
An AI-Empowered Home-Infrastructure to Minimize Medication Errors



Institute of High Performance Computing and Networking, National Research Council of Italy, 80131 Napoli, Italy
*
Author to whom correspondence should be addressed.
J. Sens. Actuator Netw. 2022, 11(1), 13; https://0-doi-org.brum.beds.ac.uk/10.3390/jsan11010013
Submission received: 21 December 2021
/
Revised: 19 January 2022
/
Accepted: 5 February 2022
/
Published: 9 February 2022
(This article belongs to the Special Issue Wireless Sensors Networks and Artificial Intelligence for Intelligent Health Monitoring)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:This article presents an Artificial Intelligence (AI)-based infrastructure to reduce medication errors while following a treatment plan at home. The system, in particular, assists patients who have some cognitive disability. The AI-based system first learns the skills of a patient using the Actor–Critic method. After assessing patients’ disabilities, the system adopts an appropriate method for the monitoring process. Available methods for monitoring the medication process are a Deep Learning (DL)-based classifier, Optical Character Recognition, and the barcode technique. The DL model is a Convolutional Neural Network (CNN) classifier that is able to detect a drug even when shown in different orientations. The second technique is an OCR based on Tesseract library that reads the name of the drug from the box. The third method is a barcode based on Zbar library that identifies the drug from the barcode available on the box. The GUI demonstrates that the system can assist patients in taking the correct drug and prevent medication errors. This integration of three different tools to monitor the medication process shows advantages as it decreases the chance of medication errors and increases the chance of correct detection. This methodology is more useful when a patient has mild cognitive impairment.
1. Introduction
A trend of shifting more and more patients (not with several symptoms) from hospitals to homes for treatment has emerged recently [1]. This trend strengthened further during the COVID-19 crises due to the effects of hospitalization on humans’ emotional statuses [2]. As a result, loads on the hospitals and costs on healthcare infrastructure have been reduced [3]. Moreover, in many countries, including Italy, Japan, the USA, and many European countries, the number of senior people is increasing at a fast rate. Elder people need more healthcare services compared to the youth. Secondly, adherence to the therapy is another issue during the treatment process. The World Healthcare Organization (WHO) has defined adherence to the therapy as “the extent to which the patient follows medical instructions”. A recent report of WHO [4] indicates 50–80% patients worldwide follow medical instructions and the treatment plan.
Furthermore, it is challenging for the patients to continue a treatment process by themselves at home if they have some cognitive disability. In such a scenario, the chance of medication errors increases [5] and sometimes, it may result in severe implications [6]. For example, the United States Institute of Medicine has estimated that medication errors affect 150,000 people yearly and 7000 patients die every year in the USA. The same situation of medication errors has been reported in Europe [7].
In addition to severe complications and deaths caused by medication errors, there are also the economic impacts of medication errors [8]. According to an estimate, the cost of hospitalization due to failure in adherence to medication therapy is around USD 13.35 billion annually, only in the USA [9]. Similarly, in Europe, the expense of medication errors is in the range from €4.5 billion to €21.8 billion annually, according to an estimate of the European Medicines Agency [7].
There are various forms of medication errors such as wrong frequency, omission, wrong dosage, or wrong medication, as classified by WHO [6]. The WHO has emphasized that “the senior people are more prone to special issues related to medication errors. The risks and consequent impacts of the medication errors have been reviewed in different surveys [5,10]. These studies emphasize the need for systems that are able to assist the elderly and patients during medical treatment at home.
Other factors that cause medication errors are insufficient knowledge of the pill, and physical and/or cognitive impairments, which brings difficulty in following the medication process correctly. Designing the improved solution to monitor a patient’s actions and, in particular, the medicine that a patient is going to take will improve the degree of adherence to the medication plan and minimize adverse events that can occur due to medication errors. Two hundred and fifty-six residents that were recruited in 55 care homes were monitored in [5] by considering a mean of 8.0 medicines. It was observed that about (178) of them had one or more medication errors. The mean number according to the study was 1.9 errors per resident. The mean potential harm from prescribing, monitoring, administration, and dispensing errors was estimated as 2.6, 3.7, 2.1, and 2.0, respectively, the scale being (0 = no harm, 10 = death). The authors highlighted that the majority of patients being at risk for medication errors is of concern. We can address this problem by taking the benefit of computing technology [11], which has brought a revolution in many areas. Machine learning (ML) tools such as Reinforcement Learning [12] have introduced many useful solutions to healthcare problems [13,14,15,16], including risk management in different environments [17,18,19,20]. We propose an Artificial Intelligence (AI)-based system that assists patients and the elderly during the medication process at home in order to minimize medication errors. The AI-based system employs a combination of Reinforcement Learning (RL), Deep Learning (DL), Optical Character Recognition (OCR), and barcode technologies [21]. The designed intelligent agent can monitor the drug-taking process. The major component of the proposed work is the RL agent that integrates multiple AI methods (DL, OCR, and barcode) and can provide assistance not only to the elderly but also to patients with cognitive disabilities in their medical treatment at home. The proposed architecture considers patients with good cognitive skills or patients that have some cognitive impairment. A feedback in audio and video form is produced when the person finishes the medication process. Such an AI-based system is an intelligent multi-agent infrastructure that assists patients in taking correct medicines. The RL agent is based on the Actor–Critic method that further integrates three different methods for monitoring a patient medicine-handling process. The first technique is an OCR that tries to read the name of the drug from the box. The second method is a barcode reader that identifies the drug from the barcode available on the box. The last method is a Convolutional Neural Network (CNN) classifier that is able to detect a drug even when shown in different orientations [22]. The advantage of integrating three different methods to monitor the medication process is that it decreases the chance of medication errors and increases the chance of correct detection. This methodology is more useful when a patient has mild cognitive impairment.
2. Related Work
This section will recall relevant literature reviews and highlight existing limitations. Few AI-based intelligent systems have been proposed to assist the older population. The Assisted Cognition Project developed by [23] uses AI methods to support and amplify the quality of life and independence for patients with Alzheimer’s disease. Another project (Aware Home) is proposed in [24], which aims to develop situation-aware environments to help senior people maintain their independence. Similarly, the Nursebot Project developed in [25] targets mobile robotic assistants to aid physical and mild cognitive decline. However, all these solutions are not suitable to monitor the medication process, and in some cases are unable to assist patients with cognitive problems.
The Autominder System [26] applies partially observable Markov decision processes to plan and schedule the Nursebot system to provide assistance for home therapy. However, the proposed architecture is not capable of preventing medication errors and is mainly designed only for the reminding process. The work of [27] uses smartphones to identify drugs by quantifying properties like color, size, and shape. However, for accurate estimation, such a methodology requires a marker to be used with known dimensions. The authors of [28] have presented a technique for the detection of some key points in the medicine box and then applied mapping using a database. The approach showed good results, but it was tested only for few boxes. In the work of [29], an intelligent pill reminder system is presented that consists of a pill reminder component and a verification component, however only one tool is used for the recognition of the medicine boxes.
