
Discovery of Novel eEF2K Inhibitors Using HTS Fingerprint Generated from Predicted Profiling of Compound-Protein Interactions


Abstract
:1. Introduction
2. Materials and Methods
2.1. Compounds
2.2. CGBFP
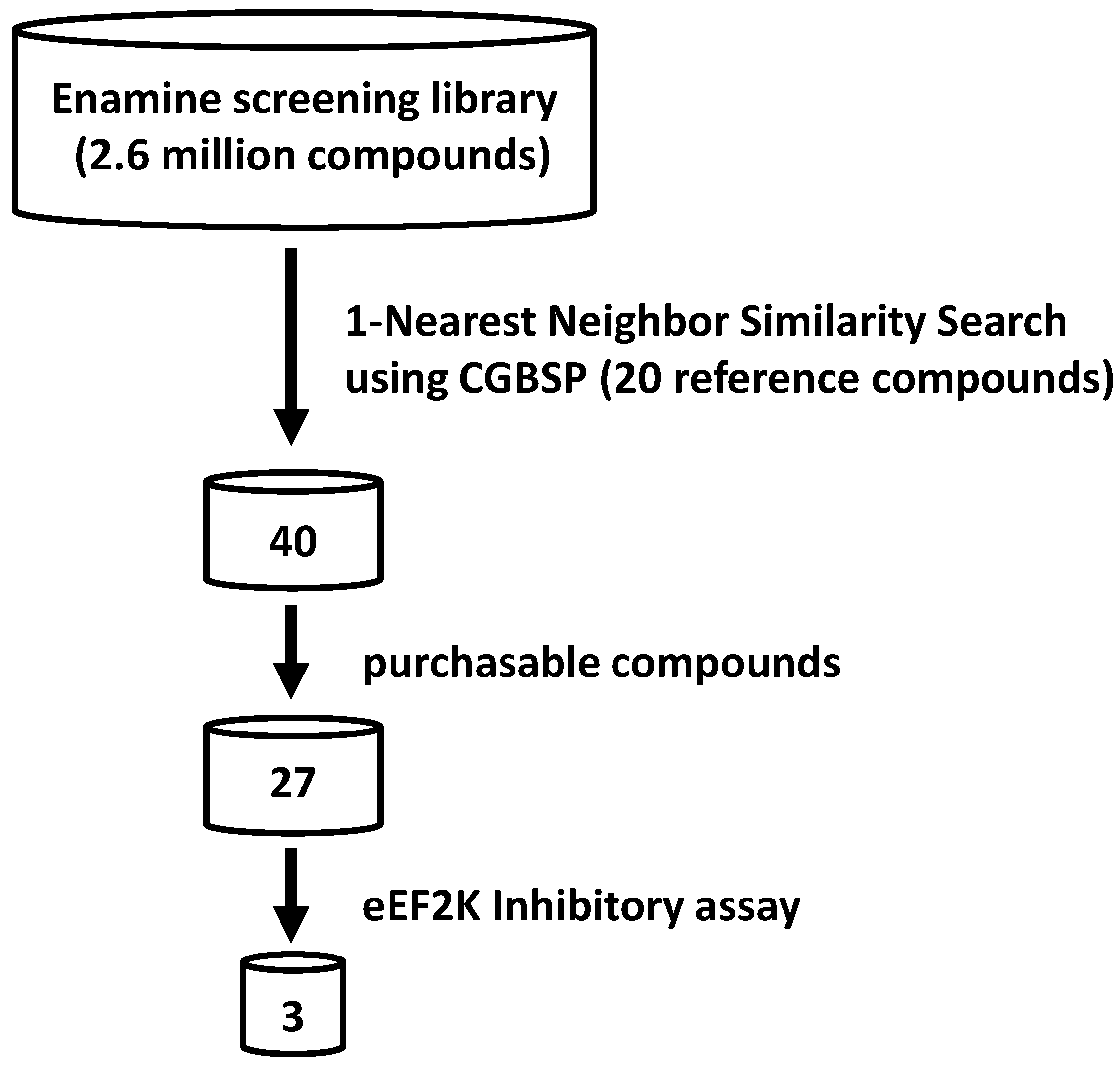
2.3. Virtual Screening Using CGBSP
2.4. In Vitro eEF2K Assay
2.5. Molecular Docking
3. Results
3.1. Concept of CGBFP
3.2. Virtual Screening Using CGBSP
- (1)
- CGBFPs are computationally generated; therefore, it has no missing information principally caused by the absence of assay data usually seen with HTSFP.
