
Risk Assessment for Personalized Health Insurance Based on Real-World Data

 ,
,  ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Data Collection
2.1. Real-World Data
2.1.1. Measurements and Reports
2.1.2. Introducing History
2.1.3. Composite Measurements
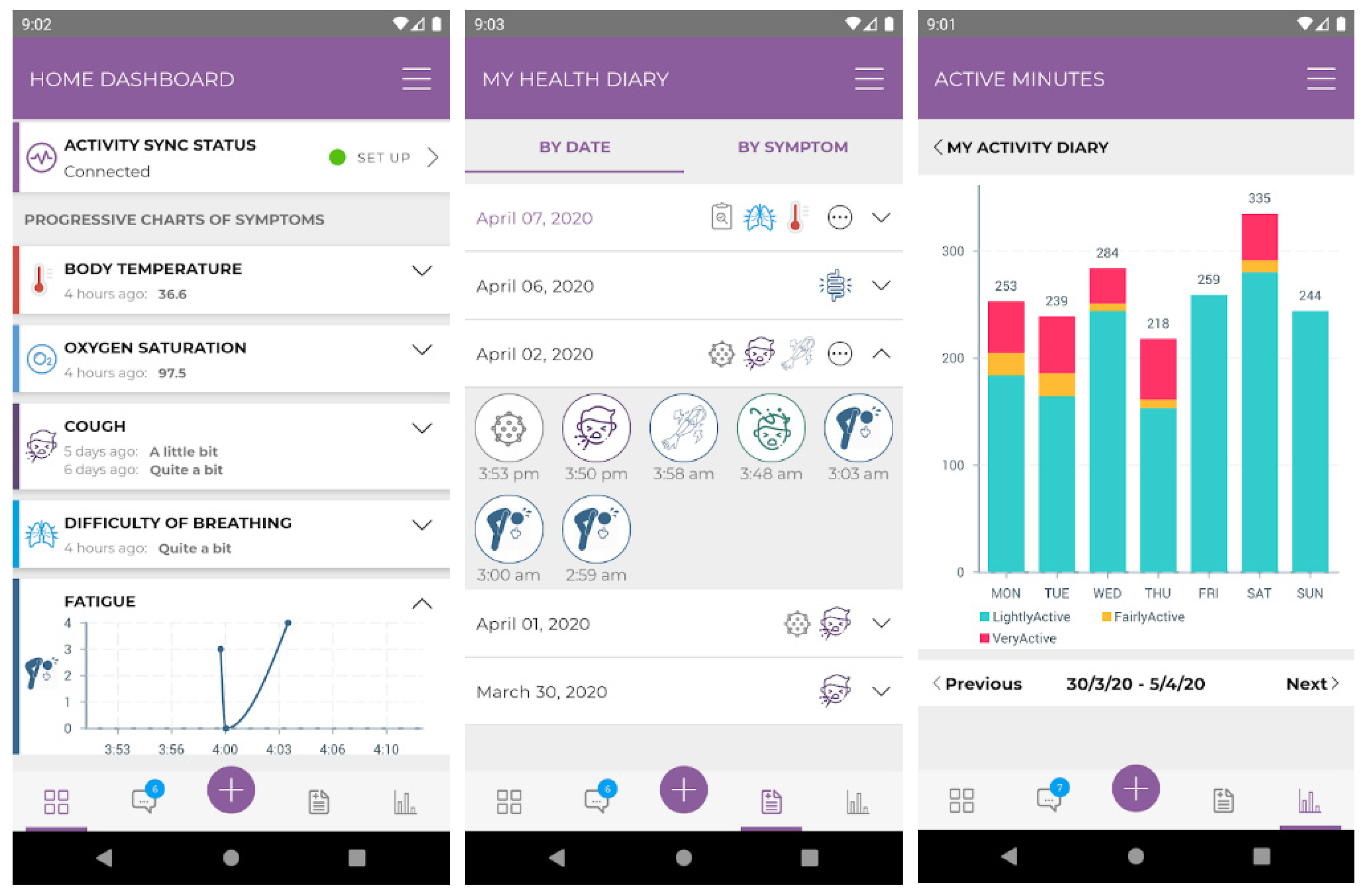
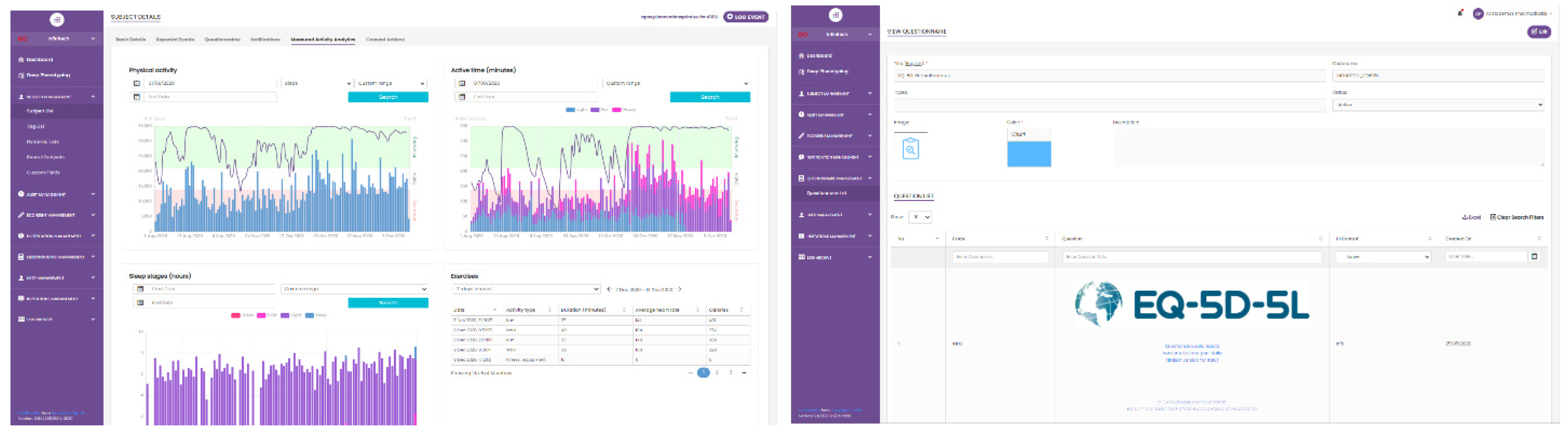
2.2. Healthentia
2.3. Synthetic RWD
3. Risk Assessment