The other two methods that could be useful in the medication process monitoring are OCR and barcode tools. These two tools are not used in many solutions that focus on assisting patients in their medication process. OCR is largely used for detection and reading text [30], and could be used for identification of the drug. Similarly, a method to identify the medicine is to use the drug box for real-time detection, identification, and information retrieval. A barcode scanner is developed in [31] to recognize the drug correctly. However, it needs the medicine box to be presented to the camera in a specific position. A working method is developed in [32] on the usefulness of a smart home to assist patients with a treatment process. The system initiates when a new drug prescription is advised by the doctor. An electronic system produces a QR code that is delivered with the prescription, indicating time period, visit details, and medication workflow information. The set of information is utilized by an expert system that manages all data produced by the prescription. The methodology assists the subjects with no cognitive disability. There is no customization of the solution depending on the patient’s skills. Implementation of different AI and IoT-based proposals for remote healthcare monitoring have been reviewed in [33]. A system based on ambient intelligence and IoT devices for student health monitoring is proposed in [34]. Authors have also employed wireless sensor networks to collect data required by ambient environments. Similarly, AI-empowered sensors for health monitoring are studied in [35]. However, both studies do not consider cognitive disability of patients. We have observed the absence verification mechanism in the reviewed papers that can validate the ingestion of the correct drug by the subject. Most of the papers limit their target to the medicine reminder, but do not have the verification mechanism. In a few frameworks, it is the patient himself that communicates the assumption of the medicine.
3. Technical Background
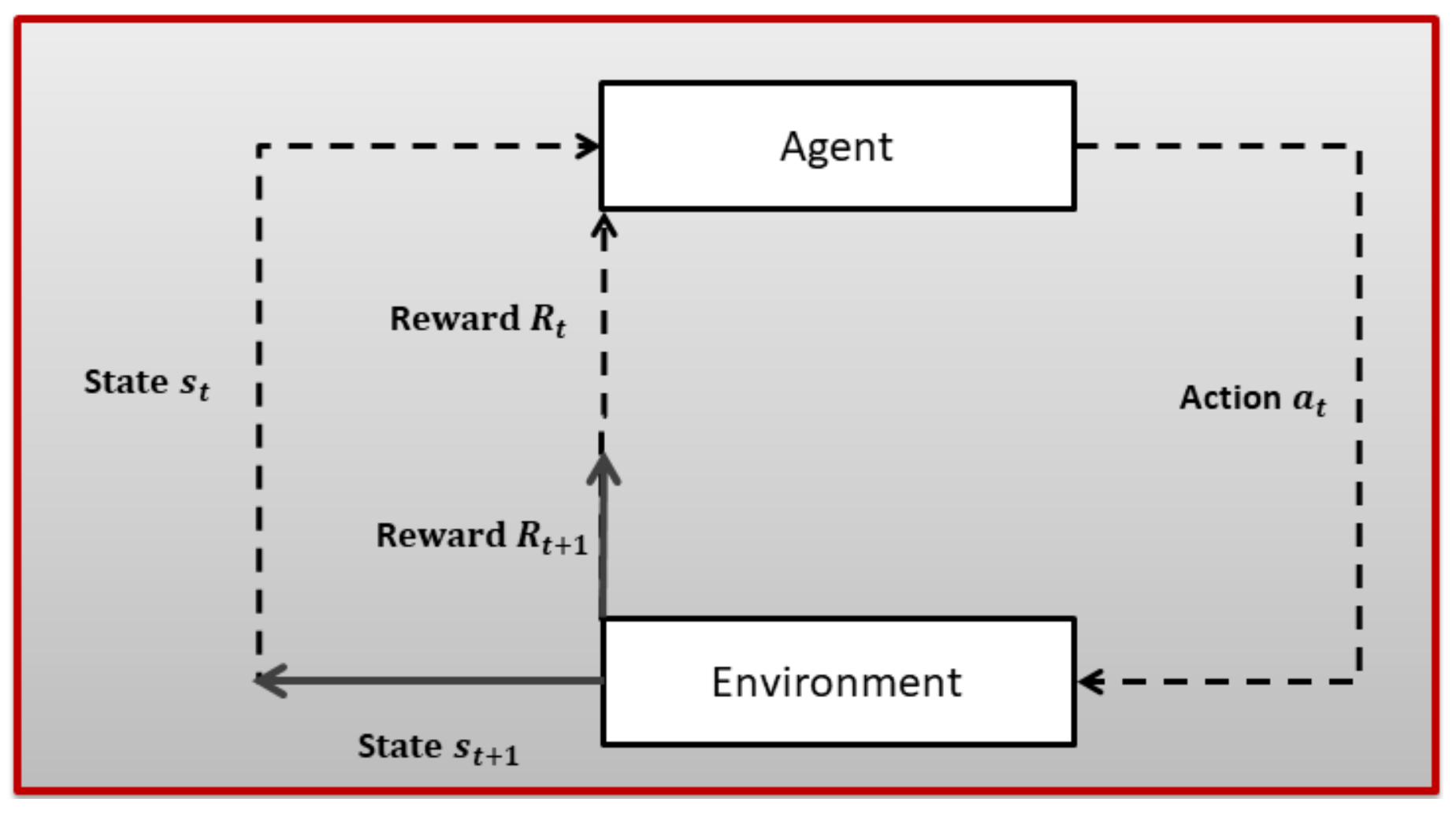
Reinforcement Learning (RL) is a subfield of ML where an agent tries to learn the dynamics of an unknown environment. To learn the characteristics of the given environment, the agent chose a certain action from a set of actions in a certain state (there is a set of state for every given environment) at time slot t and, based on the transition model of the environment, the agent reaches a new state and receives a numerical reward . After a lot of trial and error, the RL agent can learn the optimal policy for a given environment. The optimal policy tells an agent which action to choose in a given state to maximize long-term aggregated reward. An RL problem is first modeled as a Markov Decision Process (MDP), as shown in Figure 1, and then an appropriate RL algorithm is employed based on the dynamics of the underlying environment. A brief introduction to MDP is given next.
A MDP is a tuple 〈S, A, R, P, 〉; where
- S is used to denote states;
- A is used to denote actions;
- R is used to denote a reward function;
- P indicates transition probability;
- is a discount factor: ∈ [0, 1].
The Markov property, i.e., next state, is dependent only on the previous state that is assumed. A finite MDP is described by actions, states, and the environment’s dynamics. For any state–action (s,a) pair, the probability of resulted state and the corresponding reward (,r) is given as in Equation (1):
Informally, the target of the RL agent is to maximize the reward. This is to say, with the list of rewards R,R,...after time period t, the goal is to maximize the reward function as given in Equation (2):
where T is the last time interval.
The return is the sum of discounted rewards obtained after time t.
A policy defined in Equation (4) tells an agent which action to take in a given state.
Having the policy and the return , two value functions can be defined, i.e., state–value and the action–value functions. The state–value function (s) is the expected return starting from a state s and following the policy as given in Equation (5).
The action–value function (s,a) is the expected return starting from a state s, taking action a, by following the policy .
The optimal value function is one that obtains the best gains in terms of returns, as given in Equation (6).
