
Quantile Regression with Generated Regressors


1
Department of Economics, University of Iowa, Iowa City, IA 52242, USA
2
Department of Economics, University of Arizona, Tucson, AZ 85721, USA
3
Department of Economics & Finance, University of Iowa, Iowa City, IA 52242, USA
*
Author to whom correspondence should be addressed.
Econometrics 2021, 9(2), 16; https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics9020016
Submission received: 16 November 2020
/
Revised: 26 March 2021
/
Accepted: 6 April 2021
/
Published: 12 April 2021
Abstract
:This paper studies estimation and inference for linear quantile regression models with generated regressors. We suggest a practical two-step estimation procedure, where the generated regressors are computed in the first step. The asymptotic properties of the two-step estimator, namely, consistency and asymptotic normality are established. We show that the asymptotic variance-covariance matrix needs to be adjusted to account for the first-step estimation error. We propose a general estimator for the asymptotic variance-covariance, establish its consistency, and develop testing procedures for linear hypotheses in these models. Monte Carlo simulations to evaluate the finite-sample performance of the estimation and inference procedures are provided. Finally, we apply the proposed methods to study Engel curves for various commodities using data from the UK Family Expenditure Survey. We document strong heterogeneity in the estimated Engel curves along the conditional distribution of the budget share of each commodity. The empirical application also emphasizes that correctly estimating confidence intervals for the estimated Engel curves by the proposed estimator is of importance for inference.
JEL Classification:
C12; C13; C231. Introduction
Since the seminal work of Koenker and Bassett (1978), quantile regression (QR) models have provided a valuable tool in economics, finance, and statistics as a way of capturing heterogeneous effects of covariates on the outcome of interest, exposing a wide variety of forms of conditional heterogeneity under weak distributional assumptions. Importantly, QR also provides a framework for robust inference.
Applied researchers are commonly confronted with the absence of observable regressors in practice. In some cases, proxies for the unobservable variables can be found in data, while in other cases, these regressors need to be estimated. Thus, a very common strategy to deal with unobservable variables is to replace them with estimated values, that is, generated regressors (GRs).1 These GRs have important implications for the reliability of general standard estimation and inference procedures. Pagan (1984) and Murphy and Topel (2002) point out that even though consistent estimates of parameters of interest are produced when the unobserved regressors are replaced with their estimated values, the conventional ways to estimate standard errors are incorrect. Recently, Mammen et al. (2012) provide a general theory for the impact of GRs on the final estimator’s asymptotic properties in nonparametric mean regression. Hahn and Rider (2013) derive the asymptotic distribution of three-step estimators of a finite-dimensional parameter in a semiparametric mean regression models where GR is estimated parametrically or nonparametrically in the first-step.
A number of important statistical applications requires estimation of a conditional quantile function when some of the covariates are not directly observed, but are estimated in a preliminary step. Examples include, among others, stochastic volatility time-series models, triangular simultaneous equation models, censoring, sample selection models, and treatment effects models.2
This paper contributes to the literature by systematically studying and formalizing estimation and inference for linear QR models with a general semiparametric GR. The main contributions are as following. First, we suggest a practical two-step estimation procedure to estimate the parameters of interest in the QR-GR model. The first-step applies a general (semi)-parametric estimator to compute the GRs. The second step uses the GRs as regressor variables in a QR estimation. We establish the asymptotic properties of the two-step QR-GR estimator, namely, consistency and asymptotic normality. We show that the asymptotic variance-covariance matrix needs to be adjusted to account for the first-step estimation error. The basic idea is as follows. Since the first-step estimation of the unobservable regressors produces consistent estimates of the corresponding true parameters, the GRs are consistently estimated. However, the GR are included in the QR model of interest with sampling error, which introduces additional noise into the asymptotic variance-covariance matrix of the coefficients of interest. In other words, the sampling error from the first stage contaminates the second stage estimation. Therefore, the usual way of calculating the QR variance-covariance matrix fails to account for the additional source of error. Under some general conditions, the estimated limiting distribution of the first-step is used to consistently estimate the variance-covariance matrix of the parameters of interest.
The second contribution of the paper is to develop inference procedures for the QR model with GR. Though estimation and inference for conditional average models with GR have been widely studied and used in practice, the literature on QR with GR is more sparse. We develop testing procedures for general linear hypotheses in these models based on Wald-type tests, and derive their associated limiting distributions. To implement the tests, we propose an estimator for the asymptotic variance-covariance of the QR-GR coefficients, and formally establish its consistency. An important advantage of the proposed tests is that they are simple to compute and implement in practice.
Compared to the existing procedures, the QR-GR methods proposed in this paper present several distinctive advantages for applied researchers. First, instead of imposing a linear structure in the first step, as in Xiao and Koenker (2009), or imposing triangular structure between two steps, as in Ma and Koenker (2006) and Lee (2007), we work with the general case of QR-GR where no structural restrictions between the two steps or any specific functional forms and estimation strategies in the first step are imposed. That is useful in applied work since practitioners have a large range of alternatives to construct the unobservable variables by using different estimation strategies or even different data sets. Second, we establish the asymptotic properties of the QR-GR estimator for non-iid data under weak conditions. This is an important generalization for practitioners since it allows for inference in a more general class of models. Third, we develop practical inference procedures. Finally, the weak conditions we imposed for QR-GR allow for simple computational implementation.3 Linear QR models have been the workhorse of the applied research and the methods lead to a simple algorithm that can be conveniently implemented in empirical applications. Researchers can simply use existing software packages for the first-step estimation and to construct the regressors needed, for example, MLE, OLS, QR or GMM, and then apply the QR procedure with our described variance-covariance matrix adjustment.
Monte Carlo simulations assess the finite-sample properties of the proposed methods. We evaluate the QR-GR estimator in terms of empirical bias and root mean squared error, and compare its performance with methods that are not designed for dealing with GR issues. In addition, we compute the corresponding standard errors of the QR-GR estimator and evaluate its bias. The experiments suggest that the proposed approach performs very well in finite samples and effectively removes the bias of the standard errors induced by the GR. Thus, the proposed variance estimator is approximately unbiased and approximates well the true variance.
Finally, to motivate and illustrate the applicability of the methods, we consider an empirical application to study demand models, using data from the UK Family Expenditure Survey. Demand models (also known as Engel curves) represent the relationship between total expenditure and the share of various commodities to total expenditure. The QR approach is a useful tool in this example because it allows us to capture the heterogeneity in the expenditures of the different commodities along the conditional distribution of each commodity share. The first step in this exercise is to estimate the unobserved motives for budget shares of different commodities using the factor analysis proposed by Barigozzi and Moneta (2016). The unobserved factors consist of the motives of consumption as necessities, luxuries, and unitary elasticity goods. In the second step, we apply the proposed QR-GR estimator to obtain Engel curves for the commodities such as food, housing and leisure, by regressing each commodity share on the estimated motives from the first step. We found that the motives of consumption play different roles for various commodities and contributions of motives to each budget share vary over the total expenditure. Furthermore, the empirical results document important heterogeneity in the Engel curves. The estimated curves present strong heterogenous effect of the consumption motives on the budget share along the conditional distribution of the budget share in most commodities. Importantly, the empirical study underscores the importance of obtaining correct confidence intervals for the estimated Engel curves by taking into account the GR issue.
The remainder of the article is organized as follows. Section 2 introduces the QR model with GR. Section 3 establishes consistency and asymptotic normality of the two-step estimator. Section 4 proposes a consistent estimator of the variance-covariance matrix. Section 5 presents Monte Carlo simulations. Section 6 presents the empirical application to Engel curves. Section 7 concludes the article. Technical proofs are included in the Appendix A.
2. Quantile Regression with Generated Regressors
This section describes the quantile regression (QR) model with generated regressors (GRs) we consider in this paper and the two-step estimation procedure.
2.1. Model
For each fixed , we consider the following model
where is a response variable, is a k–dimensional vector of explanatory variables, is a vector of parameters, and the innovation term has conditional -quantile zero, that is .
When all the regressors in model (1) are observable, the model can be written as the following standard QR model
where is the conditional -quantile of given . In general, can depend on . The model is semiparametric in the sense that the functional form of the conditional distribution of given is left unspecified.
The parameter of interest for the researcher is in model (2). However, in many applications one or more elements of the vector of regressors may not be directly observable, but instead estimated from a model with other given variables, that is, the GRs. In this paper, we assume that some of the regressors in the vector are not observable to the researcher, i.e., are not directly observable, but are observed, where . In particular, the GR are assumed to have the following form
where the function is differentiable and known up to the unknown parameter vector for , and the variable is a q-dimensional vector of observables, and where is an error term. Thus, one can still estimate the QR model in (2) by replacing with the GR for . The GR is obtained from the following first-step estimation
where satisfies very general weak conditions as: , and is a generic function satisfying . Equation (3) defines the GR and could be satisfied by different models, we provide a few examples below. Notice that most estimators used in empirical applications satisfy this first-order representation. We will discuss these conditions more formally below. To complete the model, together with (2) and (3), we assume that .
Remark 1.
One or more elements of the regressors may be estimated in the first step. Each of the GRs could be related to different observable variables in different functional forms. For simplicity, each of the GR equations can be estimated separately, and any dependence between the GRs would be captured by the variance covariance matrix.
