
Bayesian Inference under Small Sample Sizes Using General Noninformative Priors

1
School of Reliability and Systems Engineering, Beihang University, Beijing 100191, China
2
China Aviation Power Plant Research Institute, Zhuzhou 412002, China
3
Graduate School of China Academy of Engineering Physics, Beijing 100193, China
*
Author to whom correspondence should be addressed.
Mathematics 2021, 9(21), 2810; https://0-doi-org.brum.beds.ac.uk/10.3390/math9212810
Submission received: 6 September 2021
/
Revised: 25 October 2021
/
Accepted: 3 November 2021
/
Published: 5 November 2021
(This article belongs to the Section Probability and Statistics)
Abstract
:This paper proposes a Bayesian inference method for problems with small sample sizes. A general type of noninformative prior is proposed to formulate the Bayesian posterior. It is shown that this type of prior can represent a broad range of priors such as classical noninformative priors and asymptotically locally invariant priors and can be derived as the limiting states of normal-inverse-Gamma conjugate priors, allowing for analytical evaluations of Bayesian posteriors and predictors. The performance of different noninformative priors under small sample sizes is compared using the likelihood combining both fitting and prediction performances. Laplace approximation is used to evaluate the likelihood. A realistic fatigue reliability problem was used to illustrate the method. Following that, an actual aeroengine disk lifing application with two test samples is presented, and the results are compared with the existing method.
1. Introduction
Sample sizes are often quite small in many engineering fields due to time, economic, and physical constraints, for example, life testing data of high-reliability mechanical components, large and complex engineering systems, and so on. The influence of sample size on interpreting classical significance test results has been discussed in several studies [1,2,3]. The predictive models established based on scarce samples may highly depend on the chosen parameter estimation method [4,5]. In those cases, the probabilistic approach is usually preferred over the deterministic approach [6,7,8,9,10,11]. The Bayes rule provides a consistent and rational mathematical device to incorporate relevant information and prior knowledge for probabilistic inference.
To motivate the discussion, consider an observable random variable X with a conditional probability density function (PDF) (or simply density) of , where is also a random variable. The inverse problem is to make inferences about given an observed value x of X. The Bayesian approach to the solution is to use some density over to represent the prior information of . In this way, the prior knowledge of can be encoded through the Bayes rule to obtain the posterior PDF of given x,
The forward inference, e.g., the PDF of a certain variable or the probability of an event involving , can be made on the basis of the posterior PDF. Using the method of Markov chain Monte Carlo (MCMC), samples can directly be drawn from the posterior distribution without knowing the normalizing constant in Equation (1). The Bayesian method has been successfully demonstrated in all important disciplines [12,13,14,15,16,17,18,19].
The choice of can have a great influence on the inference result. The proper choice of priors has been extensively discussed in the probability and statistics communities, and it can never be overlooked as it is one of the fundamental pieces of Bayesian inference [20,21,22,23,24,25,26]. For one thing, the formal rule of constructing a prior regardless of the data and likelihood is sought in the field of physics [9,27]. Jaynes and Bretthorst [28] argued that “problems of inference are ill-posed until we recognize three essential things. (A) The prior probabilities represent our prior information, and are to be determined, not by introspection but by logical analysis of that information. (B) Since the final conclusions depend necessarily on both the prior information and the data, it follows that, in formulating a problem, one must specify the prior information to be used just as fully as one specifies the data. (C) Our goal is that inferences are to be completely ‘objective’ in the sense that two persons with the same prior information must assign the same prior probabilities.” (p. 373). For another, the choice of a prior may highly depend on data and likelihood in practice. Gelman et al. [29] argued that “a prior can in general only be interpreted in the context of the likelihood with which it will be paired” (p. 12).
To ensure a consistent and objective inference, rules for constructing priors with minimal subjective constraints are sought. Early work on the construction of such priors is based on the “ignorance” over the parameter space using invariance techniques [27,30,31]. The fundamental reasoning is that the priors should carry the same amount of information such that a change of scale and/or a shift of location do not affect the inference results on those parameters. The ignorant prior can systematically be derived using the concept of the transformation group. Using different transformation groups, different priors can be obtained. For simplicity, such priors are loosely referred to as noninformative priors. One of the most notable priors for a scale parameter of a distribution is Jeffreys’ prior, i.e., . Jeffreys’ prior can be obtained using the tool of the transformation group under the condition that a change of scale does not change that state of knowledge. A further extension of the noninformative priors is “reference priors” [32,33]. The theoretical framework has been discussed in many studies, including, but not limited to, [31,34]. Apart from the noninformative approach to derive the priors, there are several less objective approaches to construct the priors. Gelman [35] proposed the weakly informative priors based on the idea of conditional conjugacy for hierarchical Bayesian models. The conditionally conjugate priors provide some computational convenience as a Gibbs sampler can be used to draw samples from a posterior distribution, and some parameters for inverse-Gamma distributions in Bayesian applications are suggested. Simpson et al. [36] proposed a method to build priors. The basic idea is to penalize the complexity induced by deviating from a simpler base model using the Kullback–Leibler divergence as a metric [37].
For critical problems with small sample sizes, the choice of the prior in Bayesian inference can have a great impact on the inference results, rendering an unreliable decision-making. Despite a great deal of research, including the aforementioned, having been conducted, the choice of an optimal prior is still nontrivial to make from the practical point of view, and a systematical method to cope with such cases is rarely seen. Moreover, a quantitative measure to evaluate the performance of a prior is equally important to identify the optimal prior. This study develops a noninformative Bayesian approach to probabilistic inference under small sample sizes. A general -type of noninformative prior for the location-scale family of distributions is proposed. This type of prior is further shown to be the limiting state of the commonly used normal-inverse-Gamma conjugate prior, thus allowing for an analytical evaluation of the posterior of the parameter. Given a linear model with a Gaussian error variable, the analytical form of the posterior of the model prediction can also be obtained. The informative or noninformative nature of the prior is centered more on the concept of whether the prior encodes subjective information; therefore, it is less relevant to the likelihood function (and data). The subjective information is the source of inconsistency in the inference result as different practitioners can use different subjective information in the form of assumptions, which in most cases may only be justified by oneself. However, the prior has to be built with a certain state of knowledge. This state of knowledge, or loosely called information, is not related to experience nor assumptions, but is a result of a logical reasoning process [27]. The purpose of the study is not to argue whether these assumptions are justified or not, nor to question the suitable assumptions made during the inference. This study provides an alternative to existing methods in such cases to avoid introducing subjectiveness into the Bayesian inference. In particular, when the number of samples is small, the influence of the prior can be as important as the likelihood (and data). In such cases, subjective information encoded in the prior can lead to biased results.
