A New Divergence Measure of Pythagorean Fuzzy Sets Based on Belief Function and Its Application in Medical Diagnosis


1
Institute of Fundamental and Frontier Science, University of Electronic Science and Technology of China, Chengdu 610054, China
2
Library, Sichuan Minzu College, Kangding 626001, China
*
Author to whom correspondence should be addressed.
Mathematics 2020, 8(1), 142; https://0-doi-org.brum.beds.ac.uk/10.3390/math8010142
Submission received: 21 December 2019
/
Revised: 15 January 2020
/
Accepted: 16 January 2020
/
Published: 20 January 2020
(This article belongs to the Special Issue Fuzzy Sets, Fuzzy Logic and Their Applications)
Abstract
:As the extension of the fuzzy sets (FSs) theory, the intuitionistic fuzzy sets (IFSs) play an important role in handling the uncertainty under the uncertain environments. The Pythagoreanfuzzy sets (PFSs) proposed by Yager in 2013 can deal with more uncertain situations than intuitionistic fuzzy sets because of its larger range of describing the membership grades. How to measure the distance of Pythagorean fuzzy sets is still an open issue. Jensen–Shannon divergence is a useful distance measure in the probability distribution space. In order to efficiently deal with uncertainty in practical applications, this paper proposes a new divergence measure of Pythagorean fuzzy sets, which is based on the belief function in Dempster–Shafer evidence theory, and is called PFSDM distance. It describes the Pythagorean fuzzy sets in the form of basic probability assignments (BPAs) and calculates the divergence of BPAs to get the divergence of PFSs, which is the step in establishing a link between the PFSs and BPAs. Since the proposed method combines the characters of belief function and divergence, it has a more powerful resolution than other existing methods. Additionally, an improved algorithm using PFSDM distance is proposed in medical diagnosis, which can avoid producing counter-intuitive results especially when a data conflict exists. The proposed method and the magnified algorithm are both demonstrated to be rational and practical in applications.
1. Introduction
With the development of fuzzy mathematics, medical diagnosis has addressed more and more attention from the research society of applied computer mathematics. In the diagnostic process of medical profession, improving the processing capacity of various uncertain and inconsistent information and achieving more accurate decision-making have become the major challenges in the development of medical diagnosis [1,2,3]. Up to now, the process of medical diagnosis is driven by various theoretical studies, such as fuzzy sets theory [4,5,6], intuitionistic fuzzy sets [7,8,9,10], interval-valued intuitionistic fuzzy sets [11,12,13], and quantum decision [14,15,16].
It is well known that medical diagnosis is an effective and reasonable way to handle the problem of uncertainty. Decision theory [17,18,19] has been widely applied in this field, containing a variety of theories and methods. For instance, evidence theory and its extension [20,21,22], evidential reasoning [23,24], D numbers theory [25], R numbers theory [26,27], Z numbers theory [28,29], and other hybrid methods have been used to research it from lots of aspects. The rationality and practicality of these methods have also been proven by their employment in applications, such as strategy selection [30,31,32,33,34], decision-making [35,36,37,38,39], prediction [40,41,42], and fault diagnosis [43,44]. In addition, Zadeh presented a useful theory in 1965, the fuzzy set (FS) theory [45], which drives a big step forward in decision theory. Atanassov’s intuitionistic fuzzy sets (IFSs) [46] proposed and Yager’s Pythagorean fuzzy sets (PFSs) [47] are two extensions of a fuzzy set which make use of the membership degree, non-membership degree, and the hesitancy to preciously express the uncertainty. Among them, Pythagorean fuzzy set has a larger range of expressing the uncertainy than intuitionistic fuzzy set [48,49]. Hence, the Pythagorean fuzzy set was chosen to apply for medical diagnosis in this paper.
Distance measure plays a vital role in pattern recognition, information fusion, decision-making, and other fields. The fuzzy set theory and intuitionistic fuzzy sets have been proposed for many years and their distance measurements [50,51,52] have matured compared with Pythagorean fuzzy sets. There are some useful distances for IFS after suffering the practice and the application. For instance, the Euclidean distance [53], the Hamming distance [53], and the Hausdorff metric [54] are the most widely applied distances of IFS. The distance measurement of PFSs is still an open issue, which attracts many researchers to explore the distance measurement of PFSs and its related applications. A general distance measurement of PFSs was proposed by Chen [55], is an extension of Euclidean distance and Hamming distance, and generates a reasonable result in multiple-criteria decision analysis. Wei and Wei [56] proposed a PFS measurement method based on cosine function and applied it to medical diagnosis to achieve an ideal result. Later on, Xiao [57] presented a distance measurement of PFSs based on divergence, called PFSJS distance. Among these methods of measure distance of PFSs, membership, non-membership and hesitancy are calculated based on the same weights. It is well known that the hesitancy expresses the uncertainty of membership and non-membership, so finding a proper method to distribute hesitancy to membership and non-membership can more reasonably handle the distance of PFSs. The basic probability assignment (BPA) in evidence theory presented by Dempster–Shafer [58,59] unifies uncertainty in a new set, and can handle various uncertainty reasonably. Song [60] presented a divergence measure of belief function based on Kullback–Leibler (KL) divergence [61] and Deng entropy [62], which has better results when dealing with the distance between BPAs with greater uncertainty. This paper proposes a new method to describe the PFSs in the form of BPAs, and uses an improverd divergence measurement of BPAs based on Jensen–Shannon divergence to measure the distance of PFSs. This method applied to medical diagnosis can not only get more intuitive results when the high conflicts appear in several symptoms between patients and diseases but also make higher resolution in different results.
According to the above, the structure of this article is as follows:
- The related concepts and properties of Pythagorean fuzzy set (PFS), basic probability assignment (BPA), the Jensen–Shannon divergence, and some widely applied methods of measuring distance are introduced.
- A new divergence measure of PFSs is proposed, which is called PFSDM distance. Its measurement is divided into three stages. The first is establishing a link between PFSs and BPAs. In addition, then, an improved method is proposed to measure the divergence of PFSs represented as BPAs. The third is proving the properties of PFSDM distance and expressing the feasibility and merits of the proposed method using numerical examples.
- The medical diagnosis algorithm based on Xiao’s method [57] is magnified and compares the new algorithm with other existing methods to prove its practicability.
