1. Introduction
Every year in Portugal thousands of hectares of forest are consumed by fires causing environmental, infrastructural, and personal damages [
1]. With the purpose to minimize the damages caused by fires, the Portuguese government established Fuel Management Zones (FMZs), which are zones where the vegetation has to be treated, meaning the removal or partially removal of vegetation, to protect different types of infrastructures and to also work as strategic points for fighting fires [
2,
3]. Since responsibility of the treatment of FMZs falls onto who owns a certain terrain, like like citizens, private entities, as well as counties, actively monitoring the treatments of FMZs is critical. The National Republican Guard is responsible for the monitoring of the FMZs.
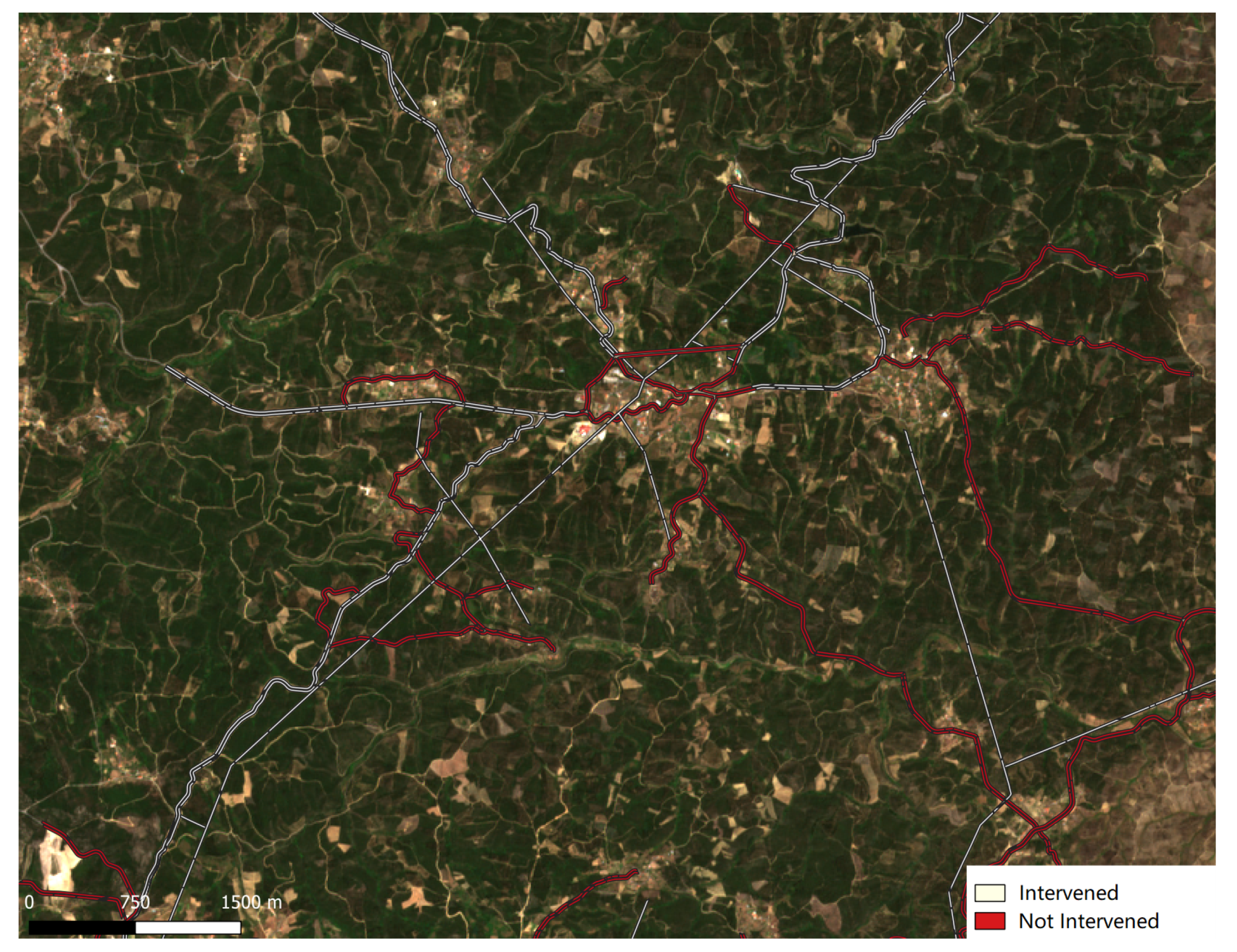
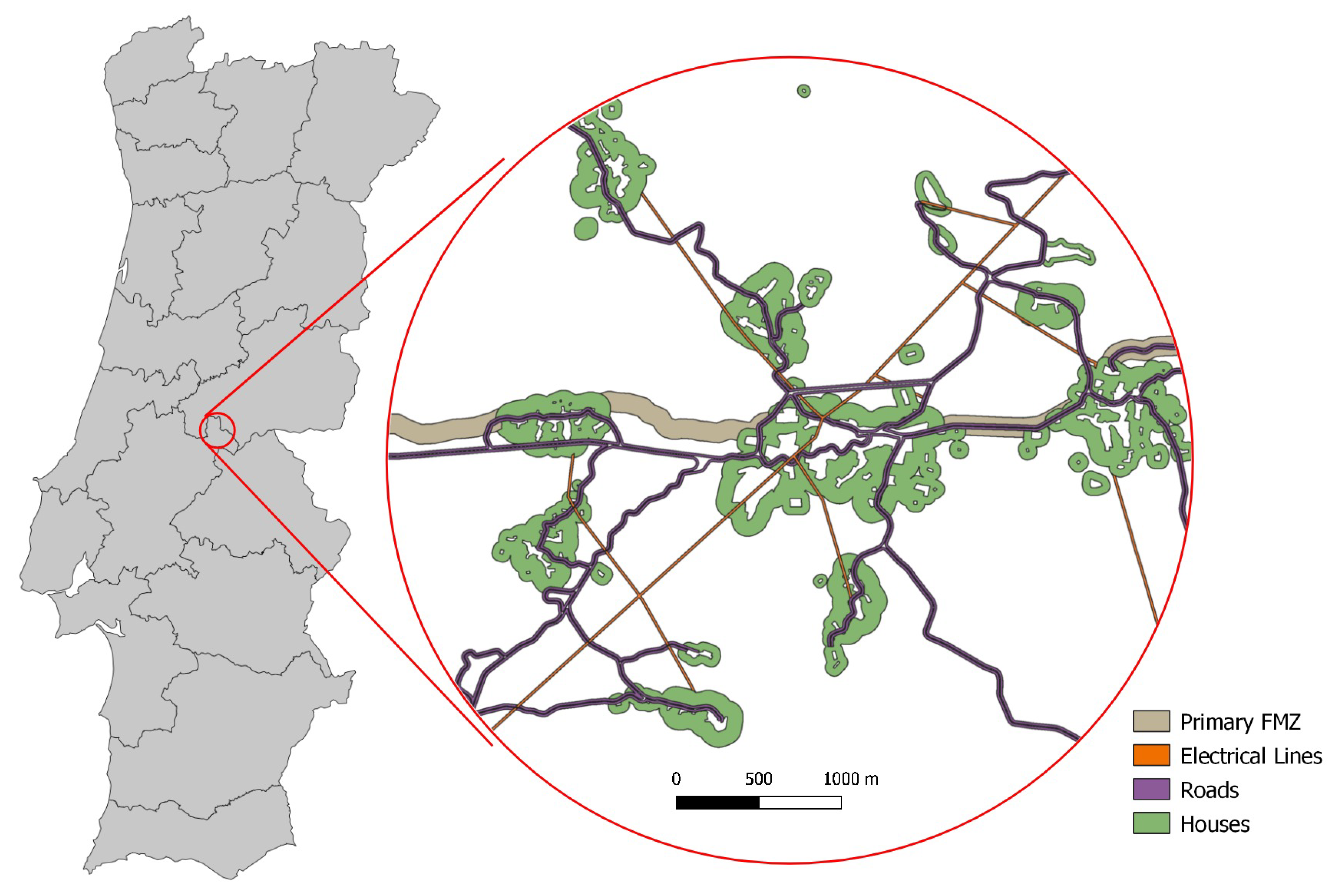
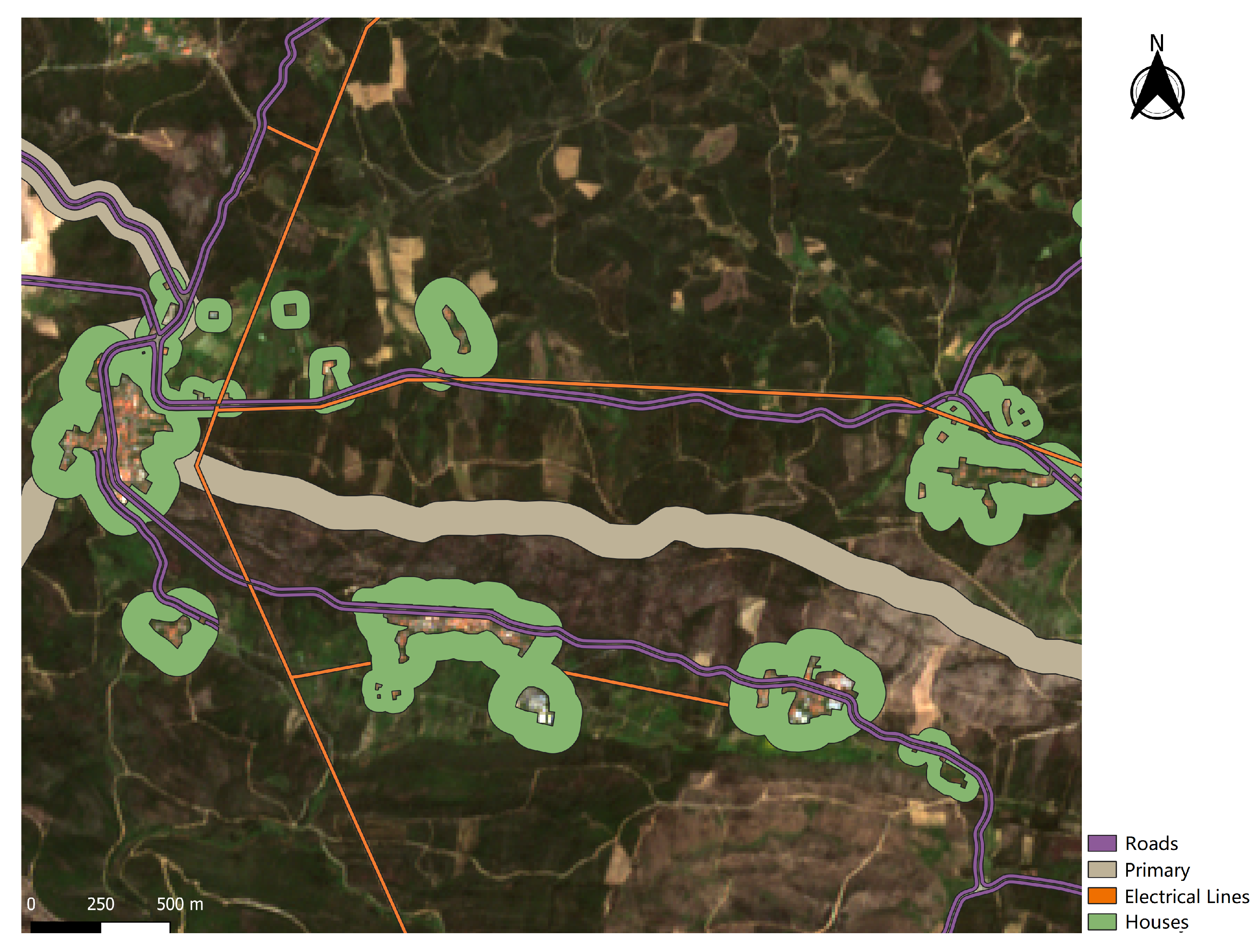
FMZs cover a large part of the Portuguese territory forming a three-level network: Primary Network, Secondary Network, and Tertiary Network. The primary network is defined at the district level, while secondary and tertiary networks are defined at the municipal and local levels. Furthermore, the interventions made in these zones are classified as follows: Fuel Reduction Zones (FRZs) and Fuel Interruption Zones (FIZs). FRZs are characterized by the removal of surface vegetation and the cutting of trees to create a separation between cups. FIZs consist of the total removal of all types of vegetation within the defined range [
4].