Remark 2.
We note that the estimation of quantile regression models with mismeasured regressors leads to inconsistent estimates and a few methodologies have been proposed to overcome this drawback (e.g., Wei and Carroll (2009); Wang et al. (2012); Firpo et al. (2017)). Thus, the problem is different from the quantile regression with generated regressors where the standard quantile estimation is still consistent.
To motivate the existence of GRs for QR models, and illustrate how a QR-GR framework could appear in practice, we include the following motivating examples:
Example 1 (Two-stage regression with proxy variables).
A very important example of GR occurs when the variables are not directly observable. For instance, assume that the variables are related to additional observable variables, , as follows
where are proxy variables, or endogenous observables, is a vector of exogenous observable variables, is a vector, the functions are unknown up to the vector , and are mutually independent innovation terms, for .
In this case, to complete the definition of the GR one needs to impose more structure on the innovation term to estimate the parameters , for . As special cases of a more general procedure which generates the regressors, consider a simple but commonly used linear model to generate one regressor, , as a function of several variables , that is, . The following are two standard examples.
Example 1.1 (Conditional average). A simple example for the GR model is a linear conditional expectation. In this case, the GR model is defined as
Example 1.2 (Conditional quantile). Another simple model for the GR is a linear conditional quantile. In this case, for a given quantile specified by the researcher, the GR model is defined as
In practice one needs to estimate the parameters in both examples and compute the GR.
Example 2 (Quantile regression with endogeneity: control function approach).
Consider the following model
where is the endogenous explanatory variable, is a scalar parameter for simplicity, and is the vector of exogenous variables, is a vector of parameters. Assume that are valid instruments. In the control function approach, one could model the endogenous explanatory variable as following:
where contains exogenous regressors . The source of the endogeneity in the model (4) comes from the correlation between and . Thus, the endogeneity can be solved by controlling for in the model. Since we do not observe , we can replace with , where could be obtained by either mean or quantile regression. This gives
where which depends on the sampling error in . Notice that is a generated regressor. Moreover, it is worthwhile noting that although the control function approach for the endogeneity issue is one of examples for the GR as in e.g., Lee (2007), we are not particularly attempting to solve the endogeneity issue in this paper. Instead, we provide a general framework and establish the asymptotic properties for the quantile models with GR.
2.2. Estimation
The estimation of the parameters of interest in model (2) involves a two-step estimation. In the first step one estimates and computes the GR from model (3). In the second step one uses the GR and other regressors, and computes the QR of interest from (2).
Estimation of the unobservables usually comes from the same sample of data – may come from a different dataset or even from the parameter estimates by another researcher. Models used to estimate the unknown parameter may generally include linear or nonlinear models. Additionally, the parameters can be estimated by various strategies. The QR-GR two-step estimation procedure is as following:
- Step 1
- Estimate from (3) and compute the fitted values for , and then obtain the generated regressors for .
- Step 2
Thus, one uses the estimates of , denoted by , in the first step, to obtain the GR . In the examples for the average and quantile models discussed previously we have the following for the first step.
Example 1.1 (Average continued). In this example, one employs the standard OLS estimator and obtains
and computes , and also . Then, the τ-th QR estimator can be obtained by (6).
Example 1.2 (Quantile continued). In this case, for a given quantile one applies the usual QR procedure to estimate and obtain . Thus, the first-step estimation is given by the following QR
Then, in the second step, for a given τ-quantile, the QR estimator can be obtained by (6).
These two practically-common cases illustrate the simple implementation of QR model with GR. We have made R routines for the QR-GR estimator and inference in the QR-GR framework available for the practitioners.
3. Asymptotic Properties
We now establish consistency and asymptotic normality of the QR-GR two-step estimator, , defined in the previous section. Proofs are collected in the Appendix A. We consider the following regularity conditions:
A1. is independent across i. The conditional distribution functions of the error term have continuous densities with a unique conditional -th quantile equal to 0, and are uniformly bounded away from 0 and ∞.
A2. There exist positive definite matrices and such that
- (i)
- ,
- (ii)
- ,
- (iii)
- .
A3. .
A4. where is a continuous function which satisfies that and .
A5. There exists a positive definite matrix where
- (i)
- , where is Jacobian of ,
- (ii)
- , where .
Conditions A1 and A2 are the usual conditions in the QR literature. Assumptions A1 allows for non-iid sampling, and A2 requires limiting matrices to be well defined. Assumptions A3–A5 refer to the GR estimation in the first step and need to be verified for each empirical application. These conditions are very mild. Assumptions A3 and A4 impose consistency and asymptotic normality, respectively, for the first-step estimator of the GR. These conditions hold for most estimators employed in empirical work in the family of M- and Z-estimators. We note that no restrictions are imposed on the functional form of except condition A5 which is a weak smoothness condition needed only for nonlinear models.
The following result states the consistency of the QR-GR estimator.
Remark 3.
A consistent estimate of the unknown parameter for in the first step suffices for the consistency of QR with GR. In other words, replacing by in a quantile regression still gives us a consistent QR estimator.
The next result establishes the asymptotic normality of the QR-GR two-step estimator.
Theorem 2 (Asymptotic normality).
The result in Theorem 2 shows that the limiting distribution of generally depends on the statistical properties of since the sampling error of generating regressor in model (3) contaminates the variance-covariance estimation in the second stage. Hence, the asymptotic variance-covariance of the two-step estimator needs to be adjusted when the regressors are generated. The adjusted variance-covariance matrix is larger, since the sampling error V from the first-step estimation enters variance-covariance matrix. Nevertheless, the sampling variation of can be ignored, at least asymptotically, if the coefficients of the GR are zero, i.e., and the corresponding part in M becomes zero. In that case, replacing the true regressors with GR will not impact the asymptotic distribution of the estimator.
Remark 4.
In general, the consistency of QR estimator with GR holds when the true regressor is replaced by GR. However, the asymptotic variance-covariance matrix of the estimator needs to be adjusted because of the sampling variation introduced by estimation of in the first step.
Remark 5.
Comparing the QR-GR estimator with regular QR estimator with the true unobserved regressors, we see that the additional second term appears in the variance-covariance matrix coming from the first-step estimation. The first-step estimation contaminates the variance-covariance matrix of in two ways: one is the sampling error of coefficient estimates in the first stage, the other is the gradient of model specification with respect to the parameter in the first stage. For the simple linear model in the first stage, the gradient is simply the regressors in the first stage. However, for nonlinear model in the first stage, the coefficient estimates show up in which makes the variance-covariance matrix of larger than when the true regressors are used for estimation.
The two-step estimation procedure in this paper is easy to implement in practice. First, since weak conditions are needed for QR-GR procedure, different estimation strategies may be used in the first step to construct the GR. Most common estimators in practice satisfy the weak conditions: for example, the simple OLS, QR, MLE methods, etc. Second, both linear and nonlinear model specifications in the first step are allowed. Finally, it is important to notice that weak conditions in the QR step include non-iid models which allow practitioners to proceed inference in a general class of models.
To further illustrate the estimation of QR models with GR, we further discuss the two common models, OLS and QR with GR. We discuss the case where only one regressor is generated in the first step. For both models, after estimating which satisfies the condition where and in the first step, one obtains the GR: where . The following examples derive the asymptotic variance-covariance matrix for both OLS and QR with GR:
Example 3 (OLS with GR).
In this example, is estimated from the model
Since the OLS estimator has a closed-form solution, one obtains . Finally, the variance-covariance matrix is given by the following result which is proved in the Appendix A, for completeness. Note that according to Proposition A2 in the Appendix A, under conditionsC1–C5,
where , and . When there is no GR or the coefficients of the GR are zero, the asymptotic variance displayed above simplifies since . In the case of , where and is an identity matrix, we obtain that , since . In addition, in the case of and , where is positive definite matrix, since , we have that .
Example 4 (QR with GR).
In this example, is estimated from the model
Unlike the simple closed-form solution in the above OLS estimate, one applies the usual QR procedure to estimate
Theorem 2 shows that
where , , and are defined in conditionsA2 and A5, and M is simplied to . In addition, one can notice that the above asymptotic variance-covariance matrix can be simplified to
To conclude this section we have two remarks. First, from the second example, one can notice that the variance for the QR with GR has the additional terms and relative to the standard QR model without GR, which has the variance . Second, intuitively, as shown in Theorem 1 and Proposition A1, in both OLS and QR frameworks, estimation with GR still produces consistent estimates. However, as shown in Theorem 2 and Proposition A2, the corresponding variance-covariance matrices need to account for two sources of error—the usual estimation error in the OLS or QR method, and the sampling error in generating the regressors.
4. Inference
In this section, we turn our attention to inference in the QR-GR model. First, we suggest an estimator for the asymptotic variance-covariance matrix of the QR-GR estimator. Second, we propose a Wald-type test for general linear hypotheses.
4.1. Variance-Covaraince Matrix Estimation
In applications, the variance-covariance matrices are unknown and need to be estimated. Now we suggest an estimator for the corresponding variance of the QR-GR estimator. The estimator is closely related to those suggested by Hendricks and Koenker (1991) and Powell (1991) and given as the following form
where
To establish the consistency of we impose the following assumptions:
B1. There exists a positive sequence of bandwidths such that and .
