
Transformation and Linearization Techniques in Optimization: A State-of-the-Art Survey

 ,
,  , and
, and 
Abstract
:1. Introduction
2. Transformations
2.1. Multiplication of Binary Variables
2.2. Multiplication of Binary and Continuous Variables
2.3. Multiplication of Two Continuous Variables
2.4. Maximum/Minimum Operators
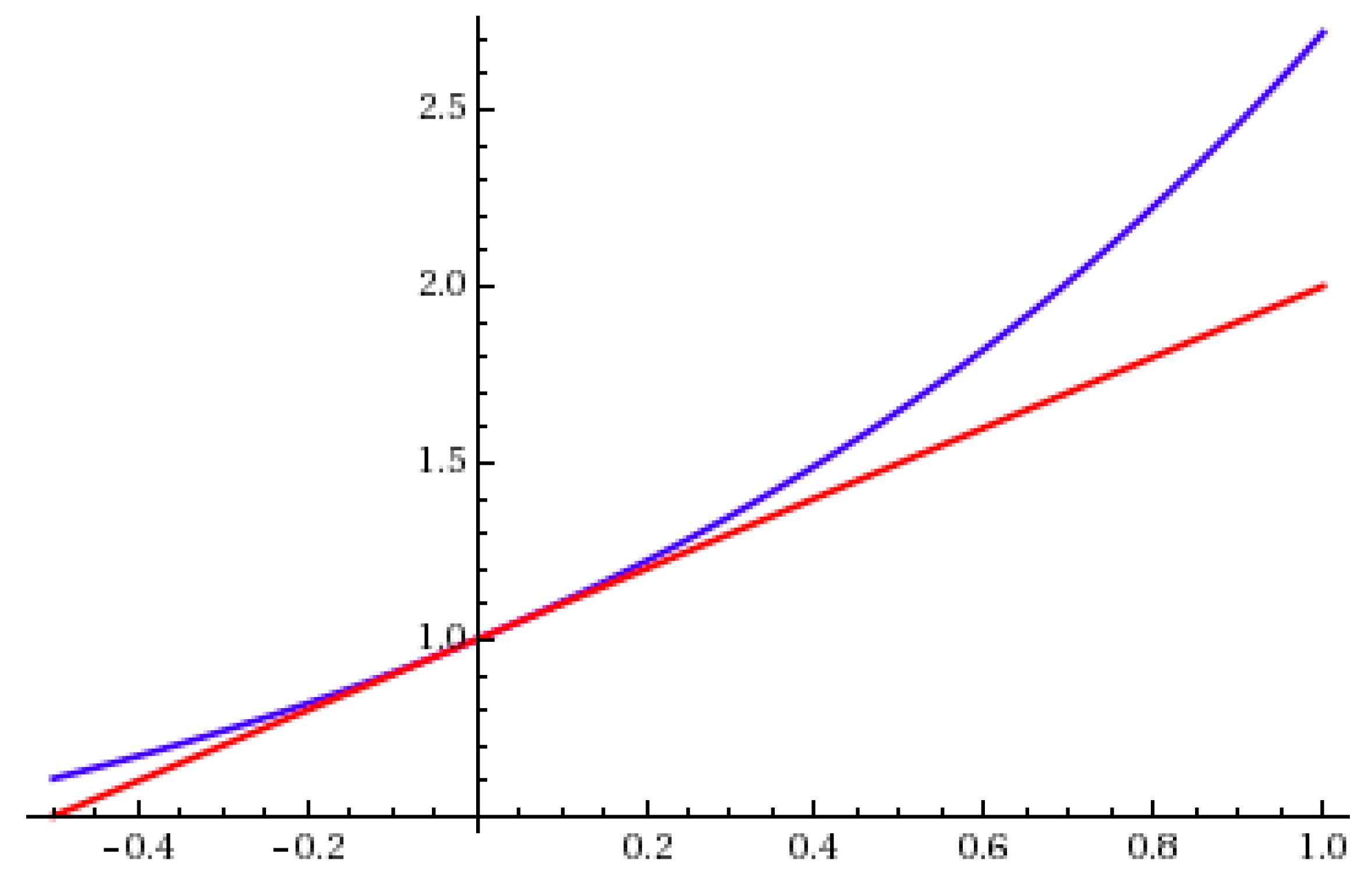
2.5. Absolute Value Function
2.5.1. Absolute Value in Constraints
2.5.2. Absolute Value in the Objective Function
2.5.3. Minimizing the Sum of Absolute Deviations
2.5.4. Minimizing the Maximum of Absolute Values
2.6. Floor and Ceiling Functions
2.7. Square Root Function
2.8. Multiple Breakpoint Function
3. Approximate Linearization Methods
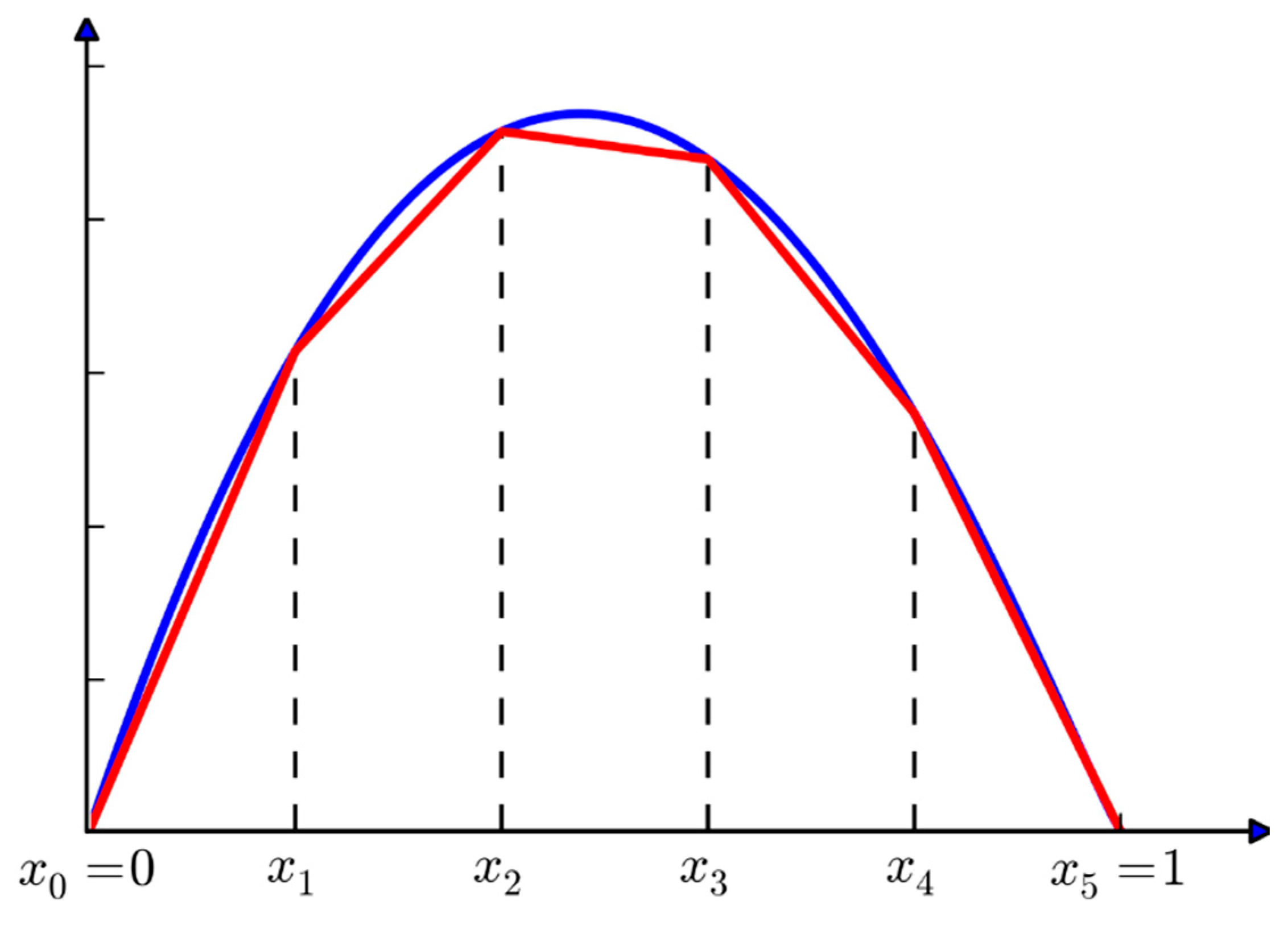
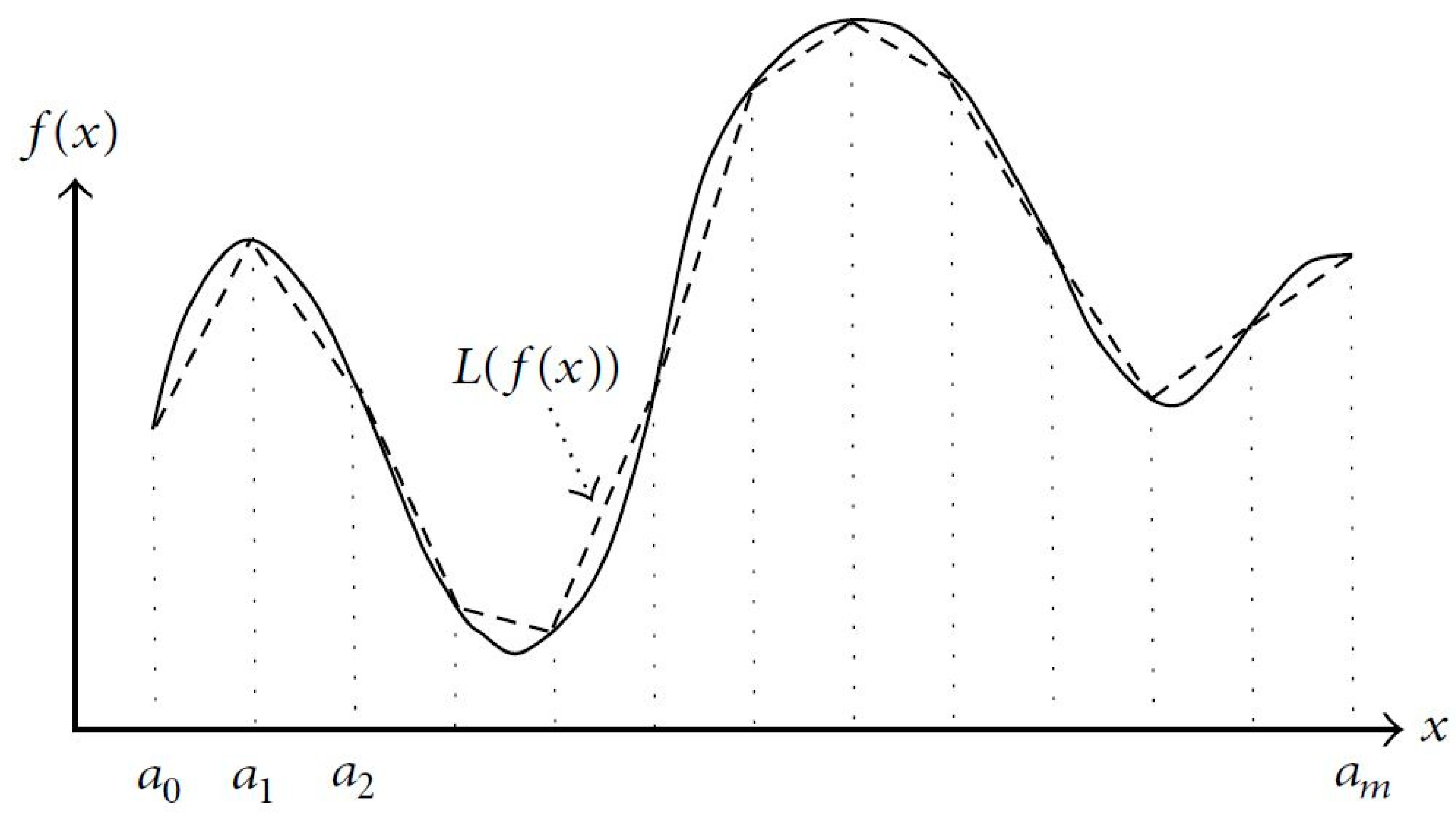
3.1. Piecewise Linear Approximation
3.1.1. Formulations
- Method 1
- Method 2
- Method 3
- Method 4
- Method 5
3.1.2. PLA-Based Algorithms
- Approximating Planar Curves
- Single Pass PLA Algorithm
- Branch and Refine
- PLAs for Accuracy
3.2. Log-Linearization via Taylor Series Approximation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Proof of Theorem 1
Appendix B. Proof of Theorem 2
Appendix C. Linearization of Quadratic Integers for n + 1
References
- Negrello, C.; Gosselet, P.; Rey, C. Nonlinearly Preconditioned FETI Solver for Substructured Formulations of Nonlinear Problems. Mathematics 2021, 9, 3165. [Google Scholar] [CrossRef]
- Petridis, K.; Drogalas, G.; Zografidou, E. Internal auditor selection using a TOPSIS/non-linear programming model. Ann. Oper. Res. 2021, 296, 513–539. [Google Scholar] [CrossRef]
