A Probabilistic Bag-to-Class Approach to Multiple-Instance Learning




1
Department of Community Medicine, Faculty of Health Science, UiT The Arctic University of Norway, N-9037 Tromsø, Norway
2
Department of Computer Science, Faculty of Information Technology and Electrical Engineering, NTNU—Norwegian University of Science and Technology, N-2815 Gjøvik, Norway
3
Department of Mathematics and Statistics, Faculty of Science and Technology, UiT The Arctic University of Norway, N-9037 Tromsø, Norway
*
Author to whom correspondence should be addressed.
Data 2020, 5(2), 56; https://0-doi-org.brum.beds.ac.uk/10.3390/data5020056
Submission received: 31 March 2020
/
Revised: 3 June 2020
/
Accepted: 23 June 2020
/
Published: 26 June 2020
(This article belongs to the Special Issue Machine Learning in Image Analysis and Pattern Recognition)
Abstract
:Multi-instance (MI) learning is a branch of machine learning, where each object (bag) consists of multiple feature vectors (instances)—for example, an image consisting of multiple patches and their corresponding feature vectors. In MI classification, each bag in the training set has a class label, but the instances are unlabeled. The instances are most commonly regarded as a set of points in a multi-dimensional space. Alternatively, instances are viewed as realizations of random vectors with corresponding probability distribution, where the bag is the distribution, not the realizations. By introducing the probability distribution space to bag-level classification problems, dissimilarities between probability distributions (divergences) can be applied. The bag-to-bag Kullback–Leibler information is asymptotically the best classifier, but the typical sparseness of MI training sets is an obstacle. We introduce bag-to-class divergence to MI learning, emphasizing the hierarchical nature of the random vectors that makes bags from the same class different. We propose two properties for bag-to-class divergences, and an additional property for sparse training sets, and propose a dissimilarity measure that fulfils them. Its performance is demonstrated on synthetic and real data. The probability distribution space is valid for MI learning, both for the theoretical analysis and applications.
Dataset: Breast tissue images available at https://bioimage.ucsb.edu/research/bio-segmentation, extracted feature vectors available at https://figshare.com/articles/MIProblems_A_repository_of_multiple_instance_learning_datasets/6633983. BreakHis data available at https://web.inf.ufpr.br/vri/databases/breast-cancer-histopathological-database-breakhis/. Code available at https://github.com/kajsam/ProbabilisticBag2Class.
Dataset License: CC BY 4.0
1. Introduction
1.1. Classification of Weakly Supervised Data
Machine-learning applications include a wide variety of data types, images being one of the most successful areas. It has had an enormous impact on image analysis, especially in replacing small sets of hand-crafted features with large sets of computer readable features, which often lack apparent or intuitive meaning. The task and problems to which machine learning is applied can be divided broadly into unsupervised and supervised learning. In supervised learning, the training data consists of K objects, , with corresponding class labels, y; . An object is typically a vector of d feature values, , observed directly or extracted from e.g., an image. In classification, the task is to build a classifier that correctly labels a new object. The training data is used to adjust the model according to the desired outcome, often maximizing the accuracy of the classifier.
For many types of images, only a small part of the image defines the class, but the label is available only at image level. This is common in medical images, such as histology slides, where the tumor cells typically make up a small proportion of the image. However, the location of those cells is not available for training. Multi-instance (MI) learning is a branch of machine learning that specifically targets problems where labels are available only at a superior level, and relates to other weakly supervised data problems, such as semi-supervised learning and transfer learning through label scarcity [1].
1.2. Multi-Instance Learning
In MI learning, each object is a set of feature vectors referred to as instances. The set , where the elements are vectors of length d, is referred to as bag. The number of instances, , varies from bag to bag, whereas the vector length is constant. In supervised MI learning, the training data consists of K sets and their corresponding class labels, .
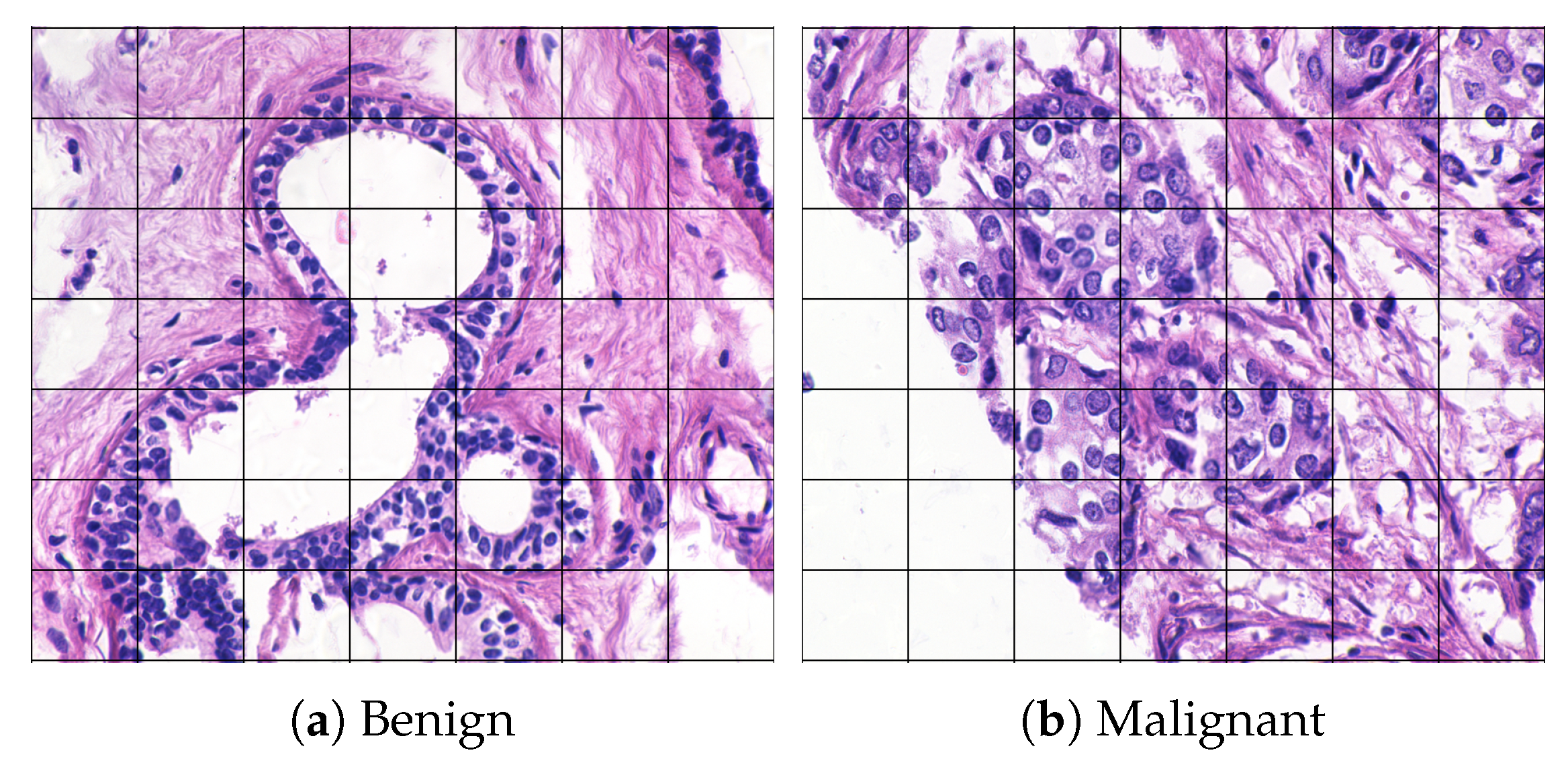
Figure 1a shows an image (bag), k, of benign breast tissue [2], divided into segments with corresponding feature vectors (instances) [3]. Correspondingly, Figure 1b shows malignant breast tissue.