The remainder of the paper is organized as follows. First, the Bayesian model with noninformative priors is developed, in particular, a general -type of noninformative prior for the location-scale family of distributions is proposed for small sample problems. The noninformative priors are further shown as the limiting states of the normal-inverse-Gamma (NIG) conjugate priors. The closed-form expressions of the Bayesian posterior and predictors using the proposed noninformative priors are obtained under a Gaussian likelihood. Next, a performance measure considering both the fitting performance and predictive performance is proposed using the concept of Bayes factors. Different priors are treated as models in a Bayesian hypothesis testing context for comparisons. Following that, the method is illustrated using two examples.
2. Bayesian Linearized Models with Noninformative Priors
To motivate the discussion, consider a general linear or linearized model:
where is a k-dimensional column vector and are independent and identical distributed random error variables. The distribution of determines the likelihood function or vice versa. Without loss of generality, the distribution belongs to a location-scale family of distributions. Furthermore, it is enough to use a single scale parameter to characterize the distribution of since any constant nonzero mean, no matter known or unknown, can be grouped into . Denote the scale parameter of as . A Bayesian model incorporates both the prior information and the observation through Bayes’ rule. Using the matrix form , the Bayesian posterior of writes:
The common Gaussian error variable, i.e., , corresponds to the following likelihood function, for n observations and n input vector where , , is a row vector of size k.
It should be noted that the error variable does not necessarily follow a Gaussian PDF, and other types of error distributions can be used. For example, the extreme-value PDF for the error corresponds to a Weibull likelihood for the log-transformed model prediction.
2.1. A General Form of Noninformative Priors—
A general () form of priors is considered here. The classical Jeffreys’ prior and the related asymptotically locally invariant priors are introduced first for the purpose of completeness.
Consider the PDF of a random variable x characterized by a parameter vector ; Jeffreys’ noninformative prior distribution of is proportional to the square root of the determinant of the Fisher information matrix, e.g.,
where is the determinant operator and is the Fisher information matrix. The key feature of it is invariance under the monotone transformation of . This feature is achieved by using the change of variables theorem. Denote the reparameterized variable or vector as ; it can be shown that:
For a Gaussian likelihood with unknown parameters and ,
Jeffreys’ prior for the joint parameter is:
where is:
and is the expectation operator. Using algebraic deduction and integration, is simplified to:
As a result, Jeffreys’ prior for is:
It is noted that the distribution of interest is , not ; therefore, the derivative is taken with respective to as a whole instead of . In other word, the parameter space is on , not . For example, the Jeffreys’ prior for , with a fixed value of , is:
The Jeffreys’ prior for and with a fixed are and , respectively. It is shown in Appendix B that the Fisher information matrix is also the Hessian matrix of the Kullback–Leibler (KL) distance of a deviated distribution with respect to the true distribution evaluated at the true parameters. For exponential families of distributions, the KL distance has analytical forms, allowing for the evaluation of the Fisher information matrix without involving integrals in Equation (9).
The asymptotically locally invariant (ALI) prior is another type of prior that satisfies the invariance under certain transformations. An ALI prior can be uniquely determined using the following equation according to [31],
where and . For a Gaussian distribution with a fixed mean and a random , the two terms are and . Solve:
to obtain the ALI prior for :
Similarly, the ALI prior for is:
When both and are random, the joint ALI prior for is:
It is noticed that the Jeffreys’, ALI, and uniform priors are reproduced from as q takes different integer values. In the following, the derivation of a prior from NIG conjugates is shown.
2.2. Derivation of the Priors as the Limiting States of NIG Conjugates under Gaussian Likelihood
In Bayesian models, for the given likelihood function, the posterior and the prior are called conjugate distributions if both are in the same family of distributions. It can be considered as the prior can be reconditioned by encoding the evidence through the likelihood; therefore, the evidence or data merely change the distribution parameters of the prior and yield another distribution of the same type, but with a different set of parameters.
For a location-scale parameter vector used in linear or linearized Bayesian models with a Gaussian likelihood, the corresponding conjugate prior is the NIG distribution. The closed-form posterior PDFs for the parameter and prediction are given in Appendix A.
Noninformative priors, including the Jeffreys’, ALI, and reference priors, for are mostly in the form of , . The uniform prior can be seen as a special case of as . It is shown as follows that these noninformative priors can be obtained as certain limiting states of NIG conjugates of . For example, the NIG distribution with parameters given by Equation (A3) can reduce to the Jeffreys’ prior:
as:
Furthermore, a -type of prior can all be derived as reduced NIG distributions. By assigning the initial values for , , and of the NIG distribution, different q values are obtained. Table 1 presents priors with different q values as reduced NIG distributions and the corresponding , , and of the NIG distributions and , , and of the resulting NIG posterior distributions. The posterior distribution of is an inverse-Gamma distribution , and the PDF is given by:
The posterior distribution of is obtained by integrating out from the joint posterior distribution of Equation (A6) as,
which is a degree-of-freedom multivariate t– distribution with a location vector of and a shape matrix of . In particular, when the NIG prior for is reduced to the Jeffreys’ prior by Equation (19), the resulting posteriors of and are:
and:
respectively. The term in Equation (22) is the sum of squared errors, given by:
The prediction posterior in this case is:
The advantage of treating the -type of noninformative prior as reduced NIG conjugates is that the Bayesian posteriors of the model prediction and parameters all have analytical forms, allowing for efficient evaluations without resorting to the MCMC techniques, as done in regular Bayesian analysis. It is worth noting that the analytical results are obtained under the condition (or assumption) that the likelihood is a Gaussian. This condition implies that the conjugate prior is an NIG. The values of the NIG parameters are obtained by equating the noninformative prior to the NIG prior. In other words, equating the two distributions for the purpose of mathematical convenience is the premise of resolving those parameter values.
