Data Augmentation vs. Domain Adaptation—A Case Study in Human Activity Recognition


Abstract
:1. Introduction
2. Methodology
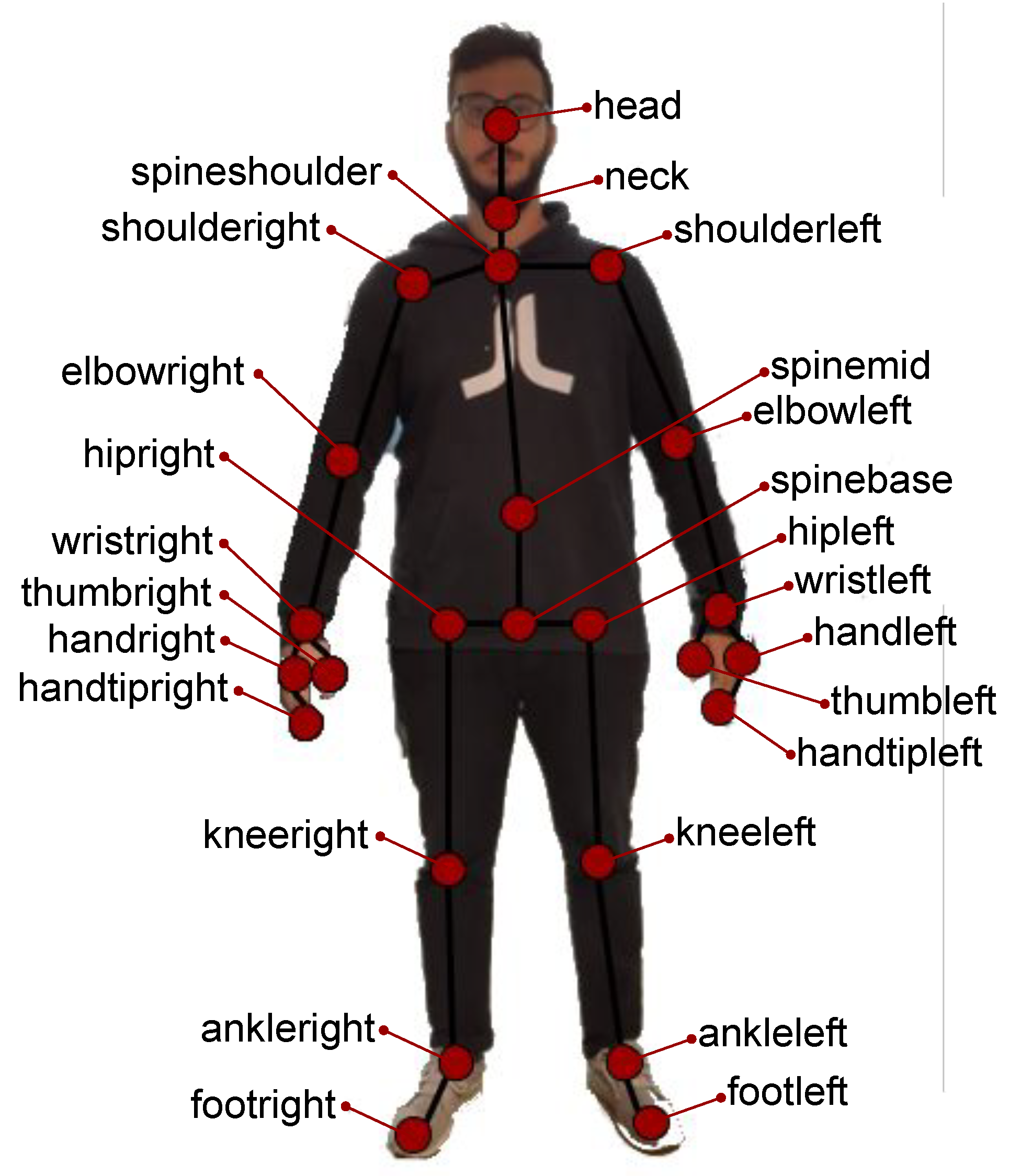
2.1. Human Activity Recognition
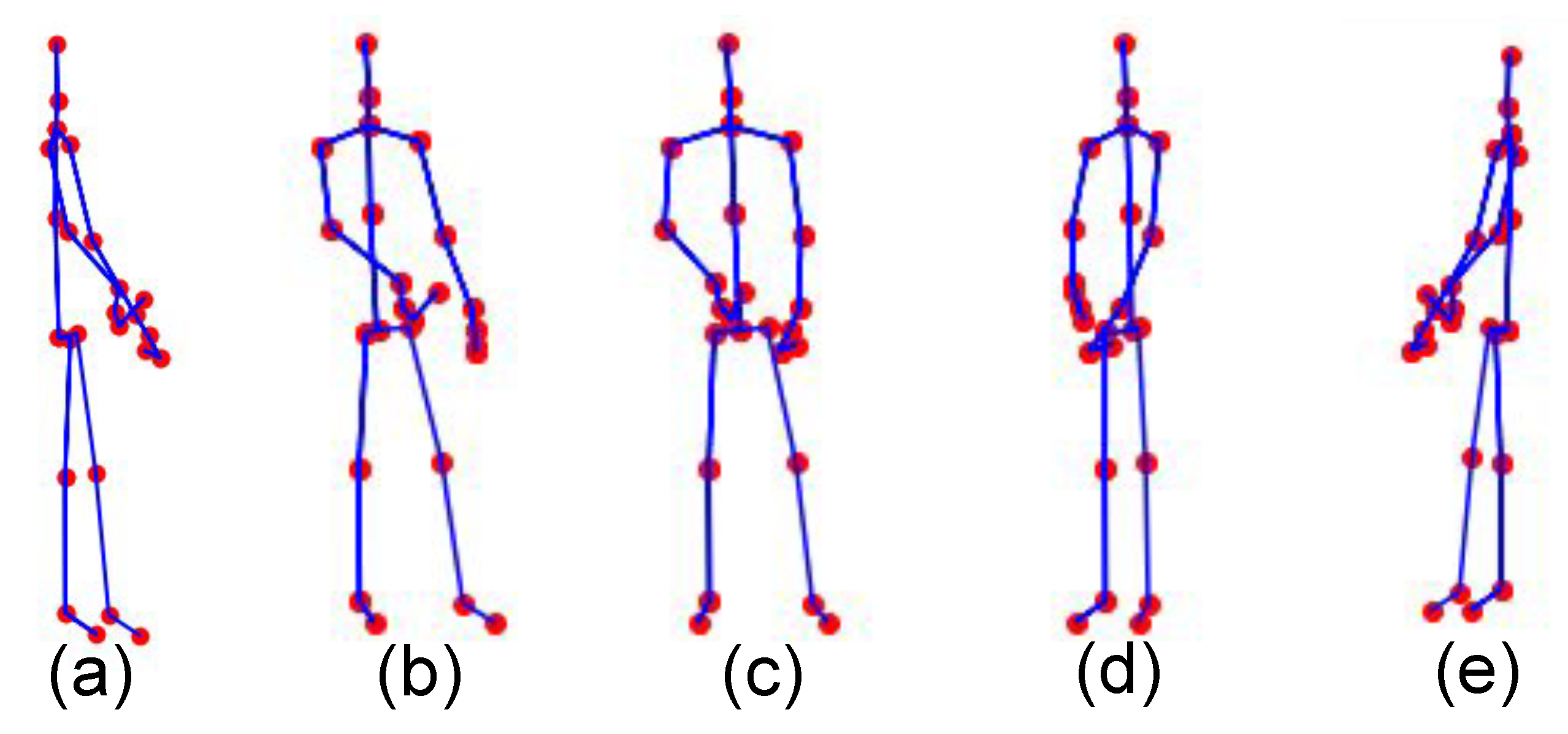
2.2. Data Augmentation
2.3. Domain Adaptation
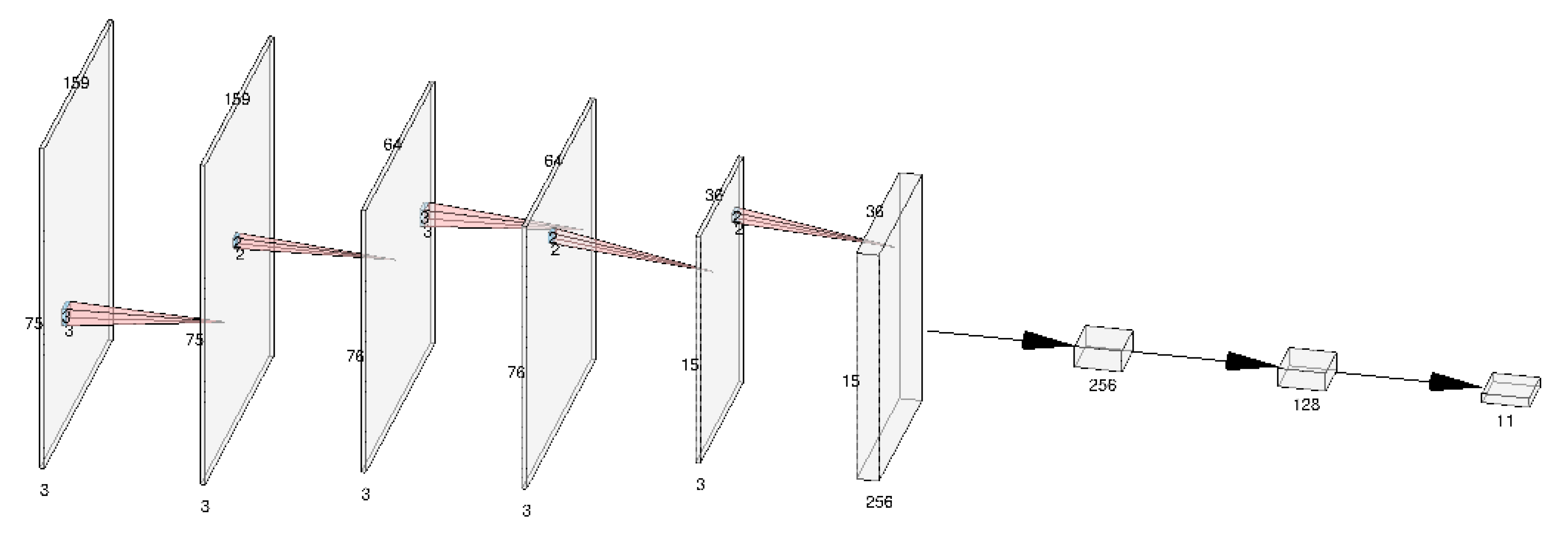
2.4. Classification
3. Experiments
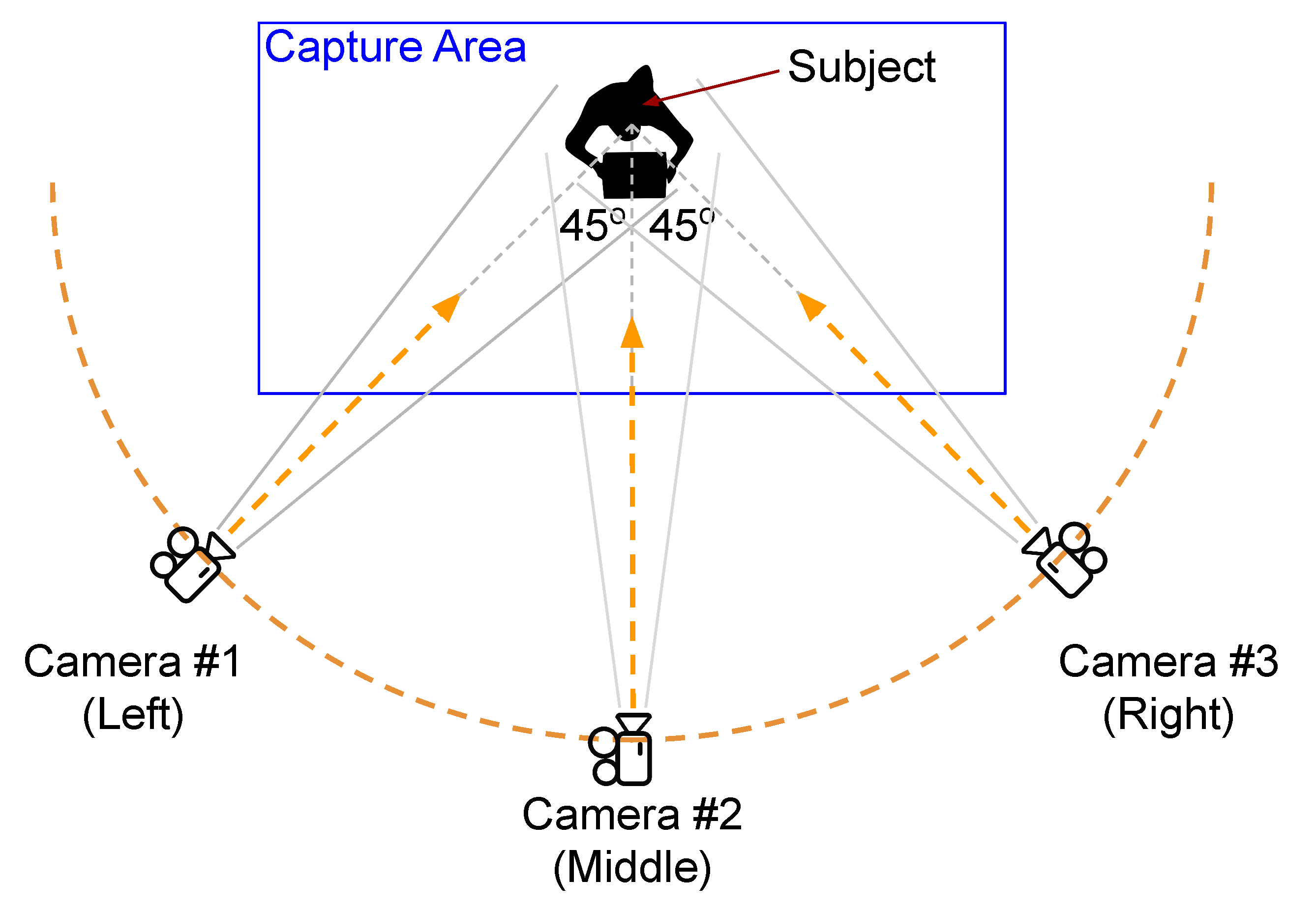
3.1. Dataset
3.2. Implementation Details
3.3. Evaluation and Results
3.3.1. Data Augmentation
3.3.2. Domain Adaptation
3.3.3. Comparisons to Other Approaches
3.4. Discussion
4. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ADDA | Adversarial Discriminative Domain Adaptation |
| ADL | Activity of Daily Living |
| CNN | Convolutional Neural Network |
| DCT | Discrete Cosine Transform |
| DFT | Discrete Fourier Transform |
| DST | Discrete Sine Transform |
| FFT | Fast Fourier Transform |
| GAN | Generative Adversarial Network |
| GPU | Graphics Processing Unit |
| HAR | Human Activity Recognition |
| RGB | Red Green Blue |
| RNN | Recurrent Neural Network |
| SDK | Software Development Kit |
| TPU | Tensor Processing Unit |
References
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Van Dyk, D.A.; Meng, X.L. The art of data augmentation. J. Comput. Graph. Stat. 2001, 10, 1–50. [Google Scholar] [CrossRef]
- Ding, J.; Chen, B.; Liu, H.; Huang, M. Convolutional neural network with data augmentation for SAR target recognition. IEEE Geosci. Remote Sens. Lett. 2016, 13, 364–368. [Google Scholar] [CrossRef]
- Li, B.; Dai, Y.; Cheng, X.; Chen, H.; Lin, Y.; He, M. Skeleton based action recognition using translation-scale invariant image mapping and multi-scale deep CNN. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 601–604. [Google Scholar]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A theory of learning from different domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef] [Green Version]