- The merits and uses of the PFSDM distance are summarized and the future direction of algorithm improvement is expected.
2. Preliminaries
In this section, the first subsection introduced the definition of Pythagorean fuzzy sets [47,48]. The main idea of basic probability assignment (BPA), Dempster–Shafer evidence theory [58,59] is in the second subsection. Some concepts of divergence are in the third subsection. In the last subsection, some existing methods for measuring the distance of PFSs are displayed.
2.1. Pythagorean Fuzzy Sets
Definition 1.
Let X be a limited universe of discourse. An intuitionistic fuzzy set (IFS) [46] M in X is defined by
where represents the degree of support for membership of the of IFS, and represents the degree of support for non-membership of the of IFS, with the condition that . and the hesitancy function of IFS reflecting the uncertainty of membership and non-membership is defined by
Definition 2.
Let x be a limited universe of discourse. A Pythagorean fuzzy set (PFS) [47,48] M in X is defined by
where represents the degree of support for membership of the of PFS, and represents the degree of support for non-membership of the of PFS, with the condition that . and the hesitancy function of PFS reflecting the uncertainty of membership and non-membership is defined by
The membership and the non-membership of PFS also can be expressed by another way. A pair of values and for each are used to represent the membership and non-membership as follows:
where . Here, we see that is expressed as radians and . In addition, .
Property 1.
([49]) Let B and C be two PFSs in X, then
- if and ,
- if and ,
- ,,
- ,
- ,
- .
2.2. Dempster–Shafer Evidence Theory
The Dempster–Shafer evidence theory [58,59] is proposed to deal with conditions that are weaker than Bayes probability [63,64], which can directly express uncertainty and unknown information [65,66], so that it has been widely used in various applications, FMEA [67,68,69], evidential reasoning [70,71,72], evaluation [73], target recognition [74], industrial alarm system [75,76], and others [77,78].
2.3. Divergence Measure
Definition 5.
Given two probabilities distribution and .
The Kullback–Leibler also has some disadvantages of its properties, and one of them is that it doesn’t satisfy the commutative property:
In order to realize the commutation in the distance measure, the Jensen–Shannon divergence is an adaptive choice.
Definition 6.
Given two probabilities distribution and .
Song’s divergence [60] is used to measure the belief function, which is capable of processing uncertainty efficiently in a highly fuzzy environment by applying the thinking of Deng entropy [62].
Definition 7.
([60]) Given two basic probability assignments (BPAs) and , the divergence between and is defined as follows:
where the holds on , which is the power subset of frame of discernment Θ and is the cardinal number of .
It is obvious that . In order to realize the commutative property, a divergence measurement based on Song’s divergence is defined as follows:
Because of thinking of the number of subsets of the mass function and averagely distributing the BPAs to these subsets, Song’s divergence is more reasonable than others when the basic probability assignments of non-singleton powers sets are larger.
2.4. Distance Measure of Pythagorean Fuzzy Sets
The Euclidean distance [53] and the Hamming distance [53] are the most widely applied distances, and Chen proposed a generalized distance measure of PFS [55], which is the extension of Hamming distance and Euclidean distance.
Definition 8.
Let X be a limited universe of discourse, and M and N are two PFSs. Chen’s distance [55] measure between PFSs M and N denoted as is defined as:
where β holds on is called the distance parameter. As the extension of the Hamming distance and Euclidean distance, if and , the Chen’s distance is equal to Hamming distance and Euclidean distance, respectively:
- if ,,
- if ,.
In the application of distance measure, the universe of discourse always has many properties. Xiao extended them as the normalized distance and proposed a divergence measure of PFSs called PFSJS based on the Jensen–Shannon divergence, which is the first work to calculate the distance of PFSs using divergence.
Let be a limited universe of discourse, two PFSs
and are in X.
Definition 9.
The normalized Hamming distance [57] denoted as is defined as:
The normalized Euclidean distance [57] denoted as is defined as:
Definition 10.
The normalized divergence measurements of Pythagorean fuzzy sets denoted as PFSJS [57] of M and N are defined as follows:
where .
According to the existing methods for measuring the PFSs’ distance, what they have in common is that the weights of membership non-membership and hesitancy are considered to be the same when calculating distances. As is well known, the hesitancy represents the uncertainty of membership degree and non-membership degree, and the belief function in evidence theory can handle the uncertainty in a more proper way. Hence, if the ability of evidence theory to handle uncertainty is combined with the high resolution of divergence in distance measurement, the PFSs’ distance measurement will be further optimized. In the next section, a new divergence measure of PFSs is proposed based on belief function, which describes the PFSs in the form of BPAs and measures the distance of PFSs by calculating the divergence of BPAs.
3. A New Divergence Measure of PFSs
In this section, a new divergence measure of PFSs, called PFSDM distance, is proposed. The first subsection shows how PFS reasonably expressed in the form of BPA. A new improved method of BPAs’ divergence measure is introduced in the second subsection, and then the PFSDM distance and its properties is proposed. In the last subsection, some examples are used to prove its properties and demonstrate its feasibility by comparing with existing other methods.
3.1. PFS Is Expressed in the Form of BPA
In the evidence theory [58,59], the basic probability assignment (BPA) represents the degree of evidence supporting A, and, according to Equations (6) and (7), the elements of power set of frame of discernment () should satisfy . Thus, the method of representing PFS in the form of BPA is shown as follows:
Definition 11.
Let X be a limited universe of discourse, according to the second form of PFS shown in Equation (5), a Pythagorean fuzzy set M in X is , the frame of discernment of M and their basic probability assignments are defined as:
- ,
- ,
- ,
- ,
where represents the degree of evidence supporting membership of M. The represents the degree of evidence supporting non-membership of M. The represents the degree of evidence supporting membership and non-membership. Because the basic focal elements and are totally exclusive, and the sum of them is equal to 1, they conform to the Dempster–Shafer evidence theory.
3.2. A New Divergence Measure of PFSs
Jensen–Shannon divergence is widely used in distance measure of probability distributions, and in this subsection, we propose an improved divergence measure of BPA based on Song’s divergence and Jensen–Shannon divergence. In addition, a new divergence measure of PFSs and its properties are proposed, which is capable of distinguishing PFSs better.
Definition 12.
