
Assessing Human Post-Editing Efforts to Compare the Performance of Three Machine Translation Engines for English to Russian Translation of Cochrane Plain Language Health Information: Results of a Randomised Comparison

 ,
,  and
and
Abstract
:1. Introduction
1.1. Cochrane and Its Multilanguage Activities
1.2. Machine Translation and Health Information
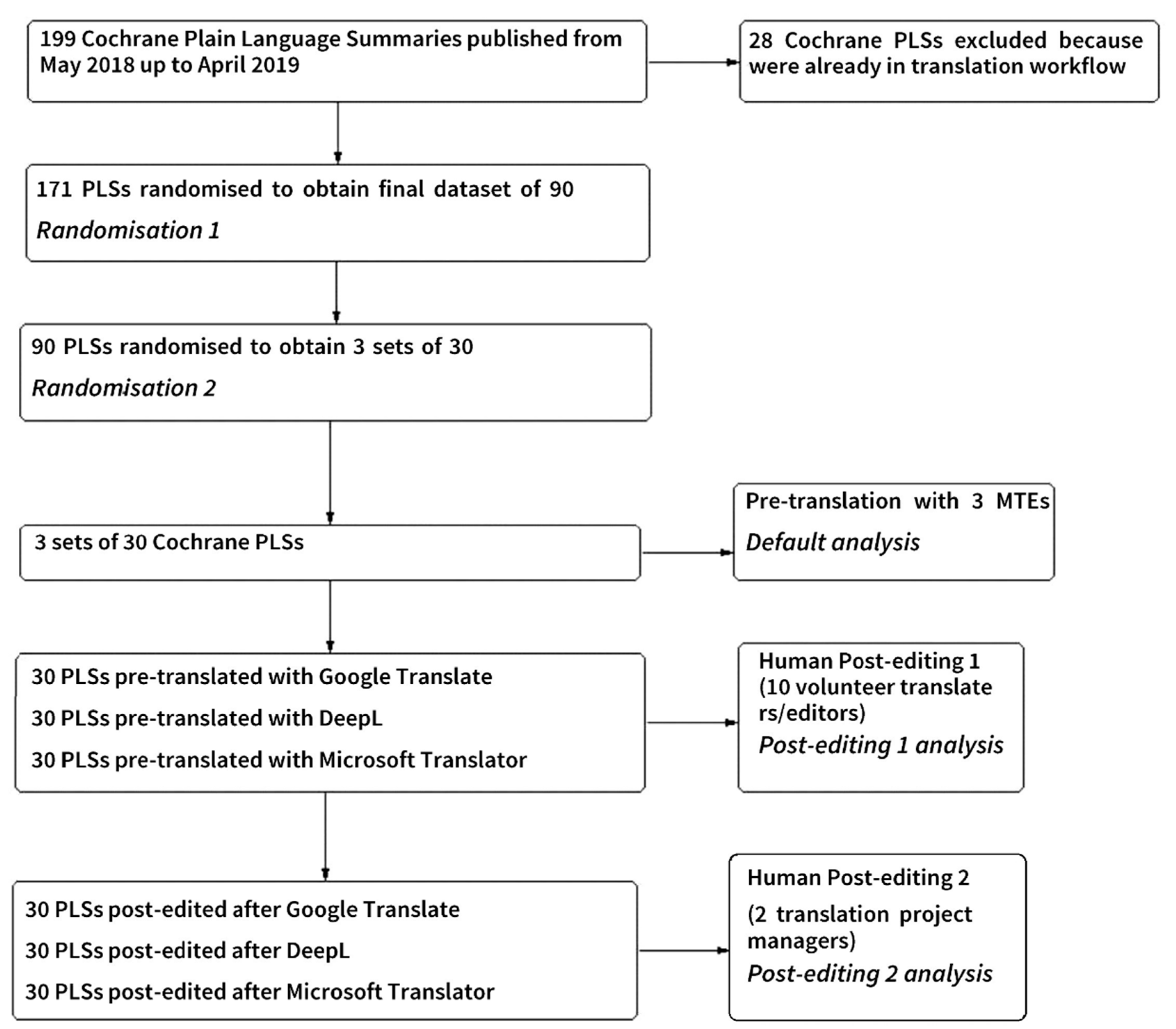
2. Materials and Methods
2.1. Preparation and Protocol Development
2.2. Memsource Features
2.3. MTE for Comparison
2.4. Principle Approach of the Study and Evaluation Method
2.5. Description of the Dataset, Selection and Randomization of Plain Language Summaries (PLSs)
2.6. Participants
2.7. Analyses and Steps of the Study
- Default analysis, to obtain MTQE-automated estimates of post-editing effort following pre-translation;
- Post-editing 1, to obtain calculations of the amount of post-edited text following the first editing step; and
- Post-editing 2, to obtain calculations of the amount of post-edited text in total following the second editing step (including any edits made in the first editing step).
