The Linear Link: Deriving Age-Specific Death Rates from Life Expectancy
by
 , , and
, , and
Marius D. Pascariu
1,2,* ,
,
Ugofilippo Basellini
3,4,
José Manuel Aburto
2,3,5 and
Vladimir Canudas-Romo
6,*
1
Biometric Risk Modelling Chapter, SCOR Global Life SE, 75795 Paris, France
2
Interdisciplinary Centre on Population Dynamics, University of Southern Denmark, 5000 Odense, Denmark
3
Max Planck Institute for Demographic Research (MPIDR), 18057 Rostock, Germany
4
Institut National D’études Démographiques (INED), 93300 Aubervilliers, France
5
Leverhulme Centre for Demographic Science, Department of Sociology and Nuffield College, University of Oxford, Oxford OX1 2BQ, UK
6
School of Demography, The Australian National University, Canberra 2600, Australia
*
Authors to whom correspondence should be addressed.
Risks 2020, 8(4), 109; https://0-doi-org.brum.beds.ac.uk/10.3390/risks8040109
Submission received: 27 July 2020
/
Revised: 11 October 2020
/
Accepted: 14 October 2020
/
Published: 20 October 2020
(This article belongs to the Special Issue Mortality Forecasting and Applications)
Abstract
:The prediction of human longevity levels in the future by direct forecasting of life expectancy offers numerous advantages, compared to methods based on extrapolation of age-specific death rates. However, the reconstruction of accurate life tables starting from a given level of life expectancy at birth, or any other age, is not straightforward. Model life tables have been extensively used for estimating age patterns of mortality in poor-data countries. We propose a new model inspired by indirect estimation techniques applied in demography, which can be used to estimate full life tables at any point in time, based on a given value of life expectancy at birth. Our model relies on the existing high correlations between levels of life expectancy and death rates across ages. The methods presented in this paper are implemented in a publicly available R package.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
Understanding human mortality dynamics is of utmost importance in the context of rapid ageing process together with the increase in length of life experienced by most populations nowadays. The link between the pension systems sustainability and changes in life expectancy is more apparent than ever in light of the recent reforms that are taking place in Europe. In countries like Germany and Finland the level of retirement benefits are linked to life expectancy, in other countries like the U.K. and France the retirement age is set to increase from the current levels and implicitly the contribution period for pensions to be extended as people live longer (Stoeldraijer et al. 2013).
In predicting demographic processes, such as human mortality, methods involving extrapolation of mortality rates or probabilities are the most common approaches. Stochastic models, such as those proposed by Lee and Carter (1992) or Cairns et al. (2006) have gained significant popularity and have been extensively used in the last two decades. Ideas that focus only on life expectancy have given rise to a new approach. The models introduced by Torri and Vaupel (2012), Raftery et al. (2014) and Dan Pascariu et al. (2018) are partially inspired by the linear time trends observed in life expectancy at birth in many developed countries, particularly in the second half of the twentieth century (Oeppen and Vaupel 2002; White 2002). These life expectancy models are very appealing because they offer the same, or higher, level of forecast accuracy in terms of life expectancy but with the advantage of being parsimonious, focusing on one variable rather than several. They rely on a measure that incorporates all the factors that influence longevity (lifestyle, access to healthcare, diet, economical status, etc.), namely life expectancy (Christensen et al. 2009). Furthermore, highly aggregated data by age provide valuable information that can be used to tackle the issue of mortality forecasting from a clearer perspective. The U.S. Census Bureau predicts the future mortality levels up to year 2100 based on projections of life expectancy at birth by sex and race, modelling an exponential decline of the gap to the observed upper asymptote of life expectancy. The period age-specific death rates are estimated in a subsequent step using these projections (United States Census Bureau 2014).
Transformation of life expectancy into mortality rates at every age can be accomplished by exploiting the regularities of age patterns of mortality. In actuarial science, the use of life tables and other models reflecting life contingencies is motivated by the need to determine insurance and pension risks, net premiums, and benefits. Basically, actuarial methods combine the life table with functions related to an assumed rate of interest (Dickson et al. 2013; Møller and Steffensen 2007). Based on the relevance of having a set of age-specific death rates, we propose a method to create such an array of values from one available life expectancy.
Our method extends the work initiated by the different systems of model life tables (Gabriel and Ronen 1958; United Nations 1955, 1967; Coale and Demeny 1966, Coale et al. 1983; Ledermann 1969; Sullivan 1972); Brass’ relational model (Brass 1971; Brass et al. 1968) and the recent extensions of techniques for estimating age patterns of mortality by Murray et al. (2003) and Wilmoth et al. (2012). Our model is also related to the work of Mayhew and Smith (2013) that uses the trends in life expectancy to establish a robust statistical relation between changes in life expectancy and survivorship. A further, similar approach to the one developed here is that of Ševčíková et al. (2016) which incorporates a method based on the Lee-Carter model for converting projected life expectancies at birth to age-specific death rates in the UN’s 2014 probabilistic population projections.
Relational models were developed for estimation purposes in poor-data contexts. These models rely on parameters that depict the relationships between various measures of age-specific and overall mortality. The parameters in a relational model are estimated from an initial analysis of historical mortality data and become fixed thereafter. Once those values have been estimated, the model simplifies to a few initial inputs like: reported child survival, records of population growth, responses to questions about fertility and mortality and in our case life expectancy at birth or at any other age. Our model recovers the entire age profile of mortality in a population based on the strong correlations between a single longevity measure, namely life expectancy, and age-specific death rates. Combining these correlations in the Lee-Carter (1992) methodology makes the proposed algorithm appealing to be used in forecasting practice. Furthermore, in recent years the accessibility of historical mortality data, such as the Human Mortality Database (HMD), means that the necessary information to estimate the parameters of the proposed model is readily available. Additionally, the linear relations between levels of life expectancy and age-specific death rates presented here, could be used for testing anomalies in information in actuarial practice.
The remainder of the article is organized as follows. First, in Section 2 a new model to derive age-specific death rates is introduced and a description of the data used in testing is provided. Section 3 shows computed results and illustrations of life expectancy decomposition into death rates in several populations, as well as comparisons of forecasts with other models. The discussion and conclusion are presented in Section 4.
2. Data and Methods
2.1. Data
The data source used in this article is the Human Mortality Database (University of California Berkeley, USA and Max Planck Institute for Demographic Research, Germany 2020), which contains historical mortality data for more than 50 homogeneous populations in 41 different countries and territories. The HMD constitutes a reliable data source because it includes high quality data that were subject to a uniform set of procedures, thus maintaining the cross-national comparability of the information.
In order to test and illustrate the performance of the method, we fit the model using the death rates computed using death counts and population exposed to the risk of death in the calendar year for the female populations of the England & Wales, France, Sweden and USA available in the HMD. The population selection was based on different degrees of model performance given by the mortality specificities of those populations, for example old age mortality in the HMD is often subject to diverse correction procedures and modelling depending on the country (Wilmoth et al. 2007).
The reconstructive power of the method for a point forecast of life expectancy is demonstrated using the 1980–2018 mortality data between age 0 and 100. Data at higher ages might be unreliable or too sparse for different populations, which would make it difficult to differentiate between data related problems or modelling issues. To compute the accuracy measures and the estimation errors, the 1965–90 data is applied to the same age range.
2.2. The Model
Given a predicted level of life expectancy the age pattern of mortality can be derived using a linear relation. The logarithm age-specific death rate at time t, denoted , can be expressed as a linear function of the logarithm of life expectancy at a given age , denoted . Formally:
where x can take values between 0 and , the highest attainable age, and can be regarded as an age-specific parameter. denotes a set of normally distributed errors with mean zero and variance . For example, when equals zero, we estimate an entire mortality curve based on life expectancy at birth using this equation; when , we estimate the mortality curve starting from age .
