The Effect of Forms’ Ratio of Conditioning on Word-Final /s/ Voicing in Mexican Spanish


Department of Linguistics, Brigham Young University, Provo, UT 84602, USA
Languages 2020, 5(4), 61; https://0-doi-org.brum.beds.ac.uk/10.3390/languages5040061
Submission received: 2 September 2020
/
Revised: 10 November 2020
/
Accepted: 11 November 2020
/
Published: 16 November 2020
(This article belongs to the Special Issue Revisiting Language Variation and Change: Looking at Metalinguistic Categories Through a Usage-Based Lens)
Abstract
:There is mounting evidence that words that occur proportionately more often in contexts that condition a phonetically-motivated sound change end up changing more rapidly than other words. Support has been found in at least modern-day Spanish, Medieval Spanish, bilingual English-Spanish, and modern-day English. This study tests whether there is support for this idea with regards to the variable voicing of word-final /s/ in Spanish. An analysis of 1431 tokens of word-final /s/ spoken by 15 female speakers of Mexican Spanish living in Salinas, California, USA is performed. The response variable is the percentage of the /s/ segment that is voiced, and the effect of a handful of predictor variables shown in the literature to condition /s/ voicing is investigated. The variable of interest is forms’ ratio of conditioning (FRC), or the proportion of times with which word types occur in the context that conditions voicing of word-final /s/. The results of a series of 40 beta regression models indicate that FRC significantly conditions the percentage of voicing of word-final /s/ in these data. Also, the effect of manipulating two aspects of FRC operationalization is analyzed. This study adds to the growing body of literature documenting the importance of cumulative contextual information in the mental representation of words.
1. Introduction
Word-final /s/ in Spanish is sometimes followed by a consonant as in (1), sometimes by a vowel as in (2), and sometimes by a pause as in (3).
(1)…saber cómo reaccionar en el momento de que los niños tienen una pregunta. ‘…knowing how to react in moments when the children have a question.’(Speaker 6)
(2)…porque una de mis hermanas1 nació en en México, en la capital… ‘…because one of my sisters was born in in Mexico, in the capital…’(Speaker 4)
(3)…en suavizar el acento del inglés. ‘…with softening the accent of English.’(Speaker 18)
When in coda position, whether followed by a consonant or a pause, /s/ can be changed to an articulation other than a voiceless dental or alveolar sibilant, the articulation that can safely be considered the canonical one.2 In many areas of the Spanish-speaking world (i.e., the Caribbean, southern Spain, and many areas of Central and South America), coda /s/ is articulated as an aspiration (e.g., e[h]tá[h] ‘2ꜱ to be’) or is not pronounced (e.g., etá). Another way /s/ can be modified is for it to be voiced, that is [z], as in example (4), which is drawn in Figure 1. As seen in Figure 1, the waveform shows periodic peaks and valleys and there are regular glottal pulses visible in the voice bar in the spectrogram.
(4)…los niños que van a estar tomando clase[z] de verano. ‘…the kids who will be taking summer classes’(Speaker 15)
In varieties of Spanish that maintain the sibilance of coda /s/ at high rates (e.g., the Spanish of central Mexico; cf. Lipski 1994), voicing of coda /s/ is common before voiced consonants (e.g., mi[z]mo ‘same’, lo[z] dedos ‘the fingers’). This context for /s/-voicing is often pointed out by authors of descriptive treatments of Spanish phonetics and phonology. Schwegler, Kempff and Ameal–Guerra (Schwegler et al. 2010, p. 308) describe this phenomenon as follows: “/s/ can only be realized as [z] when it ‘suffers’ from regressive assimilation… that is, when it is followed by a voiced consonant.”3 Referring to the voiced allophone [z] of /s/, Quilis and Fernández (1973, p. 97) say: “[the voiced allophone] is almost always produced when the /s/ phoneme precedes a voiced consonant, since, because of lack of control of the vocal cords, the voicing is transmitted to the voiceless consonant… this articulation is not consistent.”4 Alba (2001, p. 125) explicates: “When /s/ appears in syllable-final position, it tends to be voiced before a voiced consonant.”5 Hualde (2005, p. 159) states: “In dialects where /s/ is normally preserved in the coda, this segment often assimilates in voice to a voiced consonant…this segment may present only partial or incomplete voicing.” To summarize, many authors indicate that the conditioning context most propitious for coda /s/ voicing in Spanish is when this sound is followed by a voiced consonant.
Despite the tendency for coda /s/ to voice before voiced consonants in varieties of Spanish with relatively high levels of /s/ sibilance, this is not the only phonological context in which /s/ can be voiced. Intervocalic /s/ voicing in Spanish (e.g., pa[z]a ‘raisin’) has been attested in highland Ecuador (Robinson 1979; Strycharczuk et al. 2014; García 2015), in highland Colombia (Garcia 2013), in Costa Rica (Chappell 2016; Chappell and García 2017), and in Madrid, Spain (Torreira and Ernestus 2012). Various conditioning factors have been explored by these authors, including social meaning, surrounding phonological contexts, lexical frequency, and contextual predictability.
Returning to coda /s/, an increasing number of authors have shown that the voicing process before voiced consonants is not categorical, but rather it is variable. Schmidt and Willis (2011) find that in a picture-description task, /s/ is voiced before voiced consonants in only 63% of the 567 tokens of word-medial /s/ spoken by 12 speakers native to Mexico City. Those authors considered a token of /s/ to be voiced if 60% or more of the segment had visible regular glottal pulses in the voice bar of the spectrogram and regular periodic patterns in the waveform, as seen in the phonetics software Praat (Boersma and Weenink 2020). Campos-Astorkiza (2014) also reports variability of voicing of /s/ in the read speech of six female speakers in Bilbao, Spain. She finds that 57% of the tokens of /s/ had 90% or greater amount of voicing of the /s/ interval, and she attributes this variable voicing to gestural blending with surrounding segments. Sedó (2015) also studies /s/ voicing assimilation in the Basque Country in northern Spain, specifically in the regional capital city of Vitoria. Using a methodology similar to Schmidt and Willis (2011), she finds a rate of 58% voicing of /s/. Sedó, Schmidt, and Willis (Sedó et al. 2020) use controlled phrase elicitation tasks in Mexico City and in León and Vitoria, Spain. Those authors find between 43% and 63% voicing of /s/ in the conditioning context, that is, before voiced consonants. The studies cited here are a sample of the growing body of literature documenting the variable application of the assimilation process of /s/-voicing before voiced consonants in Spanish (cf. Romero 1999; Muñiz Cachón and Cuevas Alonso 2003; Campos-Astorkiza 2015, 2017, 2019; Sedó del Campo 2017).
1.1. Usage Affects Structure
Structuralist views of language propose that the system of language, or its grammar, is invariable and so-called “surface forms” are generated by applying rules and constraints to the underlying system. Such notions are rooted in at least the early twentieth century Saussurian concepts of langue ‘language’’ and parole ‘speech’ (de Saussure [1916] 1959), and continued through the mid-twentieth century with the Chomskyan ideas of competence and performance (Chomsky 1957; Chomsky 1965). Currently, Optimality Theory (Prince and Smolensky 2004) in phonological theory continues to hold onto the tenet that what is produced in speech is different from the underlying language structure, and that speech is the result of the optimal configuration of competing constraints on the underlying structure.
In contrast, usage-based models of language posit that language usage affects the structure of language, that is, its grammar and sound system. These approaches to language (e.g., Storms et al. 2000) are based on exemplar theory in psychology (cf. Hintzman and Ludlam 1980; Homa et al. 1981), and hypothesize the existence of a vast mental storage ability of language users, with little or no need for rules or constraints. Sounds and word forms, along with their phonetic, contextual, and sociolinguistic variability, are stored whole in memory. In some usage-based models of language (cf. Bybee 2001, 2002, 2010), speakers are said to hold onto actual exemplars experienced in language rather than to create an abstract prototype and then discard the experienced tokens. See Ernestus (2014) for an overview of usage- and exemplar-based perspectives of language.
Current research continues to substantiate usage-based theories of language with empirical evidence. Concerning phonetically motivated sound changes, Bybee (2002, p. 261) claims that “words that occur more often in the context for change change more rapidly than those that occur less often in that context.” She offers evidence from the deletion of word-final /d/ and /t/ in English words with consonant clusters, such as just, perfect, child, and grand. Several factors condition the deletion of /d/ and /t/ in this position, including the following phonological context, with more deletion when followed by a consonant in the next word. Crucially, she finds that words that occur frequently before words that begin with a consonant are more prone to being articulated without /d/ or /t/, even outside of that conditioning context. She makes the claim that this is due to the fact that the mental representation of those words has been affected by repeated exposure to the conditioning context.
Further support of the idea that the contexts in which words occur affects their mental representation, and therefore later production, is mounting. In English, Seyfarth (2014) analyzes the duration of words in two corpora of spoken English: the Buckeye Corpus (Pitt et al. 2007) of middle- and working-class white speakers in central Ohio, and the Switchboard Corpus (Godfrey and Holliman 1997) of telephone conversations between participants across the United States. From 41,167 word tokens in Buckeye and 107,981 word tokens in Switchboard, the author finds that words that usually occur in predictable contexts, given the preceding or following words, are usually reduced in duration. Further, the results show that words that are usually predictable are reduced even when they are adjacent to unpredictable words. The author argues that these results suggest that reduction based on predictability is stored in the mental representation of words.
Also in English, Forrest (2017) studies the speech of 132 speakers in the Raleigh, North Carolina, area and analyzes 13,167 tokens of the alternation between the canonical velar nasal [ŋ] and the stigmatized alveolar nasal [n] at the end of words with orthographic <ing>. The author finds that words that occur frequently in the context for the alveolar pronunciation are more strongly affected by lexical frequency. Conversely, words that occur infrequently in the context for an alveolar articulation are less affected by lexical frequency. Hence, the author discovers a significant interaction between the ratio with which words occur in the context for change and the overall frequency of words in which the ING alternation is possible.
Further, Sóskuthy and Hay (2017) show that over a 130 year period in New Zealand English, words that occur increasingly in utterance final position, a context favorable to durational lengthening, lengthen in all positions, including utterance-medially. They attribute this effect, and others in their study, to a production-perception loop that allows speakers to dynamically update the lexical representations of words based on their experience.
Additional empirical support of the notion that words that occur in the context for change change quicker than other words is seen in Spanish. Brown (2004) finds an effect from forms’ ratio in conditioning contexts on word-initial /s/ in the Spanish of northern New Mexico and southern Colorado. Simply put, forms’ ratio of conditioning (henceforth FRC) is the proportion with which words occur in contexts that condition a change or reduction in one or more of their sounds. As expected, words that occur proportionally more often in contexts that favor the reduction of the articulation of the initial /s/ (i.e., following a non-high vowel, as in la señora ‘the lady’) have a higher proportion of reduced articulations of /s/, that is, [h].
In a different variety of Spanish, Brown (2009) also finds an effect from the ratio with which words occur in contexts that condition change in the Spanish of Cali, Colombia. That author finds that word-final /s/ is pronounced as an aspiration (e.g., [h]) or is not pronounced at all in words that occur proportionally more often before words that begin with a consonant, which is the context in this variety of Spanish (and many others) that favor the articulatory and gestural reduction of syllable- and word-final /s/.