- (2)
- Generation of CGBFPs can be performed for all compounds, in contrast to HTSFP, which can only be performed for previously tested compounds in HTS assays.
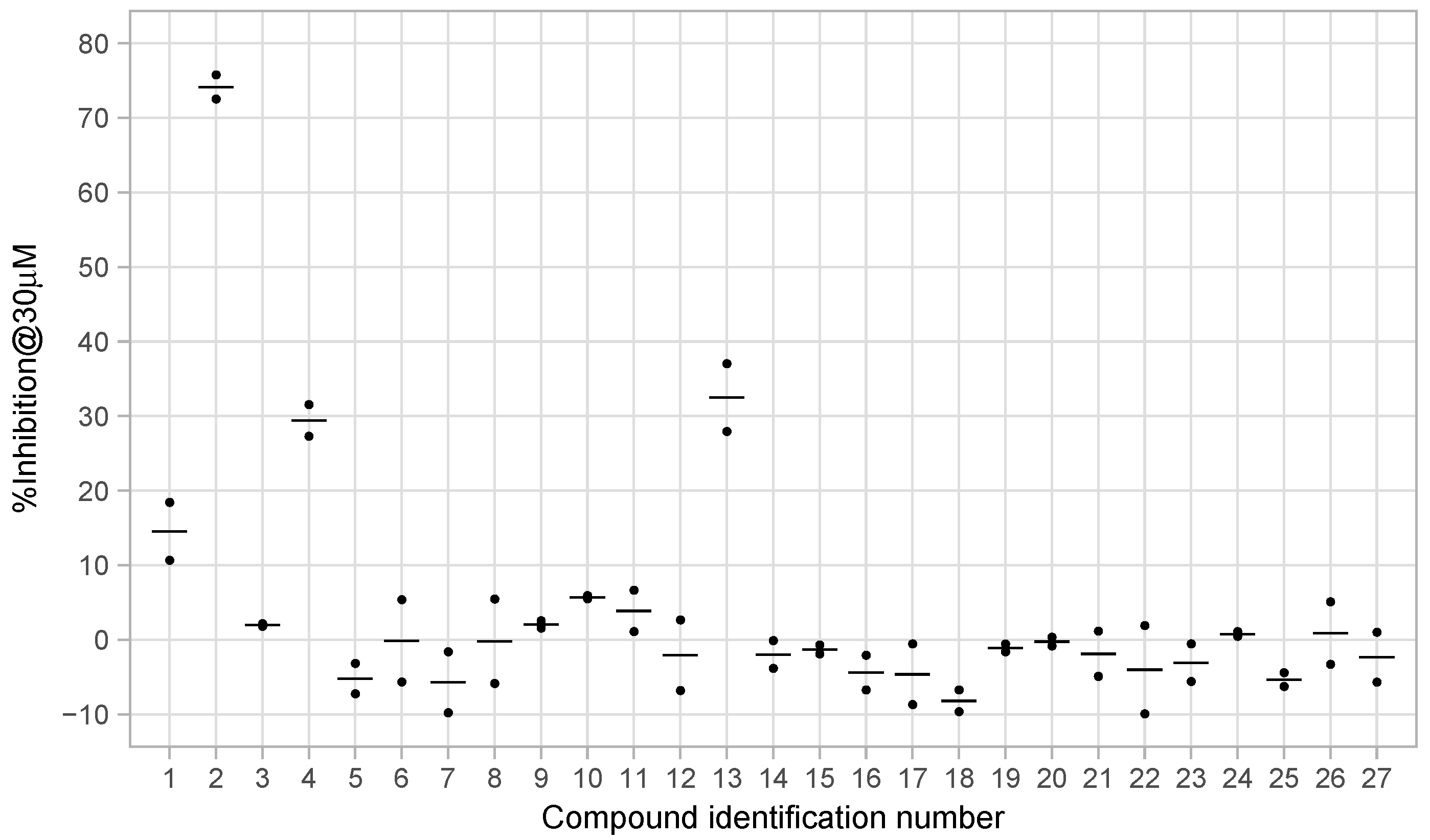
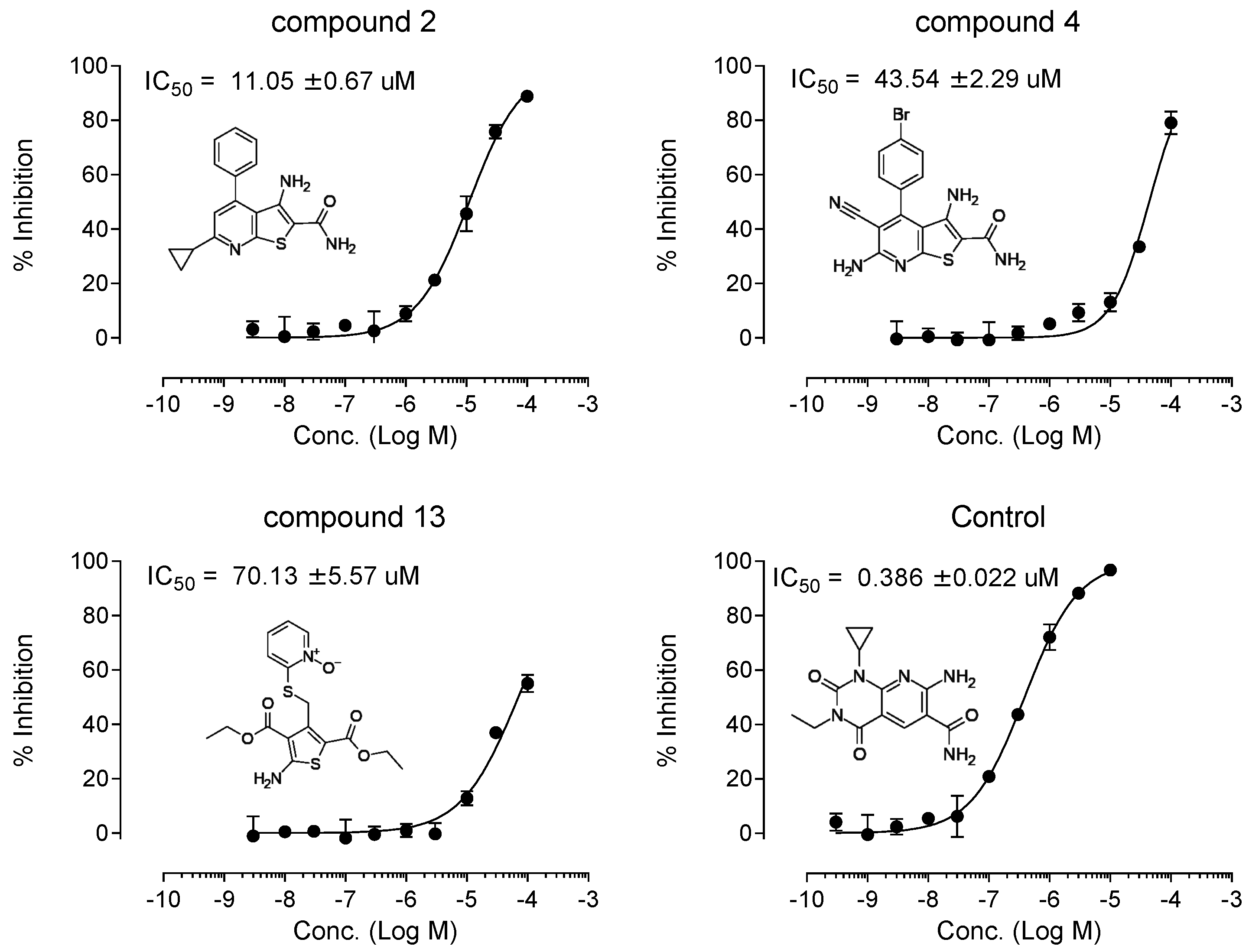
3.3. Enzyme Inhibition Assays
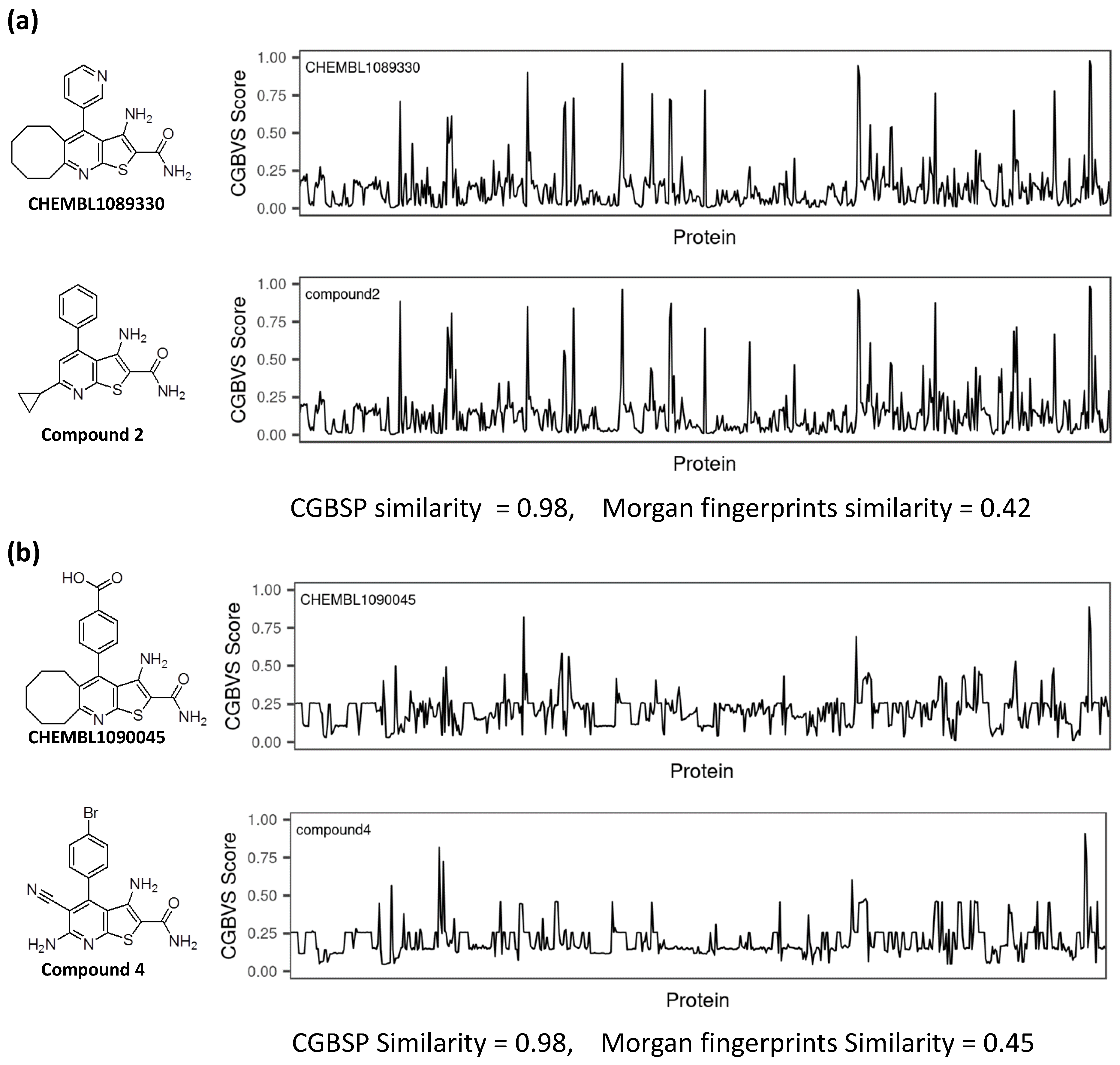
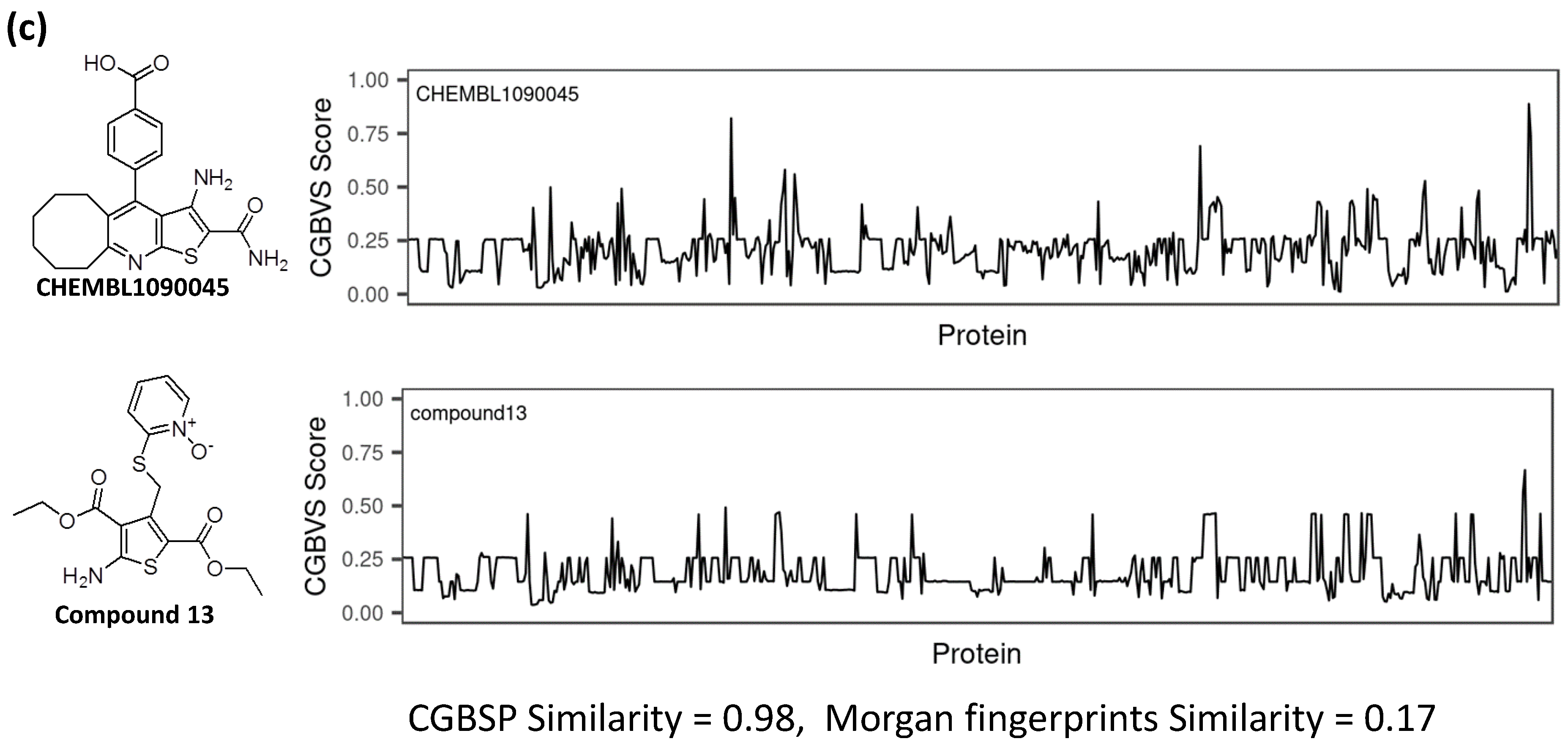
3.4. Comparison of CGBFP Profiles between Reference and Hit Compound
3.5. Molecular Docking Study
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schwanhäusser, B.; Busse, D.; Li, N.; Dittmar, G.; Schuchhardt, J.; Wolf, J.; Chen, W.; Selbach, M. Global quantification of mammalian gene expression control. Nature 2011, 473, 337–342. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kenney, J.W.; Moore, C.E.; Wang, X.; Proud, C.G. Eukaryotic elongation factor 2 kinase, an unusual enzyme with multiple roles. Adv. Biol. Regul. 2014, 55, 15–27. [Google Scholar] [CrossRef] [PubMed]
- Tavares, C.D.; O’Brien, J.P.; Abramczyk, O.; Devkota, A.K.; Shores, K.S.; Ferguson, S.B.; Kaoud, T.S.; Warthaka, M.; Marshall, K.D.; Keller, K.M.; et al. Calcium/calmodulin stimulates the autophosphorylation of elongation factor 2 kinase on Thr-348 and Ser-500 to regulate its activity and calcium dependence. Biochemistry 2012, 51, 2232–2245. [Google Scholar] [CrossRef] [Green Version]
