LASDU: A Large-Scale Aerial LiDAR Dataset for Semantic Labeling in Dense Urban Areas

 , , , and
, , , and 
Abstract
:1. Introduction
2. Benchmark Datasets from LiDAR Point Clouds
2.1. Differences between LiDAR Point Clouds Acquired with Various Platforms
2.2. Representative ALS Point Cloud Datasets for 3D Semantic Labeling
2.2.1. TUM City Campus and Abenberg ALS Dataset
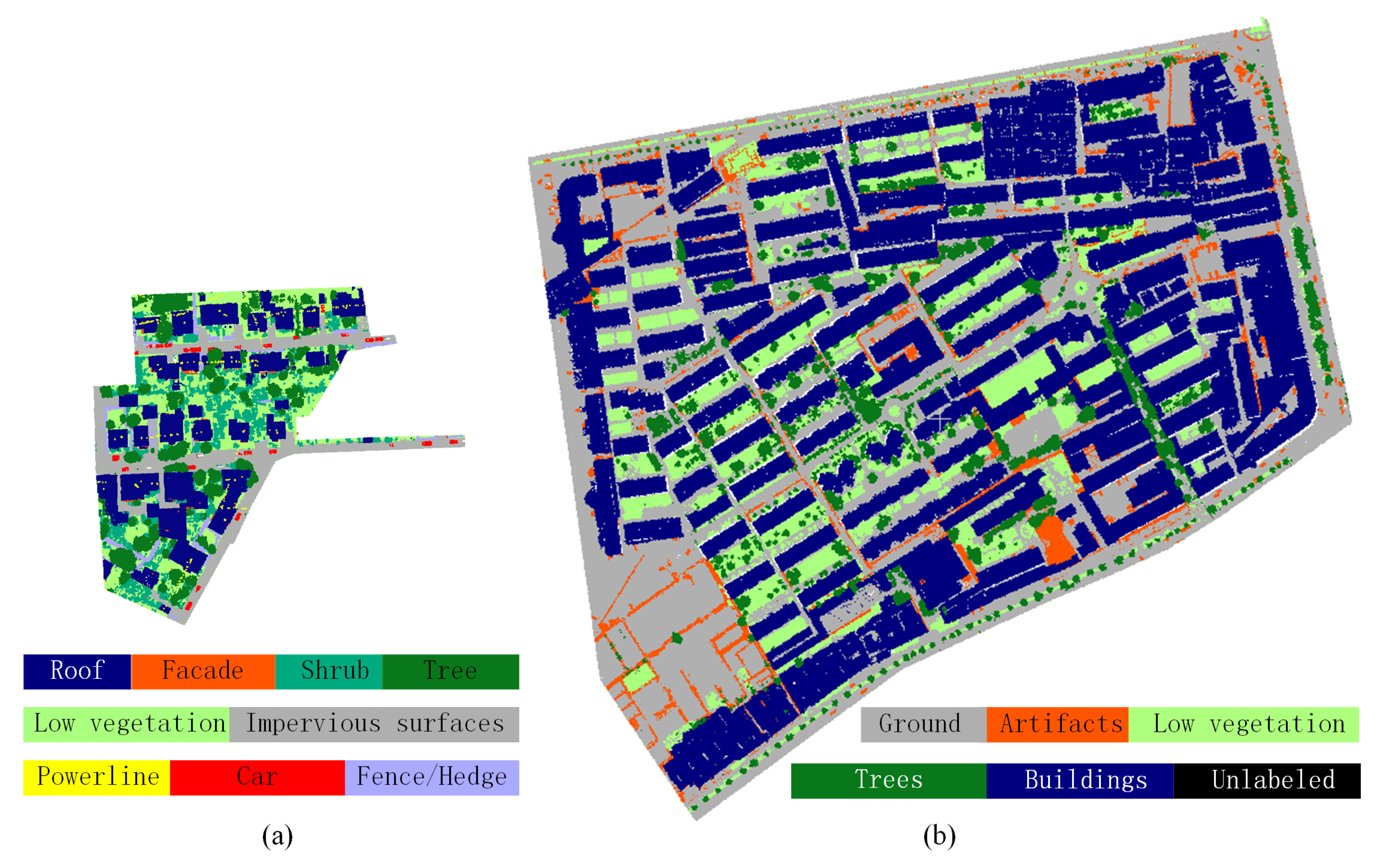
2.2.2. ISPRS Benchmark Dataset on 3D Semantic Labeling
2.2.3. Actueel Hoogtebestand Nederland Dataset
2.2.4. DublinCity Annotated LiDAR Point Cloud Dataset
