(Divergent) Participation in the California Vowel Shift by Korean Americans in Southern California



1
Department of Spanish and Portuguese, University of California, Los Angeles, CA 90095, USA
2
Independent Scholar, Santa Clara, CA 95050, USA
*
Author to whom correspondence should be addressed.
Languages 2020, 5(4), 53; https://0-doi-org.brum.beds.ac.uk/10.3390/languages5040053
Submission received: 24 September 2020
/
Revised: 31 October 2020
/
Accepted: 2 November 2020
/
Published: 6 November 2020
(This article belongs to the Special Issue Exploring Cross-linguistic Effects and Phonetic Interactions in the Context of Bilingualism)
Abstract
:This study investigates the participation in the California Vowel Shift by Korean Americans in Los Angeles. Five groups of subjects participated in a picture narrative task: first-, 1.5-, and second-generation Korean Americans, Anglo-Californians, and (non-immigrant) Korean late learners of English. Results showed a clear distinction between early vs. late bilinguals; while the first-generation Korean Americans and the late learners showed apparent signs of Korean influence, the 1.5- and the second-generation Korean Americans participated in most patterns of the California Vowel Shift. However, divergence from the Anglo-Californians was observed in early bilinguals’ speech. Similar to the late bilinguals, the 1.5-generation speakers did not systematically distinguish prenasal and non-prenasal /æ/. The second-generation speakers demonstrated a split-/æ/ system, but it was less pronounced than for the Anglo-Californians. These findings suggest that age of arrival has a strong effect on immigrant minority speakers’ participation in local sound change. In the case of the second-generation Korean Americans, certain patterns of the California Vowel Shift were even more pronounced than for the Anglo-Californians (i.e., /ɪ/-lowering, /ɑ/-/ɔ/ merger, /ʊ/- and /ʌ/-fronting). Moreover, the entire vowel space of the second-generation Korean Americans, especially female speakers, was more fronted than that of the Anglo-Californians. These findings suggest that second-generation Korean Americans may be in a more advanced stage of the California Vowel Shift than Anglo-Californians or the California Vowel Shift is on a different trajectory for these speakers. Possible explanations in relation to second-generation Korean Americans’ intersecting gender, ethnic, and racial identities, and suggestions for future research are discussed.
1. Introduction
Over the past few decades, research on second language (L2) phonology has provided empirical evidence that early bilinguals are generally more successful in acquiring L2 speech sounds than late bilinguals (Flege et al. 1995, 1997; Flege and MacKay 2011; Stevens 1999; Yeni-Komshian et al. 2000). Models in L2 phonology, such as Flege’s (1995) Speech Learning Model (SLM) and Best and Tyler’s (2007) Perceptual Assimilation Model (PAM)-L2, posit that bilinguals’ L1 and L2 phones interact in a common phonological space. Thus, the development of L2 sounds would depend on the perceptual similarity to existing L1 sounds. That is, bilinguals would assimilate an L2 sound to an L1 sound if the two are perceived identical or if the L2 sound is perceived as a deviant variant of the L1 sound. However, if an L2 sound is perceptually distinct from existing L1 sounds, bilinguals would create a new category. Early bilinguals tend to be successful at simultaneously maintaining language-internal and cross-linguistic contrasts (Chang et al. 2011) because they begin establishing L2 sounds when they are still in the process of acquiring language-general fine-grained acoustic features (Kuhl et al. 1992; Werker and Tees 1984). For late bilinguals, on the other hand, L2 sounds are introduced to an already established L1 sound system. Thus, influence from L1 speech sounds would occur to a larger extent for late bilinguals than for early bilinguals.
In the case of immigrant populations, first-generation speakers (i.e., late bilinguals) are prone to having a foreign accent in the societal language despite long residence in the host country (Baker and Trofimovich 2005). With respect to children of immigrants who are early bilinguals of their home language and the societal language, the situation becomes complicated. Some speakers do not show any signs of foreign accent in the societal language (Lloyd-Smith et al. 2020), while others demonstrate phonetic features that are different from local mainstream varieties. For instance, immigrant minority speakers who acquired the societal language natively may use phonetic features that are present in their parents’ foreign-accented speech, regardless of whether they speak their parents’ language (Fought 2003; Mendoza-Denton 1999; Mendoza-Denton and Iwai 1993; Tsukada et al. 2005). Thus, while neurological maturation associated with age of acquisition plays an important role in L2 pronunciation, there are various extralinguistic factors other than age of acquisition that contribute to the development of L2 speech sounds (e.g., quantity/quality of L2 input, relative use of L1/L2, language attitude, identity, speech register) (Jia and Aaronson 2003; Flege 1999; Zampini 2008).
1.1. Ethnicity and Participation in Local Sound Change
Since the foundational work on African American English by Labov (1972), ethnicity has been considered as one of the key factors, along with age, gender, and social class, that condition language variation in a speech community (Boberg 2004). With regard to immigrant minority groups in North America with non-English speaking backgrounds, native-born children tend to display less ethnic identification than their foreign-born parents (Hoffman and Walker 2010; Weinfeld 1985, pp. 71–77). Thus, apart from producing more native-like speech sounds in English, they demonstrate stronger assimilation to local mainstream norms. Nevertheless, studies have shown that even those who were born and raised in North America and speak English natively demonstrate some speech patterns that are distinct from the local mainstream varieties. For instance, Casillas and Simonet (2016) examined the production (and perception) of the English low vowels /æ/ and /ɑ/ by two groups of Spanish-English sequential bilinguals residing in Southern Arizona: Mexican Americans born and raised in the US Southwest by Spanish-speaking parents from Northern Mexico (i.e., native-born) and late English learners born and raised in Spanish-speaking countries, who moved to the US Southwest and lived there around 10 years (i.e., foreign-born). Both groups acquired Spanish as their L1, but the native-born speakers became more dominant in English as they grew up to the point that they were no longer able to actively communicate in Spanish. Unlike Spanish which has only one low vowel /a/, Southern Arizona English has two low vowels, /ɑ/ and /æ/, the latter of which is lowered in non-prenasal contexts, similar to California English (see Section 1.2). Casillas and Simonet (2016) found that, although the bilinguals were able to distinguish the two vowel categories, the phonetic realizations of these vowels were different from the local mainstream norms. Both groups produced more fronted /ɑ/ than English monolinguals, assimilating to the Spanish central /a/. Regarding /æ/, the foreign-born speakers produced this vowel more back than the English monolinguals (i.e., assimilation to the Spanish central /a/), whereas the native-born speakers produced it higher (i.e., weaker /æ/-lowering). These findings suggest that, even after shift to English occurs, the speech of native-born speakers may diverge from local mainstream norms either by demonstrating patterns that are traceable to their heritage language or by participating to a lesser extent in the sound change of the local mainstream variety.
From a developmental point of view, it is important to note that immigrant minority speakers who no longer speak their heritage language or have only passive knowledge of it may use speech patterns that differentiate themselves from speakers of other ethnicities. According to Labov (2001, p. 506), “[a]ll speakers who are socially defined as white, mainstream, or Euro-American, are involved in [regional sound] changes to one degree or another.” Certain patterns of regional sound change may also appear in the speech of some ethnic minority speakers that American society defines as “non-white” (e.g., Black, Hispanic, Native American, Asian). However, it is unlikely that ethnic minority speakers converge with Anglo-Americans in all aspects of their speech (Labov 2001, p. 507). Rather, they often take a different trajectory in regional sound change. For instance, studies have shown that US-born Latinos tend to resist prenasal /æ/-raising (i.e., split between prenasal and non-prenasal /æ/) and /u/-fronting, which are features that occur in many varieties of American English (Carter et al. 2020; Fought 1999; Roeder 2010; Thomas 2001). Carter et al. (2020) examined the speech of Miami-born Latinos whose parents immigrated from various Latin American countries and found that their English /u/ was more back than that of Anglo-Americans. Moreover, although the Latino speakers distinguished prenasal and non-prenasal /æ/, their /æ/ in both environments were more back than their Anglo counterparts. Resistance to prenasal /æ/-raising and /u/-fronting, which may be due to influence from the Spanish low central vowel /a/ and high back vowel /u/, has also been reported in the speech of Mexican Americans in other regions (California: Fought (1999, 2003), Michigan: Roeder (2010), Texas: Thomas (2000, 2001), Washington DC: (Tseng 2015)), although in some cases these patterns are conditioned by social factors such as gender, social class, and group affiliation (Fought 1999; Roeder 2010; Tseng 2015).
Compared to African American English and Chicano English, little research has been conducted on English spoken by Asian Americans. However, studies have found that Asian Americans, like other ethnic minority speakers, show a combination of resistance and assimilation to local sound change (Cheng 2016; Hall-Lew 2009; Hall-Lew and Starr 2010; Hoffman 2010; Ito 2010; Lee 2000, 2016). For instance, Hall-Lew (2009) found that Chinese Americans in San Francisco participated in back vowel fronting and low back vowel merger, which are two sound changes that characterize California English. However, at the same time, Chinese Americans in this region produce coda /l/-vocalization (e.g., pronouncing cold and skill as code and skew), which most likely is due to influence from Chinese phonology that lacks syllable-final /l/ (Hall-Lew and Starr 2010). This pattern appears even in speakers beyond the second generation who are English monolingual speakers. Ito (2010) examined the vowels of Hmong Americans in the Twin Cities area in Minnesota, and found that 1.5 generation and second-generation speakers were accommodating to the local /æ/-fronting, but distinguished the low back vowels /ɑ/ and /ɔ/ more clearly than Anglo-Americans who showed a trend toward near-merger.
With regard to Korean Americans, which is the target population of this study, Cheng (2016) demonstrated that Korean Americans in California participated in some aspects of the California Vowel Shift (e.g., /u/-fronting and /ɑ/-/ɔ/ merger) to the same degree as Anglo-Americans, while in others their patterns were either more pronounced (e.g., /ʊ/-fronting) or less pronounced (e.g., split between prenasal and non-prenasal /æ/) than the Anglo-Americans. Lee (2016) found that Korean Americans in Bergen County, New Jersey, which borders New York City, maintained the /ɑ/-/ɔ/ contrast and raised /ɔ/ in accordance with New York City English, but they did not produce the New York City English split-/æ/ system (Labov et al. 2006). While these studies did not discuss Korean Americans’ divergence from the white regional norms as influence from Korean phonology, it is possible that their less pronounced split-/ae/ system is related to Korean vowels which do not demonstrate such patterns. Thus, it is important to examine Korean-accented English of late bilinguals, particularly that of first-generation Korean immigrants, to see whether Korean Americans’ resistance to sound change in local mainstream varieties has to do with their exposure to Korean and Korean-accented English.
1.2. California Vowel Shift
California English is easily exposed to people in other regions through television and movies, and the speech styles of stereotypical Southern California personae portrayed in the media (e.g., Valley Girl and Surfer Dude) are often parodied (Pratt and D’Onofrio 2017). A good example of this are The Californians skits from NBC’s late-night comedy show Saturday Night Live (SNL). Pratt and D’Onofrio (2017) analyzed the vowels produced by two characters in The Californians, and found that the actors talked with more open and protruded jaws and lips to comedically portray the Valley Girl and Surfer Dude personae. The use of such articulatory settings resulted in the production of lower and more retracted front vowels and more fronted back vowels when the actors played these characters than when they played non-Californian characters. Although without a doubt these performances are exaggerated, they reflect the vocalic changes that are underway in California, namely the California Vowel Shift.
Figure 1, created from data of millennial speakers reported in D’Onofrio et al. (2019)1, demonstrates the vocalic changes involved in the California Vowel Shift. The California Vowel Shift is characterized by three main phenomena: (1) the low-back merger of /ɑ/ (e.g., bot) and /ɔ/ (e.g., bought), (2) the lowering and retraction of lax front vowels /ɪ/ (e.g., bit), /ɛ/ (e.g., bet), and /æ/ (e.g., bat), and (3) the fronting of high- and mid-back vowels /u/ (e.g., boot), /ʊ/ (e.g., book), /o/ (e.g., boat), and /ʌ/ (e.g., but) (D’Onofrio et al. 2016; D’Onofrio et al. 2019; Hagiwara 1997; Hall-Lew 2009; Hall-Lew et al. 2015; Hinton et al. 1987; Kennedy and Grama 2012; Podesva et al. 2015). Following the pattern of General American English presented in The Atlas of North American English (Labov et al. 2006), prenasal /æ/ in California English is tensed, resulting in a split between tensed /æ/ in a prenasal context (e.g., ban) and lowered /æ/ elsewhere (Eckert 2008). With regard to the back vowels /u/ and /o/, the fronting is more advanced after a coronal consonant (e.g., too and toe) due to its high F2 (i.e., fronted) environment and prohibited when followed by the velarized coda /-l/ (e.g., cool and goal), because of its low F2 (i.e., retracted) environment (Hall-Lew 2011).
While the California Vowel Shift has been understood as a chain shift affecting the front lax vowels /ɪ/, /ɛ/, and /æ/, the cause of the chain shift is under debate. Similar to the Canadian Vowel Shift in which /ɪ/, /ɛ/, and /æ/ are lowered due to the merging of /ɑ/ and /ɔ/ (Clarke et al. 1995), the lowering of /ɪ/, /ɛ/, and /æ/ in California English may also be the result of a pull-chain initiated by the /ɑ/-/ɔ/ merger. However, Kennedy and Grama (2012) found that some young California English speakers demonstrated the chain-shifted lowering of the front lax vowels, while maintaining /ɑ/ in the traditional low-central position in the vowel space. Moreover, while both male and female speakers exhibited similar F1 values for /ɪ/ and /ɛ/, the female speakers produced higher F1 values (i.e., lower vowel height) for /æ/ than the male speakers. Since women generally are leaders of linguistic change (Coates 1993; Labov 1990; Milroy and Milroy 1985; Trudgill 1972), the gender difference indicates that /æ/ is the most recent step of the chain shift (Kennedy and Grama 2012). Thus, Kennedy and Grama (2012) suggested an alternative explanation to the chain shift which involves a push-chain initiated by the lowering of /ɪ/, resulting in the lowering of /ɛ/ and subsequently the lowering of /æ/. This process is likely to be independent of the /ɑ/-/ɔ/ merger which in some cases occurs in the low-central position of /ɑ/ (Kennedy and Grama 2012) and in other cases is not fully instantiated (Hall-Lew 2009).
Chain shifts are claimed to occur in order to maintain enough phonetic distance between phonemes in the vowel space so that they are perceptually distinctive (D’Onofrio et al. 2019; Gordon 2011; Martinet 1952). If a phoneme moves within the vowel space, this leads to subsequent phonetic movements of neighboring vowels. Thus, in order to identify the vowel that triggered the movement, it is important to examine the temporal establishment of the chain shift in real or apparent time (D’Onofrio et al. 2019; Gordon 2011; Labov 2010, p. 145). That is, speakers from a certain age group in a more recent time period or younger speakers should exhibit more advanced movements of the chain shift than speakers of the same age group in an older time period or older speakers. D’Onofrio et al. (2019) conducted an apparent time study, comparing the vowels produced by speakers of four generations which were determined based on their birth year: Silent Generation (1928–1945), Baby Boomer (1946–1964), Generation X (1965–1980), and Millennial (after 1980). Results showed that, across the span of four generations, the speakers exhibited an overall reduction of dispersion mainly in the F2 dimension (i.e., frontedness), demonstrating a more advanced backing of front vowels and fronting of back vowels in younger generations. Most of these changes (i.e., /ɑ/-/ɔ/ merger, backing of /ɛ/ and /æ/, and fronting of postcoronal /u/ and /o/) appeared between the Silent and the Baby Boomer generations, suggesting that the horizontal compression of the vowel space occurred contemporaneously. In subsequent generations, continued /æ/-backing and /ɑ/-/ɔ/ merger were observed, as well as additional changes involving /ɪ/-backing, non-postcoronal /u/-fronting, lowering of /ɛ/, /æ/, and /i/, and raising of /ɑ/ and /ʌ/. These findings indicate that rather than a stepwise chain shift which has been previously claimed, the California Vowel Shift seems to show holistic compression of the vowel space. Phonologically speaking, this is contrary to the general tendency toward maximizing the phonetic space between phonemes as a means to maintain perceptual distinctiveness (Flemming 1996; Labov et al. 2006; Liljencrants and Lindblom 1972). Thus, D’Onofrio et al. (2019) proposed that the unexpected holistic compression at the root of the California Vowel Shift may be driven by speakers’ projection of localized social meanings within a community (Eckert 1989; Fought 1999; Podesva 2011), not by purely phonological motivations. That is, it is possible that vowel space compression is achieved through speakers’ manipulation of their articulatory settings (e.g., lowered jaw, protruded jaw and lips) (Pratt and D’Onofrio 2017) to index varied social meanings (e.g., young Californian, middle class membership, non-gang status, laid back, partier, urban, coastal) (D’Onofrio et al. 2019; Fought 1999; Podesva 2011; Podesva et al. 2015).
