
Inflated Unit-Birnbaum-Saunders Distribution



1
Departamento de Matemáticas y Estadística, Facultad de Ciencias Básicas, Universidad de Córdoba, Montería 230002, Colombia
2
Grupo de Investigación Davinci, Facultad de Ciencias Exactas y Aplicadas, Instituto Tecnológico Metropolitano, Medellín 050034, Colombia
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Mathematics 2022, 10(4), 667; https://0-doi-org.brum.beds.ac.uk/10.3390/math10040667
Submission received: 27 January 2022
/
Revised: 16 February 2022
/
Accepted: 17 February 2022
/
Published: 21 February 2022
(This article belongs to the Section Probability and Statistics)
Abstract
:The modeling different data behaviour like the human development index as a function of life expectancy, the water capacity of a reservoir with respect to a certain threshold, or the percentage of death rate of an infant before his or her first birthday, are situations which a researcher can face. It is noteworthy that these problems may have in common data with excessive zeros and ones. Then, it is essential to have flexible and accuracy models to fit data with these features. Given the relevance of data modeling with excessive zeros and ones, in this paper, a mixture of discrete and continuous distributions is proposed for modeling data with these behaviors. Additionally, the Unit-Birnbaum-Saunders distribution is considered with the aim to explain the continuous component of the model and the features of a Bernoulli process. The estimation of the parameters is based on the maximum likelihood method. Observed and expected information matrices are derived, illustrating interesting aspects of the likelihood approach. Finally, with practical applications by using real data we can show the advantage of using our proposal concerning the inflated beta model.
Keywords:
Unit-Birnbaum-Saunders distribution; inflated distribution; censoring; maximum likelihood estimationMSC:
60E051. Introduction
One of the most used distributions to fit fatigue and life data is the Birnbaum-Saunders (BS) distribution, which was introduced in [1]. The BS distribution has a probability density function (PDF) given by
where is the PDF of the normal distribution, is a shape parameter and is a scale parameter. If T is a random variable with BS distribution, then it is denoted as .
The BS distribution has been applied in many areas such as biology, medicine, forestry, environment, among others, and it has been extended to a large number of families of distributions. Díaz-García and Leiva-Sánchez [2] for example, introduced the extension of the BS model in the case of the elliptically symmetric distributions, while the elliptically asymmetric case was studied by Vilca-Labra and Leiva-Sánchez [3]. Another extension was considered by Martínez-Flórez et al. [4], which proposed the exponentiated (commonly known as alpha-power model) BS family of distributions. On the other hand, Moreno-Arenas et al. [5] studied the hazard proportional BS model, and Lemonte [6] proposed the multivariate Birnbaum-Saunders model.
Recently, [7] presented a type of BS distribution, which is useful to fit data with support on the interval , becoming a new alternative to the beta and Kumaraswamy [8] distributions. This new model (named unit-Birnbaum-Saunders (UBS) model) is obtained by applying the transformation , where . Note that, this type of transformation has been used by other authors such as Mazucheli et al. [9], Mazucheli et al. [10] and Menezes et al. [11] among others. It follows that with the Jacobian of the transformation obtained by calculating the first derivative of T with respect to X, which is given by . Then, by the random variable transformation theorem, see Cassella and Berguer [12] (p. 51), it follows that the PDF of the UBS model is given by
where is a shape parameter and is a scale parameter. The model is denoted as .
Statistical models to explain variables on the unit interval, such as proportions, rates or indexes have been studied by different authors, see [13,14,15,16,17,18,19,20]. Extensions of these models to situations where response variables are on the intervals , or have been considered by [21,22,23,24]. Real data applications include the proportion of deaths caused by smoking, problems related to the estimation of the gross domestic product (GDP) and so on. Note that this area has been studied by [9,10,11].
This paper aims to propose an alternative approach for modeling response variables with zero and/or one inflation. A Bernoulli model that links excessive zeros and/or ones with a group of covariates that may influence the probability of their occurrence is considered. One of the main contributions of our proposed model is that it is useful for the analysis of material fatigue data on the interval with excess of zeros and/or ones. In the literature, there are other models for fitting data on ([22,23,24]), however, these models are not explicitly applied to fitting material fatigue data. We emphasize that the Birnbaum-Saunders distribution is widely used in the analysis of this type of data.
The rest of the paper is organized as follows. In Section 2 the doubly-censored random variable is defined, and the two-part model studied by [25] to analyze this type of variables is presented. Section 3 extends the UBS model to censored data, and the excessive zeros and/or ones are considered by using a mixture of Bernoulli and a doubly-censored UBS model. The parameters estimation is made by using the maximum likelihood approach. The non-singular observed and expected (Fisher) information matrices are derived. Finally, Section 4 presents three analysis with real data sets to compare the proposed model with the modified Beta model.