B2. for all i and for some constant .
B3. for all and for all where and for some constant .
B4. There exists a bounded function such that for all i and for some near zero a.s.4
B5. satisfies the Lipschitz condition that for some constant and for all i.
Assumption B1 is a restriction on the bandwidth , which is commonly used to estimate unknown conditional densities. B2 imposes some moment condition, which is typical in the QR literature. Assumption B3 imposes smoothness and dominance conditions that are typical for nonlinear models (see, e.g., Powell (1991)). B4 imposes some local restriction on the conditional density function near zero and satisfies some moment bounds, which can be weakened at the cost of moment bounds for various cross products of the bounding functions. (see, e.g., Assumption ER of Buchinsky and Hahn (1998)). B5 imposes smoothness condition on the conditional densities and is standard in the QR literature.
The next result states the consistency of the variance-covariance QR-GR estimator.
Theorem 3 (Variance-covariance matrix estimation).
Under the assumptionsB1–B5and conditions of Theorem 2, as
In other words, , , and , where , and are defined in conditions A2 and A5, and M is defined in Theorem 3.
As a special case of more general procedure which generates the regressors, consider a linear model . The gradient of , denoted by , is reduced to , in the following examples for the average and quantile models:
Example 1.1 (Average continued). In this example, one employs the standard OLS estimator in the first step to obtain
and the standard error . Then, one is able to compute , as well as . Finally, with the second step estimation , the estimator of the corresponding variance-covariance matrix is simply .
with being the residual from the first-step estimation.
Example 1.2 (Quantile continued). In this example, for a given quantile one applies the usual QR procedure to estimate and obtains . Thus, the first-step estimation is given by the following QR
So one obtains the standard error and computes to obtain . The final formula for the estimator of the variance covariance matrix is analogous to the previous example.
4.2. Testing
In the independent and identically distributed setting, the conditional quantile functions of the response variable, given the covariates, are all parallel, implying that covariate effects shift the location of the response distribution but do not change the scale or shape. However, slope estimates often vary across quantiles, implying that it is important to test for equality of slopes across quantiles. Wald tests designed for this purpose were suggested by Koenker and Bassett (1982a); Koenker and Bassett (1982b); Koenker and Machado (1999). It is possible to formulate a wide variety of tests using variants of the proposed Wald test, from simple tests on a single quantile regression coefficient to joint tests involving many covariates and distinct quantiles at the same time.
General hypotheses on the vector can be accommodated by Wald-type tests. The Wald process and associated limiting theory provide a natural foundation for the hypothesis
where R is a full-rank matrix imposing s number of restrictions on the parameters and r is a column vector of s elements. We consider a Wald-type test where we test the coefficients for selected quantiles of interest. For simplicity, we use the model stated in Equation (2) with a single variable in the matrix. The following example is a hypotheses that may be considered in the former framework.
Example 5 (Test for slope).
A hypothesis testing for for given quantile τ can be accommodated in the model. For instance, , so and .
In general, for given , the regression Wald process can be constructed as
where .
In order to implement the test it is necessary to estimate consistently. It is possible to obtain such an estimator as suggested in Theorem 3 in the previous section, and the main components of can be obtained as in Equations (8)–(10).
Given the results on consistency of , if we are interested in testing at a particular quantile , a Chi-square test can be conducted based on the statistic . Under , the statistic is asymptotically with s-degrees of freedom, where s is the rank of the matrix R. The limiting distribution of the test is summarized in the following theorem.
Theorem 4 (Wald Test Inference).
Under , and conditionsA1–A5andB1–B5, for fixed τ,
5. Monte Carlo Simulations
In this section, we evaluate the performance of two-step QR-GR estimator and compare its performance with the usual QR estimator which does not account for the first-step estimation. Additionally, the performance of the proposed variance-covariance estimator is evaluated. The computational results are obtained in the R language.
5.1. Monte Carlo Design
We consider the following model as a data generating process:
where , and and are the parameters of interest. We set . The parameter captures the heterogeneity, hence we let . When we have a location-shift model and for the location-scale-shift. Thus, for the later model, we have that .
The regressor is unobserved but its observable counterpart x is related to observed variables w and z as follows:
where are generated as the following: , , . The parameter vectors are specified as following: . In the simulations, we consider cases where sample size , quantiles and we set the number of replications to be 1000.
For comparison, we consider two estimators of : (i) the standard (infeasible) QR using the unobserved regressors , which we label QR; (ii) the QR estimates with the GR as described above, which is defined as QR-GR. For the two-step QR-GR estimator, the estimation process is as following. In step 1, using the OLS estimation, we obtain the generated regressor (GR) from the model: , where are observables. In step 2, for each , we estimate using the QR-GR estimator of y on . We also present results for the corresponding standard errors (SE) of the estimators. For the QR-GR estimator we use the estimator in equation where , is the residual of the QR estimation, and is the default bandwidth in the R package. k is a robust estimate of the scale and the bandwidth is also commonly chosen in the R package.
5.2. Simulation Results
5.2.1. Location Shift Model
The results for the location-shift model are provided in Table 1 and Table 2. The bias, SE, and root mean squared error (RMSE) of both QR-GR and QR estimators are presented in Table 1. Different sample sizes and in the experiments are reported in the table. According to the theorems in Section 3, both estimators QR-GR and QR should be consistent. As shown in Table 1, both estimators had empirical bias very close to zero, even for small samples.
Table 1 also shows that the standard error decreased as the sample size increases. However, the QR-GR had substantially larger standard error and RMSE than the regular QR with the true regressor. This result was expected from the theoretical results. These observations reflected the fact that having a GR estimation in the first step did not affect the bias performance but induced a substantially larger variance. This confirms that the sampling error of obtaining by the GR contaminates the standard error in the second-stage QR estimation.
In Table 2 we evaluate the performance of proposed variance-covariance estimator discussed in Section 4 for . We report three statistics in Table 2. First, in column 1, we report the sample standard deviation of the QR-GR estimates based on the Monte Carlo repetitions, which approximated the true standard error of the parameter of interest. Second, the average of the proposed standard error of the QR-GR estimator is reported in the column 2. Finally, for comparison, the standard error of the usual (infeasible) QR is given in the column 3.
By comparing columns 1 and 2 of Table 2, we can see that the estimated standard errors (SE) of the proposed QR-GR was very closely to the true value given in column 1. However, the average of the estimated standard error calculated in the usual way was severely biased downwards. This result confirmed the theoretical predictions and reflected that the sampling error from the first-step estimation induced a larger variance-covariance matrix in the second step. Thus, the estimated standard errors from the conventional formula without considering the GR problem underestimated the population counterpart, and in turn severely affected the inference procedure.
5.2.2. Location-Scale Shift Model
The results for the bias and RMSE for sample sizes and are reported in Table 3. For the location-scale shift model, both QR and QR-GR estimators had small bias so that they were close to the population value of . However, as expected, the QR-GR had larger standard error and root mean square error (RMSE) than the regular QR with the true regressor for both sample sizes. Thus, the results corroborated the theoretical findings that the GR variable had no asymptotic effects in the bias performance but induced a larger variance.
As in the previous case, in Table 4 we assess the performance of the proposed variance-covariance estimator discussed in Section 4 for the location-scale model. The results were analogous. We see that the proposed QR-GR standard errors in column 2 closely approximated the true standard error in column 1. However, the estimated standard error calculated in the usual way in column 3 was severely smaller and did not approximate the true standard error well.
6. Application
6.1. A Brief Literature Review on Engel Curves
Engel curves describe how household expenditures on particular goods and services depend on household income. The analysis of Engel curves has a long history of estimating the expenditure-income relationship (see Engel (1857); Working (1943)). They are regression functions where the dependent variable is the level or the budget share of total expenses used to purchase a commodity of goods or services, and the explanatory variable, total expenditure, is usually used as a proxy for income. A very robust empirical result referred to as ‘Engel’s law’ states that the poorer a family is, the larger the budget share it spends on food. Other categories of expenditure present a less robust pattern.
Many researchers explored different functional forms for Engel curves which better fit the data. For example, Lewbel (1997) proposed a functional form for Engel curves that contains a linear function of logarithm of total expenditure and some nonlinear function of total expenditure. Nonparametric estimations also have been incorporated in the estimation of Engel curves like Blundell et al. (2007). Methods for comparing different regression functions are discussed in Lewbel (2008). These various shapes of Engel curves suggest a deeper understanding of underlying motives which drive household expenditure decisions. However, it is problematic to assume that only one motive drives the consumption of one particular category of goods or services (Chai and Moneta (2010)). For example, luxury, as a relative concept, is possible in all sorts of consumption. Barigozzi and Moneta (2016) studied a system of budget share and extracted multiple factors that span the same space of basic Engel curves. To understand how the patterns of consumption may be driven by a mixture of different motives, we use the quantile regression with generated regressor (QR-GR) framework laid out in Section 2, in order to explore the heterogeneous effects of motives over different commodity.