1.3. Vowels in Korean and Comparison between Korean and American English Vowel Systems
Modern South Korean has 7–8 monophthongs /i, e, (ɛ), a, ʌ, o, ɨ, u/ (Jang et al. 2015; Kang 2014; Kwak 2003; Lee 2000; Lee and Ramsey 2011; Yang 1996)2. Due to recent merger of the mid-front vowels /e/ and /ɛ/, which is most likely caused by the raising of /ɛ/, many Koreans no longer distinguish these vowels (Baker and Trofimovich 2005; Kang 2014; Kwak 2003; Jang et al. 2015; Lee and Ramsey 2011; Yang 1996). Studies examining Korean vowel change in apparent time (Jang et al. 2015; Kang 2014) have shown that the Korean /e/ and /ɛ/ are produced with overlapping F1 and F2 values across ages, except for some older speakers3 who produced them distinctly, supporting that young-generation Koreans have a seven-vowel system with one mid-front vowel /e/ (Kwak 2003).
Figure 2, created from data of Korean speakers in their 20s in Kang and Kong (2016)4, demonstrates the Korean vowel space. In the high region of the vowel space, Korean has three vowels /i/, /ɨ/, and /u/. While the Korean /i/ is acoustically similar to the corresponding English high front tense vowel /i/, the Korean /u/ is more back than the English high back tense vowel /u/ (Baker and Trofimovich 2005; Yang 1996; Yoon and Kim 2015). In fact, comparative studies of Seoul Korean and American English vowels have shown that the English /u/ is acoustically very similar to the Korean /ɨ/ (Baker and Trofimovich 2005; Yang 1996; Yoon and Kim 2015). The Korean /ɨ/, especially in the Seoul dialect, is undergoing change in progress in which younger-generation Koreans produce this vowel more fronted than older-generation Koreans (Jang et al. 2015; Kang 2014; Kang and Kong 2016; Lee et al. 2017)5. Thus, the overlap between the Korean /ɨ/ and the English /u/ may be due to the parallel fronting of the Korean /ɨ/ (Jang et al. 2015; Kang 2014; Kang and Kong 2016; Lee et al. 2017) and the English /u/ observed in most North American dialects (Labov et al. 2006). The Korean /u/ also exhibits fronting (Kang 2014; Lee et al. 2017), but not to the same extent as the Korean /ɨ/ and the English /u/.
In the mid region of the vowel space, Korean has two vowels /e/ and /o/ (or three vowels for speakers who do not exhibit the /e/-/ɛ/ merger). Unlike the English /e/ and /o/ which are slightly diphthongized (i.e., [eɪ], [oʊ]), the Korean /e/ and /o/ are purely monophthongal. In the case of the Korean /e/, it is also acoustically distinct from the other English mid-front vowel /ɛ/, in that the Korean /e/ is positioned higher and more fronted in the vowel space than the English /ɛ/ (Baker and Trofimovich 2005). Rather than the English /ɛ/, the Korean /e/ is acoustically more similar to the English front lax vowel /ɪ/ (Baker and Trofimovich 2005). Both the English /ɛ/ and /ɪ/ are experiencing lowering and retraction in General American English, except for the South (Labov et al. 2006). As for the Korean /o/, this vowel is positioned very high in the vowel space, close to the Korean /u/ (see Figure 2). Studies focusing on Seoul Korean have shown that the main distinction between the Korean /o/ and /u/ is in the front-back dimension (F2); the Korean /u/ is more fronted than the Korean /o/ (Jang et al. 2015; Kang and Kong 2016; Lee et al. 2017; Yoon and Kim 2015). These patterns were more clearly demonstrated in the speech of younger generation Koreans than older generation Koreans (Kang 2014; Kang and Kong 2016; Lee et al. 20176). Thus, the vowel change in Seoul Korean can be explained through a chain shift initiated by /o/-raising, which led to the fronting of /u/ and /ɨ/ (Kang 2014; Kang and Kong 2016; Lee et al. 2017). In the low region of the vowel space, Korean has one low-central vowel /a/ which is more fronted than the corresponding English low back vowel /ɑ/ (Sohn 1999; Yang 1996). With regard to the Korean near-low back vowel /ʌ/, it is more back than the corresponding English /ʌ/ (Yang 1996) which is centralized [ɐ] in General American English, except for the Inland North (Labov et al. 2006).
Yang (1996) explained the cross-linguistic differences between Korean and English vowels through Lindblom’s theory of adaptive dispersion (Lindblom 1990; Lindblom and Engstrand 1989), which proposes that speakers control sufficient perceptual contrast between phonemes, while monitoring a tradeoff between articulatory economy and perceptual distinctiveness. Yang (1996) argued that the English vowel space is characterized by the vertical expansion of low vowels resembling a rectangle, whereas the Korean vowel space is characterized by the horizontal expansion of high vowels resembling a triangle (Yang 1996). Using Lindblom’s (1990, p. 21) formula of perceptual distance, Yang (1996) demonstrated that the distance between the two extreme high vowels /i/ and /u/ was larger for Korean than for English. Given that Korean has more vowels in the high region of the vowel space (i.e., /i, ɨ, u/) than English (i.e., /i, u/), English-like fronting of /u/ would be restricted for the Korean /u/, since this would lead to an overlap with the Korean /ɨ/, causing perceptual confusion. The English /u/, on the other hand, is free to move forward without encroaching upon the space of other vowels (Yang 1996). With regard to the low region, Korean only has one vowel /a/, while English has two vowels /æ/ and /ɑ/. Thus, the Korean /a/ can be placed in the middle in the front-back dimension (i.e., corner of a regular triangle) without crowding into the space of other vowels, whereas the English /æ/ and /ɑ/ should be placed apart to maintain sufficient space between them. Yang (1996) also found that the perceptual distance between /i/ and /e/ and between /u/ and /o/ was larger for English than for Korean, which is in line with the predictions of the theory of adaptive dispersion (Lindblom 1990; Lindblom and Engstrand 1989). That is, the larger distance between the high and mid vowels in English is likely to be linked to English having intervening lax vowels /ɪ/ and /ʊ/, while Korean does not (Yang 1996).
Since Korean does not have tense-lax vowel contrasts like the English /i/-/ɪ/ and /u/-/ʊ/, Korean speakers often demonstrate difficulty in distinguishing these vowels (Baker and Trofimovich 2005; Flege et al. 1997). Baker and Trofimovich (2005) examined the acoustic properties of Korean and English vowels produced by early and late Korean-English bilinguals with varying length of residence in the US (i.e., 1 year and 7 years). They found that the late bilinguals, regardless of their length of residence in the US, produced the English /i/ and /ɪ/ and the English /u/ and /ʊ/ as two single categories which acoustically overlapped with the Korean /i/ (=English /i, ɪ/) and the Korean /u/ or /ɨ/ (=English /u, ʊ/). The late bilinguals also produced the English /ɛ/ and /æ/ as a single category, but they were dissimilar from the Korean /e/ (merged with the Korean /ɛ/). That is, the late bilinguals assimilated the English /i, ɪ/ to the Korean /i/ and assimilated the English /u, ʊ/ to the Korean /u/, while they created a new vowel category for the merged English /ɛ/-/æ/ (Baker and Trofimovich 2005). As for the early bilinguals, Baker and Trofimovich (2005) found that, regardless of the length of residence, they produced the English /i/ and /ɪ/ distinctly and their English /i/ overlapped with their Korean /i/. As for the other vowel contrasts, the early bilinguals who resided in the US for one year demonstrated similar patterns as the late bilinguals (i.e., merged English /u/-/ʊ/ and merged English /ɛ/-/æ/), whereas those with longer length of residence successfully distinguished these contrasts. For the latter group, the English /u/ overlapped with the Korean /u/, but the English /ʊ/ was produced as a separate category. Both early bilingual groups produced the English /ɪ/ as the Korean /e/. Thus, while the adult bilinguals who had three categories for the six English vowels /i, ɪ, u, ʊ, ɛ, æ/ (i.e., merged /i/-/ɪ/, merged /u/-/ʊ/, and merged /ɛ/-/æ/), the recently-arrived early bilinguals had four categories (i.e., /i/, /ɪ/, merged /u/-/ʊ/, and merged /ɛ/-/æ/), and the early bilinguals with longer length of residence distinguished all six vowels.
2. The Present Study
The goal of this study is to examine whether Korean Americans in Los Angeles participate in the California Vowel Shift. We focus on four vowel changes involved in the California Vowel Shift: (1) the lowering and retraction of front lax vowels /ɪ/, /ɛ/, and /æ/, (2) the split between non-prenasal /æ/ and prenasal /æN/, (3) the merging of low back vowels /ɑ/-/ɔ/, and (4) the fronting of /u/, /ʊ/, and /ʌ/. If Korean Americans do not exhibit the above-mentioned patterns, we explore whether their resistance to local sound change can be explained through influence from Korean phonology. To better understand this, we compare Korean Americans of three generations (first-generation, 1.5-generation, and second-generation) with Anglo-Californians and Korean international students who are late bilinguals. We predicted that, due to age effects, first-generation speakers (i.e., late bilinguals) would demonstrate stronger influence from Korean phonology than 1.5- and second-generation speakers (i.e., early bilinguals) and, thus, participate less in the California Vowel Shift. Regarding the early bilinguals, influence from Korean phonology, if any, would appear to a lesser extent for the second-generation speakers than for the 1.5-generation speakers.
With respect to patterns reflecting influence from Korean phonology, we base our predictions on the findings of Korean-English late bilinguals (Baker and Trofimovich 2005) and cross-linguistic differences between Korean and English vowels (Baker and Trofimovich 2005; Yang 1996; Yoon and Kim 2015). Regarding the lowering and retraction of /ɪ/, we predicted that, if influence from Korean phonology occurs, Korean Americans would merge this vowel with /i/, thus they would not participate in the lowering and retraction of /ɪ/. Moreover, Korean Americans would create a new single /ɛ/-/æ/ category in which /æ/ merges with /ɛ/ (Baker and Trofimovich 2005). Thus, when examining these vowels separately, Korean Americans’ /ɛ/ may demonstrate lowering and retraction, but their /æ/ would not, because it would be positioned higher in the vowel space due to the merger with /ɛ/. Additionally, in the case of the English /æ/, Korean Americans would not exhibit a split-/æ/ system, because Korean does not have an equivalent phonological pattern. With regard to the /ɑ/-/ɔ/ merger, no Korean vowel acoustically overlaps with any of these vowels. The closest vowels are the Korean /a/ (low central) and /ʌ/ (near-low back) (Baker et al. 2002; Trofimovich et al. 2011; Tsukada et al. 2005). Thus, we predicted that, if influence from Korean occurs, they would either assimilate both the English /ɑ/ and the English /ɔ/ to the Korean /a/ (Outcome 1: Participation in /ɑ/-/ɔ/ merger but more fronted than expected) or distinguish them by assimilating the English /ɑ/ to the Korean /a/ and assimilating the English /ɔ/ to the Korean /ʌ/ (Outcome 2: No participation in /ɑ/-/ɔ/ merger). As for the fronting of /u/ and /ʊ/, Korean Americans would not participate or participate less in the fronting of these vowels, because they would assimilate both vowels to the Korean /u/ (Baker and Trofimovich 2005) which is fronted, but not to the same extent as in English (Kang 2014; Yang 1996). Similarly, Korean Americans’ English /ʌ/ would be produced more back due to influence from the Korean /ʌ/ (Yang 1996).
2.1. Participants
In total, 37 Korean Americans, 4 Korean international students, and 5 Anglo-Americans participated in the study. The Korean Americans were residents of Los Angeles County in Southern California and consisted of three immigrant generations: first-generation (GEN1), 1.5-generation (GEN1.5), and second-generation (GEN2). The language background of each group is presented in Table 1. The GEN1 group (N = 8; 4F, 4M) were Koreans born and raised in South Korea (Seoul: 6, Daegu: 1, Yeongju: 17) who immigrated to the US as adults (25.8 years). They had spent an average of 26.8 years in California at the time of data collection and spoke both English and Korean on a daily basis (English: 53.7%, Korean: 46.3%). They reported that they learned English (L2) during middle school or high school (12.8 years) and rated their English intermediate-level proficiency (2.7) on a 5-point Likert scale (5 = native). The GEN1.5 group (N = 4; 1F, 3M) were also Koreans born in South Korea (Seoul: 1, unspecified: 3), but they immigrated to the US in late childhood (10.5 years). As the GEN1 group, the GEN1.5 speakers learned English as an L2 and lived in the US for a long period of time (13.3 years). However, they used English (90%) much more frequently than Korean (10%), and rated their English (5 out of 5) as proficient as or more proficient than their native Korean (4.3). The GEN2 group (N = 25; 15F, 10M) were Koreans who were either born in Los Angeles County (N = 19) or born in South Korea (N = 6; Seoul: 4, Daegu: 1, unspecified: 1) and moved to Los Angeles County at age 3 or younger. All of their parents were first-generation immigrants from Korea (Seoul and Gyeonggi: 13, Gyeongsang: 2, Jeolla: 1, Chungcheong: 1, mixed: 2, unspecified: 68). Seventeen of them were Korean-English early sequential bilinguals, while eight speakers acquired both languages simultaneously. Similar to the GEN1.5 group, the GEN2 speakers used English most of the time (English: 83.2%, Korean: 16.8%), but unlike the GEN1.5 group they rated their English proficiency (5 out of 5) much higher than their Korean proficiency (2.9 out of 5). Both the GEN1.5 and the GEN2 groups reported that, growing up, Korean was the main language of communication at home.
In this study we also included 4 Korean international students (KOR) as a baseline for Korean-accented English. The KOR speakers were born and raised in Seoul, South Korea, and came to the US to complete their undergraduate or graduate studies. These speakers were very similar to the GEN1 speakers in that they arrived in the US as adults (22.8 years), were late L2 learners of English (12.5 years), and used both English and Korean on a daily basis (English: 47.5%, Korean: 52.5%). However, compared to the GEN1 speakers, they spent less time in the US (4 years). Thus, if phonetic transfer from L1 Korean to L2 English appears, it would be strongest in this group. Lastly, 5 Anglo-Americans (2F, 3M) participated in this study as a control group for California English. All of these speakers were born and raised in Southern California (2 in Los Angeles County, 3 in San Diego County).
All participants read and signed a written informed consent form before they participated in the study. The study was conducted in accordance with the Declaration of Helsinki and the protocol was approved by the School of Literatures, Cultures, and Linguistics Institutional Review Board (SLCL-IRB) of the University of Illinois at Urbana-Champaign.
2.2. Data Collection and Analysis
Participants’ English speech data were collected during the spring and summer of 2012. In order to elicit different speech styles, we conducted a reading task (i.e., controlled speech) and a picture description task (i.e., narrative speech). For the reading task the participants read out loud a passage from Aesop’s fables The North Wind and the Sun and for the picture description task they narrated the story of a wordless picture book Frog, Where are You? (Mayer 1969). In this study we will only report our findings from the narrative speech. Speech productions were audio-recorded using an AKG C520 head-mounted microphone and a Zoom H4n digital recorder with a sampling rate of 44.1 kHz and a sample size of 16 bits. The recordings were conducted in a quiet enclosed space in various locations in Los Angeles County (e.g., participants’ home, furnished room in a church). In the case of two KOR speakers and two CA speakers, the recordings were conducted in a sound-attenuated booth at a public university in Illinois (KOR: 2, CA: 1)9 and in Arizona (CA: 1)10. After completing the tasks, the participants filled out a language background questionnaire.
