
Pathwise Convergent Approximation for the Fractional SDEs



Faculty of Mathematics and Informatics, Vilnius University, Akademijos g. 4, LT-08412 Vilnius, Lithuania
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Mathematics 2022, 10(4), 669; https://0-doi-org.brum.beds.ac.uk/10.3390/math10040669
Submission received: 20 January 2022
/
Revised: 16 February 2022
/
Accepted: 19 February 2022
/
Published: 21 February 2022
(This article belongs to the Special Issue Applied Probability)
{kind=link}
{kind=link}
Abstract
:Fractional stochastic differential equation (FSDE)-based random processes are used in a wide spectrum of scientific disciplines. However, in the majority of cases, explicit solutions for these FSDEs do not exist and approximation schemes have to be applied. In this paper, we study one-dimensional stochastic differential equations (SDEs) driven by stochastic process with Hölder continuous paths of order . Using the Lamperti transformation, we construct a backward approximation scheme for the transformed SDE. The inverse transformation provides an approximation scheme for the original SDE which converges at the rate , where h is a time step size of a uniform partition of the time interval under consideration. This approximation scheme covers wider class of FSDEs and demonstrates higher convergence rate than previous schemes by other authors in the field.
Keywords:
stochastic differential equations; fractional Brownian motion; backward approximation; Lamperti transformationMSC:
60G22; 60H10; 60H051. Introduction
Stochastic differential equations (SDEs) are used as a modeling tool in many fields of science. Currently, a lot of research is being conducted on models with fractional Brownian motion (fBm) , , since fBm introduces a memory element, which provides new and promising modeling possibilities. It should be noted that the definition of SDEs driven by fBm differs substantially from the definition used by standard Brownian-motion-driven SDEs. Furthermore, there is more than one way to define these SDEs (for example, in our paper, we will use the Riemann–Stieltjes integral to achieve this). The general conditions under which the fractional diffusion process has a unique solution were obtained in [1]. These conditions impose more strict restrictions on the coefficients than in the case of SDEs driven by standard Brownian motion (sBm).
Classical financial models such as Chan–Karoli–Longstaff–Sanders (CKLS), Cox–Ingersoll–Ross (CIR), and Ait–Sahalia are defined using SDEs driven by standard Brownian motion. Replacing the standard Brownian motion with a fractional Brownian motion, we obtain a fractional analogue of these classical models. In many of these models, the solution positivity is a desirable property. The positivity of fractional CIR model was studied in [2,3]. The conditions under which fractional CKLS, Ait–Sahalia and other models have positive solutions follow from [4,5,6]. The above-mentioned financial models have a strictly positive diffusion coefficient.
In this paper, we shall consider a one-dimensional SDE driven by an arbitrary stochastic process , , with Hölder continuous paths of order
where is a constant, and the coefficients are continuous functions. The stochastic integral in Equation (1) is a pathwise Riemann–Stieltjes integral, and thus the whole equation is understood as a pathwise Riemann–Stieltjes integral equation (special case ). The conditions under which the Equation (1) has a unique solution X were obtained in [7].
A lot of SDEs cannot be solved explicitly; thus, it is important to find their approximated solutions by applying some numerical methods. For SDEs driven by sBm, authors usually consider the convergence rate of strong Itô–Taylor approximation schemes of the SDEs solutions. From a strong convergence rate, one can obtain the pathwise convergence rate (see [8,9] and the references therein), which provides the error of the actual approximation.
For Equation (1) with and rather smooth and bounded coefficients and , different explicit approximation schemes were considered in [10,11,12,13] (see also the references therein). Particularly, in [10,12,13], Euler and other higher-order approximation schemes were considered; [11] presents a new method that converges with weaker conditions compared to the results in [12]; and in [14], less strict conditions for the coefficients were used in the explicit Euler approximation.
