1. Introduction
Nonverbal cues, such as facial expressions, body language and voice tone, play principal roles in humans’ communication, transmitting signals of the individual’s implicit intentions that cannot be expressed through spoken language. The above cues compose the emotional state which can be used to convey one’s internal state throughout an interaction. Therefore, current research is investigating the development of empathetic robots capable of perceiving emotions as an attempt to enhance the overall performance of several human–robot interaction (HRI) scenarios [
1,
2]. The present study is anticipated to benefit the development of competent social robotic platforms [
3,
4] and enhance their applications in several recent real-world scenarios [
5,
6]. All the above render affective computing an emerging research field, which aims to address a wide set of challenges that play key roles in the development of human-like intelligent systems [
7].
Based on the existing literature in the fields of psychology and neuroscience, one’s emotional state can be described following two distinct representational approaches, namely the categorical and the dimensional approaches. The first approach, introduced by Ekman, suggests the following six universal basic emotions:
happiness,
sadness,
fear,
anger,
surprise and
disgust [
8]. Following Ekman’s model, several alternative works were developed for categorical emotion estimation, either by dropping the emotional classes of
surprise and
disgust or by introducing some secondary ones, such as
hope and
neutral state [
9]. Since the vast majority of emotion recognition systems have adopted the Ekman’s categorical approach, most works resort to classification schemes [
10]. In spite of the promising performances achieved by the aforementioned methods, this approach lacks in representation capacity since the elicited information is displayed in the discrete space. The above fact, coupled with the limited number of emotional classes that can be efficiently estimated, further restricts the capacity of such systems, as also denoted by the corresponding datasets [
11]. To that end, the adoption of a continuous representation approach is of the utmost importance. Such an approach is based on the two-dimensional emotion model proposed by Russel and Barrett [
12], suggesting arousal and valence as the two distinct coefficients of human emotion. Thus, the estimation of two continuous variables is required, reducing the emotion recognition problem to a regression problem. The two estimated variables of arousal and valence lie within the range of
.
Inspired by the categorical and the dimensional emotional representations, researchers resort to respective recognition systems with the objective of perceiving the emotional state of humans. This field of affective computing exploits different modalities that transmit information regarding the subject’s internal state. Hence, contemporary recognition systems utilize facial data from RGB images [
13]; three-dimensional data [
14]; facial landmarks [
15,
16]; audio features from speech [
17]; physiological signals [
18], such as electromyography, pulse rate, galvanic skin response and respiration [
19]; sentiment analysis from text [
20]; and multimodal approaches [
21]. Each of the above modalities can be efficiently processed by a wide variety of machine learning techniques to produce the desired recognition rate. To that end, a genetic algorithm is able to choose the optimal subset of the geometric and kinematic features extracted from a Kinect sensor for advanced multimodal emotion recognition [
22]. Moreover, particle swarm optimization can achieve competitive performance in several state-of-the-art speech emotion recognition challenges [
23]. More specifically, in facial emotion recognition, the utilization of support vector machines has been proven to be particularly beneficial [
24].
Taking into consideration recent methods in computer science, the reader can easily notice the considerable advancement of deep neural networks (DNNs) in the field, thanks to their advanced feature learning capabilities [
25]. Their ability to learn robust high-level features renders their use preferable over other conventional methods in several tasks [
26]. Similarly, their rapid advent is noticeable in the field of emotion recognition for both representation models [
27,
28]. More specifically, a previous work of ours proposed an online audio–visual emotion classification system which consisted of two convolutional neural network (CNN) architectures and long short-term memory (LSTM) layers [
29] that conceive the temporal characteristics of emotion [
30]. Focusing on a dimensional emotion estimation scheme, conformable CNN unimodal architectures have been combined with LSTM layers, leading to a particularly efficient solution [
10]. Consequently, the development of even more sophisticated neural architectures and the introduction of reinforcement learning in the field further enhanced the recognition capacities of DNN-based systems [
31,
32].
