
On the Discretization of Continuous Probability Distributions Using a Probabilistic Rounding Mechanism

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. The Balanced Discretization Method
2.1. Notations
2.2. Reminders
2.3. Motivating Example and Definition
2.4. Probability Mass and Distribution Functions
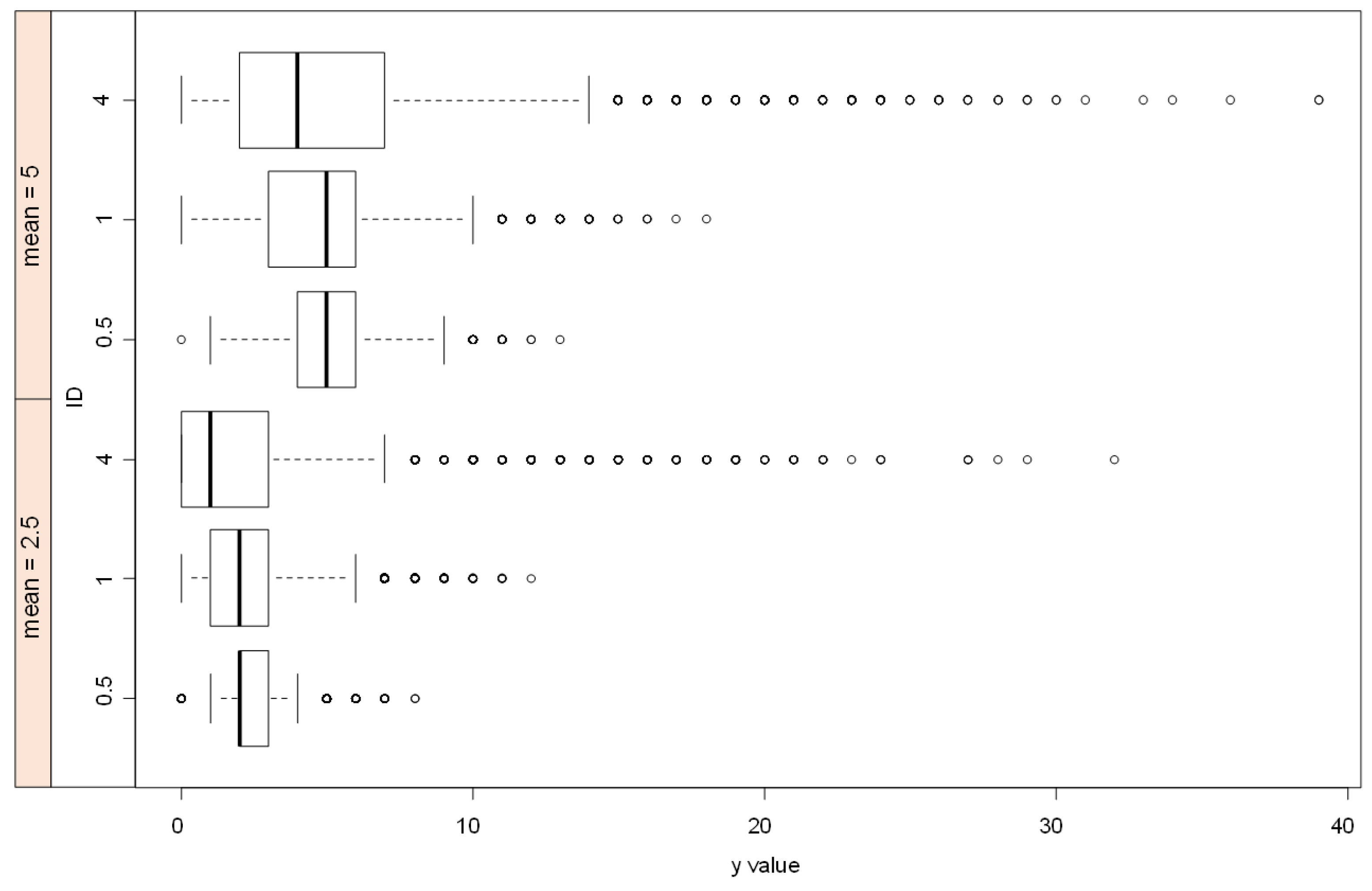
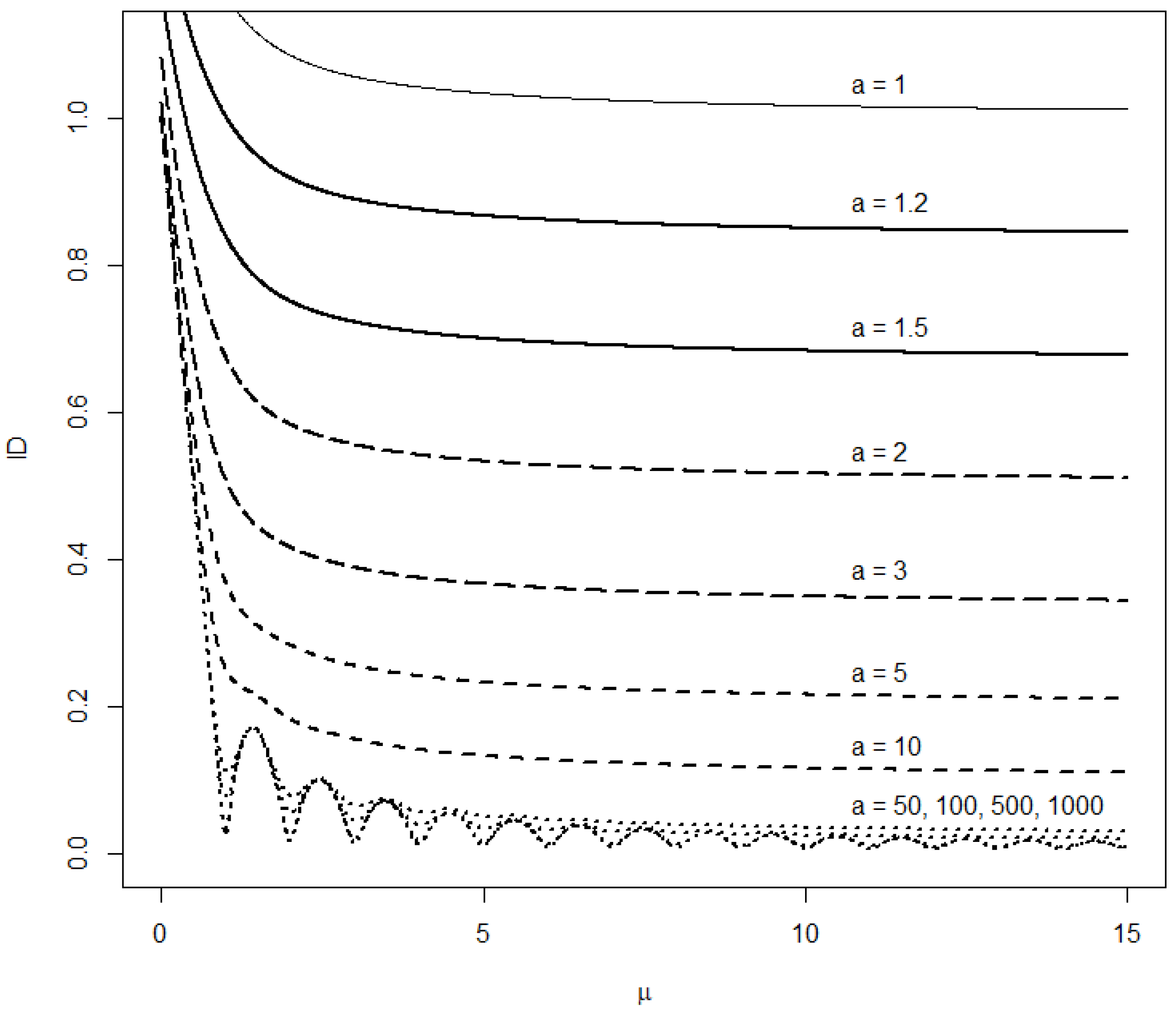
2.5. Moments and Index of Dispersion
2.6. Conditional Distributions of Latent Continuous and Binary Outcomes
2.7. Link with Mean-Preserving Discretization
3. The Balanced Discrete Gamma Family
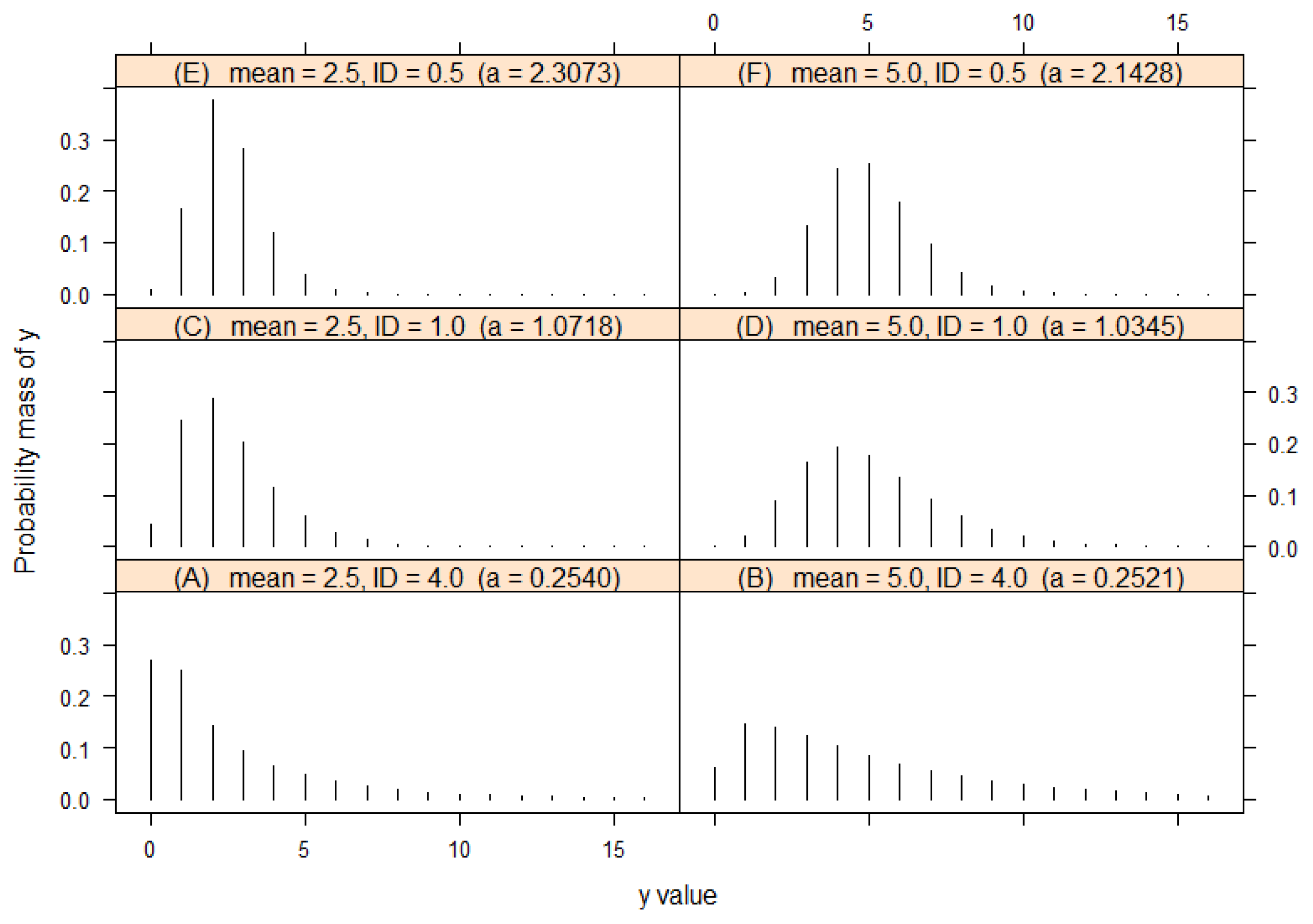
3.1. The Balanced Discrete Gamma Distribution
3.2. Comparison with Some Alternatives
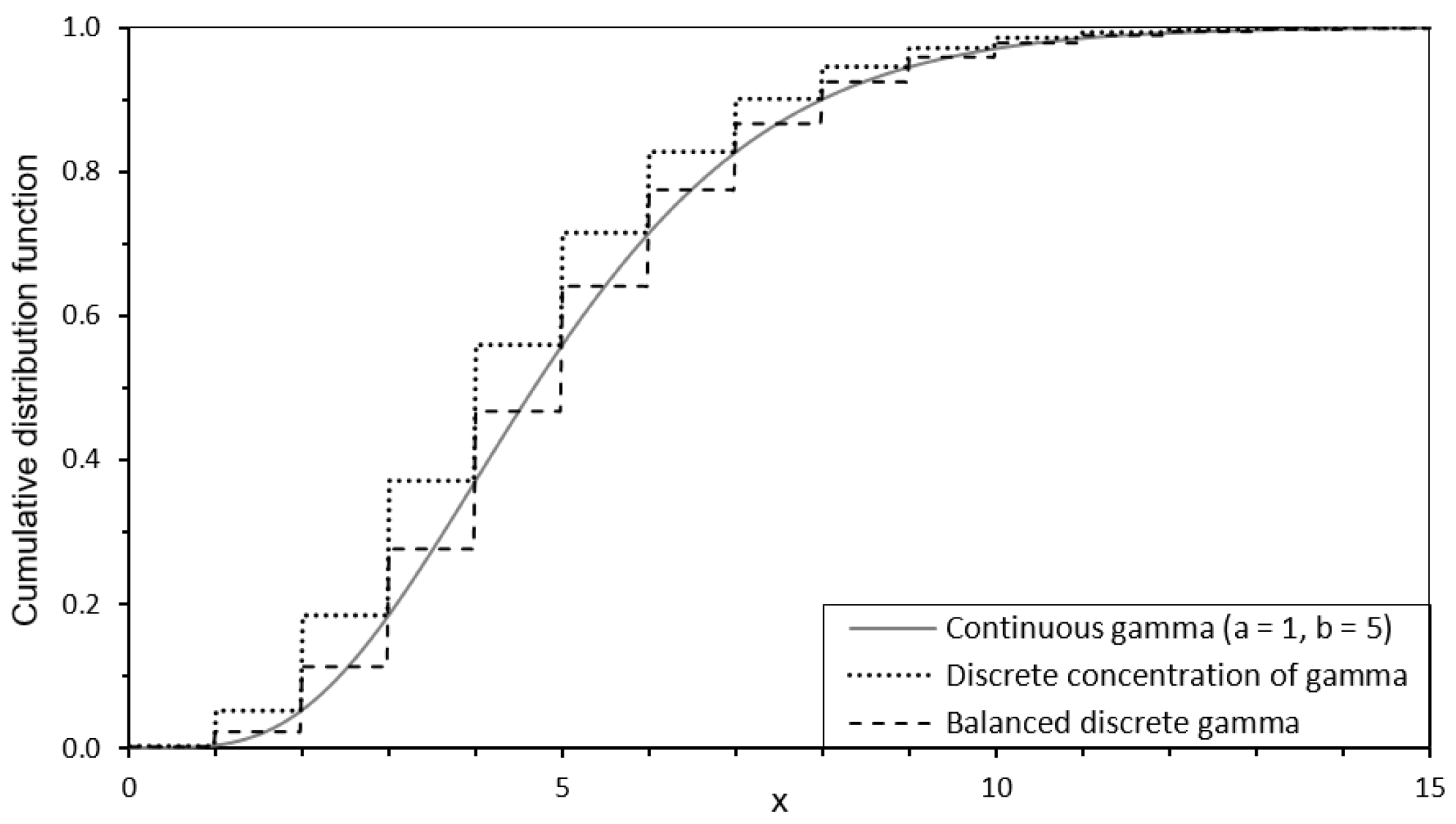
3.2.1. Balanced Discretization Versus Discrete Concentration
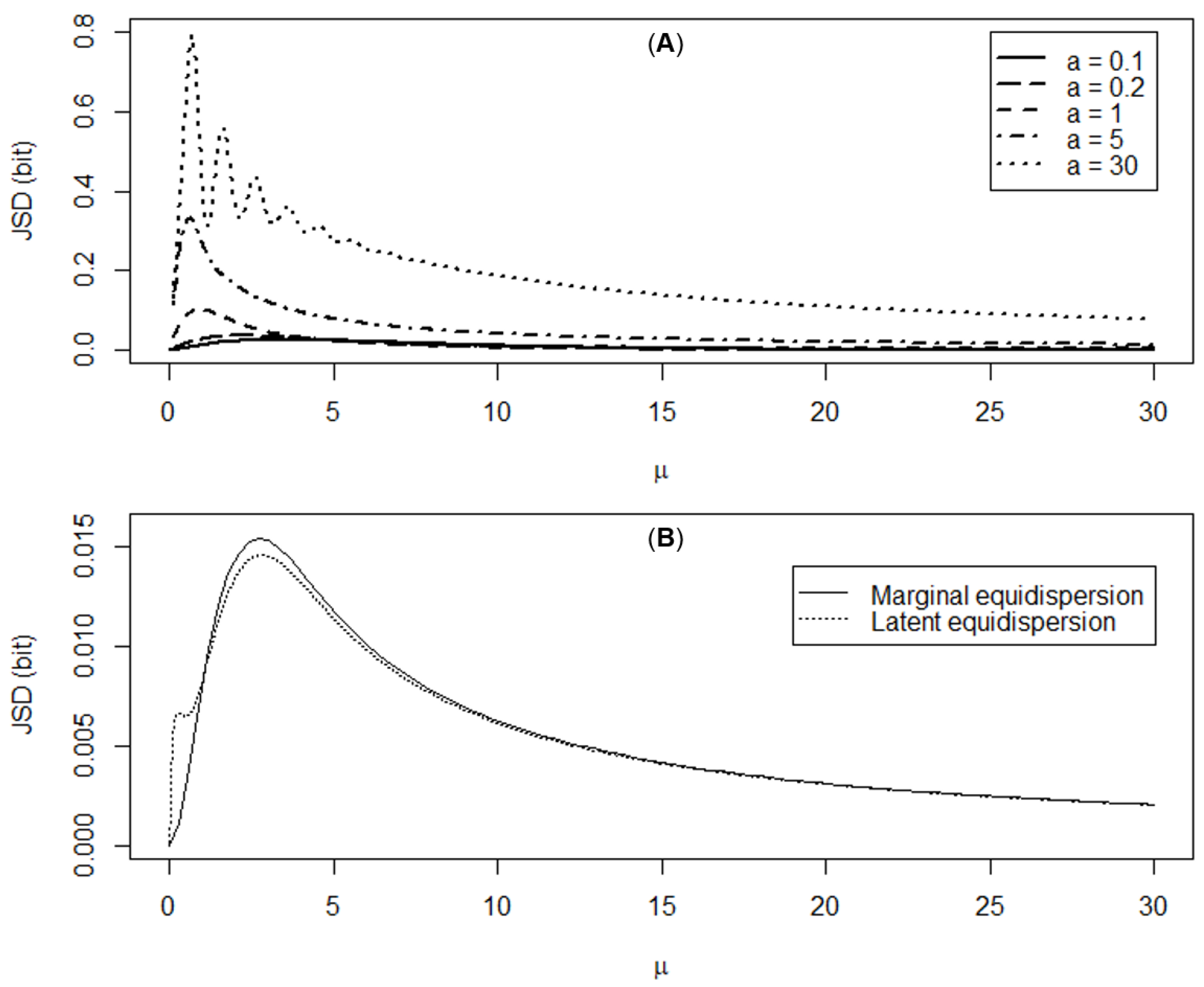
3.2.2. Distance to the Poisson Distribution under Equidispersion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Bernoulli (distribution) | |
| Balanced discrete exponential (distribution) | |
| Balanced discrete (distribution) | |
