1. Introduction
Many biomedical investigations now involve the analysis of a large and growing range of genome scale data types, including DNA sequence-derived variables, gene expression measurements, and epigenetic information. Each of these data types can provide valuable information about the complex factors contributing to a biological system, but none by itself can provide a complete picture. The need for integrative modeling approaches to realize the full potential of data growing in diversity as well as volume has been widely recognized over the last several years. Several large consortia, such as ENCODE, have been formed for the purpose of generating and analyzing multiple data sources and have also developed analysis tools for specific research domains [
1,
2,
3,
4].
Here we focus on a gene-centric approach, wherein data from genes and their cis- regulatory regions are used to identify particular processes and phenotypes in which that gene plays a role. Although there have been many promising applications for this approach, such as annotating gene function [
5], or predicting genes associated with disease pathogenesis (e.g., Reference [
6]), we focus on predicting gene essentiality. An essential gene is required for the survival of an organism under a given biological context [
7,
8]. Because of this, identifying essential genes is important for understanding the basic principles of cellular function. In addition, essential genes can affect how synthetic microorganisms are engineered, and inform the development of effective antibiotics and other drugs [
9,
10]. Although often focused on model organisms such as bacteria and yeast, several recent studies have also sought to catalog gene essentiality in humans [
11].
Essential genes can be determined by a variety of experimental methods, and are reported in several databases [
12,
13]. Because of the expense and labor involved with the experimental approaches, computational methods have been developed for the purpose of predicting essential genes, and machine learning methods that rely on training a classifier using examples of essential genes have become a common strategy [
14,
15]. Several features have been used to predict essential genes including both features of the DNA sequence such as GC content, and measured or predicted features of the translated proteins such as hydrophobicity. See Dong et al. [
16] for a comprehensive summary of the features most commonly used for predicting essential features. The authors identify five most common classes of features: evolutionary conservation, domain information, network topology, sequence component, and expression level. Another recent review [
17] surveys how network topology is also used for predicting essential genes. All potential features may be expected to have some predictive value for essentiality, but many are not particularly strong predictors by themselves. By combining these measures, the hope is to predict essential genes with a much higher degree of sensitivity and specificity than would be possible with any one measure alone.
In many studies, genomic data integration has focused on supervised classification approaches which require high-quality training sets with both positive and negative controls [
18,
19,
20]. When available training data sets are small, unreliable, or incomplete, unsupervised methods are more commonly used [
21,
22,
23,
24]. However, even training data whose labels are too incomplete for supervised approaches can provide valuable information beyond unsupervised analysis. In this work, we describe the extension of the unsupervised methods first described in [
25] to allow the use of any available positively labeled training data, even if limited, for semi-supervised learning. Alexandridis et al. [
26] describe an
ad hoc method for semi-supervised mixture modeling with incomplete training data. We build on their work and the more rigorous approach of [
27] to develop semi-supervised hierarchical mixture models for any type of training data, specifically designed to deal with the case when only positive examples such as known essential genes are available, often called “positive unlabeled learning” or PUL [
28].
Specifically, we describe a mixture model for a single data source, followed by a hierarchical mixture model for multiple data sources (e.g., sequence based, expression). Using cross-validation runs to evaluate a real world genomic scenario where an investigator may only have a small number of known positive labels, we show that the inclusion of positively labeled samples in a semi-supervised learning framework in addition to the hierarchical mixture model improves our ability to detect genes of interest when there is a small training set. Although our case study is on gene essentiality, our framework is general for any gene-centric problem, or other unit such as a metabolite, with multiple data types characterizing the gene (or unit), and a small set of positive labels.
2. Methods
We use a generative mixture model approach to represent classes of genes such as essential vs. nonessential, with a hierarchical structure to represent different types of data and the relationships between them. Mixture models have a long history and a rigorous statistical framework for inference and prediction [
29]. Hierarchical mixture models have been applied in other contexts [
30] and in a variety of bioinformatic applications [
31,
32]. In this work, the model can be represented as a graph, where nodes represent random variables, which may be hidden or observed, and the edges represent the conditional dependence structure of the variables. This approach allows for simultaneous modeling of a wide range of data sources (continuous, categorical, etc.), with computationally efficient model fitting and easily interpretable results. To build up to the hierarchical model, we first describe an unsupervised method for single mixture models in
Section 2.1, and how that can be adapted to the semi-supervised method for single mixture models in
Section 2.3. Then we extend these ideas to hierarchical mixture models for data integration, both unsupervised and semi-supervised in
Section 2.4 and
Section 2.5, with the latter being our final model.
