1. Introduction
Extreme value theory (EVT) has emerged as an invaluable toolkit for a broad range of sciences in recent decades. It attempts to predict the occurrence of extreme events by making the best use of limited available data. They can be divided into two fundamental approaches: the block maxima method and the peaks-over-threshold (POT) method, while the former splits the observation period into non-overlapping, equally-sized periods and then only analyses the maximum of each period, the latter picks extreme observations exceeding a specific high threshold [
1]. In the following, we focus on the POT method, which has proven useful in a variety of applications including financial risk management [
2,
3], insurance [
4], coastal engineering [
5,
6], and oceanography [
7,
8]. We regard the POT approach from the perspective of a marked point process (MPP): exceedances over a high threshold
u will be referred to as extreme events. Such an event is associated with an occurrence time and a mark size, the latter corresponding to the size of the excess above the threshold.
The motivation for the classical POT model can be found in the asymptotic behaviour of high threshold exceedances for identically and independently distributed (iid) data. The approach assumes that if the threshold u is chosen high enough, the extreme events follow a marked Poisson process, i.e., the number of extremes events occurring can be described by a homogeneous Poisson process and their mark sizes are iid with a generalised Pareto distribution (GPD). This process also characterises the inter-event times as being iid exponentially distributed.
In many practical settings, however, the iid assumption is violated. Short-range dependencies arising from local serial correlation of the underlying time series may cause extreme events to occur in clusters [
2]. Therefore, assuming independent exponential inter-event times may seem unreasonable. These practical issues are often tackled by using declustering methods and then fitting the marked Poisson process to the largest value of each cluster only (see, e.g., [
9]). This approach however disregards the information contained within the clusters (cf. [
10,
11]), and gives rise to the challenge of appropriately and consistently identifying clusters from given data. Relevant literature includes works on statistical declustering using the extremal index due to Leadbetter et al. [
10,
12,
13,
14,
15], on physical declustering [
10,
16,
17], or on double threshold approaches combining statistical and physical declustering [
18,
19]. However, all these declustering methods have in common that they avoid modelling the short-range dependence directly.
It is impossible to universally characterise the short-term behaviour of stationary sequences as it can take countless different forms, but imposing certain constraints on the local dependence structure enables parametric modelling thereof. One approach builds on a marked point process with a self-exciting structure to model the clustering of extreme events, leading to conditional POT approaches. The Hawkes-POT model introduced by Chavez-Demoulin et al. [
2] belongs to the general class of self-exciting Hawkes processes [
20] and allows the intensity of the occurrence of extreme events to depend on both past event times and marks. A related approach is the so-called self-exciting POT (SEPOT) suggested by McNeil et al. [
21], where one Hawkes process influences the intensity of both event times and marks. The various conditional POT models were reviewed in [
3,
22,
23,
24], and extended to a multivariate framework by Grothe et al. [
25] and Hautsch and Herrera [
26]. Conditional POT models are based on similar ideas as the epidemic-type aftershock sequence (ETAS) model proposed by Ogata [
27], which is designed to describe the occurrence of earthquakes based on previous ones and was further explored for example by Helmstetter and Sornette [
28].
In the aforementioned approaches, the conditional intensities of the events depend exponentially on the characteristics of past events implying a focus on modelling short-term dependencies explicitly, but neglecting any possible long-term correlations. However, we also have to consider settings in which long-range dependence in the underlying sequence influences the clustering behaviour so that we cannot per se assume that widely separated events are independent. Many time series of practical interest ranging from finance [
29] to hydrology [
30] and forestry [
31] have long been known to exhibit long-range dependence, implying a power-like decay of the autocovariance function
,
, i.e.,
where
and
for a stationary process [
32]. An alternative definition is based on the spectral density
with
. The spectral density of a long-range dependent series has a pole at the origin and decays hyperbolically thereafter, i.e., the spectral density is described by
where
and
[
33].
Modelling the extreme events of long-range dependent time series hence requires special attention to the characteristics that event times and marks inherit from the underlying process. Generally, long-range dependence in the underlying time series has been observed to lead to pronounced clustering of extreme events [
34,
35]. There is empirical evidence that the inter-event times may follow a Weibull [
36], a stretched exponential distribution [
37,
38,
39] or the product of a power law and a stretched exponential [
40], but these observations lack analytical justification. The inter-event times themselves have also been found to exhibit long-range dependence [
35,
41]. In numerical experiments, maxima sequences were as well found to exhibit long-range dependence and, depending on the distribution and the strength of the long-term correlations of the underlying sequence, the distribution of maxima may deviate from the asymptotics for finite block sizes [
42]. It could be suspected that the effects on the whole tail of the mark distribution might be more pronounced than when considering only a sequence of maxima.
In the context of EVT, not many parametric approaches exist that incorporate explicit modelling of the long-term dependence structure in the underlying series. One example is suggested by Hees et al. [
43] and motivated by so-called bursty extremes where event clusters are separated by long periods without any event. Hees et al. [
43] provide a parametric approach to modelling a setting in which the event occurrences follow a fractional Poisson process which was proved to be long-range dependent by Biard and Saussereau [
44]. They focus on characterising the inter-event times via the Mittag–Leffler distribution, which generalises the exponential distribution [
45,
46]. This framework can easily be complemented by additionally modelling the mark sizes through a GPD [
43].
All these variants of the POT model have in common that they explicitly model the dependence structure of the underlying times series to capture the clustering behaviour of the extreme events, either by taking into account short-term or long-term correlations. However, none of the models embeds short- and long-range dynamics at the same time. Considering real world applications, it is very likely that many financial and physical processes are governed by both short- and long-range dependencies affecting the cluster formation of their extreme events.
The focus of this paper lies on oceanographic variables which are frequently identified to be long-range dependent. Especially near the coast, sea level observations [
47,
48] and sea surface temperatures [
49,
50] were found to exhibit long-range dependence. Similar findings are reported for sea-ice thickness [
51] and significant wave height [
52,
53,
54]. The dataset we consider in our application in
Section 4 also consists of significant wave heights that were measured on the Sefton coast (UK).
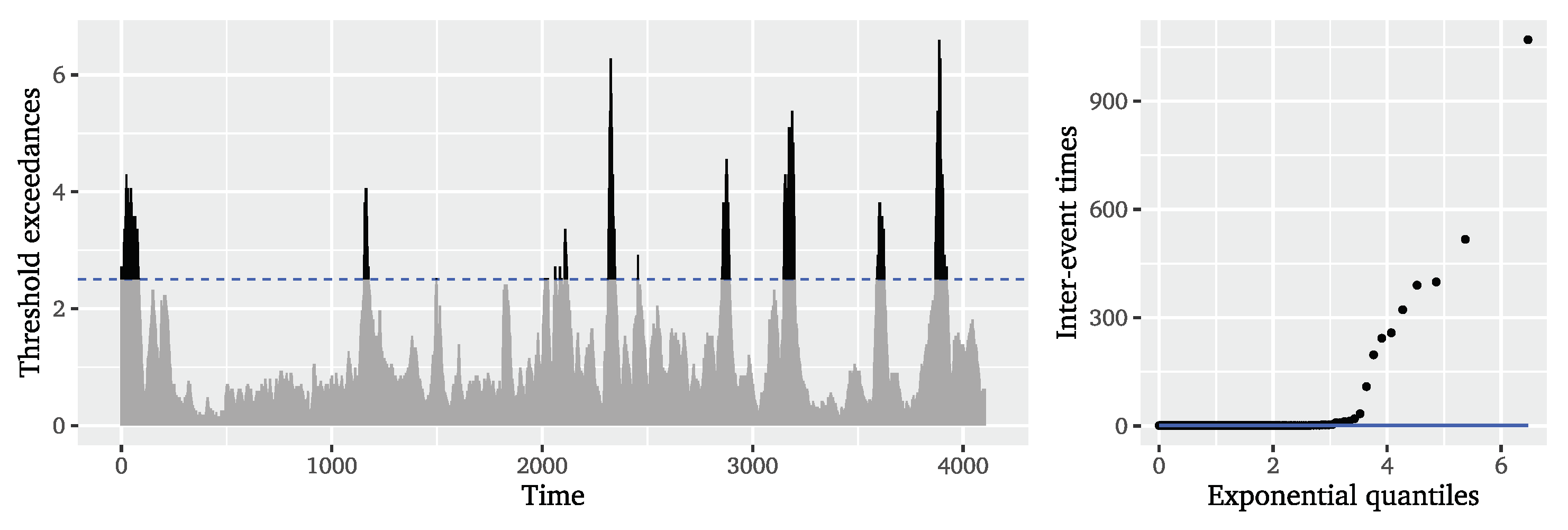
Figure 1 depicts the observed time series and illustrates the exceedances of the high threshold
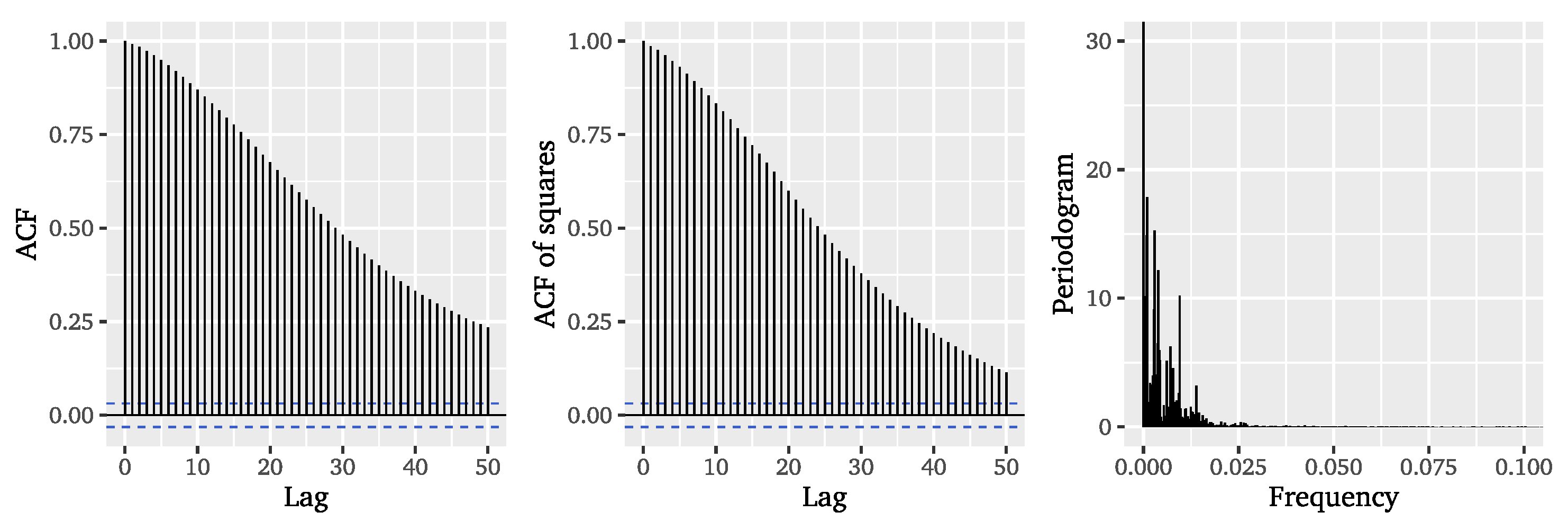
m, i.e., the extreme events. It is obvious that the extreme events appear in widely separated clusters implying strong local dependencies, which is confirmed by the empirical autocorrelation functions (ACFs) of both observations and their squares (cf.