- Patel, V.M.; Gopalan, R.; Li, R.; Chellappa, R. Visual domain adaptation: A survey of recent advances. IEEE Signal Process. Mag. 2015, 32, 53–69. [Google Scholar] [CrossRef]
- Redko, I.; Morvant, E.; Habrard, A.; Sebban, M.; Bennani, Y. Advances in Domain Adaptation Theory; Elsevier: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Zhang, J.; Han, Y.; Tang, J.; Hu, Q.; Jiang, J. Semi-supervised image-to-video adaptation for video action recognition. IEEE Trans. Cybern. 2016, 47, 960–973. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7167–7176. [Google Scholar]
- Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M. Domain-adversarial neural networks. arXiv 2014, arXiv:1412.4446. [Google Scholar]
- Cao, Z.; Long, M.; Wang, J.; Jordan, M.I. Partial transfer learning with selective adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2724–2732. [Google Scholar]
- Cao, Z.; Ma, L.; Long, M.; Wang, J. Partial adversarial domain adaptation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 135–150. [Google Scholar]
- Cao, Z.; You, K.; Long, M.; Wang, J.; Yang, Q. Learning to transfer examples for partial domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2985–2994. [Google Scholar]
- Hu, J.; Tuo, H.; Wang, C.; Qiao, L.; Zhong, H.; Jing, Z. Multi-Weight Partial Domain Adaptation. In Proceedings of the BMVC, Cardiff, UK, 9–12 September 2019; p. 5. [Google Scholar]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View adaptive recurrent neural networks for high performance human action recognition from skeleton data. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2117–2126. [Google Scholar]
- Aggarwal, J.K. Human activity recognition-A grand challenge. In Proceedings of the Digital Image Computing: Techniques and Applications (DICTA’05), Cairns, Australia, 6–8 December 2005; p. 1. [Google Scholar]