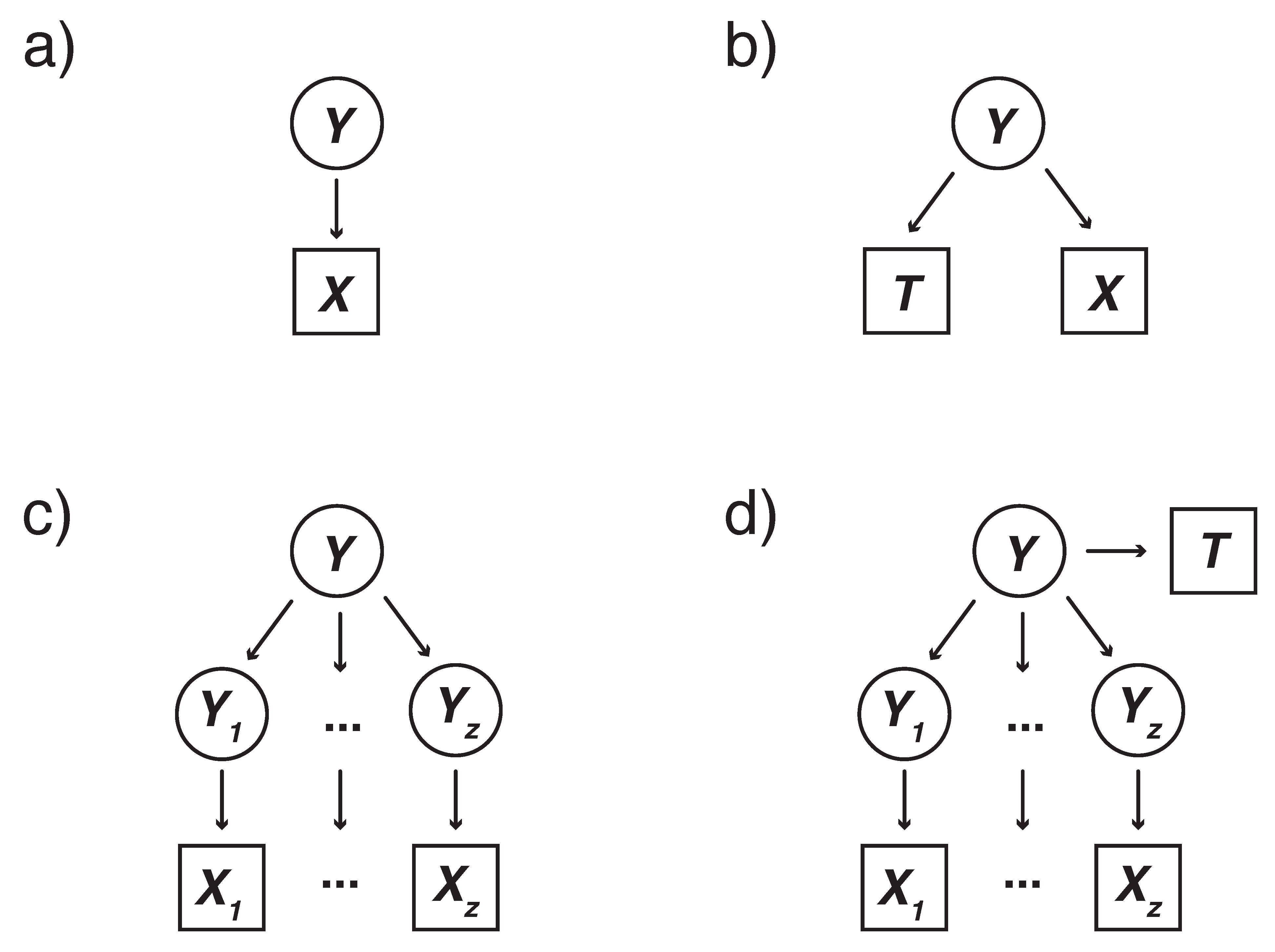
2.1. Single Mixture Model: Unsupervised Method
A
generative mixture model arises when we wish to model the distribution of one random variable
X, which depends on the value of another random variable
Y, so we say that
Y generates X. We assume
Y is a univariate categorical random variable that can take on one of
K categories (1, …,
K), while
X, which may be multivariate, can have any distribution. For notational compactness, let
, and
, with
and
. We also assume we observe
X, but not
Y—that is,
Y is
hidden. In our examples, typically
, for example “non-essential” versus “essential”. The model may also be represented graphically, as shown in
Figure 1a. Our challenge is to infer the parameters
(e.g., Gaussian mean and variance for each mixture component), which will allow us to calculate expected values for these hidden states. The joint density of
X and
Y is therefore
.
From this, for a sample
, we use the EM algorithm [
33,
34] to estimate the parameters and find the posterior probabilities
. Specifically, the EM algorithm finds the maximum likelihood estimate
by iterative maximization of the “Q-function”, or the conditional expected log-likelihood
where
is the previous iteration’s
i estimate for the parameters. For the current model,
where
Generally, is the posterior probability that given the data. In the problems at hand, is the posterior probability that gene n is essential given the particular data source being used.
Depending on the data type and the distribution, different functional forms for
f may be appropriate (e.g., discrete, continuous). In addition within a data type, different alternatives may be available. For example, the Poisson distribution may be compared to the negative binomial, and the Gaussian distribution may be compared to a longer tailed distribution like the Pearson Type VII distribution, which is a general class of distributions and contains the Student’s t distribution. For model selection among forms of
f, we use the integrated complete likelihood Bayesian information criterion (ICL-BIC) [
35] described in the
Supplementary Methods.