2.2.5. IEEE GRSS Data Fusion Contest Dataset (DFC)
2.2.6. Dayton Annotated LiDAR Earth Scan Dataset
2.2.7. Limitations of Current Benchmark Datasets of ALS Point Clouds
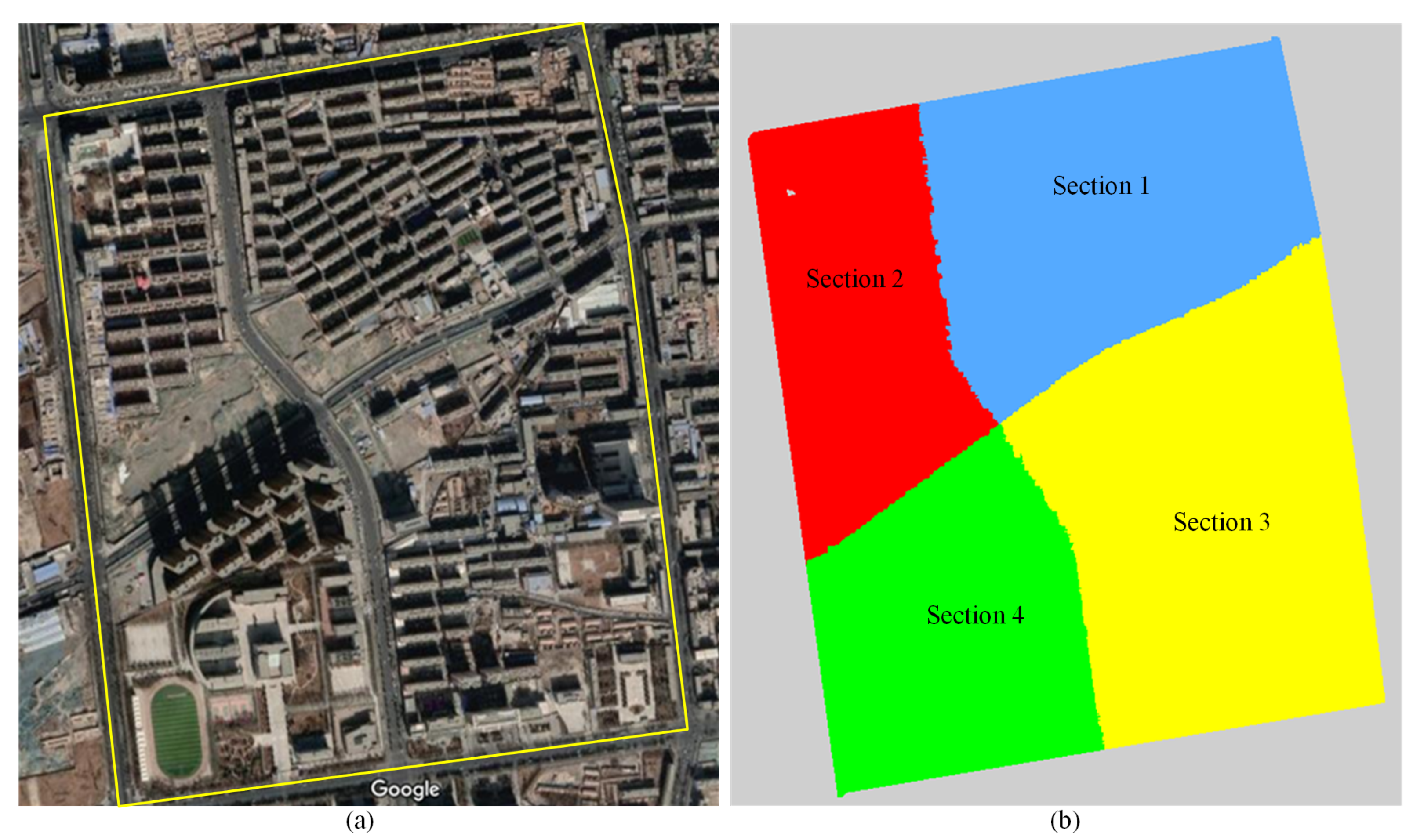
3. LASDU: Large-Scale Aerial LiDAR Point Clouds of Highly-Dense Urban Areas
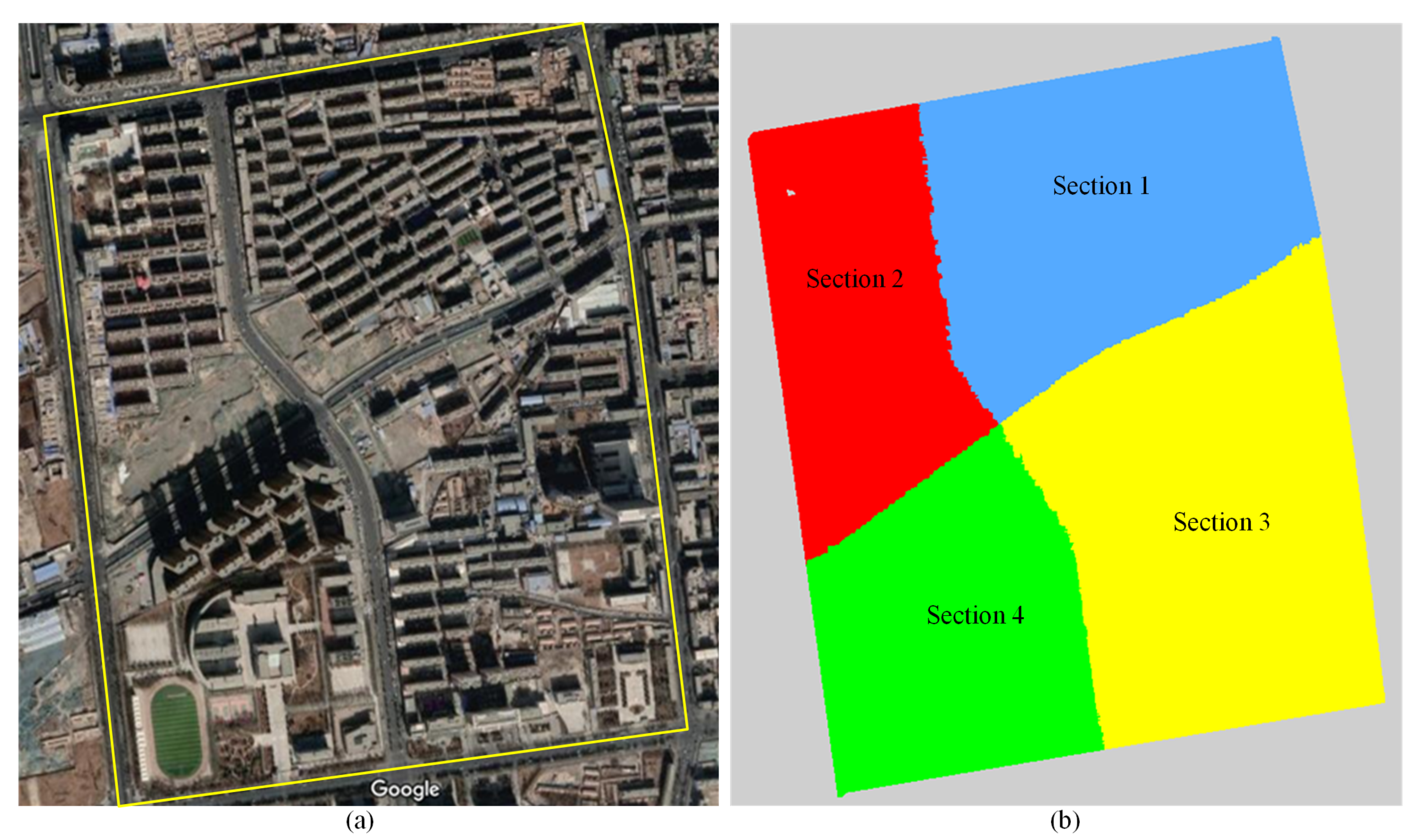
3.1. Data Acquisition
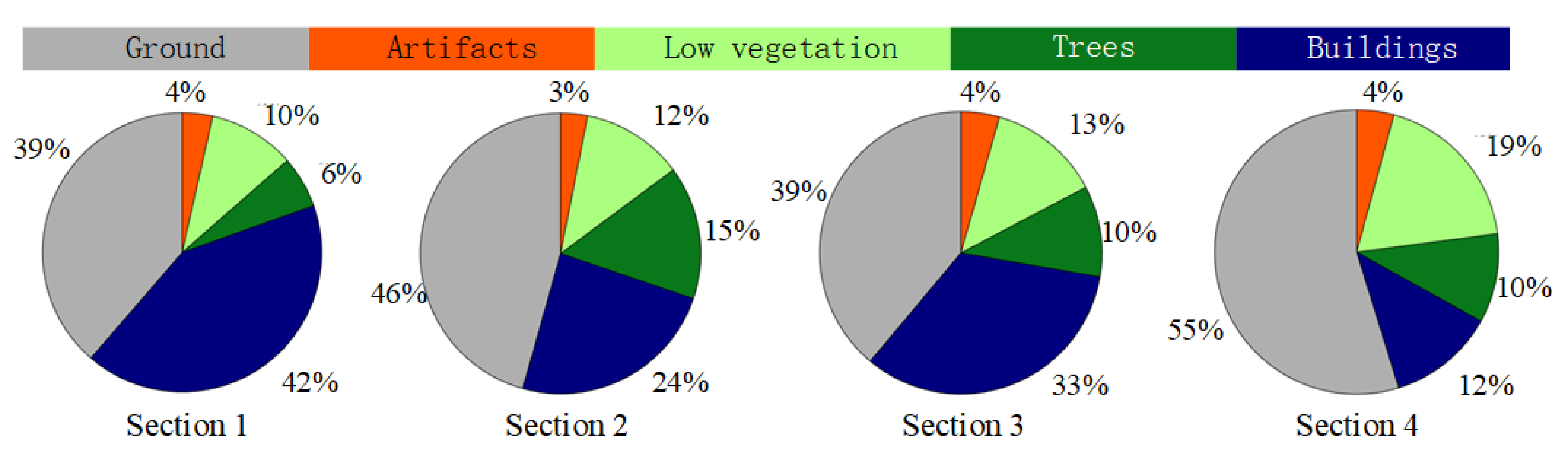
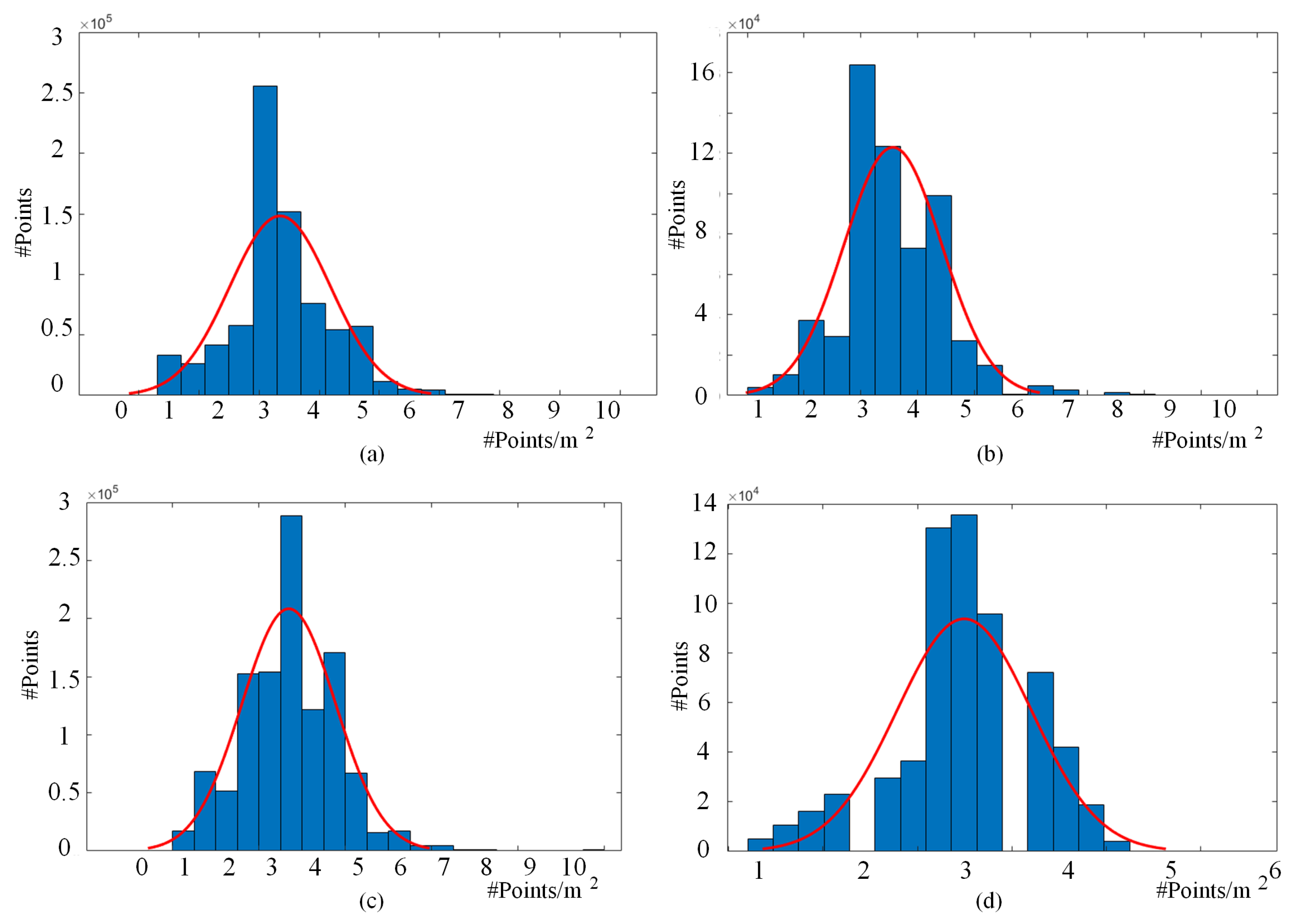
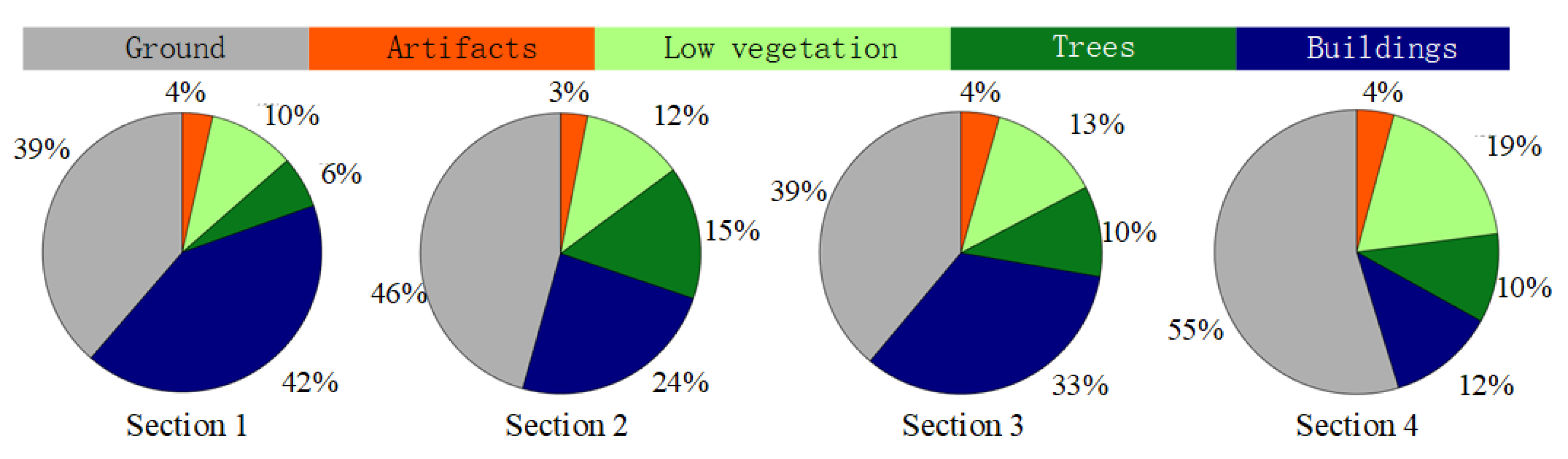
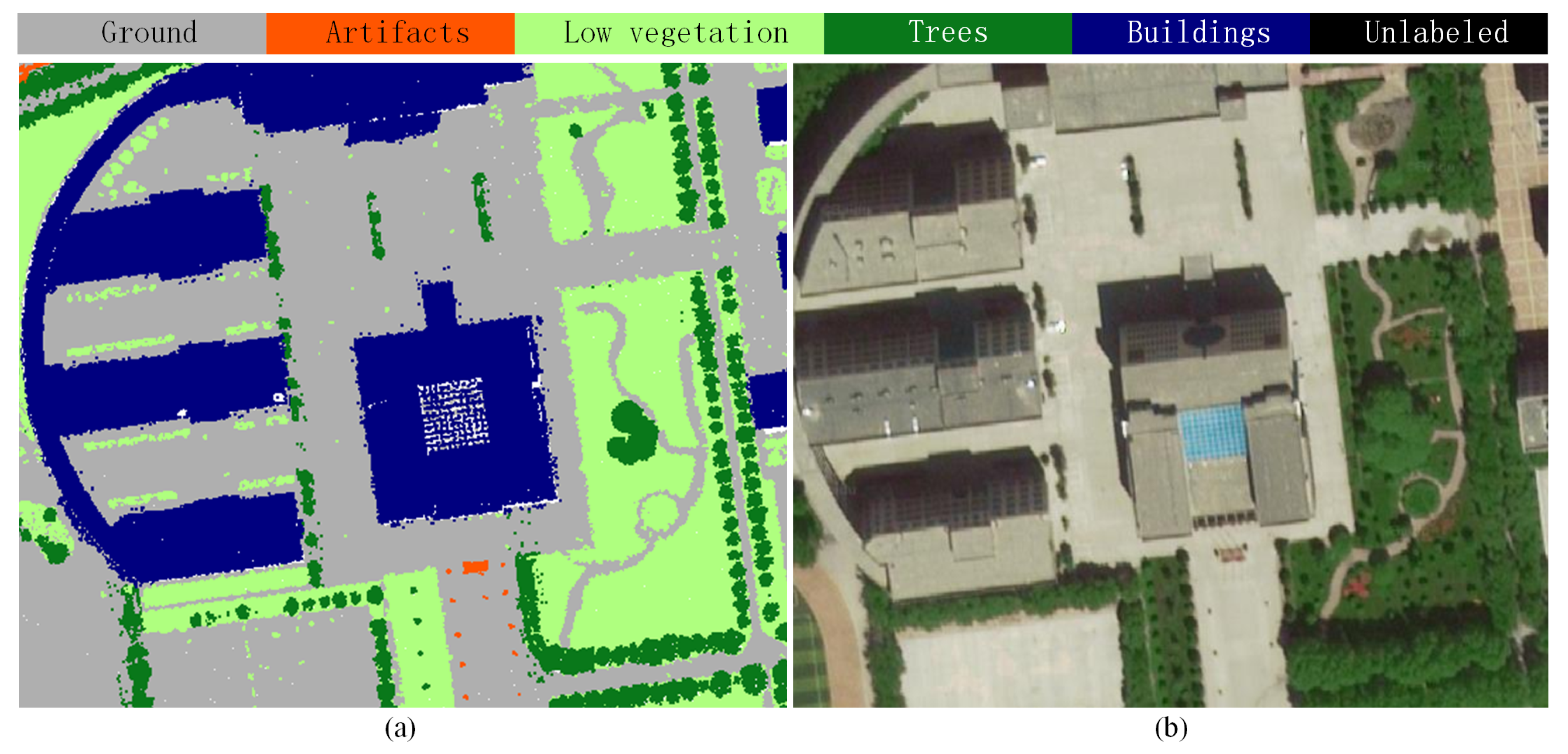
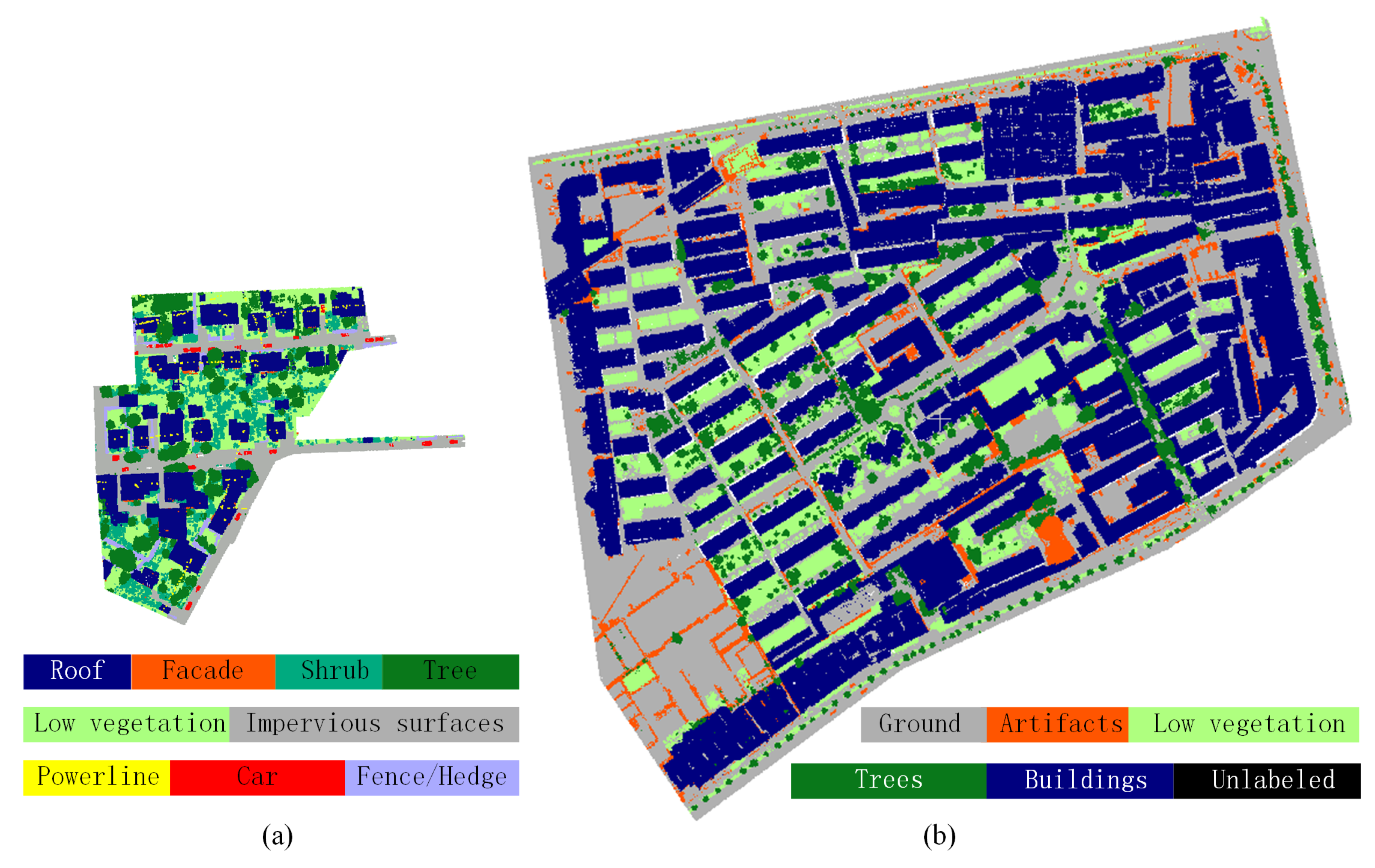
3.2. Data Description
- Positions: Recording the 3D coordinates of each point, with the unit of meters in the UTM projection.
- Intensity: Recording the intensity of reflectance of each point, with a range between 0 and 255.
- Edge of flight line: Indicating a value of 1 only when the point is at the end of a scan.
- Scan direction: Denoting the direction of the scanner mirror when transmitting a pulse.
- Number of returns: Recording the number of multiple returns per transmitted pulses.
- Scan angle: Recording scan angle of each point in degree.
- Labels: Indexing object classes of each point, with an integer index from 0 to 5.
- Label 1: Ground (color codes: #AFAFAF): artificial ground, roads, bare land.
- Label 2: Buildings (color codes: #00007F): buildings.
- Label 3: Trees (color codes: #09781A): tall and low trees.
- Label 4: Low vegetation (color codes: #AAFF7F): bushes, grass, flower beds.
- Label 5: Artifacts (color codes: #FF5500): walls, fences, light poles, vehicles, other artificial objects.
- Label 0: Unclassified (color codes: #000000): noise, outliers, and unlabeled points.
