1. Introduction
Produced from grapes of excellent quality that grow in the Douro region, Port wine is known for its renowned quality, being one of the most famous Portuguese fortified wines worldwide. In this work, we consider one well-known representative of Port wines, the Dow’s Port wine (from Symington Family Estates, the industrial partner collaborating with the present research project). This wine is mainly produced from grape varieties harvested in the vineyard of Quinta do Bomfim, often consisting of Tawny Ports, twenty, thirty and forty-year-old wine, aged in oak cask. It is important to keep in mind, however, that the high quality of these wines starts at the vineyards, where it is crucial to monitor the components and properties of the grapes that will be used as raw material for the winemaking process. Such careful control is instrumental to determine the harvesting date and to select the grapes at the optimal maturity stage according to the desired traits. This work is devoted to the development and test of a rapid and informative approach that supports wine makers in this decisive phase of the process. However, all the remaining stages, namely maceration, fermentation, extraction and aging, also need to be properly controlled to accomplish the desired wine properties. Given the importance of the harvesting stage, considerable efforts have been traditionally made by producers and researchers for controlling and monitoring the quality of the grapes, through the evaluation of relevant enological parameters over time with the aid of conventional physical and chemical methods performed off-line. Nevertheless, these standard evaluation protocols present the following disadvantages: they are time-consuming, expensive, invasive, generate chemical waste and are limited to a few samples [
1].
With the advancement of technology and the need for rapid, less expensive and non-destructive assessment of wine grape ripeness, optical sensing technologies, including visible and near infrared spectroscopy [
2,
3], fluorescence-based sensors [
4,
5], hyperspectral imaging [
1,
6], have been demonstrated to be useful in assessing grape maturity. Among them, hyperspectral imaging has emerged as an attractive and viable technology [
7,
8,
9,
10] to estimate relevant enological parameters in grape berries, showing high potential to support critical decision-making during harvesting, since it combines spectroscopy with digital imaging techniques [
11] that allows the collection of process information from across the electromagnetic spectrum in few seconds. In reflectance mode, hyperspectral imaging collects information about how grapes reflect and absorb light as a function of their wavelength [
12,
13], allowing the analysis of large number of samples and opens the possibility to analyze the grape maturation locally in the vineyards, a highly regarded feature for the wine industry. Besides the reflectance mode, transmittance has also been used in spectroscopy to determine the enological parameters in grapes, although less frequently [
14,
15,
16]. These two spectroscopic modes (reflectance and transmittance) mainly differ in the position of the sample with respect to the light source and detector. In the reflectance mode, the light source and the detector (hyperspectral camera) are placed above the sample while in the transmittance mode, the light source and the detector are positioned on opposite sides of the sample and the light must pass through the sample. The transmittance mode has the disadvantage of requiring a closer proximity to the sample because the intensity of the light is significantly attenuated when passing though the samples. For this reason, the reflectance mode is usually preferred [
1,
17].
Given the large amount of complex data produced by hyperspectral cameras, data analysis tools are required to properly convert the spectral data into the desired enological information. In this context, the use of advanced machine learning methods, in combination with hyperspectral technology in reflectance mode, has been proven to be a valid line of research to properly deal with the complexity of data, and to extract the relevant information for the prediction of enological parameters in grapes berries [
1,
2,
3,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29]. One of the main advantages of using machine learning methods relies on their ability to generalize, i.e., to estimate the enological parameters for future samples, once a proper calibration of the system is done, using training samples and the corresponding enological parameters. Nevertheless, monitoring the level of maturation is a complex problem due to the large variability of grape composition, grape variety and
terroirs over time. Thus, assessing the generalization ability of a model for different vintages and varieties is an important task, in order to assess the robustness of the final methodology. Despite the existence of numerous works published in the literature for grape ripeness assessment, most of them address the case of samples from no more than one or two harvested years. In fact, the generalization assessment of machine learning models is almost absent from the technical literature, with the exception of a few works where models were trained with grapes from one vintage/variety and tested with grapes from another vintage/variety [
2,
18,
22,
27,
29].
