
Financial Inclusion in Emerging Economies: The Application of Machine Learning and Artificial Intelligence in Credit Risk Assessment


Abstract
:1. Introduction
2. Background of Financial Inclusion
2.1. AI, Machine Learning, a Brief Overview
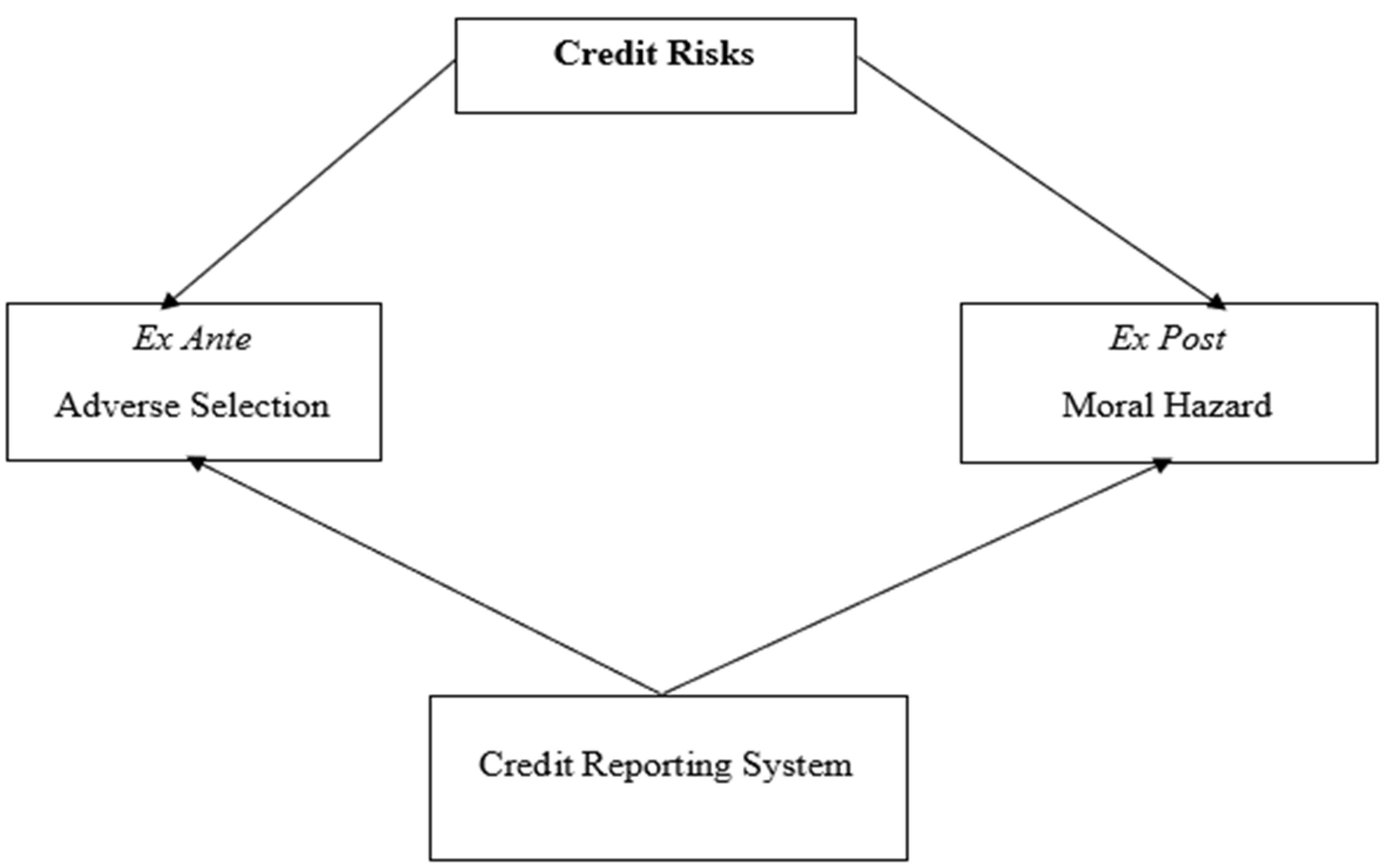
2.2. The Theories of Financial Inclusion and Credit Risk Analysis a Brief Review-Information Asymmetry and Credit Risk
2.3. The Adverse Selection Theory
2.4. Moral Hazard Theory
2.5. Empirical Literature Review
3. Methodology
3.1. Discussion of the Findings on Application of Machine Learning and AI in Credit Risk Assessments
3.2. AI, Machine Learning, and Asymmetric Information and Credit Risk Assessments
3.3. How Does AI Help to Solve the Problem of Information Asymmetry?
3.4. AI, Machine Learning and Adverse Selection
3.5. AI, Machine Learning and Moral Hazard
4. Conclusions and Policy Recommendations
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
| Impact of Artificial Intelligence and Machine Learning | Brief Description |
|---|---|
| AI, Machine Learning, and Asymmetric Information and Credit Risk Assessments | The first way in which AI can help to solve the problem of information asymmetry is through signalling and the use of big data and deep learning. One example given by Marwala and Hurwitz (2015) was the issue of social networks which are powered by AI to an extent that they can signal information in a much more accurate fashion than what a human agent can do. In this way, it is believed that AI can help to solve the problem of information asymmetry in many circumstances including the credit market |
| AI, Machine Learning and Adverse Selection | Information asymmetry in the credit market generates two problems, adverse selection, and moral hazard (Moloi and Marwala 2020a; Tfaily 2017). Moloi and Marwala (2020b) argued that the era of intense automation and digitization powered by AI can push economic agents to a form of some peculiar relationships which include the sharing of certain information that will help in opening the opportunities to harvest and store big data that can be used by economic agents such as banks to do effective credit analysis of the individuals seeking credit. Using AI economic agents can build, link, and analyses the big new data sets which are difficult for human beings. In a way, the problem of adverse selection will greatly be reduced. |
| AI, Machine Learning and Moral Hazard | The existence of ex-post information asymmetry in a contract generates moral hazard especially after signing the contract. This problem arises due to the inability of agents to be able to observe the actions of other agents. Moloi and Marwala (2020c) stated that the coming of AI will be able to reduce the problems associated with moral hazard because with AI there is no need to depend more on economic agents to be fair by disclosing material information. At the same time, it was highlighted that there is also no need to come up with innovative ways to persuade economic agents through incentives to disclose material information or using threats of penalties for them to disclose important information. As a result, AI presents a better way to harvest information about the borrower helping lenders to address the problem of moral hazard. |
