
A Two-Sample Test of High Dimensional Means Based on Posterior Bayes Factor

1
School of Mathematics and Statistics, Beijing Institute of Technology, Beijing 100081, China
2
Beijing Key Laboratory on MCAACI, Beijing Institute of Technology, Beijing 100081, China
*
Author to whom correspondence should be addressed.
Mathematics 2022, 10(10), 1741; https://0-doi-org.brum.beds.ac.uk/10.3390/math10101741
Submission received: 5 April 2022
/
Revised: 14 May 2022
/
Accepted: 17 May 2022
/
Published: 19 May 2022
(This article belongs to the Special Issue Multivariate Statistics: Theory and Its Applications)
Abstract
:In classical statistics, the primary test statistic is the likelihood ratio. However, for high dimensional data, the likelihood ratio test is no longer effective and sometimes does not work altogether. By replacing the maximum likelihood with the integral of the likelihood, the Bayes factor is obtained. The posterior Bayes factor is the ratio of the integrals of the likelihood function with respect to the posterior. In this paper, we investigate the performance of the posterior Bayes factor in high dimensional hypothesis testing through the problem of testing the equality of two multivariate normal mean vectors. The asymptotic normality of the linear function of the logarithm of the posterior Bayes factor is established. Then we construct a test with an asymptotically nominal significance level. The asymptotic power of the test is also derived. Simulation results and an application example are presented, which show good performance of the test. Hence, taking the posterior Bayes factor as a statistic in high dimensional hypothesis testing is a reasonable methodology.
1. Introduction
The likelihood ratio is the primary test statistic in hypothesis testing owing to its dominating power. However, for high dimensional data, the likelihood ratio statistic is sometimes undefined. For example, the likelihood function of a multivariate normal distribution is unbounded when the dimension of data is greater than the sample size. Even if the likelihood ratio is well-defined, its performance is unsatisfactory when the dimension is proportionally “close to" the sample size [1]. Therefore, when the dimension is large relative to the sample size, that is the so-called “large p small n” situation; how to choose a test statistic plays a key role in statistical inference.
In this article, we try to use the posterior Bayes factor to be a test statistic for high dimensional data, applying it to equality testing of two multivariate normal mean vectors. The classical likelihood ratio test statistic is the ratio of the maximum values of likelihoods, whereas the Bayes factor is the ratio of the integrated likelihoods. We chose the posterior Bayes factor rather than the prior Bayes factor because when the dimension is fixed, the former is less affected by the variations of the prior. This paper aims to investigate the ability of the posterior Bayes factor as a test statistic. As a result, a simple prior is taken for the parameter.
In multivariate analysis, testing the equality of two means is a fundamental problem. The classical procedure for this problem is the famous Hotelling T test in [2], which is based on Mahalanobis distance between the sample mean vectors weighted by the inverse sample covariance matrix. Hotelling’s T test is the most powerful invariant test when the dimension is fixed and much smaller than the total sample size [3], but it is unsatisfactory when the dimension is large relative to the sample size [1]. However, in recent decades, hypothesis testing viable for high dimensional data is increasingly demanded in many application areas such as genomics, finance, medicine, and so on. An important work [1] modifies Hotelling’s T statistic in a high dimensional setting by removing the inverse of the sample covariance from the Hotelling formulation. Some new test statistics for the mean vector are introduced by replacing the sample covariance with its diagonal in [4,5,6]. In [7], a statistic is constructed by retaining the cross-product terms in work [1]. In the sequel, ref. [8] standardizes each component of in [7] by the corresponding variance estimation and proposes a scale-invariant test. The test statistics introduced above are called “sum-of-squares type statistics” (see [9]) and attempt to get around the ill-formed sample covariance matrix. Another major approach called “projecting data” transforms high dimensional data into low dimensional data with random projection so that traditional tests can be applied. See, for example [10,11,12]. By maximizing an average signal to noise ratio, ref. [13] finds the optimal projection subspace and proposes a new test procedure based on it. Besides the two main approaches mentioned above, ref. [14] studies the rates of convergence for the high-dimensional mean and proposes tests based on the sample mean. A new test based on random subspaces is proposed by [15]. A generalized component test is presented in [16], whose statistic is the average of the squared t-statistics for all the component testing problems. A method using a multiple hypothesis test based on the maximum of standardized partial sums of logarithmic p-values statistic is introduced in [17]. More works about testing the mean vectors are presented in [18,19,20].