The present work reports the development of four different machine learning (ML) methods, including a deep learning approach, towards the assessment of grape ripeness and in particular the sugar content. The sugar content is an essential maturity index in the wine industry, and is directly related with the alcoholic strength of the wine. The ML methods considered are ridge regression (RR); partial least squares regression (PLSR); artificial neural networks (NN); and one-dimensional convolutional neural networks (1D CNN). These methods are developed and compared using an extensive dataset composed of several vintages of one variety for training, and different vintages and varieties used for testing and not employed during training. This rich dataset also incorporates the effects of natural variability such as that originated from differences between grape varieties, climate factors, sun exposition, varying water availability, heterogeneous soil quality and different altitudes, etc., which is a fundamental aspect for assessing the performance in real world conditions. Indeed, it is relevant to carry out this comparison among such different machine learning methods since the assumptions of each proposed method is different, and it is impossible to know in advance which method is most suitable for the proposed problem. The choice of using partial least squares [
3,
18,
19,
21,
23,
25,
26,
27,
28] and neural networks [
1,
18,
29,
30] methods in the current work was based on the fact that these are the most commonly applied approaches in the scientific literature for predicting enological parameters of grape berries from spectroscopic data. On the other hand, ridge regression was selected due to the excellent performance demonstrated in a previous work conducted by the authors [
