1. Introduction
On 11 February 2020, the United States was the next in a series of countries to acknowledge community spread of a deadly virus which would eventually be named COVID-19. The first COVID-19 patient was reported in the USA was in Washington State, and then the coronavirus quickly spread throughout the entire state. COVID-19 has since resulted in a high number of deaths and the confirmed cases in the United States. People and governments in the USA have been challenged by COVID-19 and its consequences [
1]. Social distancing and personal protective measures, including handwashing, wearing masks and gloves became the primary means of controlling the spread of COVID-19. There are many questions, such as “What will be the short-term and long-term consequences of COVID-19?” “How efficiently have U.S. governments responded to the COVID-19 pandemic?” And more importantly, “what factors might impact efficiency?” Efficiency measures require thoughtful consideration of the factors that affect the fast spread of COVID-19. Singh and Adhikari [
2] and Liu, Chen, Lin, and Han [
3] found that population density and percentage of elderly significantly affect the spread of COVID-19. It is imperative to control the spread of the COVID-19 with aggressive action in the U.S. Every state must plan for faster access to existing or newer testing centers and allocate enough health care employees for people who need emergent treatment.
The degree of infection varies from country to country, and the way to control infections varies according to national conditions. How the global pandemic s contained is the most concerning problem worldwide. Therefore, it is of striking significance to predict the pandemic trends of infection worldwide. The U.S. government has taken several actions to respond to the COVID-19 pandemic, such as social distancing measures, including stay-at-home duration, non-essential business closures, and bans on large gatherings. The second directive is health policy actions, including mask mandates, public funding, expanded access to telehealth services, vaccine given status, etc. The third mitigation measure includes health care provider capacity, such as health care employees and hospital beds [
4]. There are significant challenges due to unprecedented disease outbreaks, which negatively affect society as a whole and the efficiency of the COVID-19 response management in each state. Therefore, it is critical to predict the efficiency of pandemic response in the USA.
According to Correia et al. [
5], the 1918 Flu had substantial variation among U.S. states in terms of the speed and aggressiveness of its spread. The study found a direct linkage between the speed and aggressiveness of interventions and containment of the virus and death rates. However, different results were found by Eichenbaum et al. [
6]. They argued that there was a linkage between the virus spread and interactions with various economic decisions. The more people refrained from social contact, the higher impact it had on the pandemic.
It is important that every state health system put an upper boundary on the number of patients who can receive treatment. According to Gourinchas, [
7] “with a two percent case fatality rate baseline for overwhelmed health systems and 50 percent of the world population infected, 76 million people or one percent of the world population would die.”
Measuring the efficiency of decision-making units (DMUs) such as hospitals, departments, and states using multiple inputs and producing multiple outputs is a complex part of the performance measure study. Banker et al. [
8] introduced a non-parametric method to measure the technical efficiency of a set of multiple comparable DMUs, called data envelopment analysis (DEA). DEA has been used widely to analyze efficiency in the health care sector. We found several papers that used DEA to measure the health system’s efficiency in the midst of the COVID-19 pandemic, although many papers evaluate the health care system within countries and between counties [
9,
10,
11,
12].
Jouzdani et al. [
10] are the first authors to perform an exploratory analysis of the global fight against COVID-19. This study used statistical analysis and visualization techniques to distinguish the temporal confirmed case, death, and recovered cases. Multiple countries are compared and the United States had significantly higher spread of COVID-19 than other countries. Another study by Shirouyehzad et al. [
11] performed DEA analysis to measure countries’ efficiency affected by COVID-19. They used population density and health care infrastructure datasets to perform DEA analysis. Two-step analyses are performed to estimate efficiency. In the first step, technical efficiency scores are estimated based on the number of confirmed cases. In the second step, the total number of confirmed cases, the death rates, and recovered cases are considered to measure the countries’ efficiency of medical treatment.
Literature reviews analyzed the efficiency based on the ratio of a measure of some quality of life for output variable and health care resources or health care expenditure for input variables. This research study is similar to those, but considers different aspects using the undesirable output variable. Previous studies have primarily focused on identifying efficiency and lacked a scientific measure to evaluate the performance of COVID-19 when both the number of confirmed and the number of recovered are considered output together. In addition, existing studies do not address the impact of environmental factors on efficiency, ignoring the impact of social distancing, health care policy, and socioeconomic factors in the various states. Previous studies regarding efficiency have focused on input contraction or output expansion when the operational efficiency level improves. However, it is inefficient when there is an undesirable output because efficiency measures should account for the simultaneous production of undesirable and desirable output, and DEA itself cannot determine the factors related to the efficiency. The combination of DEA and Classification and Regression Tree (CART) can resolve this problem by predicting the efficiency and uncovering the determinants of the various U.S. states’ efficiency under the COVID-19 pandemic scenario.
