1. Introduction
In the last few decades, there have been an increased interest among statisticians to define new families of distributions by adding extra shape parameter (one or more) to a baseline distribution. The extra parameters of a good generator can usually give lighter tails and heavier tails, accommodate symmetric, unimodal, bimodal, right-skewed and left-skewed density function, and increase and decrease skewness and kurtosis and, more important, yield all types of the hazard function. Furthermore, the extra parameters can provide great flexibility for modelling data in several areas such as economics, engineering, reliability and medical sciences, among others. Kumar and Dharmaja [
1] proposed the reduced Kies distribution as a special case of the Kies distribution. Here, we will refer to the reduced Kies distribution as the modified Kies (MKi) distribution. The cumulative distribution function (CDF) of the MKi distribution is specified (for
) by
Its probability density function (PDF) takes the form
respectively, where
is a shape parameter. Kumar and Dharmaja [
1] observed that the MKi distribution perform better than the Weibull distribution and some of its extensions in modelling data. Kumar and Dharmaja [
2] introduced the exponentiated reduced Kies distribution and studied some properties of the distribution. Dey et al. [
3] derived the recurrence relations for the single and product moments of the MKi distribution under progressive type-II censoring scheme as well as the estimation of the distribution parameters.
In this paper, we propose a new family of distributions based on the MKi distribution. In fact, based on the T-X family pioneered by Alzaatreh et al. [
4], we construct a new generator so-called the
modified Kies generalized(MKi-
G)
family. Given a baseline distribution, the MKi-
G distribution can be used effectively for analysis purposes.
If
is the baseline CDF depending on a parameter vector
, then the CDF of the MKi-
G family is defined by
The corresponding PDF of (
1) is given by
The hazard rate (HR) function of the MKi-
G family is given by
Henceforth, a random variable with density function (
2) is denoted by
X∼MKi-
The main aim of this paper is to introduce and study a new family of distributions which called the modified Kies-
G (MKi-
G) family. We discuss some general mathematical properties of MKi-G family. Although the MKi distribution proposed by [
1] has interesting properties, it is not flexible in modeling real data because it does not contain a scale parameter. An extended model including a scale parameter has considered by taking the exponential distribution as baseline for the MKi-
G family and generate a two-parameter MKi-exponential (MKiEx) distribution, which has several desirable properties. The MKiEx distribution has a very flexible PDF, it can be positive skewed, negative skewed and symmetric, and can allow for greater flexibility of the tails. It is capable of modeling monotonically decreasing, increasing and bathtub hazard rates. Moreover, it has a closed form CDF and very easy to handle which make the distribution is candidate to use in different fields such as life testing, reliability, biomedical studies and survival analysis. Two real data applications show that the proposed distribution is very competitive to some traditional distributions with scale and shape parameters like Weibull and gamma distributions. It can also be considered as a good alternative to some recently introduced distributions such as the alpha power exponential distribution (APE) by Mahdavi and Kundu [
5], generalized odd log-logistic exponential distribution by Afify et al. [
6], and extended odd Weibull exponential distribution by Afify and Mohamed [
7].
The rest of this paper is organized as follows: in
Section 2, we obtain some mathematical properties of the MKi-G family. In
Section 3, we introduce the MKiEx distribution. Some mathematical properties of the hazard rate function of the MKiEx distribution are derived in
Section 4. The Asymptotic distributions of order statistics of the MKiEx distribution are shown in
Section 5. In
Section 6, we study the mean residual life of the MKiEx distribution. In
Section 7, the maximum likelihood estimates and the approximate confidence intervals are obtained under complete and type-II censored samples as well as the simulation study. The analysis of two real data sets are presented in
Section 8. The paper is concluded in
Section 9.
2. Properties of the MKi Generator
In this section, we obtain some mathematical properties of the MKi-G family such as mixture representation, quantiles, moments, moment generating function (MGF), order statistics, probability weighted moments (PWMs), and Rényi entropy.
2.1. Mixture Representation
Using the exponential series and the power series,
we obtain a useful linear representation for the PDF (
2) as
where
denotes the exponentiated-G (exp-G) PDF with power parameter
, and the coefficient
is given by
Equation (
4) gives the MKi-
G family PDF as a linear combination of exp-G PDFs and enable us to derive some mathematical properties of the MKi-
G family using this representation. More details about the exp-G distributions can be explored in Lemonte et al. [
8].
Integrating (
4), the CDF of
X is given by
where
is the CDF of the exp-G family with power parameter
.
2.2. Quantiles, Ordinary and Incomplete Moments
The quantile function (QF) of (
1) is given by
A random sample of size
n from (
1) can be obtained, based on (
5), as
, where
Uniform(
),
Henceforth, denotes a random variable having the exp-G distribution with power parameter .
The
rth moment of the MKi-
G family can be derived from (
4) as
The
sth incomplete moment of
X can be expressed from (
4) as
The first incomplete moment,
, follows from the last equation with
. The main applications of
refers to the mean deviations and the Bonferroni and Lorenz curves (see, Lorenz [
9] and Bonferroni [
10]).
2.3. Generating Function
In this section, we provide two formulae for the MGF of
X. The first one follows from Equation (
4)
where
is the MGF of the random variable
. Hence,
can be determined from the exp-G MGF. The second formula can also be derived from (
4) by considering
. Therefore, the MGF can be represented as
where
and
is the QF corresponding to
, i.e.,
.
2.4. Order Statistics
Let
be a random sample from the MKi-G family. The PDF of the
ith order statistic,
, is defined by
where
is the beta function.
Based on Equation (
1), we have
Using (
2) and the exponential series, we obtain
After a power series expansion (
3), we can write
Substituting (
7) in Equation (
6), the PDF of
reduces to
where
is the exp-G density with power parameter
and
Based on Equation (
8), we can obtain the properties of
from those properties of the random variable
.
Hence, the
qth moments of
follows as
2.5. Probability Weighted Moments
The
th PWM of
X following the MKi-G distribution is defined by
Based on Equation (
7), we have
2.6. Rényi Entropy
The Rényi entropy of a random variable
X has applications in some applied areas including statistics, information theory, engineering and physics, and it is used as a measure of variation of the uncertainty. The Rényi entropy is defined by
Using the PDF (
2), we obtain
Applying the exponential series to the last term, we can write
Applying the power series (
3), the last equation reduces to
Then, the Rényi entropy of the MKi-G family comes out as
where
3. The MKiEx Distribution
Consider the exponential (Ex) distribution with positive scale parameter
, and CDF given (for
) by
Let a random variable
Z have the above Ex distribution with parameter
. Then, the
rth ordinary and incomplete moments of
Z are given, respectively, by
and
, where
is the the lower incomplete gamma function.
To this end, we define the CDF of the MKiEx model, by inserting the CDF of the Ex distribution in (
1), as
The corresponding PDF of (
9) is given by
where
is a shape parameter and
is a scale parameter.
The HR function of the MKiEx distribution comes out as
The QF of the MKiEx distribution is obtained by inverting (
9) as
Note that can be used to generate MKiEx random variates.