Few articles develop tests for the means of two samples with Bayesian machineries in high dimensional settings. A Bayes factor-based testing procedure is developed by [12]. However, the statistic is still constructed with lower dimensional random projections of the high dimensional data vectors because Bayes factors based on Jeffrey’s prior involve inversion of the ill-formed sample covariance matrices, as in the classical Hotelling T test statistic in a “large p small n” setting. The approach of random projection cannot be applied when the difference of two mean vectors is dense. However, whether the difference of two mean vectors is dense or sparse is not known in applications. Aitkin [21] proposed the posterior Bayes factor, which is the ratio of the posterior means of the likelihood under each model rather than the usual prior means. Suppose two models and for common data x are considered, under which the likelihood function is , where is the parameter of dimension and belongs to the parameter space . Specifying prior to , , then the posterior Bayes factor in favor of the model , denoted by PBF, is defined as
where is the posterior mean:
and is the posterior density of :
Unlike the Bayes factor, which is highly dependent on the prior and may be very sensitive to variations in the prior, the posterior Bayes factor reduces this sensitivity to the prior. Specifically, when model is a regular submodel of , the logarithm of the posterior Bayes factor under model has
where “” means the convergence in distribution, and and denotes a Chi-square distribution with v degrees of freedom. The asymptotic distribution of the logarithm of the posterior Bayes factor is independent of the prior distribution, which further illustrates that the posterior Bayes factor is insensitive to the prior.
Inspired by [21], we consider testing the equality of two high dimensional means with the posterior Bayes factor. With an appropriate prior, the posterior Bayes factor no longer suffers the impediment of the inversion of ill-formed matrices. Additionally, compared with the approach in [12], which proposed a test based on the Bayes factor with random projections, the posterior Bayes factor can be applied for both dense and sparse cases. In this paper, a non-informative prior also works for the location parameters, while an inverse Wishart prior is taken for the covariance matrix. We establish the asymptotic normality of the logarithm of the posterior Bayes factor under the null hypothesis and derive the asymptotic power of the test. Simulation studies are carried out to investigate the performance of the proposed test. The numerical results show that the power of our test outperforms the competitors in most cases.
The rest of this article is organized as follows. In Section 2, we derive the posterior Bayes factor for testing the equality of two mean vectors in the “large p small n” setting. The asymptotic null distribution of the posterior Bayes factor and the local power function of the test are also presented. Simulation results are given in Section 3. We apply the proposed test to a real dataset in Section 4. Section 5 concludes the paper. Technical proofs and the code for performing the simulation studies are deferred to Appendix A and Appendix B.
2. Test Based on Posterior Bayes Factor
This section tries to construct the test based on the posterior Bayes factor. Let and be iid samples from p-dimensional multivariate normal distributions and , respectively, where and are vectors, and is a positively definite matrix. The goal is to test the hypotheses
In order to test Hypotheses (3) by the posterior Bayes factor, we specify the priors for the parameters , and under both the null and alternative hypotheses as
and
respectively, where is the common mean vector under the null hypothesis, and is the inverse Wishart distribution with real degrees of freedom and a positive definite matrix , .
The reasons for choosing the above priors are as follows.
- When no knowledge about the prior is available, a non-informative prior is suggested. A usual one is Jeffrey’s prior. As a result, for the parameters , , and the common parameter under the null hypothesis, we choose Jeffrey’s prior, i.e., Lebesgue measure.
- For the covariance matrix , the posterior distribution with Jeffrey’s prior does not exist when , where . Therefore, we take the inverse Wishart distribution, which is a conjugate for a normal covariance matrix.
- This paper aims to investigate whether the test with the posterior Bayes factor statistic in high dimensional settings performs better than the existing methods. If the results turn out to be as expected, the posterior Bayes factor could be suggested to be the test statistic for high dimensional datasets. Hence, we will take simple priors. Furthermore, we take in the priors for the covariance matrices with small k so that the variation of the is large.
