.5. Gradient Boosting Kriging
- A regularization technique that helps reducing overfitting;
- Support for user-defined objective functions and evaluation metrics;
- Improved efficient tree pruning mechanism;
- Multiple technical improvements like parallel processing, “built-in cross-validation”, and better handling of missing values.
2.6. Neural Networks Kriging
2.7. Optimization of the Hyperparameters
- Default values based on the literature, library authors’ recommendations, previous experience, etc.;
- Optimizations techniques, through a process called tuning.
2.8. Error Assessment
3. Results
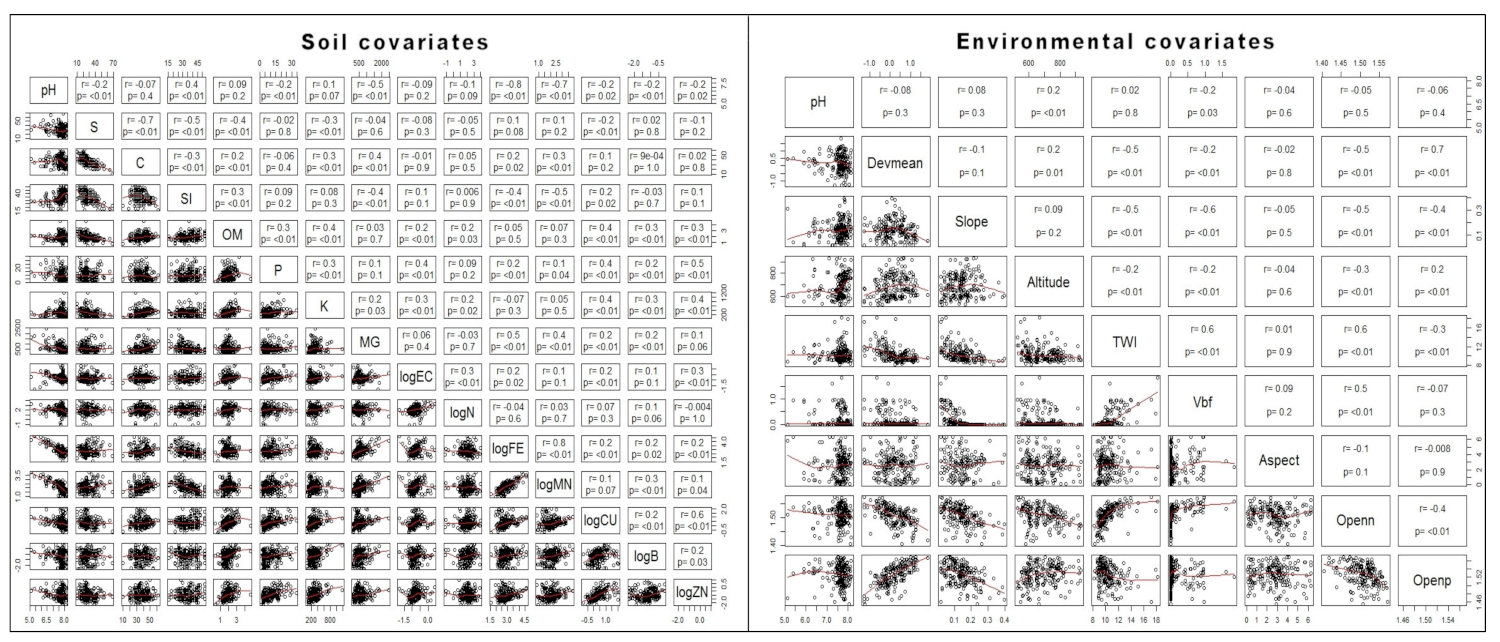
3.1. Exploratory Data Analysis
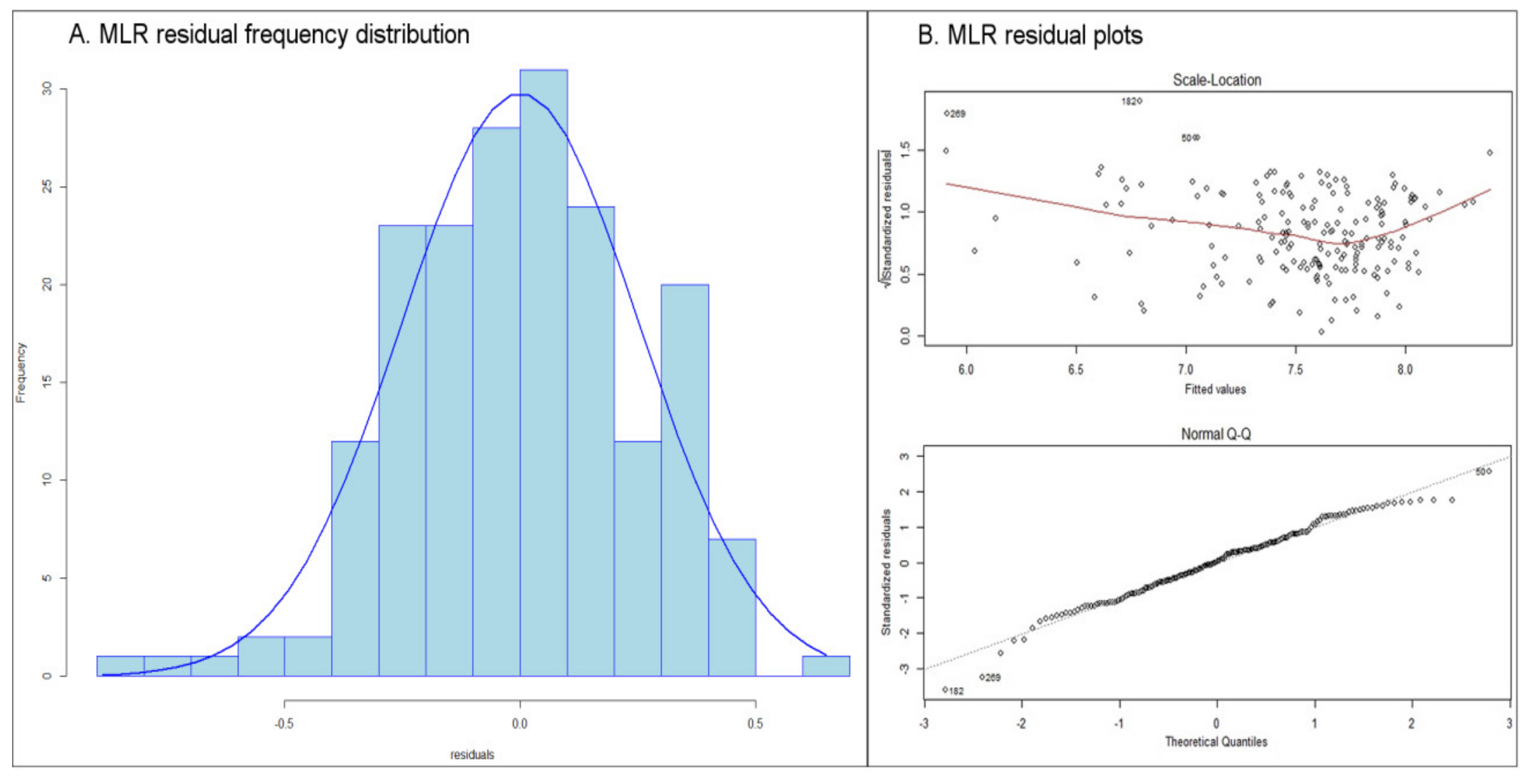
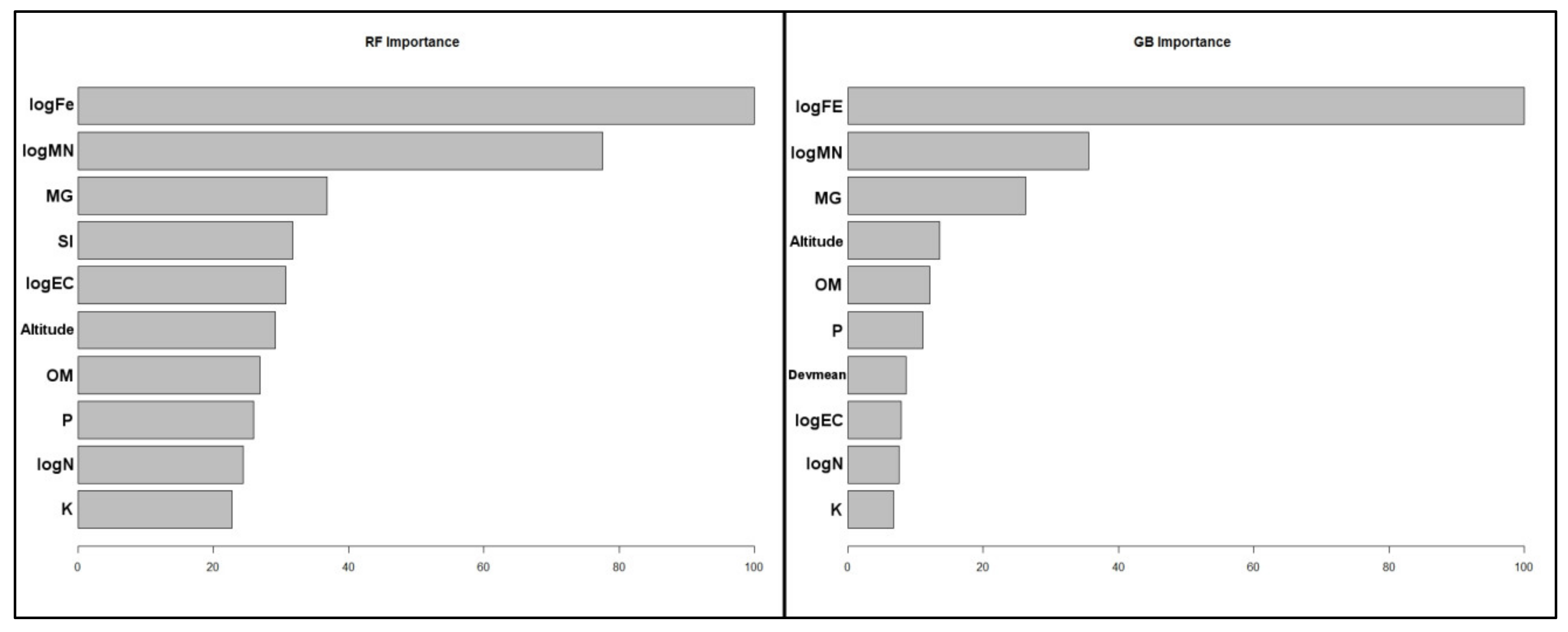
3.2. Modelling and Parameter Estimation
3.3. Performance Assessment
4. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Appelhans, T.; Mwangomo, E.; Hardy, D.R.; Hemp, A.; Nauss, T. Evaluating machine learning approaches for the interpolation of monthly air temperature at Mt. Kilimanjaro, Tanzania. Spat. Stat. 2015, 14, 91–113. [Google Scholar] [CrossRef] [Green Version]
- Baxter, S.; Oliver, M. The spatial prediction of soil mineral N and potentially available N using elevation. Geoderma 2005, 128, 325–339. [Google Scholar] [CrossRef]
- Florinsky, I.V.; Eilers, R.G.; Manning, G.; Fuller, L. Prediction of soil properties by digital terrain modelling. Environ. Model. Softw. 2002, 17, 295–311. [Google Scholar] [CrossRef]