- Stoyan, Y.; Yaskov, G. Optimized packing unequal spheres into a multiconnected domain: Mixed-integer non-linear programming approach. Int. J. Comput. Math. Comput. Syst. Theory 2021, 6, 94–111. [Google Scholar] [CrossRef]
- Dulebenets, M.A. The vessel scheduling problem in a liner shipping route with heterogeneous fleet. Int. J. Civ. Eng. 2018, 16, 19–32. [Google Scholar] [CrossRef]
- Fathollahi-Fard, A.M.; Hajiaghaei-Keshteli, M.; Tavakkoli-Moghaddam, R.; Smith, N.R. Bi-level programming for home health care supply chain considering outsourcing. J. Ind. Inf. Integr. 2021, 25, 100246. [Google Scholar] [CrossRef]
- Bertsimas, D.; Dunn, J.; Wang, Y. Near-optimal nonlinear regression trees. Oper. Res. Lett. 2021, 49, 201–206. [Google Scholar] [CrossRef]
- Fathollahi-Fard, A.M.; Woodward, L.; Akhrif, O. Sustainable distributed permutation flow-shop scheduling model based on a triple bottom line concept. J. Ind. Inf. Integr. 2021, 24, 100233. [Google Scholar] [CrossRef]
- Pauer, G.; Török, Á. Binary integer modeling of the traffic flow optimization problem, in the case of an autonomous transportation system. Oper. Res. Lett. 2021, 49, 136–143. [Google Scholar] [CrossRef]
- Guignard, M. Strong RLT1 bounds from decomposable Lagrangean relaxation for some quadratic 0–1 optimization problems with linear constraints. Ann. Oper. Res. 2020, 286, 173–200. [Google Scholar] [CrossRef]
- Hsu, H.-P.; Wang, C.-N.; Fu, H.-P.; Dang, T.-T. Joint Scheduling of Yard Crane, Yard Truck, and Quay Crane for Container Terminal Considering Vessel Stowage Plan: An Integrated Simulation-Based Optimization Approach. Mathematics 2021, 9, 2236. [Google Scholar] [CrossRef]
- Dulebenets, M.A. Advantages and disadvantages from enforcing emission restrictions within emission control areas. Marit. Bus. Rev. 2016, 1, 107–132. [Google Scholar] [CrossRef] [Green Version]