The joint densities of X and Y under the null and alternative hypotheses are
and
respectively. Then the posterior mean under can be calculated as
where
and denotes the multivariate gamma function, that is,
with , , and
The posterior mean under can be calculated as
where
and
For simplicity, we specify and . Then the posterior Bayes factor in favor of against in (3) denoted by admits an expression as
Multiplying the logarithm of the posterior Bayes factor by 2, we have
Now we want to determine a critical value , which makes the test given by the rejection region
have a significance level . Since the distribution of under the null hypothesis is unknown, the critical value is determined by means of the asymptotic distribution of it. In order to obtain its asymptotic distribution, Taylor series expansion of the logarithm function in (7) around 0 is carried out, which can be summarized as
where
and .
Denotes the spectral decomposition of by , where . Let . Then we have
When the null hypothesis is true,
. The asymptotic distribution of the above formulation can be derived with the following Lemma.
Lemma 1
([22]). Let , , , be iid s-dimensional random vectors with mean zero, covariance matrix M and finite fourth moment. For , let be real random variables which are independent of and satisfy
Then
We take , such that , . From Lemma 1, (9) needs to be normalized by
because , . To ensure equality,
is added to the right side of the equality. By now, we have
As a result,
where is the estimator of . We take
where .
We shall next prove that the first item on the right side of (11) converges in distribution to and the remaining items converge in probability to 0. If a ratio consistent estimator of is obtained, a test with a level of asymptotical significance can be constructed by (11). To this end, some usual assumptions are made as follows:
where is the largest eigenvalue of a matrix A. Let . We also assume
and
Carefully choosing , where , we ensure that
under condition (12), (13) and (15). See Appendix A for the proof. For the estimator , the following theorem shows its property.
By now, the asymptotic distributions of the linear function of the logarithm of the posterior Bayes factor can be derived.
Theorem 1.
In order to formulate a test procedure based on Lemma 2, the estimator of is demanded. The following ratio-consistent estimator for is proposed in [1]:
Inspired by it, we propose the following estimator for :
The following theorem shows the property of .
Theorem 2.
By Theorems 1 and 2, we obtain a test statistic for (3),
which is asymptotically distributed as when the null hypothesis is true. Then the rejection region of the test with approximate significance level is
where is the quantile of .
Previous results allow us to investigate the asymptotic power of the proposed test. By Theorem 1, the following conclusion is obtained.
3. Simulation
In this section, we conduct simulation studies using R language to evaluate the performance of the posterior Bayes factor-based test for various scenarios. The significance level is set to in all the simulations; and the sample sizes are . The data and are generated from multivariate normal distributions and , respectively.
We consider the following choices for .
- is the identity matrix.
- is a covariance matrix with .
- is block diagonal matrix, with block in which the diagonal entries are 1 and the off-diagonal entries are 0.15.
is for independent cases, while and are for dependent cases.
