
Improving the Accuracy of Dam Inflow Predictions Using a Long Short-Term Memory Network Coupled with Wavelet Transform and Predictor Selection

Abstract
:1. Introduction
2. Methodology
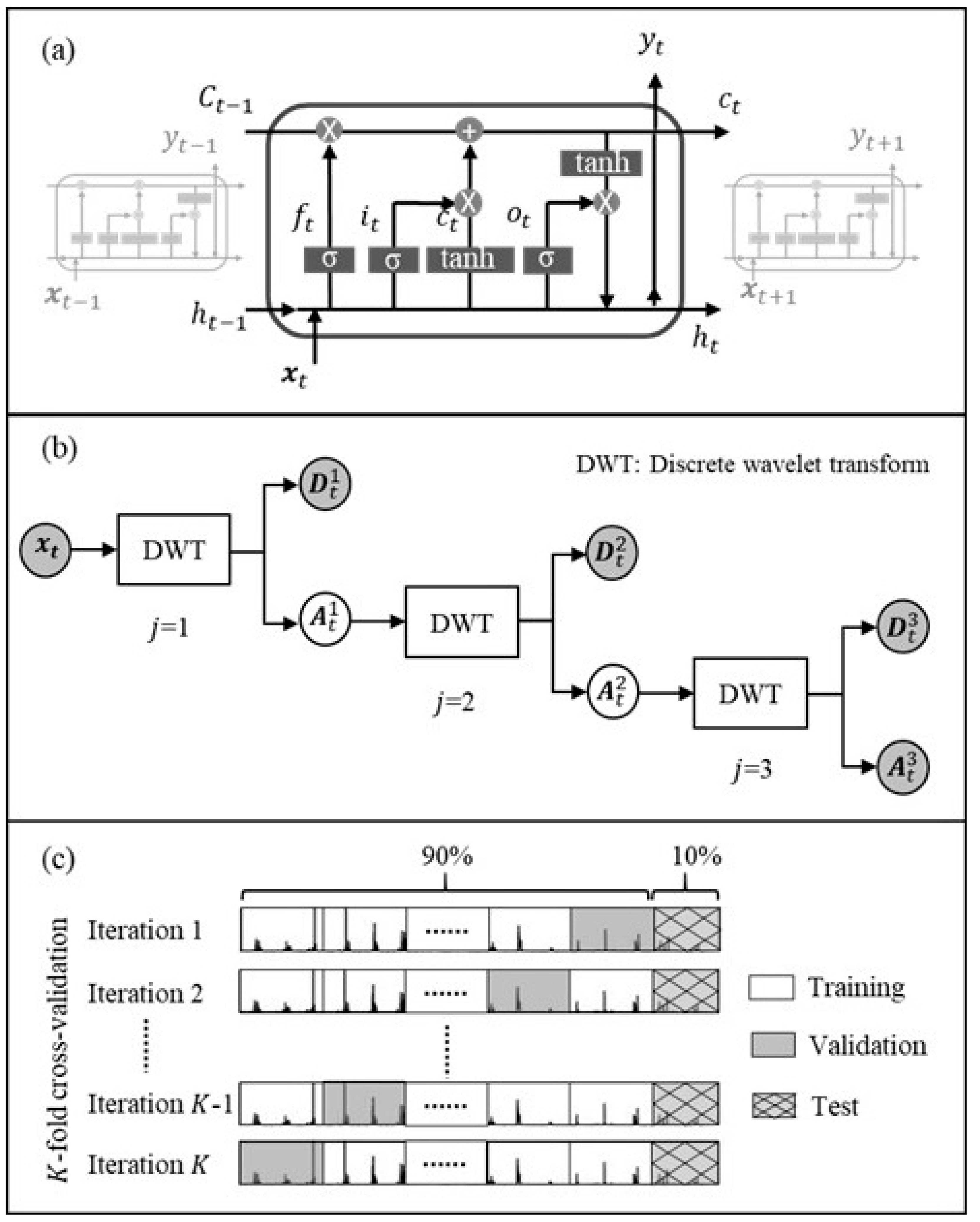
2.1. Long Short-Term Memory Network
2.2. Input Predictor Selection
2.3. Wavelet Transform
2.4. LSTM Hyper-Parameters
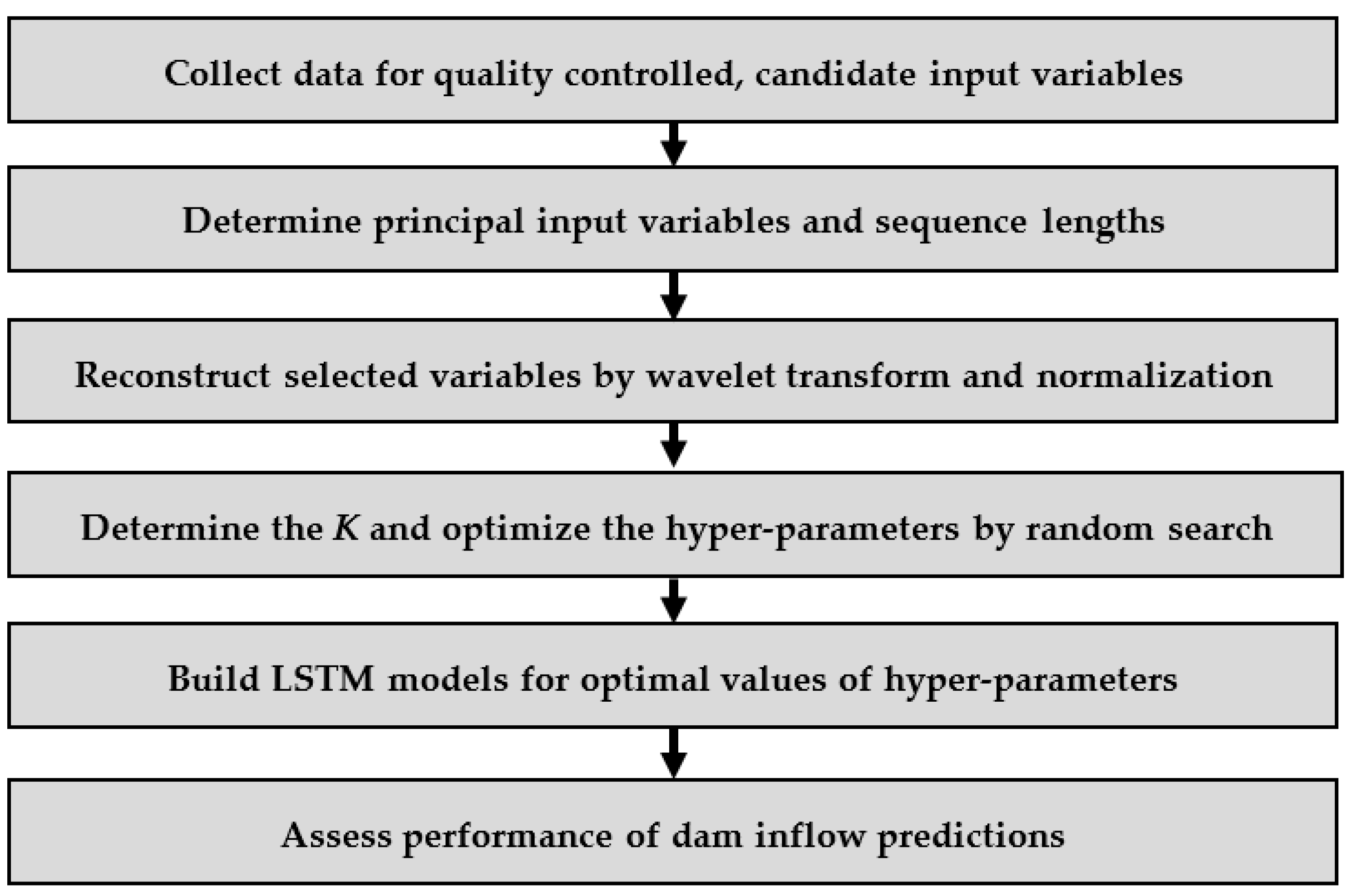
2.5. Summary of Modeling Framework
- (1)
- Collect the time series of both the target output (i.e., dam inflow) and the candidate input predictors , . Any inappropriate or missing values in the collected data should be reviewed carefully.