After defining the MDP and the selection of an RL technique for a given problem, the next issue is to maintain a delicate balance between exploration and exploitation. At each time step, the RL agent can select the best rewarding action based on its current knowledge of the environment. On the other hand, an RL agent can explore more available actions that may provide even more rewarding actions. Therefore, exploration and exploitation may not be good strategies and an RL agent should learn a trade-off between exploration and exploitation for a certain problem.
For further details on RL algorithms in general and the application of RL in healthcare in particular, the reader may refer to [12,13], respectively.
Deep learning, in particular, CNN, has brought significant contribution and revolution to computer vision and object detection. Recently, several new networks have been designed and implemented to attain greater accuracy in the competition of ImageNet large-scale visual recognition challenge. Few famous CNN-based models have achieved significant enhancement in object detection as well as in classification. For example, the AlexNet model was able to minimize the error rate to in 2012, which was in 2011 [36]. Moreover, the models of GoogLeNet [37] and VGGNet [38] won the top two positions, respectively, in 2014.
However, these models require a large amount of data for training. Transfer Learning [39] can be adopted as a solution to this problem in cases of custom and small data-sets. Transfer learning employs optimized parameters of a pre-trained model and performs training only on a few extra layers according to the needs of the underlying model. Availability of a huge database on ImageNet (http://imagenet.org/ImageNet, accessed on 20 December 2021) is useful for different studies to train the feature extraction layers. The identification of medicine can be categorized as a classification task. However, we have a small data-set, and thus we used a DL classifier using Transfer Learning. More details on DL are found in [40].
4. System Model
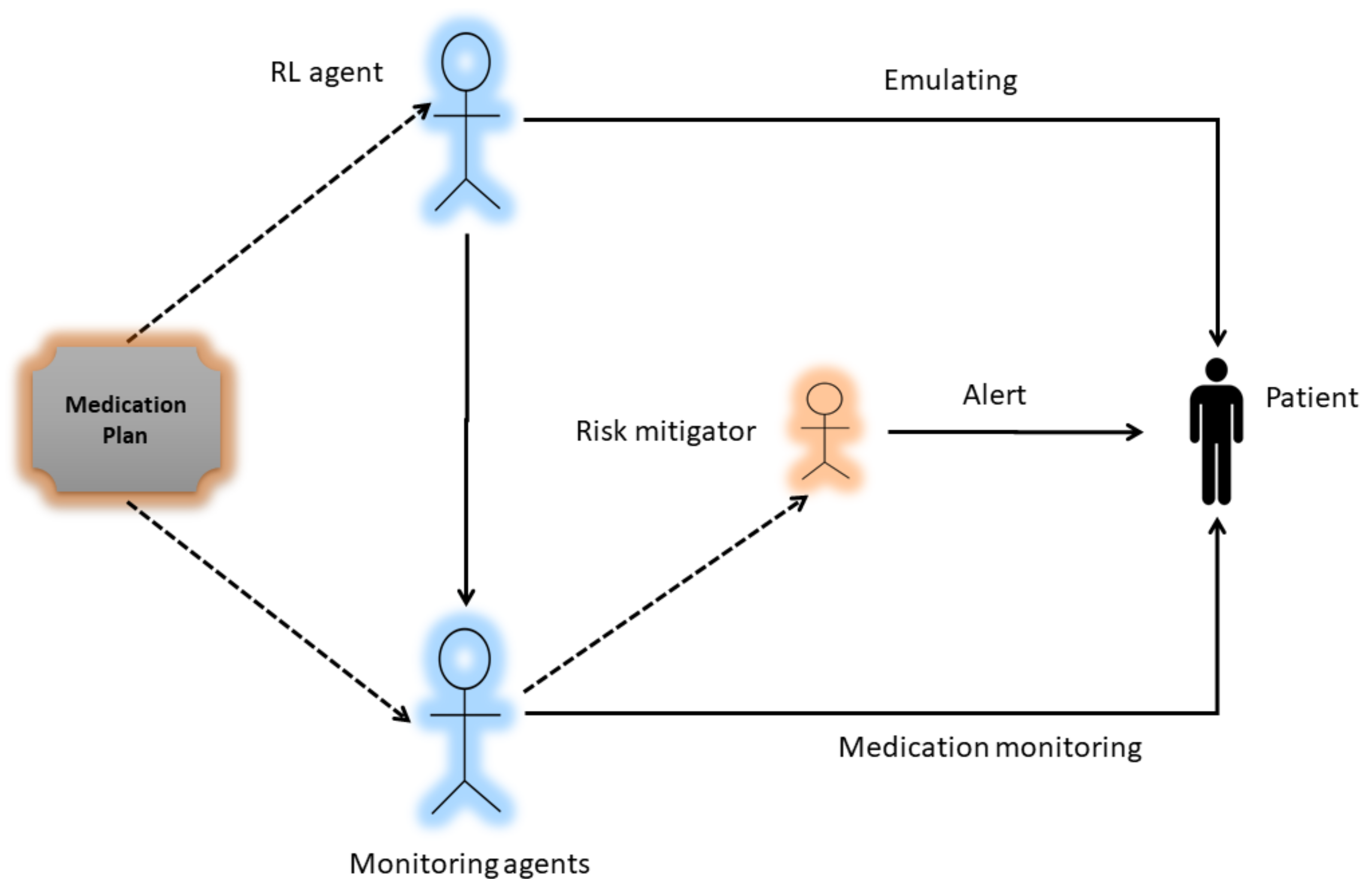
A major component of the system model is the RL Actor–Critic-based agent. It is an intelligent agent that first learns the cognitive skills of the patient by trial and error. After emulating the patient skills i.e., a patient with Cognitive Impairment (CI) or a patient with Normal Cognition (NC), the AI agent has to select one technique or a combination of techniques (DL classifer, OCR, and barcode) for monitoring the medication process as shown in Figure 2. The block diagram of the proposed work is shown in Figure 3, which presents the methodological workflow of different AI agents. All agents have the medication plan of a patient. The RL agents controls the other three AI agents (DL, OCR, barcode) and selects them as its actions according to the skills of a patient. The chosen AI agents monitor the process of medication and generates alerts if the patient is going to take the wrong drug, thus helping the patient to avoid taking the wrong medicine. The technical detail of each method is presented below.
4.1. Actor–Critic Algorithm
As described in Section 3, after modeling the given problem as an MDP, one needs to choose a suitable RL algorithm to solve the modeled MDP. In our problem, as explained in Figure 3, the RL agent has to choose a suitable monitoring method based on emulated skills of the patient. Therefore, we need a method that can continuously receive feedback on actions taken and update policy. Actor–Critic (AC) is a hybrid RL method that employs value- and policy-based schemes. The critic part of the AC algorithm estimates the value function and the actor part updates the policy distribution based on critic feedback. The pseudo code of the Actor–Critic scheme is given in Algorithm 1. The step-wise explanation of the methodology is given next.