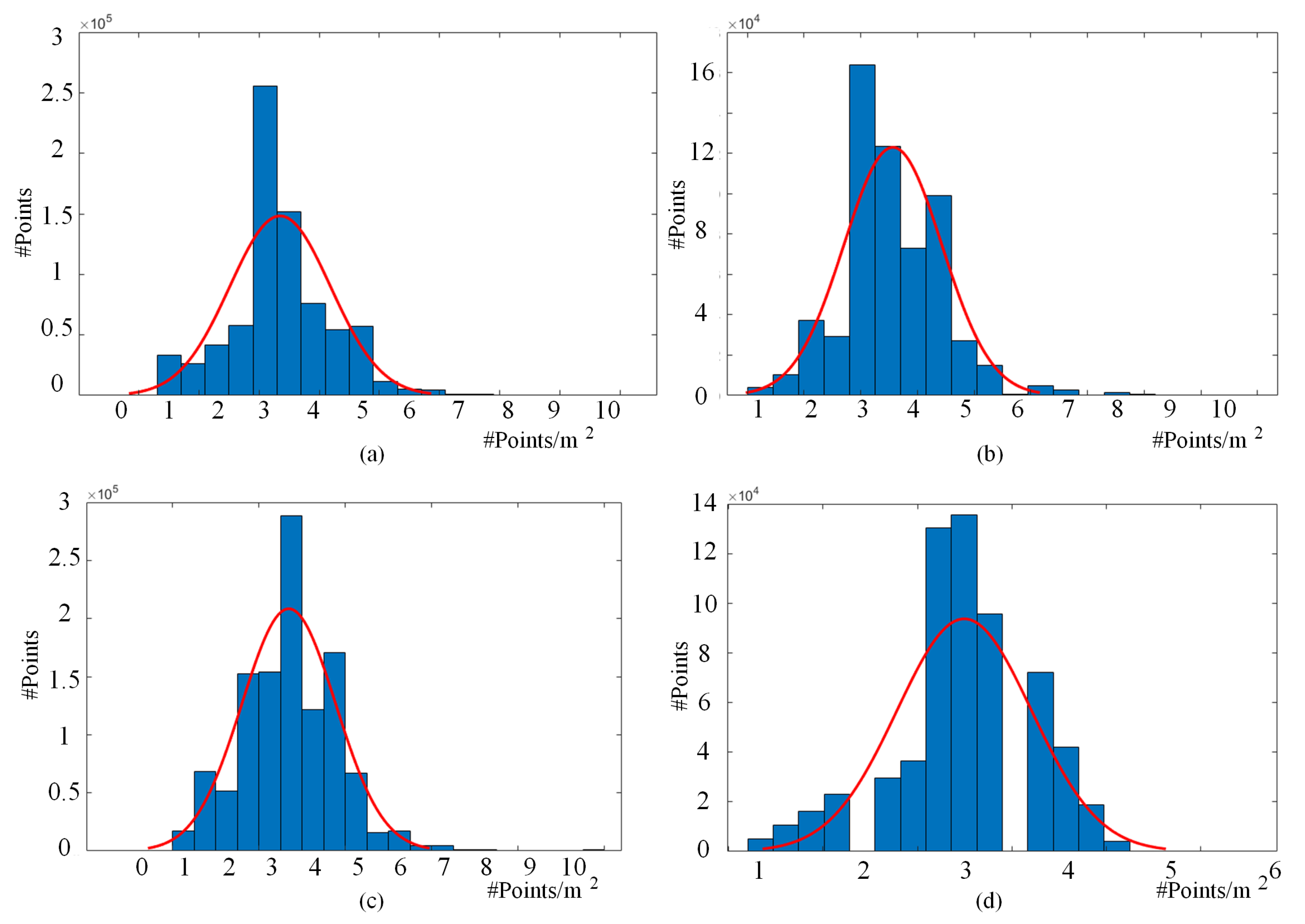
3.3. Features of the LASDU Dataset
3.4. Significance of the LASDU Dataset
3.4.1. Comparable Large Scale Data Size
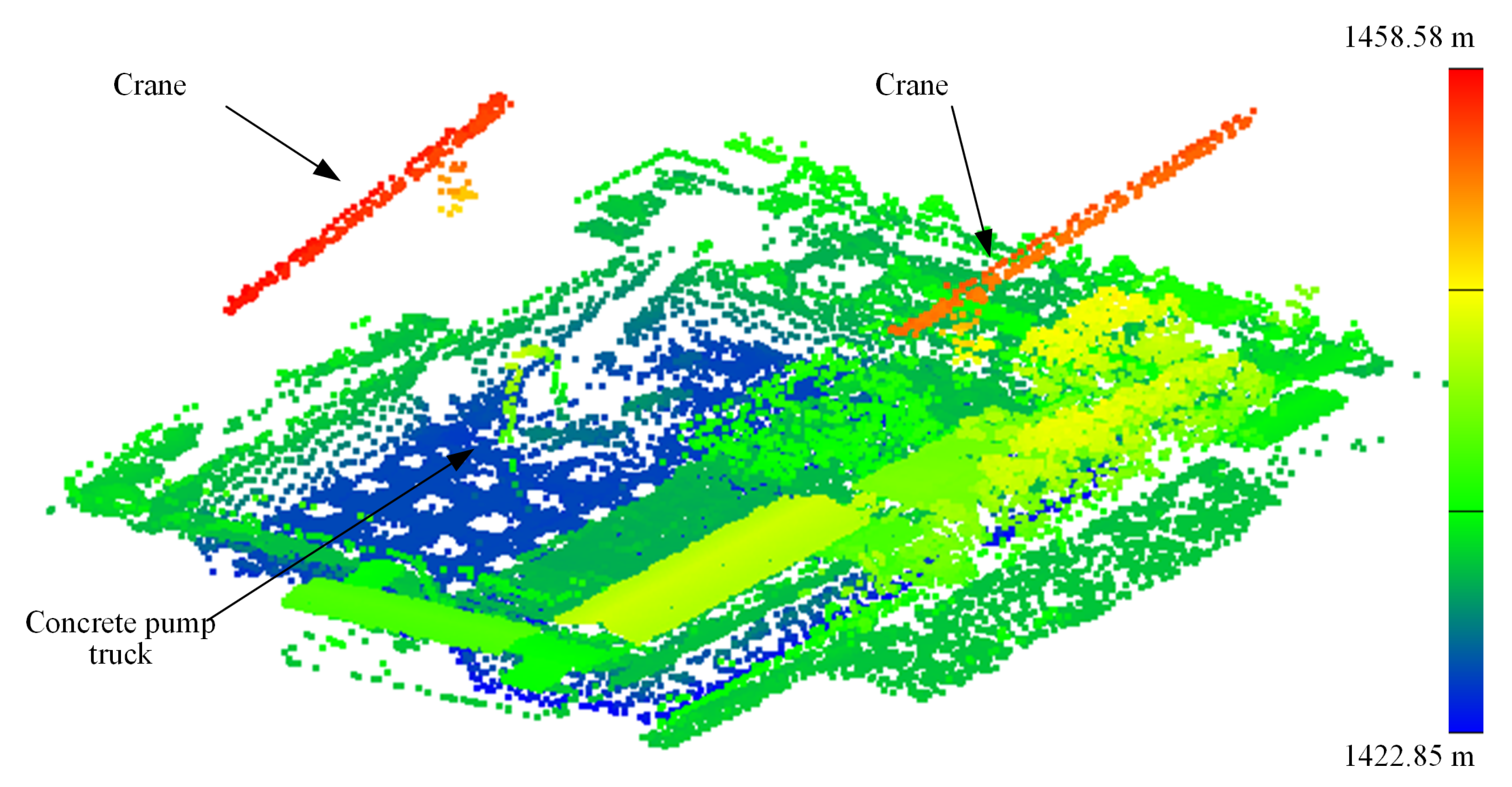
3.4.2. Challenging and Complex Scenarios
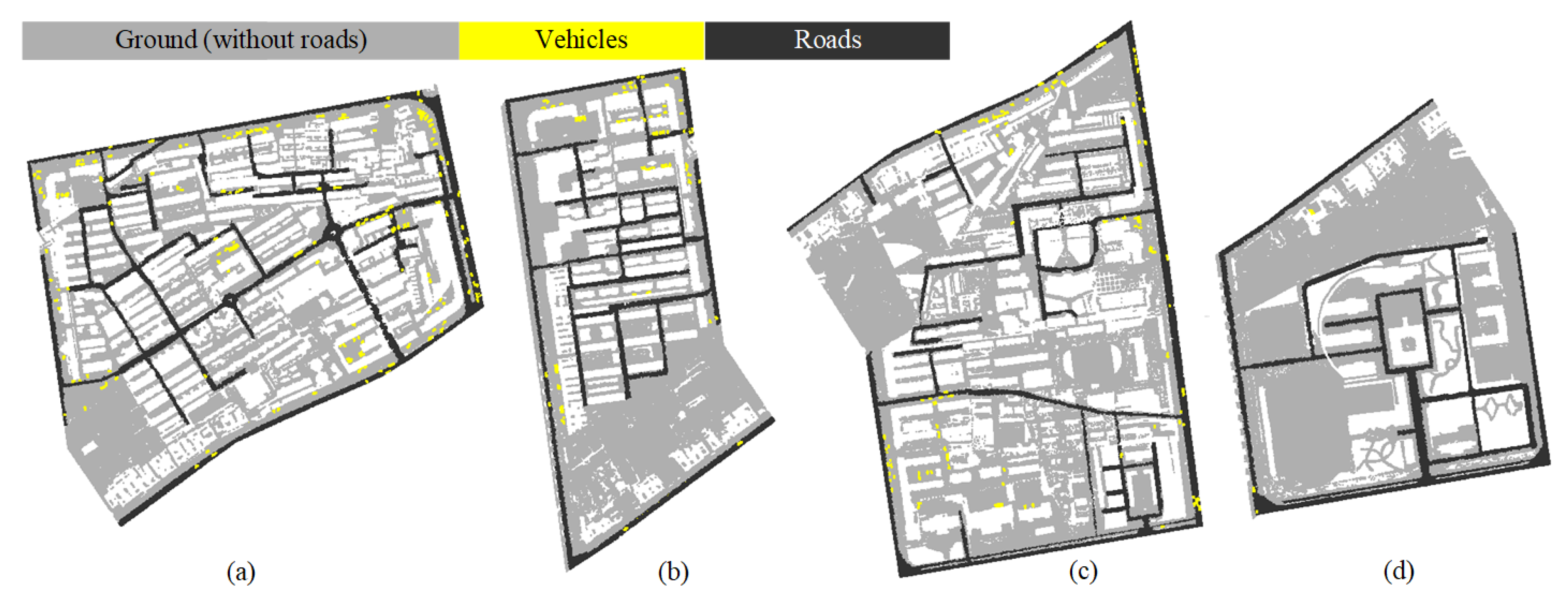
3.4.3. Potential Use for Traffic-Related Applications
4. Experimental Evaluation
4.1. Semantic Labeling Experiments
- PointNet [33]: PointNet is a neural network that directly works with point clouds and respects the permutation invariance of points in the input well. It provides a unified architecture for applications ranging from object classification to semantic segmentation.