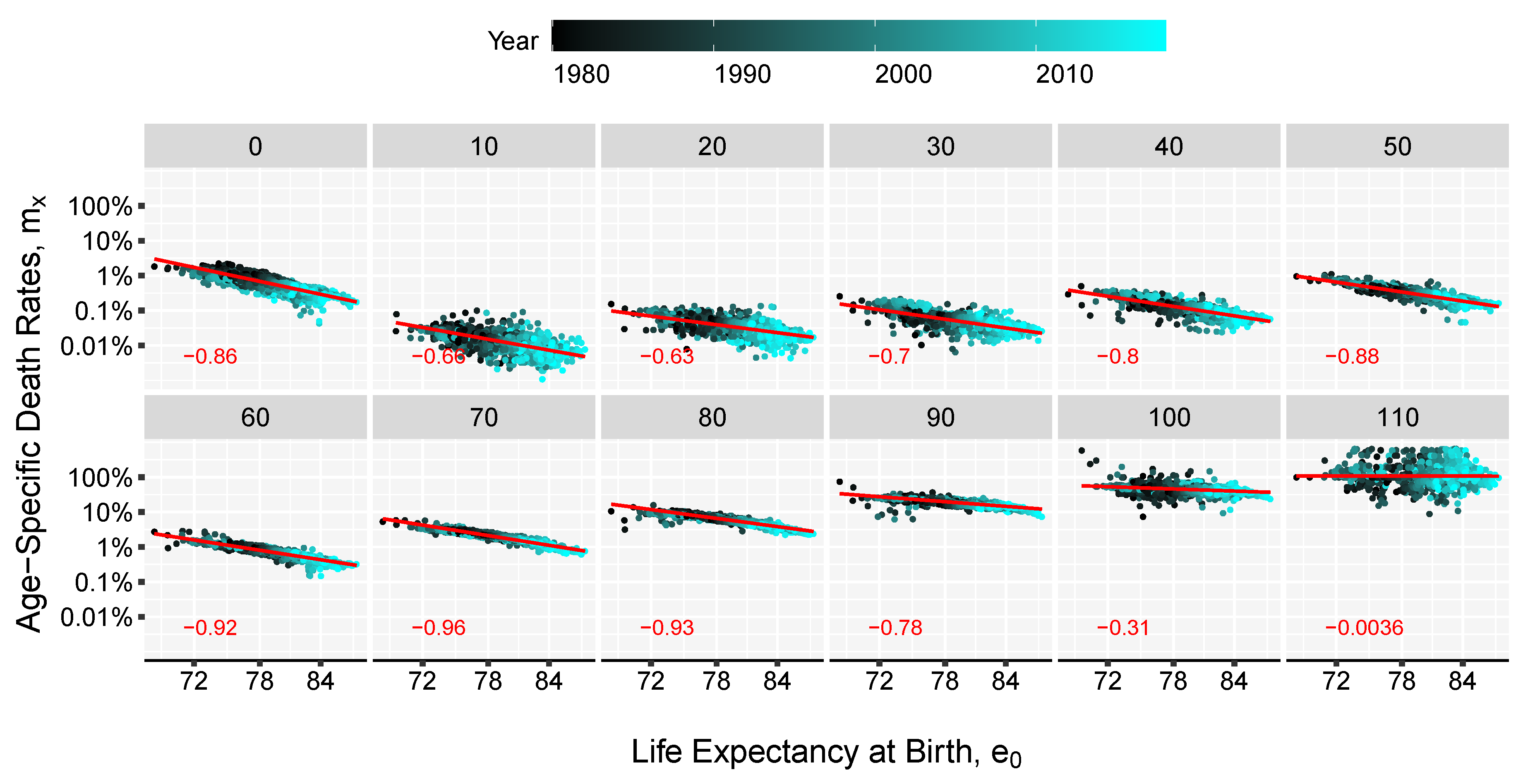
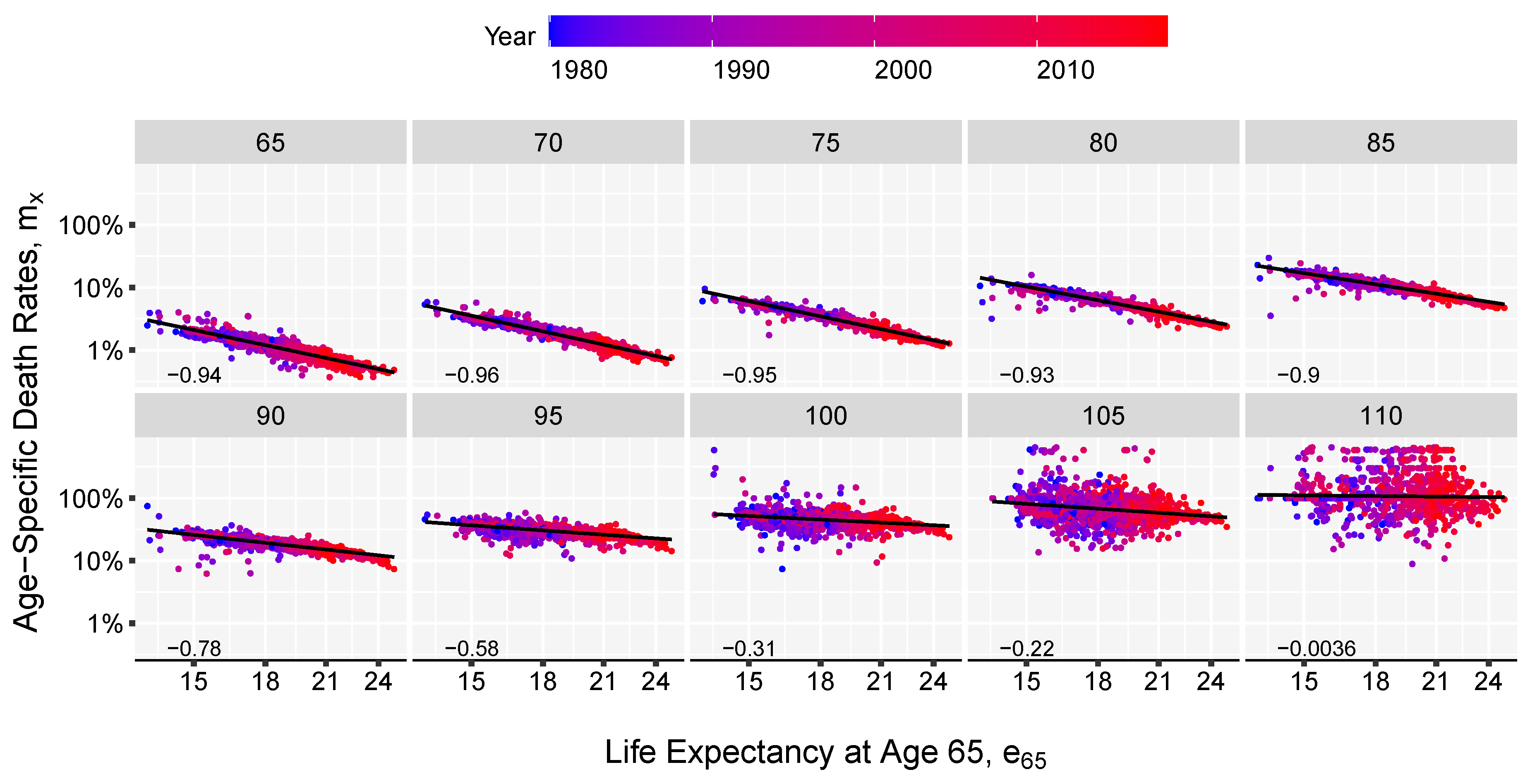
The method presented here combines the linear relations found when comparing life expectancies and age-specific death rates on a log-log scale. Figure 1 and Figure 2 show those relations, although the slopes and intercepts vary, in all cases there is a significant linear concordance between the level of overall mortality, as depicted by life expectancy, and the individual age-specific death rates especially between age 30 and 90 as displayed by the Pearson correlation coefficient. These relations have been key in much of the work on model life tables (Gabriel and Ronen 1958; United Nations 1955, 1967; Coale and Demeny 1966, Coale et al. 1983; Ledermann 1969). Inspired by the two-dimensional system (age and time) of the Log-quadratic model Wilmoth et al. (2012) and the strong linear trends in Figure 1 and Figure 2, we derive the age pattern of mortality based on a given value of life expectancy, e.g., forecasted life expectancy value, and a matrix of age-specific death rates from the past.
This model can be seen as a method that links the life expectancy at age at any point in time to a mortality curve estimated from the death rates ’s that return a life expectancy level of . Therefore we will refer to it as the linear-link (LL) model. To gain precision in the fitting of the death rates the LL model can be extended by including additional parameters:
where is the speed of mortality improvement over time at age x, k is an estimated correction factor independent of time and are independent and identically distributed random variables normally distributed with mean zero and variance . Different than the Log-quadratic model that has a fixed set of parameters for any input value, here the parameters , and k can be calculated for each set of age-specific death rates and future life expectancy. Thus, it can be seen as an extension of the log-quadratic model for countries that have good quality data, where an entire life table is completed from one target value of life expectancy.
In addition, the LL model is closely related to the LC model. Indeed, if one sets the parameters , , and , we obtain the LC model. Interpretation of the parameters are then similar with a standard age profile, the age-specific improvements in mortality, and k the amount of average mortality improvement. Despite their similarities, there are two important differences between the two models. First, while the shape of the mortality pattern is constant in the LC model, the first term of the LL changes with the level of life expectancy considered; as such, there exists a range of different baseline mortality curves of the LL model depending on the particular level of . Second, the k parameter is not modelled as a function of time, instead the parameter is used as an optimization variable affecting the shape of the age pattern of mortality to achieve the desired target life expectancy . Thus, the k parameter enhances the flexibility of the method and the accuracy of the results.
2.3. Algorithm
Let t be an observed unit of time in the interval and be a an unobserved point in time e.g., a date in the future. The objective is to convert a value of life expectancy, , into a schedule of age-specific death rates . The level of life expectancy can be a predicted value given by certain extrapolation method or the target values resulted following a subjective judgement. Input data will be a collection of observed death rates and a level of life expectancy . The steps involved in the algorithm to obtain the desired death rates are the following:
- Using the Kannisto mortality model (see Appendix A) extend to higher age groups up to age for all times t. The highest attainable age, , can be set for example to 120.
- Estimate the slope of the linear relation between life expectancy and the death-rates, , over the observation time t. This is done by using the method of the least squares approach, by minimizing the sum of squared residuals:Alternatively, the parameters of the model can be estimated by assuming that deaths follow a Poisson distribution (Brillinger 1986; Brouhns et al. 2002), , with . In order to use this approach death counts () and central exposure data () are needed. Sensitivity analysis shows that the difference between the two fitting procedure return minor discrepancies (see Appendix B in the Appendix for more details).
- Estimate the parameter by computing the singular value decomposition (SVD) of the matrix of regression residuals, , obtained in the previous step,whereand are matrices of left and right singular vectors, and is a diagonal matrix with singular values along the diagonal. The fist term of the , , is used for obtaining the estimates of . Parameter can be interpreted as the rate of mortality improvement over age.