Support for the conditioning effect of FRC has also been found in Medieval Spanish. Brown and Raymond (2012) measure the effect of FRC in that variety of Spanish on the variable Modern Spanish outcome of word-initial Latin /f/ followed by a vowel. Some words in Modern Spanish retain the /f/ from Latin (e.g., Lat. favor > Span. favor ‘favor’) while other words have lost /f/ (e.g., Lat. fabulare > Span. hablar [aβlaɾ] ‘to speak’). In addition to stress, those authors attribute the variable outcome in Modern Spanish of word-initial /f/ in Latin to FRC. Further, they argue for the preeminence of FRC over lexical frequency with this sound change.
Evidence in support of FRC has even been found in Spanish-English bilingual speech. Brown (2015) studies the speech of Spanish-English bilinguals in New Mexico, USA, and analyzes the articulation of 2629 tokens of word-initial /d/ in Spanish. She finds that cognate status is a significant contributor to the modification of this sound, such that /d/ in cognates (e.g., doctor ‘doctor’) is reduced less often than in non-cognates (e.g., después ‘after’). However, and importantly for the current paper, that author finds that the difference in the effect of cognates is likely an epiphenomenon of differences in the contextual distribution of cognates and non-cognates. After measuring forms’ ratio of occurrence in contexts that favor the reduction of word-initial /d/ (i.e., after sounds other than nasals, laterals, or pause), Brown demonstrates that cognates occur less often in those conditioning contexts, while non-cognates occur more often in those contexts.
To summarize, authors continue to add to the body of literature of empirical support of the idea that words that occur proportionately more often in contexts for change, end up changing more quickly than other words, even when the conditioning context is statistically controlled for.
1.2. The Current Study
The current study seeks to test the notion that words that occur proportionately more frequently in the context for change end up changing more quickly than words that occur less frequently in that context. This paper investigates the ratio with which Spanish words with word-final /s/ occur before a voiced consonant, and whether that ratio affects the voicing of word-final /s/, even when the following phonological context is statistically controlled for. Given Bybee’s assertion that “words that occur more often in the context for change…” (Bybee 2002, p. 261) as well as her claim that “sound change has a permanent effect on the lexical representation of the words of a language” (Bybee 2001, p. 59), the calculation of FRC is based on the proportion with which words, not phones, occur in the context for change.
Another major focus of this study is to investigate the operationalization of forms’ ratio of conditioning as a predictor variable on /s/ voicing in these data. First, the number of tokens upon which FRC is based is analyzed. It is intuitive to posit that the larger the number of tokens upon which a form’s ratio of conditioning is based, the more stable the effect of FRC will be and the more confident researchers can be that a form’s ratio of conditioning truly has an effect. With respect to a specific threshold, Brown, Raymond, Brown and File–Muriel (Brown et al. forthcoming) study the influence of FRC on word speech rate as well as /s/ duration in a sample of Colombia Spanish. They chose four tokens upon which FRC was based as the minimum threshold at or above which word tokens or /s/ tokens were included in their analysis. They state: “The cutoff of four tokens for a type was chosen as a compromise between producing an accurate estimate of our likelihood measure and retaining adequate data for testing.” This brings up the question: Would a higher threshold upon which FRC must be based result in an increased likelihood that FRC be chosen as a significant predictor of variable language phenomena? In an effort to answer this question, thresholds between three and ten words are investigated in the present study.
A third point of analysis in the present study is the predictive power of forms’ ratio of conditioning itself. By systematically removing tokens of /s/ whose FRC score lies near the median FRC score, tokens with progressively more extreme FRC scores are retained. It is logical to assume that FRC as a predictor variable will exert a significant effect as values become more extreme.
The research questions motivating this paper are as follows:
RQ1: What effect, if any, does forms’ ratio in the conditioning context (FRC) have on the amount of voicing of the word-final /s/ segment in Spanish?
RQ2: What effect, if any, does the number of tokens with which FRC is calculated have on FRC’s ability to condition word-final /s/ voicing?
RQ3: What effect, if any, does the extremeness of the FRC scores have on FRC’s ability to condition word-final /s/ voicing?
Given the growing body of literature in support of the significant effect of forms’ ratio of conditioning, it is hypothesized that the data will show that words that occur proportionately more often before voiced consonants will have more voicing of /s/, as measured by the percentage of the /s/ segment that is voiced. With regard to varying the threshold above which FRC must be based on in order for /s/ to analyzed, it is hypothesized that words whose FRC score is based on few tokens will have more statistical noise and less predictive power than words whose FRC score is based on more tokens. Concerning whether removing tokens of /s/ whose FRC lies near the middle of the FRC range, that is, near the median FRC, and therefore retaining only tokens with more extreme FRC scores, it is hypothesized that the predictive power of FRC will increase, as measured by the alpha level of the FRC variables (i.e., FRC as a main effect and FRC in interaction terms with other variables). Simply put, it seems logical that words whose FRC lies on the extremes of the FRC continuum will be more affected by FRC than words whose FRC is just barely more or less than the median FRC.
The paper is organized as follows: we have just outlined in Section 1 “Introduction” the linguistic variable under study and the theoretical framework for analysis, and posed the research questions motivating the study; Section 2 “Materials and Methods” describes the corpus accessed and the statistical analysis performed; Section 3 “Results” presents the results of a series of 40 statistical models; Section 4 “Discussion” answers the research questions in light of the results and addresses the theoretical construct under investigation; Section 5 “Conclusion” summarizes the paper.
2. Materials and Methods
In order to test whether a form’s ratio in a conditioning context, in this case, before a voiced consonant, significantly conditions the voicing of word-final /s/, a corpus of Mexican Spanish spoken in Salinas, California was utilized (Brown 2012-present). The speakers in this corpus were born and grew up in one of the west-central Mexican states of Guanajuato, Jalisco, or Michoacán. Generally, the speakers migrated during adolescence to the United States, often directly to Salinas, California, a city of approximately 150,000 habitants, approximately 75% of which were of Hispanic ethnicity in the 2010 US Census.6 The interviews that comprise the corpus were recorded between 2010 and 2012. All speakers gave their written informed consent for inclusion before they participated. The study was conducted in accordance with the norms established in the Human Subject Research Guidance, Standards and Practices document of California State University, Monterey Bay, and the protocol was approved by the Institutional Review Board of that university. The project that created the corpus was supported by a grant in 2010 from the University Corporation of Monterey Bay.
The speakers in the corpus were recorded in a Labovian sociolinguistic-interview setting (cf. Labov 1984; Tagliamonte 2006) in a sound studio of a radio station at the already mentioned university in central California, USA. The student assistants who conducted the interviews were themselves immigrants from one of the three west-central Mexican states from which the speakers originated. In many cases, the interviewers spoke with friends, classmates, and family members, and thus the interviewers are safely considered in-group speakers of the social networks of the speakers (cf. Milroy and Gordon 2003). The topics of the interviews varied naturally according to the interests of the speakers and interviewers, and in many cases, the interviews approximated a spontaneous conversation. The topics discussed included those common in conversations between friends, family members, and classmates: plans for vacations, differences between Mexico and the US, university courses, and jobs. Generally, the interviews lasted 30 min in duration, with a few approaching 45 min. The recordings were made with a solid-state Edirol R-1 and a lapel-mounted Audio-Technica microphone, sampled at 44,100 Hz, with 24 bits per sample. Once recorded, the interviews were initially transcribed by the in-group interviewers themselves, and then reviewed and revised by the principal investigator of the project that created the corpus.
A sample of the corpus was accessed for this study. The interviews of 15 female speakers between the ages of 20 and 29 (mean = 23.7, standard deviation = 3.2) were analyzed. Their average age upon arrival to the United States was 15.4 years (standard deviation = 3.2). Four came from the Mexican state of Guanajuato, seven from Jalisco, and four from Michoacán. Concerning their educational background, three had completed high school only, ten had completed or were in the process of completing a university bachelor’s degree, and two were completing a graduate degree. The heavy representation of university students is an artefact of the recruitment process, which relied on the snowball method of finding the friends, classmates, and family members of the research assistants, who themselves were undergraduate university students. Purposefully, the sociodemographic variability of the speakers in this sample was limited in order to focus on the usage-based predictor of FRC. While it may be the case that FRC varies as a function of social and regional differences, future studies might investigate this possibility.
The tokens of word-final /s/ for this study were extracted from at least ten minutes into each interview. The decision to start analyzing /s/ starting at least ten minutes into each interview was based on the hope that after some time had passed within a given interview, the speakers would be more likely to use their vernacular, or a variety of language close to it. Labov (1984) proposes that the vernacular is the most systematic type of speech because it is more likely to be free of hypercorrection and style-shifting, and is therefore the ideal language variety for studying language variation.
The coding process of the response variable was performed with the acoustic software Praat (Boersma and Weenink 2020). Each token of word-final /s/ was manually delimited with boundaries in a TextGrid. In another tier, the portion of the /s/ interval that was judged to be voiced was delimited, as was the part deemed to be unvoiced. The decision as to what portions of the /s/ interval should be marked as voiced or voiceless was made by visual and auditory inspection. Following the methodology outlined in Schmidt and Willis (2011), the spectrogram was inspected for a voice bar in the lowest part of the sound signal, and the waveform was viewed for periodicity indicative of voiced sibilance or aperiodicity indicative of voiceless sibilance. Figure 2 shows the waveform and spectrogram of one of the tokens of pensabas ‘2s thought’. As noted in the waveform in the top tier, there are periodic peaks and valleys, and in the spectrogram in the second tier, a handful of regular glottal pulses are observable in the voice bar at the bottom of the spectrogram. This token of /s/ was judged by the human rater to be 27% voiced, as the interval marked with a plus sign in the second annotation tier represents 27% of the /s/ segment marked in the first annotation tier.
While exploring the data, in addition to the human-given judgment on the amount of voicing in each token of /s/, Praat’s Voice Report was retrieved for each token of /s/ in order to compare the human-given ratio of voicing of /s/ and the machine-given proportion from Praat’s Voice Report. Unsurprisingly, the two measures of voicing of /s/ significantly correlate with each other (r = 0.7, p ≤ 0.001). However, in the analyses reported below, only the human-given ratios of voicing are reported.7
Forms’ ratio of conditioning (FRC) was calculated in a combined reference corpus of Mexican and Mexican-American spoken Spanish. The combined corpus included the corpus from which the tokens in this study were retrieved (Brown 2012-present), the Mexico City portion of the Habla Culta project (Lope Blanch 1971), the Habla Popular of Mexico City (Lope Blanch 1976), a corpus of Spanish in the Southwestern United States (Lope Blanch 1990), and a handful of interviews of spontaneous speech recorded in Irapuato, Guanajuato, by Jeffrey Turley of Brigham Young University in the early 2000s, as well as 11 interviews of the corpus El habla de Monterrey (Mexico) ‘The Speech of Monterrey’ (Rodriguez Alfano 2005). The number of words in this combined corpus is 592,195. All tokens of each word type with a token of word-final /s/ were found in the reference corpus and the proportion of times that the word type occurred before a voiced consonant was calculated. This created a continuous variable bounded between 0 and 1, with values near 0 indicating that the word type rarely occurred before a voiced consonant, and values near 1 identifying word types that usually occurred before voiced consonants. The following voiced consonants in the reference corpus are: /b/, /d/, /g/, /l/, /m/, /n/, and /r/. The mean FRC score of all word types was 0.25 (median = 0.26, standard deviation = 0.14), indicating that on average the word types occurred before a voiced consonant a fourth of the time in the reference corpus. By way of illustration, the target word posadas ‘Christmas parties’ occurs 19 times in the reference corpus, and only one of those occurrences is before a voiced consonant (i.e., /d/ in de ‘of’), while the other 18 occurrences are before voiceless consonants, vowels or punctuation (taken to represent pauses), and consequently, posadas has a low FRC score of 0.05 (one divided by 19). In contrast, the target word debemos ‘1p should’ occurs 23 times in the reference corpus, with 14 of those occurrences before a voiced consonant (i.e., nine times before de, once each before decir ‘to say’, lo ‘it’, meternos ‘put-us’, nomás ‘only’, verlo ‘see-it’), with the other 9 occurrences before voiceless consonants, vowels, and one punctuation mark. As such, debemos has a relatively high FRC value of 0.61 (14 divided by 23).