| Algorithm 1 actor critic algorithm |
Emulate , Initialize Rewards for all state–action pairs, Q to zero, Initialize tuning parameters Initialize s 1. Select OCR, BC, or DL method based on patient condition . 2. Get the next state (Right or wrong drug box) 3. Get the reward (positive in case of right drug box and negative in case of wrong drug box). 4. Update state utility function (critic). 5. Update the probability of the action using error (actor). until terminal state |
Initially, the RL agent selects an action under the current policy. We used softmax function to opt a particular action, as given in Equation (7):
In the next step, the resulting state and reward is observed as given in the Algorithm 1. In the third step, the utility of the current state , next state , and the reward is plugged in the update rule used in Temporal Difference zero , as given below in Equation (8):
In step 4 of Algorithm 1, error estimation is used to update policy. Practically, step 4 is used to weaken or strengthen the probability of a certain action based on and non-negative step-size , as can be seen in Equation (9):
For the Actor–Critic algorithm, we need a set of eligibility traces for both actor and critic. For the latter part, s trace is stored for every state and updated as given below in Equation (10):
After estimating the trace, the state can be updated as follows in Equation (11):
Similarly, for the actor, the trace is stored for every state–action pair and updated as given in Equation (12):
At the end, the probability of selecting a certain action is updated as given below in Equation (13):
4.2. Dl Classifier
Training the Convolutional Neural Network (CNN) model on a small data-set is difficult [41]. To mitigate this problem, we took advantage of transfer learning and chose VGG16 [38] as our pre-trained CNN model. In addition, using a pre-trained network that has been trained on millions of images is also helpful to compensate data-set bias, which may occur in applying DL model on small data [16].
The data-set for our CNN model was created in these steps. Firstly, we started to capture images of 12 drugs that are available in Italy. We captured images in different orientations and light conditions, as shown in Figure 4. Next, we applied preprocessing techniques such as: black background, rescaling, gray scaling, sample wise centering, standard normalization, and feature-wise centering to remove inconsistencies and incompleteness in the raw data and clean it up for model consumption. At the end, we employed methods like rotation, horizontal and vertical shift, flip, zooming, and shearing to improve the quality and quantity of data-sets.
We have arranged 700 images for each drug (total 8400 for all drugs) and used , i.e., 6720 images, and , i.e., 1680 images, for training and testing, respectively. Next, we fine-tuned the last four convolution layers of the original VGG-16 network [42]. A dropout rate of 0.5 was used between fully connected layers to avoid over-fitting and we replaced 1000 classes with 12 classes. The categorical cross-entropy was utilized as a loss function. For optimization, a momentum of 0.9 to the stochastic gradient descent and a learning rate of 0.0001 has been used.
4.3. Optical Character Recognition
One unique feature of any medicine box is that the name of the drug also serves as a distinctive identifier. Some medicine boxes may have the same name but differ in number of dosage, pills, and company. All this information is available on the drug box and can be decoded. The whole OCR method is summarized next.
1. From video, do extraction of image and apply gray scale thresholding.
2. Then apply Otsu’s method for separation of dark and light regions.
3. Then look for set of connected pixels and recognize characters and ignore logos, stripes, and barcodes.
4. Then the overlapping between bounding boxes is computed using identification method.
5. Next, apply Tesseract for character recognition.
6. At the end, apply Levenshtein distance tool for comparison on obtained string.
4.4. Barcode Method
A barcode is a technique of representing data in a visual, machine-readable form and is used widely around the globe in various contexts. At the start, barcodes represented data by varying the spacings and widths of parallel lines. Barcode identification is broadly applied in the healthcare sector, ranging from (1) For identifying patient; (2) To create the subjective, objective, assessment, and plan with barcodes; (3) For medication management.
Many medicines are available in the market with a variable number of pills and different dosages. In Italy, an unequivocal identifier is given to each medicine box. The availability of barcodes for each drug makes the identification process easy and fast. Zbar (http://zbar.sourceforge.net/, accessed on 20 December 2021) and ZXing (https://github.com/zxing/zxing, accessed on 20 December 2021) are two publicly available libraries used for barcode decoding. We use the Zbar library due to its superior performance with orientation and integrate it with the OpenCV (https://opencv.org/, accessed on 20 December 2021) library that can read any image.
The general procedure for barcode reading is as follows:
- White and black bars are used in the structure of a barcode. Data retrieval is performed by shining a light from the scanner at a barcode, then capturing the reflected light and replacing the white and black bars with binary digital signals.
- Reflections are weak in black areas while strong in white areas. A sensor receives reflections to get analog waveforms.
- The analog waveforms are then converted into a digital signal using an analog to digital converter called binarization.
- Data retrieval is done when a code system is identified from the digital signal using the decoding process.
5. Results
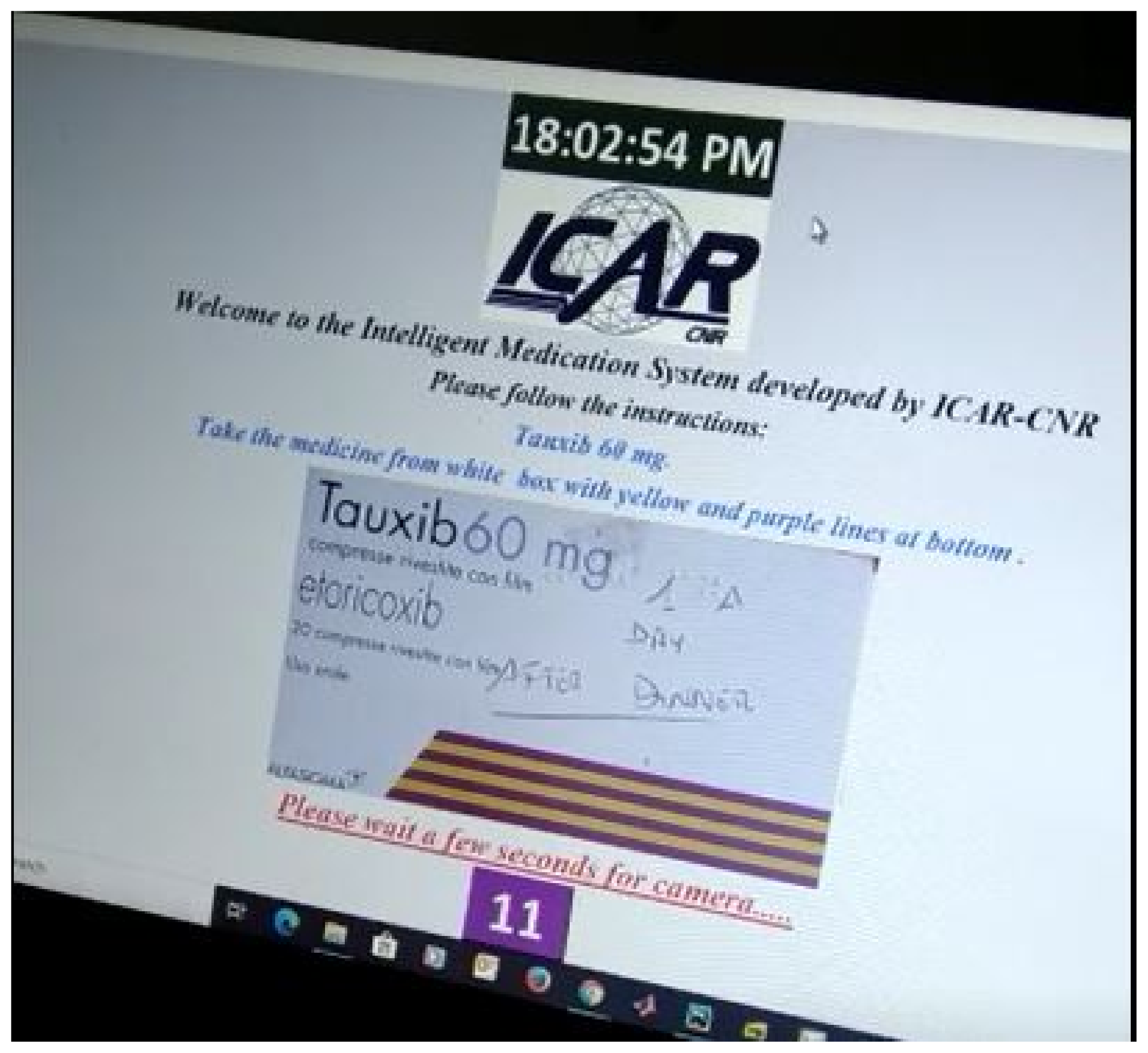
Figure 5 shows the first step of the GUI demonstration of the proposed system. Figure 5 refers to the stage when an image of the drug is presented to the patient that he/she has to take in accordance with their advised medication plan. The next stage is the selection of an appropriate monitoring tool (DL, OCR, barcode) while the patient is taking their drug.Therefore, we can see in Figure 6 that the choice (taken action) of RL agent is to use a DL classifier for drug identification.
