1. Introduction
Urbanisation coupled with major demographic transformations is, along with climate change, one of the most striking phenomena of the early 21st century [
1] and has increasingly moved into the focus of scientific work in recent decades [
2]. This development has led to a “science of cities” [
3], where with the help of quantitative mathematical models, various attempts are made to gain access to the different processes that shape and change today’s cities [
4,
5].
A major focus is the investigation of urban morphology [
6] and land use within cities and their surroundings. To describe and predict changes in land use, cellular automata are a commonly used tool [
7]. In the last decades, these are extended by mobile agents, resulting in agent-based models describing the interaction between the actors and the respective environment they are operating in [
8].
However, due to the integration of ever larger amounts of data [
9], more complex algorithms [
10], especially machine learning and deep learning, the models are becoming more and more complex [
11]. The “black-box” structure of these models, coupled with an increasing number of nuances considered in the models, leads to a loss of comprehensibility [
12]. A contrary approach is taken when certain phenomena are mapped with comparatively simple mathematical models to describe core processes of urbanisation.
A very famous model to describe urban structures was made by Walter Christaller in the early 1930s, when he developed the concept of the central place theory (CPT) [
13]. This theory is based on the assumption that from a locally homogeneous distribution of small settlements, urban hierarchies develop over time in which larger towns take over certain infrastructural tasks for their neighbours. Although the theory has been criticised (see, e.g., in [
14]), both the hierarchy in settlement structures for different regions [
15] and the regularity in the arrangement of rural settlements [
16] can be shown empirically.
While many models based on CPT focused on the development from regular to hierarchical structures [
14], less attention was paid to the development of the initial regular structures. The only approach known to us following this direction for inter-urban system deals with the regular spatial arrangement of industrial plants. Paul Krugman [
17] proposed that the regular spatial arrangement of these plants can be described by a diffusion-driven instability.
Besides diffusion-driven instability, other open thermodynamic systems can be found in nature that form regular structures such as the Taylor–Couette flow, Rayleigh–Benard convection and Benard–Maragoni convection. The order far from thermodynamic equilibrium arises by instabilities that grow, stimulated by small disturbances or imperfections [
18]. As urban systems are also open systems [
19], the question arises whether they can be described by nonlinear mathematical models of this type. In recent years, there have been increasing attempts to transfer these physical nonlinear models to intra-urban patterns or structures [
20,
21,
22].
However, we are concerned with patterns in inter-urban systems. Qualitative different pattern of urban structures can be linked to the growth mechanisms urban sprawl [
23,
24] and sprinkling [
25,
26], which have social and ecological effects [
23]. A deeper understanding of these patterns, processes and modelling possibilities [
25,
27] is therefore of great importance.
In a first step, we examine the nature of the structures formed by inter-urban systems on the basis of different examples in order to examine the applicability of these nonlinear models in future work with the knowledge that such an approach is only an indication of pattern formation mechanism [
28]. Our research question is as follows.
How are settlements arranged in different predominantly rural regions of the world?
Although there are studies that examine the regularity of settlement arrangements [
15,
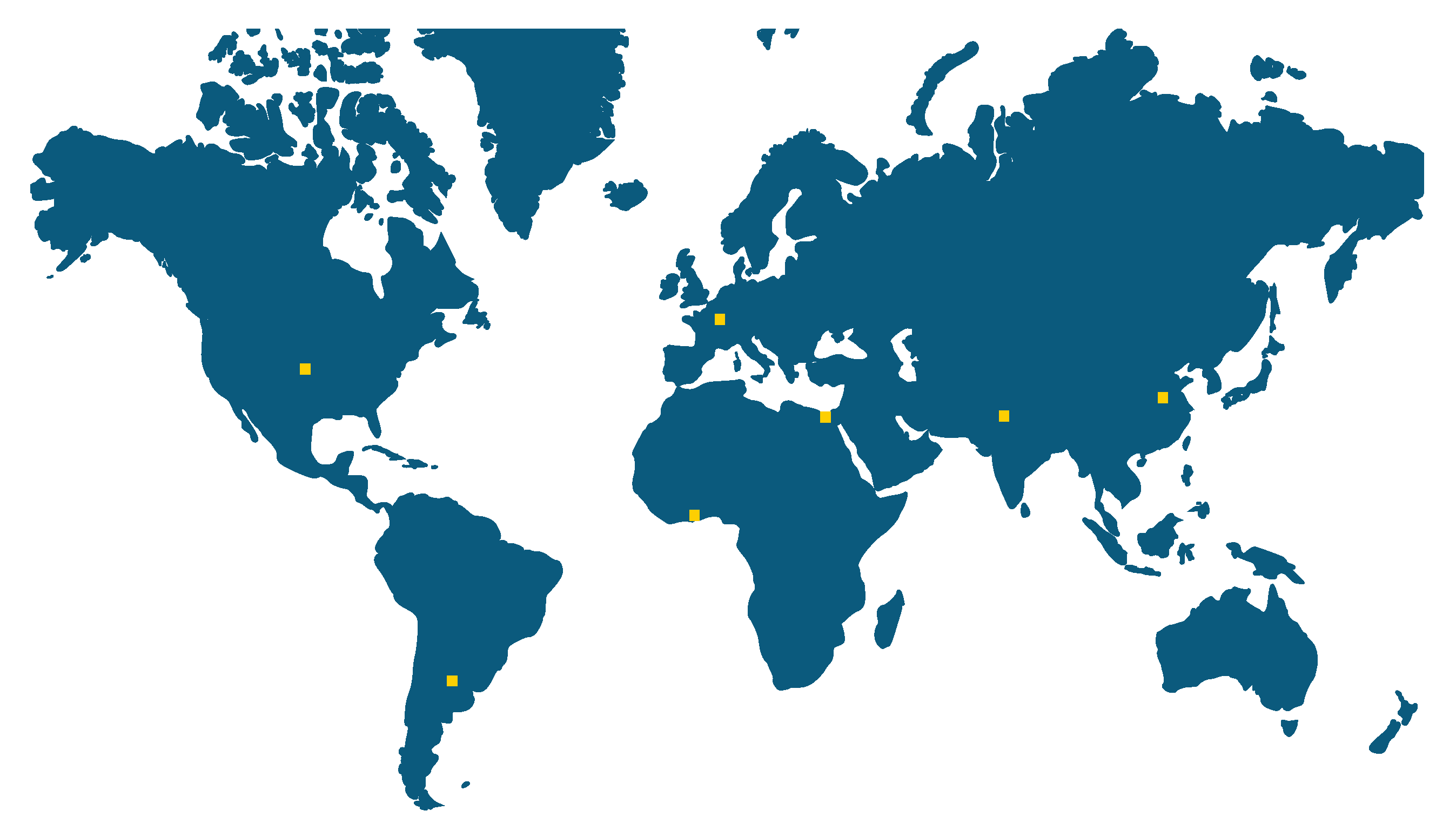
16], these are often not globally comparative. Therefore, we compare settlement patterns determined by satellite data in seven different regions of the world, using the following framework.
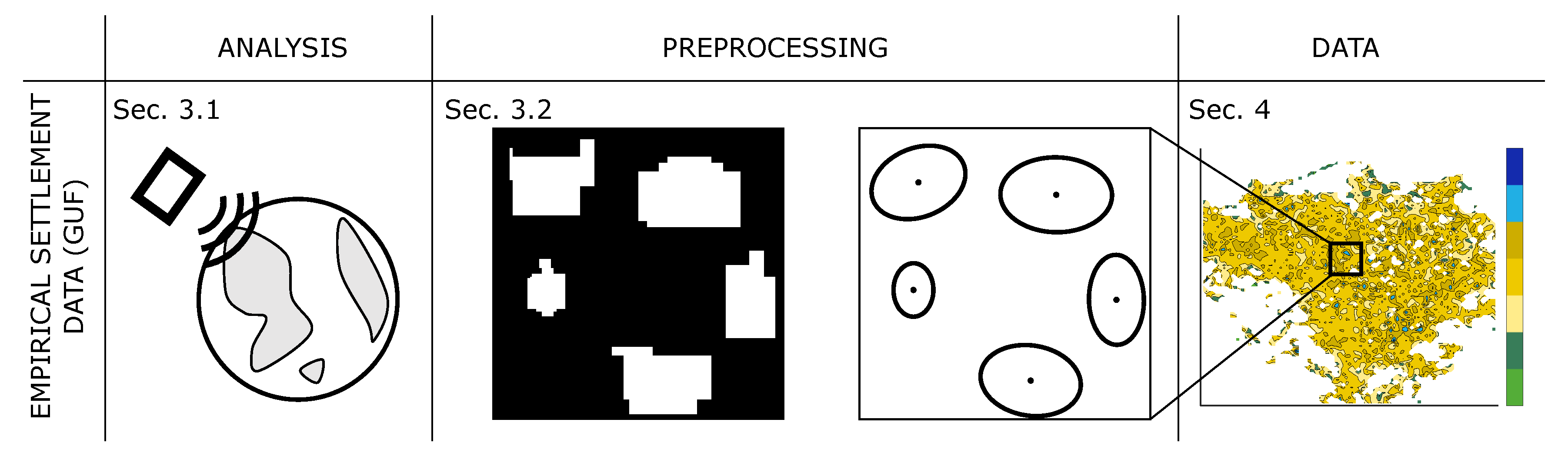
2. Conceptual Framework
Against the background of the strong spread of machine learning, a wide variety of scientific domains are concerned with patterns. In our analysis, we investigate two-dimensional binary patterns.