- Wang, P.; Li, W.; Ogunbona, P.; Wan, J.; Escalera, S. RGB-D-based human motion recognition with deep learning: A survey. Comput. Vis. Image Underst. 2018, 171, 118–139. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Shahroudy, A.; Perez, M.L.; Wang, G.; Duan, L.Y.; Chichung, A.K. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Hu, Y.; Li, Y.; Song, S.; Liu, J. Pku-mmd: A large scale benchmark for continuous multi-modal human action understanding. arXiv 2017, arXiv:1703.07475. [Google Scholar]
- Paraskevopoulos, G.; Spyrou, E.; Sgouropoulos, D.; Giannakopoulos, T.; Mylonas, P. Real-time arm gesture recognition using 3D skeleton joint data. Algorithms 2019, 12, 108. [Google Scholar] [CrossRef] [Green Version]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: a local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, Cambridge, UK, 23–26 August 2004; Volume 3, pp. 32–36. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1297–1304. [Google Scholar]
- Papadakis, A.; Mathe, E.; Vernikos, I.; Maniatis, A.; Spyrou, E.; Mylonas, P. Recognizing human actions using 3d skeletal information and cnns. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Crete, Greece, 24–26 May 2019; Springer: Cham, Switzerland, 2019; pp. 511–521. [Google Scholar]
- Lawton, M.P.; Brody, E.M. Assessment of older people: self-maintaining and instrumental activities of daily living. Gerontologist 1969, 9, 179–186. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Fu, Y.; Wang, L. Skeleton based action recognition with convolutional neural network. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 579–583. [Google Scholar]
- Wang, P.; Li, W.; Li, C.; Hou, Y. Action recognition based on joint trajectory maps with convolutional neural networks. Knowl. Based Syst. 2018, 158, 43–53. [Google Scholar] [CrossRef] [Green Version]