- Rahmati, O.; Pourghasemi, H.R.; Melesse, A.M. Application of GIS-based data driven random forest and maximum entropy models for groundwater potential mapping: A case study at Mehran Region, Iran. Catena 2016, 137, 360–372. [Google Scholar] [CrossRef]
- Bishop, T.; McBratney, A. A comparison of prediction methods for the creation of field-extent soil property maps. Geoderma 2001, 103, 149–160. [Google Scholar] [CrossRef]
- Hengl, T. A Practical Guide to Geostatistical Mapping of Environmental Variables; Office for Official Publications of the European Communities: Luxembourg, 2007. [Google Scholar]
- McBratney, A.B.; Odeh, I.O.; Bishop, T.F.; Dunbar, M.S.; Shatar, T.M. An overview of pedometric techniques for use in soil survey. Geoderma 2000, 97, 293–327. [Google Scholar] [CrossRef]
- Hengl, T.; de Jesus, J.M.; Heuvelink, G.B.; Gonzalez, M.R.; Kilibarda, M.; Blagotić, A.; Shangguan, W.; Wright, M.N.; Geng, X.; Bauer-Marschallinger, B. SoilGrids250m: Global gridded soil information based on machine learning. PLoS ONE 2017, 12, e0169748. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Keskin, H.; Grunwald, S. Regression kriging as a workhorse in the digital soil mapper’s toolbox. Geoderma 2018, 326, 22–41. [Google Scholar] [CrossRef]
- Mirzaee, S.; Ghorbani-Dashtaki, S.; Mohammadi, J.; Asadi, H.; Asadzadeh, F. Spatial variability of soil organic matter using remote sensing data. Catena 2016, 145, 118–127. [Google Scholar] [CrossRef]