Participants’ speech was orthographically transcribed on Praat TextGrids (Boersma and Weenink 2020) and forced alignment was performed using the Montreal Forced Aligner (McAuliffe et al. 2017), which generated a word tier and a phone tier. We extracted the F1 and the F2 values at the midpoint of 9 English monophthongs /i, ɪ, ɛ, æ, ɑ, ɔ, ʌ, ʊ, u/ and the durations of these vowels using a Praat script. For convenience purposes, we classified the vowels using the ARPAbet symbols: IY (=/i/), IH (=/ɪ/), EH (=/ɛ/), AE (=/æ/), AA (=/ɑ/), AO (=/ɔ/), AH (=/ʌ/), UH (=/ʊ/), and UW (=/u/). For AE, we further divided them into AE and AEN based on whether they preceded a non-nasal or a nasal consonant. A total of 28,948 tokens were obtained. In this study, we only considered vowels with primary stress and excluded vowels produced in fillers (e.g., um) or monosyllabic function words (e.g., in). Any tokens that were misaligned, too short in duration (<50 ms), or were produced with a creak, laughter, or background noise were excluded from the analyses. Moreover, in order to ensure reliable boundaries between the vowels and their neighboring sounds, we additionally excluded tokens following vowels, glides, or /r/, or tokens preceding vowels, glides, or liquids (Podesva et al. 2015). After this process, 2690 tokens remained (IY: 357, IH: 302, EH: 410, AE(N): 319, AA: 202, AO: 439, AH: 289, UH: 247, UW: 125). Raw F1 and F2 values (Hz) of these tokens were converted to a bark scale (Traunmüller 1997) and then normalized using Lobanov’s (1971) z-score procedure in the phonR package (McCloy 2016) in R (R Development Core Team 2020).
All statistical analyses and data visualizations were conducted using R (R Development Core Team 2020). In this study we examined the following patterns involved in the California Vowel Shift: (1) lowering and retraction of IH, EH, and AE, (2) AE-AEN split, (3) AA-AO merger, and (4) fronting of UW, UH, and AH. For the first three patterns (i.e., lowering/retraction, split, and merger), we analyzed both vowel height (F1) and frontedness (F2) and for the last pattern (i.e., fronting), we only analyzed vowel frontedness (F2). For statistical analyses, we performed linear mixed effects modeling in the lme4 package (Bates et al. 2015). All fixed effects were contrast coded using simple coding in which each level is compared to the reference level and the intercept is the grand mean. The fixed and random effects of the model used in each pattern are presented in the following section. The best fitting model was selected through backward elimination and model comparisons were done with likelihood ratio tests using the anova() function. Although examining variation in gender was not the main purpose of the study, we included gender as a fixed effect in all models, due to its important role in sound change (i.e., female speakers are generally the leaders of linguistic change) (Coates 1993; Labov 1990; Milroy and Milroy 1985; Trudgill 1972). The p-values were obtained via Satterthwaite approximation in the lmerTest package (Kuznetsova et al. 2017). When significant interactions were found, we conducted post-hoc pairwise comparisons in the emmeans package (Lenth 2020).
3. Results
3.1. Phonemic Status of English Vowels
Figure 3 demonstrates the vowel space by group and gender based on their mean normalized F1 and F2 values of each vowel. Before looking into the patterns of the California Vowel Shift, we first examined the phonemic status of the vowels in each group and checked whether the Korean Americans distinguished the vowel pairs IY-IH, EH-AE, UW-UH, and AH-AO. We analyzed the normalized F1 and F2 values to compare the height and the frontedness of the vowel pairs. We performed linear mixed effects modeling with vowel and gender as fixed effects and participant and item as random effects. Table 2 summarizes the statistical significance of the vowel contrasts in each group.
There was a clear distinction between the GEN2 and the GEN1.5 speakers (i.e., early bilinguals) and the GEN1 speakers (i.e., late bilinguals), in that the former groups patterned like the CA speakers and the latter group patterned like the KOR speakers. The CA speakers and the early bilinguals successfully distinguished all four vowel contrasts using vowel height and frontedness except in the case of the UH-UW contrast which was distinguished by just vowel frontedness. In comparison, the late bilinguals were able to distinguish only the front vowel contrasts either using vowel height (i.e., EH-AE) or vowel frontedness (i.e., IY-IH), while failing to distinguish the back vowel contrasts UH-UW and AH-AO.
3.2. Lowering and Retraction of IH, EH, and AE
For the lowering and retraction of front lax vowels IH, EH, and AE, we examined the effects of group and gender on the F1 (vowel height) and the F2 (vowel frontedness) of each of these vowels. We performed linear mixed effects modeling with group (CA, GEN2, GEN1.5, GEN1, KOR), gender (female, male), and the interaction between group and gender as fixed effects and participant and item as random effects. For IH, we additionally included the following segment (nasal, non-nasal) as a fixed effect, given that studies have shown that this vowel becomes raised to IY before a nasal consonant (e.g., thing) (Hinton et al. 1987). We also included the nasality of the following segment as a fixed effect for the analysis of EH. As for AE, only tokens preceding a non-nasal consonant were examined. Further analysis of the effect of the nasality of the following segment on the realization of AE (i.e., AE-AEN split) will be presented in Section 3.3. The best-fitting models included random intercepts for subject and item without any random slope, except for the F1 of IH, which included a by-item random slope for gender.
Results of IH showed that there was a main effect of group (GEN2) on both the F1 (β = 0.375, SE = 0.151, t = 2.48, p < 0.01) and the F2 (β = 0.269, SE = 0.117, t = 2.307, p < 0.05), suggesting that the GEN2 speakers produced IH significantly lower11 and more fronted than the CA speakers (i.e., reference level). The GEN1 and the KOR speakers also produced this vowel significantly more fronted than the CA speaker (GEN1: β = 0.76, SE = 0.137, t = 5.551, p < 0.001; KOR: β = 0.587, SE = 0.167, t = 3.509, p < 0.001). With regard to the effect of gender, overall, the female speakers (i.e., reference level) produced IH significantly lower and more fronted than the male speakers (F1: β = −0.46, SE = 0.128, t = −3.582, p < 0.001; F2: β = −0.497, SE = 0.093, t = −5.343, p < 0.001). For the F2, we found a significant interaction between group (GEN2) and gender (β = −0.548, SE = 0.233, t = −2.355, p < 0.05) and an interaction approaching significance between group (GEN1) and gender (β = −0.504, SE = 0.272, t = −1.852, p = 0.071). That is, the gender difference was larger for the GEN2 and the GEN1 speakers than for the CA speakers. Figure 4 presents the normalized F2 of IH, EH, and AE across groups and genders. Higher F2 values indicate more fronted realizations. Post-hoc pairwise comparison results confirmed that, while the CA speakers did not show significant difference between female and male speakers, the female GEN2 speakers and the female GEN1 speakers produced IH significantly more fronted than their male counterparts (GEN2: β = 0.814, SE = 0.09, t = 9.079, p < 0.001; GEN1: β = 0.769, SE = 0.165, t = 4.655, p < 0.01). Among the female speakers, the GEN1 speakers and the KOR speakers demonstrated the most fronted realizations of IH. When comparing across groups, the GEN1 speakers produced significantly more fronted IH than all the other groups, except for the KOR speakers (GEN1 vs. CA: β = −1.012, SE = 0.186, t = −5.435, p < 0.001; GEN1 vs. GEN2: β = −0.469, SE = 0.128, t = −3.65, p < 0.05; GEN1 vs. GEN1.5: β = −1.226, SE = 0.22, t = −5.584, p < 0.001). The KOR speakers also produced (marginally) significantly more fronted IH compared to the CA speakers (β = −0.762, SE = 0.236, t = −3.23, p = 0.064) and the GEN1.5 speakers (β = −0.976, SE = 0.261, t = −3.745, p < 0.05). Moreover, the GEN2 speakers produced significantly more fronted IH than the GEN1.5 speakers (β = 0.758, SE = 0.195, t = 3.891, p < 0.05) and the CA speakers (β = −0.544, SE = 0.155, t = −3.502, p < 0.05). The F2 of the GEN1.5 and the CA speakers did not differ. Therefore, female speakers’ IH frontedness can be summarized with the following order: KOR, GEN1 > GEN2 > GEN1.5, CA. No group difference was found among the male speakers, except for the difference between the GEN1 and the GEN2 speakers, in which the former produced significantly more fronted IH than the latter (β = −0.513, SE = 0.14, t = −3.671, p < 0.05). Regarding the effect of the following segment, we found that overall, IH preceding a nasal consonant (i.e., reference level) were significantly more fronted than in other contexts (β = 0.183, SE = 0.084, t = 2.169, p < 0.05), but they did not differ in height.
With regard to EH, there was a main effect of group (GEN1) on both the F1 (β = −0.397, SE = 0.172, t = −2.311, p < 0.05) and the F2 (β = 0.306, SE = 0.11, t = 2.796, p < 0.01), which suggests that the GEN1 speakers produced EH significantly higher and more fronted than the CA speakers (i.e., reference level). The GEN2 speakers also produced EH significantly more fronted than the CA speakers (GEN2: β = 0.249, SE = 0.09, t = 2.777, p < 0.05), but the vowel height did not differ between the two groups. As found above, the female speakers (i.e., reference level) produced EH lower and more fronted than the male speakers (F1: β = −0.777, SE = 0.116, t = −6.723, p < 0.001; F2: β = −0.605, SE = 0.074, t = −8.164, p < 0.001). Moreover, we found a significant interaction between gender and group (KOR) for the F1 (β = 0.932, SE = 0.406, t = 2.295, p < 0.05), which indicates that the gender difference was larger for the KOR speakers than for the CA speakers. Post-hoc pairwise comparison results confirmed that female and male KOR speakers’ EH did not differ in vowel height, whereas the female CA speakers produced this vowel significantly lower than the male CA speakers (β = 1.034, SE = 0.258, t = 4.005, p < 0.05). (Marginally) Significant gender differences were also found in the GEN2 (β = 1.017, SE = 0.117, t = 8.727, p < 0.001) and the GEN1 speakers (β = 0.737, SE = 0.223, t = 3.302, p = 0.054). The post-hoc test results also showed that the female GEN2 speakers produced EH with similar vowel height as the female CA and the female GEN1.5 speakers, whereas they produced EH significantly lower than the female GEN1 (β = 0.639, SE = 0.179, t = 3.577, p < 0.05) and the female KOR speakers (β = 0.774, SE = 0.23, t = 3.362, p < 0.05). No group difference in vowel height was found among the male speakers. For the F2, we found significant interactions between gender and all Korean groups, except for the GEN1.5 speakers (GEN2: β = −0.413, SE = 0.179, t = −2.308, p < 0.05; GEN1: β = −0.641, SE = 0.217, t = −2.954, p < 0.01; KOR: β = −0.533, SE = 0.261, t = −2.045, p < 0.05). This suggests that the gender difference was larger for these groups than for the CA speakers. Post-hoc pairwise comparison results confirmed that the female speakers in these groups produced EH significantly more fronted than the male speakers (GEN2: β = 0.623, SE = 0.074, t = 8.431, p < 0.001; GEN1: β = 0.851, SE = 0.143, t = 5.945, p < 0.001; KOR: β = 0.743, SE = 0.206, t = 3.6, p < 0.05), whereas no gender difference was found for the CA speakers. The post-hoc test results also revealed that the female CA speakers produced EH significantly less fronted than the female GEN2 (β = −0.456, SE = 0.131, t = −3.489, p < 0.05) and the female GEN1 speakers (β = −0.627, SE = 0.161, t = −3.888, p < 0.05). No group difference in F2 was found for the male speakers. Lastly, there was no main effect of the following segment on either measures.
Regarding (non-prenasal) AE, similar to the case of EH, we found a main effect of group (GEN1) on both the F1 (β = −0.613, SE = 0.293, t = −2.092, p < 0.05) and the F2 (β = 0.557, SE = 0.183, t = 3.049, p < 0.01), indicating that the GEN1 speakers produced AE significantly higher and more fronted than the CA speakers (i.e., reference level). Consistent with the findings of IH and EH, compared to the male speakers, the female speakers (i.e., reference level) produced AE lower (β = −0.897, SE = 0.193, t = −4.656, p < 0.001) and more fronted (β = −0.423, SE = 0.12, t = −3.552, p < 0.01). There was a significant interaction between gender and group (GEN1) for the F2 (β = −0.755, SE = −2.07, p < 0.05), which indicates that the gender difference was larger for the GEN1 speakers than for the CA speakers. Post-hoc pairwise comparison results confirmed that the female GEN1 speakers, but not the female CA speakers, produced AE significantly more fronted than their male counterparts (β = 0.863, SE = 0.234, t = 3.684, p < 0.05). Additionally, a significant gender difference was found in the GEN2 speakers (β = 0.534, SE = 0.113, t = 4.714, p < 0.01). The post-hoc test results also showed that, compared to the female CA speakers, female GEN1 speakers’ AE was more fronted, although the difference was marginally significant (β = −0.934, SE = 0.283, t = −3.301, p = 0.056). No group difference in F2 was observed for the male speakers.
3.3. AE-AEN Split
Figure 5 demonstrates the normalized F1 and F2 values of non-prenasal AE and prenasal AEN across groups. In order to test whether the height (F1) and the frontedness (F2) of these two vowel types were significantly different across groups and genders, we performed linear mixed effects modeling with vowel type (AE, AEN), group (CA, GEN2, GEN1.5, GEN1, KOR), gender (female, male), and the interactions among vowel type, group, and gender as fixed effects and participant and item as random effects. The best fitting models included random intercepts for subject and item with a by-item random slope for gender for the F1 and with a by-subject random slope for vowel for the F2.
Results showed that there were main effects of vowel type for both the F1 (β = −0.718, SE = −0.118, t = −6.097, p < 0.001) and the F2 (β = 0.515, SE = 0.097, t = 5.315, p < 0.001), which suggests that overall AEN was produced significantly higher and more fronted than AE (i.e., reference level). We also found significant interactions between vowel type and all Korean groups in both measures. That is, the difference between AE and AEN was larger for the CA speakers than for the GEN2 (F1: β = 0.794, SE = 0.182, t = 4.356, p < 0.001; F2: β = −0.693, SE = 0.172, t = −4.021, p < 0.001), the GEN1.5 (F1: β = 0.86, SE = 0.267, t = 3.222, p < 0.01; F2: β = −0.531, SE = 0.242, t = −2.19, p < 0.05), the GEN1 (F1: β = 1.185, SE = 0.248, t = 4.783, p < 0.001; F2: β = −1.001, SE = 0.221, t = −4.529, p < 0.001), and the KOR speakers (F1: β = 1.253, SE = 0.369, t = 3.391, p < 0.001; F2: β = −1.07, SE = 0.314, t = −3.407, p < 0.01). Results of post-hoc pairwise comparisons revealed that, compared to AEN, the CA and the GEN2 speakers produced AE significantly lower (CA: β = 1.537, SE = 0.188, t = 8.179, p < 0.001; GEN2: β = 0.743, SE = 0.096, t = 7.712, p < 0.001) and more fronted (CA: β = −1.174, SE = 0.169, t = −6.944, p < 0.001; GEN2: β = −0.481, SE = 0.086, t = −5.606, p < 0.001). The GEN1.5 speaker also showed slightly higher and more fronted AEN than AE, but the difference did not reach statistical significance (F1: β = 0.676, SE = 0.222, t = 3.041, p = 0.077; F2: −0.643, SE = −3.333, p = 0.057). The late learners (i.e., GEN1 and KOR) did not distinguish the two vowel types. The effect of gender on the F1 and the F2 maintained in the combined AE-AEN data (F1: β = −0.943, SE = 0.178, t = −5.3, p < 0.001; F2: β = −0.561, SE = 0.132, t = −4.244, p < 0.001). For the F2, there was a marginally significant interaction between gender and group (GEN2) (β = −0.665, SE = 0.324, t = −2.051, p = 0.05) and a significant difference between gender and group (GEN1) (β = −1.062, SE = 0.379, t = −2.803, p < 0.01). That is, the gender difference was larger for these speakers than for the CA speakers. According to the results of the post-hoc pairwise comparisons, the gender difference was significant for both the GEN2 (β = 0.603, SE = 0.126, t = 4.793, p < 0.01) and for the GEN1 speakers (β = 1, SE = 0.235, t = 4.256, p < 0.01), while the CA speakers did not show any gender difference. We also found a three-way interaction among vowel type, group (GEN1.5), and gender, suggesting that the interaction between vowel type and group (GEN1.5) showed a different pattern between female and male speakers. We further examined this by running separate models for each gender and found that, while significant interaction between vowel type and group (GEN1.5) appeared in the male data (β = −1.114, SE = 0.198, t = −5.635, p < 0.001), it did not appear in the female data. Given that we only had one female speaker in the GEN1.5 group, these results should be interpreted with caution.
