Semantic Integration of Raster Data for Earth Observation: An RDF Dataset of Territorial Unit Versions with their Land Cover



Abstract
:1. Introduction
- As a first contribution, we propose a generic vocabulary that allows the semantic and homogeneous description of spatio-temporal data to qualify predefined areas together with their provenance. This model is extendable to deal with any kind of observed EO property.
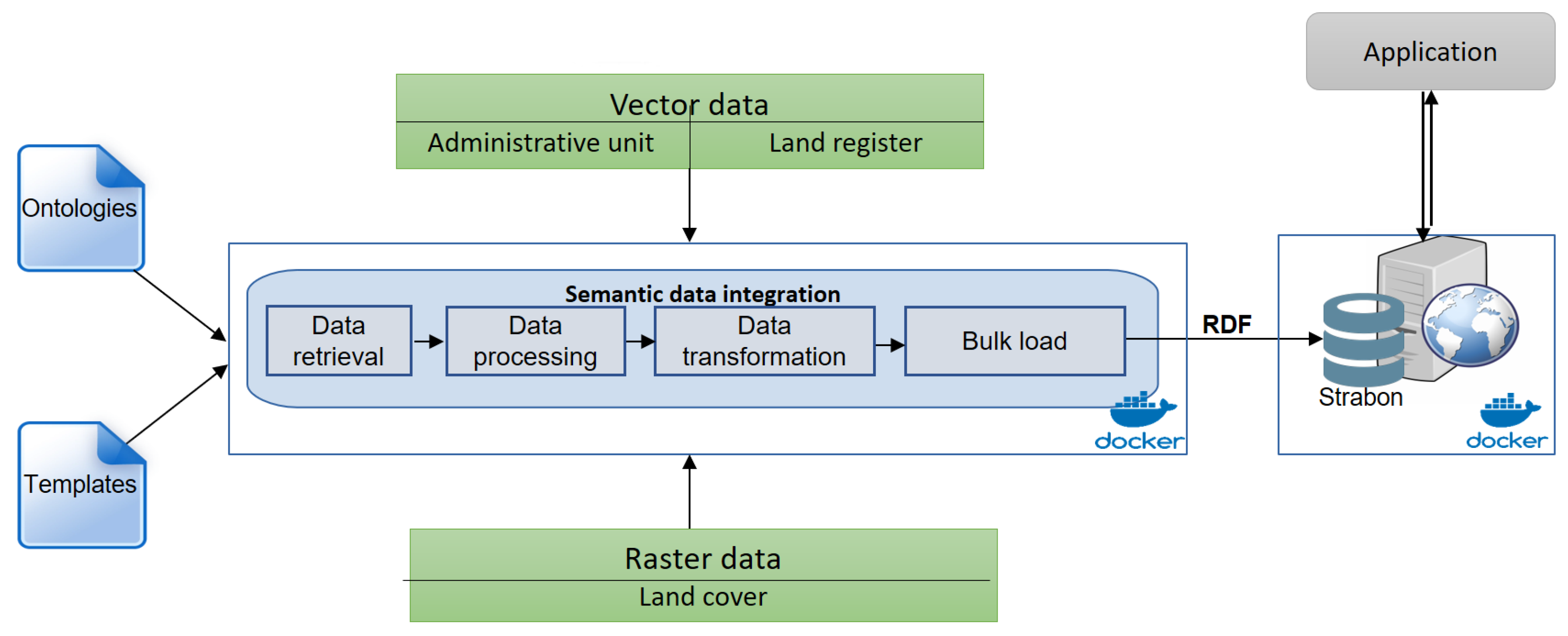
- As a second contribution, we defined a configurable semantic Extraction, Transformation, and Load (ETL) process based on the proposed model. As in [5], the extraction process starts by linking parts of the data sources schema with concepts and properties in the data model. Hence, we defined a set of transformation functions to populate the semantic model with data (represented as values) and get a homogeneous semantic data representation. One of the features of the integration process is to extract and aggregate data from rasters together with data from other sources. Then, it links the extracted data to the concepts of the semantic model and assigns it spatio-temporal dimensions, thanks to which all data can be linked and queried. This process is reproducible, as it is accessible via a docker image (https://hub.docker.com/r/h2020candela/triplification).
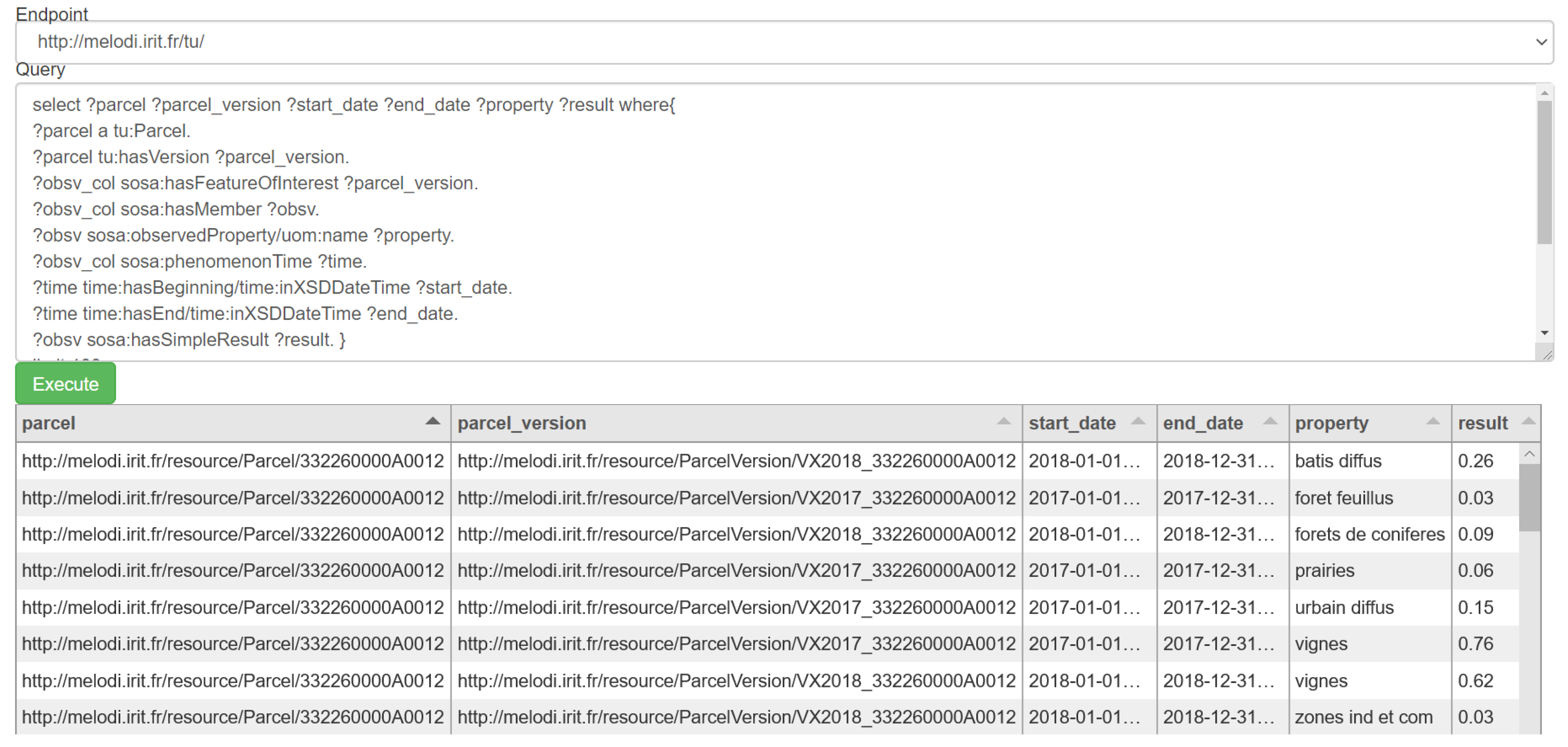
- A third contribution is the dataset resulting from the integration process of three different sources that we used for experimental validation: land cover data of a specific French winery geographic area, its administrative units, and their land registers. Stored and published as an RDF triplestore, it is exposed through a SPARQL endpoint and exploited by a semantic query interface. Given a period and a village name or a geographic area defined by its geometry, one can retrieve the land registers in this area and the evolution of their land cover during this period. These data serve as the basis for three scenarios: integration of time series observations; EO process guidance; and data cross-comparison.