Let Θ be a frame of discernment , and the power set of Θ is . The Jensen–Shannon divergence measure of two BPAs , is defined as:
where is the cardinal number of . In addition, just in case there’s a zero in the denominator, is used to replace zero in the calculation.
The improved method satisfies the symmetry and considers the number of elements in the power set. In addition, then, substituting the PFSs in the form of BPAs into Equation (18) produces the new divergence measure of Pythagorean fuzzy sets.
Definition 13.
Let X be a limited universe of discourse, according to the second form of PFS shown in Equation (5), two Pythagorean fuzzy sets M and N in X are , . The divergence measure denoted as is defined as follows:
In order to obtain higher resolution when making distance measurement, the divergence measure of PFSs, PFSDM distance, denoted as , is defined by
According to the properties of Jensen–Shannon divergence [82], the larger PFSDM distance, the more different PFSs, and the smaller PFSDM, the more similar PFSs. The properties of the PFSDM distance are displayed as follows:
Definition 14.
Let M and N be two PFSs in a limited universe of discourse , where
, .
The normalized PFSDM distance, , is defined as follows:
Property 2.
Let M, N, and O be three arbitrary PFSs in the limited universe of discourse X, then
- (P1) if , for .
- (P2), for .
- (P3), for .
- (P4), for .
Proof. (P1).
Suppose two Pythagorean fuzzy sets M and N in the limited universe of discourse X. In addition, the PFSs of them are given as follows:
,
.
Thus, the property in the Property 2 is proven. ☐
Proof. (P2).
Suppose two Pythagorean fuzzy sets M and N in the limited universe of discourse X. In addition, the PFSs of them are given as follows:
,
,
.
Given four assumptions:
- (A1) .
- (A2) .
- (A3) .
- (A4) .
Let , and . According to the above, it is obvious that is satisfied under the and . We can easily find and in terms of and . Therefore, we have:
Hence, the inequality is valid under and . In the same way, the and also satisfy the . Therefore, the inequality in the Property 2 (P2), , has been proven. ☐
Obviously, they satisfy .
Proof. (P3 & P4).
Given two PFSs and in the limited universe of discourse X. The values and represent membership degree and non-membership degree in two PFSs. According to Equation (5), M and N can be formed as
where ; ; . The and satisfy the and in terms of Definition 2. Hence, the PFSDM distance between M and N are shown in Figure 1a when and meet the requirements.
- From Figure 1a, we can find that the PFSDM distances satisfy that its values are no more than one and no less than zero no matter how the parameters and change. Thus, Property 2 (P3) has been proven.
- As shown in Figure 1b, let us make a plane when = . According to the distance graph about the plane symmetry, we can demonstrate that the PFSDM meets and the Property 2 (P4) has been proven.
☐
Up to now, we have demonstrated the four properties of PFSDM distance. In order to fully explore the characteristics and functions of PFSDM, the proposed method is compared with other existing methods such as Hamming distance, Euclidean distance, and PFSJS distance in the next subsection.
3.3. Numerical Examples
In this subsection, three numerical examples are used to prove the PFSDM distance’s feasibility and merits. The powerful resolution of proposed method is proved in Example 1.
Example 1.
Suppose a limited universe of discourse , and the PFSs and in the discourse under the Casei , which are given in Table 1.
The distance measurements are calculated by Hamming distance, Euclidean distance [55], PFSJS distance proposed by Xiao [57], Fei’s distance [83], the proposed method, and PFSDM distance are shown in Table 2.
We can easily find that the PFSDM distance, , has a satisfying performance in terms of Table 2, which produces intuitive distances when the PFSJS distance can not distinguish the similar PFSs such as , and , . In addition, because of its divergence feature, the PFSDM distance can make up for the shortcoming of subtraction to find the distance, which is displayed in , of Hamming distance and , of Euclidean distance. The other character of the proposed method for calculating the distance of PFSs is the use of basic probability assignment to express the hesitancy. As the degree of hesitancy decreases, PFSDM distance thinks it has less and less effect on the distance, which is demonstrated in , , and . In general, the PFSDM distance can handle the above cases in a proper way when some existing methods produce counter-intuitive results.
In order to make the comparison between PFSDM distance and other methods more intuitive, as membership and non-membership change, the distances’ figures are displayed in Example 2.
Example 2.
Assume two PFSs and .
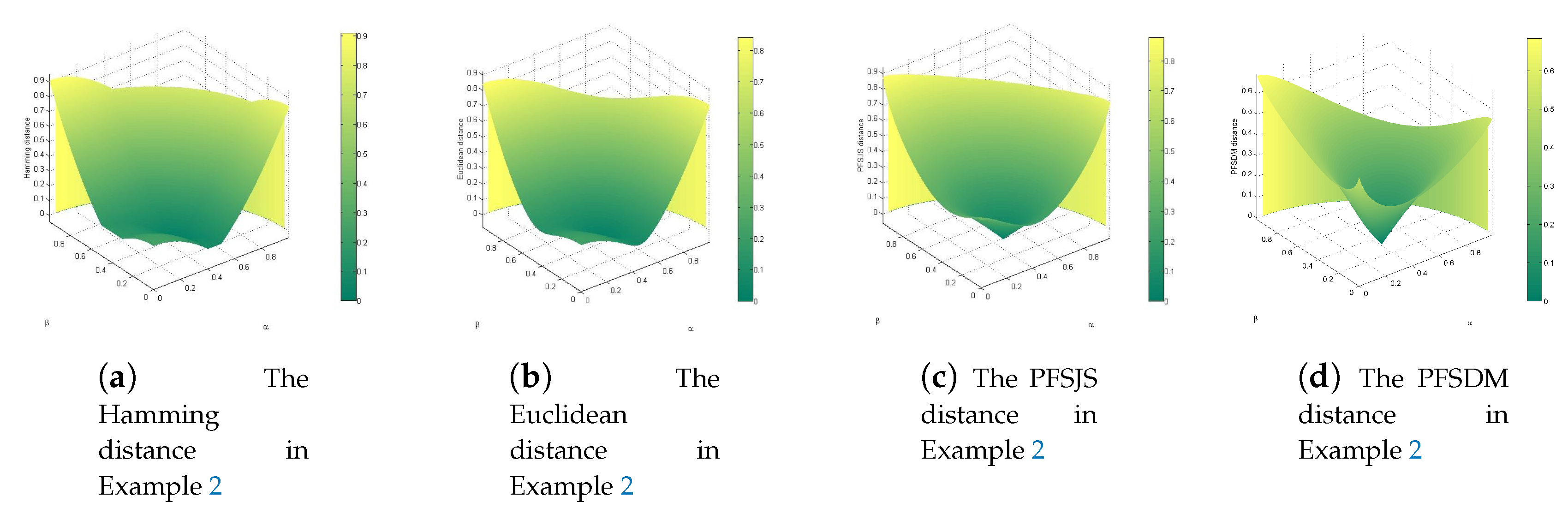
The Hamming distance [55] , Euclidean distance [55], PFSJS distance [57], and PFSDM distance are displayed in Figure 2a–d.