3.4. AA-AO Merger
Figure 6 demonstrates the normalized F1 and F2 values of AA and AO across groups. In order to test whether these two vowels are produced as one category, we performed linear mixed effects modeling with vowel (AA, AO), group (CA, GEN2, GEN1.5, GEN1, KOR), gender (female, male), and the interaction among vowel, group, and gender as fixed effects and participant and item as random effects. The best fitting models included random intercepts for subject and item with a by-subject random slope for vowel for the F1 and with a by-item random slope for gender for the F2.
Results showed that there was a main effect of vowel on both the F1 and the F2, which suggests that overall AA (i.e., reference level) was produced significantly lower and more fronted than AO (F1: β = −0.291, SE = 0.094, t = −3.102, p < 0.01; F2: β = −0.289, SE = 0.073, t = −3.947, p < 0.001). A main effect of group (GEN2) was found (β = 0.221, SE = 0.094, t = 2.354, p < 0.05) for the F2, indicating that overall the GEN2 speakers produced the vowels significantly more fronted than the CA speakers (i.e., reference level). For the F1, there was a marginally significant interaction between vowel and group (GEN1) (β = −0.419, SE = 0.208, t = −2.014, p = 0.055). Post-hoc pairwise comparison results revealed that the GEN1 speakers produced AA significantly lower than AO (β = 0.607, SE = 0.15, t = 4.051, p < 0.01), whereas the CA speakers did not distinguish these vowels. With regard to the F2, we found significant interactions between vowel and group (GEN2) (β = 0.171, SE = 0.072, t = 2.392, p < 0.05) and between vowel and group (GEN1) (β = −0.223, SE = 0.09, t = −2.468, p < 0.05). That is, the difference in F2 between AA and AO of the CA speakers was larger than the GEN2 speakers and smaller than the GEN1 speakers. Post-hoc pairwise comparison results revealed that the CA speakers and the early bilinguals (i.e., GEN2, GEN1.5) produced AA and AO similarly, whereas the late bilinguals distinguished them (GEN1: β = 0.421, SE = 0.09, t = 4.659, p < 0.001; KOR: β = 0.417, SE = 0.127, t = 3.288, p < 0.05). AA and AO did not differ in any measures across groups, except between the GEN2 and the GEN1 speakers in the production of AO (F1: β = 0.707, SE = 0.155, t = 4.549, p < 0.01; F2: β = 0.288, SE = 0.079, t = 3.629, p < 0.05). That is, the GEN2 speakers produced this vowel significantly lower and more fronted than the GEN1 speakers. The GEN2 speakers also produced AO more fronted than the CA speakers, in which the difference approached statistical significance (β = 0.306, SE = 0.093, t = 3.289, p = 0.061). Lastly, the female speakers produced the vowels significantly lower and more fronted than the male speakers (F1: β = −0.291, SE = 0.094, t = −3.102, p < 0.01; F2: β = −0.467, SE = 0.084, t = −5.55, p < 0.001).
3.5. Fronting of UW, UH, and AH
For the fronting of UW, UH, and AH, we examined the effects of group and gender on the frontedness (F2) of each of these vowels. We performed linear mixed effects modeling with group (CA, GEN2, GEN1.5, GEN1, KOR), gender (female, male), and the interaction between group and gender as fixed effects and participant and item as random effects. In the case of UW, since there was no male token in the data, we did not include the interaction between group and gender as a fixed effect. Additionally, we included the previous segment (coronal, non-coronal) as a fixed effect, since studies have shown that these vowels demonstrate more advanced fronting after coronal consonants than in other phonological environments (D’Onofrio et al. 2019; Podesva et al. 2015). The best-fitting models included random intercepts for subject and item without any random slope.
Results showed that group (GEN2) had an effect on the frontedness of UH (β = 0.581, SE = 0.171, t = 3.393, p < 0.01) and AH (β = 0.394, SE = 0.135, t = 2.922, p < 0.01). That is, compared to the CA speakers (i.e., reference level), the GEN2 speakers produced these vowels more fronted. No difference was found between the two groups in the production of UW. Lastly, regarding gender, the female speakers produced the three vowel types significantly more fronted than the male speakers (UW: β = −0.431, SE = 0.199, t = −2.159, p < 0.05; UH: β = −0.765, SE = 0.144, t = −5.318, p < 0.001; AH: β = −0.568, SE = 0.105, t = −5.415, p < 0.001). No significant interaction was found between group and gender in UH and AH. Moreover, no effect of previous segment was found in any of the vowels.
4. Discussion
4.1. Effect of Age of Arrival on the Participation in Local Sound Change
In this study we examined the effect of age of arrival on Korean Americans’ participation in the California Vowel Shift. We compared the speech of Korean Americans of three generations who clearly differed in the age of arrival to Los Angeles: first-generation (GEN1) (i.e., adulthood), 1.5-generation (GEN1.5) (i.e., late childhood), and second-generation (GEN2) (i.e., early childhood). We predicted that, despite their long residence in the US (average 26.8 years), the GEN1 speakers would show signs of L1 Korean influence in their speech, similar to Korean international students (KOR) who spent less time in the US (average 4 years). On the other hand, younger generation Koreans (i.e., GEN1.5 and GEN2) would perform more similarly to Anglo-Californians (CA) than the KOR speakers and influence from Korean phonology, if any, would appear to a lesser extent for the GEN2 speakers than for the GEN1.5 speakers.
We examined four main patterns of the California Vowel Shift: (1) lowering and retraction of IH, EH, and AE, (2) AE-AEN split, (3) AA-AO merger, and (4) fronting of UW, UH, and AH. For each vowel, we predicted the outcomes based on previous findings of Korean-English late bilinguals and cross-linguistic studies between Korean and English vowels (Baker and Trofimovich 2005; Baker et al. 2002; Trofimovich et al. 2011; Tsukada et al. 2005; Yang 1996; Yoon and Kim 2015).
With regard to IH, as Korean does not have a high front lax vowel, Korean-English late bilinguals tend to merge this vowel to IY which is almost identical to the Korean /i/ (Baker and Trofimovich 2005; Yang 1996). Thus, we predicted that, if influence from Korean phonology occurs, Korean Americans would merge IH with IY and, thus, would not participate in the lowering and retraction of IH. Results showed that the early bilinguals (i.e., GEN2 and GEN1.5) aligned with the CA speakers in that they distinguished the IY-IH contrast using both vowel height and frontedness. On the other hand, the late bilinguals (i.e., GEN1 and KOR) patterned similarly to each other; they only used vowel frontedness to distinguish the contrast. Although the GEN1 and the KOR speakers did not completely merge IH with IY, which would have been a strong indication of Korean influence, their IH approached IY in the vowel space (see Figure 3). Indeed, when comparing the difference of the average normalized F2 (i.e., vowel frontedness) between IY and IH across groups, the late bilinguals demonstrated smaller differences (GEN1: 0.11, KOR: 0.44) than the CA speakers (1.08) and the early bilinguals (GEN2: 0.89, GEN1.5: 1.35). Moreover, we found that both the GEN1 and the KOR speakers produced IH more fronted than the CA speakers. The GEN2 speakers also produced this vowel more fronted than the CA speakers. However, unlike the GEN1 and the KOR speakers, we do not believe that this is due to influence from Korean phonology, given that the GEN2 speakers additionally produced this vowel lower than the CA speakers. If the Korean /i/ had an effect on GEN2 speakers’ IH, it would have demonstrated higher vowel height than CA speakers’ IH. In fact, among the five groups, GEN2 speakers’ IH was produced with the lowest vowel height (see Footnote 12). Rather than influence from Korean phonology, GEN2 speakers’ divergence from the CA speakers could be explained through the nature of their vowel space. The vowel space of the GEN2 speakers was overall more fronted than that of the CA speakers.
Regarding EH and AE, we made different predictions for the two vowels. While Korean does not have any vowel that acoustically overlaps with either EH or AE, Korean-English bilinguals often identify both vowels as the Korean /e/ (Baker et al. 2002; Trofimovich et al. 2011), which is positioned higher in the vowel space (Baker and Trofimovich 2005; Yoon and Kim 2015). However, instead of assimilating the merged EH-AE category to the Korean /e/, Korean-English bilinguals, especially late bilinguals, tend to demonstrate two categories in the front mid/low region of the vowel space: the Korean /e/ and a single EH-AH category in which AE merges with EH (Baker and Trofimovich 2005). Therefore, we predicted that, if influence from Korean occurs, Korean Americans would merge AE with EH; their EH may demonstrate lowering and retraction, but their AE would not, because it would be positioned higher in the vowel space due to the merger with EH. Contrary to our prediction, the Korean Americans in our study maintained the EH-AE contrast regardless of their age of arrival to the US. As in the case of IH, we found a different pattern between the early bilinguals and the late bilinguals. The GEN2 and the GEN1.5 speakers performed like the CA speakers in that they produced EH and AE distinctly using both vowel height and frontedness. On the other hand, the GEN1 speakers and the KOR speakers kept the EH-AE contrast using only one measure (i.e., vowel height).
While the GEN1 speakers distinguished the EH-AH contrast, they produced both vowels higher and more fronted than the CA speakers, indicating that these speakers did not participate in the lowering and retraction of EH and AE. The GEN2 speakers also produced EH more fronted than the CA speakers, but no difference in vowel height was found between the two groups. As mentioned above, we believe that is due to their overall more fronted vowel space compared to the CA speakers. Although participants’ birth year was not the main focus of our study, it is worth pointing out that the GEN1 speakers were overall older than the other groups (see Table 1). Although we formulated our predictions with the assumption that the merger between the Korean /e/ and /ɛ/ is established across most age groups (Kang 2014; Jang et al. 2015), it is possible that the GEN1 speakers arrived in the US during the time when the merger was still in progress. For instance, Yang (1996) demonstrated that Korean male adults in the 1990s maintained the distinction between the Korean /e/ and /ɛ/, while Korean female adults produced them indistinguishably, suggesting that the Korean /e/-/ɛ/ merger was still in progress during this period and female speakers led the change. Most of the GEN1 speakers in our study immigrated to the US during the 1970s and the 1980s. After a long period of time away from Korea, it is likely that the GEN1 speakers do not participate in sound changes in Korea that are still in progress or that were established after they left. In fact, linguistic conservatism has often been observed in diasporic communities (Johannessen and Laake 2015; Parodi 2014; Polinsky 2018). Thus, it is possible that the GEN1 speakers kept the Korean /e/-/ɛ/ contrast that they brought with them, which may have affected their production of (unmerged) EH and AE.
With regard to the KOR speakers, given that these speakers were much younger than the GEN1 speakers and left Korea recently (see Table 1), it is unlikely that they maintain the Korean /e/-/ɛ/ contrast. When comparing the difference of the average normalized F1 (i.e., vowel height) between EH and AE across groups, the KOR speakers demonstrated a smaller difference (0.42), compared to the CA speakers (0.75) and the early bilinguals (GEN2: 0.64, GEN1.5: 0.66). On the other hand, GEN1 speakers’ vowel height difference between EH and AE (0.71) was comparable to that of the CA speakers and the early bilinguals. Thus, it appears that both the GEN1 and the KOR speakers demonstrate influence from Korean phonology when producing EH and AE, but in a different way. While the GEN1 speakers assimilate EH and AE to the Korean /e/ and /ɛ/, respectively, the KOR speakers acquire the EH-AE contrast using vowel height, but do so less consistently than the CA speakers, similar to the case of the IY-IH contrast. To confirm this, future research should examine GEN1 speakers’ and KOR speakers’ realization of both English and Korean vowels.
In this study, we examined whether Korean Americans produce AE differently based on the nasality of the following consonant (i.e., AE-AEN split). Korean does not demonstrate a systematic split between non-prenasal and prenasal vowels, thus, we predicted that, if influence from Korean phonology occurs, Korean Americans would not distinguish AE and AEN. Our results showed that late bilinguals (i.e., GEN1 and KOR) and the GEN1.5 speakers did not distinguish AE and AEN. The GEN2 speakers, on the other hand, produced AE and AEN distinctly using both vowel height and frontedness, but the difference between these two vowels were smaller than for the CA speakers. This finding suggests that the GEN2 speakers participate in the AE-AEN split, but to a lesser extent than the CA speakers.
Regarding the low back vowels AA and AO, Korean does not have a vowel that acoustically overlaps with any of these vowels. The closest vowels in Korean would be /a/ (low central) and /ʌ/ (near-low back) (Baker et al. 2002; Trofimovich et al. 2011; Tsukada et al. 2005). Thus, we predicted that if influence from Korean occurs, they would either assimilate both vowels to the Korean /a/ (Outcome 1: Participation in AA-AO merger but more fronted than expected) or distinguish them by assimilating AA to the Korean /a/ and assimilating AO to the Korean /ʌ/ (Outcome 2: No participation in AA-AO merger). Results showed that the late bilinguals (i.e., GEN1 and the KOR) produced AA more fronted than AO. Additionally, the GEN1 speakers produced AA lower than AO. These findings suggest that the late bilinguals did not participate in the AA-AO merger, most likely because they assimilated AA to the Korean /a/ and assimilated AO to the Korean /ʌ/ (i.e., Outcome 2). The finding that these speakers produced AO indistinctly from AH, which is the closest vowel to the Korean /ʌ/ (see Section 3.1), supports the possibility that they assimilated AO to the Korean /ʌ/. As for the GEN2 and the GEN1.5 speakers, they patterned like the CA speakers in that they showed an overlap between AA and AO. In the case of the GEN2 speakers, the AA-AO merger was even stronger than the CA speakers, suggesting that the GEN2 speakers may be in a more advanced stage of the AA-AO merger. However, compared to the CA speakers their productions were overall more fronted. Although the results seem to be pointing toward Outcome 1 (i.e., assimilation to the Korean /a/), this is unlikely. Compared to the CA speakers, GEN2 speakers’ AO was more fronted, but not lower, which would have been the case if the GEN2 speakers assimilated the merged AA-AO category to the Korean /a/. As shown in Figure 3, AA is positioned in the low-back area in GEN2 speakers’ vowel space, whereas for the late bilinguals it is positioned in the low-mid area between AE and AO. If the GEN2 speakers assimilated AA to the Korean /a/, which is what we believe happened in the speech of the late bilinguals, they would have shown similar patterns as the late bilinguals. Thus, as in the case of the front vowels, GEN2 speakers’ overall fronted vowel space seems to be a more plausible explanation to their divergence from the CA speakers.
Lastly, with regard to the high back vowels UW and UH, Korean-English bilinguals tend to assimilate both vowels to the Korean /u/ which is more back (Baker and Trofimovich 2005). Thus, we predicted that, if influence from Korean phonology occurs, Korean Americans would merge UW and UH and produce them more back than the CA speakers. Similarly, AH would be produced more back than the CA speakers due to influence from the Korean /ʌ/. Our data showed that the late bilinguals produced UW and UH indistinguishably, suggesting a strong influence from Korean phonology. However, unlike what we expected, they did not produce the merged UW-UH more back than CA speakers. One possible explanation is that, rather than to the Korean /u/, these speakers may have assimilated the UW-UH category to the Korean /ɨ/ which is acoustically more similar to these vowels. Future research examining late bilinguals’ combined L1 and L2 vowel space would help confirm this. Unlike the late bilinguals, the early bilinguals aligned with the CA speakers in that they maintained the UW-UH contrast using vowel height12. Compared to the CA speakers, only the GEN2 speakers demonstrated more fronted UH and AH. As mentioned above, we believe that this is due to their more fronted vowel space.
Overall, our data showed a clear distinction between the GEN2 and the GEN1.5 speakers (i.e., early bilinguals), on the one hand, and the GEN1 speakers (i.e., late bilinguals), on the other, confirming an effect of age of arrival to the US on Korean Americans’ realization of English vowels. Similar to the KOR speakers, the GEN1 speakers did not distinguish the front vowels contrasts IY-IH and EH-AE, using the same strategies as the CA speakers, and failed to maintain the back vowel contrasts UW-UH and AH-AO. Moreover, they did not participate in the California Vowel Shift, which is mostly likely due to influence from their L1 Korean. Unlike the late bilinguals, the early bilinguals successfully maintained the four vowel contrasts using the same phonetic strategies as the CA speakers. Moreover, the CA speakers and the early bilinguals demonstrated horizontally narrower and vertically more expanded vowel space than the late bilinguals (see Figure 3). This indicates that these speakers followed the linguistic trend of California English which is characterized by a horizontal compression of vowel space (D’Onofrio et al. 2019). However, the early bilinguals did not demonstrate a complete convergence toward the CA speakers, especially when producing non-prenasal AE and prenasal AEN. While the GEN2 speakers distinguished the two vowel types, their split was less pronounced than the CA speakers. The GEN1.5 speakers, on the other hand, did not demonstrate a systematic distinction between AE and AEN, following the patterns of the late bilinguals. Less pronounced or lack of AE-AEN split among Korean Americans has also been reported in other studies (Cheng 2016; Lee 2016). Since Korean does not have AE-AEN split, this finding suggests that Korean phonology has an effect on early bilinguals’ production of AE and AEN and that the GEN1.5 speakers demonstrate a stronger influence from Korean phonology than the GEN2 speakers due to their later exposure to California English (i.e., age effect).