Figure 2). Therefore, it is not surprising that the inter-event times appear to have a distribution clearly differing from the exponential distribution expected for iid observations, as can be observed from the quantile-quantile (QQ) plot in
Figure 1. The periodogram of the significant wave heights in
Figure 2 further hints at the presence of long-range dependence due to the pole at the origin, which is in line with the aforementioned literature.
Thus, the visual inspection of the considered dataset implies that the dependence structure of the significant wave heights exhibits both short- and long-term correlations. Of course this has to be accounted for when attempting to explicitly characterise the extremal clustering.
Therefore, with the aim of jointly modelling short- and long-range dependencies, we suggest a two-step approach in the spirit of McNeil and Frey [
55] which we will call autoregressive fractionally integrated moving average peaks-over-threshold (ARFIMA-POT) approach. Addressing the issue of heteroscedasticity in financial data, McNeil and Frey [
55] introduced the so-called GARCH-EVT approach which first fits a GARCH model to a return series and then applies standard EVT techniques to the pseudo-iid residuals from the first step. Even though there is no theory that mathematically characterises the clustering behaviour of the extremes from GARCH model residuals [
56], the two-stage method has proven to work well in practice [
57,
58,
59,
60,
61]. In a similar fashion, we propose a two-stage method combining a parametric model with a classical EVT model.
Our ARFIMA-POT approach is based on first fitting an autoregressive fractionally integrated moving average (ARFIMA) model [
62,
63] to the original oceanographic dataset and then applying the standard POT model to the ARFIMA residuals. Given that the ARFIMA model captures both short- and long-range dependence in the underlying time series, the model residuals are supposed to be iid, so that all difficulties arising for the distribution of event times and mark sizes due to the short- and long-term behaviour in the original series can be avoided. The method is inspired by the idea of prewhitening the underlying series as suggested for example by Davison and Smith [
9] to deal with non-stationarity and seasonality in POT modelling. For Hill’s estimator of the tail index, Resnick and Stărică [
64,
65] show that using the residuals of an autoregressive (AR) process is superior in terms of asymptotic variance than estimation based directly on the observations, given that the series follows an AR process and the AR model has a causal representation. This clearly indicates that prewhitening can have favourable properties in the context of EVT. Further, the idea of utilising an ARFIMA model to describe a time series in the context of oceanography is not new. ARFIMA models are a popular choice for characterising levels and trends in weather-related, hydrological and oceanographic data [
66]. Specifically, Ercan at al. [
48] for instance model the Caspian sea level using ARFIMA processes. Thus, our ARFIMA-POT approach can be interpreted as filtering the underlying oceanographic time series using an ARFIMA model before applying the classical POT method.
This paper contributes to the line of literature that aims to model the clustering behaviour of extreme events. Specifically, we consider strongly dependent significant wave height data for which high level exceedances appear in an extremely clustered manner. As this setting poses a particular challenge for traditional POT approaches, we analyse whether popular models dealing with short- or long-range dependence convey enough information about the dependence structure in the data. Moreover, we suggest the two-step ARFIMA-POT approach that captures both short- and long-range dependence in the underlying time series. Further, we verify our conclusions from the application to significant wave heights in a simulation study. The range of models reviewed is not meant to be exhaustive, but is rather supposed to present a selection of commonly used approaches modelling either the short- or long-term behaviour of extreme events, but not both simultaneously. Our results are meant to provide a basis for further discourse on the modelling of extremal clustering behaviour in EVT. We show that current tools are not flexible enough to simultaneously capture the short- and long-range dependence of the underlying process. Therefore, we want to spark new interest in researching the intersection of modelling local clustering behaviour and long-range dependence to find solutions to a question of practical interest.
The paper is organised as follows.
Section 2 reviews the basic concepts around POT modelling.
Section 3 presents the considered models. This section is divided into established models characterising extremal clustering by taking into account short- and long-range dependence, respectively, and the presentation of the two-step ARFIMA-POT approach incorporating short- and long-term dynamics simultaneously.
Section 4 applies the considered approaches to significant wave heights and discusses their performance in the presence of extremal clustering and long-range dependence.
Section 5 examines the conclusions from the application in a simulation study and
Section 6 concludes.
2. Peaks-over-Threshold Modelling
In the following, we review the univariate POT approach through the lens of point processes as introduced by Pickands [
67]. In the presentation, we loosely follow McNeil et al. [
21].
Consider a sequence of iid random variables
with some continuous distribution function
F that is in the maximum domain of attraction of a non-degenerate limiting distribution, i.e.,
for some
, so that
holds for normalising sequences
and
where
. It follows that
is a generalised extreme value (GEV) distribution with distribution function
where
, and
,
,
denote location, shape and scale parameters, respectively.
The number of exceedances above a high threshold
u can be expressed by
. Since the
are iid,
K is binomially distributed with parameters
, where
p is the probability of crossing
u, i.e.,
. Thus, as
,
K converges to a Poisson random variable with mean
. However, not only the total number of extreme events is asymptotically Poisson, but also their occurrences can be described by a Poisson point process. We can define the point process of event times as
, where
for
is either the time of an event re-scaled to
or zero, and
. Then
converges in distribution to a homogeneous Poisson point process on the space
with intensity measure
for
, where the constant intensity is given by
and the scaling sequences are absorbed into the parameters of
H (see, e.g., [
14]).
One way to describe the POT model is by means of a non-homogeneous two-dimensional Poisson point process, for which a two-dimensional pattern of points
is recorded representing the times and magnitudes of exceedances of a high threshold
u [
21,
68]. On a space
, we assume for
that the point process
is a Poisson process with intensity function
This intensity function does not depend on
t, but on
x, so that the two-dimensional Poisson process
is non-homogeneous. Considering
, the intensity measure of the process is given by
It follows that for any the implied one-dimensional process of occurrences of exceedances with level z forms a homogeneous Poisson process with intensity , which is similar to the previous result.
From this representation, we can also retrieve the GPD as the limiting distribution of the mark sizes: the limiting conditional probability that
given
, i.e., the tail of the excess distribution function over the threshold
u, is obtained from the ratio of the rates of exceeding the levels
and
u:
for a positive scaling parameter
.
exactly corresponds to the tail of the GPD model for excesses of a high threshold
u.
Hence, this representation of the POT model incorporates a homogeneous Poisson process when only considering the re-scaled event times
and iid marks
, following the GPD with distribution function
so that we can regard this POT model as an MPP.
To fit the POT model, it is sufficient to fit the Poisson point process with the intensity function (
4) for
. Due to the non-homogeneity of
, we define
. Then the likelihood for
exceedances
can be formulated as
Alternatively, the POT model can be reparameterised using
for the intensity of the one-dimensional Poisson process of event times, and
for the GPD scaling parameter that is implied for the mark sizes. In that case, the intensity function in (
4) can be reformulated using the definition
and the mark sizes
as
with
and
. The logarithm of the likelihood in (
8) can then be shown to become
where
corresponds to the likelihood of fitting a GPD to the mark sizes and
to the likelihood of a one-dimensional homogeneous Poisson process with intensity
. Thus, we can make inferences about the parameters for each partition of the log-likelihood separately.
In the POT framework, a central question is how to choose the threshold
u. Coles [
69] suggested a graphical diagnostic based on the criterion of stability domains. The method aims at identifying regions for the shape parameter
and the modified scale parameter
, in which the estimates remain constant for an increasing
u. Mazas and Hamm [
18] propose to select the lowest threshold of the highest domain of stability in order to balance the trade off between choosing a high threshold to minimise the bias and choosing a lower threshold to retain enough data for minimising the variance of the estimates.
This classical POT approach relies on the assumption that the underlying series is independent. Leadbetter [
70] extended this theory to stationary sequences satisfying certain weak dependency conditions. More specifically, stationary sequences can be shown to behave like iid series if they satisfy (i) a mixing condition to restrict the long-range dependence, and (ii) a condition restricting the local clustering of extremes. When the local condition is violated due to the short-range dependence structure of the underlying sequence, the extremal behaviour can still be accommodated in the asymptotic theory using the extremal index, but the exact clustering behaviour cannot be fully described providing the justification for explicit modelling of the short-range dependence structure. For detailed discussions on EVT for stationary sequences and the respective conditions for point processes, we refer to Leadbetter et al. [
12] and Beirlant et al. [
71].
There is no general asymptotic theory for the extremal behaviour of long-range dependent times series. Although the mixing condition for stationary sequences is meant to limit the effect of long-term correlations, certain processes exhibiting long-range dependence still satisfy it. For example, the autocovariances of Gaussian linear processes are known to fulfil Berman’s condition
for
, which is sufficient to establish that Gaussian sequences satisfy mixing and local conditions. This also includes the long-range dependent Gaussian ARFIMA model (see, e.g., [
14]). Linear processes with heavy-tailed and possibly long-range dependent innovations however exhibit local clustering of extremes measured by the extremal index (Theorem 4.47 [
33]). In practical applications, the observed effects of a long-range dependence structure in the underlying series suggest deviations from the asymptotic iid limits and pronounced clustering (cf.
Section 1). Thus, independent from the challenge of developing a more general asymptotic theory for the extremes of long-range dependent series, the presence of long-range dependence has to be accommodated for when modelling the dependency structure of extremes in finite datasets.
4. Application to Significant Wave Heights
In the following, we will now present the results of applying the aforementioned POT approaches for dependent data on significant wave heights. We consider a dataset of significant wave height measured at the WaveNet buoy (22 m water depth and from the Centre for Environment, Fisheries and Aquaculture Science:
http://wavenet.cefas.co.uk, accessed on 20 August 2021) on the Sefton coast in Liverpool Bay, UK. This dataset has already been extensively studied by Dissanayake et al. [
6,
86] among others. Analogous to Dissanayake et al. [
6], we restrict our analysis to a subsample encompassing the observations from 10 September to 9 December 2013, which were recorded in 30-min intervals. This subsample contains 4367 observations ranging from 0 to
m, amongst which are 268 missing values. The missing values were dealt with by replacing the small gaps of up to 4 observations by linear interpolation. The initial threshold for the conditional POT variants was chosen following the detailed discussion of Dissanayake et al. [
86], who selected a threshold of
m or equivalently
of the observations yielding a total of 324 events. This threshold choice is in line with well-known EVT applications to financial data in the literature, where
, or more generally a threshold between
and
, is commonly chosen (cf. [
3,
23]). Further, additional analyses using the thresholds
(
m) and
(
m) were conducted to examine the robustness of our findings, but did not show any different results and are thus omitted for brevity.
4.1. Results: Conditional POT Models
We begin by presenting the inference results for the Hawkes-POT and SEPOT models as reviewed in
Section 3.1 with both ETAS (
16) and exponential (
17) decay functions, which aim at accommodating extremal clustering by explicitly modelling short-range dependencies. We further compare how the results for significant wave heights differ from the ones for financial data given in [
2,
3,
23]. Since the considered conditional POT models were initially introduced to capture the characteristics of financial data, this comparison is essential to work out the unique features of significant wave heights.
Table 1 summarises the estimation results and log-likelihoods for the four considered model variants given the threshold of
.
For the interpretation of these inference results, we first focus on the parameter estimates influencing the conditional intensity of the MPPs through the conditional intensity of the ground process
governing the evolution of event times. Compared to the estimation results from [
2] for negative daily returns of Bayer shares and the Djind index, we find a considerably lower base rate
, which underlines the distinct extremal structure in the significant wave heights time series, where event clusters are followed by long periods without any events (cf.