In order to control for the speech rate in which /s/ was uttered, the word in which word-final /s/ occurred was delimited in an annotation tier, along with the other words in the intonation unit. These boundaries were set in order to explore the influence of three measures of speech rate on the percentage of voicing of /s/: (1) speech rate based on the number of phones per second across the entire intonation unit, excluding the word with the /s/ token (rateIU), (2) speech rate based on the number of phones per second from the beginning of the IU up until, but excluding, the word in which word-final /s/ occurred (ratepre), (3) speech rate based on the number of phones per second starting after the word with /s/ to the end of the IU (ratepost). It is important to control for speech rate immediately around each token of /s/, as speakers fluctuate their speech rate during the course of an interview based on the content of the interview at the moment and interest and reactions of the interlocutors in the interview. The two speech rates based on only a part of the intonation unit (i.e., ratepre and ratepost) each individually significantly correlate with the speech rate based on the entire intonation unit: rateIU and ratepre r = 0.5, p ≤ 0.001; rateIU and ratepost r = 0.3, p ≤ 0.001). Differently, the two speech rates based on only part of the intonation unit do not significantly correlate with each other: ratepre and ratepost r = −0.02, p = 0.4. While exploring the data, it was found that speech rate based on the segments that come after a target word (i.e., ratepost) significantly predicted voicing of /s/ most reliably. This result is expected as word-final /s/ intuitively should be most responsive to the speech rate that comes after the word with /s/, rather than the speech rate before the word or even speech rate calculated across the entire intonation unit. As a result of this data exploration, in the analyses reported below, speech rate based on the segments after the target word within the intonation unit (i.e., ratepost) is used (cf. Gahl 2008). It should be noted that diphthongs in the surrounding words within the intonation unit were treated as one and a half phones rather than two, as the duration of diphthongs might safely be considered to represent a half-way point between two singly-occurring vowels and vowels in hiatus (cf. Aguilar 1999). Additionally, centered and scaled z-scores were calculated and used in the statistical models reported below, to control for natural differences in speech rates between speakers.
Other predictor variables that have been shown to condition /s/ realization are included as well. The following phonological context was identified as either a voiced consonant or something else, whether another sound or a pause. As explained previously, the context most propitious for conditioning the voicing of word-final /s/ is a following voiced consonant (despite the fact that /s/ can be voiced in other contexts, as mentioned above). The preceding phonological context was identified as either a high vowel (i.e., /i/ or /u/, as in mis ‘my plural’ or tribus ‘tribes’) or a non-high vowel (i.e., /a/, /e/ or /o/, as in atrás ‘behind’, salones ‘classrooms’, or dijimos ‘1p said’). Researchers have reported a reducing effect on /s/ from preceding non-high vowels in New Mexican Spanish (cf. Brown 2005) and in the Spanish of Cali, Colombia (cf. Brown and Brown 2012).
Lexical frequency of individual forms, not lemmas, were found in the combined corpus of Mexican and Mexican-American spoken Spanish. Rather than enter the raw frequency numbers, logarithm numbers were entered into the statistical models reported below in order to attenuate the large disparity between the few most frequent words and all others (cf. Gries 2013, p. 254; Sonderegger et al. 2018, §3.4.7). As a means of illustrating approximate ranges along the frequency continuum, the following words fall at the lower end of the continuum, in the middle, and at the upper end, respectively, with raw frequency number in parenthesis: conservadores ‘conservative/conservational’ (5), responsabilidades ‘responsibilities’ (6), salgas ‘2s subjunctive leave’ (3); muchas ‘feminine plural many’ (629), niños ‘children’ (725), unos ‘masculine plural indefinite article’ (599); es ‘3s to be’ (9484), las ‘feminine plural definite article/object pronoun’ (4409), más ‘more’ (4280), entonces ‘then/so’ (2637).
Prosodic stress of the syllable in which word-final /s/ occurred was identified as either stressed (e.g., inglés ‘English’) or unstressed (e.g., estudios ‘studies’). When word-final /s/ preceded a vowel in the following word, resyllabification was assumed and stress was marked accordingly. For example, word-final /s/ in costumbres ‘customs’ in the bigram costumbres esas ‘those customs’ was marked as stressed because the first syllable of esas ‘those’ is stressed, whereas word-final /s/ in costumbres in the bigram costumbres están ‘customs are’ was coded as unstressed because the first syllable of están ‘are’ is unstressed. Stressed syllables are generally longer and louder than unstressed ones, and these features may have an effect on the amount of voicing of the /s/ segment.
Finally, word class was categorized. Nouns, verbs, adjectives, and adverbs were binned as content words, while other words were marked as function words. Those functions words included: determiners and pronouns (e.g., estas ‘feminine plural proximal demonstrative adjective/pronoun’, esos ‘masculine plural distal demonstrative adjective/pronoun’, unos ‘masculine plural indefinite article’, nosotros ‘1p subject pronoun’, les ‘3p dative pronoun’), clitic pronouns (e.g., empujarlos ‘push-3p accusative pronoun’, darles ‘give-3p dative pronoun’), prepositions (e.g., antes ‘before’, detrás ‘behind’), quantifiers (e.g., muchas ‘feminine many’, algunos ‘masculine some’, seis ‘six’), and expressions (e.g., gracias ‘thanks’, pues ‘discourse marker’).
Statistical Analysis
Linear regression is a common statistical model used with continuous response variables in many fields of study, including in linguistics. However, Ferrari and Cribari-Neto (2004) argue that linear regression is inappropriate with datasets in which the response variable is bounded between 0 and 1, as this type of regression may return values that fall outside of that range. The authors point out that a common solution to this drawback is to transform the values by taking the logarithm, z-score, or square root of the values, and then to model the transformed values with linear regression. However, this solution has the disadvantage of making it difficult to interpret the results with regard to the values of the original response variable. Additionally, when the response variable is not normally distributed within the 0 to 1 range, inferences made from the results can be misleading because the normal assumption of linear regression does not hold. As such, Ferrari and Cribari-Neto suggest using beta regression with continuous response variables bounded between 0 and 1 and when the data points are skewed or not normally distributed (cf. also Faraway 2016, p. 64).
With respect to linguistic inquiry, Plag et al. (2017) fit beta regression in their study of morphemic and non-morphemic /s/ and /z/ in conversational English speech in the Buckeye Corpus (Pitt et al. 2007). In their study, the authors measured the relative duration of /s/ or /z/ with regards to the duration of the word in which they occurred, thus the response variable values are proportions bounded between 0 and 1, with values close to 0 representing sibilants that made up little of the duration of the words in which they occurred, and values close to 1 representing sibilants that comprised the majority of the duration of the words in which they occurred. Unsurprisingly, the data points were skewed towards the 0 end of the continuum, as the sibilant segment usually represented a small proportion of the duration of the word.
In similar fashion, the response variable in the present study is a proportion. Here, the proportion under study is the amount of the /s/ interval that is voiced. Values near 0 identify a token of /s/ that has little voicing across its duration, and values near 1 signify a large proportion of voicing of the /s/ interval. Further, like with Plag et al.’s data, our data points are skewed towards the lower end of the continuum, as the mean ratio of voicing of /s/ is 0.25, as noted above. As such, instead of the more common linear regression, beta regression is used in this study. In their study, Plag et al. used the R package betareg (Cribari-Neto and Zeileis 2010) to fit their beta regression model. However, a limitation of that package is the lack of support for random effects. It is uncontroversial to assume that a great deal of variability in linguistic production is attributable to the idiosyncratic nature of speakers and words. As such, in order to control for this idiosyncratic nature by fitting beta regression with random effects, the R package glmmTMB (Brooks et al. 2017) was utilized in this study.
In addition to the predictor variables described above, all pairwise interactions between those main effects were also entered in the statistical models presented below. The R package buildmer (Voeten 2020), and specifically the function buildglmmTMB, was utilized to create the final models. This function finds the maximal model that still converges and then performs backward variable elimination to reach a parsimonious final model.8 As Voeten points out, Barr, Levy, Scheepers, and Tily (Barr et al. 2013) suggest that in order for a regression model to offer valid statistical inference, all possible confounding variables must be accounted for. However, Bates, Kliegl, Vasishth, and Baayen (Bates et al. 2015) argue that such an approach leads to overfitting and an appropriately parsimonious model should be fitted. For this paper, the buildglmmTMB function received as input the predictor variables noted above as well as all their pairwise interactions, in addition to random intercepts for speaker and word as well as random slopes for speaker and word with the predictor variable of interest here, FRC. The function finds the maximal model that still converges, and then performs backward stepwise variable elimination to end up with a parsimonious model with only significant main effects and interactions, and non-significant main effects that are involved in significant interactions. Additionally, in the process of finding a final model, the function also tests the utility of including or excluding the random intercepts and random slopes. The variable elimination process is based on the significance of the change in log-likelihood values between candidate models.
In order to test the effect, if any, of FRC on word-final /s/ voicing when analyzing only tokens of /s/ whose FRC measurement is based on more than a few tokens, a series of beta regression models were fitted. The threshold for inclusion in the beta regression model was iteratively increased from a starting threshold of three tokens to a final threshold of ten tokens. Consequently, the first model included tokens of /s/ in words whose FRC was based on three or more tokens in the reference corpus, while the second model included tokens of /s/ whose FRC was based on four or more tokens in the reference corpus, and so on until ten. The hypothesis is that words whose FRC is based on more tokens rather than fewer tokens will be more likely to truly have an effect from FRC. During each iteration, a minimal adequate model (cf. Gries 2013, pp. 259–61) of only significant predictor variables and significant pairwise interactions was fitted. If in the process of creating the final model, FRC as a main effect or in an interaction was retained as significant, the corresponding p-value was noted.
In addition to analyzing the effect of a moving threshold of tokens upon which FRC scores were based, another aspect of FRC of interest in this paper is the effect of analyzing only tokens with extreme FRC values. This was achieved by removing tokens of /s/ in words whose FRC score lay near the median FRC score in the dataset. The hypothesis is that words whose FRC score is more extreme, whether because it falls far above or far below the median FRC, will have a stronger effect on /s/-voicing in these data than will words whose FRC is near the median FRC in the dataset. In theoretical terms, it seems logical to posit that words that occur before a voiced /s/ much more often or much less often than other words will be more affected by the contexts in which they are used than will other words. To test this possibility, a series of beta regression models were fitted starting with all tokens across the entire FRC-range, and then additional half standard deviations of tokens centered on the median were iteratively removed, until the middle two standard deviations were excluded. Consequently, the first model included tokens from the entire FRC-range, while the second model excluded tokens whose FRC score lay within the middle half standard deviation of FRC values, centered on the median FRC. The third model removed an additional fourth of a standard deviation on either side of the median, so that tokens of /s/ whose FRC lay within a half standard deviation above or a half standard deviation below the median FRC value were removed, resulting in the middle standard deviation of tokens being excluded. This process continued until tokens whose FRC score lay within the middle two standard deviations were excluded before measuring the influence of the predictor variables.