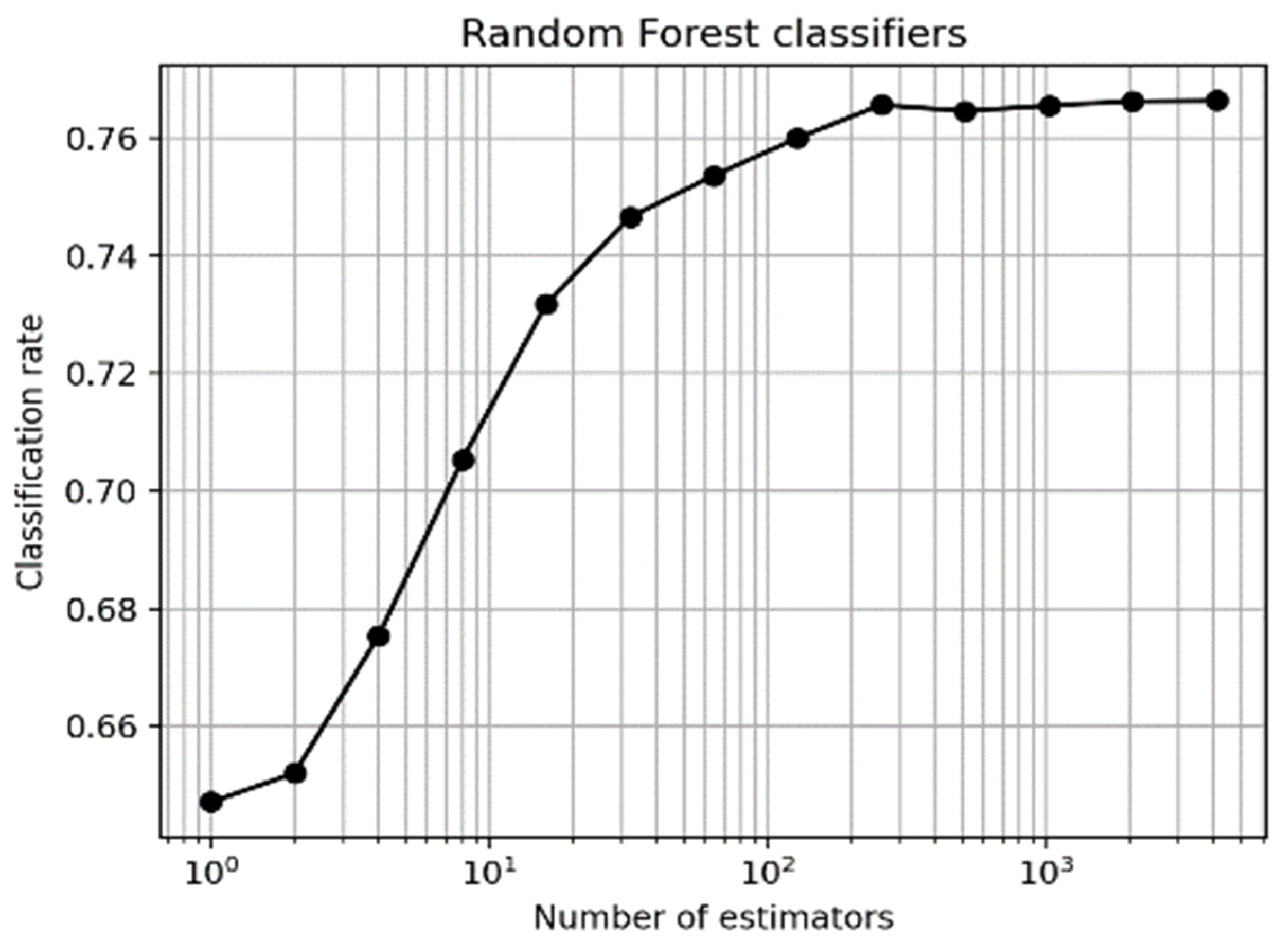
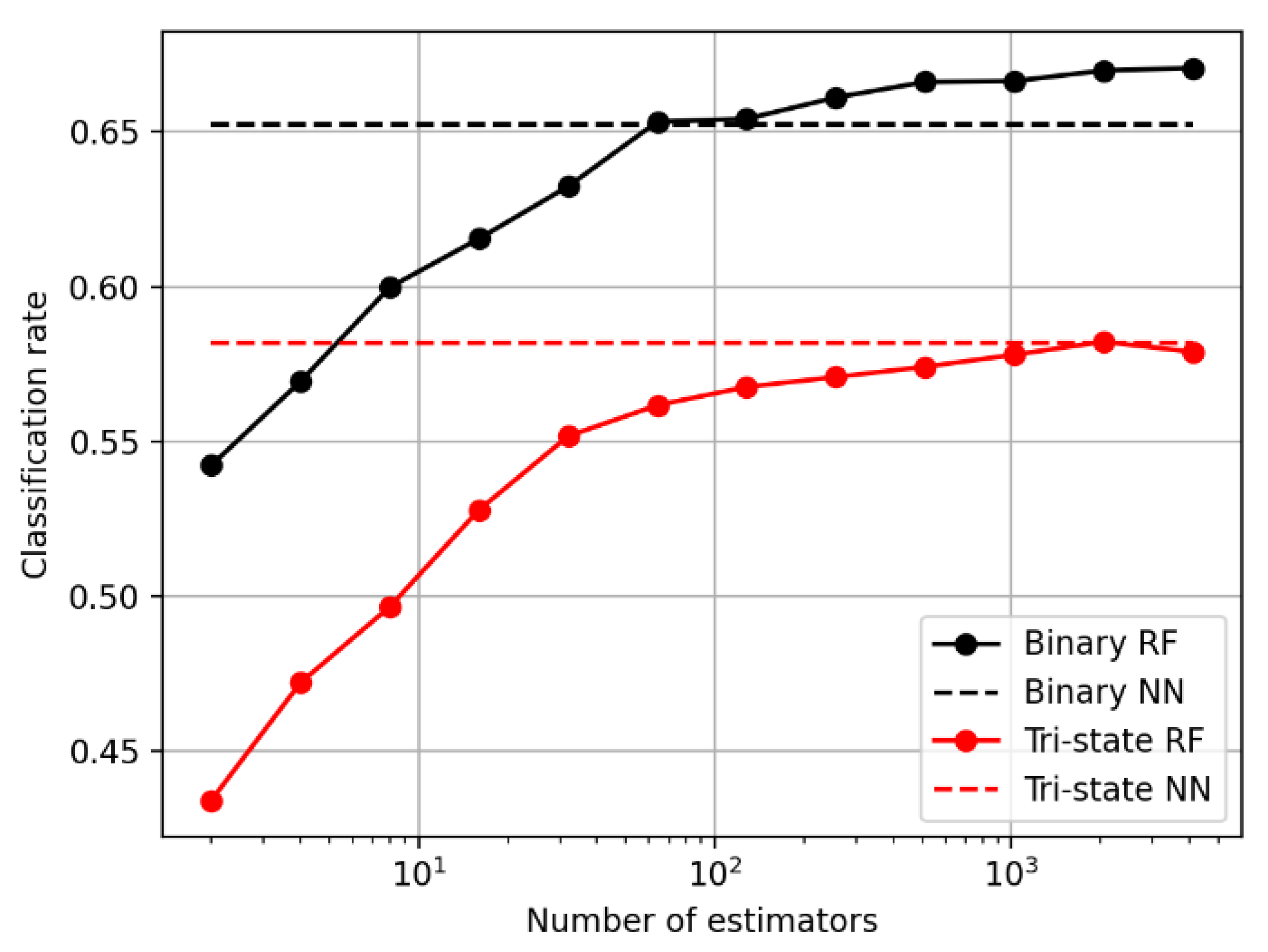
3.1. Classifiers for Short-Term Variation Prediction
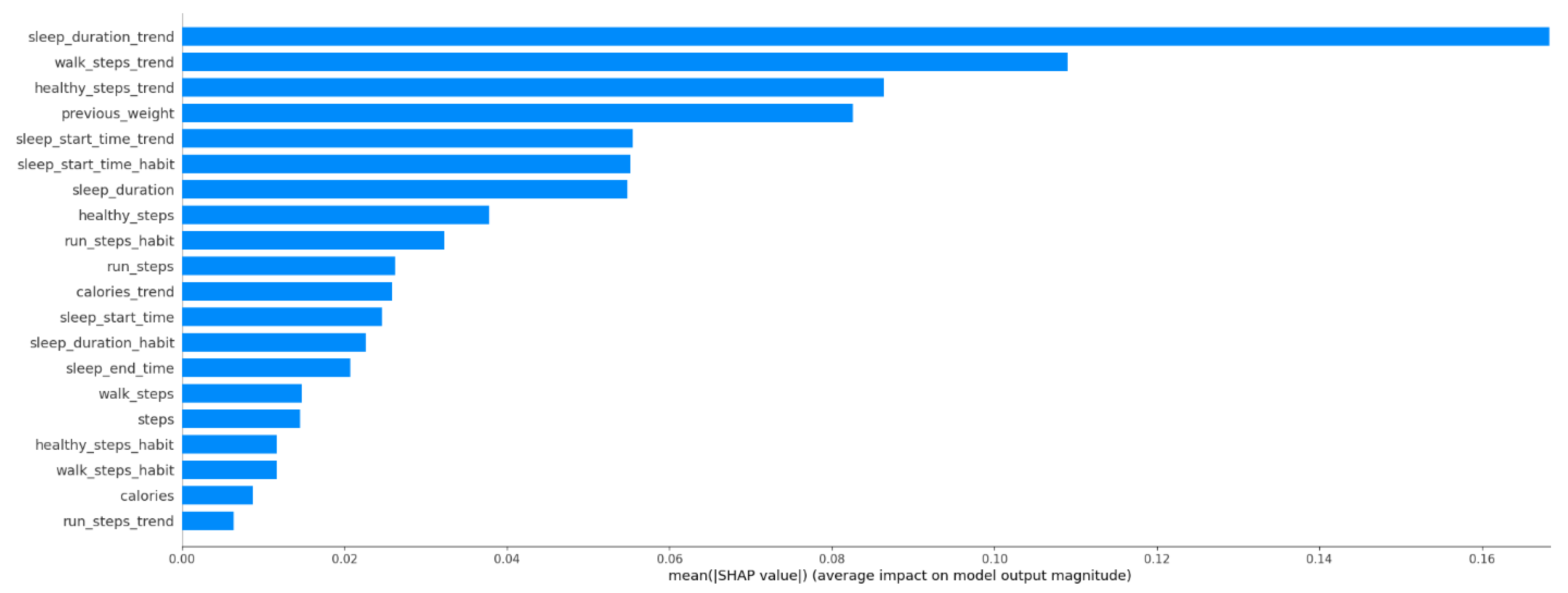
3.1.1. Predicting Weight Variation
