
A Three-Stage ACO-Based Algorithm for Parallel Batch Loading and Scheduling Problem with Batch Deterioration and Rate-Modifying Activities


Abstract
:1. Introduction
2. Literature Review
3. Mixed-Integer Programming Model
| Parameters | |
| J | set of jobs |
| F | set of families |
| B | set of batches |
| K | set of buckets |
| M | set of machines |
| Jf | set of jobs not belongings to family |
| Fj | family type of job |
| Fb | family type of batch |
| Sj | size of job |
| Pb | processing time of batch |
| Q | processing time of RMA |
| DR | deterioration rate |
| L | large number |
| SC | size of machine |
| Decision variables | |
| Xjb | Equals 1 if job is assigned in batch |
| Ybkm | Equals 1 if batch is assigned to bucket from machine |
| Zabkm | Equals 1 if batch precedes batch in bucket from machine |
| Dependent variables | |
| MS | Makespan |
| Ck | Completion time of bucket |
| Cm | Completion time of machine |
| Tb | Time gap between starting time of batch and completion time of recent RMA |
4. Multi-Fit Batch Scheduling Algorithm with the RMA Scheduling Rule
| Algorithm 1. Multi-fit algorithm with the RMA scheduling rule for the batch scheduling problem | ||||
| Input: | The set of assigned batches . | |||
| Output: | The makespan. | |||
| Begin: | Sort in non-increasing order of processing times and obtain a batch set Compute and , respectively. Let iteration . While | |||
| Let batch index . | ||||
| While | ||||
Select a batch with a sequence in . Schedule the batch to the machine according to the first-fit rule if the completion time does not exceed . If (Completion time of machine when the batch is scheduled > Completion time of machine when additionally scheduled RMA precedes the batch) then | ||||
| Schedule the RMA to precede the batch. | ||||
| End While If (All batches in are scheduled) then | ||||
| Else | ||||
| End While Output the makespan of the global best solution. | ||||
5. Ant Colony Optimization-Based Three-Stage Algorithm for Batch Scheduling Problem
5.1. Determining the Number of Buckets
| Algorithm 2. The dispatching rule | ||
| Input: | The processing time of batch
The current completion time of buckets | |
| Output: | Selected bucket which must be assigned by batch | |
| Begin: | ||
| While ) | ||
| Calculate the tentative completion time using the RMA rule | ||
| End While | ||
| Select the bucket with the smallest tentative completion time | ||
| Algorithm 3. Calculating the lower bound on the number of batches input to a machine | |||
| Input: | The number of batches; The number of machines. | ||
| Output: | Lower bound on the number of batches input to a machine. | ||
| Begin: | Let batch index
While | ||
| Select a machine using the dispatching rule. | |||
| If then | |||
| Assign a batch assuming the processing time is . | |||
| Else | |||
| Assign a batch assuming the processing time is . | |||
| . | |||
| End While Output the number of batches in machine 1 | |||
| Algorithm 4. Calculating the lower bound on the number of buckets | |||