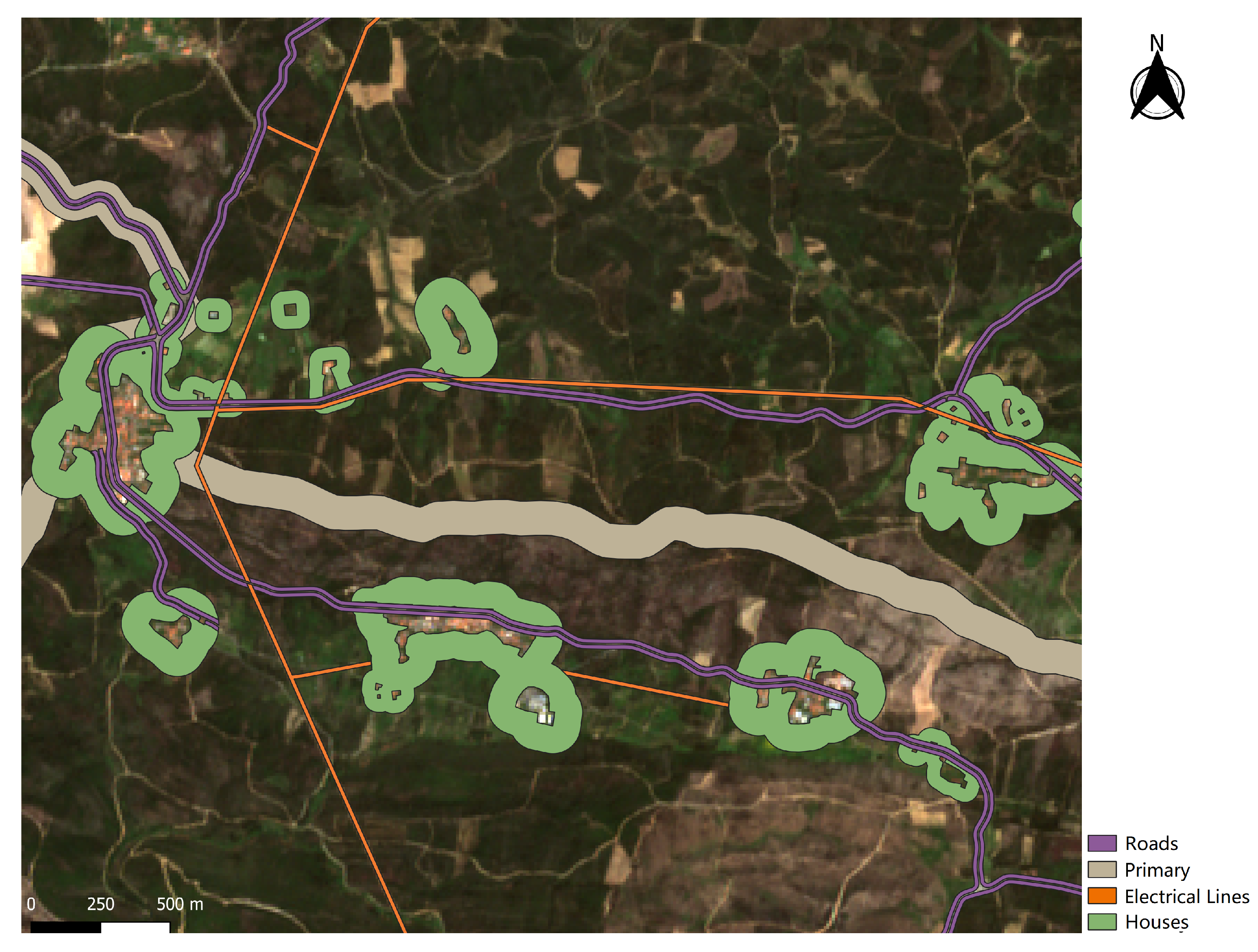
The primary FMZ covers a large part of the Portuguese territory, dividing it into plots with a size between 500 ha and 10,000 ha. This network consists of 125 m wide strips. Beyond reducing the area traveled by forest fires, these strips are also an auxiliary element in the planning of firefighting, since this network is built in strategic areas. The secondary and tertiary FMZs are defined around roads, tracks, powerlines, railways, and settlements. These networks are part of the Municipal Plan for the Defense of Forests Against Fires. The strips created along roads, tracks, and railways are of the FIZ type. Strips around individual houses and settlements are also FIZ types with the addition that the canopy of trees must be more than 5 m apart from the dwellings. High and medium voltage electrical distribution lines and natural gas transmission lines are also part of these networks.
Since FMZs can have huge extensions (thousands of hectares), it can be difficult for the authorities to monitor these zones and identify which ones require intervention. The existence of automatic or semi-automatic processes that allow the identification of FMZs that were treated, could help the monitoring process, speeding up the detection of zones in need of intervention, thus allowing timely maintenance and increasing the overall protection against forest fires. The use of machine- learning methods applied to remote sensing for large scale geographical analysis is common [
5,
6,
7,
8]. The Institute for the Conservation of Nature and Forests (ICNF) maintains the geographical information about FMZs and makes this information publicly available. Combining this information with publicly available satellite imagery from satellites such as Sentinel-1 and Sentinel-2 that that capture images with resolutions up to 10 by 10 m, opens up the possibility of integrating new methods that use remote detection in the FMZs monitoring process.
The FMZs must be treated every year so that during the fire season the vegetation inside is as reduced as possible so that these zones fulfill their purpose. The high extent of these zones and the fact that a large part of the FMZs intersects with private land can hinder the cleaning process and generate discontinuities in the treated areas of the FMZs. These factors make monitoring the treated zones or detecting zones in need of intervention a complex problem.
Although forest fires are a serious problem, there has not been extensive research into the monitoring process of FMZs. In [
9], the Normalized Difference Vegetation Index (NDVI) was used, along with geographic information of roads and agricultural fields, to identify FMZs. In a different context, the work of [
10] compared the precision of three digital surface models to estimate the elevation of the terrain in the areas that concern FMZs, in a northern part of Greece.
There are several approaches regarding crop and vegetation monitoring and biomass estimation that can be used as a basis to build a robust solution for the monitoring of FMZs. Some studies in which the focus is to classify types of crops [
8,
11,
12], others that classify tree species in forest areas [
8], and also a more comprehensive classification approaches that focus on distinguishing different types of land cover (e.g., forest, urban, agricultural areas, etc.) [
5,
13,
14]. Some studies only use data from satellite bands directly [
5,
8], although in most cases vegetation indices are used as indicators of vegetation characteristics. Some works use time series to extract more information about vegetation [
11,
14,
15]. The use of time series has already shown better results in the classification of vegetation and land cover than the use of data referring to only one date [
14,
16].
There are also some studies in which the dimension and the characteristics of the analyzed areas are similar to those of FMZs [
17,
18]. Immitzer et al. [
8] classified the vegetation in an agricultural area and a forest area using the Random Forests. In the agricultural area, 8 types of crops were classified and in the forest area 6 species of trees. Two approaches were compared: pixel-based and object-based, and it was observed that in the forest area the object-based approach obtained better results. Clevers et al. [
17] used Sentinel-2 data and vegetation indices to analyze areas similar to the size of FMZs, with 30 by 30 m. Also using the same data type Rozenstein et al. [
19] found that there is a strong correlation (
) between the NDVI and the water consumption of that plant, which may be helpful when analyzing the state of vegetation in an FMZ. Other studies attempt to estimate the production of a given crop following indicators such as Leaf Area Index (LAI) and vegetation indices [
20,
21]. Setiyono et al. [
21] used Synthetic Aperture Radar (SAR) data from Sentinel-1 and multispectral data from the MODIS satellite to estimate rice production, compared to data obtained in the field, obtaining errors of less than 10%. Castillo et al. [
22] used Sentinel-2, Sentinel-1, and elevation data, along with some vegetation indices to estimate the amount of biomass present in mangrove forests in the Philippines. The results showed a correlation between the levels of biomass with some vegetation indices and the LAI.