Figure 1). We estimate a considerably higher factor
further stressing this particular behaviour, since the most recent event, depending on its mark size, leads to a sudden, large increase in the conditional intensity of the ground process. For the models with ETAS decay functions, we find the estimates
to be significantly different from zero as opposed to the findings of [
2], where financial data is analysed. This indicates a larger influence of the time passed since a previous event on the conditional intensity for significant wave heights: the more time has passed, the smaller is the value of
and, therefore, the increasing impact on the
.
Turning to the parameter estimates impacting the conditional intensity of the MPPs through the conditional probability density function of the mark sizes
g, we first consider the two Hawkes-POT variants. Here, we observe a smaller estimate for
, indicating a lower value for
in general, and an estimate for
that is significantly different from zero, stressing the strong influence of the previous on the following mark size. For
, we find negative estimates implying a finite tail of the distribution of significant wave heights and more probability mass concentrated on smaller mark sizes compared to the positive estimate for
that is commonly found in financial data (see, e.g., [
2,
3]). For the two SEPOT variants, we retrieve smaller estimates for
and larger estimates for
compared to the results in Herrera and Schipp [
3] for the return series of various stock indices. This again shows a stronger dependence of the GPD scale parameter on past event times and mark sizes. Similar to the Hawkes-POT model variants, the estimate for
is found to be negative with the same implications as before. Overall, the estimation results for the significant wave height dataset differ significantly from the results reported in the literature for financial data for which the conditional POT models were originally suggested, stressing that the characteristics of this oceanographic time series are fundamentally different. Comparing the results for the four considered model variants, all specifications fit the significant wave height data similarly well.
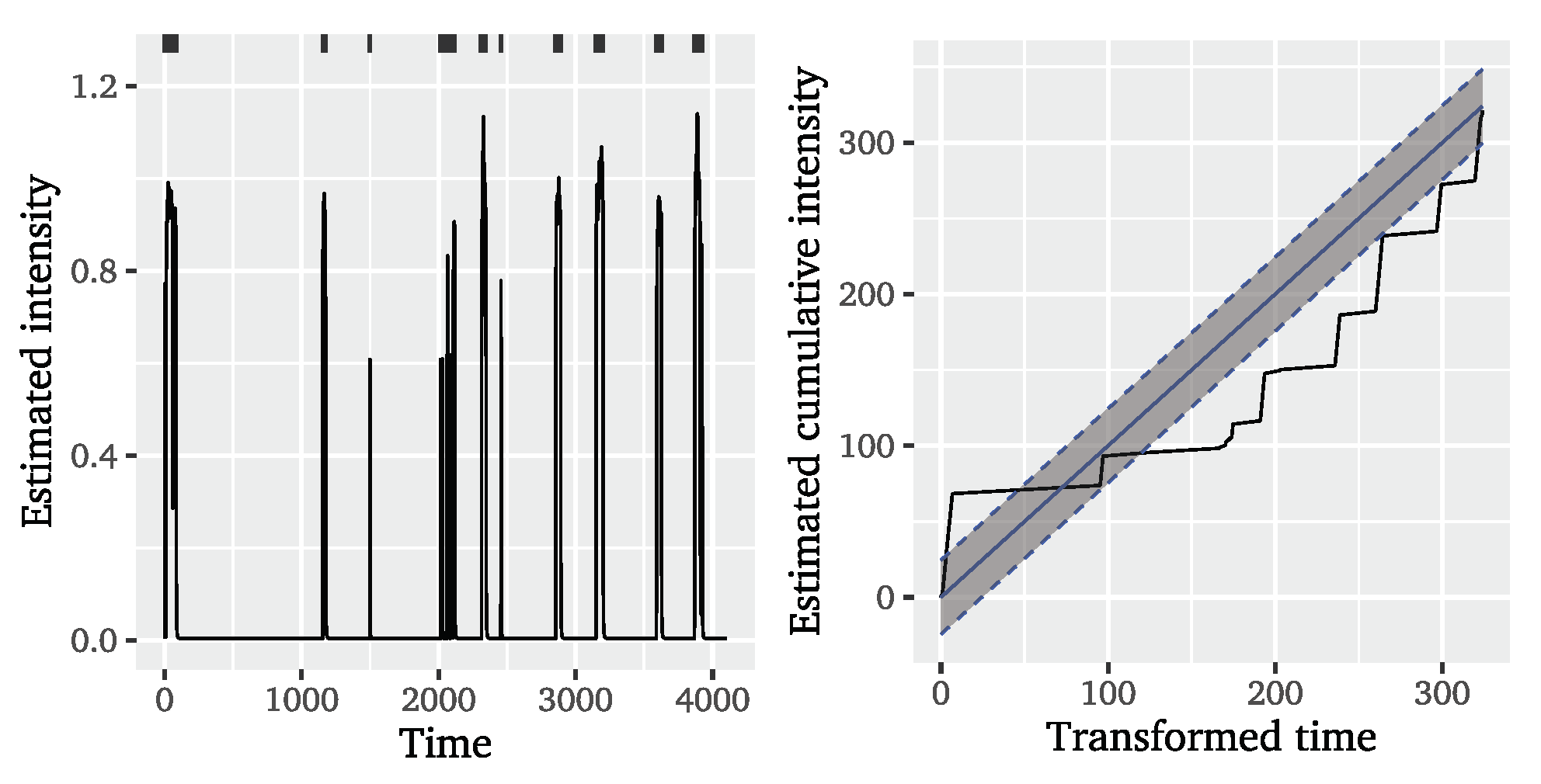
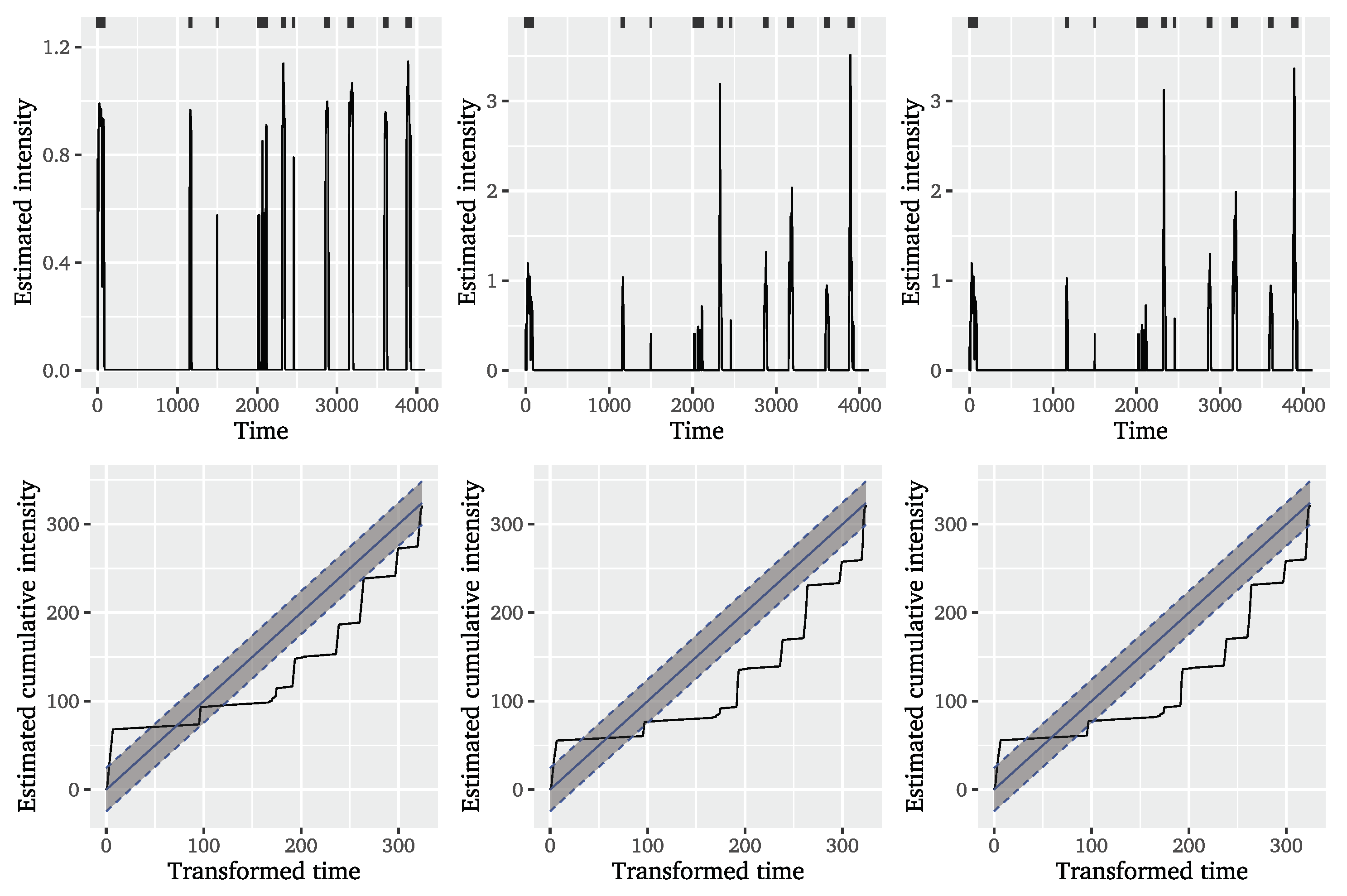
To evaluate the fit of the considered conditional POT models to the significant wave heights, we separately consider diagnostics for event time and mark modelling. For the evaluation of the fit to the event times, we look at two visual diagnostic tools: a plot of the estimated conditional intensity
and a plot of the cumulative intensity
against the time transformed based on the number of events.
Figure 3 shows these diagnostics for the Hawkes-POT model with ETAS decay for the
threshold, whereas the very similar looking plots for the exponential decay variant and both SEPOT models can be found in the
Appendix A.1 in
Figure A1.
The plotted estimated conditional intensities for the Hawkes-POT on the left of
Figure 3 strongly differ from the results found for financial data by (e.g., [
2,
23]). The occurrence of an event causes the conditional intensity to instantly increase by an amount dependent on the mark size, which is followed by a rather sudden decline towards the estimated base rate
after the last event of the cluster, likely due to the large estimated weight on the exponential dependence on past values. This is of course not realistic, but illustrates that the time span between observed events is so long that the dependencies captured by the conditional intensity fully disappear between clusters. Given the very small estimated ground intensities, it is actually very unlikely to see another event during the observation period based on these models, which contradicts the intuition that, the further away from the last event, the more likely it should be to see another cluster of events. The spiky appearance of the estimated conditional intensity results in a cumulative intensity resembling rather a step function than a line close to the bisecting one and therefore not lying within the
confidence bands of the diagonal. From these visual diagnostics, we can conclude that of the conditional POT model variants are appropriate to model the event times in the significant wave height dataset. Their conditional intensities do not seem to sufficiently capture the dependencies in the data to explain the clustering behaviour.