To be specific, we estimate unobserved factors which represent underlying motives of expenditure in the first step using the factor model in Barigozzi and Moneta (2016). We then apply quantile regression (QR) methods to the Engel curve model in the second step where budget share is regressed on the estimated factors. The proposed QR-GR model is used to study how each type of household expenditure is driven by different underlying motives. The QR-GR model has two advantages. First, an important difficulty with the model is that the estimator of the variance-covariance matrix needs to take into account the fact that unobserved factors are estimated. The proposed method is able to provide statistically reliable inference via correct estimation of the variance-covariance matrix. Second, we accommodate possible heterogeneity in the effects of total expenditure over the conditional distribution of budget shares. We find that the estimated Engel curves of budget shares are driven by a mixture of three underlying forces which are motives for a household to consume necessities, luxuries, and goods or services on which is spent the same percentage of the total budget. Additionally, we find heterogeneity in each motive along the conditional distribution of budget shares.
6.2. Data Description
The data we used in this paper is the household data from the UK Family Expenditure Survey 1997–2001 and the Expenditure and Food Survey 2002–2006.5 The data contain the information about household expenditures on different goods and services. About 7000 households were randomly selected and each household’s expenditures were recorded for 2 weeks, which enables researchers to explore various household consumption patterns. We used information about the number of family members, total expenditures, and expenditures on 13 aggregated categories: (1) housing (net); (2) fuel, light, and power; (3) food; (4) alcoholic drinks; (5) tobacco; (6) clothing and footwear; (7) household goods; (8) household services; (9) personal goods and services; (10) motoring; (11) fares and other travel; (12) leisure goods; (13) leisure services.6
In this paper, we studied a sample of about 4000 households which had two to four family members, and the budget shares of these categories were pooled over 10 years. Table 5 reports some descriptive statistics for total expenditure and 13 categories of expenditures. As shown in the table, on average, about 20% of the budget was spent on food and housing, followed by leisure (about 16%) which included leisure goods and leisure services in our analysis. In order to analyze the deflated data, we picked 2005 as the base year, and use the aggregate price index and the price indices for different categories of expenditure from price indices data (RPI).7
6.3. Empirical Analysis
Barigozzi and Moneta (2016) study a system of budget shares that are driven by latent factors. Using the factor analysis in Bai and Ng (2002), they determine the number of basic Engel curves (i.e., the rank of the system) and found that budget shares of each expenditure can be approximated by a three-factor model: (i) a decreasing function (necessities), (ii) an increasing function (luxuries), (iii) a constant function over the total expenditure (unitary elasticity goods).
We estimate the following conditional quantile function:
where the quantity denotes the household budget share of a commodity, and and are the first and second motives of total expenditure, respectively. Since the third motive is constant over the total expenditure, a constant is also included.
In order to estimate the quantile model in (13), we first obtain the motives and using a regression of factors on total expenditure. We compute these generated regressors by following the functional specifications of each motives established in Barigozzi and Moneta (2016). Denote factors by , , and , and denote the total expenditure by z. Let and . We use the following estimation steps:
- Step 1
- Obtain the fitted values (generated regressors) of the first two motives by regressing the corresponding factors on functions of the total expenditure as following:
- Step 2
- Run a quantile regression of budget shares y on the three motives where the third motive is associated with a constant:with .
Remark 6.
We note that, in step 1, the motives and are estimated by regressing the factors on the total expenditures where the factors are obtained by the principal component analysis. For the sake of notational simplicity, we assume the factors and total expenditures are observed without errors.
Remark 7.
In step 2, each motive represents specific reactions to consumption changes. The first one is interpreted as a motive to consume necessities since it is decreasing in the total expenditure, while the second one represents the motive to consume luxuries, which is increasing in the total expenditure. The third one is related to unitary elasticity goods which represents goods or services allocated the same percentage of total budget by both rich and poor households.
We estimate the coefficients in model (13) across different quantiles. For conciseness, we only report the results for food, housing and leisure. The main results in Figure 1 show how the budget shares of each commodity relate to each factors, respectively. We only show the results for and since the third motive does not vary with the family expenditure. The coefficient estimates over different quantiles reflect marginal impact of each motive on the distribution of budget shares at different quantiles. In all cases, their magnitudes varies over the level of the quantile . Thus our quantile model well identifies apparent heterogenous effects of consumption motives on the the budget shares.