4.2. Second-Generation Korean Americans’ Divergent Participation in the California Vowel Shift
In the case of the GEN2 speakers, apart from the less pronounced AE-AEN split, we found that these speakers additionally demonstrated an overall more fronted realization of the vowels than the CA speakers. Except for front vowel retraction, all the patterns of the California Vowel Shift examined in this study were observed in GEN2 speakers’ speech (i.e., front vowel lowering, back vowel fronting, AE-AEN split, AA-AO merger). In fact, in certain aspects, the GEN2 speakers seemed to be in a more advanced stage of the California Vowel Shift than the CA speakers (i.e., IH-lowering, AA-AO merger, UH- and AH-fronting). These findings, along with the less pronounced AE-AEN split, are highly consistent with those of Korean Americans in Berkeley (Cheng 2016), which suggests that Korean Americans in Southern and Northern California may share similar patterns. Based on visual inspection of participants’ vowel space in Figure 3, the GEN2 speakers seemed to demonstrate the narrowest vowel space across groups. Thus, it is possible that GEN2 speakers’ fronted vowel space occurs in combination with more advanced horizontal compression than the CA speakers.
While further examination of GEN2 speakers’ holistic vowel space (e.g., area and dispersion) should be carried out, it appears that there is a link between GEN2 speakers’ narrow vowel space and their pronounced back vowel fronting. Pronounced back vowel fronting has also been found in other Asian American groups. For instance, Hall-Lew (2009, 2011) demonstrated that Chinese Americans in San Francisco may be in a more advanced stage of back vowel fronting than Anglo-Californians. Similarly, Cheng (2016) found that, apart from the Korean Americans, South Asians also demonstrated more pronounced UH-fronting than Anglo-Californians. Thus, it is possible that some Asian Americans in California collectively demonstrate stronger participation in back vowel fronting than Anglo-Californians to express their pan-ethnic Asian American identity. According to Wei (1993, p. 1), being Asian American “implies that there can be a communal consciousness and a unique culture that is neither Asian or American, but Asian American.” US-born Asian Americans often experience microaggressions challenging their American-ness due to their phenotypic traits that are distinct from the mainstream Americans (i.e., Anglo-Americans) (Lee 2019). The shared racialization experiences, which contradicts the covert oppression exerted upon Asian Americans behind the model minority stereotype (e.g., docile, hard-working, good citizens) (Chou and Feagin 2010; Kawai 2005; Lee 2019), may lead some Asian Americans to overemphasize their American-ness using linguistic resources. In other words, the pronounced back vowel fronting observed in the GEN2 speakers may be a result of the speakers overcompensating for their perceived un-American-ness by taking the back vowel fronting of the California Vowel Shift even further than the CA speakers. This may eventually cause for the front vowels to be pushed forward in order to maintain sufficient perceptual contrasts between front and back vowels (Lindblom 1990; Lindblom and Engstrand 1989). Future research should examine the social meanings of back vowel fronting and the relationship between the degree of back vowel fronting and pan-ethnic Asian American membership across different Asian American groups, as well as its effect on the realization of front vowels.
It is important to note that, unlike the GEN2 speakers, the GEN1.5 speakers did not demonstrate pronounced back vowel fronting or an overall fronted vowel space. If we extend our argument from above, it is possible that the GEN1.5 speakers may not feel the need to overemphasize their American-ness through back vowel fronting in the same way as the GEN2 speakers, since GEN1.5 speakers often demonstrate a strong affiliation to Korean cultures as part of their dual identity (Kim and Stodolska 2013). Thus, it is likely that GEN1.5 speakers identify themselves more strongly as Koreans or Korean Americans than Asian Americans. Due to the small sample size (N = 4), it is premature to make an assumption on GEN1.5 speakers’ speech behaviors. Future research should include a balanced number of GEN1.5 and GEN2 speakers to test whether their English vowels systematically differ from each other and whether their pan-ethnic Asian American identity in relation to their Korean or Korean American identity has an effect on their realization of English vowels.
Another possible explanation to GEN2 speakers’ fronted vowel space is the social meaning associated with gender in Korean culture. Cross-linguistically, female speakers have higher fundamental frequency (F0) and formant frequencies than male speakers due to differences in their vocal anatomy (Escudero et al. 2009; Jacewicz et al. 2007; Pisanski et al. 2016; Simpson 2002; Yoon and Kim 2015). Thus, compared to male speakers, female speakers generally have a higher-pitched voice and produce vowels with lower height (i.e., higher F1) and more fronted (i.e., higher F2). In this study, we normalized participants’ formant frequencies in order to examine gender effects on English vowel production while controlling for physiological differences between female and male speakers.
As demonstrated in Figure 3, the vowel space of CA female and male speakers largely overlapped in the front-back dimension13, whereas clear gender differences were observed across Korean groups, especially among the GEN2 and the GEN1 speakers. That is, even after normalizing formant frequencies, the Korean female speakers produced English vowels more fronted than the Korean male speakers. These findings suggest that Korean female speakers shift their vowel space forward as a way to express their femininity. Femininity is indexed differently across cultures. For instance, in American culture, women use creaky voice to enhance their female desirability (Pennock-Speck 2005; Yuasa 2010), whereas Japanese women use high-pitched voice to sound cute, young, and charming (Van Bezooijen 1995; Ohara 1998; Yuasa 2010). Although to a lesser degree than in Japanese culture, Korean women also use high-pitched voice to express femininity (Ohara 1998; Puzar and Hong 2018). High-pitched voice is a characteristic of performed winsomeness called aegyo, which is the cutified and infantilized figuration of femininity in Korean culture14 (Puzar and Hong 2018). Due to the close relationship between F0 and formants, it is likely that performers of aegyo also produce fronted vowel space. According to Pisanski et al. (2016), speakers across genders and cultures modulate their vocal tract length and F0 to imitate a physically large and small body size. That is, they shorten their vocal tract and increase their F0 to sound physically small and do the opposite to sound physically large. Thus, it is possible that the GEN2 female speakers move their vowel space forward to express Korean femininity. Here we would like to emphasize that among the four Korean groups (i.e., GEN2, GEN1.5, GEN1, and KOR), gender differences surfaced most systematically in the vowels of the GEN2 and the GEN1 speakers and that the front region of GEN2 speakers’ vowel space largely overlapped with that of the GEN1 speakers. That is, GEN2 speakers’ fronted vowel space reflects features that are present in both the CA speakers (i.e., horizontal compression and vertical expansion of the vowel space) and the Korean speakers (i.e., more fronted vowel space among female than male speakers), particularly those of their parents’ generation. Although evidence of individual vowels disfavors the possibility of influence from Korean phonology, the findings suggest that the vowel space of the female GEN2 speakers is moving forward to align with the front region of the female GEN1 speakers. Studies have shown that children of immigrants who acquire the majority language natively may use ethnolectal features as additional linguistic resources to mark social meanings (e.g., association with ethnicity) (Cheshire et al. 2011; Clyne et al. 2001; Gnevsheva 2020). While ethnolectal features may originate from first-generation immigrants’ foreign-accented speech, in second generation they may be reallocated for sociolinguistic purposes (Clyne et al. 2001; Gnevsheva 2020; Hoffman and Walker 2010). Thus, it is possible that the female GEN2 speakers shift their entire vowel space forward to index their intersecting ethnic and gender identities (i.e., cute and charming Korean female persona). The vowel space shift may occur independently or in combination with pronounced back vowel fronting to additionally express their pan-ethnic Asian American identity, as proposed above. Future research should examine intra-speaker variation of GEN2 speakers’ vowel productions (e.g., style-shifting) to understand the social meanings of their fronted vowel space. Moreover, a perceptual study should be accompanied to examine whether such social meanings are shared by the Korean American community.
5. Conclusions
In this study, we examined Korean Americans’ participation in the California Vowel Shift. Although the first-generation Korean Americans had spent a much longer time in the US than the Korean international students, influence from Korean still persisted in their speech. On the other hand, Korean Americans who were born and raised in Los Angeles (i.e., second-generation) or those who came to the US during childhood (i.e., 1.5-generation) demonstrated most patterns of the California Vowel Shift. However, divergence from the Anglo-Californians was observed in their production of prenasal and non-prenasal /æ/. The 1.5-generation speakers did not systematically distinguish the two vowel types, similar to the late bilinguals. The second-generation speakers demonstrated a split-/æ/ system, but it was less pronounced than for the Anglo-Californians. These findings suggests that age of arrival has a strong effect on immigrant minority speakers’ participation in local sound change.
Our findings also showed that the second-generation Korean Americans, in particular the female speakers, demonstrated an overall more fronted realization of the vowels than the Anglo-Californians. Second-generation Korean Americans’ fronted vowel space reflected features that were present in both the Anglo-Californians (i.e., horizontal compression and vertical expansion of the vowel space) and the Korean speakers, particularly those of the first-generation Korean Americans (i.e., more fronted vowel space among female than male speakers). These findings suggest that second-generation Korean Americans may shift their vowel space forward to express their intersecting gender, racial, and ethnic identities. Future research should examine the social meanings of the fronting of vowel space.
Author Contributions
Conceptualization, J.Y.K.; Data curation, N.W.; Formal analysis, J.Y.K.; Investigation, J.Y.K. and N.W.; Methodology, J.Y.K. and N.W.; Visualization, J.Y.K. and N.W.; Writing—original draft, J.Y.K.; Writing—review & editing, J.Y.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ahn, Sang-Cheol, and Gregory K. Iverson. 2007. Structured imbalances in the emergence of the Korean vowel system. In Historical Linguistics 2005: Selected Papers from the 17th International Conference on Historical Linguistics. Edited by Joseph C. Salmons and Shannon Dubenion-Smith. Amsterdam and Philadelphia: John Benjamins, pp. 275–93. [Google Scholar]
- Baker, Wendy, and Pavel Trofimovich. 2005. Interaction of Native- and Second-Language Vowels System(s) in Early and Late Bilinguals. Language and Speech 48: 1–27. [Google Scholar] [CrossRef]
- Baker, Wendy, Pavel Trofimovich, Molly Mack, and James E. Flege. 2002. The Effect of Perceived Phonetic Similarity on Non-Native Sound Learning by Children and Adults. In Proceedings of the 26th Annual Boston University Conference on Language Development. Edited by Barbora Skarabela, Sarah Fish and Anna H.-J. Do. Somerville: Cascadilla Press, pp. 36–47. [Google Scholar]
- Bates, Douglas, Martin Maechler, Bon Bolker, and Steve Walker. 2015. Fitting Linear Mixed-effects Models Using lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Best, Catherine T., and Michael D. Tyler. 2007. Nonnative and Second-language Speech Perception: Commonalities and Complementarities. In Language Experience in Second Language Speech Learning: In Honor of James Emil Flege. Edited by Ocke-Schwen Bohn and Murray J. Munro. Amsterdam and Philadelphia: John Benjamins, pp. 13–34. [Google Scholar]
- Boberg, Charles. 2004. Ethnic Patterns in the Phonetics of Montreal English. Journal of Sociolinguistics 8: 538–68. [Google Scholar] [CrossRef]
- Boersma, Paul, and David Weenink. 2020. Praat: Doing Phonetics by Computer. Computer Program. Version 5.1.31. Available online: http://www.praat.org/ (accessed on 3 July 2020).