The images in the data set have class labels; however, the individual segments do not. This is a key characteristic of MI learning—the instances are not labeled. MI learning includes instance classification [4], clustering [5], regression [5], and multi-label learning [6,7], but this article will focus on bag classification. MI learning can also be found as integrated parts of end-to-end methods for image analysis that generate patches, extract features and do feature selection [7]. See also [8] for an overview and discussion on end-to-end neural network MI learning methods.
The term “MI learning” was introduced in an application of molecules (bags) with different shapes (instances), and their ability to bind to other molecules [9]. A molecule binds if at least one of its shapes can bind. In MI terminology, the classes in binary classification are referred to as positive, , and negative, . The assumption that a positive bag contains at least one positive instance, and a negative bag contains only negative instances is referred to as the standard MI assumption.
Many new applications violate the standard MI assumption, such as image classification [10] and text categorization [11]. Consequently, successful algorithms meet more general assumptions, see e.g., the hierarchy of Weidmann et al. [12] or Foulds and Frank’s taxonomy [13]. For a more recent review of MI classification algorithms, see e.g., [14]. Amores [15] presented the three paradigms of instance space (IS), embedded space (ES), and bag space (BS). IS methods aggregate the outcome of single-instance classifiers applied to the instances of a bag, whereas ES methods map the instances to a vector, followed by use of a single-instance classifier. In the BS paradigm, the instances are transformed to a non-vectorial space where the classification is performed, avoiding the detour via single-instance classifiers. The non-vectorial space of probability functions has not yet been introduced to the BS paradigm, despite its analytical benefits, see Section 3.2 and Section 3.3.
Although both Carbonneau et al. [16] and Amores [15] defined a bag as a set of feature vectors, Foulds and Frank [13] stated that a bag can also be modelled as a probability distribution. The distinction is necessary in analysis of classification approaches, and both viewpoints offer benefits, see Section 6.1 for a discussion.
1.3. Bag Density and Class Sparsity
Optimal classification in MI learning depends on the number of instances per bag (bag density) and the number of bags per class in the training set (class density). Sample sparsity is a common obstacle in MI learning [16], which we address in Section 3.5. High bag density ensures a precise description of each bag, whereas high class density ensures precise modelling of each class when training the classifier. In image analysis, the number of patches corresponds to the number of instances, and is commonly a user input parameter. The number of images corresponds to the number of bags, and is limited by the training set itself.
High resolution of today’s images and the increasingly common practice of sharing the images themselves instead of extracted features ensure high bag density. The number of bags available for training is still limited, and will continue to be so in the foreseeable future, especially for medical images where data collection is restricted by laws and regulations. This motivates an approach to MI learning that can exploit the increasing bag density and overcome the class sparsity.
1.4. A Probabilistic Bag-to-Class Approach to Multi-Instance Learning
We propose to model the bags as probability distributions and the instances as random samples. The bags are assumed to be random samples from their respective classes and the instance-bag sampling form a hierarchical distribution. Hierarchical distribution is novel for bag classification and novel outside the strict standard MI assumption. Unbiased estimators for the bag probability distributions ensure that as the number of instances increases (), the discrepancy between the estimate and the underlying truth diminishes, taking advantage of increasing bag density. To overcome the problem of class sparsity, the instances are aggregated at class level.
We further propose to use a bag-to-class dissimilarity measure for classification. This is novel in the MI context, where dissimilarity measures have been either instance-to-instance or bag-to-bag. With the analytical framework of probability distributions and their dissimilarity measures, we present the optimal classifier for dense class sampling as a theoretical background and identify data-independent properties for bag classification under class sparsity.
The main contribution of this article is a bag-to-class dissimilarity measure for sparse training data. It builds on:
- presenting the hierarchical model for general, non-standard MI assumptions (Section 3.3),
- introduction of bag-to-class dissimilarity measures (Section 3.5), and
- identification of two properties for bag-to-class divergence (Section 4.1).
The novelty is that it takes into account the class sparsity by comparing a bag to one class while conditioning on the other class.
In Section 5, the Kullback–Leibler (KL) information and the new dissimilarity measure is applied to data sets and the results are reported. Bags defined in the probability distribution space, in combination with bag-to-class divergence, constitutes a new framework for MI learning, which is compared to other frameworks in Section 6.
2. Related Work and State-of-the-Art
The feature vector set viewpoint seems to be the most common, but the probabilistic viewpoint was introduced already in 1998, under the assumption that instances of the same class are independent and identically distributed (i.i.d.) [17]. This assumption has been used in approaches such as estimating the expectation by the mean [18], or estimation of class distribution parameters [19], but has also been criticized [20]. The hierarchical distribution was introduced for learnability theory under the standard MI assumption for instance classification in 2016 [4]. We expand the use for more general assumptions in Section 3.3.