To analyze the factors that classify the efficiency and inefficiency of DMUs, the CART is the most transparent and comprehensible data-driven method. Breiman et al. [
12] first introduced the CART algorithm as a hierarchical arrangement of decision nodes. A general classifier is constructed in the form of several splits on factors that separate a dataset into subgroups. The CART is good at detecting and accommodating interaction effects of different variables; however, it does not perform well in handling linear relations between variables. Therefore, researchers working on CART usually combine the results from Logistic Regression (LR) to overcome CART’s drawbacks. LR is a highly popular and powerful classification approach. It is an extension of linear regression as the outcome variable is categorical. The CART and LR have been applied in data analysis in many research studies [
13,
14,
15,
16].
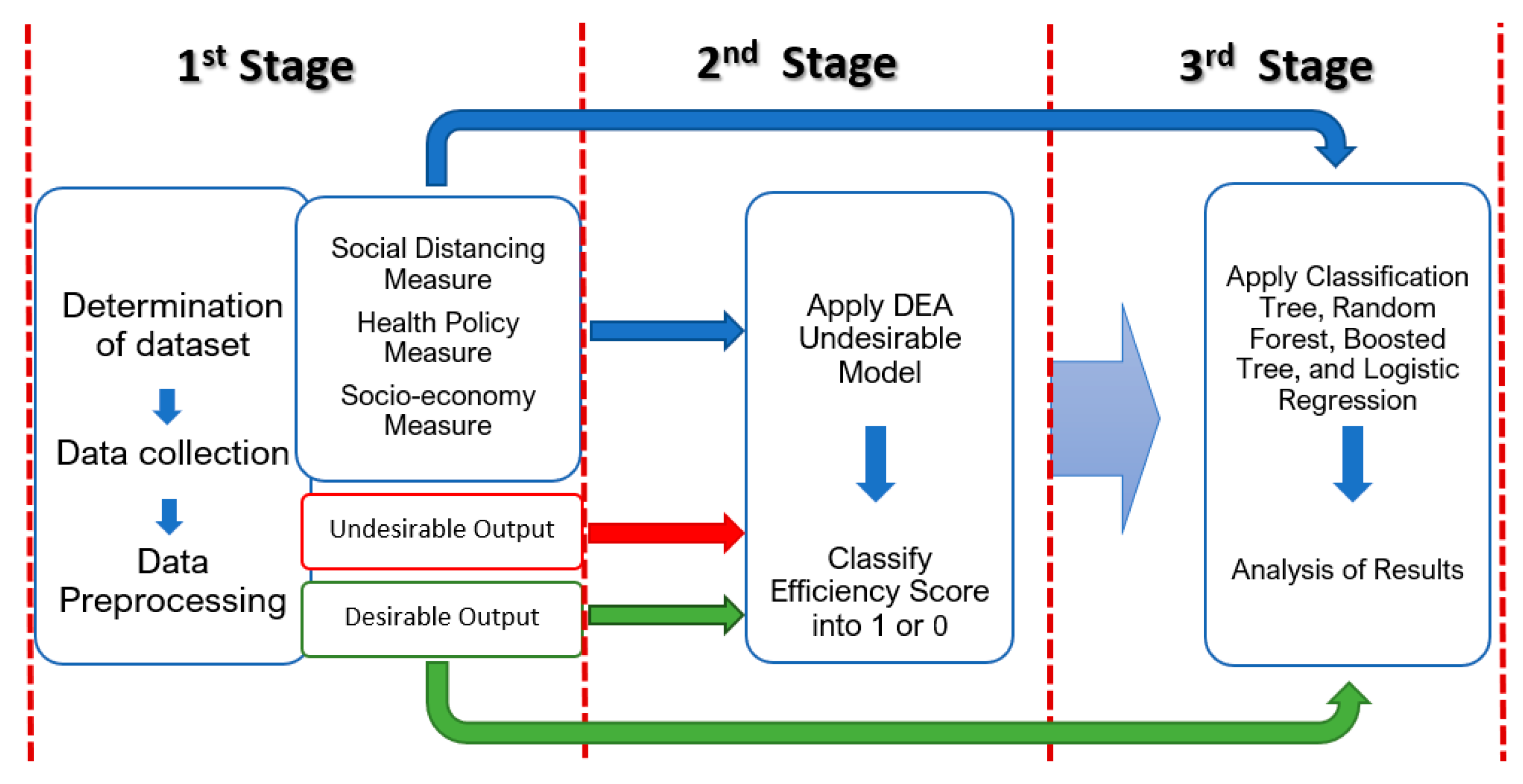
Therefore, this paper will use DEA, CART, and LR to predict state COVID-19 response performance. Besides, Boosted Tree (BT) and Random Forest (RF) were applied to compare the model performance and to evaluate the importance of variables. The combined approach of CART, LR, BT, and RF will be henceforth referred to as machine learning (ML).