2. Censoring
A variable is said to be censored when one or more of the observed values are unknown beyond an upper or lower bound. In several practical situations, censoring occurs for limitations of the measuring devices or the experimental project. For example, the needle of a scale that does not provide a reading above 200 kg for all objects that weigh more than this limit, or the measure of viral load in people with HIV. When the data are censored, the probability distribution is a mixture between a continuous and a discrete distribution, and the two-part model by Cragg [25] is a way to analyze situations where data have a mixture between a discrete and a continuous distribution. The two-part model [25] is given by
where is the probability that determines the relative contribution of the point mass.
The random variable Y is left-censored at the value c, if for a random sample of size n, only the values of Y that are greater than the constant c can be observed; whereas, for values of Y less than or equal to constant c, only the value c is observed. Therefore, the values of the random variable Y can be written as follows:
where c is said to be the censoring point, and the random variable Y has PDF given by
For the case it has the Tobit model.
A model is said to be inflated (excess of zeros and/or ones) if the probability mass for some of its points exceeds that allowed by the proposed model. In this case, it is usual to assume that the data distribution is a mixture between a standard distribution and a degenerate distribution concentrated in a point. Some cases that are studied in the statistical literature are the zero-inflated binomial (ZIB) model, zero-inflated Poisson (ZIP) model, and zero-inflated negative binomial (ZINB) model. For more illustration, see [23].
Definition 1.
A random variable Y is said to be a doubly-censored random variable if Y is left-censored and right-censored. For a random sample following certain distribution, it is defined
An extension of the model (3) for the doubly-censored case is given by
where if and zero otherwise, if and zero otherwise. It has that is the proportion of observations below constant (the lower detection limit) and the proportion of observations above constant (the upper detection limit).
If , it follows from Definition 1 that the PDF of a doubly-censored random variable Y with normal distribution (DCN), which is an extension of the Tobit model, is given by
3. The Bernoulli/Doubly Censored Birnbaum—Saunders Mixture Model
In this section, a new doubly-censored model based on unit-Birnbaum-Saunders distribution is introduced.
3.1. Mixture Model
As an alternative to the doubly-censored on interval models, the doubly-censored Tobit model, inflated beta distribution and doubly-censored power-normal model; a new model based on a mixture between a Bernoulli random variable and the asymmetric model is introduced. It is considered that the continuous part ranging in is modeled by a random variable following a distribution, while the point mass at zero can be modeled by a Bernoulli random variable with parameter , namely .
Definition 2.
A random variable X that assumes values on the closed interval is said to have a zero-and-one-inflated Bernoulli unit-Birnbaum-Saunders distribution (BUBSZOI) with parameters and p, if X has PDF given by
with and , where is the UBS distribution (2). We write . We can see that, if , then and .
Let , then the cumulative distribution function (CDF) of X is given by
where . After some algebraic manipulation, the k-th moment of can be obtained by using
for , it follows that
and
so
where is the variance of a random variable following a distribution.
3.1.1. Maximum Likelihood Estimation
Let a random sample of a BUBSZOI distribution. Defining as the sums corresponding to , and where is the indicator function for the set A, then, it follows that the log-likelihood function for the parameter vector given the sample can be written as
The elements of the score function, defined as the first partial derivative of the log-likelihood function concerning the parameters, are given by
The maximum likelihood estimator (MLE) for , can be obtained by solving the system of equations that results by equating previous derivatives to zero. Hence, we obtain the solutions and for the proportions of zeros and ones, respectively. It can be shown that the estimator is unbiased for p. The system of equations obtained for does not have an analytical solution and it must be solved by numerical methods like Newton-Raphson or quasi-Newton. The estimator is obtained as function of by
where and while is the solution of the equation
where
3.1.2. Observed Information Matrix
The elements of the observed information matrix are obtained multiplying by minus the second partial derivative of the log-likelihood function concerning each of the parameters, i.e.,
where . Then, it follows that
and
where
The elements of the Fisher information matrix can be obtained by multiplying by the expected values of the elements of the matrix of second derivatives of the log-likelihood function. Following [22] the Fisher information matrix for is given by
where , where is the error function, see [26]. We can note that the superior submatrix of matches with the Fisher information matrix of the UBS distribution. This shows that the parameters vectors and are orthogonal, so that the information matrix is blocked orthogonal and can be written as
where
and
For large samples, the MLE of follows a distribution asymptotically normal, i.e.,
resulting that the asymptotic variance , of the MLE is times the inverse of and given by
The approximation can be used to construct the confidence intervals for which are given by the formula
where is the r-th diagonal element of the matrix and is the quantile of the standard normal distribution.