References
- Akerlof, George. 1970. The market for lemons: Qualitative uncertainty and the market mechanism. Quarterly Journal of Economics 84: 488–500. [Google Scholar] [CrossRef]
- Arun, Thankom, and Rajalaxm Kamath. 2015. Financial inclusion: Policies and practices. IIMB Management Review 27: 267–87. [Google Scholar] [CrossRef] [Green Version]
- Asongu, Simplice, and Nicholas. M. Odhiambo. 2020. Information Asymmetry and Insurance in Africa. Journal of African Business, 1–17. [Google Scholar] [CrossRef]
- Berger, Allen N., Marco A. Espinosa-Vega, W. Scott Frame, and Nathan H. Miller. 2011. Why Do Borrowers Pledge Collateral? New Empirical Evidence on the Role of Asymmetric Information. Journal of Financial Intermediation 20: 55–70. [Google Scholar] [CrossRef] [Green Version]
- Berhanu, Amare Altaseb. 2005. Determinants of the Formal Source of Credit Loan Repayment Performance of Smallholder Farmers: The Case of Northwestern Ethiopia, North Gondar. Unpublished Master’s thesis, Alemaya University, Oromia, Ethiopia. [Google Scholar]
- Bhatore, Siddharth, Lalit Mohan, and Y. Raghu Reddy. 2020. Machine learning techniques for credit risk evaluation: A systematic literature review. Journal of Banking and Financial Technology 4: 111–38. [Google Scholar] [CrossRef]
- Biallas, Margarete, and Felicity O’Neill. 2020. Artificial Intelligence Innovation in Financial Services. Available online: www.ifc.org/thoughtleadership (accessed on 20 January 2021).
- Boot, Arnoud W.A., and Anjan. V. Thakor. 1994. Moral hazard and secured lending in an infinitely repeated credit market game. International Economic Review 35: 899–920. [Google Scholar] [CrossRef]
- Breeden, L. Joseph. 2020. A Survey of Machine Learning in Credit Risk Nonlinear Modelling View Project CECL Modelling Study View Project A Survey of Machine Learning in Credit Risk. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3616342 (accessed on 23 February 2021). [CrossRef]
- Bussmann, Niklas, Paolo Giudici, Dimitri Marinelli, and Jochen Papenbrock. 2020. Explainable AI in Fintech Risk Management. Frontiers in Artificial Intelligence 3. [Google Scholar] [CrossRef]
- Bussmann, Nikla, Paolo Giudici, Dimitri Marinelli, and Jochen Papenbrock. 2021. Explainable Machine Learning in Credit Risk Management. Computational Economics 57: 203–16. [Google Scholar] [CrossRef]
- Caporale, Guglielmo Maria, Mario Cerrato, and Xuan Zhang. 2016. Analyzing the Determinants of Credit Risk for General Insurance Firms in the UK. Available online: http://ssrn.com/abstract=2808513 (accessed on 20 March 2021).