| Input: | ; the lower bound on the number of batches in a machine; | ||
| Output: | the lower bound on the number of RMAs required by a machine | ||
| Begin: | Let batch index Let RMA index While | ||
| Calculate a tentative deterioration proportional to the gap between the preceding RMA and If then | |||
| Schedule RMA after . . | |||
| Else | |||
| . | |||
| End While Output | |||
5.2. Assigning Batches to Buckets
5.2.1. Pheromone Trails
5.2.2. Heuristic Information
5.2.3. Forming the Buckets
5.2.4. Updating the Pheromone Trails
5.2.5. Rule-Based Batch Sequencing
5.3. Scheduling Buckets to Machines
5.4. Overall Algorithm
| Algorithm 5. ACO-based three-stage algorithm for batch scheduling problem | |||||
| Input: | The set of assigned batches. | ||||
| Output: | The makespan | ||||
| Begin: | Compute the
and
, respectively. Compute the and , respectively. Initialize pheromone trails. Let index of iteration While | ||||
| Let index of iteration
While | |||||
| Select the number of buckets between
and
. While | |||||
| Select bucket using the dispatching rule. If (Bucket has no assigned batches) then | |||||
| Select a batch randomly. Assigned the batch to bucket . | |||||
| Else | |||||
| Select a batch using pheromone trail and heuristic information. Assign the batch to bucket . | |||||
| End While Minimize the completion time of the buckets by sequencing the batches. | |||||
| Dispatch the buckets to machines. Calculate the makespan. Update the iteration and global best solutions a = a +1 | |||||
| End While Compute and . Update and . | |||||
| End While Output the makespan of the global best solution | |||||
6. Genetic Algorithm- and Particle Swarm Optimization-Based Batch Scheduling Algorithms
| Algorithm 6. GA-based three-stage algorithm for batch scheduling problem | ||||
| Input: | The set of assigned batches from the batch loading problem | |||
| Output: | The makespan | |||
| Begin: | Compute the
and
respectively. Set the initial decoded solution. Let index of generation While | |||
| Let index of chromosome
While | ||||
| Select the number of buckets between and . Let random value Let random value Select two parent chromosomes, c, and c + 1, in sequence. | ||||
| If < Crossover rate) then | ||||
| Do one-point crossover operations. | ||||
| If < Mutation rate) then | ||||
| Do swap mutation operation. | ||||
| Decode the offspring chromosome and calculate the makespan. | ||||
| End While Reproduce the next generation parents from current-generation offspring Update the iteration and global best solutions | ||||
| End While Output the makespan of the global best solution | ||||
| Algorithm 7. PSO-based three-stage algorithm for batch scheduling problem | |||
| Input: | The set of assigned batches from the batch loading problem | ||
| Output: | The makespan | ||
| Begin: | Compute the , respectively. Set the initial solution. Let index of iteration While | ||
| Let index of particle
While | |||