- Hou, Y.; Li, Z.; Wang, P.; Li, W. Skeleton optical spectra-based action recognition using convolutional neural networks. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 807–811. [Google Scholar] [CrossRef]
- Li, C.; Hou, Y.; Wang, P.; Li, W. Joint distance maps based action recognition with convolutional neural networks. IEEE Signal Process. Lett. 2017, 24, 624–628. [Google Scholar] [CrossRef] [Green Version]
- Ke, Q.; An, S.; Bennamoun, M.; Sohel, F.; Boussaid, F. Skeletonnet: Mining deep part features for 3-d action recognition. IEEE Signal Process. Lett. 2017, 24, 731–735. [Google Scholar] [CrossRef] [Green Version]
- Steven Eyobu, O.; Han, D.S. Feature representation and data augmentation for human activity classification based on wearable IMU sensor data using a deep LSTM neural network. Sensors 2018, 18, 2892. [Google Scholar] [CrossRef] [Green Version]
- Kalouris, G.; Zacharaki, E.I.; Megalooikonomou, V. Improving CNN-based activity recognition by data augmentation and transfer learning. In Proceedings of the 2019 IEEE 17th International Conference on Industrial Informatics (INDIN), Helsinki-Espoo, Finland, 22–25 July 2019; Volume 1, pp. 1387–1394. [Google Scholar]
- Hernandez, V.; Suzuki, T.; Venture, G. Convolutional and recurrent neural network for human activity recognition: Application on American sign language. PLoS ONE 2020, 15, e0228869. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Liu, H.; Chen, C. Enhanced skeleton visualization for view invariant human action recognition. Pattern Recognit. 2017, 68, 346–362. [Google Scholar] [CrossRef]
