
Arabic Offensive and Hate Speech Detection Using a Cross-Corpora Multi-Task Learning Model

 ,
,  , and
, and
Abstract
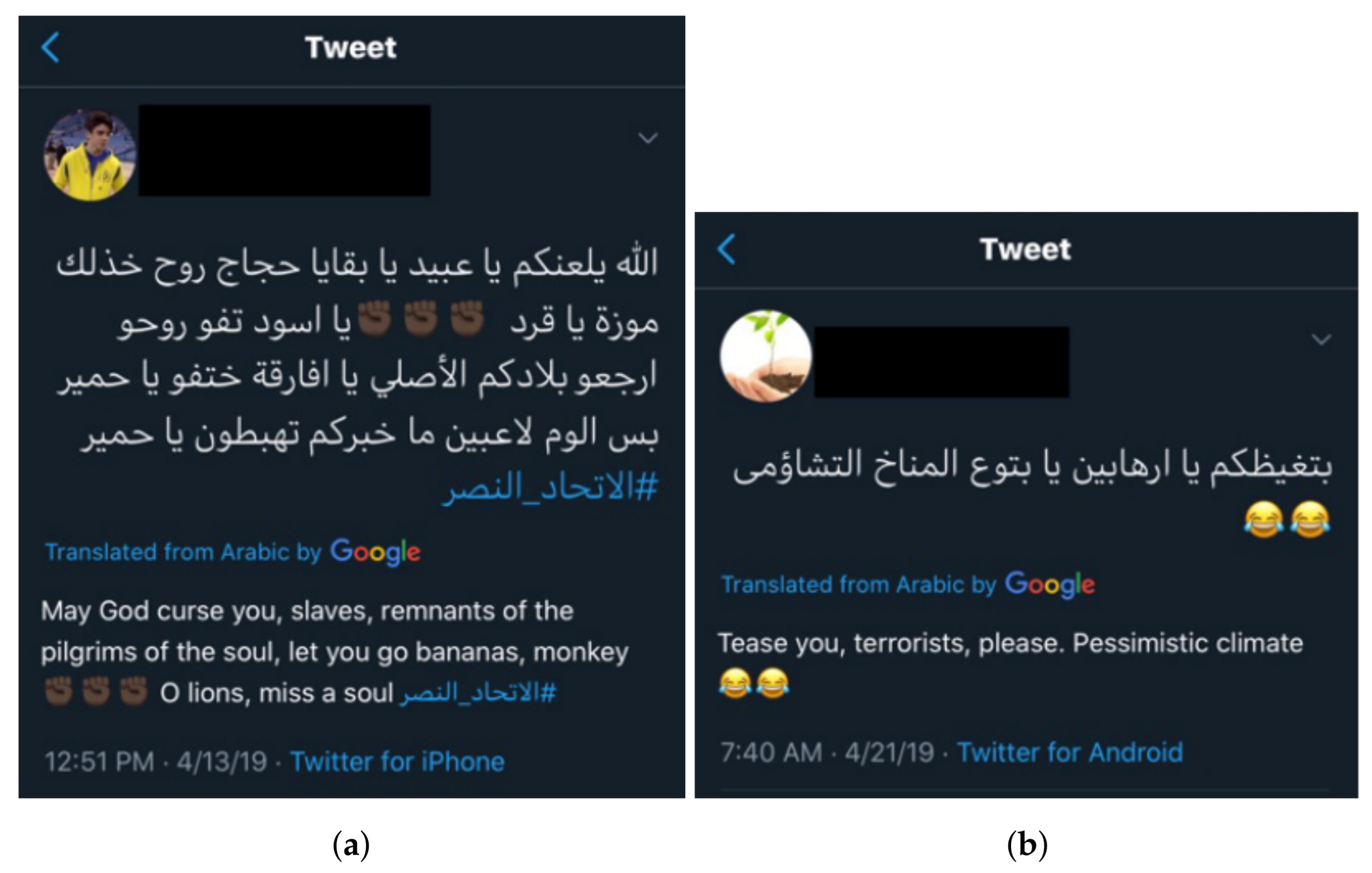
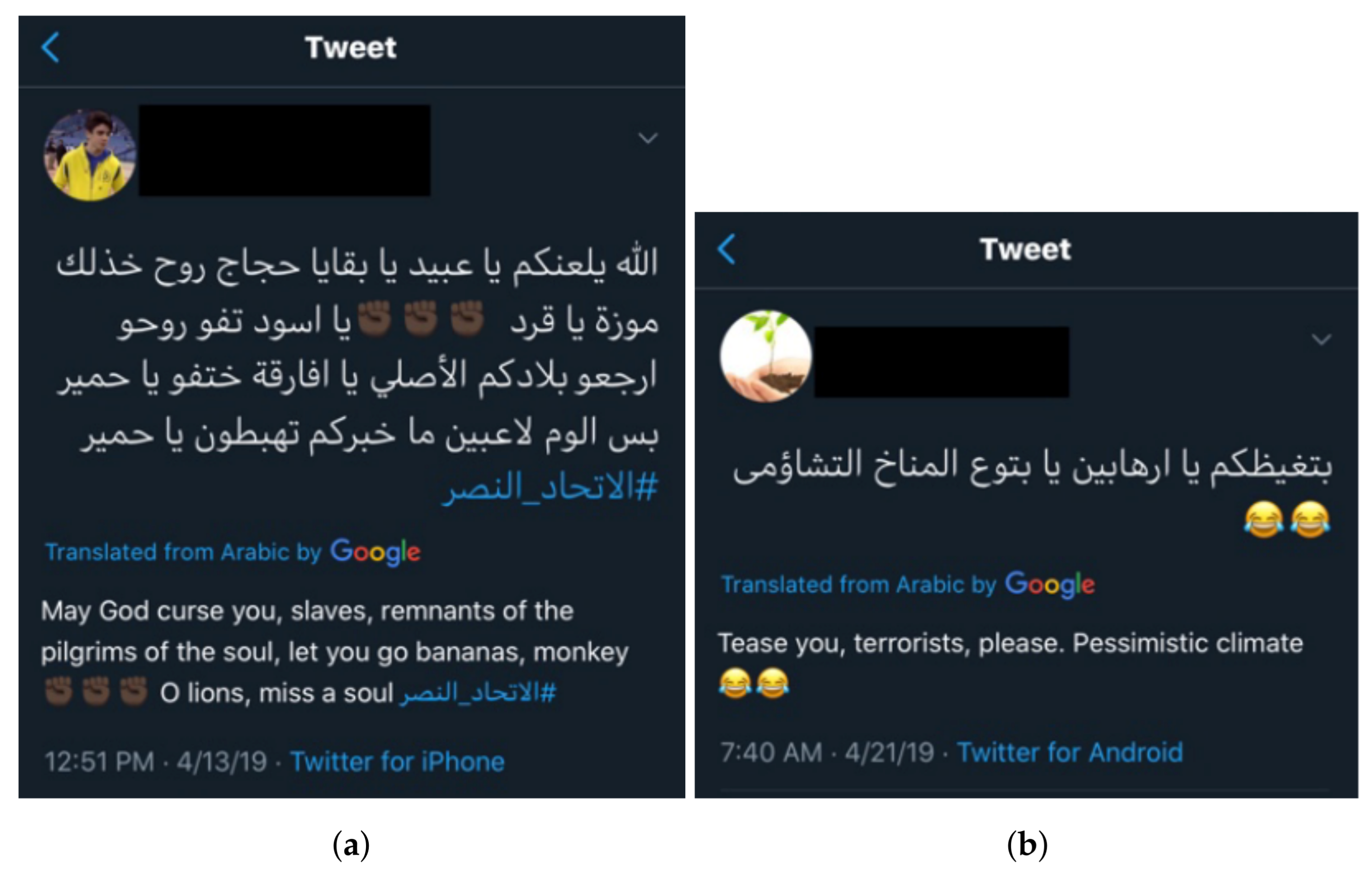
:1. Introduction
- Comprehensive evaluation of single-task and MTL models built upon Transformer language models (LMs);
- We evaluated a new pre-trained model, MarBERT, to classify both DA and MSA tweets;