- Song, Y.-Q.; Yang, L.-A.; Li, B.; Hu, Y.-M.; Wang, A.-L.; Zhou, W.; Cui, X.-S.; Liu, Y.-L. Spatial Prediction of Soil Organic Matter Using a Hybrid Geostatistical Model of an Extreme Learning Machine and Ordinary Kriging. Sustainability 2017, 9, 754. [Google Scholar] [CrossRef] [Green Version]
- Tziachris, P.; Aschonitis, V.; Chatzistathis, T.; Papadopoulou, M. Assessment of spatial hybrid methods for predicting soil organic matter using DEM derivatives and soil parameters. Catena 2019, 174, 206–216. [Google Scholar] [CrossRef]
- Hengl, T.; Nussbaum, M.; Wright, M.N.; Heuvelink, G.B.M.; Gräler, B. Random forest as a generic framework for predictive modeling of spatial and spatio-temporal variables. PeerJ 2018, 6, e5518. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brillante, L.; Gaiotti, F.; Lovat, L.; Vincenzi, S.; Giacosa, S.; Torchio, F.; Segade, S.R.; Rolle, L.; Tomasi, D. Investigating the use of gradient boosting machine, random forest and their ensemble to predict skin flavonoid content from berry physical–mechanical characteristics in wine grapes. Comput. Electron. Agric. 2015, 117, 186–193. [Google Scholar] [CrossRef]
- Ransom, C.J.; Kitchen, N.R.; Camberato, J.J.; Carter, P.R.; Ferguson, R.B.; Fernández, F.G.; Franzen, D.W.; Laboski, C.A.M.; Myers, D.B.; Nafziger, E.D.; et al. Statistical and machine learning methods evaluated for incorporating soil and weather into corn nitrogen recommendations. Comput. Electron. Agric. 2019, 164, 104872. [Google Scholar] [CrossRef] [Green Version]
- Shirzadi, A.; Shahabi, H.; Chapi, K.; Bui, D.T.; Pham, B.T.; Shahedi, K.; Ahmad, B.B. A comparative study between popular statistical and machine learning methods for simulating volume of landslides. Catena 2017, 157, 213–226. [Google Scholar] [CrossRef]