3.1.2. Predicting Well-Being Variation
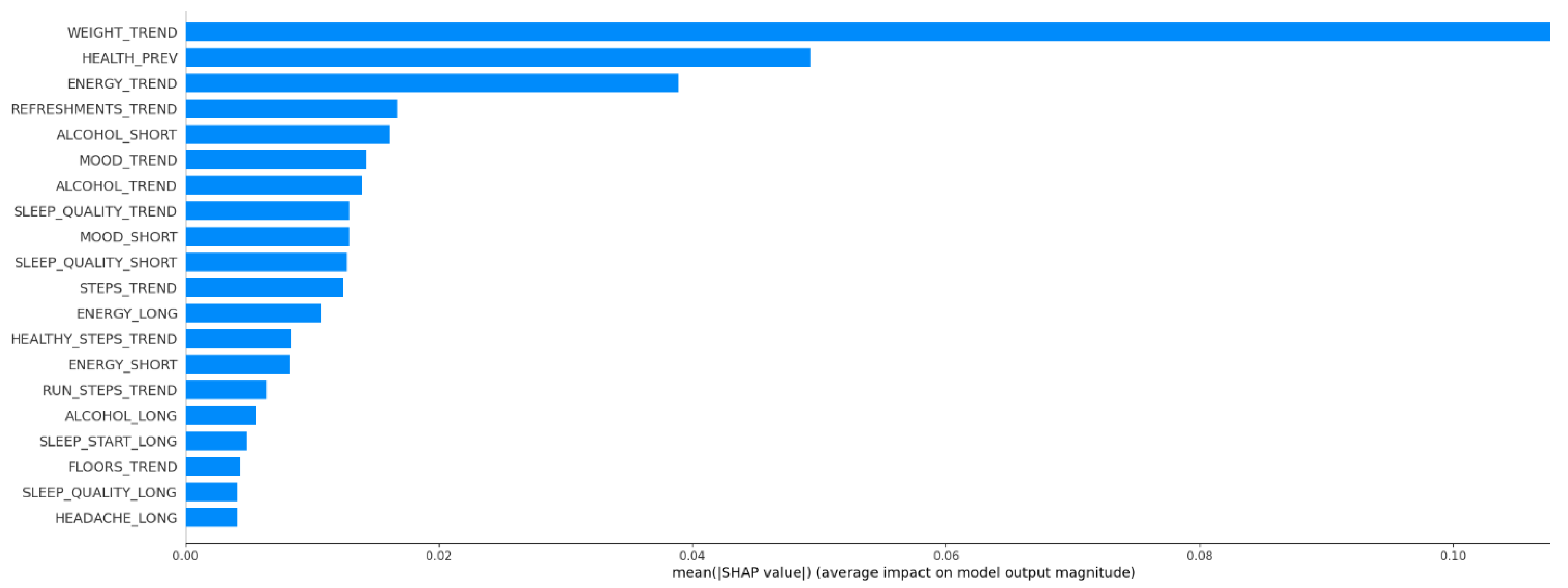
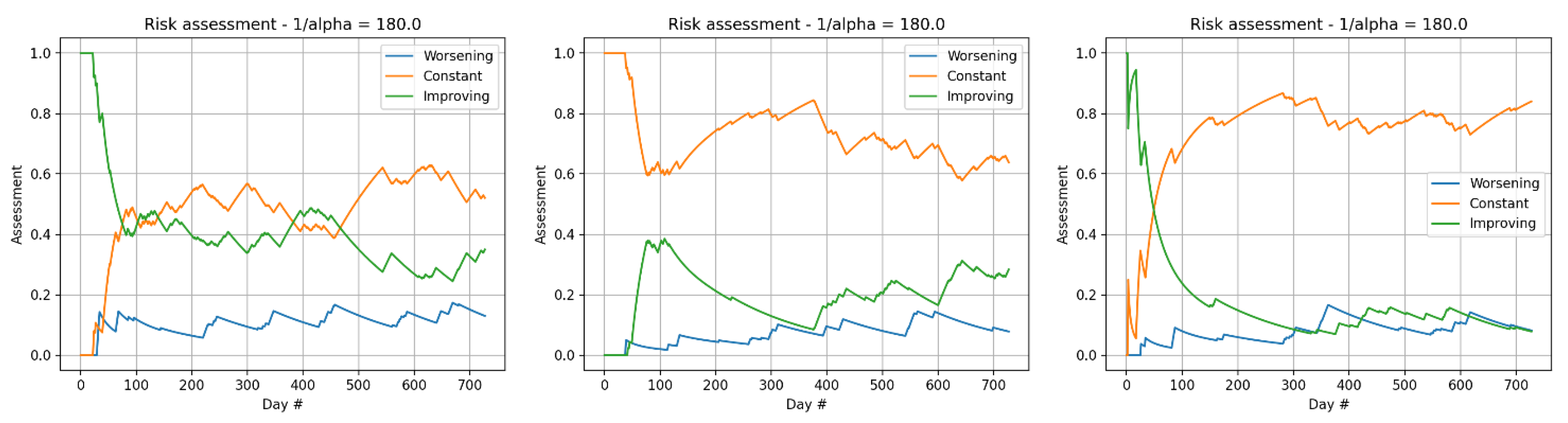
3.2. Risk Assessment from Health Predictors
3.3. Personalized Coaching
