Auto-Colorization of Historical Images Using Deep Convolutional Neural Networks

 ,
,  ,
,  ,
,  , and
, and
Abstract
:1. Introduction
- We analyze the colorization process on the dataset using the CNN-integrated model with Inception ResNetV2.
- Several pieces of research have been reported in the literature on colorization for black and white images with varieties of datasets, including heritage images of Japan, Vietnam, France (Pablo Picasso’s), ImageNet dataset, SUN dataset (4.0.0, Princeton, USA), CIFAR-10 (3.0.2, Toronto, Canada), etc. Inspired by these, we try to apply recent trends of deep learning approaches on our own dataset.
- We perform an objective and subjective evaluation of the model using various metrics such as MSE and PSNR.
- The proposed framework can be considered a base-model for the colorization of ancient images.
2. Related Works
3. Methodology
3.1. Dataset Construction
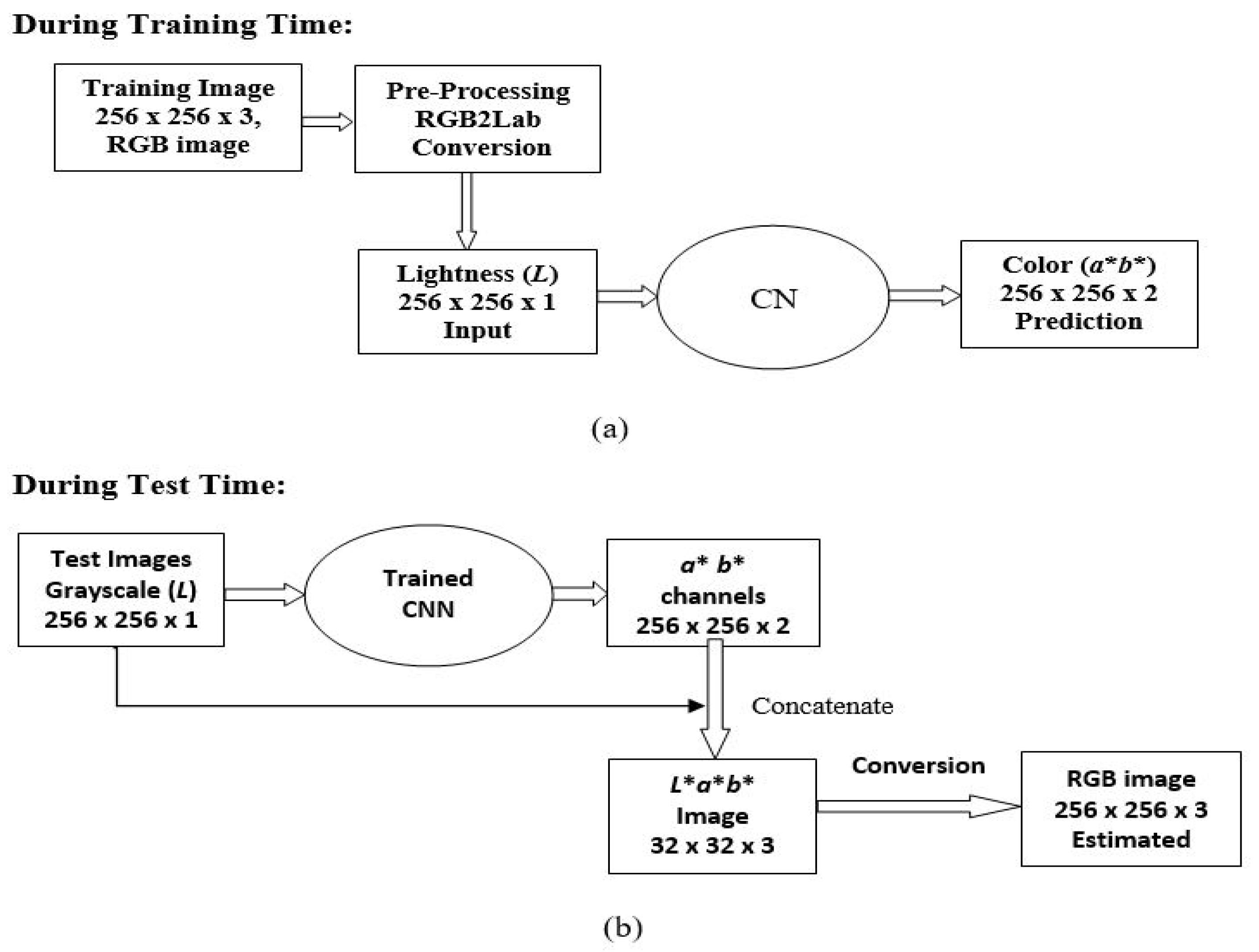
3.2. Pre-Processing Images