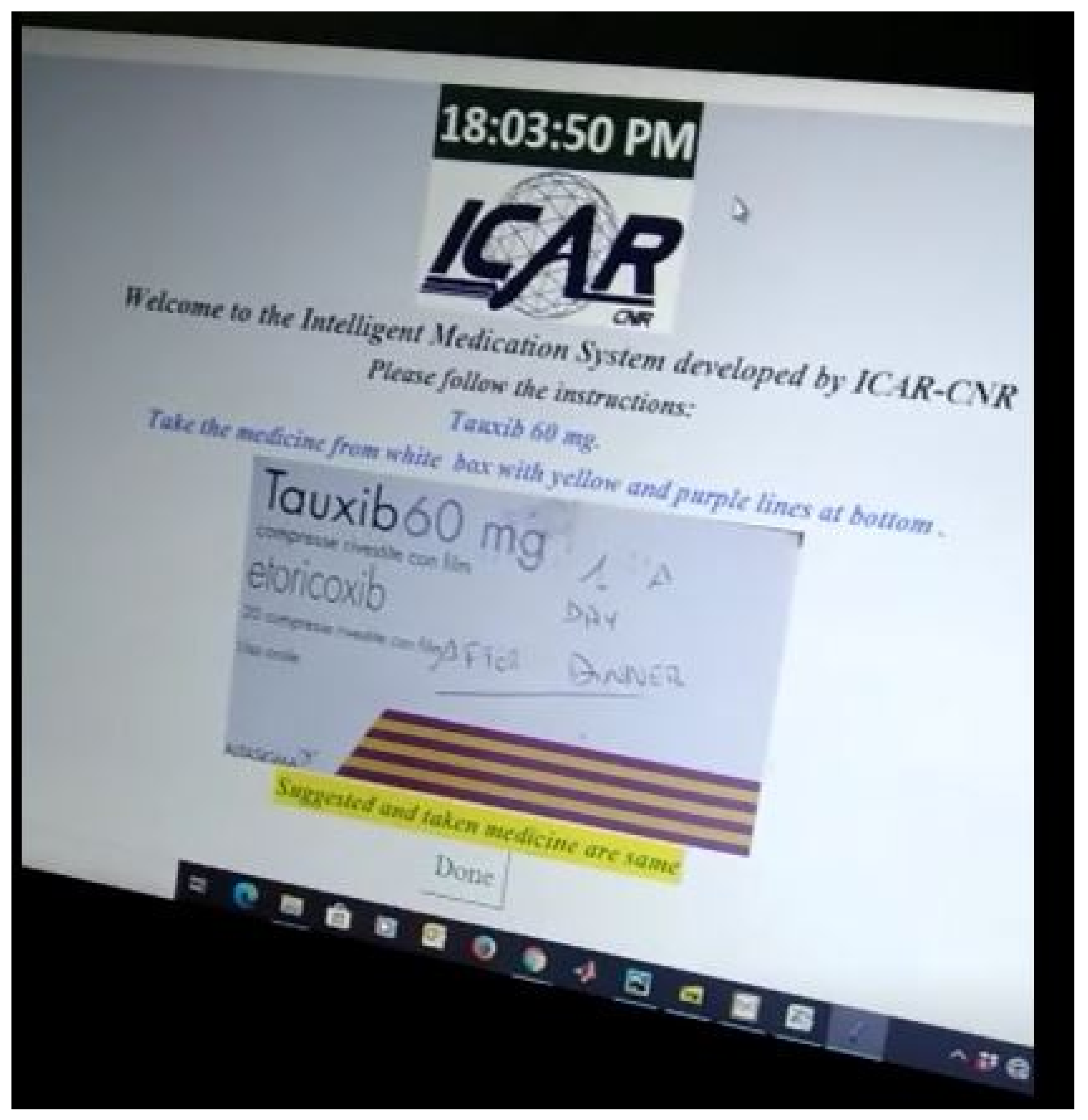
Similarly, Figure 7 shows us the case when the RL agent selects a barcode technique to monitor which drug that patient is going to take. The ultimate goal of the RL agent is to learn the most suitable tool out of the three available techniques in order to perform correct identification of the drug, which is being handled by the patient. When the patient is going to take the correct medicine, the positive feedback is returned to the RL agent. Otherwise, an alert is generated for the patient to prevent him/her from taking the wrong medicine. As can be seen in Figure 8, a confirmation message is communicated that he/she is going to take the correct medicine.
It is important to observe that, in the case of DL identification method, the system is able to recognize the drug box from the video in any orientation and light condition. However, in OCR and barcode methods, it is important that a patient presents the drug in a specific position and orientation to the camera.