The 95% confidence intervals in dashed lines are based on our proposed estimator of the asymptotic variance-covariance matrix, while the 95% confidence intervals in dotted lines are calculated by conventional QR variance-covariance estimation. Clearly, the adjusted confidence bands for QR-GR are much larger than the conventional bands which do not adjust for the GR issue. This can be observed more clearly in Table 6 which summarizes the estimated standard errors for a subset of quantiles . The table reports that the estimated standard errors from the proposed estimator (QR-GR SE) is always larger than those from the conventional estimator (QR SE). These results underscore the importance of estimating standard errors correctly by taking into account the GR issue in Engel curves.
Since both and are normalized measures of different motives, comparing the relative magnitudes of their coefficient estimates helps us to tell which motive plays a leading role in a particular commodity. For example, Figure 1a shows that the motive to consume food as necessity clearly plays a leading role relative to luxuries at all quantiles. In Figure 1c, the motive to consume leisure as luxuries is dominating a role as necessity. However, consuming housing in Figure 1b has a mixed result where both necessity and luxuries play a similar role.
To help further interpret how the patterns of budget shares are related to these unobservable motives, we show how the budget share of a particular commodity varies over the total expenditure in Figure 2, Figure 3 and Figure 4. We estimate the contribution of each motive to the budget share at different quantiles . It is interesting to see how the motive to consume a particular commodity as necessity or luxury contributes to its budget share at different levels of total expenditure.
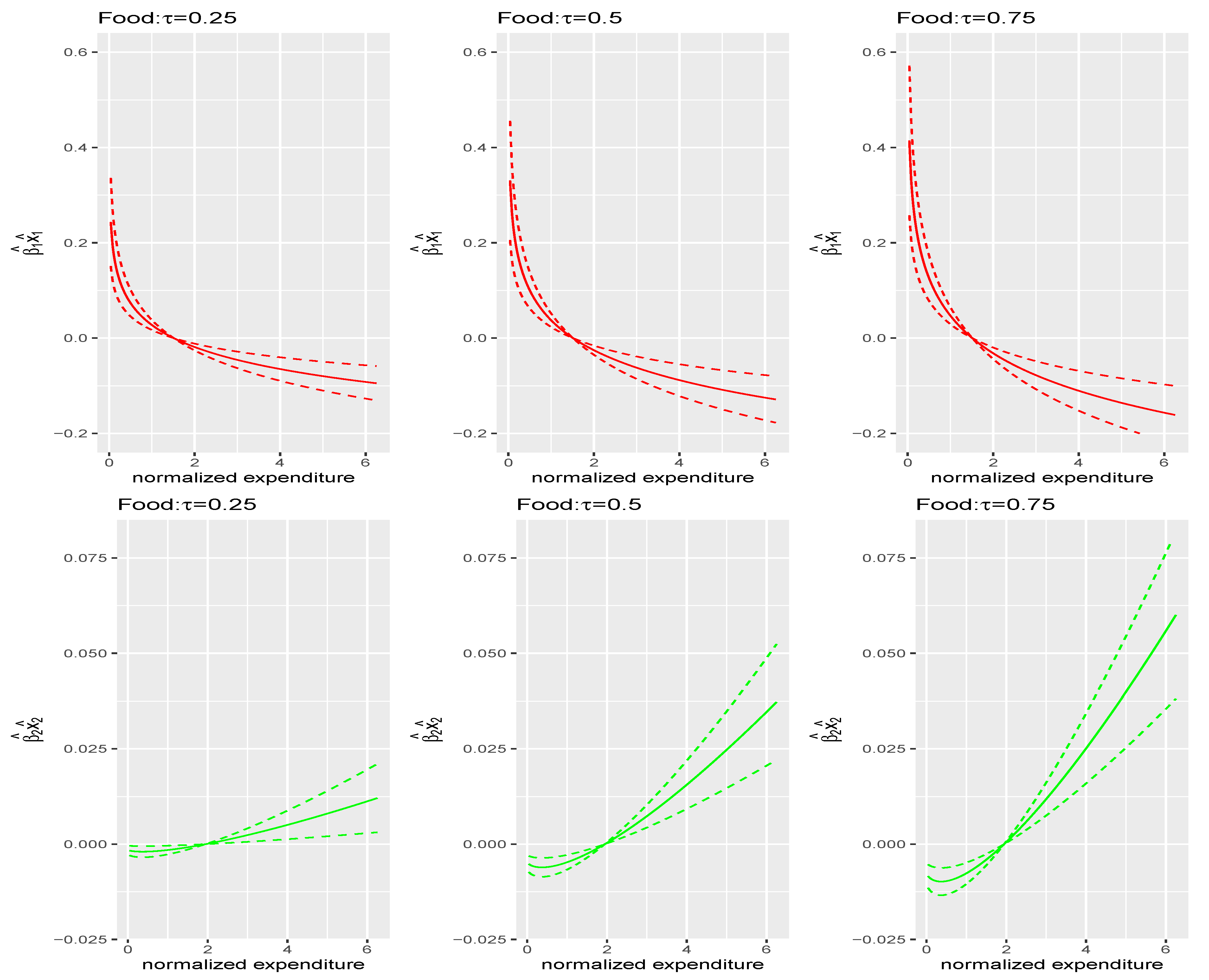
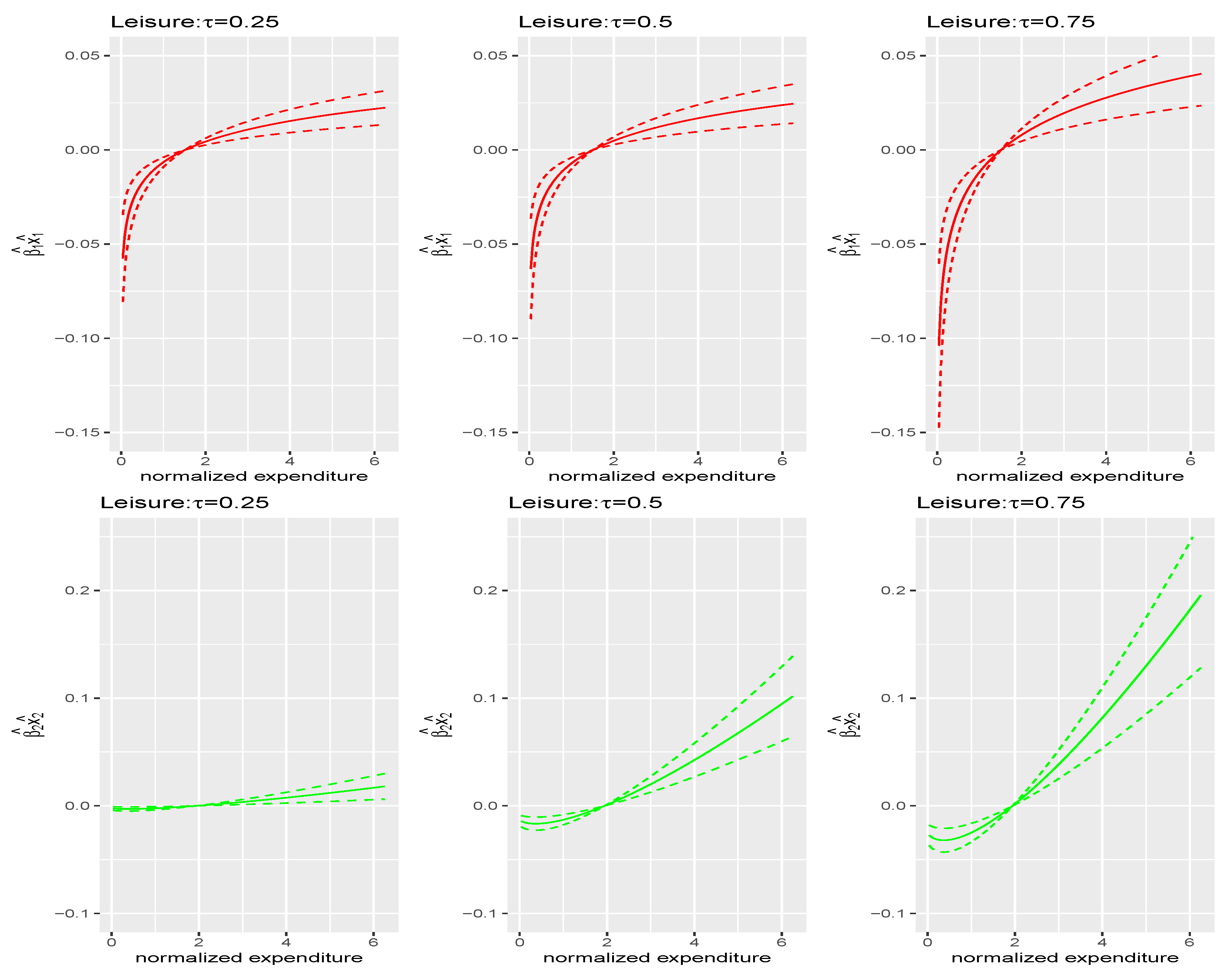
For instance, Figure 2 shows that, as total expenditure increases, the contribution of the first motive, (necessity), to food budget share decreases at all , while the second motive, (luxuries), increases, as well documented in the literature. This implies that as total expenditure increases, the motive to consume food as a necessary good decreases, while the motive to consume food as a luxury good increases. The pattern in Figure 3, which is very different from food, reflects that individuals consume housing more as necessity but less as luxury, as their total expenditure increases. The motives to consume food and housing as necessity or luxuries play opposite roles in the budget share as total expenditure changes. However, as shown in Figure 4, both motives to consume leisure increase as total expenditure increases as well. Another interesting point is that the magnitudes of those estimated factors or motives are different across different quantiles of the conditional distribution of budget shares in all three commodities.
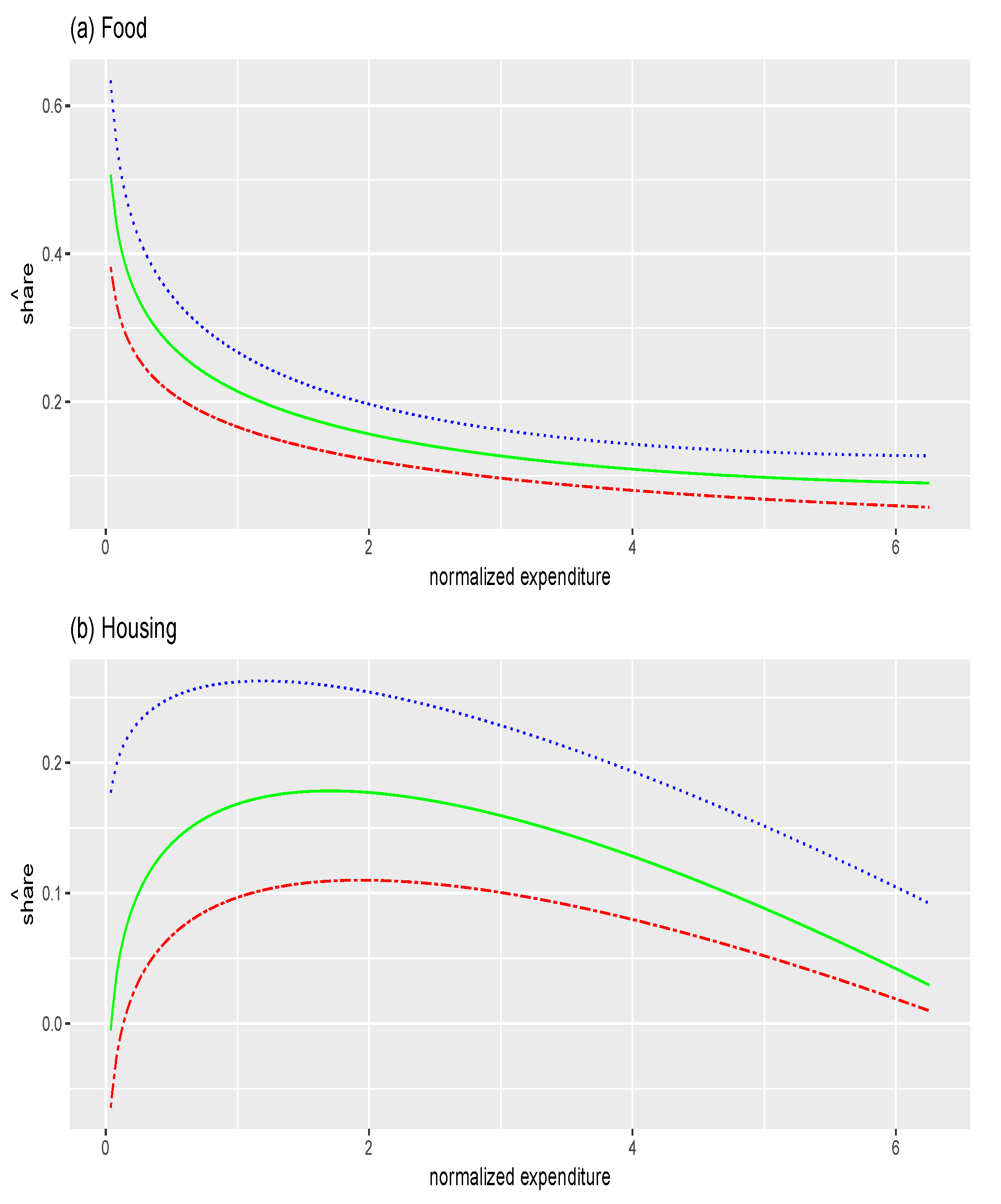
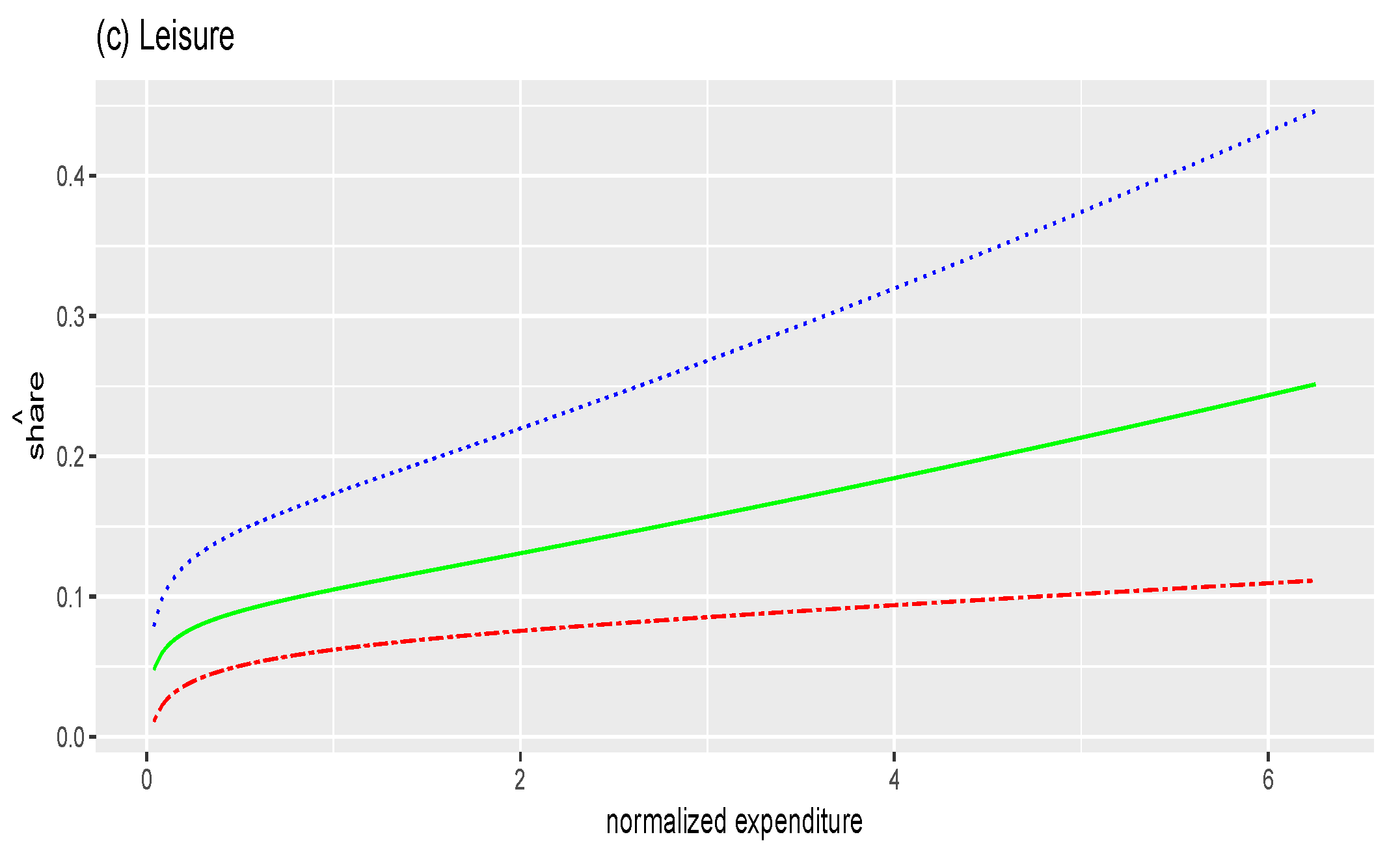
Figure 2, Figure 3 and Figure 4 suggest that the motive of consumption as necessity or luxury plays different roles over the level of total expenditure. The overall effects of total expenditure on budget shares are presented in Figure 5. The estimated budget shares are calculated by adding all three factors together. Figure 5a shows that the budget share of food decreases as total expenditure increases, which is classically referred to as Engel’s law. In Figure 5b we see a concave shape curve, that is, the budget share of housing increases for low expenditures, but decreases as total expenditure increases. In addition, individuals always raise the budget share of leisure as they consume more, as shown in Figure 5c. Finally, in housing and leisure, the shapes of the curves vary over different quantiles . There is evidence of substantial asymmetry for the expenditure on housing and leisure, while there is less evidence of asymmetry for food share. For instance, we observe a shift toward leisure at the upper quantile of the leisure share. Thus, the conditional quantile approach would be a useful tool to capture asymmetric patterns of Engel curves across quantiles of budget share.
7. Conclusions
We study estimation and inference for linear quantile regression (QR) models with generated regressors (GR). We propose a QR-GR two-step estimator for the parameters of interest and an estimator for the corresponding asymptotic variance-covariance matrix. We establish the asymptotic properties of the estimators. Monte Carlo simulation and estimation of the Engel curves using data from the UK Family Expenditure Survey confirm that taking into account the GR problem in the QR framework is essential for correct inference. Furthermore, the empirical application shows strong heterogeneity of the Engel curves over different quantiles of the conditional distribution of budget shares in most commodities.
Author Contributions
The authors equally contributed to the conceptualization, methodology, formal analysis, and writing. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Appendix A.1. Proof of the Main Results