| Select the number of buckets between and Update the factor velocity Update the factor position Decode the particle | |||
| End While Decode the particles. Update the iteration and global best solutions; | |||
| End While Output the makespan of global best solution | |||
7. Computational Experiments
7.1. Problem Parameter Settings
7.2. Algorithm Parameter Settings
7.3. Experimental Results
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Uzsoy, R. Scheduling batch processing machines with incompatible job families. Int. J. Prod. Res. 1995, 33, 2685–2708. [Google Scholar] [CrossRef]
- Jia, Z.; Wang, C.; Leung, J.Y.T. An ACO algorithm for makespan minimization in parallel batch machines with non-identical job sizes and incompatible job families. Appl. Soft Comput. 2016, 38, 395–404. [Google Scholar] [CrossRef]
- Lee, C.Y.; Leon, V.J. Machine scheduling with a rate-modifying activity. Eur. J. Oper. Res. 2001, 128, 119–128. [Google Scholar] [CrossRef]
- Joo, C.M.; Kim, B.S. Genetic algorithms for single machine scheduling with time-dependent deterioration and rate-modifying activities. Expert Syst. Appl. 2013, 40, 3036–3043. [Google Scholar] [CrossRef]
- Dupont, L.; Ghazvini, F.J. Minimizing makespan on a single batch processing machine with non-identical job sizes. J. Eur. Des Systèmes Autom. 1998, 32, 431–440. [Google Scholar]
- Zhou, S.; Chen, H.; Li, X. Distance matrix based heuristics to minimize makespan of parallel batch processing machines with arbitrary job sizes and release times. Appl. Soft Comput. J. 2017, 52, 630–641. [Google Scholar] [CrossRef]
- Dupont, L.; Dhaenens-Flipo, C. Minimizing the makespan on a batch machine with non-identical job sizes: An exact procedure. Comput. Oper. Res. 2002, 29, 807–819. [Google Scholar] [CrossRef]
- Ikura, Y.; Gimple, M. Efficient scheduling algorithms for a single batch processing machine. Oper. Res. Lett. 1986, 5, 61–65. [Google Scholar] [CrossRef]
- Lee, C.Y.; Uzsoy, R.; Martin-Vega, L.A. Efficient algorithms for scheduling semiconductor burn-in operations. Oper. Res. 1992, 40, 764–775. [Google Scholar] [CrossRef]
- Cheng, B.; Wang, Q.; Yang, S.; Hu, X. An improved ant colony optimization for scheduling identical parallel batching machines with arbitrary job sizes. Appl. Soft Comput. J. 2013, 13, 765–772. [Google Scholar] [CrossRef]
- Uzsoy, R. Scheduling a single batch processing machine with non-identical job sizes. Int. J. Prod. Res. 1994, 32, 1615–1635. [Google Scholar] [CrossRef]
- Jia, Z.; Li, X.; Leung, J.Y.T. Minimizing makespan for arbitrary size jobs with release times on P-batch machines with arbitrary capacities. Future Gener. Comput. Syst. 2017, 67, 22–34. [Google Scholar] [CrossRef]
- Ozturk, O.; Begen, M.A.; Zaric, G.S. A branch and bound algorithm for scheduling unit size jobs on parallel batching machines to minimize makespan. Int. J. Prod. Res. 2017, 55, 1815–1831. [Google Scholar] [CrossRef]