2. Related Work
2.1. Semantic Models and Semantic ETL Processes for EO Data Integration
2.2. Processing of Raster Data in a Semantic Framework
2.3. Positioning Our Contribution
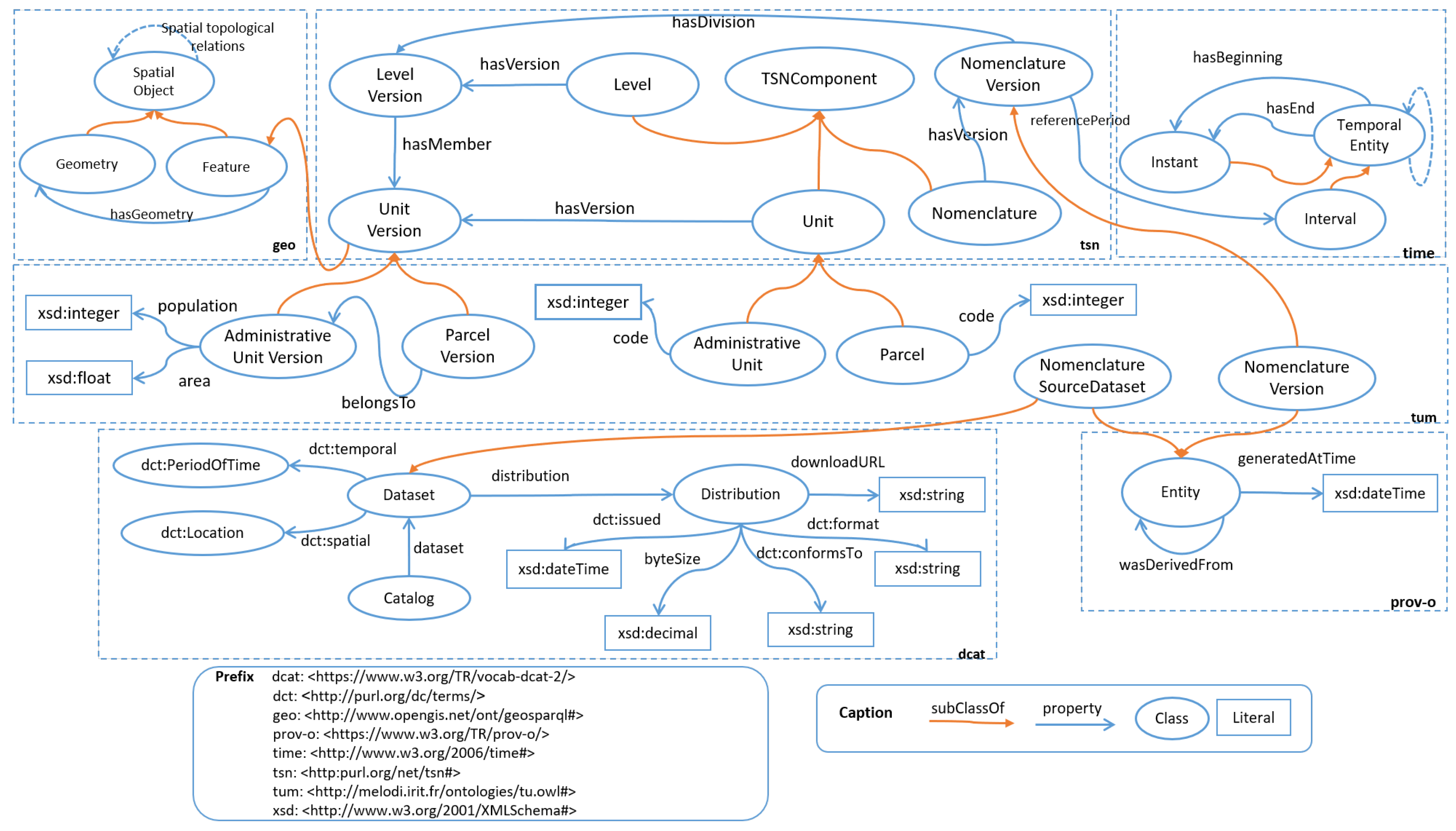
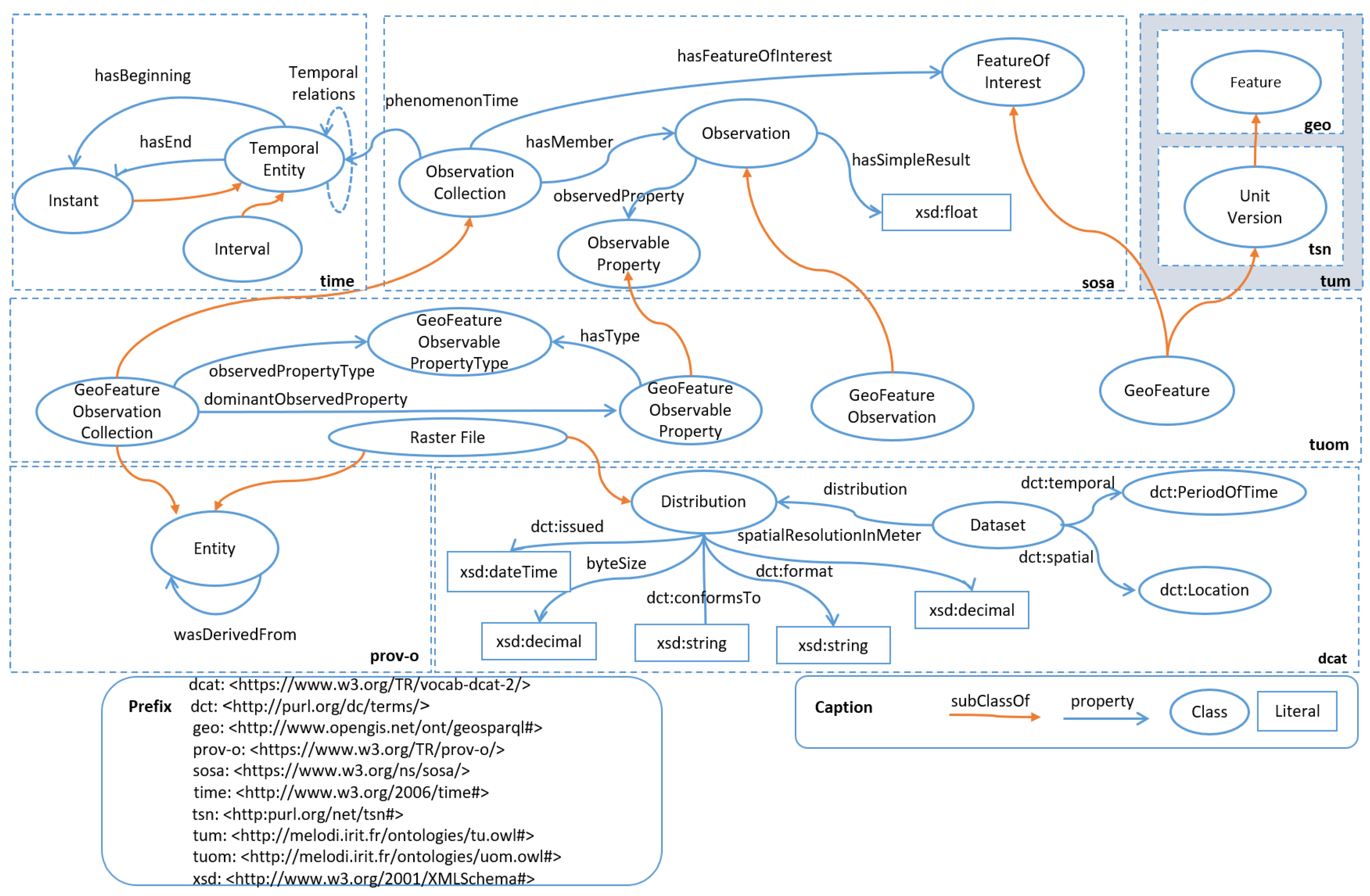
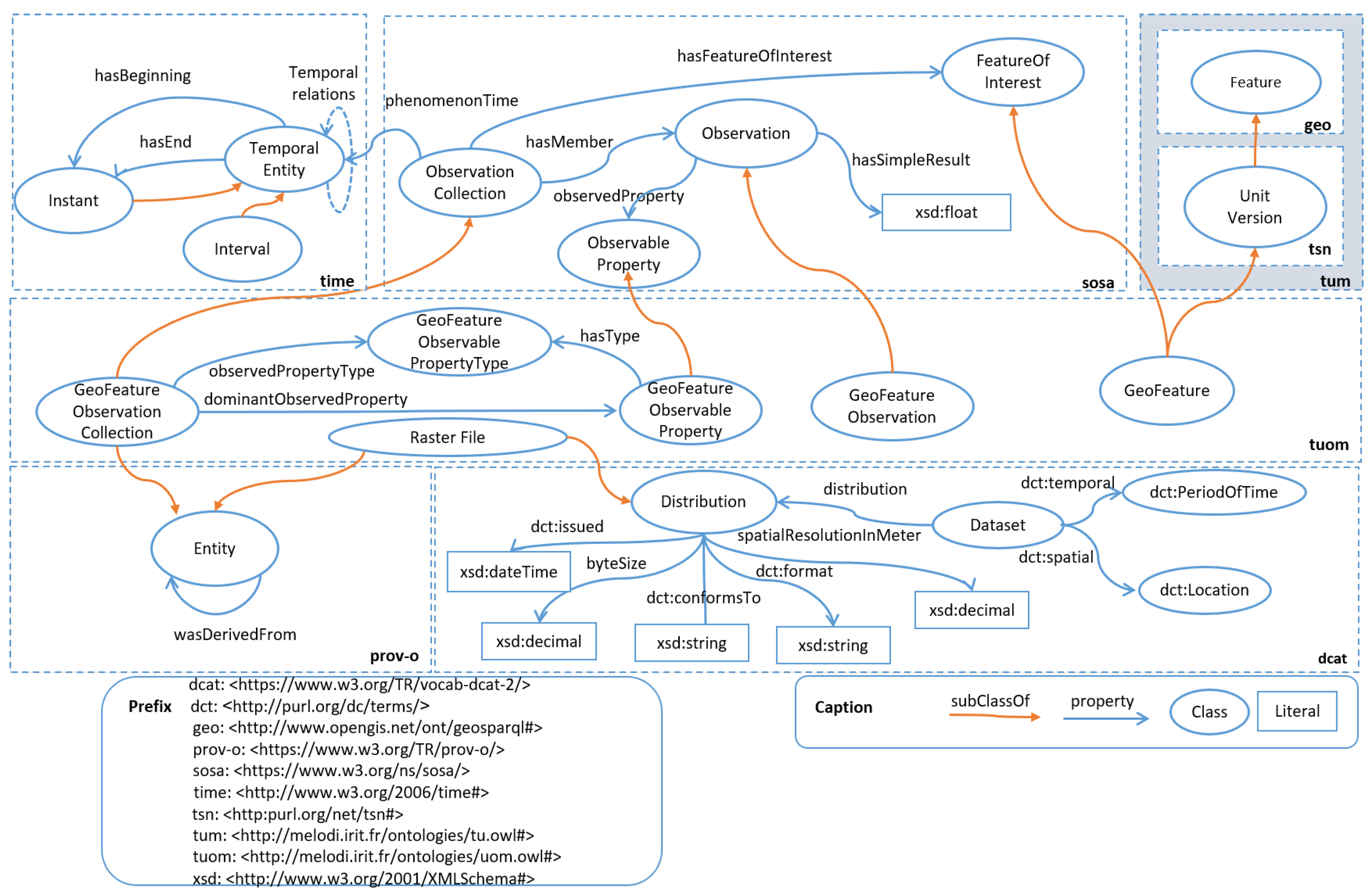
3. Semantic Models for EO Data Integration
3.1. Reused Vocabularies
3.1.1. Standard Vocabularies
3.1.2. Other Vocabularies
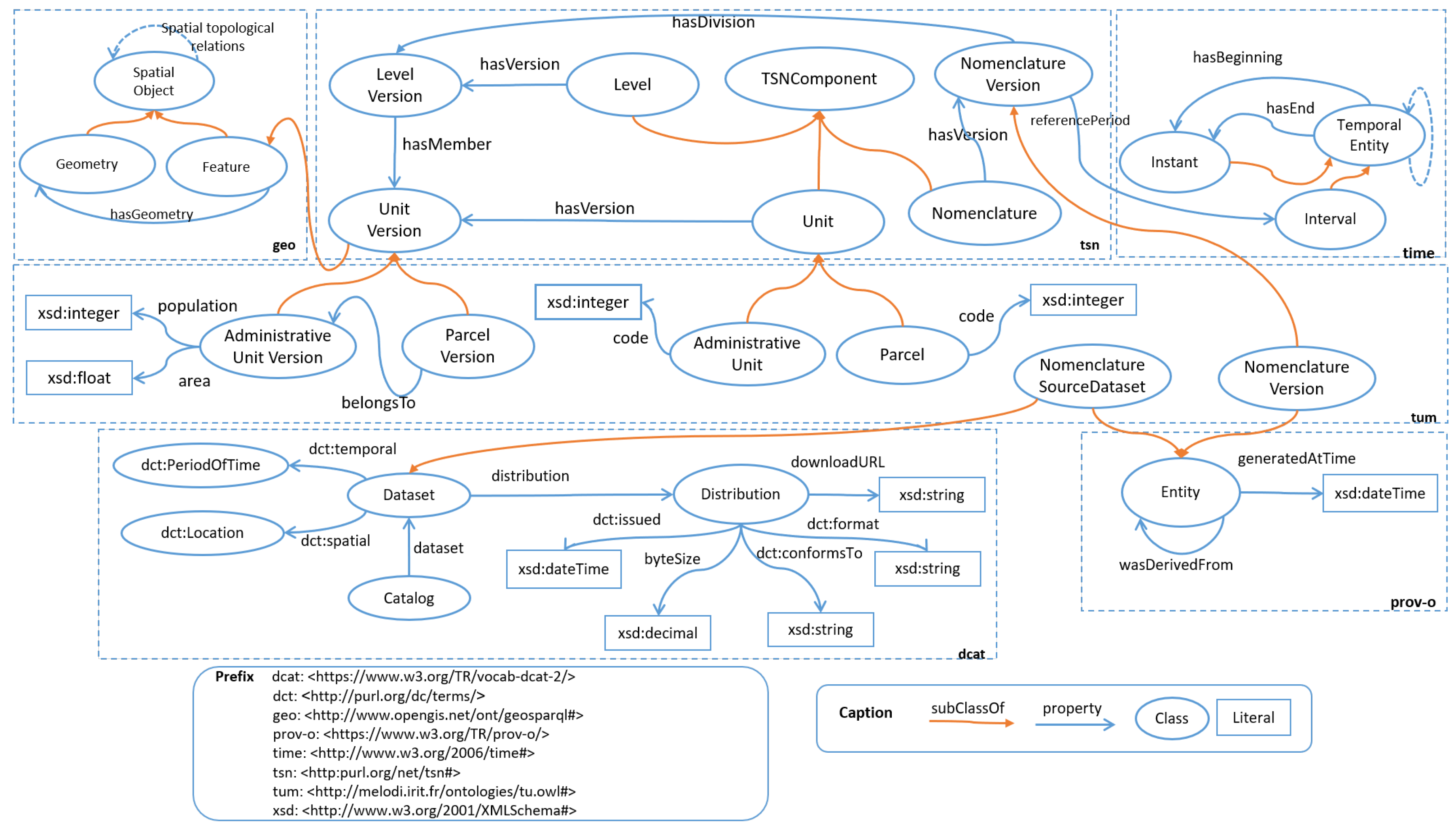
3.2. Integration Ontology
3.2.1. Territorial Unit Model (TUM)
3.2.2. Territorial Unit Observation Model (TUOM)
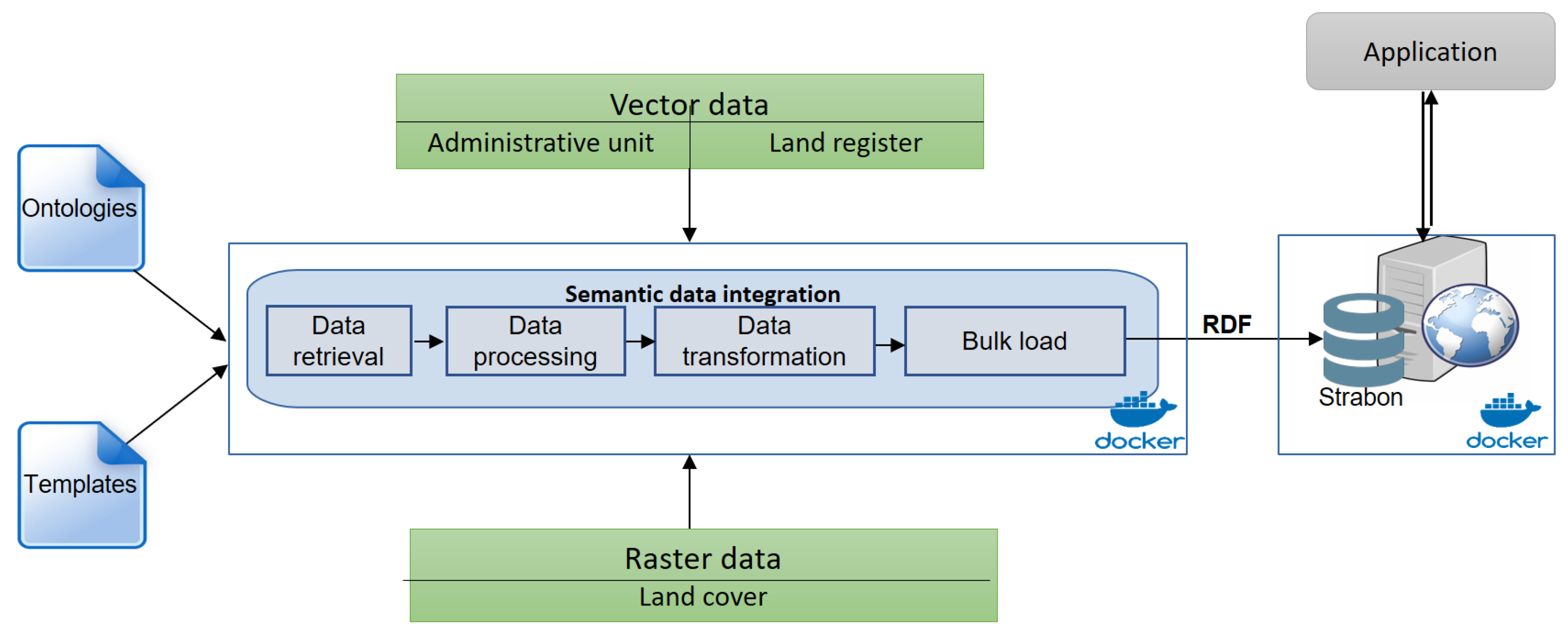
4. Semantic Integration Process
4.1. Data Sources
- Vector data sources: Vector data sources contain geofeatures with a geometry. We consider the two following vector data sources to produce our RDF dataset.
- Administrative units: French administrative units can be obtained from different open datasets, in particular, OpenStreetMap-based dataset (https://www.data.gouv.fr/en/datasets/decoupage-administratif-communal-francais-issu-d-openstreetmap/) and GeoZones dataset (https://www.data.gouv.fr/en/datasets/geozones/). The latter provides more details about administrative units than first but it is updated less frequently. For that reason, we chose the OpenStreetMap-based dataset, available as shapefiles.
- Land registers: Land register data is available from the French government data website (https://cadastre.data.gouv.fr/datasets/cadastre-etalab) in GeoJSON format or shapefiles. The dataset provides the identification and the localization of parcels from the land register.
- Raster data sources: A raster data source provides a matrix of cells (or pixels) where each cell contains a value representing the phenomenon considered by the source. Each cell covers a portion of the Earth’s surface; the size of the cells is defined by the spatial resolution of the raster. Higher spatial resolution involves more cells per unit area. When cells contain class values (e.g., land cover class), the classification must be provided to decode these values.Raster is the standard format of interchange between tools developed in the project, including tools for change detection and land cover classification from Sentinel images. Other formats will be considered in the next development. Our RDF dataset provides data computed from land cover rasters.