2.7.1. Default Analysis
- We generated the Default analysis in Memsource for all 90 PLSs to obtain the MTQE figures estimating the editing effort of the initial MT output.
- We randomized the PLSs into smaller sets for 10 post-editors: 3 PLSs per MTE for each post-editor, or 9 PLSs per post-editor in total.
- We assigned PLSs to the 10 post-editors according to randomization, and we aimed to “blind” the post-editors: we did not inform participants which MTE was used to pre-translate each PLS to avoid potential bias. However, they could have found this information in Memsource if they had looked for it; we were not able to reliably conceal that information from the post-editors.
2.7.2. Post-Editing 1 Analysis
2.7.3. Post-Editing 2 Analysis
- We randomized all 90 PLSs anew, into two sets of 45 PLSs, for two final editors.
- 2 translation project managers performed a second and final round of post-editing of all 90 PLSs.
3. Results
3.1. Default Analysis
- The 100% percentage range represents the highest possible quality estimate, and suggests that text in this range may require no editing. The MTE with the highest percentage of text in this range is perhaps the best.
- The 95–99% percentage range indicates very high-quality estimates, and suggests that text in this range may require only minor editing—perhaps only 1–5% of the text. The MTE with the highest percentage of text in this range is perhaps the best.
- The 85–94% percentage range presents texts with fairly high-quality estimates that require some editing; 6–15% of the text may need editing.
- The 75–84% percentage range indicates good- or moderate-quality estimates that require between 16–25% of text to be edited—or up to a quarter of the text.
- The 50–74% percentage range includes text with poor-quality estimates, indicating that 26–50% of the text may need editing—or up to half of the text. The MTE with the highest percentage of text in this range is perhaps the worst.
- The 0–49% percentage range represents low-quality estimates that require substantial editing; 51–100% of the text may require editing—up to the entire text. The MTE with the highest percentage of text in this range is perhaps the worst.
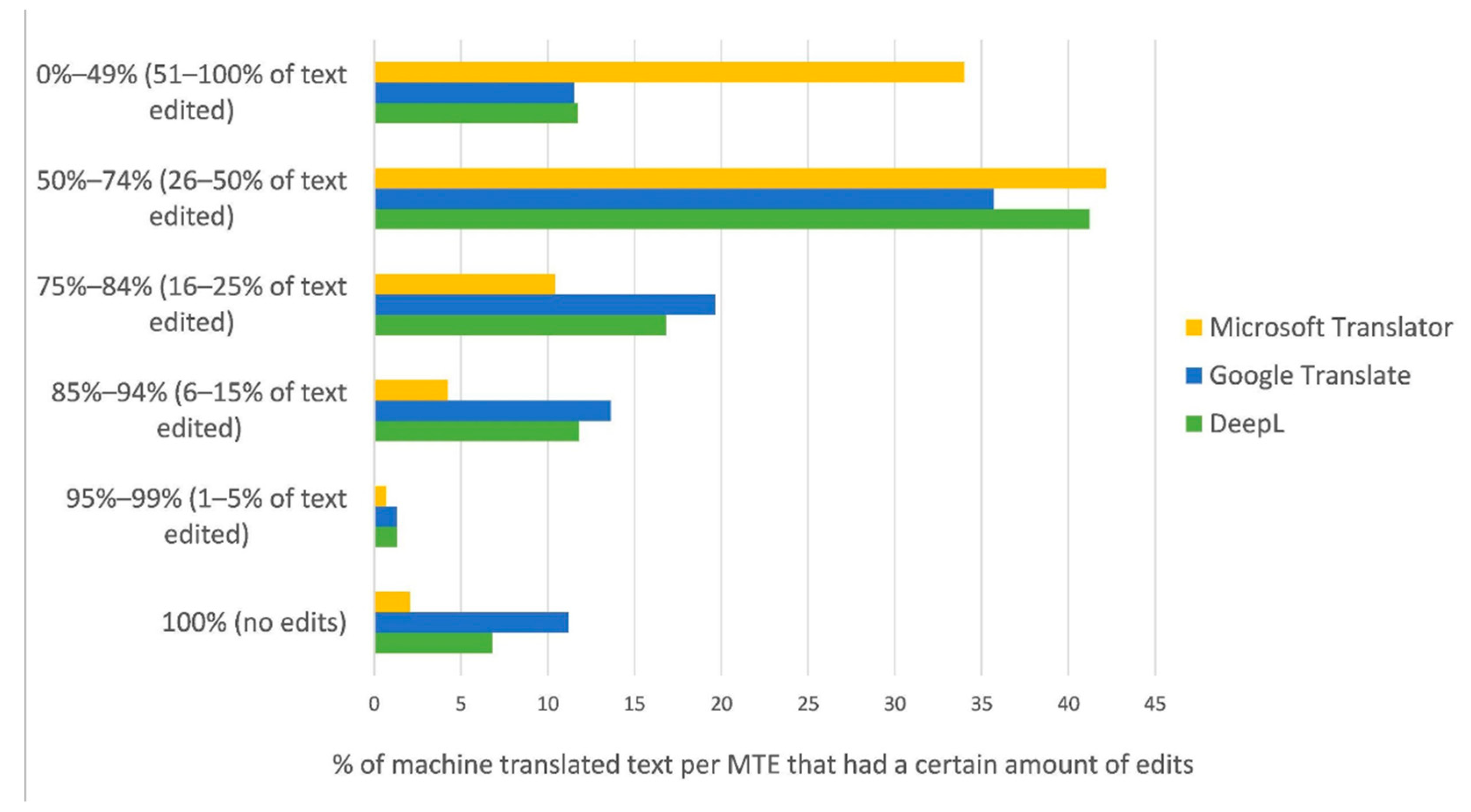
3.2. Post-Editing 1 Analysis
- The 100% percentage range indicates that no edits were made to the text. The MTE with the highest percentage of text in this range is presumably the best.
- The 95–99% percentage range means that hardly any edits were made by human post-editors; only 1–5% of the text was edited. The MTE with the highest percentage of text in this range is perhaps the best.
- The 85–94% percentage range indicates that between 6–15% of the text was edited.