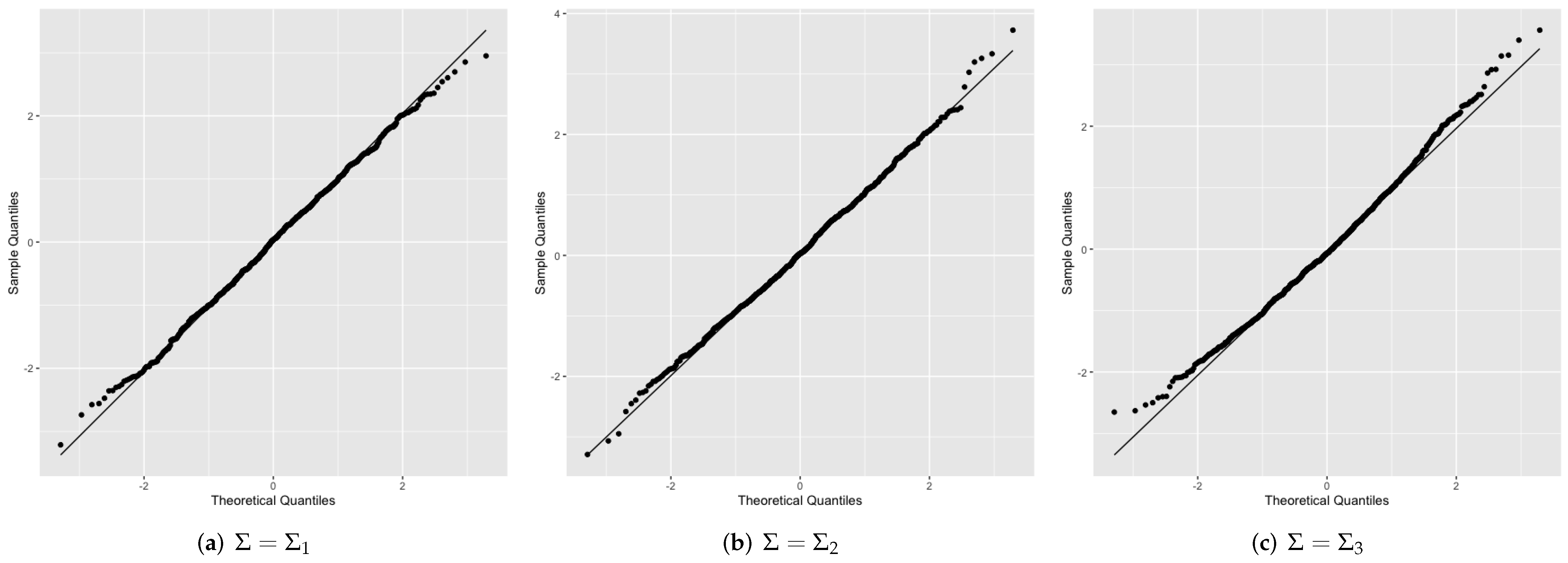
Theorem 1 shows that is a linear function of the logarithm of the posterior Bayes factor, which is asymptotically distributed as . Q–Q plots are presented in Figure 1 to reveal the asymptotic behavior of for and different choices of . We can see that points in Figure 1a–c are closely aligned along the identity line, indicating that the distributions of with different are close to .
We also compare the empirical significance levels and powers of the proposed test with several other tests, including not only tests based on the sum-of-squares-type statistics in [4], referred to as SD, and [7], referred to as CQ, but also a Bayes factor-based test which relies on two random projection approaches as in [12], referred to as RMPBT and RMPBT. In this section, the test we proposed is denoted as PB. The results of SD, CQ and RMPBT are cited from [12].
As in [12], we consider two possible alternatives, as follows. Without loss of generality, we shall always take in the simulations. The proportion of entries of the vector that are exactly zero is denoted by .
- Simulate , set randomly selected elements to 0, and scale so that .
- Simulate , set randomly selected elements to 0, and scale so that .
We take . Note that the case corresponds to the null hypothesis and the power becomes the empirical level. A larger corresponds to a more sparse alternative, while a smaller corresponds to a denser one.
For the PB test, we take and . The numerical results are calculated from 1000 replications and summarized in Table 1, Table 2, Table 3 and Table 4. Table 1 compares the empirical sizes of the tests. In general, the test PB performs best in maintaining the significance level. It can be seen that the estimated sizes of PB are reasonably close to the nominal level 0.05. Tests RMPBT and SD show lower empirical levels than the nominal one, whereas test CQ is a little higher.
Table 2, Table 3 and Table 4 compare the powers of the tests. Covariance matrix in Table 2, Table 3 and Table 4 are , and , respectively. Table 2 shows that our test PB substantively outperforms the other three tests for both dense and sparse alternatives. This implies that our method provides the most powerful test compared with the approaches of [4,7,12] for independent cases. In Table 3, the test PB performs better than its competitors in most cases. In Table 4, PB also performs better than the competitors with dense alternatives. Finally, from Table 3 and Table 4, either the prior or the posterior Bayes factor-based tests are better than others. For the dense alternative, the PB test is more powerful than RMPBT.