2.2. Training Data
For the essential gene problem, there may be a set of known essential genes for a particular organism. In many organisms this set may not be complete. Therefore, it may be useful to use information from the already identified essential genes to predict additional essential genes in an informed manner, which would improve prediction compared to a completely unsupervised approach. Ideally, supervised learning can be used, but in some cases there may not be both positive and negative examples, or the number of known essential genes may be small, therefore we focus on the semi-supervised training scenario. For the essential gene case study, the previously known essential genes are considered to be ‘labeled’ samples in our framework. The authors in [
26,
36] describe a method for including labeled data in the standard categorical mixture models, which we refer to here as the single mixture model: briefly, at the end of each E-step, update the posterior probabilities for the labeled samples based on their labels. For example, if the
nth gene is known to be in category 1 (
) then we would set
and
, regardless of the values of
calculated previously. The work in [
27] presents a more principled approach of incorporating training data into the model as an additional type of observed data, which they apply in a support vector machine (SVM) context. Here we apply their approach in a mixture model context to extend both the single and hierarchical mixture models, with an emphasis on the positive unlabeled learning (PUL) context in which only positive examples are known.
2.3. Single Mixture Model: Semi-Supervised Method
In the presence of partial training data, such as when only a few positive labels are known, we define a new random variable,
T, to represent the training labels, in addition to the observed data
X and hidden states
Y.
T is a categorical random variable that can take on the values from
, where
. If the training label is known for an observation, then
. When the training label is unknown for an observation, then
, which is always the case in the unsupervised model. In other words,
always, while
is a free parameter to be estimated. Let
be the
matrix such that
, and observe that the top
K rows of
are fixed at
, the
identity matrix, while the
th row is free:
subject to the constraint
. In contrast to fully supervised learning methods, this formulation allows us to estimate parameters using information from both labeled and unlabeled samples simultaneously, and also to make use of label information when only positive labels are available.
We incorporate the labels into the model as the sample
. For example, in our example application (
for “essential” or “non-essential”), we may have some genes known to be essential while others are of unknown binding status. Then for
,
when we know that the
mth gene is essential, while
when the status of the
nth gene is unknown. If we knew the
mth gene to be
non-essential, we would have
, but our analysis here does not consider the case of labeled negative samples. Conceptually,
Y generates both
T and
X; those samples for which
may be thought of as samples for which
Y is observed rather than hidden. We assume the values of
T are accurate, that is, there are no unlabeled samples. The model is illustrated graphically in
Figure 1b.
However, because of the fixed relationship between
Y and
, it is more practical to perform most of the calculations on the model as though
T generated
Y. To obtain
, we need only find the MLE for the
th row of
, that is,
. The joint density of all variables in the model is
or equivalently
where
, and the Q-function is
Here
, and after some simplification, the central calculation for the E-step is
The modeling of the observed data is the same as in the unsupervised case. By default, labeled samples are given the same weight as unlabeled samples in the parameter estimations. However, if we have a small training sample, we may choose to assign a higher weight
to labeled samples. We provide more information on the selection of weights in the
Supplementary Methods.
2.4. Hierarchical Mixture Model: Unsupervised Method
The previous model describes the case when there is only a single data type (e.g., one normally distributed variable) or a multivariate distribution of the same type (e.g., multivariate normal). We present a hierarchical mixture model extending the framework above for any number and types of genomic level data.
At the top of the hierarchies shown in
Figure 1c is the hidden categorical random variable
, which takes on integer values from 1 to
for some integer
. In the problem at hand, we assume
and
corresponds to essential genes. Next, let
Z denote the number of data sources, and
denote the
zth data source. The intermediate hidden categorical random variables
take on integer values from 1 to
for some integer
. The distributions of the
’s depend—directly or indirectly, depending on the model topology—on the value of
. We also define the observed random variables
(each
may be multivariate) where the distribution of
depends only on the value of
. That is, each
is generated by
. Each
generates
. This model treats all observed variables as equally important to estimating the distribution of
. We have explored alternative conditional relationships among the
Y’s in [
37].
Given
N genes, for
the estimated posterior probability that the
nth gene is of interest is
. Here
is the
nth hidden status variable, that is, a realization of
. Similarly,
is the hidden realization of
for the
nth gene, and
is the observed data for the
nth gene, with
being a realization of
. Finally,
denotes the estimated parameters of the model. See the
Supplementary Methods for full details of the estimation procedure. Briefly, the first step in the hierarchical model fitting is to fit a single mixture model to each data source, as described in the previous section, and choose the number of components
and marginal distribution which will be used for that data source. These steps follow the EM algorithm described above, and are used for initialization; the individual model fits can be updated in the full algorithm. Then after the marginal distributions are selected, this is used for initialization of the EM algorithm for the full model. The E-step consists of finding the posterior probabilities, given the data and current iteration of
, for the hidden states
for all data sources
z, and for the primary hidden state
. The M-step is a straightforward maximum likelihood estimation for the parameters
, the marginal distribution of
, and conditional relationships among the hidden variables
. More details are provided in the
Supplementary Methods.
2.5. Hierarchical Mixture Model: Semi-Supervised Method
We may add
T to the hierarchical models in the same way as to the single mixture model, producing the hierarchical model topologies seen in
Figure 1d. The main difference between
T and the
’s in this scenario is that there is no intermediate hidden variable corresponding to
T, but rather
T is generated directly by
. In the
Supplementary Methods we provide the details on the corresponding EM algorithm. This method constitutes our final semi-supervised hierarchical method and is abbreviated as Semi-HM.