- (2)
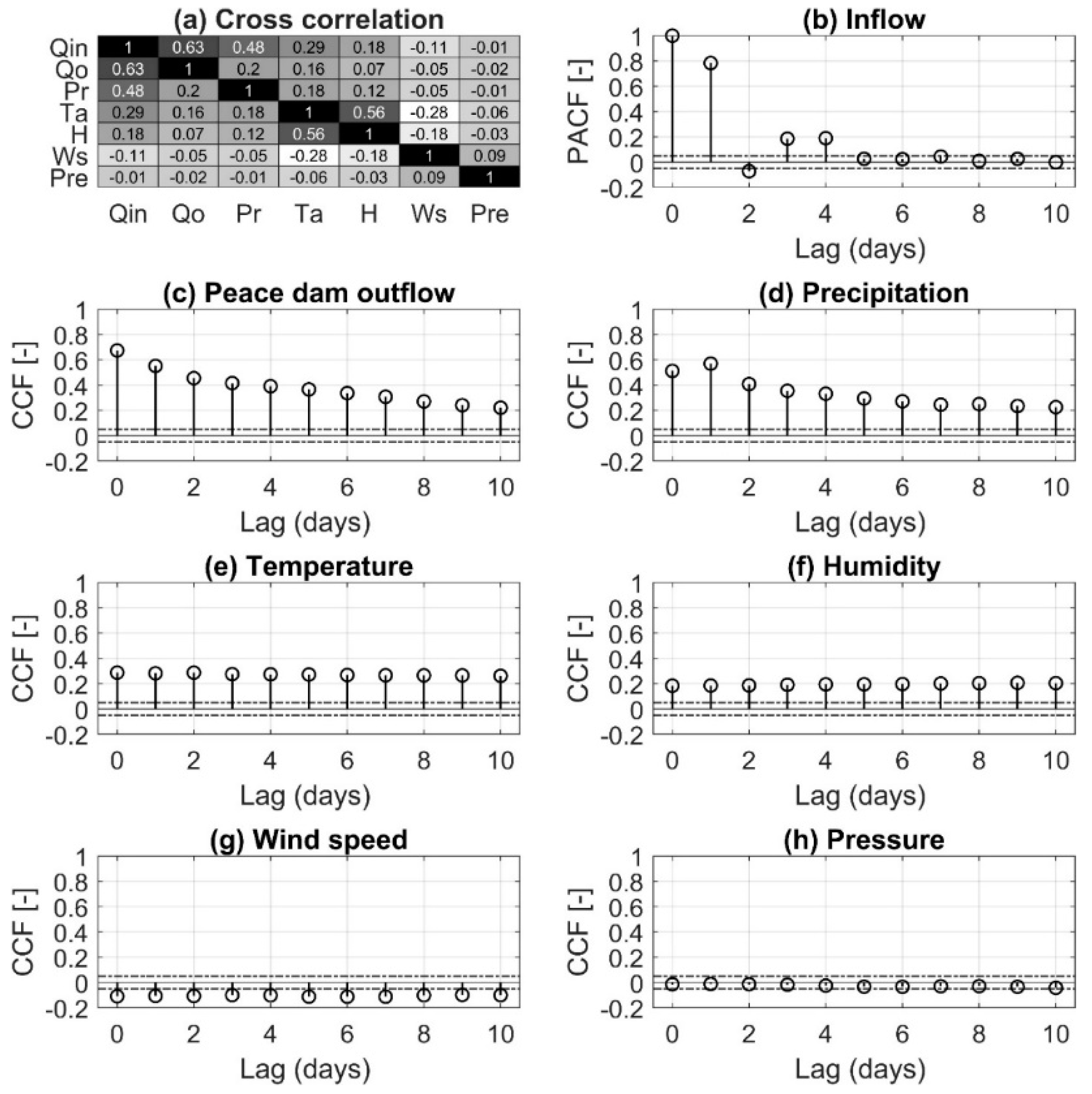
- Determine the explanatory “principal” variables , among the candidate predictors, with an appropriate lag time, using the CCF and PACF.
- (3)
- Decompose and reconstruct the selected input predictors into the wavelet-transformed subseries. These reconstructed data are normalized to values between 0 and 1, and then split into one set for training and validation and another for testing. In this study, we set 90% of the total data length for training and validation and 10% for test.
- (4)
- Determine the number of clusters for the -fold cross-validation and then optimize five hyper-parameters by the random search over the training and validation set.
- (5)
- Train and build the LSTM models, using the optimal values of hyper-parameters over the training and validation set.
- (6)
- Assess and compare the performance of LSTM models in predicting dam inflow for the test dataset. The LSTM models chosen to demonstrate the effectiveness of SWLSTM presented here are (1) a regular LSTM without both the determination of principal lags and variables and the WT, (2) a “WLSTM,” which is a regular LSTM coupled with a WT, and (3) a “SLSTM,” which is similar to a regular LSTM but performs the input specification in the Step 2.