- Sirsat, M.S.; Cernadas, E.; Fernández-Delgado, M.; Barro, S. Automatic prediction of village-wise soil fertility for several nutrients in India using a wide range of regression methods. Comput. Electron. Agric. 2018, 154, 120–133. [Google Scholar] [CrossRef]
- Kabata-Pendias, A. Trace Elements in Soils and Plants, 4th ed.; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Zhang, Y.; Biswas, A.; Adamchuk, V.I. Implementation of a sigmoid depth function to describe change of soil pH with depth. Geoderma 2017, 289, 1–10. [Google Scholar] [CrossRef]
- Sillanpää, M. Micronutrients and the Nutrient Status of Soils: A Global Study; Food & Agriculture Organization of the United Nations: Jokioinen, Finland, 1982. [Google Scholar]
- Gentili, R.; Ambrosini, R.; Montagnani, C.; Caronni, S.; Citterio, S. Effect of soil pH on the growth, reproductive investment and pollen allergenicity of Ambrosia artemisiifolia L. Front. Plant Sci. 2018, 9, 1335. [Google Scholar] [CrossRef] [Green Version]
- Hong, S.; Gan, P.; Chen, A. Environmental controls on soil pH in planted forest and its response to nitrogen deposition. Environ. Res. 2019, 172, 159–165. [Google Scholar] [CrossRef]
- He, X.; Hou, E.; Liu, Y.; Wen, D. Altitudinal patterns and controls of plant and soil nutrient concentrations and stoichiometry in subtropical China. Sci. Rep. 2016, 6, 24261. [Google Scholar] [CrossRef] [Green Version]
