Indirect Inference Estimation of Spatial Autoregressions


1
Department of Economics, Purdue University, West Lafayette, IN 47907, USA
2
School of Economics, Nanjing Audit University, Nanjing 211815, China
3
National Academy of Development and Strategy, Renmin University of China, Beijing 100872, China
*
Author to whom correspondence should be addressed.
Econometrics 2020, 8(3), 34; https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics8030034
Submission received: 1 May 2020
/
Revised: 5 August 2020
/
Accepted: 31 August 2020
/
Published: 3 September 2020
Abstract
:The ordinary least squares (OLS) estimator for spatial autoregressions may be consistent as pointed out by Lee (2002), provided that each spatial unit is influenced aggregately by a significant portion of the total units. This paper presents a unified asymptotic distribution result of the properly recentered OLS estimator and proposes a new estimator that is based on the indirect inference (II) procedure. The resulting estimator can always be used regardless of the degree of aggregate influence on each spatial unit from other units and is consistent and asymptotically normal. The new estimator does not rely on distributional assumptions and is robust to unknown heteroscedasticity. Its good finite-sample performance, in comparison with existing estimators that are also robust to heteroscedasticity, is demonstrated by a Monte Carlo study.
1. Introduction
Spatial autoregressions (SAR) have attracted lots of attention from both practical and theoretical sides in economics and other disciplines of social sciences since the classical work of Cliff and Ord (1981). Its popularity is mainly due to its parsimonious representation of the cross-sectional correlation by a weight matrix. Correlation in spatial data arises naturally due to competition, copycatting, spillover, aggregation, to name just a few. In these contexts, space embodied in the weight matrix can be defined in terms of not only geographical distance but also economic distance.
The spatial autoregression model extends autocorrelation in time series to the spatial dimension in the sense that in the structural equation a spatially “lagged” dependent variable is included as a regressor. In time series, the autoregression model can be estimated consistently by the ordinary least squares (OLS), but for the spatial autoregression, the OLS is usually regarded as an inconsistent method. Robinson (2008) provided an excellent discussion of the intuition behind this. Estimation strategies like the maximum likelihood (ML), quasi maximum likelihood (QML), instrument variables (IV), and generalized method of moments (GMM) have been proposed in the literature. The ML is the most efficient, but it imposes stringent distributional assumptions on the data generating process, whereas both the ML and QML rule out heteroscedasticity in the error term. Further, the (Q)ML method involves calculating the determinant or eigenvalues of a matrix that is of the same size as the sample, and thus many researchers dismiss its use in moderately large samples and advocate the more flexible IV and GMM estimators that may incur less computational burden and are also robust to heteroscedasticity.
Lee (2002) overturned the traditional wisdom regarding the OLS estimator in spatial autoregressions when there are exogenous regressors included. He showed that while the OLS estimator is inconsistent for spatial autoregressions with a sparse weight matrix, it can be consistent when spatial units may have small spatial impacts on other units but each unit may be influenced aggregately by a significant portion of the total units. For the special case of the so-called pure SAR model, namely, when there is no other exogenous regressor, Lee (2002) demonstrated that regardless of the structure of the weight matrix, the OLS estimator is always inconsistent.
In practice, one may have limited knowledge to judge whether a spatial unit is influenced by a significant portion of the total units. When a researcher is constructing the weight matrix, she may know the number of neighboring units for each unit, but she may be unable to tell whether the number of neighbors is significant in finite samples. Thus, this poses a challenge for practitioners regarding the usefulness of the OLS estimator: it may or may not be consistent, depending on the degree of aggregate influence on each unit from other units, which may hardly manifest itself in finite samples. This paper carefully analyzes the asymptotic distribution theory for the OLS estimator. A unified asymptotic distribution result for the recentered OLS estimator is presented under different regimes for the spatial weight matrix. Given the asymptotic result for the recentered OLS estimator, a new estimator based on the indirect inference (II) procedure is proposed.
Kyriacou et al. (2017) novelly used the II procedure to correct the inconsistency of the OLS estimator in the pure SAR model under homoscedasticity. Even though they provided promising simulation results under some mild heteroscedasticity, they have yet to show rigorously how to construct a consistent estimator with no restrictions on the form of heteroscedasticity. In contrast, this paper considers the SAR model with exogenous regressors and it adds to the existing spatial literature with unknown heteroscedasticity.1
Note that the problem of inconsistency (of the OLS estimator) is solely due to the presence of the endogenous spatially lagged variable. Once the spatial autoregression parameter is estimated consistently, the OLS procedure can be used to estimate the remaining parameters, though the asymptotic variance needs to be modified accordingly to take into account the uncertainty in the estimated spatial autoregression parameter.
The structure of this paper is as follows. In the next section, the asymptotic behavior of the OLS estimator is discussed under different spatial scenarios. The II estimator, which aims to correct the possible inconsistency of the OLS estimator, is defined and its asymptotic distribution is derived. A very important message from this section is that regardless of the degree of aggregate influence on each spatial unit from other units, the II procedure can always be used and the resulting estimator is consistent and asymptotically normal. Section 3 discusses the special case of pure SAR. Section 4 provides Monte Carlo evidence of the effectiveness of the II estimation strategy. It shows that the II estimator possesses good finite-sample performance relative to other consistent estimators that are also robust to unknown heteroscedasticity and that the II method may be favored for the purpose of hypothesis testing, especially for testing the spatial autoregression parameter. Section 5 concludes. Some useful lemmas are collected in Appendix A and proofs of the results presented in Section 2 and Section 3 are given in Appendix B.
Throughout this paper, K is used to denote a positive constant on different occasions, arbitrarily large but bounded, that does not depend on the sample size n and whose value may vary in different contexts. is the identity matrix of dimension n and is an vector of ones. For an vector , denotes its i-th element and for an matrix , denotes its -th element. and are the maximum row sum norm and maximum column sum norm, respectively. A sequence of matrices is uniformly bounded in row sum if , and is uniformly bounded in column sum if . and ⊙ are matrix trace and Hadamard product operators, respectively. denotes a square diagonal matrix with the vector spanning the main diagonal, is an column vector that collects in order the diagonal elements of the square matrix , and . The subscript 0 is used to signify the true parameter value.
2. Main Results
Consider the SAR model
where n is the total number of cross-sectional units, , , is an vector, collecting observations on the dependent variable, is an matrix of observations on k exogenous nonstochastic regressors with coefficient vector , is an matrix of spatial weights with zero diagonals, is the spatial autoregression coefficient, and is an n-dimensional vector of error terms.
For the ease of presentation, the following matrix notation is introduced in this paper:
When a matrix is presented without its argument , it means that it is evaluated at the parameter value . Namely, , , , and .
If is known (equal to its true value), the model becomes a standard linear model with being the dependent variable; otherwise, appears on the right-hand side of (1) as a spatially lagged or weighted variable. The OLS estimator of is , which may be inconsistent. Since the inconsistency of is solely due to the endogenous , the properties of (the first element of ) are discussed first in this paper. Once a consistent estimator of is available, one can show that a consistent estimator of follows immediately (see Theorem 4 to be introduced).2
Let , , , , , , and . By using the partitioned regression formula and substituting , one may put
The following assumptions are made throughout this paper.
Assumption 1.
(i) , , where the rate sequence is uniformly bounded away from zero and ; (ii) the sequence is is uniformly bounded in row and column sums; (iii) .
Assumption 2.
(i) exists; (ii) the sequence is uniformly bounded in row and column sums.
Assumption 3.
The error terms in have following properties: (i) ; (ii) for some positive constant δ; (iii) and are independent for any .
Assumption 4.
is contained in a compact parameter space Λ. For any admissible , is uniformly bounded in row and column sums.
Assumption 5.
(i) The elements of are uniformly bounded constants for all n; (ii) the probability limit Γ of exists and is nonsingular.
Assumption 6.
(i) exists and is nonzero; (ii) exists and is nonzero.
Intuitions and related discussions for Assumptions 1–5 are provided in Kelejian and Prucha (2010) and Lee (2001, 2002, 2004). Assumption 1(i) follows naturally when is row- or column-normalized, as is typically the case. Assumption 1(ii) and Assumption 2 limit the degree of dependency among the spatial units and is originated by Kelejian and Prucha (1999). Given Assumption 2, the equilibrium solution of is . Under Assumption 3, let , , and with , . Lee (2002) emphasized that Assumption 5(ii) is related to an identification condition for estimation in the least squares and IV frameworks. It rules out possible multicollinearities among and for large n and implies that the limit of is bounded away from zero.3 Assumption 6 ensures that the asymptotic variances of the (properly recentered) OLS estimator and the resulting II estimator are positive.4
2.1. The Asymptotic Behavior of the OLS estimator
From Lemma A6 in Appendix A, and are both , and are both , and . The asymptotic properties of the OLS estimator crucially depend on the magnitude of .
When is bounded, the OLS estimator cannot be consistent, since now
but the probability limit of the numerator is typically nonzero.
If , dominates the denominator in (3), then
indicating that is consistent as long as .
More interestingly, the behavior of depends on how fast diverges to infinity. If tends to infinity at a rate slower than , then dominates in the numerator, and
which implies that converges at the slower rate , but it does not converge to at rate , as is typically nonzero.