- Smooth the and parameters using splines. This step is important to obtain graduated mortality curves and avoid projecting age-specific noise in the jump-off life table. However, if the graduation is not of interest or if the input data-set is large enough, this step can be skipped.
- Compute the initial mortality rates1 by , where .
- Optimize the mortality curve given in the previous step by finding the value of k where the difference between target life expectancy and an estimated life expectancy is below a tolerance level, for example 0.001, where represents the level of life expectancy at birth computed based on the mortality rates obtained in step (5). Usually k will be in the range of depending on the length of the forecast window.
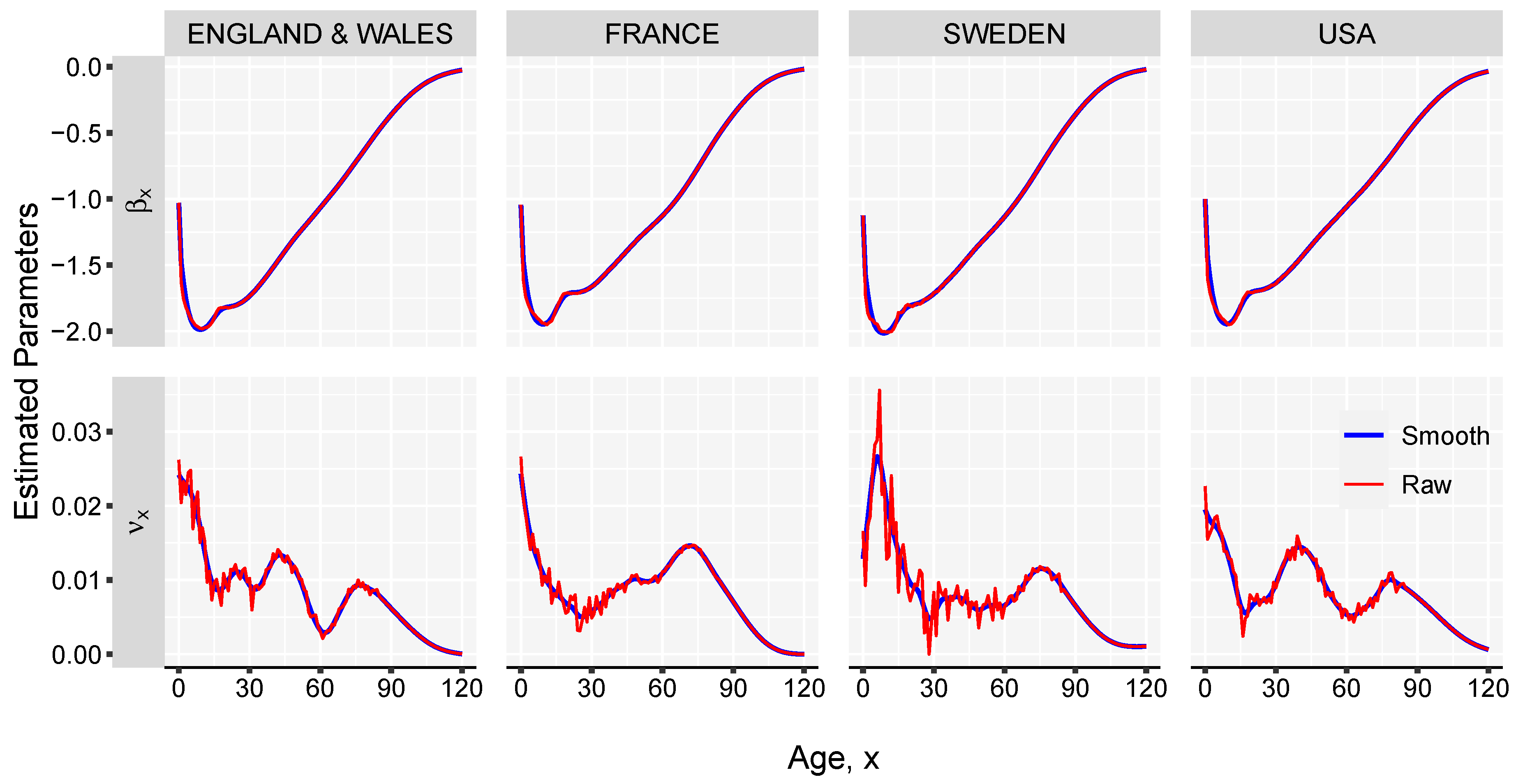
The estimated parameters for the female populations in England & Wales, France, Sweden and USA, exhibit minor differences between the countries, and capture well the important stages of human mortality: the decreasing infant mortality, the accidental hump, the adult mortality characterized by an exponential increase with age and, finally, a mortality plateau above the age of 100 years. As shown in Figure 3, the pattern differs from population to population. In the case of Sweden, a larger variance is observed over ages due to a smaller population size and more significant changes at younger ages in the period analysed.
3. Results and Illustration
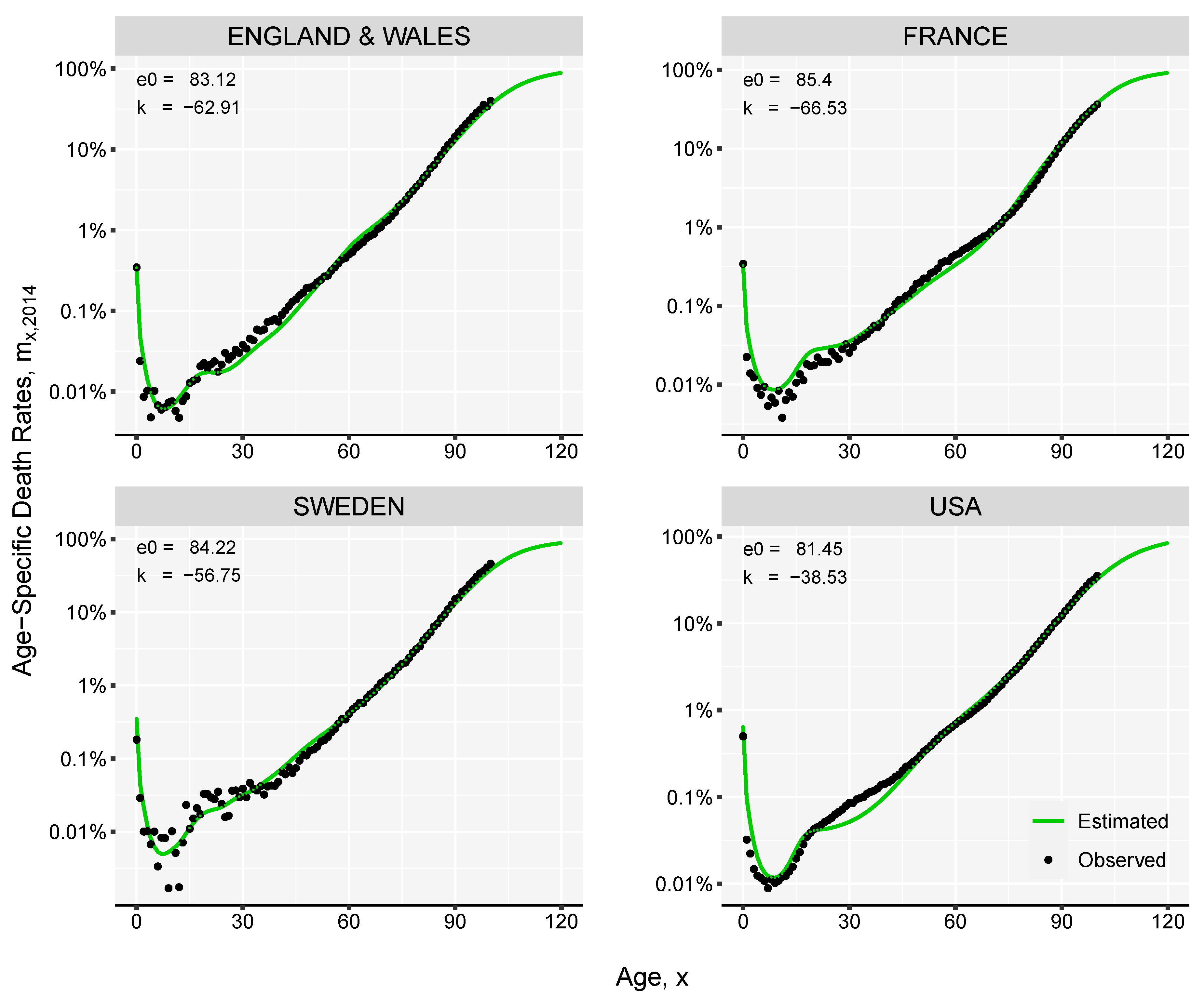
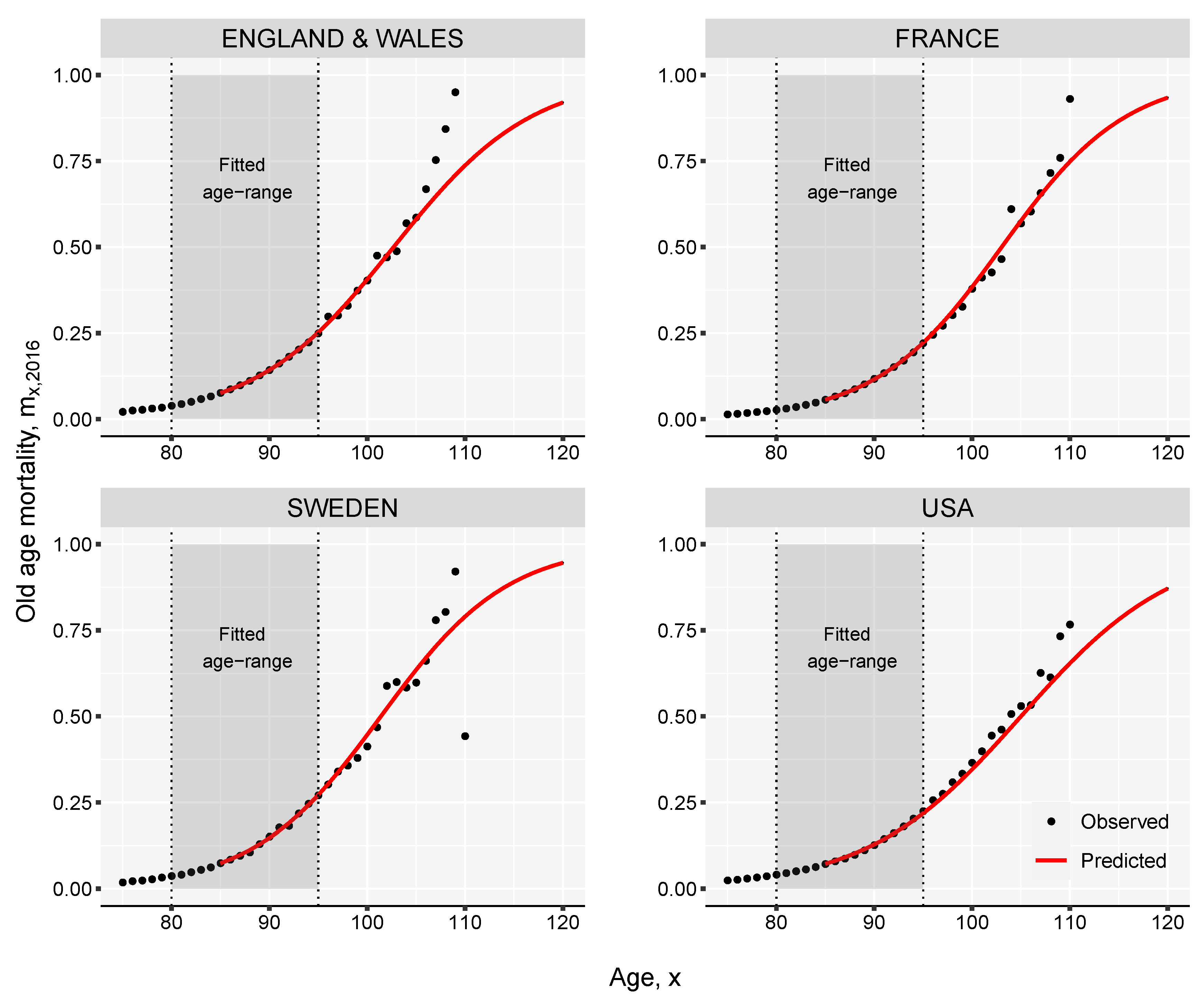