2.6. Evaluation Metrics
2.7. Open Source Software
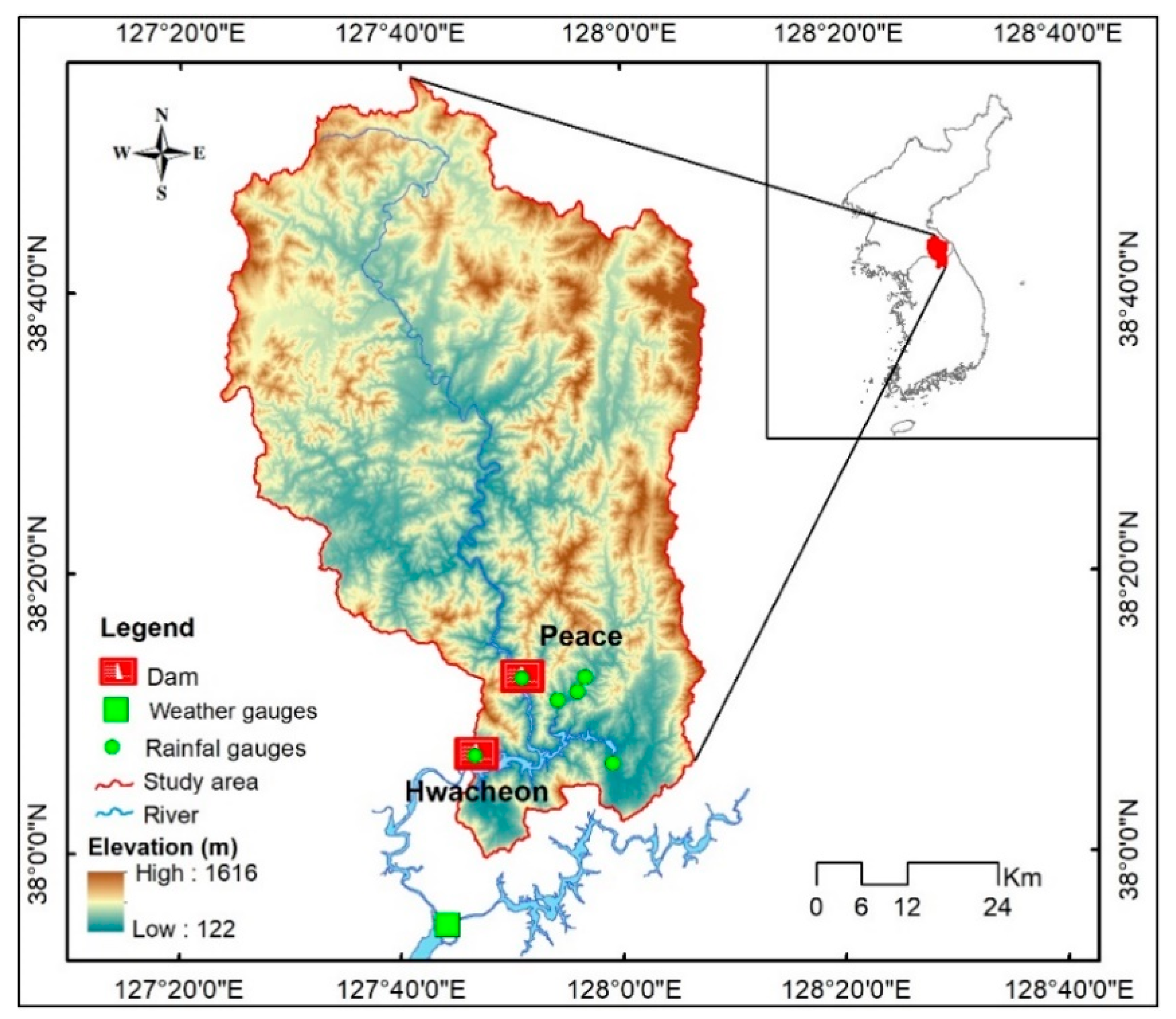
3. Study Area and Dataset
4. Results and Discussion
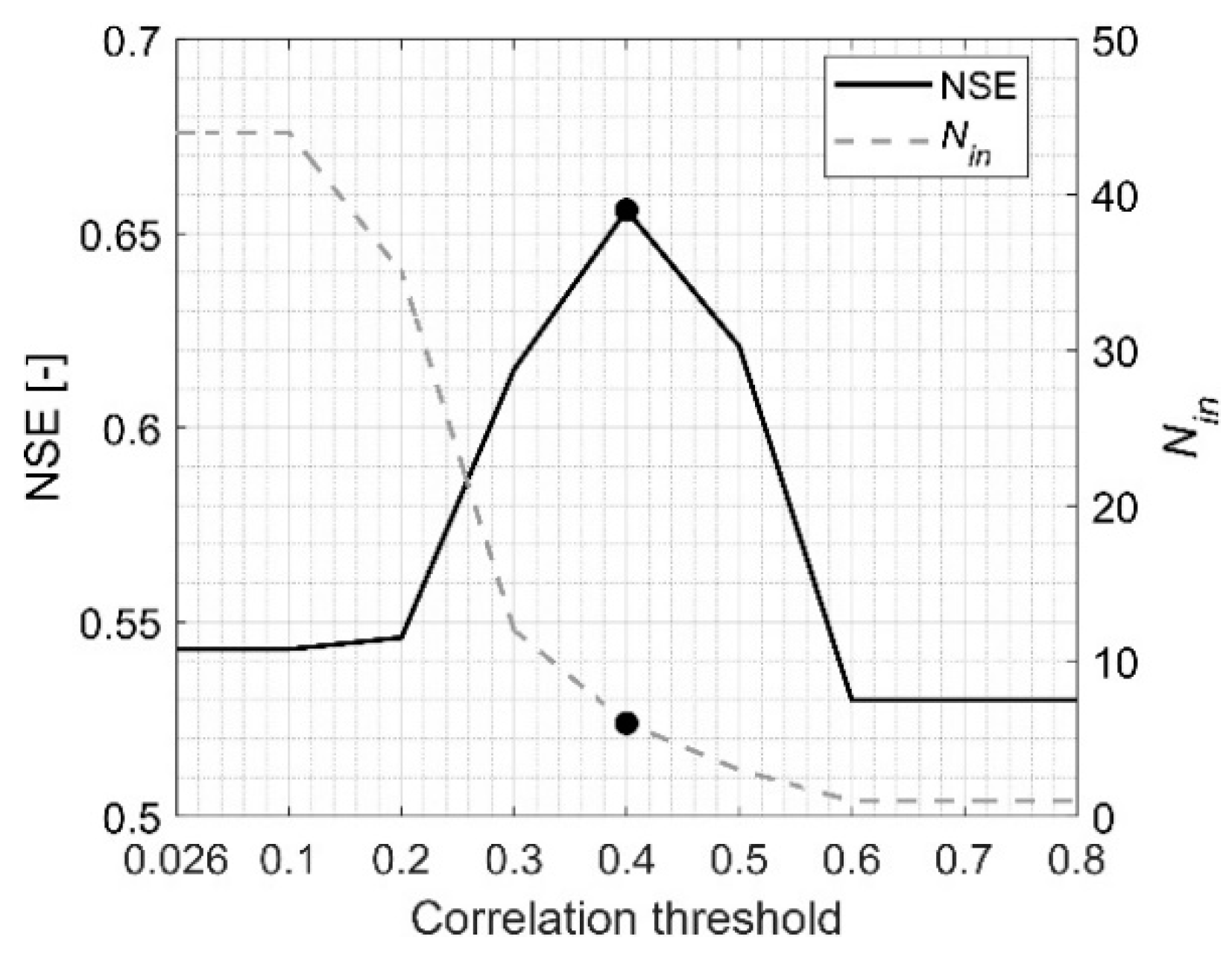
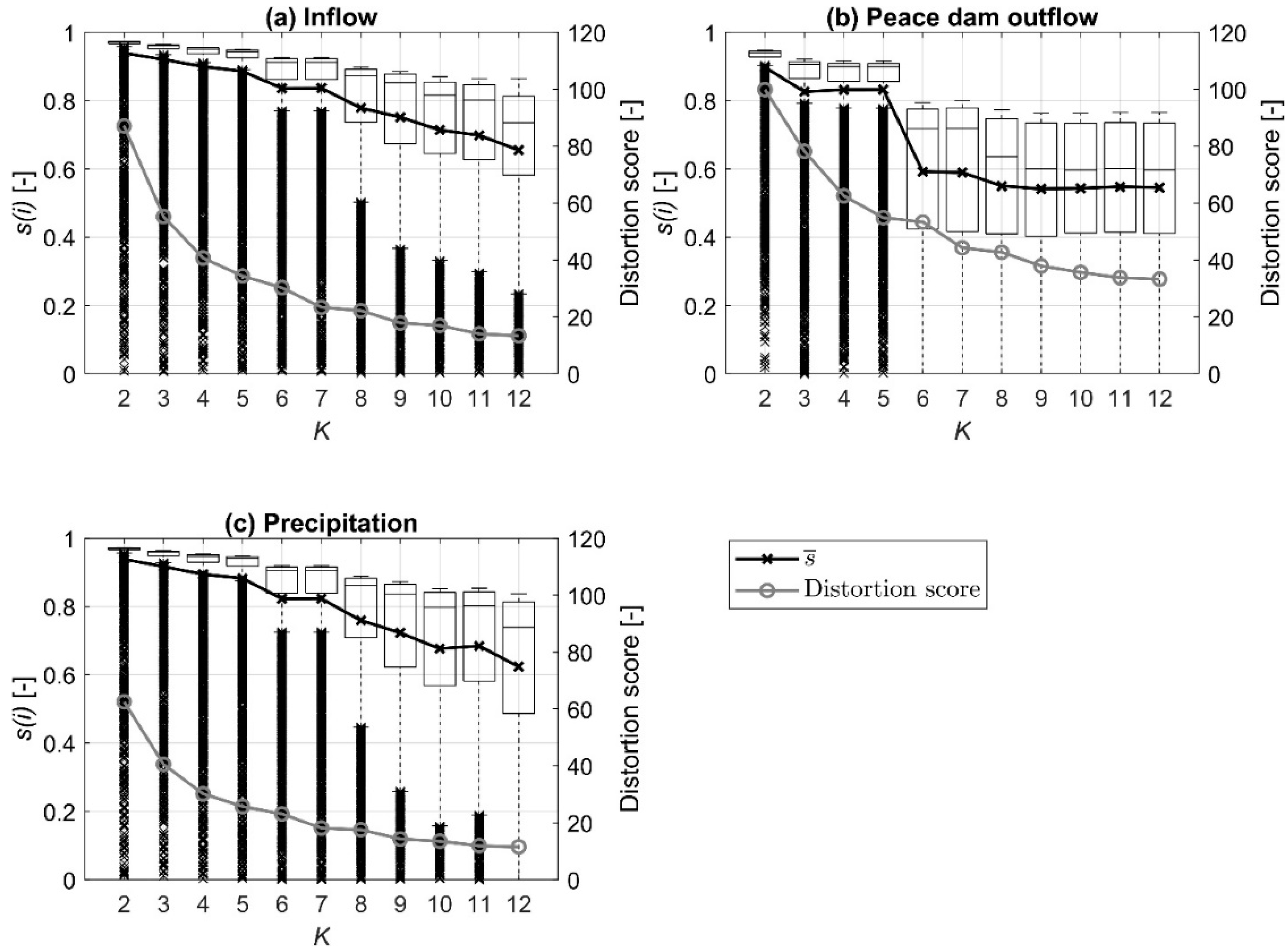
4.1. Determining Principal Input Predictors and Their Sequence Lengths
4.2. Decomposing Input Time Series by a Wavelet Transform
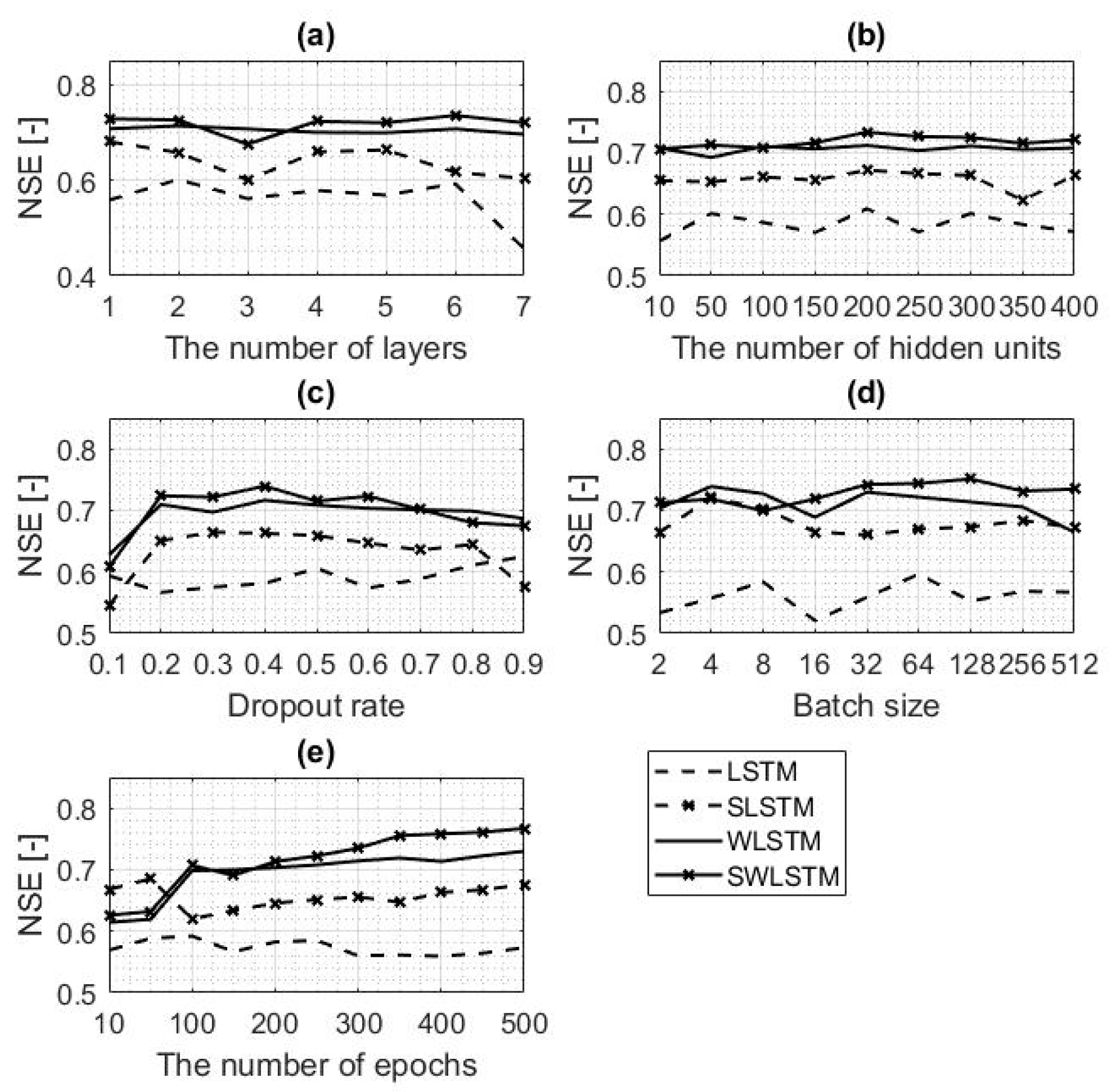
4.3. Optimizing the Hyper-Parameters
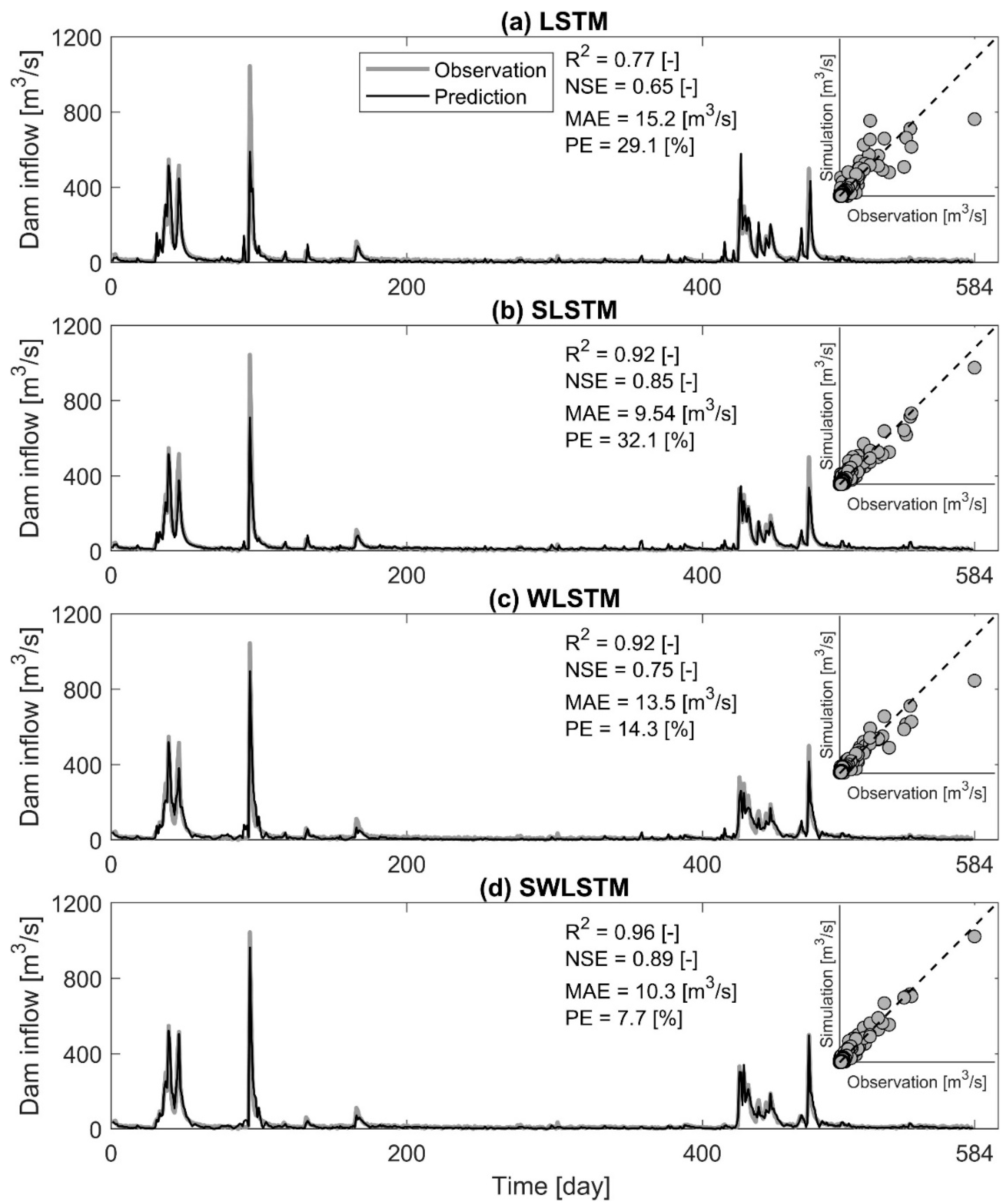
4.4. Predicting Dam Inflow with Trained LSTMs
4.5. Feasibility to Multimodal, Multitask, and Bidirectional Learning
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jothiprakash, V.; Magar, R.B. Multi-time-step ahead daily and hourly intermittent reservoir inflow prediction by artificial intelligent techniques using lumped and distributed data. J. Hydrol. 2012, 450–451, 293–307. [Google Scholar] [CrossRef]
- El-Shafie, A.; Taha, M.R.; Noureldin, A. A neuro-fuzzy model for inflow forecasting of the Nile river at Aswan high dam. Water Resour. Manag. 2006, 21, 533–556. [Google Scholar] [CrossRef]
- Seo, Y.; Kim, S.; Kisi, O.; Singh, V.P. Daily water level forecasting using wavelet decomposition and artificial intelligence techniques. J. Hydrol. 2015, 520, 224–243. [Google Scholar] [CrossRef]
- Yang, T.; Asanjan, A.A.; Welles, E.; Gao, X.; Sorooshian, S.; Liu, X. Developing reservoir monthly inflow forecasts using artificial intelligence and climate phenomenon information. Water Resour. Res. 2017, 53, 2786–2812. [Google Scholar] [CrossRef]
- Zemzami, M.; Benaabidate, L. Improvement of artificial neural networks to predict daily streamflow in a semi-arid area. Hydrol. Sci. J. 2016. [Google Scholar] [CrossRef] [Green Version]
- He, Z.H.; Tian, F.Q.; Gupta, H.V.; Hu, H.C.; Hu, H.P. Diagnostic calibration of a hydrological model in a mountain area by hydrograph partitioning. Hydrol. Earth Syst. Sci. 2015, 19, 1807–1826. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Zhou, H.; Zhang, H.; Du, G.; Zhou, J. Urban flood risk warning under rapid urbanization. Env. Res 2015, 139, 3–10. [Google Scholar] [CrossRef] [PubMed]
- Fatichi, S.; Vivoni, E.R.; Ogden, F.L.; Ivanov, V.Y.; Mirus, B.; Gochis, D.; Downer, C.W.; Camporese, M.; Davison, J.H.; Ebel, B.; et al. An overview of current applications, challenges, and future trends in distributed process-based models in hydrology. J. Hydrol. 2016, 537, 45–60. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Ivanov, V.Y. On the nonuniqueness of sediment yield at the catchment scale: The effects of soil antecedent conditions and surface shield. Water Resour. Res. 2014, 50, 1025–1045. [Google Scholar] [CrossRef]