3. Results
3.1. Descriptive Statistics
Table 4 display the descriptive statistics of variables, which are used in DEA analysis. For the undesirable output, the mean number of confirmed is found to be 503,330, while the mean number of recovered, a desirable output, is found to be 301,832. From the sample statistics, New York and New Jersey have the highest number of COVID-19 confirmed cases and Montana and Alaska have the lowest number of COVID-19 confirmed cases. In the case of the number of recovered, New York and Massachusetts have the highest number of COVID-19 recovered cases, and Alaska and Montana have the lowest number of COVID-19 recovered cases. The mean of input variables is also displayed in
Table 4. From the sample data, New York and California have the highest number of tested and Wyoming and Vermont have the lowest number of tested. California and Texas have the highest number of healthcare employees, and Wyoming and Alaska have the lowest healthcare employees. California and Texas also have the highest hospital beds, while Vermont and Alaska have the lowest hospital beds. Lastly, a high amount of public funding related to health is allocated to California and Florida, while a lower amount of public funding is allocated to Vermont and Rhode Island. In the second stage of analysis, this paper examined potential determinants (environmental factors) of efficiency through ML analysis. Descriptive statistics of environmental factors are displayed in
Table 5. Ten numerical and five categorical variables are considered to perform ML analysis.
3.2. DEA Results
Table 6 shows the summary of state efficiency scores. The results show that 23 states are efficient (efficiency score of 1), indicating that 46% of states are efficient in responding to COVID-19. The inefficient states’ efficiency scores ranged from 0.896 to 0.999, with Arkansas ranking first and Rhode Island ranking last among the inefficient states. The overall average efficiency score of inefficient state is 0.97, indicating that the states could produce, on average, 3% higher output with the same level of inputs. Based on the DEA efficiency score, states were divided into two groups for subsequent classification tree analysis: efficient (if efficiency score is equal to 1 and inefficient (if efficiency score is less than 1). We define this variable as state efficiency. State efficiency will be used as the outcome variable in the ML analysis.
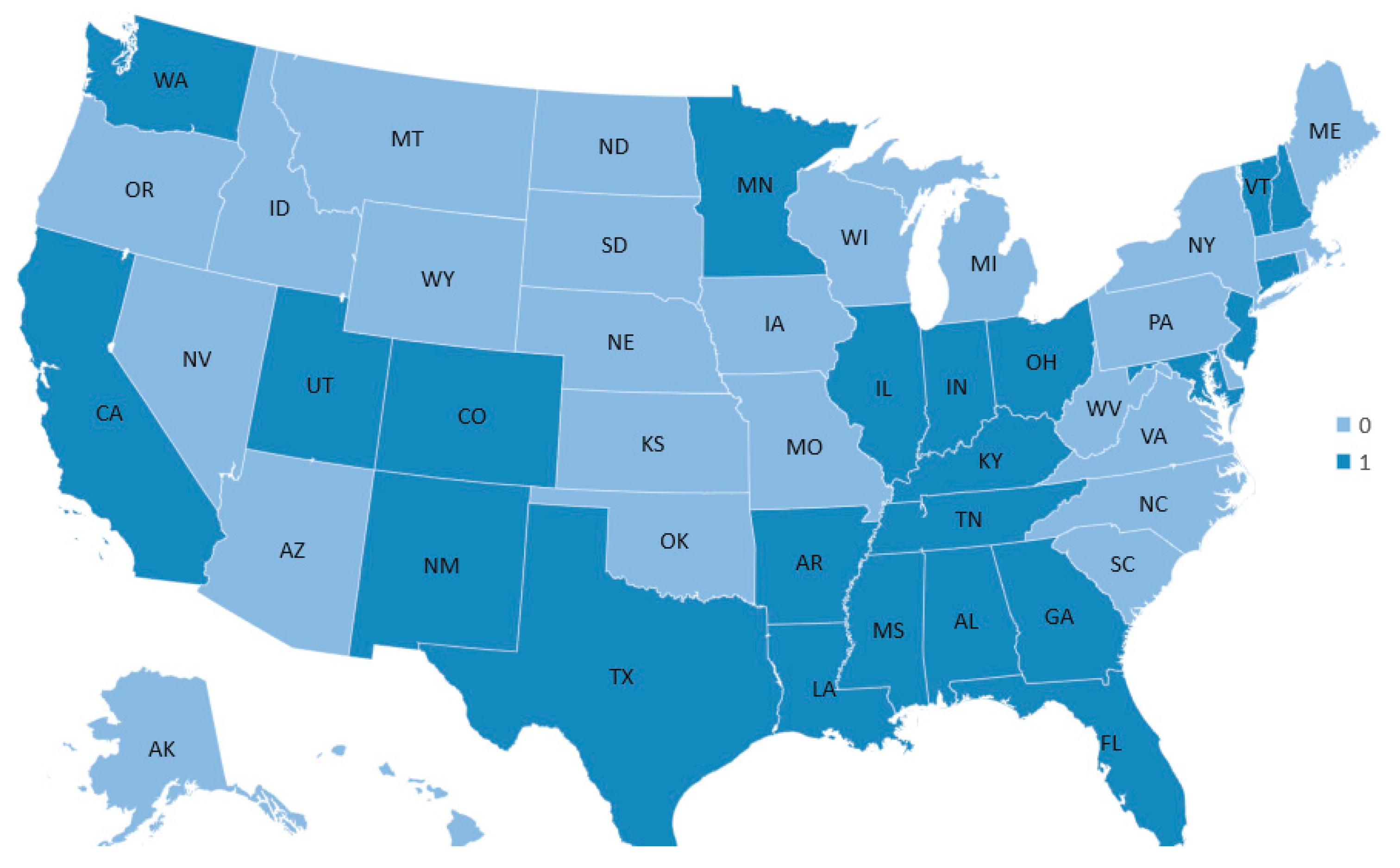
Figure 2 depicts the distribution of efficient and inefficient states. As we can see, the dark blue color indicates efficient states and the light blue color indicates inefficient states. Efficient states are mainly located in the South, some in West and Midwest region. The result indicates that there may exist a potential relationship between region and efficiency. Thus, we add region as one of the environmental factors in the analysis.