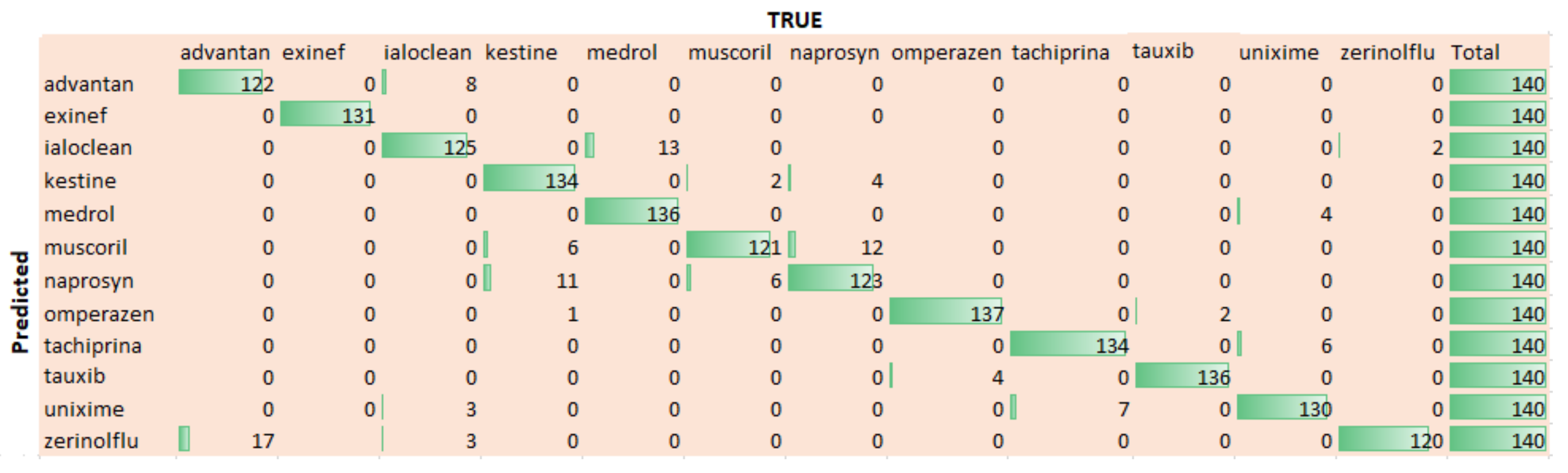
Figure 9 shows the confusion that is being computed for twelve used medicines. We can extract that the trained model performs well for most of the drugs. In fact, the difference of performance for different drugs is due to their sizes and color combination. For example, the drug Omperazen has a larger drug box and fair color combination, while the drug Muscoril is small in size, so both have comparatively high and low identification accuracy, respectively.
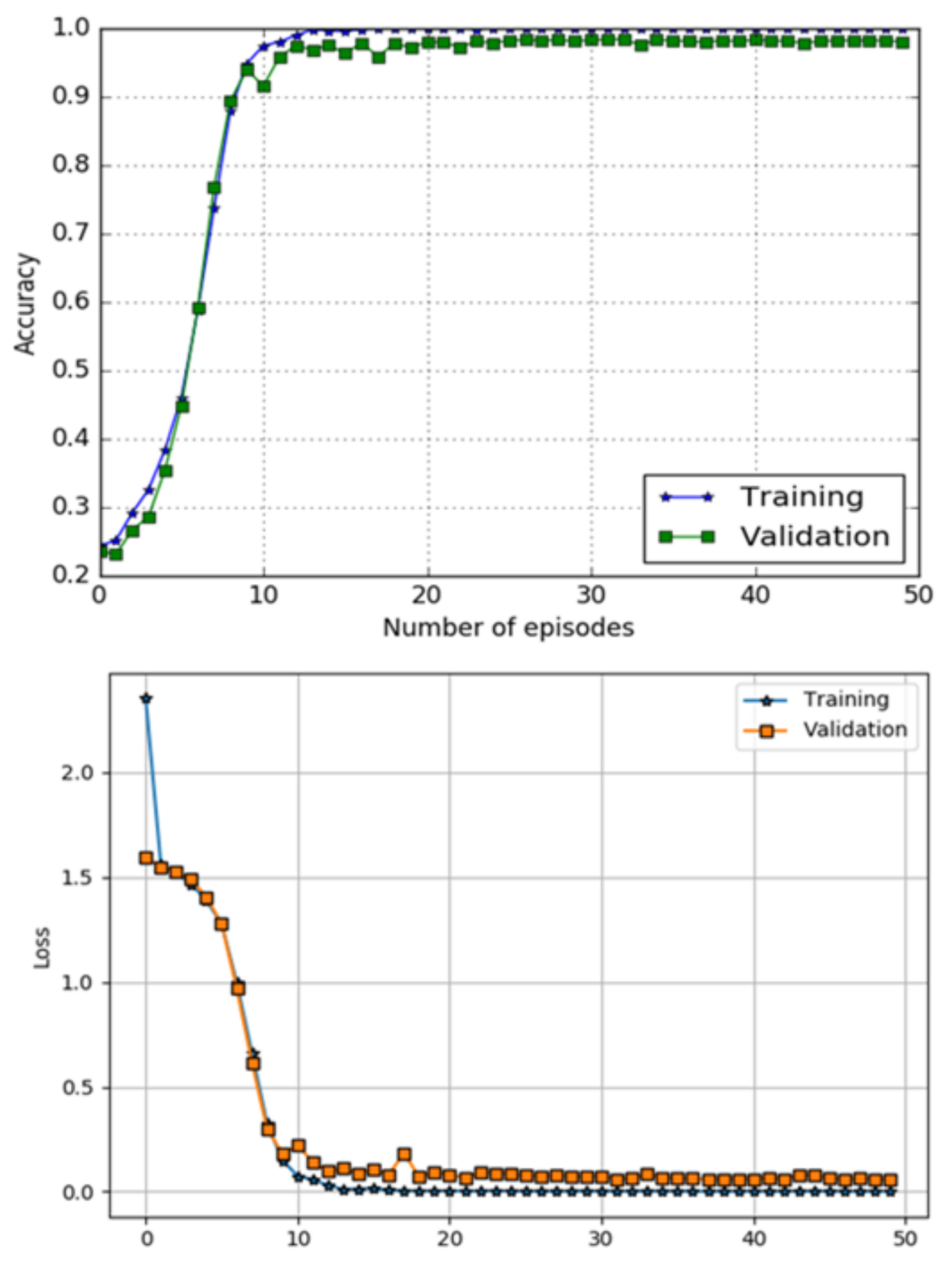
The performance of a DL component using metrics of classification accuracy and loss function is shown in Figure 10. The top image in Figure 10 shows accuracy curves for both training and testing data, while bottom image of the Figure 10 presents loss performance, respectively. The model has obtained accuracy and a loss of on the testing data-set.
