
Monthly Rainfall Prediction at Catchment Level with the Facebook Prophet Model Using Observed and CMIP5 Decadal Data

 ,
,
Abstract
:1. Introduction
2. Study Area, Data and Methods
2.1. Study Area
2.2. Data Collection
2.3. Data Processing
2.4. Model Description
2.4.1. Facebook Prophet
2.4.2. Multi-Layer Perceptron (MLP) Regressor
2.4.3. Epsilon-Support Vector Regression (SVR)
2.4.4. Gradient Boosting
2.4.5. Random Forest Regressor (RDF)
2.5. Skill Tests
2.5.1. Pearson Correlation Coefficient (PCC)
2.5.2. Anomaly Correlation Coefficient (ACC)
2.5.3. Index of Agreement (IA)
2.5.4. Mean Absolute Error (MAE)
3. Results and Discussion
3.1. Prediction Using FBP
3.2. Prediction Using Regression Models
4. Conclusions
- (i)
- FBP can reproduce dry events considerably better than wet events. This may be due to a better understanding of FBP of dry periods through the training and its multiplicative seasonality function;
- (ii)
- Following the combination of GCM-derived data (as an additional regressor) and the corresponding observed values, FBP should be able to reproduce future rainfall with higher prediction accuracy than the predictions based on the observed values only;
- (iii)
- A higher number of regressors will provide comparatively better prediction accuracy than a single additional regressor. In this case, a longer period of GCM hindcast data would elicit a higher prediction accuracy.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hansen, J.W.; Mason, S.J.; Sun, L.; Tall, A. Review of Seasonal Climate Forecasting for Agriculture in Sub-Saharan Africa. Exp. Agric. 2011, 47, 205–240. [Google Scholar] [CrossRef] [Green Version]
- Jones, J.; Hansen, J.; Royce, F.; Messina, C. Potential benefits of climate forecasting to agriculture. Agric. Ecosyst. Environ. 2000, 82, 169–184. [Google Scholar] [CrossRef]
- Mehta, V.M.; Knutson, C.L.; Rosenberg, N.J.; Olsen, J.; Wall, N.A.; Bernadt, T.K.; Hayes, M.J. Decadal Climate Information Needs of Stakeholders for Decision Support in Water and Agriculture Production Sectors: A Case Study in the Missouri River Basin. Weather Clim. Soc. 2013, 5, 27–42. [Google Scholar] [CrossRef] [Green Version]
- Apurv, T.; Mehrotra, R.; Sharma, A.; Goyal, M.K.; Dutta, S. Impact of climate change on floods in the Brahmaputra basin using CMIP5 decadal predictions. J. Hydrol. 2015, 527, 281–291. [Google Scholar] [CrossRef]
- Ouyang, Q.; Lu, W.; Xin, X.; Zhang, Y.; Cheng, W.; Yu, T. Monthly Rainfall Forecasting Using EEMD-SVR Based on Phase-Space Reconstruction. Water Resour. Manag. 2016, 30, 2311–2325. [Google Scholar] [CrossRef]
- Mislan; Haviluddin; Hardwinarto, S.; Sumaryono; Aipassa, M. Rainfall Monthly Prediction Based on Artificial Neural Network: A Case Study in Tenggarong Station, East Kalimantan-Indonesia. Procedia Comput. Sci. 2015, 59, 142–151. [Google Scholar] [CrossRef] [Green Version]
- George, J.; Janaki, L.; Gomathy, J.P. Statistical Downscaling Using Local Polynomial Regression for Rainfall Predictions—A Case Study. Water Resour. Manag. 2015, 30, 183–193. [Google Scholar] [CrossRef]
- Hung, N.Q.; Babel, M.S.; Weesakul, S.; Tripathi, N.K. An artificial neural network model for rainfall forecasting in Bangkok, Thailand. Hydrol. Earth Syst. Sci. 2009, 13, 1413–1425. [Google Scholar] [CrossRef] [Green Version]