The result of the varying thresholds of tokens upon which FRC was based (eight thresholds between three and ten tokens) and the varying amounts of tokens included based on where they lay on the FRC-range (five thresholds between first including all tokens on the FRC-range and then iteratively removing half standard deviations until the middle two standard deviations were removed), was that final models of 40 beta regressions were fitted, and the effect, if any, of FRC was observed. It should be noted that with each additional threshold, fewer tokens were available for analysis in the corresponding model. In the model with tokens from across the entire FRC-range and whose FRC was based on the lowest threshold for inclusion (i.e., three), the number of tokens analyzed was 1431. In contrast, in the model with the fewest number of tokens, because tokens whose FRC score lay within the middle two standard deviations were excluded and FRC scores were calculated on ten tokens or more, there were only 373 tokens available for analysis. Across all 40 models, the average number of tokens available was 828 (median = 814, standard deviation = 356).9
3. Results
The results of a series of 40 beta regression models reveal that FRC has a significant conditioning effect on the percentage of voicing of word-final /s/ in Spanish in these data. In 29 of the 40 models, FRC as a main effect or in an interaction term, or both, was selected as making a significant contribution to the prediction of /s/ voicing. Specifically, in 15 of the 40 models, FRC as a main effect is significant, and in 13 of those 15 models the interaction term between FRC and speech rate was also selected as significant. Additionally, in 14 different models the interaction term between FRC and the following phonological context significantly influences /s/ voicing. Figure 3 indicates on the y-axis the p-values of FRC, while the x-axis indicates the minimum number of tokens upon which FRC was calculated in the reference corpus. The five line plots vary in the amount of the FRC-range included, based on how closely tokens’ FRC scores lay to the median FRC value in the data. In the upper left plot, all tokens are included, regardless of how close to or far from the median FRC value a token’s FRC score lay. In the upper middle plot, tokens of /s/ whose FRC score lay within the middle half standard deviation centered on the median FRC are excluded. In the upper right plot, tokens of /s/ whose FRC score lay within the middle one standard deviation of FRC values are excluded, and so forth with the other line plots. The solid line represents FRC as a main effect, the dotted line represents the interaction term between FRC and the following phonological context, and the dashed line represents the interaction between FRC and speech rate. See Figure 3.
Concerning the extremeness of FRC scores, that is, where tokens lay on the FRC-range, the results of the 40 beta regression models reveal an effect. When all tokens across the entire FRC-range are included regardless of how close their FRC score lay to the median value, FRC was not selected as significant, hence the lack of any line representing FRC in the upper left line plot in Figure 3. Conversely, with moderate amounts of the middle of the FRC-range excluded (i.e., half standard deviation and one standard deviation), the interaction between FRC and following phonological context was selected as significant in 14 of the 16 models, as shown in the upper middle and upper right line plots in Figure 3. Further, when a considerable amount of the middle of the FRC-range is excluded (i.e., one and half standard deviations and two standard deviations), the interaction between FRC and following phonological context is no longer significant. However, the interaction between FRC and speech rate in 13 of the 16 models is significant, and FRC as a main effect is significant in 15 of those 16 models, as represented in the lower two line plots in Figure 3. In summary, with tokens of /s/ whose FRC score lay immediately near the median FRC value in the data, FRC was not selected as making a significant contribution to the prediction of /s/ voicing. In contrast, when tokens of /s/ whose FRC lay in the middle of the FRC-range were excluded, FRC was significant. Specifically, with moderate amounts of middle FRC-range tokens removed, the interaction between FRC and following phonological context was significant, and when considerable amounts of middle FRC-range tokens were removed so that only tokens with extreme FRC values were retained, FRC as a main effect and in the interaction between FRC and speech rate were significant.
Turning to the minimum number of tokens upon which FRC was calculated in the reference corpus, there is little effect from this variable. In three of the five line plots in Figure 3, there is no effect from varying the minimum threshold upon with FRC was calculated. For example, in the upper left line plot, it made no difference whether the minimum threshold was set to three or ten, or any number between; FRC was not selected as significant in any of the eight models represented in that line plot. Similarly, there is no effect from varying the minimum threshold along the x-axis in the upper middle line plot; the interaction term between FRC and following phonological context is significant, while FRC as a main effect is not, regardless of the threshold upon which FRC was calculated. Likewise, in the lower middle line plot in Figure 3, no effect is present from varying the threshold; FRC as a main effect and in the interaction term with speech rate is significant in all eight models, regardless of the minimum threshold noted on the x-axis. In a different manner, when the middle one standard deviation of tokens on the FRC-range are excluded, there is a slight effect from the minimum threshold of tokens upon which FRC was calculated. As seen in the upper right line plot in Figure 3, when FRC was calculated with a minimum threshold of three or a minimum threshold of ten, FRC was not significant, as evidenced by the absence of a line at those points on the x-axis. When the middle one and a half standard deviations on the FRC-range are excluded (lower left line plot), there are differences in FRC as a function of varying the minimum threshold upon which FRC was calculated. Specifically, with the threshold set to three, FRC does not significantly condition /s/ voicing. However, with the threshold set to four, FRC as a main effect is significant, and this is the case with all subsequent thresholds up to and including the maximum threshold of ten. Further, the interaction between FRC and speech rate begins to exert a significant influence starting with a threshold of six and continues to do so through the rest of the thresholds up to and including ten.
As mentioned previously, a major point of interest in this study is how the operationalization of FRC affects this predictor’s ability to condition word-final /s/ voicing in Spanish. In addition to exploring how FRC is measured, we were also interested in describing the influence of other predictor variables. To that end, a beta regression model with conversative parameters for the number of tokens with which FRC was calculated and the extremeness of values on the FRC-range was fitted. This model is based on tokens of /s/ whose FRC score was calculated with at least five tokens in the reference corpus, and tokens whose FRC score lay outside of the middle half standard deviation on the FRC-range. The backward variable selection process chose the following predictor (fixed) variables as making a significant contribution to the prediction of /s/ voicing: following phonological context, speech rate, and word class as main effects, and the interaction terms between FRC and following phonological context, following context and preceding vowel height, following context and prosodic stress, following context and lexical frequency, and finally, word class and lexical frequency. Additionally, the model selection process removed the random slopes for speaker and word with FRC and the random intercept for word, but kept the random intercept for speaker. For more details, see Table 1.
As mentioned, the interaction term between FRC and following phonological context significantly conditions percentage /s/ voicing in the beta regression reported in Table 1. As expected, as FRC increases, so does the percentage of the /s/ segment that is voiced. See Figure 4, a scatterplot of percentage /s/ voicing by FRC; the 95% confidence intervals around the regression line are indicated with a gray band. As seen in that figure, when followed by a voiced consonant, the /s/ segment has a higher percentage of voicing than when it is followed by other phonological contexts, whether other sounds or a pause. This effect is evidenced by the fact that the regression line in the left-hand scatterplot is in a higher vertical position than the regression line in the right-hand scatterplot. Further, we observed that the regression line in the left-hand scatterplot is more sloped than that in the right-hand scatterplot. It appears that the conditioning effect of FRC (the cumulative contextual effect) is magnified when in the favorable context for voicing (the online contextual effect).
In addition to affecting /s/ voicing in the interaction with FRC, the following phonological context as a main effect significantly conditions the percentage of word-final /s/ voicing. As expected, when followed by a voiced consonant, the context pointed out by many authors as propitious for voicing of /s/, word-final /s/ is more voiced. When followed by a voiced consonant, the mean percentage of the /s/ segment that is voiced is 65%, while that percentage drops to 22% when followed by another sound or a pause. Figure 5 visualizes the effect of following phonological context on the percentage of voicing of word-final /s/ in a boxplot. The dark horizontal lines in the boxes indicate the median percentage voiced, while the X identifies the mean voicing per group. The bottom and top of the boxes indicate the first and third quartiles, respectively.
As noted in Table 1, speech rate also significantly conditions word-final /s/ voicing in the beta regression reported there. As expected, as speech rate increases, the percentage of the /s/ segment that is voiced also increases. See Figure 6 for more details.
The fourth predictor variable selected as making a significant contribution to /s/ voicing in Table 1 is word class. There is more voicing of the word-final /s/ segment in function words than in content words. See Figure 7 for more details.
As noted in Table 1, in addition to the interaction between FRC and the following phonological context, a handful of other interaction terms were selected as significant in the model: the interaction between the following phonological context and the preceding vowel, the interaction between the following phonological context and stress, the interaction between the following phonological context and lexical frequency, and the interaction between word class and lexical frequency. A following voiced consonant after word-final /s/ magnifies the effect of other predictor variables that it interacts with. For example, when word-final /s/ is followed by a voiced consonant, the effect of a preceding high vowel is intensified, such that the mean percentage of voicing of /s/ in that context is 80.5%, but 63.9% when preceded by a non-high vowel, a difference of 16.6 percentage points (80.5%−63.9%). Differently, when /s/ is followed by something other than a voiced consonant, whether another sound or a pause, /s/ is voiced on average at a rate of 25.2% when preceded by a high vowel, and 22.3% when preceded by a non-high vowel, a difference of only 2.9 percentage points. Similarly, a following voiced consonant seems to also magnify the conditioning effect of stress. When followed by a voiced consonant, on average 66.6% of the /s/ interval is voiced in unstressed syllables, and 61.1% in stressed syllables, a difference of 5.5 percentage points. However, when followed by something other than a voiced consonant, whether another sound or a pause, on average 22.2% of the /s/ interval is voiced in unstressed syllables, and 23.3% in stressed ones, a difference of only 1.1 percentage points. Likewise, the effect of lexical frequency might be magnified when /s/ is followed by a voiced consonant. As seen in Figure 8, the effect of lexical frequency on voicing /s/ is smaller when word-final /s/ is followed by something other than a voiced consonant, as evidenced by the less sloped regression line in the right scatterplot in the figure. However, the fact that a horizontal line could be drawn within the confidence intervals in the left scatterplot in the figure calls into question the influence of lexical frequency on voicing of /s/ when word-final /s/ is followed by a voiced consonant.
Finally, the interaction between word class and lexical frequency was selected as making a significant contribution to the prediction of /s/ voicing in these data. As expected, /s/ voicing increases as lexical frequency increases, but only among the content words; there is no effect from lexical frequency on function words. See Figure 9 for further details.
In summary, the series of 40 beta regression models shows that FRC as a main effect and in interactions with other predictors significantly conditions voicing of word-final /s/ in this sample of Mexican Spanish.