If , and are of the same order in the numerator, so
indicating that converges at rate , but at this rate it does not converge to , as in general is nonzero.
If tends to infinity at a rate faster than (and yet smaller than n), namely, (and , then in the numerator dominates ,
indicating that converges to at rate and is asymptotically normal if one applies a central limit theorem to .
One sees that the asymptotic behavior of depends on the magnitude of , which may be unknown in practice. The following theorem shows that if one can properly recenter , then a unified asymptotic distribution result follows.
Theorem 1.
Under Assumptions 1–6, the OLS estimator of in the SAR model (1) has the following asymptotic distribution,
where
with
Remark 1.
The recentering term is in fact . One could have recentered by . (This is the approach taken by Kyriacou et al. (2017) when dealing with the special case of pure SAR model.) But then by following a similar expansion as in the proof of Theorem 1 (see Appendix B.1), one can find that the asymptotic variance of the resulting recentered estimator is much more complicated, involving the variances of and as well as their covariance.
Remark 2.
When , the recentering term is in fact and the asymptotic distribution of centers at zero, so one does not need to recenter by ; nor does one need to recenter it by , which is also as in Theorem 2 to be introduced.
Remark 3.
When diverges, one may single out dominating terms in and so that a finer expression of can be presented. For example, under divergent , one can replace with and replace with its dominating term . When is bounded, however, such replacements are not available and one needs to keep all the term in and . Moreover, since depends on higher-order moments of u, namely, and , then, with bounded , the asymptotic variance v of the recentered OLS estimator depends on them, too.
Remark 4.
In view of Remark 3, under divergent , if further , namely, under homoscedasticity with , then v corresponds to the top left element of . This, together with Remark 2, is in line with the observation in Lee (2002) that the (consistent, uncentered) OLS estimator (when ) has the same limiting distribution of the optimal IV estimator and under normality it has the same limiting distribution of the ML estimator. It also implies that under other cases of divergent (slower than or equal to rate ), as long as the OLS estimator is properly recentered, it achieves the same limiting distribution.
Remark 5.
Theorem 1 gives a unified representation of the asymptotic distribution of the properly recentered OLS estimator, regardless of the possibly unknown magnitude of . Further, it facilitates the construction of the indirect inference estimator to be introduced that corrects the inconsistency, when present, of the OLS estimator.
2.2. The Indirect Inference Estimator
One can see from Theorem 1 in the previous subsection that the OLS estimator may have an asymptotic bias. Yet a direct feasible bias-correction procedure is not possible, since the bias itself depends on unknown parameters, including , which may not be consistently estimated by the OLS estimator . Following Phillips (2012) and Kyriacou et al. (2017), one may define the binding function that involves the bias of . Unfortunately, the resulting binding function then involves the unknown , which appears in the recentering quantity for the OLS estimator in (7). The strategy in this paper is to replace with a term that is of the same order of and at the same time does not directly involve .
Recall that . Then under a general form of unknown heteroscedasticity, , where . If is known, then can be consistently estimated by . Let . Now one may be able to replace with and use as the recentering quantity.
Theorem 2.
Under Assumptions 1–6, the OLS estimator of in the SAR model (1) has the following asymptotic distribution:
where
Remark 6.
When one replaces that involves the unknown and appears in the recentering term of the OLS estimator, the asymptotic variance η of the newly recentered estimator no longer involves and . This stands in contrast to the asymptotic variance v (see Remark 3). So replacing with facilitates not only the construction of the indirect inference estimator to be introduced but also the inference procedure.
Given Theorem (2) and the observed sample data and , one can always define the sample binding function. Recall that and are functions of the parameter (as well as ). So the binding function can be defined as
and the II estimator inverts this binding function:
Intuitively, the II estimator defined as such tries to match from the observed data to its expectation, at least approximately. Typically, the expectation may be approximated, to an arbitrary degree of accuracy, via the method of simulations, as in the original spirit of Gouriéroux et al. (1993) and Smith (1993); however, in simulations one needs to make some distributional assumption to generate the pseudo error term. Instead one may use some analytical approximation as in Phillips (2012), Kyriacou et al. (2017), and this paper.
In the definition of the II estimator as in (10), it is implicitly assumed that the binding function is invertible. Note that is a function of and the sample data and and thus it is random.5
Assumption 7.
For all , the binding function (9) is monotonic in λ with probability 1 and when is bounded, , where
One can see from the expression (A.10) in Appendix B.3 that the derivative of the binding function with respect to is
For divergent , one can show that the converges almost surely to zero for all . So in large samples, Assumption 7 is more likely to hold. Assumption 7 lists the conditions under which the II estimator exists and is consistent. It would be desirable if one could lay down some primitive conditions on the data matrix , the weight matrix , and the parameter space so that Assumption 7 would be satisfied. Given the sample data, one may plot the binding function against to verify numerically the validity of this assumption. Simulations as in Gospodinov et al. (2017) may also help to establish this assumption’s credibility.
Theorem 3.
Remark 7.
Since when diverges, converges almost surely to 1, the asymptotic distribution of the II estimator is identical to that of the properly recentered OLS estimator. Further, under divergent , dominates and dominates , so . In light of Remark 4, this means that under homoscedasticity, the II estimator defined as in (10) is as efficient as the optimal IV estimator and can be as efficient as the ML estimator if the spatial data is normally distributed. (The same conclusion holds for the slightly modified II estimator, designed specifically under homoscedasticity, in Appendix B.6.)
Remark 8.
Theorem 3 shows that regardless of the magnitude of , which researchers may not know in practice, one can always apply the II procedure after the OLS estimation is done. At worst, when , this procedure is redundant (see Remark 2), but still the resulting II estimator has exactly the same asymptotic distribution as the consistent OLS estimator (since , see Remark 7). Otherwise, the II procedure provides a correction to the inconsistent OLS estimator.
Once the spatial autoregression parameter is consistently estimated by , one can estimate the parameter vector by
where .
Theorem 4.
For the SAR model (1), under Assumptions 1–7, the OLS estimator of defined as in (13) has the asymptotic distribution
and jointly,
where , assumed to exist and be positive definite, is given by (A.14) and γ is given by (A.15), respectively, in Appendix B.4.
Remark 9.
One can see (from Appendix B.4) that the expression of contains the traditional OLS variance term under heteroscedasticity, , as well as terms that signal the additional uncertainty introduced by in the definition of as in (13).
In practice, in order to make asymptotically valid inference from the II estimation strategy, one needs to estimate , , and in Theorems 3 and 4 by , , and , respectively, where and ’s are the sample residuals from the II estimation.6
3. The Special Case of Pure SAR
It is worthwhile to discuss the case when there is no , namely, the so-called pure SAR model
This case is of special interest since there is no IV available. On the other hand, the QML estimator is not consistent under heteroscedasticity. Kyriacou et al. (2017) were the first to explore the possibility of using the II procedure to correct the inconsistency of the OLS estimator under some mild form of heteroscedasticity and their results were quite promising. In this paper, no restrictions are imposed on the form of the unknown heteroscedasticity.
Given the expansion (3), one can see obviously that
regardless of the magnitude of . Proceeding similarly as before, as long as , one can write , , and . (See Lemma A6 in Appendix A). Then, by a Nagar-type (Nagar (1959)) expansion,
Assumption 6 needs to be modified accordingly to ensure the asymptotic variance of the properly recentered exists and is positive. Now let and
Assumption 8.
(i)
exists and is positive; (ii)
exists and is positive.
Corollary 1.
Under Assumptions 1–4 and 8, the OLS estimator of λ in the pure SAR model (14) has the following asymptotic distribution,
where v is defined as in Assumption 8(i).
Corollary 2.
Under Assumptions 1–4 and 8, the OLS estimator of λ in the pure SAR model (14) has the following asymptotic distribution:
where η is defined as in Assumption 8(ii).
Let the sample binding function be
Accordingly, Assumption 7 is modified as follows.
Assumption 9.
For all λ in Λ, the binding function (18) is monotonic in λ with probability 1 and , where
Corollary 3.
Remark 10.
If (namely, under homoscedasticity) and ones uses as the recentering term, which fortunately does not involve the unknown variance parameter , then the binding function, its derivative, and the asymptotic distribution of the resulting II estimator can be modified accordingly as in Kyriacou et al. (2017). In contrast to the SAR model with , the recentered OLS estimator and the II estimator in the pure SAR model have convergence rate .
Remark 11.
Remark 12.
Admittedly, the convergence rate in (20) depends on . However, this does not prevent one from using the II estimator if one is interested in estimating the pure SAR model, since the binding function (18) does not involve . For inference purpose, since η defined as in Assumption 8(ii) has the scaling factor , one can see that once and the sample residuals are available, the standard error of can be calculated as , where , , and .