3. Assessment of Noninformative Priors
To evaluate the performance of priors, the Bayesian model assessment method using efficient asymptotic approximations is proposed. The idea is to recast the assessment as a model comparison problem. The participating models here are the posteriors obtained with different priors. The comparison can then be made using Bayes’ factors in a Bayesian hypothesis testing context.
3.1. Fitting Performance
The Bayes factor, on the basis of observed data , evaluating the plausibility of two different models, and , can be expressed as:
The comparison of two models can be made based on the ratio of the posterior probabilities of the models:
The ratio, when the prior probabilities of the models are equal, is reduced to the Bayes factor of Equation (26). The assessment of the Bayes factors involves two integrals over the parameter space of . The integrands for models and are and , respectively.
For general multidimensional integration, asymptotic approximation or simulation-based estimation are two commonly used methods. The Laplace approximation method evaluates the integral as a multivariate normal distribution. Consider the above integrand term in Equation (26), i.e., . Drop the model symbol for simplicity of the derivation, and denote as . The natural logarithm of the integrand, , i.e., , can be expressed using Taylor expansion around its mode as:
where is the gradient of evaluated at , is the Hessian matrix of evaluated at , and are higher-order terms. When the higher-order terms are negligible,
The term is zero at the mode of the distribution where the gradient is zero; therefore, expanding around eliminates the term and yields:
Exponentiate the above equation to obtain:
Realizing the first term of the above equation is a constant and the last term is the variable part of a multivariate normal distribution with a mean vector of and a covariance matrix , the integration of writes,
Notice that is a k-dimensional vector, so is a -dimensional vector. Using the result of Equation (32), the integral associated with the jth model in Equation (26) is:
where is the mode of the distribution and is the covariance matrix, i.e., the inverse of the negative Hessian matrix of evaluated at . Proper numerical derivative methods based on finite difference schemes can achieve reliable results for the gradient and the Hessian in the following equation.
Experience has shown that for a distribution with a single mode and approximately symmetric, the Laplace approximation method can achieve accurate results for engineering applications [38,39].
It should be noted that the -type of noninformative prior is not a proper prior, i.e., the normalizing constant for is not bounded for ; therefore, it is necessary to limit the support of to a proper range and to have a finite normalizing constant. Assume the effective range of is for ; the normalizing constant is:
3.2. Predictive Performance
The predictive performance for a model is measured by the likelihood of the data that are not used for model parameter estimation. The likelihood of the future measurement data with the posterior PDF of writes:
where is evaluated using Equation (33).
The comprehensive performance integrating both fitting performance and predictive performance in terms of likelihood in the joint space of is:
Realize that Equations (32), (36) and (37) can all be evaluated using the method of Laplace approximation, and the performance of different priors can quantitatively be compared. It is noted that the likelihood is the product of the fitting component and the prediction component, and the influence of the prior is incorporated in the fitting component, i.e., .
4. Application Examples
To illustrate the proposed Bayesian inference with noninformative priors, two examples are presented. The results were compared with the classical least squares approach. The fitting and comprehensive performance of the -type of priors were evaluated using the method of Laplace approximation.
4.1. Low-Cycle Fatigue Reliability Assessment with Sparse Samples
The above numerical example reveals the advantage of using a noninformative prior over the flat prior in probabilistic inference under small sample sizes. To examine its usefulness in realistic problems and further compare the performance of different noninformative priors, a fatigue life prediction problem is presented.
The low-cycle fatigue testing data reported in ASTM E739-10 [40] were used and shown in Table 2. The cyclic strain amplitudes were (∼0.016, ∼0.0068, ∼0.0016, ∼0.0005), and each level had two or three data points. The following log-linear model was adopted,
where and are model parameters that need to be identified. It should be noted that other variants of the above equation can be used to include material plasticity, the mean stress effect, etc. The discrepancy between the experimental data and the model prediction can be modeled using an uncertain variable with zero mean and a standard deviation of . To compare with the regular least squares method, a Gaussian likelihood was assumed, and the Bayesian posterior is:
The exponent q takes the values of to generate a flat prior and different noninformative priors, and , is the ith experimental data points of the total n data points used for parameter estimation.
Notice that when , the above equation reduces to a regular least squares format. One data point () was arbitrarily chosen for prediction performance evaluation, and the rest eight data points were used to estimate the model parameters using Equation (39).