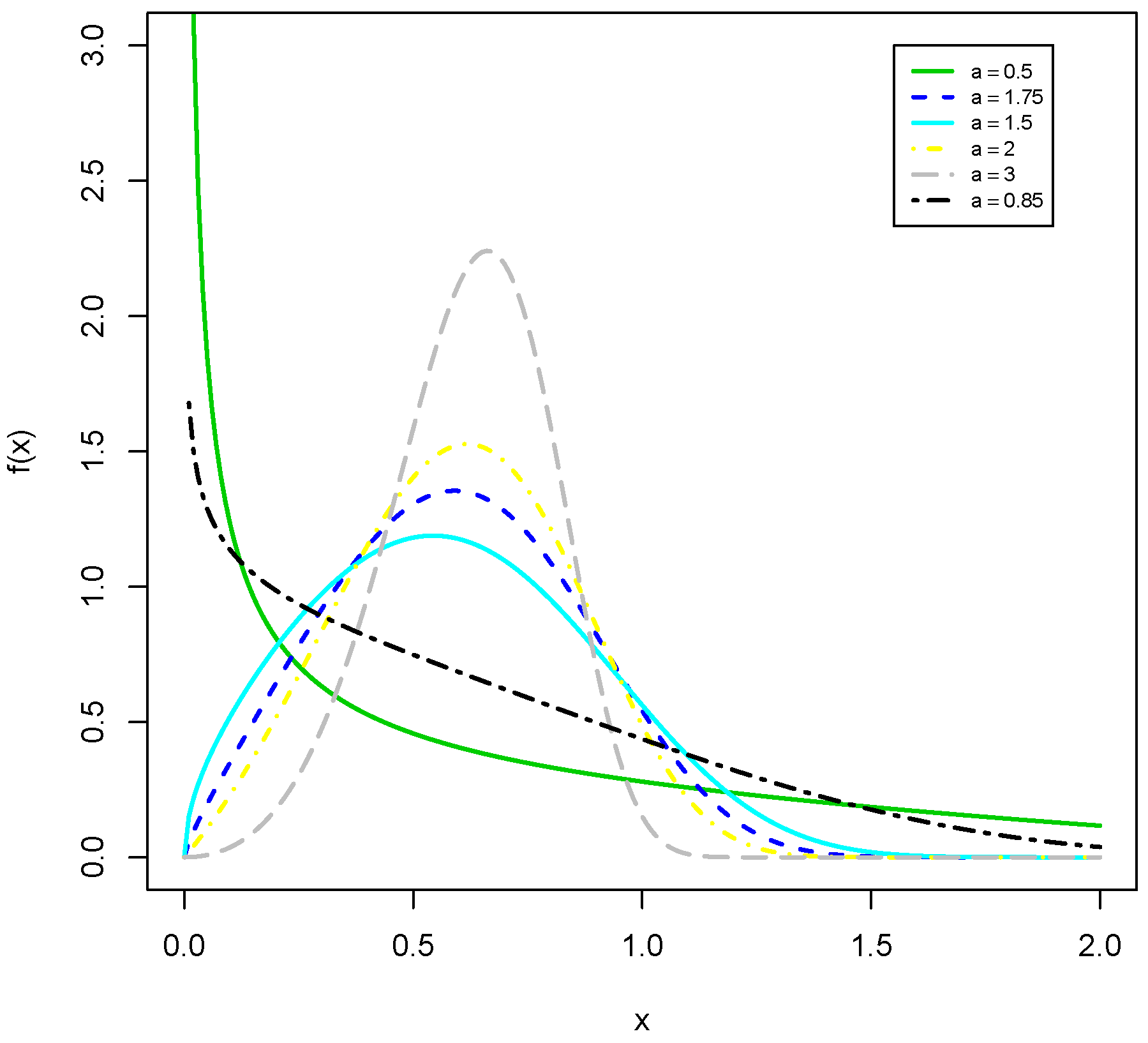
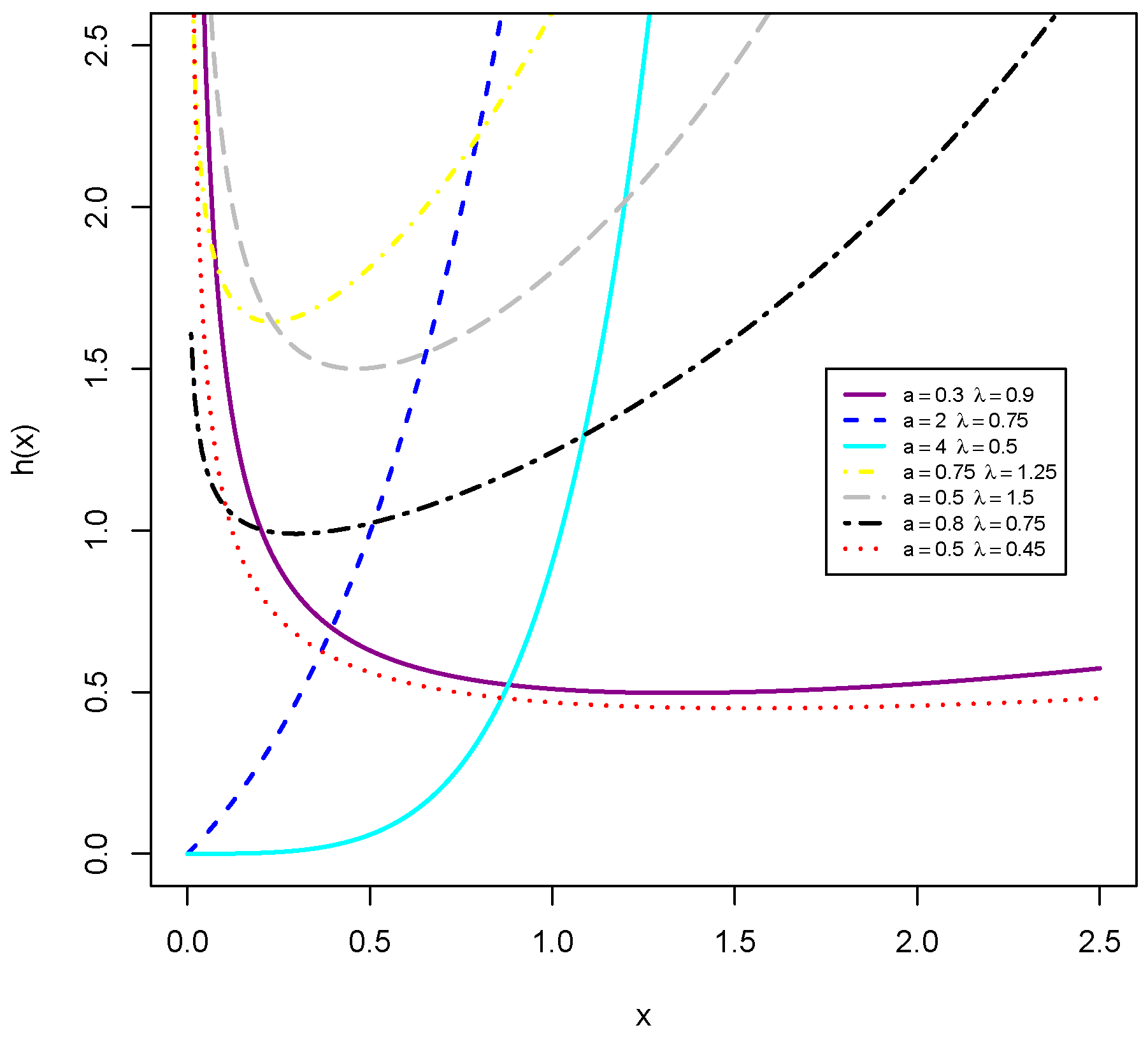
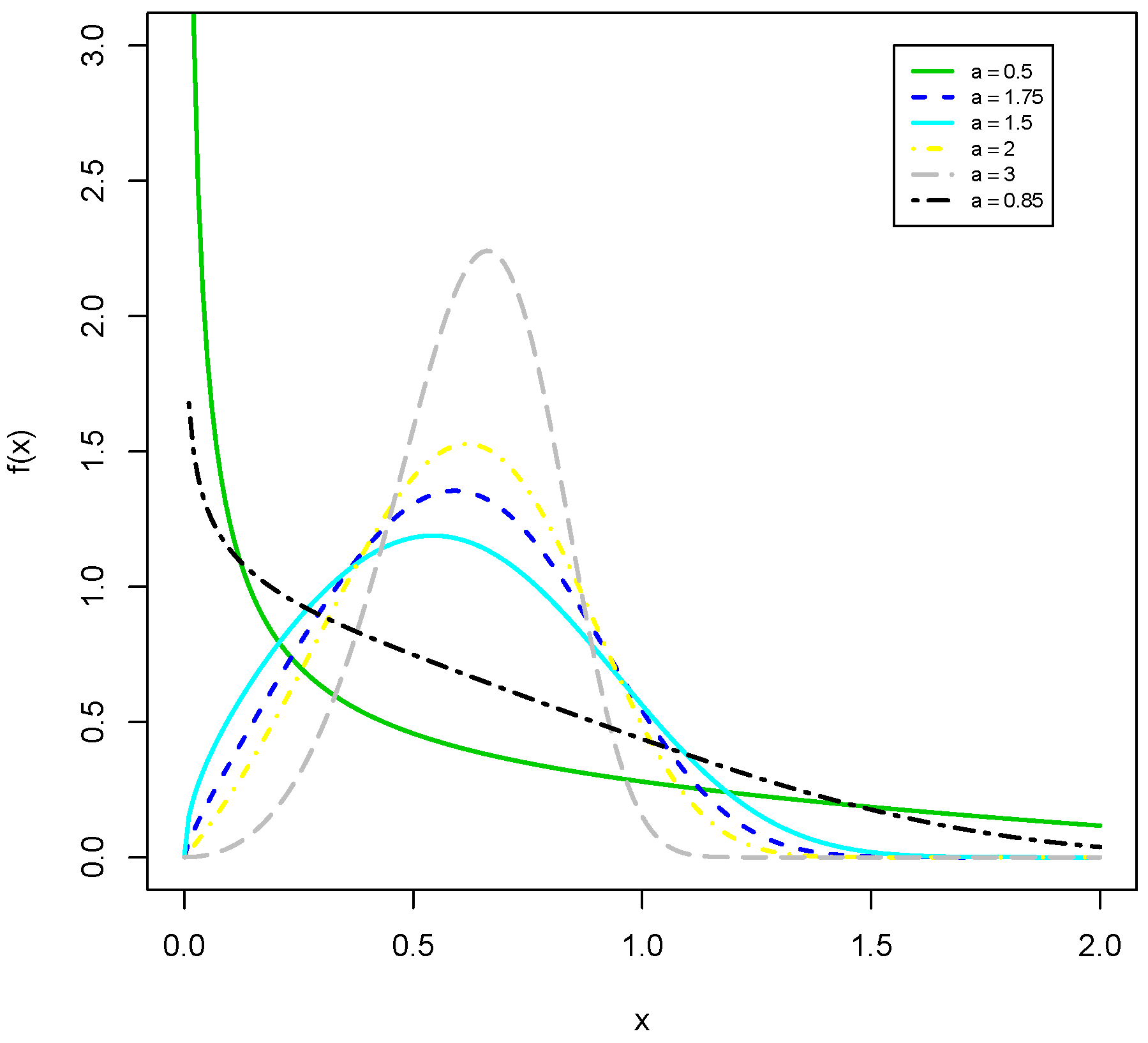
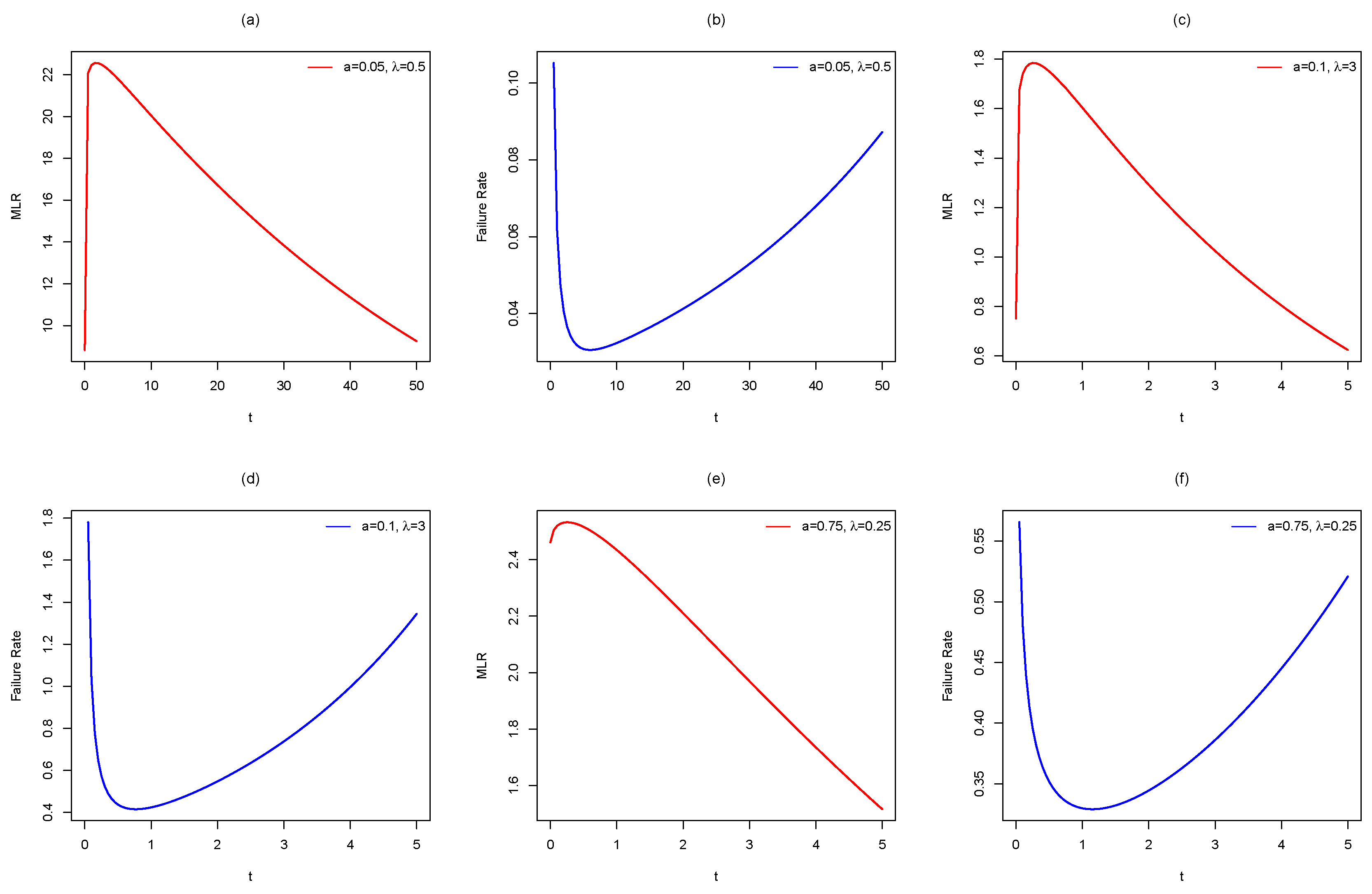
Remark 1. Using (4) and the generalized binomial expansion, the MKiEx density reduces towhereis the PDF of the Ex distribution with scale parameter, and Equation (13) means that the MKiEx density can be expressed as a linear mixture of Ex densities. Hence, the properties of the MKiEx distribution can be obtained simply from those of the Ex distribution. Figure 1 and
Figure 2 display some plots of the PDF and HR function, respectively, of the MKiEx distribution for selected values of
a and
. The plots of
Figure 2 indicate that the HR function of the MKiEx model can be increasing, decreasing and bathtub shaped. One of the advantages of the MKiEx distribution over the exponential distribution is that the the last one cannot model phenomenon showing increasing, decreasing and bathtub failure rate shapes and therefore it becomes more flexible for analyzing lifetime data.