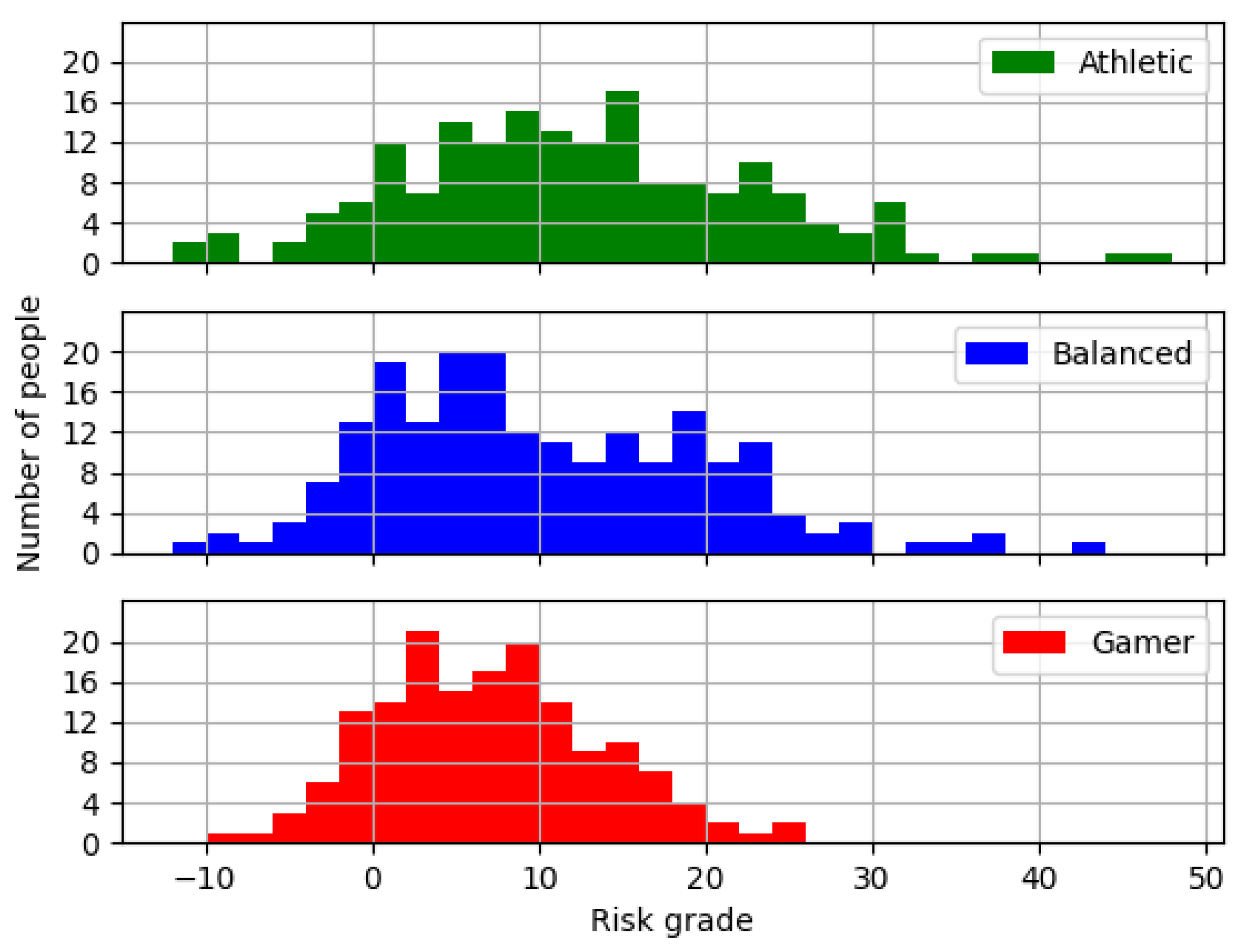
4. Personalized Insurance Products Pilot of INFINITECH
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Android Developers. 2019. Sensors Overview. Available online: https://developer.android.com/guide/topics/sensors/sensors_overview (accessed on 1 March 2021).
- Apple. 2020. HealthKit. Available online: https://developer.apple.com/health-fitness/ (accessed on 1 March 2021).