3.3. Comparison of CART and LR
We use state efficiency as the outcome variable. As mentioned previously, input variables are PD, LGB, NEBC, SHD, Urban, EATS, MASKM, NTP, NVGP, THBP, PF, GDP, HCEP, PI, and REG. By using Bootstrap sampling method, the original dataset was increased to 220 records [
31]. Then, we randomly partitioned the dataset into training (70% of records) and validation (30% of records). The training dataset is used to construct the CART and LR model.
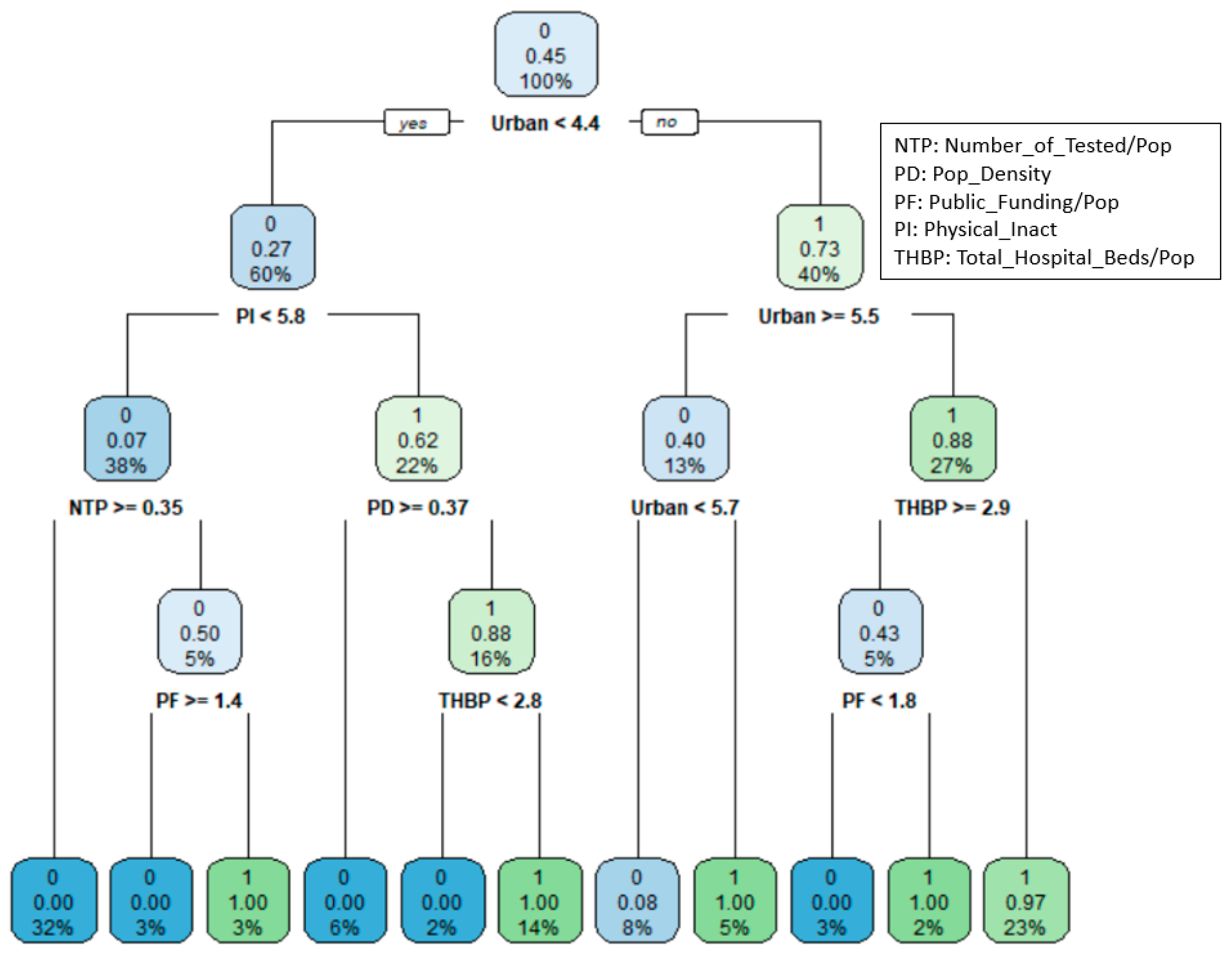
Figure 3 shows the classification tree with 10 splits for the states’ COVID-19 efficiency. The top node includes all the records in the training data, of which 45% of states are efficient, and 55% of states are inefficient. The “0” in the top node’s rectangle denotes the majority group is inefficient (0 = inefficient). The first split is on Urban. A state with Urban percentage less than 4.4 will go to the left child node and a state with Urban percentage greater than or equal to 4.4 will go to the right child node.