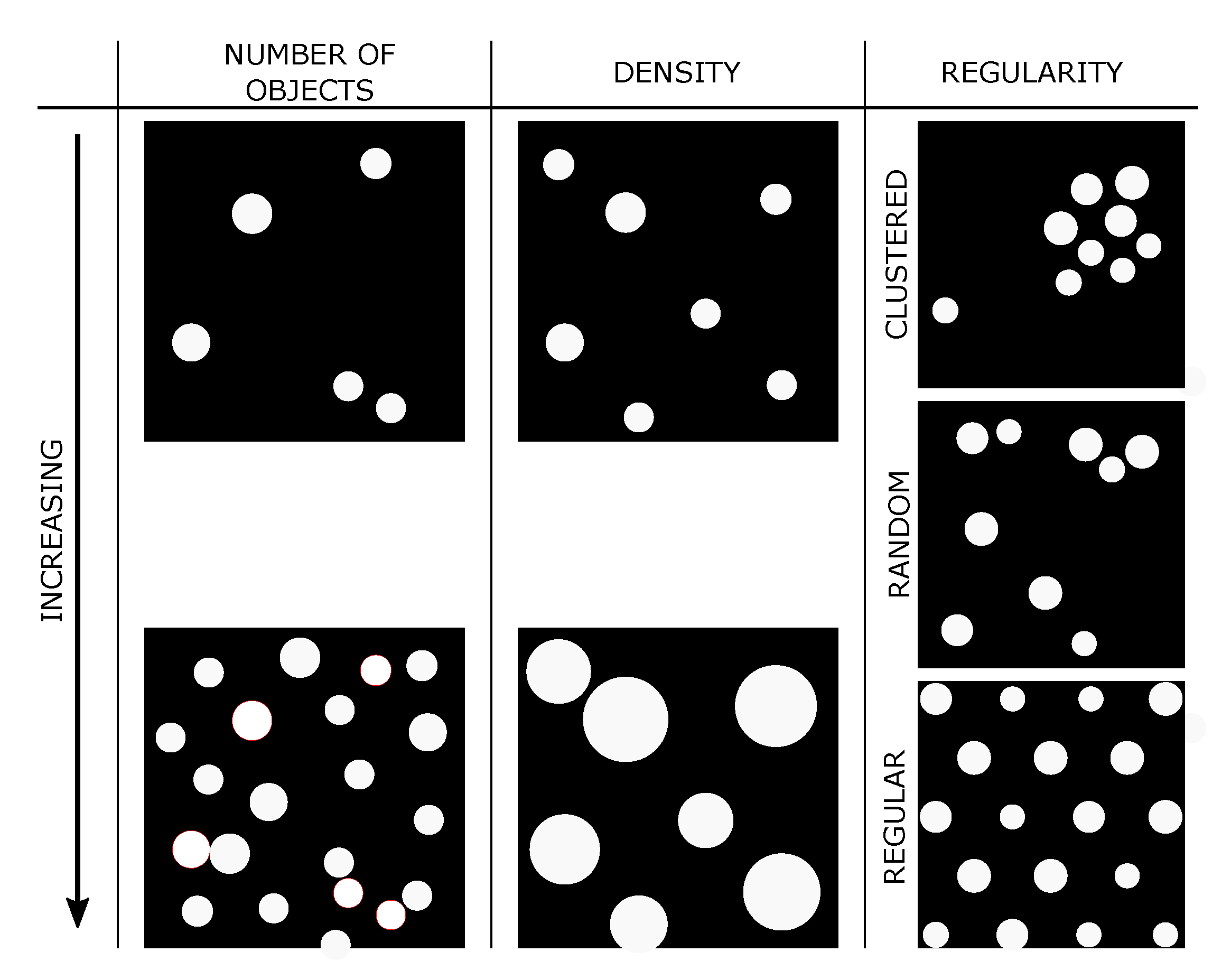
To answer the research questions stated above, consistent methods are in need. The properties of the settlement patterns have to be quantified in a correct yet condensed manner, to be able to compare settlement structures in different regions. Therefore, we use the following three parameters (
Figure 1),
- (i)
the number of objects investigated;
- (ii)
the density of objects within the investigated area; and
- (iii)
the regularity, which we quantify with a special characteristic value.
While the number and density represent continuous values from “low” to “high”, the regularity is divided into three classes. These are clustered, random and regular. In this procedure we neglect the shape of the individual objects. With these methods we quantify settlement patterns, using the framework in
Figure 2.
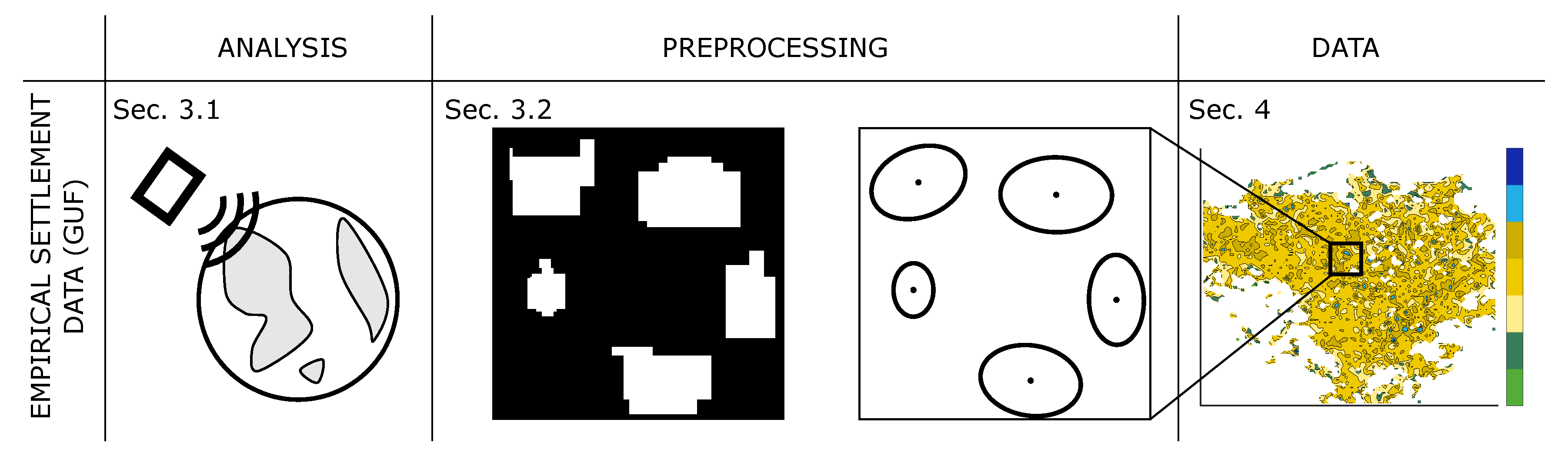
We first present and briefly explain in
Section 3 the empirical data and analysis methods used before we present the results in
Section 4 and discuss them afterwards in
Section 5.
4. Analysis
4.1. Settlement Arrangement
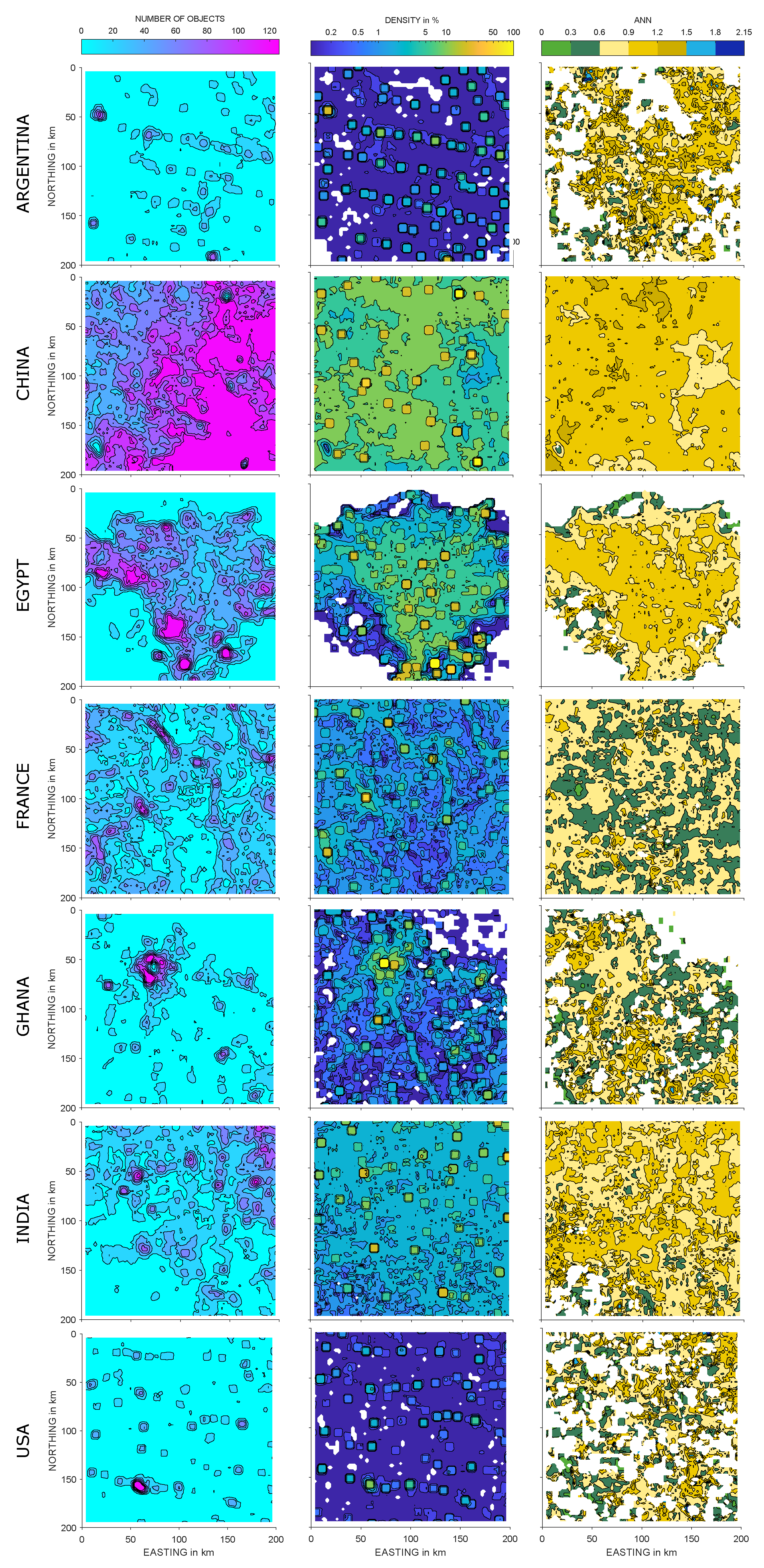
In
Figure 5, the parameters
and
for sample squares with a length of 8 km are shown.
