
Computation of High-Frequency Sub-National Spatial Consumer Price Indexes Using Web Scraping Techniques



Abstract
:1. Introduction
2. Using Online Data for Price Statistics
3. Methods and Data
3.1. Time-Interaction-Region Product Dummy (TiRPD) Models
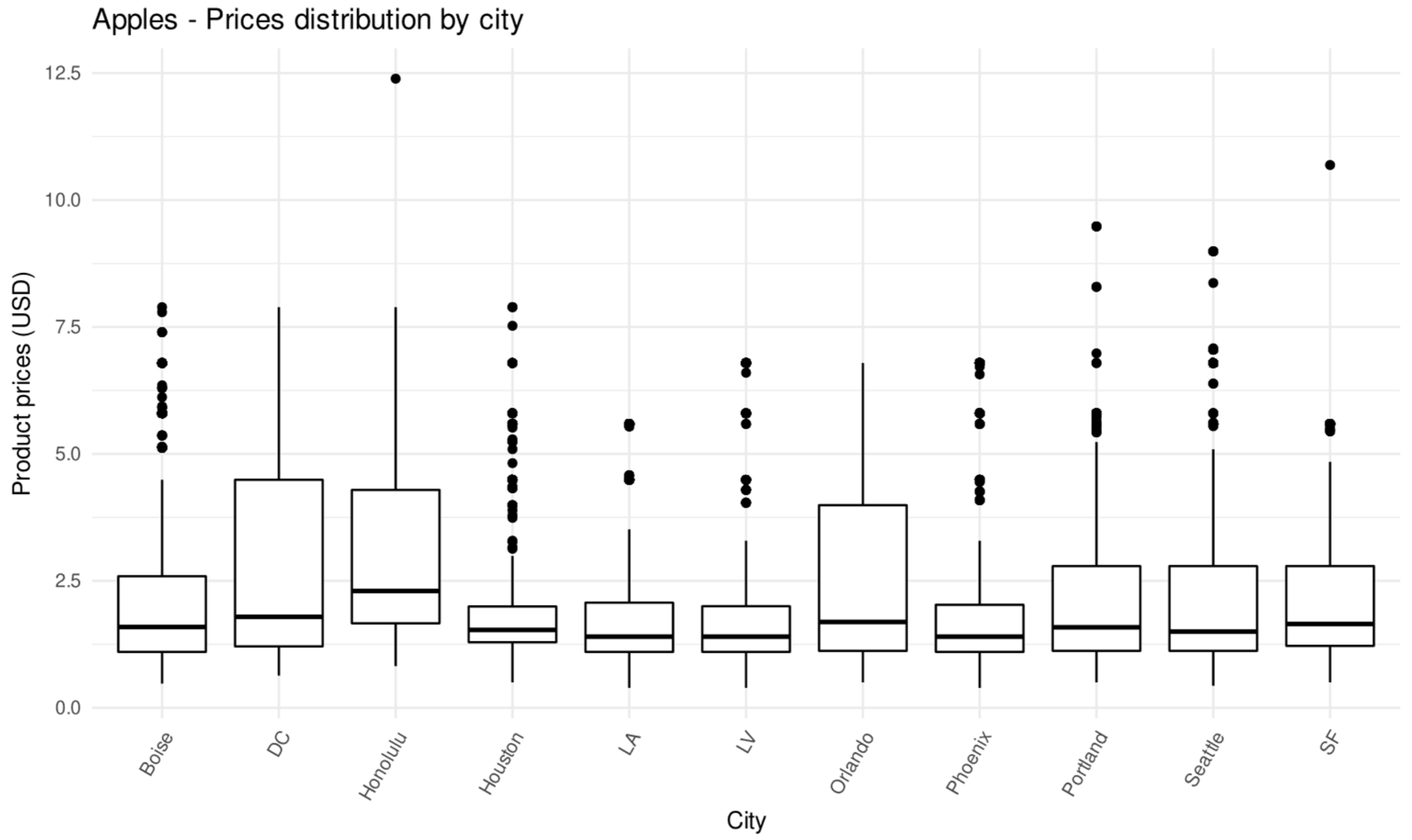
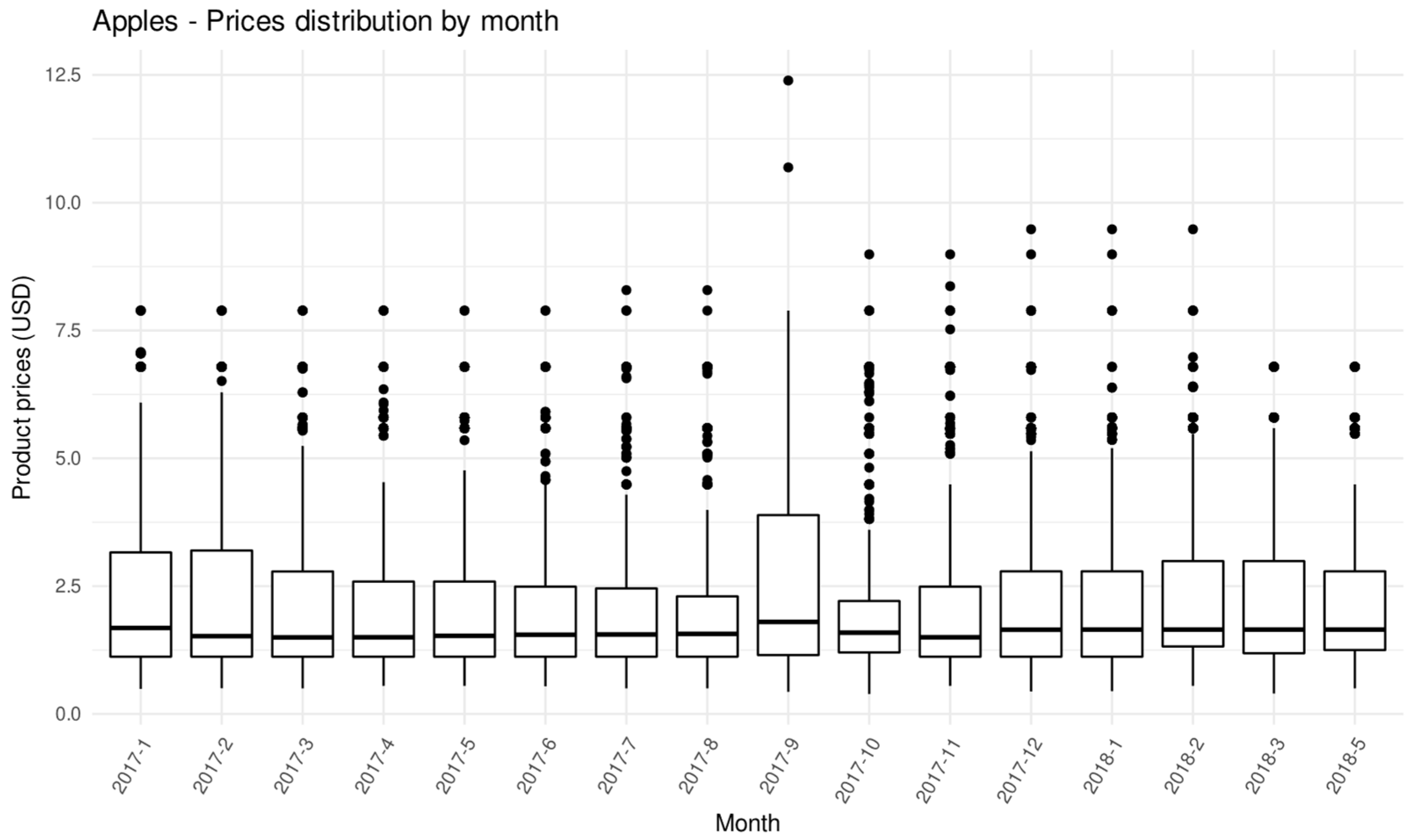
3.2. Data Acquisition and Description
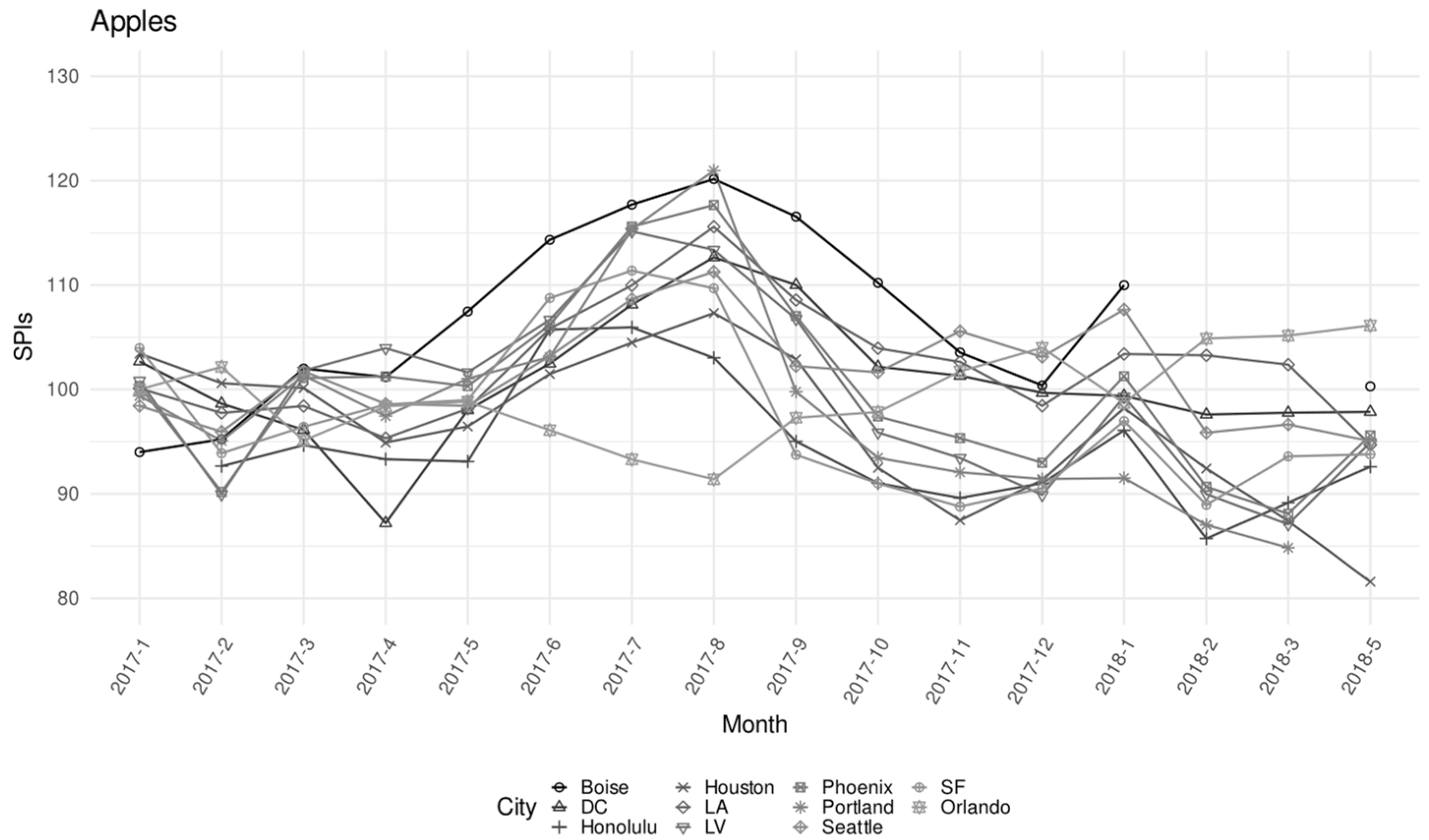
4. Results from TiCPD Models
5. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | Statistics Netherlands, in the context of international EuroGroups Register project, explored the use of Wikipedia as a source for collecting relevant information for the maintenance of the register of internationally operating enterprises (ten Bosch et al. 2018). The United States Department of Agriculture has explored the use of web-scraped data to assess undercoverage of the National Agricultural Statistics Service by developing a list frame of all potential farms in the USA (Young and Jacobsen 2021). |
| 2 | PPPs are essentially spatial price index numbers. The concept of purchasing power parity is used to measure the price level in one location compared to that in another location. More specifically, at the international level, purchasing power parities of currencies are defined as the number of currency units of a country that can purchase the same basket of goods and services that can be purchased with one unit of currency of a reference currency (World Bank 2013). PPPs are calculated for product groups and for each of the various levels of aggregation up to and including gross domestic product (GDP). |