- Mekanik, F.; Lee, T.S.; Imteaz, M.A. Rainfall Modeling Using Artificial Neural Network for a Mountainous Region in West Iran. In Proceedings of the 19th International Congress on Modelling and Simulation, Perth, Australia, 12–16 December 2011; pp. 3518–3524. [Google Scholar] [CrossRef]
- Ali, M.; Deo, R.C.; Downs, N.J.; Maraseni, T. Monthly rainfall forecasting with Markov Chain Monte Carlo simulations integrated with statistical bivariate copulas. In Handbook of Probabilistic Models; Butterworth-Heinemann: Oxford, UK, 2020; pp. 89–105. [Google Scholar] [CrossRef]
- Hossain, I.; Rasel, H.M.; Alam Imteaz, M.; Mekanik, F. Long-term seasonal rainfall forecasting using linear and non-linear modelling approaches: A case study for Western Australia. Arch. Meteorol. Geophys. Bioclimatol. Ser. B 2019, 132, 131–141. [Google Scholar] [CrossRef]
- Hong, W.-C. Rainfall forecasting by technological machine learning models. Appl. Math. Comput. 2008, 200, 41–57. [Google Scholar] [CrossRef]
- Rajeevan, M. Prediction of Indian Summer Monsoon: Status, Problems and Prospects. Curr. Sci. 2001, 81, 1451–1457. [Google Scholar]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Machiwal, D.; Jha, M.K. Hydrologic Time Series Analysis: Theory and Practice; Springer: Dordrecht, The Netherlands, 2012; ISBN 978-94-007-1861-6. [Google Scholar]
- Dastorani, M.; Mirzavand, M.; Dastorani, M.T.; Sadatinejad, S.J. Comparative study among different time series models applied to monthly rainfall forecasting in semi-arid climate condition. Nat. Hazards 2016, 81, 1811–1827. [Google Scholar] [CrossRef]
- Meinke, H.; Sivakumar, M.V.K.; Motha, R.P.; Nelson, R. Preface: Climate Predictions for Better Agricultural Risk Management. Aust. J. Agric. Res. 2007, 58, 935–938. [Google Scholar] [CrossRef]
- Lee, J.; Kim, C.-G.; Lee, J.E.; Kim, N.W.; Kim, H. Application of Artificial Neural Networks to Rainfall Forecasting in the Geum River Basin, Korea. Water 2018, 10, 1448. [Google Scholar] [CrossRef] [Green Version]
- Shen, S.-L.; Zhang, N.; Zhou, A.; Yin, Z.-Y. Enhancement of neural networks with an alternative activation function tanhLU. Expert Syst. Appl. 2022, 199, 117181. [Google Scholar] [CrossRef]
- Lin, S.-S.; Zhang, N.; Zhou, A.; Shen, S.-L. Time-series prediction of shield movement performance during tunneling based on hybrid model. Tunn. Undergr. Space Technol. 2021, 119, 104245. [Google Scholar] [CrossRef]
- Wu, X.; Hongxing, C.; Flitman, A.; Fengying, W.; Guolin, F. Forecasting Monsoon Precipitation Using Artificial Neural Networks. Adv. Atmos. Sci. 2001, 18, 950–958. [Google Scholar] [CrossRef]
- Chakraverty, S.; Gupta, P. Comparison of neural network configurations in the long-range forecast of southwest monsoon rainfall over India. Neural Comput. Appl. 2007, 17, 187–192. [Google Scholar] [CrossRef]
- Chattopadhyay, S.; Chattopadhyay, G. Comparative study among different neural net learning algorithms applied to rainfall time series. Meteorol. Appl. 2008, 15, 273–280. [Google Scholar] [CrossRef]
- Committee, A.S. of C. E. T. Artificial Neural Networks in Hydrology. II: Hydrologic Applications by the ASCE Task Committee on Application of Artificial Neural Networks in Hydrology. J. Hydrol. Eng. 2000, 5, 115–123. [Google Scholar]
- Ramírez, M.C.; Ferreira, N.J.; Velho, H.F.C. Linear and Nonlinear Statistical Downscaling for Rainfall Forecasting over Southeastern Brazil. Weather Forecast. 2006, 21, 969–989. [Google Scholar] [CrossRef]