- Ryazanov, A.G.; Shestakova, E.A.; Natapov, P.G. Phosphorylation of elongation factor 2 by EF-2 kinase affects rate of translation. Nature 1988, 334, 170–173. [Google Scholar] [CrossRef]
- Carlberg, U.; Nilsson, A.; Nygård, O. Functional properties of phosphorylated elongation factor 2. Eur. J. Biochem. 1990, 191, 639–645. [Google Scholar] [CrossRef]
- Wang, X.; Xie, J.; Proud, C.G. Eukaryotic elongation factor 2 kinase (eEF2K) in cancer. Cancers 2017, 9, 162. [Google Scholar] [CrossRef] [Green Version]
- Kameshima, S.; Kazama, K.; Okada, M.; Yamawaki, H. Eukaryotic elongation factor 2 kinase mediates monocrotaline-induced pulmonary arterial hypertension via reactive oxygen species-dependent vascular remodeling. Am. J. Physiol. Heart Circ. Physiol. 2015, 308, H1298–H1305. [Google Scholar] [CrossRef] [Green Version]
- Jan, A.; Jansonius, B.; Delaidelli, A.; Somasekharan, S.P.; Vandal, M.; Negri, G.L.; Moerman, D.; MacKenzie, I.; Calon, F.; Hayden, M.R.; et al. eEF2K inhibition blocks Aβ42 neurotoxicity by promoting an NRF2 antioxidant response. Acta Neuropathol. Commun. 2017, 133, 101–119. [Google Scholar] [CrossRef]