4. Discussion
The first research question (RQ1) inquires whether forms’ ratio of conditioning (FRC) has an effect on the percentage of word-final /s/ that is voiced in this sample of Mexican Spanish. The results of 40 beta regression models by 15 female speakers between the ages of 20 and 29 in Salinas, California, USA show that FRC significantly conditions word-final /s/ voicing. Words that occur more often before a voiced consonant, as measured in a combined corpus of spoken Mexican and Mexican-American Spanish, show higher percentages of voicing of the /s/ segment than words that occur less often in that context, even when that conditioning context is statistically controlled for. As mentioned above, authors of descriptive treatments of Spanish phonetics and phonology (e.g., Quilis and Fernández 1973; Alba 2001; Hualde 2005; Schwegler et al. 2010) often point to a following voiced consonant as the context in which Spanish /s/ is voiced, and these results confirm those assertions. It should be noted that a following voiced consonant is not the only context in which voicing of Spanish /s/ occurs, as has been described by authors cited previously (e.g., Strycharczuk et al. 2014; Garcia 2013; Chappell and García 2017; Torreira and Ernestus 2012). To summarize, the backward variable elimination process of 29 of the 40 beta regression models fitted retained FRC as a significant main effect or as a significant interaction term, or both. These results lend additional empirical support to the tenet of usage-based and emergentist models of language that posit that the contexts in which words are used affects the structure of those words by storing cumulative contextual experience in the mental representation of words (cf. Bybee 2001, 2002, 2010).
The results of a single beta regression with a conservative parameterization of FRC (i.e., tokens of /s/ whose FRC score was based on at least five tokens and whose FRC score lay outside of the middle half standard deviation on the FRC-range) also contribute to the description of word-final /s/ voicing in Spanish. As expected, a following voiced consonant conditions higher percentages of /s/ voicing than do other following phonological contexts (whether other sounds or a pause). Thus, we see that following voiced consonants, whether during online speech production or cumulative exposure to that context as measured by FRC, condition word-final /s/ voicing. It is intuitive to reason that in order for FRC, a measure of cumulative exposure to the conditioning context, to have a significant influence on /s/ voicing, the online context in the moment of speech production must first have a significant conditioning effect. If this were not the case, how could the cumulative exposure to that context ever exert a significant conditioning effect?
The results also reveal that the interaction term between following phonological context and FRC significantly conditions /s/ voicing in these data. This result falls in line what has been reported by other authors with respect to the interactive effect of FRC and the phonological context upon which it is based. Brown and Alba (2017) show that the effect of FRC interacts with the propitious phonological context for fricational reduction of word-initial /f/ in Spanish, as measured by the center of gravity of /f/. In that study, the influence of FRC was assuaged when measured in the conditioning context. Brown (2018) shows that the conditioning effect of FRC also significantly interacts with the phonological context upon which it is based in an analysis of the duration and center of gravity of /s/ in Spanish, such that the effect of FRC is enlarged when measured in the conditioning context. Future studies will do well to continue exploring the interaction between FRC and the phonological context upon which it is based, and especially the magnifying effect that the favorable phonological context has on FRC’s conditioning effect on the response variable in question in some studies (e.g., Brown 2018), while having an inhibitory effect with other variables (e.g., Brown and Alba 2017).
The second and third research questions deal with two aspects of the operationalization of FRC and how variability in the parameterization of those two features might affect FRC’s conditioning effect on word-final /s/ voicing. Namely, RQ2 inquires what effect the number of tokens with which FRC is calculated might have on FRC’s ability to condition /s/ voicing, while RQ3 questions how the extremeness of the FRC values might be a factor in FRC’s influence. Concerning RQ2, the results show that there is an effect from iteratively retaining only tokens of /s/ whose FRC scores are based on increasingly larger numbers of tokens in the reference corpus. However, the effect is smaller and less consistent than expected. In three of the five sets of eight models (i.e., in three of the five line plots in Figure 3), there is no difference on the significance of FRC as a main effect or in an interaction term when the threshold of the number of tokens upon which FRC was calculated was increased from three tokens to ten tokens. Specifically, with tokens of /s/ whose FRC score spans the entire FRC-range, there was no difference in the effect of FRC from varying the threshold upon which it was based: FRC did not exert a significant influence regardless of whether it was based on three tokens or ten, or any other number between those ends of the threshold continuum. Similarly, when tokens of /s/ whose FRC score lay within the middle half standard deviation were removed before analyzing the effect of the predictor variables, the interaction term between FRC and following phonological context was selected as a significant predictor of /s/ voicing, regardless of the threshold upon which FRC was calculated, whether it was three or ten, or any number in between. In like manner, when tokens of /s/ whose FRC value lay within the middle two standard deviations of the FRC-range were removed, there was no effect from varying the threshold upon which FRC was calculated: FRC as a main effect and in the interaction term with speech rate were significant regardless of whether the threshold was three or ten, or any number in between. In contrast, when tokens of /s/ whose FRC value lay within the middle one standard deviation were removed, the influence of FRC was affected, but in an inconsistent manner. With the threshold for inclusion set to three tokens in the reference corpus, FRC was not selected as significant. However, with the threshold set to four, the interaction between FRC and following phonological context was selected as a significant. This trend continued through a threshold of nine. Oddly, with a threshold of ten tokens upon which FRC was based, the effect from the interaction term drops out. It is unclear whether this inconsistent behavior is the result of the cognitive organization of these words in memory or simply statistical noise in these data. Turning to the set of eight models of /s/ voicing when tokens whose FRC score lay within the middle one and a half standard deviations were excluded, we see perhaps the most consistent influence on FRC by varying the minimum threshold upon which FRC was based. In the model with a minimum threshold of three tokens, FRC did not significantly contribute to the prediction of /s/ voicing. However, with a threshold of four tokens, FRC as a main effect was selected as significant, and this effect continued through to the maximum threshold of ten. Further, in the model with a threshold of six tokens, the interaction term between FRC and speech rate was selected as significantly predicting /s/ voicing, and this pattern continued through the models with a threshold between six and the maximum threshold of ten. As hypothesized, as the minimum number upon which FRC was based in the reference corpus increased, the effect of FRC became significant and continued to be significant as the thresholds increased. This set of eight regression models is the only set among the five sets that seems to confirm the hypothesis that increasing the number of tokens upon which FRC is based removes statistical noise and allows FRC to exert a significant effect. It could be the case that FRC scores based on few tokens are unreliable because of simple chance. For example, if a high FRC score is based on only, say, three tokens, it might be that those particular three tokens happen in contexts propitious for conditioning the change, but if all tokens of the word type were analyzed, the FRC score might be lower. By raising the number of tokens upon which FRC is based, we draw closer to the actual distribution of the word tokens among contexts that condition the change and contexts that do not. However, as mentioned, this possibility is only observable in one of the five sets of eight models, and as such, future studies would do well to investigate this hypothesis further.
The third research question (RQ3) inquired what effect the extremeness of the FRC values might have on FRC’s ability to condition /s/ voicing. It is intuitive to posit that FRC values that lay far from the median FRC in the dataset will exert a stronger influence on /s/ voicing than FRC values that lay closer to that median. In an effort to explore this possibility, successively larger portions of the middle FRC-range were removed so that only tokens with increasingly more extreme FRC values were analyzed. We observed that when tokens with more extreme FRC scores were retained, FRC exerted a significant conditioning effect on /s/ voicing. Specifically, in the set of eight models in which all tokens of /s/ were retained, regardless of how close to or far from the median FRC value their FRC score lay, FRC was not selected as a significant predictor of /s/ voicing in these data. However, when a moderate amount of the middle FRC-range was excluded (i.e., a half standard deviation and then subsequently, one standard deviation), the interaction term between FRC and following phonological context exerted a significant effect. Finally, with substantial amounts of the middle FRC-range excluded (i.e., one and a half standard deviations and then subsequently, two standard deviations), FRC as a main effect as well as the interaction between FRC and speech rate significantly conditioned /s/ voicing. Hence, the hypothesis is confirmed that FRC will exercise a significant influence on /s/ voicing with increasingly extreme FRC values. What remains unclear is why the interaction between FRC and following phonological context drops out as a significant predictor in the sets of models with substantial amounts of the middle FRC-range excluded. Future studies might analyze further the effect that the extremeness of FRC values has on FRC’s ability to condition word-final /s/ voicing in Spanish.
In the end, these data support the idea that the number of tokens with which FRC is calculated can affect FRC’s ability to condition /s/ voicing, although the evidence in support of this idea is inconsistent and limited. As observed, the extremeness of the FRC values also affects FRC’s influence on word-final /s/ voicing in Spanish. Future research would do well to continue exploring the manner in which FRC is operationalized, and how those operationalizations affect FRC’s ability to condition variable linguistic phenomena.
5. Conclusions
The analysis of word-final /s/ spoken by 15 female speakers of Mexican Spanish aged 20 to 29 years living in Salinas, California, USA provides evidence in support of the notion that “words that occur more often in the context for change change more rapidly than those that occur less often in that context” (Bybee 2002, p. 261). A series of 40 beta regression models shows that forms’ ratio of conditioning (FRC) significantly conditions the percentage of the /s/ segment that is voiced. In this sample of Mexican Spanish, words with word-final /s/ that occur proportionately more often before a voiced consonant, the conditioning context, show higher percentage of voicing of /s/, even when the following phonological context in speech production is brought under statistical control. It is argued that this effect comes from the cumulative exposure to the conditioning context, which is stored in the mental representation of those words. Rather than rigid mental entries, words are malleable cognitive entities that are sensitive to and changed by the contexts in which they are used.
This study also makes a first approximation to analyzing the operationalization of FRC as a predictor variable. While there is a growing body of literature presenting empirical evidence in favor of the conditioning effect of FRC, previous studies do little to explicate the variable effect of FRC as aspects of this predictor variable are manipulated. The present study analyzed the effect of the number of words with which FRC is calculated on FRC’s ability to condition a response variable. Further, the effect of retaining only tokens with increasingly extreme FRC values was investigated. In conclusion, this study provides evidence in favor of the utility of including FRC as a factor in the study of variable linguistic phenomena, as well as of the importance of exploring the manners by which FRC is operationalized.
Supplementary Materials
The following are available online at https://0-www-mdpi-com.brum.beds.ac.uk/2226-471X/5/4/61/s1, “R_code_for_MS_for_Languages.html”, “data_voicing_coded.csv”.
Funding
We express appreciation to the University Corporation of Monterey Bay for their financial support for the creation of corpus from which the tokens in this study were extracted.
Acknowledgments
Thanks are expressed to Micaela Wilson, Dallyn Giles and Dan Martin for helping with the manual delimitation of sounds and words in the Praat TextGrid files. Kristi Brown contributed word-smithing edits, and they are much appreciated. Also, I appreciate the constructive feedback of two anonymous reviewers. All faults and errors remain mine alone.
Conflicts of Interest
The author declares no conflict of interest. The funding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Aguilar, Lourdes. 1999. Hiatus and diphthong: Acoustic cues and speech situation differences. Speech Communication 28: 57–74. [Google Scholar] [CrossRef]
- Alba, Orlando. 2001. Manual de Fonética Hispánica. Santo Domingo: Editorial Plaza Mayor. [Google Scholar]
- Barr, Dale J., Roger Levy, Christoph Scheepers, and Harry J. Tily. 2013. Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language 68: 255–78. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bates, Douglas, Reinhold Kliegl, Shravan Vasishth, and Harald Baayen. 2015. Parsimonious Mixed Models. Available online: https://arxiv.org/abs/1506.04967v2 (accessed on 15 August 2020).
- Boersma, Paul, and David Weenink. 2020. Praat: Doing Phonetics by Computer. Version 6.1.16. Available online: www.praat.org (accessed on 6 June 2020).