- The 75%–84% percentage range means that between 16–25% of the text was edited—or up to a quarter of the text.
- The 50–74% percentage range indicates that between 26–50% of the text was edited—or up to a quarter of the text. The MTE with the highest percentage of text in this range is perhaps the worst.
- The 0–49% percentage range means that between 51–100% of the text was edited—or up to the entire text. The MTE with the highest percentage of text in this range is probably the worst.
3.3. Post-Editing 2 Analysis
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Useem, J.; Brennan, A.; LaValley, M.; Vickery, M.; Ameli, O.; Reinen, N.; Gill, C.J. Systematic Differences between Cochrane and Non-Cochrane Meta-Analyses on the Same Topic: A Matched Pair Analysis. PLoS ONE 2015, 10, e0144980. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koletsi, D.; Fleming, P.S.; Michelaki, I.; Pandis, N. Heterogeneity in Cochrane and non-Cochrane meta-analyses in orthodontics. J. Dent. 2018, 74, 90–94. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- von Elm, E.; Ravaud, P.; Maclehose, H.; Mbuagbaw, L.; Garner, P.; Ried, J.; Bonfill, X. Translating Cochrane reviews to ensure that healthcare decision-making is informed by high-quality research evidence. PLoS Med. 2013, 10, e1001516. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ziganshina, L.E.; Jørgensen, K.J.; Kazan, C. The first ever Cochrane event in Russia and Russian speaking countries—Cochrane Russia Launch—Evidence-based medicine: Achievements and barriers (QiQUM 2015) International Conference, Kazan, 7–8 December 2015. Int. J. Risk Saf. Med. 2016, 28, 221–226. [Google Scholar] [CrossRef] [PubMed]
- Stix, G. The elusive goal of machine translation. Sci. Am. 2006, 294, 92–95. [Google Scholar] [CrossRef] [PubMed]
- Zulfiqar, S.; Wahab, M.F.; Sarwar, M.I.; Lieberwirth, I. Is Machine Translation a Reliable Tool for Reading German Scientific Databases and Research Articles? J. Chem. Inf. Model. 2018, 58, 2214–2223. [Google Scholar] [CrossRef] [PubMed]
- Wołk, K.; Marasek, K.; Glinkowski, W. Telemedicine as a special case of machine translation. Comput. Med. Imaging Graph. 2015, 46 Pt 2, 249–256. [Google Scholar] [CrossRef] [Green Version]
- Dew, K.N.; Turner, A.M.; Choi, Y.K.; Bosold, A.; Kirchhoff, K. Development of machine translation technology for assisting health communication: A systematic review. J. Biomed. Inform. 2018, 85, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Dew, K.; Turner, A.M.; Desai, L.; Martin, N.; Laurenzi, A.; Kirchhoff, K. PHAST: A Collaborative Machine Translation and Post-Editing Tool for Public Health. AMIA Annu. Symp. Proc. 2015, 2015, 492–501. [Google Scholar] [PubMed]