It should be noted that the abstraction of the data in GUF to the centre of gravity and surface area of the object can lead to densities greater than 100%. This is the case when a large number of objects with a large size have their centre of gravity in the sample square, but their dimensions considerably exceed the sample square’s border. This results in a settlement area that is larger than the area of the sample square. We limit the value of density to 100%.
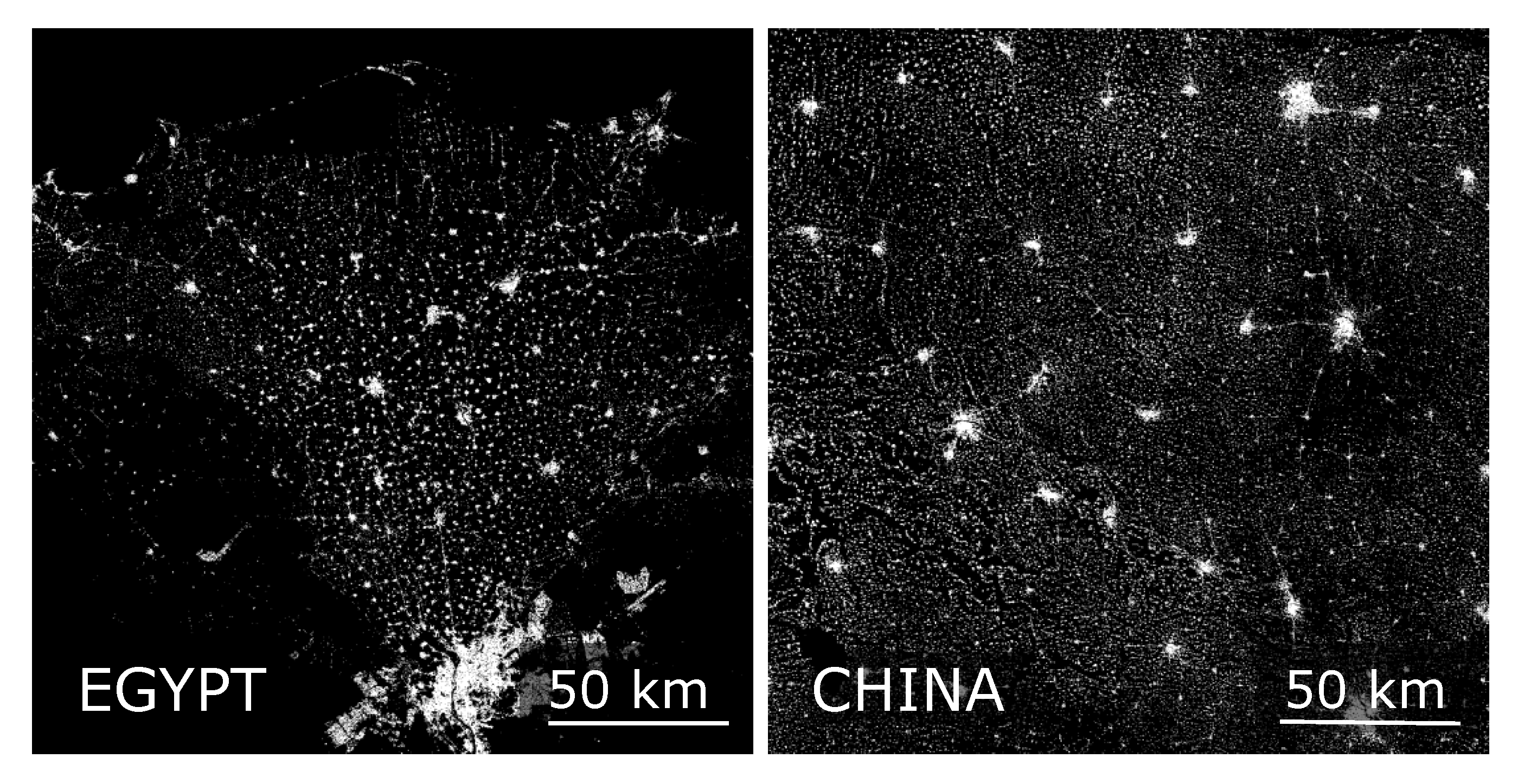
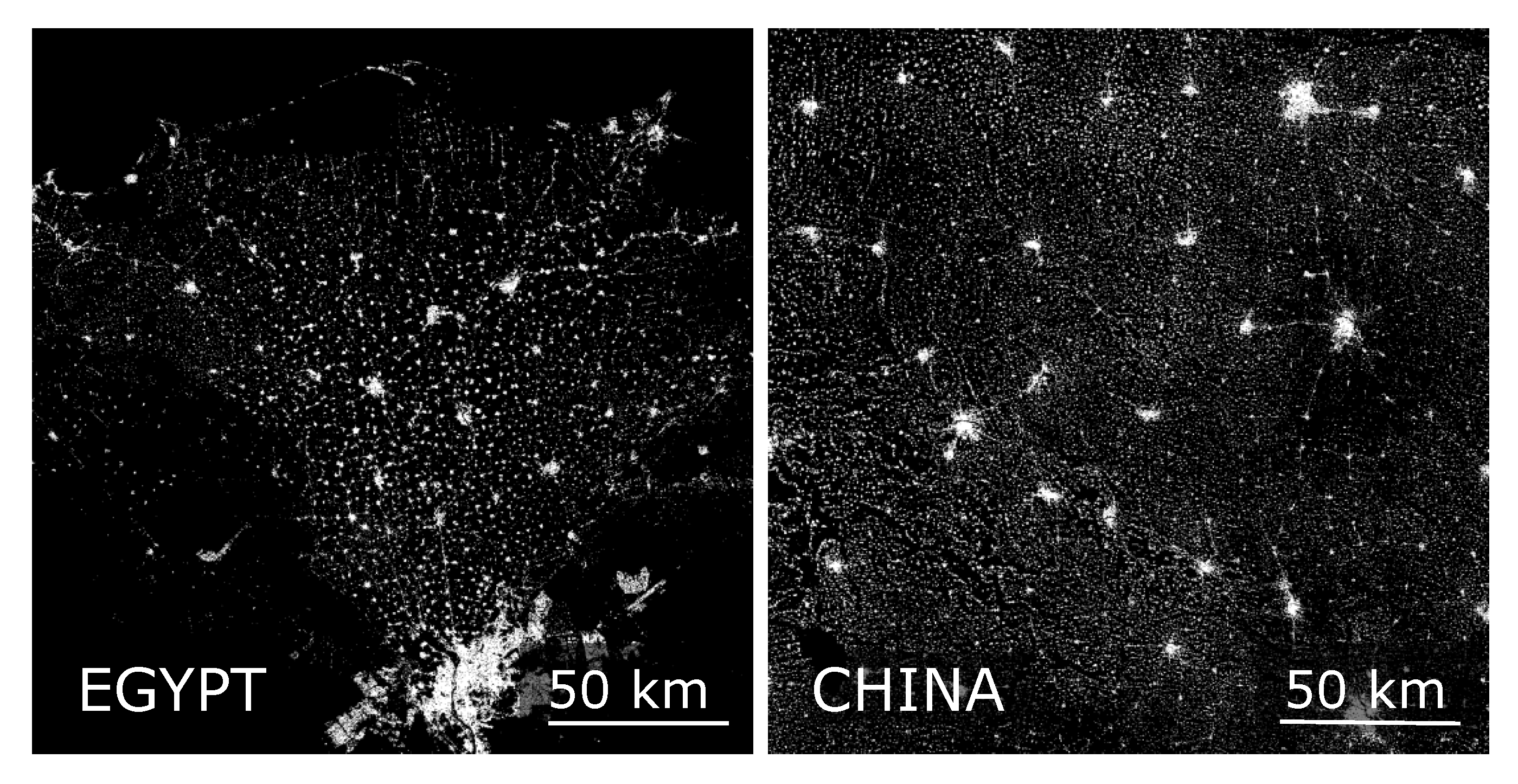
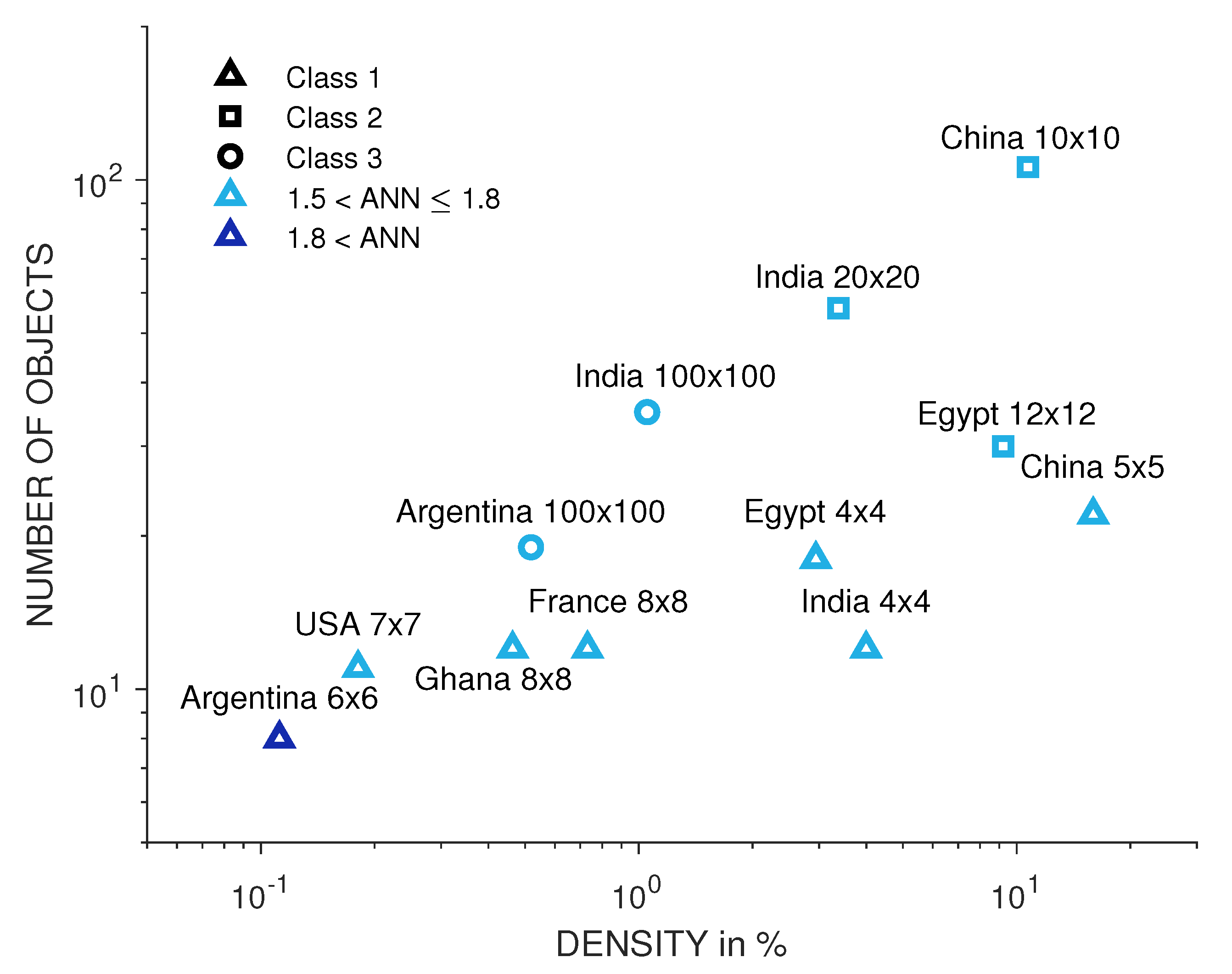
Figure 5 allows us to characterise each data set: Data set Argentina shows equidistant spots with higher levels of density, which belong to larger cities in the observed region. The southeastern corner in the data set China is characterised by high numbers of objects and low density, therefore representing small settlement objects. The settlements in the data set Egypt clearly follow the Nile Delta and the agglomeration of Cairo can be identified easily. The vein-shaped areas with low porosities that run through the data set France are characterised by rivers on whose banks a higher number of settlement objects can be found. In the data set Ghana, the clustering of settlement objects around the million city of Kumansi is clearly visible. Clusters of dense settlement structures are located in the north of the data set India, while the southern part contains very few settlement objects. The data set USA includes only a small number of objects, which have a small expansion. Therefore, the chosen sample square length is not suitable for
evaluation in this data set.
In every regions the clear majority of sample squares is characterised as random distribution by the . Nevertheless, the individual data sets do have differences: In the data set Argentina, the majority of sample squares is represented by an ranging from to ; in the data sets China and Egypt, most of the sample squares have an greater and smaller ; in France, Ghana, India and USA, the dominating range is .
Nevertheless, in some regions a small percentage of squares, e.g., 2.7% in data set Argentina and 2.6% in data set USA, contain, according to the
, regular structures (see
Table A2).
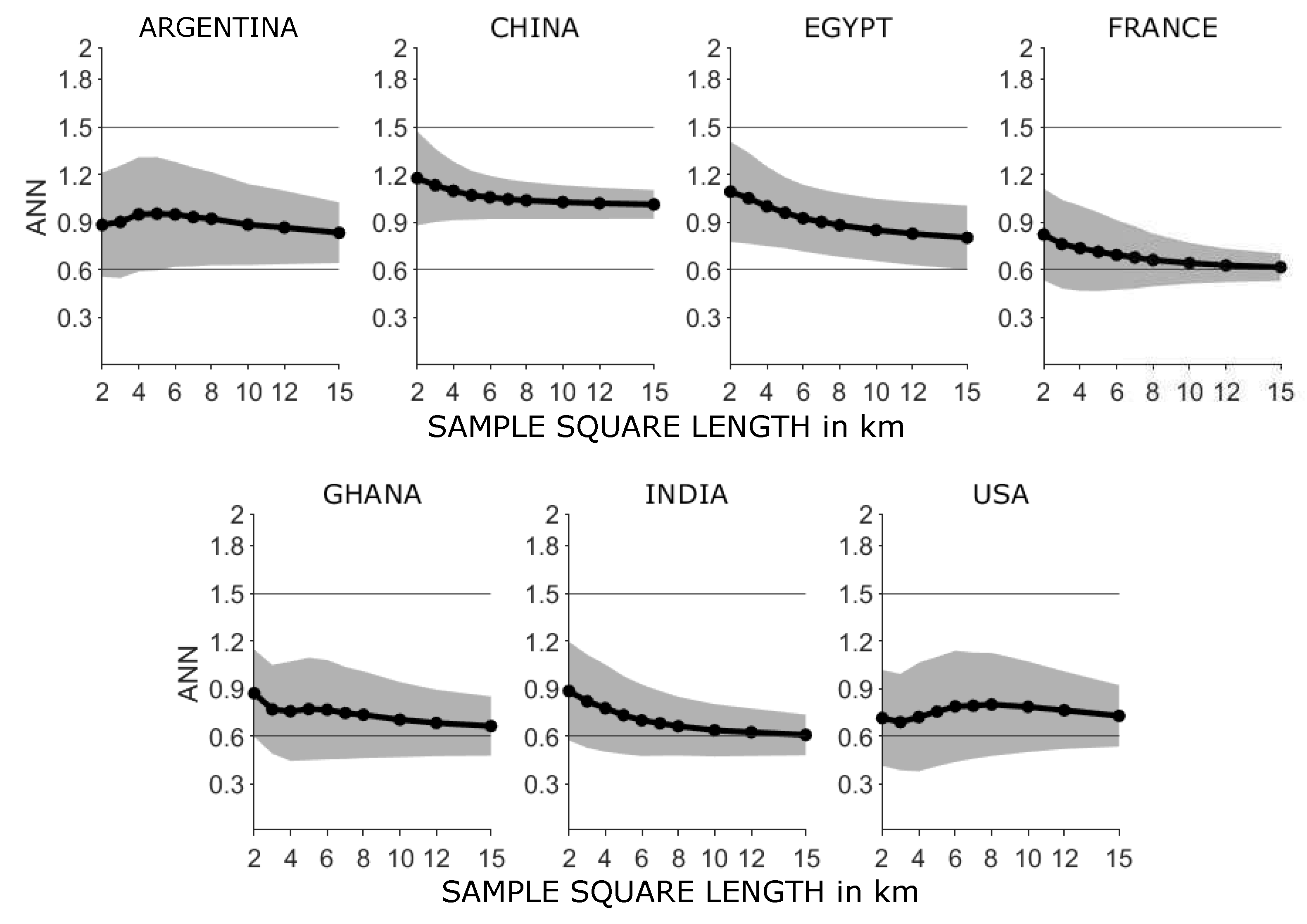
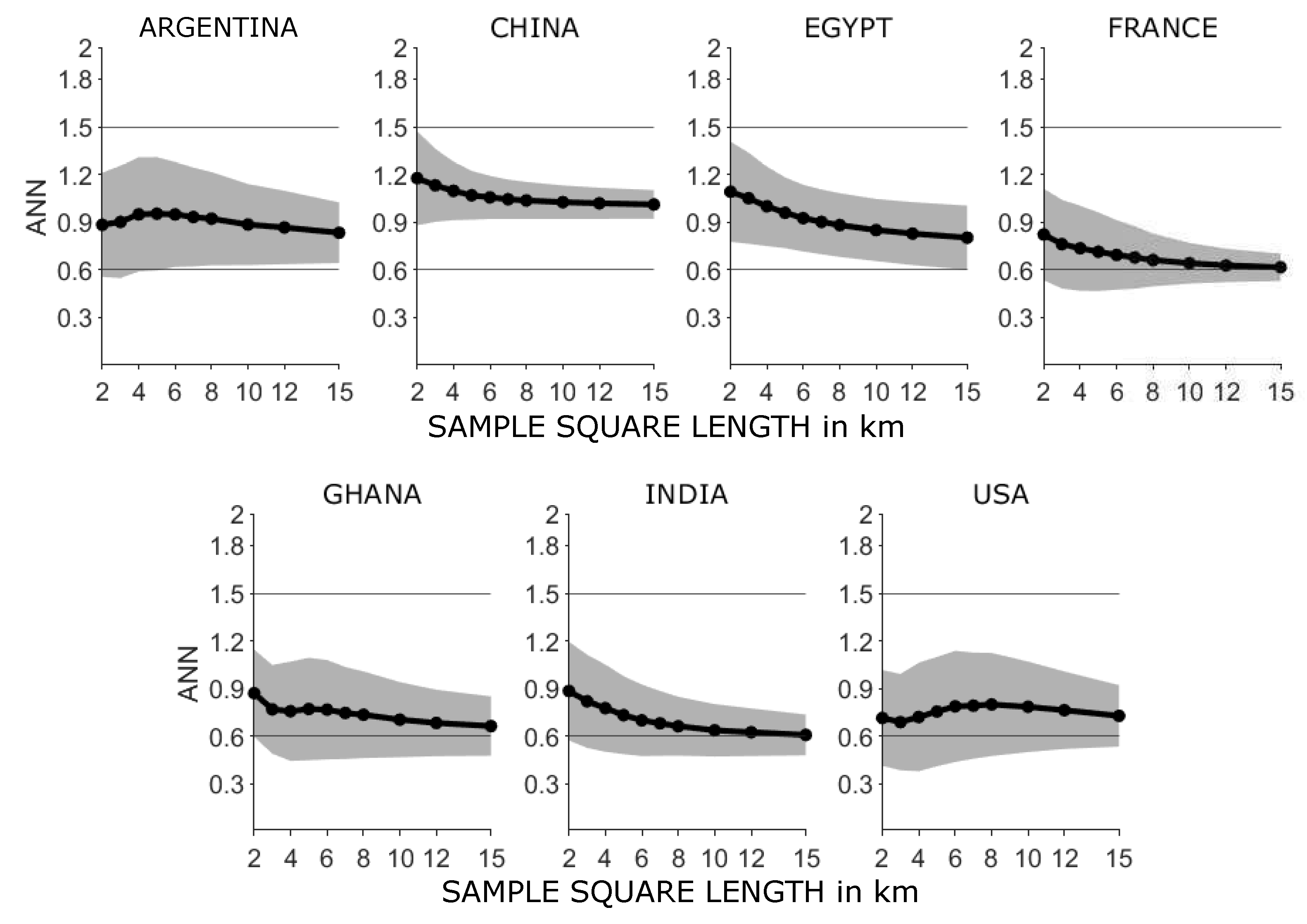
In order to investigate the arrangement of settlement objects in more detail, the described analysis with sample squares was repeated for squares with different edge lengths. The averaged results are shown in
Figure 6. The effect of the sample squares’ size on the
becomes visible: With increasing edge length the