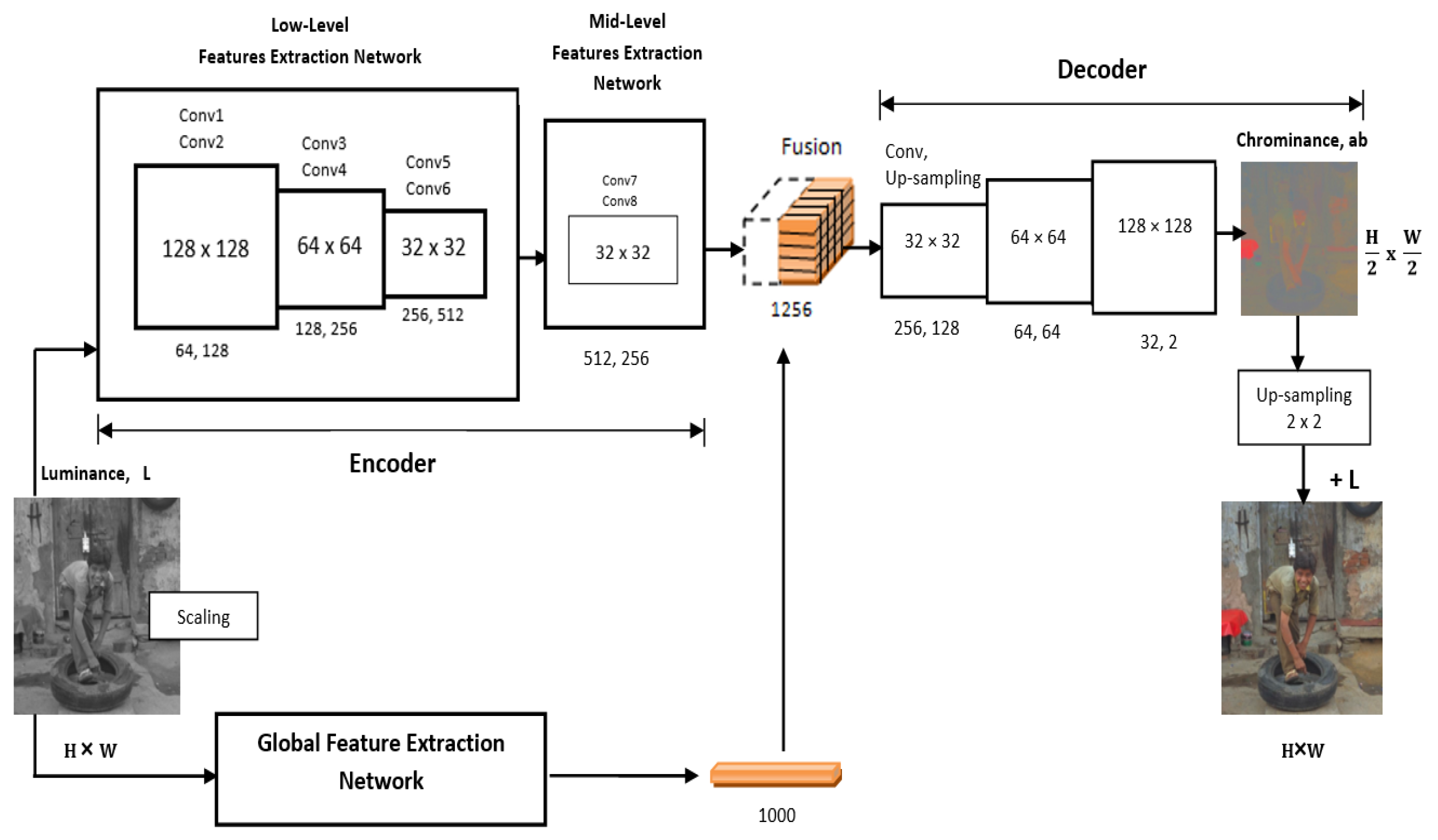
3.3. CNN Model Architecture
3.3.1. Encoder Unit
3.3.2. Global Feature Extractor
3.3.3. Fusion Layer
3.3.4. Decoder Unit
3.4. Optimization and Learning
4. Results and Discussion
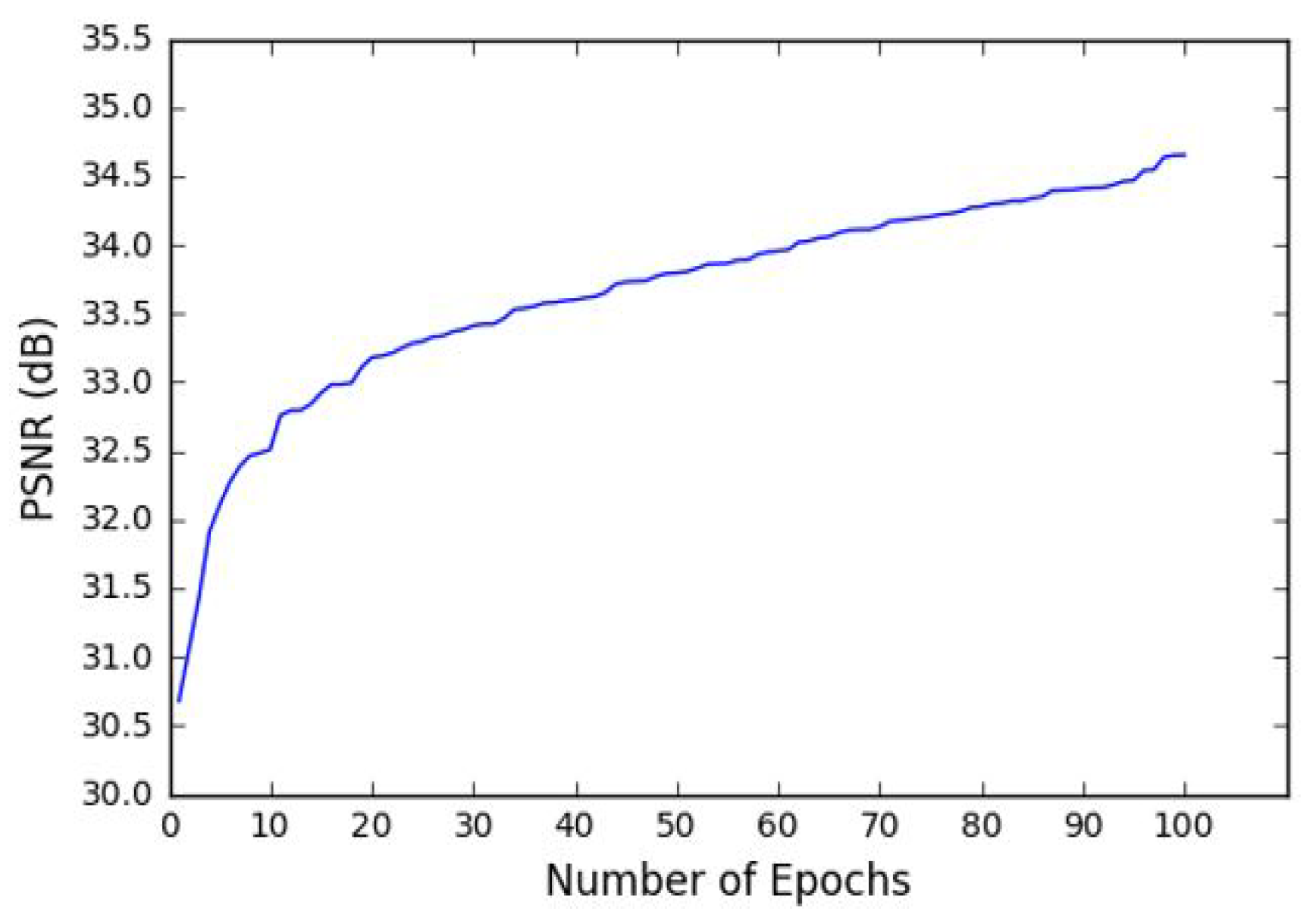
4.1. Training
4.1.1. Colorization Results on Test Images
4.1.2. Colorization Results on Validation Images
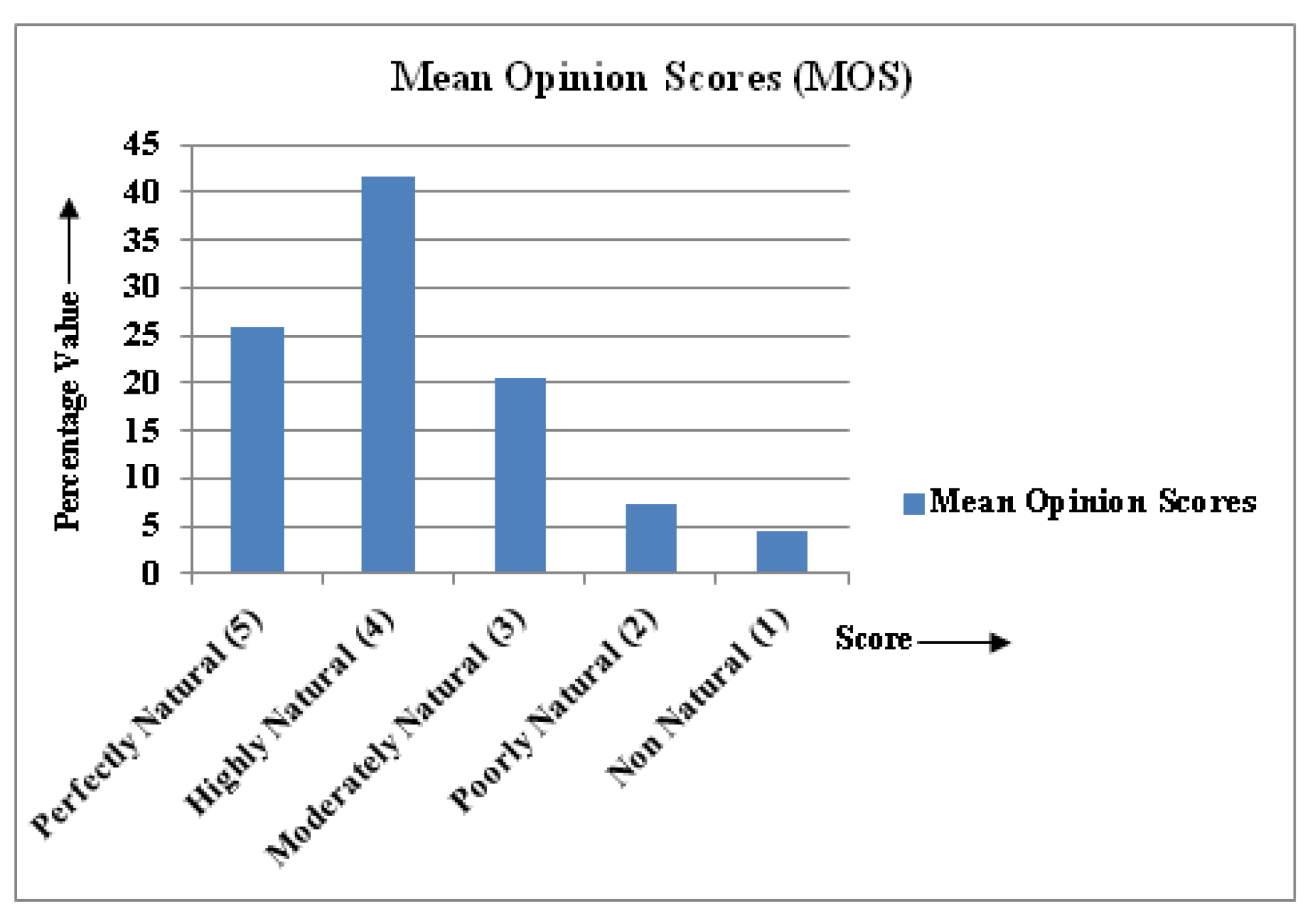
4.2. User Study
4.3. Comparative Study
5. Conclusions and Future Work
5.1. Concluding Remarks
5.2. Limitations and Future Directions
- Despite offering good results on user satisfaction, the performance of the proposed method for coloring small details can be further improved. In this research, only a 1.2 K image dataset was used due to computational complexities, but the performance on unseen images highly depends on the contents of the images used for the training. Therefore, increasing the size and variability of the training set with a more powerful GPU may obtain a better result.