- Land cover rasters: Each pixel of land cover rasters provides information about the physical coverage of the Earth’s surface at this place. Coverage may be over forests, grasslands or croplands for instance. Each type of cover is associated with a number according to the specific classification, and the pixel value is set to one of these numbers. There are different sources of land covers, with their classification. A global-scale source is GLC-SHARE (http://www.fao.org/geospatial/resources/detail/en/c/1036591/), created by FAO in 2012, provided in raster format as GeoTIFF files. CLC datasets (https://www.data.gouv.fr/en/datasets/corine-land-cover-occupation-des-sols-en-france) are based on the CLC vocabulary (http://dd.eionet.europa.eu/vocabulary/landcover/clc). The two most recent ones were published for 2012 and 2018. A more specific French land cover is that of CESBIO (http://osr-CESBIO.ups-tlse.fr/~oso/). A new version is provided yearly, starting from 2016 (dataset for 2009, 2010, 2011, and 2014 are also available) in raster format as a GeoTIFF file. In particular, CESBIO-LC is mainly based on Sentinel-2 images acquired all year long, whereas GLC-SHARE combines various EO sources. Moreover, while the GLC-SHARE has global coverage, with a spatial resolution of 1000 m per pixel, CESBIO-LC only covers France with a spatial resolution of 10 m. We selected the CESBIO datasets and the corresponding land cover classification because of its high-quality.
4.2. Semantic ETL Process
- Data retrieval: At this step, the datasets of interest are identified according to spatial and temporal criteria and retrieved using dedicated search mechanisms. This step can be done in a semi-automatic way with the help of dedicated scripts. For example, the dataset containing information of a French village can be retrieved based on its INSEE code and the publication year. In the case of land cover rasters, a detailed description of the land cover classes used to code the raster must also be retrieved. Such a vocabulary is usually described by a text (CESBIO-LC) or PDF file (CLC or GLC-SHARE).
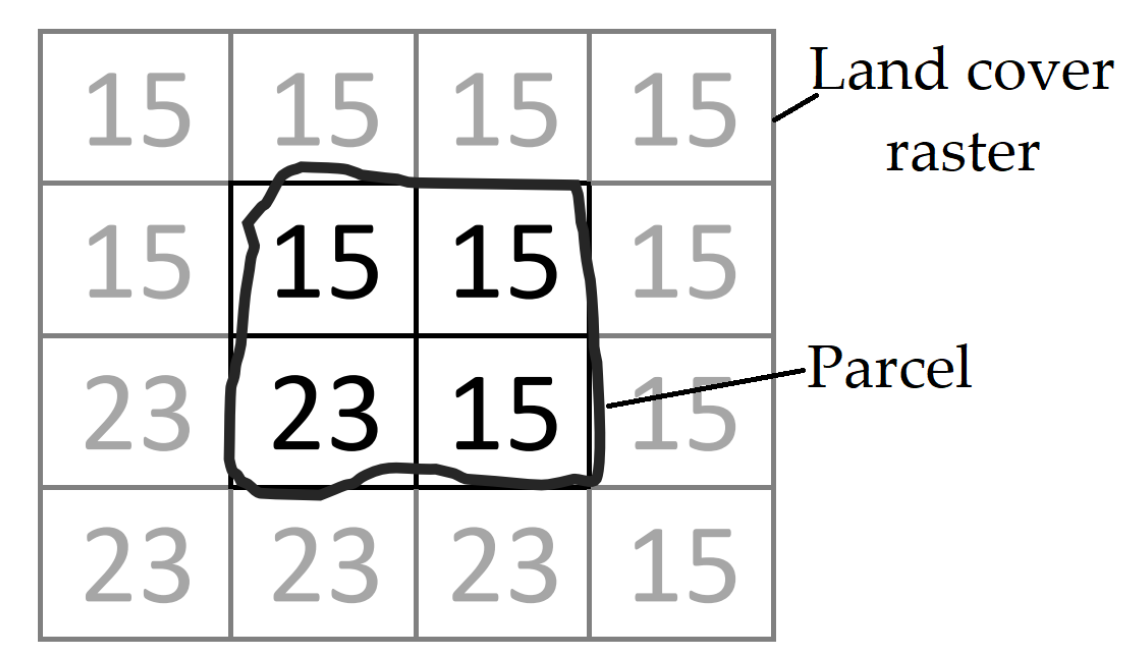
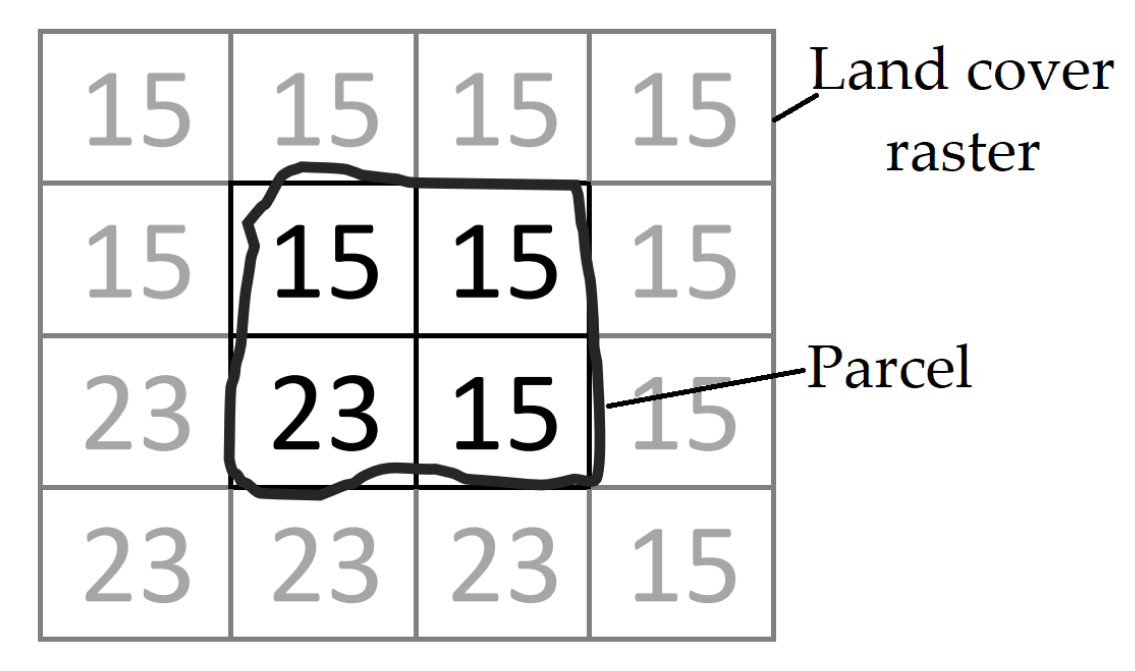
- Data extraction: This step aims at extracting and structuring data from the data sources. Firstly, metadata (e.g., issue date, format, CRS, or spatial extent) is extracted. The, entity geometry in vector files is matched to the WGS84 CRS, which is the default CRS of GeoSPARQL. Rasters are processed to qualify territorial units: either new properties (e.g., mean values) are extracted through pixel aggregation or a spatial mask is used to eliminate undesired areas (i.e., only the area inside the unit footprint is preserved). For example, the land cover of a parcel is computed from a raster in three steps:
- (a)
- Reproject the parcel and the land cover raster onto the same CRS.
- (b)
- Apply the parcel (the geometry of the parcel version at a given date) as a mask on the raster.
- (c)
- Calculate the percentage of each land cover class occupying the parcel. For example in Figure 3, the parcel covers four pixels: three of them are annotated as vineyards (code 15), the last one is water (code 23). In other words, 75% of the parcel are vineyards and the rest is water.
The result of this step is a temporary JSON structure that is used for transformation at the next step. We chose JSON because it can describe both observations and geospatial features. - Data transformation: This step aims at transforming the processed data into a semantic one. Templates defining the mapping between the source schema and the ontologies are used as a basis in this process. They are usually handwritten and make the mappings explicit. Data translation tools, such as D2RQ (http://d2rq.org/), Ultrawrap (https://capsenta.com/ultrawrap/), Morph (http://mayor2.dia.fi.upm.es/oeg-upm/index.php/en/technologies/315-morph-rdb/), Ontop (http://ontop.inf.unibz.it/), or GeoTriples (http://geotriples.di.uoa.gr/) using such mappings can be used. However, we have chosen to evolve the mapping template and processing mechanism of our recent work [27] because more functions can be added to perform more sophisticated operations that are not possible in alternative approaches. The output of this step is a set of RDF files.At this step, the land cover classification (class codes and label) is also transformed into RDF as instances of two classes: tuom:GeoFeatureObservablePropertyType and tuom:GeoFeatureObservableProperty. The transformation process takes as input the classification described by a CSV structure composed of two columns (code and label) and can be independently performed with the one for raster. Appendix A is an example of JSON structure extracted at the previous step.Appendix B presents an extract of the templates used to transform extracted information into RDF format. In these templates, the valueToLiteral function is used to transform a value to literal and the $Instance_X keyword is used to automatically initiate an instance of class X by defining its URI. The variables (begin with $.) represent the values of the JSON representation.Appendix C lists some RDF triples generated from the JSON structure presented in Appendix A using the above templates.
- Data load: the final step consists of importing the RDF files into the triplestore.
4.3. System Architecture
- Strabon extends the Sesame triplestore with the capacity of storing spatial RDF data in the PostgreSQL DBMS enhanced with PostGIS. The triplestore has a good overall performance thanks to particular optimization techniques that allow spatial operations to take advantage of PostGIS functionality instead of relying on external libraries [31]. For complex applications that include both spatial joins or spatial aggregations, Strabon is the only RDF store that performed well [32].
- Strabon also provides a SPARQL endpoint that helps to access the content of the triplestore. The interface also provides an additional possibility to manage the knowledge base, for instance storing and updating functionalities with SPARQL Update.