- Jia, Z.; Yan, J.; Leung, J.Y.T.; Li, K.; Chen, H. Ant colony optimization algorithm for scheduling jobs with fuzzy processing time on parallel batch machines with different capacities. Appl. Soft Comput. J. 2019, 75, 548–561. [Google Scholar] [CrossRef]
- Arroyo, J.E.C.; Leung, J.Y.T. Scheduling unrelated parallel batch processing machines with non-identical job sizes and unequal ready times. Comput. Oper. Res. 2017, 78, 117–128. [Google Scholar] [CrossRef]
- Arroyo, J.E.C.; Leung, J.Y.T. An effective iterated greedy algorithm for scheduling unrelated parallel batch machines with non-identical capacities and unequal ready times. Comput. Ind. Eng. 2017, 105, 84–100. [Google Scholar] [CrossRef]
- Arroyo, J.E.C.; Leung, J.Y.T.; Tavares, R.G. An iterated greedy algorithm for total flow time minimization in unrelated parallel batch machines with unequal job release times. Eng. Appl. Artif. Intell. 2019, 77, 239–254. [Google Scholar] [CrossRef]
- Gao, Y.; Yuan, J. Unbounded parallel-batch scheduling under agreeable release and processing to minimize total weighted number of tardy jobs. J. Comb. Optim. 2019, 38, 698–711. [Google Scholar] [CrossRef]
- Zhou, S.; Xie, J.; Du, N.; Pang, Y. A random-keys genetic algorithm for scheduling unrelated parallel batch processing machines with different capacities and arbitrary job sizes. Appl. Math. Comput. 2018, 334, 254–268. [Google Scholar] [CrossRef]
- Li, X.; Zhang, K. Single batch processing machine scheduling with two-dimensional bin packing constraints. Int. J. Prod. Econ. 2018, 196, 113–121. [Google Scholar] [CrossRef]
- Fu, R.; Tian, J.; Li, S.; Yuan, J. An optimal online algorithm for the parallel-batch scheduling with job processing time compatibilities. J. Comb. Optim. 2017, 34, 1187–1197. [Google Scholar] [CrossRef]
- Azizoglu, M.; Webster, S. Scheduling a batch processing machine with incompatible job families. Comput. Ind. Eng. 2001, 39, 325–335. [Google Scholar] [CrossRef]
- Yao, S.; Jiang, Z.; Li, N. A branch and bound algorithm for minimizing total completion time on a single batch machine with incompatible job families and dynamic arrivals. Comput. Oper. Res. 2012, 39, 939–951. [Google Scholar] [CrossRef]
- Jolai, F. Minimizing number of tardy jobs on a batch processing machine with incompatible job families. Eur. J. Oper. Res. 2005, 162, 184–190. [Google Scholar] [CrossRef]
- Balasubramanian, H.; Mönch, L.; Fowler, J.; Pfund, M. Genetic algorithm based scheduling of parallel batch machines with incompatible job families to minimize total weighted tardiness. Int. J. Prod. Res. 2004, 42, 1621–1638. [Google Scholar] [CrossRef]
- Li, X.L.; Li, Y.P.; Huang, Y.L. Heuristics and lower bound for minimizing maximum lateness on a batch processing machine with incompatible job families. Comput. Oper. Res. 2019, 106, 91–101. [Google Scholar] [CrossRef]
- Ham, A.; Fowler, J.W.; Cakici, E. Constraint programming approach for scheduling jobs with release times, non-identical sizes, and incompatible families on parallel batching machines. IEEE Trans. Semicond. Manuf. 2017, 30, 500–507. [Google Scholar] [CrossRef]