The purpose of this work is to obtain an approximation scheme under weaker conditions and of a higher order convergence rate than in the articles mentioned above. For this, we require the diffusion coefficient to be strictly positive, i.e., . Such restriction on a diffusion coefficient was used in [11,13]. Since the diffusion coefficient is strictly positive, we can use the Lamperti transformation and transform a considerable SDE into simpler SDE with constant diffusion coefficient. The transformed SDE can be approximated accordingly to the chosen scheme, and the inverse transformation provides an approximation scheme for the original SDE. This strategy has been successfully applied to classical CIR, Heston- volatility, Ait–Sahalia, and other models using a backward (also called drift-implicit) Euler–Maruyama scheme [15,16,17] to obtain a strong convergence rate. This idea has also been successfully applied to fractional CIR model [18], fractional CKLS, Ait–Sahalia, and other models (see [4,5,6]) when they have positive solutions.
The paper is organized in the following way. In Section 2, we present the main results of the paper. Section 3 contains proofs of the main theorems. In Section 4, the fractional Pearson diffusion process and the model from [11] are considered as modeling examples. Finally, in Appendix A, we propose an approximation of the integrated fBm, which was used for the simulation results. Moreover, some results on pathwise integration, fBm, and almost sure convergence are listed in Appendix B and Appendix C as well.
2. Main Result
Assume that for some and for any ,
and the process Z has Hölder continuous paths of order , i.e., there exists a random variable such that
Under these conditions given in [7] (see also [1]), Equation (1) has a unique solution X such that a.s. for any . The definitions of the norm are given in Appendix B.
In addition to the conditions formulated in (2)–(3), we will require that the diffusion term be such that
Note that condition (3) implies that the function is continuously differentiable on . Thus, under condition , the Lamperti transform
has the inverse function , which is strictly monotone and differentiable
Set . By chain rule, we obtain
where ,
Since under conditions (2)–(3) there exists a unique solution of (1), the equation
has a unique solution under these same conditions.
To state our main results, we use the following requirements on function f:
f is continuously differentiable on ;
Assume that there exists a constant such that for all ;
Assume that there exists a constant such that for all , where ;
Assume that the function f on is twice continuous differentiable and there exists a constant such that for all .
Let be a sequence of uniform partitions of the interval , and let , . For the solution Y of the SDE (5), define the following backward approximation scheme:
For the simplicity of notation, we introduce the symbol . Let be a sequence of r.v.s, let be an a.s. nonnegative r.v., and let be a vanishing sequence. Then means that for all n. In particular, means that the sequence is a.s. bounded.
Define
where constants K and M are given in and , .
Theorem 1.
Suppose that the function f in (5) satisfies conditions –. Assume that the sequence of uniform partitions π of the interval is such that . Then for , it follows that
Remark 1.
Note that this result is not applicable for CKLS, Heston-volatility, or Ait–Sahalia models, since conditionis not satisfied.
Theorem 2.
Assume that SDE (1) has unique solution and conditions of Theorem 1 are satisfied. Then for , it follows that
3. Proofs of Theorems
Firstly, we prove that the backward approximation (6) is well defined.
Lemma 1.
Let the conditionsandbe satisfied. The function
is strictly monotone and,for any.
Remark 2.
Note that forand, there is no restriction on h.
Proof .
Under the assumptions and , the function is strictly monotone. Indeed,
for .
From Lemma 1, it follows that for each , the equation has a unique solution for . Consequently, the backward approximation scheme is well defined if conditions and are satisfied and .
3.1. Proof of Theorem 1
Applying the chain rule, we obtain that
For simplicity of notation, we introduce the following:
Applying assumptions and , we transform equality (11) into a recursive inequality. Indeed,
for . Thus,
Further, by applying inequality , , we obtain that
where and .
Now, recursively from (12), we obtain that
We have , ; thus, we obtain that
if . Consequently,
where
To finish the proof of Theorem 1, it remains to estimate and . From Lemmas 2 and 3 below, it follows that
Thus,
Lemma 2.
Under the assumptions of Theorem 1
Proof .
We start by estimating the first term in (10). Since the function is continuous and the process Y is continuous, then . From the Hölder continuity of Z, we obtain
Thus,
From the Love–Young inequality, it follows that
Therefore, the second term in (10) has the following estimate:
Finally, for the third term in (10), we obtain the estimate
The proof is complete. □
Lemma 3.
Assume that conditionis satisfied. Then
Proof .