- PointNet++ [34]: PointNet firstly learns global features with MLPs with raw point clouds. PointNet++ applies PointNet to local neighborhoods of each point to capture local features, and a hierarchical approach is taken to capture features with multi-scale local context.
- Hierarchical Data Augmented PointNet++ (HDA-PointNet++): This is an improved method based on the original PointNet++, which was proposed in the previous work [13] as the multi-scale deep features (MDF) in the context of hierarchical deep feature learning (HDL) method. It was developed based on a hierarchical data augmentation strategy, in which sizable urban point cloud datasets are divided into multi-scale point sets, enhancing the capability of dealing with scale variations. This hierarchical sampling strategy is a trade-off solution for object integrity and fine-grained details.
4.2. Evaluation Metrics
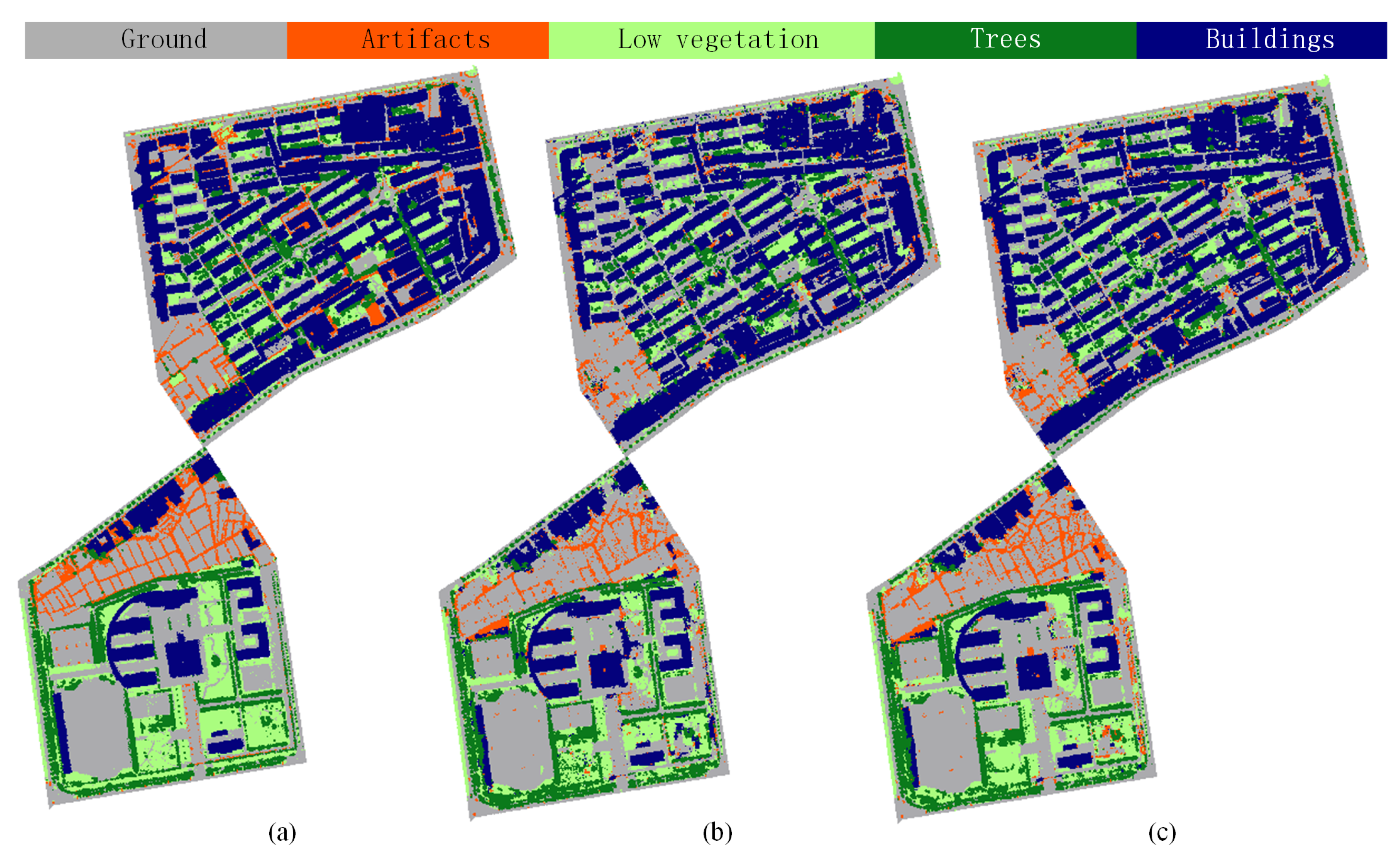
5. Results and Discussions
5.1. Preprocessing and Training
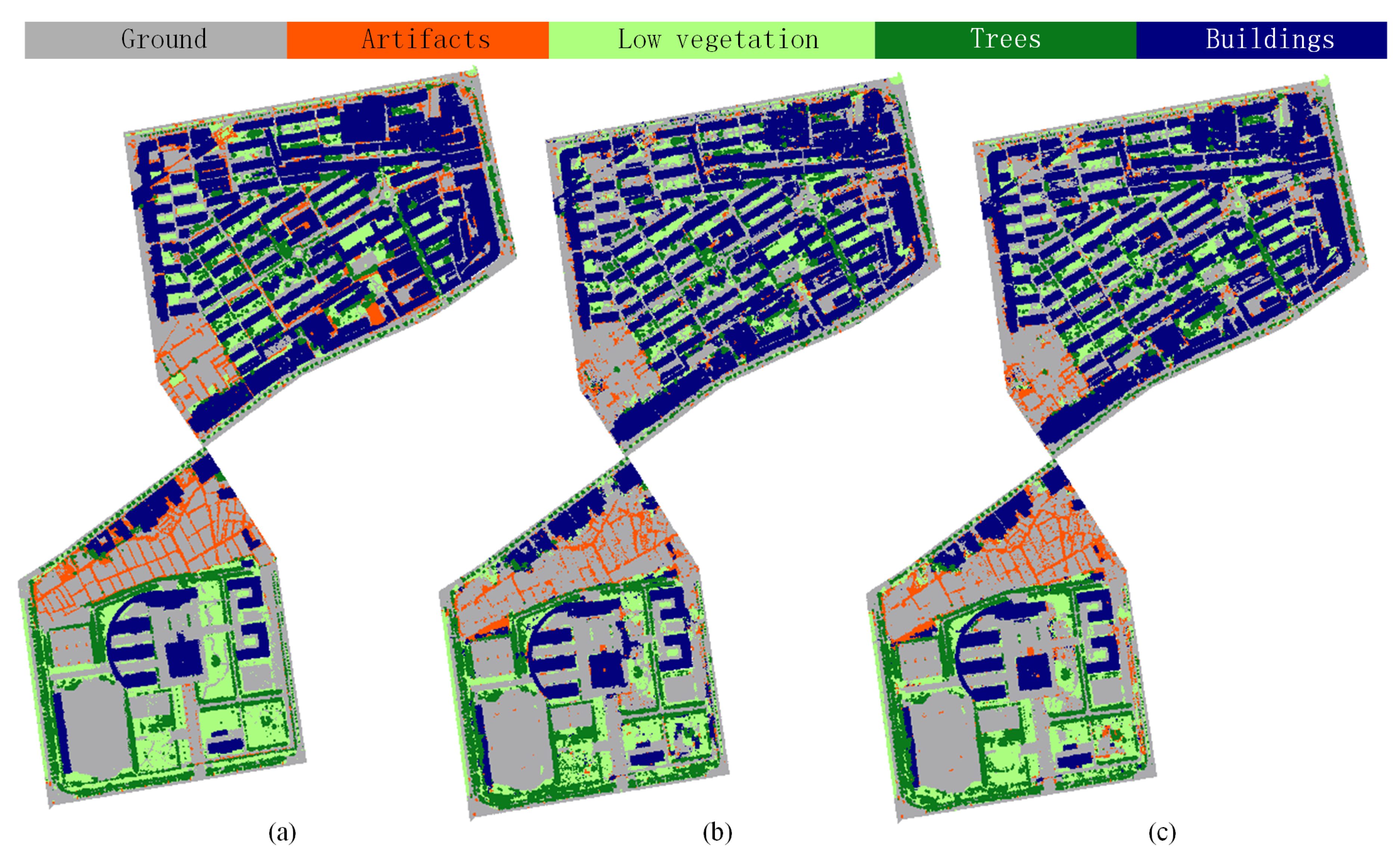
5.2. Classification Results of LASDU Dataset Using Only Point Positions
5.3. Classification Results of LASDU Dataset Using Additional Point Intensities
5.4. Discussion on Hierarchical/Multi-Scale Strategy for Large-Scale Urban Semantic Labeling
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Vosselman, G.; Maas, H.G. Airborne and Terrestrial Laser Scanning; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Xie, Y.; Tian, J.; Zhu, X. Linking Points With Labels in 3D: A Review of Point Cloud Semantic Segmentation. IEEE Geosci. Remote Sens. Mag. 2020. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Nan, L.; Xia, R.; Zhao, J.; Wonka, P. PLADE: A Plane-Based Descriptor for Point Cloud Registration with Small Overlap. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2530–2540. [Google Scholar] [CrossRef]
- Dong, Z.; Yang, B.; Liang, F.; Huang, R.; Scherer, S. Hierarchical registration of unordered TLS point clouds based on binary shape context descriptor. ISPRS J. Photogramm. Remote Sens. 2018, 144, 61–79. [Google Scholar] [CrossRef]
- Dong, Z.; Liang, F.; Yang, B.; Xu, Y.; Zang, Y.; Li, J.; Wang, Y.; Dai, W.; Fan, H.; Hyyppä, J.; et al. Registration of large-scale terrestrial laser scanner point clouds: A review and benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 163, 327–342. [Google Scholar] [CrossRef]
- Munoz, D.; Bagnell, J.A.; Vandapel, N.; Hebert, M. Contextual classification with functional max-margin markov networks. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 20–26 June 2009; pp. 975–982. [Google Scholar]
- Niemeyer, J.; Rottensteiner, F.; Sörgel, U. Contextual classification of lidar data and building object detection in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. SEMANTIC3D.NET: A new large-scale point cloud classification benchmark. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, IV-1-W1, 91–98. [Google Scholar] [CrossRef] [Green Version]
- Gehrung, J.; Hebel, M.; Arens, M.; Stilla, U. An approach to extract moving objects from mls data using a volumetric background representation. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4. [Google Scholar] [CrossRef] [Green Version]
- Roynard, X.; Deschaud, J.E.; Goulette, F. Paris-Lille-3D: A large and high-quality ground-truth urban point cloud dataset for automatic segmentation and classification. Int. J. Robot. Res. 2018, 37, 545–557. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Bai, M.; Mattyus, G.; Chu, H.; Luo, W.; Yang, B.; Liang, J.; Cheverie, J.; Fidler, S.; Urtasun, R. TorontoCity: Seeing the World with a Million Eyes. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Tan, W.; Qin, N.; Ma, L.; Li, Y.; Du, J.; Cai, G.; Yang, K.; Li, J. Toronto-3D: A Large-scale Mobile LiDAR Dataset for Semantic Segmentation of Urban Roadways. arXiv 2020, arXiv:2003.08284. [Google Scholar]
- Huang, R.; Xu, Y.; Hong, D.; Yao, W.; Ghamisi, P.; Stilla, U. Deep point embedding for urban classification using ALS point clouds: A new perspective from local to global. ISPRS J. Photogramm. Remote Sens. 2020, 163, 62–81. [Google Scholar] [CrossRef]