- Brown, Janice. 2011. Re-framing “Kawaii”: Interrogating Global Anxieties Surrounding the Culture of ‘Cute’ in Japanese Art and Consumer Products. International Journal of the Image 1: 1–10. [Google Scholar] [CrossRef]
- Carter, Phillip E., Lydda L. Valdez, and Nandi Sims. 2020. New Dialect Formation through Language Contact: Vocalic and Prosodic Developments in Miami English. American Speech 95: 119–48. [Google Scholar] [CrossRef]
- Casillas, Joseph V., and Miquel Simonet. 2016. Production and Perception of the English/æ/-/ɑ/Contrast in Switched-dominance Speakers. Second Language Research 32: 171–95. [Google Scholar] [CrossRef]
- Chang, Charles B., Yao Yao, Erin F. Haynes, and Russell Rhodes. 2011. Production of Phonetic and Phonological Contrast by Heritage Speakers of Mandarin. The Journal of the Acoustical Society of America 129: 3964–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheng, Andrew. 2016. A Survey of English Vowel Spaces of Asian American Californians. UC Berkeley Phonetics and Phonology Lab Annual Report 12: 348–84. [Google Scholar]
- Cheshire, Jenny, Paul Kerswill, Sue Fox, and Eivind Torgersen. 2011. Contact, the Feature Pool and the Speech Community: The Emergence of Multicultural London English. Journal of Sociolinguistics 15: 151–96. [Google Scholar] [CrossRef] [Green Version]
- Chou, Rosalind S., and Joe R. Feagin. 2010. The Myth of the Model Minority: Asian Americans Facing Racism. Boulder: Paradigm Publishers. [Google Scholar]
- Clarke, Sandra, Ford Elms, and Amani Youssef. 1995. The Third Dialect of English: Some Canadian Evidence. Language Variation and Change 7: 209–28. [Google Scholar] [CrossRef]
- Clyne, Michael G., Edina Eisikovits, and Laura F. Tollfree. 2001. Ethnic varieties of Australian English. In English in Australia. Edited by David Blair and Peter Collins. Amsterdam: John Benjamins, pp. 223–38. [Google Scholar]
- Coates, Jennifer. 1993. Women, Men, and Language: A Sociolinguistic Account of Gender Differences in Language, 2nd ed. London: Longman. [Google Scholar]
- D’Onofrio, Annette, Penelope Eckert, Robert J. Podesva, Teresa Pratt, and Janneke Van Hofwegen. 2016. The Low Vowels in California’s Central Valley. Publication of the American Dialect Society 101: 11–32. [Google Scholar] [CrossRef]
- D’Onofrio, Annette, Teresa Pratt, and Janneke Van Hofwegen. 2019. Compression in the California Vowel Shift: Tracking Generational Sound Change in California’s Central Valley. Language Variation and Change 31: 193–217. [Google Scholar] [CrossRef]
- Eckert, Penelope. 1989. Jocks and Burnouts: Social Categories and Identity in the High School. New York: Teachers College Press. [Google Scholar]
- Eckert, Penelope. 2008. Where Do Ethnolects Stop? International Journal of Bilingualism 12: 25–42. [Google Scholar] [CrossRef] [Green Version]
- Escudero, Paola, Paul Boersma, Adréia Schurt Rauber, and Ricardo A. H. Bion. 2009. A Cross-dialect Acoustic Description of vowels: Brazilian and European Portuguese. The Journal of the Acoustical Society of America 126: 1379–93. [Google Scholar] [CrossRef] [Green Version]
- Farris, Catherine S. 1994. A Semiotic Analysis of Sajiao as a Gender Marked Communication Style in Chinese. In Unbound Taiwan: Closeups from a Distance, Select Papers 8. Edited by Marshall Johnson and Fred Y. L. Chiu. Chicago: Center for East Asian Studies, University of Chicago, pp. 2–29. [Google Scholar]
- Flege, James. E. 1995. Second-language Speech Learning: Theory, Findings, and Problems. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by Winifred Strange. Timonium: York Press, pp. 229–73. [Google Scholar]
- Flege, James. E. 1999. Age of Learning and Second-language Speech. In Second Language Acquisition and the Critical Period Hypothesis. Edited by David Birdsong. Mahwah: Lawrence Erlbaum Press, pp. 101–32. [Google Scholar]
- Flege, James E., and Ian R. A. MacKay. 2011. What Accounts for “Age” Effects on Overall Degree of Foreign Accent? In Achievements and Perspectives in the Acquisition of Second Language Speech. New Sounds. Edited by Magdalena Wrembel, Malgorzata Kul and Katarzyna Dziubalska-Kołaczyk. Bern: Peter Lang, vol. 2, pp. 65–82. [Google Scholar]
- Flege, James. E., Murray Munro, and Ian R. A. MacKay. 1995. Factors Affecting Strength of Perceived Foreign Accent in a Second Language. Journal of the Acoustical Society of America 97: 3125–34. [Google Scholar] [CrossRef]
- Flege, James. E., Ocke-Schewen Bohn, and Sunyoung Jang. 1997. Effects of Experience on Non-native Speakers’ Production and Perception of English Vowels. Journal of Phonetics 25: 437–70. [Google Scholar] [CrossRef] [Green Version]
- Flemming, Edward. 1996. Evidence for Constraints on Contrast: The Dispersion Theory of Contrast. UCLA Working Papers in Phonology 1: 86–106. [Google Scholar]
- Fought, Carmen. 1999. A Majority Sound Change in a Minority Community:/u/-Fronting in Chicano English. Journal of Sociolinguistics 3: 5–23. [Google Scholar] [CrossRef]
- Fought, Carmen. 2003. Chicano English in Context. New York: Macmillan. [Google Scholar]
- Gnevsheva, Ksenia. 2020. The Role of Style in the Ethnolect: Style-Shifting in the Use of Ethnolectal Features in the First- and Second-generation Speakers. International Journal of Bilingualism, 1–20. [Google Scholar] [CrossRef]
- Goffman, Erving. 1979. Gender Advertisements, 2nd ed. Cambridge: Harvard University Press. [Google Scholar]
- Gordon, Matthew. 2011. Methodological and Theoretical Issues in the Study of Chain Shifting. Language and Linguistics Compass 5: 784–94. [Google Scholar] [CrossRef]
- Hagiwara, Robert. 1997. Dialect Variation and Formant Frequency: The American English Vowels Revisited. Journal of the Acoustical Society of America 102: 655–8. [Google Scholar] [CrossRef]
- Hall-Lew, Lauren. 2009. Ethnicity and Sound Change in San Francisco English. Proceedings of the Annual Meeting of the Berkeley Linguistics Society 35: 111–22. [Google Scholar] [CrossRef] [Green Version]
- Hall-Lew, Lauren. 2011. The Completion of a Sound Change in California English. Proceedings of the International Congress of Phonetic Sciences 17: 807–10. [Google Scholar]
- Hall-Lew, Lauren, and Rebecca L. Starr. 2010. Beyond the 2nd Generation: English Use Among Chinese Americans in the San Francisco Bay Area. English Today 26: 12–19. [Google Scholar] [CrossRef] [Green Version]
- Hall-Lew, Lauren, Amanda Cardoso, Yova Kemenchedjieva, Kieran Wilson, Ruaridh Purse, and Julie Saigusa. 2015. San Francisco English and the California Vowel Shift. Paper presented at 18th International Conference of the Phonetic Sciences, Glasgow, UK, 10–14 August 2015. [Google Scholar]
- Hinton, Leanne, Birch Moonwomon, Sue Bremner, Herb Luthin, Mary Van Clay, Jean Lerner, and Hazel Corcoran. 1987. It’s Not Just the Valley Girls: A study of California English. Paper presented at Thirteenth Annual Meeting of the Berkeley Linguistics Society, Berkeley, CA, USA, 14–16 February 1987; pp. 117–28. [Google Scholar]
- Hoffman, Michol F. 2010. The Role of Social Factors in the Canadian Vowel Shift: Evidence from Toronto. American Speech 85: 121–40. [Google Scholar] [CrossRef]
- Hoffman, Michol F., and James A. Walker. 2010. Ethnolects and the City: Ethnic Orientation and Linguistic Variation in Toronto English. Language Variation and Change 22: 37–67. [Google Scholar] [CrossRef]
- Ito, Rika. 2010. Accommodation to the Local Majority Norm by Hmong Americans in the Twin Cities, Minnesota. American Speech 85: 141–62. [Google Scholar] [CrossRef]
- Jacewicz, Ewa, Robert Allen Fox, and Joseph Salmons. 2007. Vowel Space Areas across Dialects and Gender. In Proceedings of the 16th International Congress of Phonetic Sciences. Edited by Jürgen Trouvain and William John Barry. Saarbrücken: University of Saarland, pp. 1465–68. [Google Scholar]
- Jang, Hyejin, Jiyoung Shin, and Hosung Nam. 2015. Aspects of Vowels by Ages in Seoul Dialect. Studies in Phonetics, Phonology, and Morphology 21: 341–58. [Google Scholar] [CrossRef]
- Jia, Gisela, and Doris Aaronson. 2003. A Longitudinal Study of Chinese Children and Adolescents Learning English in the United States. Applied Psycholinguistics 24: 131–61. [Google Scholar] [CrossRef]
- Johannessen, Janne Bondi, and Signe Laake. 2015. On two myths of the Norwegian language in America: Is it old-fashioned? Is it approaching the written Bokmål standard? In Germanic Heritage Languages in North America. Edited by Janne Bondi Johannessen and Joseph C. Salmons. Amsterdam and Philadelphia: John Benjamins, pp. 299–322. [Google Scholar]
- Kang, Yoonjung. 2014. A Corpus-based Study of Positional Variation in Seoul Korean Vowels. Japanese/Korean Linguistics 23: 1–20. [Google Scholar]
- Kang, Jieun, and Eun Jong Kong. 2016. Static and Dynamic Spectral Properties of the Monophthong Vowels in Seoul Korean: Implication on Sound Change. Phonetics and Speech Sciences 8: 39–47. [Google Scholar] [CrossRef] [Green Version]
- Kawai, Yuko. 2005. Stereotyping Asian Americans: The Dialectic of the Model Minority and the Yellow Peril. The Howard Journal of Communications 16: 109–30. [Google Scholar] [CrossRef]
- Kennedy, Robert, and James Grama. 2012. Chain Shifting and Centralization in California Vowels: An Acoustic Analysis. American Speech 87: 39–56. [Google Scholar] [CrossRef]
- Kim, Jungeun, and Monika Stodolska. 2013. Impacts of Diaspora Travel on Ethnic Identity Development among 1.5 Generation Korean American College Students. Journal of Tourism and Cultural Change 11: 187–207. [Google Scholar] [CrossRef]
- Kuhl, Patricia K., Karern A. Williams, Francisco Lacerda, Kenneth N. Stevens, and Björn Lindblom. 1992. Linguistic Experience Alters Phonetic Perception in Infants by 6 Months of Age. Science 255: 606–8. [Google Scholar] [CrossRef]
- Kuznetsova Alexandra, Brockhoff Per B., and Christensen Rune H. B. 2017. LmerTest Package: Tests in Linear Mixed Effects Models. Journal of Statistical Software 82: 1–26. [Google Scholar] [CrossRef] [Green Version]
- Kwak, Chung-gu. 2003. The Vowel System of Contemporary Korean and Direction of Change. Journal of Korean Linguistics 41: 59–91. [Google Scholar]
- Labov, William. 1972. Language in the Inner City: Studies in Black English Vernacular. Philadelphia: University of Pennsylvania Press. [Google Scholar]
- Labov, William. 1990. The Intersection of Sex and Social Class in the Course of Linguistic Change. Language Variation and Change 2: 205–54. [Google Scholar] [CrossRef] [Green Version]
- Labov, William. 2001. Principles of Linguistic Change: Social Factors. Malden: Wiley-Blackwell, vol. 2. [Google Scholar]
- Labov, William. 2010. Principles of Linguistic Change: Cognitive and Cultural Factors. Malden: Wiley-Blackwell, vol. 3. [Google Scholar]
- Labov, William, Sharon Ash, and Charles Boberg. 2006. The Atlas of North American English: Phonetics, Phonology, and Sound Change. New York: Mouton de Gruyter. [Google Scholar]
- Lee, Hikyong. 2000. Korean Americans as Speakers of English: The Acquisition of General and Regional Features. Ph.D. dissertation, University of Pennsylvania, Philadelphia, PA, USA. [Google Scholar]
- Lee, Jinsok. 2016. The Participation of a Northern New Jersey Korean American Community in Local and National Language Variation. American Speech 91: 327–60. [Google Scholar] [CrossRef]
- Lee, Jess. 2019. Many Dimensions of Asian American Pan-ethnicity. Sociology Compass 13: 1–16. [Google Scholar] [CrossRef]
- Lee, Ki-Moon, and S. Robert Ramsey. 2011. A History of the Korean Language. Cambridge: Cambridge University Press. [Google Scholar]
- Lee, Hyangwon, Woobong Shin, and Jiyoung Shin. 2017. A Sociophonetic Study on High/Mid Back Vowels in Korean. Phonetics and Speech Sciences 9: 39–51. [Google Scholar]
- Lenth, Russell. 2020. Emmeans: Estimated Marginal Means, aka Least-Squares Means. R Package Version 1.5.0. Available online: https://CRAN.R-project.org/package=emmeans (accessed on 8 September 2020).
- Liljencrants, Johan, and Björn Lindblom. 1972. Numerical Simulation of Vowel Quality Systems: The Role of Perceptual Contrast. Language 48: 839–62. [Google Scholar] [CrossRef] [Green Version]
- Lindblom, Björn. 1990. Explaining Phonetic Variation: A Sketch of the H&H Theory. In Speech Production and Speech Modelling. Edited by William J. Hardcastle and Alain Marchal. Dordrecht: Springer, pp. 403–39. [Google Scholar]
- Lindblom, Björn, and Olle Engstrand. 1989. In What Sense is Speech Quantal? Journal of Phonetics 17: 107–21. [Google Scholar] [CrossRef]
- Lloyd-Smith, Anika, Marieke Einfeldt, and Tanja Kupisch. 2020. Italian-German Bilinguals: The Effects of Heritage Language Use on Accent in Early-Acquired Languages. International Journal of Bilingualism 24: 289–304. [Google Scholar] [CrossRef]
- Lobanov, Boris. 1971. Classification of Russian Vowels Spoken by Different Speakers. Journal of the Acoustical Society of America 49: 606–8. [Google Scholar] [CrossRef]
- Madge, Leila. 1998. Capitalizing on ‘Cuteness’: The Aesthetics of Social Relations in a New Postwar Japanese Order. Japanstudien 9: 155–74. [Google Scholar] [CrossRef] [Green Version]
- Martinet, André. 1952. Function, Structure, and Sound Change. Word 8: 1–32. [Google Scholar] [CrossRef]
- Mayer, Mercer. 1969. Frog, Where Are You? New York: Dial Press. [Google Scholar]
- McAuliffe, Michael, Michaela Socolof, Sarah Mihuc, Michael Wagner, and Morgan Sonderegger. 2017. Montreal Forced Aligner [Computer Program]. Version 0.9.0. Available online: http://montrealcorpustools.github.io/Montreal-Forced-Aligner/ (accessed on 17 January 2017).
- McCloy, Daniel R. 2016. PhonR: Tools for Phoneticians and Phonologists. R Package Version 1.0-7. Available online: https://CRAN.R-project.org/package=phonR (accessed on 8 September 2020).
- Mendoza-Denton, Norma. 1999. Fighting Words: Latina Girls, Gangs, and Language Attitudes. In Speaking Chicana: Voice, Power, and Identity. Edited by D. Letticia Galindo and María D. Gonzales. Tucson: University of Arizona Press, pp. 39–56. [Google Scholar]
- Mendoza-Denton, Norma, and Melissa Iwai. 1993. They Speak more Caucasian: Generation Differences in the Speech of Japanese-Americans. In Texas Linguistics Forum, Number 33. Austin: University of Texas, Department of Linguistics, pp. 58–67. [Google Scholar]
- Milroy, James, and Lesley Milroy. 1985. Linguistic Change, Social Network and Speaker Innovation. Journal of Linguistics 21: 339–84. [Google Scholar] [CrossRef] [Green Version]
- Ohara, Yumiko. 1998. Two Languages, Two Cultures, and Two Vocal Apparati? Sociolinguistic Explanation for Phonetic Phenomena in Bilingual Speakers of Korean and Japanese. In The Life of Language, the Language of Life: Selected Papers from the First College-Wide Conference for Students in Languages, Linguistics, and Literature. Edited by Dina Yoshimi and Marilyn Plumlee. Honolulu: University of Hawaii at Manoa, pp. 124–33. [Google Scholar]
- Parodi, Claudia. 2014. El español de Los Ángeles: Koineización y diglosia. In Lenguas, Estructuras y Hablantes: Estudios en Homenaje a Thomas C. Smith Stark. Edited by R. Barriga Villanueva and E. Herrera Zendejas. Tlalpan: El Colegio de México, Centro de Estudios Lingüísticos y Literarios, pp. 1101–23. [Google Scholar]
- Pennock-Speck, Barry. 2005. The Changing Voice of Women. In Actas del XXVIII Congreso Internacional de AEDEAN. Edited by Juan José Calvo García de Leonardo, Jesús Tronch Pérez, Milagros del Saz Rubio, Carme Manuel Cuenca, Barry Pennock Speck and Maria José Coperías Aguilar. Valencia: Dept. de Filologia Anglesa i Alemanya, Univ. de València, pp. 407–15. [Google Scholar]
- Pisanski, Katarzyna, Emanual C. Mora, Annette Pisanski, David Reby, Piotr Sorokowski, Tomasz Frackowiak, and David R. Feinberg. 2016. Volitional Exaggeration of Boday Size through Fundamental and Formant Frequency Modulation in Humans. Scientific Reports 6: 34389. [Google Scholar] [CrossRef]
- Podesva, Robert J. 2011. The California Vowel Shift and Gay Identity. American Speech 86: 32–51. [Google Scholar] [CrossRef] [Green Version]
- Podesva, Robert J., Annette D’Onofrio, Janneke Van Hofwegen, and Seung Kyung Kim. 2015. Country Ideology and the California Vowel Shift. Language Variation and Change 27: 157–86. [Google Scholar] [CrossRef]
- Polinsky, Maria. 2018. Heritage Languages and Their Speakers. Cambridge: Cambridge University Press, vol. 159. [Google Scholar]
- Pratt, Teresa, and Annette D’Onofrio. 2017. Jaw Setting and the California Vowel Shift in Parodic Performance. Language in Society 46: 283–312. [Google Scholar] [CrossRef]
- Puzar, Aljosa, and Yewon Hong. 2018. Korean Cuties: Understanding Performed Winsomeness (Aegyo) in South Korea. The Asia Pacific Journal of Anthropology 19: 333–49. [Google Scholar] [CrossRef]
- R Development Core Team. 2020. R Development Core Team, R: A Language and Environment for Statistical Computing. Available online: https://www.r-project.org/ (accessed on 8 September 2020).
- Roeder, Rebecca V. 2010. Northern Cities Mexican American English: Vowel Production and Perception. American Speech 85: 163–84. [Google Scholar] [CrossRef]
- Simpson, Adrian P. 2002. Gender-specific Articulatory-acoustic Relations in Vowel Sequences. Journal of Phonetics 30: 417–35. [Google Scholar] [CrossRef]
- Sohn, Ho-min. 1999. The Korean Language. Cambridge: Cambridge University Press. [Google Scholar]
- Stevens, Gillian. 1999. Age at Immigration and Second Language Proficiency among Foreign-born Adults. Language in Society 28: 555–78. [Google Scholar] [CrossRef]
- Thomas, Erik R. 2000. Spectral Differences in/ai/Offsets Conditioned by Voicing of the Following Consonant. Journal of Phonetics 28: 1–25. [Google Scholar] [CrossRef]
- Thomas, Erik R. 2001. An Acoustic Analysis of Vowel Variation in New World English. In Publication of the American Dialect Society 85. Durham: Duke University Press. [Google Scholar]
- Traunmüller, Hartmut. 1997. Auditory Scales of Frequency Representation. Stockholm: Department of Linguistics, Stockholm University, Available online: http://www.ling.su.se/staff/hartmut/bark.htm (accessed on 8 September 2020).