- We propose a model to explore the multi-corpus-based learning using Arabic LMs and MTL to improve the classification performance on Arabic offensive and hate speech detection.
2. Related Works
2.1. Hate and Offensive Speech Detection in English
2.2. Hate and Offensive Speech Detection in Arabic
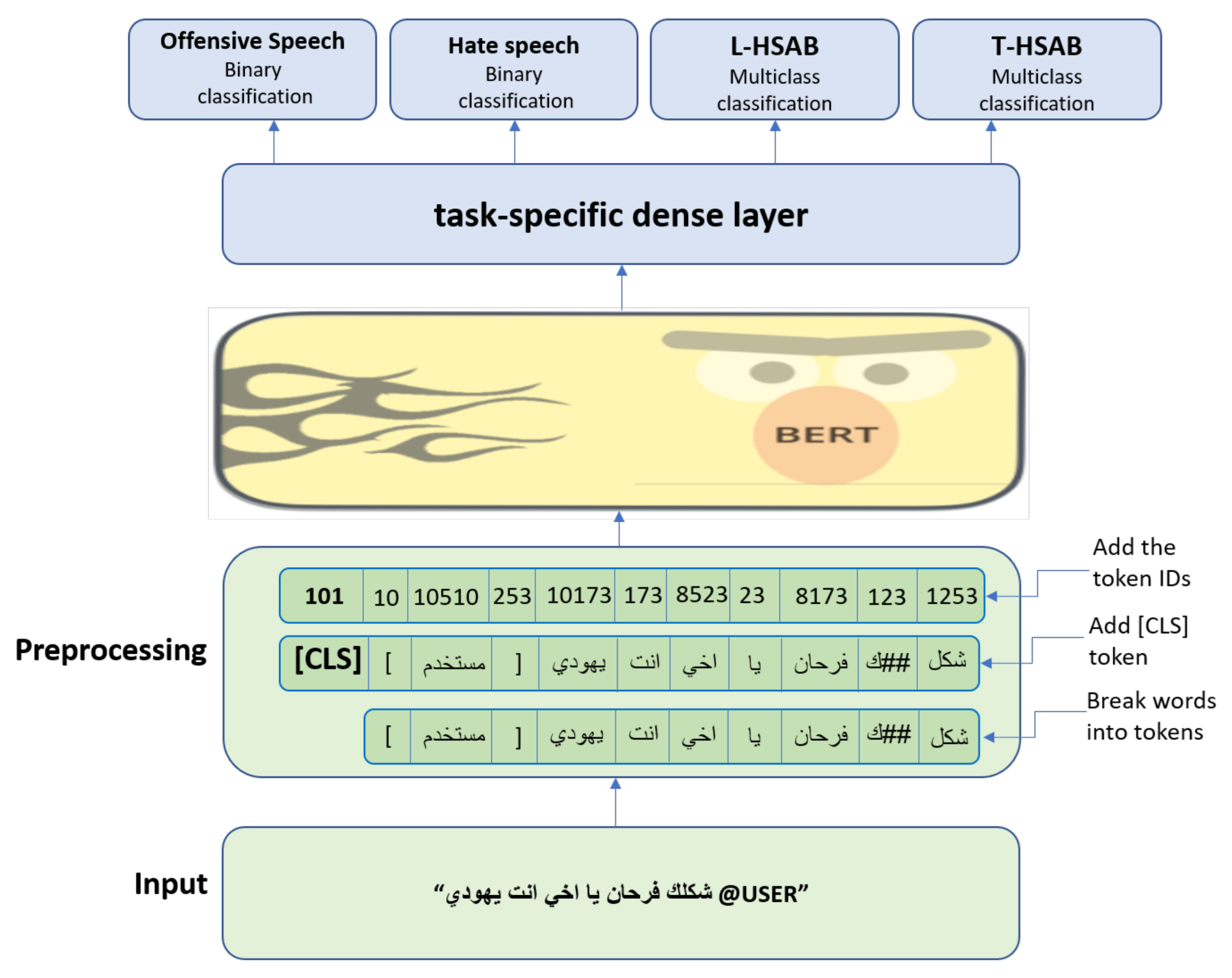
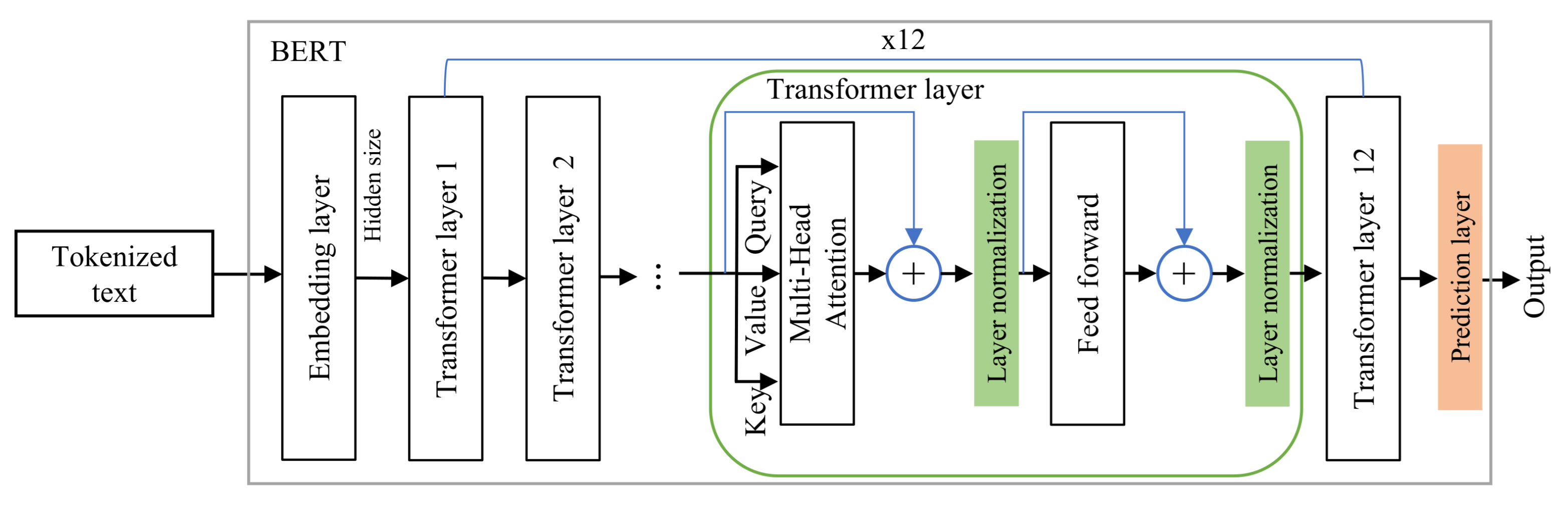
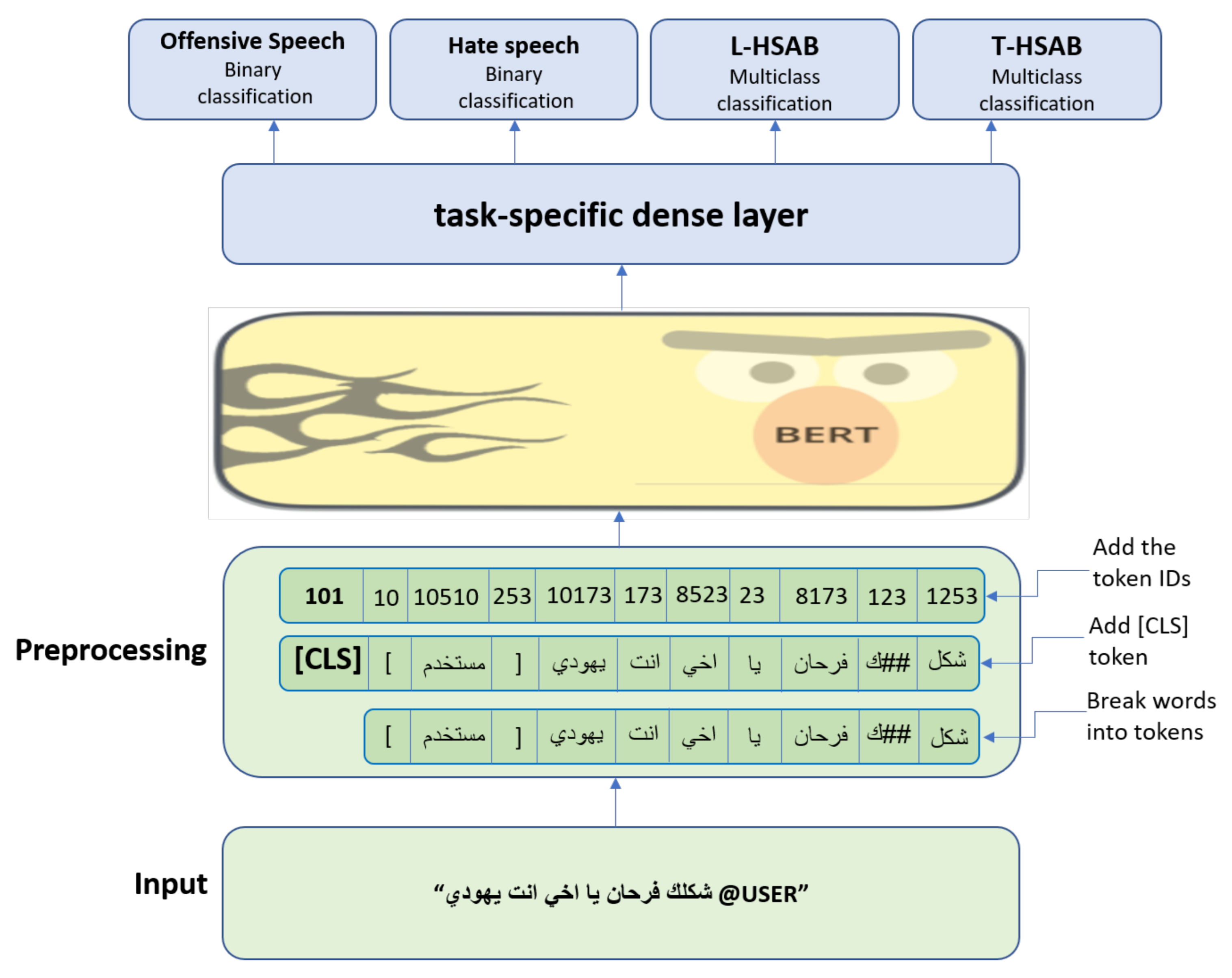
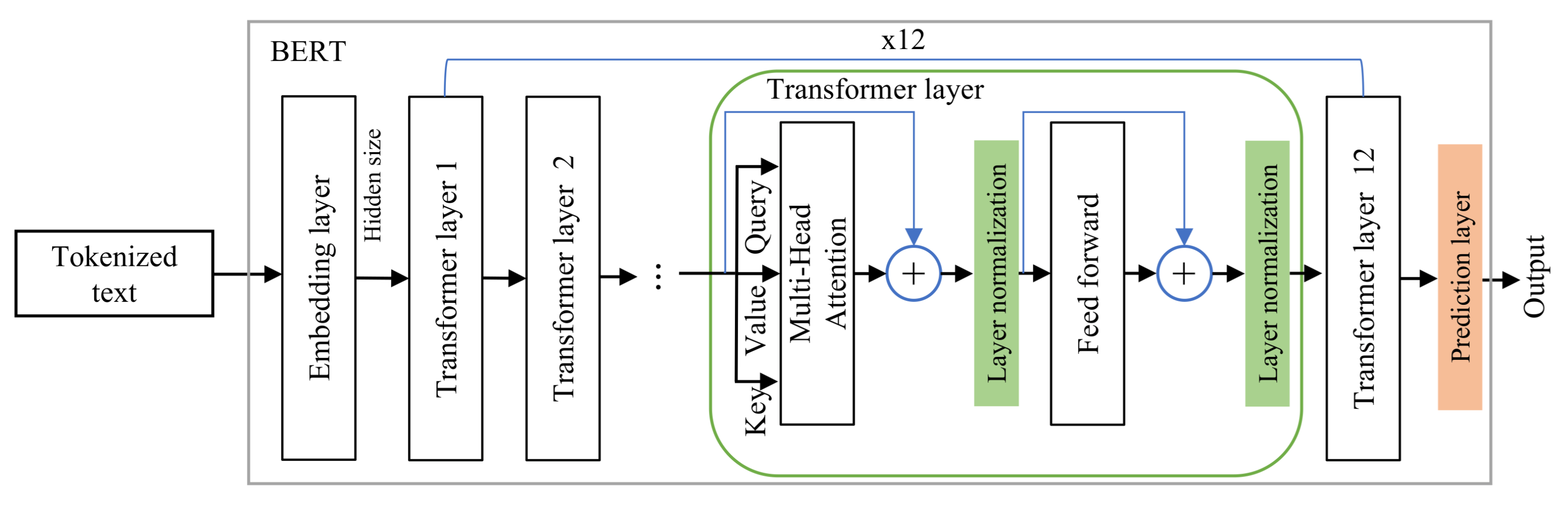