- Khandelwal, I.; Adhikari, R.; Verma, G. Time Series Forecasting Using Hybrid ARIMA and ANN Models Based on DWT Decomposition. Procedia Comput. Sci. 2015, 48, 173–179. [Google Scholar] [CrossRef] [Green Version]
- Unnikrishnan, P.; Jothiprakash, V. Hybrid SSA-ARIMA-ANN Model for Forecasting Daily Rainfall. Water Resour. Manag. 2020, 34, 3609–3623. [Google Scholar] [CrossRef]
- Trejo, A.; Martín, M.J.; Gómez-Quintana, A.; Cava, R.; García-Parra, J.J.; Ramírez, M.R. Effect of slicing of top quality (Montanera) Iberian dry-cured chorizo on the stability to high pressure treatment and storage. J. Food Sci. 2021, 86, 1963–1978. [Google Scholar] [CrossRef]
- Toharudin, T.; Pontoh, R.S.; Caraka, R.E.; Zahroh, S.; Lee, Y.; Chen, R.C. Employing long short-term memory and Facebook prophet model in air temperature forecasting. Commun. Stat. Simul. Comput. 2021, 2021, 1854302. [Google Scholar] [CrossRef]
- Samal, K.K.R.; Babu, K.S.; Das, S.K.; Acharaya, A. Time Series based Air Pollution Forecasting using SARIMA and Prophet Model. In Proceedings of the 2019 International Conference on Information Technology and Computer Communications, Singapore, 16–18 August 2019; pp. 80–85. [Google Scholar] [CrossRef]
- Subashini, A.; K, S.; Saranya, S.; Harsha, U. Forecasting Website Traffic Using Prophet Time Series Model. Int. Res. J. Multidiscip. Technov. 2019, 1, 56–63. [Google Scholar] [CrossRef]
- Climate-Data. Brisbane Climate: Average Weather, Temperature, Rainfall. 2020. Available online: https://www.climatestotravel.com/climate/australia/brisbane (accessed on 25 March 2021).
- Australian Bureau of Meteorology (BoM). Annual Rainfall. State of the Environment (Department of Environment and Science). Queensland Government. 2020. Available online: https://www.stateoftheenvironment.des.qld.gov.au/climate/climate-observations/annual-rainfall (accessed on 21 July 2021).
- Frost, A.J.; Ramchurn, A.; Smith, A. The Bureau ’s Operational AWRA Landscape (AWRA-L) Model; Technical Report; Bureau of Meteorology (BoM): Melbourne, Australia, 2016. [Google Scholar]
- Jones, P.W. First- and Second-Order Conservative Remapping Schemes for Grids in Spherical Coordinates. Mon. Weather Rev. 1999, 127, 2204–2210. [Google Scholar] [CrossRef]
- Hossain, M.M.; Garg, N.; Anwar, A.H.M.F.; Prakash, M. Comparing Spatial Interpolation Methods for CMIP5 Monthly Precipitation at Catchment Scale. Indian Water Resour. Soc. 2021, 41, 28–34. [Google Scholar]
- Taylor, S.J.; Letham, B. Forecasting at Scale. Am. Stat. 2018, 72, 37–45. [Google Scholar] [CrossRef]
- Hossain, M.M.; Anwar, A.H.M.F.; Garg, N.; Prakash, M.; Bari, M. Evaluation of CMIP5 Decadal Precipitation at Catchment Level. Int. J. Climatol. 2022. under-review. [Google Scholar]
- Hossain, M.; Garg, N.; Anwar, A.H.M.F.; Prakash, M.; Bari, M. Intercomparison of drift correction alternatives for CMIP5 decadal precipitation. Int. J. Clim. 2021, 42, 1015–1037. [Google Scholar] [CrossRef]
- Wilks, D.S. Statistical Methods in the Atmospheric Sciences, 3rd ed.; Volume 100 (International Geophysics); Academic Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Wilmot, C.J. Some Comments on the Evaluation of Model Performance. Bull. Am. Meteorol. Soc. 1982, 63, 1309–1313. [Google Scholar] [CrossRef] [Green Version]
- Kourentzes, N. Additive and Multiplicative Seasonality—Can You Identify Them Correctly? 2014. Available online: https://kourentzes.com/forecasting/2014/11/09/additive-and-multiplicative-seasonality/ (accessed on 4 August 2021).