All the information presented in these works serves as a knowledge base to establish an adequate strategy to carry out the classification of interventions and monitoring the state of vegetation in FMZs. This paper presents an automated machine- learning approach that leverages time series to detect if an FMZs was treated or not using open satellite data at a resolution of 10 by 10 m. To the best of our knowledge, this is the first work that proposes a machine- learning approach to detect if the FMZs are maintained according to the law. Machine learning combined with remote sensing can accelerate the process of monitoring these FMZs which otherwise would be time-consuming. Furthermore, the monetary costs associated with the manual labor required to monitor the FMZs could be mitigated by using open satellite data. The contributions from this paper are as follows: (1) a methodology for detecting interventions in FMZs is presented, which uses information about vegetation present inside and outside the FMZs. This approach can be used to analyze any FMZ type that roughly follows the specifications, dimensions, shape, and purpose; (2) a set of software tools that given the vector information about the FMZs and a set of satellite images can extract metrics from the time- series patterns, and estimate if the FMZs was or not maintained properly with a high degree of accuracy.
This paper is organized as follows:
Section 2 describes the experimental processing pipeline, showing how the data was acquired and processed, how the FMZs were clustered, and how the data sets were created.
Section 3 shows and compares the results by pairing multiple algorithms with different data sets. Finally,
Section 4 and
Section 5 presents the discussion and conclusions.
3. Results
In this section, the results for both the static analysis (one date only,
Section 3.1) and temporal analysis (time-series data from 2018,
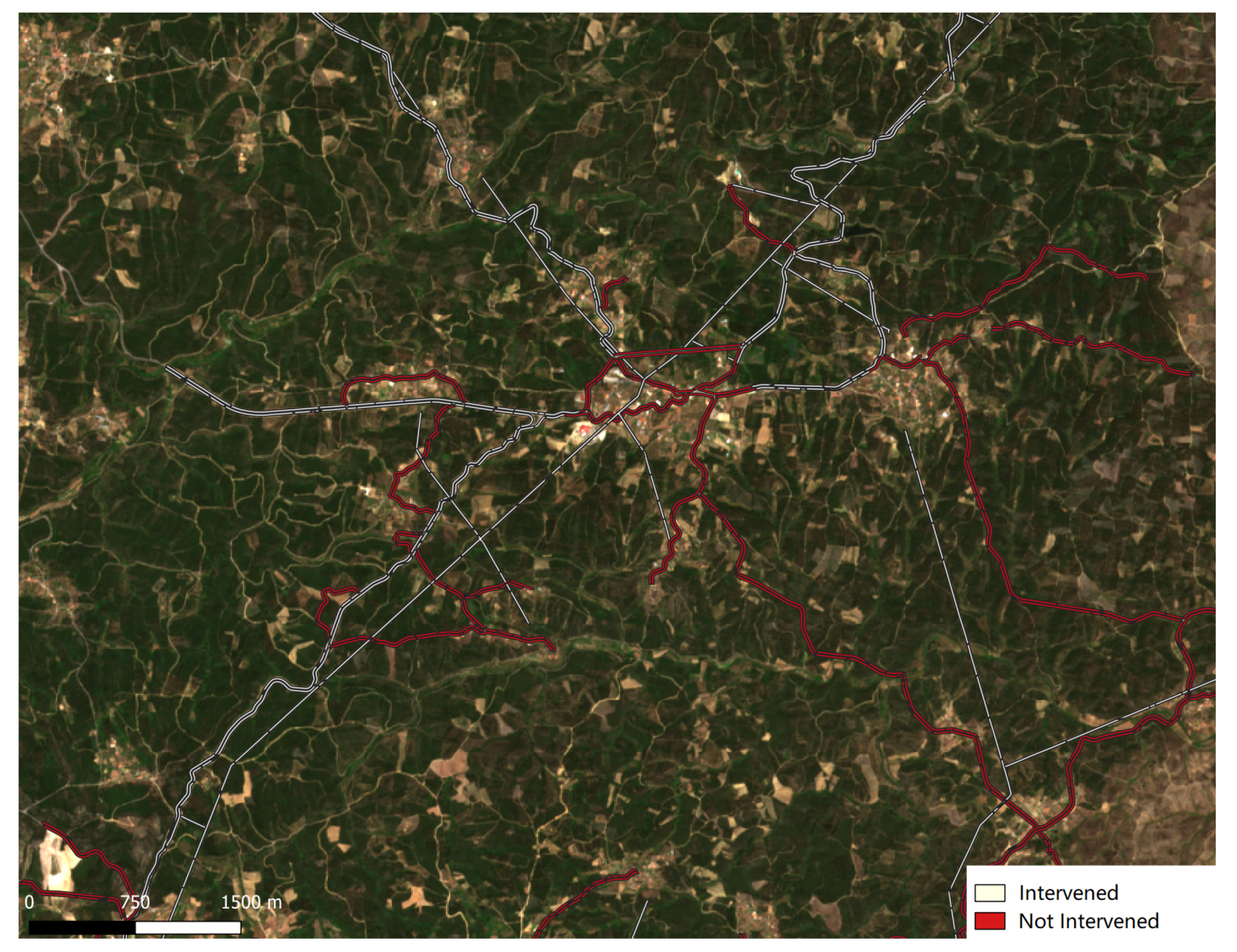
Section 3.2) are presented for roads. Other types of FMZ were left out a more detailed analyses due to uncertainty and absence of ground truth. For both types of analysis, the four chosen algorithms (KNN, RF, SVM, and XGBoost) were trained on all the defined data sets. Furthermore, all experiences of temporal analysis were repeated with and without Sentinel-1 data, as this allowed the assessment of the impact that radar data has in the detection of FMZs interventions. Both the code and the data used to obtain these results are available online at
https://bitbucket.org/rfafonso/fuel-management-zones-interventions/commits/cef0be1.
3.1. Static Analysis
The first analysis consists of comparing different data sets using only Sentinel-2 data from just one date, 12 September, this is the date closest to our ground truth.
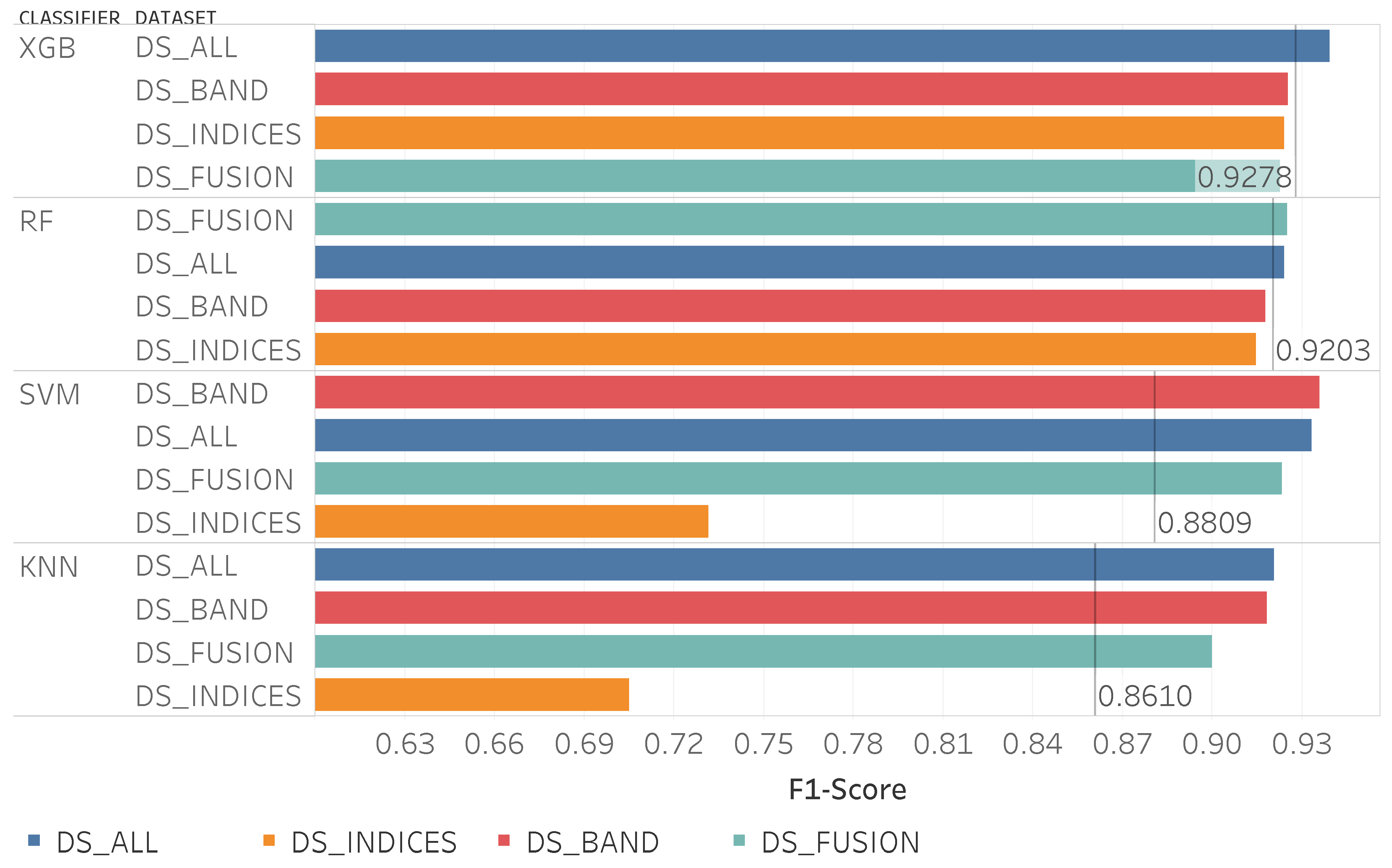
Figure 9 shows the F1-score values for the used algorithms and the different data sets, note that the data sets are sorted by performance and by model. The RF and XGBoost were the algorithms that achieved better results, with RF reaching slightly better values.
The data set DS_ALL consistently delivered good results for all the algorithms and the best result was achieved using this data set with the RF algorithm. The data set choice, in this case, can have a great impact on the results, in some cases, it has an impact in the F1-score superior to 4%. The lowest result was obtained using the data set DS_INDICES with SVM, resulting in an F1-score of 0.83.