- Soto, X.; Perez-de-Viñaspre, O.; Labaka, G.; Oronoz, M. Neural machine translation of clinical texts between long distance languages. J. Am. Med. Inform. Assoc. 2019, 26, 1478–1487. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.; Xia, F.; Deleger, L.; Solti, I. Statistical machine translation for biomedical text: Are we there yet? AMIA Annu. Symp. Proc. 2011, 2011, 1290–1299. [Google Scholar] [PubMed]
- Health in My Language. 2020. Available online: http://www.himl.eu/ (accessed on 31 January 2021).
- Martikainen, H. Post-Editing Neural MT in Medical LSP: Lexico-Grammatical Patterns and Distortion in the Communication of Specialized Knowledge. Informatics 2019, 6, 26. [Google Scholar] [CrossRef] [Green Version]
- Das, P.; Kuznetsova, A.; Zhu, M.; Milanaik, R. Dangers of Machine Translation: The Need for Professionally Translated Anticipatory Guidance Resources for Limited English Proficiency Caregivers. Clin. Pediatr. 2019, 58, 247–249. [Google Scholar] [CrossRef] [PubMed]
- Lund, H.; Juhl, C.B.; Nørgaard, B.; Draborg, E.; Henriksen, M.; Andreasen, J.; Christensen, R.; Nasser, M.; Ciliska, D.; Tugwell, P.; et al. Using an evidence-based research approach to place your results into context after the study is performed to ensure usefulness of the conclusion. J. Clin. Epidemiol. 2020, 129, 167–171. [Google Scholar] [CrossRef] [PubMed]
- Lund, H.; Juhl, C.B.; Nørgaard, B.; Draborg, E.; Henriksen, M.; Andreasen, J.; Christensen, R.; Nasser, M.; Ciliska, D.; Clarke, M.; et al. Using an evidence-based research approach before a new study is conducted to ensure value. J. Clin. Epidemiol. 2020, 129, 158–166. [Google Scholar] [CrossRef] [PubMed]
- Lund, H.; Juhl, C. Doing meaningful systematic reviews is no gravy train. Lancet 2020, 395, 1905. [Google Scholar] [CrossRef]
- Lund, H.; Brunnhuber, K.; Juhl, C.; Robinson, K.; Leenaars, M.; Dorch, B.F.; Jamtvedt, G.; Nortvedt, M.W.; Christensen, R.; Chalmers, I. Towards evidence based research. BMJ 2016, 355, i5440. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Memsource. Machine Translation Quality Estimation. Memsource Help Center. 2020. Available online: https://help.memsource.com/hc/en-us/articles/360012527380 (accessed on 31 January 2021).
- Memsource. Analysis Overview. Memsource Help Center. 2020. Available online: https://help.memsource.com/hc/en-us/articles/360013675760 (accessed on 31 January 2021).
- Wikipedia. “DeepL Translator”. 2021. Available online: https://en.wikipedia.org/wiki/DeepL_Translator (accessed on 31 January 2021).
- Wikipedia. Google Neural Machine Translation. 2021. Available online: https://en.wikipedia.org/wiki/Google_Neural_Machine_Translation (accessed on 31 January 2021).