- Arumugam, Subramanian, and R. Bhargavi. 2019. A survey on driving behavior analysis in usage based insurance using big data. Journal of Big Data 6: 1–21. [Google Scholar] [CrossRef] [Green Version]
- Baudat, Gaston, and Fatiha Anouar. 2000. Generalized discriminant analysis using a kernel approach. Neural Computation 12: 2385–404. [Google Scholar] [CrossRef] [PubMed]
- Bermúdez, Lluís, Dimitris Karlis, and Isabel Morillo. 2020. Modelling Unobserved Heterogeneity in Claim Counts Using Finite Mixture Models. Risks 8: 10. [Google Scholar] [CrossRef] [Green Version]
- Bishop, Christopher M. 2006. Pattern Recognition and Machine Learning. New York: Springer. [Google Scholar]
- Blackmore, Peter. 2016a. Digital Risk Profiling Transforms Insurance. Available online: https://www.insurancethoughtleadership.com/digital-risk-profiling-transforms-insurance/ (accessed on 1 March 2021).
- Blackmore, Peter. 2016b. Easier Approach to Risk Profiling. Available online: https://www.insurancethoughtleadership.com/easier-approach-to-risk-profiling/ (accessed on 1 March 2021).
- Breiman, Leo. 2001. Random Forests. Machine Learning 45: 5–32. [Google Scholar] [CrossRef] [Green Version]
- Burri, Rama Devi, Ram Burri, Ramesh Reddy Bojja, and S. Buruga. 2019. Insurance Claim Analysis Using Machine Learning Algorithms. International Journal of Innovative Technology and Exploring Engineering 8: 147–55. [Google Scholar]
- Fitbit. 2020. Technology That’s Inventing the Future. Available online: https://www.fitbit.com/global/us/technology (accessed on 1 March 2021).
- Gage, Thomas, Richard Bishop, and Jonathan Morris. 2015. The Increasing Importance of Vehicle-Based Risk Assessment for the Vehicle Insurance Industry. Minnesota Journal of Law, Science & Technology 16: 771. [Google Scholar]
- Garmin. 2020. Technology. Available online: https://www.garmin.com/en-US/garmin-technology/ (accessed on 1 March 2021).
- Garrow, John S., and Joan Webster. 1985. Quetelet’s index (W/H2) as a measure of fatness. International Journal of Obesity 9: 147–53. [Google Scholar]
- Grey, Margaret. 2017. Lifestyle Determinants of Health: Isn’t it all about genes and environment? Nursing Outlook 65: 501–15. [Google Scholar] [CrossRef]
- Guthrie, Nicole L., Jason Carpenter, Katherine L. Edwards, Kevin J. Appelbaum, Sourav Dey, David M. Eisenberg, David L. Katz, and Mark A. Berman. 2019. Emergence of digital biomarkers to predict and modify treatment efficacy: Machine learning study. BMJ Open 9: e030710. [Google Scholar] [CrossRef] [Green Version]
- Infinitech H2020. 2020. Infinitech HInfinitech—The Flagship Project for Digital Finance in Europe. Available online: https://www.infinitech-h2020.eu/ (accessed on 1 March 2021).
- Innovation Sprint. 2020. Healthentia: Driving Real World Evidence in Research & Patient Care. Available online: https://innovationsprint.eu/healthentia (accessed on 1 March 2021).