| 3 | Grocerybear is a brokerage for market intelligence who gathers local pricing and market information on what consumers pay for basic goods. The research team received a large dataset of historical microdata from Grocerybear under a Confidential Data Exchange agreement. Grocerybear authorized the publication of the aggregated dataset used for the present study (Benedetti et al. 2021). More details on the Grocerybear project are available at https://www.grocerybear.com (accessed on 15 December 2021). |
| 4 | Dataset and code used for this paper are made publicly available as Open Data (Benedetti et al. 2021). |
| 5 | At the international level, PPPs are compiled by the International Comparison Program (ICP), which is administered by the World Bank and overseen by the United Nations Statistical Commission with the collaboration of the OECD, EUROSTAT, and other regional organizations (see World Bank 2013, chapter 4 for details). |
| 6 | Entry-level items (ELIs) are the ultimate sampling units for the selection of the unique product or service within the outlet by the BLS national office in order to estimate CPI in the US. |
References
- Aizcorbe, Ana, and Bettina Aten. 2004. An Approach to Pooled Time and Space Comparisons. Paper presented at SSHRC Conference on Index Number Theory and the Measurement of Prices and Productivity, Vancouver, BC, Canada, October 15. [Google Scholar]
- Aizcorbe, Ana, Carol Corrado, and Mark Doms. 2000. Constructing Price and Quantity Indexes for High Technology Goods. Washington, DC: NBER/CRIW Summer Institute, Industrial Output Section, Division of Research and Statistics, Federal Reserve Board. [Google Scholar]
- Aten, Bettina. 2005. Report on Interarea Price Levels; Working Paper No. 2005–2011. Suitland: Bureau of Economic Analysis.