2.6. Essentiality Application
2.6.1. Feature Description
Multiple data sources have been used to predict essential genes within a species including both features of the DNA sequence such as GC content, and measured and predicted features of the proteins translated from the genes, such as hydrophobicity and subcellular localization. All of the features may be expected to be have predictive value for essentiality, but many are not particularly strong predictors. By combining these measures, the hope is to predict essential genes with a much higher degree of sensitivity and specificity than would be possible with any one measure alone. For example, Liu et al. [
38] and Guo et al. [
39] have shown the high accuracy of using sequence features for predicting bacterial and human essential genes, respectively. To predict essentiality of the genes in
S. cerevisiae, our analysis uses features associated with each gene from two sources: (1) fourteen sequence-derived features from [
18] and (2) eight additional features from the Ensembl website [
40]. Feature definitions are listed in
Table 1. A total of 3 of 22 features (vacuole, in how many of five proks blast and intron) were removed from the analysis due to low content (less than 5% of non-zero values), for a final number of 19 features.
2.6.2. Cross-Validation Strategy: Unsupervised
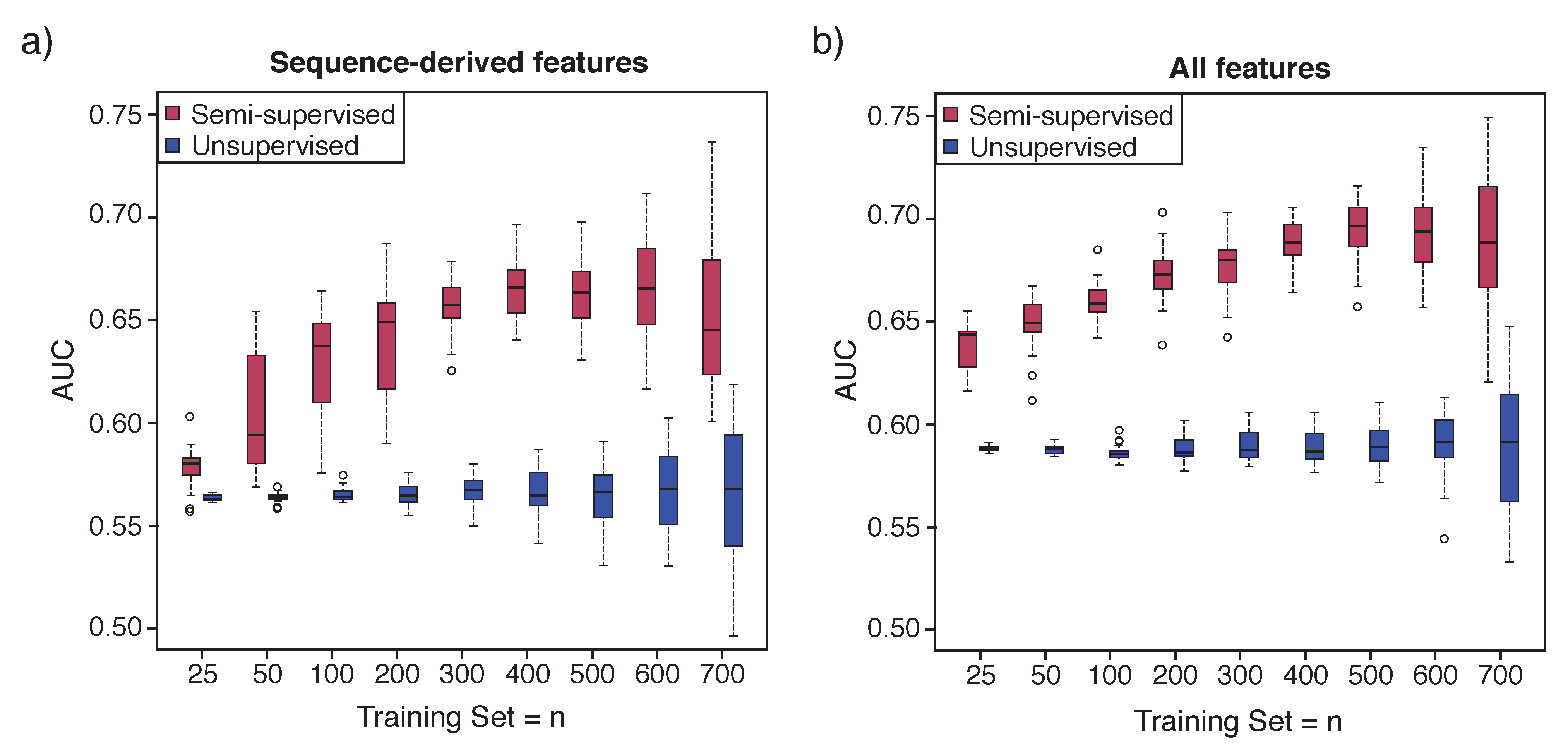
First, for the hierarchical mixture model, the semi-supervised version
Figure 1, Model 1d was compared to the unsupervised version
Figure 1, Model 1c described in Dvorkin et al. [
25]. For the semi-supervised method, we started with the set of 769 essential genes (positive labels) of the total 3500 genes. We performed cross-validation with a range of training set sizes with minimum training set size of 25, chosen to be greater than the number of features to prevent rank deficiency in training sets. For each training set
n size, we randomly sampled
n essential genes (
n = 25 to 700 in increments of 5). Multiple iterations (
I = 30) were run to average metrics used to evaluate performance. For the unsupervised method, there is no training set since no information is used to cluster genes. We used
to find two clusters, and then the cluster with the highest percentage of essential genes was considered the set of genes predicted as essential, and the other cluster was considered the set of genes predicted as non-essential. We then evaluated prediction performance on the same set of test genes used for the semi-supervised comparison. This procedure was repeated multiple iterations as described above.