31], concerning berry component predictions using one vintage and variety. Finally, convolutional neural networks, one of the most popular architectures of deep learning, have been emerging in the computer science domain with excellent results in extracting complex patterns of data for a wide field of applications. Thus, this method was selected to assess whether a one-dimensional convolutional neural network architecture can bring added value to this prediction context. Details of the scientific literature for the prediction of sugar content in wine grape berries using spectroscopic data in reflectance mode are summarized in
Table 1.
The major novelty of this work is the use of a large database collected over an extended period of time, composed by different varieties and vintages, to perform a comparison between distinct classes of machine learning methods, including the most recent deep learning class. To the best of our knowledge, this is one of the first works where conventional machine learning methods are compared with a deep learning algorithm to predict sugar content of grapes through spectroscopic measurements.
2. Material and Methods
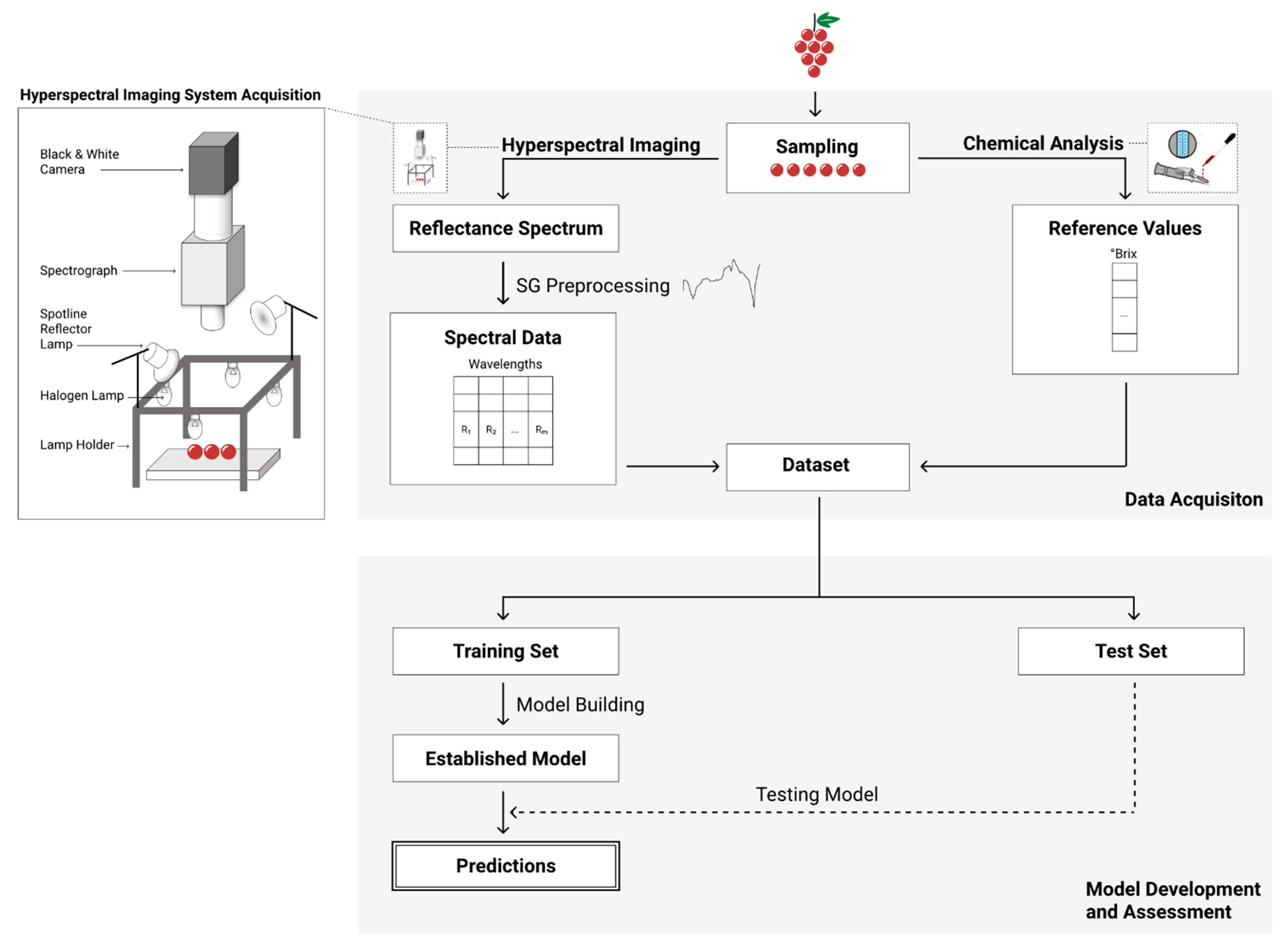
Figure 1 portrays the overall workflow followed in this study. The main steps are briefly described in the following subsections.
2.1. Samples Description
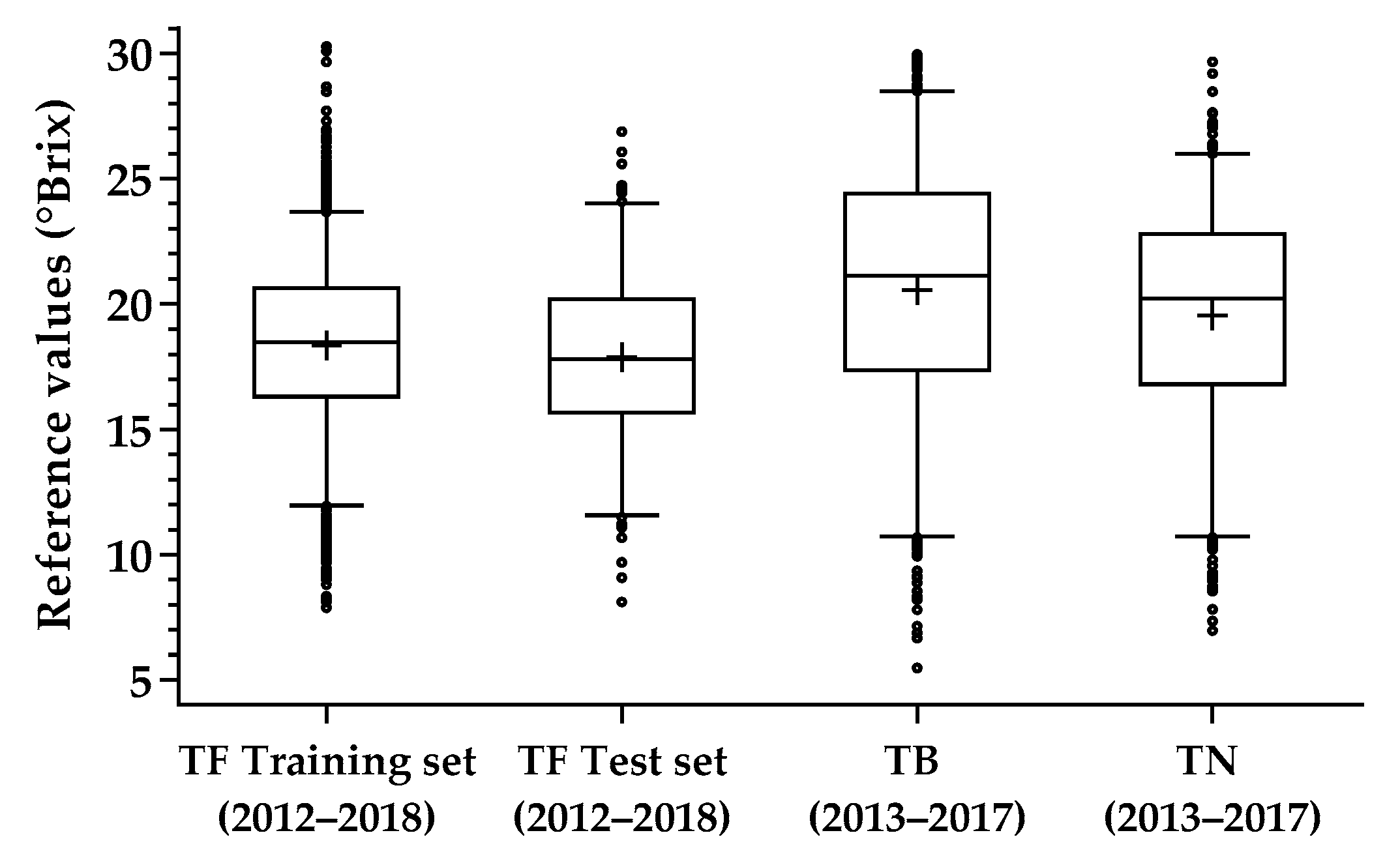