- Pasha, J.; Dulebenets, M.A.; Kavoosi, M.; Abioye, O.F.; Theophilus, O.; Wang, H.; Kampmann, R.; Guo, W. Holistic tactical-level planning in liner shipping: An exact optimization approach. J. Shipp. Trade 2020, 5, 8. [Google Scholar] [CrossRef]
- Dulebenets, M.A. A comprehensive multi-objective optimization model for the vessel scheduling problem in liner shipping. Int. J. Prod. Econ. 2018, 196, 293–318. [Google Scholar] [CrossRef]
- Cameron, S.H. Piece-wise linear approximations. In Technical Report CSTN-106; Computer Science Division, IIT Research Institute: Chicago, IL, USA, 1966. [Google Scholar]
- Bradley, S.P.; Hax, A.C.; Magnanti, T.L. Applied Mathematical Programming; Addison-Wesley: Reading, MA, USA, 1977. [Google Scholar]
- Gajjar, H.K.; Adil, G.K. A piecewise linearization for retail shelf space allocation problem and a local search heuristic. Ann. Oper. Res. 2010, 179, 149–167. [Google Scholar] [CrossRef]
- Geißler, B.; Martin, A.; Morsi, A.; Schewe, L. Using piecewise linear functions for solving MINLPs. In Mixed Integer Nonlinear Programming; Lee, J., Leyffer, S., Eds.; Springer: New York, NY, USA, 2012; Volume 154, pp. 287–314. [Google Scholar]
- Sridhar, S.; Linderoth, J.; Luedtke, J. Locally ideal formulations for piecewise linear functions with indicator variables. Oper. Res. Lett. 2013, 41, 627–632. [Google Scholar] [CrossRef] [Green Version]
- Andrade-Pineda, J.L.; Canca, D.; Gonzalez-R, P.L. On modelling non-linear quantity discounts in a supplier selection problem by mixed linear integer optimization. Ann. Oper. Res. 2017, 258, 301–346. [Google Scholar] [CrossRef]