2.6.3. Cross-Validation Strategy: Supervised
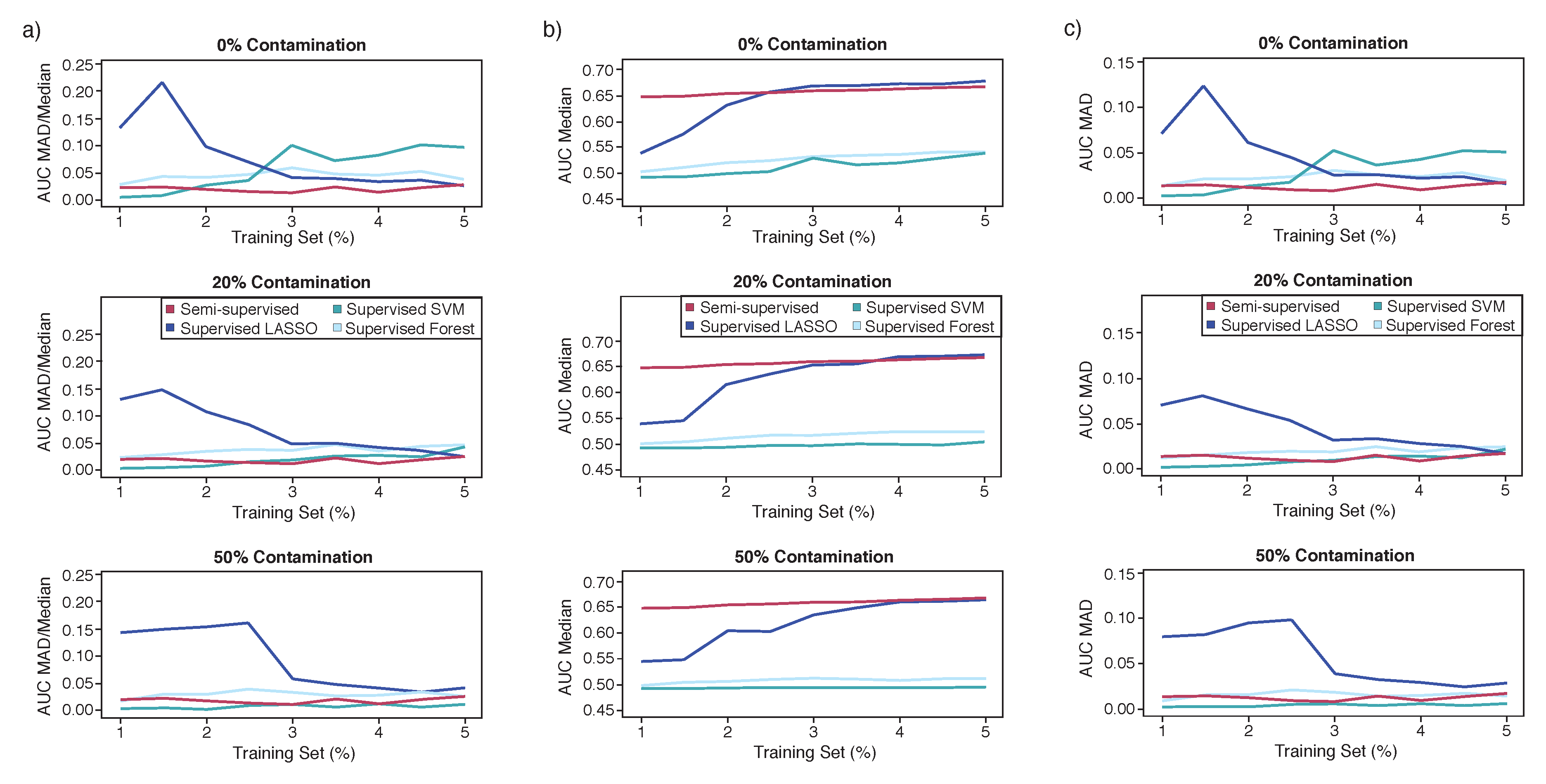
Second, the semi-supervised hierarchical mixture model was compared with other supervised methods. Supervised methods are often used to predict gene essentiality, and require both positive and negative labels. Because of the extensive experimental studies in the yeast
S. cerevisiae, we have a comprehensive catalog of essentiality in this model organism. However, in other organisms, we may only have experimental data on a handful of essential genes, which define our known positive labels to be used to predict additional essential genes. In many supervised methods for essentiality, all non-labeled genes are considered to be ‘negatives’ (i.e., non-essential). However, this set may contain additional essential genes, where genes labeled as non-essential may in fact be essential, but have not been confirmed for essentiality yet. That is, these are the yet to be discovered essential genes that are usually considered to be ‘negatives’, when applying supervised methods. We argue this to be the more probable scenario in the essentiality classification because the likelihood of yeast surviving with a knock-out of a truly essential gene regardless of laboratory conditions is nearly zero. Yet, poor nutrient media, uncontrolled temperature regulation during growth phase, or an unknown, unintentional intervention may result in the misclassification from essential to non-essential. Therefore, this results in a situation where essential genes are always labeled positive but a subset of non-essential genes may change status to essential, so they were initially incorrectly labeled as negative. For comparisons with the supervised methods, therefore we introduced this type of contamination, i.e., genes incorrectly labeled as negative, but which are in fact positive (
Figure 2). Contamination only affects the negative labels and therefore does not play a role in either unsupervised or semi-supervised methods, but may affect supervised methods.