Three varieties widely used to produce Port wine in one of the oldest appellation regions of the world, the Portuguese Douro region, were selected to conduct this study: Touriga Franca (TF), Touriga Nacional (TN) and Tinta Barroca (TB). These grape varieties were selected due to their importance to the Porto wine industry, and were harvested from vineyards of Quinta do Bomfim, Pinhão (Portugal), in three different locations within the vineyard (from vines with small, medium and large vigor) and with two different sun expositions (sunny and shaded sides). Grape samples of TF were collected in 2012, 2013, 2014, 2016, 2017 and 2018 vintages, while TN and TB varieties were harvested in 2013, 2014, 2016 and 2017 vintages. All vintages and varieties were collected between the beginning of veraison and maturity, composing a total of 1748 samples for TF, 454 samples for TN and 463 samples for TB. TF samples were used to develop and test the predictive models while TN and TB were only used to test the generalization capacity of models created with TF for different varieties.
Each sample for each variety was composed of six (from 2012 to 2014 vintages) or twelve (from 2016 to 2018 vintages) grape berries randomly collected from a single bunch with their pedicel attached. This small number of grape berries per sample was used due to the practice of some wineries to select the best berries from each bunch for the production of high-quality wines [
1,
29]. The increase from six to twelve grape berries per sample was due to the fact that sometimes, depending on the variety, six grape berries may not be enough to obtain a representative sample for carrying out the conventional analysis. A line-scan hyperspectral image acquisition (described in
Section 2.2) was performed using fresh grape samples and after imaging, and before conventional analysis, all samples were frozen at −18 °C.