3.2. Mixture Under Reparameterization
A representation of the Bernoulli/UBS mixture model in the form of the doubly-censored model given in (4), that is, it could be written based on the probabilities of the limit points and , call them and respectively, can be obtained under the reparameterization used by [23] by letting and , where and with , which leads to the PDF given by
which is denoted by . If , then the CDF of X is given by
where .
Given a random sample of size n of a , the log-likelihood function to estimate the parameter vector can be written as
Then, the score equations follow by equating to zero the score functions, and leading to the following equations
which can be solved numerically by using Newton-Raphson. From equations and it is obtained the estimator of the proportion of zeros in the sample and , the proportions of ones in the sample. In this new model, the Fisher information matrix can be written as where the elements of are given by and with as were computed for the model .
For this new parameterization, the parameters of the censored and non-censored parts of the model are orthogonal, so the corresponding MLEs are asymptotically orthogonal and the parameters can be estimated separately.
For n large,
meaning that is consistent and asymptotically normally distributed with sample variance
3.3. Censored Models for Zero or One Inflation
Particular cases of the previous zero-and-one-inflated model, are the situation of zero-inflated and one-inflated. In the case of the zero-inflated, the density function is given by:
where . This model is denoted . The log-likelihood function of can be written as:
The MLEs of the parameters and are obtained numerically from the equations and , as in the general case of the model . For the case of the parameter , the estimate is obtained from the equation and it is given by , which is the estimated proportion of zeros in the sample.
The variance of the MLE vector takes the form
In the case of the one-inflated, the likelihood function is given by:
where . This is denoted by . The log-likelihood function of can be written as