- Hackel, T.; Wegner, J.D.; Schindler, K. Fast semantic segmentation of 3D point clouds with strongly varying density. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3. [Google Scholar]
- Rusu, R.B. Semantic 3D object maps for everyday manipulation in human living environments. KI-Künstliche Intelligenz 2010, 24, 345–348. [Google Scholar] [CrossRef] [Green Version]
- Remondino, F. From point cloud to surface: The modeling and visualization problem. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2003, 34. [Google Scholar] [CrossRef]
- Xu, Y.; Heogner, L.; Tuttas, S.; Stilla, U. A voxel- and graph-based strategy for segmenting man-made infrastructures using perceptual grouping laws: Comparison and evaluation. Photogramm. Eng. Remote Sens. 2018, 84, 377–391. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- Reitberger, J.; Schnörr, C.; Krzystek, P.; Stilla, U. 3D segmentation of single trees exploiting full waveform LIDAR data. ISPRS J. Photogramm. Remote Sens. 2009, 64, 561–574. [Google Scholar] [CrossRef]
- Jeong, N.; Hwang, H.; Matson, E.T. Evaluation of low-cost lidar sensor for application in indoor uav navigation. In Proceedings of the 2018 IEEE Sensors Applications Symposium (SAS), Seoul, Korea, 12–14 March 2018; pp. 1–5. [Google Scholar]
- Hebel, M.; Arens, M.; Stilla, U. Change detection in urban areas by object-based analysis and on-the-fly comparison of multi-view ALS data. ISPRS J. Photogramm. Remote Sens. 2013, 86, 52–64. [Google Scholar] [CrossRef]
- Cramer, M. The DGPF-test on digital airborne camera evaluation–overview and test design. Photogramm. Fernerkund. Geoinf. 2010, 2010, 73–82. [Google Scholar] [CrossRef] [PubMed]
- Rottensteiner, F.; Sohn, G.; Jung, J.; Gerke, M.; Baillard, C.; Benitez, S.; Breitkopf, U. The ISPRS benchmark on urban object classification and 3D building reconstruction. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 1, 293–298. [Google Scholar] [CrossRef] [Green Version]
- Xu, S.; Vosselman, G.; Elberink, S.O. Multiple-entity based classification of airborne laser scanning data in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 88, 1–15. [Google Scholar] [CrossRef]
- Vosselman, G.; Coenen, M.; Rottensteiner, F. Contextual segment-based classification of airborne laser scanner data. ISPRS J. Photogramm. Remote Sens. 2017, 128, 354–371. [Google Scholar] [CrossRef]
- Zolanvari, S.; Ruano, S.; Rana, A.; Cummins, A.; da Silva, R.E.; Rahbar, M.; Smolic, A. DublinCity: Annotated LiDAR Point Cloud and its Applications. arXiv 2019, arXiv:1909.03613. [Google Scholar]
- Truong-Hong, L.; Laefer, D.; Lindenbergh, R. Automatic detection of road edges from aerial laser scanning data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 1135–1140. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Du, B.; Zhang, L.; Cerra, D.; Pato, M.; Carmona, E.; Prasad, S.; Yokoya, N.; Hänsch, R.; Le Saux, B. Advanced multi-sensor optical remote sensing for urban land use and land cover classification: Outcome of the 2018 IEEE GRSS Data Fusion Contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1709–1724. [Google Scholar] [CrossRef]
- Varney, N.; Asari, V.K.; Graehling, Q. DALES: A Large-scale Aerial LiDAR Data Set for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 186–187. [Google Scholar]
- Li, X.; Cheng, G.; Liu, S.; Xiao, Q.; Ma, M.; Jin, R.; Che, T.; Liu, Q.; Wang, W.; Qi, Y.; et al. Heihe watershed allied telemetry experimental research (HiWATER): Scientific objectives and experimental design. Bull. Am. Meteorol. Soc. 2013, 94, 1145–1160. [Google Scholar] [CrossRef]
- Li, X.; Liu, S.; Xiao, Q.; Ma, M.; Jin, R.; Che, T.; Wang, W.; Hu, X.; Xu, Z.; Wen, J.; et al. A multiscale dataset for understanding complex eco-hydrological processes in a heterogeneous oasis system. Sci. Data 2017, 4, 170083. [Google Scholar] [CrossRef] [Green Version]
- Vo, A.V.; Truong-Hong, L.; Laefer, D.F.; Bertolotto, M. Octree-based region growing for point cloud segmentation. ISPRS J. Photogramm. Remote Sens. 2015, 104, 88–100. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 4. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 5099–5108. [Google Scholar]