4. An Application Example
To further explore the practical utility of the posterior Bayes factor-based test, we analyze a real dataset about the small round blue cell tumors (SRBCTs), which is available at https://file.biolab.si/biolab/supp/bi-cancer/projections/info/SRBCT.html, accessed on 1 March 2022.
The SRBCTs are four different childhood tumors including Ewing’s family of tumors (EWS), neuroblastoma (NB), non-Hodgkin lymphoma (BL) and rhabdomyosarcoma (RMS). Our interest is in examining the equality of means of the genes between the EWS and the RMS tumor groups. The dataset contains 29 examples of EWS and 25 examples of RMS with 2038 genes. The observed test statistic of PB is T with p-value , indicating a serious deviation from the null hypothesis.
5. Conclusions
In this article, we explore the potential for the posterior Bayes factor to be a statistic for testing the mean equality of two high dimensional populations. A closed form of the posterior Bayes factor is obtained with simple priors for the model parameters. Asymptotic normality of the posterior Bayes factor is established, and the corresponding test is constructed. Numerical studies and a real-life example show the superiority of the test. Therefore, we recommend the posterior Bayes factor as a test statistic for hypothesis testing in high dimensional settings.
Author Contributions
Conceptualization, X.X.; methodology, X.X.; software, Y.J.; validation, Y.J. and X.X.; formal analysis, Y.J. and X.X.; writing—original draft preparation, Y.J.; writing—review and editing, Y.J.; visualization, Y.J.; supervision, X.X.; project administration, X.X.; funding acquisition, X.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China under grant number 11471035.
Institutional Review Board Statement
The study did not require ethical approval.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to thank the anonymous referee for the insightful suggestions and comments, which significantly improve the quality and the exposition of the paper.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Appendix A. Proof
The Proof of (16).
Substituting for V in B,
Let
then
and
Hence
Because , we have . Hence,
It follows that
and
Consequently,
Therefore,
can be written as
where , are independently distributed according to the normal distribution . It follows that
By elementary calculation, we have
Since
it follows that,
Hence,
By (A6), we have
Under the null hypothesis,
By elementary calculation, we have
Therefore,
Because
we can obtain
as .
We can conclude
Because , we have
Similarly, we can prove that
By (A9),
Under the assumption (14),
□
Proof of Lemma 2.
By Cauchy–Schwarz inequality and (A3),
We know that
where
Therefore,
Hence
We conclude
The Lemma is proved. □
Proof of Theorem 1.
From (18),
Under the null hypothesis, we know that
Hence,
We know that
and
As
and
we have
Because
we have
By Lemma 1,
Therefore,
By now, (1) in Theorem 1 has been proved.
Under the alternative hypothesis, we have
Let
Since
Because ,
Hence, we can conclude that
In the proof of Theorem 1, we proved that
where is a random vector distributed according to . Hence, we have
Therefore,
(2) in Theorem 1 has been proved. □
Proof of Theorem 2.