The cross-validation strategy for the supervised case incorporates an unbalanced strategy to the test set along with a contamination rate, which are described below (
Figure 2). For an unbalanced design, test sets utilize the remaining genes not used in the training sets rather than a balanced strategy which matches training and testing set sizes. The unbalanced strategy was chosen because, in practice, an investigator would typically want to test all the remaining genes for essentiality rather than just a subset of genes.
Semi-supervised was compared against three supervised methods (LASSO, SVM, and Random Forests [
41,
42,
43]) at low training set sizes. Performance of these four methods was compared across training set sizes between 1% (
n = 35) and 10% (
n = 350) from all 3500 genes. Genes randomly chosen for the supervised training sets reflect the same ratio of positive and negative labels as seen in the full data set. Among the 3500 yeast genes, there are 769 essential genes resulting in a 21% ratio. As an example, at 1% training size, 35 randomly chosen genes contained 7 positive labels (21% of 35) and 28 negative labels for supervised methods, while semi-supervised methods were trained on the
same training set size, which would be 35 positively labeled genes for this example. We also performed a secondary analysis where the semi-supervised methods had a training set with the
same number of positive labeled genes, which would be seven in this example.
In order to mimic contamination, negative labels were reassigned a positive label at rates of 0%, 20%, and 50%. The 20% contamination would correspond to an organism with overall essential gene counts like S. cerevisiae, where the 50% contamination is considered as an extreme example to look at trends in performance due to contamination.
For all results, unique initial seeds were chosen based on the iteration number, training set size, and contamination (for supervised comparison only). Results were summarized over 100 iterations of random sampling. Once the cross-validation data were generated by a seed, the same data were used to compare each method.
2.6.4. Cross-Validation Strategy: Semi-Supervised
As a final comparison, we also evaluated Semi-HM compared to another semi-supervised PUL approach that does not group variables for data integration. We searched the CRAN R package repository for alternative semi-supervised approaches. However, most packages in CRAN are focused on unsupervised or supervised approaches, but there was a recent package AdaSampling [
44,
45] focused on the PUL problem and utilizes prediction probabilities from a model to iteratively update the unlabeled training data using a variety of different learners. For Semi-HM we applied the same training set selection procedure described above. For AdaSampling, we made adjustments for the training set selection procedure since it requires additional unlabeled data as part of the iterative training process. After setting a percentage of genes positive labels were chosen (e.g., 5% for both Semi-HM and AdaSampling), we randomly selected the same number of negatively labeled genes to be ‘unlabeled’, in addition to a random set of ‘unlabeled’ genes from all other genes using different sizes. For example, for 5% training set size, 175 known positive genes were used for training and the ‘unlabeled’ set consisted of 175 negative genes, and additional genes selected randomly from all other genes (sizes of 50, 100, 300, or 600 were chosen). Performance was assessed on all other genes not included in this process. As classifiers, we tried K Nearest Neighbors (KNN) or logistic regression, which were built into the package. We ran a single classifier, rather than the ensemble approach also available in the package, to be more comparable to Semi-HM.
2.6.5. Algorithms
All cross-validation runs were performed in R version 3.3.3. The semi-supervised and unsupervised analyses detailed in this work utilized functions from the lcmix package. The lcmix package developed and implemented in [
25] can be downloaded from
http://r-forge.r-project.org/projects/lcmix/ (accessed on 13 May 2021). The other semi-supervised method was performed using the AdaSampling package in R. LASSO was performed using the glmnet command in the glmnet package [
46]. Using cv.glmnet, k-fold cross validation optimized the minimum lambda for the LASSO function. SVM analysis used the svm command under the e1071 package [
47]. Various runs using different criteria revealed that a radial kernel density and C-classification optimized performance. Random Forest was performed with the randomForest command under the randomForest package [
48].
2.6.6. Performance
The area under the curve (AUC) was determined using the ROC curve (1-specificity by sensitivity). Then the AUC mean, AUC variance, and a robust coefficient of variation (AUC median absolute deviation/AUC median) of the three supervised methods were contrasted against the semi-supervised method. Because LASSO outperformed the other supervised models in AUC across all training set sizes and contamination rates, a closer evaluation of its performance was compared with the semi-supervised method. In order to fairly compare LASSO performance to the semi-supervised method, the prediction scores were re-scaled to be between 0 and 1. Precision, recall, and f-measure further discriminated the two methods with four rescaled prediction score cutoffs including the median and prediction scores of 0.5, 0.8, and 0.95. The median cutoff is a relative measure based on the data while the other three cutoffs are absolute. The f-measure was calculated from the average precision and recall at each training set size from 1% to 5%.
2.6.7. Gene Enrichment in Saccharomyces cerevisiae
Semi-HM was run using a 10% training size and a posterior probability cutoff of 95% to identify genes as true positives. Enrichment analysis was performed using the Panther Pathway Classification System [
49].