5. Results and Discussion
5.1. Integration of Time Series Observations
5.2. EO Process Guidance
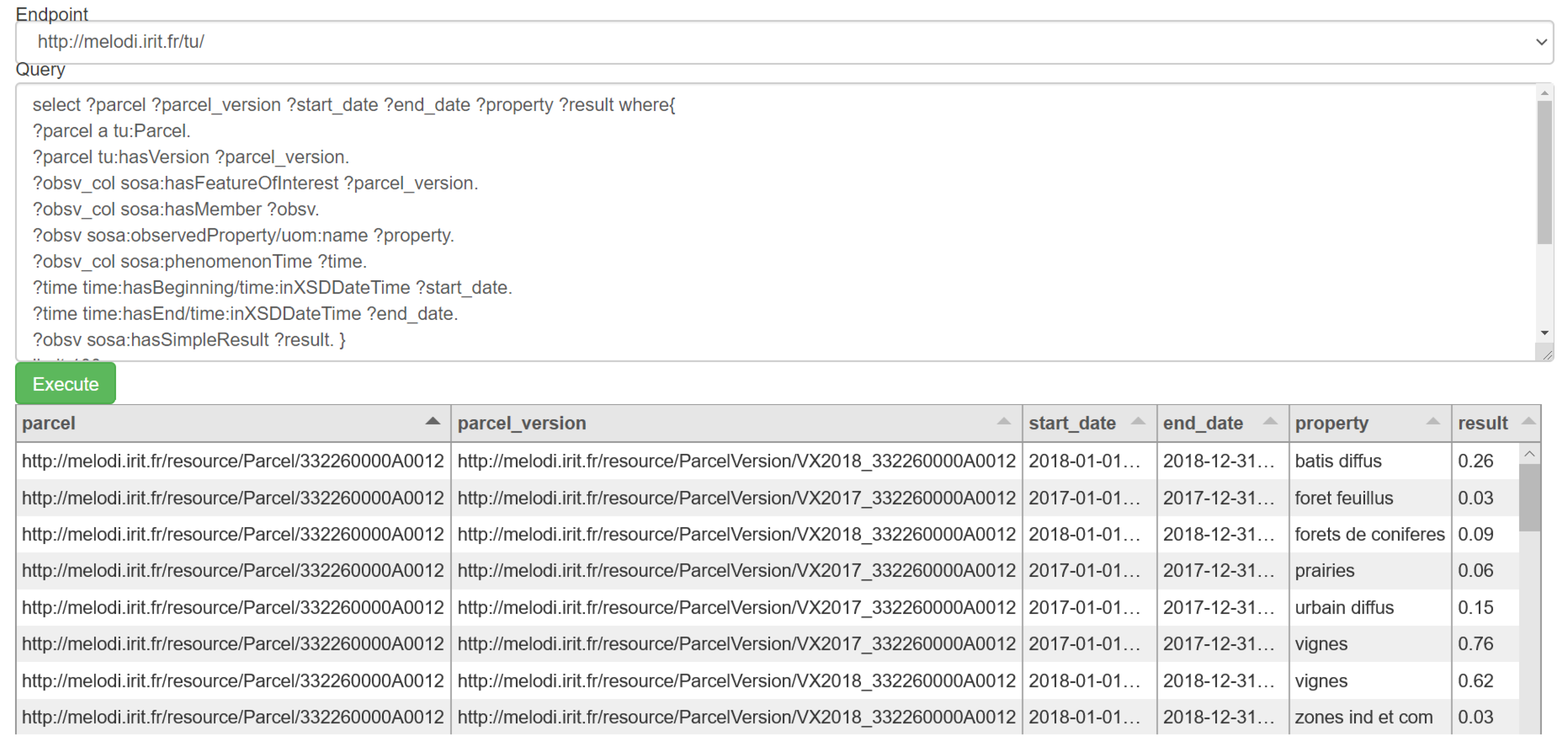
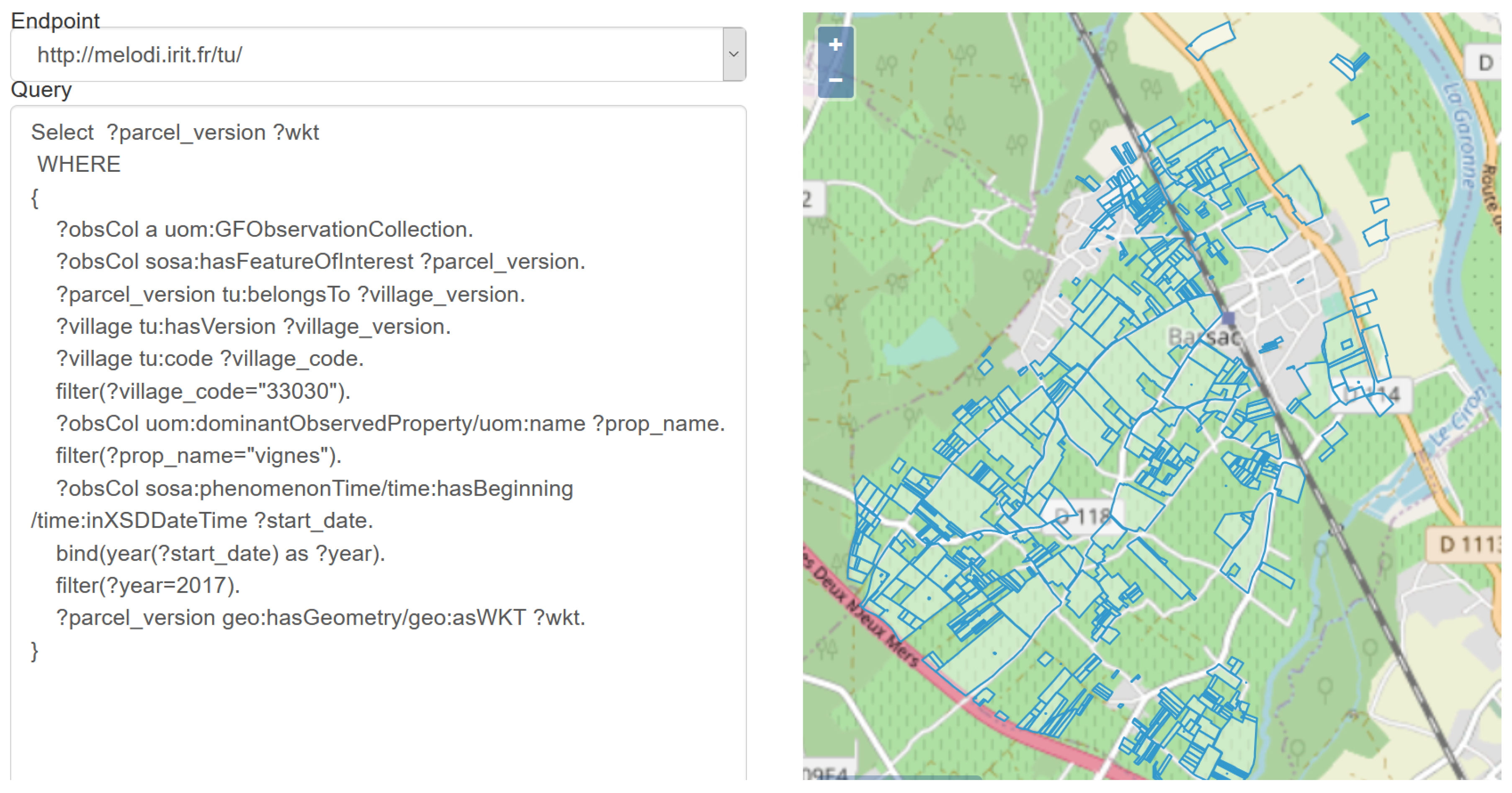
- Change detection in vineyards: the use case aims to detect changes in vineyard vegetation due to natural hazards such as frost or hail. The semantic database can be used to retrieve and locate vineyard parcels through time. Figure 7 illustrates the query and resulting data when querying all vineyard parcels of the Barsac village (code 33030) in 2017. The vineyard parcels are displayed on the map. Having identified the vineyard parcels, one can retrieve the corresponding images for change detection analysis.