We can know from the observation that Figure 2a–c have similar trends, but the PFSDM distance is different in Figure 2d. It resembles an inverted cone centered on the point because it has a more uniform trend as α and β change. Suppose four PFSs , , , as follows:
- ,
- ,
- ,
- .
After calculation, we know that
To verify that PFSDM distance changes more evenly, the Hamming distance [55] and , Euclidean distance [55] and , PFSJS distance [57] and , PFSDM distance , and are calculated and results are obtained as follows:
- ,
- ,
- ,
- .
In the situation of membership degree and non-membership degree changing equally, we can clearly find that the ratio of distance changes α is different, and the PFSDM distance’s is closest to 1 among them, which demonstrate that its variation trend is more even than others when membership and non-membership change the same.
The previous examples demonstrate the feasibility of PFSDM distance through numerical analysis. It is well known that pattern recognition is one of the important applications of distance measure. Paul [84] modifies Zhang and Xu’s distance measure of PFSs and applies them to pattern recognition. In the next example, the proposed method is applied {to pattern recognition to prove its rationality.
Example 3.
Suppose a limited universe of discourse , and represent four materials of building respectively, and B is an unknown material. Their PFSs are given in Table 3, and we need to recognize the type of B in A by finding the smallest distance from them. The results of Paul’s method and proposed method, PFSDM distance, are given in Table 4:
In the process of calculation, we use a negligible number such as to replace the zero, which is a good method to avoid having a zero denominator. The smallest PFSDM distance of them is , so the material B belongs to , which is identical to the result of Paul’s modified method. Hence, PFSDM distance is capable of achieving the desired effect when applied to real-life problems.
In this section, the PFSDM distance for measuring the divergence of PFSs is proposed. Some numerical examples are used to prove its properties and compared with other existing methods. The PFSDM distance has been proven that it not only is rational and practical but has more powerful resolution and a more uniform trend as well, which is because the proposed method combines the properties of BPA handling uncertainty and divergence’s character distinguishing similar data.
4. Application in Medical Diagnosis
In this section, a modified algorithm for medical diagnosis is designed, which is improved based on Xiao’s algorithm [57]. The new algorithm utilizes the PFSDM distance and obtains excellent results in application.
Problem statement: Suppose a limited universe of discourse , and the represent the symptoms of diseases and patients. Assume existing m number of patients listed as and o number of diseases listed as . The symptoms of diseases and patients represented by Pythagorean fuzzy sets are as follows:
We need to utilize the distance measure to recognize which diseases the patients contract.
- Step1
- For every symptom, calculate the PFSDM distance in terms of Equation (20) between and , where .
- Step2
- Calculate the weight of every symptom in medical diagnosis:.
- Step3
- Diagnose the symptoms of the patient and the symptoms of the disease.Calculate the weighted average PFSDM distance .
- Step4
- For each weighted average PFSDM distance, the patients can be classified to diseases , in which , .
When the specific symptoms of the patient conflict with the symptoms of the disease, the proposed algorithm considers that the conflicted symptoms are paid more attention in the medical diagnosis. If all symptoms are diagnosed with the same weight, abnormal symptoms will be ignored when the symptom base is large. In the later examples, the applications of the proposed algorithm and its comparisons with other existing algorithm are shown.
Example 4.
([85]) Assume there are four patients, , , , and , denoted as . Five symptoms, , , , , and , are observed, denoted as . Additionally, five diagnoses, , , , , and , are defined, represented as . Then, the Pythagorean fuzzy relations and are displayed in Table 5 and Table 6.
The results diagnosis by the proposed algorithm and Xiao’s method [57] are displayed in Table 7 and Table 8. By observing the experimental results of proposed method, it is obvious that the has the least for , has the least for , has the least for , and has the least for ; Hence, the conclusions are obvious in Table 8.
As shown in Table 9, obviously the proposed method generates the same results as Samuel’s method and Xiao’s method, which can demonstrate that the proposed algorithm is capable of finishing medical diagnosis problems. In addition to doing this, we can find that the proposed method has better resolution than Xiao’s method by observing Table 7 and Table 8.
Example 5.
([2,11,57,87,88,89,90]) Assume four patients exist, namely, , , , and , denoted as . Five symptoms are observed, in which they are , , , , and , denoted as . Additionally, five diagnoses, namely, , , , , and , are defined, represented as . The numerical values respectively represented the membership and non-membership grade of the Pythagorean fuzzy set. Then, through the evaluation of the proposed distance measurement, the Pythagorean fuzzy sets’ distance of and the Pythagorean fuzzy sets’ distance of are displayed in the following Table 10 and Table 11.
After calculating the distance by the proposed method and Xiao’s method to measure the data, the results are generated in Table 12 and Table 13. The results of () are different because of the data marked red in Table 10 and Table 11. Though the is more similar to in other data intuitively, it generates a conflicted data in (). We use a weighted average to assign weights to symptoms. Hence, when the patient matches most of the symptoms of the disease, but one of the symptoms conflicts, the proposed algorithm will give greater weight to the effect of this symptom on the diagnosis of the disease, which will make the diagnosis of a complex disease with many symptoms more accurate.
By comparing other applied widely methods of medical diagnosis and their results in Table 14, we can find that the diagnosis of () is controversial and its results in Table 13 are similar between () and (). On the contrary, () and () have a bigger difference in Table 12, which means that the new method is quite certain of the result.