- Aten, Bettina. 2006. Interarea price levels: An experimental methodology. Monthly Labor Review 129: 47–61. [Google Scholar]
- Aten, Bettina, Eric B. Figueroa, and Troy. M. Martin. 2014. Regional Price Parities for States and Metropolitan Ares, 2006–2010; Washington, DC: Survey of Current Business, Bureau of Economic Analisis.
- Barcaroli, Giulio, and Monica Scannapieco. 2019. Integration of ICT survey data and Internet data from enterprises websites at the Italian National Institute of Statistics. Statistical Journal of the IAOS 354: 643–56. [Google Scholar] [CrossRef]
- Benedetti, Ilaria, Tiziana Laureti, Luigi Palumbo, and Brandon Rose. 2021. US consumer prices data 2017-18 for sub-national CPI-U calculations using TiPRD model and R implementation. Mendeley Data. [Google Scholar] [CrossRef]
- Biggeri, Luigi, Tiziana Laureti, and Federico Polidoro. 2017. Computing sub-national PPPs with CPI data: An empirical analysis on Italian data using country product dummy models. Social Indicators Research 131: 93–121. [Google Scholar] [CrossRef]
- Breton, Robert, Tanya Flower, Matthew Mayhew, Elizabeth Metcalfe, Natasha Milliken, Christopher Payne, Thomas Smith, Joe Winton, and Ainslie Woods. 2016. Research Indices Using Web Scraped Data: May 2016 Update; Newport: Office for National Statistics.
- Bricongne, Jean-Charles, Baptiste Meunier, and Pouget Sylvain. 2021. Web Scraping Housing Prices in Real-time: The COVID-19 Crisis in the UK. Working Paper, Banque de France. Available online: https://entreprises.banque-france.fr/sites/default/files/medias/documents/wp827_0.pdf (accessed on 1 December 2021).
- Brunner, Karola. 2014. Automated Price Collection via the Internet; Wiesbaden: DESTATIS. Available online: https://www.destatis.de/EN/Methods/WISTAScientificJournal/Downloads/automated-price-collection-brunner-042014.pdf?__blob=publicationFile (accessed on 15 December 2021).
- Cavallo, Alberto. 2017. Are Online and Offline Prices Similar? Evidence from Multi-Channel Retailers. American Economic Review 107: 283–303. [Google Scholar] [CrossRef] [Green Version]
- Cavallo, Alberto, and Roberto Rigobon. 2016. The Billion Prices Project: Using Online Prices for Measurement and Research. Journal of Economic Perspectives 30: 151–78. [Google Scholar] [CrossRef] [Green Version]
- Cavallo, Alberto, W. Erwin Diewert, Robert C. Feenstra, Robert Inklaar, and Marcel P. Timmer. 2018. Using online prices for measuring real consumption across countries. AEA Papers and Proceedings 108: 483–87. [Google Scholar] [CrossRef] [Green Version]
- Chow, Gregory C. 1960. Tests of equality between sets of coefficients in two linear regressions. Econometrica: Journal of the Econometric Society 28: 591–605. [Google Scholar] [CrossRef]
- Clements, Kenneth W., and Haji Yaakob Izan. 1987. The Measurement of Inflation: A Stochastic Approach. Journal of Business and Economic Statistics 5: 339–50. [Google Scholar]
- Clements, Kenneth W., Izan HY Izan, and E. Antony Selvanathan. 2006. Stochastic Index Numbers: A Review. International Statistical Review 74: 235–70. [Google Scholar] [CrossRef]
- Costa, Alex, Jaume Garcia, Josep Lluís Raymond, and Daniel Sanchez-Serra. 2019. Subnational Purchasing Power of Parity in OECD Countries: Estimates Based on the Balassa-Samuelson Hypothesis. Paris: OECD. [Google Scholar]
- de Haan, Jan. 2015. A Framework for Large Scale Use of Scanner Data in the Dutch CPI. Paper presented at the 14th Ottawa Group Meeting, Tokyo, Japan, May 20–22. [Google Scholar]
- de Haan, Jan, and RensHendriks. 2013. Online Data, Fixed Effects and the Construction of High-Frequency Price Indexes. Sidney: Economic Measurement Group Workshop, pp. 28–29. Available online: https://www.business.unsw.edu.au/research-site/centreforappliedeconomicresearch-site/Documents/Jan-de-Haan-Online-Price-Indexes.pdf (accessed on 15 December 2021).
- de Haan, Jan, and Frances Krsinich. 2014. Scanner Data and the Treatment of Quality Change in Nonrevisable Price Indexes. Journal of Business and Economic Statistics 32: 341–58. [Google Scholar] [CrossRef]
- de Haan, Jan, Ren Hendriks, and Michael Scholz. 2021. Price Measurement Using Scanner Data: Time-Product Dummy Versus Time Dummy Hedonic Indexes. Review of Income and Wealth 67: 394–417. [Google Scholar] [CrossRef]
- Diewert. 2010. On the Stochastic Approach to Index Numbers. In Price and Productivity Measurement. Bloomington: Trafford Press, pp. 235–62. [Google Scholar]
- Dumbacher, Brian, and Cavan Capps. 2016. Big data methods for scraping government tax revenue from the web. Paper presented at the Joint Statistical Meetings, Section on Statistical Learning and Data Science, Chicago, IL, USA, July 30–June 4. [Google Scholar]
- Eurostat. 2020. Practical Guidelines on Web Scraping for the HICP. EUROPEAN COMMISSION EUROSTAT. Directorate C: Macro-Economic Statistics. Unit C-4: Price Statistics. Purchasing Power Parities. Housing Statistics. European Commission. Available online: https://ec.europa.eu/eurostat/documents/272892/12032198/Guidelines-web-scraping-HICP-11-2020.pdf/ (accessed on 1 December 2021).