Analyzing in more detail the combination that generated the best results (RF using
DS_ALL data set) using a confusion matrix (
Table 3) the class of “not treated” sections was the one with a higher F1-score of 0.98 and with a precision and recall of 0.98 and 0.99, respectively. The class of “treated” sections had a lower F1-score value of 0.82.
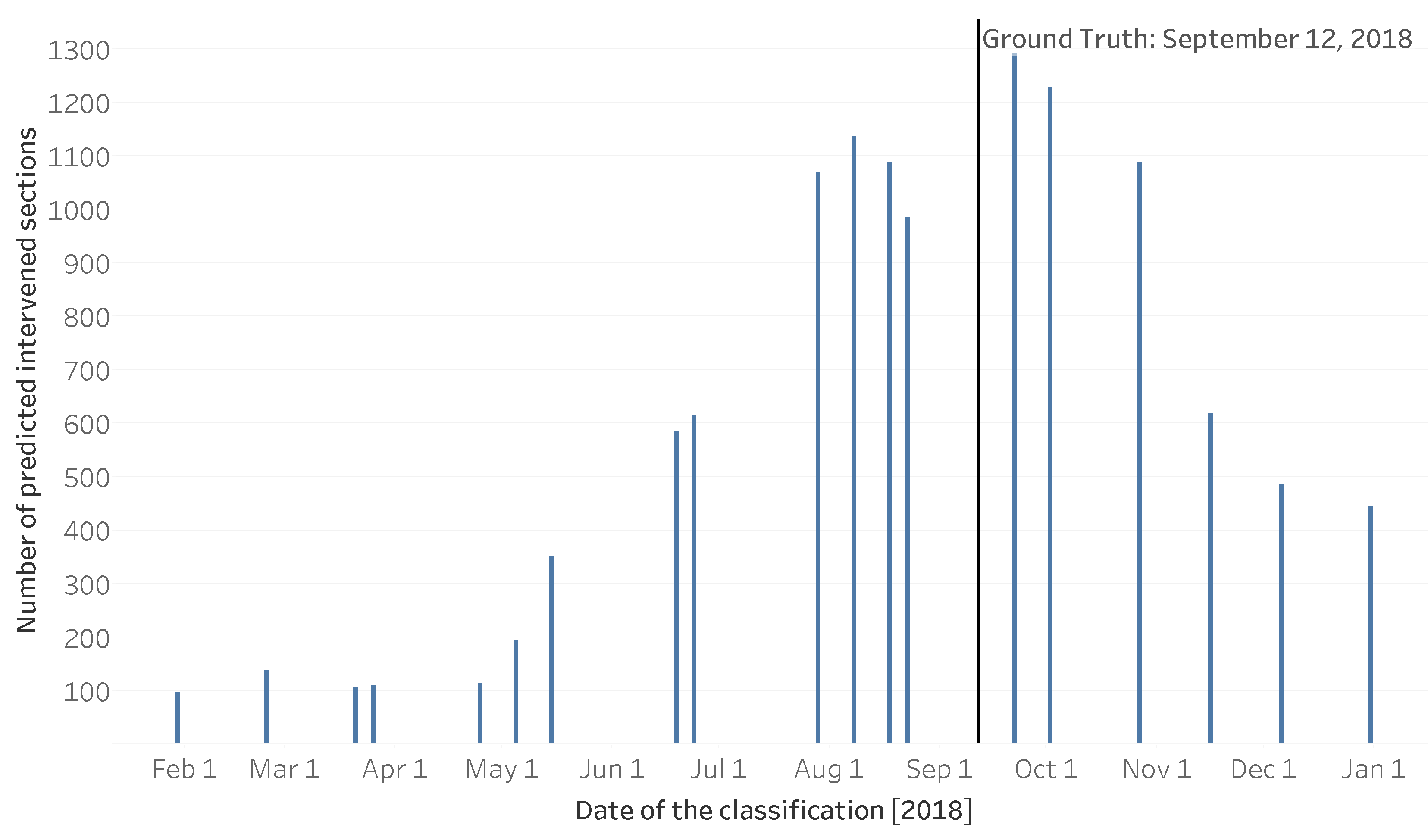
Although the best model performs quite well, the previous results are only shown to one date, 12 September, given there is only ground truth for that particular date. Since the static analysis only uses reference satellite images from one date to train the model, the other left out products can be used to check if the behavior of the algorithm is as expected. This model (RF) was trained with a reference image from 12 September and the ground truth until the same date. The model was then applied for each date that had Sentinel-2 data. This shows how the model behaves with data before (start of the year), during (middle of the year), and after the interventions (end of the year). This analysis is especially interesting because the ground truth shows interventions in FMZs up to 12 September, meaning interventions can appear in images at distinct points in time before that date. In
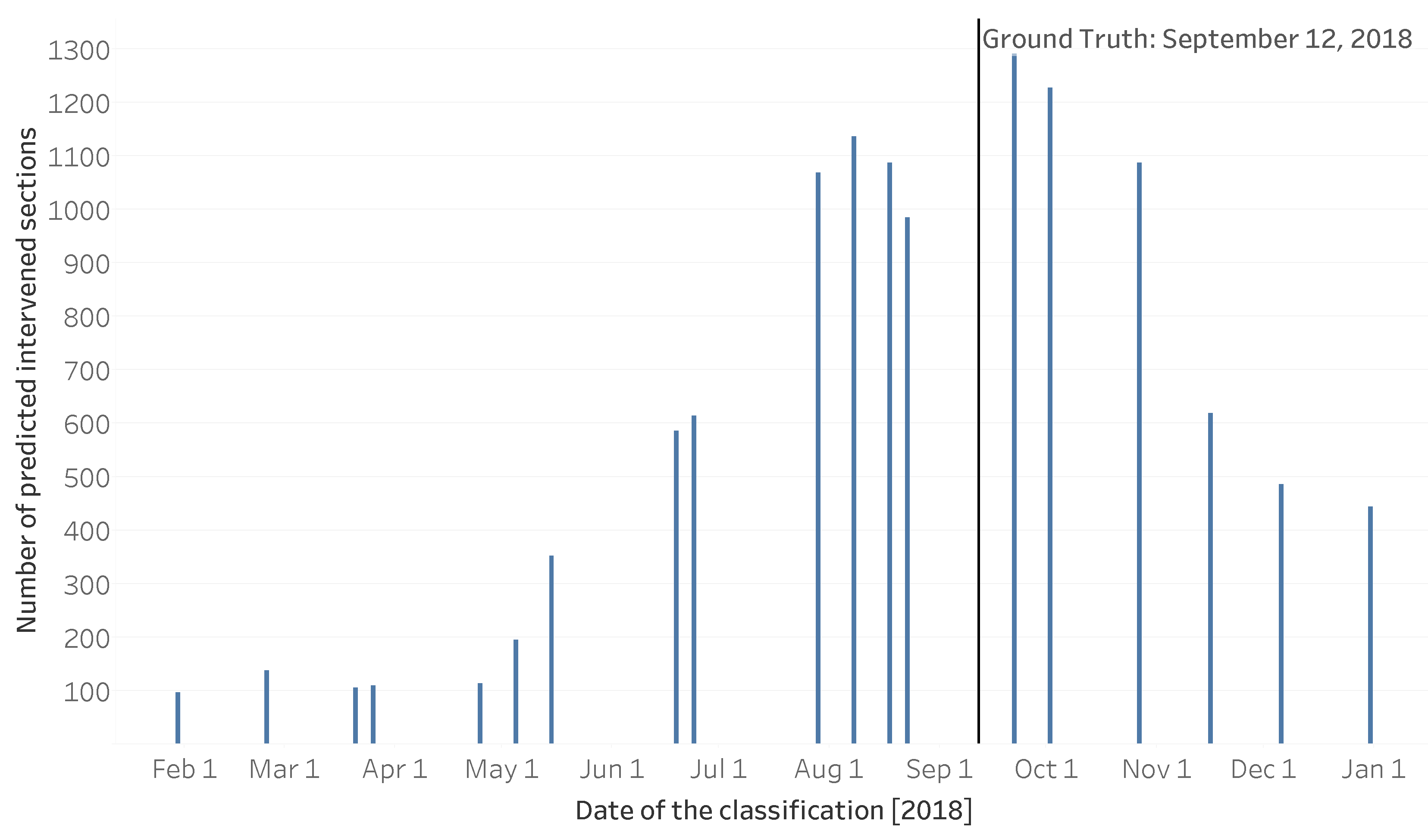
Figure 10 the number of sections classified as treated for each date is presented.
There are no precise metrics for the results of the dates before and during the observed intervention period because the ground truth does not have the date of intervention for each section. As the classification advances throughout the year, the number of detected interventions starts to climb as soon as the first intervention is made. As more FMZs are cleaned throughout the year the model can detect those interventions. After the ground truth date, the number of detected intervention zones starts declining, mainly due to vegetation regrowth and shadows or dark area pixels in the images at the end of the year.
3.2. Temporal Analysis
The FMZs along roads were also analyzed using time- series data with three main structures: Sentinel-1 data, Sentinel-2 data, and with the combination of Sentinel-2 and Sentinel-1 data.
3.2.1. One Satellite: Sentinel-1
For the Sentinel-1 data approach, dual-polarization (VV and VH) and multiple orbit (Ascending and Descending) products were used (DS_SAR). Even when using a temporal approach, the precision for this satellite was considerably lower than for Sentinel-2 in the static analysis, fluctuating between an F1-Score of 0.6208 and 0.6872 for all models and with a low Kappa score between 0.2508 and 0.3769. Nevertheless, the RF obtained an F1-score of 0.69. On the other hand, SVM and KNN obtained lower results, since they were unable to classify correctly treated sections, classifying most of the samples as non-treated sections. This behavior is also true for the other models, thus the low Kappa agreement values.
When analyzing in more detail the confusion matrix (
Table 4) of the RF results, it shows that the metrics of the untreated sections had a great influence on the value of the global F1-score, since the treated sections only had an F1-score 0.44.
3.2.2. One Satellite: Sentinel-2
Figure 11 shows the classification results for the time- series experiment using only Sentinel-2 data, note that the data sets are sorted by performance and by model. All data sets, except for
DS_INDICES, obtained similar results. Comparing
DS_INDICES with the other data sets, for the KNN and SVM algorithms, results were significantly lower, being around 22% lower than the best for the KNN. Unlike the static analysis, the results from the SVM classifier managed to outperform ensemble methods (excluding the data set
DS_INDICES). The best algorithm was the SVM with an F1-score of 0.93, nevertheless, XGBoost, and RF generated results that have less variance across data sets.