Proof of Theorem 1 (Consistency).
Let be the two-step quantile regression (QR) with generated regressors (GR) estimator, and be the usual (infeasible) QR estimator with true unobservable variables. Consider
Under the standard QR conditions A1 and A2, we have that the second term in Equation (A1) satisfies that
and the following linear representation
where .
Let and . By noticing that and , and by expanding the first term in Equation (A1) , we have
where the third equality follows from an Taylor expansion for for and where is matrix, is matrix, and is vector.
As seen in (A3), can be rewritten as
By taking the derivative of with respect to , one can notice that the contribution of the term is .
It follows that
Note that by assumption A3 and is bounded by assumptions A2 and A5, we have that . Therefore, as , we have
□
Proof of Theorem 2 (Asymptotic normality).
Recall that is the two-step QR-GR estimator and is the infeasible QR estimator. Consider the following
Under the usual QR conditions A1 and A2, we have that the second term in Equation (A5) has the standard QR expansion as
and satisfies a Central Limit Theorem such that
where .
By noticing that and , and by expanding the first term in Equation (A5) , we have
As seen in (A6), the Bahadur representation for can be rewritten as
Taking the derivative of with respect to and noticing that the contribution of the term is , we get
where
Thus, we have the following representation
Note that since by assumption A4 and is bounded by assumptions A2 and A5, we have that . Therefore, we have by assumption A3 that
Substituting A4 where in the above equation, we obtain that
where .
□
Proof of Theorem 3 (Consistency of variance-covariance matrix).
(i) Claim that , in other words,
By definition:
We show that and are close to each other element by element:
(a) For , , we have
Assumption B3 implies the following uniform convergence by applying the uniform weak law of large number (UWLLN): ( means expectation in terms of joint distribution)
and assumption A3 that for implies that
It follows that
(b) For , , similarly by applying UWLLN, we have
and the consistency of implies that
It follows that
After claiming (a) and (b), we have
(ii) Claim that .
To obtain a consistent estimator of which contains unknown conditional density function, the estimator replaces the conditional density functions by uniform kernel weights.
Define
Denote and .
(a) Consider
Notice that
and
For any and any , n is large enough that
We can find a bound for such that it can be arbitrarily small in probability if is chosen to be sufficiently small. Since the bound for is easy to derive, we only show that .
Inequality (A11) can be rewritten as
Then we have
where A is some bound for by assumption B4.
(b) We now show . Note that
For the first term, it has zero expectation and if and are k-dimensional vectors with and consider the variance of the first term,
where the second equality holds because all the cross-product terms are zero by the law of iterated expectations, and is some bound for by assumption B2. Therefore, the first term converges in quadratic mean to zero, which implies that it converges to zero in probability.
For the second term,
where and the last inequality uses assumption B5.
Combining claim (a) and (b), we have .
(iii) Claim that :
Define
where and . Similar to Part (ii), we need to show that and . is easy to derive by following the idea in Part (ii)(b), we only show that .
Combining the above two inequalities, assumption B3 and (A14), we have
Similar to Part (ii)(a), we can find a bound for , such that it can be arbitrarily small in probability if is chosen sufficiently small. Since the bounds for , and are easy to derive, we only show that as follows:
for some satisfying , where the last inequality holds by assumption B4.
(iv) Claim that .
Denote and . To obtain a consistent estimator of M which contains unknown conditional density function, the estimator replaces the conditional density functions by uniform kernel weights:
Define
Similar to Part (ii), we need to show that and . is easy to derive by following the idea in Part (ii)(b), we only show that .
Consider
Notice that
and
From (A12), we already have
We can find a bound for such that it can be arbitrarily small in probability if is chosen sufficiently small. Since the bounds for and are easy to derive using the similar argument we used in part (iii), we only show that as following:
where is some bound for by assumptions A2, A4 and A5. □
Proof of Theorem 4.
The proof of Theorem 4 is simple; it follows from observing that for any fixed , by Theorem 2
and under the null hypothesis,
Since by Theorem 3, is a consistent estimator of , by the Slutsky’s theorem,
□
Appendix A.2. OLS with Generated Regressors
In order to compare our quantile regression with generated regressor framework with the OLS with generated regressor (OLS-GR), we include the detailed assumptions and propositions for the OLS case in this section.
where , is a vector, , is a vector and is known but is unknown and .
Let be a -consistent estimator of , and we obtain the generated regressors as . Let be the OLS-GR estimator from the equation
where . We impose the following regularity conditions.
Conditions:
C1. , .
C2. .
C3. The observations are i.i.d. across i with and for some , is a nonsingular matrix, and .
C4. , where .
C5. , which is bounded.
We first state the consistency of the OLS-GR estimator.