Remark 2. The rth ordinary and incomplete moments of the MKiEx follows from (13) as The skewness and kurtosis measures can be evaluated from the ordinary moments using well-known relationships.
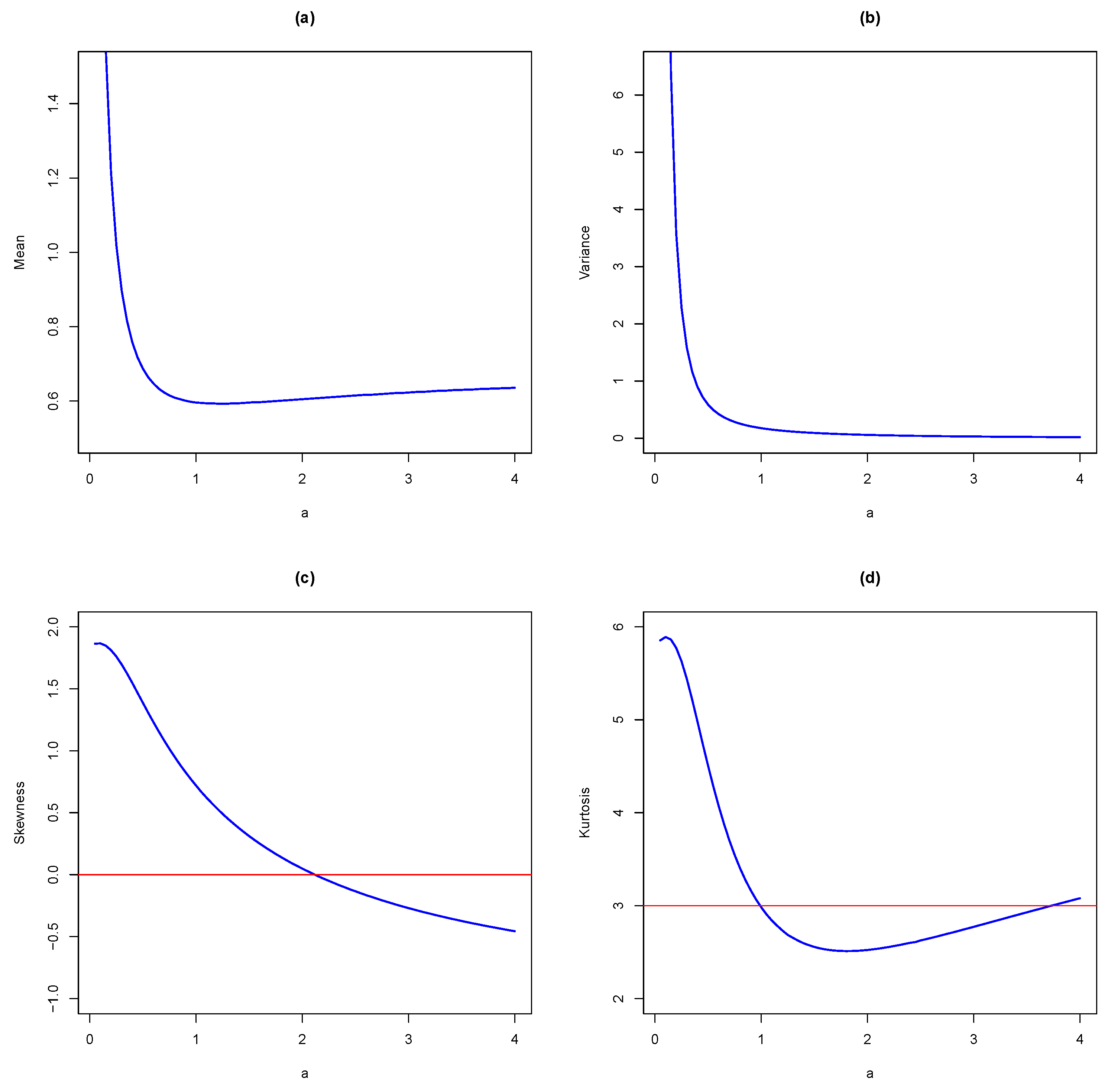
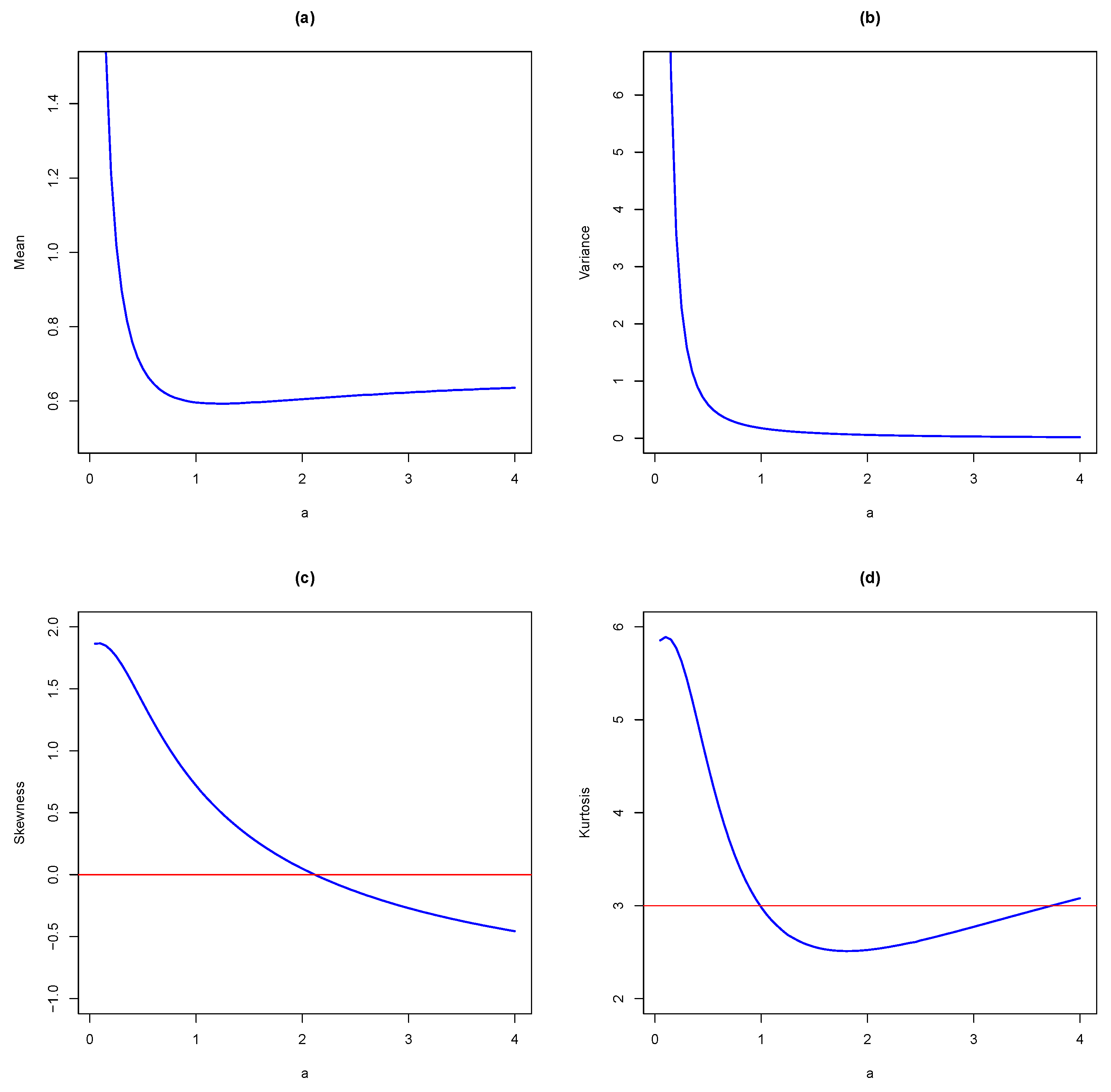
Figure 3 presents the mean, variance, skewness and kurtosis of the MKiEx as a function in the shape parameter
a with
.