The next split is on PI for states with Urban percentage less than 4.4 and Urban percentage for state with Urban percentage greater than equal to 4.4. The terminal node shows the final classification for states. Among the 11 terminal nodes, five lead to the classification of “efficient” and six lead to “inefficient” classification. From the classification tree the most important variable for efficiency is the Urban. State with Urban percentage less 4.4, PI less than 5.8, and NTP greater than or equal to 0.35 are considered as inefficient states. If Urban percentage is less than 5.5 but greater than or equal to 4.4 and THBP is less than 2.9, then state is considered as efficient. In overall, Urban, PI, NTP, PD, THBP, and PF directly affect the classification of the states.
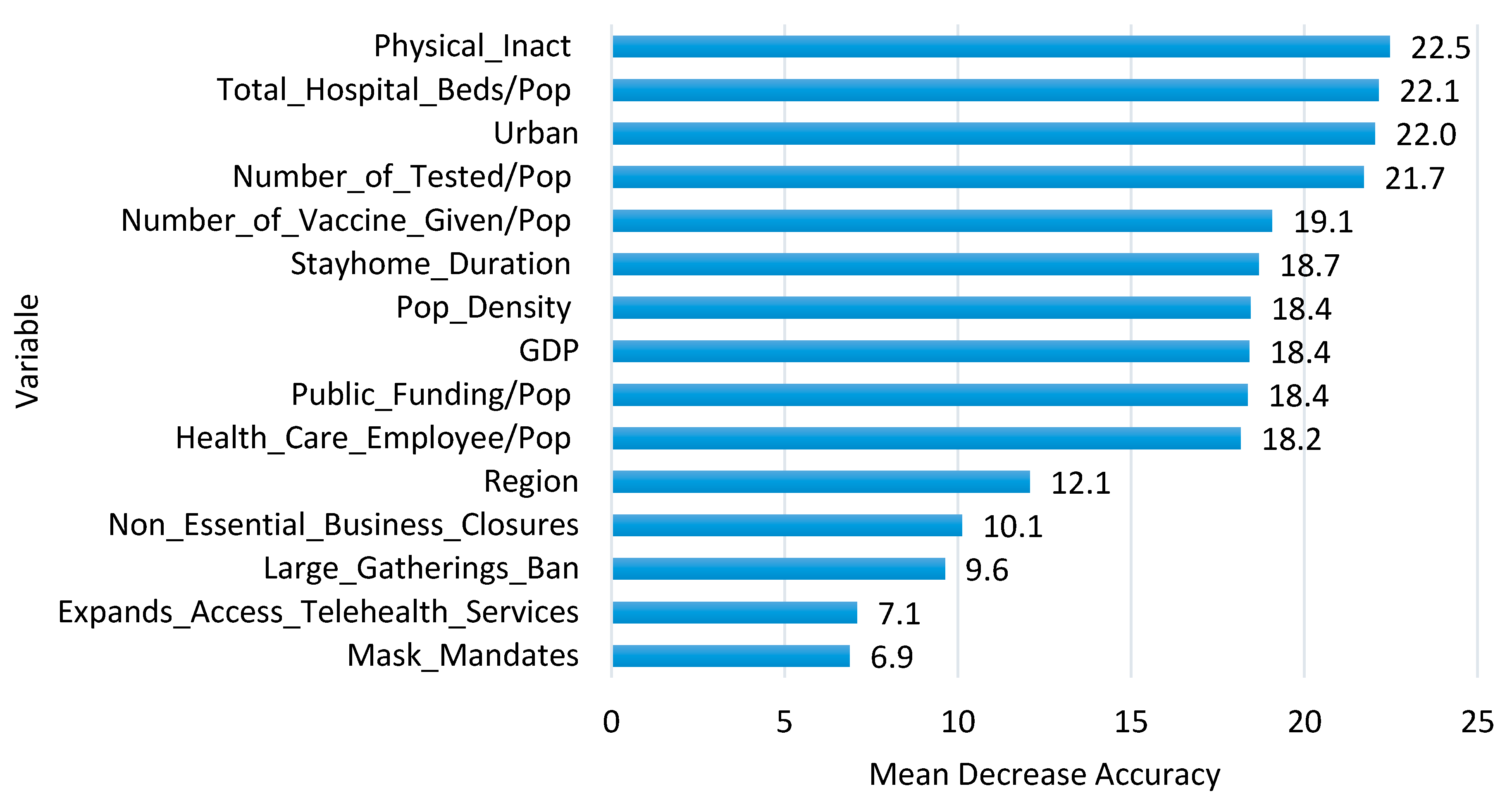
Figure 4 shows the importance of predictor variables generated from the RF model. As can be seen in the figure, PI has the highest mean decrease accuracy score (22.5), followed by THBP (22.1), Urban (22.0), NTP (21.7), which are the most important variables for predicting state efficiency. It shows similar findings in Classification Tree (
Figure 3) in that Urban, PI, THBP, NTP, PD are top priorities in classifying state efficiency levels. On the other hand, MASKM (6.9) and EATS (7.1) shows the lowest mean decrease accuracy score, which are the least important variables for predicting state efficiency, meaning that we might not need to retain all of the environmental factors to create a predictive model.