- Eurostat. 2021. Internet Purchases by Individuals [Data Base]. Available online: https://ec.europa.eu/eurostat/web/digital-economy-and-society/data/database (accessed on 1 December 2021).
- EUROSTAT OECD. 2012. Eurostat-OECD Methodological Manual on Purchasing Power Parities; Luxembourg: Publications Office of the European Union, ISBN 978-92-79-25983-8. ISSN 1977-0375. [CrossRef]
- Harchaoui, Tarek M., and Robert V. Janssen. 2018. How can big data enhance the timeliness of official statistics? The case of the US consumer price index. International Journal of Forecasting 34: 225–34. [Google Scholar] [CrossRef]
- Hill, Robert. J. 2004. Constructing price indexes across space and time: The case of the European Union. American Economic Review 94: 1379–410. [Google Scholar] [CrossRef] [Green Version]
- Hill, Robert. J., and Iqbal A. Syed. 2015. Improving International Comparisons of Prices at Basic Heading Level: An Application to the Asia-Pacific Region. Review of Income and Wealth 61: 515–39. [Google Scholar] [CrossRef]
- Hill, Robert J., and Marcel P. Timmer. 2006. Standard errors as weights in multilateral price indexes. Journal of Business & Economic Statistics 24: 366–77. [Google Scholar]
- International Comparison Program—ICP. 2021. A Guide to the Compilation of Subnational Purchasing Power Parities (PPPs). Washington, DC: World Bank Group, Available online: https://thedocs.worldbank.org/en/doc/6448cdb85ae0f46ae2b37beb59f7602f-0050022021/original/2-03-RA-Item-07-DRAFT-Subnational-PPP-guide-Biggeri-and-Rao.pdf (accessed on 15 December 2021).
- Jaworski, Krystian. 2021. Measuring food inflation during the COVID-19 pandemic in real time using online data: A case study of Poland. British Food Journal 123: 160–80. [Google Scholar] [CrossRef]
- Juszczak, Adam. 2021. The use of web-scraped data to analyze the dynamics of footwear prices. Journal of Economics and Management 43: 251–69. [Google Scholar] [CrossRef]
- Kokoski, Mary. 1991. New research on interarea consumer price differences. Monthly Labor Review 114: 31. [Google Scholar]
- Kokoski, Mary, Brent Moulton, and Kimberly Zieschang. 1999. Interarea price comparisons for heterogenous goods and several levels of commodity aggregation. In International and Interarea Comparisons of Income, Output and Prices. Edited by Alan Heston and Robert E. Lipsey. Chicago: University of Chicago Press, pp. 123–66. [Google Scholar]
- Konny, Crystal, Brendan Williams, and David Friedman. 2019. Big Data in the US Consumer Price Index: Experiences and Plans. In Big Data for 21st Century Economic Statistics. Chicago: University of Chicago Press. [Google Scholar]
- Laureti, Tiziana, and Federico Polidoro. 2022. Using scanner data for computing consumer spatial price indexes at regional level: An empirical application for grocery products in Italy. Journal of Official Statistics. in press. [Google Scholar] [CrossRef]
- Laureti, Tiziana, and D. S. Prasada Rao. 2018. Measuring spatial price level differences within a country: Current status and future developments. Studies of Applied Economics 36: 119–48. [Google Scholar] [CrossRef]
- Macias, Paweł, and Damien Stelmasiak. 2019. Food Inflation Nowcasting with Web Scraped Data. NBP Working Paper. Warsaw: Narodowy Bank Polski, Education & Publishing Department, p. 302. [Google Scholar]
- Majumder, Amita, and Ranjan Ray. 2020. National and subnational purchasing power parity: A review. Decision 47: 103–24. [Google Scholar] [CrossRef]
- Mehrhoff, Jens. 2019. Introduction–The Value Chain of Scanner and Web Scraped Data. Economie et Statistique 509: 5–11. [Google Scholar] [CrossRef] [Green Version]
- Montero, Jose Maria, Tiziana Laureti, Roman Mínguez, and Gema Fernández-Avilés. 2020. A stochastic model with penalized coefficients for spatial price comparisons: An application to regional price indexes in Italy. Review of Income and Wealth 66: 512–33. [Google Scholar] [CrossRef]
- Nygaard, Ragnhild. 2015. The Use of Online Prices in the Norwegian Consumer Price Index; Oslo: Statistics Norway.
- Oancea, Bogdan, and Marian Necula. 2019. Web scraping techniques for price statistics—The Romanian experience. Statistical Journal of the IAOS 35: 657–67. [Google Scholar] [CrossRef]
- OECD. 2020. E-Commerce in the Time of COVID-19, Tackling Coronavirus (COVID-19) Contributing to a Global Effort. Paris, October, Available online: https://www.oecd.org/coronavirus/policy-responses/e-commerce-in-the-time-of-covid-19-3a2b78e8/ (accessed on 15 December 2021).
- OECD, The World Bank, The United Nations Economic Commission for Europe, and Statistical Office of the European Communities and Luxembourg. 2004. Consumer Price Index Manual: Theory and Practice. An Electronic Updated Version of the Manual Can Be Found at the Web Site of ILO. Geneva: International Labour Organization. [Google Scholar]
- Polidoro, Federico, Riccardo Giannini, Rosanna Lo Conte, Stefano Mosca, and Francesca Rossetti. 2015. Web Scraping Techniques to Collect Data on Consumer Electronics and Airfares for Italian HICP Compilation. Statistical Journal of the IAOS 31: 165–76. [Google Scholar] [CrossRef] [Green Version]
- Rao, D. S. Prasada, and Gholamreza Hajargasht. 2016. Stochastic Approach to Computation of Purchasing Power Parities in the International Comparison Program (ICP). Journal of Econometrics 191: 414–25. [Google Scholar] [CrossRef] [Green Version]
- Rokicki, Bartlomiej, and Geoffrey J. D. Hewings. 2019. Regional price deflators in Poland: Evidence from NUTS-2 and NUTS-3 regions. Spatial Economic Analysis 14: 88–105. [Google Scholar] [CrossRef]
- Selvanathan, E. Anthony. 1989. A Note on the Stochastic Approach to Index Numbers. Journal of Business and Economic Statistics 7: 471–74. [Google Scholar]
- Selvanathan, E. Anthony, and D. S. Prasada Rao. 1994. Index Numbers: A Stochastic Approach. London: Macmillan. [Google Scholar]
- Sharma, Anupam, and Deepika Jhamb. 2020. Changing Consumer Behaviours Towards Online Shopping-An Impact Of COVID 19. Academy of Marketing Studies Journal 24: 1–10. [Google Scholar]
- Sherwood, Mark K. 1975. Family budgets and geographic differences in price levels. Monthly Labor Review 98: 8–15. [Google Scholar]
- Souza, Thaís Góes de, Fernanda D. R. Fonseca, Vivian de Oliveira Fernandes, and Julio C. Pedrassoli. 2021. Exploratory Spatial Analysis of Housing Prices Obtained from Web Scraping Technique. The International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences 43: 135–40. [Google Scholar] [CrossRef]
- Statistics Canada. 2019. Web Scraping. Available online: https://www.statcan.gc.ca/eng/our-data/where/web-scraping (accessed on 1 December 2021).