- Middelbeek, J.; Clark, K.; Venselaar, H.; Huynen, M.A.; Van Leeuwen, F.N. The alpha-kinase family: An exceptional branch on the protein kinase tree. Cell. Mol. Life Sci. 2010, 67, 875–890. [Google Scholar] [CrossRef] [Green Version]
- Gschwendt, M.; Kittstein, W.; Marks, F. Elongation factor-2 kinase: Effective inhibition by the novel protein kinase inhibitor rottlerin and relative insensitivity towards staurosporine. FEBS Lett. 1994, 338, 85–88. [Google Scholar] [CrossRef] [Green Version]
- Arora, S.; Yang, J.M.; Kinzy, T.G.; Utsumi, R.; Okamoto, T.; Kitayama, T.; Ortiz, P.A.; Hait, W.N. Identification and characterization of an inhibitor of eukaryotic elongation factor 2 kinase against human cancer cell lines. Cancer Res. 2003, 63, 6894–6899. [Google Scholar] [PubMed]
- Chen, Z.; Gopalakrishnan, S.M.; Bui, M.H.; Soni, N.B.; Warrior, U.; Johnson, E.F.; Donnelly, J.B.; Glaser, K.B. 1-Benzyl-3-cetyl-2-methylimidazolium iodide (NH125) induces phosphorylation of eukaryotic elongation factor-2 (eEF2): A cautionary note on the anticancer mechanism of an eEF2 kinase inhibitor. J. Biol. Chem. 2011, 286, 43951–43958. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Devkota, A.K.; Warthaka, M.; Edupuganti, R.; Tavares, C.D.; Johnson, W.H.; Ozpolat, B.; Cho, E.J.; Dalby, K.N. High-throughput screens for eEF-2 kinase. J. Biomol. Screen. 2014, 19, 445–452. [Google Scholar] [CrossRef] [Green Version]