2.2. Data Acquisition
Hyperspectral measurements were collected using the following hyperspectral imaging system acquisition (
Figure 1): a hyperspectral camera, composed of a JAI Pulnix (JAI, Yokohama, Japan) black and white camera and a Specim Imspector V10E spectrograph (Specim, Oulu, Filand); lighting, using a lamp holder with 300 × 300 × 175 mm
3 (length × width × height) that held four 20 W, 12 V halogen lamps and two 40 W, 220 V blue reflector lamps (Spotline, Philips, Eindhoven, The Netherlands). The halogen lamps were powered by continuous current power supplies to avoid light flickering and the reflector lamps were powered at only 110 V to reduce lighting and prevent camera saturation. The acquired images have a spatial resolution of 1040 × 1392 pixels, where 1040 pixels correspond to the wavelength channels, ranging between 380 and 1028 nm, with approximately 0.6 nm width for each channel. The 1392 pixels stand for the spatial dimension (one line over the samples) with approximately 110 mm of width. The distance between the camera and the sample base was set to 420 mm, and the camera was controlled with the Coyote software from JAI. All the hyperspectral measurements were done inside a semi-darkened room and at room temperature (20 °C). After image collection, the grape berries were identified and extracted using a threshold-based segmentation method.
Regarding the established lighting conditions (
Figure 1), measurements were done in reflectance mode. To do so, it was necessary to determine the reflectance values, aiming to correct signal variations caused by the illumination and the hyperspectral camera. Reflectance is defined as the ratio between the total intensity of light reflected by a sample and the total intensity of light incident on the sample. To compute the intensity of light that illuminates the grape berries, a white reference target called Spectralon (Specim, Oulu, Filand) was used. Spectralon reflects almost 100% of the light that reaches its surface in the ultraviolet, visible and infra-red wavelengths. Thus, for a given wavelength,
λ, and, due to the use of hyperspectral imaging, also for a certain position,
x, the reflectance,
R, is computed as:
where
GI is the intensity of light reflected by the grape berries,
SI the intensity of light coming from the white reference target and
DI the dark current signal (electronic noise) associated to hyperspectral camera output acquired by keeping the camera shutter closed. The dark current signal depends on the camera electronics and must be subtracted from the grape berries and Spectralon intensities to avoid tampering in the determination of the reflectance values.
In the present work, the hyperspectral measurements for each sample were carried out along the berry “equator”, considering the pedicel as the pole, and for three different berry positions corresponding to berry rotations of approximately 120° between positions, allowing that the whole equator was imaged. In order to minimize the measurement noise, an accumulation of 32 hyperspectral images were acquired for
SI(
x,
λ),
DI(
x,
λ) and for each set of positions in
GI(
x,
λ). The final hyperspectral images were obtained by averaging the 32 images and, after the identification of grape berries, the reflectance values were calculated through Equation (1). To create a unique reflectance spectrum for each sample, the reflectance spectra measured for all berries’ points were averaged over the spatial dimension and positions. Furthermore, to properly develop the predictive models, it was also necessary to determine the reference values for the sugar content, through conventional chemical analysis. In this work, for each analytical sample, the grapes were defrosted, crushed and the °Brix was then determined by refractometry [
32].
After data acquisition, each acquired spectrum was paired with the reference measurements for the sugar contents to create the final datasets. Moreover, in order to handle undesirable physical phenomena in the spectra and to develop more parsimonious and stable predictive models, the spectral data was preprocessed using Savitzky–Golay first derivative. More information about the data acquisition process and measurement protocols are available in [
1,
18,
22,
29].
2.3. Predictive Methods
Four different approaches were considered in this work (RR, PLSR, NN and 1D CNN) for the predictive model. A brief description of these four approaches is provided below as more detailed descriptions are provided in the literature [
1,
18,
29,
33,
34,
35].