- Summers, Robert. 1973. International price comparisons based upon incomplete data. Review Income Wealth 19: 1–16. [Google Scholar] [CrossRef]
- ten Bosch, Olav, Dick Windmeijer, Arnout van Delden, and Guido van den Heuvel. 2018. Web scraping meets survey design: Combining forces. Paper presented at the Big Data Meets Survey Science Conference, Bigsurv18 Conference, Barcelona, Spain, October 25–27. [Google Scholar]
- ten Bosch, Olav, and Dick Windmeijer. 2014. On the Use of Internet Robots for Official Statistics. Paper presented at the Meeting on the Management of Statistical Information Systems (MSIS 2014), Dublin, Ireland and Manila, Philippines, April 14–16. [Google Scholar]
- UNCTAD. 2020. COVID-19 and E-Commerce, Finding from a Survey of Online Consumers in 9 Countries; Geneva: United Nation Conference on trade and Development, UNCTAD. Available online: https://unctad.org/system/files/official-document/dtlstictinf2020d1_en.pdf (accessed on 1 December 2021).
- Varma, Manishkumar, Vinay Kumar, B. V. Sangvikar, and Avinash Pawar. 2020. İmpact of social media, security risks and reputation of e-retailer on consumer buying intentions through trust in online buying: A structural equation modeling approach. Journal of Critical Reviews 7: 119–27. [Google Scholar]
- Virgillito, Antonino, and Federico Polidoro. 2019. Big Data Techniques for Supporting Official Statistics: The Use of Web Scraping for Collecting Price Data. In Web Services: Concepts, Methodologies, Tools, and Applications. Pennsylvania: IGI Global, pp. 728–44. [Google Scholar]
- World Bank. 2013. Measuring the Real Size of the World Economy: The Framework, Methodology, and Results of the International Comparison Program—ICP. Washington, DC: World Bank. [Google Scholar] [CrossRef]