- Tziachris, P.; Metaxa, E.; Papadopoulos, F.; Papadopoulou, M. Spatial Modelling and Prediction Assessment of Soil Iron Using Kriging Interpolation with pH as Auxiliary Information. ISPRS Int. J. Geo-Inf. 2017, 6, 283. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, M. The Caret Package. Available online: http://topepo.github.io/caret/index.html (accessed on 20 January 2020).
- Hengl, T.; Heuvelink, G.B.; Rossiter, D.G. About regression-kriging: From equations to case studies. Comput. Geosci. 2007, 33, 1301–1315. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cambardella, C.; Moorman, T.; Parkin, T.; Karlen, D.; Novak, J.; Turco, R.; Konopka, A. Field-scale variability of soil properties in central Iowa soils. Soil Sci. Soc. Am. J. 1994, 58, 1501–1511. [Google Scholar] [CrossRef]
- Chirici, G.; Scotti, R.; Montaghi, A.; Barbati, A.; Cartisano, R.; Lopez, G.; Marchetti, M.; McRoberts, R.E.; Olsson, H.; Corona, P. Stochastic gradient boosting classification trees for forest fuel types mapping through airborne laser scanning and IRS LISS-III imagery. Int. J. Appl. Earth Obs. Geoinf. 2013, 25, 87–97. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar]
- Wright, M.N.; Ziegler, A. ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J. Stat. Softw. 2017, 77, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Cutler, A.; Liaw, A.; Wiener, M. Breiman and Cutler’s Random Forests for Classification and Regression. Available online: https://cran.r-project.org/web/packages/randomForest/randomForest.pdf (accessed on 20 January 2020).