Ridge regression (RR) is a popular machine learning method that belongs to the class of penalized regression methods. It imposes a squared penalty (L
2-norm) on the magnitude of the regression coefficients, constraining their magnitude to be low. The penalty term stabilizes the estimation of the coefficients, mitigating the effects of collinearity, overfitting, and improving model robustness. In this regard, the regression coefficients,
, are obtained by solving the following optimization problem (2):
where
is the squared L
2-norm penalization,
is the
ith observed response value,
is the corresponding model prediction and
γ controls the bias-variance tradeoff, weighting the contribution of the classical least-squares term with the penalization term for the regression coefficient size. Suitable values of
γ were selected through k-fold cross-validation in order to control the bias-variance tradeoff and impose an adequate penalization for maximum prediction accuracy [
33].
Partial least squares regression (PLSR) is a method widely used in chemometrics and related areas, fitting into the class of latent variables. The basic assumptions of PLSR rely on the inference of new variables called latent variables (LV), corresponding to the projections of the input (
X) and output (
Y) sets of variables into new subspaces, where the covariance between
X and
Y is maximized [
36]. The number of latent variables was chosen by minimizing the root mean squared error obtained through k-fold cross-validation. The maximum number of latent variables considered was set to eighty.
Artificial neural networks (NN) form another class of machine learning methods, consisting of parallel assemblies of non-linear mathematical units disposed in layers mimicking the function of neurons in the brain [
37]. This method has the ability of learning from patterns that constitute the training set [
38]. In this work we used a feedforward multilayer perceptron, composed of several layers of neurons interconnected by weights that store the knowledge acquired during the learning process [
1]. During the training process, the weights are computed iteratively in order to minimize the deviations between the estimates and the reference sugar contents. Each iteration for weights adjustment is called an epoch. Furthermore, the neural networks were trained using the Levenberg–Marquardt algorithm [
37], a backpropagation approach with a variable learning rate that is more efficient than the conventional algorithm approach. The training step was repeated for 100 different randomly generated initial weights and was stopped when the number of epochs with the lowest mean squared error for validation was achieved (known as early stopping). The hyperbolic tangent (non-linear function) and the identity (linear function) were the activation functions used to compute the hidden and output neurons, respectively. As the input data dimensionality of a neural network should be kept as low as possible to provide model parsimony and lower the risk of overfitting, principal component analysis (PCA) was applied to reduce the high dimensionality of the spectra. To find the optimal number of principal components, a range between one and eighty was tested. The procedure of k-fold cross-validation was also adopted for the development of the neural network model.
Convolutional neural networks (CNN), abbreviated as ConvNets herein, belong to the deep learning class of machine learning methods and have been applied in different research fields, notably for image classification. CNN models usually contain layers of 2D convolutional kernels [
34]. However, in our approach, the sets of spectral data resulting from hyperspectral imaging procedure are one-dimensional (1D), which implies using a 1D kernel in the CNN instead of the commonly employed 2D or 3D kernels. The customized 1D CNN (see
Figure 2) was built in Python using keras v.2.2.4 package, fed with a one-dimensional input (1040 × 1) and followed by two one-dimensional convolutional layers. Twenty 1D filters were used in each convolutional layer with sixteen and eight 1D kernel sizes, respectively, using a rectified linear unit (ReLU) as non-linear activation function. This way we aim to capture first the coarse spectral connections and then refine them. Pooling layers are usually employed after the convolutional layers to reduce the dimensionality of feature maps. However, they are not always used in problems dealing with one-dimensional spectral data [
39,
40], being simply replaced in these circumstances by a convolutional layer with increased stride and usually without significant loss in accuracy [
39,
41]. This modification also simplifies the network structure. In this work, we adopt the strategy of not using pooling layers, building a simpler 1D CNN (i.e., with fewer layers) to derive the model. Thus, the ‘same’ padding was used and the stride value of the first convolutional layer was set to one and the second to eight. The outputs arising from the final convolutional layer were flattened and a dropout layer was added to avoid overfitting before connecting to a fully connected dense layer with a ReLU activation function. The output layer was a single dense neuron with a linear activation function. The training process was done using the Adadelta optimizer [
42] and the convolutional weights were initiated using ‘Glorot uniform’ initialization [
43] and computed, iteratively, for 300 epochs. Batch size was set to 64. To obtain the model, an early stopping was included and the mean squared error was defined as loss function.