- Brooks, Mollie E., Kasper Kristensen, Koen J. van Benthem, Arni Magnusson, Casper W. Berg, Anders Nielsen, Hans J. Skaug, Martin Maechler, and Benjamin M. Bolker. 2017. glmmTMB Balances Speed and Flexibility Among Packages for Zero-inflated Generalized Linear Mixed Modeling. The R Journal 9: 378–400. [Google Scholar] [CrossRef] [Green Version]
- Brown, Earl K. 2009. A Usage-Based Account of Syllable- and Word-Final /s/ Reduction in Four Dialects of Spanish. LINCOM Studies in Romance Linguistics 62. Munich: Lincom Europa. [Google Scholar]
- Brown, Earl K. 2012. Corpus of Mexican Spanish in Salinas, California [Website]. Available online: http://itcdland.csumb.edu/~eabrown/ (accessed on 15 October 2019).
- Brown, Earl K. 2018. The company that word-boundary sounds keep: The effect of contextual ratio frequency on word-final /s/ in a sample of Mexican Spanish. In Functionalist and Usage-Based Approaches to the Study of Language: In Honor of Joan L. Bybee. Edited by Aaron Smith and Dawn Nordquist. Studies in Language Companion Series 192; Amsterdam: John Benjamins Publishing Company, pp. 107–25. [Google Scholar] [CrossRef]
- Brown, Esther L. 2004. The Reduction of Syllable Initial /s/ in the Spanish of New Mexico and Southern Colorado: A Usage-Based Approach. Unpublished. Doctoral thesis, University of New Mexico, Albuquerque, NM, USA. [Google Scholar]
- Brown, Esther L. 2005. New Mexican Spanish: Insight into the Variable Reduction of “la ehe inihial” (/s-/). Hispania 88: 813–24. [Google Scholar] [CrossRef]
- Brown, Esther L. 2015. The role of discourse context frequency in phonological variation: A usage-based approach to bilingual speech production. International Journal of Bilingualism 19: 387–406. [Google Scholar] [CrossRef]
- Brown, Earl K., and Matthew C. Alba. 2017. The role of contextual frequency in the articulation of initial /f/ in Modern Spanish: The same effect as in the reduction of Latin /f/? Language Variation and Change 29: 57–78. [Google Scholar] [CrossRef]
- Brown, Earl K., and Esther L. Brown. 2012. Syllable-final and syllable-initial /s/ reduction in Cali, Colombia: One variable or two? In Colombian Varieties of Spanish. Edited by Richard File-Muriel and Rafael Orozco. Madrid: Iberoamericana, pp. 89–106. [Google Scholar]
- Brown, Esther L., and William D. Raymond. 2012. How discourse context shapes the lexicon: Explaining the distribution of Spanish f-/h words. Diachronica 29: 139–61. [Google Scholar] [CrossRef] [Green Version]
- Brown, Esther L., William D. Raymond, Earl Kjar Brown, and Richard J. File-Muriel. Forthcoming. Lexically specific accumulation in memory of word and segment speech rates.
- Bybee, Joan. 2001. Phonology and Language Use. Cambridge Studies in Linguistics 94. Cambridge: Cambridge University Press. [Google Scholar]
- Bybee, Joan. 2002. Word frequency and context of use in the lexical diffusion of phonetically conditioned sound change. Language Variation and Change 14: 261–90. [Google Scholar] [CrossRef] [Green Version]
- Bybee, Joan. 2010. Language, Usage and Cognition. Cambridge: Cambridge University Press. [Google Scholar]
- Campos-Astorkiza, Rebeka. 2014. Sibilant voicing assimilation in peninsular Spanish as gestural blending. In Variation within and across Romance Languages. Edited by Marie-Helene Cote and Eric Mathieu. Amsterdam and Philadelphia: John Benjamins Publishing Company, pp. 17–37. [Google Scholar]
- Campos-Astorkiza, Rebeka. 2015. Segmental and prosodic conditionings on gradient voicing assimilation in Spanish. In Hispanic Linguistics at the Crossroads: Theoretical Linguistics, Language Acquisition and Language Contact. Edited by Rachel Klassen, Juana M. Liceras, Valenzuela. Issues in Hispanic and Lusophone Linguistics 4. Amsterdam and Philadelphia: John Benjamins Publishing Company, pp. 127–44. [Google Scholar] [CrossRef]
- Campos-Astorkiza, Rebeka. 2017. Voicing assimilation and weakening of /s/ in Iberian Spanish: Connecting both phenomena in a gestural model. In Current Trends in Experimental Phonetics. Edited by V. Marrero Aguiar and E. Estebas Vilaplana. Madrid: UNED/CSIC, pp. 42–47. [Google Scholar]
- Campos-Astorkiza, Rebeka. 2019. Modeling assimilation: The case of sibilant voicing in Spanish. In Romance Phonetics and Phonology. Edited by Mark Gibson and Juana Gil. Oxford: Oxford University Press, pp. 241–75. [Google Scholar]
- Chappell, Whitney. 2016. On the social perception of intervocalic /s/ voicing in Costa Rican Spanish. Language Variation and Change 28: 357–78. [Google Scholar] [CrossRef]
- Chappell, Whitney, and Christina García. 2017. Variable production and indexical social meaning: On the potential physiological origin of intervocalic /s/ voicing in Costa Rican Spanish. Studies in Hispanic and Lusophone Linguistics 10: 1–37. [Google Scholar] [CrossRef]
- Chomsky, Noam. 1957. Syntactic Structures. The Hague: Mouton. [Google Scholar]
- Chomsky, Noam. 1965. Aspects of the Theory of Syntax. Cambridge: MIT Press. [Google Scholar]
- Cribari-Neto, Francisco, and Achim Zeileis. 2010. Beta Regression in R. Journal of Statistical Software 34: 1–24. [Google Scholar] [CrossRef] [Green Version]
- de Saussure, Ferdinand. 1959. Course in General Linguistics. New York: Philosophical Library. First published 1916. [Google Scholar]
- Ernestus, Mirjam. 2014. Acoustic reduction and the roles of abstractions and exemplars in speech processing. Lingua 142: 27–41. [Google Scholar] [CrossRef] [Green Version]
- Faraway, Julian J. 2016. Extending the Linear Model with R: Generalized Linear, Mixed Effects and Nonparametric Regression Models, 2nd ed.Boca Raton: CRC Press. [Google Scholar]
- Ferrari, Silvia, and Francisco Cribari-Neto. 2004. Beta Regression for Modelling Rates and Proportions. Journal of Applied Statistics 31: 799–815. [Google Scholar] [CrossRef]
- Forrest, Jon. 2017. The dynamic interaction between lexical and contextual frequency: A case study of (ING). Language Variation and Change 29: 129–56. [Google Scholar] [CrossRef]
- Gahl, Susanne. 2008. Time and Thyme Are Not Homophones: The Effect of Lemma Frequency on Word Durations in Spontaneous Speech. Language 84: 474–96. [Google Scholar] [CrossRef]
- Garcia, Alison. 2013. Allophonic Variation in the Spanish Sibilant Fricative. Unpublished. Doctoral thesis, University of Wisconsin, Milwaukee, WI, USA. [Google Scholar]
- García, Christina. 2015. Gradience and Variability of Intervocalic /s/ Voicing in Highland Ecuadorian Spanish. Unpublished. Doctoral thesis, The Ohio State University, Columbus, OH, USA. [Google Scholar]
- Godfrey, John J., and Edward Holliman. 1997. Switchboard-1, 2nd ed. Philadelphia: Linguistic Data Consortium. [Google Scholar]
- Gries, Stefan Th. 2013. Statistics for Linguistics with R: A Practical Introduction, 2nd ed. Berlin: De Gruyter Mouton. [Google Scholar]
- Hintzman, Douglas L., and Genevieve Ludlam. 1980. Differential forgetting of prototypes and old instances: Simulation by an exemplar-based classification model. Memory & Cognition 8: 378–82. [Google Scholar] [CrossRef]
- Homa, Donald, Sharon Sterling, and Lawrence Trepel. 1981. Limitations of exemplar-based generalization and the abstraction of categorical information. Journal of Experimental Psychology: Human Learning and Memory 7: 418–39. [Google Scholar] [CrossRef]
- Hualde, José Ignacio. 2005. The Sounds of Spanish. New York: Cambridge University Press. [Google Scholar]
- Labov, William. 1984. Field Methods of the Project on Linguistic Change and Variation. In Language in Use: Readings in Sociolinguistics. Edited by John Baugh and Joel Sherzer. Englewood Cliffs: Prentice Hall, pp. 28–53. [Google Scholar]
- Lipski, John. 1994. Latin American Spanish. New York: Longman. [Google Scholar]
- Lope Blanch, Juan M. 1971. El Habla de la Ciudad de México: Materiales para su Estudio. México: Universidad Nacional Autónoma de México. [Google Scholar]
- Lope Blanch, Juan M. 1976. El Habla Popular de la Ciudad de México: Materiales para su Estudio. México: Universidad Nacional Autónoma de México. [Google Scholar]
- Lope Blanch, Juan M. 1990. El Español Hablado en el Suroeste de los Estados Unidos: Materiales para su Estudio. México: Universidad Nacional Autónoma de México. [Google Scholar]
- Milroy, Lesley, and Matthew J. Gordon. 2003. Sociolinguistics: Method and Interpretation. Language in Society 34. Malden: Blackwell. [Google Scholar]
- Muñiz Cachón, Carmen, and Miguel Cuevas Alonso. 2003. Grados de sonorización de la consonante /s/ en el español de Asturias. Revista de Filoloxía Asturiana 3: 291–304. [Google Scholar]
- Pitt, Mark A., Laura Dilley, Keith Johnson, Scott Kiesling, William Raymond, Elizabeth Hume, and Eric Fosler-Lussier. 2007. Buckeye Corpus of Conversational Speech, 2nd ed. Columbus: Department of Psychology, Ohio State University. [Google Scholar]
- Plag, Ingo, Julia Homann, and Gero Kunter. 2017. Homophony and morphology: The acoustics of word-final S in English. Journal of Linguistics 53: 181–216. [Google Scholar] [CrossRef] [Green Version]
- Prince, Alan, and Paul Smolensky. 2004. Optimality Theory: Constraint Interaction in Generative Grammar. Malden: Blackwell Publishing. [Google Scholar]
- Quilis, Antonio, and Joseph A. Fernández. 1973. Curso de Fonética y Fonología Españolas: Para Estudiantes Angloamericanos. Madrid: Consejo Superior de Investigaciones Científicas. [Google Scholar]
- Robinson, Kimball L. 1979. On the Voicing of Intervocalic S in the Ecuadorian Highlands. Romance Philology 33: 137–43. [Google Scholar]
- Rodriguez Alfano, Lidia. 2005. Investigación Sociolingüística del Habla de Monterrey: Su Trayectoria en una Página Electrónica. México: Editorial Trillas. [Google Scholar]
- Romero, Joaquín. 1999. An effect of voicing assimilation on gestural coordination. In Proceedings of the XIVth International Congress of Phonetic Sciences. Edited by John H. Ohala. San Francisco: University of California. [Google Scholar]
- Ryant, Neville, and Mark Liberman. n.d. Large-Scale Analysis of Spanish /s/-Lenition Using Audiobooks. Linguistic Data Consortium. Available online: http://languagelog.ldc.upenn.edu/myl/ICA2016a.pdf (accessed on 10 November 2020).