- Randall, D.A.; Wood, R.A.; Bony, S.; Colman, R.; Fichefet, T.; Fyfe, J.; Kattsov, V.; Pitman, A.; Shukla, J.; Srinivasan, J.; et al. Climate Models and Their Evaluation. In Climate Change 2007: The Physical Science Basis; Contribution of Working Group I to the Fourth Assessment Report of the IPCC (FAR); Cambridge University Press: Cambridge, UK, 2007; pp. 589–662. [Google Scholar]
- Sun, Y.; Solomon, S.; Dai, A.; Portmann, R. How Often Will It Rain? J. Clim. 2007, 20, 4801–4818. [Google Scholar] [CrossRef]
- Stephens, G.L.; L ’Ecuyer, T.; Forbes, R.; Gettelmen, A.; Golaz, J.-C.; Bodas-Salcedo, A.; Suzuki, K.; Gabriel, P.; Haynes, J. Dreary state of precipitation in global models. J. Geophys. Res. Earth Surf. 2010, 115, 014532. [Google Scholar] [CrossRef]
- Islam, S.A.; Bari, M.; Anwar, A.H.M.F. Assessment of Hydrologic Impact of Climate Change on Ord River Catchment of Western Australia for Water Resources Planning: A Multi-Model Ensemble Approach. In Proceedings of the 19th International Congress on Modelling and Simulation, Perth, Australia, 12–16 December 2011. [Google Scholar] [CrossRef]
- Islam, S.A.; Bari, M.A.; Anwar, A.H.M.F. Hydrologic impact of climate change on Murray–Hotham catchment of Western Australia: A projection of rainfall–runoff for future water resources planning. Hydrol. Earth Syst. Sci. 2014, 18, 3591–3614. [Google Scholar] [CrossRef] [Green Version]