Applying condition , we obtain
Since
then the proof is complete. □
3.2. Proof of Theorem 2
Note that
where , and
Since the function satisfies condition (2), then
In addition, as the function increases and (15) is satisfied, then there exists a random variable such that
Thus, the required result follows from Theorem 1.
4. Modeling
In this section, we will apply obtained theoretical results for concrete SDEs. In particular, the Pearson fractional diffusion process and the model from [11] based on trigonometric functions satisfy the conditions of Theorem 1. We chose to investigate the fractional Pearson diffusion process as it is better known and more widely used. However, the same simulation and investigation methodology can be applied to the second model as well.
4.1. Pearson Diffusion
Consider the Pearson diffusion process
with
Assume that . Then the diffusion coefficient has bounded first- and second-order derivatives, and Equation (16) has a unique solution since the drift and diffusion coefficients satisfy conditions (2)–(3).
To check the conditions –, we have to find the expressions of the functions , , .
Note that
where
Since
and
then
Further,
Thus,
To simplify the analysis of derivatives and to allow the simulation itself, we take specific expressions of coefficients. Let
The Lamperti transformation of and its inverse are defined as follows:
Note that
Thus, from (15), it follows that
This is enough for Theorem 2 to be true (see equality (14)) if the conditions of Theorem 1 are satisfied.
Now we verify conditions –. Condition is satisfied (see (18)). By inserting the expressions of coefficients a and b, we obtain
Since the function is continuous and increasing then from above, it follows that the functions , , and are bounded. Thus, conditions – are satisfied.
4.2. Numerical Simulation
Notice that the approximation Scheme (6) is not final. In order to obtain the original process approximation, the inverse Lamperti transform has to be applied. However, Scheme (6) is implicit and both the number of calculations needed and the general complexity of the approximation can be reduced by combining the Scheme (6) and Lamperti transform simultaneously:
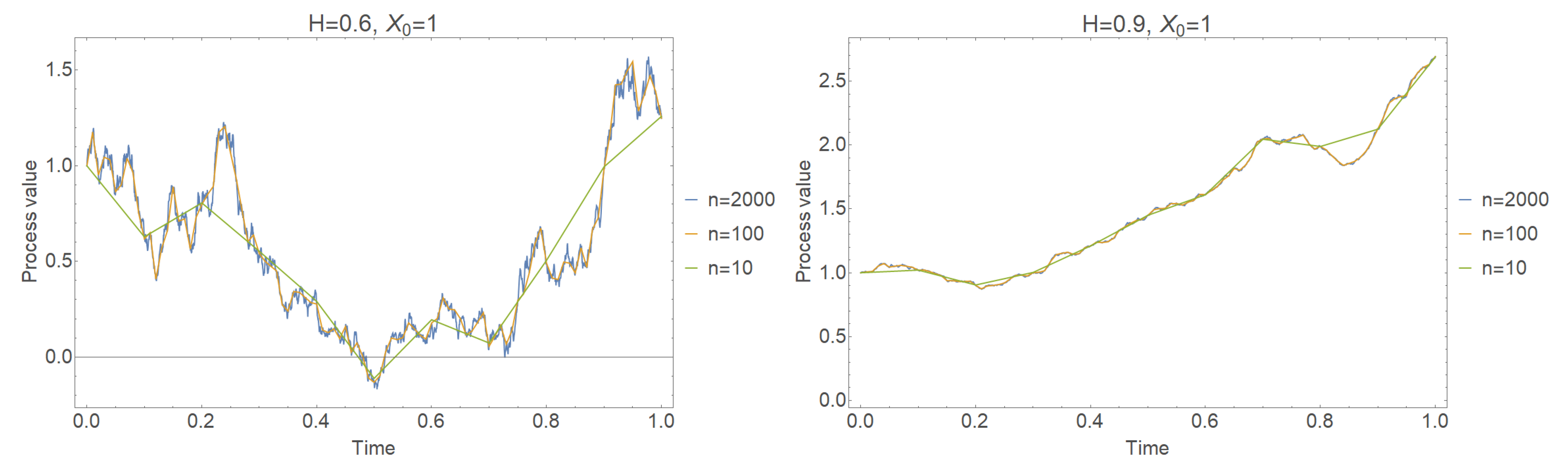
Now, using this finalized Scheme (20) we can generate trajectories of any process satisfying conditions of Theorem 1 (see Figure 1).