- Young, Linda J., and Michael Jacobsen. 2021. Sample Design and Estimation When Using a Web-Scraped List Frame and Capture-Recapture Methods. Journal of Agricultural, Biological and Environmental Statistics, 1–19. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ELI | CPI-U Weight | N. of Observations | N. of Unique Products | Monthly Price (USD) | |||
|---|---|---|---|---|---|---|---|
| Min | Avg | Max | St. Dev. | ||||
| Apple | 0.073% | 6126 | 169 | 0.39 | 2.32 | 12.39 | 1.73 |
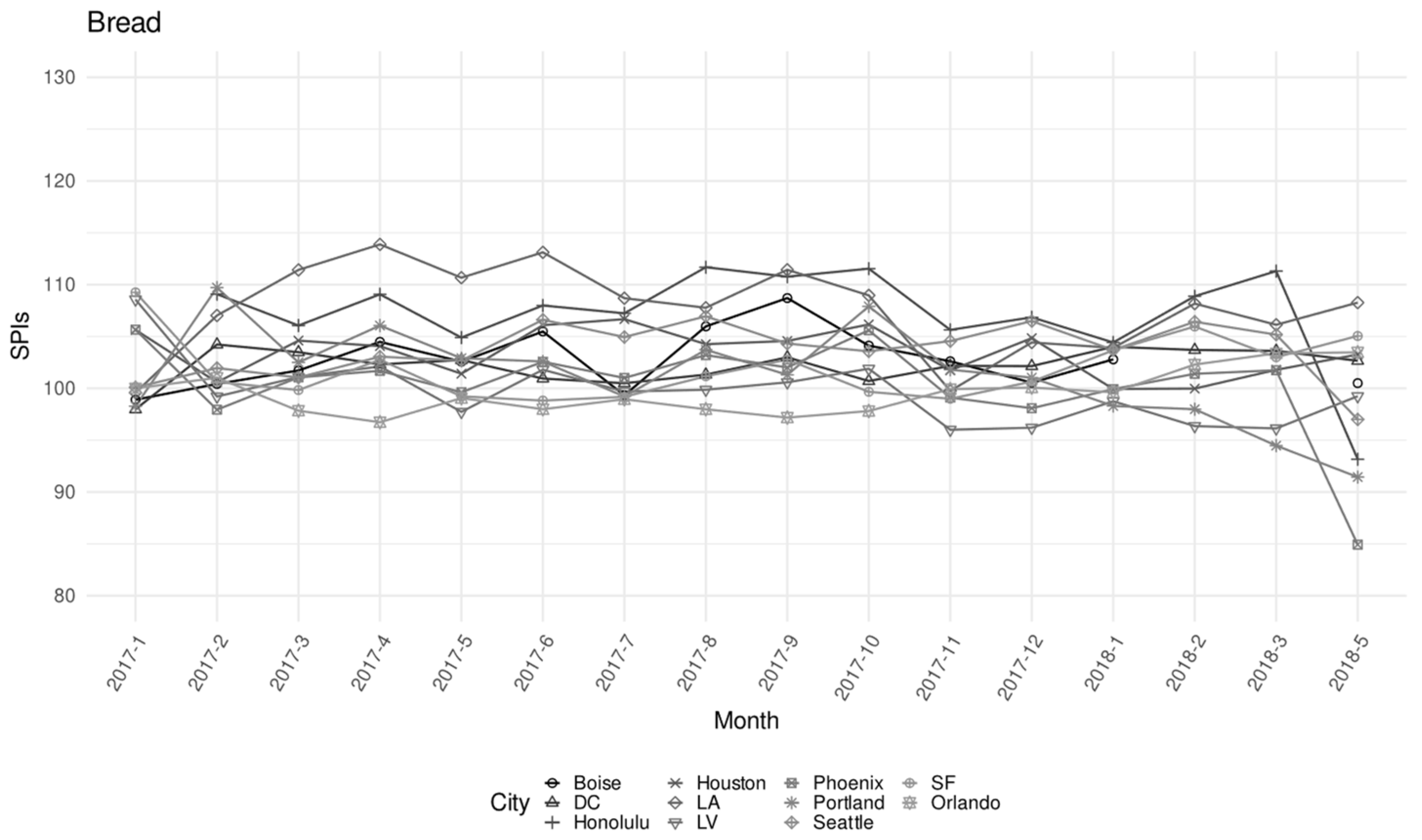
| Bread | 0.200% | 17,794 | 651 | 0.89 | 3.87 | 9.59 | 1.47 |
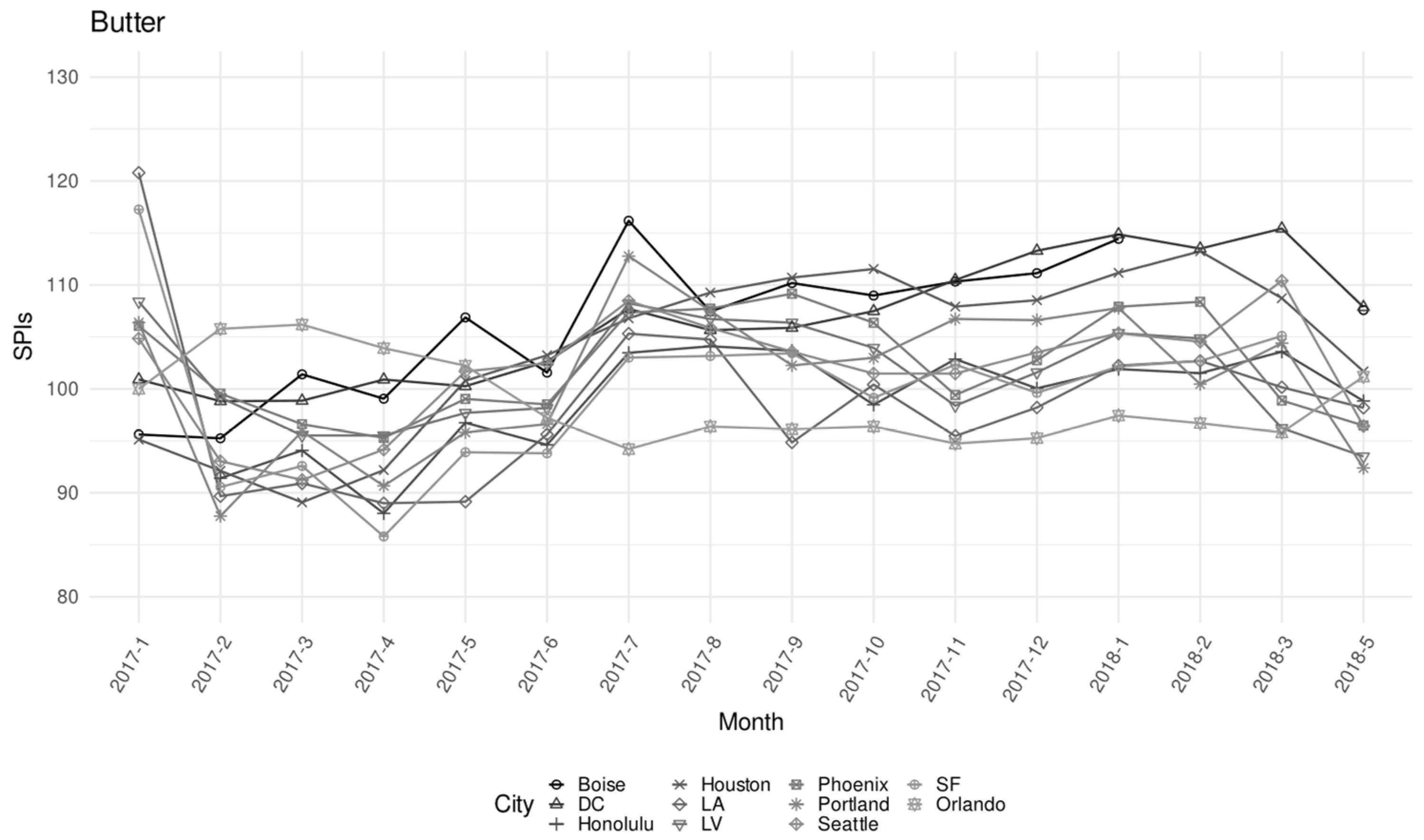
| Butter | 0.063% | 7139 | 160 | 1.25 | 4.94 | 14.09 | 1.96 |
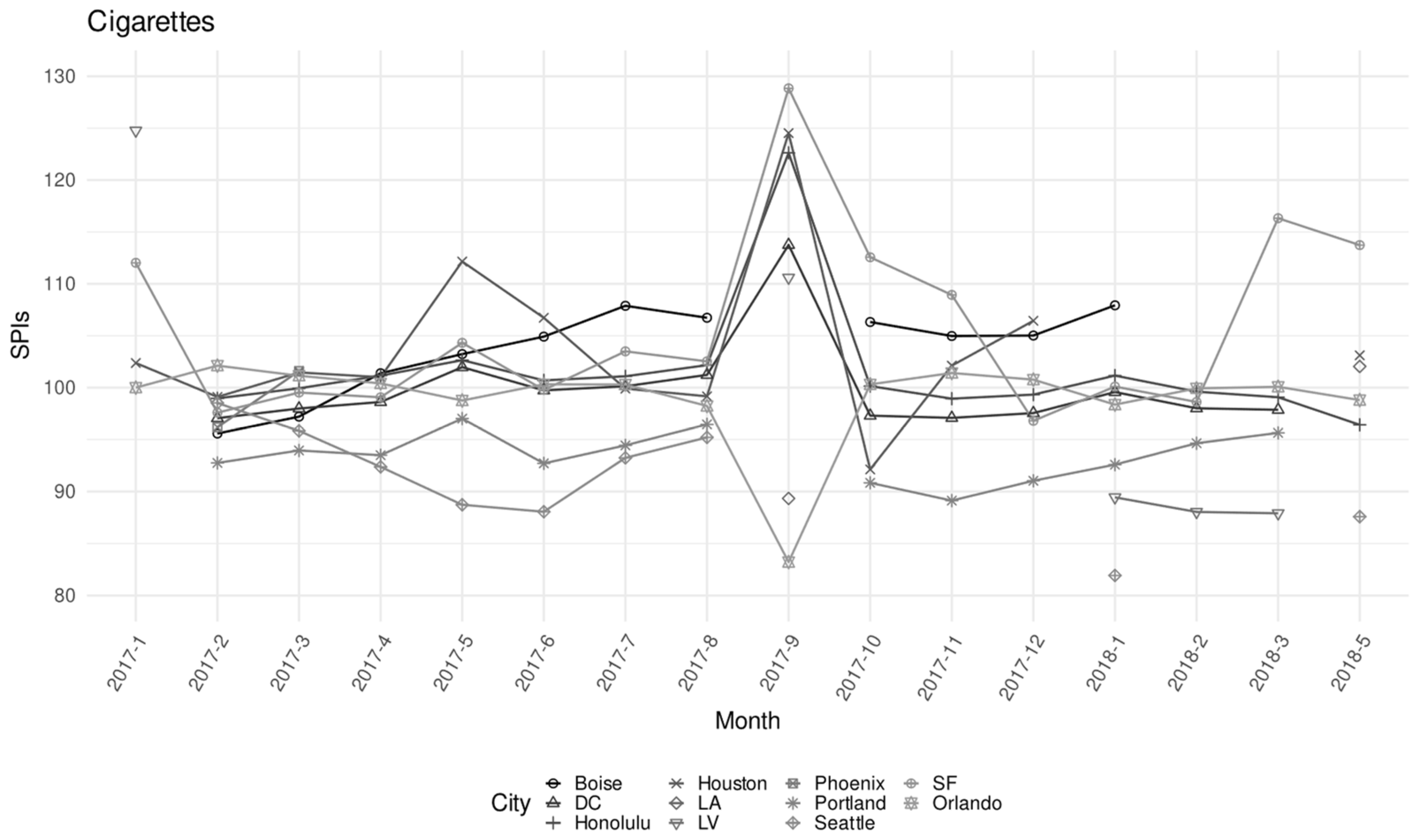
| Cigarettes | 0.529% | 2347 | 342 | 0.69 | 16.69 | 117.59 | 21.71 |
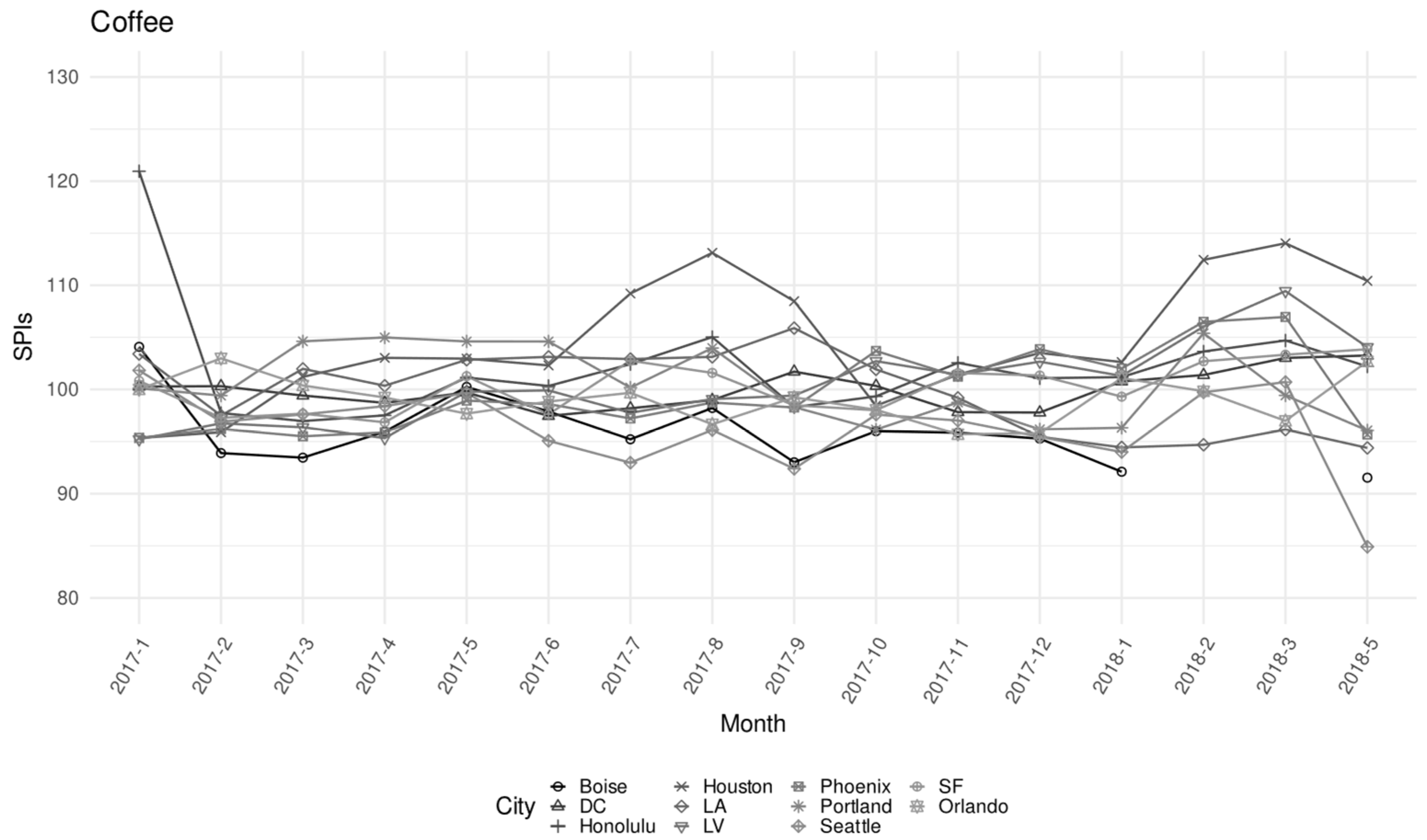
| Coffee | 0.169% | 77,450 | 2850 | 0.89 | 8.41 | 140.69 | 4.52 |
| Total | 1.034% | 110,856 | 4172 | ||||
| City (ref. Orlando) | Coeff. | p-Value |
|---|---|---|
| Boise | 0.193 | 0.000 |
| DC | 0.158 | 0.000 |
| Honolulu | 0.423 | 0.000 |
| Houston | 0.197 | 0.000 |
| LA | 0.120 | 0.017 |
| LV | 0.195 | 0.000 |
| Phoenix | 0.184 | 0.000 |
| Portland | 0.222 | 0.000 |
| Seattle | 0.148 | 0.001 |
| SF | 0.161 | 0.003 |
| AIC = −253.38 | BIC = 11.83 | R2 = 0.96 |
| Log-lik = 198.69 |
| Time (ref. 2017_08) | Coeff. | p-Value |
|---|---|---|
| 2017-01 | 0.086 | 0.029 |
| 2017-02 | 0.091 | 0.020 |
| 2017-03 | 0.032 | 0.413 |
| 2017-04 | 0.042 | 0.304 |
| 2017-05 | 0.050 | 0.219 |
| 2017-06 | 0.031 | 0.463 |
| 2017-07 | −0.022 | 0.619 |
| 2017-09 | 0.031 | 0.435 |
| 2017-10 | 0.082 | 0.039 |
| 2017-11 | 0.096 | 0.015 |
| 2017-12 | 0.118 | 0.003 |
| 2018-01 | 0.059 | 0.137 |
| 2018-02 | 0.110 | 0.005 |
| 2018-03 | 0.108 | 0.008 |
| 2018-05 | 0.116 | 0.007 |
| AIC = −242.93 | BIC = −60.77 | R2 = 0.95 |
| Log-lik = 243.47 |