- Maurer, E.P.; Hidalgo, H.G. Utility of daily vs. monthly large-scale climate data: An intercomparison of two statistical downscaling methods. Hydrol. Earth Syst. Sci. 2008, 12, 551–563. [Google Scholar] [CrossRef] [Green Version]
- Mehrotra, R.; Sharma, A. Development and Application of a Multisite Rainfall Stochastic Downscaling Framework for Climate Change Impact Assessment. Water Resour. Res. 2010, 46, 008423. [Google Scholar] [CrossRef]
- White, B. The Importance of Climate Variability and Seasonal Forecasting to the Australian Economy. In Applications of Seasonal Climate Forecasting in Agricultural and Natural Ecosystems; Hammer, G.L., Nicholls, N., Mitchell, C., Eds.; Springer: Dordrecht, The Netherlands, 2000; Volume 21, pp. 1–22. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modelling Centre (or Group) | Resolutions (Lon × Lat) | Initialization Year (1960–2005) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 60 | 65 | 70 | 75 | 80 | 85 | 90 | 95 | 00 | 05 | ||
| Number of Ensembles | |||||||||||
| EC-EARTH | (1.125 × 1.1215) | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 10 | 18 |
| MRI-CGCM3 | (1.125 × 1.1215) | 06 | 08 | 09 | 09 | 06 | 09 | 09 | 09 | 09 | 06 |