- Kim, J.; Ivanov, V.Y.; Katopodes, N.D. Hydraulic resistance to overland flow on surfaces with partially submerged vegetation. Water Resour. Res. 2012, 48. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Dwelle, M.C.; Kampf, S.K.; Fatichi, S.; Ivanov, V.Y. On the non-uniqueness of the hydro-geomorphic responses in a zero-order catchment with respect to soil moisture. Adv. Water Resour. 2016, 92, 73–89. [Google Scholar] [CrossRef] [Green Version]
- Warnock, A.; Kim, J.; Ivanov, V.; Katopodes, N.D. Self-Adaptive Kinematic-Dynamic Model for Overland Flow. J. Hydraul. Eng. 2014, 140, 169–181. [Google Scholar] [CrossRef]
- Tran, V.N.; Dwelle, M.C.; Sargsyan, K.; Ivanov, V.Y.; Kim, J. A Novel Modeling Framework for Computationally Efficient and Accurate Real-Time Ensemble Flood Forecasting With Uncertainty Quantification. Water Resour. Res. 2020, 56. [Google Scholar] [CrossRef]
- Tran, V.N.; Kim, J. Quantification of predictive uncertainty with a metamodel: Toward more efficient hydrologic simulations. Stoch. Environ. Res. Risk Assess. 2019, 33, 1453–1476. [Google Scholar] [CrossRef]
- Clark, M.P.; Bierkens, M.F.P.; Samaniego, L.; Woods, R.A.; Uijlenhoet, R.; Bennett, K.E.; Pauwels, V.R.N.; Cai, X.; Wood, A.W.; Peters-Lidard, C.D. The evolution of process-based hydrologic models: Historical challenges and the collective quest for physical realism. Hydrol. Earth Syst. Sci. 2017, 21, 3427–3440. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tran, V.N.; Kim, J. Toward an Efficient Uncertainty Quantification of Streamflow Predictions Using Sparse Polynomial Chaos Expansion. Water 2021, 13, 203. [Google Scholar] [CrossRef]
- Kim, J.; Ivanov, V.Y. A holistic, multi-scale dynamic downscaling framework for climate impact assessments and challenges of addressing finer-scale watershed dynamics. J. Hydrol. 2015, 522, 645–660. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Lee, J.; Kim, D.; Kang, B. The role of rainfall spatial variability in estimating areal reduction factors. J. Hydrol. 2019, 568, 416–426. [Google Scholar] [CrossRef]
- Dwelle, M.C.; Kim, J.; Sargsyan, K.; Ivanov, V.Y. Streamflow, stomata, and soil pits: Sources of inference for complex models with fast, robust uncertainty quantification. Adv. Water Resour. 2019, 125, 13–31. [Google Scholar] [CrossRef]
- Kim, J.; Ivanov, V.Y.; Fatichi, S. Environmental stochasticity controls soil erosion variability. Sci. Rep. 2016, 6, 22065. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Ivanov, V.Y.; Fatichi, S. Soil erosion assessment-Mind the gap. Geophys. Res. Lett. 2016, 43, 12446–12456. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Herrnegger, M.; Sampson, A.K.; Hochreiter, S.; Nearing, G.S. Toward Improved Predictions in Ungauged Basins: Exploiting the Power of Machine Learning. Water Resour. Res. 2019, 55, 11344–11354. [Google Scholar] [CrossRef] [Green Version]
- Marcais, J.; de Dreuzy, J.R. Prospective Interest of Deep Learning for Hydrological Inference. Ground Water 2017, 55, 688–692. [Google Scholar] [CrossRef]