As in the case of the zero-inflated, the MLEs of the parameters and are obtained numerically from the equations and while is estimated from equation , thus, it is obtained the estimator , which is the proportion of ones in the sample.
The variance of the MLE of the parameter vector , is
3.4. Testing Nested Models
Let consider and with corresponding density functions and , respectively, the likelihood ratio statistic to compare models is given by
This likelihood ratio statistic does not have a chi-square distribution. To overcome this problem, Vuong [27] proposed an alternative approach based on the Kullback-Liebler information criterion, [28]. The statistic is given by
where
is an estimator for the variance of .
Hence, it was shown that, as ,
under
then, the models are equivalent. At the 5% level, being the critical value, the model is rejected if , that is, .
4. Real Data Illustrations
In this section, the usefulness of the proposed models is presented. The BUBSZOI and BUBSZI distributions are fitted to real data sets.
4.1. Illustration 1 of the BUBSZOI Model
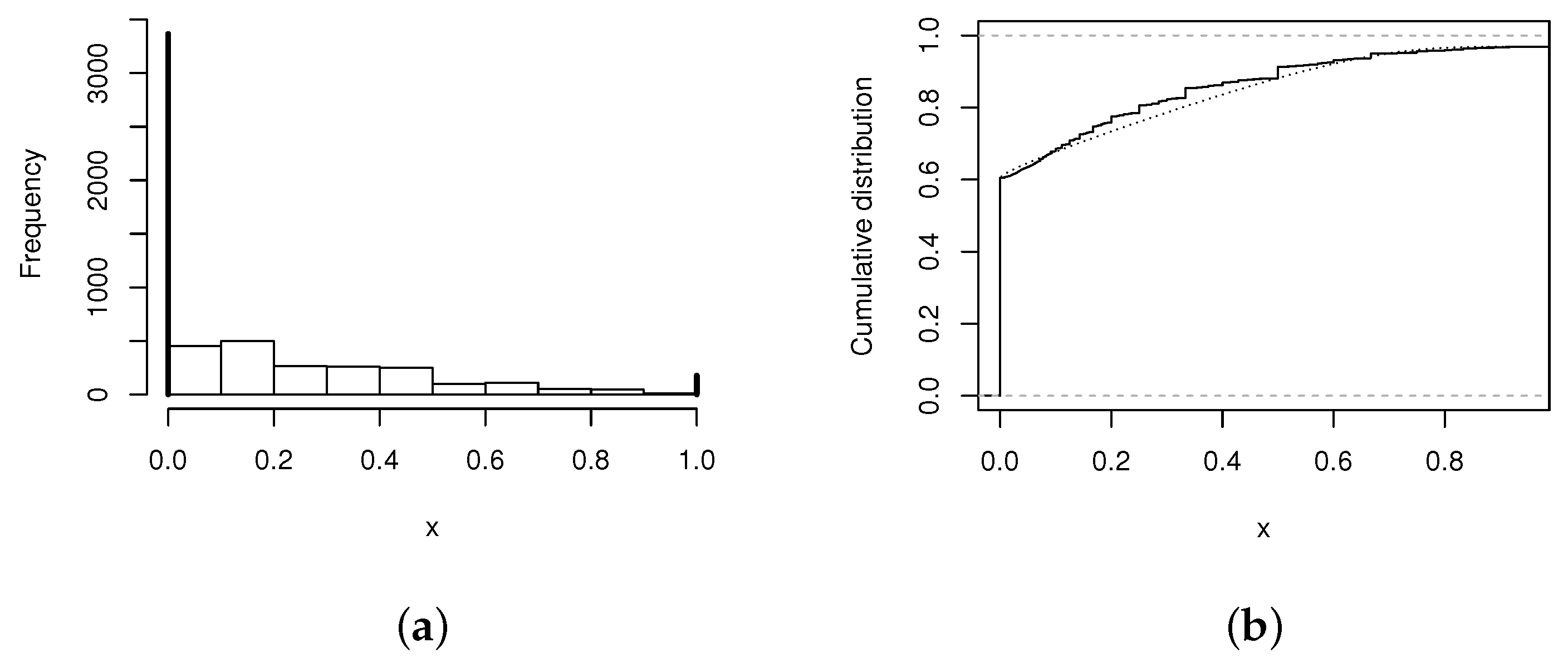
For this illustration, we use the data set available at http:www.datasus.gov.br, (accesed date: 27 November 2021). This data set corresponds to the proportions of infant deaths in 5561 Brazilian counties. The histogram, that show the behavior of the data, is given in the following Figure 1 (on left).
Table 1 shows some descriptive statistics of the data set. For this data set, the inflated beta (BEINF) distribution was fitted, Ref. [23]. In addition, the MBLPN model proposed by [22] is fitted, where is assumed a mixture of a Bernoulli random variable for the discrete part, and a log-power-normal model for the continuous part (between zero and one). This is denoted by . The BUBSZOI model is also fitted. The MLEs (with standard errors in parentheses) of the fitted parameter models are given in Table 2. Figure 1b is the CDF for the BUBSZOI model, showing that the model presents a good fit for the studied data set.