| Balanced discrete gamma (distribution) | |
| BDG | Balanced discrete gamma |
| Continuous distribution (distribution) | |
| Discrete concentration (distribution) | |
| Gamma (distribution) | |
| ID | Index of dispersion |
| JSD | Jensen–Shannon divergence |
| probability density function | |
| pmf | probability mass function |
| quf | quantile function |
| suf | survival function |
Appendix A. Proofs of Lemmas and Propositions
Appendix A.1. Proof of Lemma 1
Appendix A.2. Proof of Proposition 1
Appendix A.3. Proof of Proposition 2
Appendix A.4. Proof of Proposition 3
Appendix A.5. Proof of Proposition 4
References
- Hilbe, J.M. Negative Binomial Regression; Cambridge University Press: Cambridge, UK, 2011; p. 573. [Google Scholar]
- Sellers, K.F.; Shmueli, G. Data dispersion: Now you see it ⋯ now you don’t. Commun. Stat. Theory Methods 2013, 42, 3134–3147. [Google Scholar] [CrossRef] [Green Version]
- Hagmark, P.E. On construction and simulation of count data models. Math. Comput. Simul. 2008, 77, 72–80. [Google Scholar] [CrossRef]
- Wedderburn, R.W. Quasi-likelihood functions, generalized linear models, and the Gauss—Newton method. Biometrika 1974, 61, 439–447. [Google Scholar] [CrossRef]
- Consul, P.; Famoye, F. Generalized Poisson regression model. Commun. Stat. Theory Methods 1992, 21, 89–109. [Google Scholar] [CrossRef]
- Bonat, W.H.; Jørgensen, B.; Kokonendji, C.C.; Hinde, J.; Demétrio, C.G. Extended Poisson–Tweedie: Properties and regression models for count data. Stat. Model. 2018, 18, 24–49. [Google Scholar] [CrossRef] [Green Version]
- Conway, R.W.; Maxwell, W.L. A queuing model with state dependent service rates. J. Ind. Eng. 1962, 12, 132–136. [Google Scholar]
- Efron, B. Double exponential families and their use in generalized linear regression. J. Am. Stat. Assoc. 1986, 81, 709–721. [Google Scholar] [CrossRef]
- Zou, Y.; Geedipally, S.R.; Lord, D. Evaluating the double Poisson generalized linear model. Accid. Anal. Prev. 2013, 59, 497–505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Winkelmann, R. A count data model for gamma waiting times. Stat. Pap. 1996, 37, 177–187. [Google Scholar] [CrossRef]