- Carbó, Santiago, Howard E. Gardner, and Philip Molyneux. 2005. Financial Exclusion. Berlin: Springer. [Google Scholar]
- Chamberlain, Trevor, Sutan Hidayat, and Rahman Khokhar. 2020. Credit risk in Islamic banking: Evidence from the GCC. Journal of Islamic Accounting and Business Research 11: 1055–81. [Google Scholar] [CrossRef]
- Chow, Jacky C.K. 2017. Analysis of Financial Credit Risk Using Machine Learning. arXiv arXiv:1802.05326. [Google Scholar]
- Danėnas, Paulius, and Gintautas Garšva. 2010. Support Vector Machines and Their Application in Credit Risk Evaluation Process. Available online: https://www.researchgate.net/publication/235659762_support_vector_machines_and_their_application_in_credit_risk_evaluation_process (accessed on 10 March 2021).
- Eaton, Jonathan, and Mark Gersovitz. 1981. Debt with potential repudiation: Theoretical and empirical analysis. The Review of Economic Studies 48: 289–309. [Google Scholar] [CrossRef]
- Emeana, Ezinne M., Liz Trenchard, and Katharina Dehnen-Schmutz. 2020. The revolution of mobile phone-enabled services for agricultural development (m-Agri services) in Africa: The challenges for sustainability. Sustainability 12: 485. [Google Scholar] [CrossRef] [Green Version]
- Galindo, Jorge, and Pablo Tamayo. 2000. Credit Risk Assessment Using Statistical and Machine Learning: Basic Methodology and Risk Modeling Applications. Computational Economics 15: 107–43. [Google Scholar] [CrossRef]
- Gu, Shihao, Bryan Kelly, and Dacheng Xiu. 2018. NBER Working Paper Series Empirical Asset Pricing via Machine Learning Empirical Asset Pricing via Machine Learning. Available online: http://www.nber.org/papers/w25398 (accessed on 2 March 2021).
- Gui, Liyu. 2019. University of California Los Angeles Application of Machine Learning Algorithms in Predicting Credit Card Default Payment. Los Angeles: University of California. [Google Scholar]
- Hellwig, Martin. 1987. Some recent developments in the theory of competition in markets with adverse selection. European Economic Review 31: 319–25. [Google Scholar] [CrossRef]
- Henze, Janosch, and Christian Ulrichs. 2016. The Potential and Limitations of Mobile-Learning and Other Services in the Agriculture Sector of Kenya Using Phone Applications. Paper presented at 12th European International Farming Systems Association (IFSA) Symposium, Social and Technological Transformation of Farming Systems: Diverging and Converging Pathways, Shropshire, UK, July 12–15. [Google Scholar]
- Imarticus. 2019. What Is Credit Risk Analysis and Why It Is Important? Available online: https://blog.imarticus.org/what-is-credit-risk-analysis-and-why-it-is-important/ (accessed on 14 May 2021).
- Karlan, Dean, and Jonathan Zinman. 2009. Observing unobservable: Identifying information asymmetries with a consumer credit field experiment. Econometrica 77: 1993–2008. [Google Scholar]
- Leeladhar. 2005. Taking Banking Services to Common Man: Financial Inclusion. Commemorative Lecture by Shri Leeladhar. Ernakulum: Fedbank Hormis Memorial Foundation. [Google Scholar]
- Levine, Ross. 2005. Finance and growth: Theory and evidence. In Handbook of Economic Growth. Amsterdam: Elsevier, vol. 1, pp. 865–934. [Google Scholar]
- Lynn, Theo, John G. Mooney, Pierangelo Rosati, and Mark Cummins. 2019. Palgrave Studies in Digital Business and Enabling Technologies Series Editors: Disrupting Finance FinTech and Strategy in the 21st Century. Available online: http://www.palgrave.com/gp/series/16004 (accessed on 5 February 2021).