To compare BUBSZOI model against the MBLPN model of [22] and the BEINF model, a test of non-nested models is used. Let the BUBSZOI model and the MBLPN model, the Vuong’s approach leads to the observed value which is not greater than the critical value and hence, the MBLPN distribution is not better than the BUBSZOI model. Similarly, to compare the BUBSZOI and BEINF models, it has which is greater than the critical value which favors the BUBSZOI model, then the best model to fit the data is the BUBSZOI.
4.2. Illustration of the BUBSZI Model
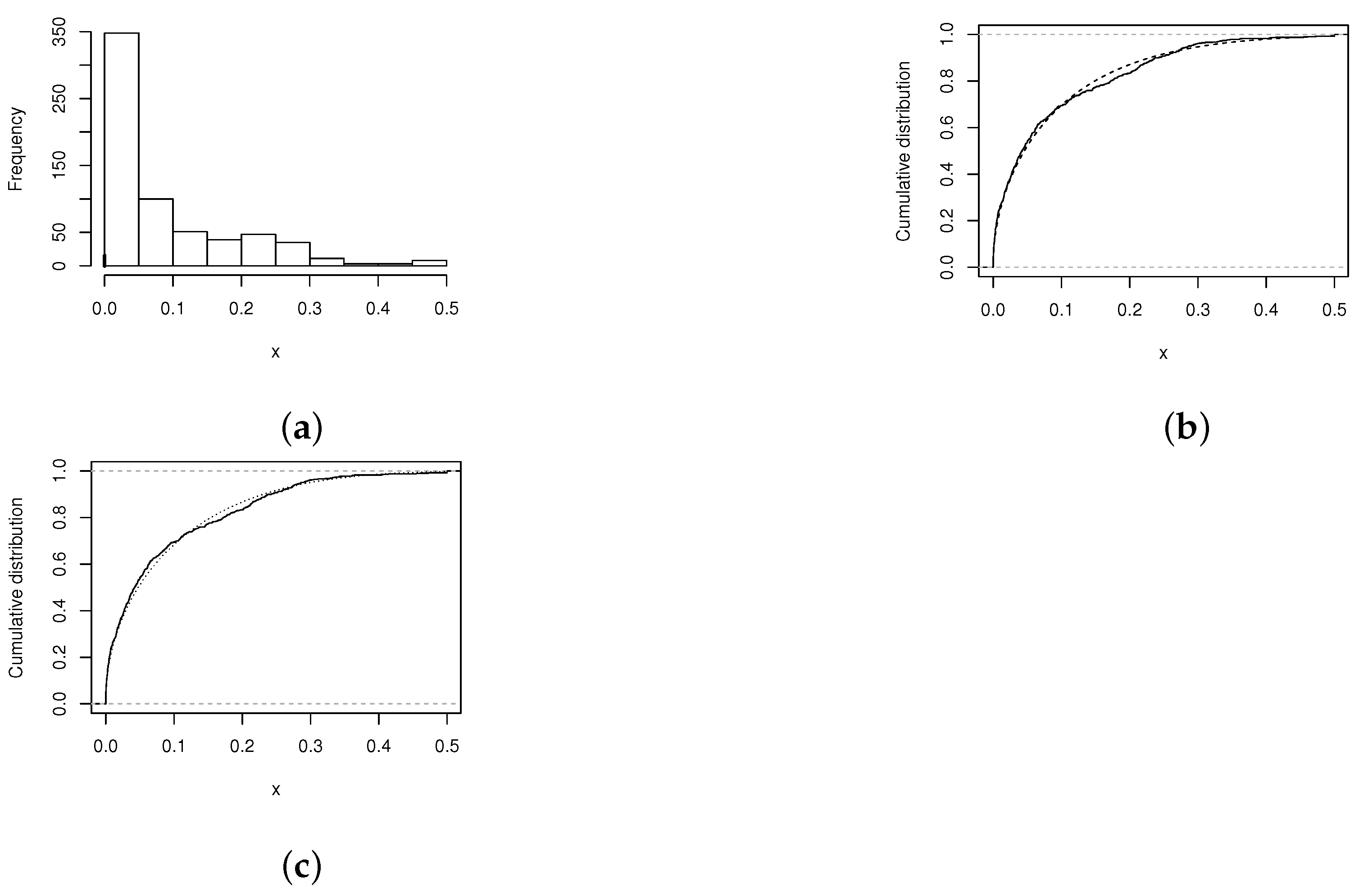
A situation in which our model can be useful, occurs when we want to fit a statistical model to data sets related to percentages of people with some feature of interest (with high or low frequency of occurrence). For example, this second illustration uses the database available and explained in detail at http:www.pnud.org.br (accessed date: 14 September 2021), corresponding to the percentage of people whit certain poverty conditions. Here, the frequency histogram of the data is presented in Figure 2a. Note that their shape is as an inverted J, a feature that can be modeled by the BEZI model, see [23], it is assumed a mixture of a Bernoulli random variable for the discrete part and a beta regression for the continuous (between zero and one), which is denoted by . The total number of zeros in the sample is represented with a vertical bar at zero. Additionally, we consider a left-censored Tobit model and the BUBSZI distribution. The MLEs (with standard errors in parentheses) of the parameters of the proposed models are presented in Table 3.
Figure 2 also shows the CDF for the BEZI and BUBSZI model, illustrating the fact that the models present a good fit for the studied data set.
Now, being the BUBSZI model and the BEZI model, the Vuong’s approach leads to the observed value . This value is greater than the critical point and hence, the BUBSZI distribution is the best model. Similarly, for comparing models BUBSZI and Tobit, we have which favors the BUBSZI model, then the best model to fit the data is the BUBSZI model.