RR, PLSR and NNs computations were conducted in the MATLAB R2019b environment (MathWorks, Inc., Natick, Massachusetts, United States).
2.4. Model Development and Assessment
In order to develop, assess and compare the predictive ability of the different estimated models, the data (spectral and the respective reference measurements) were split into training and independent test sets, using a stratified scheme based on the response percentiles. To perform this step, the data for each Touriga Franca vintage (from 2012 to 2018) was grouped into 5 intervals according to the following sugar content percentiles: 20th, 40th, 60th and 80th. In each group of percentile intervals, 10% of samples were reserved for the independent test set and the remaining were used for model training. The final datasets (training and independent test sets) were formed by collecting the respective TF samples partitioned for each vintage. This independent test set was used in the test phase to assess the prediction performance of each method in order to ensure an unbiased measurement of the model’s robustness.
Regarding the ridge regression, partial least square and neural networks methods, a stratified k-fold cross-validation approach was used during model training in order to select the suitable hyperparameter(s) mentioned in
Section 2.3 for each predictive method. This was done using 9-fold cross-validation wherein the data was partitioned in nine folds, eight used for training and one for validation. Training was repeated nine times using a different validation fold each time. The cross-validation results presented in this work consist of the average of the results obtained in the nine folds when they were used for validation. The final models were trained using the nine folds and the respective best hyperparameter(s) obtained by k-fold cross-validation approach. For the development of the proposed one-dimensional convolutional neural network architecture, unlike the other three methods, the training set was divided into calibration and validation sets using the same stratified scheme based on percentiles explained above, with 10% of TF samples reserved for validation set. The calibration set was used to estimate the model and the validation set was applied to tune the internal parameters (weights and biases).
The performance of each machine learning method (RR, PLS, NN and 1D CNN) was assessed and compared using the independent test set formed with all samples of TF vintages not employed during the training stage, and the model’s generalization ability was evaluated through all samples of TN and TB varieties (different years and varieties) as independent test sets.
Table 2 provides detailed information about the training and independent test sets created to conduct the comparison.