Denote the spectral decomposition of by , where . We can rewrite C as
where and
Now substitute the expression of k into the inequality,
Noting that , by
we have
Hence
and
With (A11),
Similarly, we have
therefore
As ,
and
Therefore, with (A11),
Then,
The authors of [1] have proved that
Appendix B. R code
| rm(list = ls(all = TRUE)) |
| library(MASS) |
| library(Matrix) |
| #install.packages("lava") |
| library(lava) |
| n1=70 |
| n2=70 |
| n=n1+n2 |
| p=1000 |
| M=1000 |
| m=2*p |
| mu1=rep(0,p) |
| #Sigma 1 |
| Sigma1=diag(1,p) |
| #Sigma 2 |
| #ro=0.4 |
| #Sigma2_0=matrix(1,p,p) |
| #for (i in 1:p) { |
| # for (j in 1:p) { |
| # k<-abs(j-i) |
| # Sigma2_0[i,j]=ro^{k} |
| # } |
| #} |
| #Sigma2<-Sigma2_0 |
| #Sigma 3 |
| #Sigma3_1=diag(0.85,25)+matrix(0.15,25,25) |
| #list2 <- NULL |
| #for (i in 1:(p/25)){ |
| # list2[[i]] <- Sigma3_1 |
| #} |
| #Sigma3<-as.matrix(bdiag(list2)) |
| Sigma=Sigma1 |
| delta=0.975 |
| t1=proc.time() |
| p0=delta*p |
| mu20=mvrnorm(1,rep(1,p),diag(rep(1, p))) |
| mu20_xiabiao=sort(sample(1:p,p0)) |
| for (i in 1:p0){mu20[mu20_xiabiao[i]]=0} |
| #alternative 1 |
| scal=sqrt((t(mu20)%*%solve(Sigma)%*%(mu20))/2) |
| #alternative 2 |
| #scal=sqrt(t(mu20)%*%(mu20)/sqrt(tr(t(Sigma)%*%Sigma))/0.1) |
| mu2=mu20/rep(scal,p) |
| c=0 |
| T_BF=rep(0,M) |
| for (q in 1:M) { |
| xi<-mvrnorm(n1,mu1,Sigma) |
| yi<-mvrnorm(n2,mu2,Sigma) |
| x_mean<-rep(0,p) |
| for(i in 1:p){ |
| x_mean[i]=mean(xi[,i]) |
| } |
| y_mean<-rep(0,p) |
| for(i in 1:p){ |
| y_mean[i]=mean(yi[,i]) |
| } |
| z1=matrix(0,n1,p) |
| for (l in 1:n1) { |
| z1[l,]=x_mean |
| } |
| z2=matrix(0,n2,p) |
| for (l in 1:n2) { |
| z2[l,]=y_mean |
| } |
| A<-t(xi-z1)%*%(xi-z1)+t(yi-z2)%*%(yi-z2) |
| k<-1/log10(n)/(eigen(A)$values[1])/(p) |
| V<-k*diag(rep(1, p)) |
| B=((m+2*(n))*solve(solve(V)+2*(A))-(m+n)/2*solve(solve(V)+A)) |
| T=n1*n2/(n)*(t(x_mean-y_mean)%*%B%*%(x_mean-y_mean)) |
| S_n<-A/(n-2) |
| mu_T=tr(B%*%S_n) |
| sigma_T<-tr((B%*%S_n)%*%(B%*%S_n))-1/(n-2)*(tr(B%*%S_n))^2 |
| T_BF[q]=(T-mu_T)/sqrt(2*sigma_T) |
| if(T_BF[q]>=qnorm(0.95)){c=c+1} |
| } |
| t2=proc.time() |
| t=t2-t1 |
| cat("power =", c/M,"time",t[3][[1]],"s","\n") |
References
- Bai, Z.; Saranadasa, H. Effect of high dimension: By an example of a two sample problem. Stat. Sin. 1996, 6, 311–329. [Google Scholar]
- Hotelling, H. The Generalization of Student’s Ratio. Ann. Math. Stat. 1931, 2, 360–378. [Google Scholar] [CrossRef]
- Anderson, T.W. An Introduction to Multivariate Statistical Analysis; Technical Report; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1958. [Google Scholar]
- Srivastava, M.S.; Du, M. A test for the mean vector with fewer observations than the dimension. J. Multivar. Anal. 2008, 99, 386–402. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, M.S. A test for the mean vector with fewer observations than the dimension under non-normality. J. Multivar. Anal. 2009, 100, 518–532. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, M.S.; Katayama, S.; Kano, Y. A two sample test in high dimensional data. J. Multivar. Anal. 2013, 114, 349–358. [Google Scholar] [CrossRef]
- Chen, S.X.; Qin, Y.L. A two-sample test for high-dimensional data with applications to gene-set testing. Ann. Stat. 2010, 38, 808–835. [Google Scholar] [CrossRef] [Green Version]