| MPI-ESM-LR | (1.875 × 1.865) | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 |
| MPI-ESM-MR | (1.875 × 1.865) | 03 | 03 | 03 | 03 | 03 | 03 | 03 | 03 | 03 | 03 |
| MIROC4h | (0.5625 × 0.5616) | 03 | 03 | 03 | 06 | 06 | 06 | 06 | 06 | 06 | 06 |
| MIROC5 | (1.4062 × 1.4007) | 06 | 06 | 06 | 06 | 04 | 06 | 06 | 06 | 06 | 06 |
| CanCM4 | (2.8125 × 2.7905) | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 |
| CMCC-CM | (0.75 × 0.748) | 03 | 03 | 03 | 03 | 03 | 03 | 03 | 03 | 03 | 03 |
| Location (Lon/Lat) | Cases | Skills | Under and Overestimation of Total Rainfall (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | PCC | ACC | IA | 1Y | 3Y | 5Y | 8Y | ||
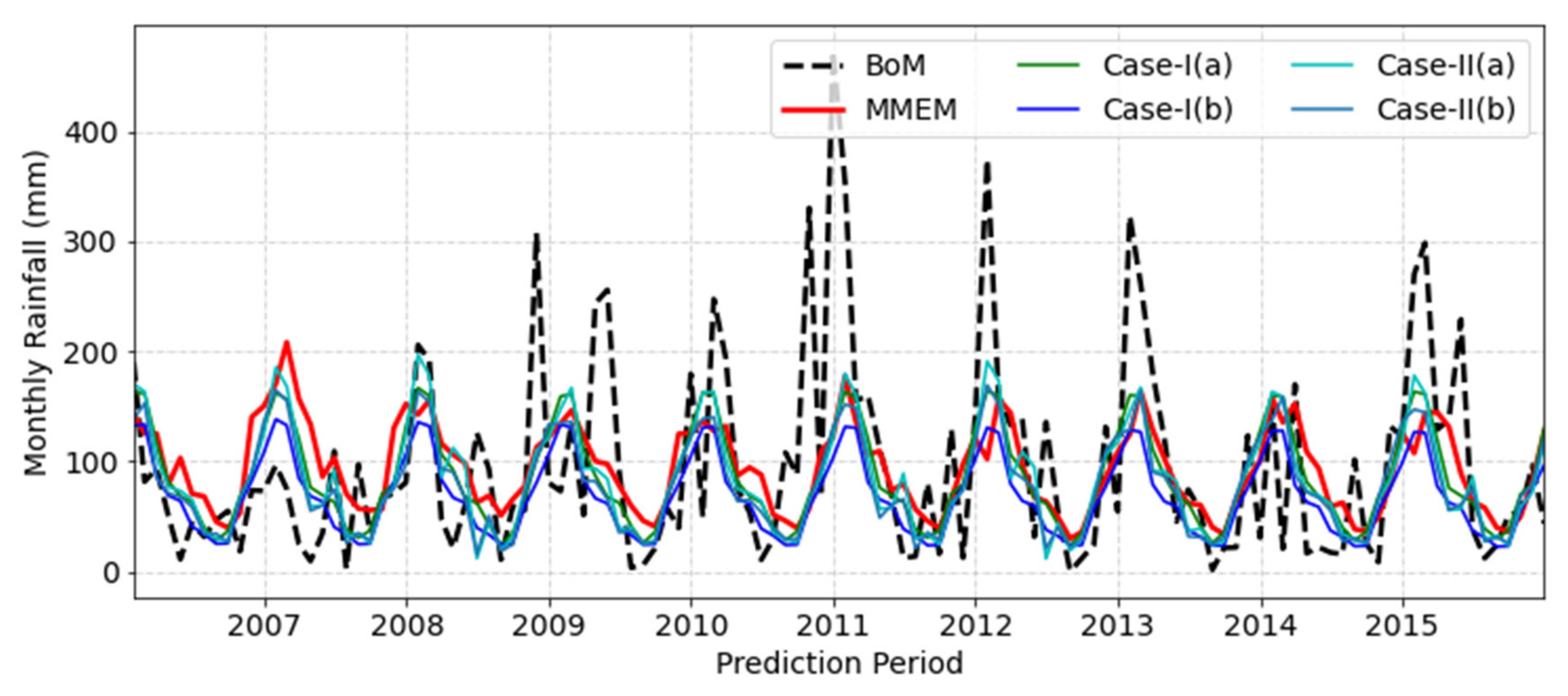
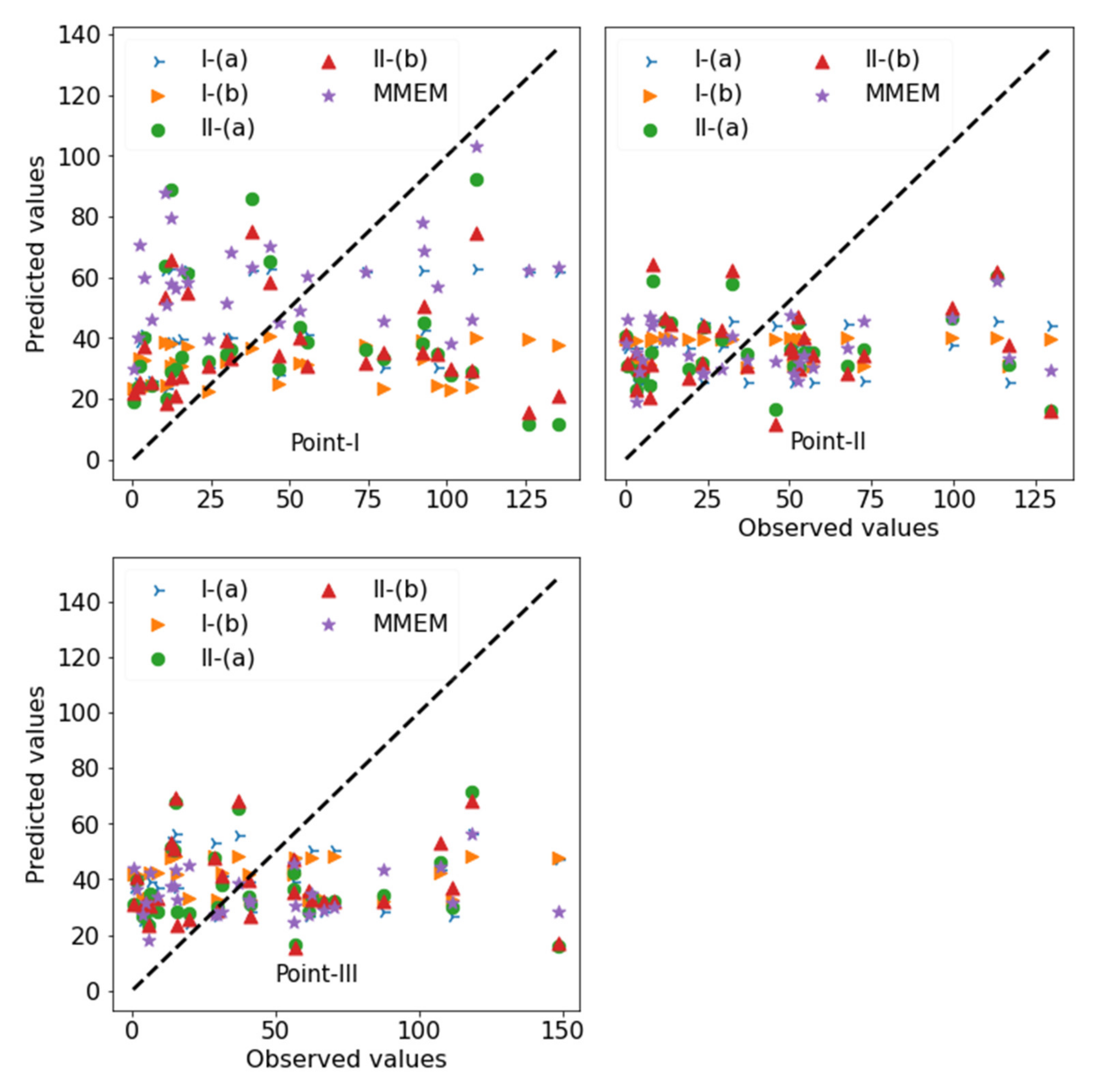
| Point-I (153.05 E/27.50 S) | I-(a) | 53.6 | 0.549 | 0.536 | 0.615 | 35.9 | 14.6 | −7.2 | −11.2 |
| I-(b) | 55.9 | 0.526 | 0.418 | 0.491 | 11.9 | −5.94 | −24.6 | −28.7 | |
| II-(a) | 54.9 | 0.533 | 0.517 | 0.622 | 33.5 | 15.1 | −8.34 | −12.8 | |
| II-(b) | 55.1 | 0.528 | 0.488 | 0.577 | 24.8 | 5.25 | −16.0 | −19.3 | |
| MMEM | 58.11 | 0.434 | 0.433 | 0.510 | 48.6 | 35.6 | 5.64 | −3.1 | |
| Point-II (152.0 E/27.0 S) | I-(a) | 40.8 | 0.497 | 0.496 | 0.603 | 50.2 | 26.5 | 2.12 | −10.4 |