Dissimilarities in MI learning have been categorized as instance-to-instance or bag-to-bag [15,21]. The bag-to-prototype approach in [21] offers an in-between category, but the theoretical framework is missing. Bag-to-class dissimilarity has not been studied within the MI framework, but has been used under the i.i.d. given class assumption for image classification [22]. The sparseness of training sets was also addressed: if the instances are aggregated on class level, a denser representation is achieved. Many MI algorithms use dissimilarities, e.g., graph distances [23], Hausdorff metrics [24], functions of the Euclidean distance [14,25], and distribution parameter-based distances [14]. The performances of dissimilarities on specific data sets have been investigated [14,19,21,25,26], but more analytical comparisons are missing. A large class of commonly used kernels are also distances [27], and hence, many kernel-based approaches in MI learning can be viewed as dissimilarity-based approaches. In [28], the Fisher kernel is used as input to a support vector machine (SVM), whereas in [11,20] the kernels are an integrated part of the methods.
The non-vectorial graph space was used in [20,23]. We introduce the non-vectorial space of probability functions as an extension within the BS paradigm for bag classification through dissimilarity measures between distributions in Section 3.2.
The KL information was applied in [22], and is a much-used divergence function. It is closely connected to the Fisher information [29] used in [28] and to the cross entropy used as loss function in [8]. We propose a conditional KL information in Section 4.2, which differs from the earlier proposed weighted KL information [30] whose weight is a constant function of X.
There is a wide variety in MI learning, both in methods and data sets, and it should be clear that state-of-the-art will depend on the type of data. Sudharshan et al. [31] gave a comparison of 12 MI classification methods and five state-of-the-art general classification methods on a well-described, publicly available histology image data set. All methods included have shown best performance on other data sets. The five methods that showed best performance for at least one of the data subsets serve as state-of-the-art baseline for evaluation in Section 5.3.
Cheplygina et al. [1] gave an overview of MI learning applications in different categories, but no comparison was made. The work of Sudharshan et al. falls into the “Histology/Microscopy” category, and the overview offers a potential expansion of histology state-of-the-art. Among the 12 listed articles, Zhang et al. [32] concluded that GPMIL outperforms Citation-kNN, which is one of the 12 methods in [31], but not one of the 5 best-performing. Kandemir et al. [3], Li et al. [33] and Tomczak et al. [34] presented methods that outperform GPMIL on a publicly available data set. We include these as comparison.
Of the remaining articles, none of them present an extensive comparison to other methods, their data sets are either non-public [35,36,37,38], no longer available [39], or the reference is not complete [40,41], which make them unsuitable for comparison. Jia et al. [42] presented a segmentation method, and is therefore not comparable.
3. Theoretical Background and Intuitions
3.1. Notation
Subscript and superscript and refer to the class label of the bag, subscript and superscript + and − refer to the unknown instance label.
- X: instance random vector
- C: class, either or
- B: bag
- : probability distribution
- : feature vector (instance) in set k,
- : set of feature vectors k of size
- : bag label
- : sample space for instances
- : sample space for positive instances
- : sample space for negative instances
- : sample space of positive bags
- : sample space of negative bags
- : posterior class probability, given instance sample
- : parameter random vector
- : parameter vector
- : probability distribution for instances in bag B
- : parameterized probability distribution of bag k
- : probability distribution for instances from the positive class
- : probability distribution for instances from the negative class
- : instance label
- : probability of positive instances
- : divergence from to
- : probability density function (PDF) for bag k
- : divergence from to
We assume , and equivalently , for all distributions.
3.2. The Non-Vectorial Space of Probability Functions
The intuition behind the probabilistic approach in MI learning can be understood through image analysis and tumor classification. Figure 1a represents parts of a tumor, chosen carefully for diagnostic purposes. The process from biological material to image contains steps whose outcome is influenced by subjective choices and randomness: The precise day the patient is admitted influences the state of the tumor; the specific parts of the tumor that are extracted for staining; the actual stain varies from batch to batch, and the imaging equipment has multiple parameter settings. All this means that the same tumor would have produced a different image under different circumstances. The process from image to feature vector set also contains several steps: Patch size, grid or random patches, color conversion, etc. In summary, the observed feature vectors are a representation of an underlying object, and that representation may vary, even if the object remains fixed.
From the probabilistic viewpoint, an instance, , is a realization of a random vector, X, with probability distribution and sample space . The bag is the probability distribution , and the set of instances, , is multiple realizations of X. The task of an MI classifier is to classify the bag given the observations, .
The posterior class probability, , is an effective classifier if the standard MI assumption holds, since it is defined as:
where is the positive instance space, and the positive and negative instance spaces are disjoint.
Bayes’ rule, , can be used when the posterior probability is unknown. An assumption used to estimate the probability distribution of instance given the class, , is that instances from bags of the same class are i.i.d. random samples. However, this is a poor description for MI learning.
3.3. Hierarchical Distributions
As an illustrative example, let the instances be the color of image patches from the class sea or desert, and let image k depict a blue sea like in Figure 2a with instances , and image ℓ depict a turquoise sea like in Figure 2b with instances . The instances are realizations from and , respectively, where is the parameter indicating the colors. If the instance distribution were dependent only on class, then , which is clearly not the case. Instance distributions are dependent not only on class, but also on bag. The random vectors in are i.i.d., but have a different distribution than those in . An important distinction between uncertain objects, whose distribution depends solely on the class label [43,44], and MI learning is that the instances of two bags from the same class are not from the same distribution.