3. Proposed Model
4. Experimental Setup
4.1. Description of Datasets
4.2. Experiment Settings
4.3. Performance Measures and Models Training
5. Results and Discussions
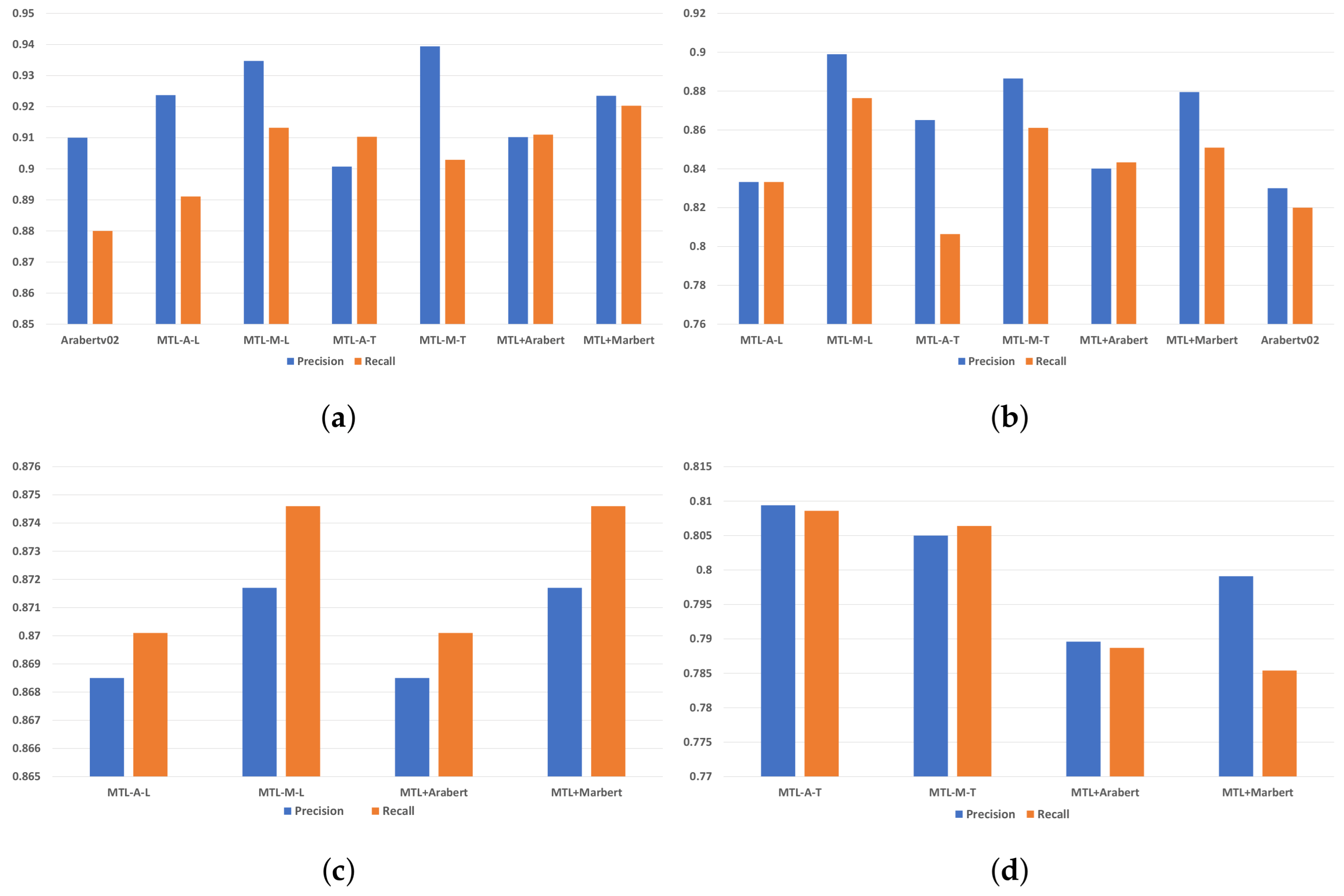
5.1. Experimental Series 1
- AraBERT v02: is a single-task model fine-tuned on both OSACT-OFF and OSACT-HS datasets separately;
- MTL-A-L and MTL-A-T: are MTL models with AraBERT used in the shared part, and OSACT-OFF, OSACT-HS, and T-HSAB are used in the specific task part;
- MTL-M-L and MTL-M-T: are MTL models with MarBERT covering Maghreb region dialect and MSA used in the shared part, and OSACT-OFF, OSACT-HS, and T-HSAB are used in the specific task part;
- MTL-AraBERT and MTL-MarBERT: are MTL models with AraBERT and MarBERT used in the shared part, respectively. In both models, all four datasets are used in the task part.