Proposition A1.
Proof of Proposition A1.
Recall that
Thus,
where . Using the mean value expansion, we have
Since , . It implies that . Since and , it follows that
Or,
where , using . Since and G is bounded, then
Therefore, . □
Next, we state the asymptotic normality of the OLS-GR estimator.
Proposition A2.
In model (A15), under the assumptionsC4–C5and the conditions in Proposition 1, the OLS-GR is asymptotically normal, i.e.,
where .
Proof of Proposition A2.
Note that from
By rearranging we obtain
where . Using the mean value expansion, we have
Since , . It implies that . Since , it follows that
where , using . By Assumption C4,
Hence, .
By the Central Limit Theorem, we obtain
where . □
| 1. | Examples of generated regressors include models of interest involving expectations of future variables, such as expected prices or sales or inflation that have been generated as the predictions of some dynamic model (Engle (1982)). “Unanticipated” components of aggregate money growth in macroeconomic models (Barro (1977); Barro (1978)). |
| 2. | In particular, Xiao and Koenker (2009) develop QR with GR in the context of GARCH models. Chen et al. (2015) propose a quantile factor model. Lee (2007) applied a control function approach to generate instruments and resolve the endogeneity, and Ma and Koenker (2006) develop QR for recursive structural equation models. Chernozhukov et al. (2015) suggest QR with censoring and endogeneity. Arellano and Bonhomme (2016) discuss the correction of the QR estimates for nonrandom sample selection. Chernozhukov and Hansen (2005, 2006) develop a model of quantile treatment effects. Ackerberg et al. (2014) suggest two-step GMM where the moment functions can be seen as the score of QR. |
| 3. | R codes are provided for all methods, simulations, and applications. |
| 4. | We note that where for . We also note that for any and for all i, and . Additionally, by applying A2, A4 and A5. |
| 5. | These data have been previously used by Barigozzi and Moneta (2016). |
| 6. | The way to aggregate consumption follows Barigozzi and Moneta (2016). |
| 7. | RPI is obtained from UK Office for National Statistics (http://www.ons.gov.uk/ (accessed on January 2019)). To deflate the data, we divided the nominal total expenditure by the aggregate price index. Additionally, the nominal budget share, as a ratio of nominal level of expenditure over nominal total budget, was multiplied by a ratio of the total price index over a price index for the particular expenditure. |
References
- Ackerberg, Daniel, Xiaohong Chen, Jinyong Hahn, and Zhipeng Liao. 2014. Asymptotic efficiency of semiparametric two-step gmm. Review of Economic Studies 288: 919–43. [Google Scholar] [CrossRef] [Green Version]
- Arellano, Manuel, and Stéphane Bonhomme. 2018. Sample selection in quantile regression: A survey. In Handbook of Quantile Regression. Edited by Koenker Roger, Victor Chernozhukov, Xuming He and Limin Peng. Boca Raton: CRC/Chapman-Hall. [Google Scholar]
- Bai, Jushan, and Serena Ng. 2002. Determining the number of factors in approximate factor models. Econometrica 70: 191–221. [Google Scholar] [CrossRef] [Green Version]
- Barigozzi, Matteo, and Alessio Moneta. 2016. Identifying the independent sources of consumption variation. Journal of Applied Econometrics 31: 420–49. [Google Scholar] [CrossRef] [Green Version]
- Barro, Robert J. 1977. Unanticipated money growth and unemployment in the united states. The American Economic Review 67: 101–15. [Google Scholar]
- Barro, Robert J. 1978. Unanticipated money, output, and the price level in the united states. Journal of Political Economy 86: 549–80. [Google Scholar] [CrossRef]
- Blundell, Richard, Xiaohong Chen, and Dennis Kristensen. 2007. Semi-nonparametric iv estimation of shape-invariant engel curves. Econometrica 75: 1613–69. [Google Scholar] [CrossRef] [Green Version]
- Buchinsky, Moshe, and Jinyong Hahn. 1998. An alternative estimator for the censored quantile regression model. Econometrica 66: 653–71. [Google Scholar] [CrossRef]
- Chai, Andreas, and Alessio Moneta. 2010. Retrospectives: Engel curves. Journal of Economic Perspectives 24: 225–40. [Google Scholar] [CrossRef] [Green Version]
- Chen, Liang, Juan Jose Dolado, and Jesus Gonzalo. 2015. Quantile factor models. arXiv arXiv:1911.02173. [Google Scholar]
- Chernozhukov, Victor, Ivan Fernandez-Val, and A. E. Kowalski. 2015. Quantile regression with censoring and endogeneity. Journal of Econometrics 186: 201–21. [Google Scholar] [CrossRef]
- Chernozhukov, Victor, and Christian Hansen. 2005. An iv model of quantile treatment effects. Econometrica 73: 245–61. [Google Scholar] [CrossRef] [Green Version]
- Chernozhukov, Victor, and Christian Hansen. 2006. Instrumental quantile regression inference for structural and treatment effects models. Journal of Econometrics 132: 491–525. [Google Scholar] [CrossRef]
- Engel, Ernst. 1857. Die productions-und consumtionsverhältnisse des königreichs sachsen. Zeitschrift des Statistischen Bureaus des Königlich Sächsischen Ministeriums des Innern 8: 1–54. [Google Scholar]
- Engle, Robert F. 1982. Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation. Econometrica 50: 987–1007. [Google Scholar] [CrossRef]
- Firpo, Sergio, Antonio F. Galvao, and Suyong Song. 2017. Measurement errors in quantile regression models. Journal of Econometrics 198: 146–64. [Google Scholar] [CrossRef]
- Hahn, Jinyong, and Geert Rider. 2013. Asymptotic variance of semiparametric estimators with generated regressors. Econometrica 81: 315–40. [Google Scholar]
- Hendricks, Wallace, and Roger Koenker. 1991. Hierarchical spline models for conditional quantiles and the demand for electricity. Journal of the American Statistical Association 87: 58–68. [Google Scholar] [CrossRef]
- Koenker, Roger, and Gilbert Bassett. 1978. Regression quantiles. Econometrica 46: 33–50. [Google Scholar] [CrossRef]
- Koenker, Roger, and Gilbert Bassett. 1982a. Robust tests for heteroscedasticity based on regression quantiles. Econometrica 50: 43–61. [Google Scholar] [CrossRef] [Green Version]
- Koenker, Roger, and Gilbert Bassett. 1982b. Tests of linear hypotheses and l1 estimation. Econometrica 50: 1577–84. [Google Scholar] [CrossRef]
- Koenker, Roger, and José A. F. Machado. 1999. Goodness of fit and related inference processes for quantile regression. Journal of the American Statistical Association 94: 1296–310. [Google Scholar] [CrossRef]
- Lee, Sokbae. 2007. Endogeneity in quantile regression models: A control function approach. Journal of Econometrics 141: 1131–58. [Google Scholar] [CrossRef] [Green Version]
- Lewbel, Arthur. 1997. Consumer demand systems and household equivalence scales. Handbook of Applied Econometrics 2: 167–201. [Google Scholar]
- Lewbel, Arthur. 2008. Engel curves. The New Palgrave Dictionary of Economics 2: 1–4. [Google Scholar]
- Ma, Lingjie, and Roger Koenker. 2006. Quantile regression methods for recursive structural equation models. Journal of Econometrics 134: 471–506. [Google Scholar] [CrossRef] [Green Version]
- Mammen, Enno, Christoph Rothe, and Melanie Schienle. 2012. Nonparametric regression with nonparametrically generated covariates. Annals of Statistics 40: 1132–70. [Google Scholar] [CrossRef]
- Murphy, Kevin M., and Robert H. Topel. 2002. Estimation and inference in two-step econometric models. Journal of Business & Economic Statistics 20: 88–97. [Google Scholar]
- Pagan, Adrian. 1984. Econometric issues in the analysis of regressions with generated regressors. International Economic Review 25: 221–47. [Google Scholar] [CrossRef]
- Powell, James L. 1991. Estimation of monotonic regression models under quantile regressions. In Nonparametric and Semiparametric Models in Econometrics. Edited by William A. Barnett, James Powell and George E. Tauchen. Cambridge: Cambridge University Press. [Google Scholar]
- Wang, Huixia Judy, Leonard A. Stefanski, and Zhongyi Zhu. 2012. Corrected-loss estimation for quantile regression with covariate measurement errors. Biometrika 99: 405–21. [Google Scholar] [CrossRef] [Green Version]
- Wei, Ying, and Raymond J. Carroll. 2009. Quantile regression with measurement error. Journal of the American Statistical Association 104: 1129–43. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Working, Holbrook. 1943. Statistical laws of family expenditure. Journal of the American Statistical Association 38: 43–56. [Google Scholar] [CrossRef]
- Xiao, Zhijie, and Roger Koenker. 2009. Conditional quantile estimation for generalized autoregressive conditional heteroscedasticity models. Journal of the American Statistical Association 104: 1696–712. [Google Scholar] [CrossRef]
Figure 1.
Coefficient estimates of motives 1 and 2 and their 95% confidence intervals. (a) food budget share; (b) housing budget share; (c) leisure budget share. Upper row: coefficient estimates of factor 1; lower row: coefficient estimates of factor 2. Black line: OLS coefficient estimate; solid line: quantile regression (QR) coefficient estimate; dotted line: 95% confidence intervals obtained by conventional estimation; dashed line: 95% confidence intervals obtained by our proposed estimation.