LR is another method for predicting the efficiency of the categorical outcome variable. Efficiency is predicted based on a number of environmental factors.
Table 7 shows the odds ratios (OR) and
p-value of the different significance levels. For the environmental factor of NEBC, two dummy variables are added when constructing a LR model, and All with Reduced Capacity is considered as a reference category. The odds of being efficient for NEBCNo is 0.0004, which indicates that No action is less likely to be efficient than the All with Reduced Capacity holding all other variables as constant.
For the EATS factor, No is considered as a reference category. The odds of being efficient for Yes is 57.5526, which indicates that Yes increases the likelihood of efficiency than No. For REG, three dummy variables are added, and the Midwest is considered as a reference category. The odds of being efficient for REGNortheast is 0.0856, which indicates that Northeast is less likely to be efficient than the Midwest. Both South and West Regions decrease the likelihood of efficiency. Take GDP as an example to explain the quantitative variable. For one unit increase in GDP, the odds of being classified as an efficient state increase by a factor of 4.5465.
Considering the coefficients’ statistical significance (
p-value < 0.05), PD, LGBLifted, NEBCNo, NEBCSome, SHD, Urban, EATSYes, MASKMYes, NTP, NVGP, THBP, GDP, and PI are statistically significant to predict the efficiency. On the other hand, LGBBelow25, PF, HCEP, REGNortheast, REGSouth, and REGWest were not related to efficiency. These factors are consistent with factor importance ranking obtained from RF (see
Figure 4).
Among the 15 considered environmental factors, twelve factors (original categorical variables are considered) affect efficiency significantly in the LR model, and six factors are effective in constructing an optimal classification tree. Five environmental factors found significant in the LR model were also found significant in the classification tree.
3.4. Performance Evaluation
We used a confusion matrix to evaluate the performance of different models.
Table 8 summarizes the correct and incorrect classifications for four different models using training and validation data.
For the classification tree, out of 154 cases of training data, 69 cases are predicted to be efficient with an accuracy of 99% and 83 cases are predicted to be inefficient with an accuracy of 98.81%. The overall accuracy is 98.70%. For the validation data, 66 cases are considered in which 27 cases are correctly classified as efficient and 33 cases are correctly classified as inefficient. The efficiency accuracy rate is found to be 96.43% and the inefficiency accuracy rate is found to be 86.84%. The classification tree’s overall accuracy level is 90.91%, which indicates a relatively high level of confidence.
For BT and RF, the training data has an estimated accuracy rate of 100%. The accuracy rate reduces to 95.45% for the validation data. The efficiency and inefficiency accuracy rates are 100% and 92% respectively, which indicates that these two models are good at classifying efficient and inefficient states.