- Cameron, A.C.; Johansson, P. Count data regression using series expansions: With applications. J. Appl. Econom. 1997, 12, 203–223. [Google Scholar] [CrossRef] [Green Version]
- Klakattawi, H.; Vinciotti, V.; Yu, K. A simple and adaptive dispersion regression model for count data. Entropy 2018, 20, 142. [Google Scholar] [CrossRef] [Green Version]
- Zeviani, W.M.; Ribeiro, P.J., Jr.; Bonat, W.H.; Shimakura, S.E.; Muniz, J.A. The Gamma-count distribution in the analysis of experimental underdispersed data. J. Appl. Stat. 2014, 41, 2616–2626. [Google Scholar] [CrossRef] [Green Version]
- Chakraborty, S. Generating discrete analogues of continuous probability distributions-A survey of methods and constructions. J. Stat. Distrib. Appl. 2015, 2, 30. [Google Scholar] [CrossRef] [Green Version]
- Plan, E.L. Modeling and simulation of count data. CPT Pharmacomet. Syst. Pharmacol. 2014, 3, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Veraart, A.E. Modeling, simulation and inference for multivariate time series of counts using trawl processes. J. Multivar. Anal. 2019, 169, 110–129. [Google Scholar] [CrossRef] [Green Version]
- Roy, D.; Dasgupta, T.A. A discretizing approach for evaluating reliability of complex systems under stress-strength model. IEEE Trans. Reliab. 2001, 50, 145–150. [Google Scholar] [CrossRef]
- Hagmark, P.E. A new concept for count distributions. Stat. Probab. Lett. 2009, 79, 1120–1124. [Google Scholar] [CrossRef] [Green Version]
- Hagmark, P.E. An Exceptional Generalization of the Poisson Distribution. Open J. Stat. 2012, 2, 313–318. [Google Scholar] [CrossRef] [Green Version]
- Chakraborty, S. A New Discrete Distribution Related to Generalized Gamma Distribution and Its Properties. Commun. Stat. Theory Methods 2013, 44, 1691–1705. [Google Scholar] [CrossRef]
- Holland, B.S. Some Results on the discretization of continuous probability distributions. Technometrics 1975, 17, 333–339. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–38. [Google Scholar] [CrossRef]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data, 2nd ed.; Wiley Series in Probability and Statistics; Wiley-Interscience: New York, NY, USA, 2002. [Google Scholar]