- Stefanello, F.; Buriol, L.S.; Hirsch, M.J.; Pardalos, P.M.; Querido, T.; Resende, M.G.C.; Ritt, M. On the minimization of traffic congestion in road networks with tolls. Ann. Oper. Res. 2017, 249, 119–139. [Google Scholar] [CrossRef]
- Meyer, R.R.A. Theoretical and computational comparison of ‘Equivalent’ mixed-integer formulations. Nav. Res. Logist. 1981, 28, 115–131. [Google Scholar] [CrossRef] [Green Version]
- Jeroslow, R.G.; Lowe, J.K. Modeling with integer variables. In Mathematical Programming at Oberwolfach II. Mathematical Programming Studies; Korte, B., Ritter, K., Eds.; Springer: Berlin/Heidelberg, Germany, 1984; Volume 22. [Google Scholar]
- Jeroslow, R.G.; Lowe, J.K. Experimental results on new techniques for integer programming formulations. J. Oper. Res. Soc. 1985, 36, 393–403. [Google Scholar] [CrossRef]
- Balas, E. Disjunctive programming and a hierarchy of relaxations for discrete optimization problems. SIAM J. Algebraic Discret. Methods 1985, 6, 466–486. [Google Scholar] [CrossRef]
- Johnson, E.L. Modeling and Strong Linear Programs for Mixed Integer Programming. In Algorithms and Model Formulations in Mathematical Programming; NATO ASI Series (Series F: Computer and Systems Sciences); Wallace, S.W., Ed.; Springer: Berlin/Heidelberg, Germany, 1989; Volume 51. [Google Scholar]
- Wolsey, L.A. Strong formulations for mixed integer programming: A survey. Math. Program. 1989, 45, 173–191. [Google Scholar] [CrossRef]
- Sherali, H.D.; Adams, W.P. A hierarchy of relaxations between the continuous and convex hull representations for zero-one programming problems. SIAM J. Discret. Math. 1990, 3, 411–430. [Google Scholar] [CrossRef]