From the above two examples, the magnified method’s feasibility and merits have been demonstrated. The feasibility of the new algorithm is illustrated by comparing the results of three methods in Example 4, and it can be intuitively found from Table 7 and Table 8 that the new algorithm has higher resolution. In the second Example 5, more methods were compared in Table 14. The new algorithm uses weighted summation to make the previously disputed results more certain, which proves that it considers that the higher conflicted symptoms play a more important role in the diagnostic process.
5. Conclusions
In this paper, we propose a new divergence measure, called PFSDM distance, based on belief function, and modify the algorithm based on Xiao’s method. The proposed method can produce intuitive results and its feasibility is proven by comparing with the existing method. In addition to this, the new method has more even change trend and better performance when the PFSs have larger hesitancy. In addition, we then apply the new algorithm to medical diagnosis and get the desired effect. The new algorithm has better resolution, which is helpful to ruling thresholds in practical applications. Consequently, the main contributions of this article are as follows:
- A method to express the PFS in the form of BPA is proposed, which is the first time to establish a link between them.
- A new distance measure between PFSs, called the PFSDM distance, based on Jensen–Shannon divergence and belief function, is proposed. Combining the characters of divergence and BPA contributes to more powerful resolution and even more of a change trend than existing methods.
- A modified medical diagnosis algorithm is proposed based on Xiao’s method, which utilized the weighted summation to magnify the resolution of algorithm and increase the influence of conflicted data.
- The new divergence measure and the modified algorithm both have satisfying performance in the applications of pattern recognition and medical diagnosis.
It is well known that medical diagnosis is not a accurate procedure and uncertainty is always present in cases. Though we get a definite result in Example 5 by the proposed algorithm, more cases are supposed to be examined in further research to get a safer result. In future research, we will try to explore more PFSs’ properties by using the belief function in evidence theory further and apply them to more situations such as the multi-criteria decision-making and pattern recognition.
Author Contributions
Methodology, Q.Z. and Y.D.; Writing–original draft, Q.Z.; Writing–review & editing, H.M. and Y.D. All authors have read and agreed to the published version of the manuscript.
Funding
The work is partially supported by the National Natural Science Foundation of China (Grant No. 61973332) and the General Natural Research Program of Sichuan Minzu College (Grant No. XYZB18013ZB).
Acknowledgments
The work is partially supported by the National Natural Science Foundation of China (Grant No. 61973332) and the General Natural Research Program of Sichuan Minzu College (Grant No. XYZB18013ZB). The authors greatly appreciate the reviews’ suggestions and editor’s encouragement.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Cao, Z.; Ding, W.; Wang, Y.K.; Hussain, F.K.; Al-Jumaily, A.; Lin, C.T. Effects of Repetitive SSVEPs on EEG Complexity using Multiscale Inherent Fuzzy Entropy. Neurocomputing 2019. [Google Scholar] [CrossRef] [Green Version]
- De, S.K.; Biswas, R.; Roy, A.R. An application of intuitionistic fuzzy sets in medical diagnosis. Fuzzy Sets Syst. 2001, 117, 209–213. [Google Scholar] [CrossRef]
- Cao, Z.; Lin, C.T.; Lai, K.L.; Ko, L.W.; King, J.T.; Liao, K.K.; Fuh, J.L.; Wang, S.J. Extraction of SSVEPs-based Inherent fuzzy entropy using a wearable headband EEG in migraine patients. IEEE Trans. Fuzzy Syst. 2019. [Google Scholar] [CrossRef] [Green Version]
- Ding, W.; Lin, C.T.; Cao, Z. Deep neuro-cognitive co-evolution for fuzzy attribute reduction by quantum leaping PSO with nearest-neighbor memeplexes. IEEE Trans. Cybern. 2018, 49, 2744–2757. [Google Scholar] [CrossRef]
- Xiao, F. EFMCDM: Evidential fuzzy multicriteria decision-making based on belief entropy. IEEE Trans. Fuzzy Syst. 2019. [Google Scholar] [CrossRef]
- Tripathy, B.; Arun, K. A new approach to soft sets, soft multisets and their properties. Int. J. Reason.-Based Intell. Syst. 2015, 7, 244–253. [Google Scholar] [CrossRef]
- Song, Y.; Fu, Q.; Wang, Y.F.; Wang, X. Divergence-based cross entropy and uncertainty measures of Atanassov’s intuitionistic fuzzy sets with their application in decision making. Appl. Soft Comput. 2019, 84, 105703. [Google Scholar] [CrossRef]
- Feng, F.; Liang, M.; Fujita, H.; Yager, R.R.; Liu, X. Lexicographic Orders of Intuitionistic Fuzzy Values and Their Relationships. Mathematics 2019, 7, 166. [Google Scholar] [CrossRef] [Green Version]
- Mondal, K.; Pramanik, S. Intuitionistic fuzzy similarity measure based on tangent function and its application to multi-attribute decision-making. Glob. J. Adv. Res. 2015, 2, 464–471. [Google Scholar]
- Song, Y.; Wang, X.; Zhu, J.; Lei, L. Sensor dynamic reliability evaluation based on evidence theory and intuitionistic fuzzy sets. Appl. Intell. 2018, 48, 3950–3962. [Google Scholar] [CrossRef]
- Wei, C.P.; Wang, P.; Zhang, Y.Z. Entropy, similarity measure of interval-valued intuitionistic fuzzy sets and their applications. Inf. Sci. 2011, 181, 4273–4286. [Google Scholar] [CrossRef]