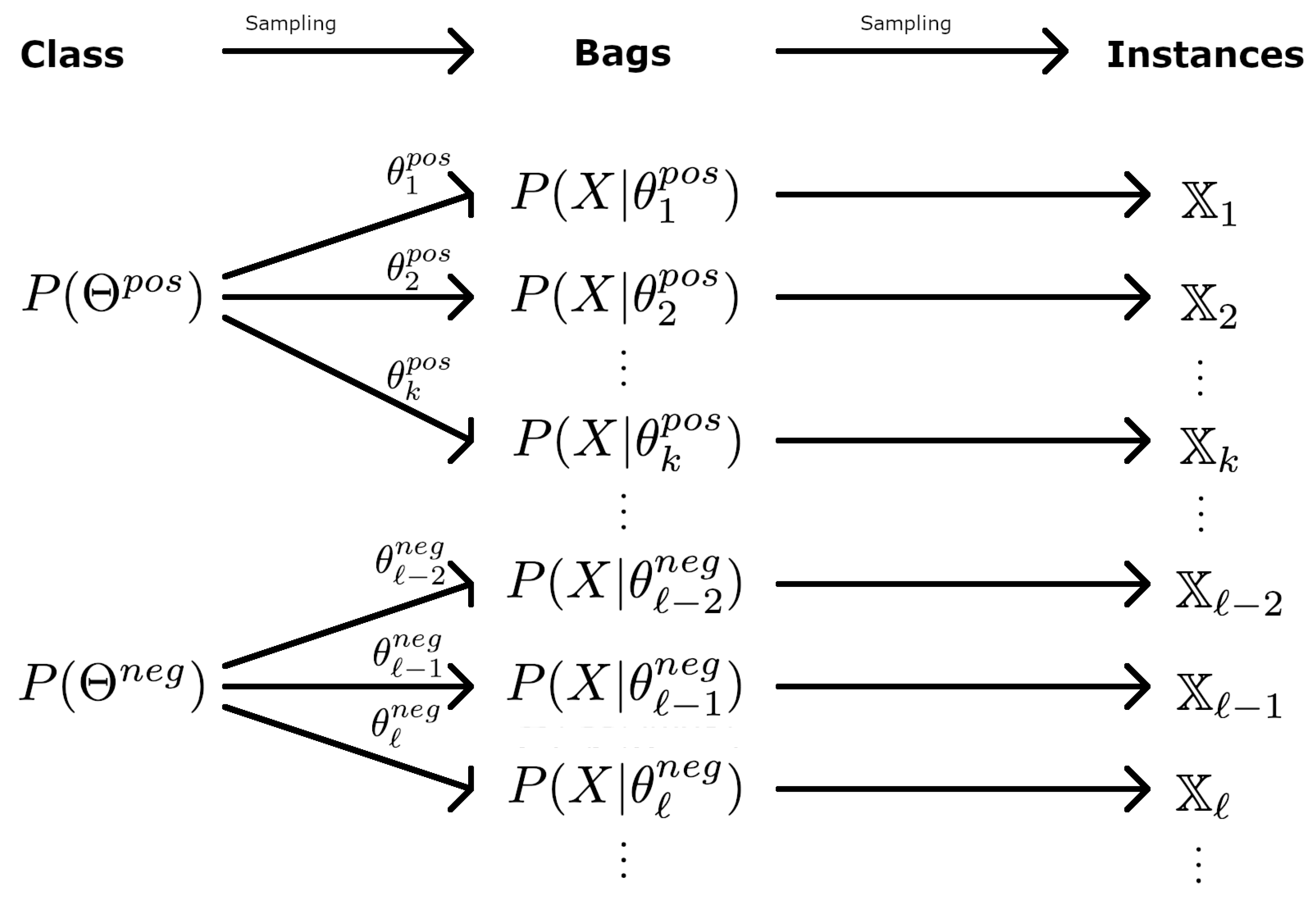
The dependency nature for MI learning can be described as a hierarchical distribution (Equation (1)), where a bag, B, is defined as the probability distribution of its instances, , and the bag space, , is a set of distributions. A bag is itself a realization from the sample space of bags, whose distribution depends on the class. The generative model of instances from a positive or negative bag follows a hierarchical distribution:
respectively. From a practical viewpoint, can be considered parametric functions, , where the sampling of a bag corresponds to sampling the parameter vector that defines its distribution:
The parametric generative model is shown in Figure 3.
The common view in MI learning is that a bag consists of positive and negative instances, which corresponds to a bag being a mixture of a positive and a negative distribution. Consider tumor images labeled or , with instances extracted from patches. Let and denote the probability distributions of positive and negative segments, respectively, of image k. The distribution of bag k is a mixture distribution:
where , where if instance i is positive. The parameter vector defines the bag. The probability of positive segments, , depends on the image’s class label, and hence is sampled from or . The characteristics of positive and negative segments vary from image to image. Hence, and are realizations of random variables, with corresponding probability distributions and . The generative model of instances from a positive bag is:
The corresponding sampling procedure from positive bag, k, is
- Step 1: Draw from , from , and from . These three parameters define the bag.
- Step 2: For , draw from , draw from if , and from otherwise.
The generative model and sampling procedure for negative bags are equivalent to that of positive bags.
By imposing restrictions, assumptions can be accurately described, e.g., the standard MI assumption: at least one positive instance in a positive bag: ; no positive instances in a negative bag: ; the positive and negative instance spaces are disjoint.
Equation (3) is the generative model of MI problems, assuming that the instances have unknown class labels and that the distributions are parametric. The parameters , and are i.i.d. samples from their respective distributions, but are not observed and are hard to estimate due to the very nature of MI learning: the instances are not labeled. Instead, can be estimated from the observed instances, and a divergence function can serve as classifier.
The instance i.i.d. assumption is not inherent to the probability distribution viewpoint, but the asymptotic results for the KL information discussed in Section 3.5 rely on it. In many applications, such as image analysis with sliding windows, the instances are best represented as dependent samples, but the dependencies are hard to estimate, and the independence assumption is often the best approximation. Doran and Ray [4] showed that the independence assumption is an approximation of dependent instances, but comes with the cost of slower convergence.
3.4. Dissimilarities in MI Learning
The information contained at bag-level is converted before it is fed into a classifier. If the bags are sets, they are commonly converted into distances. Dissimilarities in MI learning can be categorized as instance-to-instance, bag-to-bag or bag-to-class. Amores [15] implicitly assumed metricity for dissimilarity functions [27] in the BS paradigm, but there is nothing inherent to MI learning that imposes these restrictions. In the case where bags are probability distributions, distances are no longer applicable since they live in a non-vectorial space. Distances are a special case of dissimilarity functions, and the equivalent for probability distributions are referred to as divergences, . Although distances fulfil three properties by definition—among them symmetry and zero distance for identical sets—divergences do not have such properties, by definition.
A group of divergences named f-divergences has properties that are reasonable to demand for measuring the ability to distinguish probability distributions [45,46]:
- Equality and orthogonality: An f-divergence takes its minimum when the two probability functions are equal and its maximum when they are orthogonal. This means that two identical bags will have minimum dissimilarity between them, and that two bags without shared sample space will have maximum dissimilarity. A definition of orthogonal distributions can be found in [47].
- Monotonicity: The f-divergences possess a monotonicity property that can be thought of as an equivalent to the triangle property for distances: For a family of densities with monotone likelihood ratio, if , then . This is valid, e.g., for Gaussian densities with equal variance and mean . This means that if the distance between and is larger than the distance between and , the divergence is larger or equal. The f-divergences are not symmetric by definition, but some of them are.