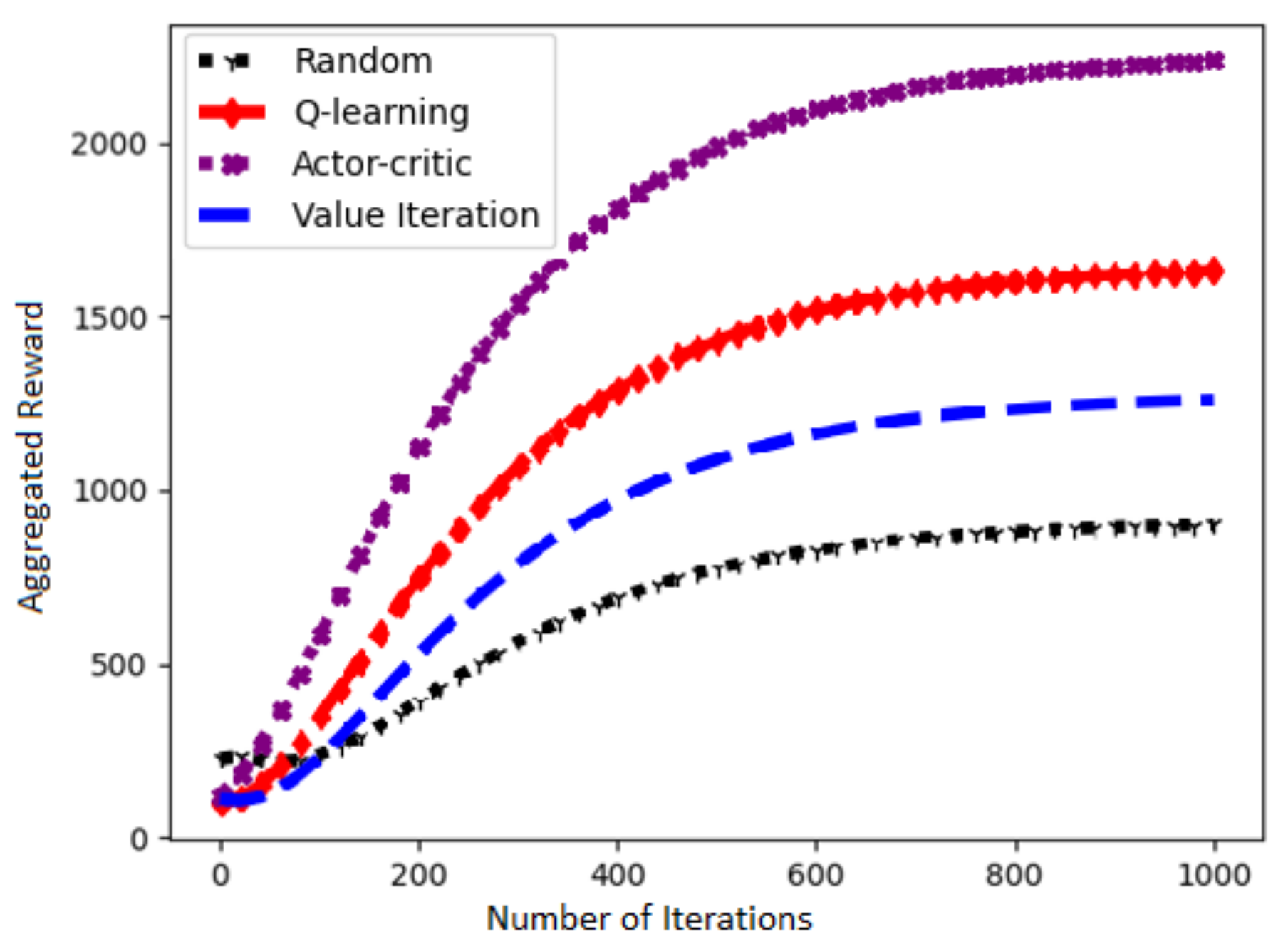
Figure 11 presents a performance of our chosen Actor–Critic algorithm and three other RL algorithms in terms of learning rate against number of iterations. It is evident that the choice of Actor–Critc algorithm to solve our problem is fairly correct.
6. Conclusions
We have demonstrated an AI-based infrastructure that assists patients and elderly during the medication process at home. The system applies AI modern techniques such as RL algorithm, DL-based classification, OCR, and barcode to monitor a patient taking a specific drug. The GUI implementation of the infrastructure has shown that it is able to assist patients and minimize medication errors that nowadays cause damages and the death of many patients every year.
Author Contributions
Conceptualization, M.N. and A.C.; methodology, M.N. and A.C.; investigation, M.N; writing—original draft preparation, M.N.; writing—review and editing, A.C.; supervision, A.C.; funding acquisition, A.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work is partially supported by the AMICO project, which has received funding from the National Programs (PON) of the Italian Ministry of Education, Universities and Research (MIUR): code ARS0100900 (Decree n.1989, 26 July 2018).
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Rennke, S.; Ranji, S.R. Transitional care strategies from hospital to home: A review for the neurohospitalist. Neurohospitalist 2015, 5, 35–42. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alzahrani, N. The effect of hospitalization on patients’ emotional and psychological well-being among adult patients: An integrative review. Appl. Nurs. Res. 2021, 61, 151488. [Google Scholar] [CrossRef] [PubMed]
- Stadhouders, N.; Kruse, F.; Tanke, M.; Koolman, X.; Jeurissen, P. Effective healthcare cost-containment policies: A systematic review. Health Policy 2019, 123, 71–79. [Google Scholar] [CrossRef] [PubMed]
- World Healthcare Organization. Adherence to Long-Term Therapies: Evidence for Action. Available online: http://www.who.int/chp/knowledge/adherence_full_report.pdf (accessed on 31 October 2020).
- Barber, N.; Alldred, D.; Raynor, D.; Dickinson, R.; Garfield, S.; Jesson, B.; Lim, R.; Savage, I.; Standage, C.; Buckle, P.; et al. Care homes’ use of medicines study: Prevalence, causes and potential harm of medication errors in care homes for older people. Qual. Saf. Health Care 2009, 18, 341–346. [Google Scholar] [CrossRef]
- World Healthcare Organization. Medication Errors. Available online: http://apps.who.int/iris/bitstream/handle/10665/252274/9789241511643\protect\discretionary{\char\hyphenchar\font}{}{}eng.pdf (accessed on 10 November 2020).
- European Medicines Agency. Streaming EMA Public Communication on Medication Errors. Available online: https://www.ema.europa.eu/documents/other/streamlining-ema-public-communication-medication-errors_en.pdf (accessed on 20 November 2020).