| I-(b) | 41.0 | 0.484 | 0.484 | 0.581 | 50.7 | 27.1 | 2.46 | −6.4 | |
| II-(a) | 40.8 | 0.489 | 0.486 | 0.593 | 47.3 | 26.3 | 0.53 | −8.4 | |
| II-(b) | 39.8 | 0.519 | 0.517 | 0.611 | 38.5 | 22.7 | −1.42 | −8.2 | |
| MMEM | 41.4 | 0.494 | 0.493 | 0.612 | 58.2 | 39.3 | 13.8 | −5.6 | |
| Point-III (152.05 E/27.30 S) | I-(a) | 46.1 | 0..491 | 0.490 | 0.588 | 54.4 | 24.1 | 3.4 | −6.7 |
| I-(b) | 48.1 | 0.471 | 0.470 | 0.583 | 65.5 | 32.1 | 10.6 | −0.15 | |
| II-(a) | 46.9 | 0.464 | 0.460 | 0.567 | 51.7 | 23.1 | 1.1 | −9.9 | |
| II-(b) | 45.2 | 0.490 | 0.485 | 0.580 | 44.6 | 18.7 | −1.6 | −10.2 | |
| MMEM | 44.7 | 0.489 | 0.474 | 0.571 | 48.7 | 23.9 | −0.8 | −14.2 | |
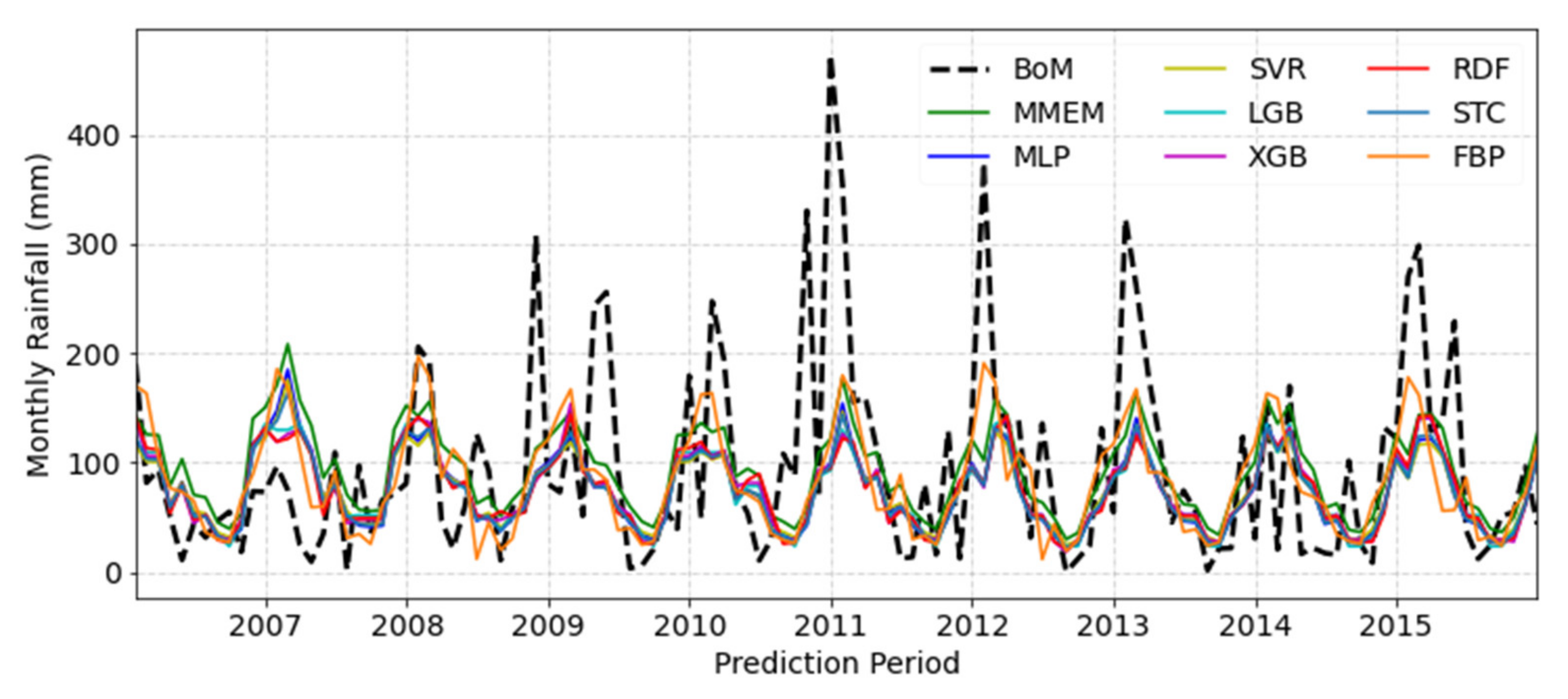
| Models | Point-I | Point-II | Point-III | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | PCC | ACC | IA | MAE | PCC | ACC | IA | MAE | PCC | ACC | IA | |
| MLP | 57.1 | 0.430 | 0.371 | 0.445 | 39.3 | 0.480 | 0.450 | 0.515 | 43.5 | 0.476 | 0.427 | 0.494 |
| SVR | 57.6 | 0.430 | 0.361 | 0.418 | 39.3 | 0.481 | 0.447 | 0.516 | 43.5 | 0.478 | 0.430 | 0.487 |
| LGB | 56.6 | 0.432 | 0.374 | 0.442 | 39.5 | 0.469 | 0.432 | 0.510 | 43.7 | 0.466 | 0.425 | 0.493 |
| XGB | 57.2 | 0.427 | 0.370 | 0.439 | 39.7 | 0.451 | 0.417 | 0.503 | 44.1 | 0.444 | 0.410 | 0.484 |