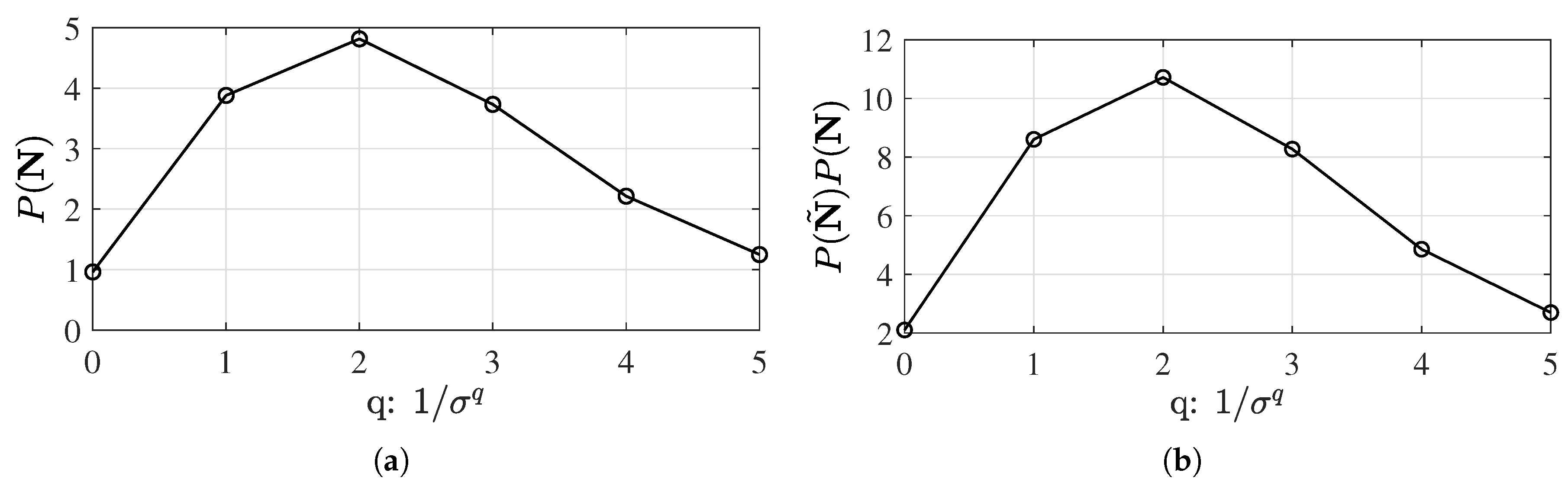
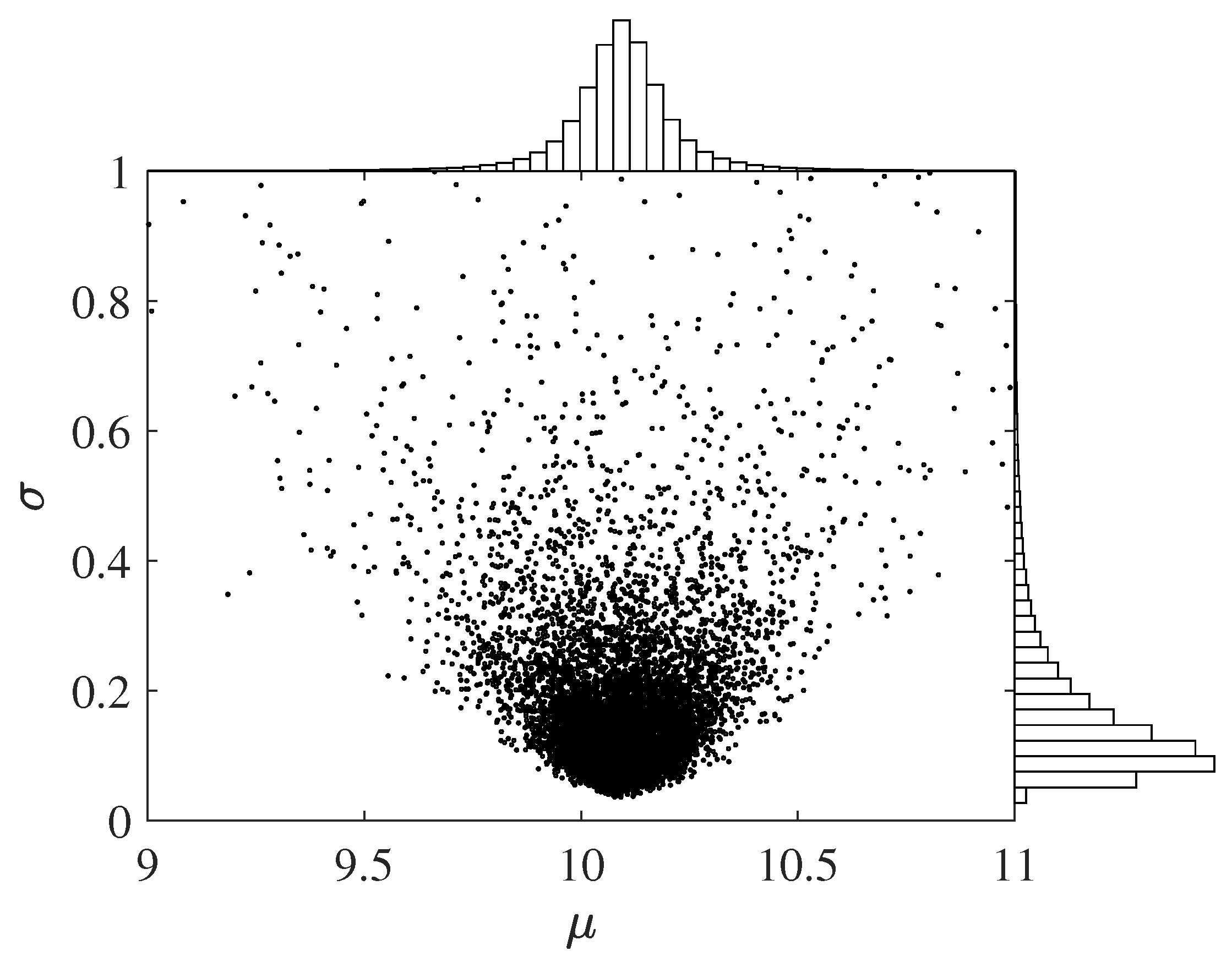
To compare the performance of -type priors, were used to represent the regular least squares, Jeffreys’, and ALI priors. The likelihood of the fitting performance and prediction performance was evaluated using the method of Laplace approximation, and results are shown in Figure 1. The total likelihood of the fitting and prediction results indicates that the Jeffreys’ prior outperformed the others. The result associated with is the Bayesian version of the regular least squares estimation.
To further demonstrate the difference between the regular least squares and noninformative Bayesian approach under this sample size, the following reliability problem was considered. The fatigue life given a prescribed probability of failure (POF) was calculated for the cyclic strain range () between and . Given a cyclic strain range and a POF, the fatigue life can be expressed as:
For the regular least squares estimator, it can be obtained using the t-statistics given by Equation (A9) where should be replaced with the prescribed POF because only the lower one-sided bound is needed. For the Bayesian with Jeffreys’ prior, the one-side bound can trivially be obtained using the POF-quantile of the prediction results evaluated using MCMC samples of the posterior POF. Figure 2 presents the comparisons of the fatigue life results where the obvious difference was observed. The results of the noninformative Bayesian were larger than those of regular least squares, indicating a longer fatigue life for the same risk level, i.e., POF.