5.2. Experimental Series 2
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Castaño-Pulgarín, S.A.; Suárez-Betancur, N.; Vega, L.M.T.; López, H.M.H. Internet, social media and online hate speech. Systematic review. Aggress. Violent Behav. 2021, 58, 101608. [Google Scholar] [CrossRef]
- Chetty, N.; Alathur, S. Hate speech review in the context of online social networks. Aggress. Violent Behav. 2018, 40, 108–118. [Google Scholar] [CrossRef]
- Ul Rehman, Z.; Abbas, S.; Khan, M.A.; Mustafa, G.; Fayyaz, H.; Hanif, M.; Saeed, M.A. Understanding the language of ISIS: An empirical approach to detect radical content on twitter using machine learning. Comput. Mater. Contin. 2020, 66, 1075–1090. [Google Scholar] [CrossRef]
- Mladenovic, M.; Ošmjanski, V.; Stankovic, S.V. Cyber-Aggression, Cyberbullying, and Cyber-grooming. ACM Comput. Surv. 2021, 54, 1–42. [Google Scholar] [CrossRef]
- Cambria, E.; White, B. Jumping NLP curves: A review of natural language processing research. IEEE Comput. Intell. Mag. 2014, 9, 48–57. [Google Scholar] [CrossRef]
- Mäntylä, M.V.; Graziotin, D.; Kuutila, M. The evolution of sentiment analysis—A review of research topics, venues, and top cited papers. Comput. Sci. Rev. 2018, 27, 16–32. [Google Scholar] [CrossRef] [Green Version]
- Kapočiūtė-Dzikienė, J.; Damaševičius, R.; Woźniak, M. Sentiment analysis of Lithuanian texts using traditional and deep learning approaches. Computers 2019, 8, 4. [Google Scholar] [CrossRef] [Green Version]
- Kumar, A.; Dikshit, S.; Albuquerque, V.H.C. Explainable Artificial Intelligence for Sarcasm Detection in Dialogues. Wirel. Commun. Mob. Comput. 2021, 2021, 2939334. [Google Scholar] [CrossRef]
- Rivera-Trigueros, I. Machine translation systems and quality assessment: A systematic review. Lang. Resour. Eval. 2021. [Google Scholar] [CrossRef]
- Wani, T.M.; Gunawan, T.S.; Qadri, S.A.A.; Kartiwi, M.; Ambikairajah, E. A Comprehensive Review of Speech Emotion Recognition Systems. IEEE Access 2021, 9, 47795–47814. [Google Scholar] [CrossRef]
- Kapočiute-Dzikiene, J. A domain-specific generative chatbot trained from little data. Appl. Sci. 2020, 10, 2221. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.A.; Tsou, M.H.; Janowicz, K.; Clarke, K.C.; Jankowski, P. Reshaping the urban hierarchy: Patterns of information diffusion on social media. Geo-Spat. Inf. Sci. 2019, 22, 149–165. [Google Scholar] [CrossRef] [Green Version]
- Lock, O.; Pettit, C. Social media as passive geo-participation in transportation planning–how effective are topic modeling & sentiment analysis in comparison with citizen surveys? Geo-Spat. Inf. Sci. 2020, 23, 275–292. [Google Scholar]
- Kapočiūtė-Dzikienė, J.; Krilavičius, T. Topic classification problem solving for morphologically complex languages. In International Conference on Information and Software Technologies; Springer: Cham, Switzerland, 2016; Volume 639, pp. 511–524. [Google Scholar]
- Mansoor, M.; Ur Rehman, Z.; Shaheen, M.; Khan, M.A.; Habib, M. Deep learning based semantic similarity detection using text data. Inf. Technol. Control 2020, 49, 495–510. [Google Scholar] [CrossRef]
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic text summarization: A comprehensive survey. Expert Syst. Appl. 2021, 165, 113679. [Google Scholar] [CrossRef]
- Kapočiūtė-Dzikienė, J.; Salimbajevs, A.; Skadiņš, R. Monolingual and cross-lingual intent detection without training data in target languages. Electronics 2021, 10, 1412. [Google Scholar] [CrossRef]
- Islam, M.R.; Liu, S.; Wang, X.; Xu, G. Deep learning for misinformation detection on online social networks: A survey and new perspectives. Soc. Netw. Anal. Min. 2020, 10, 1–20. [Google Scholar] [CrossRef]
- Krilavičius, T.; Medelis, Ž.; Kapočiūtė-Dzikienė, J.; Žalandauskas, T. News media analysis using focused crawl and natural language processing: Case of Lithuanian news websites. In International Conference on Information and Software Technologies; Springer: Berlin/Heidelberg, Germany, 2012; pp. 48–61. [Google Scholar]
- Tesfagergish, S.G.; Kapočiūtė-Dzikienė, J. Part-of-speech tagging via deep neural networks for northern-Ethiopic languages. Inf. Technol. Control 2020, 49, 482–494. [Google Scholar]
- Neal, T.; Sundararajan, K.; Fatima, A.; Yan, Y.; Xiang, Y.; Woodard, D. Surveying stylometry techniques and applications. ACM Comput. Surv. 2017, 50, 1–36. [Google Scholar] [CrossRef]
- Venckauskas, A.; Karpavicius, A.; Damaševičius, R.; Marcinkevičius, R.; Kapočiūte-Dzikiené, J.; Napoli, C. Open class authorship attribution of lithuanian internet comments using one-class classifier. In Proceedings of the 2017 Federated Conference on Computer Science and Information Systems (FedCSIS), Prague, Czech Republic, 3–6 September 2017; pp. 373–382. [Google Scholar]
- Tesfagergish, S.G.; Damaševičius, R.; Kapočiūtė-Dzikienė, J. Deep Fake Recognition in Tweets Using Text Augmentation, Word Embeddings and Deep Learning. In International Conference on Computational Science and Its Applications; Springer: Cham, Switzerland, 2021; Volume 12954, pp. 523–538. [Google Scholar]