- Theoharis, T.; Papaioannou, G.; Platis, N.; Patrikalakis, N.M. Graphics and Visualization: Principles & Algorithms; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Csurka, G. A comprehensive survey on domain adaptation for visual applications. In Domain Adaptation in Computer Vision Applications; Springer: Cham, Switzerland, 2017; pp. 1–35. [Google Scholar]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef] [Green Version]
- Pikramenos, G.; Mathe, E.; Vali, E.; Vernikos, I.; Papadakis, A.; Spyrou, E.; Mylonas, P. An adversarial semi-supervised approach for action recognition from pose information. Neural Comput. Appl. 2020, 1–15. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Wortman, J. Learning bounds for domain adaptation. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2008; pp. 129–136. [Google Scholar]
- Cover, T.M. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Arjovsky, M.; Bottou, L. Towards principled methods for training generative adversarial networks. arXiv 2017, arXiv:1701.04862. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 8 October 2020).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M. TensorFlow: A system for Large-Scale Maching Learning. In Proceedings of the USENIX Symposium on Operating Systems Design and Implementation (OSDI), Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Baselines | Data Augmentation | Domain Adaptation | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S | 0 | 1 | 5 | 10 | ||||||||||
| 0 | 1 | 5 | 10 | 0 | 1 | 5 | 10 | |||||||
| 0.85 | - | 0.85 | 0.86 | 0.92 | - | 0.61 | 0.73 | 0.77 | 0.93 | 0.84 | 0.86 | 0.89 | 0.92 | |
| 0.41 | - | 0.60 | 0.70 | 0.75 | - | 0.51 | 0.61 | 0.71 | 0.85 | 0.50 | 0.63 | 0.78 | 0.82 | |
| 0.83 | - | 0.83 | 0.87 | 0.90 | - | 0.51 | 0.68 | 0.79 | 0.85 | 0.83 | 0.84 | 0.87 | 0.91 | |
| 0.78 | - | 0.80 | 0.85 | 0.90 | - | 0.51 | 0.70 | 0.76 | 0.90 | 0.83 | 0.83 | 0.86 | 0.91 | |
| 0.44 | - | 0.60 | 0.76 | 0.81 | - | 0.51 | 0.65 | 0.77 | 0.69 | 0.53 | 0.65 | 0.80 | 0.86 | |