We perform back-testing against the observed mortality for the female populations living in England & Wales, France, Sweden and USA. We take the period of 1965–1990 as reference and use the death-rates and life expectancies at birth in this time interval to fit our model. Based on single values of life expectancy at birth observed in the subsequent years we derive complete mortality curves. For example, the estimation of the age-specific death rates in 2018 is demonstrated in Figure 4. The reconstructed mortality curves are in general smoother than the observed data; this is more evident in the case of Sweden, where the population is smaller compared with the other three countries.
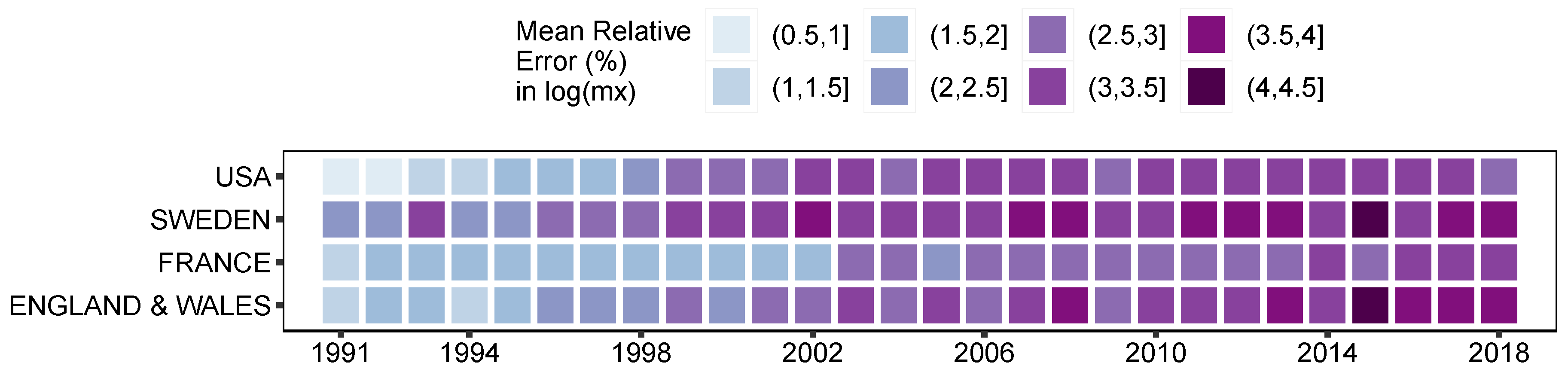
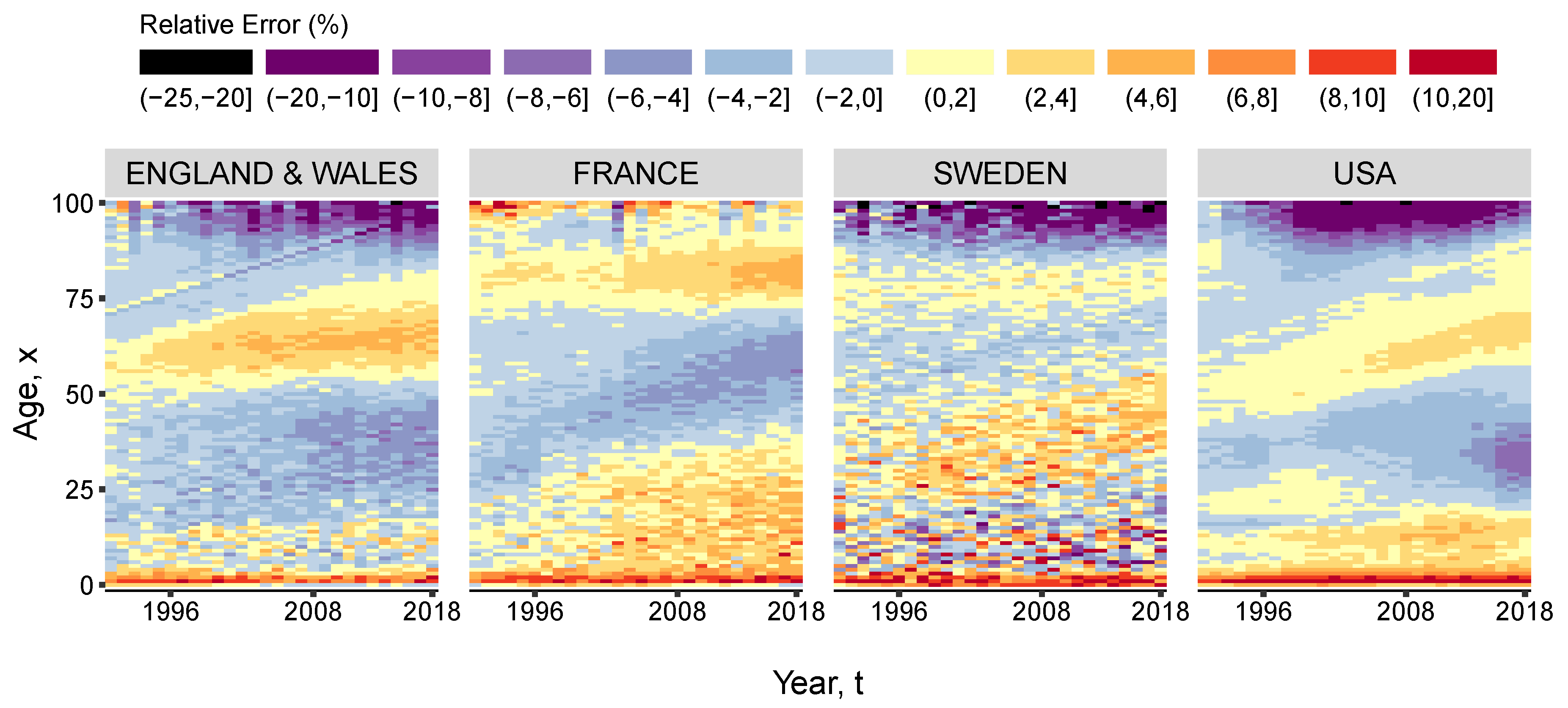
Figure 5 shows that the average relative error of the estimated log-death rates, compared to the actual rates between 1991 and 2018, is between 0.9% and 4.3%. It can be also noted that the longer the prediction interval, the larger the errors. In the case of female populations living in England & Wales, France, Sweden and USA, the largest errors occurred in 2016; nonetheless these are smaller than 4.3% of the actual log-death rate. This value is an average over the entire comparable age range (0–100). The largest impact on the overall accuracy occurs at advanced ages, where the level of uncertainty is higher. Figure 6 offers a view of the error distribution by age and time. However, the life expectancy at birth computed based on the estimated death rates matches exactly the actual life expectancy in the respective year and country.