4.3. Illustration 2 of the BUBSZOI Model
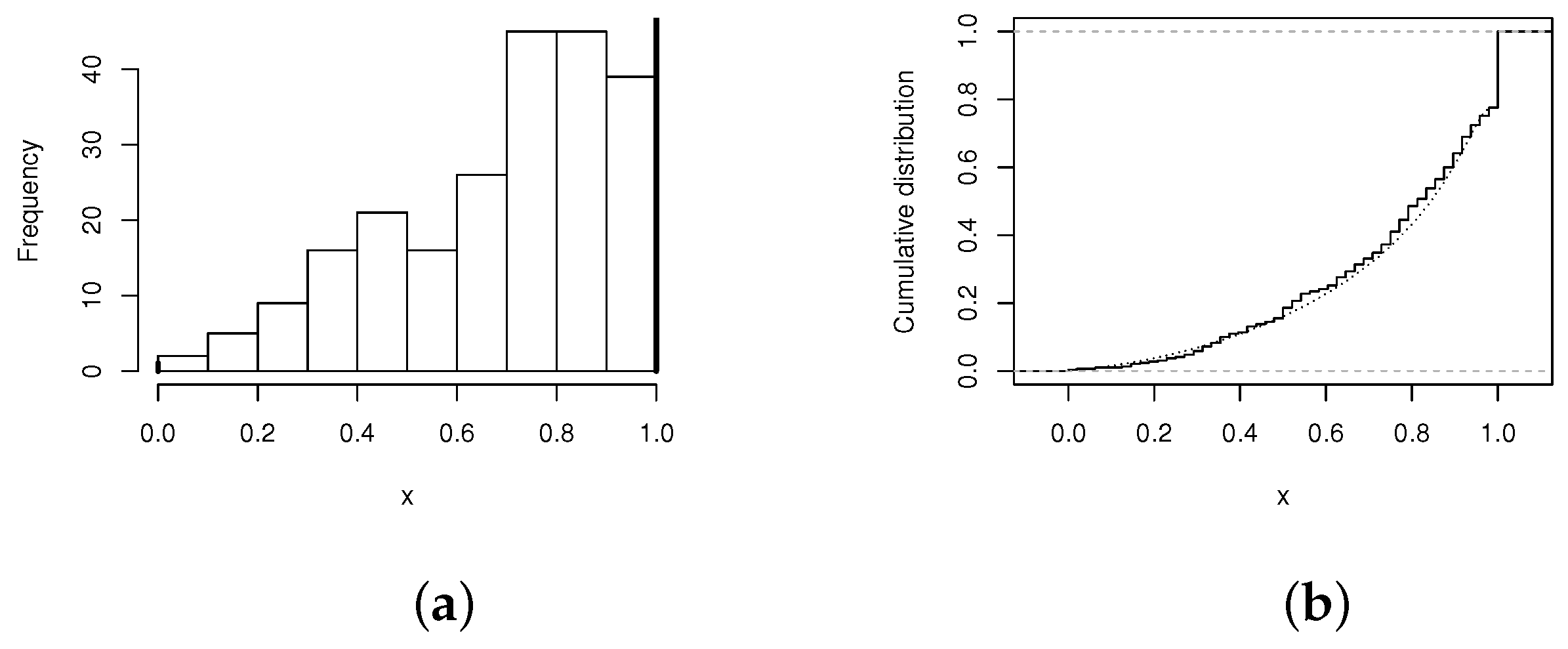
As was mentioned in the introduction, medicine is an important area of application of our model. So, this new illustration is made by using the data set which was studied by [29] and corresponds to a clinical marker of periodontal disease. The histogram of the response (proportion of diseased tooth sites of the incisors tooth), is presented in Figure 3a showing the data behavior. Notice that, the data set presents high inflation of , but for some units, we have .
We fit the beta and BUBSZOI models to the data set. The MLEs of the and of the beta model are given by and , while for the BUBSZOI model, we obtained the MLEs and . The estimates of the and in both models are and .
The value of Vuong’s statistic to compare the models under consideration is given by , which is greater than which favors the BUBSZOI model, so the best model to fit the data is the BUBSZOI model. Figure 3 (on right), presents the CDF of the BUBSZOI model, illustrating the fact that the model presents a good fit for the studied data set.
5. Concluding Remarks
The modeling of data with excessive zeros or ones is a task that is required in areas like economy, medicine, agriculture, and so on. Possible applications in these areas could be related to the modeling of the infant mortality rate, the proportion of deaths caused by smoking, a clinical marker of periodontal disease, the estimation of the gross domestic product, or the mortality in traffic accidents, among others. As shown in previous sections, different alternatives could be found in the literature to model this behavior, as the extensions of the inflated beta model, which were used to compare their performance with our proposal.
This paper discusses an alternative to the beta regression model in the situation of excessive zeros and/or ones. The approach is based on an extension of the Tobit model with excess of zeros considered in [30]. The estimation is based on the likelihood approach and the Fisher information matrix is derived having orthogonality between the parameters, which simplifies large sample properties of the maximum likelihood estimators. Three illustrations with real data show that the proposed models can be even better than the extensions of the inflated beta model considered in [23].
Author Contributions
Conceptualization, G.M.-F., R.T.-F. and C.B.-C.; data curation, R.T.-F. and C.B.-C.; formal analysis, G.M.-F. and R.T.-F.; funding acquisition, C.B.-C.; investigation, G.M.-F. and R.T.-F.; methodology, G.M.-F.; project administration, G.M.-F. and C.B.-C.; resources, G.M.-F., R.T.-F. and C.B.-C.; supervision, G.M.-F., R.T.-F. and C.B.-C.; visualization, C.B.-C.; writing—original draft, C.B.-C.; writing—review and editing, C.B.-C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Instituto Tecnológico Metropolitano (ITM) through the project (P21112) Fortalecimiento y consolidación del grupo didáctica y modelamiento en ciencias exactas y aplicadas DAVINCI para responder a las necesidades de las industrias 4.0.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Details about data available are given in Section 4.