- Vimala Rani, M.; Mathirajan, M. Performance evaluation of ATC based greedy heuristic algorithms in scheduling diffusion furnace in wafer fabrication. J. Inf. Optim. Sci. 2016, 37, 717–762. [Google Scholar] [CrossRef]
- Gupta, J.N.D.; Gupta, S.K. Single facility scheduling with nonlinear processing times. Comput. Industiral Eng. 1988, 14, 387–393. [Google Scholar] [CrossRef]
- Ding, J.; Shen, L.; Lü, Z.; Peng, B. Parallel machine scheduling with completion-time-based criteria and sequence-dependent deterioration. Comput. Oper. Res. 2019, 103, 35–45. [Google Scholar] [CrossRef]
- Browne, S.; Yechiali, U. Scheduling deteriorating jobs on a single processor. Oper. Res. 1990, 38, 495–498. [Google Scholar] [CrossRef] [Green Version]
- Soleimani, H.; Ghaderi, H.; Tsai, P.W.; Zarbakhshnia, N.; Maleki, M. Scheduling of unrelated parallel machines considering sequence-related setup time, start time-dependent deterioration, position-dependent learning and power consumption minimization. J. Clean. Prod. 2020, 249, 119428. [Google Scholar] [CrossRef]
- Joo, C.M.; Kim, B.S. Machine scheduling of time-dependent deteriorating jobs with determining the optimal number of rate modifying activities and the position of the activities. J. Adv. Mech. Des. Syst. Manuf. 2015, 9, JAMDSM0007. [Google Scholar] [CrossRef] [Green Version]
- Woo, Y.B.; Jung, S.W.; Kim, B.S. A rule-based genetic algorithm with an improvement heuristic for unrelated parallel machine scheduling problem with time-dependent deterioration and multiple rate-modifying activities. Comput. Ind. Eng. 2017, 109, 179–190. [Google Scholar] [CrossRef]
- Abdullah, M.; Süer, G.A. Consideration of skills in assembly lines and seru production systems. Asian J. Manag. Sci. Appl. 2019, 4, 99–123. [Google Scholar] [CrossRef]
- Gai, Y.; Yin, Y.; Tang, J.; Liu, S. Minimizing makespan of a production batch within concurrent systems: Seru production perspective. J. Manag. Sci. Eng. 2020, in press. [Google Scholar] [CrossRef]
- Liu, F.; Niu, B.; Xing, M.; Wu, L.; Feng, Y. Optimal cross-trained worker assignment for a hybrid seru production system to minimize makespan and workload imbalance. Comput. Ind. Eng. 2021, 160, 107552. [Google Scholar] [CrossRef]






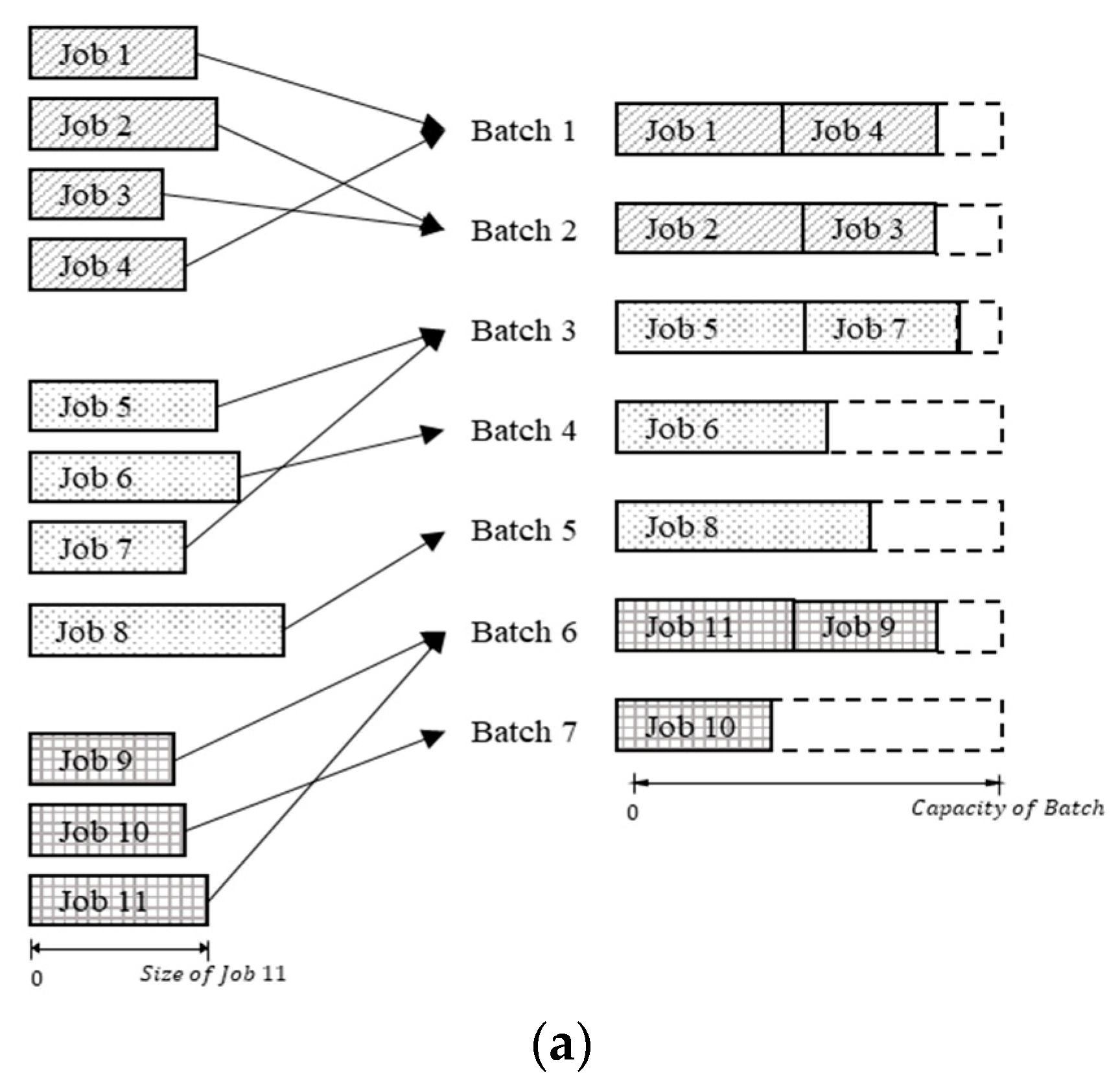{kind=link}
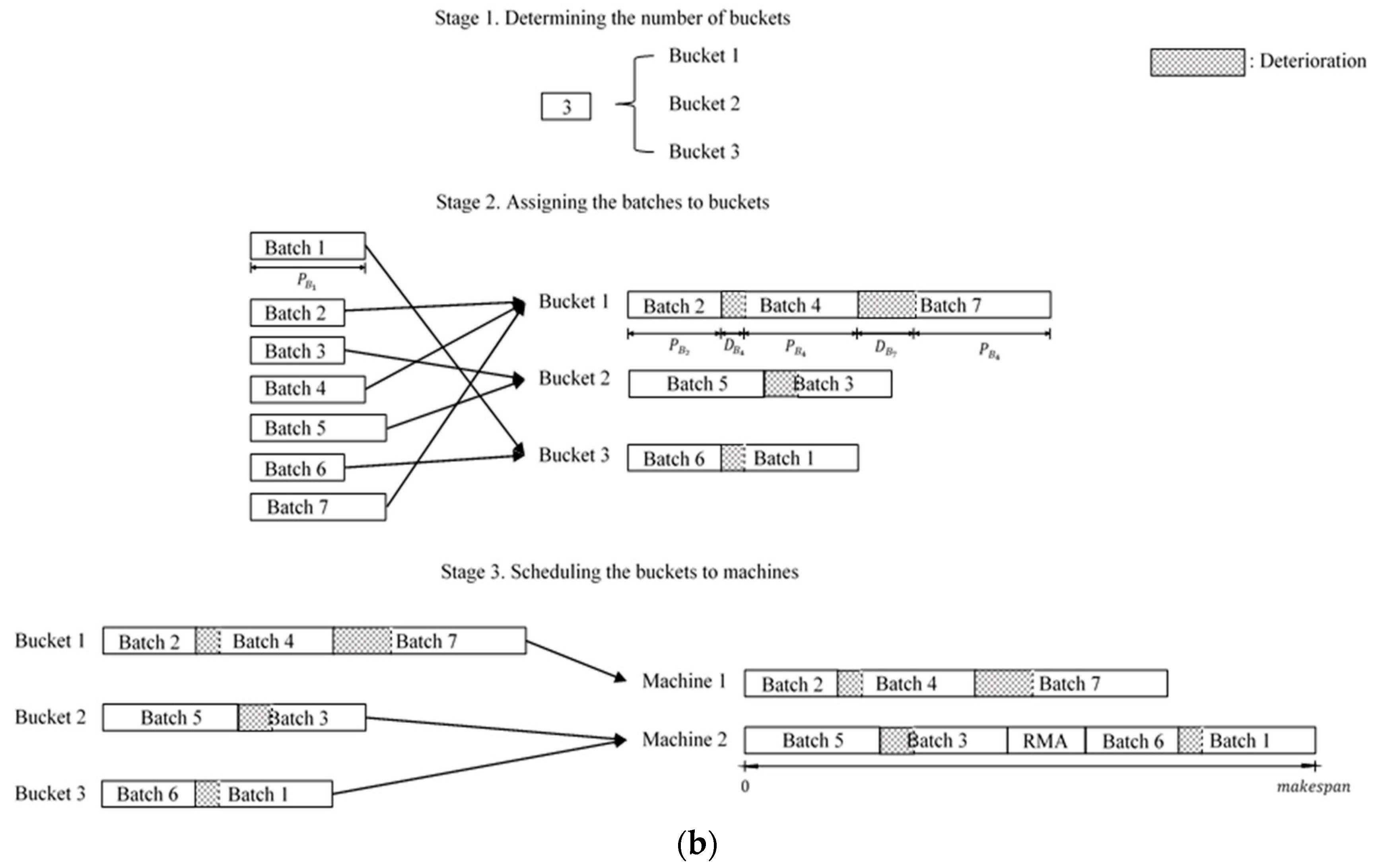{kind=link}
{kind=link}
{kind=link}
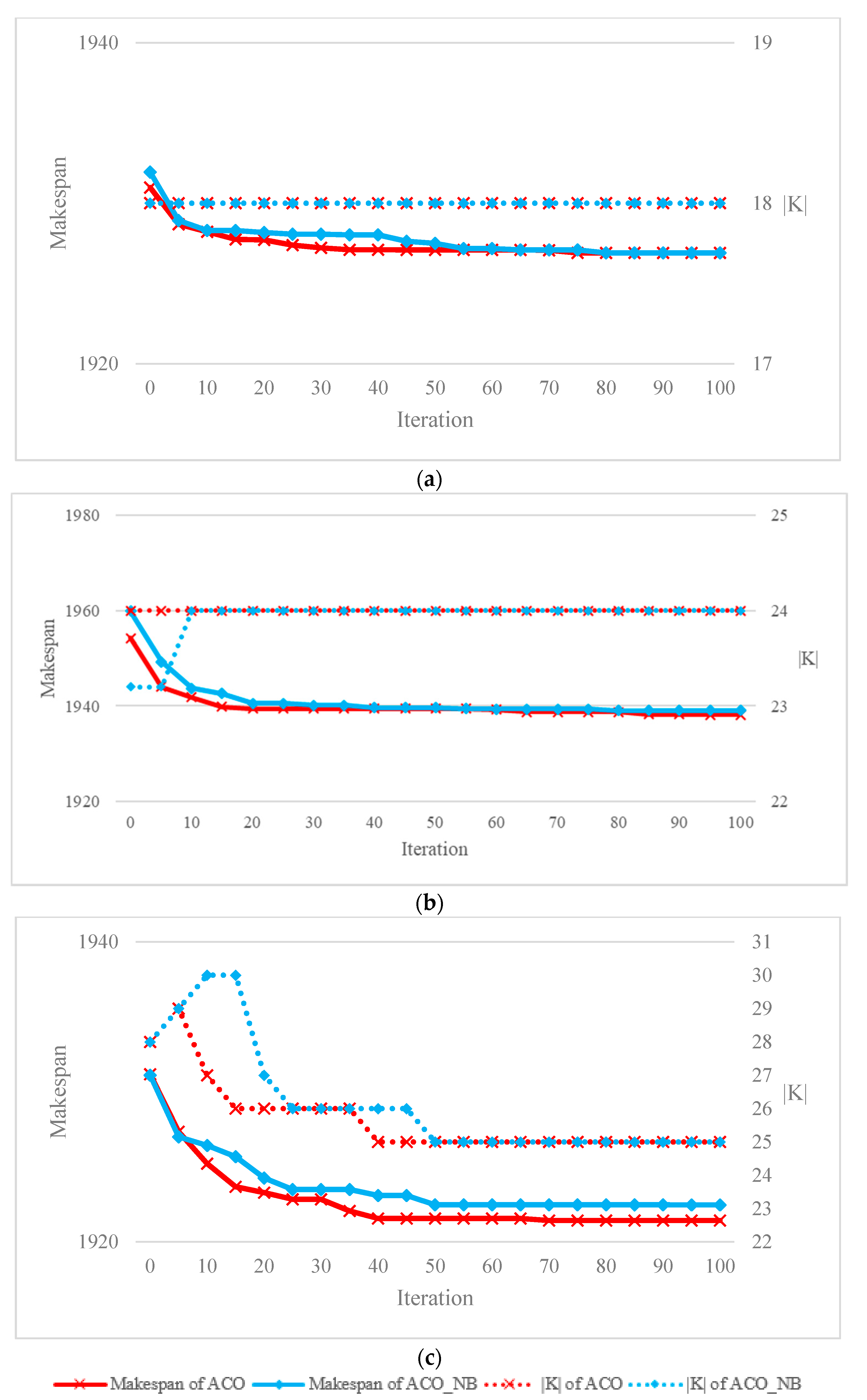{kind=link}
| Mfg. System | Production Methods | Family Constraint | Job sizes | Deterioration Constraint | Recovery Process | Method | Objective | |
|---|---|---|---|---|---|---|---|---|
| Woo et al. [34] | Parallel | Single | No family | N/A | Time-dependent deterioration | RMA | GA | Makespan |
| Ding et al. [30] | Parallel | Single | No family | N/A | Sequence-dependent deterioration | No recovery | ECA | Completion time |
| Soleimani et al. [32] | Parallel | Single | No family | N/A | Time-dependent deterioration | No recovery | GA, CSO, IABC | Mean weighted tardiness |