- Dahooie, J.H.; Zavadskas, E.K.; Abolhasani, M.; Vanaki, A.; Turskis, Z. A Novel Approach for Evaluation of Projects Using an Interval–Valued Fuzzy Additive Ratio Assessment ARAS Method: A Case Study of Oil and Gas Well Drilling Projects. Symmetry 2018, 10, 45. [Google Scholar] [CrossRef] [Green Version]
- Pan, Y.; Zhang, L.; Li, Z.; Ding, L. Improved Fuzzy Bayesian Network-Based Risk Analysis With Interval-Valued Fuzzy Sets and D-S Evidence Theory. IEEE Trans. Fuzzy Syst. 2019. [Google Scholar] [CrossRef]
- Ding, W.; Lin, C.T.; Prasad, M.; Cao, Z.; Wang, J. A layered-coevolution-based attribute-boosted reduction using adaptive quantum-behavior PSO and its consistent segmentation for neonates brain tissue. IEEE Trans. Fuzzy Syst. 2017, 26, 1177–1191. [Google Scholar] [CrossRef] [Green Version]
- Gao, X.; Deng, Y. Quantum Model of Mass Function. Int. J. Intell. Syst. 2020, 35, 267–282. [Google Scholar] [CrossRef]
- Chatterjee, K.; Zavadskas, E.K.; Tamoaitien, J.; Adhikary, K.; Kar, S. A Hybrid MCDM Technique for Risk Management in Construction Projects. Symmetry 2018, 10, 46. [Google Scholar] [CrossRef] [Green Version]
- Cao, Z.; Chuang, C.H.; King, J.K.; Lin, C.T. Multi-channel EEG recordings during a sustained-attention driving task. Sci. Data 2019, 6. [Google Scholar] [CrossRef] [Green Version]
- Palash, D.; Hazarika, G.C. Construction of families of probability boxes and corresponding membership functions at different fractiles. Expert Syst. 2017, 34, e12202. [Google Scholar]
- Talhofer, V.; Hošková-Mayerová, Š.; Hofmann, A. Multi-criteria Analysis. In Quality of Spatial Data in Command and Control System; Springer: Cham, Switzerland, 2019; pp. 39–48. [Google Scholar]
- Su, X.; Li, L.; Qian, H.; Sankaran, M.; Deng, Y. A new rule to combine dependent bodies of evidence. Soft Comput. 2019, 23, 9793–9799. [Google Scholar] [CrossRef]
- Jiang, W. A correlation coefficient for belief functions. Int. J. Approx. Reason. 2018, 103, 94–106. [Google Scholar] [CrossRef] [Green Version]
- Dutta, P. An uncertainty measure and fusion rule for conflict evidences of big data via Dempster–Shafer theory. Int. J. Image Data Fusion 2018, 9, 152–169. [Google Scholar] [CrossRef]
- Fu, C.; Chang, W.; Xue, M.; Yang, S. Multiple criteria group decision-making with belief distributions and distributed preference relations. Eur. J. Oper. Res. 2019, 273, 623–633. [Google Scholar] [CrossRef]
- Tripathy, B.; Mittal, D. Hadoop based uncertain possibilistic kernelized c-means algorithms for image segmentation and a comparative analysis. Appl. Soft Comput. 2016, 46, 886–923. [Google Scholar] [CrossRef]
- Seiti, H.; Hafezalkotob, A.; Najaf, S.E. Developing a novel risk-based MCDM approach based on D numbers and fuzzy information axiom and its applications in preventive maintenance planning. Appl. Soft Comput. 2019. [Google Scholar] [CrossRef]
- Seiti, H.; Hafezalkotob, A.; Martinez, L. R-sets, Comprehensive Fuzzy Sets Risk Modeling for Risk-based Information Fusion and Decision-making. IEEE Trans. Fuzzy Syst. 2019. [Google Scholar] [CrossRef]
- Seiti, H.; Hafezalkotob, A. Developing the R-TOPSIS methodology for risk-based preventive maintenance planning: A case study in rolling mill company. Comput. Ind. Eng. 2019, 128, 622–636. [Google Scholar] [CrossRef]
- Jiang, W.; Cao, Y.; Deng, X. A novel Z-network model based on Bayesian network and Z-number. IEEE Trans. Fuzzy Syst. 2019. [Google Scholar] [CrossRef]
- Kang, B.; Zhang, P.; Gao, Z.; Chhipi-Shrestha, G.; Hewage, K.; Sadiq, R. Environmental assessment under uncertainty using Dempster–Shafer theory and Z-numbers. J. Ambient Intell. Humaniz. Comput. 2019, 1–20. [Google Scholar] [CrossRef]
- Seiti, H.; Hafezalkotob, A.; Fattahi, R. Extending a pessimistic–optimistic fuzzy information axiom based approach considering acceptable risk: Application in the selection of maintenance strategy. Appl. Soft Comput. 2018, 67, 895–909. [Google Scholar] [CrossRef]
- Deng, X.; Jiang, W. Evaluating green supply chain management practices under fuzzy environment: A novel method based on D number theory. Int. J. Fuzzy Syst. 2019, 21, 1389–1402. [Google Scholar] [CrossRef]
- Xiao, F.; Zhang, Z.; Abawajy, J. Workflow scheduling in distributed systems under fuzzy environment. J. Intell. Fuzzy Syst. 2019, 37, 5323–5333. [Google Scholar] [CrossRef]
- Chakraborty, S.; Tripathy, B. Privacy preserving anonymization of social networks using eigenvector centrality approach. Intell. Data Anal. 2016, 20, 543–560. [Google Scholar] [CrossRef]
- Fang, R.; Liao, H.; Yang, J.B.; Xu, D.L. Generalised probabilistic linguistic evidential reasoning approach for multi-criteria decision-making under uncertainty. J. Oper. Res. Soc. 2019, in press. [Google Scholar] [CrossRef]
- Liao, H.; Wu, X. DNMA: A double normalization-based multiple aggregation method for multi-expert multi-criteria decision-making. Omega 2019. [Google Scholar] [CrossRef]
- Feng, F.; Fujita, H.; Ali, M.I.; Yager, R.R.; Liu, X. Another view on generalized intuitionistic fuzzy soft sets and related multiattribute decision-making methods. IEEE Trans. Fuzzy Syst. 2018, 27, 474–488. [Google Scholar] [CrossRef]
- Fei, L. On interval-valued fuzzy decision-making using soft likelihood functions. Int. J. Intell. Syst. 2019, 34, 1631–1652. [Google Scholar] [CrossRef]
- Liao, H.; Mi, X.; Xu, Z. A survey of decision-making methods with probabilistic linguistic information: Bibliometrics, preliminaries, methodologies, applications and future directions. Fuzzy Optim. Decis. Mak. 2019. [Google Scholar] [CrossRef]