4. Monte Carlo Evidence
In this section, Monte Carlo simulations are provided to demonstrate the performance of (as well as in (13)) in finite samples, in comparison with consistent estimators that are also robust under heteroscedasticity: the optimal robust GMM estimator of Lin and Lee (2010) and the modified QML (MQML) estimator of Liu and Yang (2015). For the optimal robust GMM estimator of Lin and Lee (2010), and are used as the optimal moment conditions, see Debarsy et al. (2015). They involve (appearing in ) and as well as the covariance matrix . For and , an initial estimation is constructed from the simple 2SLS with and as IV’s. One may assume a model for and then estimate the assumed model so as to construct the moment conditions. In this section, two choices are made regarding this: one is to use and as the moment conditions and the other is to use and with the true (known in simulations) plugged in. The two resulting estimators are denoted by GMM and GMM(), respectively, in Table 1, Table 2, Table 3 and Table 4. One would expect that in practice the performance of the optimal robust GMM estimator with an estimated appearing in the moment conditions would most likely stand between the two.
In each experiment, for each estimator, reported are the bias and root mean squared error (RMSE) from 1000 Monte Carlo simulations. The empirical rejection probabilities of the relevant t tests for testing each parameter equal to its true value at are also reported, denoted by , where the asymptotic variances for and , as discussed in the last paragraph of Section 2, are estimated with the unknowns replaced by their estimates based on the II procedure.7
For the purpose of comparison, the experimental design in Lin and Lee (2010) is followed closely. The spatial scenario under a group interaction weight matrix of Case (1991) is considered. The exogenous variables include a constant term and two independently distributed random variables following and , respectively. The size of each group is determined by a random variable. The error terms follow a zero-mean normal distribution with variances varying across groups. Two variance structures (V1 and V2) are considered. V1: for each group, if the group size is greater than 10, then the error variance is the same as the group size; otherwise, the variance is the inverse of the square of the group size. V2: for each group, the error variance is the inverse of the group size. Two sets of parameter configurations are used: and , named P1 and P2, respectively. Different degrees of spatial autocorrelation are considered: . Results are reported in Table 1, Table 2, Table 3 and Table 4.
Some interesting observations arise. Firstly, all the consistent estimators deliver almost unbiased results across all the experimental configurations, though the estimated intercept term associated with is relatively more biased. Secondly, among the consistent estimators, the optimal robust GMM using the true usually achieves the smallest RMSE. The other three estimators have very similar performance in terms of RMSE. Thirdly, for the purpose of hypothesis testing, it appears that the II-based procedure is as good as the one based on (the infeasible) GMM(), with the empirical rejection rates matching very closely the nominal size. The MQML of Liu and Yang (2015) tends to deliver under-sized t-test regarding the spatial autoregression parameter when its value is relatively high. For example, in Table 4, one sees the rejection rates of and , under and , respectively, for testing equal to its true value when from a t-test based on Liu and Yang (2015). This under-size problem, when the degree of spatial correlation is high, also carries over to the t test associated with the intercept parameter. The GMM estimator, when one is unsure of the error variance structure and uses and as the moment conditions, delivers very disappointing size performance in Table 4 when testing either the spatial autoregression parameter or the intercept parameter: the rejection rates approach around at the nominal size.
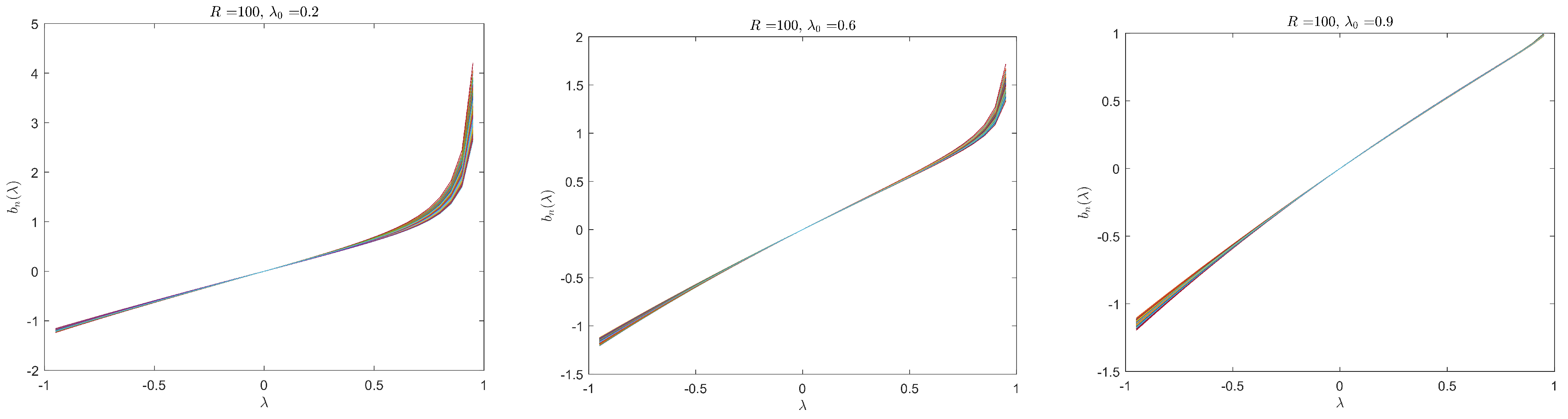
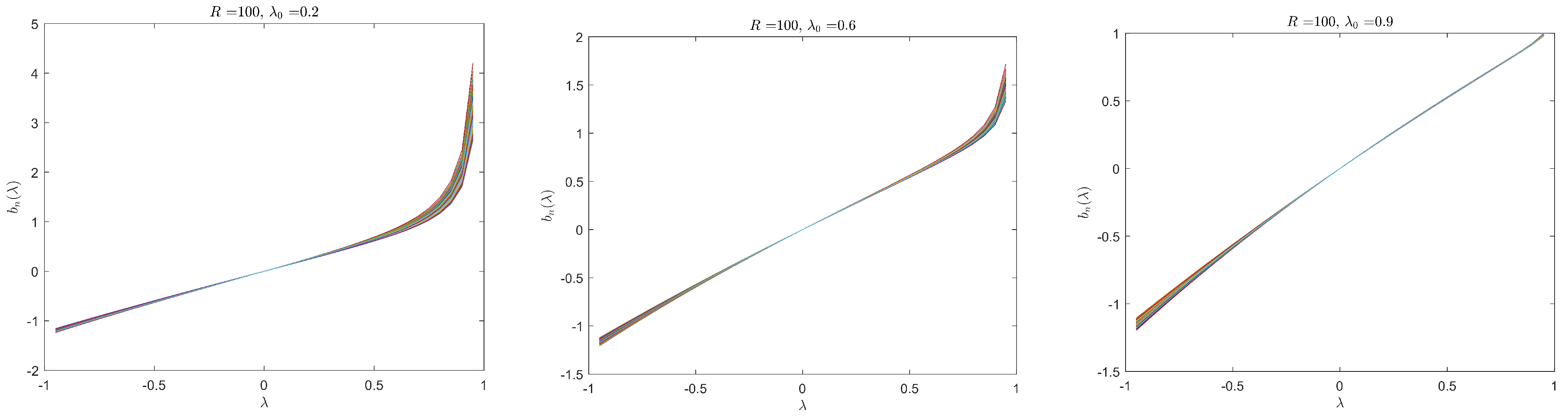
Given the simulated data, it is worthwhile to look at a plot of the binding function to check whether the binding function is monotonic, as required by Assumption 7. Figure 1 is drawn for 1000 simulated data sets under variance structure V1 and parameter configuration P1 with .8 Recall that for a given and the exogenous , the data generating process generates the observable data and the binding function is a function of . Figure 1 clearly illustrates that the binding function is a monotonic function of and thus the monotonicity condition in Assumption 7 is numerically valid. Figures drawn for the simulated data under other configurations display similar patterns and are omitted.
One may wonder about the performance of the proposed II estimator under homoscedasticity, relative to the QML estimator of Lee (2004) and the best GMM estimator of Lee (2007).9 Table 5 and Table 6 report the Monte Carlo results under parameter configurations P1 and P2, but now the error term is simulated as a standard normal random variable. The exogenous variables were simulated the same as before. From Table 5 and Table 6, one observes that the II estimator is slightly better than the best GMM estimator of Lee (2007), usually delivering smaller finite-sample bias and lower RMSE. Both methods have good finite-sample size performance in terms of the t test. The finite-sample performance of the QML, on the other hand, is quite different from what the asymptotic theory predicts. Its bias is more severe than the other two and it also gives higher RMSE. Moreover, its size performance is very poor.
The simulation results suggest that the II estimator could be used at least as a complement to other consistent estimators proposed in the literature that are robust to unknown heteroscedasticity. The II method may be favored for the purpose of hypothesis testing, especially for testing the spatial autoregression parameter. It also has very good finite-sample performance under homoscedasticity.
5. Concluding Remarks
Lee (2002) challenged the traditional wisdom that the OLS estimator is biased and inconsistent in spatial autoregressions and showed that it may be consistent under some special circumstances if there are exogenous regressors included. This paper thoroughly examines the asymptotic behavior of the OLS estimator under different specifications of the degree of aggregate influence on each unit from other units and provides a unified asymptotic distribution result of the recentered OLS estimator. Based on this, an indirect inference estimator, which is consistent and asymptotically normal, is introduced. The new estimator is relatively easy to calculate, does not rely on distributional assumptions on the data, and is robust to heteroscedasticity. Monte Carlo experiments in this paper show the good finite-sample performance of the II estimator in comparison with other consistent estimators that are robust to unknown heteroscedasticity.