- DiMatteo, M.R. Evidence-based strategies to foster adherence and improve patient outcomes: The author’s recent meta-analysis indicates that patients do not follow treatment recommendations unless they know what to do, are committed to doing it, and have the resources to be able to adhere. JAAPA-J. Am. Acad. Physicians Assist. 2004, 17, 18–22. [Google Scholar]
- Sullivan, S.D. Noncompliance with medication regimens and subsequent hospitalization: A literature analysis and cost of hospitalization estimate. J. Res. Pharm. Econ. 1990, 2, 19–33. [Google Scholar]
- Perri, M., III; Menon, A.M.; Deshpande, A.D.; Shinde, S.B.; Jiang, R.; Cooper, J.W.; Cook, C.L.; Griffin, S.C.; Lorys, R.A. Adverse outcomes associated with inappropriate drug use in nursing homes. Ann. Pharmacother. 2005, 39, 405–411. [Google Scholar] [CrossRef] [PubMed]
- Bakhouya, M.; Campbell, R.; Coronato, A.; Pietro, G.D.; Ranganathan, A. Introduction to Special Section on Formal Methods in Pervasive Computing. ACM Trans. Auton. Adapt. Syst. 2012, 7, 6. [Google Scholar] [CrossRef]
- Naeem, M.; Rizvi, S.T.H.; Coronato, A. A Gentle Introduction to Reinforcement Learning and its Application in Different Fields. IEEE Access 2020, 8, 209320–209344. [Google Scholar] [CrossRef]
- Coronato, A.; Naeem, M.; De Pietro, G.; Paragliola, G. Reinforcement learning for intelligent healthcare applications: A survey. Artif. Intell. Med. 2020, 109, 101964. [Google Scholar] [CrossRef]
- Coronato, A.; Naeem, M. Ambient Intelligence for Home Medical Treatment Error Prevention. In Proceedings of the 2021 17th International Conference on Intelligent Environments (IE), Dubai, United Arab Emirates, 21–24 June 2021; pp. 1–8. [Google Scholar]
- Coronato, A.; Paragliola, G. A structured approach for the designing of safe aal applications. Expert Syst. Appl. 2017, 85, 1–13. [Google Scholar] [CrossRef]
- Ciampi, M.; Coronato, A.; Naeem, M.; Silvestri, S. An intelligent environment for preventing medication errors in home treatment. Expert Syst. Appl. 2022, 193, 116434. [Google Scholar] [CrossRef]
- Paragliola, G.; Naeem, M. Risk management for nuclear medical department using reinforcement learning algorithms. J. Reliab. Intell. Environ. 2019, 5, 105–113. [Google Scholar] [CrossRef]
- Coronato, A.; De Pietro, G. Tools for the Rapid Prototyping of Provably Correct Ambient Intelligence Applications. IEEE Trans. Softw. Eng. 2012, 38, 975–991. [Google Scholar] [CrossRef]
- Cinque, M.; Coronato, A.; Testa, A. A failure modes and effects analysis of mobile health monitoring systems. In Innovations and Advances in Computer, Information, Systems Sciences, and Engineering; Springer: New York, NY, USA, 2013; pp. 569–582. [Google Scholar]
- Testa, A.; Cinque, M.; Coronato, A.; De Pietro, G.; Augusto, J.C. Heuristic strategies for assessing wireless sensor network resiliency: An event-based formal approach. J. Heuristics 2015, 21, 145–175. [Google Scholar] [CrossRef] [Green Version]
- Coronato, A.; Pietro, G.D. Formal Design of Ambient Intelligence Applications. Computer 2010, 43, 60–68. [Google Scholar] [CrossRef]
- Naeem, M.; Paragiola, G.; Coronato, A.; De Pietro, G. A CNN-based monitoring system to minimize medication errors during treatment process at home. In Proceedings of the 3rd International Conference on Applications of Intelligent Systems, Las Palmas de Gran Canaria, Spain, 7–9 January 2020; pp. 1–5. [Google Scholar]
- Kautz, H.; Arnstein, L.; Borriello, G.; Etzioni, O.; Fox, D. An overview of the assisted cognition project. In Proceedings of the AAAI—2002 Workshop on Automation as Caregiver: The Role of Intelligent Technology in Elder Care, Edmonton, AB, Canada, 29 July 2002. [Google Scholar]
- Mynatt, E.D.; Essa, I.; Rogers, W. Increasing the Opportunities for Aging in Place. In Proceedings of the CUU’00: 2000 Conference on Universal Usability, Arlington, VA, USA, 16–17 November 2000; Association for Computing Machinery: New York, NY, USA, 2000; pp. 65–71. [Google Scholar] [CrossRef]
- Pineau, J.; Montemerlo, M.; Pollack, M.; Roy, N.; Thrun, S. Towards robotic assistants in nursing homes: Challenges and results. Robot. Auton. Syst. 2003, 42, 271–281. [Google Scholar] [CrossRef]
- Pollack, M.E. Planning Technology for Intelligent Cognitive Orthotics; AIPS, 2002; pp. 322–332. Available online: https://www.aaai.org/Papers/AIPS/2002/AIPS02-033.pdf (accessed on 20 December 2021).
- Hartl, A. Computer-vision based pharmaceutical pill recognition on mobile phones. In Proceedings of the 14th Central European Seminar on Computer Graphics, Budmerice, Slovakia, 10–12 May 2010; p. 5. [Google Scholar]
- Benjamim, X.C.; Gomes, R.B.; Burlamaqui, A.F.; Gonçalves, L.M.G. Visual identification of medicine boxes using features matching. In Proceedings of the 2012 IEEE International Conference on Virtual Environments Human-Computer Interfaces and Measurement Systems (VECIMS) Proceedings, Tianjin, China, 2–4 July 2012; pp. 43–47. [Google Scholar]
- Naeem, M.; Paragliola, G.; Coronato, A. A reinforcement learning and deep learning based intelligent system for the support of impaired patients in home treatment. Expert Syst. Appl. 2020, 168, 114285. [Google Scholar] [CrossRef]
- Neumann, L.; Matas, J. Real-time scene text localization and recognition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3538–3545. [Google Scholar]
- Al-Quwayfili, N.I.; Al-Khalifa, H.S. AraMedReader: An arabic medicine identifier using barcodes. In Proceedings of the International Conference on Human-Computer Interaction, Heraklion, Crete, Greece, 22–27 June 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 383–388. [Google Scholar]
- Ramljak, M. Smart home medication reminder system. In Proceedings of the 2017 25th International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 21–23 September 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Alshamrani, M. IoT and artificial intelligence implementations for remote healthcare monitoring systems: A survey. J. King Saud-Univ.-Comput. Inf. Sci. 2021. [Google Scholar] [CrossRef]
- Hong-tan, L.; Cui-hua, K.; Muthu, B.; Sivaparthipan, C. Big data and ambient intelligence in IoT-based wireless student health monitoring system. Aggress. Violent Behav. 2021, 101601. [Google Scholar] [CrossRef]
- Mirmomeni, M.; Fazio, T.; von Cavallar, S.; Harrer, S. From wearables to THINKables: Artificial intelligence-enabled sensors for health monitoring. In Wearable Sensors; Elsevier: Amsterdam, The Netherlands, 2021; pp. 339–356. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. A Deep Convolutional Activation Feature for Generic Visual Recognition; UC Berkeley & ICSI: Berkeley, CA, USA, 2013. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Aytar, Y.; Zisserman, A. Tabula rasa: Model transfer for object category detection. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2252–2259. [Google Scholar]
- Chui, K.T.; Fung, D.C.L.; Lytras, M.D.; Lam, T.M. Predicting at-risk university students in a virtual learning environment via a machine learning algorithm. Comput. Hum. Behav. 2020, 107, 105584. [Google Scholar] [CrossRef]
Figure 1.
The Reinforcement Learning problem.

Figure 2.
Working of RL algorithm.

Figure 3.
Block diagram of the System.

Figure 4.
Some manually captured images of the drug ‘Medrol’.

Figure 5.
GUI demonstration-1.

Figure 6.
GUI demonstration-2.

Figure 7.
GUI demonstration-3.

Figure 8.
GUI demonstration-4.

Figure 9.
Confusion Matrix for 12 drugs.

Figure 10.
Accuracy and loss performance DL classifier.

Figure 11.
Learn curves of the RL algorithms.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Naeem, M.; Coronato, A. An AI-Empowered Home-Infrastructure to Minimize Medication Errors. J. Sens. Actuator Netw. 2022, 11, 13. https://0-doi-org.brum.beds.ac.uk/10.3390/jsan11010013
AMA Style
Naeem M, Coronato A. An AI-Empowered Home-Infrastructure to Minimize Medication Errors. Journal of Sensor and Actuator Networks. 2022; 11(1):13. https://0-doi-org.brum.beds.ac.uk/10.3390/jsan11010013
Chicago/Turabian StyleNaeem, Muddasar, and Antonio Coronato. 2022. "An AI-Empowered Home-Infrastructure to Minimize Medication Errors" Journal of Sensor and Actuator Networks 11, no. 1: 13. https://0-doi-org.brum.beds.ac.uk/10.3390/jsan11010013
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.