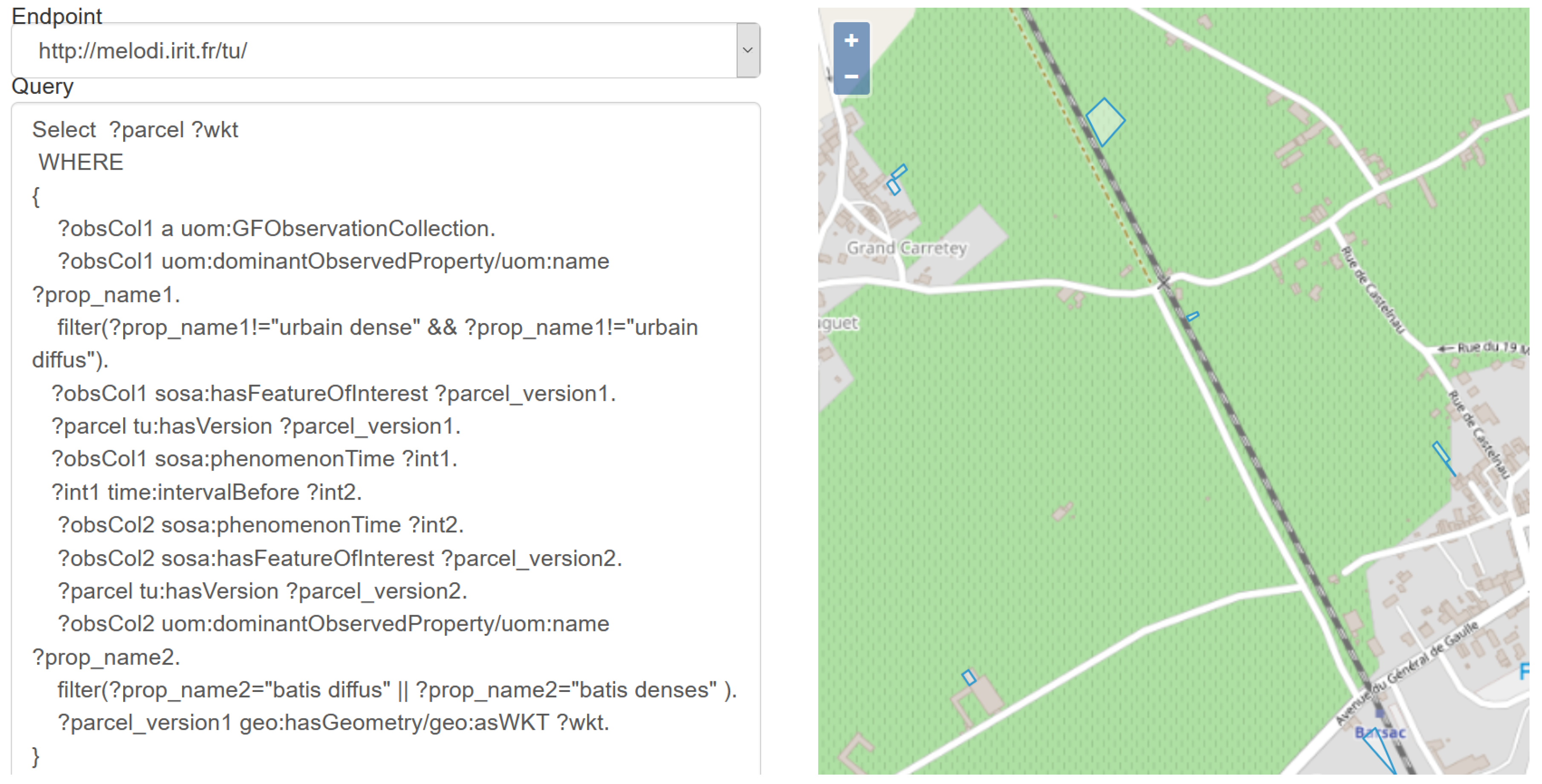
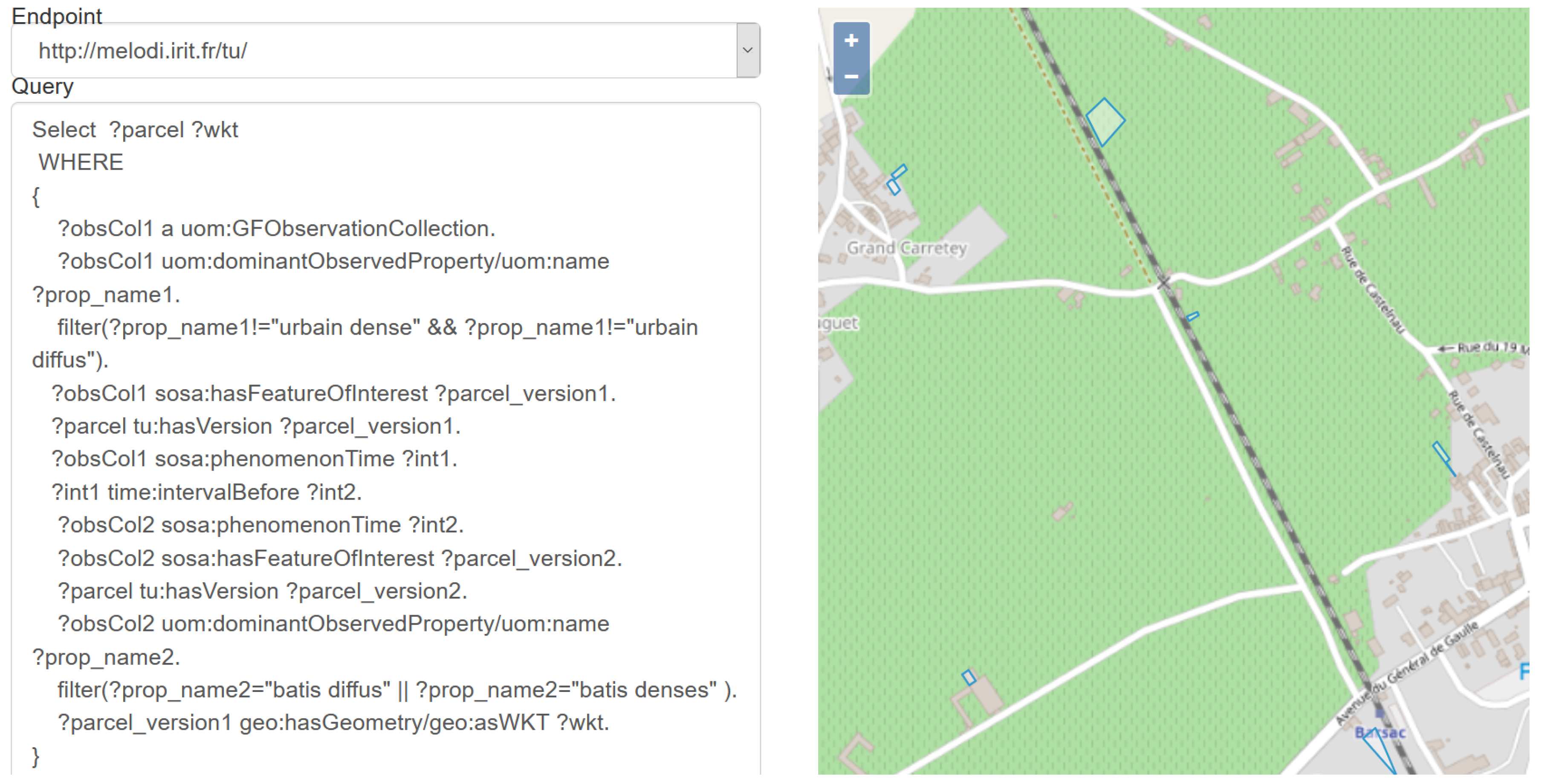
- Urban expansion and agriculture: the use case studies the effect of urban expansion on agricultural areas due to the continuous development of human settlements. Additionally, it tries to analyze the changes in agricultural land covers through time due to the climatic changes that force farmers to shift their crops to achieve higher economic returns. The knowledge base is then exploited as a reference from which agricultural parcels that had been transformed into urban can be queried. Figure 8 demonstrates such a query; transformed parcels located on the northwest of the Barsac village are highlighted on the map (surrounded areas). While this scenario is close to the first use case, here with the land cover indexes being stored for each year, one can identify the parcels that have been impacted by an evolution (land cover evolution).
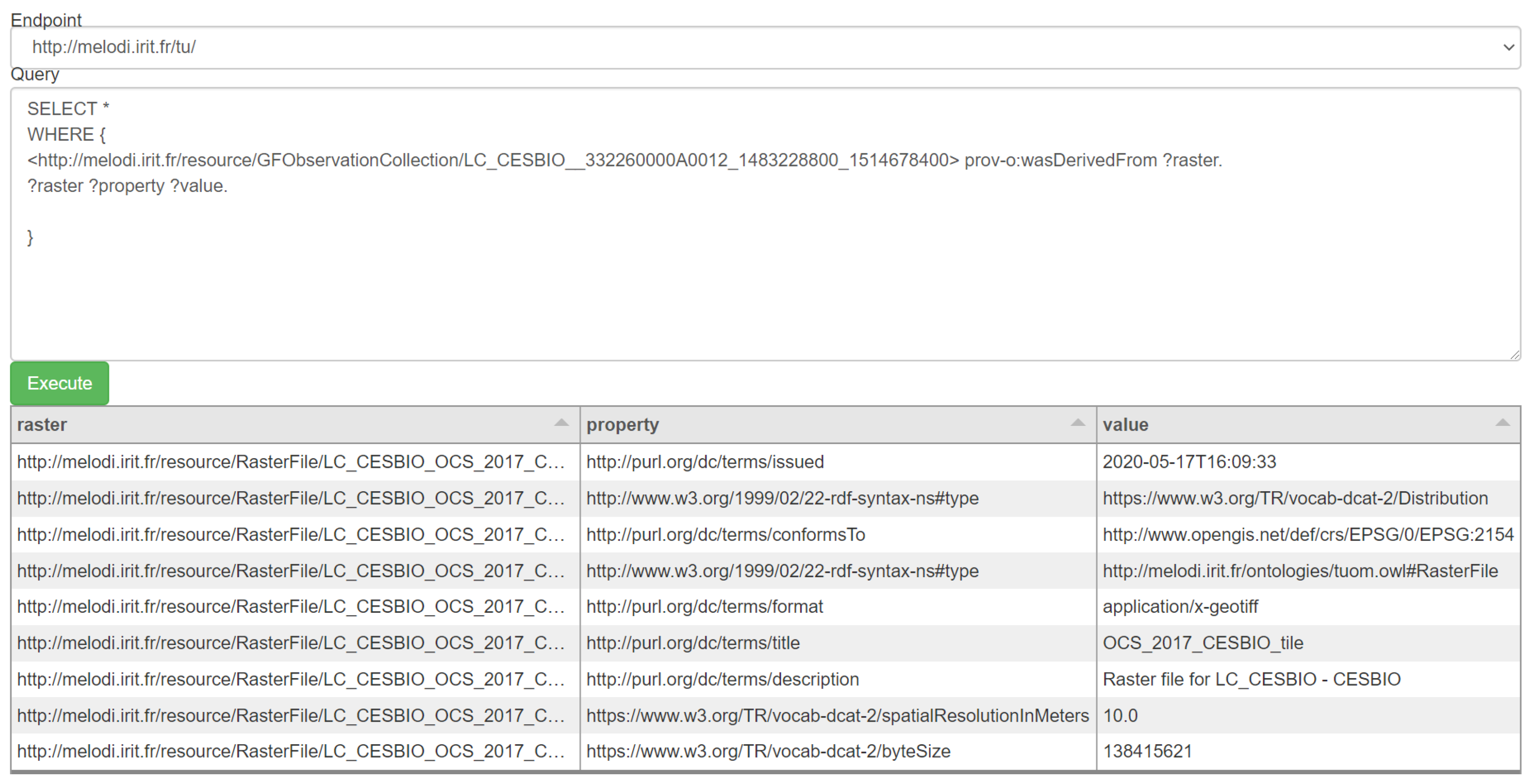
5.3. Data Cross-Comparison
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Data Extraction
{
"type": "LC_CESBIO",
"raster": "LC_CESBIO_OCS_2017_CESBIO_tile",
"foi": "VX2017_330300000A0480",
"startDate": "2017-01-01",
"endDate": "2017-12-31",
"observations": [{
"property": 11,
"result": 0.1
},
{
"property": 31,
"result": 0.9
}
]
}
Appendix B. Data Transformation Templates
Appendix B.1. Template for Administrative Unit Dataset
$Instance a tum:AdminUnit.