- Žitkus, V.; Butkiene, R.; Butleris, R.; Maskeliunas, R.; Damaševičius, R.; Woźniak, M. Minimalistic Approach to Coreference Resolution in Lithuanian Medical Records. Comput. Math. Methods Med. 2019, 2019, 9079840. [Google Scholar] [CrossRef] [Green Version]
- Behera, R.K.; Das, S.; Rath, S.K.; Misra, S.; Damasevicius, R. Comparative study of real time machine learning models for stock prediction through streaming data. J. Univers. Comput. Sci. 2020, 26, 1128–1147. [Google Scholar] [CrossRef]
- Shao, Z.; Sumari, N.S.; Portnov, A.; Ujoh, F.; Musakwa, W.; Mandela, P.J. Urban sprawl and its impact on sustainable urban development: A combination of remote sensing and social media data. Geo-Spat. Inf. Sci. 2021, 24, 241–255. [Google Scholar] [CrossRef]
- Xu, L.; Ma, A. Coarse-to-fine waterlogging probability assessment based on remote sensing image and social media data. Geo-Spat. Inf. Sci. 2021, 24, 279–301. [Google Scholar] [CrossRef]
- Amin, S.; Uddin, M.I.; Al-Baity, H.H.; Zeb, M.A.; Khan, M.A. Machine learning approach for COVID-19 detection on twitter. Comput. Mater. Contin. 2021, 68, 2231–2247. [Google Scholar] [CrossRef]
- Babić, K.; Petrović, M.; Beliga, S.; Martinčić-Ipšić, S.; Jarynowski, A.; Meštrović, A. COVID-19-Related Communication on Twitter: Analysis of the Croatian and Polish Attitudes. In Proceedings of Sixth International Congress on Information and Communication Technology; Springer: Singapore, 2022; Volume 216, pp. 379–390. [Google Scholar]
- Habash, N.Y. Introduction to Arabic natural language processing. Synth. Lect. Hum. Lang. Technol. 2010, 3, 1–187. [Google Scholar] [CrossRef]
- Shaalan, K.; Siddiqui, S.; Alkhatib, M.; Abdel Monem, A. Challenges in Arabic natural language processing. In Computational Linguistics, Speech and Image Processing for Arabic Language; World Scientific: Singapore, 2019; pp. 59–83. [Google Scholar]
- Darwish, K. Building a shallow Arabic morphological analyser in one day. In Proceedings of the ACL-02 Workshop on Computational Approaches to Semitic Languages, Philadelphia, PA, USA, 11 July 2002. [Google Scholar]
- Ray, S.K.; Shaalan, K. A Review and Future Perspectives of Arabic Question Answering Systems. IEEE Trans. Knowl. Data Eng. 2016, 28, 3169–3190. [Google Scholar] [CrossRef]
- Guellil, I.; Saâdane, H.; Azouaou, F.; Gueni, B.; Nouvel, D. Arabic natural language processing: An overview. J. King Saud Univ. Comput. Inf. Sci. 2021, 33, 497–507. [Google Scholar] [CrossRef]
- MacAvaney, S.; Yao, H.; Yang, E.; Russell, K.; Goharian, N.; Frieder, O. Hate speech detection: Challenges and solutions. PLoS ONE 2019, 14, e0221152. [Google Scholar] [CrossRef]
- Fortuna, P.; Nunes, S. A survey on automatic detection of hate speech in text. ACM Comput. Surv. 2018, 51, 1–30. [Google Scholar] [CrossRef]
- Ayo, F.E.; Folorunso, O.; Ibharalu, F.T.; Osinuga, I.A. Machine learning techniques for hate speech classification of twitter data: State-of-The-Art, future challenges and research directions. Comput. Sci. Rev. 2020, 38, 100311. [Google Scholar] [CrossRef]
- Khairy, M.; Mahmoud, T.M.; Abd-El-Hafeez, T. Automatic Detection of Cyberbullying and Abusive Language in Arabic Content on Social Networks: A Survey. Procedia CIRP 2021, 189, 156–166. [Google Scholar]
- Rosa, H.; Pereira, N.; Ribeiro, R.; Ferreira, P.C.; Carvalho, J.P.; Oliveira, S.; Coheur, L.; Paulino, P.; Veiga Simão, A.M.; Trancoso, I. Automatic cyberbullying detection: A systematic review. Comput. Hum. Behav. 2019, 93, 333–345. [Google Scholar] [CrossRef]
- Van Hee, C.; Jacobs, G.; Emmery, C.; DeSmet, B.; Lefever, E.; Verhoeven, B.; De Pauw, G.; Daelemans, W.; Hoste, V. Automatic detection of cyberbullying in social media text. PLoS ONE 2018, 13, e0203794. [Google Scholar] [CrossRef] [PubMed]
- Antoun, W.; Baly, F.; Hajj, H. Arabert: Transformer-based model for arabic language understanding. arXiv 2020, arXiv:2003.00104. [Google Scholar]
- Waseem, Z.; Hovy, D. Hateful symbols or hateful people? Predictive features for hate speech detection on twitter. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 12–17 June 2016; pp. 88–93. [Google Scholar]
- Gambäck, B.; Sikdar, U.K. Using convolutional neural networks to classify hate-speech. In Proceedings of the First Workshop on Abusive Language Online, Vancouver, BC, Canada, 4 August 2017; pp. 85–90. [Google Scholar]
- Pitsilis, G.K.; Ramampiaro, H.; Langseth, H. Effective hate-speech detection in Twitter data using recurrent neural networks. Appl. Intell. 2018, 48, 4730–4742. [Google Scholar] [CrossRef] [Green Version]
- Watanabe, H.; Bouazizi, M.; Ohtsuki, T. Hate Speech on Twitter: A Pragmatic Approach to Collect Hateful and Offensive Expressions and Perform Hate Speech Detection. IEEE Access 2018, 6, 13825–13835. [Google Scholar] [CrossRef]
- Basile, V.; Bosco, C.; Fersini, E.; Nozza, D.; Patti, V.; Rangel Pardo, F.M.; Rosso, P.; Sanguinetti, M. SemEval-2019 Task 5: Multilingual Detection of Hate Speech Against Immigrants and Women in Twitter. In Proceedings of the 13th International Workshop on Semantic Evaluation; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 54–63. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Céspedes, M.; Yuan, S.; Tar, C.; et al. Universal sentence encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. Semeval-2019 task 6: Identifying and categorizing offensive language in social media (offenseval). arXiv 2019, arXiv:1903.08983. [Google Scholar]