In order to test the conversion reliability of a forecast value of life expectancy, we compare the results generated by the LL model against the predicted mortality from the Lee-Carter model (1992).
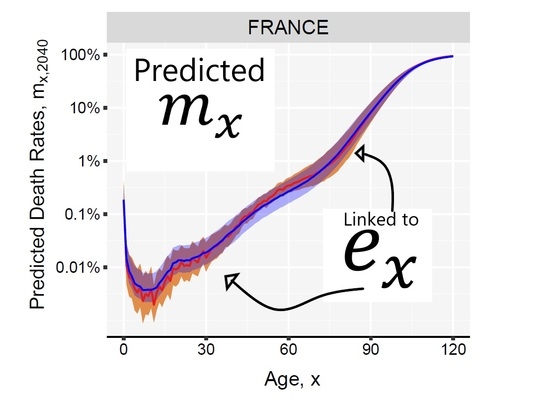
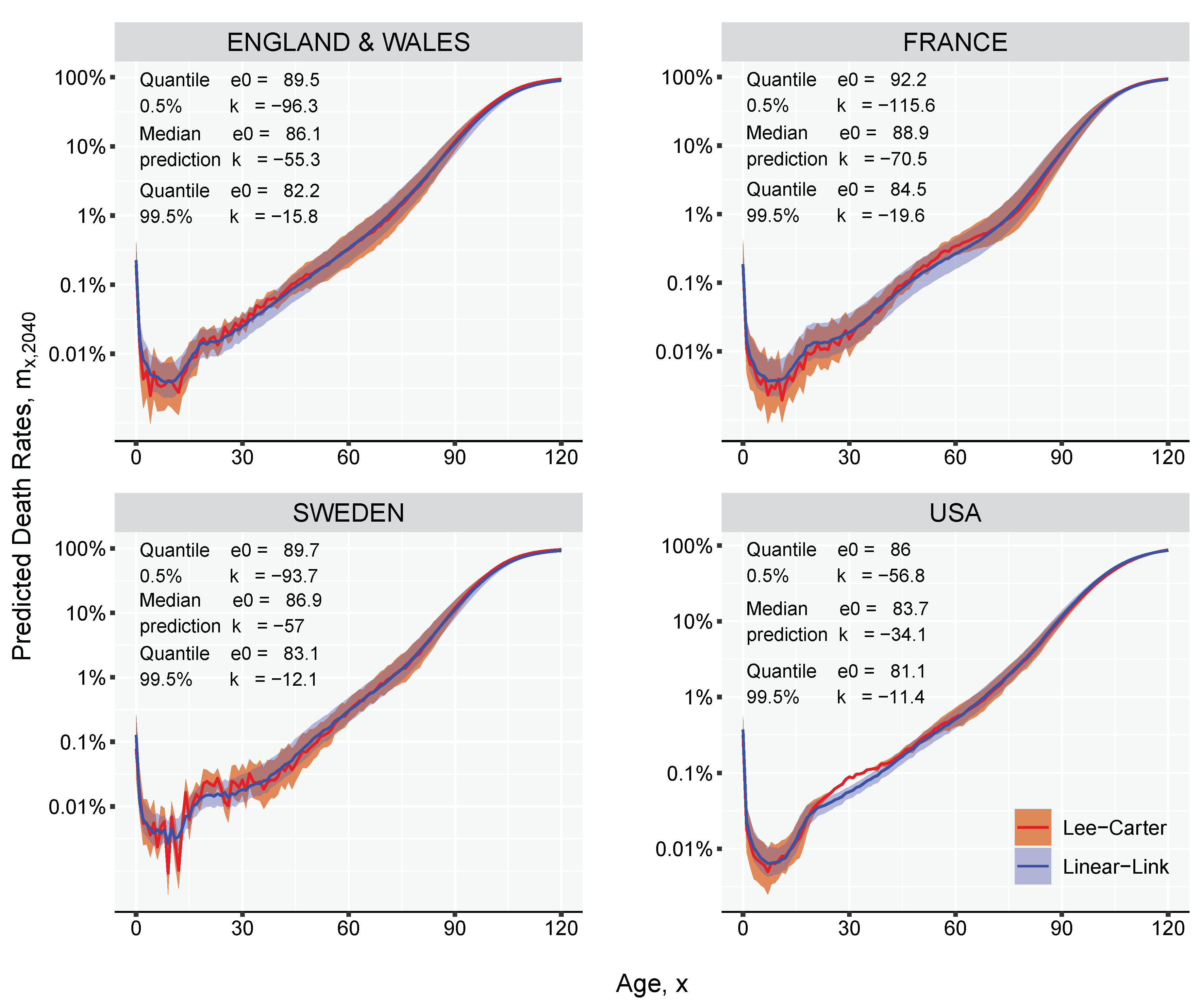
The LC model is fitted over the 0–95 age-range using the historical data from 1980 to 2018, and used to forecast death rates 22 years in the future, until 2040. The estimated matrix of predicted death rates between age 0 and age 95 is extended up to age 120 using the Kannisto model (see Equation (A1) in the Appendix A). If multiple projections are simulated for the same forecast point, the LC would produce a range of outcomes that can be translated into life expectancies using standard life table calculations. Any predicted life expectancy given by LC is used as an input value in the LL model to derive the mortality curve, thus obtaining two comparable curves. For every simulated trajectory, the LL method can produce a mortality curve, generating the uncertainty around the median prediction. Figure 7 shows that the reconstruction method employed by the LL model gives an almost coincident mortality curve when compared with the LC curve for female populations in 2040. The 99% prediction intervals are computed based on ten thousand Monte-Carlo simulations. Besides the LL model showing a more smooth age-pattern when compared with the LC results, it can perfectly estimate the predetermined life expectancy, and it exploits the linear relationship between mortality and life expectancy producing mortality profiles that are less distorted around the age dimensions when forecasted far into the future.
4. Discussion
We have introduced a simple method, the Linear-link model, to derive the entire schedule of age-specific death rates, based on a single value of life expectancy and prior knowledge of human mortality patterns. The model is based on the observed linearity between age-specific death rates, , and life expectancy at a certain age, . The model can be regarded as a decomposition approach of the human mortality curve between the general age pattern, , and an age-specific speed of improvement, . The method is inspired by: (1) the Log-quadratic model (Wilmoth et al. 2012) in the sense of using a leading indicator in determining the age pattern of mortality; (2) the model introduced by Ševčíková et al. (2016) by adopting an inverse approach to death rates estimation starting from life expectancy; (3) the Lee-Carter model (1992) using the same interpretation of mortality improvement over time and age; and finally (4) the Li et al. (2013) method to model the rotation of age patterns of mortality decline for long-term projections.
The method can be useful in three different situations: future target life expectancy, life tables for countries with deficient data and historical life table construction. The former is the one explored in the present manuscript, while the latter two are only briefly discussed since their development goes beyond the scope of the paper of presenting the LL model. Future work is envisioned to apply and compare the proposed Linear-link with other approaches in contexts of lower data quality or availability.
First the model can be used in forecasting practice when the level of life expectancy is forecast first. We showed that this model can accurately reconstruct a Lee-Carter forecast starting from a single value of life expectancy at birth. This is important, because the Linear-link model offers the possibility of taking advantage of the more regular pattern of the life expectancy evolution. It is much easier and parsimonious, from a technical perspective to forecast one time series of expectation of life than to extrapolate 100 or 110 series of death probabilities corresponding to each age group. In the same manner adult mortality can be estimated based on a value of life expectancy at an advanced age, say age 65. In Figure 2, we showed that the linearity between death rates at advance ages and life expectancy at age 65 on a log scale is maintained. A greater variation is observed only at advanced ages, above 100, where data is sparse in general.
Second, the method can be used to build model life tables and estimate the current age patterns of mortality in poor-data countries or regions, like Sub-Saharan Africa or Central Asia. National and international agencies usually make use of indirect estimation methods heavily based on expert judgment to determine demographic indicators and compensate for the lack of data. Relational models where one indicator (e.g. life expectancy of the population) is based on another (e.g. survival rates in a specific age range) are common. The LL method intends to provide a new solution within this framework i.e. the transition from a life expectancy measure to an age specific mortality pattern. As in the case of relational models the method alone cannot represent a solution for all data-deficient regions however, in the hands of a qualified country specialist capable of making an educated guess on life expectancy and borrow information from populations with identical characteristics and good quality data the advantages of the Linear-Link method are obvious. The parameters of the model can be estimated in this case based on a collection of historical life tables from several regions or populations, possibly with higher data quality. Once the parameters have been estimated, and implicitly the model life table, they remain fixed. The relevant mortality curve is simply calibrated in accordance with a single value of life expectancy at birth or any other age instead of child mortality like in the case of Wilmoth et al. (2012). In our analysis we show examples using high quality data from developed countries in order to demonstrate the efficiency of the model, and to be able to assess the accuracy of the mortality curve reconstruction. However, the estimation procedure and the steps of the algorithm are the same for this case too.
Third, the LL model can be a useful tool in a variety of research contexts of historical demography like backward projections and estimation of mortality levels in historical populations. Due to the existence of scarce non-standardized population data in the past and population census only for the more recent times, the very possibility of projecting mortality backward is of theoretical interest (Ediev 2011).