In this paper, no attempt is made to conduct some comparison of the asymptotic variances of the GMM and II estimators. The II estimator in this paper may be interpreted as an estimator that uses one moment condition, namely, by matching the OLS estimator with its approximate analytical expectation. In contrast, the GMM estimator in Lin and Lee (2010) is based on a set of exact expectations of bilinear and quadratic forms in . The OLS estimator itself is based on an incorrect moment condition, namely, exogeneity of . It is not clear whether correcting an incorrect moment condition is as efficient as using a set of correct moment conditions. A fruitful strategy is perhaps to design a combined estimator.10 Another possible extension is to consider the more general higher-order SARAR (spatial autoregressive model with spatial autoregressive disturbances) with heteroscedastic innovations as in Badinger and Egger (2011) and Jin and Lee (2019). In this more general setup, the II procedure may be implemented as follows. One can first derive the approximate analytical expectation of the OLS estimator of the parameters in the SAR part, taken the parameters in the disturbance part as given, and thus design a “corrected” SAR estimator. Then based on the residuals that arise from the “corrected” SAR estimator, one can derive approximate analytical expectation of the OLS estimator of the parameters in the disturbance part. In the end, one can jointly estimate all the parameters in the SAR and disturbance parts by using the two sets of approximate analytical expectations. Some preliminary simulations show very promising results from this approach. Rigorous treatments of these extensions are left for future studies.
Author Contributions
The three authors of the paper have contributed equally, via joint efforts, regarding both ideas, research, and writing. Conceptualization, Y.B. and X.L.; methodology, Y.B.; software, Y.B. and X.L.; validation, Y.B., X.L. and L.Y.; formal analysis, Y.B., X.L. and L.Y.; investigation, Y.B.; resources, not applicable; writing–original draft preparation, Y.B.; writing–review and editing, Y.B., X.L. and L.Y.; visualization, Y.B.; supervision, not applicable; project administration, Y.B., X.L. and L.Y.; funding acquisition, L.Y. All authors have read and agreed to the published version of the manuscript.
Funding
Lihong Yang’s research was partially supported by the National Natural Science Foundation of China under Grant No. 71573269.
Acknowledgments
The authors are grateful to the three anonymous referees, seminar participants at Huazhong Agricultural University, Huazhong University of Science and Technology, Nanjing Audit University, Shandong University, South China Normal University, and University of California, Riverside, and conference participants at the 2019 CES conference (Dalian) for their helpful comments. Jeff Ello from the Krannert Computing Center at Purdue University kindly created a virtual machine from a computer cluster to facilitate the simulations conducted in an early version of this paper. The authors are responsible for all remaining errors.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Lemmas
This appendix collects several lemmas that are useful for deriving the main results. Some of these results (without proofs) were either derived or presented in different ways, see Kelejian and Prucha (1999, 2001) and Lee (2001, 2002, 2004).
Lemma A1.
If and are uniformly bounded in row and column sums, then so are and .
Lemma A2.
Suppose has its elements of order . If is uniformly bounded in column sum, then the elements of are ; if is uniformly bounded in row sum, then the elements of are . In either case, tr.
Lemma A3.
For a product involving (powers of) and , , where , , , , , , all being integers, under Assumptions 1 and 2, its elements are of order and its trace is of order .
Proof.
Under Assumptions 1 and 2, from Lemma A2, the elements of are and . From Lemma A1, is uniformly bounded in row and column sums. By successive using of Lemma A1, is uniformly bounded in row and column sums, and through Lemma A2, the elements of are and . Similarly, such a claim applies to , which is also uniformly bounded in row and column sums. Then is uniformly bounded in row and column sums with its elements being and . Proceeding similarly, one can see that the product shares these properties too. □
Lemma A4.
For the sequence with the elements following Assumption 3, let and be nonrandom, then
Lemma A5.
Under Assumptions 1–5,
Proof.
From (A.1), . Under Assumption 3, is uniformly bounded, so from Lemma A3. Lee (2004) shows that, under Assumption 5, is nonsingular if and only if both the limits of and are nonsingular, indicating that and . Also from Lee (2004), is uniformly bounded in row and column sums, and then from Lemmas A2 and A3. Similarly, one can show . As for , its expectation is zero and its variance is given by , which is bounded by . Then it follows that . Similarly, . Note that is uniformly bounded in row and column sums through Lemmas A1 and A2. Given that the elements of are uniformly bounded, one has . Then it follows that . □
Lemma A6.
Under Assumptions 1–5, , , , and . When there is no , then , , , and
Proof.
Given Lemmas A4 and A5,
and
are obvious. Using Lemma A4,
where in view of Lemma A3 and A5, is the leading term. Similarly,
in which is the leading term. For the case when there is no , the results are obvious. □
Lemma A7.
Suppose is a sequence of matrices with uniformly bounded row and column sums. Let be a sequence of constants with uniformly bounded elements and for some . For the sequence that satisfies Assumption 3, let . Then
Appendix B. Proofs
The proofs of Theorems 1–4 in Section 2 and Corollary 2 in Section 3 are provided in this appendix and those of Corollaries 1 and 3, which follow similarly, are skipped.
Appendix B.1. Proof of Theorem 1
Appendix B.2. Proof of Theorem 2
Proof.
Note that
in view of , and . Then
It follows from Lemma A7 that
where
by using Lemma A4 and the fact that . □
Appendix B.3. Proof of Theorem 3
Proof.
One can apply the extended delta method as in Phillips (2012) to derive the asymptotic distribution of . For this purpose, one needs to check a technical condition, namely, the should be asymptotically locally equicontinuous at : for given , if and ,
The first derivative of the binding function is
By substituting and using Lemmas A2–A4, one can see that the second term in (A.10) converges almost surely to a bounded constant for all . In a similar way, one can show
also converges almost surely to a bounded constant. Thus, for some that lies between and ,
With all these results, (12) follows immediately from Theorem 1 of Phillips (2012) and Theorem 2 in this paper. □
Appendix B.4. Proof of Theorem 4
Proof.
Upon substitution,
where (from Theorem 3). Further, , , and (from Lemma A5). Note that if one expands ,
From the proof of Theorem 2,
Given the above results, one has
One can check that Lemma A7 can be applied to each element or any nonstochastic linear combination of elements of under such a representation. So converges to a normal distribution, with the asymptotic covariance matrix,
The asymptotic covariance between and follows from the expansion of (see (A.11) and (A.12)) and that of (see (A.13)), given by
□
Appendix B.5. Proof of Corollary 2
Appendix B.6. The Case of Homoscedastic Error Term
If (and further , , ), then the recentering term in (7) becomes . To make the II procedure feasible, one may replace by . Similar to the proof of Theorem 2, one can put
where , , . In particular,
Define the binding function as and . Assume . The asymptotic distribution of resulting from this binding function follows similarly from the proofs of Theorems 3 and 4, given by
where
and
References
- Badinger, Harald, and Peter Egger. 2011. Estimation of higher-order spatial autoregressive cross-section models with heteroscedastic disturbances. Papers in Regional Science 90: 213–35. [Google Scholar] [CrossRef]
- Case, Anne C. 1991. Spatial patterns in household demand. Econometrica 59: 953–65. [Google Scholar] [CrossRef] [Green Version]
- Cheng, Xu, Zhipeng Liao, and Ruoyao Shi. 2019. On uniform asymptotic risk of averaging GMM estimators. Quantitative Economics 3: 931–97. [Google Scholar] [CrossRef]
- Cliff, Andrew David, and J. Keith Ord. 1981. Spatial Processes: Models and Applications. London: Pion Ltd. [Google Scholar]
- Debarsy, Nicolas, Fei Jin, and Lung-Fei Lee. 2015. Large sample properties of the matrix exponential spatial specification with an applicationto FDI. Journal of Econometrics 188: 1–21. [Google Scholar] [CrossRef] [Green Version]
- Gospodinov, Nikolay, Ivana Komunjer, and Serena Ng. 2017. Simulated minimum distance estimation of dynamic models with errors-in-variables. Journal of Econometrics 200: 181–93. [Google Scholar] [CrossRef]
- Gouriéroux, Christian, Alain Monfort, and Eric Renault. 1993. Indirect inference. Journal of Applied Econometrics 8: S85–S118. [Google Scholar] [CrossRef]
- Jin, Fei, and Lung-Fei Lee. 2019. GEL estimation and tests of spatial autoregressive models. Journal of Econometrics 208: 585–612. [Google Scholar] [CrossRef]
- Kelejian, Harry H., and Ingmar R. Prucha. 1999. A generalized moments estimator for the autoregressive parameter in a spatial model. International Economic Review 40: 509–33. [Google Scholar] [CrossRef] [Green Version]
- Kelejian, Harry H., and Ingmar R. Prucha. 2001. On the asymptotic distribution of the Moran I test statistic with applications. Journal of Econometrics 104: 219–57. [Google Scholar] [CrossRef] [Green Version]