- Cho, S.I.; Koketsu, M.; Ishihara, H.; Matsushita, M.; Nairn, A.C.; Fukazawa, H.; Uehara, Y. Novel compounds,‘1, 3-selenazine derivatives’ as specific inhibitors of eukaryotic elongation factor-2 kinase. BBA-GEN Subj. 2000, 1475, 207–215. [Google Scholar] [CrossRef]
- Lockman, J.W.; Reeder, M.D.; Suzuki, K.; Ostanin, K.; Hoff, R.; Bhoite, L.; Austin, H.; Baichwal, V.; Willardsen, J.A. Inhibition of eEF2-K by thieno [2, 3-b] pyridine analogues. Bioorg. Med. Chem. Lett. 2010, 20, 2283–2286. [Google Scholar] [CrossRef]
- Hori, H.; Nagasawa, H.; Ishibashi, M.; Uto, Y.; Hirata, A.; Saijo, K.; Ohkura, K.; Kirk, K.L.; Uehara, Y. TX-1123: An antitumor 2-hydroxyarylidene-4-cyclopentene-1, 3-dione as a protein tyrosine kinase inhibitor having low mitochondrial toxicity. Bioorg. Med. Chem. 2002, 10, 3257–3265. [Google Scholar] [CrossRef]
- Petrone, P.M.; Simms, B.; Nigsch, F.; Lounkine, E.; Kutchukian, P.; Cornett, A.; Deng, Z.; Davies, J.W.; Jenkins, J.L.; Glick, M. Rethinking molecular similarity: Comparing compounds on the basis of biological activity. ACS Chem. Biol. 2012, 7, 1399–1409. [Google Scholar] [CrossRef]