Table 5 shows the confusion matrix for the best results, with SVM using the
DS_BAND data set. The “not treated” sections class had very high metrics close to 1. For the “treated” sections class, the metrics were lower, but still good, with an F1-score of 0.88, with only 10 sections being incorrectly classified as treated.
Using time-series there is an improvement in the classification of treated and not treated sections for FMZs along roads when compared with the static analysis, with the F1-score of the treated sections class rising from 0.82 to 0.88.
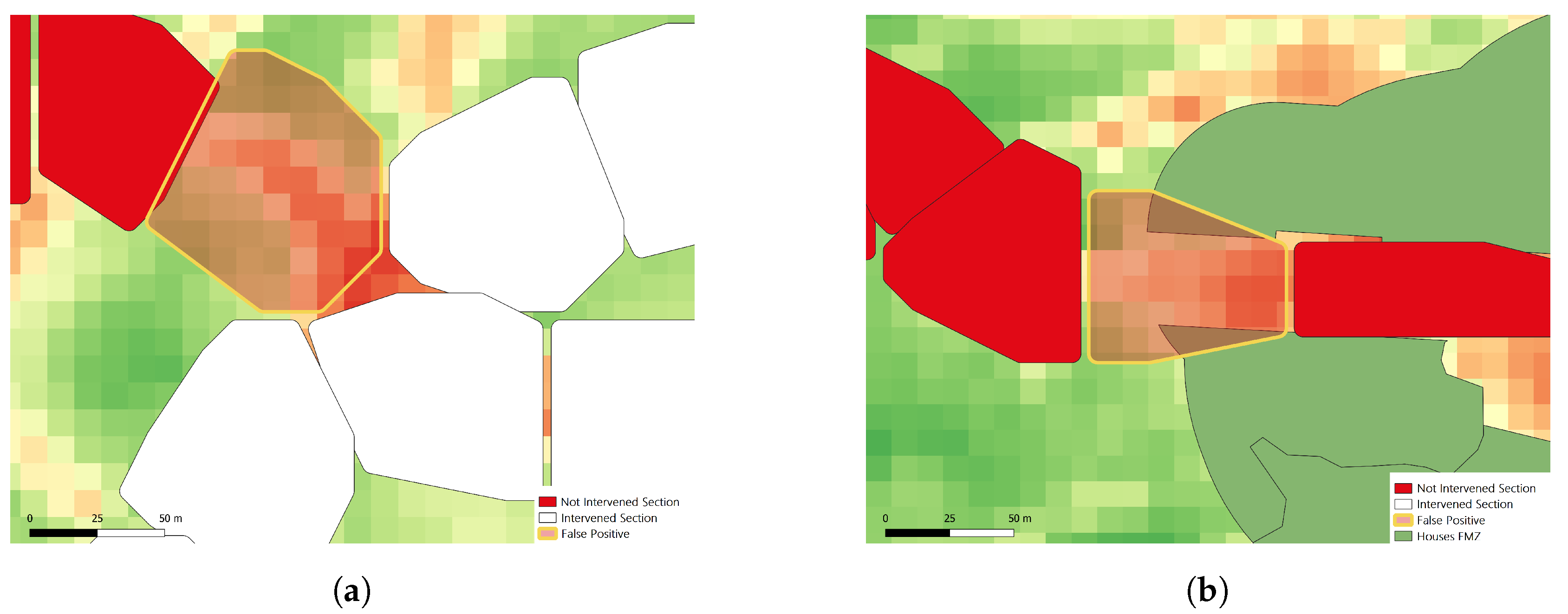
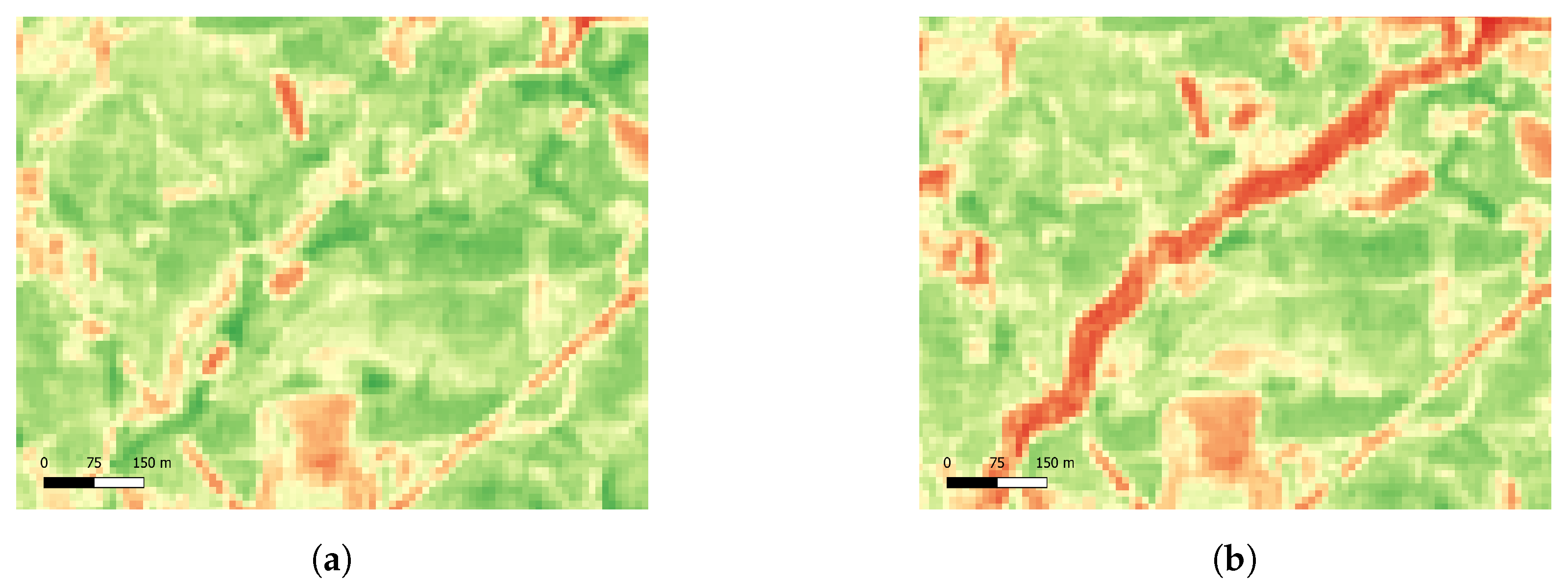
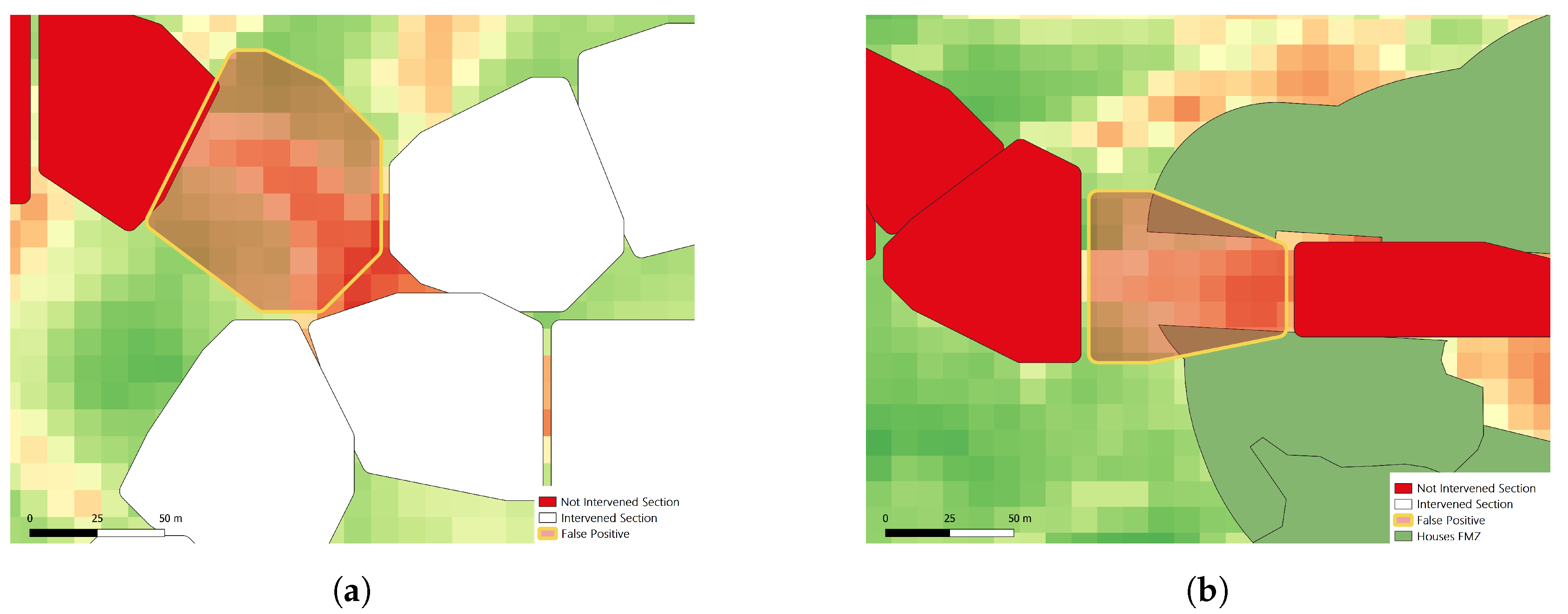
Analyzing the errors in more detail, in
Figure 12 there are two examples of sections that were incorrectly classified as treated. These sections are in areas of intersection between FMZs that were treated and FMZs that were not treated (
Figure 12a) or in the limit between the interior and exterior of house clusters (
Figure 12b).
3.2.3. Both Satellites: Sentinel-1 and Sentinel-2
The information from Sentinel-2 and Sentinel-1 was merged to analyze if it had impact in the results.