- Feng, L.; Zou, C.; Wang, Z.; Zhu, L. Two-sample Behrens-Fisher problem for high-dimensional data. Stat. Sin. 2015, 25, 1297–1312. [Google Scholar] [CrossRef] [Green Version]
- Cai, T.T.; Liu, W.; Xia, Y. Two-sample test of high dimensional means under dependence. J. R. Stat. Soc. Ser. B Stat. Methodol. 2014, 76, 349–372. [Google Scholar]
- Lopes, M.; Jacob, L.; Wainwright, M.J. A more powerful two-sample test in high dimensions using random projection. Adv. Neural Inf. Process. Syst. 2011, 24, 1206–1214. [Google Scholar]
- Srivastava, R.; Li, P.; Ruppert, D. RAPTT: An exact two-sample test in high dimensions using random projections. J. Comput. Graph. Stat. 2016, 25, 954–970. [Google Scholar] [CrossRef]
- Zoh, R.S.; Sarkar, A.; Carroll, R.J.; Mallick, B.K. A powerful Bayesian test for equality of means in high dimensions. J. Am. Stat. Assoc. 2018, 113, 1733–1741. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Xu, X. On two-sample mean tests under spiked covariances. J. Multivar. Anal. 2018, 167, 225–249. [Google Scholar] [CrossRef]
- Kuelbs, J.; Vidyashankar, A.N. Asymptotic inference for high-dimensional data. Ann. Stat. 2010, 38, 836–869. [Google Scholar] [CrossRef] [Green Version]
- Thulin, M. A high-dimensional two-sample test for the mean using random subspaces. Comput. Stat. Data Anal. 2014, 74, 26–38. [Google Scholar] [CrossRef] [Green Version]
- Gregory, K.B.; Carroll, R.J.; Baladandayuthapani, V.; Lahiri, S.N. A two-sample test for equality of means in high dimension. J. Am. Stat. Assoc. 2015, 110, 837–849. [Google Scholar] [CrossRef] [PubMed]
- Yu, W.; Xu, W.; Zhu, L. A combined p-value test for the mean difference of high-dimensional data. Sci. China Math. 2018, 62, 961. [Google Scholar] [CrossRef]
- Chen, S.X.; Li, J.; Zhong, P.S. Two-sample and ANOVA tests for high dimensional means. Ann. Stat. 2019, 47, 1443–1474. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.T.; Guo, J.; Zhou, B.; Cheng, M.Y. A simple two-sample test in high dimensions based on L2-norm. J. Am. Stat. Assoc. 2020, 115, 1011–1027. [Google Scholar] [CrossRef]
- Zhu, Y.; Bradic, J. Significance testing in non-sparse high-dimensional linear models. Electron. J. Stat. 2018, 12, 3312–3364. [Google Scholar] [CrossRef]
- Aitkin, M. Posterior bayes factors. J. R. Stat. Soc. Ser. B Methodol. 1991, 53, 111–128. [Google Scholar] [CrossRef]
- Wang, R.; Xu, X. Least favorable direction test for multivariate analysis of variance in high dimension. Stat. Sin. 2021, 31, 723–747. [Google Scholar] [CrossRef]
Figure 1.
Quantile–Quantile plot of asymptotic distribution for under the null hypothesis against for different based on 1000 independently generated with , .
Figure 1.
Quantile–Quantile plot of asymptotic distribution for under the null hypothesis against for different based on 1000 independently generated with , .


{kind=link}
Table 1.
Empirical sizes based on 1000 replications with , and . RMPBT is the approach of [12], SD is the approach of [4] and CQ is the approach of [7].
| RMPBT | RMPBT | SD | CQ | ||
|---|---|---|---|---|---|
| 0.049 | 0.031 | 0.030 | 0.040 | 0.063 | |
| 0.052 | 0.038 | 0.035 | 0.037 | 0.049 | |
| 0.060 | 0.060 | 0.040 | 0.045 | 0.063 |
Table 2.