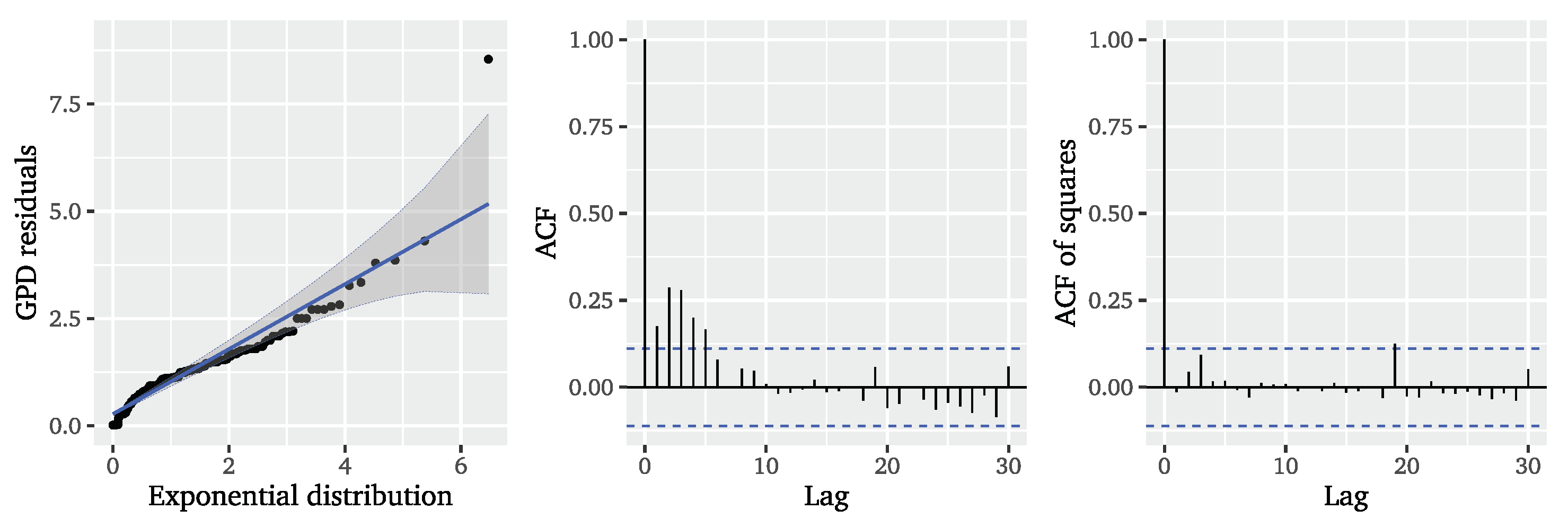
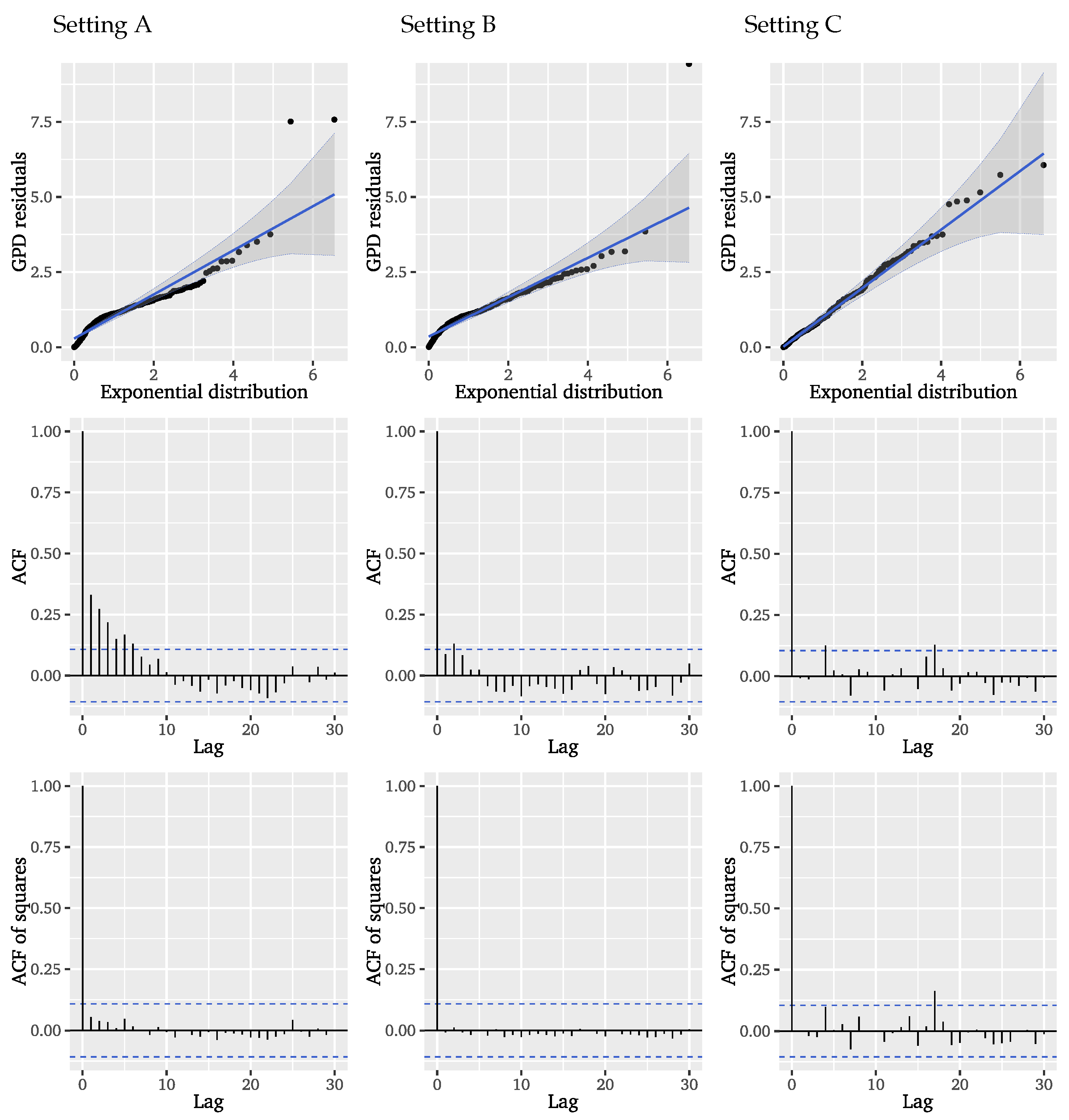
To evaluate the model fit for the event marks, we consider unit exponential QQ plots and plots of the ACF for the GPD residuals
.
Figure 4 depicts these visual diagnostics for the Hawkes-POT model with ETAS decay function. Similar results for the exponential decay and both SEPOT models can be found in the
Appendix A.2 (
Figure A2). The QQ plots reveal that in none of the considered setups the residuals are well-described by a unit exponential distribution as would be expected from a perfect fit. Although the Hawkes-POT model variants seem to give a more reasonable picture than the SEPOT model variants, the QQ plots confirm that there are still dependencies present that are not accounted for in the modelling of the mark sizes. This is validated by the ACF of the GPD residuals, which clearly depicts remaining autocorrelations for the first five lags indicating that the approach neglects dependencies. The squared residuals in contrast exhibit no systematic autocorrelations. From the residual diagnostics we can conclude that neither the considered Hawkes-POT nor SEPOT models can satisfactorily characterise the mark sizes in the significant wave height data. We may suspect that the long-range correlation found in the underlying series is responsible for depedencies that cannot be captured by the considered Hawkes-POT and SEPOT models. For this reason, we now turn to the next model that incorporates long-range dependence.
4.2. Results: Mittag–Leffler Distribution
Following Hees et al. [
43], we fit the Mittag–Leffler distribution to the inter-event times using the
R packages
MittagLeffleR [
88] and
CTRE [
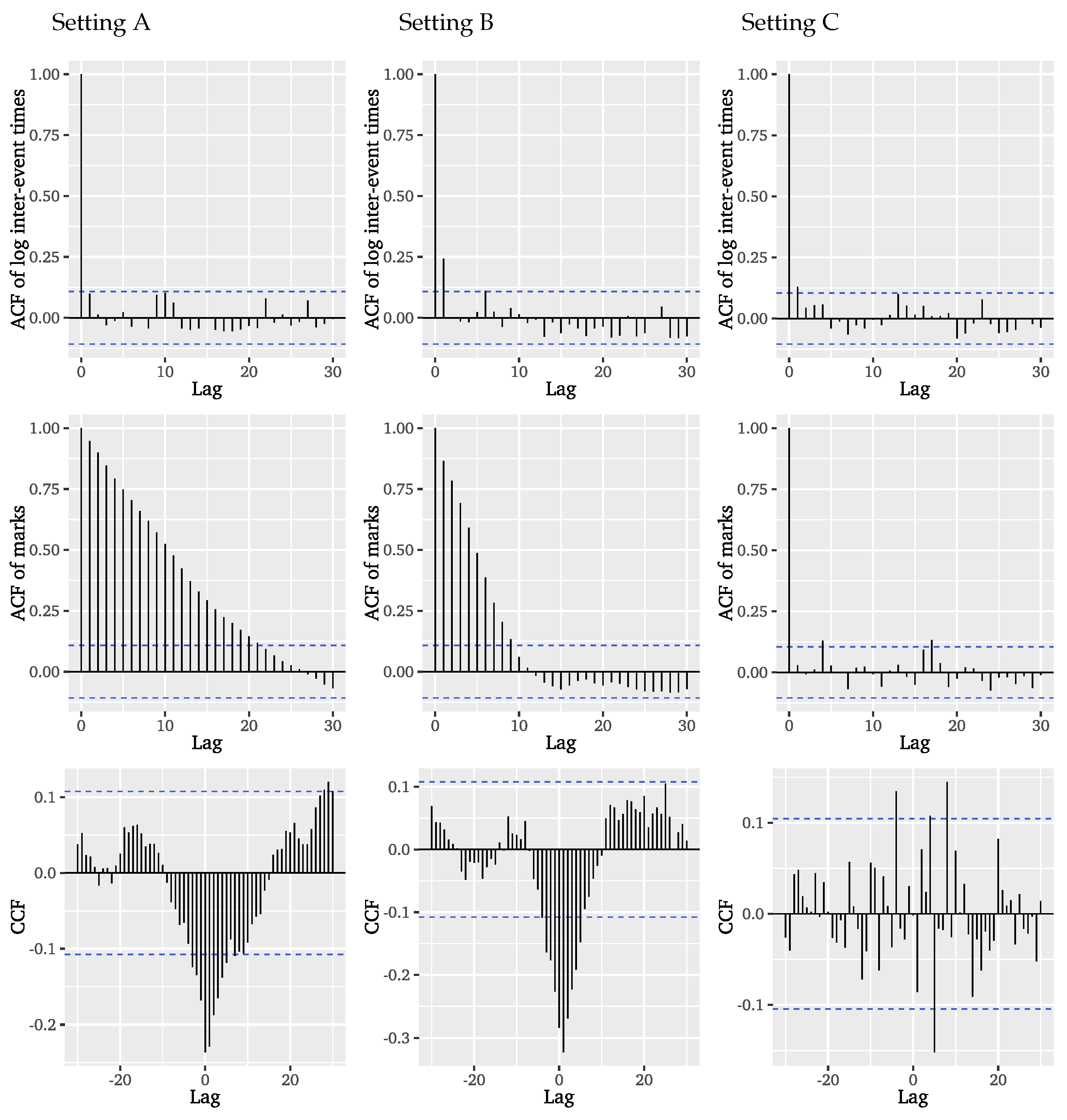
89]. We begin by checking the necessary assumptions. Firstly, the inter-event times and event marks are not supposed to exhibit any (inter-)dependencies. The ACF of the logarithmic inter-event times in
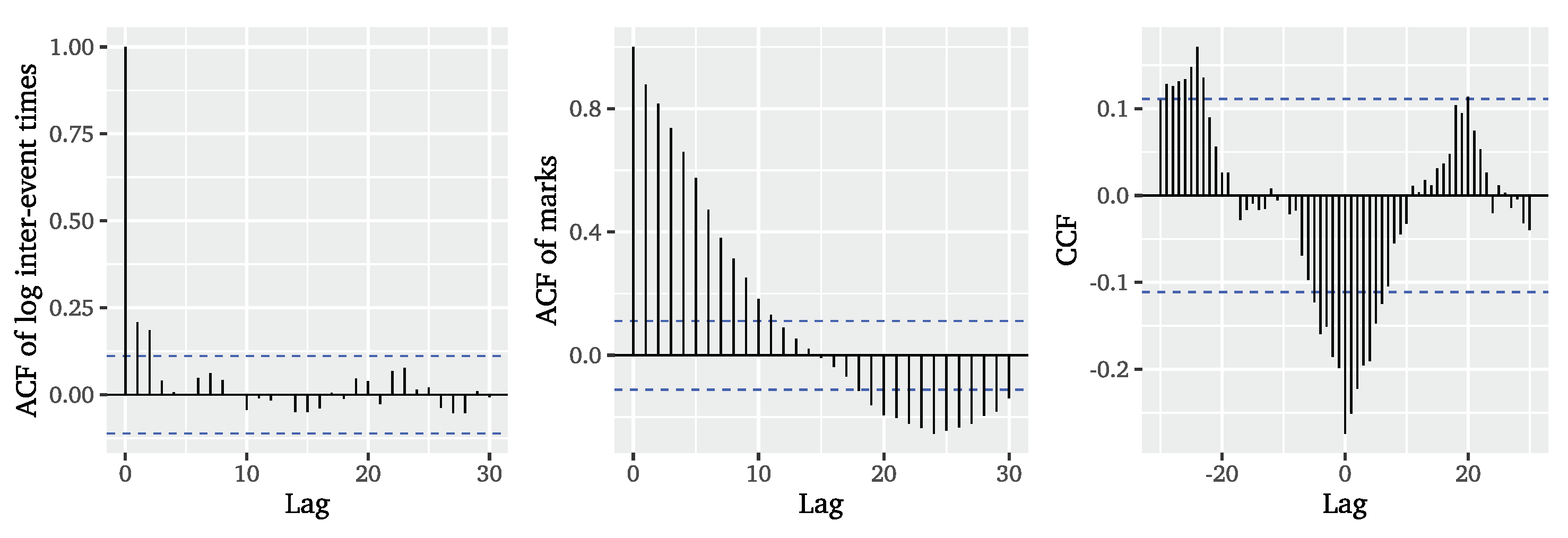
Figure 5 reveals small autocorrelations for low lags, whereas the ACF of the event marks in
Figure 5 shows strong autocorrelation for many lags.