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Heung, B.; Ho, H.C.; Zhang, J.; Knudby, A.; Bulmer, C.E.; Schmidt, M.G. An overview and comparison of machine-learning techniques for classification purposes in digital soil mapping. Geoderma 2016, 265, 62–77. [Google Scholar] [CrossRef]
- Ripley, B.D.; Hjort, N. Pattern Recognition and Neural Networks; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S-PLUS.; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Alwosheel, A.; van Cranenburgh, S.; Chorus, C.G. Is your dataset big enough? Sample size requirements when using artificial neural networks for discrete choice analysis. J. Choice Model. 2018, 28, 167–182. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Mather, P.M. The use of backpropagating artificial neural networks in land cover classification. Int. J. Remote Sens. 2003, 24, 4907–4938. [Google Scholar] [CrossRef]
- Hengl, T.; Leenaars, J.G.; Shepherd, K.D.; Walsh, M.G.; Heuvelink, G.B.; Mamo, T.; Tilahun, H.; Berkhout, E.; Cooper, M.; Fegraus, E. Soil nutrient maps of Sub-Saharan Africa: Assessment of soil nutrient content at 250 m spatial resolution using machine learning. Nutr. Cycl. Agroecosystems 2017, 109, 77–102. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Covariate | Category | Unit | Method (for Soil Covariates) | |
|---|---|---|---|---|
| 1 | Clay (C) | soil | % | Particle size analysis with hydrometer (or Bouyoucos) |
| 2 | Silt (Si) | soil | % | Same as for clay |
| 3 | Sand (S) | soil | % | Same as for clay |
| 4 | Electric conductivity (EC) | soil | mS/cm | In soil saturation extract |
| 5 | Organic matter (OM) | soil | % | Wet digestion |
| 6 | Nitrogen (N) | soil | ppm | With 2M KCl |
| 7 | Phosphorus (P) | soil | ppm | Olsen |
| 8 | Potassium (K) | soil | ppm | With ammonium acetate at pH = 7.0 |
| 9 | Magnesium (Mg) | soil | ppm | With ammonium acetate at pH = 7.0 |
| 10 | Iron (Fe) | soil | ppm | DTPA |
| 11 | Zinc (Zn) | soil | ppm | DTPA |
| 12 | Manganese (Mn) | soil | ppm | DTPA |
| 13 | Copper (Cu) | soil | ppm | DTPA |
| 14 | Boron (B) | soil | ppm | Azomethine-H |
| 15 | Elevation (altitude) | env/tal | m | - |
| 16 | Slope | env/tal | radians | - |
| 17 | Aspect | env/tal | radians | - |
| 18 | SAGA wetness index (TWI) | env/tal | - | |
| 19 | Negative topographic openness (openn) | env/tal | radians | - |
| 20 | Positive topographic openness (openp) | env/tal | radians | - |
| 21 | Deviation from mean value (devmean) | env/tal | - | |
| 22 | Multiresolution index of valley bottom flatness (vbf) | env/tal | - |
| Hyperparameter | Packages | Description |
|---|---|---|
| mtry | ranger, randomForest | The number of random features used in each tree. |
| ntree | ranger, randomForest | The number of grown trees. |
| Hyperparameter | Methods | Description |
|---|---|---|
| nrounds | xgbDART, xgbTree | Boosting iterations |
| max_depth | xgbDART, xgbTree | Max tree depth |
| eta | xgbDART, xgbTree | Shrinkage |
| gamma | xgbDART, xgbTree | Minimum loss reduction |
| subsample | xgbDART, xgbTree | Subsample percentage |
| colsample_bytree | xgbDART, xgbTree | Subsample ratio of columns |