- Kelejian, Harry H., and Ingmar R. Prucha. 2010. Specification and estimation of spatial autoregressive models with autoregressive and heteroskedastic disturbances. Journal of Econometrics 157: 53–67. [Google Scholar] [CrossRef] [Green Version]
- Kyriacou, Maria, Peter C. B. Phillips, and Francesca Rossi. 2017. Indirect inference in spatial autoregression. The Econometrics Journal 20: 168–89. [Google Scholar] [CrossRef]
- Lam, Clifford, and Pedro C. L. Souza. 2019. Estimation and selection of spatial weight matrix in a spatial lag model. Journal of Business and Economic Statistics 3: 693–710. [Google Scholar] [CrossRef]
- Lee, Lung-Fei. 2001. Asymptotic Distribution of Quasi-Maximum Likelihood Estimators for Spatial Autoregressive Models I: Spatial Autoregressive Processes. Working Paper. Columbus: Department of Econommics, Ohio State University. [Google Scholar]
- Lee, Lung-Fei. 2002. Consistency and efficiency of least squares estimation for mixed regressive, spatial autoregressive models. Econometric Theory 18: 252–77. [Google Scholar] [CrossRef]
- Lee, Lung-Fei. 2004. Asymptotic distribution of quasi-maximum likelihood estimators for spatial autoregressive models. Econometrica 72: 1899–925. [Google Scholar] [CrossRef]
- Lee, Lung-Fei. 2007. GMM and 2SLS estimation of mixed regressive, spatial autoregressive models. Journal of Econometrics 137: 489–514. [Google Scholar] [CrossRef]
- Lin, Xu, and Lung-Fei Lee. 2010. GMM estimation of spatial autoregressive models with unknown heteroskedasticity. Journal of Econometrics 157: 34–52. [Google Scholar] [CrossRef]
- Liu, Shew Fan, and Zhenlin Yang. 2015. Modified QML estimation of spatial autoregressive models with unknown heteroskedasticity and nonnormality. Regional Science and Urban Economics 52: 50–70. [Google Scholar] [CrossRef]
- Nagar, Anirudh L. 1959. The bias and moment matrix of the general k-class estimators of the parameters in simultaneous equations. Econometrica 27: 575–95. [Google Scholar] [CrossRef]
- Phillips, Peter C. B. 2012. Folklore theorems, implicit maps, and indirect inference. Econometrica 80: 425–54. [Google Scholar]
- Robinson, Peter M. 2008. Correlation testing in time series, spatial and cross-sectional data. Journal of Econometrics 147: 5–16. [Google Scholar] [CrossRef] [Green Version]
- Smith, Anthony A., Jr. 1993. Estimating nonlinear time-series models using simulated vector autoregressions. Journal of Applied Econometrics 8: S63–S84. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Xinyu, and Jihai Yu. 2018. Spatial weights matrix election and model averaging for spatial autoregressive models. Journal of Econometrics 203: 1–18. [Google Scholar] [CrossRef]
| 1. | Recent literature on dealing with heteroscedasticity in the spatial framework includes Kelejian and Prucha (2010), Badinger and Egger (2011), Liu and Yang (2015), Jin and Lee (2019), among others. An essential idea in this strand of literature is to use some moment conditions that are robust to unknown heteroscedasticity. |
| 2. | It should be pointed out when (and , where is the order of magnitude of elements of ), is consistent, as shown in Lee (2002), and thus one may not need to seek a consistent estimator of separately and then use it to construct a consistent estimator of . In practice, one may not know a priori the rate of , but the II estimator to be introduced is always consistent regardless of the rate of . |
| 3. | Multicollinearities can happen, for example, when and is row-normalized. Lee (2004) showed that under homoscedasticity, however, the QML estimator can still be consistent in spite of violation of this condition. Since the II estimator to be discussed in this paper is to correct the possible inconsistency of the OLS estimator, Assumption 5(ii) is maintained. |
| 4. | The asymptotic variances are given by and , respectively, for the (properly recentered) OLS estimator and the resulting II estimator. Their explicit expressions are given respectively in Theorems 1 and 2 to be introduced. Assumption 5(ii) implies that exists and is nonzero. It can be shown (see Appendix A) that , where the covariance term disappears under normality, and . When diverges, is the dominating term in as well as . Then the usual condition that exists and is nonsingular is sufficient for Assumption 6 to hold. When is bounded, a more precise characterization of a sufficient condition is not immediately obvious. Essentially, it requires, in addition to the existence and nonsingularity of , the existence of and , where and . |
| 5. | The use of observed, endogenous but non-simulated, variables within the binding function does not appear to be common. An interesting example is Gospodinov et al. (2017), where the authors used observed data within the binding function to hedge against misspecification bias. In their set-up of the autoregressive distributed lag model with a latent scalar predictor under the presence of measurement error, a similar technical difficulty exists regarding the invertibility condition of their binding function and they resorted to simulations to approximate the binding function and then the invertibility condition is numerically verified based on the approximated binding function. |
| 6. | This follows similarly from the proof of Proposition 2 in Lin and Lee (2010). |
| 7. | Neither Lin and Lee (2010) nor Liu and Yang (2015) reported how the inference procedures based on their estimators would perform in finite samples. |
| 8. | Each sub-figure contains 1000 lines, one for each of the simulated data set. |
| 9. | The authors thank a referee for suggesting this comparison. Since one needs to concentrate out the scalar error variance instead of the nuisance matrix , the II procedure needs to be modified, see Appendix B.6. |
| 10. | Very recently, Zhang and Yu (2018) and Lam and Souza (2019) proposed combining spatial weight matrices in recognition of possible misspecification of the weight matrix and Cheng et al. (2019) suggested combining a conservative GMM estimator based on valid moment conditions and an aggressive GMM estimator based on both valid and possibly misspecified moment conditions. |
Figure 1.
under variance structure V1 and parameter configuration P1, .

{kind=link}
Table 1.
Estimation of spatial autoregressions (SAR) with variance structure V1 and parameter configuration P1.
Table 1.
Estimation of spatial autoregressions (SAR) with variance structure V1 and parameter configuration P1.
| MQML | GMM | GMM() | II | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R | Bias | RMSE | Bias | RMSE | Bias | RMSE | Bias | RMSE | |||||||||
| 100 | 0.2 | −0.009 | 0.067 | 3.6% | −0.015 | 0.073 | 5.8% | 0.000 | 0.01 | 4.9% | −0.009 | 0.067 | 3.8% | ||||
| 0.8 | 0.034 | 0.367 | 4.5% | 0.050 | 0.377 | 5.4% | 0.001 | 0.036 | 5.6% | 0.033 | 0.367 | 4.7% | |||||
| 0.2 | −0.002 | 0.099 | 5.0% | −0.002 | 0.099 | 5.1% | 0.000 | 0.008 | 5.5% | −0.002 | 0.099 | 5.0% | |||||
| 1.5 | −0.004 | 0.088 | 4.9% | −0.005 | 0.088 | 5.1% | 0.000 | 0.007 | 4.1% | −0.004 | 0.088 | 4.9% | |||||
| 0.6 | −0.005 | 0.035 | 3.0% | −0.008 | 0.039 | 7.2% | 0.000 | 0.005 | 5.3% | −0.005 | 0.035 | 4.1% | |||||
| 0.8 | 0.032 | 0.366 | 3.8% | 0.047 | 0.378 | 5.9% | 0.001 | 0.037 | 5.6% | 0.031 | 0.367 | 4.7% | |||||
| 0.2 | −0.001 | 0.102 | 5.5% | −0.001 | 0.102 | 5.5% | 0.000 | 0.008 | 5.7% | −0.001 | 0.102 | 5.5% | |||||
| 1.5 | 0.004 | 0.089 | 4.9% | 0.004 | 0.089 | 4.9% | 0.000 | 0.007 | 4.6% | 0.004 | 0.089 | 4.9% | |||||
| 0.9 | −0.001 | 0.009 | 0.3% | −0.002 | 0.01 | 7.7% | 0.000 | 0.001 | 6.1% | −0.001 | 0.009 | 4.3% | |||||
| 0.8 | 0.022 | 0.367 | 4.0% | 0.037 | 0.378 | 6.0% | 0.003 | 0.04 | 6.5% | 0.02 | 0.367 | 5.6% | |||||
| 0.2 | −0.002 | 0.102 | 4.4% | −0.002 | 0.102 | 4.4% | 0.000 | 0.008 | 5.3% | −0.002 | 0.102 | 4.4% | |||||
| 1.5 | 0.000 | 0.093 | 5.9% | 0.000 | 0.094 | 6.0% | 0.000 | 0.007 | 4.7% | 0.00 | 0.094 | 6.1% | |||||
| 200 | 0.2 | 0.000 | 0.047 | 5.6% | −0.003 | 0.051 | 8.0% | 0.000 | 0.007 | 5.3% | 0.000 | 0.047 | 6.1% | ||||
| 0.8 | −0.005 | 0.255 | 5.1% | 0.003 | 0.261 | 5.8% | 0.001 | 0.026 | 6.9% | −0.005 | 0.255 | 5.2% | |||||
| 0.2 | 0.002 | 0.071 | 5.8% | 0.001 | 0.071 | 5.7% | 0.000 | 0.006 | 5.4% | 0.002 | 0.071 | 5.8% | |||||
| 1.5 | 0.003 | 0.061 | 3.3% | 0.002 | 0.061 | 3.4% | 0.000 | 0.005 | 5.4% | 0.003 | 0.061 | 3.3% | |||||
| 0.6 | −0.003 | 0.025 | 2.2% | −0.005 | 0.028 | 8.6% | 0.000 | 0.004 | 5.1% | −0.003 | 0.025 | 5.0% | |||||
| 0.8 | 0.021 | 0.256 | 4.1% | 0.030 | 0.264 | 6.0% | 0.000 | 0.026 | 5.2% | 0.020 | 0.256 | 4.7% | |||||
| 0.2 | −0.001 | 0.069 | 4.5% | −0.001 | 0.069 | 4.6% | 0.000 | 0.006 | 5.7% | −0.001 | 0.069 | 4.5% | |||||
| 1.5 | 0.000 | 0.062 | 4.2% | −0.001 | 0.062 | 4.3% | 0.000 | 0.005 | 4.9% | 0.000 | 0.062 | 4.2% | |||||
| 0.9 | −0.001 | 0.006 | 0.7% | −0.001 | 0.007 | 8.3% | 0.000 | 0.001 | 6.0% | −0.001 | 0.006 | 4.7% | |||||
| 0.8 | 0.022 | 0.262 | 4.2% | 0.030 | 0.269 | 6.7% | 0.000 | 0.026 | 4.5% | 0.021 | 0.262 | 5.7% | |||||
| 0.2 | −0.001 | 0.072 | 5.5% | −0.001 | 0.072 | 5.3% | 0.000 | 0.005 | 4.8% | −0.001 | 0.072 | 5.5% | |||||
| 1.5 | 0.000 | 0.063 | 3.8% | 0.000 | 0.063 | 3.9% | 0.000 | 0.005 | 4.4% | 0.000 | 0.063 | 3.8% | |||||
The weight matrix is a social interaction matrix , , . Reported for each estimator are the bias, root mean squared error (RMSE), and the empirical size of the t test for each parameter equal to its true value at from 1000 simulations. The exogenous regressors are , , , and is independent of . The group size follows . The error terms follow a zero-mean independent normal distribution. The variance structure is such that if , the error variance in the j-th group is and otherwise is , .