Divergences as functions of probability distributions have not been used in MI learning, due to the lack of a probability function space defined for the BS paradigm, despite the benefit of analysis independent of specific data sets [48]. Cheplygina et al. [14] proposed using the Cauchy-Schwarz divergence with a Gaussian kernel, but as a function of the instances in the bag-to-bag setting. The KL information [29] is a non-symmetric f-divergence, often used in both statistics and computer science, and is defined as follows for two probability density functions (PDFs) and :
An example of a symmetric f-divergence is the Bhattacharyya (BH) distance, defined as
and can be a better choice if the absolute difference, and not the ratio, differentiates the two PDFs. The appropriate divergence for a specific task can be chosen based on identified properties, e.g., for clustering [49], or a new dissimilarity function can be proposed [50].
3.5. Bag-to-Class Dissimilarity
Bag-to-bag classification can be thought of as model selection: Two bags from the training set, and are the models, and unlabeled bag is the sample distribution, and is labeled according to which model it resembles the most. The log-ratio test is the most powerful for model selection under certain conditions (Neyman–Pearson lemma). It is possible then to perform the log-ratio test between and each of the bags in the training set.
The training set in MI learning is the instances, since the bag distributions are unknown. Under the assumption that the instances from each bag are i.i.d. samples, the KL information has a special role in model selection, both from the frequentist and the Bayesian perspective. Let be the sample distribution (unlabeled bag), and let and be two models (labeled bags). Then the expectation over of the log-ratio of the two models, , is equal to . In other words, the log-ratio test reveals the model closest to the sampling distribution in terms of KL information [51]. From the Bayesian viewpoint, the Akaike Information Criterion (AIC) reveals the model closest to the data in terms of KL information, and is asymptotically equivalent to Bayes factor under certain assumptions [52].
An obstacles arises: The core of MI learning is that bags from the same class are not equal, e.g., two images of the sea, so that the model is most likely not in the training set. In fact, for probability distributions with continuous parameters, the probability of the new bag being in the training set is zero. For ratio-based divergences, such as the f-divergences, the difference between and becomes arbitrary. Despite their necessary properties as dissimilarity measures, and the KL information’s property as most powerful model selector, we see that they can fail in practice.
If the bag sampling is sparse, the dissimilarity between and the labeled bags becomes somewhat arbitrary regarding the true label of . The risk is high for ratio-based divergences such as the KL information, since for . The bag-to-bag KL information is asymptotically the best choice of divergence function, but this is not the case for sparse training sets. Bag-to-class dissimilarity makes up for some of the sparseness by aggregation of instances. Consider an image segment of color deep green, which appears in sea images, but not in desert images, and a segment of color white, which appears in both classes (waves and clouds). If the combination deep green and white does not appear in the training set, then a bag-to-bag KL information will result in infinite dissimilarity for all bags, regardless of class, but the bag-to-class KL information will be finite for the sea class.
Let be the probability distribution of a random vector from the bags of class C. Let and be the divergences between the unlabeled bag and each of the classes. Choice of divergence is not obvious, since is different from both and , but can be done by identification of properties.
4. Properties for Bag-Level Classification
4.1. Properties for Bag-to-Class Divergences
We argue that the equality, orthogonality and monotonicity properties possessed by f-divergences are reasonable also for bag-to-class divergences, although less likely to occur in practice:
The equality property and the monotonicity property are valid for uncertain objects, but in practice it can occur with sparse class sampling, and we therefore argue that these properties are valid also for bag-to-class divergences. The opposite implies that a bag can be regarded more similar to one class, even though its probability distribution is identical to the other class (equality), or that, e.g., if , and are Gaussian distributions with the same variance and means , we can have that . In other words, we can have that the divergence between the bag and the positive class is larger than between the bag and the negative class, although the bag mean is closer to the positive class mean. This is clearly not appropriate for a dissimilarity measure.
The orthogonality property is reasonable for bag-to-class divergences: If there is no common sample space between bag and class, the divergence should take its maximum. In conclusion, f-divergences is the correct group for bag-to-class divergences.
There may be other desirable properties for bag-to-class divergences, where the aim is no longer to compare an i.i.d. sample to a model, but to compare an i.i.d. sample to an aggregation of models where the sample comes from one of them. We here propose two properties for bag-to-class divergences regarding infinite bag-to-class ratio and zero instance probability. Denote the divergence between an unlabeled bag and the reference distribution, , by .
In the sea images example, the class contains all possible colors that the sea can have, whereas a bag consists only of the colors of that particular moment in time. If the bag contains something that the class does not, e.g., brown color, this should be reflected in a larger divergence. However, the class should be allowed to contain something that the bag does not without this resulting in a similarly large divergence.