| rate_drop | xgbDART | Fraction of trees dropped |
| skip_drop | xgbDART | Probability of skipping drop-out |
| min_child_weight | xgbDART, xgbTree | Minimum sum of instance weight |
| Hyperparameter | Methods | Description |
|---|---|---|
| size | avNNet, nnet | The number of units in the hidden layer. |
| decay | avNNet, nnet | The parameter for weight decay. |
| bag | avNNet | A logical value for bagging for each repeat. |
| linout | avNNet, nnet | A switch for linear output units. |
| trace | avNNet, nnet | A switch for tracing optimization. |
| maxit | avNNet, nnet | The maximum number of iterations. |
| Metric | Equation |
|---|---|
| Mean absolute error (MAE) | |
| Root-mean-square error (RMSE) | |
| Coefficient of determination (R2) |
| Variables | Mean | SD | Median | Min | Max | Range | Skew | Kurtosis |
|---|---|---|---|---|---|---|---|---|
| ■S | 28.62 | 10.14 | 26 | 10 | 68 | 58 | 0.93 | 1.23 |
| C** | 37.26 | 9.29 | 38 | 10 | 62 | 52 | 0.03 | −0.39 |
| SI | 34.12 | 7.86 | 32 | 16 | 60 | 44 | 0.33 | −0.22 |
| pH | 7.52 | 0.51 | 7.66 | 5.12 | 8.13 | 3.01 | −2.03 | 4.38 |
| OM** | 1.93 | 0.56 | 1.86 | 0.37 | 4.68 | 4.31 | 0.86 | 1.94 |
| P** | 9.84 | 6.47 | 8.09 | 1.21 | 34.41 | 33.2 | 1.31 | 1.6 |
| K** | 310.03 | 158.71 | 284 | 73 | 1190 | 1117 | 1.89 | 5.8 |
| MG** | 606.95 | 356.25 | 523 | 124 | 2438 | 2314 | 1.65 | 3.66 |
| Devmean* | 0.2 | 0.61 | 0.17 | −1.29 | 1.84 | 3.13 | −0.1 | −0.43 |
| Slope | 0.14 | 0.07 | 0.14 | 0.02 | 0.4 | 0.38 | 0.67 | 0.47 |
| Altitude | 685.15 | 92.28 | 670 | 527 | 935 | 408 | 0.44 | −0.54 |
| TWI | 10.34 | 1.54 | 9.92 | 8.18 | 18.19 | 10.02 | 2.06 | 6.02 |
| Vbf | 0.17 | 0.31 | 0.01 | 0 | 1.85 | 1.85 | 2.2 | 5.05 |
| Aspect | 2.75 | 1.59 | 2.74 | 0.08 | 6.28 | 6.2 | 0.31 | −0.49 |
| Openn | 1.51 | 0.03 | 1.51 | 1.4 | 1.57 | 0.17 | −0.62 | 0.3 |
| Openp | 1.53 | 0.03 | 1.53 | 1.44 | 1.57 | 0.13 | −0.65 | 0.22 |
| logEC* | −0.83 | 0.29 | −0.87 | −1.81 | 0.38 | 2.19 | 0.68 | 2.42 |
| logN** | 1.99 | 0.76 | 2.05 | −1.17 | 3.96 | 5.13 | −0.72 | 2.11 |
| logFe** | 2.89 | 0.54 | 2.79 | 1.53 | 4.64 | 3.11 | 0.79 | 0.77 |
| logMn** | 2.13 | 0.57 | 2.12 | 0.87 | 3.94 | 3.08 | 0.32 | 0.18 |
| logCu | 0.37 | 0.53 | 0.28 | −0.87 | 2.08 | 2.95 | 0.85 | 0.88 |
| logB | −1.18 | 0.48 | −1.17 | −2.3 | −0.12 | 2.19 | −0.36 | −0.35 |
| logZn | −0.97 | 0.61 | −1.1 | −2.3 | 0.95 | 3.25 | 0.64 | −0.06 |
| Hyperparameter | Ranger (Default Values) | rf (Default Values) | Ranger (Optimized Values) | rf (Optimized Values) |
|---|---|---|---|---|
| mtry | 8 | 8 | 9 | 9 |
| splitrule | variance | - | variance | - |
| min.node.size | 5 | - | 2 | - |
| Hyperparameter | xgbDART (Default Values) | xgbTree (Default Values) | xgbDART (Optimized Values) | xgbTree (Optimized Values) |
|---|---|---|---|---|
| nrounds | 500 | 500 | 954 | 199 |
| max_depth | 6 | 6 | 1 | 4 |
| eta | 0.3 | 0.3 | 0.4247 | 0.1828 |
| gamma | 0 | 0 | 0.59 | 1.002 |
| subsample | 0.5 | 0.5 | 0.7706 | 0.508 |
| colsample_bytree | 0.5 | 0.5 | 0.3876 | 0.358 |
| rate_drop | 0 | - | 0.3613 | - |
| skip_drop | 0 | - | 0.8432 | - |
| min_child_weight | 1 | 1 | 0 | 4 |