There are two limitations of our proposed approach that should be mentioned: (i) its dependency on age-specific mortality information, which is needed to estimate the model’s parameters, and (ii) the accuracy of such information. The former one is particularly relevant for countries with lower data quality and availability, and it can be overcome by borrowing information from neighboring regions, as in the spirit of model life tables. The second limitation is more generally shared by any methodology that aims at modeling and forecasting mortality age-patterns.
According to our analysis, the optimal number of years to be used in the fitting of the model is between 30 and 35 years. If a longer time interval was used, the parameter estimates would lose their relevance. For example, the present rate of improvement in the death rates is different from that experienced 50 years ago, because of fundamental changes in society and scientific advances during this period (Bengtsson 2006; Rau et al. 2008). In the same manner over a longer period of time the linearity between life expectancy and death rates might be challenged, however this should be investigated from case to case.
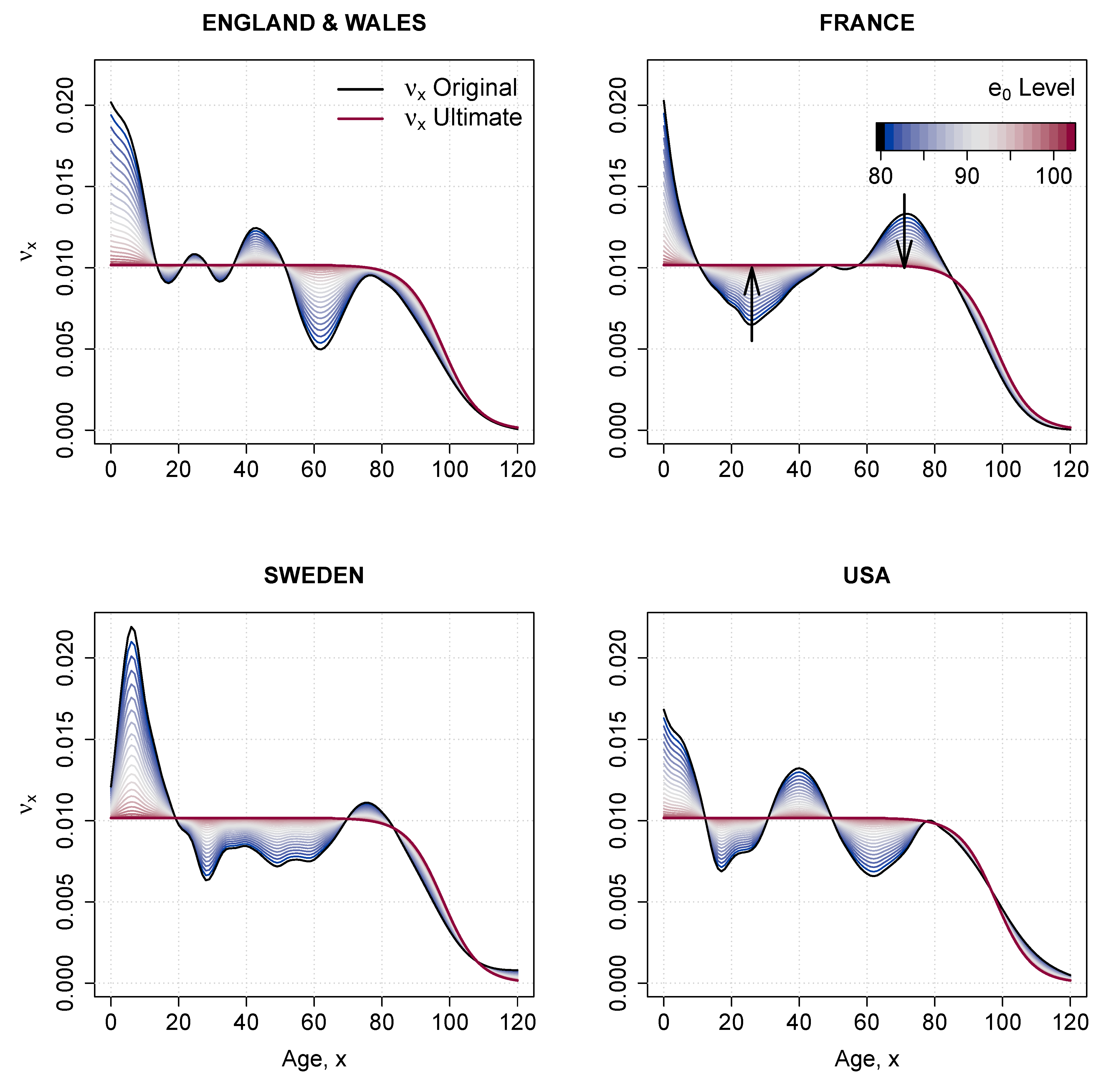
The speed of improvement in age-specific death rates over ages changes over time. For example, in recent decades, a faster pace of improvement was observed at ages 65 and above (Shkolnikov et al. 2011; Vaupel 1997). We address the possibility of experiencing accelerating or decelerating speeds of mortality improvements over different age ranges by assigning different weights to the estimated curve when the life expectancy at birth continues to advance over age 75. The effect of this method can be best observed in Figure 7 in the case of France. Under the implicit assumption of constant mortality improvements, the LC forecast generates a second mortality hump around age 50. The estimated mortality curve given by the LL model has a less pronounced effect due to the rotated parameter. See a detailed description of the method in Appendix C.
The evolution of human mortality is a complex process that is driven by a large number of factors and can not be explained by a single statistical model. The Linear-link method offers an alternative approach to deriving the unknown levels of mortality in the future. In contrast with methods like the Lee-Carter model that extrapolate age-specific rates or probabilities directly the method presented here recognizes life expectancy as the main driver of mortality at any given age and employs an indirect estimation algorithm. These methods can complement each other and help us understand better the future longevity experienced by populations.
5. Reproducible Research
The presented model and algorithm is implemented using the R programming language (R Core Team 2019) and can be downloaded and installed in form of an R software package from authors’ GitHub repository. The results and figures for the four countries presented in this article can be reproduced using the code and data saved in the R package.
Author Contributions
Conceptualization, M.D.P.; methodology, M.D.P. and V.C.-R.; software, M.D.P., U.B. and J.M.A.; validation, V.C.-R., J.M.A. and U.B.; formal analysis, M.D.P.; investigation, M.D.P.; writing–original draft preparation, M.D.P.; writing–review and editing, V.C.-R., J.M.A. and U.B.; visualization, M.D.P. and U.B.; supervision, V.C.-R.; funding acquisition, M.D.P. All authors have read and agreed to the published version of the manuscript.
Funding
This work was conducted within the "Modelling and Forecasting Age-Specific Death at Older Age", Project [No. 95-103-31186], under the management of the University of Southern Denmark, Institute of Public Health with the generous financial support of the SCOR Corporate Foundation for Science. The authors thank the funding institution. J.M.A was supported by the British Academy’s Newton International Fellowship.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Appendix A. The Kannisto Model
Normally, mortality data is available in tables that contain detailed information up to age 85, 100 or 110, with last age group being open. In order to extend the mortality rates up to age 120, the Kannisto method (Thatcher et al. 1998) for old-age mortality with an asymptote equal to one can be employed:
which can also be written as a linear function of age
Figure A1.
Extension of female mortality rates using the Kannisto model in 2016.

Assuming that the parameters and can be derived by maximizing the log-likelihood function:
where denotes the number of deaths that occurred at age x, represents the population exposed to risk at the same age, and is the age-specific death rate.
The Kannisto model is not only useful to obtain values for oldest-old mortality but also to smooth the rates computed on smaller sample sizes. The case of Sweden presented in Figure A1 can be relevant here, where in 2016 the number of females aged 100 and above was less than 1700. A small sample size can create difficulties in obtaining reliable mortality estimates based only on empirical observations. Outliers are expected to show up from year to year.
Appendix B. Maximum Likelihood Estimation
Assuming that deaths are Poisson distributed, the LL model can be fitted by maximising the log-likelihood given by
where C is a constant. The parameters are estimated following an updating scheme proposed by Brouhns et al. (2002) based on the Newton-Raphson algorithm. The updating procedure, with initial values , and , is as follows:
where , is the estimated number of deaths after iteration w.
The maximum likelihood estimation (MLE) has several advantages over least squares (OLS) and SVD methods or even weighted least squares (WLS) used in Wilmoth et al. (2007). Several reasons have been given in the literature (Alho 2000; Brouhns et al. 2002). One example would be the increasing confidence intervals by age. This is because in the OLS estimation via SVD the errors are assumed to be homoskedastic and normally distributed, which is quite a heavy assumption. The logarithm of the observed force of mortality is much more variable at older ages than at younger ages because of the much smaller absolute number of deaths at older ages. Therefore, since the number of deaths is a counting variable, the Poisson assumption seems more reasonable (Brillinger 1986).