Acknowledgments
G.M.-F. and R.T.-F. acknowledges the support given by Universidad de Córdoba, Montería, Colombia. C.B.-C. extends their sincere gratitude to the Instituto Tecnológico Metropolitano (ITM).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Birnbaum, Z.W.; Saunders, S.C. A new family of life distributions. J. Appl. Probab. 1969, 6, 319–327. [Google Scholar] [CrossRef]
- Díaz-García, J.A.; Leiva-Sánchez, V. A new family of life distributions based on the elliptically contoured distributions. J. Stat. Plan. Inference 2005, 128, 445–457. [Google Scholar] [CrossRef]
- Vilca-Labra, F.; Leiva-Sánchez, V. A new fatigue life model based on the family of skew-elliptical distributions. Commun. Stat. Theory Methods 2006, 35, 229–244. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, H.W. An alpha-power extension for the Birnbaum-Saunders distribution. Statistics 2014, 48, 896–912. [Google Scholar] [CrossRef]
- Moreno-Arenas, G.; Martínez-Flórez, G.; Barrera-Causil, C. Proportional hazard Birnbaum-Saunders distribution with application to the survival data analysis. Rev. Colomb. Estadística 2016, 39, 129–147. [Google Scholar] [CrossRef]
- Lemonte, A.J. Multivariate Birnbaum-Saunders regression model. J. Stat. Comput. Simul. 2013, 46, 2244–2257. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Dey, S. The unit-Birnbaum-Saunders distribution with applications. Chil. J. Stat. 2018, 9, 47–57. [Google Scholar]
- Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Dey, S. Improved maximum-likelihood estimators for the parameters of the unit-gamma distribution. Commun. Stat. Theory Methods 2018, 47, 3767–3778. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Ghitany, M.E. The unit-Weibull distribution and associated inference. J. Appl. Probab. Stat. 2018, 13, 1–22. [Google Scholar]
- Menezes, A.F.B.; Mazucheli, J.; Dey, S. The unit-logistic distribution: Different methods of estimation. Pesqui. Oper. 2018, 38, 555–578. [Google Scholar] [CrossRef]
- Cassella, G.; Berger, R.L. Statistical Inference; Duxbury: Belmont, CA, USA, 2002. [Google Scholar]
- Bayes, C.L.; Bazan, J.L.; García, C. A new robust regression model for proportions. Bayesian Anal. 2012, 7, 841–866. [Google Scholar] [CrossRef]
- Branscum, A.J.; Johnson, W.O.; Thurmond, M.C. Bayesian beta regression: Applications to household expenditure data and genetic distance between foot-and-mouth diseases viruses. Aust. N. Z. J. Stat. 2007, 49, 287–301. [Google Scholar] [CrossRef]
- Cribari-Neto, F.; Vasconcellos, K.L.P. Nearly unbiased maximum likelihood estimation for the beta distribution. J. Stat. Comput. Simul. 2002, 72, 107–118. [Google Scholar] [CrossRef]
- Ferrari, S.; Cribari-Neto, F. Beta regression for modelling rates and proportions. J. Appl. Stat. 2004, 31, 799–815. [Google Scholar] [CrossRef]
- Kieschnick, R.; McCullough, B.D. Regression analysis of variates observed on (0, 1): Percentages, proportions and fractions. Stat. Model. 2003, 3, 193–213. [Google Scholar] [CrossRef] [Green Version]
- Lemonte, A.J.; Cribari-Neto, F.; Vasconcellos, K.L.P. Improved statistical inference for the two-parameter Birnbaum-Saunders distribution. Comput. Stat. Data Anal. 2007, 51, 4656–4681. [Google Scholar] [CrossRef]
- Paolino, P. Maximum likelihood estimation of models with beta-distributed dependent variables. Political Anal. 2001, 9, 325–346. [Google Scholar] [CrossRef]
- Vasconcellos, K.L.P.; Cribari-Neto, F. Improved maximum likelihood estimation in a new class of beta regression models. Braz. J. Probab. Stat. 2005, 19, 13–31. [Google Scholar]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, H.W. Doubly censored power-normal regression models with inflation. Test 2014, 24, 265–286. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, H.W. Power-models for proportions with zero/one excess. Appl. Math. Inf. Sci. 2018, 24, 293–303. [Google Scholar] [CrossRef]
- Ospina, R.; Ferrari, S.L.P. Inflated beta distribution. Stat. Pap. 2010, 51, 111–126. [Google Scholar] [CrossRef] [Green Version]
- Ospina, R.; Ferrari, S.L.P. A general class of zero-or-one inflated beta regression models. Comput. Stat. Data Anal. 2012, 56, 1609–1623. [Google Scholar] [CrossRef] [Green Version]
- Cragg, J. Some statistical models for limited dependent variables with application to the demand for durable goods. Econometrica 1971, 39, 829–844. [Google Scholar] [CrossRef]
- Prudnikov, A.P.; Brychkov, Y.A.; Marichev, O.I. Inntegrals and Series: More Special Functions; Gordon and Breach Science Publishers: New York, NY, USA, 1990. [Google Scholar]
- Vuong, Q.H. Likelihood ratio tests for model selection and non-nested hypotheses. Econometrica 1989, 57, 307–333. [Google Scholar] [CrossRef] [Green Version]
- Kullback, S.; Leibler, R.A. On information and sufficiencys. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Galvis, D.M.; Lachos, V.H.; Bandyphaday, D. Augmented mixed models for clustered proportion data. Stat. Methods Med. Res. 2017, 26, 880–897. [Google Scholar]
- Moulton, L.H.; Halsey, N.A. A mixture model with detection limits for regression analyses of antibody response to vaccine. Biometrics 1995, 51, 1570–1578. [Google Scholar] [CrossRef]
Figure 1.