From the result by LR model, out of 154 cases of training data, 55 cases are predicted to be efficient with an accuracy of 78.57% and 74 cases are predicted to be inefficient with an accuracy of 88.10%. The overall accuracy is 83.77%. For the validation data, 66 cases are considered in which 22 cases are correctly classified as efficient and 32 cases are correctly classified as inefficient. The efficiency accuracy rate is found to be 78.57% and inefficiency accuracy rate is found to be 84.21%. The overall accuracy level for the LR is 81.82%.
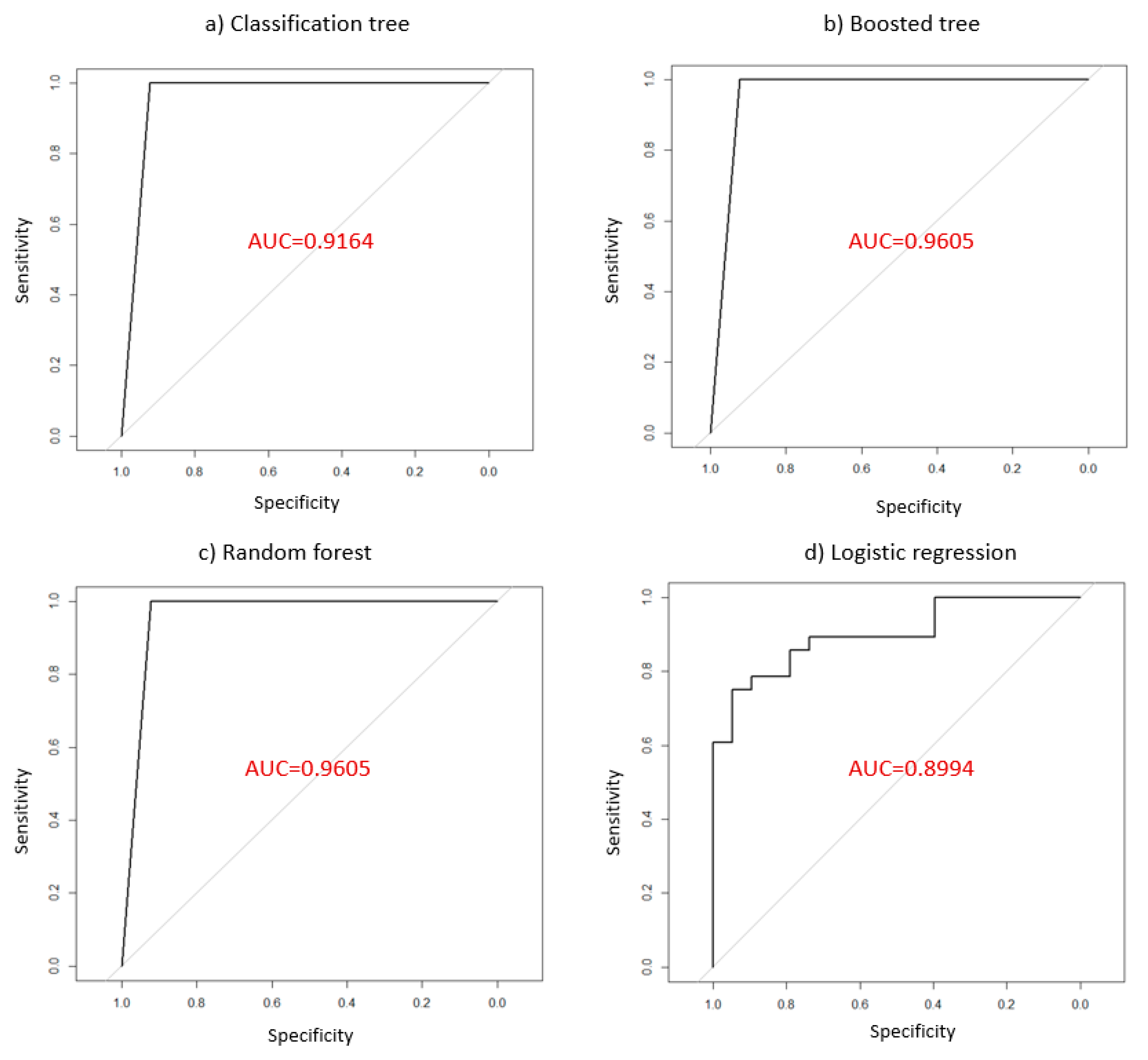
Figure 5 shows the ROC curves for the four different models. The ROC curve plots the different pairs of specificity and sensitivity as the cutoff value decreases from 1 to 0. Area under the curve (AUC), which ranges from 1 (perfect prediction) to 0.5 (random coin flipping), is used to measure the model’s performance. AUC is found to be 0.9164 for CART, 0.9605 for BT, 0.9605 for RF, and 0.8994 for LR. From this measure, BR and RF are better methods to predict the efficiency than CART and LR. However, CART is better than LR. Meanwhile, BT and RF are combined from the results of multiple trees and they allow for better consistency of results and robustness of predictions. They usually perform better than a single tree. However, their result cannot be displayed in a tree-like diagram. An RF and BT aka “black-box model” is less interpretable than a single classification tree. Therefore, we only compared lift chart for classification tree and logistic regression in
Figure 6.
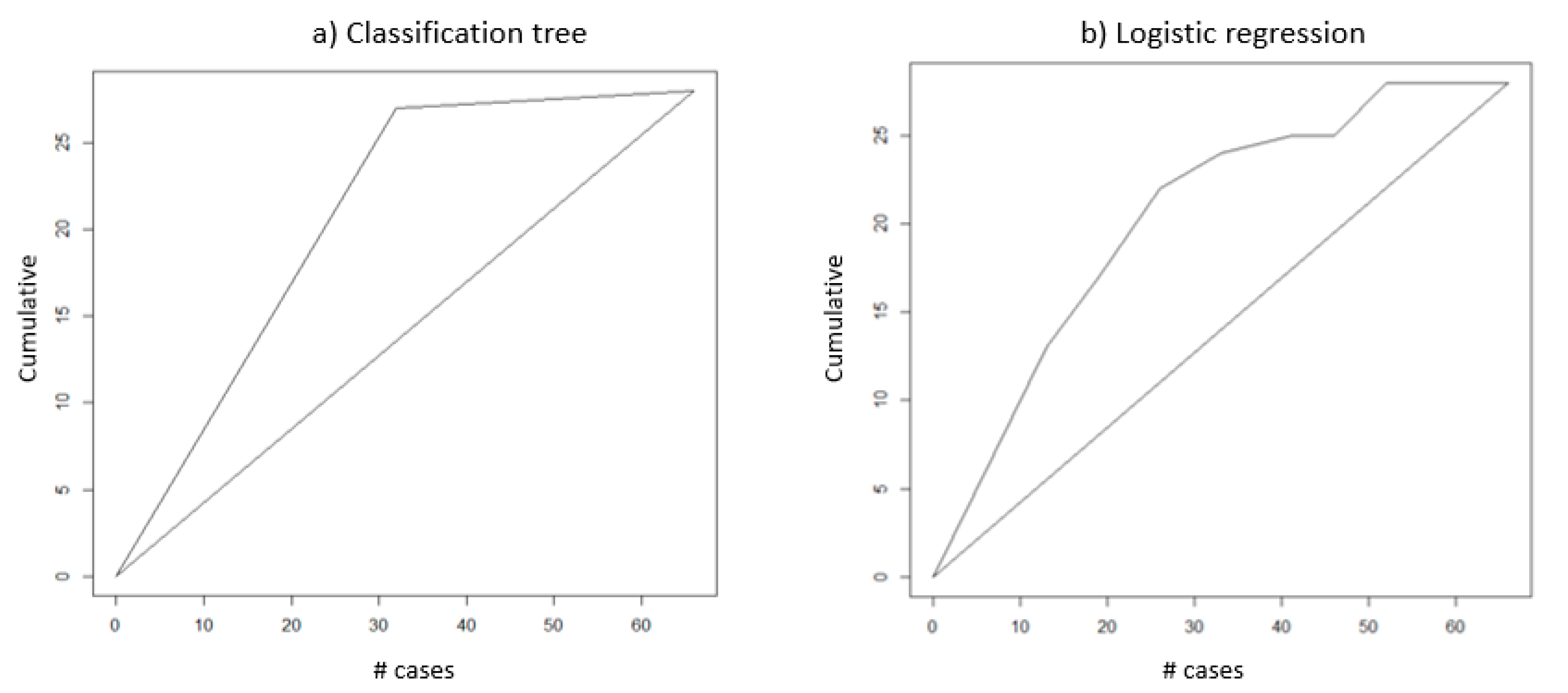
The lift chart helps visualize for measuring model performance, which is the ratio between results obtained from the predictive and random classification models. The greater the area between the baseline and the lift curve, the better the model.
As it can be seen from
Figure 6, if the top 30 records are selected, CART can correctly classify 25 records (83%) and the LR model can correctly classify 23 records (77%). If the top 40 records are selected, CART can correctly classify 27 records (68%) and the LR model can correctly classify 25 records (63%). From the analysis result, CART performs better than LR and these two models are much better than random classification.
4. Conclusions
The application of DEA, CART, and LR on measuring the COVID-19 response performance of states gives a new angle to fight against the Coronavirus outbreak. From DEA analysis, the finding indicated that 23 out of 50 states were efficient in responding to COVID-19. As a second stage, CART and LR are used to find the associated relationship between efficiency and 15 environmental variables. Variables are categorized into three measurement groups: social distancing measure, health policy measure, and socioeconomic measure to run four ML models.
CART identified the six key predictors: Urban, PI, NTP, PD, THBP, and PF. RF and BT were extensions of a single classification tree to improve the classification tool’s robustness. RF produced variable importance scores, which show the measure of relative contribution of the different environmental factors. From the importance of predictor variable analysis, using RF, PI, THBP, Urban, NTP, and NVGP were among the top 5 priorities in classifying the efficiency. Lastly, researchers used the LR approach to predict the efficiency for comparison with our other proposed models. Five environmental factors such as Urban, PI, NTP, PD, and THBP being found significantly in LR model were also found significantly in CART.