Table 2.
Estimation of SAR with variance structure V1 and parameter configuration P2.
| MQML | GMM | GMM() | II | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R | Bias | RMSE | Bias | RMSE | Bias | RMSE | Bias | RMSE | |||||||||
| 100 | 0.2 | −0.010 | 0.076 | 5.5% | −0.014 | 0.078 | 5.9% | −0.003 | 0.049 | 5.4% | −0.009 | 0.076 | 5.7% | ||||
| 0.2 | 0.007 | 0.335 | 5.7% | 0.013 | 0.336 | 6.0% | 0.005 | 0.056 | 5.8% | 0.007 | 0.335 | 5.8% | |||||
| 0.2 | 0.001 | 0.102 | 5.7% | 0.001 | 0.102 | 5.7% | −0.001 | 0.008 | 6.3% | 0.001 | 0.102 | 5.7% | |||||
| 0.1 | 0.000 | 0.095 | 5.9% | 0.000 | 0.096 | 5.9% | 0.000 | 0.007 | 6.0% | 0.000 | 0.095 | 5.9% | |||||
| 0.6 | −0.005 | 0.039 | 2.8% | −0.007 | 0.040 | 5.2% | −0.002 | 0.026 | 4.8% | −0.004 | 0.039 | 4.6% | |||||
| 0.2 | −0.004 | 0.330 | 4.1% | 0.002 | 0.331 | 4.3% | 0.005 | 0.058 | 5.3% | −0.004 | 0.330 | 4.2% | |||||
| 0.2 | 0.005 | 0.100 | 4.3% | 0.005 | 0.100 | 4.4% | 0.000 | 0.008 | 6.4% | 0.005 | 0.100 | 4.3% | |||||
| 0.1 | 0.000 | 0.091 | 5.6% | 0.000 | 0.091 | 5.7% | 0.000 | 0.007 | 5.3% | 0.000 | 0.091 | 5.6% | |||||
| 0.9 | −0.001 | 0.010 | 0.9% | −0.002 | 0.010 | 4.6% | 0.000 | 0.006 | 3.9% | −0.001 | 0.010 | 5.0% | |||||
| 0.2 | 0.013 | 0.335 | 5.2% | 0.018 | 0.336 | 6.1% | 0.001 | 0.055 | 4.1% | 0.012 | 0.335 | 5.7% | |||||
| 0.2 | −0.001 | 0.102 | 5.2% | −0.001 | 0.102 | 5.4% | 0.000 | 0.008 | 7.3% | −0.001 | 0.102 | 5.2% | |||||
| 0.1 | 0.002 | 0.089 | 5.1% | 0.002 | 0.089 | 5.1% | 0.000 | 0.007 | 5.9% | 0.002 | 0.089 | 5.1% | |||||
| 200 | 0.2 | −0.007 | 0.054 | 5.4% | −0.009 | 0.055 | 5.9% | −0.005 | 0.034 | 5.6% | −0.007 | 0.054 | 5.9% | ||||
| 0.2 | 0.013 | 0.231 | 4.7% | 0.016 | 0.232 | 4.7% | 0.006 | 0.040 | 6.0% | 0.013 | 0.231 | 4.7% | |||||
| 0.2 | −0.002 | 0.071 | 4.3% | −0.002 | 0.071 | 4.4% | 0.000 | 0.005 | 5.1% | −0.002 | 0.071 | 4.3% | |||||
| 0.1 | 0.000 | 0.064 | 4.7% | 0.000 | 0.064 | 4.7% | 0.000 | 0.005 | 5.1% | 0.000 | 0.064 | 4.7% | |||||
| 0.6 | −0.003 | 0.027 | 2.8% | −0.004 | 0.027 | 5.3% | −0.001 | 0.017 | 4.1% | −0.003 | 0.027 | 4.9% | |||||
| 0.2 | −0.001 | 0.233 | 5.2% | 0.001 | 0.233 | 5.4% | 0.002 | 0.039 | 4.4% | −0.002 | 0.233 | 5.2% | |||||
| 0.2 | 0.003 | 0.071 | 4.7% | 0.003 | 0.071 | 4.7% | 0.000 | 0.005 | 5.1% | 0.003 | 0.071 | 4.7% | |||||
| 0.1 | 0.000 | 0.063 | 5.5% | 0.000 | 0.063 | 5.5% | 0.000 | 0.005 | 5.8% | 0.000 | 0.063 | 5.5% | |||||
| 0.9 | −0.001 | 0.007 | 1.3% | −0.001 | 0.007 | 5.7% | −0.001 | 0.005 | 4.9% | −0.001 | 0.007 | 5.3% | |||||
| 0.2 | 0.012 | 0.232 | 3.4% | 0.015 | 0.233 | 4.2% | 0.004 | 0.039 | 5.0% | 0.012 | 0.232 | 4.1% | |||||
| 0.2 | −0.002 | 0.072 | 5.0% | −0.002 | 0.072 | 5.1% | 0.000 | 0.006 | 5.5% | −0.002 | 0.072 | 5.0% | |||||
| 0.1 | 0.002 | 0.063 | 5.0% | 0.002 | 0.063 | 5.0% | 0.000 | 0.005 | 6.7% | 0.002 | 0.063 | 5.0% | |||||
The weight matrix is a social interaction matrix , , . Reported for each estimator are the bias, RMSE, and the empirical size of the t test for each parameter equal to its true value at from 1000 simulations. The exogenous regressors are , , , and is independent of . The group size follows . The error terms follow a zero-mean independent normal distribution. The variance structure is such that if , the error variance in the j-th group is and otherwise is , .
Table 3.
Estimation of SAR with variance structure V2 and parameter configuration P1.