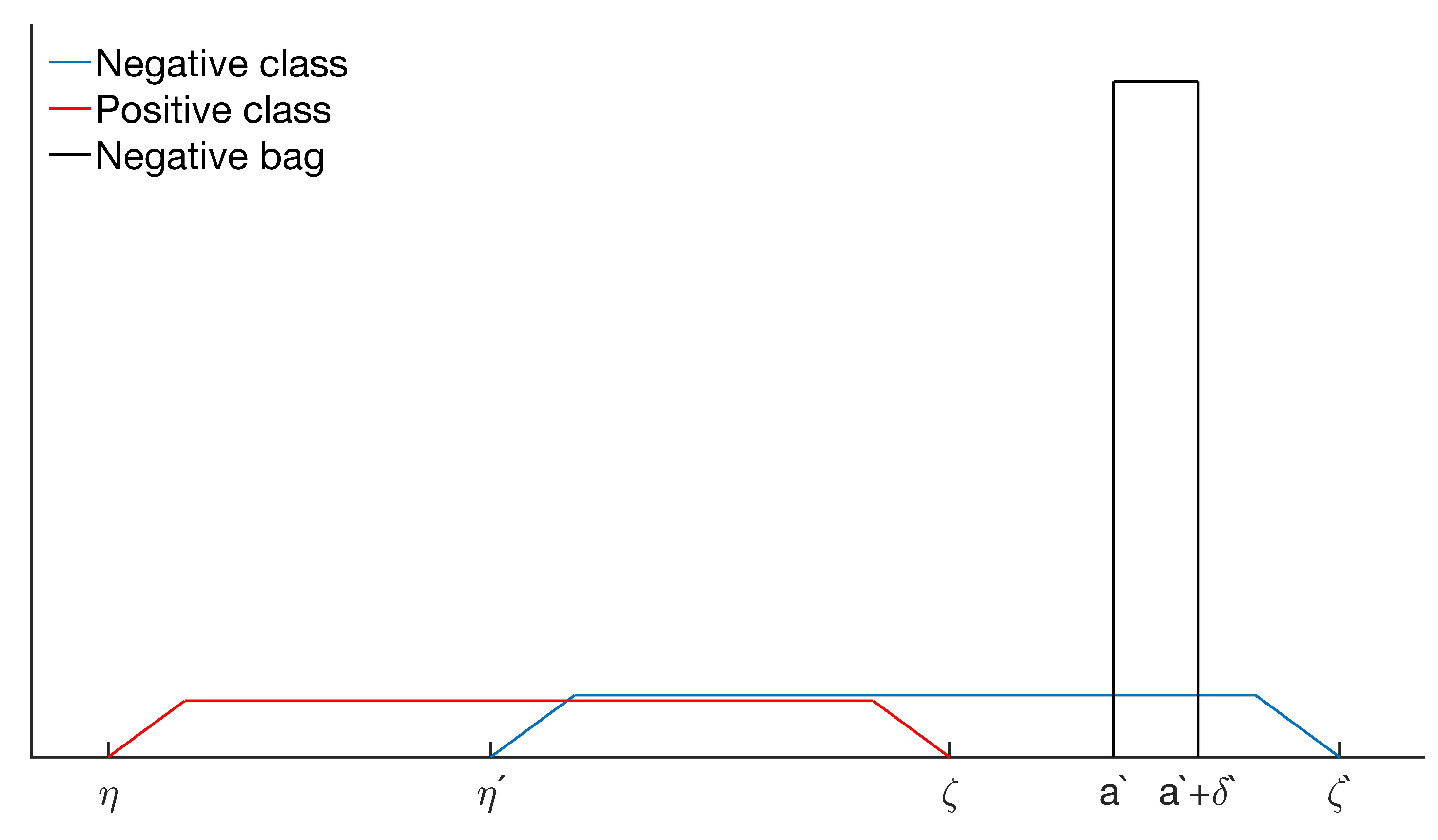
As a motivating example, consider the following: A positive bag, , is a continuous uniform distribution , sampled according to :
A negative bag, , is sampled according to :
and let so that there is an overlap between the two classes. For both positive and negative bags, we have that for a subspace of and for a different subspace of , merely reflecting that the variability in instances within a class is larger than within a bag, as illustrated in Figure 4.
If is a sample from the negative class, and for some subspace of it can easily be classified. From the above analysis, large bag-to-class ratio should be reflected in large divergence, whereas large class-to-bag ratio should not.
Property 1: Let be the subspace of where the bag-to-class ratio is larger than some M:
and let be its complement. Let be the contribution to the total divergence for that subspace: . Let be the subspace of where the class-to-bag ratio is larger than some M:
and let be its complement. Let be the contribution to the total divergence for that subspace: .
approaches the maximum contribution as . does not approach the maximum contribution as :
Property 1 cannot be fulfilled by a symmetric divergence. This property is necessary in cases where the sample space of a bag is a subset of the sample space of the class, , e.g., for uniform distributions, and in cases where the variance of a bag is smaller than the variance of the class.
Consider . Because , this occurs for the subspace of where is smaller than some and is not. We argue that when , there should be no contribution to the divergence due to the very nature of MI learning: a bag is not a representation of the entire class, but only a small part of it.
Consider an unlabeled image coming from the class sea, and a binary classification problem with desert as the alternative class. If the unlabeled image contains only blue and white colors, it should not influence the divergence how the different shades of brown or green are distributed in the two classes, as it does not influence the likelihood of this bag coming from one class or the other. This is in contrast to bag-to-bag divergences, where this indicates a bad sample-model match.
As a second motivating example, consider the same positive class as before, and the two alternative negative classes defined by:
For bag classification, the question becomes: from which class is a specific bag sampled? It is equally probable that a bag comes from each of the two negative classes, since and only differ where , and we argue that should be equal to .
Property 2: Let be the subspace of where is larger than some :
and let be its complement. Let be the contribution to the total divergence for that subspace: .
The contribution to the total divergence approaches zero as :
This property is necessary when the bag distributions are mixture distributions with possibly zero mixture proportion. It also covers the case when the bags are different distributions, not merely have different parameters, which can be modelled as a mixture of all possible distributions in the class and only one non-zero mixture proportion.
KL information is the only divergence that fulfils these two properties among the non-symmetric divergences listed in [53]. See Appendix A. As there is no complete list of divergences, it is possible that other divergences that the authors are not aware of fulfil these properties.
4.2. A Class-Conditional Dissimilarity for MI Classification
In the sea and desert images example, consider an unlabeled image with a pink segment, e.g., a boat. If pink is absent in the training set, then the bag-to-class KL information will be infinite for both classes. We therefore propose the following property:
Property 3: For the subspace of where the alternative class probability, , is smaller than some , the contribution to the total divergence, , approaches zero as :
Let be the subspace of where is larger than some :
and let be its complement. Let be the contribution to the total divergence for that subspace: .
The contribution to the total divergence approaches zero as :
We present a class-conditional dissimilarity that accounts for this:
which also fulfils Properties 1 and 2, see Appendix A.
4.3. Bag-Level Divergence Classification
With a proper dissimilarity measure, the classification task is, in theory, straightforward: A bag is given the label of its most similar class. With dense bag and class sample, the KL bag-to-bag classifier is the most powerful. There are, however, a couple of practical obstacles: The distributions from where the instances have been drawn are not known, and must be estimated. The divergences usually do not have analytical solutions, and must therefore be approximated.
We propose two similar methods based on either the ratio of bag-to-class divergences, , or the class-conditional dissimilarity in Equation (6). We propose using the KL information (Equation (4)), and report for the BH distance (Equation (5)) for comparison, but any divergence function can be applied.
Given a training set and a set, , of instances drawn from an unknown distribution, , with unknown class label , and let denote the set of all and denote the set of all . The bag-level divergence classification follows the steps:
Common methods for PDF estimation are Gaussian mixture models (GMMs) and kernel density estimation (KDE). The integrals in step 2 are commonly approximated by importance sampling and Riemann sums. In rare cases, e.g., when the distributions are Gaussian, the divergences can be calculated directly. The threshold t can be pre-defined based on, e.g., misclassification penalty and prior class probabilities, or estimated from the training set by leave-one-out cross-validation. When the feature dimension is high and the number of instances in each bag is low, PDF estimation becomes arbitrary. A solution is to estimate separate PDFs for each dimension, calculate the corresponding divergences , and treat them as inputs into a classifier replacing step 3.