Figure 3 shows that the mean is an increasing then decreasing then increasing function in the shape parameter
a, while the variance is an increasing then decreasing function in
a.
Figure 3 indicates that the MKiEx is a flexible distribution. It can be symmetric, right skewed and left skewed. Moreover, it can be mesokurtic, platykurtic and leptokurtic. From
Figure 3c,d, it is observed that for small values of
a, the skewness and kurtosis increase then decrease as
a increases.
4. Some Mathematical Properties for the HR Function of the MKiEx Distribution
The HR function of the MKiEx distribution given via Equation (
11) discloses that for small values of
x (i.e.,
), we have that
and hence it is a decreasing function in
x provided that
. On the other hand, we have that for large values of
x (i.e.,
),
and so it is a growing function in
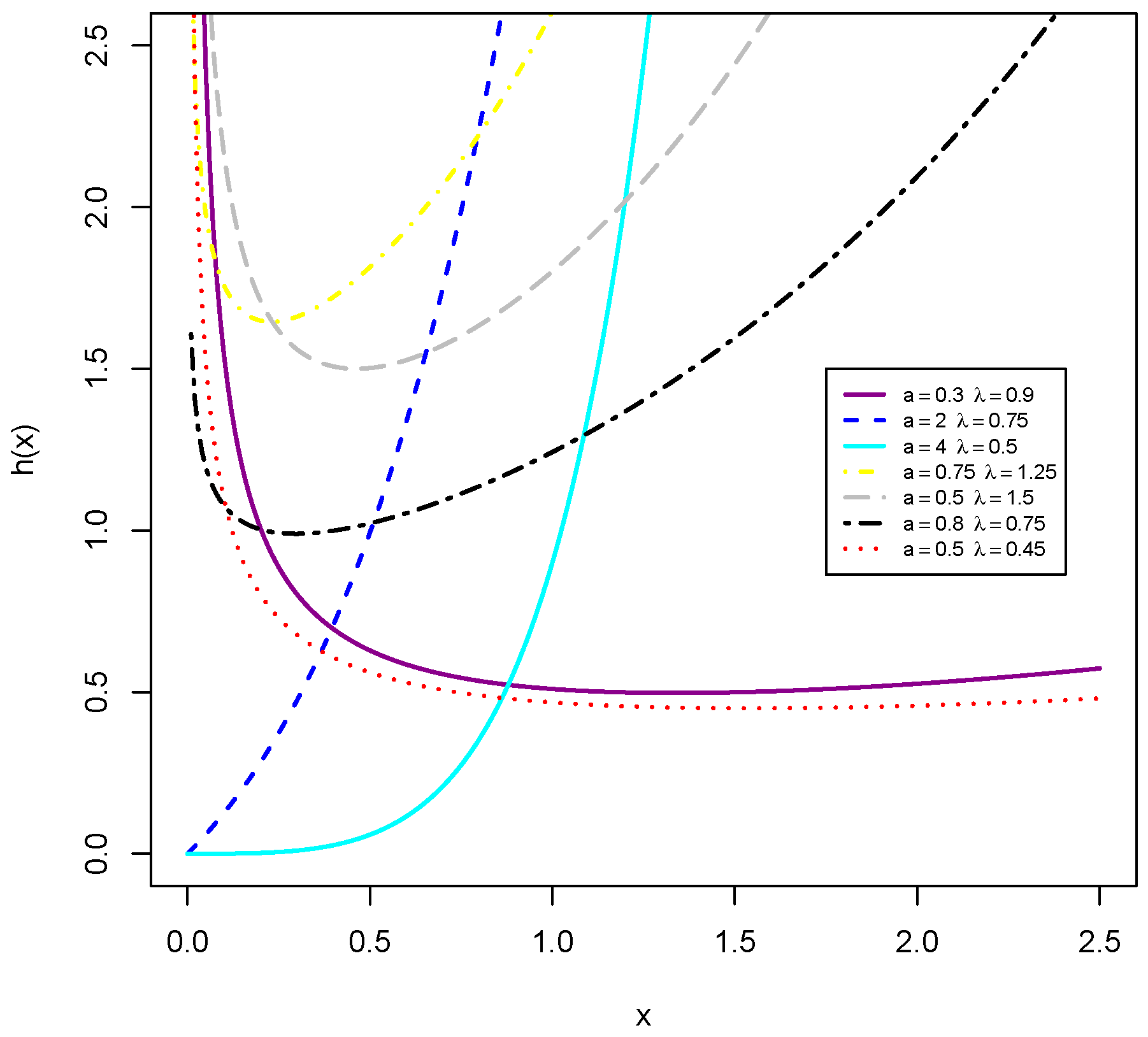
x. Therefore, the MKiEx distribution is useful in modeling aging HR or bathtub-shaped HR. It is worth mentioning that most lifetime distributions with bathtub-shaped HR have some problems related to increasing number of parameters, algebraic complexity, and estimation problems. Interestingly, the MKiEx distribution has a bathtub-shaped HR that based on only two parameters.
Proposition 1. The HR function of MKiEx distribution is an increasing function forand is a bathtub-shaped for
Proof. The first derivative of
is
Clearly, if
it then follows that
for all
x and thus
is an increasing function in
Now suppose that
then
if and only if
Therefore, if and only if and if and only if This implies that has a minimum value at which completes the proof. ☐
5. Asymptotic Distributions of Order Statistics of the MKiEx Distribution
Order statistics are widely used in many different fields of statistical theory and applications. Suppose that
are, independent and identically distributed random variables from the MKiEx distribution. The PDF of the
ith order statistic, say
, for
, is given by
where
Certainly, extreme statistics such as and are members of the class of order statistics. The PDF of these extreme statistics are usually do not possess a closed form distribution (as in our case) and, therefore, asymptotics to their distributions are demanding because their applications are wide spread in many interesting areas. The following proposition provides the asymptotics distributions for the first and largest order statistic functions.