- Niemeyer, J.; Rottensteiner, F.; Sörgel, U.; Heipke, C. Hierarchical higher order crf for the classification of airborne lidar point clouds in urban areas. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.-ISPRS Arch. 2016, 41, 655–662. [Google Scholar] [CrossRef] [Green Version]
- Zhao, R.; Pang, M.; Wang, J. Classifying airborne LiDAR point clouds via deep features learned by a multi-scale convolutional neural network. Int. J. Geogr. Inf. Sci. 2018, 32, 960–979. [Google Scholar] [CrossRef]
- Zhang, L.; Li, Z.; Li, A.; Liu, F. Large-scale urban point cloud labeling and reconstruction. ISPRS J. Photogramm. Remote Sens. 2018, 138, 86–100. [Google Scholar] [CrossRef]
- Winiwarter, L.; Mandlburger, G.; Schmohl, S.; Pfeifer, N. Classification of ALS Point Clouds Using End-to-End Deep Learning. PFG–J. Photogramm. Remote Sens. Geoinf. Sci. 2019, 87, 75–90. [Google Scholar] [CrossRef]
- Li, W.; Wang, F.D.; Xia, G.S. A geometry-attentional network for ALS point cloud classification. ISPRS J. Photogramm. Remote Sens. 2020, 164, 26–40. [Google Scholar] [CrossRef]
- Qin, N.; Hu, X.; Wang, P.; Shan, J.; Li, Y. Semantic Labeling of ALS Point Cloud via Learning Voxel and Pixel Representations. IEEE Geosci. Remote Sens. Lett. 2019, 17, 859–863. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Size (km2) | # Points (million) | Density (pts/m2) | # Classes | Sensor | Features |
|---|---|---|---|---|---|---|
| TUM-ALS [21] | - | 5.4 | ≈16 | 4 | - | Temporal data for change detection |
| Vaihingen [22,23] | 0.32 | 1.16 | ≈4 | 9 | ALS50 | Detailed labels of urban artifacts |
| AHN3 [24,25] | - | - | 8–60 | 5 | - | Cover the entire Netherlands |
| DublinCity [26,27] | 2 | 260 | 348.43 | 13 | - | Highest density, hierarchical labels |
| DFC [28] | 5.01 | 20.05 | ≈4 | 21 | Optech Titan MW | Multi-spectral information |
| DALES [29] | 10 | 500 | ≈50 | 8 | Riegl Q1560 | Largest spanning area |
| LASDU | 1.02 | 3.12 | ≈4 | 5 | ALS70 | Dense and complex urban scenario |
| Methods | Metrics | Artifacts | Buildings | Ground | Low_veg | Trees | ||
|---|---|---|---|---|---|---|---|---|
| PointNet [33] | 63.64 | 85.34 | 57.52 | 20.96 | 42.43 | 63.02 | 44.04 | |
| 00.02 | 62.34 | 97.46 | 06.89 | 03.79 | ||||
| 31.83 | 73.84 | 77.49 | 13.92 | 23.11 | ||||
| 28.65 | 90.09 | 58.44 | 38.18 | 78.53 | 65.19 | 51.09 | ||
| PointNet++ [34] | 14.26 | 63.55 | 91.32 | 19.34 | 28.53 | |||
| 21.45 | 76.82 | 74.88 | 28.76 | 53.53 | ||||
| 41.46 | 93.55 | 83.17 | 63.92 | 84.56 | 83.11 | 71.70 | ||
| HDA-PointNet++ [13] | 34.58 | 94.86 | 91.24 | 43.50 | 86.41 | |||
| 37.87 | 94.20 | 87.20 | 53.71 | 85.49 |
| Methods | Metrics | Artifacts | Buildings | Ground | Low_veg | Trees | ||
|---|---|---|---|---|---|---|---|---|
| PointNet++ [34] | 34.74 | 91.44 | 85.83 | 66.77 | 78.38 | 82.84 | 70.96 | |
| 27.78 | 89.82 | 89.65 | 59.58 | 85.59 | ||||
| 31.26 | 90.63 | 87.74 | 63.17 | 81.98 | ||||
| HDA-PointNet++ [13] | 38.66 | 95.91 | 85.73 | 69.47 | 79.98 | 84.37 | 73.25 | |
| 35.11 | 90.40 | 91.75 | 61.01 | 84.51 | ||||
| 36.89 | 93.16 | 88.74 | 65.24 | 82.24 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, Z.; Xu, Y.; Huang, R.; Tong, X.; Li, X.; Liu, X.; Luan, K.; Hoegner, L.; Stilla, U. LASDU: A Large-Scale Aerial LiDAR Dataset for Semantic Labeling in Dense Urban Areas. ISPRS Int. J. Geo-Inf. 2020, 9, 450. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9070450
Ye Z, Xu Y, Huang R, Tong X, Li X, Liu X, Luan K, Hoegner L, Stilla U. LASDU: A Large-Scale Aerial LiDAR Dataset for Semantic Labeling in Dense Urban Areas. ISPRS International Journal of Geo-Information. 2020; 9(7):450. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9070450
Chicago/Turabian StyleYe, Zhen, Yusheng Xu, Rong Huang, Xiaohua Tong, Xin Li, Xiangfeng Liu, Kuifeng Luan, Ludwig Hoegner, and Uwe Stilla. 2020. "LASDU: A Large-Scale Aerial LiDAR Dataset for Semantic Labeling in Dense Urban Areas" ISPRS International Journal of Geo-Information 9, no. 7: 450. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9070450