- Riniker, S.; Wang, Y.; Jenkins, J.L.; Landrum, G.A. Using information from historical high-throughput screens to predict active compounds. J. Chem. Inf. Model. 2014, 54, 1880–1891. [Google Scholar] [CrossRef]
- Wassermann, A.M.; Lounkine, E.; Urban, L.; Whitebread, S.; Chen, S.; Hughes, K.; Guo, H.; Kutlina, E.; Fekete, A.; Klumpp, M.; et al. A screening pattern recognition method finds new and divergent targets for drugs and natural products. ACS Chemical. Biol. 2014, 9, 1622–1631. [Google Scholar] [CrossRef]
- Wassermann, A.M.; Kutchukian, P.S.; Lounkine, E.; Luethi, T.; Hamon, J.; Bocker, M.T.; Malik, H.A.; Cowan-Jacob, S.W.; Glick, M. Efficient search of chemical space: Navigating from fragments to structurally diverse chemotypes. J. Med. Chem. 2013, 56, 8879–8891. [Google Scholar] [CrossRef]
- Helal, K.Y.; Maciejewski, M.; Gregori-Puigjane, E.; Glick, M.; Wassermann, A.M. Public domain HTS fingerprints: Design and evaluation of compound bioactivity profiles from PubChem’s bioassay repository. J. Chem. Inf. Model. 2016, 56, 390–398. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Bolton, E.; Dracheva, S.; Karapetyan, K.; Shoemaker, B.A.; Suzek, T.O.; Wang, J.; Xiao, J.; Zhang, J.; Bryant, S.H. An overview of the PubChem BioAssay resource. Nucleic Acids Res. 2010, 38, D255–D266. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheng, T.; Li, Q.; Wang, Y.; Bryant, S.H. Identifying compound-target associations by combining bioactivity profile similarity search and public databases mining. J. Chem. Inf. Model. 2011, 51, 2440–2448. [Google Scholar] [CrossRef]
- Cortes Cabrera, A.; Lucena-Agell, D.; Redondo-Horcajo, M.; Barasoain, I.; Díaz, J.F.; Fasching, B.; Petrone, P.M. Aggregated compound biological signatures facilitate phenotypic drug discovery and target elucidation. ACS Chem. Biol. 2016, 11, 3024–3034. [Google Scholar] [CrossRef]
- Yabuuchi, H.; Niijima, S.; Takematsu, H.; Ida, T.; Hirokawa, T.; Hara, T.; Ogawa, T.; Minowa, Y.; Tsujimoto, G.; Okuno, Y. Analysis of multiple compound-protein interactions reveals novel bioactive molecules. Mol. Syst. Biol. 2014, 7, 472. [Google Scholar] [CrossRef]
- Brown, J.; Okuno, Y. Systems biology and systems chemistry: New directions for drug discovery. Chem. Biol. 2012, 19, 23–28. [Google Scholar] [CrossRef] [Green Version]
- INTAGE Healthcare Inc. CzeekS. Available online: https://www.intage-healthcare.co.jp/service/data-science/insilico/czeeks/ (accessed on 19 April 2021).