$Instance tum:code valueToLiteral($.insee, string).
$Instance tum:hasVersion $Instance_AdminUnitVersion.
$Instance_AdminUnitVersion a tum:AdminUnitVersion.
$Instance_AdminUnitVersion tum:name valueToLiteral($.name, string).
$Instance_AdminUnitVersion tum:area valueToLiteral($.area, float).
$Instance_AdminUnitVersion geo:hasGeometry $Instance_Geometry.
$Instance_Geometry a geo:Geometry.
$Instance_Geometry geo:asWKT valueToLiteral($.wkt, wktLiteral).
Appendix B.2. Template for Parcel Dataset
$Instance a tum:Parcel.
$Instance tum:code valueToLiteral($.id, string).
$Instance tum:contenance valueToLiteral($.contenance, integer).
$Instance tum:hasVersion $Instance_ParcelVersion.
$Instance_ParcelVersion tum:belongsTo valueToInstance($.village,
AdminUnitVersion)
$Instance_ParcelVersion geo:hasGeometry $Instance_Geometry.
$Instance_Geometry a geo:Geometry.
$Instance_Geometry geo:asWKT valueToLiteral($.wkt, wktLiteral).
Appendix B.3. Template for Land Cover Dataset
$Instance a tuom:GFObservationCollection.
$Instance a dcat:Dataset.
$Instance a prov-o:Entity.
$Instance tuom:observedPropertyType valueToInstance($.type,
GFObservablePropertyType).
$Instance prov-o:wasDerivedFrom valueToInstance($.raster, RasterFile).
$Instance sosa:hasFeatureOfInterest valueToInstance($.foi, ParcelVersion).
$Instance sosa:phenomenonTime valueToInterval($.startDate, $.endDate).
#loop
$Instance sosa:hasMember $Instance_GFObservation.
$Instance_GFObservation a tuom:GFObservation.
$Instance_GFObservation sosa:hasSimpleResult valueToLiteral($.result, float).
$Instance_GFObservation sosa:observedProperty
valueToInstance($.property, GFObservableProperty).
Appendix C. Output RDF Data
Appendix C.1. Administrative Unit Data
:AdminUnit/33030
a tum:AdminUnit; tum:code "33030"^^xsd:string;
tum:hasVersion :AdminUnitVersion/V2017_L3_33030.
:AdminUnitVersion/V2017_L3_33030
a tum:AdminUnitVersion; tum:name "Barsac"^^xsd:string; tum:area "1451.0"
^^xsd:float;
geo:hasGeometry :Geometry/V2017_L3_33030.
:AdminUnitVersion/V2018_L3_33030
a tum:AdminUnitVersion; tum:name "Barsac"^^xsd:string; tum:area "1451.0"
^^xsd:float;
geo:hasGeometry :Geometry/V2018_L3_33030.
:Geometry/V2017_L3_33030 geo:asWKT "POLYGON ((..))".
:Geometry/V2018_L3_33030 geo:asWKT "POLYGON ((..))".
Appendix C.2. Parcel Data
:Parcel/330300000A0480
a tum:Parcel; tum:code "330300000A0480"^^xsd:string; tum:contenance
"64120"^^xsd:integer;
tum:hasVersion :ParcelVersion/VX2017_330300000A0480;
tum:hasVersion :ParcelVersion/VX2018_330300000A0480.
:ParcelVersion/VX2017_330300000A0480
a tum:ParcelVersion; tum:belongsTo :AdminUnitVersion/V2017_L3_33030;
geo:hasGeometry :Geometry/VX2017_330300000A0480.
:ParcelVersion/VX2018_330300000A0480
a tum:ParcelVersion; tum:belongsTo :AdminUnitVersion/V2018_L3_33030;
geo:hasGeometry :Geometry/VX2018_330300000A0480.
:Geometry/VX2018_330300000A0480 geo:asWKT "POLYGON ((..))". :Geometry/VX2017_330300000A0480 geo:asWKT "POLYGON ((..))".
Appendix C.3. Land Cover Data
#Land cover observations for 2017
:GFObservationCollection/LC_CESBIO__330300000A0480_1483228800_1514678400
a tuom:GFObservationCollection; a dcat:Dataset; a prov-o:Entity;
tuom:observedPropertyType :GFObservablePropertyType/LC_CESBIO;
prov-o:wasDerivedFrom :RasterFile/LC_CESBIO_OCS_2017_CESBIO_tile;
sosa:hasFeatureOfInterest :ParcelVersion/VX2017_330300000A0480;
sosa:phenomenonTime :Interval/1483228800_1514678400;
sosa:hasMember :GFObservation/LC_CESBIO__330300000A0480_11_1483228800_
1514678400;
sosa:hasMember :GFObservation/LC_CESBIO__330300000A0480_31_1483228800_
1514678400.
:GFObservation/LC_CESBIO__330300000A0480_11_1483228800_1514678400
a tuom:GFObservation; sosa:hasSimpleResult "0.1"^^xsd:float;
sosa:observedProperty :GFObservableProperty/LC_CESBIO_11.
:GFObservation/LC_CESBIO__330300000A0480_31_1483228800_1514678400
a tuom:GFObservation; sosa:hasSimpleResult "0.9"^^xsd:float;
sosa:observedProperty:GFObservableProperty/LC_CESBIO_31.
:GFObservableProperty/LC_CESBIO_11 tuom:name "culture ete"^^xsd:string. :GFObservableProperty/LC_CESBIO_31 tuom:name "foret feuillus"^^xsd:string.
#Land cover observations for 2018
:GFObservationCollection/LC_CESBIO18_330300000A0480_1514764800_1546214400
a tuom:GFObservationCollection; a dcat:Dataset; a prov-o:Entity;
tuom:observedPropertyType :GFObservablePropertyType/LC_CESBIO18;
prov-o:wasDerivedFrom :RasterFile/LC_CESBIO_OCS_2018_CESBIO_tile;
sosa:hasFeatureOfInterest :ParcelVersion/VX2018_330300000A0480;
sosa:phenomenonTime :Interval/1514764800_1546214400;
sosa:hasMember :GFObservation/LC_CESBIO18_330300000A0480_10_1514764800_
1546214400;
sosa:hasMember :GFObservation/LC_CESBIO18_330300000A0480_16_1514764800_
1546214400.
:GFObservation/LC_CESBIO18_330300000A0480_10_1514764800_1546214400
a tuom:GFObservation; sosa:hasSimpleResult "0.12"^^xsd:float;
sosa:observedProperty :GFObservableProperty/LC_CESBIO18_10.
:GFObservation/LC_CESBIO18_330300000A0480_16_1514764800_1546214400
a tuom:GFObservation; sosa:hasSimpleResult "0.88"^^xsd:float;
sosa:observedProperty:GFObservableProperty/LC_CESBIO18_16.
:GFObservableProperty/LC_CESBIO18_10 tuom:name "mais"^^xsd:string. :GFObservableProperty/LC_CESBIO18_16 tuom:name "forets de feuillus"^^xsd:string.