- In this research, we used the simplest and the most widely used objective image quality matrices, such as MSE and PSNR that perform estimation based on only absolute errors. Thus, regression with cross-entropy might yield a better result. In addition, a better quantitative evaluation of colorized results is possible by using structural similarity index measure because it considers the structure of samples of interest in addition to luminance and contrast.
- Generative Adversarial Network (GAN)-based architectures [30,31,32] have the potential to produce natural color distribution. It can be considered as an alternative to the loss function where the generator model maps grayscale images to color image space, and the discriminator model is trained to predict the probability that a given colorization was sampled from data distribution rather than being generated by the generator model, conditioned on the grayscale image. The generator takes a grayscale image and outputs an RGB version of that image which is fed to the discriminator. The generator tries to produce synthetic data and the discriminator tries to distinguish between synthetic and real data. The ultimate objective is to produce a better result, which is visually appealing. With regard to this, the integration of GAN into the proposed image colorization framework is worthy of investigation with the aim of improved results.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Martínez, B.; Casas, S.; Vidal-González, M.; Vera, L.; García-Pereira, I. TinajAR: An edutainment augmented reality mirror for the dissemination and reinterpretation of cultural heritage. Multimodal Technol. Interact. 2018, 2, 33. [Google Scholar] [CrossRef] [Green Version]
- Portalés, C.; Rodrigues, J.M.; Rodrigues Gonçalves, A.; Alba, E.; Sebastián, J. Digital Cultural Heritage. Available online: https://0-www-mdpi-com.brum.beds.ac.uk/2414-4088/2/3/58 (accessed on 20 December 2020).
- Casas, S.; Gimeno, J.; Casanova-Salas, P.; Riera, J.V.; Portalés, C. Virtual and Augmented Reality for the Visualization of Summarized Information in Smart Cities: A Use Case for the City of Dubai. In Smart Systems Design, Applications, and Challenges; IGI Global: Pennsylvania, PA, USA, 2020; pp. 299–325. [Google Scholar]
- Guidi, G.; Beraldin, J.A.; Atzeni, C. High-accuracy 3D modeling of cultural heritage: The digitizing of Donatello’s “Maddalena”. IEEE Trans. Image Process. 2004, 13, 370–380. [Google Scholar] [CrossRef] [PubMed]
- Andreetto, M.; Brusco, N.; Cortelazzo, G.M. Automatic 3D modeling of textured cultural heritage objects. IEEE Trans. Image Process. 2004, 13, 354–369. [Google Scholar] [CrossRef] [PubMed]
- Elazab, N.; Soliman, H.; El-Sappagh, S.; Islam, S.; Elmogy, M. Objective Diagnosis for Histopathological Images Based on Machine Learning Techniques: Classical Approaches and New Trends. Mathematics 2020, 8, 1863. [Google Scholar] [CrossRef]