However, the task of emotion recognition, which is confronted by all the above works, focuses on the estimation of a human’s emotional state during a moment or a very short period of time. A momentary or even a short-term estimation of one’s emotional state is not able to capture the actual state of that person. The above constitutes an open topic in ongoing research into user profiling and authentication, which aims to create a pattern using behavioral biometric techniques [
33]. To understand that, the reader can imagine the difference that the state of anger can convey in the case of an introverted and an extroverted person. The above ambiguity inspired us to investigate the development of a behavioral modeling tool based on the experience gained throughout an interaction with a subject. Thus, previous knowledge of emotional variation can be used to normalize the momentary emotional state with a subject-specific behavioral pattern. Such an attempt is followed by a set of difficulties owing to the spontaneous nature of HRI scenarios. Firstly, physiological signals are difficult to exploit in natural HRI scenarios. Moreover, the audio modality cannot be selected since the interaction usually consists of nonverbal parts that also have to be processed by the system. In terms of facial data, the exploitation of facial landmarks is highly desirable as they provide a more robust representation of the human face when the subject moves, a fact that is commonly observed during a natural interaction. In a previous work of ours, we discussed the benefits of understanding the long-term behavior of a subject throughout an interaction and proceeded with a first attempt of providing such an estimation [
34]. The introduced system performed the following: (a) extracted the facial landmarks from a subject; (b) used a DNN architecture to predict the values of arousal and valence; (c) built a long-term overview of their behavior according to emotional variations during the interaction; (d) displayed both the momentary and the long-term estimated values on the two-dimensional unit circle through a user-friendly dashboard. The present paper extends the above work, providing the following qualities:
Enhanced continuous emotion recognition performance, employing recurrent neural network (RNN) architectures instead of the DNN ones;
Competitive recognition results compared with the state-of-the-art approaches in the field, following the more strict and realistic leave-one-speakers-group-out (LOSGO) evaluation protocol [
35];
Implementation of an efficient and user-friendly human behavior modeling tool based on the experience gained through interaction.
The remainder of the paper comprises the following structure.
Section 2 lists the utilized materials and methods of the system, namely the dataset adopted for the experimental studies and the evaluation of the system, as well as the modules that constitute the final total system. In
Section 3, we display the ablation and experimental studies conducted to conclude an efficient emotion recognition system and the validation procedure followed to assess its final performance.
Section 4 provides an extensive discussion regarding the application of the proposed system and its importance in HRI and assisted living environments, while
Section 5 concludes with a summary of the paper, and
Section 6 discusses interesting subjects for future work.
4. Discussion
In this section, we hold a conversation about the proposed system as a whole. More specifically, we demonstrate an updated version of the dashboard introduced in our previous work, focusing on a user-friendly and low-complexity solution. Subsequently, we discuss the beneficiary role of the system in application fields, such as HRI and collaboration tasks, as well as in more specific tasks, such as robots in assisted living environments.
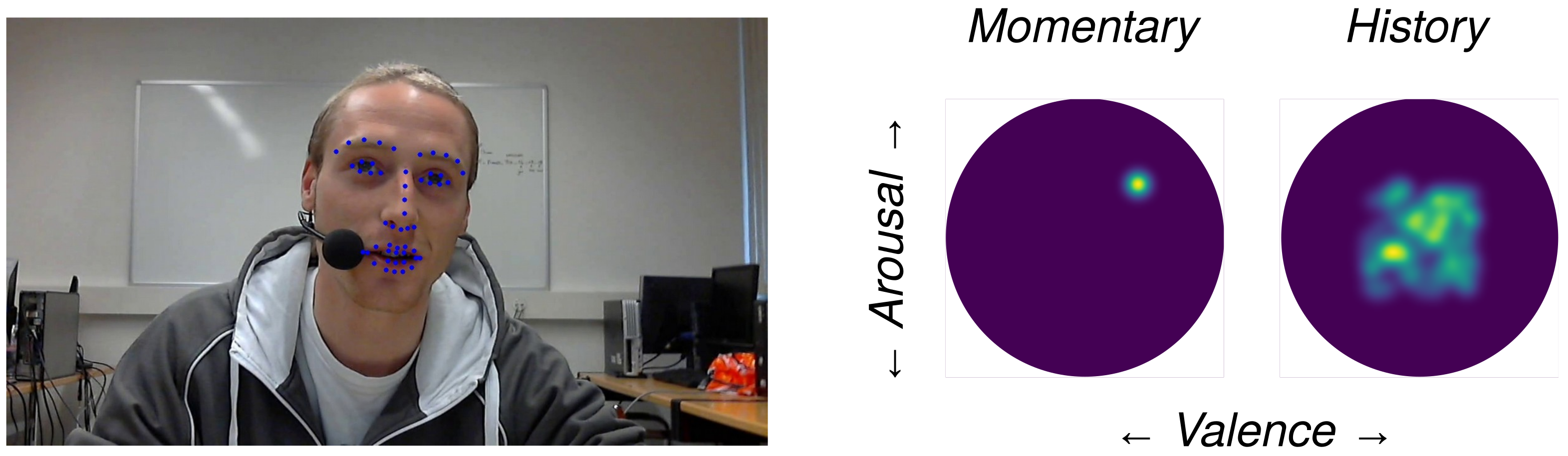
To begin with, in
Figure 6, an indicative graphical snapshot of the proposed tool is depicted. The left part of the dashboard provides a demonstration of the current frame of the processing video, where the estimated facial keypoints of the Facial Landmark Extraction Tool are projected on the image plane. We believe that the above part is crucial since on the one hand, it provides the user with a general overview, regarding the development of the processing procedure in the case of video processing, while in cases of real-time execution, the speaker is capable of continuously supervising their position to the camera and accordingly correcting their position and/or orientation, if needed. On the other hand, the projection of the extracted facial landmarks on the illustrated frame is also highly desirable since it provides feedback on the capability of efficiently tracking the interaction. Thus, the user is informed that the environmental conditions, such as illumination and background, as well as their position and point of view, allow the accurate surveillance of the system. At this point, we have to consider that the efficient extraction of the facial keypoints is of the utmost importance for the final performance of the system. Consequently, we deduce that the above part provides the user with a higher level of certainty, knowing that they can observe the general procedure and proceed to corrective actions.