- Liu, P.; Li, W.; Zou, L. NULI at SemEval-2019 Task 6: Transfer Learning for Offensive Language Detection using Bidirectional Transformers. In Proceedings of the 13th International Workshop on Semantic Evaluation; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 87–91. [Google Scholar]
- Liu, X.; He, P.; Chen, W.; Gao, J. Multi-task deep neural networks for natural language understanding. arXiv 2019, arXiv:1901.11504. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Albadi, N.; Kurdi, M.; Mishra, S. Are they Our Brothers? Analysis and Detection of Religious Hate Speech in the Arabic Twittersphere. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 28–31 August 2018; pp. 69–76. [Google Scholar]
- Ashi, M.; Siddiqui, M.; Nadeem, F. Pre-trained Word Embeddings for Arabic Aspect-Based Sentiment Analysis of Airline Tweets. In Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2019; pp. 241–251. [Google Scholar] [CrossRef]
- Ousidhoum, N.; Lin, Z.; Zhang, H.; Song, Y.; Yeung, D.Y. Multilingual and Multi-Aspect Hate Speech Analysis. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Association for Computational Linguistics: Hong Kong, China, 2019; pp. 4675–4684. [Google Scholar]
- Ruder, S.; Bingel, J.; Augenstein, I.; Søgaard, A. Latent multi-task architecture learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4822–4829. [Google Scholar]
- Mulki, H.; Haddad, H.; Ali, C.B.; Alshabani, H. L-hsab: A levantine twitter dataset for hate speech and abusive language. In Proceedings of the Third Workshop on Abusive Language Online, Florence, Italy, 1 August 2019; pp. 111–118. [Google Scholar]
- Djandji, M.; Baly, F.; Antoun, W.; Hajj, H. Multi-Task Learning using AraBert for Offensive Language Detection. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection; European Language Resource Association: Marseille, France, 2020; pp. 97–101. [Google Scholar]
- Mubarak, H.; Darwish, K.; Magdy, W.; Elsayed, T.; Al-Khalifa, H. Overview of OSACT4 Arabic Offensive Language Detection Shared Task. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection; European Language Resource Association: Marseille, France, 2020; pp. 48–52. [Google Scholar]
- Abu Farha, I.; Magdy, W. Multitask Learning for Arabic Offensive Language and Hate-Speech Detection. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection; European Language Resource Association: Marseille, France, 2020; pp. 86–90. [Google Scholar]
- Abu Farha, I.; Magdy, W. Mazajak: An Online Arabic Sentiment Analyser. In Proceedings of the Fourth Arabic Natural Language Processing Workshop; Association for Computational Linguistics: Florence, Italy, 2019; pp. 192–198. [Google Scholar] [CrossRef] [Green Version]
- Hassan, S.; Samih, Y.; Mubarak, H.; Abdelali, A.; Rashed, A.; Chowdhury, S.A. ALT Submission for OSACT Shared Task on Offensive Language Detection. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection; European Language Resource Association: Marseille, France, 2020; pp. 61–65. [Google Scholar]
- Otiefy, Y.; Abdelmalek, A.; El Hosary, I. WOLI at SemEval-2020 Task 12: Arabic Offensive Language Identification on Different Twitter Datasets. In Proceedings of the Fourteenth Workshop on Semantic Evaluation (Online); International Committee for Computational Linguistics: Barcelona, Spain, 2020; pp. 2237–2243. [Google Scholar]
- Husain, F.; Uzuner, O. Leveraging Offensive Language for Sarcasm and Sentiment Detection in Arabic. In Proceedings of the Sixth Arabic Natural Language Processing Workshop (Virtual); Association for Computational Linguistics: Kyiv, Ukraine, 2021; pp. 364–369. [Google Scholar]
- El Mahdaouy, A.; El Mekki, A.; Essefar, K.; El Mamoun, N.; Berrada, I.; Khoumsi, A. Deep Multi-Task Model for Sarcasm Detection and Sentiment Analysis in Arabic Language. In Proceedings of the Sixth Arabic Natural Language Processing Workshop (Virtual); Association for Computational Linguistics: Kyiv, Ukraine, 2021; pp. 334–339. [Google Scholar]
- Abdul-Mageed, M.; Elmadany, A.; Nagoudi, E.M.B. ARBERT & MARBERT: Deep Bidirectional Transformers for Arabic. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 7088–7105. [Google Scholar] [CrossRef]
- Duwairi, R.; Hayajneh, A.; Quwaider, M. A Deep Learning Framework for Automatic Detection of Hate Speech Embedded in Arabic Tweets. Arab. J. Sci. Eng. 2021, 46, 4001–4014. [Google Scholar] [CrossRef]
- Alsaaran, N.; Alrabiah, M. Arabic Named Entity Recognition: A BERT-BGRU Approach. Comput. Mater. Contin. 2021, 68, 471–485. [Google Scholar] [CrossRef]
- Boudjellal, N.; Zhang, H.; Khan, A.; Ahmad, A.; Naseem, R.; Shang, J.; Dai, L. ABioNER: A BERT-Based Model for Arabic Biomedical Named-Entity Recognition. Complexity 2021, 2021, 1–6. [Google Scholar] [CrossRef]