- Trofimovich, Pavel, Wendy Baker, and Molly Mack. 2011. Context- and Experience-based Effects on the Learning of Vowels in a Second Language. Studies in the Linguistics Sciences 31: 167–86. [Google Scholar]
- Trudgill, Peter. 1972. Sex, Covert Prestige and Linguistic Change in the Urban British English of Norwich. Language in Society 1: 179–95. [Google Scholar] [CrossRef] [Green Version]
- Tseng, Amelia. 2015. Vowel Variation, Style, and Identity Construction in the English of Latinos in Washington, D.C. Ph.D. dissertation, Georgetown University, Washington, DC, USA. [Google Scholar]
- Tsukada, Kimiko, David Birdsong, Ellen Bialystok, Molly Mack, Hyekyung Sung, and James E. Flege. 2005. A Developmental Study of English Vowel Production and Perception by Native Korean Adults and Children. Journal of Phonetics 33: 263–90. [Google Scholar] [CrossRef]
- Van Bezooijen, Reneé. 1995. Sociocultural Aspects of Pitch Differences between Japanese and Dutch Women. Language and Speech 38: 253–65. [Google Scholar] [CrossRef]
- Wei, William. 1993. The Asian American Movement. Philadelphia: Temple University Press. [Google Scholar]
- Weinfeld, Morton. 1985. Myth and Reality in the Canadian Mosaic: Affective ethnicity. In Ethnicity and Ethnic Relations in Canada: A Book of Readings, 2nd ed. Edited by Rita M. Bienvenue and Jay E. Goldstein. Toronto: Butterworths, pp. 65–86. [Google Scholar]
- Werker, Janet F., and Richard C. Tees. 1984. Cross-language Speech Perception: Evidence for Perceptual Reorganization during the First Year of Life. Infant Behavior and Development 7: 49–63. [Google Scholar] [CrossRef]
- Yang, Byunggon. 1996. A Comparative Study of American English and Korean Vowels Produced by Male and Female Speakers. Journal of Phonetics 24: 245–61. [Google Scholar] [CrossRef] [Green Version]
- Yeni-Komshian, Grace H., James E. Flege, and Serena Liu. 2000. Pronunciation Proficiency in the First and Second Languages of Korean-English Bilinguals. Bilingualism: Language and Cognition 3: 131–49. [Google Scholar] [CrossRef]
- Yoon, Kyuchul, and Soonok Kim. 2015. A Comparative Study on the Male and Female Vowel Formants of the Korean Corpus of Spontaneous Speech. Phonetics and Speech Sciences 7: 131–38. [Google Scholar] [CrossRef] [Green Version]
- Yuasa, Ikuko Patricia. 2010. Creaky Voice: A New Feminine Voice Quality for Young Urban-oriented Upwardly Mobile American Women? American Speech 85: 315–37. [Google Scholar] [CrossRef]
- Zampini, Mary. 2008. L2 Speech Production Research: Findings, Issues and Advances. In Phonology and Second Language Acquisition. Edited by Jette. G. Hansen Edwards and Mary Zampini. Amsterdam: John Benjamins, pp. 219–50. [Google Scholar]
| 1 | Figure 1 was created based on the data of millennial speakers reported in Table A1 in D’Onofrio et al. (2019). Note that BOOK-type tokens (i.e., /ʊ/) were not examined in D’Onofrio et al. (2019), thus, we added the fronting of /ʊ/ in Figure 1 based on previous studies on the California Vowel Shift (e.g., Podesva et al. 2015; Pratt and D’Onofrio 2017). |
| 2 | In some cases, front rounded vowels /y/ and /ø/ may be additionally observed in the speech of older generation speakers, but in modern South Korean these sounds are mostly replaced by the diphthongs [we] and [wi], respectively (Ahn and Iverson 2007; Kwak 2003; Jang et al. 2015). |
| 3 | Kang (2014) specified these speakers as male speakers born before 1962 (i.e., birth-year-based), while in Jang et al. (2015), these speakers were male and female speakers in their 60s (i.e., age-based). Since the data in Jang et al. (2015) were collected between 2014 and 2015, we speculate that these speakers were born between 1945 and 1955. |
| 4 | Figure 2 was created by averaging the data of male and female speakers in their 20s reported in Table 1 in Kang and Kong (2016). |
| 5 | In a cross-dialectal study, Lee et al. (2017) found that speakers of other Korean dialects (i.e., South Jeolla, South Gyeongsang, and Jaeju) showed converging patterns to Seoul Korean. |
| 6 | Despite dialectal differences, Lee et al. (2017) showed that the /o/-raising in other Korean dialects demonstrates converging patterns to the Seoul dialect, similar to the case of the fronting of /ɨ/ and /u/. |
| 7 | Both Daegu and Yeongju are cities in North Gyeongsang region in South Korea. |
| 8 | The areas are divided by regions, indicated by the suffix Do in Korean, in which different varieties of Korean are spoken. |
| 9 | The two KOR speakers and the CA speaker had spent 2 years, 2 years, and 1 year, respectively, in Illinois at the time of data collection. |
| 10 | The CA speaker was temporarily visiting Arizona at the time of data collection, but was residing in Los Angeles County. |
| 11 | In fact, among the five groups, GEN2 speakers’ IH was produced with the lowest vowel height. Results of the same model with the GEN2 speakers as the reference group (instead of the CA speakers) confirmed that, except for the GEN1.5 speakers, the GEN2 speakers produced IH significantly lower than the other groups (CA: β = −0.375, SE = 0.151, t = −2.48, p < 0.05; GEN1: β = −0.699, SE = 0.124, t = −5.622, p < 0.001; KOR: β = −0.603, SE = 0.17, t = −3.556, p < 0.001). |