In image analysis, it has become more and more common that MI data sets are limited by the number of (labeled) bags per class, more than the number of instances per bag. With the proposed algorithm, the PDF estimates improve with increasing number of instances, and the aggregation of class instances allows for sparser bag samples.
5. Experiments
5.1. Simulated Data and Class Sparsity
The following study exemplifies the difference between BH distance ratio, , KL information ratio, , and as classifiers for sparse training data. We investigate how the three divergences vary in accordance with the number of bags in the training set. The minimum dissimilarity bag-to-bag classifiers are also implemented, based on KL information and BH distance. The number of instances from each bag is 50, the number of bags in the training set is varied from 1 to 25 from each class, and the number of bags in the test set is 100. Each bag and its instances are sampled as described in Equation (3), and the area under the receiver operating characteristic (ROC) curve (AUC) serves as performance measure. For simplicity, we use Gaussian distributions in one dimension for Sim 1-Sim 4:
- Sim 1: : No positive instances in negative bags.
- Sim 2: : Positive instances in negative bags.
- Sim 3: : Positive and negative instances have the same expectation of the mean, but unequal variance.
- Sim 4: : Positive instances are sampled from two distributions with unequal mean expectation.
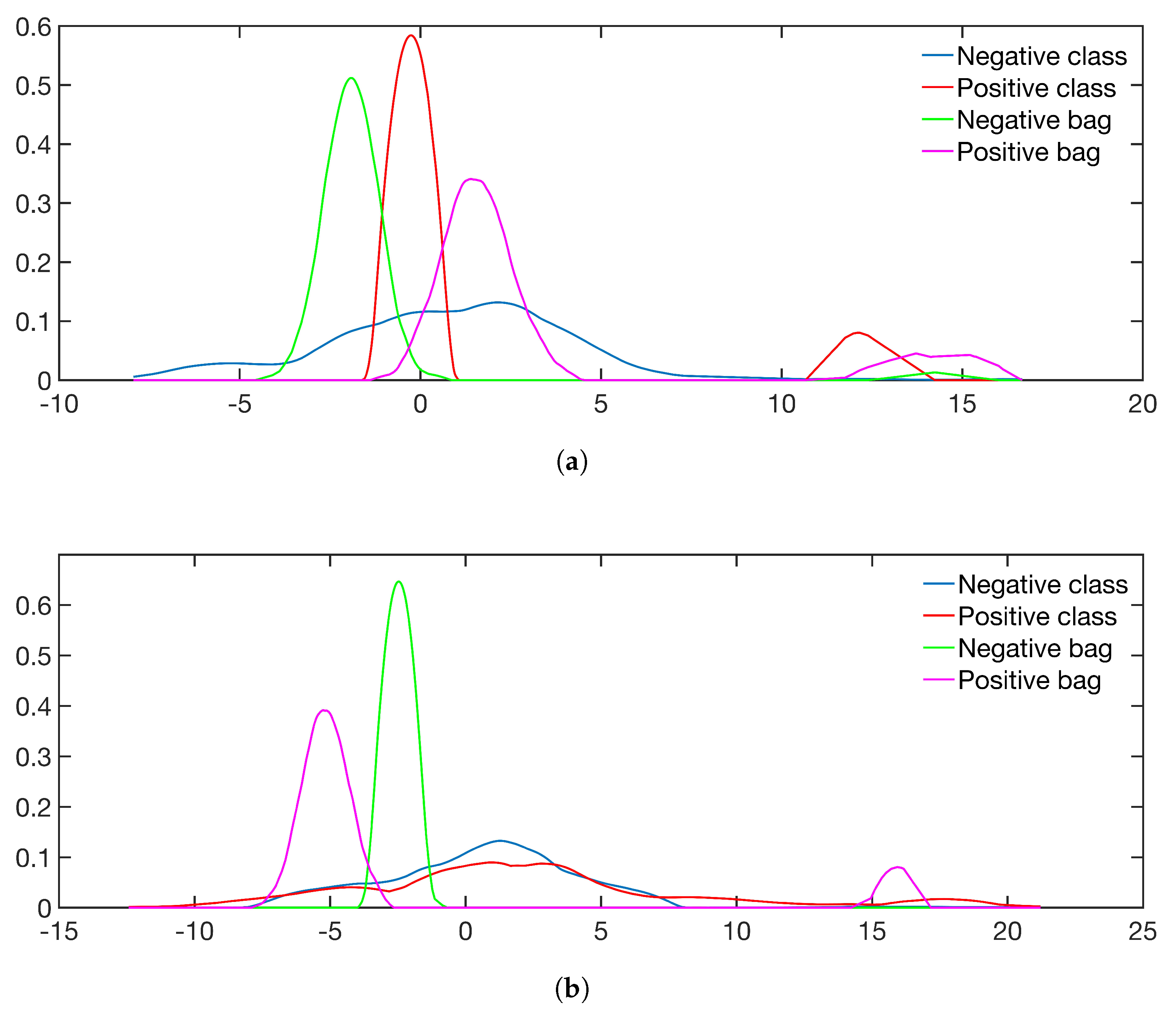
We add Sim 5 and Sim 6 for the discussion on instance labels in Section 6, as follows: Sim 5 is an uncertain object classification, where the positive bags are lognormal densities with and , and negative bags are Gaussian mixtures densities with , , , and . These two densities are nearly identical, see [54], p. 15. In Sim 6, the parameters of Sim 5 are i.i.d. observations from Gaussian distributions, each with for the Gaussian mixture, and for the lognormal distribution. Figure 5 shows the estimated class densities and two estimated bag densities for Sim 2 with 10 negative bags in the training set.
We use the following details for the algorithm in (7): 1. KDE fitting: Epanechnikov kernel with estimated bandwidth varying with the number of observations. 2. Integrals: Importance sampling. 3. Classifier: t is varied to give the full range of sensitivities and specificities necessary to calculate AUC.
Table 1 shows the mean AUCs for 50 repetitions.