- Wikipedia. Microsoft Translator. 2021. Available online: https://en.wikipedia.org/wiki/Microsoft_Translator (accessed on 31 January 2021).
- TAUS. Automated MT Evaluation Metrics. 2021. Available online: https://blog.taus.net/knowledgehub/automated-mt-evaluation-metrics (accessed on 31 January 2021).
- Jelicic Kadic, A.; Fidahic, M.; Vujcic, M.; Saric, F.; Propadalo, I.; Marelja, I.; Dosenovic, S.; Puljak, L. Cochrane plain language summaries are highly heterogeneous with low adherence to the standards. BMC Med. Res. Methodol. 2016, 16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- DeepL. DeepL Pro—Terms and Conditions. 2021. Available online: https://www.deepl.com/en/pro-license/ (accessed on 31 January 2021).



{kind=link}
{kind=link}
| Measure (Rounded Values) | DeepL | Google Translate | Microsoft Translator |
|---|---|---|---|
| Median (Q1/Q3) | 433 (365/546) | 455 (389/574) | 523 (402/594) |
| Mean (SD) | 450 (±134) | 484 (±123) | 510 (±123) |
| MTQE Range | DeepL | Google Translate | Microsoft Translator | |
|---|---|---|---|---|
| % of MT or TM text in each range 1 | % of MT or TM text in each range 1 | % of MT or TM text in each range 1 | ||
| All | 100 (100 [100–100]) | 100 (100 [100–100]) | 100 (100 [100–100]) | |
| Repetitions | 1.18 (0 [0–2.3]) | 0.75 (0 [0–1.15]) | 0.33 (0 [0–0]) | |
| 101% TM | 0.67 (0 [0–0]) | 0 (0 [0–0]) | 0 (0 [0–0]) | |
| 100% (no edits expected) | TM | 4.66 (3.10 [2.2–6.1]) | 4.17 (2.65 [1.9–3.3]) | 3.47 (3.25 [2.1–4.1]) |
| NT | 0 (0 [0–0]) | 0 (0 [0–0]) | 0 (0 [0–0]) | |
| MT | 0.03 (0 [0–0]) | 0.09 (0 [0–0]) | 0.01 (0 [0–0]) | |
| 95–99% (1–5% of text to be edited) | TM | 1.19 (0 [0–0.5]) | 0.73 (0 [0–1.3]) | 1.10 (0 [0–1.1]) |
| NT | 0.03 (0 [0–0]) | 0.03 (0 [0–0]) | 0 (0 [0–0]) | |
| MT | 0 (0 [0–0]) | 0 (0 [0–0]) | 0 (0 [0–0]) | |
| 85–94% (6–15% of text to be edited) | TM | 0 (0 [0–2]) | 0 (0 [0–1.5]) | 0 (0 [0–0]) |
| MT | 0 (0 [0–0]) | 0 (0 [0–0]) | 0 (0 [0–0]) | |
| 75–84% (16–25% of text to be edited) | TM | 1.94 (0 [0–3]) | 2.18 (0.35 [0.0–3.9]) | 1.31 (0 [0–1.7]) |
| MT | 35.70 (35.95 [26.1–44.1]) | 37.92 (39.5 [24.2–54.2]) | 33.37 (31.65 [21.7–43.5]) | |
| 50–74% (26–50% of text to be edited) | MT | 6.04 (3.55 [1.1–7.3]) | 4.00 (3.4 [0.8–6.8]) | 4.78 (2.7 [0.8–7.9]) |
| 0–49% (51–100% of text to be edited) | MT | 47.00 (48.15 [37.3–59.3]) | 48.87 (48.15 [36.2–59.5]) | 54.82 (55.15 [44.8–64.2]) |
| Percentage Range of Edits | DeepL | Google Translate | Microsoft Translator | ||||||
|---|---|---|---|---|---|---|---|---|---|
| % of MT or TM text in each range of edits 1 | % of MT or TM text in each range of edits 1 | % of MT or TM text in each range of edits 1 | |||||||