(a) Histogram of the death proportions. (b) Graphs: empiric (solid line), BUBSZOI model (dotted line).
Figure 1.
(a) Histogram of the death proportions. (b) Graphs: empiric (solid line), BUBSZOI model (dotted line).

Figure 2.
(a) Histogram of the death proportions. (b) Graphs: empiric (solid line), BEZI (dashed line). (c) Graphs: empiric (solid line), BUBSZI (dotted line).
Figure 2.
(a) Histogram of the death proportions. (b) Graphs: empiric (solid line), BEZI (dashed line). (c) Graphs: empiric (solid line), BUBSZI (dotted line).

Figure 3.
(a) Histogram of the the variable X. (b) Graphs: empiric (solid line), BUBSZOI (dotted line).
Figure 3.
(a) Histogram of the the variable X. (b) Graphs: empiric (solid line), BUBSZOI (dotted line).


{kind=link}
{kind=link}
{kind=link}
Table 1.
Statistical summary of the infant deaths data.
| Data | n | Mean | SE | Bias | Kurtosis |
|---|---|---|---|---|---|
| Complete | 5561 | 0.137 | 0.246 | 2.069 | 6.647 |
| Non-censored | 3541 | 0.292 | 0.216 | 0.811 | 2.94 |
Table 2.
The MLE of the parameters of the mixtures of the Bernoulli distribution with: Beta, LPN and UBS models.
Table 2.
The MLE of the parameters of the mixtures of the Bernoulli distribution with: Beta, LPN and UBS models.
| Est. | BEINF | MBLPN | BUBSZOI |
|---|---|---|---|
| 0.297 (0.004) | 0.661 (0.0066) | – | |
| 0.456 (0.005) | 0.022 (0.0030) | – | |
| – | 0.001 (0.001) | 0.783 (0.012) | |
| – | – | 1.198 (0.019) | |
| 0.606 (0.007) | 0.606 (0.007) | 0.606 (0.007) | |
| 0.031 (0.002) | 0.031 (0.002) | 0.031 (0.002) |
Table 3.
The MLE of the parameters of the BEZI, Tobit and BUBSZI models.
| Est. | BEZI | Tobit | BUBSZI |
|---|---|---|---|
| 0.088 (0.004) | 0.085 (0.004) | – | |
| 6.290 (0.404) | 0.104 (0.003) | – | |
| – | – | 0.575 (0.016) | |
| – | – | 2.993 (0.066) | |
| 0.023 (0.006) | – | 0.023 (0.006) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Martínez-Flórez, G.; Tovar-Falón, R.; Barrera-Causil, C. Inflated Unit-Birnbaum-Saunders Distribution. Mathematics 2022, 10, 667. https://0-doi-org.brum.beds.ac.uk/10.3390/math10040667
AMA Style
Martínez-Flórez G, Tovar-Falón R, Barrera-Causil C. Inflated Unit-Birnbaum-Saunders Distribution. Mathematics. 2022; 10(4):667. https://0-doi-org.brum.beds.ac.uk/10.3390/math10040667
Chicago/Turabian StyleMartínez-Flórez, Guillermo, Roger Tovar-Falón, and Carlos Barrera-Causil. 2022. "Inflated Unit-Birnbaum-Saunders Distribution" Mathematics 10, no. 4: 667. https://0-doi-org.brum.beds.ac.uk/10.3390/math10040667
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.