Figure 13 presents the F1-score values for the different algorithms and data sets, note that the data sets are sorted by performance and by model. Globally these values maintained a behavior similar to the values observed using only Sentinel-2 data. For the SVM, the best F1-score values did not change in comparison to using the Sentinel-2 data. For the RF, the F1-score slightly increased in all data sets. This data combination had the biggest impact in the XGBoost results, raising the F1-score more than 1% in comparison to using just Sentinel-2 data. In this experiment, the XGBoost was the algorithm with the best results reaching an F1-score of 0.94. Overall, using Sentinel-1 data together with Sentinel-2 data showed some improvements in the results of the algorithms.
3.3. Estimation of FMZs Intervention Date
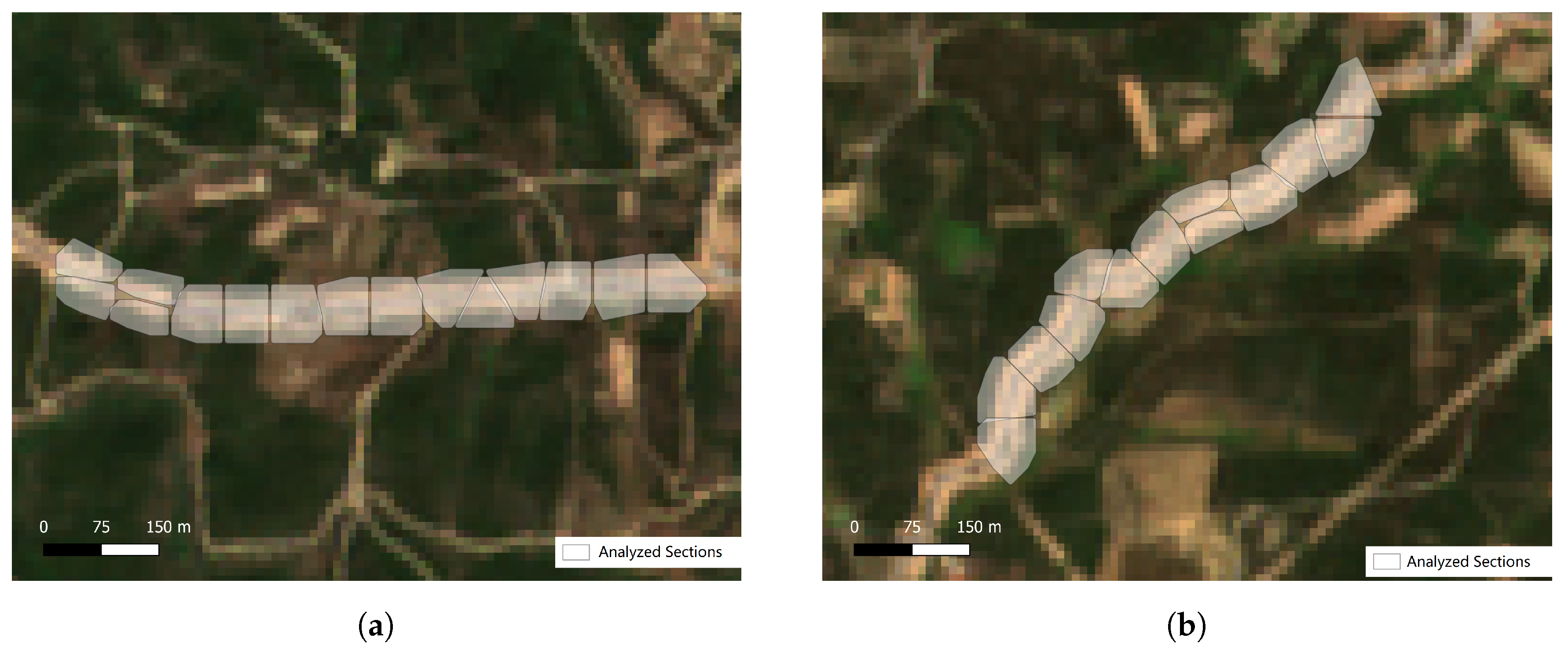
This work aims to classify if FMZs are treated and maintained but it is also interesting to establish when those same FMZs are treated. For this purpose, an extra experiment was carried out to try to estimate the dates on which interventions in FMZs occurred. To achieve this, some clusters sections were selected for further analysis. These sections were treated at the same time of the year, but are part of two different locations: Site A (
Figure 14a) and Site B (
Figure 14b).
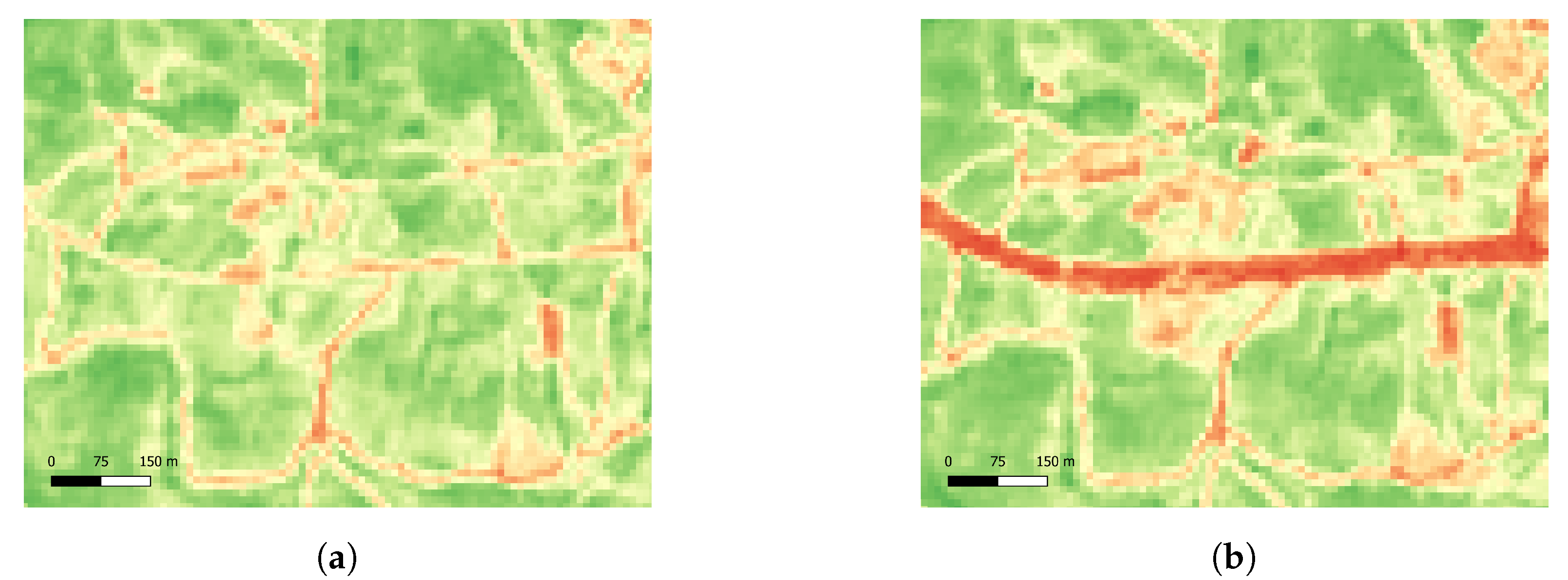
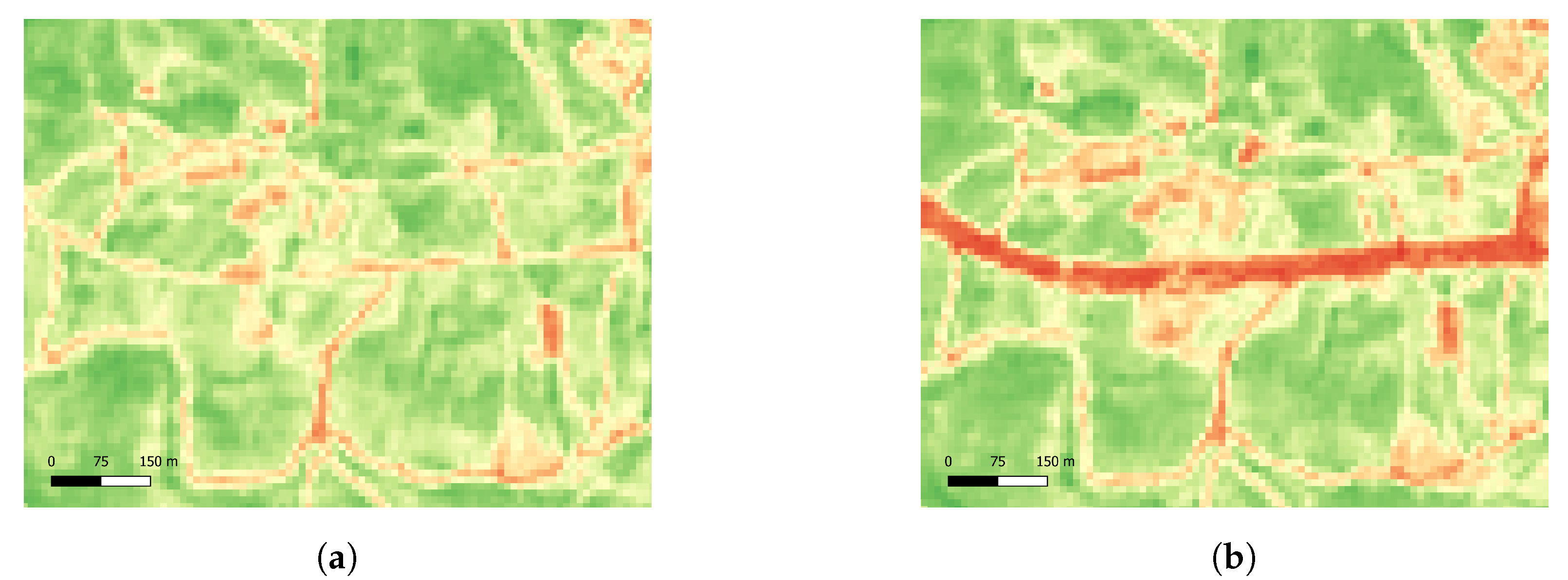
These FMZs in particular were selected due to their official data not being yet available by the Mação City Hall, and because the intervention of FMZs around roads is more easily noticeable in satellite images. As it can be seen in
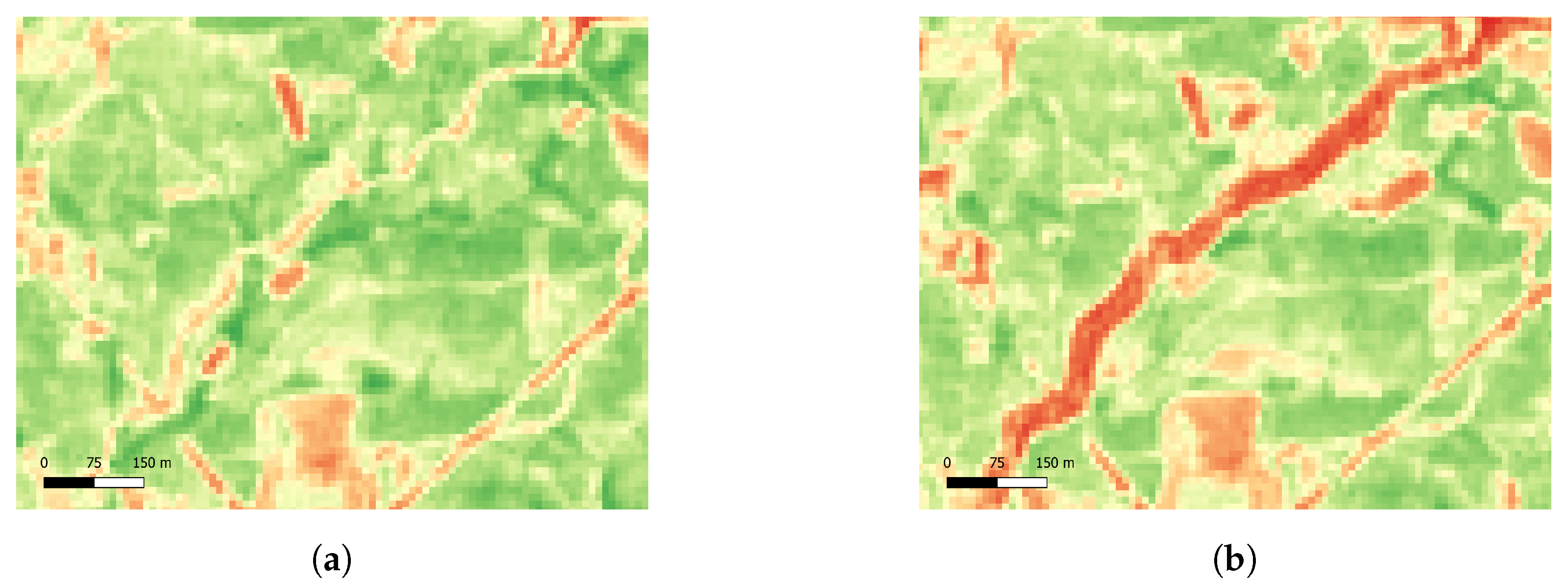
Figure 15, for Site A, the NDVI values before and after intervention have drastic changes. The same can be observed for Site B in
Figure 16. A simple threshold value was used as the classifier using the temporal pattern
(Equation (
4)) which calculates the difference of the
(Equation (
2)) in two consecutive dates. By establishing a threshold of
, an FMZ is assumed to be treated when
. This index represents a sudden drop of the FMZ NDVI values in consecutive months, while the values on the outer buffer have little variation.
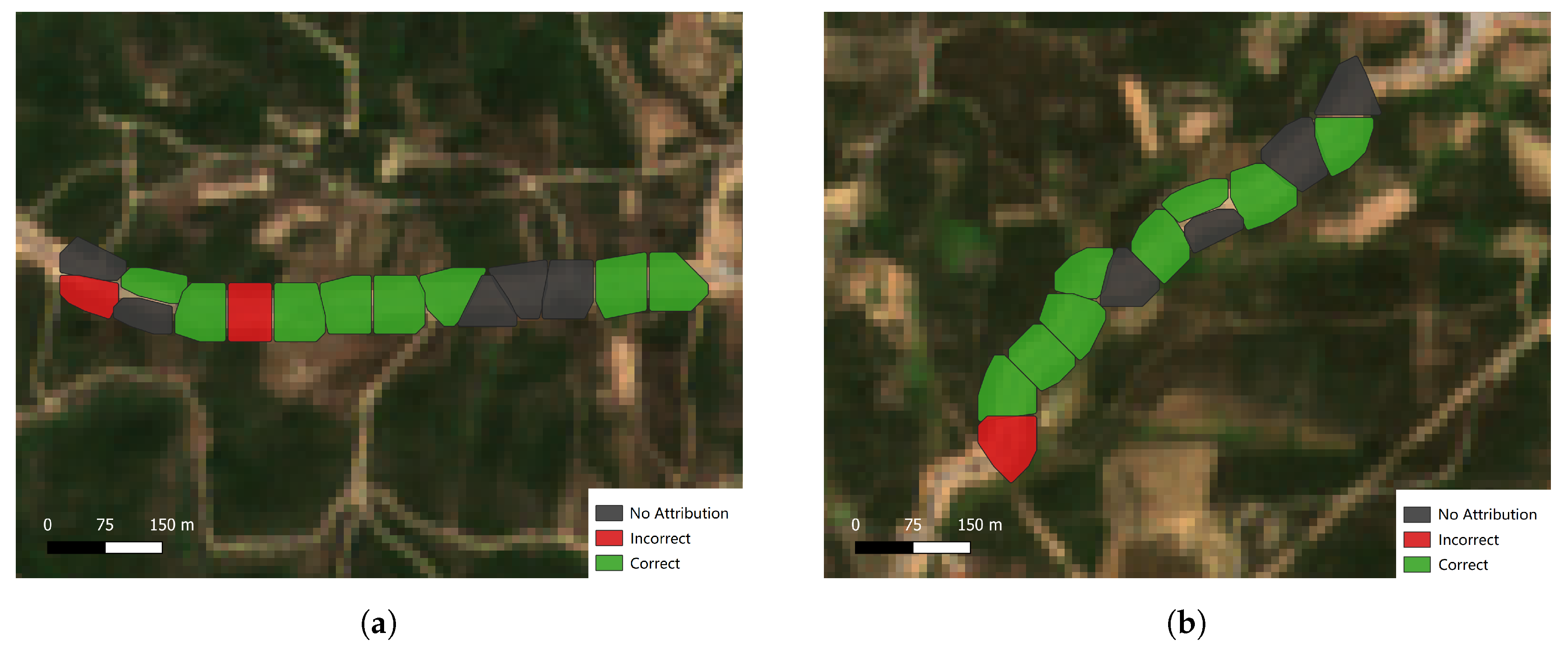
The results for both sites are presented in
Figure 17. In both cases, most of the estimated intervention dates correspond to the manual observed date, only failing in 3 cluster sections out of 28. However, for several sections, there were no results. In sum, 16 sections were estimated correctly, 3 incorrectly and 9 had no attribution of an estimated intervention date (i.e.,
).
4. Discussion
In this paper, two types of analysis were carried out: a static analysis, using only Sentinel-2 data from one date, and a temporal analysis using the temporal patterns of the Sentinel-2 and Sentinel-1 characteristics. The FMZs along roads were analyzed using classification algorithms and temporal patterns to classify which FMZ sections that were treated. An evaluation of the different classification algorithms was also carried out, both in the temporal analysis and in the static analysis, comparing the results of these algorithms using different data sets. In addition to these classification experiments, an experiment was also carried out to try to determine the dates of the intervention of the FMZs along roads. In this section, the results of the various experiments are discussed.