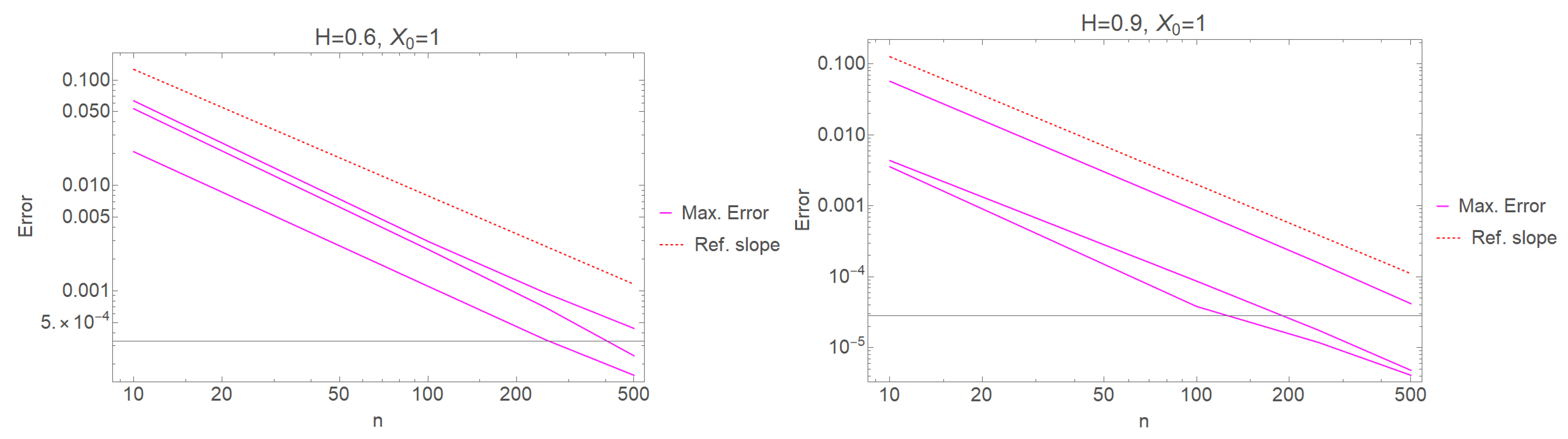
To compare the theoretical and empirical convergence rates of the Pearson process (19), we simulate the “exact” solution trajectories by using an approximation scheme (20) for a comparatively much smaller step size . Since the object of the numerical experiment is investigation of the convergence rate, which is not dependent on the values of constants, the most basic set of values for (16) is sufficient (i.e., ). We see from Figure 2 that the empirical maximum error coincides with the theoretical result in Theorem 2 (reference slope).
Of course, it should be noted that we assume fBm values provided by Wolfram Mathematica programming language function FractionalBrownianMotionProcess to be not approximate but "true" values of fractional Brownian motion and that the same assumption is being made about the approximation of integrated fBm too.
5. Conclusions
We introduced an improved type of approximation scheme for certain SDEs. In comparison with the previous research in the field, due to less strict conditions, this approximation covers a wider class of stochastic processes and is proven to have a higher convergence rate. These theoretical results were supported by numerical experiments. Furthermore, we proposed a simple and direct approximation scheme with estimated convergence rate for integrated fractional Brownian motion, which can be applied by other authors modelling their own approximation schemes.
Author Contributions
Conceptualization, K.K.; methodology, K.K. and A.M.; software, A.M.; validation, K.K. and A.M.; formal analysis, K.K. and A.M.; investigation, K.K. and A.M.; writing—original draft preparation, K.K. and A.M.; writing—review and editing, K.K. and A.M.; visualization, A.M.; supervision, K.K.; project administration, K.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CEV | Constant elasticity of variance model |
| CIR | Cox–Ingersoll–Ross model |
| CKLS | Chan–Karolyi–Longstaff–Sanders model |
| FSDE | Fractional stochastic differential equation |
| fBm | Fractional Brownian motion |
| sBm | Standard Brownian motion |
| SDE | Stochastic differential equation |
Appendix A. Approximation of Integrated fBm
Analogously to the approximation of standard Riemann integral, we propose that the integral (A1) can be replaced by the sum , where , and , . For simplicity of notation, . This method enables simple and direct use of fractional Brownian motion simulation packages provided in the most mathematical programming languages (Wolfram Mathematica was used for our simulations).