2.6.8. Discovery of Essential Genes in Saccharomyces mikatae
The
Saccharomyces mikatae genome is not as well annotated as the
Saccharomyces cerevisiae genome. Thus, the goal of this application was to show how we can use a more annotated genome to train the model and then use the trained model to make predictions of essentiality on a less annotated genome. Therefore, there were no essentiality labels from the database available, but based on our predictions. Then, we found the orthologs of the predicted genes in
S. cerevisiae, where there is annotation, and performed enrichment analysis. Fourteen sequence-derived features were downloaded from the Saccharomyces Genome Database [
50] for
S. mikatae. One variable, ‘close_stop_ratio’, was removed from analysis due to collinearity with other features. The fitted model from 3500
S. cerevisiae genes was applied to 4551
S. mikatae genes to determine essentiality with a posterior probability cutoff selected visually using the density plot of the posterior probabilities. The cutoff was selected based on the value that separated the bimodal peaks in the density plot. A gene enrichment analysis summarized the predicted essential genes for
S. mikatae. To investigate which biological pathways and processes that the
S. mikatae open reading frames (ORF) predicted to be essential are involved in, we performed gene enrichment analysis. First, we used the data reported in Seringhaus et al. [
18] to identify homologs for each of the ORFs predicted to be essential in our analysis. We used the online Gene Ontology tool [
51] to perform enrichment analysis using the Fisher’s test and false discovery (FDR) option.
2.6.9. Availability of Data and Material
The datasets analyzed in this current study are available from [
18,
52] and the following repositories [
40,
53].
4. Discussion
The focus of the cross-validation runs was to evaluate a real world genomic scenario where an investigator may only have a small number of known positive labels. We compared the semi-supervised hierarchical mixture model to unsupervised, semi-supervised, and supervised methods with multiple data types. Our results indicate that the combination of a hierarchical mixture model and a semi-supervised approach (Semi-HM) improves prediction compared to using one or the other (hierarchical mixture model or semi-supervised). In summary, there were three comparisons. The first comparison (unsupervised method,
Figure 3) focuses on the semi-supervised component by comparing a hierarchical mixture model with or without semi-supervised learning. The second comparison (supervised method,
Figure 4,
Figure 5,
Figure 6 and
Figure 7) focuses on both components by comparing the hierarchical mixture model and semi-supervised method with leading supervised methods that do not rely on hierarchical mixture models. Although both components are changing, we believe it is important to include a comparison with supervised methods because they are a standard in many applications even with small training sets. Finally the third comparison (semi-supervised,
Supplementary Figure S4), focuses on the hierarchical mixture model component by comparing semi-supervised approaches with or without the hierarchical mixture model.
Not unexpectedly because it uses partial information, Semi-HM outperformed the corresponding unsupervised method across a wide range of training set sizes of the essential genes, and data sources. Although Semi-HM outperforms the unsupervised version by utilizing the knowledge of having positive labels, it comes at the cost of some computational time.
For comparisons with the supervised methods, we introduced contamination, by falsely labeling positive genes as negative and not the reverse. We argue this to be the more probable scenario in the essentiality classification because in many prediction methods, all non-known essential genes are treated as negatives (non-essential), but they may in fact be positives (essential) but have not been confirmed yet. Contamination does not play a role in either unsupervised or semi-supervised methods, but may affect supervised methods. Contaminated negative labels causes decreased AUC in the supervised algorithms (
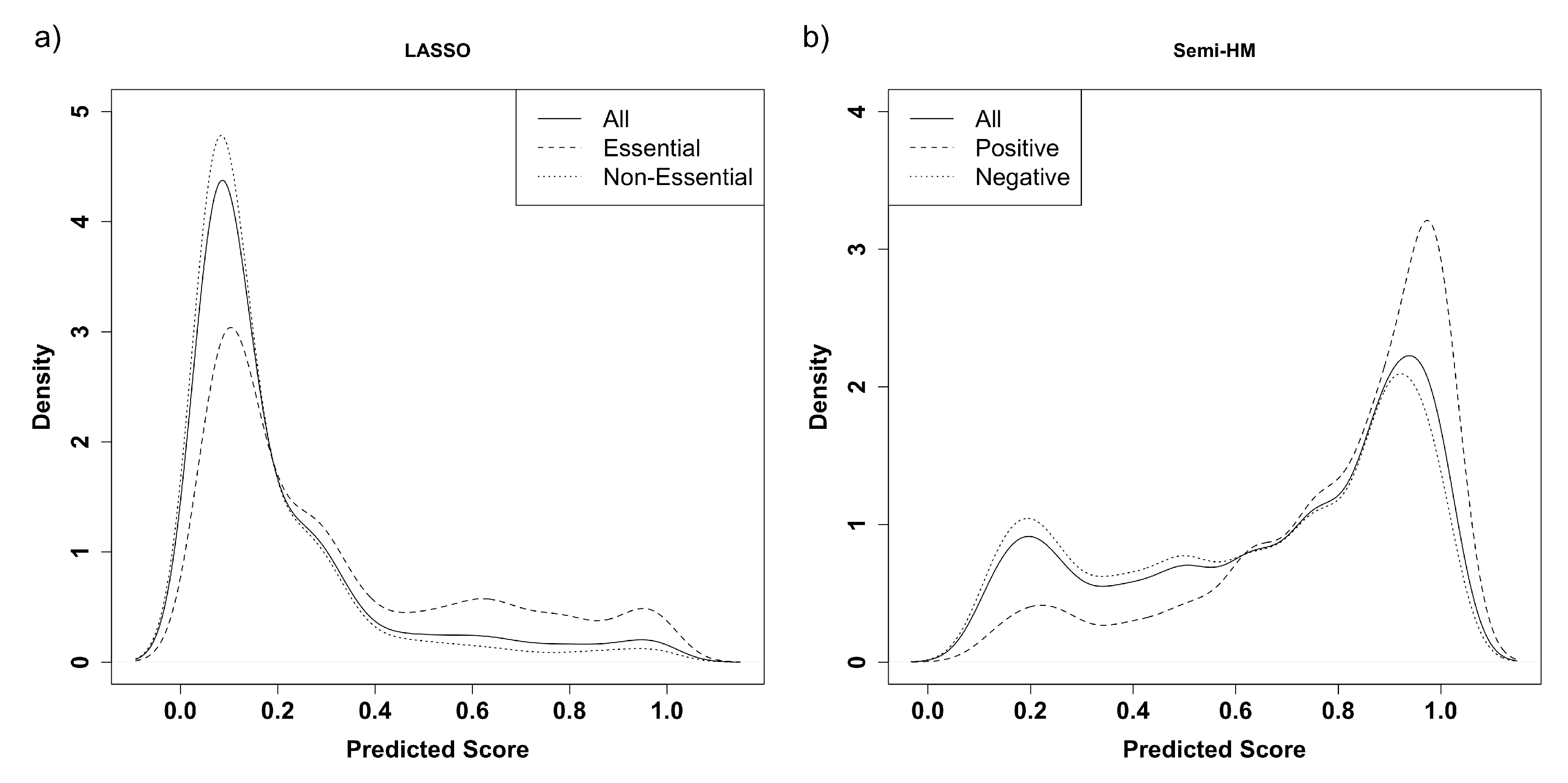