| Time | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| City | 2017-01 | 2017-02 | 2017-03 | 2017-04 | 2017-05 | 2017-06 | 2017-07 | 2017-08 | 2017-09 | 2017-10 | 2017-11 | 2017-12 |
| Orlando | 0.109 | 0.131 | 0.047 | 0.056 | 0.060 | 0.035 | −0.011 | Ref. | 0.051 | 0.095 | 0.118 | 0.135 |
| (0.014) | (0.003) | (0.289) | (0.224) | (0.197) | (0.471) | (0.824) | - | (0.260) | (0.035) | (0.007) | (0.003) | |
| Boise | −0.246 | −0.310 | −0.242 | −0.205 | −0.133 | −0.076 | −0.007 | 0.204 | −0.055 | −0.141 | −0.196 | −0.236 |
| (0.000) | (0.000) | (0.000) | (0.005) | (0.075) | (0.313) | (0.928) | (0.000) | (0.435) | (0.044) | (0.004) | (0.001) | |
| DC | −0.136 | −0.155 | −0.179 | −0.279 | −0.140 | −0.100 | −0.048 | 0.167 | −0.023 | −0.114 | −0.130 | −0.140 |
| (0.025) | (0.010) | (0.003) | (0.000) | (0.026) | (0.128) | (0.478) | (0.000) | (0.698) | (0.070) | (0.033) | (0.024) | |
| Honolulu | −0.107 | −0.148 | −0.077 | −0.057 | −0.065 | −0.030 | 0.027 | 0.400 | −0.063 | −0.144 | −0.153 | −0.150 |
| (0.112) | (0.031) | (0.258) | (0.409) | (0.352) | (0.676) | (0.705) | (0.000) | (0.367) | (0.040) | (0.023) | (0.027) | |
| Houston | −0.135 | −0.182 | −0.099 | −0.143 | −0.160 | −0.126 | −0.043 | 0.188 | −0.091 | −0.166 | −0.213 | −0.235 |
| (0.044) | (0.006) | (0.143) | (0.037) | 0.021 | (0.067) | (0.540 | (0.000) | (0.148) | (0.012) | (0.001) | (0.000) | |
| LA | −0.162 | −0.207 | −0.137 | −0.138 | −0.119 | −0.086 | −0.017 | 0.110 | −0.060 | −0.146 | −0.121 | −0.146 |
| (0.016) | (0.002) | (0.045) | (0.044) | 0.081 | (0.222) | (0.808) | (0.000) | (0.387) | (0.030) | (0.066) | (0.026) | |
| LV | −0.182 | −0.264 | −0.146 | −0.085 | −0.118 | −0.064 | −0.042 | 0.184 | −0.097 | −0.265 | −0.219 | −0.282 |
| (0.007) | (0.000) | (0.030) | (0.215) | 0.092 | (0.379) | (0.576) | (0.000) | (0.164) | (0.000) | (0.001) | (0.000) | |