Figure 1.
Coefficient estimates of motives 1 and 2 and their 95% confidence intervals. (a) food budget share; (b) housing budget share; (c) leisure budget share. Upper row: coefficient estimates of factor 1; lower row: coefficient estimates of factor 2. Black line: OLS coefficient estimate; solid line: quantile regression (QR) coefficient estimate; dotted line: 95% confidence intervals obtained by conventional estimation; dashed line: 95% confidence intervals obtained by our proposed estimation.

Figure 2.
Contributions of motive 1 (upper row) and motive 2 (lower row) to food budget share; dotted lines are the corresponding confidence intervals.
Figure 2.
Contributions of motive 1 (upper row) and motive 2 (lower row) to food budget share; dotted lines are the corresponding confidence intervals.

Figure 3.
Contributions of motive 1 (upper row) and motive 2 (lower row) to housing budget share; dotted lines are the corresponding confidence intervals.
Figure 3.
Contributions of motive 1 (upper row) and motive 2 (lower row) to housing budget share; dotted lines are the corresponding confidence intervals.

Figure 4.
Contributions of motive 1 (upper row) and motive 2 (lower row) to leisure budget share; dotted lines are the corresponding confidence intervals.
Figure 4.
Contributions of motive 1 (upper row) and motive 2 (lower row) to leisure budget share; dotted lines are the corresponding confidence intervals.

Figure 5.
Fitted values of budget share where . (a) food; (b) housing; (c) leisure. Red two dashed line: corresponding coefficients estimated at ; green solid line: corresponding coefficients estimated at ; blue dotted line: corresponding coefficients estimated at .
Figure 5.
Fitted values of budget share where . (a) food; (b) housing; (c) leisure. Red two dashed line: corresponding coefficients estimated at ; green solid line: corresponding coefficients estimated at ; blue dotted line: corresponding coefficients estimated at .



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Simulation results: Bias, SE, and root mean squared error (RMSE) for , population value of .
Table 1.
Simulation results: Bias, SE, and root mean squared error (RMSE) for , population value of .
| Bias | SE | RMSE | Bias | SE | RMSE | ||
| QR | 0.000 | 0.012 | 0.012 | 0.000 | 0.004 | 0.004 | |
| QR-GR | −0.002 | 0.107 | 0.107 | −0.002 | 0.032 | 0.032 | |
| QR | 0.000 | 0.009 | 0.009 | 0.000 | 0.003 | 0.003 | |
| QR-GR | 0.003 | 0.101 | 0.101 | 0.000 | 0.032 | 0.032 | |
| QR | 0.000 | 0.008 | 0.008 | 0.000 | 0.003 | 0.003 | |
| QR-GR | −0.002 | 0.102 | 0.102 | 0.001 | 0.031 | 0.031 | |
| QR | 0.000 | 0.009 | 0.009 | 0.000 | 0.003 | 0.003 | |
| QR-GR | 0.003 | 0.099 | 0.099 | −0.002 | 0.032 | 0.032 | |
| QR | 0.000 | 0.011 | 0.011 | 0.000 | 0.004 | 0.004 | |
| QR-GR | 0.005 | 0.102 | 0.102 | 0.000 | 0.032 | 0.032 | |
Table 2.
Simulation results for variance and covariance matrix. .
| Empirical SE | Proposed QR-GR SE | Naive QR SE | |
|---|---|---|---|
| 0.032 | 0.032 | 0.004 | |
| 0.032 | 0.032 | 0.003 | |
| 0.031 | 0.032 | 0.003 | |
| 0.032 | 0.032 | 0.003 | |
| 0.032 | 0.032 | 0.004 |
Table 3.
Simulation results: Bias, SE, RMSE for , population value of of .
| Bias | SE | RMSE | Bias | SE | RMSE | ||
| QR | 0.053 | 0.286 | 0.291 | 0.138 | 0.092 | 0.166 | |
| QR-GR | 0.087 | 0.447 | 0.455 | 0.140 | 0.140 | 0.197 | |
| QR | 0.014 | 0.207 | 0.207 | 0.028 | 0.061 | 0.067 | |
| QR-GR | 0.048 | 0.510 | 0.512 | 0.037 | 0.148 | 0.152 | |
| QR | 0.001 | 0.183 | 0.183 | −0.002 | 0.055 | 0.055 | |
| QR-GR | 0.005 | 0.573 | 0.573 | 0.006 | 0.165 | 0.165 | |
| QR | −0.015 | 0.205 | 0.205 | −0.028 | 0.064 | 0.070 | |
| QR-GR | −0.009 | 0.635 | 0.635 | −0.047 | 0.200 | 0.206 | |
| QR | −0.048 | 0.270 | 0.274 | −0.144 | 0.094 | 0.172 | |
| QR-GR | −0.109 | 0.803 | 0.811 | −0.158 | 0.237 | 0.285 | |
Table 4.
Simulation results for variance and covariance matrix.
| Empirical SE | Proposed QR-GR SE | Naive QR SE | |
|---|---|---|---|
| 0.140 | 0.136 | 0.092 | |
| 0.148 | 0.162 | 0.088 | |
| 0.165 | 0.185 | 0.089 | |
| 0.200 | 0.207 | 0.088 | |
| 0.237 | 0.241 | 0.093 |
Table 5.
Descriptive statistics.
| Sample Size | Min | Max | Mean | Std. Dev. |
|---|---|---|---|---|
| Total expenditure | 9.97 | 1587.95 | 442.92 | 253.96 |
| Housing net | −0.18 | 0.97 | 0.18 | 0.12 |
| Fuel light power | −0.15 | 0.79 | 0.04 | 0.04 |
| Food | 0.00 | 0.88 | 0.19 | 0.09 |
| Alcoholic drink | 0.00 | 0.53 | 0.04 | 0.05 |
| Tobacco | 0.00 | 0.81 | 0.02 | 0.05 |
| Clothing and footwear | 0.00 | 0.63 | 0.05 | 0.06 |
| Household goods | 0.00 | 0.84 | 0.07 | 0.08 |
| Household services | 0.00 | 0.89 | 0.06 | 0.05 |
| Personal goods and services | 0.00 | 0.82 | 0.04 | 0.04 |
| Motoring | −1.90 | 0.88 | 0.13 | 0.12 |
| Fares and other travel | 0.00 | 0.76 | 0.02 | 0.05 |
| Leisure goods | 0.00 | 0.85 | 0.04 | 0.05 |
| Leisure services | 0.00 | 1.15 | 0.12 | 0.12 |
Table 6.
Coefficient estimates of motives 1 and 2 and their standard errors at quantiles 0.25, 0.5, 0.75 for (a) food, (b) housing and (c) leisure. Columns 1 and 4: coefficient estimates; Columns 2 and 5: standard error calculated in adjusted QR estimation; column 3 and 6: standard error calculated in conventional QR estimation.
Table 6.
Coefficient estimates of motives 1 and 2 and their standard errors at quantiles 0.25, 0.5, 0.75 for (a) food, (b) housing and (c) leisure. Columns 1 and 4: coefficient estimates; Columns 2 and 5: standard error calculated in adjusted QR estimation; column 3 and 6: standard error calculated in conventional QR estimation.
| (a) Food | ||||||
| QR-GR SE | QR SE | QR-GR SE | QR SE | |||
| = 0.25 | 0.103 | 0.020 | 0.002 | 0.005 | 0.002 | 0.001 |
| = 0.5 | 0.140 | 0.027 | 0.003 | 0.014 | 0.003 | 0.002 |
| = 0.75 | 0.176 | 0.034 | 0.003 | 0.023 | 0.004 | 0.002 |
| (b) Housing | ||||||
| QR-GR SE | QR SE | QR-GR SE | QR SE | |||
| = 0.25 | −0.078 | 0.015 | 0.002 | −0.060 | 0.010 | 0.002 |
| = 0.5 | −0.084 | 0.017 | 0.003 | −0.079 | 0.013 | 0.002 |
| = 0.75 | −0.042 | 0.010 | 0.006 | −0.073 | 0.013 | 0.004 |
| (c) Leisure | ||||||
| QR-GR SE | QR SE | QR-GR SE | QR SE | |||
| = 0.25 | −0.024 | 0.005 | 0.002 | 0.007 | 0.002 | 0.002 |
| = 0.5 | −0.027 | 0.006 | 0.003 | 0.038 | 0.007 | 0.003 |
| = 0.75 | −0.044 | 0.009 | 0.004 | 0.073 | 0.013 | 0.005 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Chen, L.; Galvao, A.F.; Song, S. Quantile Regression with Generated Regressors. Econometrics 2021, 9, 16. https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics9020016
AMA Style
Chen L, Galvao AF, Song S. Quantile Regression with Generated Regressors. Econometrics. 2021; 9(2):16. https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics9020016
Chicago/Turabian StyleChen, Liqiong, Antonio F. Galvao, and Suyong Song. 2021. "Quantile Regression with Generated Regressors" Econometrics 9, no. 2: 16. https://0-doi-org.brum.beds.ac.uk/10.3390/econometrics9020016
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.