decreases, whereas in sparsely populated areas an increase to medium sample square edge lengths is detected before the decrease. It also becomes clear that the settlement objects in the data sets China and Egypt are more regularly distributed than the settlements in the other data sets.
However, sample squares with regular settlement distribution can be found for all data sets. For the share of regular sample squares in the each data refer to
Table A2. While for a sample window size of 2 × 2 km
the proportion of windows with a
is between 0.8% (USA) and ~14% (China), for 3 × 3 km
between 0.95% (France) and 4% (India), for larger sample windows (15 × 15 km
) the values are between 0 % for China and 0.23% for Argentina (
Table A2). Areas of regular settlement structures can thus be observed above all in small settlement sections.
All sample squares listed with result in a z-value above 1.96. In this case, the delivers the reliable result of a non-random distribution.
The investigated regions show noticeable differences in terms of number of objects, density and portion of regular spots in the settlement structures. Nevertheless, similarities in the data sets Argentina and USA, and Egypt and India can be seen.
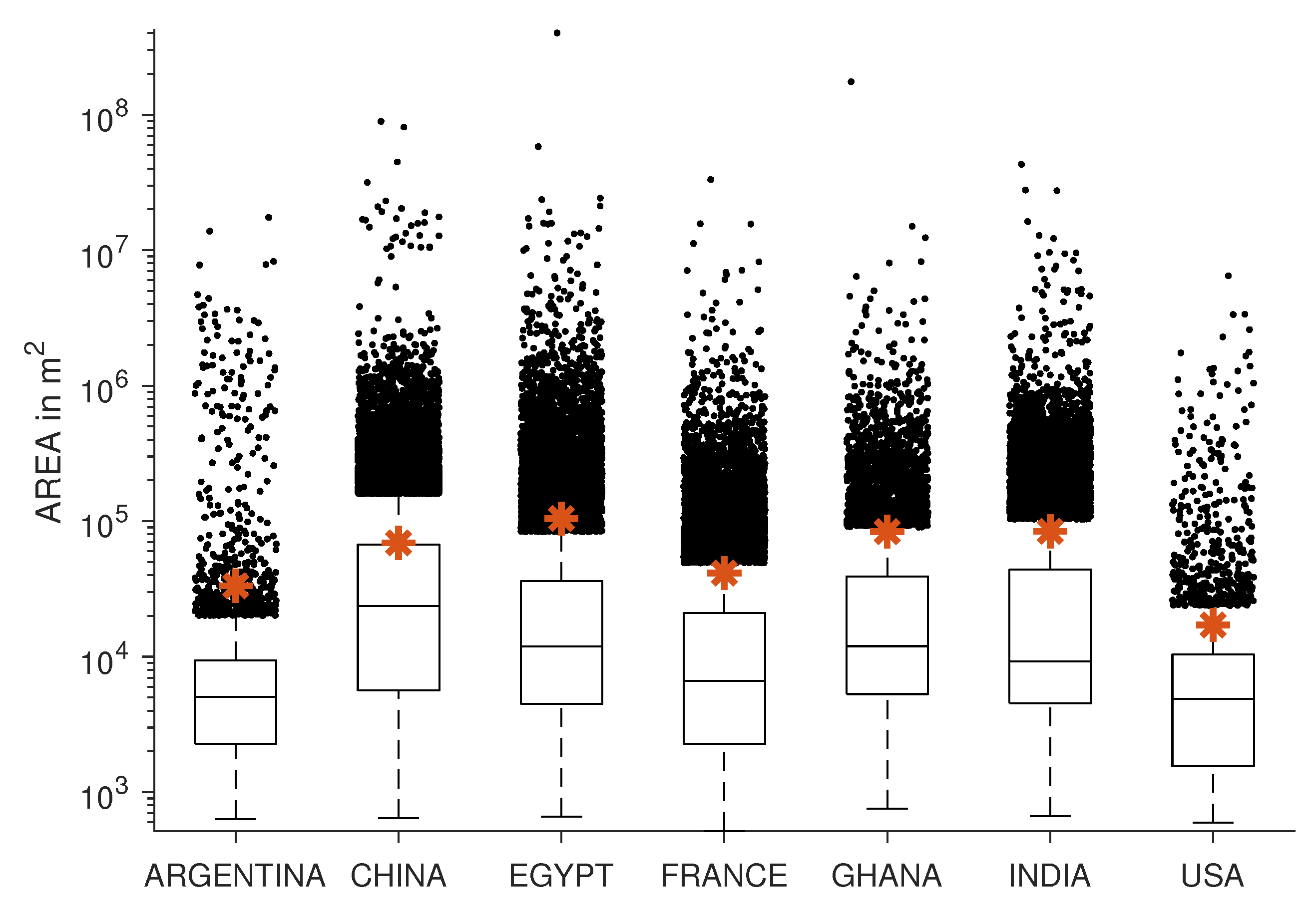
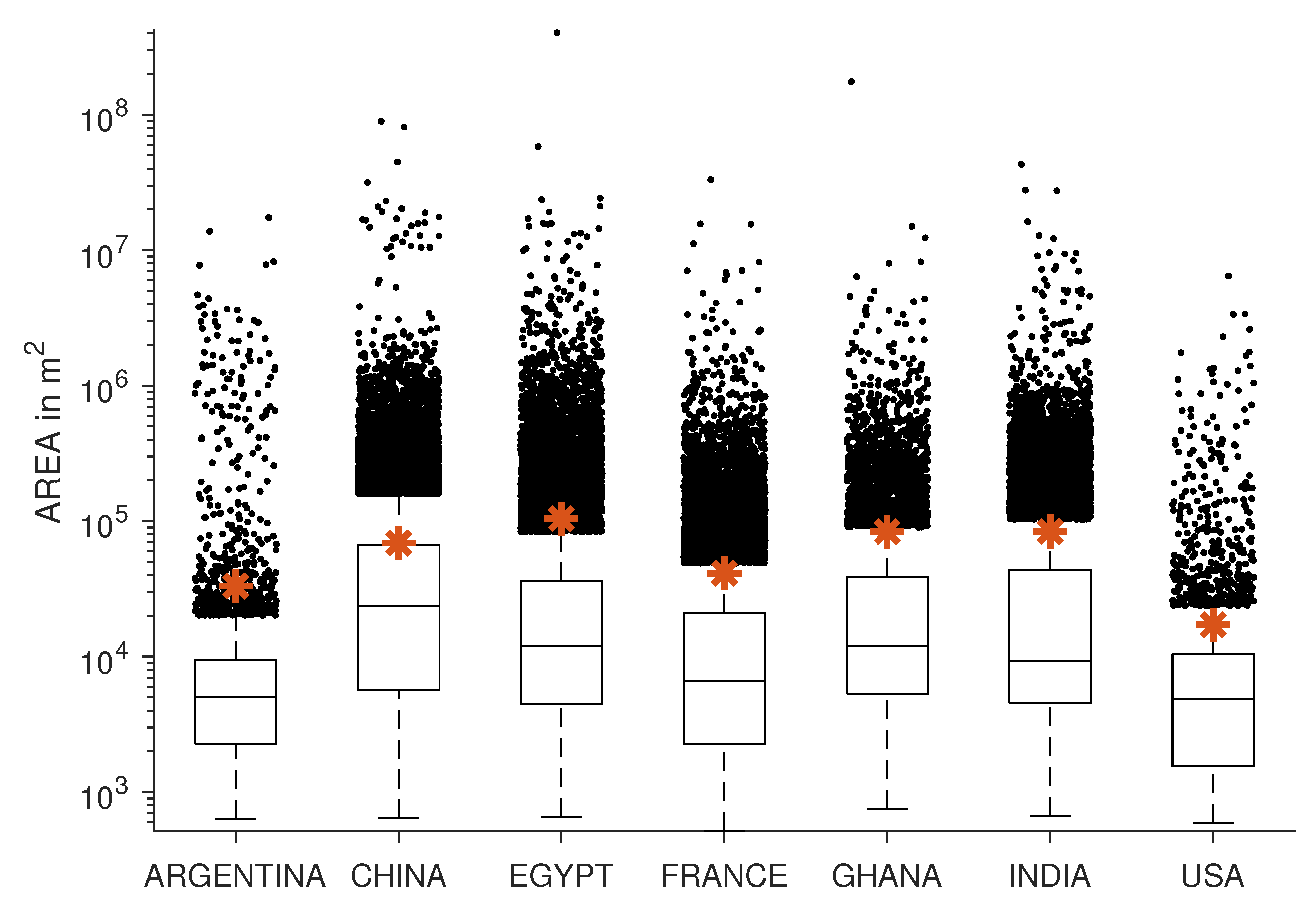
4.2. Size Distribution
To examine some of the points from above more closely, in addition to the three parameters
and
, the the size distribution of the expansion of the settlement objects in all data sets was examined, see
Figure 7. It is found that the median of all seven data sets is in a similar range of
m
, as well as the geometric mean
given in
Table 1. The characteristic size of the inter-urban structures investigated here is thus in the same range as the intra-urban structures of morphological slums investigated in [
35,
36].
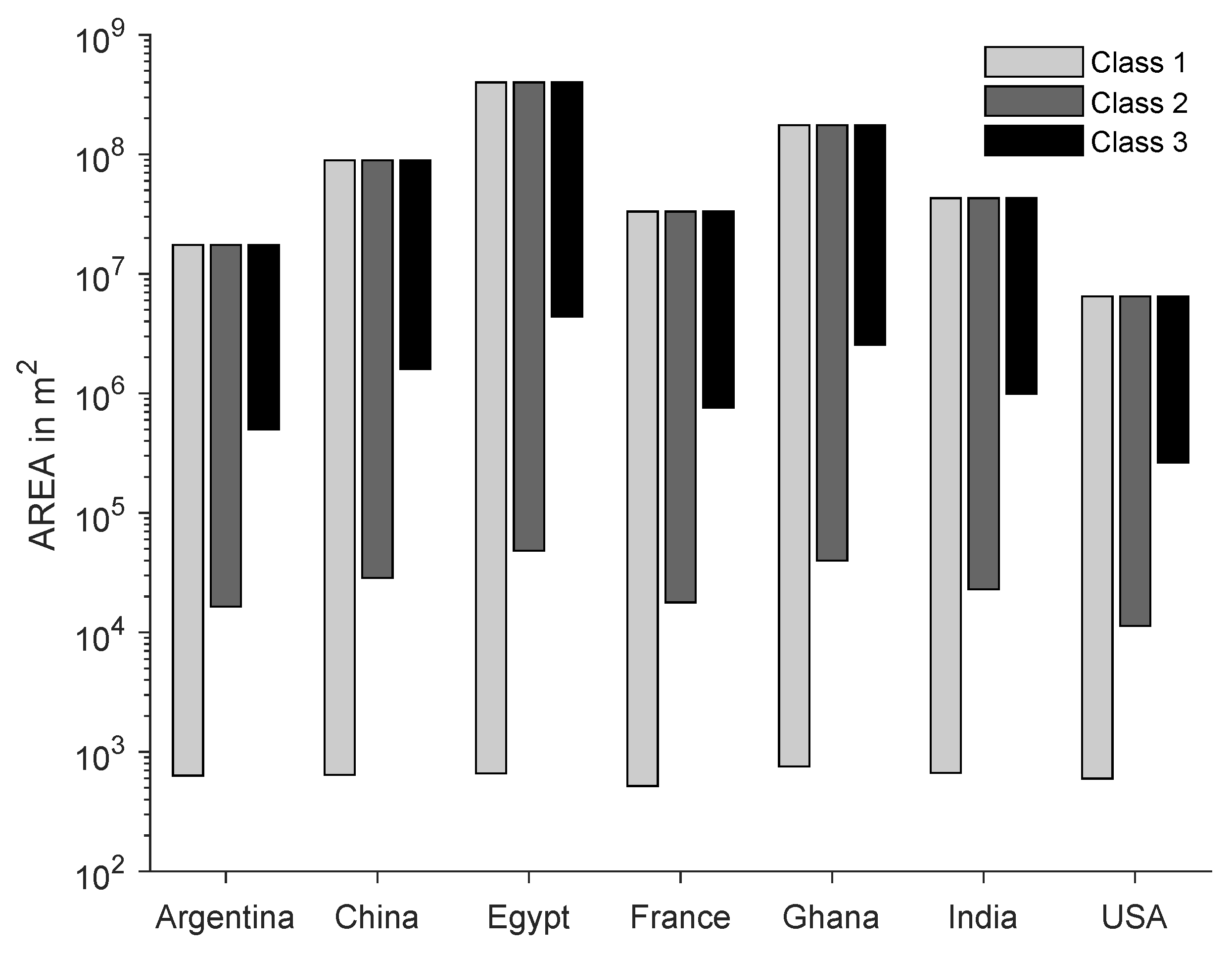
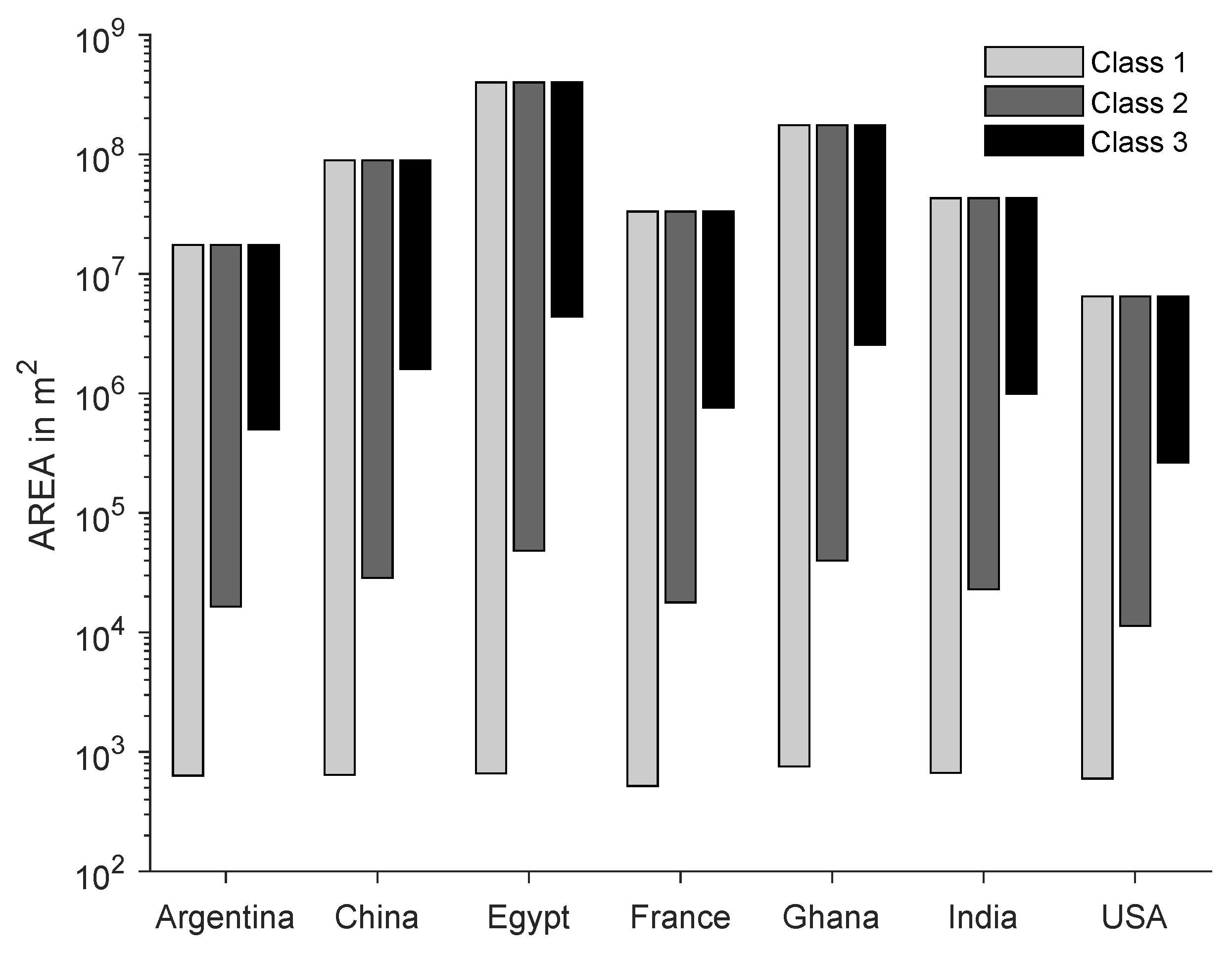
It also becomes clear that there are few settlement objects to be found in the regions investigated in Argentina and the USA. In addition, these two data sets do not contain as many large settlement objects as the other investigated regions, and are very similar in this aspect. This fact does not seem surprising, as the data sets show a part of the Argentinean Pampas and the American Great Plains. In the following, these two areas are referred to as sparsely populated. The data set China contains by far the most settlement objects, which also have the largest extension. The data sets India and Egypt contain a similar number of objects and have a characteristic size of the objects, which differs only slightly. Both number and characteristic length range between the extremes of the sparsely populated data sets and the extremely dense populated data set China.