| Phoenix | −0.174 | −0.256 | −0.145 | −0.108 | −0.122 | −0.072 | −0.030 | 0.170 | −0.092 | −0.226 | −0.191 | −0.233 |
| (0.008) | (0.000) | (0.029) | (0.111) | 0.074 | (0.310) | (0.678) | (0.000) | (0.168) | (0.001) | (0.004) | (0.000) | |
| Portland | −0.271 | −0.284 | −0.211 | −0.250 | −0.199 | −0.141 | −0.026 | 0.212 | −0.186 | −0.273 | −0.312 | −0.333 |
| (0.000) | (0.000) | (0.001) | (0.000) | 0.002 | (0.035) | (0.695) | (0.000) | (0.003) | (0.000) | (0.000) | (0.000) | |
| Seattle | −0.136 | −0.184 | −0.115 | −0.118 | −0.106 | −0.064 | 0.007 | 0.125 | −0.085 | −0.124 | −0.065 | −0.082 |
| (0.025) | (0.002) | (0.060) | (0.058) | 0.094 | (0.323) | (0.911) | (0.000) | (0.176) | (0.044) | (0.277) | (0.174) | |
| SF | −0.179 | −0.213 | −0.151 | −0.084 | −0.083 | −0.033 | 0.013 | 0.126 | −0.179 | −0.272 | −0.253 | −0.228 |
| (0.010) | (0.002) | (0.028) | (0.229) | 0.241 | (0.652) | (0.868) | (0.000) | (0.009) | (0.000) | (0.000) | (0.001) | |
| AIC | BIC | R2 | Log-likelihood | |||||||||
| −3.329 | −1.356 | 0.94 | 1971.92 | |||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benedetti, I.; Laureti, T.; Palumbo, L.; Rose, B.M. Computation of High-Frequency Sub-National Spatial Consumer Price Indexes Using Web Scraping Techniques. Economies 2022, 10, 95. https://0-doi-org.brum.beds.ac.uk/10.3390/economies10040095
Benedetti I, Laureti T, Palumbo L, Rose BM. Computation of High-Frequency Sub-National Spatial Consumer Price Indexes Using Web Scraping Techniques. Economies. 2022; 10(4):95. https://0-doi-org.brum.beds.ac.uk/10.3390/economies10040095
Chicago/Turabian StyleBenedetti, Ilaria, Tiziana Laureti, Luigi Palumbo, and Brandon M. Rose. 2022. "Computation of High-Frequency Sub-National Spatial Consumer Price Indexes Using Web Scraping Techniques" Economies 10, no. 4: 95. https://0-doi-org.brum.beds.ac.uk/10.3390/economies10040095