Different classification algorithms were used in this work: RF, SVM, XGBoost, and KNN. The algorithms that stand out are XGBoost and RF, which in almost all experiments achieved the best results. The algorithms that generally obtained the worst results were SVM and KNN. In the static analysis, SVM obtained the lowest results using the data set DS_INDICES. However, in the temporal analysis, the results of these algorithms improved considerably in such a way that SVM was immediately behind XGBoost using data from Sentinel-2. Nevertheless, ensemble methods, such as RF and XGBoost, methods can consistently achieve high performance and the performance per dataset does not vary by a big margin.
Regarding the data, five different data sets were compared: DS_ALL, DS_INDICES, DS_BAND, DS_FUSION, and DS_SAR. In the static analysis, only data from Sentinel-2 was used and in the temporal analysis information from Sentinel-1 was added. In both temporal and static analysis, the DS_ALL data set was always among the data sets with the highest metrics, being the best in most experiments due to having more information available for the algorithms. The DS_INDICES obtained worse results in almost all experiments in comparison to the DS_BAND data set, often with a big difference between the results of both. In the temporal analysis, for the RF and XGBoost algorithms, the DS_INDICES obtained an F1-score close to the best results; however for the SVM and KNN the results were lower, with a difference of 22% for the best result in one of the tests (using KNN in the FMZs along roads). It can be concluded that vegetation indices by themselves are not expressive enough to model the properties of the FMZs to determine if they were treated or not. Furthermore, the SVM and KNN showed a tendency to overfit on DS_INDICES.
The temporal analysis using the data set DS_SAR (just Sentinel-1 data) generated significantly lower results. Although it achieved an average F1-Score, the Kappa reached as low as 0.25. This shows that this type of data is not reliable enough to be used for this type of application. Further research is needed to see if it is possible to leverage more performance from SAR data, either with new models or a different processing pipeline (e.g., adding textural information). SAR data is especially interesting when there is not multispectral data available, for example when there is cloud coverage over the study area. Even with the low performance of SAR, the combination of Sentinel-1 and Sentinel-2 showed slight improvements in the results, with the most significant improvement in the F1-score, increasing by almost 2%. Although the global F1-score is equal when using only Sentinel-2 data and Sentinel-2 in conjunction with Sentinel-1 data, there was a difference in the results for the treated sections class. With just data from Sentinel-2, the treated sections class had an F1-score of 0.88, when adding Sentinel-1 data this value raised to 0.90. The combination of Sentinel-1 and Sentinel-2 can increase the performance of the proposed algorithms. Even though the increase in performance was measured at 2%, the high availability of Sentinel-1 data (not affected by cloud coverage) can be beneficial. However, it must be considered its only main drawback associated with the data prepossessing complexity.