Figure 4). However, regardless of contamination rates, the prediction scores for Semi-HM outperformed LASSO in AUC and f-measure at training set sizes below 3%. Furthermore, for these cases, the supervised methods such as LASSO displayed uni-modal distributions of their predicted probabilities. In contrast, the multi-modality of our semi-supervised prediction scores provides a more natural cutoff than the uni-modal distribution displayed by LASSO in
Figure 6.
There are alternative semi-supervised methods reviewed in [
55]. These methods typically rely on “self-training”, where a supervised classifier is trained on the limited available labeled data, then unlabeled observations are classified. The classifier is then updated based on both the known labels and new predicted labels and this procedure is repeated iteratively until convergence (e.g., Reference [
56]). Other methods designed for “positive unlabeled learning” (PUL) identify a set of “reliable” negative observations from the unlabeled data based on features specific to the positive set or other heuristics, and then iteratively repeat the training and prediction process (e.g., References [
57,
58]). We applied a method designed for PUL called AdaSampling [
44,
45] and found, as with the previous comparisons, that Semi-HM which relies on hierarchical mixture modeling of predictors shows advantages over other methods when the training set is small.
In general, predicting gene essentiality is challenging as we only observed up to 0.70 for the largest AUC in any of our results. Each of the individual predictors AUC is relatively low, but integrating multiple weak predictors helps performance. Performance for predicting gene essentiality in bacterial species tends to be higher 0.80–0.90 (e.g., References [
38,
59,
60,
61]). For yeast, we find that AUC values tend to be lower than for bacterial species. Values range from 0.55 to 0.69 [
62], 0.65 to 0.75 [
63], 0.77 [
64], 0.75 to 0.79 [
54], and 0.82 [
65]. We have primarily used sequenced based features, with the exception of one expression feature. Some of the cited methods with higher observed AUC use alternative features (e.g., network topology, gene ontology-based features, more gene expression) and larger training set sizes. Our method can be improved by exploring some of these alternative features (see recent review [
66]), as was seen in
Figure 3 where an expanded feature set provided modest improvement in overall mean and variance of the AUC. Furthermore, exploration of what types of genes are misclassified (
Tables S1 and S2) may help suggest the types of features that should be included. However, we specifically focus on the problem of a small positive training set, which occurs in other types of bioinformatics problems. For example, another motivating problem is the prediction of transcription factor target genes based on expression data, DNA binding data and conservation [
25]. In that case, there were only 117 known genes regulated in the relevant pathway out of 13,326
Drosophila melanogaster genes, corresponding to 1%, which would be considered a relatively small training set, where Semi-HM shows advantages over other strategies under model misspecification [
25].
Finally, we demonstrate an application of Semi-HM where it was trained in a well annotated genome (
S. cerevisiae) and then used to predict essential genes in a less annotated genome (
S. mikatae). There is no gold standard to evaluate performance so we used the enrichment analysis to explore the results, which indicated genes relevant to essentiality. However, most of the genes predicted to be essential in
S. mikatae did not have homologs that were essential genes in
S. cerevisiae, which may be explained by a variety of factors including imperfect homology determination. Without a gold standard we cannot benchmark performance but include this analysis as a demonstration, which may be improved within the Semi-HM framework by using additional variables as discussed above (only sequence-derived were used for this demonstration), by using ensemble learning as in [
45], and by incorporating imbalanced learning principles [
67] since there are fewer essential genes compared to non-essential genes.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}