- Sherali, H.D.; Adams, W.P. A hierarchy of relaxations and convex hull characterizations for mixed-integer zero-one programming problems. Discret. Appl. Math. 1994, 52, 83–106. [Google Scholar] [CrossRef] [Green Version]
- Williams, H.P. Model Building in Mathematical Programming, 5th ed.; WILEY: Hoboken, NJ, USA, 2013. [Google Scholar]
- Glover, F. Improved linear integer programming formulations of nonlinear integer problems. Manag. Sci. 1975, 22, 455–460. [Google Scholar] [CrossRef] [Green Version]
- Balas, E.; Mazzola, J.B. Nonlinear 0-1 programming: I. Linearization techniques. Math. Program. 1984, 30, 2–12. [Google Scholar] [CrossRef]
- Balas, E.; Mazzola, J.B. Nonlinear 0-1 programming: II. Dominance relations and algorithms. Math. Program. 1984, 30, 22–45. [Google Scholar] [CrossRef]
- Adams, W.P.; Sherali, H.D. A tight linearization and an algorithm for zero-one quadratic programming problems. Manag. Sci. 1986, 32, 1274–1290. [Google Scholar] [CrossRef]
- Adams, W.P.; Sherali, H.D. Linearization strategies for a class of zero-one mixed integer programming problems. Oper. Res. 1990, 38, 217–226. [Google Scholar] [CrossRef]
- Adams, W.P.; Sherali, H.D. Mixed-integer bilinear programming problems. Math. Program. 1993, 59, 279–305. [Google Scholar] [CrossRef]
- Adams, W.P.; Billionnet, A.; Sutter, A. Unconstrained 0-1 optimization and lagrangean relaxation. Discret. Appl. Math. 1990, 29, 131–142. [Google Scholar] [CrossRef] [Green Version]
- Bisschop, J. AIMMS Optimization Modeling. 2021. Available online: https://documentation.aimms.com/aimms_modeling.html (accessed on 25 February 2021).
- Rahil, A. Linearization of Mixed Integer Programming. 2012. Available online: www.iems.ucf.edu/qzheng/grpmbr/seminar/Anees_Linear_General_Slides.pdf (accessed on 25 February 2021).