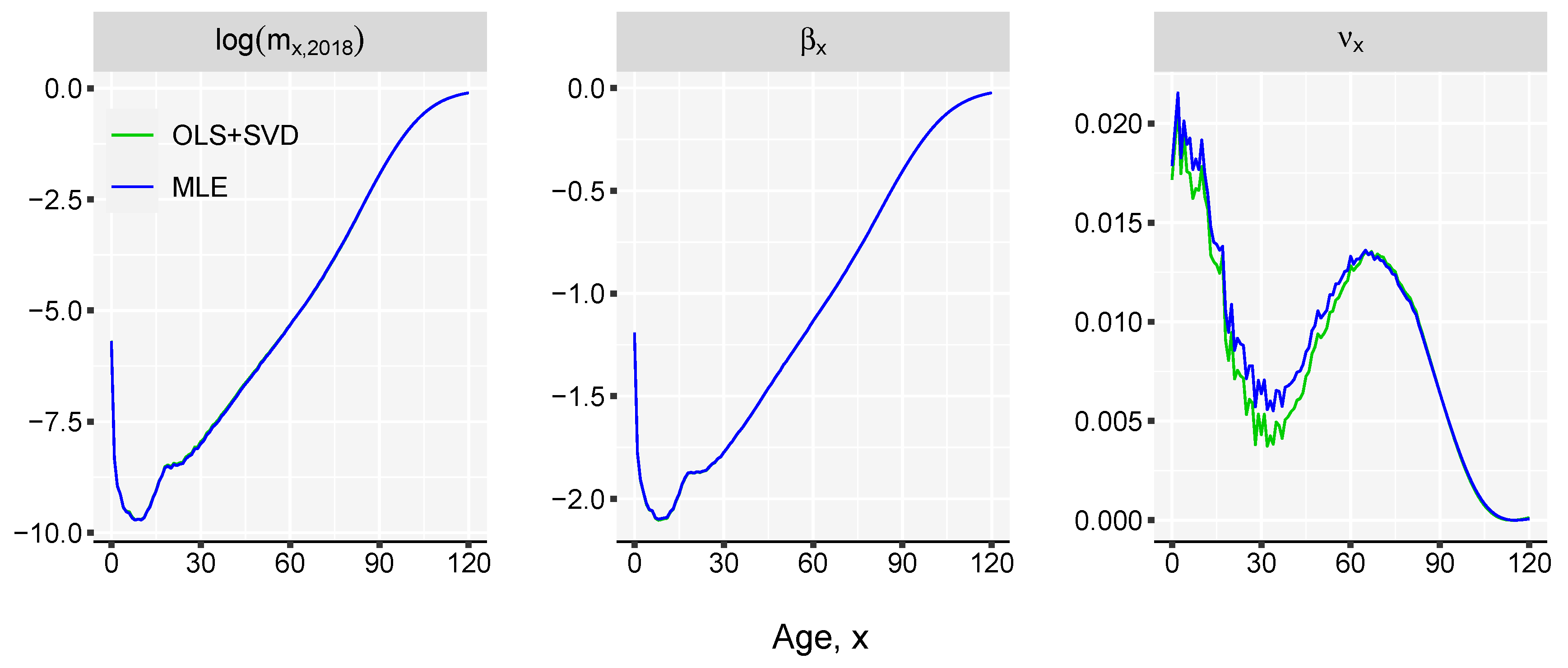
However, in order to use this approach we need death counts and exposures , which are not always available. This being the reason why the model described by Equation (1) is chosen in the article. Our methodology is targeting populations with deficient data as well as populations whose estimates of mortality rates are provided without disaggregation by deaths and exposures. Although conceptually a Poisson setting would be better, the SVD approach is a pragmatic decision for practical reasons. As shown in Figure A2 the difference between the two estimation methods for the case of England & Wales females is very small but the data requirements is higher in the case of MLE.
Figure A2.
Comparison of the fitted mortality curves and parameter estimates of the Linear-Link model using the OLS+SVD and MLE fitting procedures. England & Wales female data for 1980–2018 period is used.
Figure A2.
Comparison of the fitted mortality curves and parameter estimates of the Linear-Link model using the OLS+SVD and MLE fitting procedures. England & Wales female data for 1980–2018 period is used.

Appendix C. Rotation of Mortality Improvements
One of the main limitations of the LC model (1992) is the central assumption of constant rates of mortality declines at different ages, resulting from the time-invariant coefficient of age-specific mortality improvements (Bongaarts 2005). The assumption has been violated in several low-mortality countries in recent decades, because rates of mortality improvements have tended to decline over time at younger ages, and they have risen at older ages (Kannisto et al. 1994; Vaupel et al. 1998; Wilmoth and Horiuchi 1999).
It is important to take into consideration the changing age pattern of mortality improvements to produce more accurate mortality forecasts, and projection methodologies that ignore such rotation will lead to errors, particularly in the projected age patterns of future death rates (Li et al. 2013). Li et al. proposed an extension of the LC method to incorporate the rotation of the age patterns of mortality decline for long-term projections.
Here, we propose a modification of the original Li et al. (2013) methodology that ensures the rotation of the rate of mortality improvement over age in the LL model, . The methodology is composed of two different steps.
First, we derive an ultimate schedule of mortality improvements, , from the estimated coefficient . In particular, the ultimate rates of improvement between ages 0 and 65 are set equal to the average improvement at adolescent and adult ages (15–65); from age 65 onwards, improvements decrease following a logistic shape, and they converge to zero at age 130.
Second, we smooth the transition from to using the weight function proposed by Li et al. (2013). The transition, and therefore the degree of rotation of , is dependent on , the predicted value of life expectancy at birth (an input in our LL model). Formally, the weight function can be expressed as:
Because parameter is scaled in order to take values between 0 and 1 the ultimate pattern of mortality improvement by age will be the same for all countries. If the scaling process is ignored, the same pattern is obtained in all cases with a different level of between age 0 and 65. The estimated death rates would be the same in both case because of the adjustment provided by k parameter.
The power of the smooth-weight function, p, regulates the speed of the rotation. It varies between 0 and 1, and lower values correspond to faster rotations for levels of closer to 80. The level of life expectancy at which the rotation finishes, , is also arbitrary; here, we follow the recommendations of Li et al. (2013) and set the intermediate value of 0.5 for p and the age 102 for .
The rotated coefficient of mortality improvement over age, denoted , can thus be written as:
Figure A3.
Assumption of the change in pattern following the increase in life expectancy at birth from 75 to 102 years.
Figure A3.
Assumption of the change in pattern following the increase in life expectancy at birth from 75 to 102 years.

References
- Alho, Juha M. 2000. The Lee-Carter method for forecasting mortality, with various extensions and applications, Ronald Lee, January 2000. North American Actuarial Journal 4: 91–93. [Google Scholar] [CrossRef]
- Bengtsson, Tommy. 2006. Linear increase in life expectancy: Past and present. Perspective on Mortality Forecasting. III. The Linear Rise in Life Expectancy: History and Present 3: 83–99. [Google Scholar]
- Bongaarts, John. 2005. Long-range trends in adult mortality: Models and projection methods. Demography 42: 23–49. [Google Scholar] [CrossRef]
- Brass, William. 1971. On the scale of mortality. Biological Aspects of Demography 10: 69–110. [Google Scholar]
- Brass, William, Ansley J. Coale, Paul Demeny, Don F. Heisel, Frank Lorimer, Anatole Romaniuk, and Etienne Van De Walle. 1968. The Demography of Tropical Africa. Princeton: Princeton University Press. [Google Scholar]
- Brillinger, David R. 1986. A biometrics invited paper with discussion: The natural variability of vital rates and associated statistics. Biometrics 42: 693–734. [Google Scholar] [CrossRef]
- Brouhns, Natacha, Michel Denuit, and Jeroen K. Vermunt. 2002. A poisson log-bilinear regression approach to the construction of projected lifetables. Insurance: Mathematics and Economics 31: 373–93. [Google Scholar] [CrossRef] [Green Version]
- Cairns, Andrew J.G., David Blake, and Kevin Dowd. 2006. A two factor model for stochastic mortality with parameter uncertainty: Theory and calibration. Journal of Risk and Insurance 73: 687–718. [Google Scholar] [CrossRef]
- Christensen, Kaare, Gabriele Doblhammer, Roland Rau, and James W. Vaupel. 2009. Ageing populations: The challenges ahead. The lancet 374: 1196–208. [Google Scholar] [CrossRef] [Green Version]
- Coale, Ansley J., and Paul George Demeny. 1966. Regional Model Life Tables and Stable Populations. Princeton: Princeton University Press. [Google Scholar]
- Coale, Ansley J., Paul George Demeny, and Barbara Vaughan. 1983. Models of mortality and age composition. In Regional Model Life Tables and Stable Population, 2nd ed. New York: Academic Press, vol.193, pp. 3–7. [Google Scholar]
- Dan Pascariu, Marius, Valdimir Canudas-Romo, and W. James Vaupel. 2018. The double-gap life expectancy forecasting model. Insurance: Mathematics and Economics 78: 339–350. [Google Scholar] [CrossRef]
- Dickson, David C. M., Mary R. Hardy, and Howard R. Waters. 2013. Actuarial Mathematics for Life Contingent Risks. Cambridge: Cambridge University Press. [Google Scholar]
- Ediev, Dalkhat M. 2011. Robust backward population projections made possible. International Journal of Forecasting 27: 1241–47. [Google Scholar] [CrossRef]
- Gabriel, K. R., and Ilana Ronen. 1958. Estimates of mortality from infant mortality rates. Population Studies 12: 164–69. [Google Scholar] [CrossRef]
- Kannisto, Vaino, Jens Lauritsen, A. Roger Thatcher, and James W. Vaupel. 1994. Reductions in mortality at advanced ages: Several decades of evidence from 27 countries. Population and Development Review 20: 793–810. [Google Scholar] [CrossRef]
- Ledermann, S. 1969. Nouvelles Tables-Types de Mortalité. Travaux et documents—Institut national d’études démographiques. Paris: Presses Universitaires de France. [Google Scholar]
- Lee, Ronald D., and Lawrence R. Carter. 1992. Modeling and forecasting U.S. mortality. Journal of the American Statistical Association 87: 659–71. [Google Scholar] [CrossRef]
- Li, Nan, Ronald Lee, and Patrick Gerland. 2013. Extending the Lee-Carter method to model the rotation of age patterns of mortality decline for long-term projections. Demography 50: 2037–51. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mayhew, Les, and David Smith. 2013. A new method of projecting populations based on trends in life expectancy and survival. Population Studies 67: 157–70. [Google Scholar] [CrossRef] [Green Version]
- Møller, Thomas, and Mogens Steffensen. 2007. Market-Valuation Methods in Life and Pension Insurance. Cambridge: Cambridge University Press. [Google Scholar]
- Murray, Christopher J. L., Brodie D. Ferguson, Alan D. Lopez, Michel Guillot, Joshua A. Salomon, and Omar Ahmad. 2003. Modified logit life table system: Principles, empirical validation, and application. Population Studies 57: 165–82. [Google Scholar] [CrossRef]