Finally, as it isas it is not only important to know if FMZs are treated but also when, a final experiment was carried out. The main goal was to create an algorithm that could roughly estimate the dates of the interventions. In both study areas, the algorithm performed very well, identifying most of the intervention dates right compared to the ones obtained after a manual examination. This experiment had the role of proof of concept, as the sample size was smaller, but it serves as a starting point for future research on intervention date estimation. This work can aid in solving ambiguities and uncertainty in the ground truth about FMZs.
The thorough research for related work yielded no previous studies that directly approach the analysis of the state of FMZs. In general, the presented results are quite good and showed that the use of remote sensing techniques in conjunction with classification algorithms can help in the detection of interventions in the FMZs, promoting fire protection around the detected areas.
5. Conclusions
This work presented a new method to detect interventions in FMZs using machine- learning algorithms and satellite images from Sentinel-2 and Sentinel-1. Combining machine- learning and open satellite data could reduce the costs associated with manual checkups of FMZs. This process is also scalable as it would only require the extraction of more satellite images over the study area. The main technique used to detect an intervention was to extract information about the vegetation in both the interior and exterior of an FMZ to detect variations. This approach required the creation of buffers outside the FMZ, in vegetation zones, which depending on the type of FMZ can be complex to generate. This information about the interior and exterior of FMZs is then used to generate new features from the input satellite spectral and radiometric images. The proposed method can serve as a baseline for future work into the detection of vegetation growth and maintenance in forest fire-sensitive areas, in this case, the FMZs.
The results show that the usage of satellite data can be used to detect if an FMZ is properly clean and maintained, thus improving forest fire protection. As expected, due to having more information, time-series data had better results than using only a single date. Furthermore, from all the data sets tested, DS_ALL had the best scores overall. Regarding the used machine- learning algorithms, ensemble methods (RF and XGBoost) prove to be robust when working with remote sensing data by having good scores across the board. In the experiments, the best scores were achieved by XGBoost when combined with the best data set, DS_FUSION, which uses spectral and radar data as well as some derived vegetation indices.
Although the results presented in this work refer to road FMZs, other experiments in other types of FMZs were done, in particular for the electrical lines FMZs. Due to some uncertainty about the ground truth of this type of FMZ, the results are not shown here. Nevertheless, the preliminary work is promising, even though it cannot have the same level of certainty of results due to uncertainty in the ground truth. Apart from that, scores for the electrical lines FMZs could be affected by various factors like like regular maintenance due to the risk of fire ignition associated with these lines, making the detection of vegetation change more difficult; the size of the sections for this type of FMZ is smaller resulting in less information in comparison to the road’s sections. Future work will be done to mitigate the uncertainty about the ground truth of these FMZs types, allowing the proposed algorithms to be valuable for many different types of FMZs.


 ,
, 






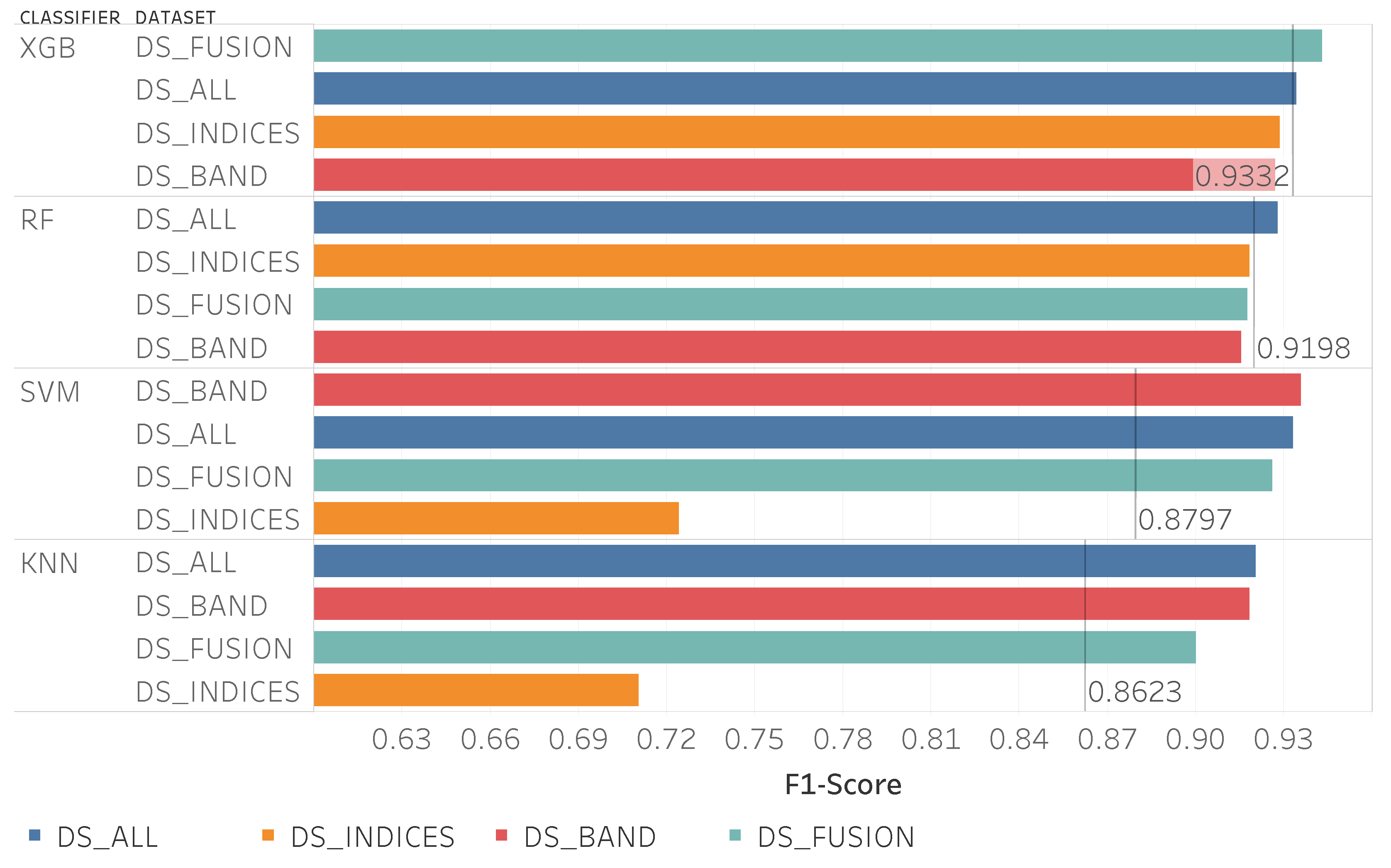


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
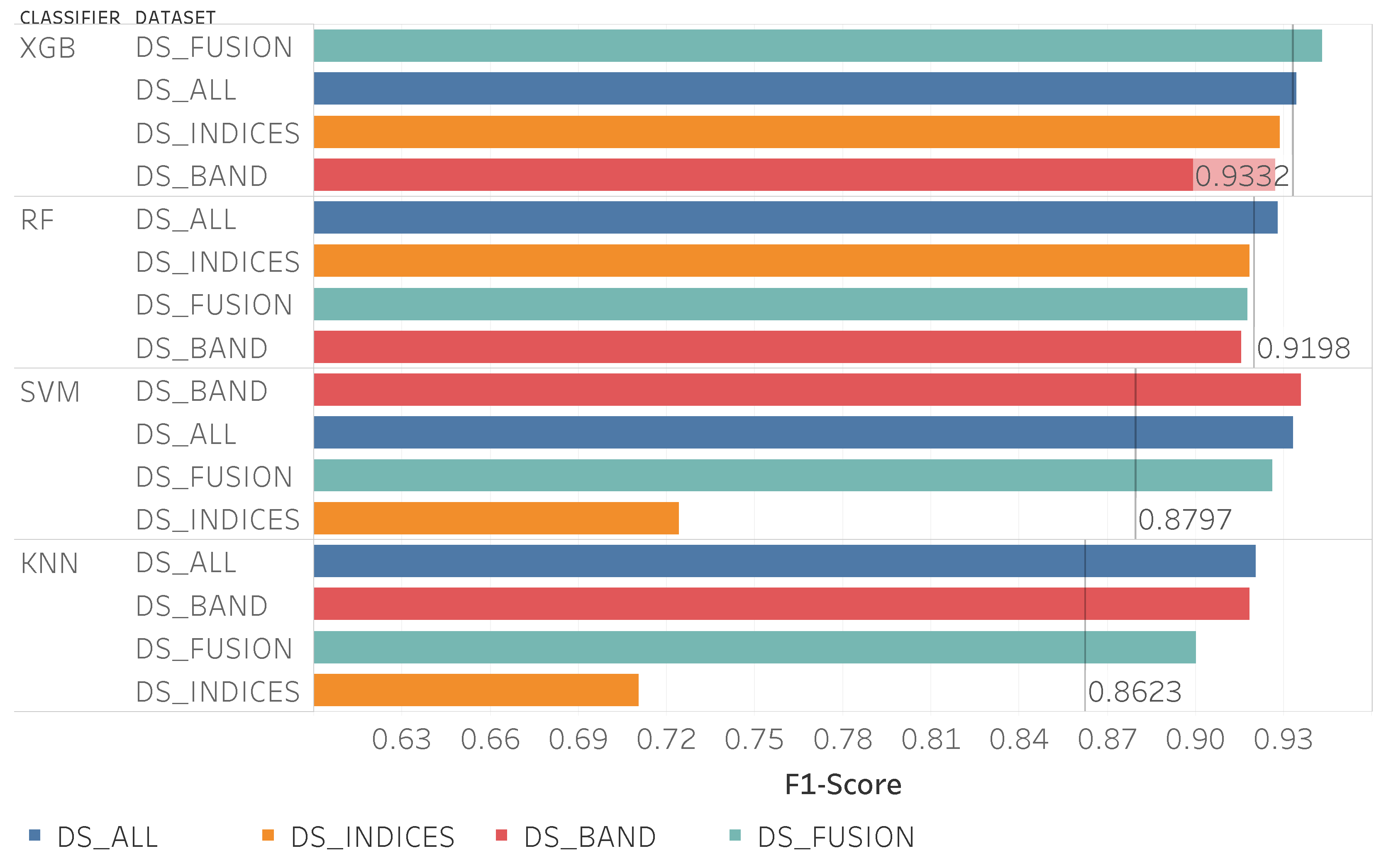{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}