Proposition 2. Letbe a random sample from MKiEx distribution. We have
- (i)
The asymptotic distribution of the largest order statistics belongs to the domain of attraction for maxima of Gumbel type, i.e.,whereandare normalizing constants. - (ii)
The asymptotic distribution of the smallest order statistics belongs to the domain of attraction for minima of Weibull type, i.e.,whereandare normalizing constants.
Proof. (i) Since
so we need to check whether the von Mises condition for the maximum domain of attraction of the Gumbel distribution are satisfied or not, see for example Embrechts et al. ([
11], Equation (3.25), p. 140) or Theorem (8.3.3) (iii) of Arnold et al. [
12]. Specifically, we need to show that
or equivalently, we have to show that
Since
it then follows that
where
On substituting these quantities into Equation (
15), we have
Clearly the second term in Equation (
16) goes to 0, as
and hence the result follows. The normalizing constants can be chosen using Theorem (8.3.4) (iii) of [
12]. Additionally, since the von Mises condition is satisfied for the current problem, it follows Theorem (8.3.4) (iii) of [
12] that
and
For (ii), observe that for sufficiently small values of
x (
), we have that
Since
and
it follows from Theorem (8.3.6) (ii) in [
12] that the limiting distribution is
where the normalized constants can be calculated from Theorem (8.3.6) (ii) of [
12] by taking
and
☐
6. Mean Residual Life
There is an additional important reliability measure which assess the mean remaining life expectancy of a component(individual) last to the time t. This measure is referred to as the mean residual life (MRL) function. The usefulness of the ML function lies in characterizing the entire residual failure time behind the time t contrary to the HR function which describes the failure in a small interval beyond t.
Mathematically speaking, the MRL function for a random variable
X at time
t is determined as the expected value of the conditional random variable of
as given below
Observe that
It is observed that there is an interesting relation between HR function and MRL function as given below
where
is the first derivative of
. Note that Equation (
18) can be obtained by differentiating Equation (
17) with respect to
Apparently, Equation (
18) indicates that the lifetime distribution can be uniquely defined using
and
functions. Further, the inverse of the MRL and HR function are approximately equivalent when
Explicit and approximate expressions for are given in the following section.
6.1. MRL of the MKiEx Distribution
The first incomplete moments of the MKiEx model is
The MRL of
X is defined by
where
is given by (
19) and
is the survival function of the MKiEx distribution.
The MRL of
X follows, by inserting
in (
20), as
The computation of
via Equation (
21) is unattractive. Alternatively, we provide an asymptotic tractable approximation to
for sufficiently large value of
t (
). We have the following proposition.
Proposition 3. For sufficiently large value ofi.e., aswe have that Proof. We have that
where
As
we have that
Since
for small
x (
), it then follows that
On substituting
and letting
and
, Equation (
23) becomes
where
and
Observe that
and
for large values of
(
Accordingly,
Since it then follows that as Consequently, we have that ☐
Table 1 reports some values for the MRL function using asymptotic approximation in (
22) as well as numerical integration for different choices of the parameters
a and
and several time points. It is noted that the two approximation methods are close and consistent when the time point increases; that is, the values obtained from Equation (
22) become near of the values computed from numerical integration.
A useful approximation for the mean of the MKiEx distribution is
where
a is a shape parameter. The mean of the MKiEx distribution is determined by
This can be extended to be a log-linear regression model by making
where
is a parameter vector of length
p and
is the vector of covariates or risk factors,
. Specifically, the log-linear model can be written as
where
is the expectation operator,
Y is the MKiEx random variable,
and
. This would allow a variety of useful analyses, including a conventional nonlinear regression analysis. While the current paper aims to study the current distribution in terms of mathematical and statistical properties, we will consider the class of log-linear models relating to the proposed distribution in a future article.
6.2. MRL Shapes and Changing Points
In spite of MKiEx distribution has increasing or bathtub-shaped HR, we only focus on studying the changing points of the bathtub-shaped HR. Several researchers have discussed the connection between the HR and MRL functions. For instance, Gupta and Akman [
13,
14] proved that if a component has bathtub-shaped HR function, then its matching MRL function is upside-down bathtub, given that
Mi [
15] has proved that for the bathtub-shaped failure rate with a single inflection point
the MRL function has a unimodal shaped with a single turning point
such that
; that is, the changing point of the MRL of a bathtub-shaped lifetime distribution go a head of that of the HR. For details on general results between the relation of MRL and HR functions, the reader is referred to Tang et al. [
16]. We have the following proposition.
Proposition 4. LetMKi-G(a,λ) with. The MRL of X has the upside-down bathtub shape.
Proof. Since for
and
, we have that
. Therefore, it follows that
where the last equality followed on using integration by substitution along with the gamma function. Since
and
(
), it then follows that
and, therefore, the result holds. ☐
We have the following proposition.
Proposition 5. The asymptotic behaviors of the HR function and the reciprocal of the MRL are equivalent as, i.e., Proof. If we prove that
then we are finished. Observe that
Upon using Equation (
22) as
, we have that
and, hence, the result follows. ☐
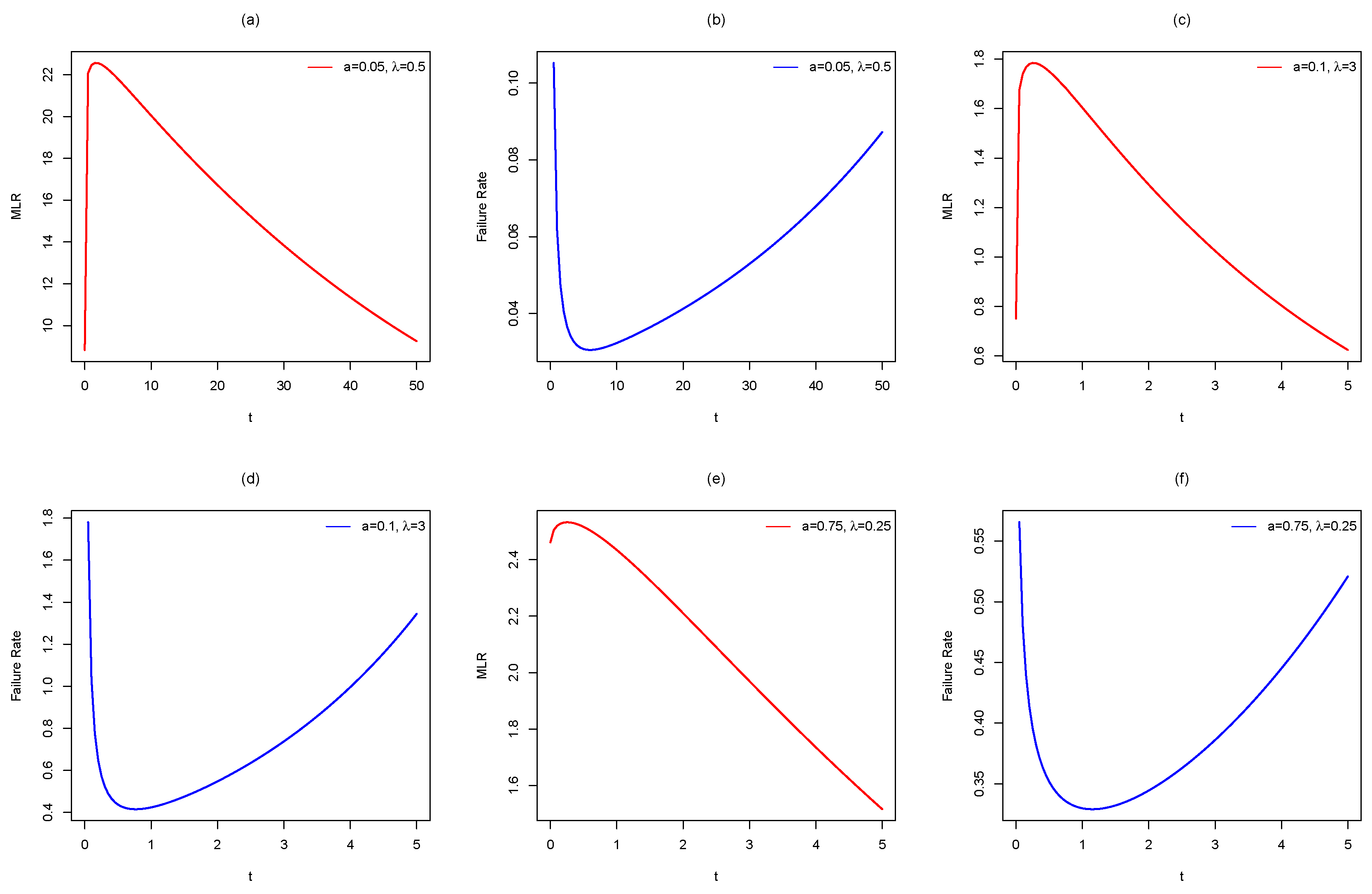
Here, we illustrate the relation between the MRL and HR functions for the Mkies distribution by using diagrams of the MRL and HR functions simultaneously.