- Schmidt, Lauren B, and Erik W Willis. 2011. Systematic Investigation of Voicing Assimilation of Spanish /s/ in Mexico City. In Selected Proceedings of the 5th Conference on Laboratory Approaches to Romance Phonology. Edited by Scott M. Alvord. Somerville: Cascadilla Proceedings Project, pp. 1–20. [Google Scholar]
- Schwegler, Armin, Juergen Kempff, and Ana Ameal-Guerra. 2010. Fonética Y Fonología Españolas, 4th ed. New York: John Wiley and Sons. [Google Scholar]
- Sedó del Campo, M. Beatriz. 2017. La Sonorización de /s/ en Posición de coda en el Español del País Vasco: Factores Lingüísticos y no Lingüísticos. Unpublished. Doctoral thesis, Indiana University, Bloomington, IN, USA. [Google Scholar]
- Sedó, Beatriz, Lauren B. Schmidt, and Erik W. Willis. 2020. Rethinking the phonological process of /s/ voicing assimilation in Spanish: An acoustic comparison of three regional varieties. Studies in Hispanic and Lusophone Linguistics 13: 167–217. [Google Scholar] [CrossRef]
- Sedó, Beatriz. 2015. [s] vs. [z]: Regressive voicing assimilation in the Basque Country. In Selected Proceedings of the 6th Conference on Laboratory Approaches to Romance Phonology. Edited by Erik W. Willis, Pedro Martín Butragueño and Esther Herrera Zendejas. Somerville: Cascadilla Proceedings Project, pp. 30–51. [Google Scholar]
- Seyfarth, Scott. 2014. Word informativity influences acoustic duration: Effects of contextual predictability on lexical representation. Cognition 133: 140–55. [Google Scholar] [CrossRef] [PubMed]
- Sonderegger, Morgan, Michael Wagner, and Francisco Torreira. 2018. Quantitative Methods for Linguistic Data, Version 1.0; Available online: http://people.linguistics.mcgill.ca/~morgan/book (accessed on 15 May 2020).
- Sóskuthy, Márton, and Jennifer Hay. 2017. Changing word usage predicts changing word durations in New Zealand English. Cognition 166: 298–313. [Google Scholar] [CrossRef]
- Storms, Gert, Paul De Boeck, and Wim Ruts. 2000. Prototype and Exemplar-Based Information in Natural Language Categories. Journal of Memory and Language 42: 51–73. [Google Scholar] [CrossRef] [Green Version]
- Strycharczuk, Patrycja, Marijn Van’T Veer, Martine Bruil, and Kathrin Linke. 2014. Phonetic evidence on phonology—Morphosyntax interactions: Sibilant voicing in Quito Spanish. Journal of Linguistics 50: 403–52. [Google Scholar] [CrossRef] [Green Version]
- Tagliamonte, Sali. 2006. Analysing Sociolinguistic Variation. Key Topics in Sociolinguistics. New York: Cambridge University Press. [Google Scholar]
- Torreira, Francisco, and Mirjam Ernestus. 2012. Weakening of Intervocalic /s/ in the Nijmegen Corpus of Casual Spanish. Phonetica 69: 124–48. [Google Scholar] [CrossRef] [Green Version]
- Voeten, Cesko C. 2020. Buildmer: Stepwise Elimination and Term Reordering for Mixed-Effects Regression. Available online: https://CRAN.R-project.org/package=buildmer (accessed on 15 August 2020).
| 1 | Orthographic <h> in Modern Spanish has no phonetic value, aside from [ʧ] in the digraph <ch>, [ʝ] when followed by a grapheme that usually represents a high front vowel followed by a non-high vowel, e.g., hielo ‘ice’, and [w] when followed by a grapheme represening a high back vowel followed by a non-high vowel, e.g., huerta ‘garden’. |
| 2 | Modification of onset /s/ is also possible, but is less common (cf. Lipski 1994, p. 209; Brown 2004). |
| 3 | Translation ours from original Spanish: “/s/ sólo puede realizarse como [z] cuando esta ‘sufre’ una asimilación regresiva y se sonoriza… esto es, cuando le sigue una consonante sonora”. |
| 4 | “Se produce casi siempre que el fonema /s/ precede a una consonante sonora, ya que, entonces, por descontrol de las cuerdas vocales, se transmite la sonorización a la consonante sorda… esta realización no es constante”. |
| 5 | “Cuando la /s/ aparece en posición final de sílaba, tiende a sonorizarse delante de consonante sonora”. |
| 6 | |