References
- Villegas, J.; Sánchez Pastor, H.; Hernanz, L.; Checa, M.; Roman, D. Enabling the Use of Sentinel-2 and LiDAR Data for Common Agriculture Policy Funds Assignment. Int. J. Geo-Inf. 2017, 6, 255. [Google Scholar]
- Lambin, E.; Geist, H. Land-Use and Land-Cover Change; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Espinoza-Molina, D.; Nikolaou, C.; Dumitru, C.O.; Bereta, K.; Koubarakis, M.; Schwarz, G.; Datcu, M. Very-High-Resolution SAR Images and Linked Open Data Analytics Based on Ontologies. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1696–1708. [Google Scholar] [CrossRef] [Green Version]
- Dumitru, C.; Schwarz, G.; Datcu, M. Land Cover Semantic Annotation Derived from High-Resolution SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2215–2232. [Google Scholar] [CrossRef] [Green Version]
- Bergamaschi, S.; Guerra, F.; Orsini, M.; Sartori, C.; Vincini, M. A semantic approach to ETL technologies. Data Knowl. Eng. 2011, 70, 717–731. [Google Scholar] [CrossRef]
- Tran, B.H.; Aussenac-Gilles, N.; Comparot, C.; Trojahn, C. An Approach for Integrating Earth Observation, Change Detection and Contextual Data for Semantic Search. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Waikoloa, HI, USA, 19–24 July 2020. [Google Scholar]
- Zinke, C.; Ngomo, A.C.N. Discovering and Linking Spatio-Temporal Big Linked Data. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 411–414. [Google Scholar]
- Brizhinev, D.; Toyer, S.; Taylor, K.; Zhang, Z. Publishing and Using Earth Observation Data with the RDF Data Cube and the Discrete Global Grid System; Technical Report; W3C and OGC: Wayland, MA, USA, 2017. [Google Scholar]
- Lefort, L.; Bobruk, J.; Haller, A.; Taylor, K.; Woolf, A. A Linked Sensor Data Cube for a 100 Year Homogenised Daily Temperature Dataset. In Proceedings of the 5th International Workshop on Semantic Sensor Networks, Boston, MA, USA, 12 November 2012; pp. 1–16. [Google Scholar]
- Augustin, H.; Sudmanns, M.; Tiede, D.; Lang, S.; Baraldi, A. Semantic Earth observation data cubes. Data 2019, 4, 102. [Google Scholar] [CrossRef] [Green Version]
- Bereta, K.; Caumont, H.; Daniels, U.; Goor, E.; Koubarakis, M.; Pantazi, D.A.; Stamoulis, G.; Ubels, S.; Venus, V.; Wahyudi, F. The Copernicus App Lab project: Easy Access to Copernicus Data. In Proceedings of the 22nd International Conference on Extending Database Technology (EDBT), Lisbon, Portugal, 26–29 March 2019. [Google Scholar]
- Abburu, S.; Dube, N.; Nayak, M.R.; Golla, S. An Ontology Based Methodology for Satellite Data Semantic Interoperability. Adv. Electr. Comput. Eng. 2015, 15, 105–110. [Google Scholar] [CrossRef]
- Blower, J.; Clifford, D.; Goncalves, P.; Koubarakis, M. The MELODIES project: Integrationg diverse data using linked data and cloud computing. In Proceedings of the 2014 conference on Big Data from Space (BiDS’14), Frascati, Italy, 12–14 November 2014; pp. 244–247. [Google Scholar]
- Sukhobok, D.; Sanchez, H.; Estrada, J.; Roman, D. Linked Data for Common Agriculture Policy: Enabling Semantic Querying over Sentinel-2 and LiDAR Data. In Proceedings of the ISWC 2017 Posters & Demonstrations and Industry Tracks co-located with 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, 23–25 October 2017; Available online: http://ceur-ws.org/Vol-1963/##paper559 (accessed on 20 August 2020).
- Alirezaie, M.; Kiselev, A.; Längkvist, M.; Klügl, F.; Loutfi, A. An Ontology-Based Reasoning Framework for Querying Satellite Images for Disaster Monitoring. Sensors 2017, 17, 2545. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Masmoudi, M.; Taktak, H.; Ben Abdallah Ben Lamine, S.; Boukadi, k.; Karray, M.H.; Baazaoui Zghal, H.; Archimede, B.; Mrissa, M.; Guegan, C.G. PREDICAT: A Semantic Service-Oriented Platform for Data Interoperability and Linking in Earth Observation and Disaster Prediction. In Proceedings of the SOCA 2018: The 11th IEEE International conference on service oriented computing and applications, Paris, Fance, 20–22 November 2018; pp. 194–201. [Google Scholar]
- Andrejev, A.; Misev, D.; Baumann, P.; Risch, T. Spatio-Temporal Gridded Data Processing on the Semantic Web. In Proceedings of the DSDIS 2015—2015 IEEE International Conference on Data Science and Data Intensive Systems, Sidney, Australia, 13–15 December 2015; pp. 38–45. [Google Scholar]
- Bereta, K.; Xiao, G.; Koubarakis, M. Ontop-spatial: Ontop of geospatial databases. J. Web Semant. 2019, 58, 100514. [Google Scholar] [CrossRef]
- Arocena, J.; Lozano, J.; Quartulli, M.; Olaizola, I.; Bermudez, J. Linked open data for raster and vector geospatial information processing. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 18–25 July 2015; pp. 5023–5026. [Google Scholar]
- Homburg, T.; Prudhomme, C.; Würriehausen, F.; Karmacharya, A.; Boochs, F.; Roxin, A.; Cruz, C. Interpreting Heterogeneous Geospatial Data Using Semantic Web Technologies. In Proceedings of the International Conference on Computational Science and Its Applications, Beijing, China, 4–7 July 2016; pp. 240–255. [Google Scholar]
- Nishanbaev, I.; Champion, E.; Mcmeekin, D. A Survey of Geospatial Semantic Web for Cultural Heritage. Heritage 2019, 2, 1471–1498. [Google Scholar] [CrossRef] [Green Version]
- Bernard, C.; Villanova-Oliver, M.; Gensel, J.; Dao, H. Modeling Changes in Territorial Partitions over Time: Ontologies TSN and TSN-change. In Proceedings of the SAC’18: The 33rd Annual ACM Symposium on Applied Computing, Pau, France, 9–13 April 2018; pp. 866–875. [Google Scholar] [CrossRef]
- Kolas, D.; Perry, M.; Herring, J. Getting Started with GeoSPARQL; Technical Report; OGC: Wayland, MA, USA, 2013. [Google Scholar]
- Hobbs, J.R.; Pan, F. An ontology of time for the semantic web. ACM Trans. Asian Lang. Inf. Process. 2004, 3, 66–85. [Google Scholar] [CrossRef]
- Janowicz, K.; Haller, A.; Cox, S.J.; Phuoc, D.L.; Lefrançois, M. SOSA: A lightweight ontology for sensors, observations, samples, and actuators. J. Web Semant. 2019, 56, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Welty, C.; Fikes, R. A Reusable Ontology for Fluents in OWL. In Proceedings of the FOIS 2006: The 4th International Conference on Formal Ontology in Information Systems, Amsterdam, NL, USA, 9–11 November 2006; IOS Press: Baltimore, MD, USA; pp. 226–236. [Google Scholar]
- Arenas, H.; Aussenac-Gilles, N.; Comparot, C.; Trojahn, C. Semantic Integration of Geospatial Data from Earth Observations. In Proceedings of the EKAW 2016 Satellite Events—20th International Conference on Knowledge Engineering and Knowledge Management, Bologna, Italy, 19–23 November 2016; pp. 97–100. [Google Scholar]
- Battle, R.; Kolas, D. Enabling the Geospatial Semantic Web with Parliament and GeoSPARQL. Semant. Web 2012, 3, 355–370. [Google Scholar] [CrossRef]
- Kyzirakos, K.; Karpathiotakis, M.; Koubarakis, M. Strabon: A Semantic Geospatial Dbms. In The Semantic Web ISWC 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 295–311. [Google Scholar]
- Scheider, S.; Degbelo, A.; Lemmens, R.; van Elzakker, C.; Zimmerhof, P.; Kostic, N.; Jones, J.; Banhatti, G. Exploratory querying of SPARQL endpoints in space and time. Semant. Web 2017, 8, 65–86. [Google Scholar] [CrossRef]
- Patroumpas, K.; Giannopoulos, G.; Athanasiou, S. Towards GeoSpatial Semantic Data Management: Strengths, Weaknesses, and Challenges Ahead. In Proceedings of the SIGSPATIAL’14: 22nd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; pp. 301–310. [Google Scholar]
- Ioannidis, T.; Garbis, G.; Kyzirakos, K.; Bereta, K.; Koubarakis, M. Evaluating Geospatial RDF stores Using the Benchmark Geographica 2. arXiv 2019, arXiv:1906.01933. [Google Scholar]
- Dumitru, C.O.; Schwarz, G.; Pulak-Siwiec, A.; Kulawik, B.; Lorenzo, J.; Datcu, M. Earth Observation Data Mining: A Use Case for Forest Monitoring. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 5359–5362. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Presented Work | Main Reused Ontologies | Published | Reusable | Temporality | Source Metadata | Query Language | Raster Support |
|---|---|---|---|---|---|---|---|
| [3] | stModel | X | stSPARQL | X | |||
| [11] | GeoSPARQL OWL-Time Data Cube | X | X | X | GeoSPARQL | ||
| [13] | stModel | X | stSPARQL | ||||
| [14] | GeoSPARQL Data Cube, DUL | X | X | GeoSPARQL | |||
| [15] | GeoSPARQL DUL | GeoSPARQL | X | ||||
| [16] | SSN, CCO BFO, ENVO | X | X | X | SPARQL | ||
| [17] | none | X | SciSPARQL | X | |||
| [18] | GeoSPARQL | GeoSPARQL | X | ||||
| [19] | GeoSPARQL | GeoSPARQL | X | ||||
| [20] | GeoSPARQL | X | GeoSPARQL | X | |||
| Ours | GeoSPARQL OWL-Time SOSA, PROV-O TSN | X | X | X | X | GeoSPARQL | X |
| Presented Work | Integration Approach | Vector Input | Raster Representation | Storage |
|---|---|---|---|---|
| [3] | Materialization | Entities based extraction (Fixed patches) | RDB->Strabon | |
| [15] | Unknown | Entities based extraction | Unknown | |
| [17] | Materialization | Coverage | Array | |
| [18] | On-demand mapping | Coverage | PostGIS | |
| [19] | Materialization | X | Entities based extraction | Strabon |
| [20] | On-demand mapping | Entities based extraction (Polygonizing) | RDB | |
| Ours | Materialization | X | Entities based extraction | Strabon |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, B.-H.; Aussenac-Gilles, N.; Comparot, C.; Trojahn, C. Semantic Integration of Raster Data for Earth Observation: An RDF Dataset of Territorial Unit Versions with their Land Cover. ISPRS Int. J. Geo-Inf. 2020, 9, 503. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9090503
Tran B-H, Aussenac-Gilles N, Comparot C, Trojahn C. Semantic Integration of Raster Data for Earth Observation: An RDF Dataset of Territorial Unit Versions with their Land Cover. ISPRS International Journal of Geo-Information. 2020; 9(9):503. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9090503
Chicago/Turabian StyleTran, Ba-Huy, Nathalie Aussenac-Gilles, Catherine Comparot, and Cassia Trojahn. 2020. "Semantic Integration of Raster Data for Earth Observation: An RDF Dataset of Territorial Unit Versions with their Land Cover" ISPRS International Journal of Geo-Information 9, no. 9: 503. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9090503