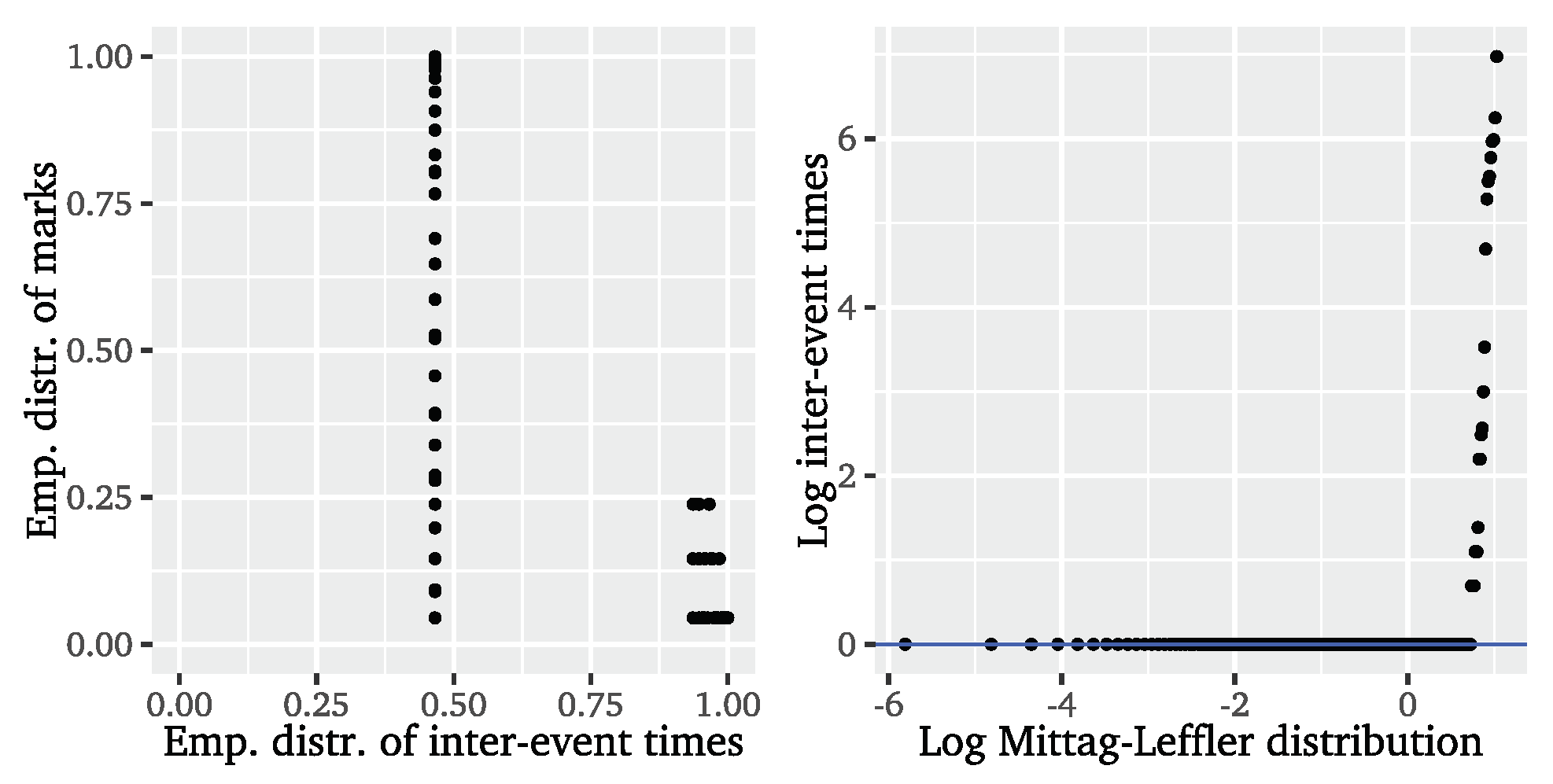
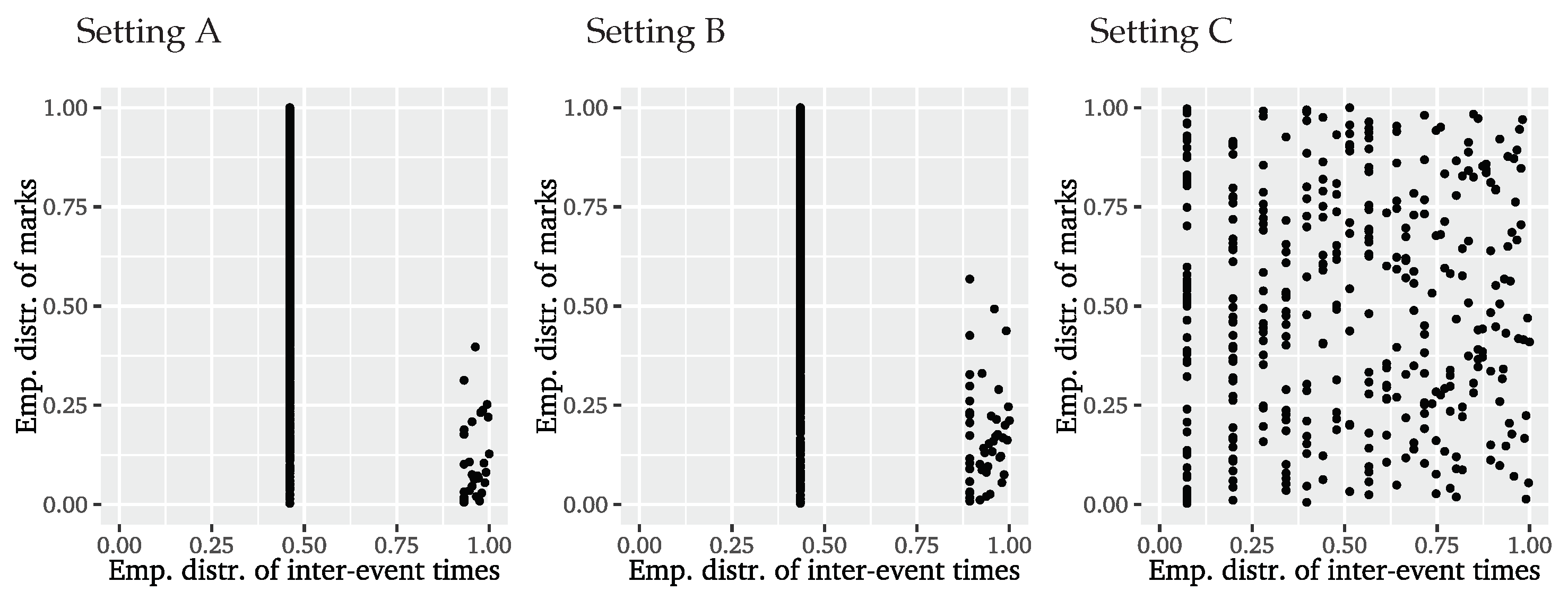
Considering the cross-correlation function (CCF) of inter-event times and event marks, we observe that the series are also cross-correlated, so that we clearly have to reject the independence assumption. The coupling of inter-event times and event marks is further confirmed by the empirical copula presented on the left of
Figure 6. If both were uncoupled, the points would be evenly distributed over the
space. What we find instead is that the empirical copula is dominated by strong extremal clustering. The particular shape can be explained by events being mostly separated by a single time unit, so that there is an accumulation of points for this inter-event time combined with all possible values of event marks. After a long inter-event time, i.e., a long period without an event, we rather record smaller event marks, indicating that event clusters usually start with smaller marks which then magnify for the successive events.