- Kudo, T.; Richardson, J. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv 2018, arXiv:1808.06226. [Google Scholar]
- Husain, F. OSACT4 Shared Task on Offensive Language Detection: Intensive Preprocessing-Based Approach. arXiv 2020, arXiv:2005.07297. [Google Scholar]
- Haddad, H.; Mulki, H.; Oueslati, A. T-HSAB: A Tunisian Hate Speech and Abusive Dataset. In Communications in Computer and Information Science; Springer International Publishing: Cham, Switzerland, 2019; pp. 251–263. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art natural language processing. arXiv 2019, arXiv:1910.03771. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Task | Model | Evaluation | Dataset |
|---|---|---|---|---|
| Hate and offensive speech in English | ||||
| Wassem et al. [42] | HS | Logistic regression classifier | 73.93% F1-score | 16 K samples annotated for HS |
| Gamback et al. [43] | HS | Convolutional neural network(CNN) | 78% F1-score | 16 K tweets Data provided by [42] |
| Pitsilis et al. [44] | HS | Single and multiple LSTM classifiers | 87% recall 88% precision | 16 K Data provided by [42] |
| Basile et al. [46] | HS | Support Vector Machine (SVM) | 45.1% F1-score | SemEval 2019 (Task5) |
| Ping et al. [49] | OFF and HS | Pre-trained BERT model | 82.9 F1-score | SemEval 2019 |
| Liu et al. [50] | Multiple tasks | Multitask Learning (MTL) | / | Glue benchmark |
| Hate and offensive speech in Arabic | ||||
| Albadi et al. [52] | HS | Lexicon-based classifier and SVM classifier | 79% accuracy | 6.6 K of religious HS tweets |
| Ousidhoum et al. [54] | HS | MTL | 35% F1-score | 13 K trilingual HS tweets |
| Mulki et al. [56] | OFF and HS | SVM and Naive Bayes classifier | 83.6% F1-score | 6 K of Tunisian HS tweets |
| Djandji et al. [57] | OFF and HS | MTL | 90% F1-score | OSACT4 shared task 2000 tweets |
| Abu Farha et al. [59] | OFF and HS | CNN-BiLSTM and MTL | 90.4% F1-score | OSACT4 shared task 2000 tweets |
| Hassan et al. [61] | OFF and HS | CNN, CNN-BiLSTM, and multilingual BERT | 80.6% F1-score | OSACT4 shared task 2000 tweets |
| Otiefy et al. [62] | OFF | SVM | 88.72% F1-score | SemEval2020 shared task |
| Husain et al. [63] | Sarcasm detection and SA | AraBERT and SalamBERT | 69.22% F1-score | WANLP 2021 shared task 15.5 K tweets |
| El mahdaouy et al. [64] | Sarcasm detection and SA | AraBERT and MTL | 74.8% F1-score | WANLP 2021 shared task |
| Duwairi et al. [66] | HS | CNN, CNN-LSTM, and CNN-BiLSTM | 81% accuracy | 9.8 K HS tweets |
| Dataset | Language | Total Samples | Label | Training Set | Development Set | Test Set |
|---|---|---|---|---|---|---|
| OSACT-HS | Arabic MSA Arabic DA | 10 K | HS NOT HS | 361 6639 | 44 956 | 101 1899 |
| OSACT-OFF | Arabic MSA Arabic DA | 10 K | OFF NOT OFF | 1410 5590 | 179 821 | 402 1598 |
| L-HSAB | Syrian DA Lebanese DA | 6024 | Abusive Hate Normal | 1226 325 2539 | 258 74 544 | 243 67 567 |
| T-HSAB | Tunisian DA | 5846 | Abusive Hate Normal | 791 757 2668 | 166 160 578 | 169 161 574 |
| Model | OSACT-OFF * | OSACT-HS * | L-HSAB ** | T-HSAB ** | ||||
|---|---|---|---|---|---|---|---|---|
| Acc (%) | F1 (%) | Acc (%) | F1 (%) | Acc (%) | F1 (%) | Acc (%) | F1 (%) | |
| AraBERT v02 | 94 | 90.0 | 97 | 83.0 | - | - | - | - |
| MTL-A-L | 94.20 | 90.62 | 96.80 | 83.32 | 94.20 | 86.90 | - | - |
| MTL-M-L | 95.20 | 92.34 | 97.90 | 88.73 | 87.46 | 87.18 | - | - |
| MTL-A-T | 93.85 | 90.54 | 97.03 | 83.28 | - | - | 80.86 | 80.50 |
| MTL-M-T | 95.05 | 91.97 | 97.65 | 87.33 | - | - | 80.64 | 80.25 |
| MTL-AraBERT | 94.25 | 91.06 | 96.95 | 84.17 | 86.09 | 86.02 | 78.87 | 78.89 |
| MTL-MarBERT | 95.00 | 92.19 | 97.50 | 86.46 | 82.55 | 83.46 | 78.54 | 79.02 |
| Model | OSACT-OFF * | OSACT-HS * | L-HSAB ** | T-HSAB ** | ||||
|---|---|---|---|---|---|---|---|---|
| Acc (%) | F1 (%) | Acc (%) | F1 (%) | Acc (%) | F1 (%) | Acc (%) | F1 (%) | |
| Abu farha et al. [59] | - | 87.7 | - | 76 | - | - | - | - |
| Djandji et al. [57] | - | 90 | - | 82.28 | - | - | - | - |
| Mulki et al. [56] | - | - | - | - | 88.4 | 74.4 | - | - |
| Haddad et al. [71] | - | - | - | - | - | - | 87.9 | 83.6 |
| MTL-M-L | 95.20 | 92.34 | 97.90 | 88.73 | 87.46 | 87.18 | - | - |
| MTL-A-T | 93.85 | 90.54 | 97.03 | 83.28 | - | - | 80.86 | 80.50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aldjanabi, W.; Dahou, A.; Al-qaness, M.A.A.; Elaziz, M.A.; Helmi, A.M.; Damaševičius, R. Arabic Offensive and Hate Speech Detection Using a Cross-Corpora Multi-Task Learning Model. Informatics 2021, 8, 69. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8040069
Aldjanabi W, Dahou A, Al-qaness MAA, Elaziz MA, Helmi AM, Damaševičius R. Arabic Offensive and Hate Speech Detection Using a Cross-Corpora Multi-Task Learning Model. Informatics. 2021; 8(4):69. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8040069
Chicago/Turabian StyleAldjanabi, Wassen, Abdelghani Dahou, Mohammed A. A. Al-qaness, Mohamed Abd Elaziz, Ahmed Mohamed Helmi, and Robertas Damaševičius. 2021. "Arabic Offensive and Hate Speech Detection Using a Cross-Corpora Multi-Task Learning Model" Informatics 8, no. 4: 69. https://0-doi-org.brum.beds.ac.uk/10.3390/informatics8040069