Our study is well justified by assessing the performance of different model’s confusion matrix, ROC curve, and lift chart. BT and RF were better predictive models because of higher accuracy rate and higher AUC value. Moreover, CART performed better than LR. Although DEA can explain the efficiency scores, but it cannot explain the environmental factors related to the inefficiency of the DMUs. Therefore, the CART and LR approaches help explain the efficiency results obtained by DEA by observing the environmental factors associated with efficiency and inefficiency.
This study’s results may be of interest to health care decision-makers who are involved in COVID-19 response management planning and wish to maximize the statewide performance.
First, health care decision-makers in government and industry need to incorporate the results of this study, which focus on social distancing measures, health policy measures, and socioeconomic measures in addition to experimental results. The functioning of the COVID-19 pandemic may be encumbered by increasing health care provider capacity that may be difficult to expand based on current capacity level. COVID-19 spreads rapidly to urban areas, where higher population density exists. Moreover, states with high populations tend to be efficient; thus, paying attention to the rural areas with states with lower populations is important to improve the efficiency. States could allocate additional health care resources such as a health care employee and hospital bed by establishing a resource consortium program between states for effective utilization of health care resource. States should also establish effective vaccine allocation program to maximize the vaccine supply. Knowing the factor affecting the efficiency will be very important for health care policy makers to establish the COVID-19 responding policy for each state. Our results might be the set of rules that can be used for health care policymakers to improve statewide pandemic response performance.
Secondly, health care decision-makers can supplement our study results by conducting window analysis of states’ operational efficiency. One limitation of this study is that detailed panel data for some of the variables, such as number of health care employees, population density, GDP, and public funding, were not publicly available. Usually, they were aggregated into one year. The limitation of the study can be overcome if disaggregated monthly or weekly data is available. These are important parameters that health care decision-makers should include when modeling the determinants of efficiency in COVID-19 or similar unprecedented pandemic situation in the future. Our study has taken one step towards evaluating the proper mechanisms that can help U.S. governments improve their efficiency regarding COVID-19. Future research should find out which measure would work best in this context. Moreover, this study used a bootstrapping sampling method to tackle our issue. We think that use of county-level to predict the efficiency would be a good idea, but this is beyond the scope of this paper.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}