The data sets Ghana and France cannot be easily classified into the categories of sparsely, medium and densely populated areas. France has a similarly large number of objects as India and Egypt, but contains objects of much smaller dimensions, whereas in Ghana, the extent of the objects is comparable with the extent of the objects in the data set India and the number of objects is close to the number of sparsely populated data sets.
4.3. Classes
The small percentage of regular structures in
Section 4.1 seems surprising when visually comparing the results to the GUF data, e.g., for Egypt (see
Figure 4). The larger cities in the Nile Delta appear to be equidistant to each other, like it was shown for the cities in the Nile Valley [
15]. Taking that into account a second analysis regarding only settlement objects larger in size, is carried out.
The data is divided into three logarithmic bins, ranging from the smallest object’s area to the largest object’s area. The entirety of objects, contained in the three bins, has been analysed in the previous subsections. In the following, this data set is referred to as
Class 1. The middle and the last bin containing medium and large objects are denoted as
Class 2, while the large objects are representing
Class 3. For a visualisation of the data sets’ division into classes, please refer to
Figure A1. The different classes in the data set Egypt are depicted in
Figure 8.
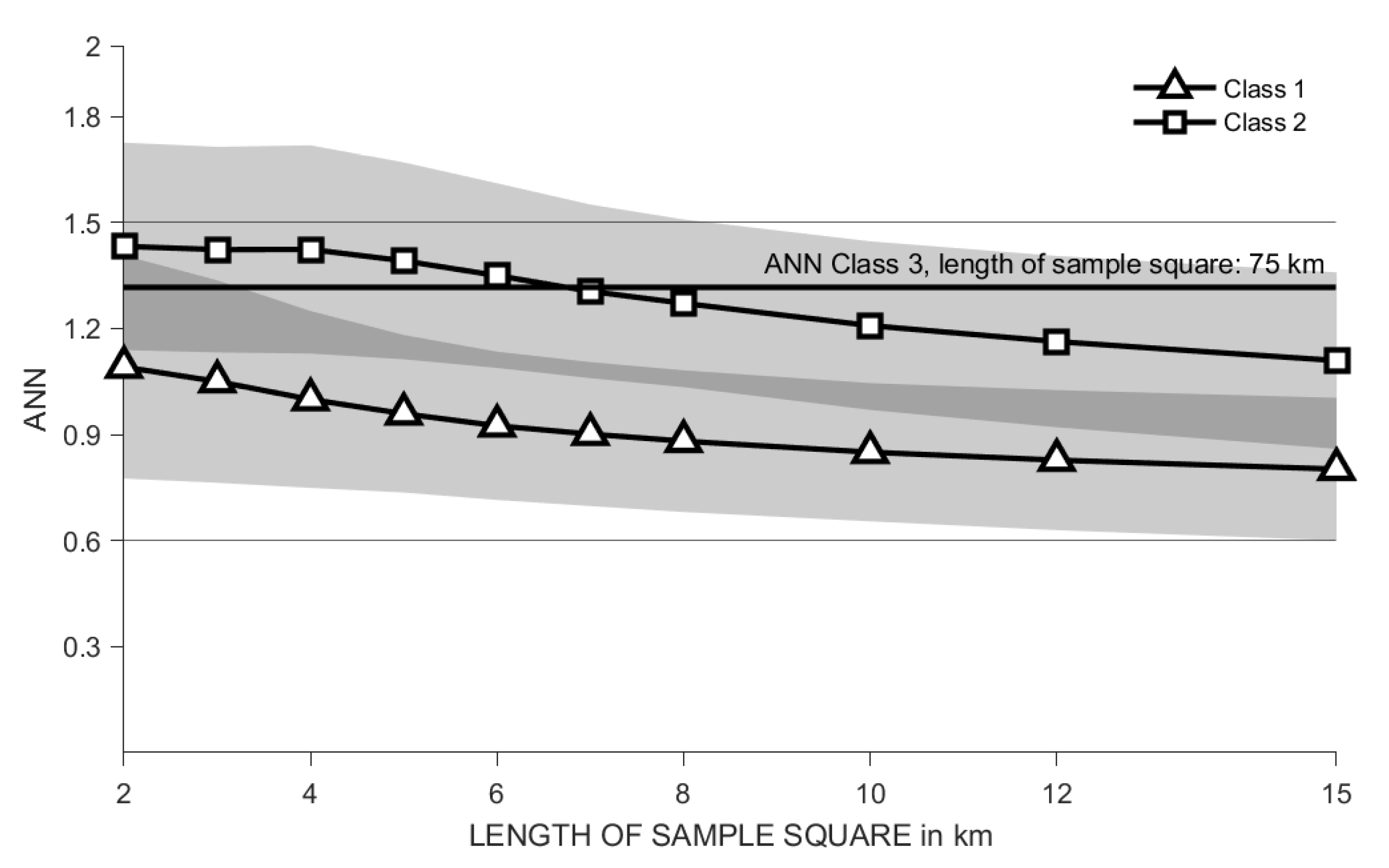
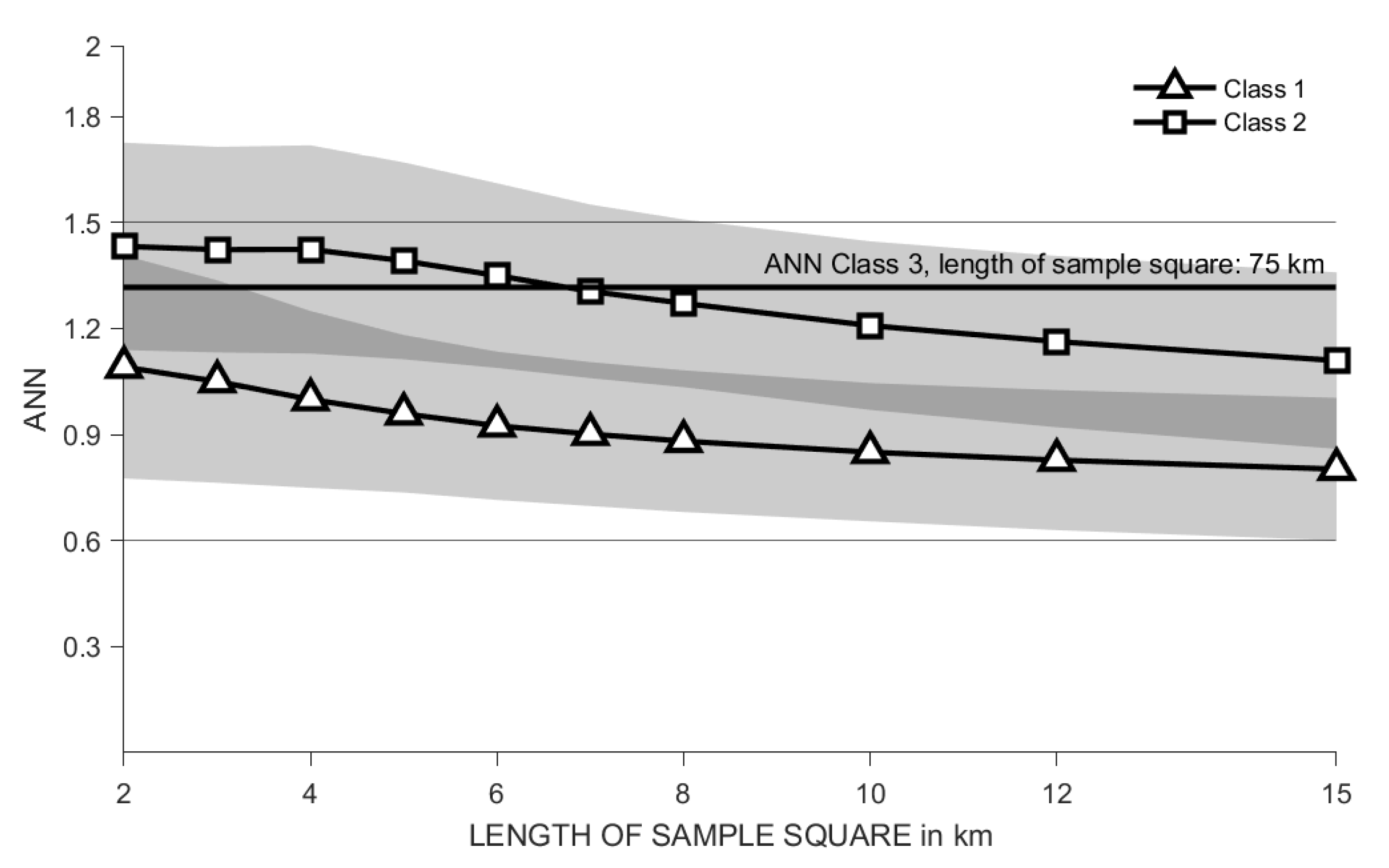
Repeating the described analysis with regarding only
Class 2, the mean
in the data set Egypt increases, see
Figure 9. In the data set Egypt there are only few objects in
Class 3, that is why the sample square length must be increased significantly to allow a evaluation of the
. Therefore, the analysis results are not easily comparable with those for
Class 1 and
Class 2. To get an impression of the results for
Class 3,
Figure 9 gives the average
for sample squares with edge length equal to 75 km, taking into account only the objects of
Class 3.
Similar results can be obtained by analysing Class 2 or Class 3 in the other data sets. Some data sets show higher proportions of regular windows in Class 3 than in Class 1, while others show higher proportions of regular windows in Class 2 than in Class 1. This leads to the hypothesis that settlement objects larger in size are arranged in a more regular pattern than the entirety of settlement objects.
When not just identifying the