- Oeppen, Jim, and James W. Vaupel. 2002. Broken limits to life expectancy. Science 296: 1029–31. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. 2019. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. [Google Scholar]
- Raftery, Adrian E., Nevena Lalic, and Patrick Gerland. 2014. Joint probabilistic projection of female and male life expectancy. Demographic Research 30: 795. [Google Scholar] [CrossRef] [Green Version]
- Rau, Roland, Eugeny Soroko, Domantas Jasilionis, and James W. Vaupel. 2008. Continued reductions in mortality at advanced ages. Population and Development Review 34: 747–68. [Google Scholar] [CrossRef]
- Ševčíková, Hana, Nan Li, Vladimíra Kantorová, Patrick Gerland, and Adrian E. Raftery. 2016. Age-specific mortality and fertility rates for probabilistic population projections. In Dynamic Demographic Analysis. Berlin and Heidelberg: Springer, pp. 285–310. [Google Scholar]
- Shkolnikov, Vladimir M., Dmitri A. Jdanov, Evgeny M. Andreev, and James W. Vaupel. 2011. Steep increase in best-practice cohort life expectancy. Population and Development Review 37: 419–34. [Google Scholar] [CrossRef]
- Stoeldraijer, Lenny, Coen van Duin, Leo van Wissen, and Fanny Janssen. 2013. Impact of different mortality forecasting methods and explicit assumptions on projected future life expectancy: The case of the netherlands. Demographic Research 29: 323–53. [Google Scholar] [CrossRef] [Green Version]
- Sullivan, Jeremiah M. 1972. Models for the estimation of the probability of dying between birth and exact ages of early childhood. Population Studies 26: 79–97. [Google Scholar] [CrossRef]
- Thatcher, A. Roger, Väinö Kannisto, and James W. Vaupel. 1998. The Force of Mortality at Ages 80 to 120. Odense: Odense University Press. [Google Scholar]
- Torri, Tiziana, and James W. Vaupel. 2012. Forecasting life expectancy in an international context. International Journal of Forecasting 28: 519–31. [Google Scholar] [CrossRef]
- United Nations. 1955. Age and Sex Patterns of Mortality: Model Life Tables for Under-Developed Countries; Population Studies, No. 22. New York: Department of Social Affairs.
- United Nations. 1967. Methods for Estimating Basic Demographic Measures from Incomplete Data: Manuals and Methods of Estimating Populations; Manual IV. Population Studies, No. 42. New York: Department of Social Affairs.
- United States Census Bureau. 2014. Methodology, Assumptions, and Inputs for the 2014 National Projections; Washington: Census Bureau.
- University of California Berkeley, USA and Max Planck Institute for Demographic Research, Germany. 2020. Human Mortality Database. 2020. Available online: https://www.mortality.org/ (accessed on 30 September 2020).
- Vaupel, James W. 1997. The remarkable improvements in survival at older ages. Philosophical Transactions of the Royal Society of London B: Biological Sciences 352: 1799–804. [Google Scholar] [CrossRef]
- Vaupel, James W., James R. Carey, Kaare Christensen, Thomas E. Johnson, Anatoli I. Yashin, Niels V. Holm, Ivan A. Iachine, Väinö Kannisto, Aziz A. Khazaeli, Pablo Liedo, and et al. 1998. Biodemographic trajectories of longevity. Science 280: 855–60. [Google Scholar] [CrossRef] [PubMed]
- White, Kevin M. 2002. Longevity advances in high-income countries, 1955–1996. Population and Development Review 28: 59–76. [Google Scholar] [CrossRef]
- Wilmoth, John, Sarah Zureick, Vladimir Canudas-Romo, Mie Inoue, and Cheryl Sawyer. 2012. A flexible two-dimensional mortality model for use in indirect estimation. Population Studies 66: 1–28. [Google Scholar] [CrossRef]
- Wilmoth, John R., K. Andreev, D. Jdanov, Dana A. Glei, C. Boe, M. Bubenheim, D. Philipov, V. Shkolnikov, and P. Vachon. 2007. Methods protocol for the human mortality database. University of California, Berkeley, and Max Planck Institute for Demographic Research, Rostock 9: 10–11. [Google Scholar]
- Wilmoth, John R., and Shiro Horiuchi. 1999. Rectangularization revisited: Variability of age at death within human populations. Demography 36: 475–95. [Google Scholar] [CrossRef]
Figure 1.
Linear relation between life expectancy at birth and death-rates on a log-log scale, by age displayed together with the Pearson correlation coefficient, in the bottom left end of the panels. Each panel contains data for a specific age. The axis are labelled in normal scale for better interpretability. Based on HMD mortality data starting from 1980 for 41 countries and territories.
Figure 1.
Linear relation between life expectancy at birth and death-rates on a log-log scale, by age displayed together with the Pearson correlation coefficient, in the bottom left end of the panels. Each panel contains data for a specific age. The axis are labelled in normal scale for better interpretability. Based on HMD mortality data starting from 1980 for 41 countries and territories.

Figure 2.
Linear relation between life expectancy at age 65 and death-rates on a log-log scale, by age displayed together with the Pearson correlation coefficient, in the bottom left end of the panels. Each panel contains data for a specific age. The axis are labelled in normal scale for better interpretability. Based on HMD mortality data starting from 1980 for 41 countries and territories.
Figure 2.
Linear relation between life expectancy at age 65 and death-rates on a log-log scale, by age displayed together with the Pearson correlation coefficient, in the bottom left end of the panels. Each panel contains data for a specific age. The axis are labelled in normal scale for better interpretability. Based on HMD mortality data starting from 1980 for 41 countries and territories.

Figure 3.
Estimated parameters of the Linear-link model, using HMD data from 1980 to 2018 and life expectancy at birth .
Figure 3.
Estimated parameters of the Linear-link model, using HMD data from 1980 to 2018 and life expectancy at birth .

Figure 4.
Observed and estimated death rates for female populations in 2018. Computed based on mortality data in the period 1965–1990.
Figure 4.
Observed and estimated death rates for female populations in 2018. Computed based on mortality data in the period 1965–1990.

Figure 5.
Mean absolute errors (%) of the estimated log-death rates against the actual log-death rates between 1991 and 2018. Computed based on female mortality data in the period 1965–1990.
Figure 5.
Mean absolute errors (%) of the estimated log-death rates against the actual log-death rates between 1991 and 2018. Computed based on female mortality data in the period 1965–1990.

Figure 6.
Relative errors (%) of the estimated log-death rates against the actual log-death rates between 1991 and 2018. Computed as (observed-estimated)/ observed log death rates. Based on female mortality data in the period 1965–1990.
Figure 6.
Relative errors (%) of the estimated log-death rates against the actual log-death rates between 1991 and 2018. Computed as (observed-estimated)/ observed log death rates. Based on female mortality data in the period 1965–1990.

Figure 7.
Comparison of the mortality curves predicted by Lee-Carter and Linear-Link models in 2040 from female populations. The models are fitted on the 1980–2018 historical period.
Figure 7.
Comparison of the mortality curves predicted by Lee-Carter and Linear-Link models in 2040 from female populations. The models are fitted on the 1980–2018 historical period.

| 1 | The change in age-specific death rates can be assumed to be constant over time, in which case the fitted is used in computing . Or, a shift in the speed of improvement can be imposed by “rotating” the coefficients. For more details see Section in the Appendix C. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Pascariu, M.D.; Basellini, U.; Aburto, J.M.; Canudas-Romo, V. The Linear Link: Deriving Age-Specific Death Rates from Life Expectancy. Risks 2020, 8, 109. https://0-doi-org.brum.beds.ac.uk/10.3390/risks8040109
AMA Style
Pascariu MD, Basellini U, Aburto JM, Canudas-Romo V. The Linear Link: Deriving Age-Specific Death Rates from Life Expectancy. Risks. 2020; 8(4):109. https://0-doi-org.brum.beds.ac.uk/10.3390/risks8040109
Chicago/Turabian StylePascariu, Marius D., Ugofilippo Basellini, José Manuel Aburto, and Vladimir Canudas-Romo. 2020. "The Linear Link: Deriving Age-Specific Death Rates from Life Expectancy" Risks 8, no. 4: 109. https://0-doi-org.brum.beds.ac.uk/10.3390/risks8040109
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.