The central part of the dashboard shows the CERT’s momentary estimation of the speaker’s emotional state for the specific frame depicted in the right part of the dashboard. The predicted arousal and valence values of the CERT are projected on the two-dimensional Russel’s unit circle. Valence is represented by the horizontal axis (x-axis) and arousal by the vertical one (y-axis). Hence, the momentary emotional state occupies a particular point within Russel’s circle. At the next time step, the new values of arousal and valence are calculated and projected, in the form of a new point. The result that the user observes is a point that continuously moves within the unit circle.
Concentrating on the main contribution of this work, which constitutes the modeling of a speaker’s long-term behavior during an interaction, the right part of the dashboard provides the pictorial result. A similar two-dimensional unit circle, from now on called a history circle, is utilized to provide the projection space of the estimated behavioral pattern. Valence and arousal are represented by the horizontal and vertical axes, respectively. Thus, at each time step, the point provided by the momentary estimation is incorporated into the history circle. The incorporation is realized by adding the current estimated value to the previous ones stored in the history circle. The stored values are previously multiplied by a discount factor
, thus fading the older estimations and paying more attention to the recent ones. The obtained illustrative result, shown in
Figure 6, is a heatmap within the history circle. The lighter the value of the map, the more frequently the specific emotional state is expressed by the speaker throughout the interaction.
Bringing the presentation of the dashboard to a close, we discuss its benefits along with several fields of application in HRI and assisted living scenarios. With the last term, “robotics in assisted living”, also known as aging in place [
47], we refer to the specific field of research that focuses on the design, development and test of efficient robotic platforms, enabling elderly people to live and be served in their own houses [
48]. The above entails the amenity of a wide variety of services from the side of the technology providers focusing on safety, health monitoring, supervision and assistance in everyday activities, i.e., cleaning, object movement, cooking, etc. [
49,
50]. Some technological solutions examined in this field include smart houses, wearable devices, ambient sensors and robotic platforms [
51,
52]. The main advantage of the robotic solution lies in the mobility that it provides, enabling the continuous supervision of the elderly, as well as its capability of proceeding to several actions when required [
53]. However, the relatively low level of comfort that older people feel when they coexist with a robotic agent, that in some way inspects their movements, remains an open unanswered question. Therefore, the development of efficient tools that improve the capacity of the robotic agent to comprehend the state of the subject is highly desired, so as to cultivate a sense of familiarity [
54].
Considering the above, the reader can understand our concern regarding the transparent operation of the proposed tool, under the prism of communicating the basic steps of its processing procedure to the interacting person. As far as the main task of the introduced system is concerned, namely the long-term behavior estimation, we envisage it under the aspect of user personality profiling. Considering the deviating personality patterns, the same momentary emotion expressed by two different subjects can imply totally different meanings regarding their internal state. An indicative example can be the different meanings of anger by an introverted and an extroverted person. Thus, the ability of humans to create a behavioral model of other people, gives us the ability to weight the impact of the expressed emotions. The proposed system provides the exact same capability since the creation of the subject’s behavioral history enables the comparison of the contextually perceived momentary emotional state against the subjects behavioral pattern, leading to individualized conclusions regarding its internal state. The above can be used both for comparing momentary estimations against the user’s complete behavior profile or against shorter behavioral patterns, such as daily mood, according to the nature of the interaction.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}