4.2. Aeroengine Turbine Disk Lifing and Failure Rate Assessment
The prescribed safe life is a critical parameter for airworthiness and service health management of turbine disks in aeroengines. To determine the prescribed safe life for turbine disks, life testing with a number of disks is performed using disk samples in a rotating pit. The number of tested piece is usually less than five due to the cost and time constraints; sometimes, only one or two test pieces are available. The determination of the prescribed safe life must be carefully made to mitigate the risk. A general and standard procedure described in [41] is centered on the idea that two source of uncertainty, namely the sampling uncertainty and the life distribution uncertainty, should be incorporated. To account for the sampling uncertainty, the 95% single-sided lower bound of the sample mean is used as the mean of the life distribution. To account for the uncertainty of the life distribution itself, no more than one in seven-hundred fifty service disks is allowed to develop an engineering crack. The total safety margin is a 1/750 cumulative failure probability to a 95% confidence.
The prescribed safe life is assumed to be a log-normal random variable, and the log-life is a normally distributed variable. Denote the mean and standard deviation of the normal distribution of the log-life as and . The 95% single-sided lower bound of the sample mean can be expressed as:
where is the geometric mean of the life, is the single-sided lower bound of the geometric mean, , and is the inverse cumulative density function (CDF) of the standard normal variable when the standard deviation is known. For the 95% single-sided lower bound, . When the standard deviation is unknown, the estimate of the standard deviation based on the samples should be used. In such cases, the value of is obtained using the Student distribution with a degree of freedom (DOF) of , i.e., . The function is the inverse CDF of the Student distribution with a DOF of . The 1/750 failure probability log-life corresponds to the shift from the mean of the log-life distribution. When using as the mean of the log-life distribution, the 1/750 failure probability life writes:
The safety factor that ensures a 1/750 failure to a 95% confidence can be expressed by transforming Equation (43) into the linear scale as:
It is seen that the prescribed safe life depends on the number of tested samples n and the standard deviation of the distribution. The deterministic prescribed safe life is finally obtained as:
The cumulative burst probability when the disk is used y cycles can be expressed as:
where is the log-transformed geometric mean of the samples and y is the log-transformed number of cycles, i.e., . The failure rate in terms of the failures per cycle can be expressed as:
where is the burst PDF:
The sampling uncertainty in the log-transformed geometric mean can be quantified using the sampling PDF. The sample mean distributes according to:
where s is the standard deviation of the sample, is the standard Student distribution with a DOF of , and .
The final failure rate can be obtained by marginalizing out the sampling error variable as:
With the above discussion, turbine disk life testing results on two disks were obtained as shown in Table 3.
It is seen that the key information is the standard deviation of the population. For one thing, whether it is considered as a known quantity requires a justification, and its actual value relies on empirical evidence and historical data. For another, when it needs to be estimated from the samples, the proper method should be used due to its limited sample size.
4.2.1. Existing Method
Previous disk life testing results showed that the scatter factor, defined as the ratio of the maximum life () over the minimum life (), is less than six. Furthermore, and are considered as the and points of the normal distribution of the log-life. With the above empirical evidence and assumption The empirical evidence of , combined with the assumption that , yields:
The safety factor that ensures a 1/750 failure to a 95% confidence can be expressed, by substituting Equation (51) into Equation (43) as,
Given that assumption that the standard deviation of the log-life distribution is known, the first equation of the right-hand side in Equation (49) is used. In addition, the term for rare events. In such a case, the hazard rate function Equation (50) reduces to the convolution of two normal PDFs, and the resulting hazard rate function is:
Note that ; the hazard rate in terms of failure per flight hour is found by using the chain rule as,
where is the exchange rate (cycles/hour) converting the cycle to equivalent engine flight hours. Using the data in Table 3, the log-transformed geometric mean 24,205, the standard deviation of the log-life distribution is , and the standard deviation of the sampling distribution is . Substitute these parameters into Equation (45) to obtain the prescribed safe life as cycles.
4.2.2. The Proposed Noninformative Bayesian Method
Without relying on the empirical evidence and the assumption, the noninformative Bayesian estimator for of the log-life distribution can be obtained by writing the posterior of the likelihood of samples with a noninformative prior. For a demonstration, the prior of was used, and the posterior writes,
where D denotes the event of observed life samples . To estimate and , samples were drawn from Equation (55) using the MCMC method. The resulting histogram of the samples is shown in Figure 3. The 95% single-sided confidence bound can be estimated using the 0.05-quantile of the MCMC samples as or 19,259 in the linear scale. Centering on , the value corresponding to a 1/750 cumulative failure probability was found by subtracting by . The term was estimated using the MCMC sample mean, and in this case, it was found as . Consequently, after applying the two safety margins, the prescribed safe life (in log scale) using the noninformative Bayesian method was found as or 10,911 cycles.
The failure rates calculated using the existing method and the proposed noninformative Bayesian method are compared in Figure 4. The failure rate per flight hour was based on an exchange rate .
Based on the results shown in Figure 4, the usable flight hours obtained using the noninformative Bayesian method were about 1000 h more than those obtained using the existing method given the same risk constraint. For example, the flight hours corresponding to a failure rate of /h were 2734 and 1734, respectively, for the two methods. When the failure rate was required to be /h, the usable flight hours were 3817 and 2720, respectively. It should be noted that the proposed noninformative Bayesian method does not rely on empirical evidence and assumptions other than the log-normal distribution for disk life.