Power analysis of 4 tests assuming the true covariance matrix is ; and . RMPBT is the approach of [12], SD is the approach of [4] and CQ is the approach of [7].
| RMPBT | RMPBT | SD | CQ | |||
|---|---|---|---|---|---|---|
| Alternative 1 | 0.975 | 0.470 | 0.332 | 0.309 | 0.384 | 0.450 |
| 0.950 | 0.478 | 0.388 | 0.339 | 0.423 | 0.474 | |
| 0.800 | 0.482 | 0.337 | 0.304 | 0.389 | 0.448 | |
| 0.750 | 0.482 | 0.348 | 0.294 | 0.401 | 0.470 | |
| 0.500 | 0.485 | 0.372 | 0.343 | 0.422 | 0.473 | |
| Alternative 2 | 0.975 | 0.764 | 0.685 | 0.612 | 0.722 | 0.761 |
| 0.950 | 0.797 | 0.694 | 0.612 | 0.741 | 0.775 | |
| 0.800 | 0.785 | 0.660 | 0.581 | 0.717 | 0.762 | |
| 0.750 | 0.806 | 0.695 | 0.616 | 0.756 | 0.789 | |
| 0.500 | 0.786 | 0.677 | 0.588 | 0.727 | 0.767 |
Table 3.
Power analysis of 4 tests assuming the true covariance matrix is . and ; RMPBT is the approach of [12], SD is the approach of [4] and CQ is the approach of [7].
| RMPBT | RMPBT | SD | CQ | |||
|---|---|---|---|---|---|---|
| Alternative 1 | 0.975 | 0.269 | 0.259 | 0.243 | 0.219 | 0.266 |
| 0.950 | 0.277 | 0.249 | 0.232 | 0.209 | 0.258 | |
| 0.800 | 0.282 | 0.261 | 0.222 | 0.221 | 0.270 | |
| 0.750 | 0.299 | 0.264 | 0.236 | 0.242 | 0.284 | |
| 0.500 | 0.336 | 0.303 | 0.265 | 0.268 | 0.326 | |
| Alternative 2 | 0.975 | 0.783 | 0.791 | 0.738 | 0.722 | 0.768 |
| 0.950 | 0.780 | 0.786 | 0.734 | 0.718 | 0.766 | |
| 0.800 | 0.794 | 0.755 | 0.699 | 0.700 | 0.756 | |
| 0.750 | 0.792 | 0.772 | 0.722 | 0.730 | 0.785 | |
| 0.500 | 0.789 | 0.753 | 0.686 | 0.720 | 0.766 |
Table 4.
Power analysis of 4 tests assuming the true covariance matrix is ; and . RMPBT is the approach of [12], SD is the approach of [4] and CQ is the approach of [7].
| RMPBT | RMPBT | SD | CQ | |||
|---|---|---|---|---|---|---|
| Alternative 1 | 0.975 | 0.296 | 0.315 | 0.278 | 0.245 | 0.294 |
| 0.950 | 0.303 | 0.335 | 0.307 | 0.270 | 0.311 | |
| 0.800 | 0.332 | 0.348 | 0.318 | 0.285 | 0.343 | |
| 0.750 | 0.357 | 0.327 | 0.294 | 0.278 | 0.331 | |
| 0.500 | 0.422 | 0.414 | 0.379 | 0.353 | 0.401 | |
| Alternative 2 | 0.975 | 0.785 | 0.836 | 0.776 | 0.716 | 0.755 |
| 0.950 | 0.801 | 0.827 | 0.776 | 0.730 | 0.782 | |
| 0.800 | 0.795 | 0.796 | 0.734 | 0.728 | 0.775 | |
| 0.750 | 0.793 | 0.790 | 0.727 | 0.718 | 0.764 | |
| 0.500 | 0.778 | 0.774 | 0.717 | 0.720 | 0.761 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Jiang, Y.; Xu, X. A Two-Sample Test of High Dimensional Means Based on Posterior Bayes Factor. Mathematics 2022, 10, 1741. https://0-doi-org.brum.beds.ac.uk/10.3390/math10101741
AMA Style
Jiang Y, Xu X. A Two-Sample Test of High Dimensional Means Based on Posterior Bayes Factor. Mathematics. 2022; 10(10):1741. https://0-doi-org.brum.beds.ac.uk/10.3390/math10101741
Chicago/Turabian StyleJiang, Yuanyuan, and Xingzhong Xu. 2022. "A Two-Sample Test of High Dimensional Means Based on Posterior Bayes Factor" Mathematics 10, no. 10: 1741. https://0-doi-org.brum.beds.ac.uk/10.3390/math10101741
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.