- Asghari, M.; Mirzapour Al-e-hashem, S.M.J. A Green Delivery-Pickup Problem for Home Hemodialysis Machines; Sharing Economy in Distributing Scarce Resources. Transp. Res. Part E 2020, 134, 101815. [Google Scholar] [CrossRef]
- Asghari, M.; Mirzapour Al-e-hashem, S.M.J.; Rekik, Y. Environmental and social implications of incorporating carpooling service on a customized bus system. Comput. Oper. Res. 2022, in press. [Google Scholar]
- Mojtahedi, M.; Fathollahi-Fard, A.M.; Tavakkoli-Moghaddam, R.; Newton, S. Sustainable vehicle routing problem for coordinated solid waste management. J. Ind. Inf. Integr. 2021, 23, 100220. [Google Scholar] [CrossRef]
- Mohammadi, S.; Mirzapour Al-e-Hashem, S.M.J.; Rekik, Y. An integrated production scheduling and delivery route planning with multi-purpose machines: A case study from a furniture manufacturing company. Int. J. Prod. Econ. 2020, 219, 347–359. [Google Scholar] [CrossRef]
- Mangasarian, O.L.; Meyer, R.R. Absolute value equations. Linear Algebra Appl. 2006, 419, 359–367. [Google Scholar] [CrossRef] [Green Version]
- Mangasarian, O.L. Absolute value equation solution via concave minimization. Optim. Lett. 2007, 1, 3–8. [Google Scholar] [CrossRef]
- Mangasarian, O.L. Absolute value programming. Comput. Optim. Appl. 2007, 36, 43–53. [Google Scholar] [CrossRef]
- Mangasarian, O.L. A generalized Newton method for absolute value equations. Optim. Lett. 2009, 3, 101–108. [Google Scholar] [CrossRef]
- Caccetta, L.; Qu, B.; Zhou, G. A globally and quadratically convergent method for absolute value equations. Comput. Optim. Appl. 2001, 48, 45–58. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Ferguson, R.O.; Sargent, L.A. Linear Programming: Fundamentals and Applications; Mc Graw-Hill Book Company: New York, NY, USA, 1958. [Google Scholar]
- McCarl, B.A.; Spreen, T.H. Applied Mathematical Programming Using Algebraic Systems. 1997. Available online: http://agecon2.tamu.edu/people/faculty/mccarl-bruce/books.htm (accessed on 25 February 2021).
- Gelfand, I.M.; Shen, A. Algebra. Springer Science & Business Media. Birkhäuser Boston, 2003. Available online: https://books.google.com/books?id=Z9z7iliyFD0C (accessed on 25 February 2021).
- Kwon, T.J.; Draper, J. Floating-point division and square root using a Taylor-series expansion algorithm. Microelectron. J. 2009, 40, 1601–1605. [Google Scholar] [CrossRef] [Green Version]
- Del Moral, P.; Niclas, A. A Taylor expansion of the square root matrix function. J. Math. Anal. Appl. 2018, 465, 259–266. [Google Scholar] [CrossRef]
- Tsai, J.F. An optimization approach for supply chain management models with quantity discount policy. Eur. J. Oper. Res. 2007, 177, 982–994. [Google Scholar] [CrossRef]
- Mirzapour Al-e-hashem, S.M.J.; Baboli, A.; Sazvar, Z. A stochastic aggregate production planning model in a green supply chain: Considering flexible lead times, nonlinear purchase and shortage cost functions. Eur. J. Oper. Res. 2013, 230, 26–41. [Google Scholar] [CrossRef]
- Dembo, R.S. Current state of the art of algorithms and computer software for geometric programming. J. Optim. Theory Appl. 1978, 26, 149–183. [Google Scholar] [CrossRef]
- McCarl, B.A.; Tice, T. Should Quadratic Programming Problems be Approximated? Am. J. Agric. Econ. 1982, 64, 585–589. [Google Scholar] [CrossRef]
- McCarl, B.A.; Onal, H. Linear Approximation Using MOTAD and Separable Programming: Should it be Done? Am. J. Agric. Econ. 1989, 71, 158–166. [Google Scholar] [CrossRef]
- Li, H.L.; Chang, C.T.; Tsai, J.F. Approximately global optimization for assortment problems using piecewise linearization techniques. Eur. J. Oper. Res. 2002, 140, 584–589. [Google Scholar] [CrossRef]
- Bazaraa, M.S.; Sherali, H.D.; Shetty, C.M. Nonlinear Programming: Theory and Algorithms, 3rd ed.; Wiley-Interscience: New York, NY, USA, 2013. [Google Scholar]
- Hillier, F.S.; Lieberman, G.J. Introduction to Operations Research, 9th ed.; McGraw-Hill: New York, NY, USA, 2009. [Google Scholar]
- Taha, H.A. Operations Research an Introduction, 10th ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2017. [Google Scholar]
- Lin, M.H.; Carlsson, J.G.; Ge, D.; Shi, J.; Tsai, J.F. A Review of Piecewise Linearization Methods. Math. Probl. Eng. 2013, 2013, 101376. [Google Scholar] [CrossRef] [Green Version]