- Nourani, V.; Hosseini Baghanam, A.; Adamowski, J.; Kisi, O. Applications of hybrid wavelet–Artificial Intelligence models in hydrology: A review. J. Hydrol. 2014, 514, 358–377. [Google Scholar] [CrossRef]
- Aksoy, H.; Dahamsheh, A. Markov chain-incorporated and synthetic data-supported conditional artificial neural network models for forecasting monthly precipitation in arid regions. J. Hydrol. 2018, 562, 758–779. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; El-shafie, A.; Jaafar, O.; Afan, H.A.; Sayl, K.N. Artificial intelligence based models for stream-flow forecasting: 2000–2015. J. Hydrol. 2015, 530, 829–844. [Google Scholar] [CrossRef]
- Shen, C. A Transdisciplinary Review of Deep Learning Research and Its Relevance for Water Resources Scientists. Water Resour. Res. 2018, 54, 8558–8593. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. J. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutnik, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, C.; Wu, Q.; Li, H.; Jian, S.; Li, N.; Lou, Z. Deep Learning with a Long Short-Term Memory Networks Approach for Rainfall-Runoff Simulation. Water 2018, 10, 1543. [Google Scholar] [CrossRef] [Green Version]
- Le, H.; Lee, J. Application of Long Short-Term Memory (LSTM) Neural Network for Flood Forecasting. Water 2019, 11, 1387. [Google Scholar] [CrossRef] [Green Version]
- Ni, L.; Wang, D.; Singh, V.P.; Wu, J.; Wang, Y.; Tao, Y.; Zhang, J. Streamflow and rainfall forecasting by two long short-term memory-based models. J. Hydrol. 2020, 583, 124296. [Google Scholar] [CrossRef]
- Xiang, Z.; Yan, J.; Demir, I. A Rainfall-Runoff Model With LSTM-Based Sequence-to-Sequence Learning. Water Resour. Res. 2020, 56. [Google Scholar] [CrossRef]
- Adamowski, J.; Sun, K. Development of a coupled wavelet transform and neural network method for flow forecasting of non-perennial rivers in semi-arid watersheds. J. Hydrol. 2010, 390, 85–91. [Google Scholar] [CrossRef]
- Bowden, G.J.; Maier, H.R.; Dandy, G.C. Input determination for neural network models in water resources applications. Part 2. Case study: Forecasting salinity in a river. J. Hydrol. 2005, 301, 93–107. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall–runoff modelling using Long Short-Term Memory (LSTM) networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef] [Green Version]
- Lee, T.; Shin, J.-Y.; Kim, J.-S.; Singh, V.P. Stochastic simulation on reproducing long-term memory of hydroclimatological variables using deep learning model. J. Hydrol. 2020, 582, 124540. [Google Scholar] [CrossRef]
- Ravansalar, M.; Rajaee, T.; Kisi, O. Wavelet-linear genetic programming: A new approach for modeling monthly streamflow. J. Hydrol. 2017, 549, 461–475. [Google Scholar] [CrossRef]