| TM | MT | All | TM | MT | All | TM | MT | All | |
| All | 9.22 (6.35 [4.4–11.1]) | 90.78 (93.65 [88.9–95.6]) | 100 (100 [100–100]) | 6.46 (4.9 [3.9–7.6]) | 93.54 (95.1 [92.4–96.1]) | 100 (100 [100–100]) | 6.16 (5.6 [3.9–7.6]) | 93.84 (94.35 [92.4–96.1]) | 100 (100 [100–100]) |
| Repetitions | 1.18 (0 [0.0–2.3]) | - | 1.18 (0 [0.0–2.3]) | 0.75 (0 [0.0–1.5]) | - | 0.75 (0 [0.0–1.5]) | 0.31 (0 [0–0]) | - | 0.31 (0 [0–0]) |
| 100% (no edits) | 4.49 (2.9 [2.3–5.6]) | 12.95 (11.65 [5.1–18.1]) # | 17.44 (14.35 [10.5–26.5]) # | 3.25 (2.3 [1.7–3.0]) | 17.82 (15.2 [4.1–28.7]) # | 21.08 (18.35 [6.0–31.2]) # | 3.2 (3.25 [2.1–4.2]) | 4.73 (3.4 [0.6–6.6]) # | 7.93 (6.9 [4.7–10.4] # |
| 95–99% (1–5% of text edited) | 0.27 (0 [0–0]) | 2.64 (0 [0–0]) | 2.91 (0 [0.0–3.4]) | 0.12 (0 [0–0]) | 2.96 (0 [0.0-6.6]) | 3.08 (0 [0.0–6.6]) | 0 (0 [0–0]) | 1.12 (0 [0.0–2.2]) | 1.12 (0 [0.0–2.2]) |
| 85–94% (6–15% of text edited) | 0.52 (0 [0–0]) | 16.82 (14.5 [8.9–25.9]) # | 17.33 (15.05 [8.9–25.9]) # | 0.44 (0 [0–0]) | 20.98 (20.05 [7.2–30.2]) # | 21.43 (20.45 [10.5–30.2]) # | 0.02 (0 [0–0]) | 6.19 (6.5 [0.0–10.5]) # | 6.20 (6.5 [0.0–10.5]) # |
| 75–84% (16–25% of text edited) | 0.76 (0 [0.0–0.7]) | 16.08 (16.3 [7.0–20.3]) | 16.83 (16.55 [7.0–23.5]) | 0.43(0 [0.0–0.4]) | 15.99 (16.9 [9.6–23.1]) | 16.43 (16.9 [9.7–24.2]) | 0.34 (0.00 [0.0–0.6]) | 13.49 (12.25 [6.2–20.4]) | 13.83 (13.2 [7.2–20.4]) |
| 50–74% (26–50% of text edited) | 1.7 (0.7 [0.0–1.8]) | 33.37 (31.95 [17.5–49.6]) | 35.06 (37.15 [17.5–50.4]) | 1.01 (0.55 [0.0–0.8]) | 27.79 (27.2 [10.0–44.2]) # | 28.79 (28.65 [10.7–44.2]) # | 1.21 (0.50 [0.0–2.2]) | 41.35 (38.65 [32.9–52.6]) # | 42.56 (39.3 [34.5–55.0]) # |
| 0–49% (51–100% of text edited) | 0.31 (0 [0.0–0.6]) | 8.92 (7.2 [1.3–12.7]) # | 9.23 (7.55 [2.0–12.7]) # | 0.44 (0 [0.0–0.7]) | 8.01 (4.7 [0.0–10.9]) # | 8.44 (5.25 [0.0–10.9]) # | 1.06 (0.25 [0.0–1.8]) | 26.97 (25.55 [9.8–41.6]) # | 28 (25.85 [9.8–43.4]) # |
| Percentage Range of Edits | DeepL | Google Translate | Microsoft Translator | ||||||
|---|---|---|---|---|---|---|---|---|---|
| % of MT or TM text in each range of edits 1 | % of MT or TM text in each range of edits 1 | % of MT or TM text in each range of edits 1 | |||||||
| TM | MT | All | TM | MT | All | TM | MT | All | |
| All | 10.23 (8.8 [5.0–12.2]) | 89.77 (91.2 [87.8–95.0]) | 100 (100 [100–100]) | 6.99 (5.25 [4.1–9.0]) | 93.01 (94.75 [91.0–95.9]) | 100 (100 [100–100]) | 6.43 (5.80 [3.9–7.9]) | 93.57 (94.20 [92.1–96.1]) | 100 (100 [100–100]) |
| Repetitions | 1.18 (0 [0.0–2.3]) | 0 | 1.18 (0 [0.0–2.3]) | 0.75 (0 [0.0–1.5]) | 0 | 0.75 (0 [0.0–1.5]) | 0.33 (0 [0–0]) | 0 | 0.33 (0 [0–0]) |