- Mardani, A.; Nilashi, M.; Zavadskas, E.K.; Awang, S.R.; Zare, H.; Jamal, N.M. Decision Making Methods Based on Fuzzy Aggregation Operators: Three Decades Review from 1986 to 2017. Int. J. Inf. Technol. Decis. Mak. 2018, 17, 391–466. [Google Scholar] [CrossRef]
- Zhou, D.; Al-Durra, A.; Zhang, K.; Ravey, A.; Gao, F. A robust prognostic indicator for renewable energy technologies: A novel error correction grey prediction model. IEEE Trans. Ind. Electron. 2019, 66, 9312–9325. [Google Scholar] [CrossRef]
- Dutta, P. Modeling of variability and uncertainty in human health risk assessment. MethodsX 2017, 4, 76–85. [Google Scholar] [CrossRef]
- Wu, X.; Liao, H. A consensus-based probabilistic linguistic gained and lost dominance score method. Eur. J. Oper. Res. 2019, 272, 1017–1027. [Google Scholar] [CrossRef]
- Seiti, H.; Hafezalkotob, A.; Najafi, S.; Khalaj, M. A risk-based fuzzy evidential framework for FMEA analysis under uncertainty: An interval-valued DS approach. J. Intell. Fuzzy Syst. 2018, 5, 1–12. [Google Scholar] [CrossRef]
- Liu, B.; Deng, Y. Risk Evaluation in Failure Mode and Effects Analysis Based on D Numbers Theory. Int. J. Comput. Commun. Control 2019, 14, 672–691. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Atanassov, K.T. Intuitionistic fuzzy sets. In Intuitionistic Fuzzy Sets; Springer: Heidelberg, Germany, 1999; pp. 1–137. [Google Scholar]
- Yager, R.R.; Abbasov, A.M. Pythagorean membership grades, complex numbers, and decision-making. Int. J. Intell. Syst. 2013, 28, 436–452. [Google Scholar] [CrossRef]
- Yager, R.R. Pythagorean membership grades in multicriteria decision-making. IEEE Trans. Fuzzy Syst. 2013, 22, 958–965. [Google Scholar] [CrossRef]
- Yager, R.R. Properties and applications of Pythagorean fuzzy sets. In Imprecision and Uncertainty in Information Representation and Processing; Springer: Cham, Switzerland, 2016; pp. 119–136. [Google Scholar]
- Xiao, F. A distance measure for intuitionistic fuzzy sets and its application to pattern classification problems. IEEE Trans. Syst. Man Cybern. Syst. 2019. [Google Scholar] [CrossRef]
- Song, Y.; Wang, X.; Quan, W.; Huang, W. A new approach to construct similarity measure for intuitionistic fuzzy sets. Soft Comput. 2019, 23, 1985–1998. [Google Scholar] [CrossRef]
- Tripathy, B.; Mohanty, R.; Sooraj, T. On intuitionistic fuzzy soft set and its application in group decision-making. In Proceedings of the 2016 International Conference on Emerging Trends in Engineering, Technology and Science (ICETETS), Pudukkottai, India, 24–26 February 2016; pp. 1–5. [Google Scholar]
- Szmidt, E.; Kacprzyk, J. Distances between intuitionistic fuzzy sets. Fuzzy Sets Syst. 2000, 114, 505–518. [Google Scholar] [CrossRef]
- Grzegorzewski, P. Distances between intuitionistic fuzzy sets and/or interval-valued fuzzy sets based on the Hausdorff metric. Fuzzy Sets Syst. 2004, 148, 319–328. [Google Scholar] [CrossRef]
- Chen, T.Y. Remoteness index-based Pythagorean fuzzy VIKOR methods with a generalized distance measure for multiple criteria decision analysis. Inf. Fusion 2018, 41, 129–150. [Google Scholar] [CrossRef]
- Wei, G.; Wei, Y. Similarity measures of Pythagorean fuzzy sets based on the cosine function and their applications. Int. J. Intell. Syst. 2018, 33, 634–652. [Google Scholar] [CrossRef]
- Xiao, F.; Ding, W. Divergence measure of Pythagorean fuzzy sets and its application in medical diagnosis. Appl. Soft Comput. 2019, 79, 254–267. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976; Volume 42. [Google Scholar]
- Dempster, A.P. Upper and lower probability inferences based on a sample from a finite univariate population. Biometrika 1967, 54, 515–528. [Google Scholar] [CrossRef]
- Song, Y.; Deng, Y. Divergence measure of belief function and its application in data fusion. IEEE Access 2019, 7, 107465–107472. [Google Scholar] [CrossRef]
- Kullback, S. Information Theory and Statistics; Courier Corporation: Chelmsford, MA, USA, 1997. [Google Scholar]
- Deng, Y. Deng entropy. Chaos Solitons Fractals 2016, 91, 549–553. [Google Scholar] [CrossRef]
- Zhou, M.; Liu, X.B.; Chen, Y.W.; Qian, X.F.; Yang, J.B.; Wu, J. Assignment of attribute weights with belief distributions for MADM under uncertainties. Knowl.-Based Syst. 2019. [Google Scholar] [CrossRef]
- Deng, X.; Jiang, W. A total uncertainty measure for D numbers based on belief intervals. Int. J. Intell. Syst. 2019, 34, 3302–3316. [Google Scholar] [CrossRef] [Green Version]
- Xiao, F. Generalization of Dempster–Shafer theory: A complex mass function. Appl. Intell. 2019, in press. [Google Scholar]
- Gao, X.; Liu, F.; Pan, L.; Deng, Y.; Tsai, S.B. Uncertainty measure based on Tsallis entropy in evidence theory. Int. J. Intell. Syst. 2019, 34, 3105–3120. [Google Scholar] [CrossRef]
- Wang, H.; Deng, X.; Zhang, Z.; Jiang, W. A New Failure Mode and Effects Analysis Method Based on Dempster–Shafer Theory by Integrating Evidential Network. IEEE Access 2019, 7, 79579–79591. [Google Scholar] [CrossRef]
- Jiang, W.; Zhang, Z.; Deng, X. A Novel Failure Mode and Effects Analysis Method Based on Fuzzy Evidential Reasoning Rules. IEEE Access 2019, 7, 113605–113615. [Google Scholar] [CrossRef]
- Zhang, H.; Deng, Y. Weighted belief function of sensor data fusion in engine fault diagnosis. Soft Comput. 2019. [Google Scholar] [CrossRef]