5. Conclusions
The study developed a noninformative Bayesian inference method for small sample problems. In particular, a -type of prior was proposed to formulate the Bayesian posterior. It was shown that this type of prior can represent the classical Jeffreys’ prior (Fisher information), flat prior, and asymptotic locally invariant prior. More importantly, this type of prior was derived as the limiting state of normal-inverse-Gamma (NIG) conjugate priors, allowing for fast and efficient evaluations of the Bayesian posteriors and predictors in closed-form expressions under a Gaussian likelihood. To illustrate the overall method and compare the performance of noninformative priors, a realistic fatigue reliability problem was discussed in detail. The combined fitting and prediction performance in terms of the likelihood was used to evaluate different priors. It was observed that Jeffreys’ prior, , yielded the maximum likelihood. The developed method was further applied to an actual aeroengine disk lifing problem with two test samples, and the results on the prescribed safe life and risk in terms of failure/hour were comparable with those obtained using the existing method incorporating the empirical evidence and assumptions. It should be emphasized that the study did not promote abandoning justified experience and/or information in prior construction. It was argued in this study that in the absence of those data or experience, the noninformative prior should be used to avoid introducing unjustified information into the prior. The following conclusions were drawn based on the current results:
- The -type of prior can be used equivalently as the NIG conjugate priors at their limiting states. The great features of conjugate priors, such as having analytical posterior and prediction PDFs under a Gaussian likelihood, can be retained when using noninformative priors for Bayesian linear regression analysis;
- For the -type of noninformative prior, the classical Jeffreys’ prior yielded an optimal fitting and prediction performance in terms of the likelihood or Bayes factors. When , the Bayesian estimator reduces to the regular least squares estimator. The results of the two case studies showed the advantage of using the noninformative Bayesian estimator with the prior of over the regular least squares estimator and other empirical methods under small sample sizes.
Author Contributions
Conceptualization, X.G.; Data curation, S.W.; Formal analysis, W.W. and M.H.; Methodology, J.H., W.W. and X.G.; Resources, M.H. and S.W. All authors have read and agreed to the published version of the manuscript.
Funding
The study was supported by National Natural Science Foundation of China, Nos. 11872088, 12088101, NSAF U1930403, CAEP CX20200035, and 2020-JCJQ-JJ-465. The support is gratefully acknowledged.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Acknowledgments
The study was supported by National Natural Science Foundation of China, Nos. 11872088, 12088101, NSAF U1930403, CAEP CX20200035, and 2020-JCJQ-JJ-465. The support is gratefully acknowledged.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Conjugate Prior, Posterior, and Prediction
Assume a general linear model with a parameter vector and a Gaussian likelihood with a scale parameter , i.e., the modeling error .
Appendix A.1. Conjugate Prior
It is known that when the likelihood function belongs to the exponential family, a conjugate prior exists and belongs also to the exponential family. To obtain the joint conjugate using , it is necessary to look at the conjugate prior of first. For a Gaussian likelihood with an unknown variance and zero mean, the conjugate prior for is an inverse Gamma distribution, i.e., , and is expressed as:
where and are shape and scale parameters, respectively. The posterior distribution of , given n data points, has the following new shape and scale parameters:
where is the sum of squared errors. Consider the joint conjugate of (), a widely adopted conjugate prior for Bayesian linear regression is the normal-inverse-Gamma (NIG) prior for , and it can be written as Equation (A3).
where:
and:
Using the inverse gamma distribution for , the initial distribution parameter still needs to be determined. Unfortunately, there is no formal rule to do that. Gelman [35] discussed the inverse-Gamma distribution where was set to a low value such as 1, 0.01, or 0.001. A difficulty of this prior is that must be set to a proper value. Inferences become very sensitive to for cases where low values of are possible. Due to this reason, the family of priors for was not recommended by the author. It was further argued that the resulting inference based on it for cases where is estimated near zero was the case for which classical and Bayesian inferences differed the most [35]. Browne and Draper [42] also mentioned this disadvantage and suggested using a uniform one to reduce this defect. However, choosing an appropriate value for for still requires attention and understanding of the data. Indeed, the effect of the prior and its parameters is highly subjected to the data and problem, and its sensitivity to Bayesian inferences based on sparse data or extensive data can be dramatically different as the data dominants the posterior due to the law of large numbers.
Appendix A.2. Posterior Distribution
The posterior distribution of is expressed as:
The term is the marginal distribution of the data. It can be shown that after some algebraic operations, the posterior can be written as:
where:
The initial NIG conjugate parameter is updated to a new set of parameters .
Appendix A.3. Prediction
The Bayesian prediction of the response given the data can be obtained using the above distributions with a new set of input variable . Denote the corresponding prediction as . The prediction posterior distribution of can be expressed as:
when a single point is evaluated, Equation (A8) is reduced to a one-dimensional Student distribution, and the confidence interval is readily evaluated using the inverse Student distribution. For multipoint simultaneous evaluations, the interval contours can be approximated using a few methods as suggested in [43].
To compare, the simple linear regression results of the prediction mean and bounds are given. The prediction mean is , and the prediction bounds of level are:
where is the maximum likelihood estimator of . It is known that is also identical to the least squares estimator and the Bayesian estimator, i.e., Equation (23). The term represents the -percentile value of the standard Student t-distribution with degrees of freedom, and is the standard error of the prediction given by:
where the term is the discrepancy vector between the model and observation, also called the residual or error. As multiple points are estimated, the F-statistic can be used instead of the t-statistic to yield the Working–Hotelling confidence intervals [44],
where represents the -percentile value of the F-distribution with degrees of freedom.
Appendix B. Fisher Information Matrix and Kullback–Leibler Divergence
The equivalence of the Fisher information matrix and the Kullback–Leibler divergence can be shown as follows. The matrix form of the Fisher information matrix of a continuous PDF with a parameter vector writes,
Under the condition that the integration and derivation may be exchanged and the log-function is twice differentiable, the following Equation (A13) can be attained.
It is noted that:
The following result, that is the negative expected Hessian matrix of the log-function is equal to the Fisher information matrix, can be obtained.
where is recognized as the Hessian matrix of , denoted as . The Fisher information matrix can loosely be thought of as the curvature matrix of the log-function graph.