in the sample squares but also the number of settlement objects regarded to calculate the index, it becomes clear that the sample squares with higher
usually include less objects (see
Table A2). When analysing
Class 2 and
Class 3, the number of settlement objects decreases while the sample square’s edge length is kept constant. One may argue that the
in
Class 2 and
Class 3 therefore only increases because decreasing number objects in the sample squares. Regarding
Table 2 this is not the case. Only for small sample squares with high
the data set
Class 1 includes more data points than in
Class 2. For larger sample squares the number of objects increases when moving from
Class 1 to
Class 2.
4.4. Regular Settlement Structures
None of the seven regions studied consists mainly of regular settlement structures. However, regular structures can be identified for all seven data sets—see
Figure 10.
Table 3 shows three such sections with
from the GUF and their parameters. It should be noted that the sections of the data sets China and Egypt for
Class 2 do not appear to be distributed as regularly as the high
suggests. This is due to the fact that in
Class 2 the small objects, which are, in this case, clustered around the larger ones, are not taken into account.
5. Discussion
The regions investigated in this study, especially rural areas, show different settlement patterns. The GUF is analysed with three parameters (number, density and regularity) that define a two dimensional pattern without considering the shape of the different objects. However, the analysis carried out is limited to a specific data set at a defined point in time. When assessing the results, it must be taken into account that the data may contain artefacts that are not discussed further here. For an evaluation of the original GUF data, please refer to the corresponding publications [
37].
Looking at the size distribution of the different settlements and their mean value, it is striking that the values of ~0.01 km
found here are similar to those from intra-urban analyses [
35,
36]. This size seems to be an universal quantity of settlement structures, as it is also similar to the size of city blocks in American and Australian Cities [
38].
We use the
as a method to quantify the regularities of patterns in awareness of the limitations of this approach: The influences of the area and number of objects taken into account for the calculation cannot be neglected (for a more detailed discussion on pattern indices we refer to the work in [
39]). The disadvantages are understandable, as the spatial arrangement of a structure is reduced to a single parameter leading to an information loss. As the