- Willett, P.; Barnard, J.M.; Downs, G.M. Chemical similarity searching. J. Chem. Inf. Comput. Sci. 1998, 38, 983–996. [Google Scholar] [CrossRef] [Green Version]
- Mendez, D.; Gaulton, A.; Bento, A.P.; Chambers, J.; De Veij, M.; Felix, E.; Magarinos, M.P.; Mosquera, J.F.; Mutowo, P.; Nowotka, M.; et al. ChEMBL: Towards direct deposition of bioassay data. Nucleic Acids Res. 2019, 47, D930–D940. [Google Scholar] [CrossRef]
- Hert, J.; Willett, P.; Wilton, D.J.; Acklin, P.; Azzaoui, K.; Jacoby, E.; Schuffenhauer, A. Comparison of fingerprint-based methods for virtual screening using multiple bioactive reference structures. J. Chem. Inf. Comput. Sci. 2004, 44, 1177–1185. [Google Scholar] [CrossRef]
- GraphPad Software. GraphPad Prism Version 9.0.2. Available online: https://www.graphpad.com (accessed on 19 April 2021).
- Waterhouse, A.; Bertoni, M.; Bienert, S.; Studer, G.; Tauriello, G.; Gumienny, R.; Heer, F.T.; de Beer, T.A.P.; Rempfer, C.; Bordoli, L.; et al. SWISS-MODEL: Homology modelling of protein structures and complexes. Nucleic Acids Res. 2018, 46, W296–W303. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Ye, Q.; Jia, Z.; Côté, G.P. Characterization of the catalytic and nucleotide binding properties of the α-kinase domain of Dictyostelium myosin-II heavy chain kinase A. J. Biol. Chem. 2015, 290, 23935–23946. [Google Scholar] [CrossRef] [Green Version]
- Trott, O.; Olson, A.J. AutoDock Vina: Improving the speed and accuracy of docking with a new scoring function, efficient optimization, and multithreading. J. Comput. Chem. 2010, 31, 455–461. [Google Scholar] [CrossRef] [Green Version]
- Krieger, E.; Vriend, G. YASARA View—Molecular graphics for all devices—From smartphones to workstations. Bioinformatics 2014, 30, 2981–2982. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- alvascience Srl. alvaDesc Version 1.0.8. Available online: https://www.alvascience.com (accessed on 19 April 2021).
- Mauri, A.; Consonni, V.; Pavan, M.; Todeschini, R. Dragon software: An easy approach to molecular descriptor calculations. Match 2006, 56, 237–248. [Google Scholar]
- Li, Z.R.; Lin, H.H.; Han, L.; Jiang, L.; Chen, X.; Chen, Y.Z. PROFEAT: A web server for computing structural and physicochemical features of proteins and peptides from amino acid sequence. Nucleic Acids Res. 2006, 34, W32–W37. [Google Scholar] [CrossRef] [Green Version]
- Rogers, D.; Hahn, M. Extended-connectivity fingerprints. J. Chem. Inf. Model. 2010, 50, 742–754. [Google Scholar] [CrossRef]
- Rogers, D.J.; Tanimoto, T.T. A computer program for classifying plants. Science 1960, 132, 1115–1118. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ChEMBL ID | Structure | IC (M) | Ref |
|---|---|---|---|
| CHEMBL1094018 |  | 0.11 | 14 |
| CHEMBL1092820 |  | 0.17 | 14 |
| CHEMBL1977874 |  | 0.28 | 11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoshimori, A.; Kawasaki, E.; Murakami, R.; Kanai, C. Discovery of Novel eEF2K Inhibitors Using HTS Fingerprint Generated from Predicted Profiling of Compound-Protein Interactions. Medicines 2021, 8, 23. https://0-doi-org.brum.beds.ac.uk/10.3390/medicines8050023
Yoshimori A, Kawasaki E, Murakami R, Kanai C. Discovery of Novel eEF2K Inhibitors Using HTS Fingerprint Generated from Predicted Profiling of Compound-Protein Interactions. Medicines. 2021; 8(5):23. https://0-doi-org.brum.beds.ac.uk/10.3390/medicines8050023
Chicago/Turabian StyleYoshimori, Atsushi, Enzo Kawasaki, Ryuta Murakami, and Chisato Kanai. 2021. "Discovery of Novel eEF2K Inhibitors Using HTS Fingerprint Generated from Predicted Profiling of Compound-Protein Interactions" Medicines 8, no. 5: 23. https://0-doi-org.brum.beds.ac.uk/10.3390/medicines8050023