- Leyshon, Andrew, and Nigel Thrift. 1995. Geographies of financial exclusion: Financial abandonment in Britain and the United States. Transactions of the Institute of British Geographers, 312–41. [Google Scholar] [CrossRef]
- Marwala, Tshilidzi. 2015. Impact of Artificial Intelligence on Economic Theory. Available online: https://www.researchgate.net/publication/281486806_Impact_of_Artificial_Intelligence_on_Economic_Theory (accessed on 10 February 2021).
- Marwala, Tshilidzi, and Evan Hurwitz. 2015. Artificial Intelligence and Asymmetric Information Theory. Available online: https://www.researchgate.net/publication/282906709_Artificial_Intelligence_and_Asymmetric_Information_Theory (accessed on 10 February 2021).
- Mhlanga, David. 2020. Financial Inclusion and Poverty Reduction: Evidence from Small Scale Agricultural Sector in Manicaland Province of Zimbabwe. Available online: http://repository.nwu.ac.za/handle/10394/34615 (accessed on 1 August 2020).
- Mhlanga, David. 2021. Artificial Intelligence in the Industry 4.0, and Its Impact on Poverty, Innovation, Infrastructure Development, and the Sustainable Development Goals: Lessons from Emerging Economies? Sustainability 13: 5788. [Google Scholar] [CrossRef]
- Mhlanga, David, and Varaidzo Denhere. 2021. Determinants of Financial Inclusion in Southern Africa. Studia Universitatis Babes-Bolyai 65: 39–52. [Google Scholar] [CrossRef]
- Mohan, Rakesh. 2006. Economic Growth, Financial Deepening and Financial Inclusion. In Migrant Worker Remittances, Micro-Finance, and the Informal Economy: Prospects and Issues, Paper presented at Annual Bankers’ Conference, Hyderabad, India, November 3. Working Paper No. 21. Geneva: Social Finance Unit, International Labour Office. [Google Scholar]
- Mohiuddin, Yasmeen. 1993. Credit Worthiness of Poor Women: A Comparison of Some Minimalist Credit Programmes in Asia: A Preliminary Analysis [with Comments]. The Pakistan Development Review 32: 1199–209. [Google Scholar] [CrossRef]
- Moloi, Tankiso, and Tshilidzi Marwala. 2020a. Advanced Information and Knowledge Processing. Available online: http://0-www-springer-com.brum.beds.ac.uk/series/4738 (accessed on 10 February 2021).
- Moloi, Tankiso, and Tshilidzi Marwala. 2020b. Adverse selection. In Advanced Information and Knowledge Processing. Berlin/Heidelberg: Springer, pp. 71–79. [Google Scholar] [CrossRef]
- Moloi, Tankiso, and Tshilidzi Marwala. 2020c. Moral hazard. In Advanced Information and Knowledge Processing. Berlin/Heidelberg: Springer, pp. 81–88. [Google Scholar] [CrossRef]
- Moscatelli, Mirko, Fabio Parlapiano, Simone Narizzano, and Gianluca Viggiano. 2020. Corporate default forecasting with machine learning. Expert Systems with Applications 161: 113567. [Google Scholar] [CrossRef]
- Ndanshau, Michael, and Njau Frank. 2021. Empirical Investigation into Demand-Side Determinants of Financial Inclusion in Tanzania. African Journal of Economic Review 9: 172–90. [Google Scholar]
- Nyoni, T. E. Avender, and Ntandoyenkosi Matshisela. 2018. Credit Scoring Using Machine Learning Algorithms View Project Factors Affecting Cotton Production in Zimbabwe (1968–2018) View Project. Available online: https://www.researchgate.net/publication/336240486 (accessed on 22 July 2021).
- Okoroafor, O. K. David, Sesan Adeniji, Oluseyi O. K. David, Adeniji Sesan Oluseyi, and Awe Emmanuel. 2018. Empirical Analysis of the Determinants of Financial Inclusion in Nigeria: 1990–2016. Journal of Finance and Economics 6: 19–25. [Google Scholar] [CrossRef]
- Ozili, Peterson K. 2020. Financial inclusion research around the world: A review. Forum for Social Economics. [Google Scholar] [CrossRef]
- Punniyamoorthy, Murugesan, and P. Sridevi. 2016. Identification of a standard AI-based technique for credit risk analysis. Benchmarking 23: 1381–90. [Google Scholar] [CrossRef]
- Saito, Kuniyoshi, and Daisuke Tsuruta. 2018. Information asymmetry in small and medium enterprise credit guarantee schemes: Evidence from Japan. Applied Economics 50: 2469–85. [Google Scholar] [CrossRef]
- Sarma, Mandira. 2008. Index of Financial Inclusion. Available online: https://www.icrier.org/pdf/Working_Paper_215.pdf (accessed on 10 February 2021).