| 100% (no edits) | 3.90 (2.85 [2.1–5.1]) | 6.82 (6.2 [1.9–9.3]) # | 10.72 (9.65 [5.1–12.2]) # | 3.28 (2.20 [1.4–3.1]) | 11.2 (6.25 [2.5–22.7]) # | 14.51 (12.25 [4.2–24.3]) # | 3.02 (2.80 [2.1–3.8]) | 2.05 (1.5 [0.0–2.9]) # | 5.07 (4.5 [3.3–6.4]) # |
| 95–99% (1–5% of text edited) | 0 (0 [0–0]) | 1.31 (0 [0–0]) | 1.31 (0 [0–0]) | 0.12 (0 [0–0]) | 1.29 (0.00 [0.0–2.2]) | 1.41 (0.00 [0.0–2.8]) | 0 (0 [0–0]) | 0.70 (0 [0–0]) | 0.70 (0 [0–0]) |
| 85–94% (6–15% of text edited) | 0.42 (0 [0–0]) | 11.83 (10.9 [6.9–18.2]) # | 12.25 (10.9 [6.9–18.7]) # | 0.39 (0.00 [0.0–0.0]) | 13.63 (12 [7.1–19.4]) # | 14.02 (12.75 [7.1–19.4]) # | 0 (0 [0–0]) | 4.23 (3.65 [0.0–5.9]) # | 4.23 (3.65 [0.0–5.9]) # |
| 75–84% (16–25% of text edited) | 0.95 (0.00 [0.0–1.3]) | 16.84 (17.3 [9.2–24.3]) # | 17.79 (17.8 [9.2–24.3]) # | 0.53 (0 [0.0–0.7]) | 19.65 (19.05 [9.8–29.8]) # | 20.18 (19.05 [9.8–29.8]) # | 0.53 (0 [0.0–1.0]) | 10.41 (9.55 [4.5–14.6]) # | 10.94 (9.6 [5.0–15.5]) # |
| 50–74% (26–50% of text edited) | 3.16 (1.3 [0.7–2.1]) | 41.23 (43.55 [30.7–54.9]) | 44.39 (45.85 [33.2–57.9] | 1.42 (0.8 [0.0–1.5]) | 35.7 (35.45 [25.1–46.9]) | 37.12 (40.15 [25.6-48.7]) | 1.52 (0.80 [0.0–2.8]) | 42.17 (43.6 [35.0–50.4]) | 43.69 (44.30 [35.9–52.8]) |
| 0–49% (51–100% of text edited) | 0.62 (0 [0.0–0.8]) | 11.74 (10.25 [4.4–16.2]) # | 12.37 (10.25 [5.3–17.0]) # | 0.48 (0 [0.0–0.4]) | 11.52 (7.85 [4.7–14.2]) # | 12.00 (8.85 [5.0–15.0]) # | 1.03 (0 [0.0–1.5]) | 34.00 (34.25 [21.9–44.2] # | 35.03 (34.25 [22.2–45.3]) # |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ziganshina, L.E.; Yudina, E.V.; Gabdrakhmanov, A.I.; Ried, J. Assessing Human Post-Editing Efforts to Compare the Performance of Three Machine Translation Engines for English to Russian Translation of Cochrane Plain Language Health Information: Results of a Randomised Comparison. Informatics 2021, 8, 9. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8010009
Ziganshina LE, Yudina EV, Gabdrakhmanov AI, Ried J. Assessing Human Post-Editing Efforts to Compare the Performance of Three Machine Translation Engines for English to Russian Translation of Cochrane Plain Language Health Information: Results of a Randomised Comparison. Informatics. 2021; 8(1):9. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8010009
Chicago/Turabian StyleZiganshina, Liliya Eugenevna, Ekaterina V. Yudina, Azat I. Gabdrakhmanov, and Juliane Ried. 2021. "Assessing Human Post-Editing Efforts to Compare the Performance of Three Machine Translation Engines for English to Russian Translation of Cochrane Plain Language Health Information: Results of a Randomised Comparison" Informatics 8, no. 1: 9. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8010009