- Zhang, H.; Singh, V.P.; Wang, B.; Yu, Y. CEREF: A hybrid data-driven model for forecasting annual streamflow from a socio-hydrological system. J. Hydrol. 2016, 540, 246–256. [Google Scholar] [CrossRef]
- Ahmad, S.K.; Hossain, F. A generic data-driven technique for forecasting of reservoir inflow: Application for hydropower maximization. Environ. Model. Softw. 2019, 119, 147–165. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C. Time Series Analysis: Forecasting and Control, 4th ed.; Wiley: Hoboken, NJ, USA, 2008. [Google Scholar] [CrossRef]
- Belayneh, A.; Adamowski, J.; Khalil, B.; Quilty, J. Coupling machine learning methods with wavelet transforms and the bootstrap and boosting ensemble approaches for drought prediction. Atmos. Res. 2016, 172–173, 37–47. [Google Scholar] [CrossRef]
- Maheswaran, R.; Khosa, R. Comparative study of different wavelets for hydrologic forecasting. Comput. Geosci. 2012, 46, 284–295. [Google Scholar] [CrossRef]
- Shensa, M.J. The discrete wavelet transform: Wedding the a trous and Mallat algorithms. IEEE Trans. Signal Process. 1992, 40, 2464–2482. [Google Scholar] [CrossRef] [Green Version]
- Quilty, J.; Adamowski, J. Addressing the incorrect usage of wavelet-based hydrological and water resources forecasting models for real-world applications with best practices and a new forecasting framework. J. Hydrol. 2018, 563, 336–353. [Google Scholar] [CrossRef]
- Budu, K. Comparison of Wavelet-Based ANN and Regression Models for Reservoir Inflow Forecasting. J. Hydrol. Eng. 2014, 19, 1385–1400. [Google Scholar] [CrossRef]
- Nayak, P.C.; Venkatesh, B.; Krishna, B.; Jain, S.K. Rainfall-runoff modeling using conceptual, data driven, and wavelet based computing approach. J. Hydrol. 2013, 493, 57–67. [Google Scholar] [CrossRef]
- Nourani, V.; Komasi, M.; Mano, A. A Multivariate ANN-Wavelet Approach for Rainfall–Runoff Modeling. Water Resour. Manag. 2009, 23, 2877–2894. [Google Scholar] [CrossRef]
- Venkata Ramana, R.; Krishna, B.; Kumar, S.R.; Pandey, N.G. Monthly Rainfall Prediction Using Wavelet Neural Network Analysis. Water Resour. Manag. 2013, 27, 3697–3711. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Das, D.; Avancha, S.; Mudigere, D.; Vaidynathan, K.; Sridharan, S.; Kalamkar, D.; Kaul, B.; Dubey, P. Distributed Deep Learning Using Synchronous Stochastic Gradient Descent. arXiv 2016, arXiv:1602.06709. [Google Scholar]
- Kratzert, F.; Klotz, D.; Shalev, G.; Klambauer, G.; Hochreiter, S.; Nearing, G. Towards learning universal, regional, and local hydrological behaviors via machine learning applied to large-sample datasets. Hydrol. Earth Syst. Sci. 2019, 23, 5089–5110. [Google Scholar] [CrossRef] [Green Version]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Mantovani, R.G.; Rossi, A.L.D.; Vanschoren, J.; Bischl, B.; De Carvalho, A.C. Effectiveness of Random Search in SVM hyper-parameter tuning. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Wu, L.; Perin, G.; Picek, S. I Choose You: Automated Hyperparameter Tuning for Deep Learning-based Side-channel Analysis. Cryptol. Eprint Arch. 2020, 2020, 1293. [Google Scholar]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-Validation. In Encyclopedia of Database Systems; Liu, L., ÖZsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 532–538. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Rossum, G. Python Reference Manual; CWI (Centre for Mathematics and Computer Science): Amsterdam, The Netherlands, 1995. [Google Scholar]
- Van der Walt, S.; Colbert, S.C.; Varoquaux, G. The NumPy Array: A Structure for Efficient Numerical Computation. Comput. Sci. Eng. 2011, 13, 22–30. [Google Scholar] [CrossRef] [Green Version]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Louppe, G.; et al. Scikit-learn: Machine Learning in Python. arXiv 2012, arXiv:1201.0490. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Chollet, F.O. Keras: Deep Learning Library for Theano and Tensorflow. 2015. Available online: https://github.com/fchollet/keras (accessed on 19 March 2019).
- Dobrescu, A.; Giuffrida, M.V.; Tsaftaris, S.A. Doing More With Less: A Multitask Deep Learning Approach in Plant Phenotyping. Front. Plant Sci. 2020, 11, 141. [Google Scholar] [CrossRef]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A. DISTILLER: Encrypted traffic classification via multimodal multitask deep learning. J. Netw. Comput. Appl. 2021, 102985. [Google Scholar] [CrossRef]
- Du, S.; Li, T.; Yang, Y.; Horng, S.-J. Multivariate time series forecasting via attention-based encoder–decoder framework. Neurocomputing 2020, 388, 269–279. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
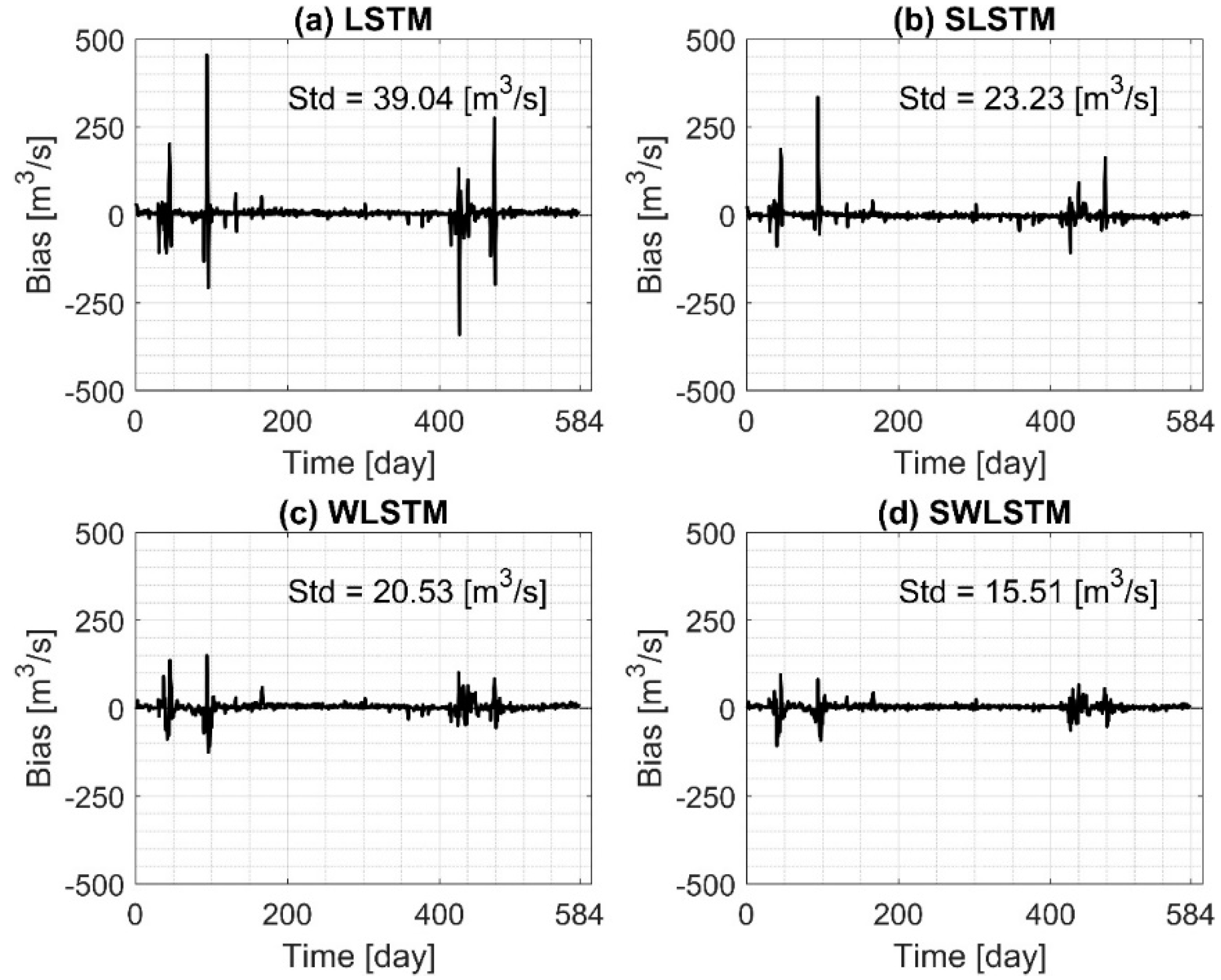{kind=link}
| Study | Data-Driven Model | Predictor Selection | Data Processing | Hyper-Parameter Determination |
|---|---|---|---|---|
| Kratzert et al. [37] | LSTM | Ad-hoc | Normalization | Trial and error |
| Hu et al. [31] | ANN, LSTM | Ad-hoc | Normalization | Ad-hoc |
| Lee et al. [38] | AR, FFNN, RNN | Ad-hoc | Copula-based transformation | Trial and error |
| Ni et al. [33] | LSTM, CNN | Ad-hoc | WT | Ad-hoc |
| Xiang et al. [34] | LSTM | Ad-hoc | Moving average | Ad-hoc |
| Yang et al. [4] | ANN, RF, SVM | Visual * | Normalization | Trial and error |
| Ahmad and Hossain [41] | ANN | Visual * | Moving average | Trial and error |
| This study | LSTM | Optimal ** | WT, Normalization | Optimization |
| Layer | Parameter | Shape |
|---|---|---|
| 1 | [ ] | |
| [ ] | ||
| [] | ||
| 2 | [ ] | |
| [ ] | ||
| [ ] | ||
| ⋮ | ⋮ | ⋮ |
| [ ] | ||
| [ ] | ||
| [ ] | ||
| Dense | [ ] | |
| [] |
| Variable * | Station Name | Station ID | Longitude | Latitude | Source |
|---|---|---|---|---|---|