The root mean squared error (RMSE) was used as an evaluation criterion of the model and to compare the proposed approaches.
4. Conclusions
In the present work, we propose an approach that lays the groundwork for the development of an on-the-fly non-invasive sensing methodology for predicting and monitoring the key enological parameters of Port wine grape berries that are essential for their ripeness assessment.
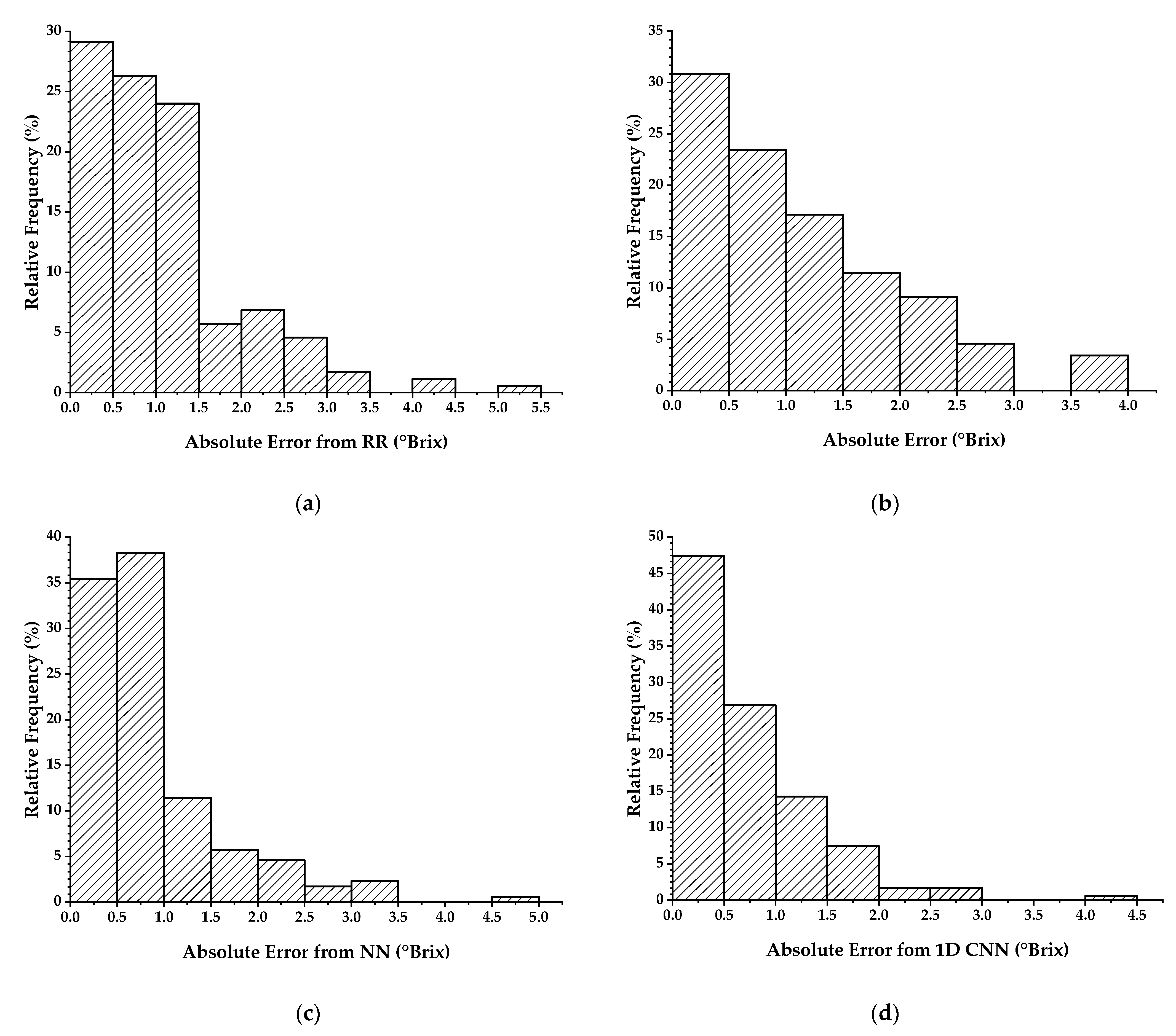
Four different machine learning methods (ridge regression, partial least squares, neural networks and convolutional neural networks) were developed and compared for predicting the sugar content in grapes, one of the parameters most related to grape maturity. This comparison focused on the generalization ability for different vintages and varieties not employed in the training model. The prediction errors obtained by each method were within acceptable ranges, and as a result, the general performance achieved was indeed highly satisfactory in terms of robustness. Furthermore, these results reveal that the proposed 1D CNN architecture can be successfully applied to estimate sugar content of wine grape berries, achieving a better performance rate when compared with the other three methods of ridge regression, partial least squares and neural networks.
Additionally, this study shows that the differences in terroir and grape varieties have a considerable impact in the grape ripening stage within and between vintages and, consequently, on the robustness of the predictive models. Nevertheless, the combination of hyperspectral imaging technology with appropriate machine learning approaches proved to be a competitive candidate for the development of a powerful tool for fast, non-destructive and non-invasive evaluation of grape quality, and consequently, a potential tool to achieve desired wine properties and quality standards. In particular, the results obtained in the present work are promising to accurately measure the sugar content of wine grapes during ripening, providing important information to adapt the procedure defined at the laboratory level (laboratory-acquired data) to an on-the-fly non-invasive sensing approach. Furthermore, these results suggest that the increase of the number of training samples will further improve the robustness of the prediction models, making its use irrespective of the specific vintage year. The addition of pooling layers to the 1D CNN architecture should also be subjected to future research in order to compare its performance with the current architecture and verify whether or not the use of pooling layers can bring more predictive power to the problem. Finally, it is important in future research to perform field hyperspectral data acquisition to upscale these models at real conditions.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}