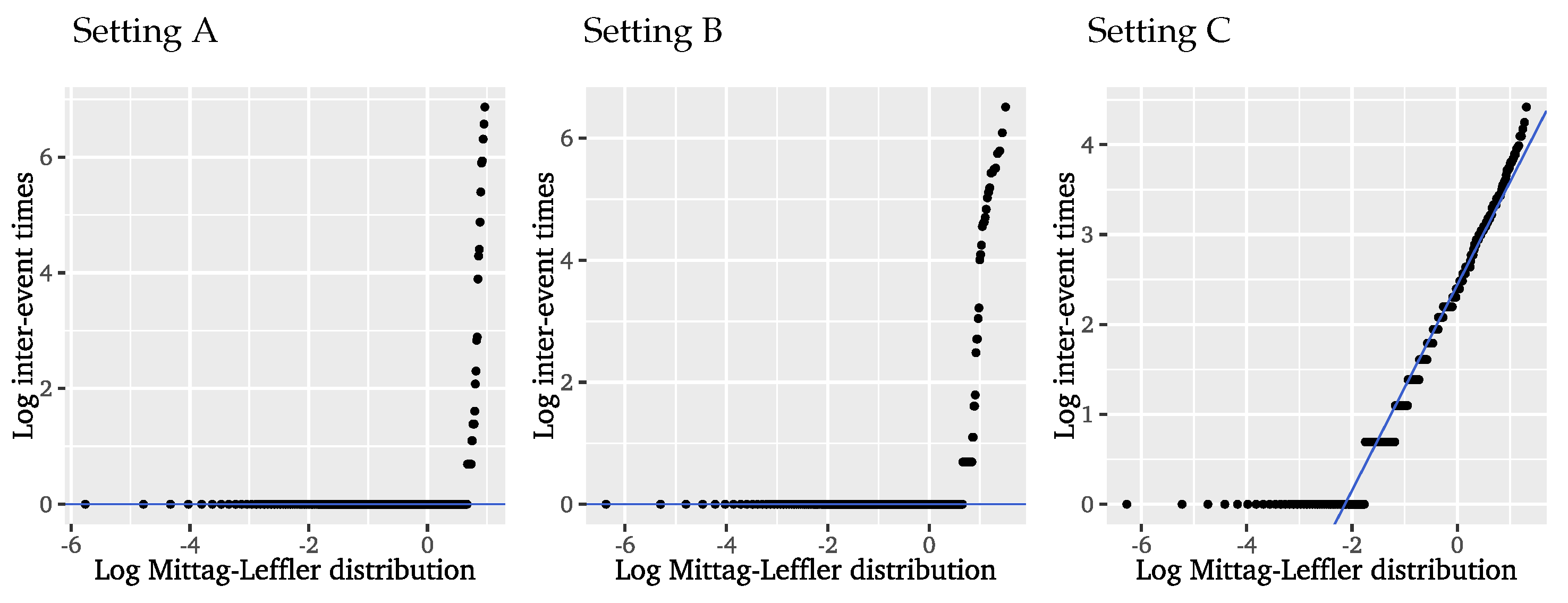
According to Hees et al. [
43], the suitability of the Mittag–Leffler distribution can be verified using a logarithmic Mittag–Leffler QQ plot for the logarithmic inter-event times, displayed on the right of
Figure 6. The tail parameter is determined via log-moment estimation yielding
with a
confidence interval of
, which again strongly contradicts the model assumptions, while the scale is set to 1 for this diagnostic. It is obvious that the Mittag–Leffler distribution does not fit the inter-event times of the significant wave heights. Again, it appears that we have too much probability mass concentrated on lower, or more precisely, unit inter-event times, indicating that the present extremal clustering is too strong to be captured with this approach. Representing the long gaps between clusters, we further find a few inter-event times that are too large to appear under a Mittag–Leffler distribution. Given these results, we can conclude that the Mittag–Leffler distribution does not provide a better fit to the inter-event times of the significant wave heights than the exponential distribution arising in the limit of iid data. Even though this approach incorporates long-range dependence, it does only account for it in the event times and disregards any local, short-range dependencies affecting the distribution of event and inter-event times.
Although the assumptions are obviously violated, we include the parameter estimates of the Mittag–Leffler distribution for the significant wave height data for completeness. The stability plots for the tail and re-scaled scale are presented in
Figure 7 and do not give clear stable regions for the parameter estimates. For the tail parameter, the only rather stable region we can identify is around the estimate
, which is consistent with the previous estimation and again clearly violates the model assumptions. Additionally, the scale parameter is dependent on the number of events, indicating that the model is not suitable for the significant wave height dataset.
To date, neither the applied conditional POT methods nor the fitted Mittag–Leffler distribution satisfactorily explain the extremal clustering in the significant wave height data. Either the models fail to account for the long-range dependence in the mark sizes inherited from the dependence structure of the underlying observations, or the short-range dependencies between the event times are disregarded. Therefore, we continue with applying the two-step ARFIMA-POT approach which aims at capturing the full dependence structure of the underlying observations, in order to avoid the need for explicit modelling of inherited properties in the event times and mark sizes all together.
4.3. Results: Two-Step ARFIMA-POT Approach
In the first stage of the two-step ARFIMA-POT approach, we seek to identify and fit the ARFIMA
model that is most suitable for describing the significant wave heights. Using the
R package
arfima [
90], we systematically estimate the model parameters including
d for various combinations of
p and
q orders and find the ARFIMA model with
and
to minimise both AIC and BIC.
Table 2 reports the parameter estimates for the selected ARFIMA model. The corresponding fractional difference parameter is estimated as
indicating the presence of mild long-range dependence.
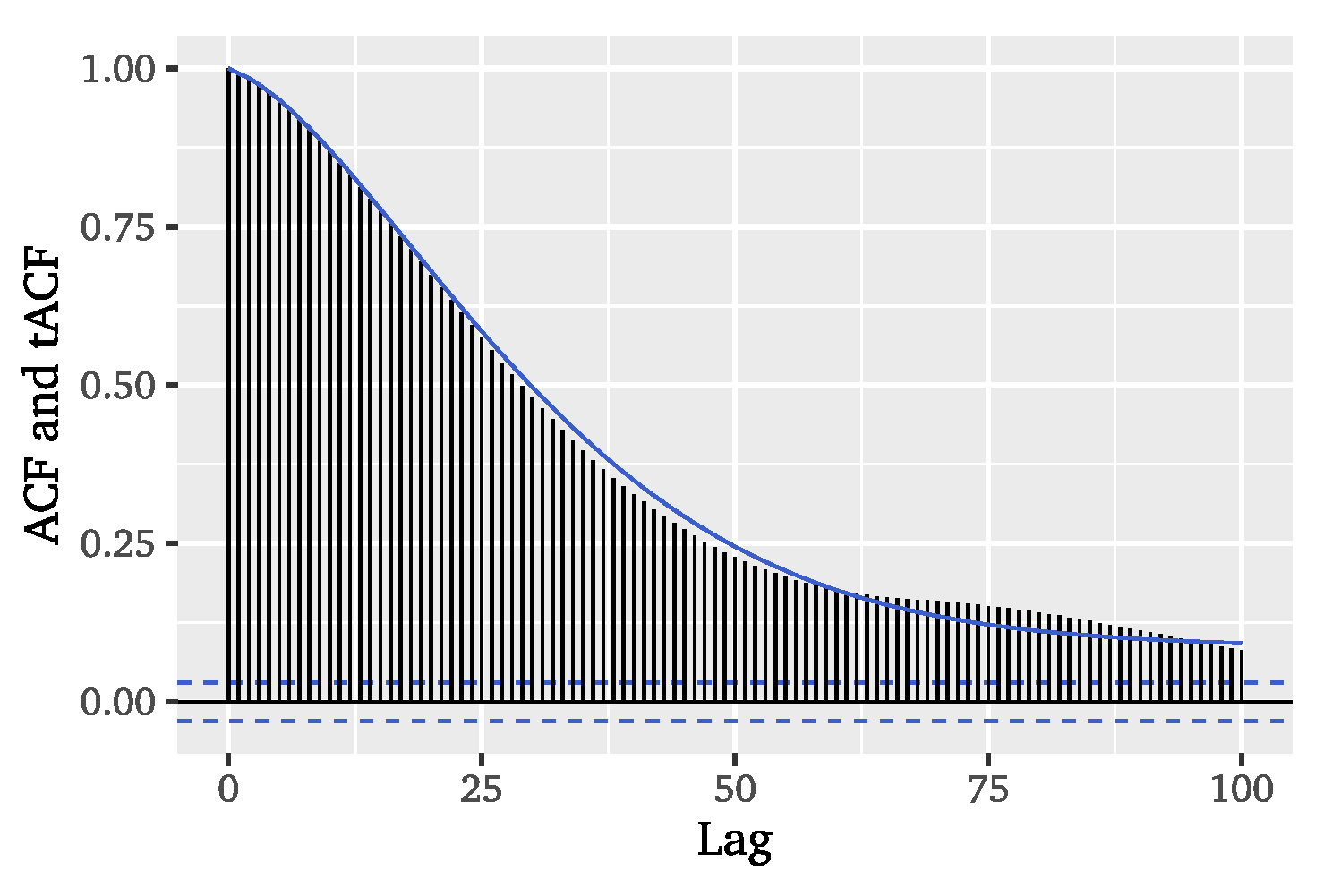
Comparing the theoretical ACF of the chosen ARFIMA model to the empirical ACF of the dataset in
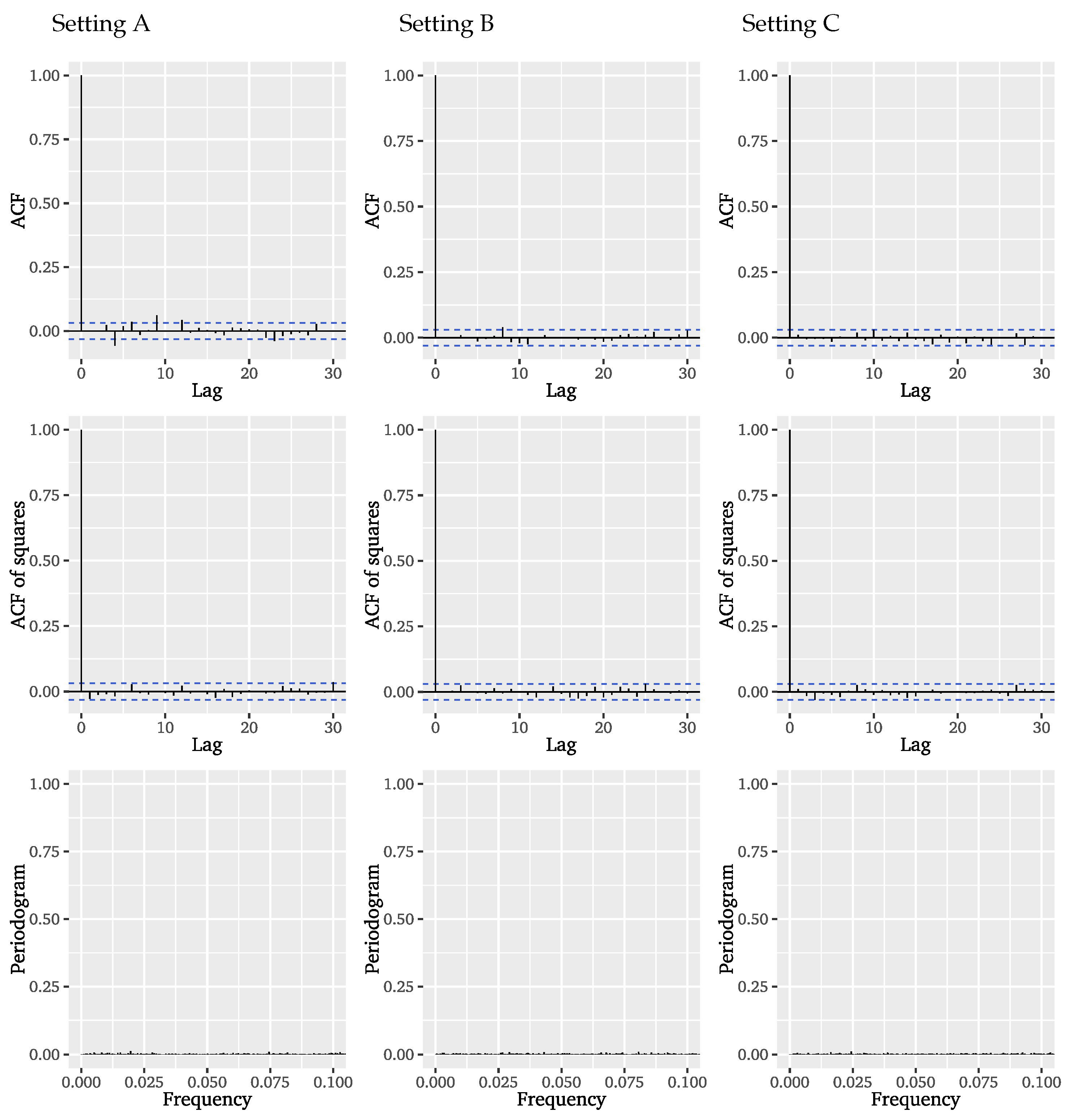
Figure 8, we can conclude that the selected model specification satisfactorily captures the autocorrelation structure of the significant wave heights.