still gives a first indication of the regularity of the pattern, it is an appropriate metric to answer the research questions formulated above.
Looking at the analysed regions from a macroscopic view, settlement clusters can be found, especially towards the coastlines. This is due to the fact that the process of settlement formation does not take place homogeneously over an area, but the proximity to resources and infrastructure (fishing, trade and economy) seems to play a role in the choice of location. The area boundaries also have a great influence on the result: while south of the region studied in Ghana the Atlantic Ocean begins directly and north of it the rainforest, in China the region is part of a very large inter-urban structure with high regularities [
16].
The empirical results show a correlation between high density and a high number of objects (
Table A2). At the same time, the density and the number of objects correlate strongly (
) with the percentage of areas of high regularity (high
), especially when using small investigation windows (2 × 2 km
). With larger windows, the number of objects in areas with high
values decreases, so that it is uncertain how valid the results on the regularity are. It is also qualitatively shown in
Table 3 that although density and
can be mapped, the size distribution in the empirical data fluctuates more than a theoretically regular pattern. As indicated by an analysis for large cities in the Nile Valley [
15], the analyses can be continued in different classes. In further studies, the regularity of the larger cities introduced in
Section 4.3 should be examined in detail.
At the beginning of this paper we asked the question whether urban structures (or parts of them) are arranged in a regular pattern and thus exhibit a typical property of non-equilibrium pattern formation in dissipative, open systems. As one might expect, regular structures cannot be observed in the entire study areas. However, we have been able to identify regular settlement patterns, especially in areas with a high number and density of settlement structures.
Based on these findings, a further step is to investigate which models can be used to depict the pattern formation of urban structures. For example, it can be analysed whether reaction–diffusion models, the pattern formation through the interaction of different morphogenes, are suitable to describe the structure formation. For this purpose, fundamental work by Rudy et al. [
40] or Zhao et al. [