| Ozturk et al. [13] | Parallel | Batch | No family | Identical | No deterioration | No recovery | B&B | Makespan |
| Jia et al. [14] | Parallel | Batch | No family | Non-identical | No deterioration | No recovery | ACO | Makespan |
| Jia et al. [12] | Parallel | Batch | No family | Non-identical | No deterioration | No recovery | ACO | Makespan |
| Arroyo et al. [17] | Parallel | Batch | No family | Non-identical | No deterioration | No recovery | Iterated greedy | Total flow time |
| Li et al. [26] | Parallel | Batch | Incompatible family | Non-identical | No deterioration | No recovery | LB | Lateness |
| Jia et al. [2] | Parallel | Batch | Incompatible family | Non-identical | No deterioration | No recovery | ACO | Makespan |
| This paper | Parallel | Batch | Incompatible family | Non-identical | Time-dependent deterioration | RMA | ACO | Makespan |
| Factor 1 | Factor 2 | Factor 3 | Factor 4 | Factor 5 |
|---|---|---|---|---|
| Number of Ants | Evaporation Rate | Iteration Limit | Updating Parameter | Relative Importance of Heuristic Information |
| A | B (1): 0.5 | C (1): 10 | D | E (1): 4 |
| A | B (2): 0.6 | C (2): 30 | D | E (2): 6 |
| A | B (3): 0.7 | C (3): 50 | D | E (3): 8 |
| A | B (4): 0.8 | C (4): 70 | D | E (4): 10 |
| A | B (5): 0.9 | C (5): 90 | D | E (5): 12 |
| Scenario No. | Factor Levels | ||||
|---|---|---|---|---|---|
| A | B | C | D | E | |
| 1 | A (1) | B (1) | C (1) | D (1) | E (1) |
| 2 | A (1) | B (2) | C (2) | D (2) | E (2) |
| 3 | A (1) | B (3) | C (3) | D (3) | E (3) |
| 4 | A (1) | B (4) | C (4) | D (4) | E (4) |
| 5 | A (1) | B (5) | C (5) | D (5) | E (5) |
| 6 | A (2) | B (1) | C (2) | D (3) | E (4) |
| 7 | A (2) | B (2) | C (3) | D (4) | E (5) |
| 8 | A (2) | B (3) | C (4) | D (5) | E (1) |
| 9 | A (2) | B (4) | C (5) | D (1) | E (2) |
| 10 | A (2) | B (5) | C (1) | D (2) | E (3) |
| 11 | A (3) | B (1) | C (3) | D (5) | E (2) |
| 12 | A (3) | B (2) | C (4) | D (1) | E (3) |
| 13 | A (3) | B (3) | C (5) | D (2) | E (4) |
| 14 | A (3) | B (4) | C (1) | D (3) | E (5) |
| 15 | A (3) | B (5) | C (2) | D (4) | E (1) |
| 16 | A (4) | B (1) | C (4) | D (2) | E (5) |
| 17 | A (4) | B (2) | C (5) | D (3) | E (1) |
| 18 | A (4) | B (3) | C (1) | D (4) | E (2) |
| 19 | A (4) | B (4) | C (2) | D (5) | E (3) |
| 20 | A (4) | B (5) | C (3) | D (1) | E (4) |
| 21 | A (5) | B (1) | C (5) | D (4) | E (3) |
| 22 | A (5) | B (2) | C (1) | D (5) | E (4) |
| 23 | A (5) | B (3) | C (2) | D (1) | E (5) |
| 24 | A (5) | B (4) | C (3) | D (2) | E (1) |
| 25 | A (5) | B (5) | C (4) | D (3) | E (2) |
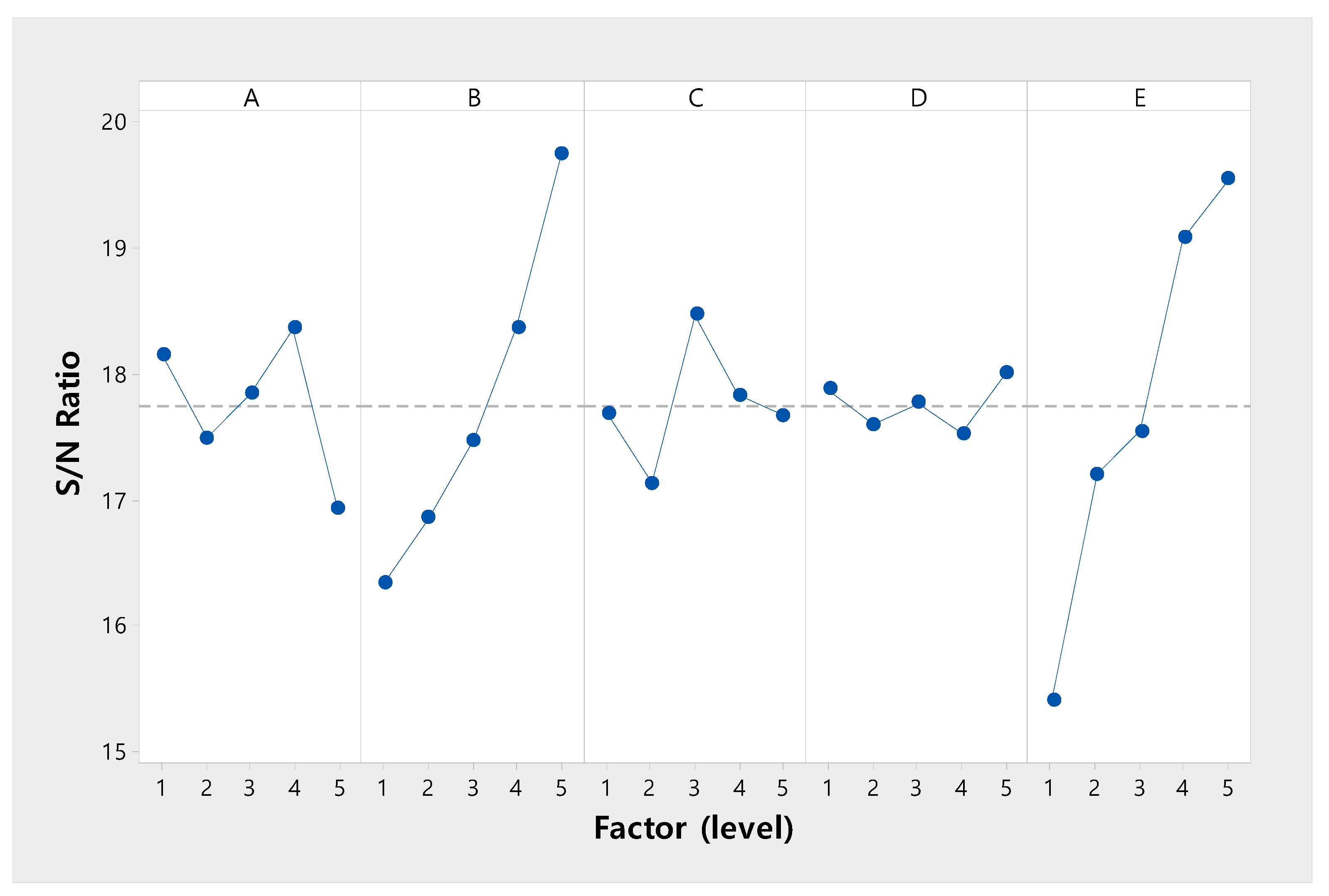
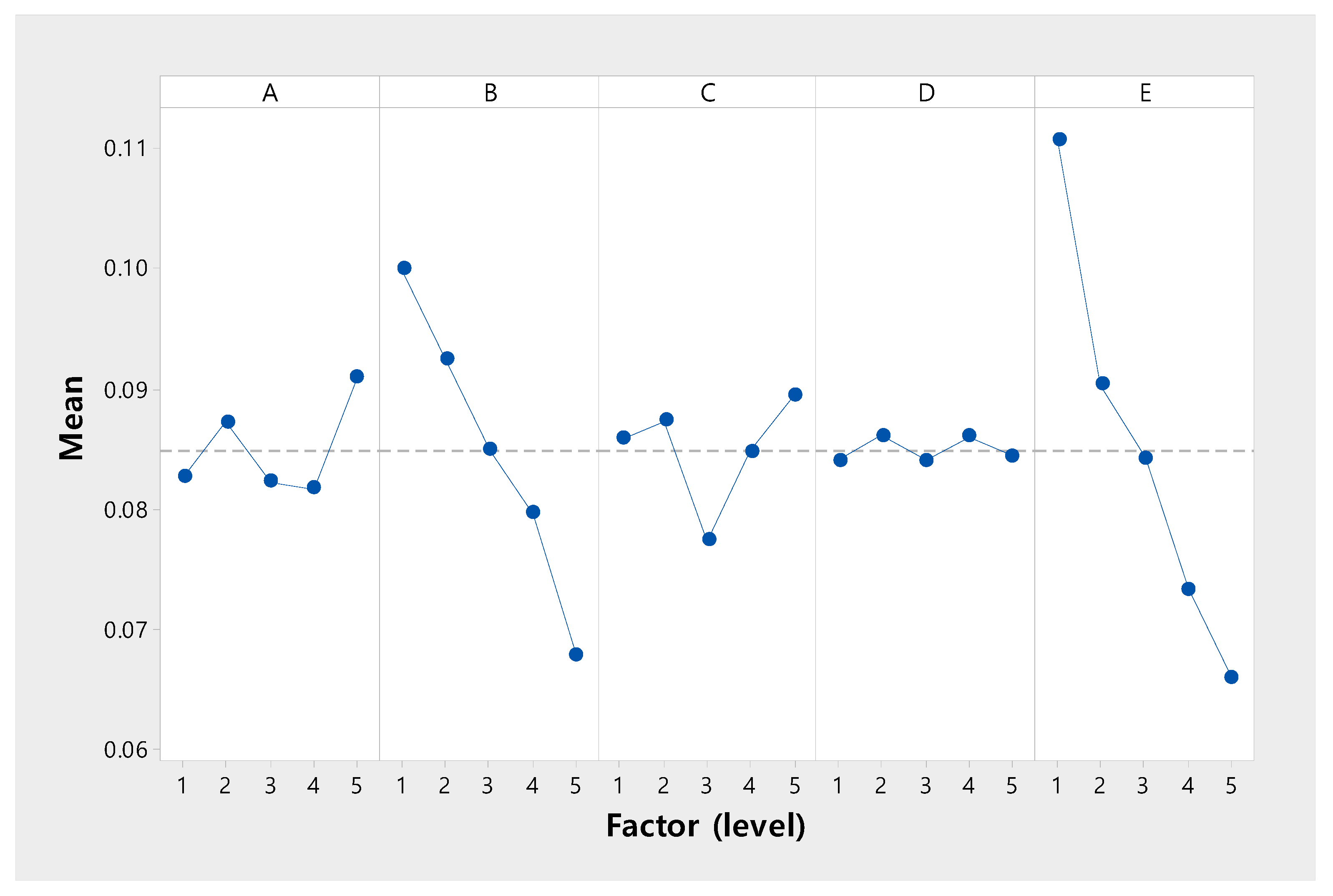
| Factor | SS | df | V | -Value | |
|---|---|---|---|---|---|
| A | 0.2593 | 4 | 0.0648 | 2.6456 | 0.1844 |
| B | 1.4578 | 4 | 0.3644 | 14.8721 | 0.0114 |
| C | 0.1809 | 4 | 0.0452 | 1.8459 | 0.2836 |
| D(Error) | 0.0980 | 0.0245 | |||
| E | 0.2144 | 4 | 0.5360 | 21.8756 | 0.0055 |
| Total | 4.1404 | 20 |