| 12 | It is noteworthy that the CA speakers and the early bilinguals did not use vowel frontedness to distinguish the UW-UH contrast, whereas they used both vowel height and frontedness when distinguishing other contrasts (see Table 2). We suspect that this is linked to the lack of a main effect of previous consonant on the production of UW and UH. The findings of this study differed from previous research (D’Onofrio et al. 2019; Hall-Lew 2009; Podesva et al. 2015) in that the production of UW and UH was not conditioned by the phonological context that encourages fronting (i.e., post-coronal position). Although our data do not have enough tokens in post-coronal position to further examine its effect on individual speakers, these findings seem to indicate that the fronting of UW and UH is well established among the CA speakers and the early bilinguals. A similar claim has been made by Hall-Lew (2009, 2011) that back vowel fronting is nearing completion in Northern California. |
| 13 | The only gender difference in the CA group was found in the vowel height of EH. That is, the CA female speakers produced EH lower than the male speakers. Kennedy and Grama (2012) found similar results in that female and male Californians in Santa Barbara (Southern California) differed in the height of AE (i.e., women produced it lower than men), but did not show any significant difference in vowel frontedness. Since women in general are leaders of sound changes (Coates 1993; Milroy and Milroy 1985; Labov 1990; Trudgill 1972), it appears that the lowering of mid and low front vowels EH and AE is still in progress in California English, whereas changes in the front-back dimension (i.e., retraction of front vowels and fronting of back vowels) may be nearing stability for the CA speakers. |
| 14 | According to Puzar and Hong (2018), aegyo is not a direct emulation of child behaviors, but a performative repertoire of secondary infantilisation (Goffman 1979, pp. 72–77) used for various purposes (e.g., playfulness, seduction, negotiation, pleasing superiors). Thus, performers of aegyo, particularly young women, use this speech style to “negotiate the imbalance of power within patriarchal, androcentric and ageist/gerontocratic environments” (Puzar and Hong 2018). Similar concepts exist in other East Asian cultures, such as sajiao in China (Farris 1994) and kawaii in Japan (Brown 2011; Madge 1998). |
Figure 1.
California Vowel Shift (adapted from D’Onofrio et al. (2019)).
Figure 1.
California Vowel Shift (adapted from D’Onofrio et al. (2019)).

Figure 2.
Korean vowel space of young generation Koreans (adapted from Kang and Kong (2016)).
Figure 2.
Korean vowel space of young generation Koreans (adapted from Kang and Kong (2016)).

Figure 3.
Normalized F1-F2 space by group and gender.

Figure 4.
Normalized F2 across groups: (a) IH; (b) EH; (c) AE.

Figure 5.
AE and AEN across groups: (a) Normalized F1; (b) Normalized F2.

Figure 6.
AA and AO across groups: (a) Normalized F1; (b) Normalized F2.


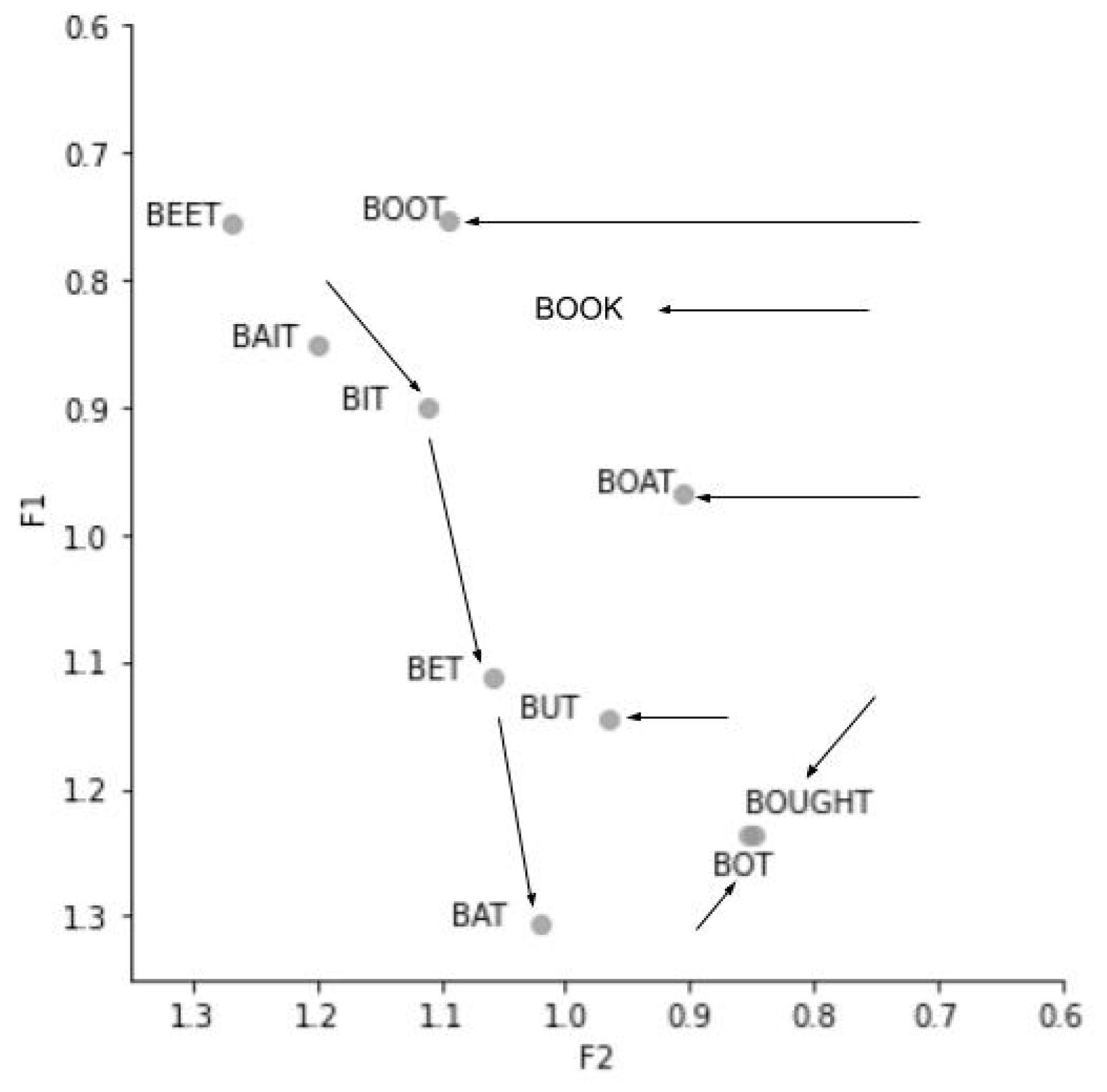{kind=link}
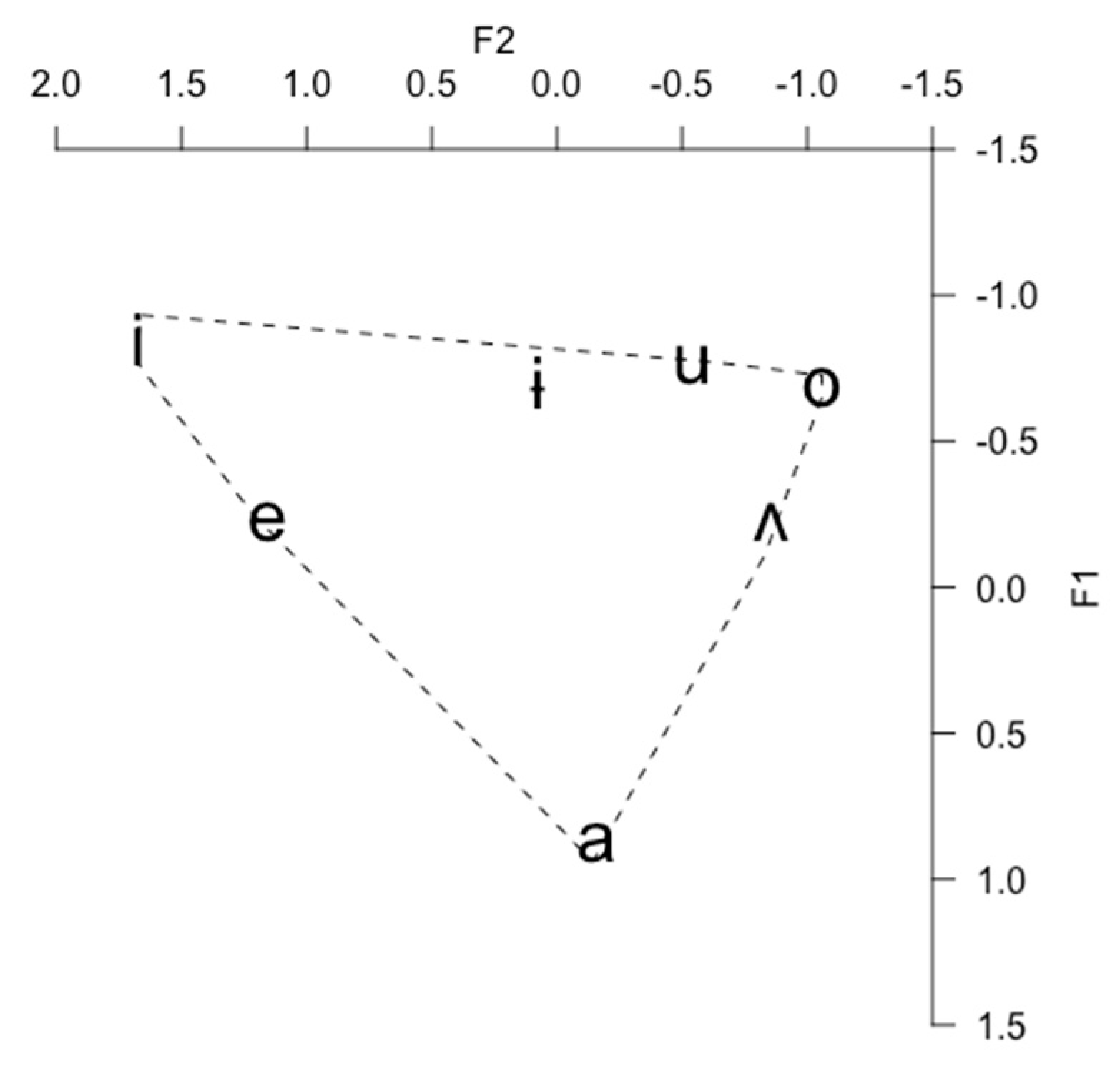{kind=link}
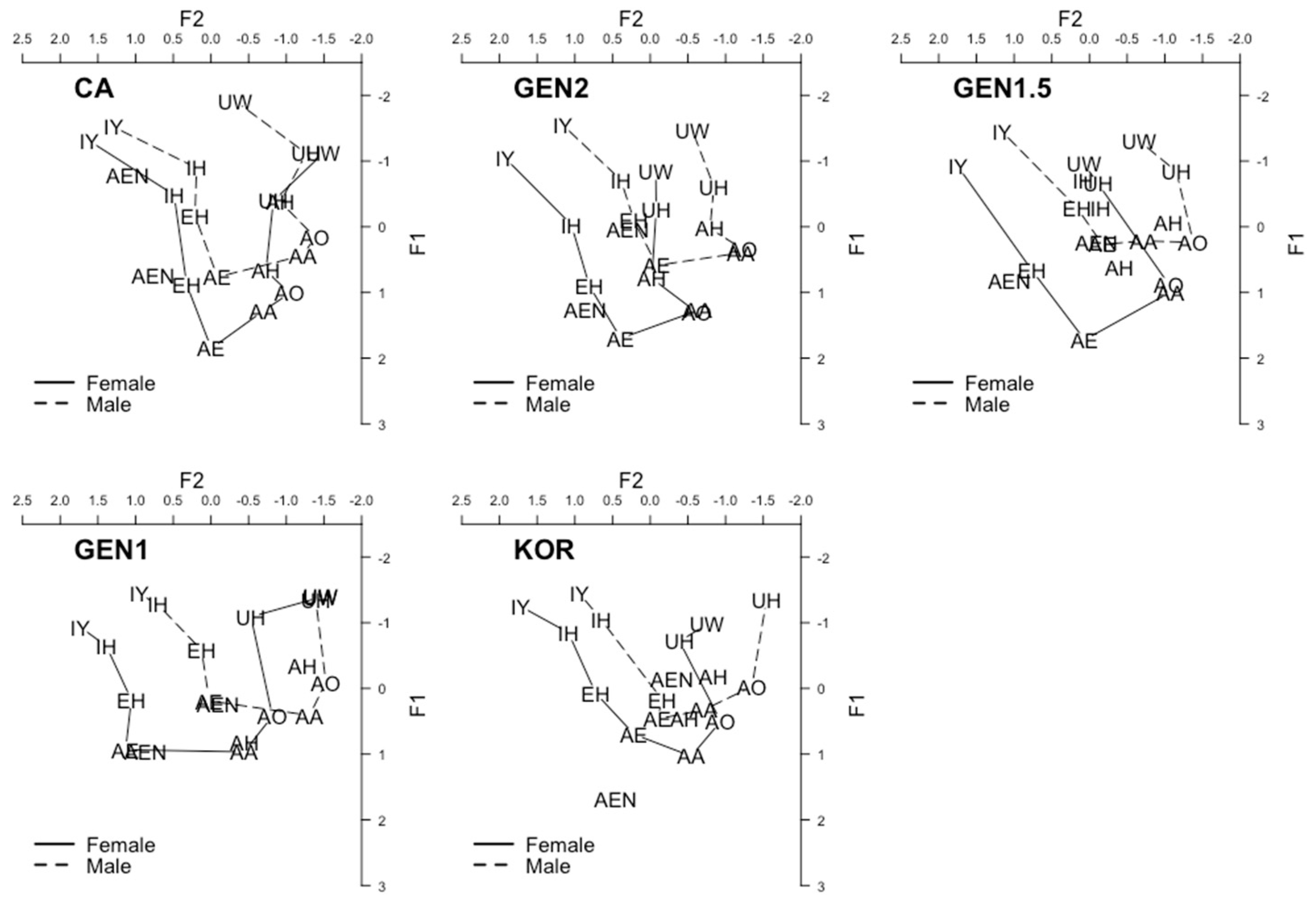{kind=link}
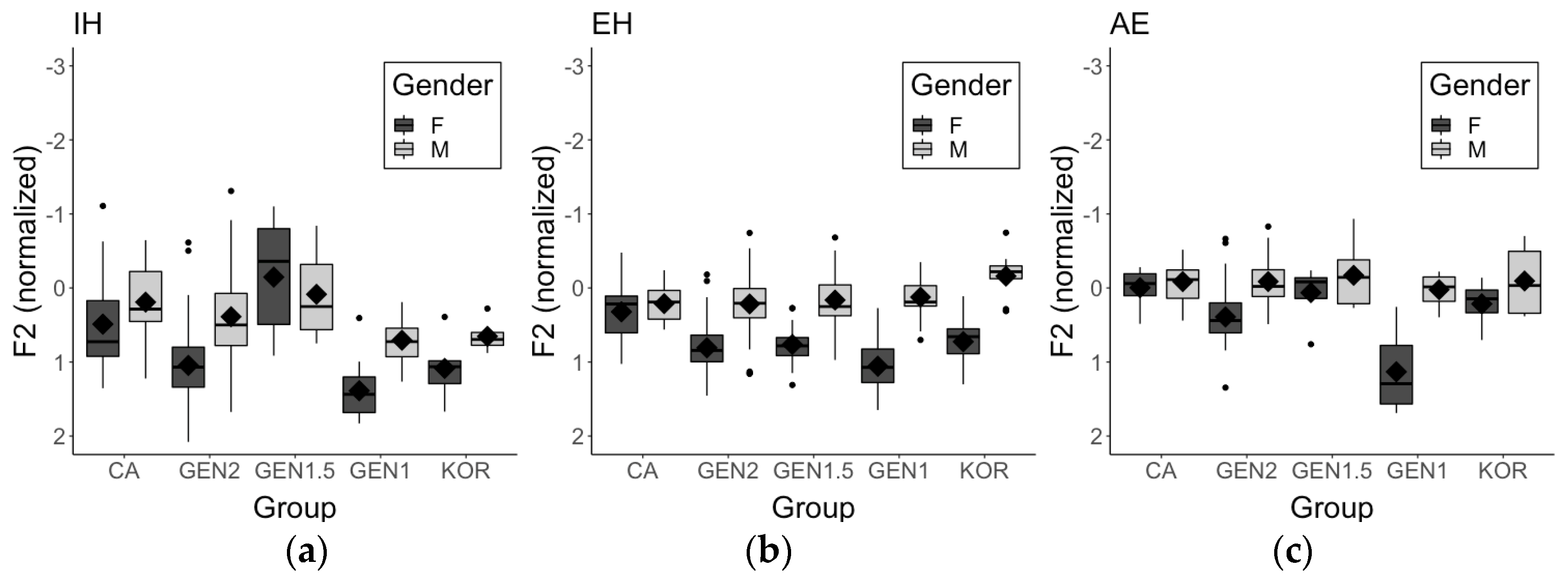{kind=link}
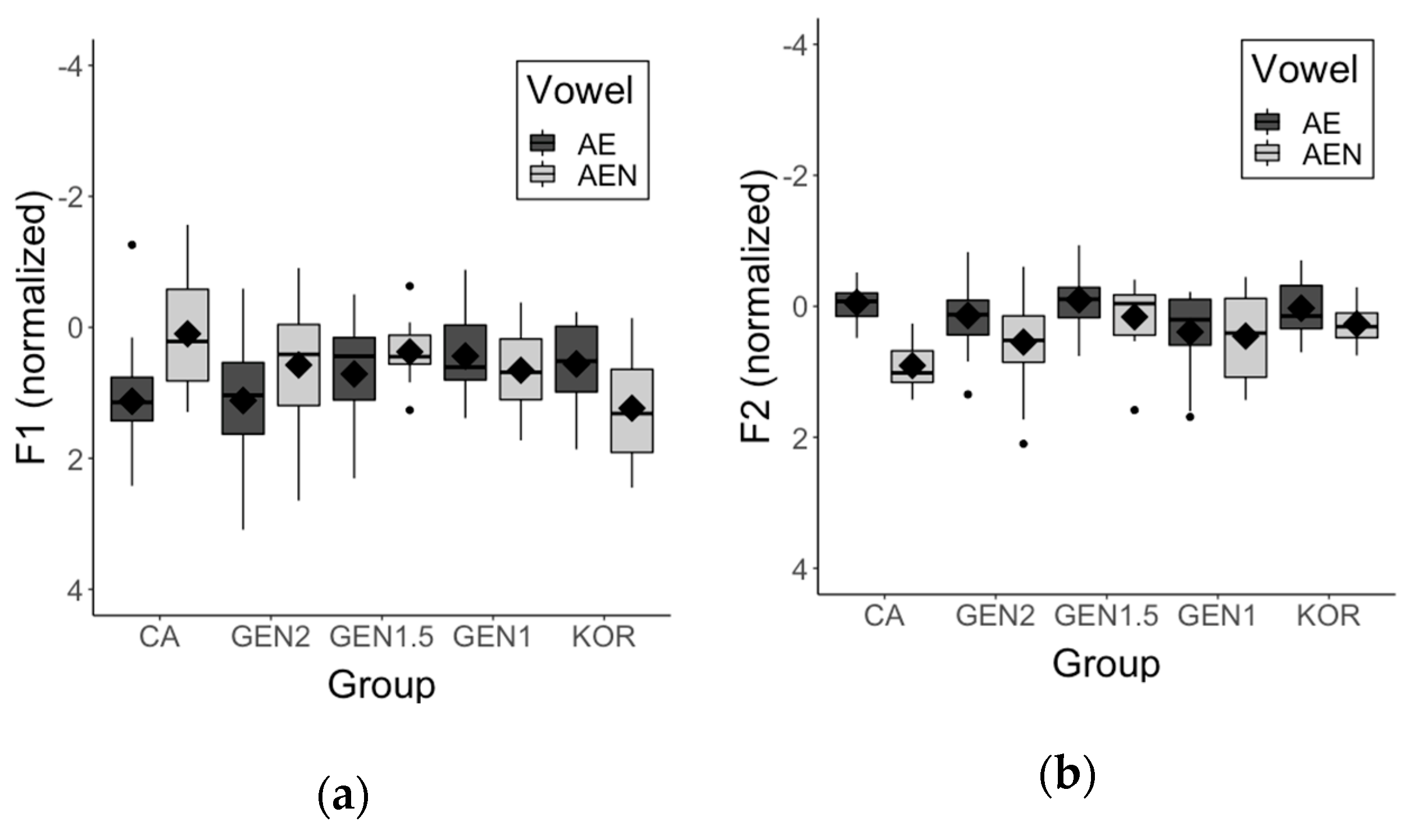{kind=link}
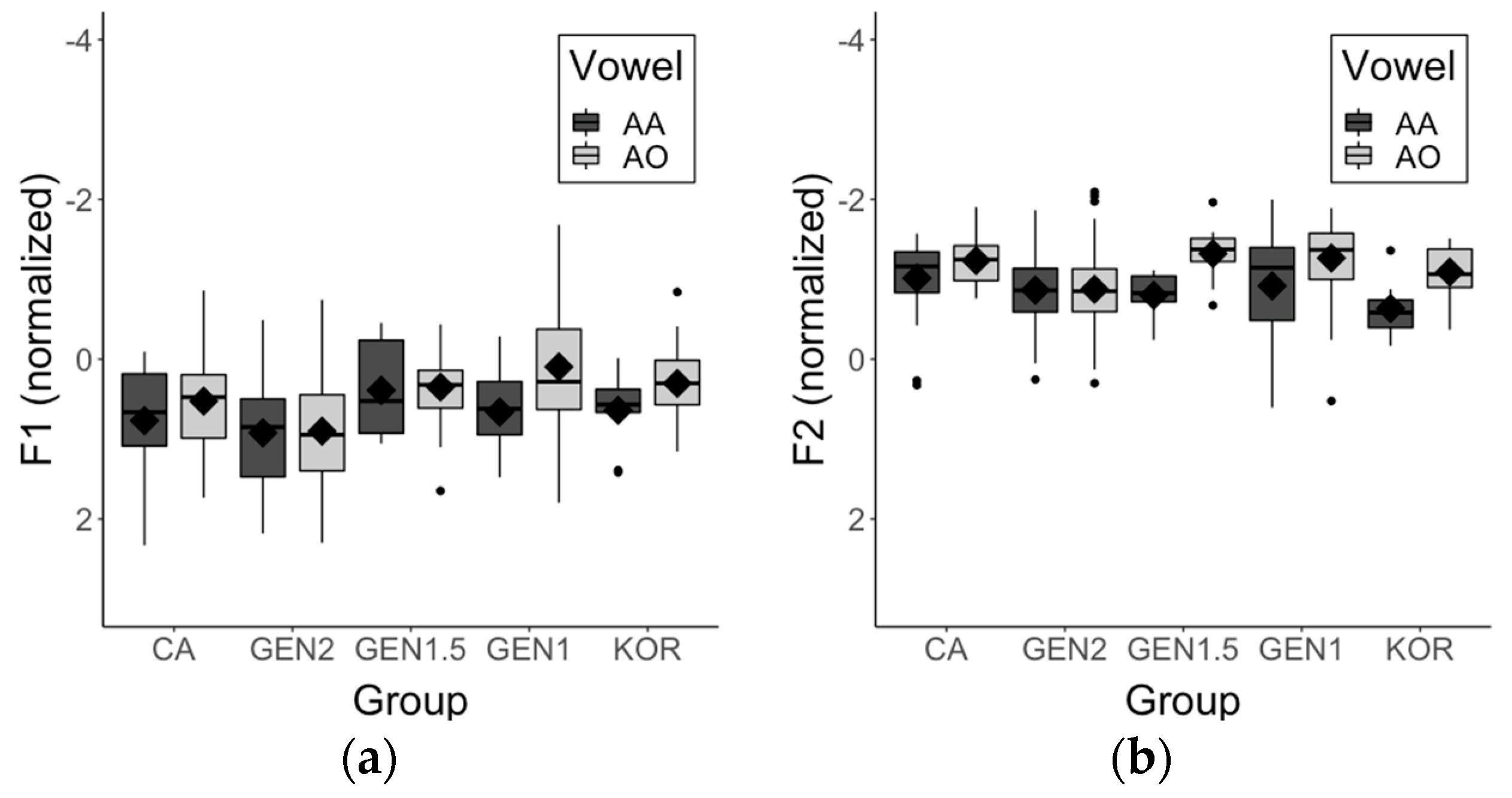{kind=link}
Table 1.
Participants’ language backgrounds (standard deviation is presented in parentheses).
| GEN1 (N = 8) | GEN1.5 (N = 4) | GEN2 (N = 25) | KOR (N = 4) | CA (N = 5) | |
|---|---|---|---|---|---|
| Gender | 4F, 4M | 1F, 3M | 15F, 10M | 2F, 2M | 2F, 3M |
| Age (years) | 49.5 (9.3) | 23.8 (3.8) | 24.7 (4.4) | 26.8 (6.1) | 30.8 (15.4) |
| Age of arrival (years) | 25.8 (5) | 10.5 (1.7) | 0.5 (0.9) | 22.8 (7.1) | - |
| Length of residence (years) | 26.8 (10.6) | 13.3 (4.9) | - | 4 (4.3) | - |
| English use | 53.7% (24.5) | 90% (4) | 83.2% (15.8) | 47.5% (5) | 82% (18.3) |
| Korean use | 46.3% (2.4) | 10% (4) | 16.8% (15.8) | 52.5% (5) | - |
| English proficiency 1–5 (=Native) | 2.7 (0.8) | 5 (0) | 5 (0.1) | 3.7 (0.6) | 5 (0) |
| Korean proficiency 1–5 (=Native) | 5 (0) | 4.3 (1) | 2.9 (0.7) | 5 (0) | - |
Table 2.
Summary of the statistical results of English vowel contrasts.
| IY vs. IH | EH vs. AE | UH vs. UW | AH vs. AO | |
|---|---|---|---|---|
| CA | F1: ***/F2: *** | F1: ***/F2: ** | F1: ***/F2: n.s. | F1: ***/F2: ** |
| GEN2 | F1: ***/F2: *** | F1: ***/F2: *** | F1: ***/F2: n.s. | F1: ***/F2: *** |
| GEN1.5 | F1: ***/F2: *** | F1: ***/F2: *** | F1: **/F2: n.s. | F1: */F2: p = 0.057 |
| GEN1 | F1: n.s./F2: * | F1: ***/F2: n.s. | F1: n.s./F2: n.s. | F1: n.s./F2: n.s. |
| KOR | F1: n.s./F2: * | F1: */F2: n.s. | F1: n.s./F2: n.s. | F1: n.s./F2: n.s. |
***: p < 0.001, **: p < 0.01, *: p < 0.05, n.s.: non-significant.
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Kim, J.Y.; Wong, N. (Divergent) Participation in the California Vowel Shift by Korean Americans in Southern California. Languages 2020, 5, 53. https://0-doi-org.brum.beds.ac.uk/10.3390/languages5040053
AMA Style
Kim JY, Wong N. (Divergent) Participation in the California Vowel Shift by Korean Americans in Southern California. Languages. 2020; 5(4):53. https://0-doi-org.brum.beds.ac.uk/10.3390/languages5040053
Chicago/Turabian StyleKim, Ji Young, and Nicole Wong. 2020. "(Divergent) Participation in the California Vowel Shift by Korean Americans in Southern California" Languages 5, no. 4: 53. https://0-doi-org.brum.beds.ac.uk/10.3390/languages5040053