| 7 | It should be noted that manual delimitation of sounds is only one of several methods to study variable sound production. For example, Ryant and Liberman (n.d.) demonstrate the usefulness of utilizing automated forced alignment of sounds in audiobooks to study /s/-lenition in Spanish. |
| 8 | This is the case if “order” and “backward”, the default settings, are passed to the “direction” parameter in the function call. |
| 9 | The dataset used and the R code written to perform the analyses reported below are available as Supplementary Materials online. |
Figure 1.
Waveform and spectrogram of voiced /s/ in phrase clases de verano ‘summer classes’.

Figure 2.
Sample token of word with /s/ pensabas.

Figure 3.
p-values of FRC as a main effect and in interactions in 40 beta regression models.

Figure 4.
Scatterplots of percentage voiced of /s/ by forms’ ratio of conditioning (FRC) by the following phonological context.
Figure 4.
Scatterplots of percentage voiced of /s/ by forms’ ratio of conditioning (FRC) by the following phonological context.

Figure 5.
Boxplot of percentage voiced of the /s/ segment by following phonological context.

Figure 6.
Scatterplot of percentage voiced of /s/ by speech rate.

Figure 7.
Boxplot of percentage of /s/ voicing by word class.

Figure 8.
Scatterplots of percentage /s/ voicing by lexical frequency by following phonological context.
Figure 8.
Scatterplots of percentage /s/ voicing by lexical frequency by following phonological context.

Figure 9.
Scatterplots of percentage /s/ voicing by lexical frequency by word class.


{kind=link}
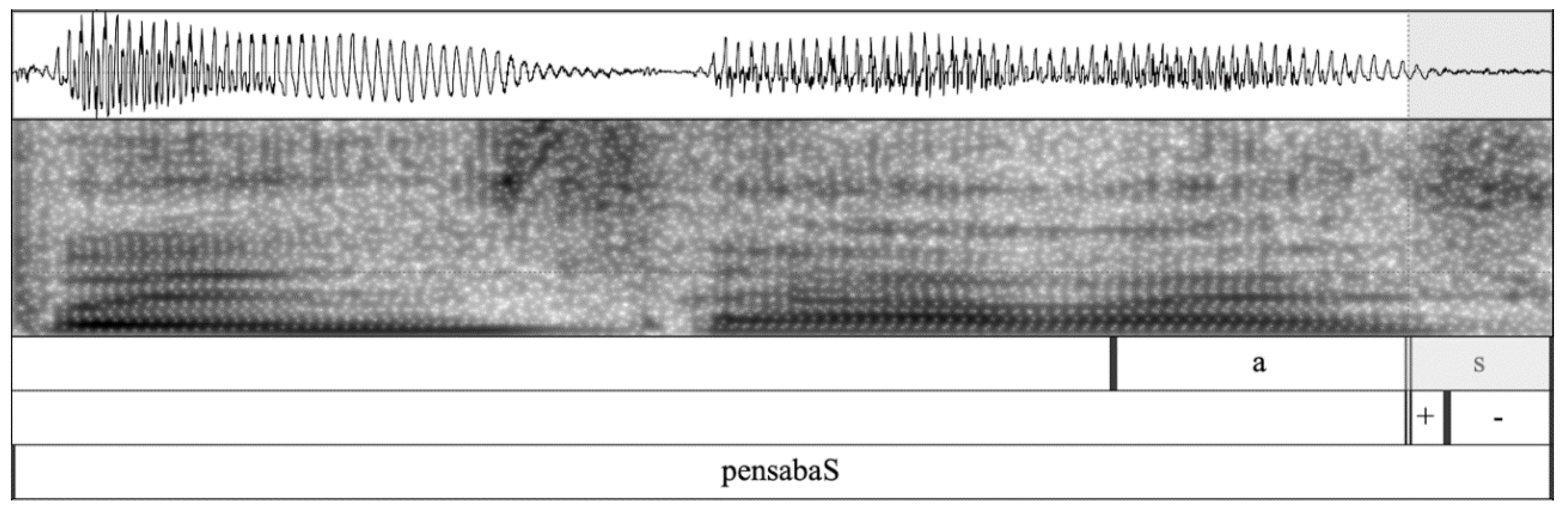{kind=link}
{kind=link}
{kind=link}
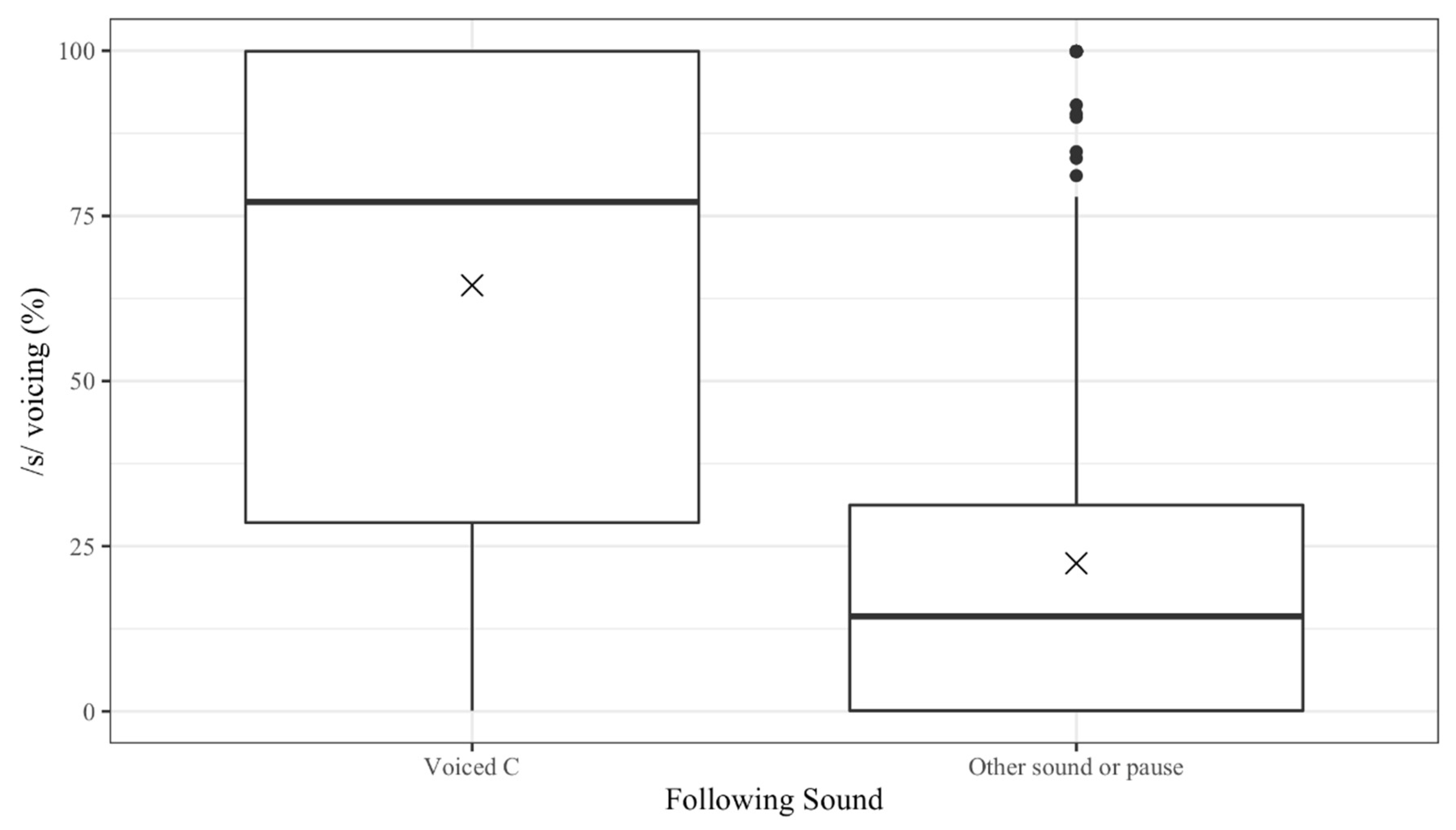{kind=link}
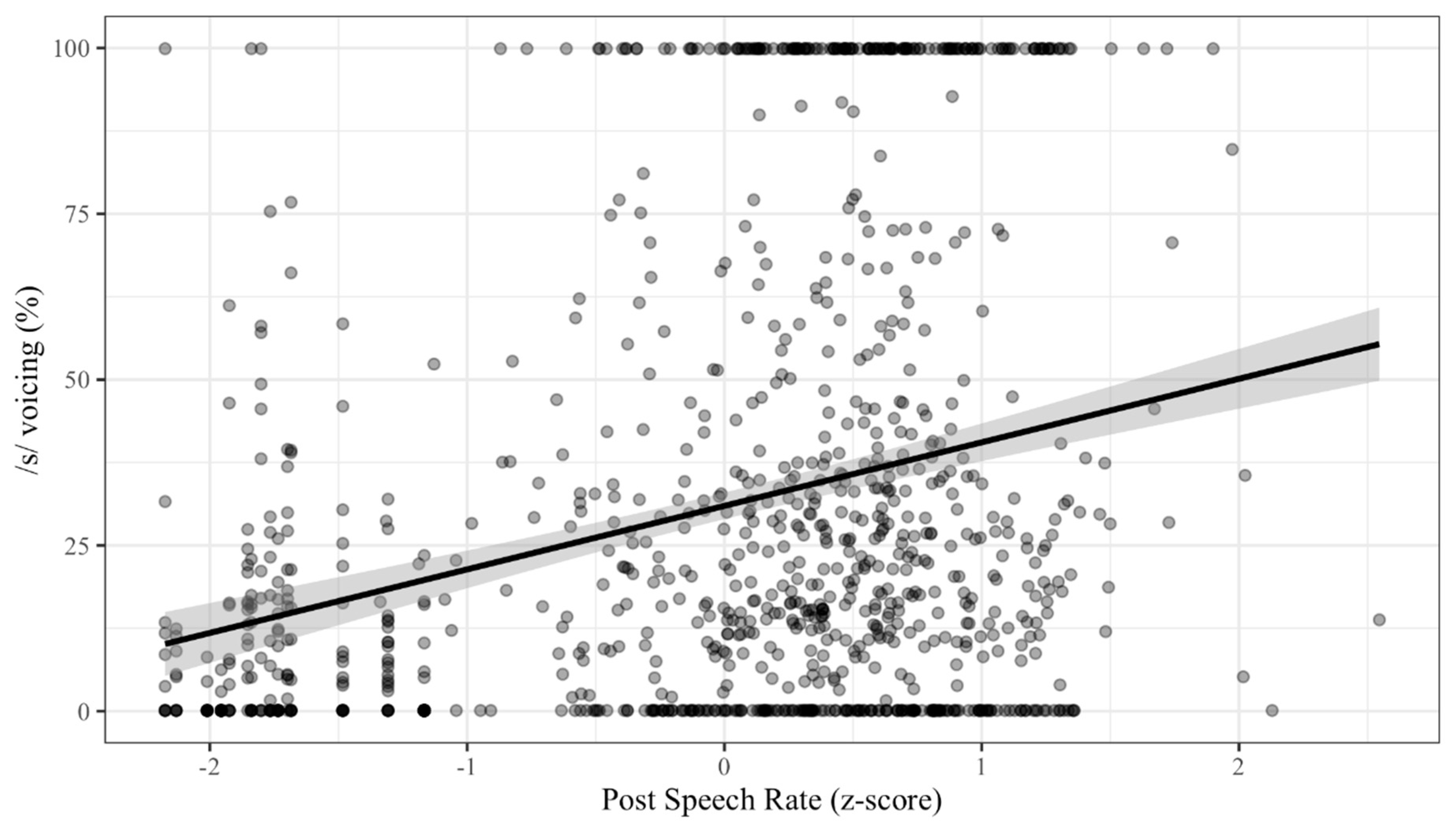{kind=link}
{kind=link}
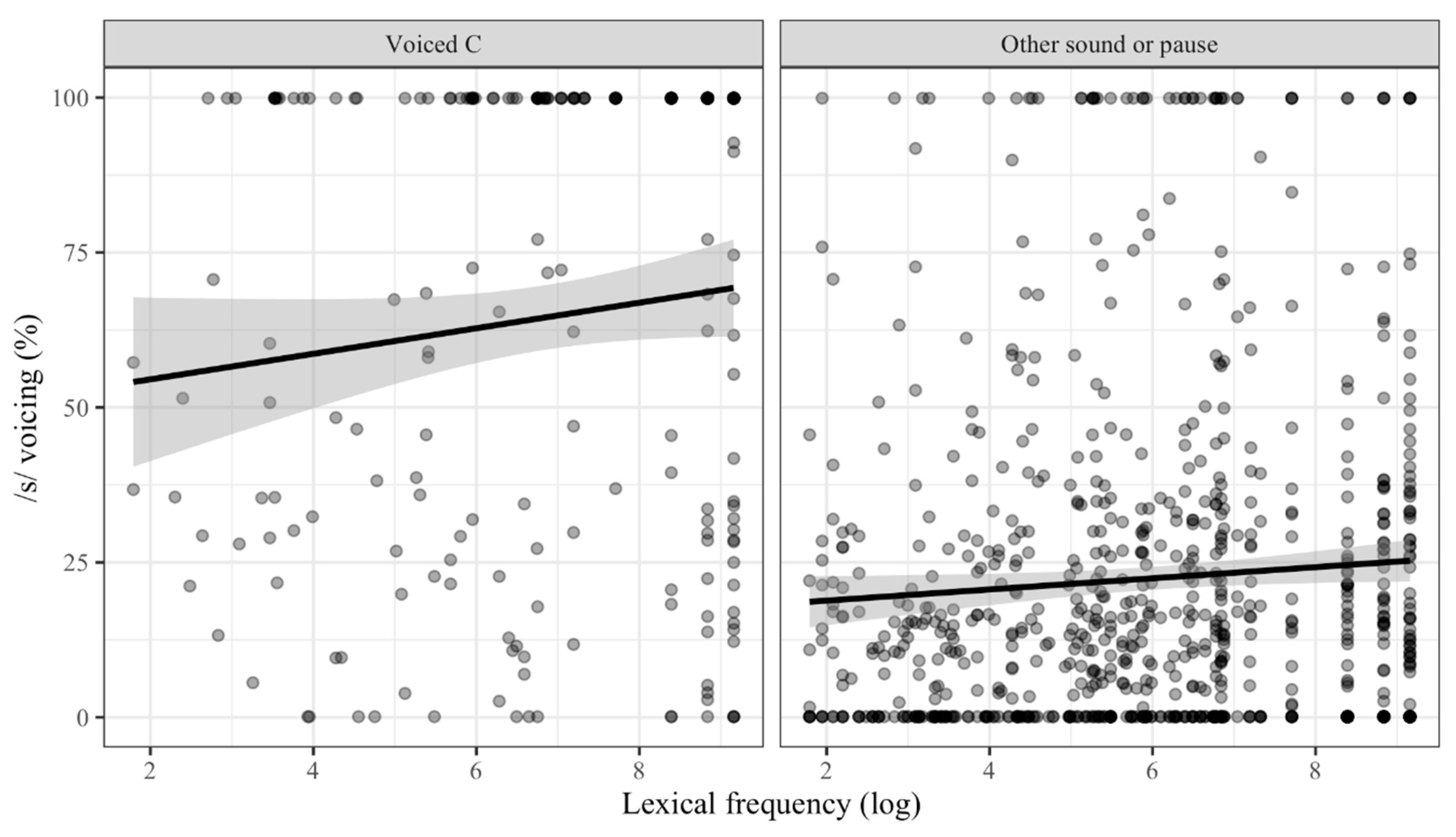{kind=link}
{kind=link}
Table 1.
Final beta regression model of percentage voicing of /s/ with tokens whose FRC is based on at least 5 tokens in the reference corpus and whose FRC values lay outside the middle half standard deviation on the FRC-range.
Table 1.
Final beta regression model of percentage voicing of /s/ with tokens whose FRC is based on at least 5 tokens in the reference corpus and whose FRC values lay outside the middle half standard deviation on the FRC-range.
| Random Effects | Variance | Standard Deviation | N Groups | ||
|---|---|---|---|---|---|
| Speaker (intercept) | 0.10 | 0.32 | 15 | ||
| Fixed effects: | Estimate | Standard Error | z-value | p-value | Significance |
| Intercept | −1.00 | 0.26 | −3.85 | ≤0.001 | *** |
| FRC: Fol. phon. context | 1.55 | 0.73 | 2.13 | 0.03 | * |
| FRC | 0.22 | 0.47 | 0.47 | 0.64 | ns |
| Fol. phon. context (voiced C) | 1.35 | 0.57 | 2.36 | 0.02 | * |
| Speech rate (z-score) | 0.22 | 0.04 | 5.36 | ≤0.001 | *** |
| Wd. class (function) | 1.12 | 0.37 | 3.08 | 0.002 | ** |
| Pre. vowel (non-hi V) | −0.01 | 0.21 | −0.07 | 0.94 | ns |
| Stress (stressed) | −0.09 | 0.11 | −0.77 | 0.44 | ns |
| Lex. freq. (log) | 0.03 | 0.03 | 1.04 | 0.3 | ns |
| Fol. phon. context (voiced C): Pre vowel (non-hi V) | −1.06 | 0.52 | −2.03 | 0.04 | * |
| Fol phon context (voiced C): Stress (stressed) | −0.5 | 0.22 | −2.25 | 0.02 | * |
| Fol. phon. context (voiced C): Lex. freq. (log) | 0.1 | 0.04 | 2.41 | 0.0159 | * |
| Wd class (function): Lex freq (log) | −0.16 | 0.05 | −3.13 | 0.002 | ** |
N = 1034; AIC = −2334.8; BIC = −2260.6; log-likelihood = 1182.4. p-Value significance codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘ns’ 1.
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Brown, E.K. The Effect of Forms’ Ratio of Conditioning on Word-Final /s/ Voicing in Mexican Spanish. Languages 2020, 5, 61. https://0-doi-org.brum.beds.ac.uk/10.3390/languages5040061
AMA Style
Brown EK. The Effect of Forms’ Ratio of Conditioning on Word-Final /s/ Voicing in Mexican Spanish. Languages. 2020; 5(4):61. https://0-doi-org.brum.beds.ac.uk/10.3390/languages5040061
Chicago/Turabian StyleBrown, Earl Kjar. 2020. "The Effect of Forms’ Ratio of Conditioning on Word-Final /s/ Voicing in Mexican Spanish" Languages 5, no. 4: 61. https://0-doi-org.brum.beds.ac.uk/10.3390/languages5040061