- Sinclair, Stephen. 2001. Financial Exclusion: An Introductory Survey. CRSIS. Edinburgh: Edinburgh College of Art/Heriot-Watt University. [Google Scholar]
- Sousa, Maria Rocha, João Gama, and Elísio Brandão. 2016. A new dynamic modelling framework for credit risk assessment. Expert Systems with Applications 45: 341–51. [Google Scholar] [CrossRef] [Green Version]
- Spence, Michael. 1973. Job Market Signaling. In Quarterly Journal of Economics. Cambridge: The MIT Press, vol. 87, pp. 355–74. [Google Scholar]
- Stiglitz, Joseph Eugene, and Andrew Weiss. 1981. Credit Rationing in Markets with Imperfect Information. The American Economic Review 71: 393–410. [Google Scholar]
- Stiglitz, Joseph Eugene. 1974. Incentives and Risk-Sharing in Sharecropping. Review of Economic Studies. Oxford Journals 41: 219–55. [Google Scholar] [CrossRef] [Green Version]
- Strusani, Davide, and Georges Vivien Houngbonon. 2019. The Role of Artificial Intelligence in Supporting Development in Emerging Markets. Available online: www.ifc.org/thoughtleadership (accessed on 10 March 2021).
- Tfaily, Ali. 2017. Proceedings of the 11 the International Management Conference the Role of Management in the Economic Paradigm of the XXI st Century Managing Information Asymmetry and Credit Risk—A Theoretical Perspective. Available online: https://ideas.repec.org/a/rom/mancon/v11y2017i1p652-659.html (accessed on 6 March 2021).
- Thorat, Usha. 2007. Usha Thorat: Financial Inclusion—The Indian Experience. Central Bank Articles and Speeches. Available online: https://www.bis.org/review/r070626f.pdf (accessed on 4 March 2021).
- Tinsley, Elaine, and Natalia Agapitova. 2018. Private Sector Solutions to Helping Smallholders Succeed Social Enterprise Business Models in the Agriculture Sector. Washington, DC: World Bank. [Google Scholar]
- Ullah, Zaib, Fadi Al-Turjman, Leonardo Mostarda, and Roberto Gagliardi. 2020. Applications of Artificial Intelligence and Machine learning in smart cities. In Computer Communications. Amsterdam: Elsevier B.V., vol. 154, pp. 313–23. [Google Scholar] [CrossRef]
- Witzany, Jiri. 2017. Credit Risk Management. In Credit Risk Management. Cham: Springer International Publishing, pp. 5–18. [Google Scholar] [CrossRef]
- Wu, Cheng-Feng, Mahdi Fathi, David. M. Chiang, and Panagote M. Pardalos. 2020. Credit guarantee mechanism with information asymmetry: A single-sourcing model. International Journal of Production Research 58: 4877–93. [Google Scholar] [CrossRef]
- Xie, Minzhen. 2019. Development of Artificial Intelligence and Effects on Financial System. Journal of Physics: Conference Series 1187. [Google Scholar] [CrossRef]
- Yigitcanlar, Tan, Kevin C. Desouza, Luke Butler, and Farnoosh Roozkhosh. 2020. Contributions and Risks of Artificial Intelligence (AI) in Building Smarter Cities: Insights from a Systematic Review of the Literature. Energies 13: 1473. [Google Scholar] [CrossRef] [Green Version]
- Yin, Chang, Cuiqing Jiang, Hemant K. Jain, and Zhao Wang. 2020. Evaluating the credit risk of SMEs using legal judgments. Decision Support Systems 136: 113364. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mhlanga, D. Financial Inclusion in Emerging Economies: The Application of Machine Learning and Artificial Intelligence in Credit Risk Assessment. Int. J. Financial Stud. 2021, 9, 39. https://0-doi-org.brum.beds.ac.uk/10.3390/ijfs9030039
Mhlanga D. Financial Inclusion in Emerging Economies: The Application of Machine Learning and Artificial Intelligence in Credit Risk Assessment. International Journal of Financial Studies. 2021; 9(3):39. https://0-doi-org.brum.beds.ac.uk/10.3390/ijfs9030039
Chicago/Turabian StyleMhlanga, David. 2021. "Financial Inclusion in Emerging Economies: The Application of Machine Learning and Artificial Intelligence in Credit Risk Assessment" International Journal of Financial Studies 9, no. 3: 39. https://0-doi-org.brum.beds.ac.uk/10.3390/ijfs9030039