| CPLEX | ACO | ACO_NB | GA | PSO | MF | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Opt. | Time | RPD | Time | RPD | Time | RPD | Time | RPD | Time | RPD | |||
| 1 | 1 | 1 | 65 | 0.02 | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.02 | 0.00 | 0.01 | 0.00 |
| 1 | 1 | 2 | 217.2 | 0.24 | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.02 | 0.00 | 0.01 | 0.73 |
| 1 | 2 | 1 | 149 | 0.14 | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.02 | 0.00 | 0.01 | 0.00 |
| 1 | 2 | 2 | 423 | 5.93 | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.02 | 0.00 | 0.01 | 3.30 |
| 2 | 1 | 1 | 136 | 0.12 | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.03 | 0.00 | 0.01 | 0.73 |
| 2 | 1 | 2 | 246 | 8.85 | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.03 | 0.00 | 0.01 | 9.75 |
| 2 | 2 | 1 | 219 | 9.412 | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.03 | 0.00 | 0.01 | 2.73 |
| 2 | 2 | 2 | N/A | 7200+ | N/A | N/A | N/A | N/A | N/A | ||||
| Avg. | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.02 | 0.00 | 0.01 | 2.16 | ||||
| Best | ACO | ACO_NB | GA | PSO | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPD | Time | RPD | Time | RPD | Time | RPD | Time | |||||
| 4 | 3 | 3 | 3 | 964.68 | 0.08 | 0.50 | 0.08 | 0.48 | 0.59 | 0.22 | 2.16 | 0.15 |
| 4 | 3 | 3 | 4 | 1458.448 | 0.00 | 1.09 | 0.00 | 1.10 | 0.96 | 0.42 | 1.10 | 0.28 |
| 4 | 3 | 4 | 3 | 1402.04 | 0.29 | 1.19 | 0.29 | 1.17 | 0.07 | 0.55 | 1.55 | 0.39 |
| 4 | 3 | 4 | 4 | 1776.96 | 1.36 | 2.62 | 1.39 | 3.37 | 0.15 | 1.03 | 1.89 | 0.56 |
| 4 | 4 | 3 | 3 | 859.28 | 0.00 | 0.65 | 0.00 | 0.69 | 0.43 | 0.38 | 0.47 | 0.27 |
| 4 | 4 | 3 | 4 | 1498.52 | 0.22 | 3.49 | 0.30 | 3.23 | 0.48 | 1.21 | 2.73 | 0.60 |
| 4 | 4 | 4 | 3 | 1218.04 | 0.00 | 1.40 | 0.00 | 1.48 | 1.54 | 0.53 | 1.28 | 0.54 |
| 4 | 4 | 4 | 4 | 1806.64 | 0.51 | 7.96 | 0.53 | 6.81 | 0.14 | 2.34 | 1.80 | 1.28 |
| 4 | 5 | 3 | 3 | 953.6 | 0.00 | 1.00 | 0.00 | 1.14 | 0.39 | 0.72 | 0.39 | 0.46 |
| 4 | 5 | 3 | 4 | 1383.896 | 0.00 | 3.50 | 0.00 | 3.19 | 1.08 | 1.01 | 1.07 | 0.92 |
| 4 | 5 | 4 | 3 | 1324.6 | 0.64 | 3.72 | 0.67 | 3.74 | 0.10 | 1.97 | 1.96 | 0.94 |
| 4 | 5 | 4 | 4 | 1924.68 | 0.00 | 7.12 | 0.00 | 6.75 | 0.73 | 2.62 | 0.82 | 1.76 |
| 5 | 3 | 3 | 3 | 944 | 0.00 | 0.28 | 0.00 | 0.31 | 0.79 | 0.22 | 0.91 | 0.14 |
| 5 | 3 | 3 | 4 | 1347.904 | 0.08 | 1.28 | 0.09 | 1.30 | 0.32 | 0.53 | 2.29 | 0.25 |
| 5 | 3 | 4 | 3 | 1168.44 | 0.12 | 1.12 | 0.14 | 1.08 | 0.27 | 0.54 | 1.58 | 0.29 |
| 5 | 3 | 4 | 4 | 1922.64 | 0.00 | 3.32 | 0.01 | 2.91 | 0.86 | 1.17 | 1.03 | 0.58 |
| 5 | 4 | 3 | 3 | 966 | 0.00 | 0.64 | 0.00 | 0.78 | 0.56 | 0.43 | 0.59 | 0.27 |
| 5 | 4 | 3 | 4 | 1583.16 | 0.61 | 3.52 | 0.60 | 3.26 | 0.27 | 1.31 | 1.27 | 0.53 |
| 5 | 4 | 4 | 3 | 1206.48 | 0.00 | 1.86 | 0.00 | 1.94 | 1.42 | 0.56 | 1.13 | 0.55 |
| 5 | 4 | 4 | 4 | 1733.96 | 0.00 | 5.08 | 0.00 | 4.52 | 1.54 | 1.68 | 1.67 | 1.03 |
| 5 | 5 | 3 | 3 | 977.6 | 0.73 | 1.80 | 0.78 | 2.18 | 0.22 | 0.89 | 3.51 | 0.52 |
| 5 | 5 | 3 | 4 | 1360.248 | 0.06 | 5.22 | 0.10 | 5.39 | 1.05 | 2.51 | 2.31 | 0.97 |