| RDF | 57.2 | 0.426 | 0.369 | 0.441 | 39.9 | 0.427 | 0.372 | 0.433 | 44.0 | 0.421 | 0.359 | 0.412 |
| STC | 57.1 | 0.434 | 0.365 | 0.435 | 39.1 | 0.483 | 0.425 | 0.475 | 43.4 | 0.464 | 0.405 | 0.464 |
| FBP(II-a) | 54.9 | 0.533 | 0.517 | 0.622 | 40.9 | 0.489 | 0.486 | 0.593 | 46.9 | 0.464 | 0.460 | 0.567 |
| MMEM | 58.1 | 0.434 | 0.433 | 0.510 | 41.4 | 0.494 | 0.493 | 0.612 | 44.7 | 0.489 | 0.474 | 0.571 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hossain, M.M.; Anwar, A.H.M.F.; Garg, N.; Prakash, M.; Bari, M. Monthly Rainfall Prediction at Catchment Level with the Facebook Prophet Model Using Observed and CMIP5 Decadal Data. Hydrology 2022, 9, 111. https://0-doi-org.brum.beds.ac.uk/10.3390/hydrology9060111
Hossain MM, Anwar AHMF, Garg N, Prakash M, Bari M. Monthly Rainfall Prediction at Catchment Level with the Facebook Prophet Model Using Observed and CMIP5 Decadal Data. Hydrology. 2022; 9(6):111. https://0-doi-org.brum.beds.ac.uk/10.3390/hydrology9060111
Chicago/Turabian StyleHossain, Md Monowar, A. H. M. Faisal Anwar, Nikhil Garg, Mahesh Prakash, and Mohammed Bari. 2022. "Monthly Rainfall Prediction at Catchment Level with the Facebook Prophet Model Using Observed and CMIP5 Decadal Data" Hydrology 9, no. 6: 111. https://0-doi-org.brum.beds.ac.uk/10.3390/hydrology9060111