The Kullback–Leibler divergence, also called the relative entropy, between two distributions can be written as:
Expand around to the second order to have,
Substitute Equation (A17) into Equation (A16):
where . The first term of the right-hand side of Equation (A18) is zero; and the second term of the right-hand side is related to Equation (A15). The KL divergence can finally be expressed as,
Furthermore, differentiate Equation (A16) with respect to to obtain:
Continue to differentiate Equation (A20) with respect to to obtain:
Notice that the expectation of the second term in Equation (A21), when , reads,
and the first term is the Fisher information matrix. As a result, the Fisher information matrix is the Hessian matrix of the Kullback–Leibler distance evaluated at the true parameter .
References
- Royall, R.M. The effect of sample size on the meaning of significance tests. Am. Stat. 1986, 40, 313–315. [Google Scholar]
- Raudys, S.J.; Jain, A.K. Small sample size effects in statistical pattern recognition: Recommendations for practitioners. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 252–264. [Google Scholar] [CrossRef]
- Nelson, C.R.; Kim, M.J. Predictable stock returns: The role of small sample bias. J. Financ. 1993, 48, 641–661. [Google Scholar] [CrossRef]
- Fan, X.; Thompson, B.; Wang, L. Effects of sample size, estimation methods, and model specification on structural equation modeling fit indexes. Struct. Equ. Model. A Multidiscip. J. 1999, 6, 56–83. [Google Scholar] [CrossRef]
- McNeish, D. On using Bayesian methods to address small sample problems. Struct. Equ. Model. A Multidiscip. J. 2016, 23, 750–773. [Google Scholar] [CrossRef]
- Winkler, R.L. Probabilistic prediction: Some experimental results. J. Am. Stat. Assoc. 1971, 66, 675–685. [Google Scholar] [CrossRef]
- Melchers, R.E.; Beck, A.T. Structural Reliability Analysis and Prediction; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- He, J.; Chen, J.; Guan, X. Lifetime distribution selection for complete and censored multi-level testing data and its influence on probability of failure estimates. Struct. Multidiscip. Optim. 2020, 62, 1–17. [Google Scholar] [CrossRef]
- Du, Y.M.; Ma, Y.H.; Wei, Y.F.; Guan, X.; Sun, C. Maximum entropy approach to reliability. Phys. Rev. E 2020, 101, 012106. [Google Scholar] [CrossRef]
- Zhou, D.; He, J.; Du, Y.M.; Sun, C.; Guan, X. Probabilistic information fusion with point, moment and interval data in reliability assessment. Reliab. Eng. Syst. Saf. 2021, 213, 107790. [Google Scholar] [CrossRef]
- Gao, C.; Fang, Z.; Lin, J.; Guan, X.; He, J. Model averaging and probability of detection estimation under hierarchical uncertainties for Lamb wave detection. Mech. Syst. Signal Process. 2022, 165, 108302. [Google Scholar] [CrossRef]
- Gregory, P. Bayesian Logical Data Analysis for the Physical Sciences: A Comparative Approach with Mathematica Support; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Guan, X.; Jha, R.; Liu, Y. Model selection, updating, and averaging for probabilistic fatigue damage prognosis. Struct. Saf. 2011, 33, 242–249. [Google Scholar] [CrossRef]
- Hamdia, K.M.; Zhuang, X.; He, P.; Rabczuk, T. Fracture toughness of polymeric particle nanocomposites: Evaluation of models performance using Bayesian method. Compos. Sci. Technol. 2016, 126, 122–129. [Google Scholar] [CrossRef]
- Yang, J.; He, J.; Guan, X.; Wang, D.; Chen, H.; Zhang, W.; Liu, Y. A probabilistic crack size quantification method using in-situ Lamb wave test and Bayesian updating. Mech. Syst. Signal Process. 2016, 78, 118–133. [Google Scholar] [CrossRef]
- Wang, D.; He, J.; Guan, X.; Yang, J.; Zhang, W. A model assessment method for predicting structural fatigue life using Lamb waves. Ultrasonics 2018, 84, 319–328. [Google Scholar] [CrossRef]
- Guan, X.; He, J. Life time extension of turbine rotating components under risk constraints: A state-of-the-art review and case study. Int. J. Fatigue 2019, 129, 104799. [Google Scholar] [CrossRef]
- He, J.; Huo, H.; Guan, X.; Yang, J. A Lamb wave quantification model for inclined cracks with experimental validation. Chin. J. Aeronaut. 2021, 34, 601–611. [Google Scholar] [CrossRef]
- Huo, H.; He, J.; Guan, X. A Bayesian fusion method for composite damage identification using Lamb wave. Struct. Health Monit. 2020, 1475921720945000. [Google Scholar] [CrossRef]
- Berger, J.O. Robust Bayesian analysis: Sensitivity to the prior. J. Stat. Plan. Inference 1990, 25, 303–328. [Google Scholar] [CrossRef]
- Berger, J.O.; Moreno, E.; Pericchi, L.R.; Bayarri, M.J.; Bernardo, J.M.; Cano, J.A.; De la Horra, J.; Martín, J.; Ríos-Insúa, D.; Betrò, B.; et al. An overview of robust Bayesian analysis. Test 1994, 3, 5–124. [Google Scholar] [CrossRef]
- Kass, R.E.; Wasserman, L. The selection of prior distributions by formal rules. J. Am. Stat. Assoc. 1996, 91, 1343–1370. [Google Scholar] [CrossRef]
- Bishop, P.; Bloomfield, R.; Littlewood, B.; Povyakalo, A.; Wright, D. Toward a formalism for conservative claims about the dependability of software-based systems. IEEE Trans. Softw. Eng. 2010, 37, 708–717. [Google Scholar] [CrossRef]
- Gelman, A.; Hennig, C. Beyond subjective and objective in statistics. J. R. Stat. Soc. Ser. A 2017, 180, 967–1033. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Shields, M.D. The effect of prior probabilities on quantification and propagation of imprecise probabilities resulting from small datasets. Comput. Methods Appl. Mech. Eng. 2018, 334, 483–506. [Google Scholar] [CrossRef] [Green Version]
- Schervish, M.J.; DeGroot, M.H. Probability and Statistics; Pearson Education: London, UK, 2014. [Google Scholar]