41] can be referred to, who have identified the underlying mechanisms of pattern formation by analysing image sequences. Their proposed methods can be used to analyse time-resolved settlement maps and quantify their changes by using concepts from physics.
Since regular structures were identified mainly in small evaluation windows, the nonlinear pattern formation models to be developed should also focus primarily on small scales.
6. Conclusions
The results in this paper aid to answer whether settlements are arranged regularly in different regions of the world. The motivation for posing this question is whether cities as thermodynamic open systems share similarities in pattern with dissipative structures.
The settlement patterns of seven regions in five continents were investigated. While the region in China had a high number of settlement objects and a high settlement density, and the regions in the USA and Argentina had a low number of objects and settlement density, the other regions studied (Ghana, France, India and Egypt) were in between. The settlement density and the number of settlements correlate with each other, which can be explained by the relatively similar size distributions of the settlements with a geometric mean of nearly 0.01 km. The number of settlements as well as the density correlates with the proportion of sample windows with a high regularity . The analyses with the highest resolution (sample window of 2 × 2 km) showed that between approximately 1% (USA) and 14% (China) of the investigated area show regular settlement structures. This means that the more densely populated a region is, the more likely it is that regular settlement structures can be found in it.
These results can be used to develop mathematical models that can describe the pattern formation of urban structures by models of non-equilibrium thermodynamics. Furthermore, the results could be expanded in future work and brought together with other research fields: For example, (i) in infrastructural studies it could be analysed whether the temporal development of transport infrastructures had an influence on the inter-urban pattern formation. Furthermore, (ii) it could be investigated to what extent political systems (politics and policies) are correlated with pattern formation. These aspects could then be explicitly considered in the mathematical models. Finally, (iii) it can be investigated to what extent the economic development of a region is related to or influences the arrangement of settlements. All these insights are useful for a better understanding of urbanisation processes and can, for example, help urban planners to develop sustainable concepts to meet these challenges.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}