Figure 4b exhibits that the HR function has a bathtub-shaped with a unique turning point, that occurs at
The the matching style of the MRL is given in
Figure 4a, which demonstrates a unimodal shaped. The diagram signifies that the changing point of the MRL
take place before that of the HR. The HR function given in
Figure 4d shows the bathtub-shaped with inflection point happen at
and, again, the matching MRL inflection point is
, which occurs before
,
Figure 4c Similarly, the HR in
Figure 4f exhibits a bathtub-shaped HR with the inflection point of the HR occurs at
, whereas the inflection point of the corresponding MRL given in
Figure 4e occurs at
8. Data Analysis
In this section, the MKiEx distribution is fitted to two real data sets and compared with other some competitive models. The fitted distributions are compared using some goodness-of-fit measures such as (Akaike information), (consistent Akaike information), (Bayesian information), and (Hannan-Quinn information) criterions. We also consider the maximized log-likelihood under the model () along with (Cramér-von Mises) and (Anderson-Darling) statistics.
The first data set is reported by Murthy et al. [
17], and it represents failure times for a particular windshield device (84 observations). These data were studied by Afify et al. [
18]. The second data set is reported by Xu et al. [
19], and it contains 40 observations about time-to-failure (10
) of turbocharger of one type of engine. These data were studied by Afify et al. [
20] and Cordeior et al. [
21].
The new MKiEx model is compared with some competing models, such as the Marshall-Olkin exponential (MOEx) (Marshall and Olkin, [
22]), Weibull (W), APEx, Kumaraswamy exponential (KEx), gamma (Ga), beta exponential (BEx) (Nadarajah and Kotz, [
23]), exponentiated exponential (EEx) (Gupta and Kundu, [
24]) and Ex distributions, whose PDFs (for
) are:
Table 5 and
Table 6 report the numerical values of analytical measures for the competing distributions to both analyzed data sets. The maximum likelihood estimates and associated standard errors of the parameters are listed in
Table 7 and
Table 8.
In
Table 5 and
Table 6, we compare the fits of the MKiEx distribution with the W, MOEx APEx, KEx, Ga, BEx, EEx and Ex models. The values in
Table 5 and
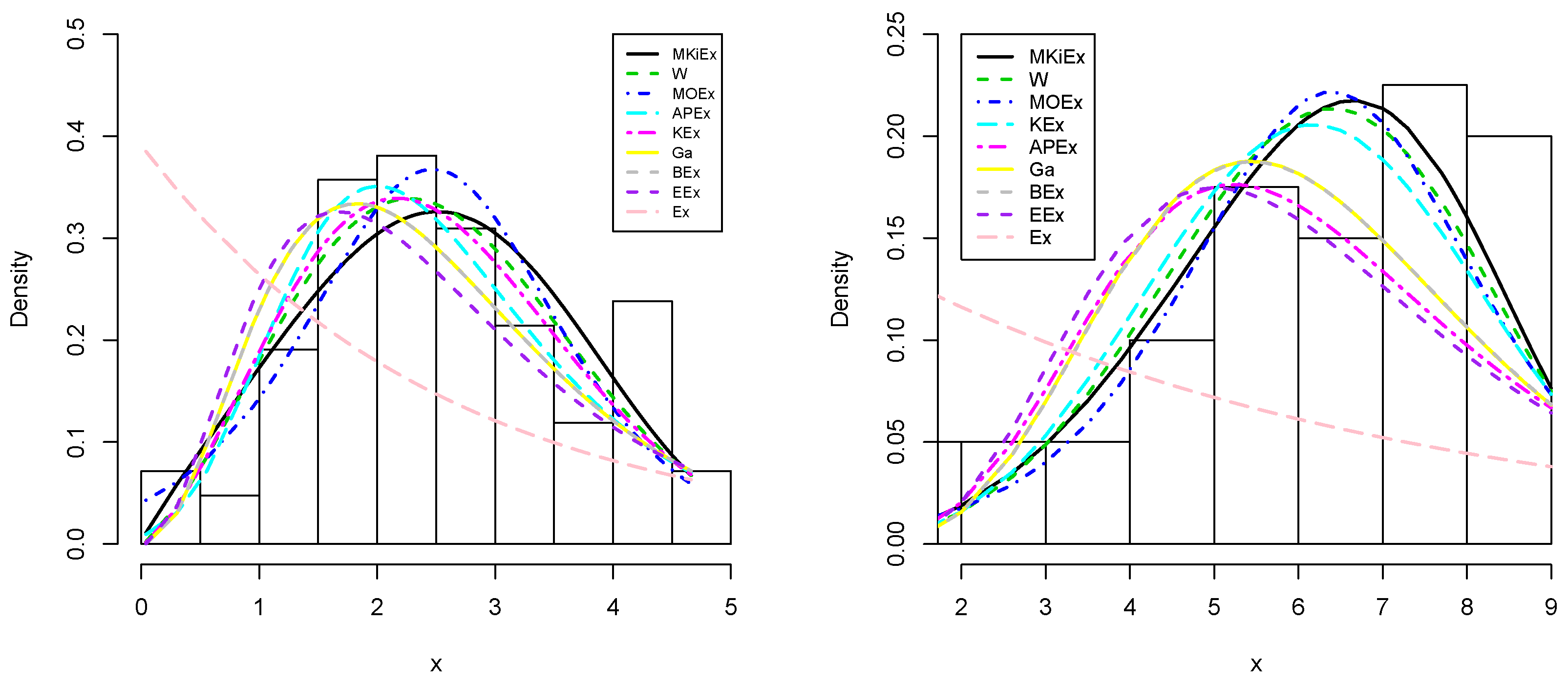
Table 6 illustrate that the MKiEx distribution has close fit for both data sets, among the competing models. The histogram of the two data sets and the fitted MKiEx PDF are displayed in
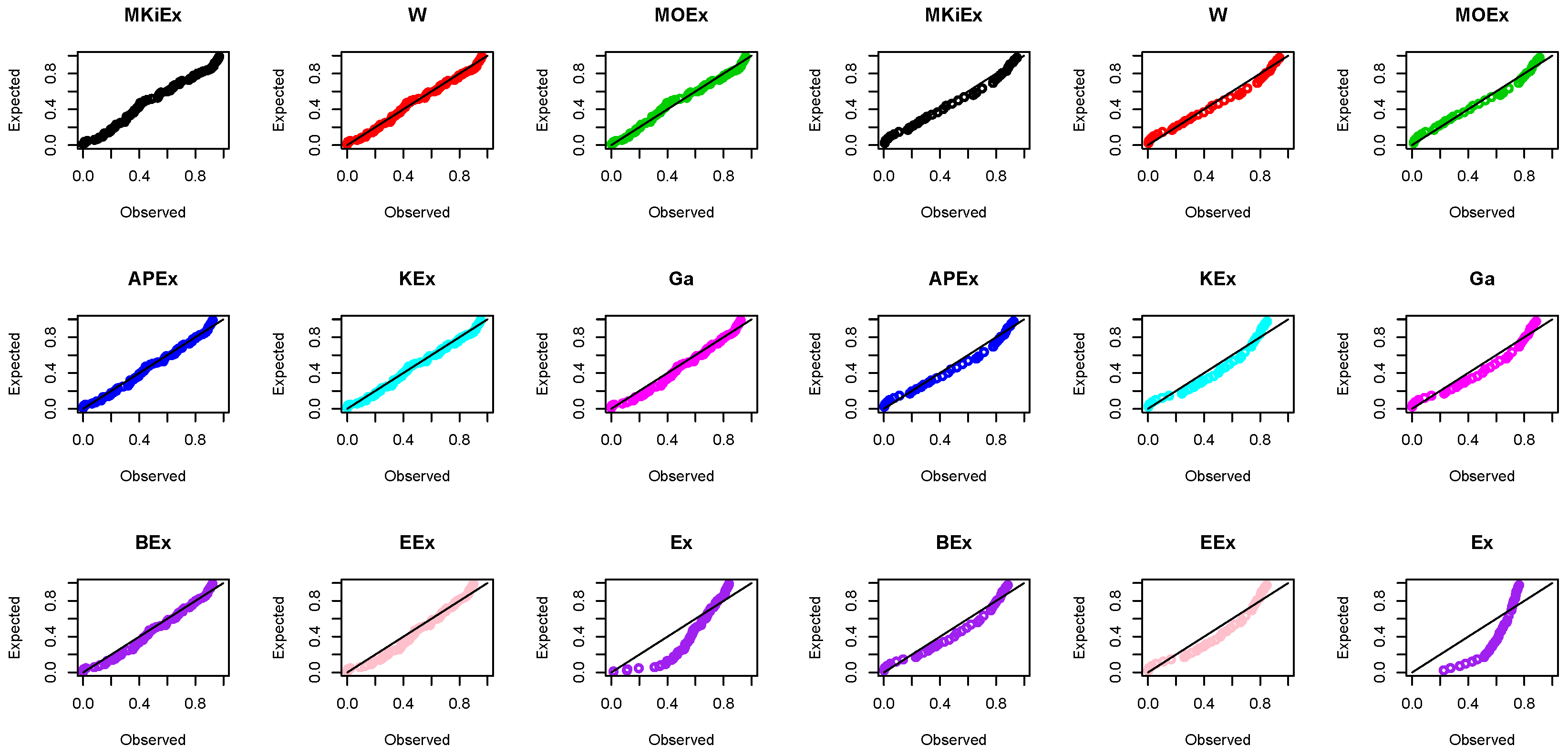
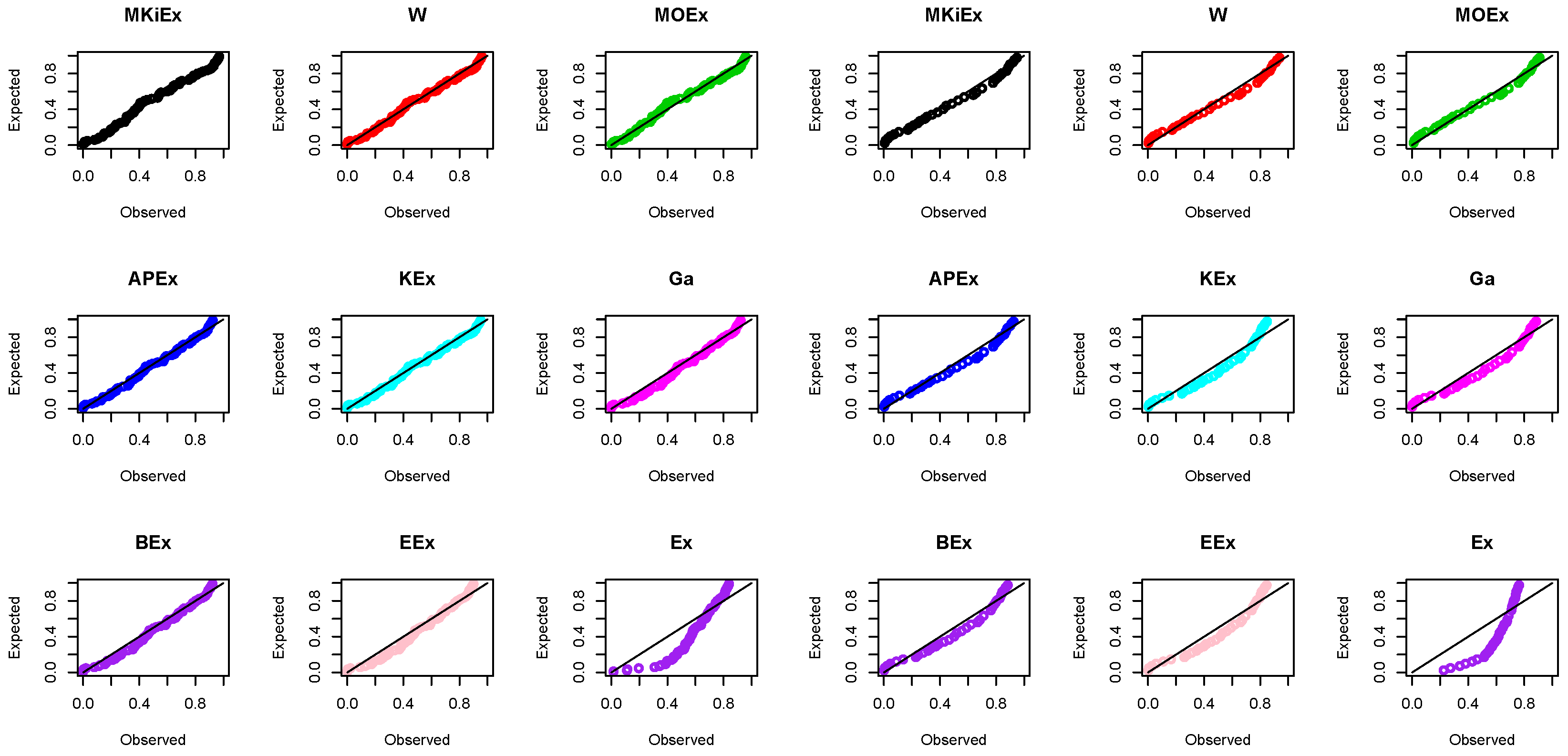
Figure 5. Further, the PP plots of the first and second data sets are displayed in
Figure 6.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}