| MQML | GMM | GMM() | II | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R | Bias | RMSE | Bias | RMSE | Bias | RMSE | Bias | RMSE | |||||||||
| 100 | 0.2 | 0.000 | 0.014 | 4.6% | 0.000 | 0.014 | 5.2% | −0.001 | 0.013 | 4.9% | 0.000 | 0.014 | 5.0% | ||||
| 0.8 | 0.001 | 0.047 | 3.6% | 0.000 | 0.047 | 3.7% | 0.003 | 0.042 | 3.7% | 0.001 | 0.046 | 3.7% | |||||
| 0.2 | 0.000 | 0.008 | 4.1% | 0.000 | 0.008 | 4.1% | 0.000 | 0.008 | 5.1% | 0.000 | 0.008 | 4.2% | |||||
| 1.5 | 0.000 | 0.008 | 5.3% | 0.000 | 0.008 | 5.4% | 0.000 | 0.007 | 4.6% | 0.000 | 0.008 | 5.3% | |||||
| 0.6 | 0.000 | 0.008 | 4.3% | 0.000 | 0.008 | 4.9% | −0.001 | 0.007 | 4.3% | 0.000 | 0.008 | 4.6% | |||||
| 0.8 | 0.001 | 0.049 | 4.5% | 0.002 | 0.049 | 5.7% | 0.002 | 0.043 | 4.3% | 0.001 | 0.049 | 5.5% | |||||
| 0.2 | 0.000 | 0.008 | 5.3% | 0.000 | 0.008 | 5.1% | 0.000 | 0.008 | 4.9% | 0.000 | 0.008 | 5.2% | |||||
| 1.5 | 0.000 | 0.008 | 5.3% | 0.000 | 0.008 | 5.4% | 0.000 | 0.007 | 4.7% | 0.000 | 0.008 | 5.3% | |||||
| 0.9 | 0.000 | 0.002 | 5.1% | 0.000 | 0.002 | 7.8% | 0.000 | 0.002 | 5.9% | 0.000 | 0.002 | 6.8% | |||||
| 0.8 | 0.002 | 0.050 | 4.1% | 0.002 | 0.050 | 5.8% | 0.002 | 0.045 | 4.9% | 0.002 | 0.049 | 4.6% | |||||
| 0.2 | 0.000 | 0.008 | 5.4% | 0.000 | 0.008 | 5.4% | 0.000 | 0.008 | 5.6% | 0.000 | 0.008 | 5.4% | |||||
| 1.5 | 0.000 | 0.008 | 5.2% | 0.000 | 0.008 | 5.2% | 0.000 | 0.007 | 4.7% | 0.000 | 0.008 | 5.0% | |||||
| 200 | 0.2 | 0.000 | 0.010 | 3.8% | 0.000 | 0.010 | 4.7% | 0.000 | 0.009 | 3.8% | 0.000 | 0.010 | 4.4% | ||||
| 0.8 | 0.001 | 0.033 | 4.6% | 0.001 | 0.033 | 4.1% | 0.001 | 0.030 | 2.6% | 0.001 | 0.033 | 4.6% | |||||
| 0.2 | 0.000 | 0.006 | 4.6% | 0.000 | 0.006 | 4.6% | 0.000 | 0.005 | 4.7% | 0.000 | 0.006 | 4.6% | |||||
| 1.5 | 0.000 | 0.005 | 4.9% | 0.000 | 0.005 | 4.6% | 0.000 | 0.005 | 5.5% | 0.000 | 0.005 | 4.9% | |||||
| 0.6 | 0.000 | 0.005 | 3.9% | 0.000 | 0.006 | 5.4% | 0.000 | 0.005 | 4.5% | 0.000 | 0.005 | 4.6% | |||||
| 0.8 | 0.000 | 0.034 | 3.7% | −0.001 | 0.034 | 5.0% | 0.000 | 0.030 | 3.8% | 0.000 | 0.034 | 3.9% | |||||
| 0.2 | 0.000 | 0.006 | 5.9% | 0.000 | 0.006 | 6.1% | 0.000 | 0.006 | 5.1% | 0.000 | 0.006 | 5.9% | |||||
| 1.5 | 0.000 | 0.006 | 5.5% | 0.000 | 0.006 | 5.4% | 0.000 | 0.005 | 4.8% | 0.000 | 0.006 | 5.6% | |||||
| 0.9 | 0.000 | 0.001 | 3.9% | 0.000 | 0.001 | 5.9% | 0.000 | 0.001 | 5.4% | 0.000 | 0.001 | 5.0% | |||||
| 0.8 | −0.001 | 0.035 | 4.3% | −0.002 | 0.035 | 5.4% | 0.000 | 0.031 | 5.8% | −0.001 | 0.034 | 5.0% | |||||
| 0.2 | 0.000 | 0.006 | 3.8% | 0.000 | 0.006 | 3.9% | 0.000 | 0.005 | 4.4% | 0.000 | 0.006 | 3.8% | |||||
| 1.5 | 0.000 | 0.006 | 5.1% | 0.000 | 0.006 | 5.2% | 0.000 | 0.005 | 4.6% | 0.000 | 0.006 | 5.5% | |||||
The weight matrix is a social interaction matrix , , . Reported for each estimator are the bias, RMSE, and the empirical size of the t test for each parameter equal to its true value at from 1000 simulations. The exogenous regressors are , , , and is independent of . The group size follows . The error terms follow a zero-mean independent normal distribution. The variance structure is such that the error variance in the j-th group is , .
Table 4.
Estimation of SAR with variance structure V2 and parameter configuration P2.
| MQML | GMM | GMM() | II | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R | Bias | RMSE | Bias | RMSE | Bias | RMSE | Bias | RMSE | |||||||||
| 100 | 0.2 | −0.005 | 0.058 | 5.2% | −0.004 | 0.080 | 19.0% | −0.005 | 0.051 | 6.4% | −0.005 | 0.058 | 5.9% | ||||
| 0.2 | 0.006 | 0.066 | 5.0% | 0.006 | 0.086 | 15.4% | 0.006 | 0.058 | 6.4% | 0.006 | 0.066 | 6.7% | |||||
| 0.2 | 0.000 | 0.008 | 4.8% | 0.000 | 0.008 | 4.9% | 0.000 | 0.008 | 5.2% | 0.000 | 0.008 | 4.8% | |||||
| 0.1 | 0.000 | 0.008 | 4.6% | 0.000 | 0.008 | 4.6% | 0.000 | 0.007 | 4.8% | 0.000 | 0.008 | 4.6% | |||||
| 0.6 | −0.003 | 0.029 | 1.4% | −0.001 | 0.042 | 19.7% | −0.003 | 0.027 | 6.5% | −0.003 | 0.029 | 5.5% | |||||
| 0.2 | 0.007 | 0.067 | 1.5% | 0.003 | 0.091 | 17.9% | 0.007 | 0.061 | 6.2% | 0.006 | 0.067 | 5.2% | |||||
| 0.2 | 0.000 | 0.008 | 3.7% | 0.000 | 0.008 | 3.6% | 0.000 | 0.008 | 4.2% | 0.000 | 0.008 | 3.8% | |||||
| 0.1 | 0.000 | 0.007 | 4.4% | 0.000 | 0.007 | 4.0% | 0.000 | 0.007 | 5.6% | 0.000 | 0.007 | 4.4% | |||||
| 0.9 | −0.001 | 0.008 | 0.4% | −0.001 | 0.011 | 19.2% | −0.001 | 0.007 | 5.4% | −0.001 | 0.007 | 5.8% | |||||
| 0.2 | 0.009 | 0.067 | 0.4% | 0.008 | 0.093 | 17.8% | 0.009 | 0.059 | 4.4% | 0.007 | 0.065 | 5.0% | |||||
| 0.2 | 0.000 | 0.009 | 4.8% | 0.000 | 0.009 | 5.7% | 0.000 | 0.008 | 6.1% | 0.000 | 0.009 | 5.1% | |||||
| 0.1 | 0.000 | 0.008 | 5.5% | 0.000 | 0.008 | 5.7% | 0.000 | 0.007 | 5.6% | 0.000 | 0.008 | 5.6% | |||||
| 200 | 0.2 | −0.003 | 0.039 | 5.4% | −0.004 | 0.058 | 20.1% | −0.004 | 0.035 | 5.9% | −0.003 | 0.039 | 6.0% | ||||
| 0.2 | 0.005 | 0.045 | 4.9% | 0.006 | 0.064 | 17.1% | 0.005 | 0.041 | 6.4% | 0.004 | 0.045 | 5.7% | |||||
| 0.2 | −0.001 | 0.006 | 5.3% | −0.001 | 0.006 | 5.6% | 0.000 | 0.006 | 5.4% | −0.001 | 0.006 | 5.3% | |||||
| 0.1 | 0.000 | 0.005 | 5.8% | 0.000 | 0.005 | 5.7% | 0.000 | 0.005 | 5.3% | 0.000 | 0.005 | 5.8% | |||||
| 0.6 | −0.002 | 0.020 | 0.7% | −0.001 | 0.029 | 16.8% | −0.003 | 0.018 | 4.8% | −0.001 | 0.020 | 4.6% | |||||
| 0.2 | 0.003 | 0.045 | 1.1% | 0.002 | 0.062 | 15.6% | 0.005 | 0.040 | 4.3% | 0.002 | 0.044 | 4.5% | |||||
| 0.2 | 0.000 | 0.006 | 5.0% | 0.000 | 0.006 | 5.0% | 0.000 | 0.005 | 4.9% | 0.000 | 0.006 | 5.0% | |||||
| 0.1 | 0.000 | 0.005 | 5.3% | 0.000 | 0.005 | 5.2% | 0.000 | 0.005 | 5.2% | 0.000 | 0.005 | 5.1% | |||||
| 0.9 | 0.000 | 0.005 | 0.1% | 0.000 | 0.008 | 17.3% | 0.000 | 0.004 | 5.4% | 0.000 | 0.005 | 4.7% | |||||
| 0.2 | 0.002 | 0.045 | 0.2% | 0.002 | 0.064 | 15.9% | 0.003 | 0.039 | 3.7% | 0.002 | 0.044 | 3.9% | |||||
| 0.2 | 0.000 | 0.006 | 4.4% | 0.000 | 0.006 | 5.3% | 0.000 | 0.006 | 4.6% | 0.000 | 0.006 | 4.7% | |||||
| 0.1 | 0.000 | 0.005 | 5.8% | 0.000 | 0.005 | 5.8% | 0.000 | 0.005 | 5.1% | 0.000 | 0.005 | 5.9% | |||||
The weight matrix is a social interaction matrix , , . Reported for each estimator are the bias, RMSE, and the empirical size of the t test for each parameter equal to its true value at from 1000 simulations. The exogenous regressors are , , , and is independent of . The group size follows . The error terms follow a zero-mean independent normal distribution. The variance structure is such that the error variance in the j-th group is , .