| 5 | 5 | 4 | 3 | 1152 | 0.00 | 2.76 | 0.00 | 2.98 | 1.06 | 0.89 | 0.73 | 0.90 |
| 5 | 5 | 4 | 4 | 1827.6 | 0.11 | 15.07 | 0.16 | 14.06 | 0.10 | 4.65 | 1.64 | 2.09 |
| 6 | 3 | 3 | 3 | 990.92 | 0.72 | 0.55 | 0.73 | 0.57 | 0.36 | 0.31 | 2.20 | 0.16 |
| 6 | 3 | 3 | 4 | 1449.64 | 0.06 | 1.47 | 0.07 | 1.52 | 0.31 | 0.66 | 0.92 | 0.27 |
| 6 | 3 | 4 | 3 | 1300.6 | 0.00 | 0.62 | 0.00 | 0.71 | 0.45 | 0.39 | 0.52 | 0.28 |
| 6 | 3 | 4 | 4 | 1932.56 | 0.02 | 3.25 | 0.02 | 2.99 | 0.80 | 1.43 | 0.95 | 0.53 |
| 6 | 4 | 3 | 3 | 915.04 | 0.08 | 1.14 | 0.11 | 0.95 | 0.25 | 0.54 | 1.72 | 0.26 |
| 6 | 4 | 3 | 4 | 1382.528 | 0.26 | 3.27 | 0.27 | 3.73 | 1.48 | 1.35 | 2.98 | 0.52 |
| 6 | 4 | 4 | 3 | 1286.6 | 0.00 | 1.52 | 0.00 | 1.67 | 0.35 | 0.93 | 0.41 | 0.66 |
| 6 | 4 | 4 | 4 | 1959.84 | 0.06 | 8.84 | 0.08 | 7.50 | 1.33 | 3.27 | 2.65 | 1.33 |
| 6 | 5 | 3 | 3 | 962.8 | 0.00 | 1.35 | 0.01 | 1.66 | 0.64 | 0.73 | 0.67 | 0.47 |
| 6 | 5 | 3 | 4 | 1437.832 | 0.32 | 5.16 | 0.38 | 5.81 | 1.74 | 1.83 | 2.33 | 0.90 |
| 6 | 5 | 4 | 3 | 1306.64 | 0.06 | 4.24 | 0.06 | 4.35 | 0.21 | 1.90 | 1.19 | 1.02 |
| 6 | 5 | 4 | 4 | 1919.76 | 0.08 | 13.48 | 0.09 | 12.55 | 0.40 | 4.64 | 1.88 | 1.91 |
| Avg. | 0.18 | 3.36 | 0.19 | 3.27 | 0.65 | 1.29 | 1.51 | 0.68 | ||||
| . | Mean | St. Dev. | St. e. Mean | Lower | -Value | -Value | |
|---|---|---|---|---|---|---|---|
| Paired -test for ACO_NB-ACO | 0.16 | 3.75 | 0.001 | ||||
| ACO_NB | 36 | 1386.2 | 337.0 | 56.2 | |||
| ACO | 36 | 1385.8 | 336.8 | 56.1 | |||
| Difference | 36 | 0.35 | 0.56 | 0.09 |
| ACO | GA | PSO | |
|---|---|---|---|
| 4 | 0.35 | 0.51 | 1.36 |
| 5 | 0.40 | 0.42 | 1.66 |
| 6 | 0.23 | 0.51 | 1.63 |
| Average | 0.33 | 0.48 | 1.55 |
| N | Mean | St. Dev. | St. e. Mean | Lower | t-Value | -Value | |
|---|---|---|---|---|---|---|---|
| Paired t-test for PSO-ACO | 15.577 | 18.04 | 0.000 | ||||
| PSO | 180 | 1403.6 | 339.0 | 25.3 | |||
| ACO | 180 | 1386.1 | 332.6 | 24.8 | |||
| Difference | 180 | 17.490 | 13.009 | 0.970 | |||
| Paired t-test for GA-ACO | 0.209 | 2.21 | 0.029 | ||||
| GA | 180 | 1388.1 | 332.5 | 24.8 | |||
| ACO | 180 | 1386.1 | 332.6 | 24.8 | |||
| Difference | 180 | 1.987 | 12.090 | 0.901 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jang, J.W.; Kim, Y.J.; Kim, B.S. A Three-Stage ACO-Based Algorithm for Parallel Batch Loading and Scheduling Problem with Batch Deterioration and Rate-Modifying Activities. Mathematics 2022, 10, 657. https://0-doi-org.brum.beds.ac.uk/10.3390/math10040657
Jang JW, Kim YJ, Kim BS. A Three-Stage ACO-Based Algorithm for Parallel Batch Loading and Scheduling Problem with Batch Deterioration and Rate-Modifying Activities. Mathematics. 2022; 10(4):657. https://0-doi-org.brum.beds.ac.uk/10.3390/math10040657
Chicago/Turabian StyleJang, Jae Won, Yong Jae Kim, and Byung Soo Kim. 2022. "A Three-Stage ACO-Based Algorithm for Parallel Batch Loading and Scheduling Problem with Batch Deterioration and Rate-Modifying Activities" Mathematics 10, no. 4: 657. https://0-doi-org.brum.beds.ac.uk/10.3390/math10040657