Now, to prove the correctness of this approximation, we estimate
After that, applying Lemma A1 (see Appendix C), we will obtain the rate of a.s. convergence of the difference
First, we shall introduce the concept of generalized harmonic numbers (GHN). We define
where is a complex variable as generalized harmonic numbers.
Here are some important properties of GHN sums [19].
Proposition A1.
The following identity is true
where.
Proposition A2.
The following identity is true
where.
Using these properties, the following result can be proven.
Theorem A1.
These equalities are true:
- Integral expectation
- Product sum expectation
- Mixed products
Proof .
Now, applying Proposition A2 provides us the result.
The mixed product of integral and sum is estimated the following way:
□
For further reasoning, we are going to need one elementary theorem from mathematical analysis.
Theorem A2.
Letbe a non-decreasing continuous function and let
Then
Proposition A3.
The following asymptotics occur
where
Proof .
First, note that from Theorem A1, we obtain
□
Appendix B. Pathwise Integration and fBm
For any , denote the space of -Hölder continuous functions equipped with the norm
Let , . Denote , the space of real-valued measurable functions such that
Theorem A3
Love–Young inequality has the form, for any,
wheredenotes the Riemann zeta function, i.e.,.
Corollary 3.
Let F be a continuous differentiable function,,,. Then
Proof .
Note that . In fact, note that
Theorem A4
(Chain rule (see [21], p. 10)). Let be a function such that for each , , . Let be a differentiable function with locally Lipschitz partial derivatives , . Then each is Riemann–Stieltjes integrable with respect to and
Theorem A5
(Hölder continuity of (see [21], p. 4)). It is known that almost all sample paths of an fBm are locally Hölder of order strictly less than . To be more precise, for all , there exists a nonnegative random variable such that for all , and
for all , where .
Appendix C. Almost Sure Convergence
Lemma A1
([8]). Let and for . In addition, let , , be a sequence of random variables such that
for all and all . Then for all , there exists a random variable such that
for all . Moreover, for all .
References
- Nualart, D.; Răşcanu, A. Differential equations driven by fractional Brownian motion. Collect. Math. 2002, 53, 55–81. [Google Scholar]
- Hu, Y.; Nualart, D.; Song, X. A singular stochastic differential equation driven by fractional Brownian motion. Stat. Probab. Lett. 2008, 78, 2075–2085. [Google Scholar] [CrossRef] [Green Version]
- Mishura, Y.; Yurchenko-Tytarenko, A. Fractional Cox–Ingersoll–Ross process with non-zero “mean”. Mod. Stoch. Theory Appl. 2018, 5, 99–111. [Google Scholar] [CrossRef]
- Zhang, S.Q.; Yuan, C. Stochastic differential equations driven by fractional Brownian motion with locally Lipschitz drift and their Euler approximation. Proc. R. Soc. Edinb. A 2021, 151, 1278–1304. [Google Scholar] [CrossRef]
- Kubilius, K. Estimation of the Hurst index of the solutions of fractional SDE with locally Lipschitz drift. Nonlinear Anal. Model. Control 2020, 25, 1059–1078. [Google Scholar] [CrossRef]
- Kubilius, K.; Medžiūnas, A. Positive solutions of the fractional SDEs with non-Lipschitz diffusion coefficient. Mathematics 2021, 9, 18. [Google Scholar] [CrossRef]
- Mishura, Y.; Shevchenko, G. Mixed stochastic differential equations with long-range dependence: Existence, uniqueness and convergence of solutions. Comput. Math. 2012, 64, 3217–3227. [Google Scholar] [CrossRef] [Green Version]
- Kloeden, P.; Neuenkirch, A. The pathwise convergence of approximation schemes for stochastic differential equations. LMS J. Comput. Math. 2007, 10, 235–253. [Google Scholar] [CrossRef] [Green Version]