- Joseph-Shehu, Elizabeth M., Busisiwe P. Ncama, and Omolola O. Irinoye. 2019. Health-promoting lifestyle behaviour: A determinant for noncommunicable diseases risk factors among employees in a Nigerian University. Global Journal of Health Science 11: 1–15. [Google Scholar] [CrossRef]
- Lansbury, Lynn N., Helen Clare Roberts, Esther Clift, Annie Herklots, Nicola Robinson, and Avan A. Sayer. 2017. Use of the electronic Frailty Index to identify vulnerable patients: A pilot study in primary care. British Journal of General Practice 67: e751–e756. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lundberg, Scott, and Su-In Lee. 2017a. A Unified Approach to Interpreting Model Predictions. Paper presented at Advances in Neural Information Processing Systems (NIPS2017), Long Beach, CA, USA, December 4–9. [Google Scholar]
- Lundberg, Scott M., and Su-In Lee. 2017b. Consistent feature attribution for tree ensembles. arXiv arXiv:1706.06060. [Google Scholar]
- Lundberg, Scott M., Gabriel Erion, Hugh Chen, Alex DeGrave, Jordan M. Prutkin, Bala Nair, Ronit Katz, Jonathan Himmelfarb, Nisha Bansal, and Su-In Lee. 2020. From local explanations to global understanding with explainable AI for trees. Nature Machine Intelligence 2: 56–67. [Google Scholar] [CrossRef]
- Moghaddam, Baback. 2002. Principal manifolds and probabilistic subspaces for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 24: 780–88. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, M. J., R. Marçôa, J. Moutinho, P. Oliveira, I. Ladeira, R. Lima, and M. Guimarães. 2019. Reference equations for the 6-min walk distance in healthy Portuguese subjects 18–70 years old. Pulmonology Journal 25: 83–89. [Google Scholar] [CrossRef]
- Pnevmatikakis, Aristodemos, and Lazaros Polymenakos. 2009. Subclass Linear Discriminant Analysis for Video-Based Face Recognition. Journal of Visual Communication and Image Representation 20: 543–51. [Google Scholar] [CrossRef]
- Qazvini, Marjan. 2019. On the validation of claims with excess zeros in liability insurance: A comparative study. Risks 7: 71. [Google Scholar] [CrossRef] [Green Version]
- Revicki, Dennis A., David Osoba, Diane Fairclough, Ivan Barofsky, Rick Berzon, N. K. Leidy, and Margaret Rothman. 2000. Recommendations on health-realted quality of life research to support labeling and promotional claims in the United States. Quality of Life Research 9: 887–900. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, Jürgen. 2015. Deep Learning in Neural Networks: An Overview. Neural Networks 61: 85–117. [Google Scholar] [CrossRef] [Green Version]
- Stanaway, Jeffrey D., Ashkan Afshin, Emmanuela Gakidou, Stephen S. Lim, Degu Abate, Kalkidan Hassen Abate, Cristiana Abbafati, Nooshin Abbasi, Hedayat Abbastabar, Foad Abd-Allah, and et al. 2018. Global, regional, and national comparative risk assessment of 84 behavioural, environmental and occupational, and metabolic risks or clusters of risks for 195 countries and territories, 1990–2017: A systematic analysis for the Global Burden of Disease Study 2017. Global Health Metrics 392: 1923–94. [Google Scholar]
- Stolk, Elly, Kristina Ludwig, Kim Rand, Ben van Hout, and Juan Manuel Ramos-Goñi. 2019. Overview, Update, and Lessons Learned from the International EQ-5D-5L Valuation Work: Version 2 of the EQ-5D-5L Valuation Protocol. Value in Health 22: 23–30. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Theodoridis, S., and K. Koutroumbas. 2008. Pattern Recognition, 4th ed. Orlando: Academic Press, Inc. [Google Scholar]
- US Food and Drug Administration. 2009. Patient-Reported Outcome Measures: Use in Medical Products Development to Support Labelling Claims. FDA Guidance Document UCM193282. Available online: https://www.fda.gov/media/77832/download (accessed on 1 March 2021).
- US Food and Drug Administration. 2017. Use of Real-World Evidence to Support Regulatory Decision-Making for Medical Devices: Guidance for Industry and Food and Drug Administration Staff. Available online: https://www.fda.gov/downloads/medicaldevices/deviceregulationandguidance/guidancedocuments/ucm513027.pdf (accessed on 1 March 2021).
- Weidner, Wiltrud, Fabian W. G. Transchel, and Robert Weidner. 2017. Telematic driving profile classification in car insurance pricing. Annals of Actuarial Science 11: 213–36. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Manli, and Aleix M. Martinez. 2006. Subclass discriminant analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence 28: 1274–86. [Google Scholar] [PubMed] [Green Version]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pnevmatikakis, A.; Kanavos, S.; Matikas, G.; Kostopoulou, K.; Cesario, A.; Kyriazakos, S. Risk Assessment for Personalized Health Insurance Based on Real-World Data. Risks 2021, 9, 46. https://0-doi-org.brum.beds.ac.uk/10.3390/risks9030046
Pnevmatikakis A, Kanavos S, Matikas G, Kostopoulou K, Cesario A, Kyriazakos S. Risk Assessment for Personalized Health Insurance Based on Real-World Data. Risks. 2021; 9(3):46. https://0-doi-org.brum.beds.ac.uk/10.3390/risks9030046
Chicago/Turabian StylePnevmatikakis, Aristodemos, Stathis Kanavos, George Matikas, Konstantina Kostopoulou, Alfredo Cesario, and Sofoklis Kyriazakos. 2021. "Risk Assessment for Personalized Health Insurance Based on Real-World Data" Risks 9, no. 3: 46. https://0-doi-org.brum.beds.ac.uk/10.3390/risks9030046