| 0.85 | - | 0.85 | 0.86 | 0.91 | - | 0.61 | 0.70 | 0.77 | 0.88 | 0.85 | 0.85 | 0.88 | 0.92 | |
| mean | 0.69 | - | 0.76 | 0.82 | 0.87 | - | 0.54 | 0.68 | 0.76 | 0.85 | 0.73 | 0.78 | 0.85 | 0.89 |
| Baselines | Data Augmentation | Domain Adaptation | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S | 0 | 1 | 5 | 10 | ||||||||||
| 0 | 1 | 5 | 10 | 0 | 1 | 5 | 10 | |||||||
| 0.85 | - | 0.90 | 0.90 | 0.85 | - | 0.61 | 0.71 | 0.78 | 0.92 | 0.81 | 0.77 | 0.86 | 0.88 | |
| 0.42 | - | 0.67 | 0.81 | 0.82 | - | 0.49 | 0.53 | 0.57 | 0.82 | 0.51 | 0.55 | 0.727 | 0.79 | |
| 0.84 | - | 0.81 | 0.88 | 0.93 | - | 0.48 | 0.57 | 0.64 | 0.83 | 0.81 | 0.86 | 0.85 | 0.94 | |
| 0.79 | - | 0.80 | 0.83 | 0.90 | - | 0.47 | 0.65 | 0.71 | 0.90 | 0.80 | 0.81 | 0.83 | 0.92 | |
| 0.45 | - | 0.78 | 0.77 | 0.82 | - | 0.47 | 0.53 | 0.57 | 0.65 | 0.52 | 0.67 | 0.80 | 0.88 | |
| 0.86 | - | 0.84 | 0.88 | 0.92 | - | 0.55 | 0.64 | 0.77 | 0.86 | 0.86 | 0.71 | 0.86 | 0.88 | |
| mean | 0.71 | - | 0.80 | 0.85 | 0.87 | - | 0.51 | 0.59 | 0.67 | 0.83 | 0.72 | 0.73 | 0.83 | 0.88 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Spyrou, E.; Mathe, E.; Pikramenos, G.; Kechagias, K.; Mylonas, P. Data Augmentation vs. Domain Adaptation—A Case Study in Human Activity Recognition. Technologies 2020, 8, 55. https://0-doi-org.brum.beds.ac.uk/10.3390/technologies8040055
Spyrou E, Mathe E, Pikramenos G, Kechagias K, Mylonas P. Data Augmentation vs. Domain Adaptation—A Case Study in Human Activity Recognition. Technologies. 2020; 8(4):55. https://0-doi-org.brum.beds.ac.uk/10.3390/technologies8040055
Chicago/Turabian StyleSpyrou, Evaggelos, Eirini Mathe, Georgios Pikramenos, Konstantinos Kechagias, and Phivos Mylonas. 2020. "Data Augmentation vs. Domain Adaptation—A Case Study in Human Activity Recognition" Technologies 8, no. 4: 55. https://0-doi-org.brum.beds.ac.uk/10.3390/technologies8040055