| Qin (m3/s) | Hwacheon dam | 1010310 | 127°46′60″ | 38° 7′0″ | Water Resources Management Information System (http://www.wamis.go.kr:8081/ENG/, accessed on 1st January 2020) |
| Qo (m3/s) | Peace dam | 1009710 | 127°50′55″ | 38°12′43″ | |
| Pr (mm) | Hwacheongunchung | 10094010 | 127°50′54″ | 38°12′34″ | |
| Bangsanchogyo | 10104030 | 127°56′35″ | 38°12′36″ | ||
| Hwacheondam | 10104050 | 127°46′38″ | 38° 7′2″ | ||
| Geumakri | 10104060 | 127°55′52″ | 38°11′36″ | ||
| Suibcheon | 10104170 | 127°54′5″ | 38°10′59″ | ||
| Yanggu Seocheon | 10104171 | 127°59′3″ | 38° 6′28″ | ||
| Ta (°C) | Chuncheon | 101 | 127°44′8.51″ | 37°54’59.27″ | Automated Surface Observing System (https://data.kma.go.kr/cmmn/main.do, accessed on 1st January 2020) |
| H (%) | |||||
| Ws (m/s) | |||||
| Pre (hPa) |
| Model | x | y |
|---|---|---|
| LSTM | ||
| SLSTM | ||
| WLSTM | ||
| SWLSTM |
| The Number of Layers | The Number of Hidden Units | Dropout Rate | Batch Size | The Number of Epochs | |
|---|---|---|---|---|---|
| Figure 7a | 1, 2, 3, 4, 5, 6, 7 | 100 | 0.1 | 512 | 200 |
| Figure 7b | 1 | 10, 50, 100, 150, 200, 250, 300, 350, 400 | 0.1 | 512 | 200 |
| Figure 7c | 1 | 20 | 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9 | 512 | 200 |
| Figure 7d | 1 | 20 | 0.1 | 2, 4, 8, 16, 32, 64, 128, 256, 512 | 200 |
| Figure 7e | 1 | 20 | 0.1 | 512 | 10, 50, 100, 200, 250, 300, 350, 400, 450, 500 |
| Hyper-Parameters | Range | LSTM | SLSTM | WLSTM | SWLSTM |
|---|---|---|---|---|---|
| The number of layers | [1–7] | 2 | 2 | 2 | 2 |
| The number of hidden units | [10–400] | 100 | 150 | 200 | 200 |
| The number of epochs | [10–500] | 250 | 250 | 250 | 250 |
| Dropout rate | [0.1–0.9] | 0.3 | 0.5 | 0.5 | 0.6 |
| Batch size | [2–512] | 8 | 8 | 32 | 32 |
| Relative “Difference” Metric (%) | SWLSTM vs. LSTM | SWLSTM vs. SLSTM | SWLSTM vs. WLSTM |
|---|---|---|---|
| 82.5 | 50 | 49.5 | |
| 68.4 | 27.7 | 53.4 | |
| 29.8 | −8.4 | 25.5 | |
| 75 | 77.3 | 48.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, T.D.; Tran, V.N.; Kim, J. Improving the Accuracy of Dam Inflow Predictions Using a Long Short-Term Memory Network Coupled with Wavelet Transform and Predictor Selection. Mathematics 2021, 9, 551. https://0-doi-org.brum.beds.ac.uk/10.3390/math9050551
Tran TD, Tran VN, Kim J. Improving the Accuracy of Dam Inflow Predictions Using a Long Short-Term Memory Network Coupled with Wavelet Transform and Predictor Selection. Mathematics. 2021; 9(5):551. https://0-doi-org.brum.beds.ac.uk/10.3390/math9050551
Chicago/Turabian StyleTran, Trung Duc, Vinh Ngoc Tran, and Jongho Kim. 2021. "Improving the Accuracy of Dam Inflow Predictions Using a Long Short-Term Memory Network Coupled with Wavelet Transform and Predictor Selection" Mathematics 9, no. 5: 551. https://0-doi-org.brum.beds.ac.uk/10.3390/math9050551