- Li, H.L.; Yu, C.S. Global optimization method for nonconvex separable programming problems. Eur. J. Oper. Res. 1999, 117, 275–292. [Google Scholar] [CrossRef]
- Li, H.L.; Tsai, J.F. Treating free variables in generalized geometric global optimization programs. J. Glob. Optim. 2005, 33, 1–13. [Google Scholar] [CrossRef]
- Topaloglu, H.; Powell, W.B. An algorithm for approximating piecewise linear concave functions from sample gradients. Oper. Res. Lett. 2003, 31, 66–76. [Google Scholar] [CrossRef]
- Padberg, M. Approximating separable nonlinear functions via mixed zero-one programs. Oper. Res. Lett. 2000, 27, 1–5. [Google Scholar] [CrossRef] [Green Version]
- Li, H.L. An efficient method for solving linear goal programming problems. J. Optim. Theory Appl. 1996, 90, 465–469. [Google Scholar] [CrossRef]
- Croxton, K.L.; Gendron, B.; Magnanti, T.L. A comparison of mixed-integer programming models for nonconvex piecewise linear cost minimization problems. Manag. Sci. 2003, 49, 1268–1273. [Google Scholar] [CrossRef] [Green Version]
- Li, H.L.; Lu, H.C.; Huang, C.H.; Hu, N.Z. A superior representation method for piecewise linear functions. INFORMS J. Comput. 2009, 21, 314–321. [Google Scholar] [CrossRef]
- Vielma, J.P.; Ahmed, S.; Nemhauser, G. A note on a superior representation method for piecewise linear functions. INFORMS J. Comput. 2010, 22, 493–497. [Google Scholar] [CrossRef] [Green Version]
- Vielma, J.P.; Nemhauser, G. Modeling disjunctive constraints with a logarithmic number of binary variables and constraints. Math. Program. 2011, 128, 49–72. [Google Scholar] [CrossRef]
- Tsai, J.F.; Lin, M.H. An efficient global approach for posynomial geometric programming problems. INFORMS J. Comput. 2011, 23, 483–492. [Google Scholar] [CrossRef]
- Ahmadi, H.; Martí, J.R.; Moshref, A. Piecewise linear approximation of generators cost functions using max-affine functions. In Proceedings of the 2013 IEEE Power & Energy Society General Meeting, Vancouver, BC, Canada, 21–25 July 2013; pp. 1–5. [Google Scholar]
- Ajili, F.; El Sakkout, H. A Probe-Based Algorithm for Piecewise Linear Optimization in Scheduling. Ann. Oper. Res. 2003, 118, 35–48. [Google Scholar] [CrossRef]
- Keha, A.B.; De Farias, I.R.; Nemhauser, G.L. A branch-and-cut algorithm without binary variables for nonconvex piecewise linear optimization. Oper. Res. 2006, 54, 847–858. [Google Scholar] [CrossRef]
- Imamoto, A.; Tang, B. Optimal piecewise linear approximation of convex functions. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 22–24 October 2008; pp. 1191–1194. [Google Scholar]
- Melo, W.; Fampa, M.; Raupp, F. Two linear approximation algorithms for convex mixed integer nonlinear programming. Ann. Oper. Res. 2020. [Google Scholar] [CrossRef]
- Williams, C.M. An efficient algorithm for the piecewise linear approximation of planar curves. Comput. Graph. Image Process. 1978, 8, 286–293. [Google Scholar] [CrossRef]
- Gritzali, F.; Papakonstantinou, G. A fast piecewise linear approximation algorithm. Signal Process. 1983, 5, 221–227. [Google Scholar] [CrossRef]
- Leyffer, S.; Sartenaer, A.; Wanufelle, E. Branch-and-Refine for Mixed-Integer Nonconvex Global Optimization; ANL/MCS-P1547-0908; Argonne National Laboratory: Argonne, IL, USA, 2008; preprint.
- Gong, J.; You, F. Global optimization for sustainable design and synthesis of algae processing network for CO2 mitigation and biofuel production using life cycle optimization. AIChE J. 2014, 60, 3195–3210. [Google Scholar] [CrossRef]
- Nishikawa, H. Accurate Piecewise Linear Continuous Approximations to One-Dimensional Curves: Error Estimates and Algorithms; Department of Aerospace Engineering, University of Michigan: Ann Arbor, MI, USA, 1998. [Google Scholar]
- Uhlig, H. A toolkit for analyzing nonlinear dynamic stochastic models easily. In Computational Methods for the Study of Dynamic Economies; Marimon, R., Scott, A., Eds.; Oxford University Press: New York, NY, USA, 1999; pp. 30–61. [Google Scholar]
- Zietz, J. Log-Linearizing Around the Steady State: A Guide with Examples. Available online: https://ssrn.com/abstract=951753 (accessed on 25 February 2021).