- Kloeden, P.E.; Neuenkirch, A. Recent Developments in Computational Finance Foundations, Algorithms and Applications; World Scientific: Singapore, 2013. [Google Scholar]
- Deya, A.; Neuenkirch, A.; Tindel, S.A. Milstein-type scheme without Lévy area terms for SDEs driven by fractional brownian motion. Ann. L’I.H.P. Probab. Stat. 2012, 48, 518–550. [Google Scholar] [CrossRef]
- Jamshidi, N.; Kamrani, M. Convergence of a numerical scheme associated to stochastic differential equations with fractional Brownian motion. Appl. Numer. Math. 2021, 167, 108–118. [Google Scholar] [CrossRef]
- Neuenkirch, A.; Nourdin, I. Exact rate of convergence of some approximation schemes associated to SDEs driven by a fractional Brownian motion. J. Theoret. Probab. 2007, 20, 871–899. [Google Scholar] [CrossRef] [Green Version]
- Neuenkirch, A. Optimal pointwise approximation of stochastic differential equations driven by fractional Brownian motion. Stoch. Process Their Appl. 2008, 118, 2294–2333. [Google Scholar] [CrossRef] [Green Version]
- Mishura, Y.; Shevchenko, G. The rate of convergence for Euler approximations of solutions of stochastic differential equations driven by fractional Brownian motion. Int. J. Probab. Stoch. Process. 2008, 80, 489–511. [Google Scholar] [CrossRef] [Green Version]
- Alfonsi, A. Strong order one convergence of a drift implicit Euler scheme: Application to the CIR process. Stat. Probab. Lett. 2013, 83, 602–607. [Google Scholar] [CrossRef] [Green Version]
- Dereich, S.; Neuenkirch, A.; Szpruch, L. An Euler-type method for the strong approximation of the Cox–Ingersoll–Ross process. Proc. R. Soc. A Math. Phys. Eng. Sci. 2012, 468, 1105–1115. [Google Scholar] [CrossRef] [Green Version]
- Neuenkirch, A.; Szpruch, L. First order strong approximations of scalar SDEs defined in a domain. Numer. Math. 2014, 128, 103–136. [Google Scholar] [CrossRef]
- Hong, J.; Huang, C.; Kamrani, M.; Wang, X. Optimal strong convergence rate of a backward Euler type scheme for the Cox–Ingersoll–Ross model driven by fractional Brownian motion. Stoch. Process Their Appl. 2020, 130, 2675–2692. [Google Scholar] [CrossRef] [Green Version]
- Medžiūnas, A. On the Congruence of Finite Generalized Harmonic Numbers Sums Modulo p2. Ann. Pol. Math 2020, 126, 279–292. [Google Scholar] [CrossRef]
- Abundo, M.; Pirozzi, E. On the Integral of the Fractional Brownian Motion and Some Pseudo-Fractional Gaussian Processes. Mathematics 2019, 7, 991. [Google Scholar] [CrossRef] [Green Version]
- Kubilius, K.; Mishura, Y.; Ralchenko, K. Parameter Estimation in Fractional Diffusion Models; Bocconi & Springer Series; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
Figure 1.
Approximation trajectories of Pearson process for conditions (19).
Figure 1.
Approximation trajectories of Pearson process for conditions (19).

Figure 2.
Maximum error of several approximation trajectories of Pearson process for conditions (19) in comparison to reference slope.
Figure 2.
Maximum error of several approximation trajectories of Pearson process for conditions (19) in comparison to reference slope.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Kubilius, K.; Medžiūnas, A. Pathwise Convergent Approximation for the Fractional SDEs. Mathematics 2022, 10, 669. https://0-doi-org.brum.beds.ac.uk/10.3390/math10040669
AMA Style
Kubilius K, Medžiūnas A. Pathwise Convergent Approximation for the Fractional SDEs. Mathematics. 2022; 10(4):669. https://0-doi-org.brum.beds.ac.uk/10.3390/math10040669
Chicago/Turabian StyleKubilius, Kęstutis, and Aidas Medžiūnas. 2022. "Pathwise Convergent Approximation for the Fractional SDEs" Mathematics 10, no. 4: 669. https://0-doi-org.brum.beds.ac.uk/10.3390/math10040669
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.