- Chakraborty, S.; Chakravarty, D. Discrete Gamma Distributions: Properties and Parameter Estimations. Commun. Stat. Theory Methods 2012, 41, 3301–3324. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- MATLAB. Version 9.0.0 (R2016a); The MathWorks Inc.: Natick, MA, USA, 2016. [Google Scholar]
- Roy, D. Reliability measures in the discrete bivariate set-up and related characterization results for a bivariate geometric distribution. J. Multivar. Anal. 1993, 46, 362–373. [Google Scholar] [CrossRef] [Green Version]
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Delpha, C.; Diallo, D. Performance of Jensen Shannon Divergence in Incipient Fault Detection and Estimation. In Proceedings of the ICASSP 2019, 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2742–2746. [Google Scholar]
- Daganzo, C.F.; Gayah, V.V.; Gonzales, E.J. The potential of parsimonious models for understanding large scale transportation systems and answering big picture questions. EURO J. Transp. Logist. 2012, 1, 47–65. [Google Scholar] [CrossRef] [Green Version]
- Roy, D.; Ghosh, T. A new discretization approach with application in reliability estimation. IEEE Trans. Reliab. 2009, 58, 456–461. [Google Scholar] [CrossRef]
- Bracquemond, C.; Gaudoin, O. A survey on discrete lifetime distributions. Int. J. Reliab. Qual. Saf. Eng. 2003, 10, 69–98. [Google Scholar] [CrossRef]
- Kaehler, J. Laws of iterated expectations for higher order central moments. Stat. Pap. 1990, 31, 295–299. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tovissodé, C.F.; Honfo, S.H.; Doumatè, J.T.; Glèlè Kakaï, R. On the Discretization of Continuous Probability Distributions Using a Probabilistic Rounding Mechanism. Mathematics 2021, 9, 555. https://0-doi-org.brum.beds.ac.uk/10.3390/math9050555
Tovissodé CF, Honfo SH, Doumatè JT, Glèlè Kakaï R. On the Discretization of Continuous Probability Distributions Using a Probabilistic Rounding Mechanism. Mathematics. 2021; 9(5):555. https://0-doi-org.brum.beds.ac.uk/10.3390/math9050555
Chicago/Turabian StyleTovissodé, Chénangnon Frédéric, Sèwanou Hermann Honfo, Jonas Têlé Doumatè, and Romain Glèlè Kakaï. 2021. "On the Discretization of Continuous Probability Distributions Using a Probabilistic Rounding Mechanism" Mathematics 9, no. 5: 555. https://0-doi-org.brum.beds.ac.uk/10.3390/math9050555