- McCandless, G. The ABCs of RBCs: An Introduction to Dynamic Macroeconomic Models; Harvard University Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Griffith, R.E.; Stewart, R.A. A Nonlinear Programming Technique for the Optimization of Continuous Processing Systems. Manag. Sci. 1961, 7, 379–392. [Google Scholar] [CrossRef]
- Pasha, J.; Dulebenets, M.A.; Fathollahi-Fard, A.M.; Tian, G.; Lau, Y.Y.; Singh, P.; Liang, B. An integrated optimization method for tactical-level planning in liner shipping with heterogeneous ship fleet and environmental considerations. Adv. Eng. Inform. 2021, 48, 101299. [Google Scholar] [CrossRef]
- Dulebenets, M.A. The green vessel scheduling problem with transit time requirements in a liner shipping route with Emission Control Areas. Alex. Eng. J. 2018, 57, 331–342. [Google Scholar] [CrossRef]
- Theophilus, O.; Dulebenets, M.A.; Pasha, J.; Lau, Y.Y.; Fathollahi-Fard, A.M.; Mazaheri, A. Truck scheduling optimization at a cold-chain cross-docking terminal with product perishability considerations. Comput. Ind. Eng. 2021, 156, 107240. [Google Scholar] [CrossRef]
- Borevich, Z.I.; Shafarevich, I.R. Number Theory. In Mathematical Symbols; Academic Press: Cambridge, MA, USA, 1966. [Google Scholar]





{kind=link}
{kind=link}
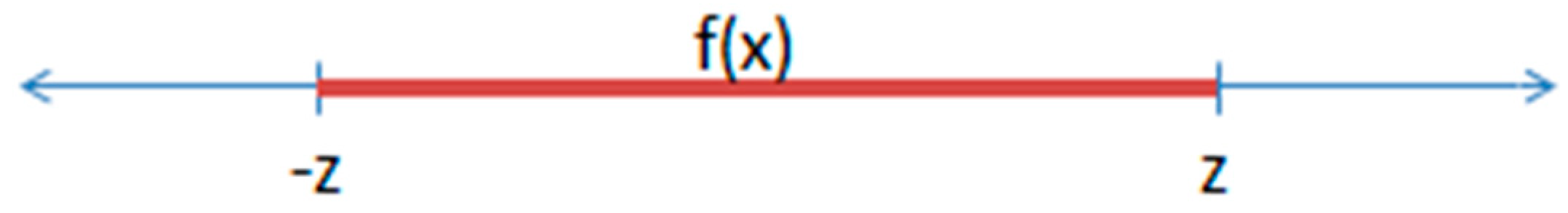{kind=link}
{kind=link}
| Constraints | Imply | |||
|---|---|---|---|---|
| 0 | 0 | 0 | ||
| 0 | 1 | 0 | ||
| 1 | 0 | 0 | ||
| 1 | 1 | 1 | ||
| Constraints | Imply | |||
|---|---|---|---|---|
| 0 | 0 | |||
| 1 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asghari, M.; Fathollahi-Fard, A.M.; Mirzapour Al-e-hashem, S.M.J.; Dulebenets, M.A. Transformation and Linearization Techniques in Optimization: A State-of-the-Art Survey. Mathematics 2022, 10, 283. https://0-doi-org.brum.beds.ac.uk/10.3390/math10020283
Asghari M, Fathollahi-Fard AM, Mirzapour Al-e-hashem SMJ, Dulebenets MA. Transformation and Linearization Techniques in Optimization: A State-of-the-Art Survey. Mathematics. 2022; 10(2):283. https://0-doi-org.brum.beds.ac.uk/10.3390/math10020283
Chicago/Turabian StyleAsghari, Mohammad, Amir M. Fathollahi-Fard, S. M. J. Mirzapour Al-e-hashem, and Maxim A. Dulebenets. 2022. "Transformation and Linearization Techniques in Optimization: A State-of-the-Art Survey" Mathematics 10, no. 2: 283. https://0-doi-org.brum.beds.ac.uk/10.3390/math10020283