Table 5.
Estimation of SAR under homoscedasticity with parameter configuration P1.
| QML | GMM | II | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R | Bias | RMSE | Bias | RMSE | Bias | RMSE | |||||||
| 100 | 0.2 | 0.014 | 0.043 | 19.0% | −0.007 | 0.040 | 7.5% | −0.003 | 0.037 | 5.6% | |||
| 0.8 | −0.032 | 0.146 | 18.5% | 0.025 | 0.144 | 6.7% | 0.013 | 0.138 | 6.3% | ||||
| 0.2 | −0.002 | 0.029 | 15.9% | −0.002 | 0.029 | 6.1% | −0.002 | 0.029 | 6.1% | ||||
| 1.5 | −0.001 | 0.026 | 17.7% | −0.002 | 0.026 | 6.1% | −0.001 | 0.026 | 5.9% | ||||
| 0.6 | 0.026 | 0.032 | 34.1% | −0.004 | 0.020 | 5.4% | −0.002 | 0.019 | 5.2% | ||||
| 0.8 | −0.137 | 0.188 | 26.5% | 0.022 | 0.137 | 5.4% | 0.010 | 0.131 | 4.7% | ||||
| 0.2 | −0.001 | 0.029 | 17.3% | −0.001 | 0.029 | 5.1% | 0.000 | 0.029 | 5.1% | ||||
| 1.5 | −0.005 | 0.026 | 15.3% | 0.000 | 0.026 | 4.5% | 0.001 | 0.026 | 4.4% | ||||
| 0.9 | 0.011 | 0.011 | 51.3% | −0.001 | 0.005 | 5.2% | 0.000 | 0.005 | 4.1% | ||||
| 0.8 | −0.213 | 0.248 | 39.9% | 0.022 | 0.140 | 5.5% | 0.009 | 0.134 | 5.0% | ||||
| 0.2 | −0.002 | 0.028 | 14.5% | −0.001 | 0.028 | 4.3% | −0.001 | 0.028 | 3.9% | ||||
| 1.5 | −0.011 | 0.029 | 19.8% | 0.001 | 0.027 | 5.1% | 0.001 | 0.027 | 4.7% | ||||
| 200 | 0.2 | 0.017 | 0.032 | 23.0% | −0.003 | 0.026 | 5.6% | −0.001 | 0.025 | 4.3% | |||
| 0.8 | −0.044 | 0.103 | 18.6% | 0.009 | 0.094 | 5.0% | 0.003 | 0.090 | 3.6% | ||||
| 0.2 | −0.001 | 0.020 | 15.7% | −0.001 | 0.020 | 4.1% | −0.001 | 0.020 | 4.2% | ||||
| 1.5 | 0.001 | 0.017 | 14.1% | 0.001 | 0.017 | 4.6% | 0.001 | 0.017 | 4.9% | ||||
| 0.6 | 0.028 | 0.030 | 62.1% | −0.002 | 0.014 | 5.3% | −0.001 | 0.013 | 4.2% | ||||
| 0.8 | −0.145 | 0.172 | 47.1% | 0.009 | 0.096 | 4.8% | 0.003 | 0.093 | 3.8% | ||||
| 0.2 | 0.000 | 0.021 | 18.4% | 0.000 | 0.021 | 4.5% | 0.000 | 0.021 | 4.5% | ||||
| 1.5 | −0.005 | 0.019 | 18.1% | 0.000 | 0.018 | 5.3% | 0.001 | 0.018 | 4.8% | ||||
| 0.9 | 0.011 | 0.011 | 85.1% | 0.000 | 0.004 | 6.3% | 0.000 | 0.003 | 4.1% | ||||
| 0.8 | −0.220 | 0.237 | 68.7% | 0.009 | 0.097 | 5.9% | 0.004 | 0.093 | 5.0% | ||||
| 0.2 | −0.002 | 0.021 | 17.7% | 0.000 | 0.021 | 4.5% | 0.000 | 0.021 | 4.4% | ||||
| 1.5 | −0.014 | 0.023 | 25.0% | −0.002 | 0.019 | 4.6% | −0.001 | 0.019 | 4.5% | ||||
The weight matrix is a social interaction matrix , , . Reported for each estimator are the bias, RMSE, and the empirical size of the t test for each parameter equal to its true value at from 1000 simulations. The exogenous regressors are , , , and is independent of . The group size follows . The error terms follow a standard normal distribution.
Table 6.
Estimation of SAR under homoscedasticity with parameter configuration P2.
| QML | GMM | II | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R | Bias | RMSE | Bias | RMSE | Bias | RMSE | |||||||
| 100 | 0.2 | 0.041 | 0.078 | 13.3% | −0.007 | 0.056 | 5.7% | −0.004 | 0.055 | 5.6% | |||
| 0.2 | −0.037 | 0.121 | 14.7% | 0.017 | 0.112 | 5.3% | 0.011 | 0.109 | 5.1% | ||||
| 0.2 | −0.002 | 0.029 | 16.2% | −0.004 | 0.029 | 5.9% | −0.002 | 0.029 | 6.0% | ||||
| 0.1 | 0.000 | 0.026 | 18.0% | −0.001 | 0.026 | 6.6% | 0.000 | 0.026 | 6.4% | ||||
| 0.6 | 0.072 | 0.076 | 29.7% | −0.004 | 0.029 | 4.6% | −0.002 | 0.028 | 4.3% | ||||
| 0.2 | −0.149 | 0.181 | 25.9% | 0.007 | 0.108 | 5.3% | 0.001 | 0.107 | 5.6% | ||||
| 0.2 | −0.001 | 0.029 | 16.4% | −0.001 | 0.029 | 5.2% | 0.001 | 0.029 | 5.2% | ||||
| 0.1 | 0.000 | 0.026 | 18.2% | 0.000 | 0.027 | 6.6% | 0.001 | 0.027 | 6.2% | ||||
| 0.9 | 0.026 | 0.027 | 48.5% | −0.001 | 0.008 | 5.3% | −0.001 | 0.008 | 5.3% | ||||
| 0.2 | −0.214 | 0.235 | 38.4% | 0.010 | 0.110 | 5.3% | 0.004 | 0.109 | 4.9% | ||||
| 0.2 | −0.003 | 0.028 | 15.8% | 0.000 | 0.028 | 4.0% | 0.001 | 0.028 | 4.2% | ||||
| 0.1 | −0.002 | 0.025 | 15.2% | 0.000 | 0.026 | 5.1% | 0.001 | 0.026 | 4.9% | ||||
| 200 | 0.2 | 0.046 | 0.064 | 23.3% | −0.004 | 0.038 | 4.6% | −0.003 | 0.038 | 4.5% | |||
| 0.2 | −0.046 | 0.093 | 18.7% | 0.009 | 0.079 | 5.3% | 0.005 | 0.078 | 4.7% | ||||
| 0.2 | −0.001 | 0.021 | 17.5% | −0.002 | 0.021 | 6.0% | −0.001 | 0.021 | 5.6% | ||||
| 0.1 | 0.000 | 0.018 | 15.8% | 0.000 | 0.018 | 4.3% | 0.000 | 0.018 | 4.0% | ||||
| 0.6 | 0.074 | 0.076 | 70.7% | −0.002 | 0.020 | 4.8% | −0.001 | 0.020 | 4.6% | ||||
| 0.2 | −0.152 | 0.170 | 49.3% | 0.004 | 0.081 | 6.3% | 0.000 | 0.079 | 5.9% | ||||
| 0.2 | −0.002 | 0.021 | 17.6% | −0.001 | 0.021 | 5.0% | 0.001 | 0.021 | 5.0% | ||||
| 0.1 | 0.000 | 0.019 | 17.8% | 0.000 | 0.019 | 6.1% | 0.001 | 0.019 | 6.4% | ||||
| 0.9 | 0.027 | 0.027 | 95.2% | −0.001 | 0.005 | 4.6% | 0.000 | 0.005 | 4.1% | ||||
| 0.2 | −0.218 | 0.229 | 72.6% | 0.005 | 0.081 | 6.0% | 0.001 | 0.079 | 5.2% | ||||
| 0.2 | −0.003 | 0.020 | 15.3% | 0.000 | 0.020 | 4.8% | 0.001 | 0.020 | 4.8% | ||||
| 0.1 | −0.001 | 0.018 | 15.0% | 0.000 | 0.018 | 4.2% | 0.001 | 0.018 | 3.9% | ||||
The weight matrix is a social interaction matrix , , . Reported for each estimator are the bias, RMSE, and the empirical size of the t test for each parameter equal to its true value at from 1000 simulations. The exogenous regressors are , , , and is independent of . The group size follows . The error terms follow a standard normal distribution.
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Bao, Y.; Liu, X.; Yang, L. Indirect Inference Estimation of Spatial Autoregressions. Econometrics 2020, 8, 34. https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics8030034
AMA Style
Bao Y, Liu X, Yang L. Indirect Inference Estimation of Spatial Autoregressions. Econometrics. 2020; 8(3):34. https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics8030034
Chicago/Turabian StyleBao, Yong, Xiaotian Liu, and Lihong Yang. 2020. "Indirect Inference Estimation of Spatial Autoregressions" Econometrics 8, no. 3: 34. https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics8030034
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.