- Jaynes, E.T. Prior probabilities. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 227–241. [Google Scholar] [CrossRef]
- Jaynes, E.; Bretthorst, G. Probability Theory: The Logic of Science; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Gelman, A.; Simpson, D.; Betancourt, M. The prior can often only be understood in the context of the likelihood. Entropy 2017, 19, 555. [Google Scholar] [CrossRef] [Green Version]
- Jeffreys, H. An Invariant Form for the Prior Probability in Estimation Problems. Proc. R. Soc. Lond. Ser. A 1946, 186, 453–461. [Google Scholar]
- Hartigan, J. Invariant prior distributions. Ann. Math. Stat. 1964, 35, 836–845. [Google Scholar] [CrossRef]
- Bernardo, J.M. Reference posterior distributions for Bayesian inference. J. R. Stat. Soc. Ser. B 1979, 41, 113–147. [Google Scholar] [CrossRef]
- Berger, J.O.; Bernardo, J.M. Ordered group reference priors with application to the multinomial problem. Biometrika 1992, 79, 25–37. [Google Scholar] [CrossRef]
- Jeffreys, H. The Theory of Probability; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Gelman, A. Prior distributions for variance parameters in hierarchical models (comment on article by Browne and Draper). Bayesian Anal. 2006, 1, 515–534. [Google Scholar] [CrossRef]
- Simpson, D.; Rue, H.; Riebler, A.; Martins, T.G.; Sørbye, S.H. Penalising model component complexity: A principled, practical approach to constructing priors. Stat. Sci. 2017, 32, 1–28. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Guan, X.; He, J.; Jha, R.; Liu, Y. An efficient analytical Bayesian method for reliability and system response updating based on Laplace and inverse first-order reliability computations. Reliab. Eng. Syst. Saf. 2012, 97, 1–13. [Google Scholar] [CrossRef]
- He, J.; Guan, X.; Jha, R. Improve the accuracy of asymptotic approximation in reliability problems involving multimodal distributions. IEEE Trans. Reliab. 2016, 65, 1724–1736. [Google Scholar] [CrossRef]
- American Society for Testing and Materials. ASTM E739-10(2015)-Standard Practice for Statistical Analysis of Linear or Linearized Stress-Life (S-N) and Strain-Life (ε-N) Fatigue Data; ASTM International: West Conshohocken, PA, USA, 2015. [Google Scholar]
- Boyd-Lee, A.; Harrison, G.; Henderson, M. Evaluation of standard life assessment procedures and life extension methodologies for fracture-critical components. Int. J. Fatigue 2001, 23, 11–19. [Google Scholar] [CrossRef]
- Browne, W.J.; Draper, D. A comparison of Bayesian and likelihood-based methods for fitting multilevel models. Bayesian Anal. 2006, 1, 473–514. [Google Scholar] [CrossRef]
- Kotz, S.; Nadarajah, S. Multivariate T-Distributions and Their Applications; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Graybill, F.A.; Bowden, D.C. Linear segment confidence bands for simple linear models. J. Am. Stat. Assoc. 1967, 62, 403–408. [Google Scholar] [CrossRef]
Figure 1.
(a) MCMC samples drawn from the noninformative Bayesian posterior with Jeffreys’ prior () and (b) the fatigue life results at obtained with the regular least squares (LS) estimator and noninformative Bayesian (NB).
Figure 1.
(a) MCMC samples drawn from the noninformative Bayesian posterior with Jeffreys’ prior () and (b) the fatigue life results at obtained with the regular least squares (LS) estimator and noninformative Bayesian (NB).

Figure 2.
(a) The fitting performance evaluated with different priors and (b) the prediction performance evaluated with different priors. One data point is considered for the prediction.
Figure 2.
(a) The fitting performance evaluated with different priors and (b) the prediction performance evaluated with different priors. One data point is considered for the prediction.

Figure 3.
Samples drawn from the posterior PDF and histograms.

Figure 4.
Comparisons of the failure rate results of the two methods. The solid line and the dashed line are results from the noninformative Bayesian (NB) and existing method (Ref.), respectively.
Figure 4.
Comparisons of the failure rate results of the two methods. The solid line and the dashed line are results from the noninformative Bayesian (NB) and existing method (Ref.), respectively.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
-type of prior as limiting state cases of the NIG distribution and its NIG posteriors.
| Prior | NIG Prior | Posterior → NIG |
|---|---|---|
| flat | ||
Table 2.
Low-cycle fatigue testing data. Source: [40].
Table 2.
Low-cycle fatigue testing data. Source: [40].
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 0.01636 | 0.01609 | 0.00675 | 0.00682 | 0.00179 | 0.00160 | 0.00165 | 0.00053 | 0.00054 | |
| N | 168 | 200 | 1000 | 1180 | 4730 | 8035 | 5254 | 28,617 | 32,650 |
Table 3.
Spin rig testing results on two disks.
| Disk No. | No. of Cycles |
|---|---|
| 1 | 27,000 |
| 2 | 21,700 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
He, J.; Wang, W.; Huang, M.; Wang, S.; Guan, X. Bayesian Inference under Small Sample Sizes Using General Noninformative Priors. Mathematics 2021, 9, 2810. https://0-doi-org.brum.beds.ac.uk/10.3390/math9212810
AMA Style
He J, Wang W, Huang M, Wang S, Guan X. Bayesian Inference under Small Sample Sizes Using General Noninformative Priors. Mathematics. 2021; 9(21):2810. https://0-doi-org.brum.beds.ac.uk/10.3390/math9212810
Chicago/Turabian StyleHe, Jingjing, Wei Wang, Min Huang, Shaohua Wang, and Xuefei Guan. 2021. "Bayesian Inference under Small Sample Sizes Using General Noninformative Priors" Mathematics 9, no. 21: 2810. https://0-doi-org.brum.beds.ac.uk/10.3390/math9212810
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.