| Hyperparameter | nnet (Default Values) | avNNet (Default Values) | nnet (Optimized Values) | avNNet (Optimized Values) |
|---|---|---|---|---|
| size | 20 | 20 | 2 | 15 |
| decay | 0 | 0 | 0.3892 | 0.0144 |
| bag | - | TRUE | - | TRUE |
| linout | TRUE | TRUE | TRUE | TRUE |
| trace | FALSE | FALSE | FALSE | FALSE |
| maxit | 100 | 100 | 100 | 100 |
| Model | Package-Method | Hyperparameters/rs | RMSE | R2 | MAE |
|---|---|---|---|---|---|
| Ordinary kriging (OK) | - | - | 0.482 | 0.236 | 0.328 |
| Multiple regression (MLR) | - | - | 0.345 | 0.608 | 0.254 |
| Regression kriging (RK) | - | - | 0.336 | 0.626 | 0.242 |
| Random forests (RFrgD) | ranger-ranger | default | 0.260 | 0.783 | 0.183 |
| Random forests (RFrgO) | ranger-ranger | optimized | 0.259 | 0.781 | 0.182 |
| Random forests kriging (RFKrg) | ranger-ranger | optimized | 0.264 | 0.779 | 0.178 |
| Random forests (RFrfD) | randomForest-rf | default | 0.260 | 0.780 | 0.184 |
| Random forests (RFrfO) | randomForest-rf | optimized | 0.259 | 0.784 | 0.180 |
| Random forests kriging (RFKrf) | randomForest-rf | optimized | 0.263 | 0.781 | 0.178 |
| Gradient boosting (GBxgbTD) | xgboost-xgbTree | default | 0.293 | 0.719 | 0.224 |
| Gradient boosting (GBxgbTO) | xgboost-xgbTree | optimized | 0.279 | 0.750 | 0.190 |
| Gradient boosting kriging (GBKxgbT) | xgboost-xgbTree | optimized | 0.262 | 0.778 | 0.177 |
| Gradient boosting (GBxgbDD) | xgboost-xgbDART | default | 0.310 | 0.690 | 0.232 |
| Gradient boosting (GBxgbDO) | xgboost-xgbDART | optimized | 0.283 | 0.743 | 0.203 |
| Gradient boosting kriging (GBKxgbD) | xgboost-xgbDART | optimized | 0.271 | 0.765 | 0.187 |
| Neural networks (NNnnD) | nnet-nnet | default | 0.468 | 0.278 | 0.312 |
| Neural networks (NNnnO) | nnet-nnet | optimized | 0.268 | 0.760 | 0.192 |
| Neural networks kriging (NNKnn) | nnet-nnet | optimized | 0.272 | 0.766 | 0.182 |
| Neural networks (NNavD) | nnet-avNNet | default | 0.353 | 0.618 | 0.261 |
| Neural networks (NNavO) | nnet-avNNet | optimized | 0.299 | 0.704 | 0.218 |
| Neural networks kriging (NNKav) | nnet-avNNet | optimized | 0.274 | 0.757 | 0.188 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tziachris, P.; Aschonitis, V.; Chatzistathis, T.; Papadopoulou, M.; Doukas, I.D. Comparing Machine Learning Models and Hybrid Geostatistical Methods Using Environmental and Soil Covariates for Soil pH Prediction. ISPRS Int. J. Geo-Inf. 2020, 9, 276. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9040276
Tziachris P, Aschonitis V, Chatzistathis T, Papadopoulou M, Doukas ID. Comparing Machine Learning Models and Hybrid Geostatistical Methods Using Environmental and Soil Covariates for Soil pH Prediction. ISPRS International Journal of Geo-Information. 2020; 9(4):276. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9040276
Chicago/Turabian StyleTziachris, Panagiotis, Vassilis Aschonitis, Theocharis Chatzistathis, Maria Papadopoulou, and Ioannis (John) D. Doukas. 2020. "Comparing Machine Learning Models and Hybrid Geostatistical Methods Using Environmental and Soil Covariates for Soil pH Prediction" ISPRS International Journal of Geo-Information 9, no. 4: 276. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9040276