- Kim, H.I.; Yoo, S.B. Trends in Super-High-Definition Imaging Techniques Based on Deep Neural Networks. Mathematics 2020, 8, 1907. [Google Scholar] [CrossRef]
- Levin, A.; Lischinski, D.; Weiss, Y. Colorization using optimization. In ACM SIGGRAPH 2004 Papers; ACM: Los Angeles, CA, USA, 2004; pp. 689–694. [Google Scholar]
- Huang, Y.C.; Tung, Y.S.; Chen, J.C.; Wang, S.W.; Wu, J.L. An adaptive edge detection based colorization algorithm and its applications. In Proceedings of the 13th Annual ACM International Conference on Multimedia, Hilton, Singapore, 6–11 November 2005; pp. 351–354. [Google Scholar]
- Yatziv, L.; Sapiro, G. Fast image and video colorization using chrominance blending. IEEE Trans. Image Process. 2006, 15, 1120–1129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reinhard, E.; Adhikhmin, M.; Gooch, B.; Shirley, P. Color transfer between images. IEEE Comput. Graph. Appl. 2001, 21, 34–41. [Google Scholar] [CrossRef]
- Welsh, T.; Ashikhmin, M.; Mueller, K. Transferring color to greyscale images. In Proceedings of the 29th Annual Conference on Computer Graphics and Interactive Techniques, San Antonio, TX, USA, 23–26 July 2002; pp. 277–280. [Google Scholar]
- Ironi, R.; Cohen-Or, D.; Lischinski, D. Colorization by Example. Rendering Techniques. Available online: https://www.cs.tau.ac.il/~dcor/onlinepapers/papers/colorization05.pdf (accessed on 10 July 2020).
- Bugeau, A.; Ta, V.T. Patch-based image colorization. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba Science City, Japan, 11–15 November 2012; pp. 3058–3061. [Google Scholar]
- Zeng, D.; Dai, Y.; Li, F.; Wang, J.; Sangaiah, A.K. Aspect based sentiment analysis by a linguistically regularized CNN with gated mechanism. J. Intell. Fuzzy Syst. 2019, 36, 3971–3980. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A. Colorful image colorization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 16–18 October 2016; pp. 649–666. [Google Scholar]
- Luo, Y.; Qin, J.; Xiang, X.; Tan, Y.; Liu, Q.; Xiang, L. Coverless real-time image information hiding based on image block matching and dense convolutional network. J. Real-Time Image Process. 2020, 17, 125–135. [Google Scholar] [CrossRef]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Let there be color! Joint end-to-end learning of global and local image priors for automatic image colorization with simultaneous classification. Acm Trans. Graph. (ToG) 2016, 35, 1–11. [Google Scholar] [CrossRef]
- Agrawal, M.; Sawhney, K. Exploring Convolutional Neural Networks for Automatic Image Colorization. Available online: http://cs231n.stanford.edu/reports/2017/pdfs/409.pdf (accessed on 10 July 2020).
- Karpathy, A. Cs231n convolutional neural networks for visual recognition. Available online: http://cs231n.stanford.edu/2016/ (accessed on 1 August 2020).