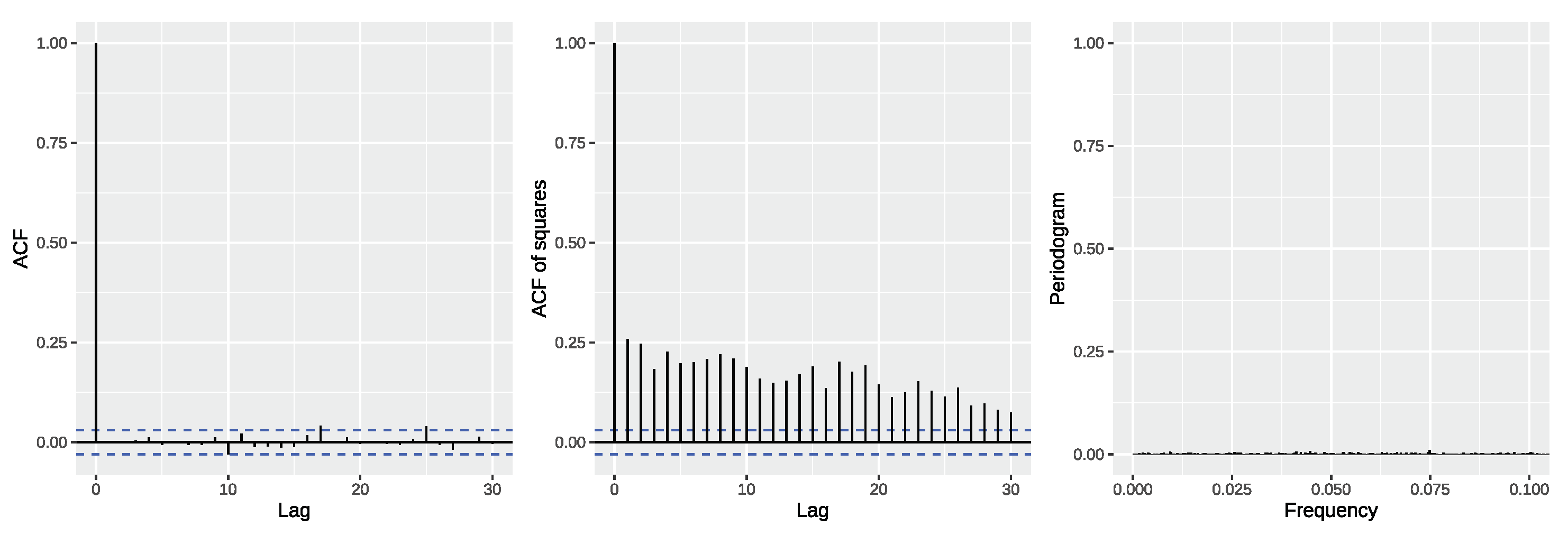
Further,
Figure 9 provides visual diagnostics for the ARFIMA model residuals in the form of plotted ACFs of residuals and squared residuals as well the periodogram of the residuals. These diagnostic suggest that, apart from some variance clustering, there are no dependencies left in the residuals. Since we deliberately refrained from modelling the conditional variance of the significant wave heights in order to solely find an explicit representation of the dependence structure of the underlying series, the residual diagnostics confirm suitability of the classical POT model for the ARFIMA model residuals. An additional Ljung-Box test for the smallest possible lag choice, which results from the model orders and corresponds to 9 lags in this case (see [
91]), does not reject the null hypothesis of no autocorrelation in the ARFIMA residuals for the considered lags on a
level (
p-value: 0.1642).
In the second stage of the ARFIMA-POT approach, we apply the classical POT method to the ARFIMA residuals using the
R packages
POT [
92] and
extRemes [
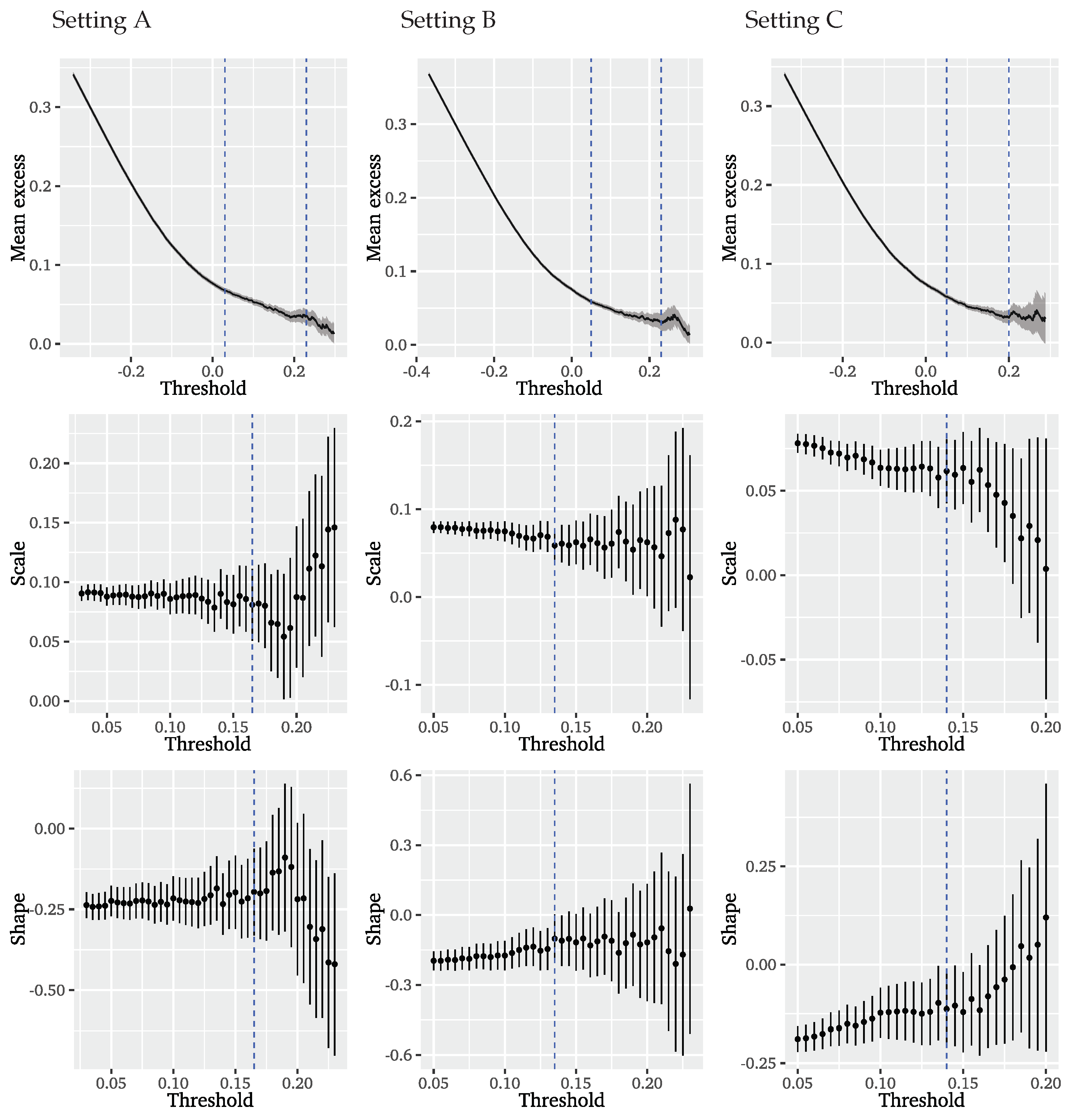
93]. The threshold is chosen from the mean residual life plot and GPD parameter stability plots given in
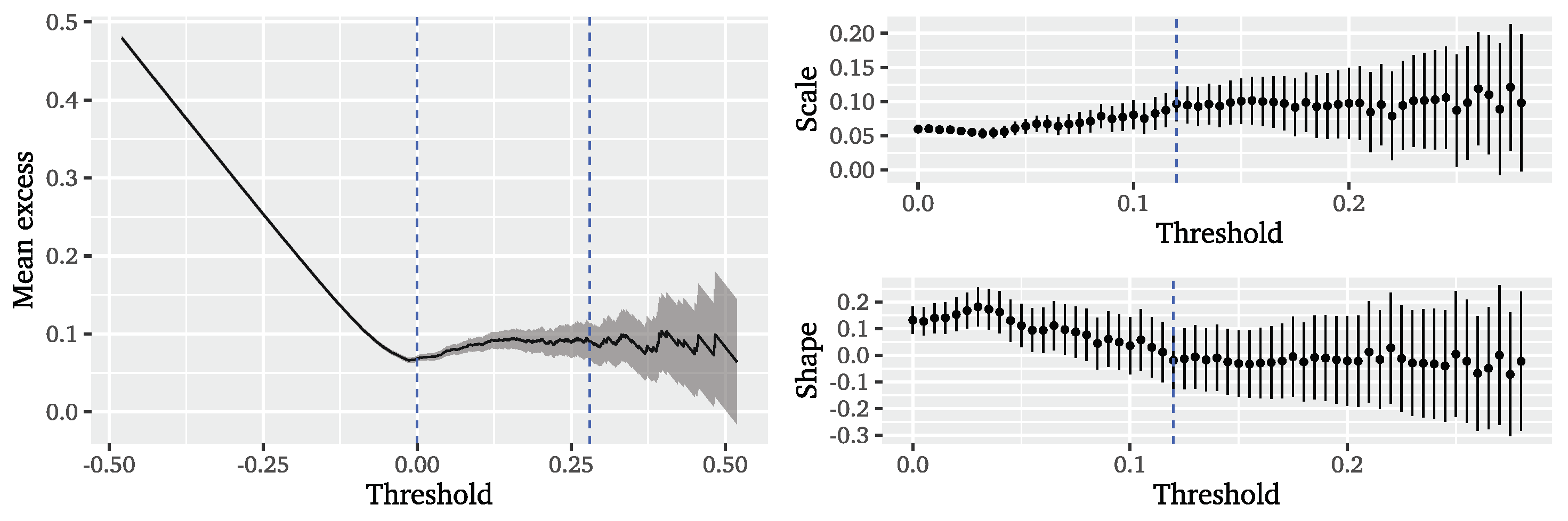
Figure 10. The mean excess plot shows a course linear in
u from 0 to
and is rather constant between
and
. Choosing a higher threshold is not sensible due to the erratic course of the mean excess and too few remaining observations. The GPD parameter stability plots suggest a long stable region for both GPD parameter estimates following a threshold of
that corresponds to
of data and matches the threshold from the mean residual life plot. Thus, we base the second step of the ARFIMA-POT approach on a threshold corresponding to
of data.