- Zhou, M.; Liu, X.B.; Chen, Y.W.; Yang, J.B. Evidential reasoning rule for MADM with both weights and reliabilities in group decision-making. Knowl.-Based Syst. 2018, 143, 142–161. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, Y.; Dezert, J.; Cuzzolin, F. Evidence combination based on credal belief redistribution for pattern classification. IEEE Trans. Fuzzy Syst. 2019. [Google Scholar] [CrossRef] [Green Version]
- Zhou, M.; Liu, X.; Yang, J. Evidential reasoning approach for MADM based on incomplete interval value. J. Intell. Fuzzy Syst. 2017, 33, 3707–3721. [Google Scholar] [CrossRef] [Green Version]
- Gao, S.; Deng, Y. An evidential evaluation of nuclear safeguards. Int. J. Distrib. Sens. Netw. 2020, 16. [Google Scholar] [CrossRef] [Green Version]
- Pan, L.; Deng, Y. An association coefficient of belief function and its application in target recognition system. Int. J. Intell. Syst. 2020, 35, 85–104. [Google Scholar] [CrossRef]
- Xu, X.; Xu, H.; Wen, C.; Li, J.; Hou, P.; Zhang, J. A belief rule-based evidence updating method for industrial alarm system design. Control Eng. Pract. 2018, 81, 73–84. [Google Scholar] [CrossRef]
- Xu, X.; Li, S.; Song, X.; Wen, C.; Xu, D. The optimal design of industrial alarm systems based on evidence theory. Control Eng. Pract. 2016, 46, 142–156. [Google Scholar] [CrossRef]
- Li, Y.; Deng, Y. Intuitionistic Evidence Sets. IEEE Access 2019, 7, 106417–106426. [Google Scholar] [CrossRef]
- Luo, Z.; Deng, Y. A matrix method of basic belief assignment’s negation in Dempster–Shafer theory. IEEE Trans. Fuzzy Syst. 2019, 27. [Google Scholar] [CrossRef]
- Jiang, W.; Huang, C.; Deng, X. A new probability transformation method based on a correlation coefficient of belief functions. Int. J. Intell. Syst. 2019, 34, 1337–1347. [Google Scholar] [CrossRef]
- Zhang, W.; Deng, Y. Combining conflicting evidence using the DEMATEL method. Soft Comput. 2019, 23, 8207–8216. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, K.; Deng, Y. Base belief function: An efficient method of conflict management. J. Ambient Intell. Humaniz. Comput. 2019, 10, 3427–3437. [Google Scholar] [CrossRef]
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef] [Green Version]
- Fei, L.; Deng, Y. Multi-criteria decision-making in Pythagorean fuzzy environment. Appl. Intell. 2019. [Google Scholar] [CrossRef]
- Ejegwa, P.A. Modified Zhang and Xu’s distance measure for Pythagorean fuzzy sets and its application to pattern recognition problems. Neural Comput. Appl. 2019. [Google Scholar] [CrossRef]
- Ngan, R.T.; Ali, M. δ-equality of intuitionistic fuzzy sets: A new proximity measure and applications in medical diagnosis. Appl. Intell. 2018, 48, 499–525. [Google Scholar]
- Samuel, A.E.; Rajakumar, S. Intuitionistic Fuzzy Set with Modal Operators in Medical Diagnosis. Adv. Fuzzy Math. 2017, 12, 167–175. [Google Scholar]
- Peng, X.; Yuan, H.; Yang, Y. Pythagorean fuzzy information measures and their applications. Int. J. Intell. Syst. 2017, 32, 991–1029. [Google Scholar] [CrossRef]
- Szmidt, E.; Kacprzyk, J. Intuitionistic fuzzy sets in intelligent data analysis for medical diagnosis. In International Conference on Computational Science; Springer: Berlin/Heidelberg, Germnay, 2001; pp. 263–271. [Google Scholar]
- Vlachos, I.K.; Sergiadis, G.D. Intuitionistic fuzzy information–applications to pattern recognition. Pattern Recognit. Lett. 2007, 28, 197–206. [Google Scholar] [CrossRef]
- Ye, J. Cosine similarity measures for intuitionistic fuzzy sets and their applications. Math. Comput. Model. 2011, 53, 91–97. [Google Scholar] [CrossRef]
Figure 1.
The results in the proof.

Figure 2.
The results in Example 2.


{kind=link}
{kind=link}
Table 1.
Two PFSs and under different cases.
| PFSs | Case1 | Case2 | Case3 |
|---|---|---|---|
| PFSs | Case4 | Case5 | Case6 |
| PFSs | Case7 | Case8 | Case9 |
Table 2.
The comparison of different methods’ results.
| Methods | Case1 | Case2 | Case3 | Case4 | Case5 | Case6 | Case7 | Case8 | Case9 |
|---|---|---|---|---|---|---|---|---|---|
| [55] | |||||||||
| [55] | |||||||||
| [83] | |||||||||
| [57] | |||||||||
Table 3.
The Pythagorean fuzzy sets of building materials in Example 3.
| PFS | |||||
|---|---|---|---|---|---|
| PFS | |||||
Table 4.
The results generated by two methods in Example 3.
Table 5.
The symptoms of the patients in Example 4.
Table 6.
The symptoms of the diagnoses in Example 4.
Table 7.
The results generated by the Xiao method in Example 4.
| 3842 | ||||||
Table 8.
The results generated by the proposed method in Example 4.
| 5281 | ||||||
Table 10.
The symptoms of the patients in Example 5.
Table 11.
The symptoms of the diagnoses in Example 5.
Table 12.
The results generated by proposed method in Example 5.
Table 13.
The results generated by Xiao’s method in Exmple 5.
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhou, Q.; Mo, H.; Deng, Y. A New Divergence Measure of Pythagorean Fuzzy Sets Based on Belief Function and Its Application in Medical Diagnosis. Mathematics 2020, 8, 142. https://0-doi-org.brum.beds.ac.uk/10.3390/math8010142
AMA Style
Zhou Q, Mo H, Deng Y. A New Divergence Measure of Pythagorean Fuzzy Sets Based on Belief Function and Its Application in Medical Diagnosis. Mathematics. 2020; 8(1):142. https://0-doi-org.brum.beds.ac.uk/10.3390/math8010142
Chicago/Turabian StyleZhou, Qianli, Hongming Mo, and Yong Deng. 2020. "A New Divergence Measure of Pythagorean Fuzzy Sets Based on Belief Function and Its Application in Medical Diagnosis" Mathematics 8, no. 1: 142. https://0-doi-org.brum.beds.ac.uk/10.3390/math8010142
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.