- Vu, M.T.; Beurton-Aimar, M.; Le, V.L. Heritage Image Classification by Convolution Neural Networks. In Proceedings of the 2018 1st International Conference on Multimedia Analysis and Pattern Recognition (MAPR), Ho Chi Minh City, Vietnam, 9–10 May 2018; pp. 1–6. [Google Scholar]
- Varga, D.; Szabo, C.A.; Sziranyi, T. Automatic cartoon colorization based on convolutional neural network. In Proceedings of the 15th International Workshop on Content-Based Multimedia Indexing, Florence, Italy, 19–21 June 2017; pp. 1–6. [Google Scholar]
- Baldassarre, F.; Morín, D.G.; Rodés-Guirao, L. Deep koalarization: Image Colorization Using Cnns and Inception-Resnet-v2. arXiv 2017, arXiv:1712.03400. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-Resnet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef] [Green Version]
- Liu, D.; Jiang, Y.; Pei, M.; Liu, S. Emotional image color transfer via deep learning. Pattern Recognit. Lett. 2018, 110, 16–22. [Google Scholar] [CrossRef]
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Isogawa, M.; Mikami, D.; Takahashi, K.; Kimata, H. Image quality assessment for inpainted images via learning to rank. Multimed. Tools Appl. 2019, 78, 1399–1418. [Google Scholar] [CrossRef] [Green Version]
- Nazeri, K.; Ng, E.; Ebrahimi, M. Image colorization using generative adversarial networks. In Proceedings of the International Conference on Articulated Motion and Deformable Objects, Palma de Mallorca, Spain, 12–13 July 2018; pp. 85–94. [Google Scholar]
- Kiani, L.; Saeed, M.; Nezamabadi-pour, H. Image Colorization Using Generative Adversarial Networks and Transfer Learning. In Proceedings of the 2020 International Conference on Machine Vision and Image Processing (MVIP), Tehran, Iran, 18–20 February 2020; pp. 1–6. [Google Scholar]
- Blanch, M.G.; Mrak, M.; Smeaton, A.F.; O’Connor, N.E. End-to-End Conditional GAN-based Architectures for Image Colourisation. In Proceedings of the 2019 IEEE 21st International Workshop on Multimedia Signal Processing (MMSP), Kuala Lumpur, Malaysia, 27–29 September 2019; pp. 1–6. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Culture | Heritage | History | Total |
|---|---|---|---|---|
| Test (Grayscale) | 44 | 65 | 41 | 150 |
| Train (RGB) | 305 | 350 | 315 | 970 |
| Encoder | Fusion | Decoder | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Layer | Kernel | Stride | Outputs | Layer | Kernel | Stride | Outputs | Layer | Kernel | Stride | Outputs |
| conv | 3 × 3 | 2 × 2 | 64 | fusion | - | - | 256 | conv | 3 × 3 | 1 × 1 | 128 |
| conv | 3 × 3 | 1 × 1 | 128 | conv | 1 × 1 | 1 × 1 | 256 | upsamp | - | - | 128 |
| conv | 3 × 3 | 2 × 2 | 128 | conv | 3 × 3 | 1 × 1 | 64 | ||||
| conv | 3 × 3 | 1 × 1 | 256 | conv | 3 × 3 | 1 × 1 | 64 | ||||
| conv | 3 × 3 | 2 × 2 | 256 | upsamp | - | - | 64 | ||||
| conv | 3 × 3 | 1 × 1 | 512 | conv | 3 × 3 | 1 × 1 | 32 | ||||
| conv | 3 × 3 | 1 × 1 | 512 | conv | 3 × 3 | 1 × 1 | 2 | ||||
| conv | 3 × 3 | 1 × 1 | 256 | ||||||||
| Model | MSE | Model Accuracy | Batch Size | Epoch | Training Time (hours) |
|---|---|---|---|---|---|
| CNN with Inception | 6.08% | 75.23% | 20 | 200 | 6.25 |
| CNN with Inception | 19.11% | 67.10% | 20 | 100 | 2.61 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joshi, M.R.; Nkenyereye, L.; Joshi, G.P.; Islam, S.M.R.; Abdullah-Al-Wadud, M.; Shrestha, S. Auto-Colorization of Historical Images Using Deep Convolutional Neural Networks. Mathematics 2020, 8, 2258. https://0-doi-org.brum.beds.ac.uk/10.3390/math8122258
Joshi MR, Nkenyereye L, Joshi GP, Islam SMR, Abdullah-Al-Wadud M, Shrestha S. Auto-Colorization of Historical Images Using Deep Convolutional Neural Networks. Mathematics. 2020; 8(12):2258. https://0-doi-org.brum.beds.ac.uk/10.3390/math8122258
Chicago/Turabian StyleJoshi, Madhab Raj, Lewis Nkenyereye, Gyanendra Prasad Joshi, S. M. Riazul Islam, Mohammad Abdullah-Al-Wadud, and Surendra Shrestha. 2020. "Auto-Colorization of Historical Images Using Deep Convolutional Neural Networks" Mathematics 8, no. 12: 2258. https://0-doi-org.brum.beds.ac.uk/10.3390/math8122258