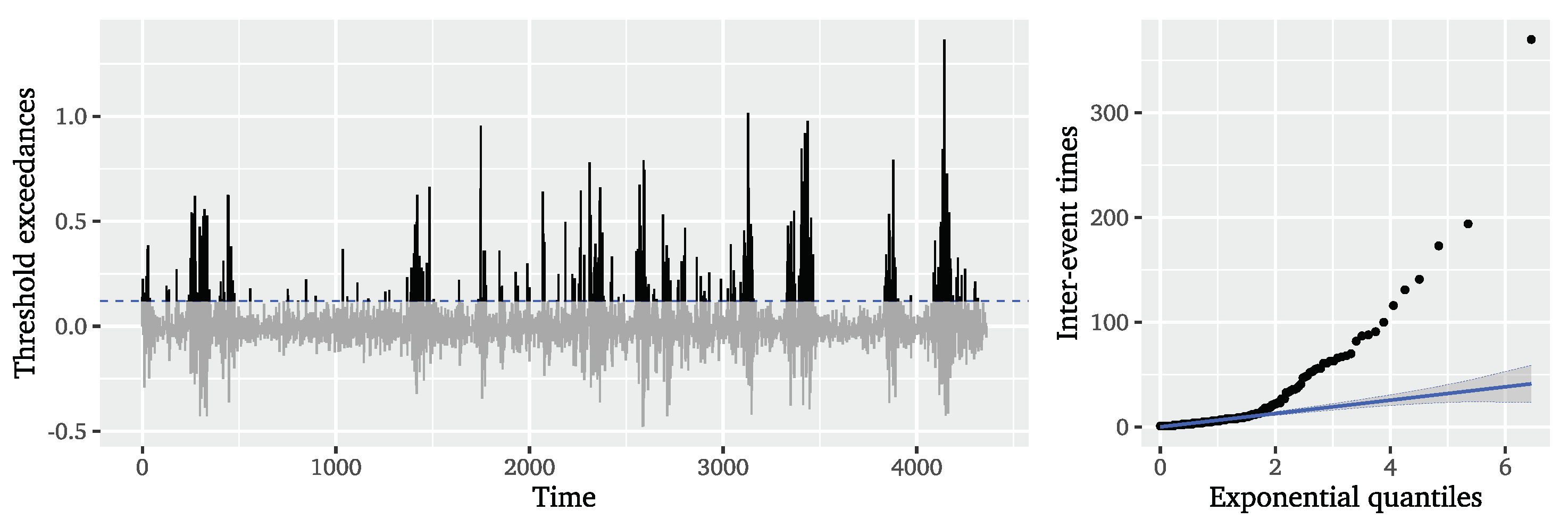
Based on the ARFIMA residuals,
Figure 11 displays the exceedances of the selected threshold. In line with the autocorrelations found in the ACF of the squared ARFIMA residuals (cf.
Figure 9), the extreme events still appear to be slightly clustered, but the long gaps without clusters that governed the original significant wave height series are no longer as distinct. The QQ plot of the inter-event times on the right of
Figure 11 still depicts the tails of the inter-event times as lying outside the confidence bands of the exponential distribution, but this is much closer to the exponential distribution than what was observable for the original time series (cf.
Figure 1). We can note that the two-step ARFIMA-POT approach improves the predictability of event times over the original series, but the dynamics of the significant wave height series affecting the distribution of event times are not captured in their entirety.
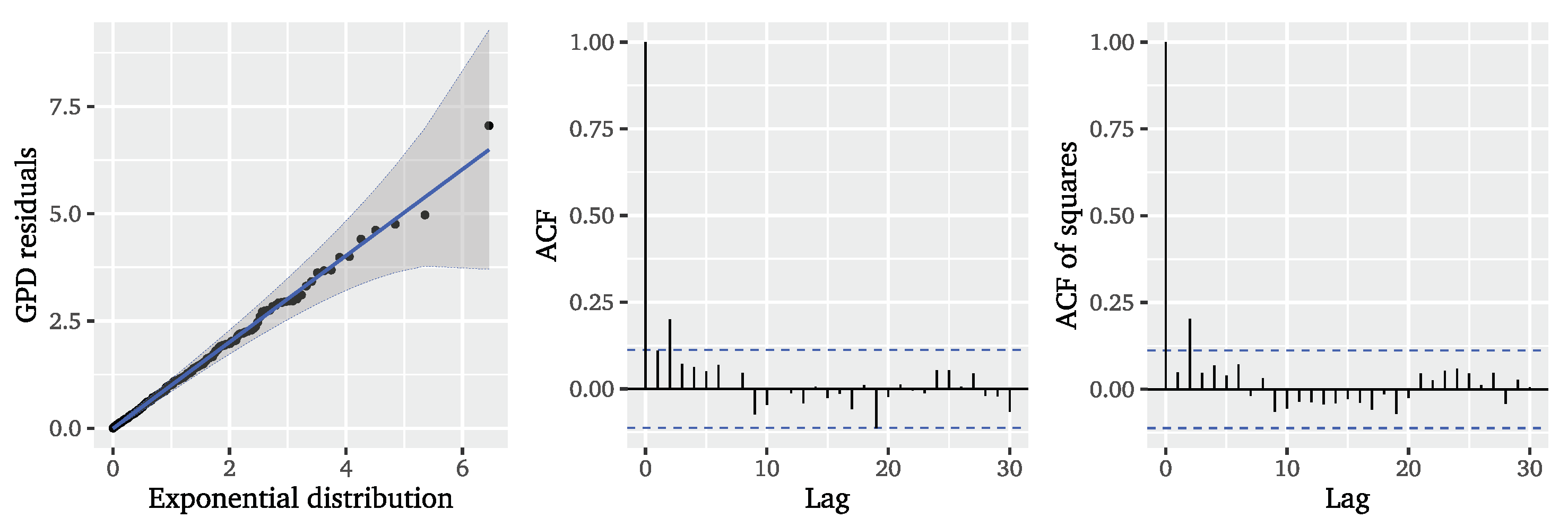
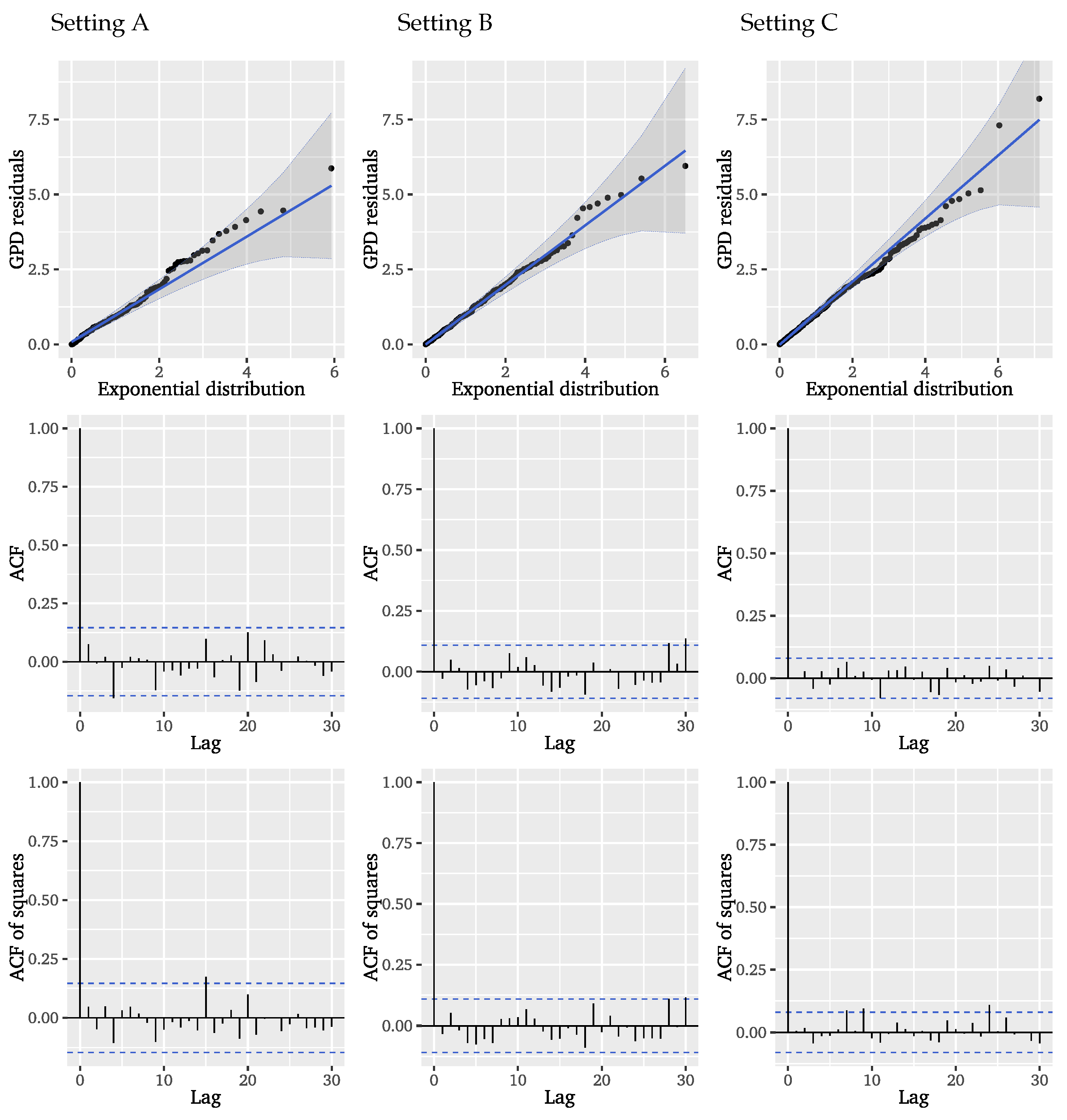
We fit a GPD to the ARFIMA residuals via maximum likelihood estimation and obtain the estimates
and
for scale and shape parameters, respectively. Similar to the results for the conditional POT approaches, the estimated shape parameter is negative, indicating a finite tail of the distribution of ARFIMA residuals and a concentration of probability mass on the smaller mark sizes. Based on the estimated GPD residuals,
Figure 12 provides visual diagnostics. The QQ plot illustrates that the GPD residuals are following a unit exponential distribution very closely. Compared with the results for the Hawkes-POT in
Figure 4, we find a clearly improved model fit. Considering the ACF of the GPD residuals and squared residuals, we observe that, apart from lag 2, there is no autocorrelation left, indicating that the two-step ARFIMA-POT approach satisfactorily models the dependencies in the underlying significant wave height series which may affect the distribution of the mark sizes.
In summary, the two-step ARFIMA-POT approach improves upon the considered conditional POT approaches in terms of model fit for the mark sizes, and upon the fit of the Mittag–Leffler distribution for the inter-event times. Clearly, the two-step method is an imperfect solution to modelling significant wave heights, but we show that incorporating both short- and long-range dependencies in a parametric approach can be a more successful pathway than focusing on short- or long-term dynamics alone. To review these conclusions, we systematically break down the effects of short- and long-range dependence on the model fits in the following section.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



