5.2. The Impact of Pdf Estimation and Comparison to Other Methods
We use a public data set from UCSB Center for Bio-Image Informatics to demonstrate the impact of PDF estimation method and for comparison with other MI classification methods. The UCSB data set consists of 58 breast tumor histology images, as seen in Figure 1). There are 32 images labeled as benign and 26 as malignant. The image patches are of size pixels, and 708 features have been extracted from each patch. The mean number of instances per bag is 35. We have used the published instance values [14] to minimize other sources of variation than the classification algorithms. Following the procedure in [3], the principal components are used for dimension reduction, and 4-fold cross-validation is used so that and are fitted only to the instances in the training folds. Table 2 shows the AUC for and for three different methods for PDF estimation. GMMs are fitted to the first principal component, using an EM-algorithm, with number of components chosen by minimum AIC. In addition, KDE as in Section 5.1, and KDE with Gaussian kernel and optimal bandwidth [55] is used.
5.3. Comparison to State-of-the-Art Methods
The benchmark data sets that have been used for comparison of MIL methods have particularly low number of instances compared to the number of features. e.g., in , more than half of the bags contain less than 5 instances, and in , one fourth of the bags contain less than 5 instances. It is obvious that a PDF-based method will not work. The COREL data base, previously used in MIL method comparisons, is no longer available, only data sets with extracted features. Again, the number of instances is too low for density estimation. In addition, [56] showed how the feature extraction methods influence the results of MIL classifiers.
We here present the results of and compared to the five best-performing MIL methods using the BreakHis data set, as presented in [31]. This data set is suited for PDF-based methods, since the images themselves are available, and hence, the number of instances can be adjusted to assure a sufficiently dense sampling. We follow the procedure in [31], using the 162 parameter-free threshold adjacency statistics (PFTAS) features for 1000 image patches of size . Dimension reduction is done by principal components, so that of the variance is explained, and the dimension is reduced to about 25, depending on which data set, see Table 4. Each data set is split into training, validation and test sets (35%/35%/30%), where we use the exact same five test sets as [31]. There are multiple images from the same tumor, but the data set is split so that the same tumor does not appear in both training/validation and test set.
We use the following details for the algorithm in (7):
- GMMs are fitted with components, and the number of components is chosen by minimum AIC. To save computation time, the number of components is estimated for 10 bags sampled from the training set. The median number of components is used to fit the bag PDFs in the rest of the algorithm, see Table 4. For the class PDFs, a random subsample of 10% of the instances is taken from each bag, to reduce computation time.
- Integrals: Importance sampling.
- Classification: To estimate the threshold, t, the training set is used to estimate and , and the divergences between the bags in the validation set and and are calculated. The threshold, , that gives the highest accuracy will then serve as threshold for the test set.
Please note that the bags from the test set is not involved in picking the number of components or estimating .
5.4. Results
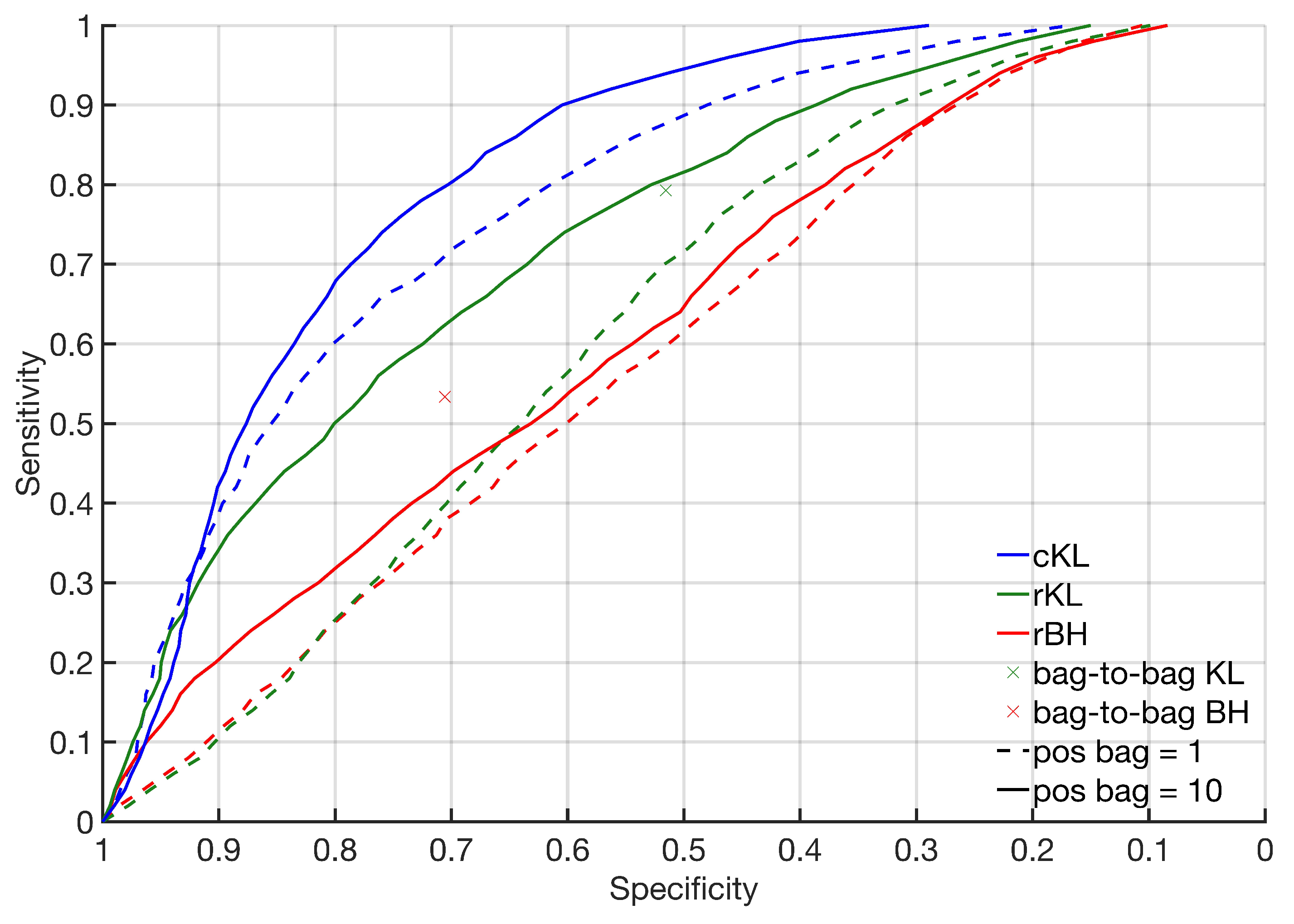
The general trend in Table 1 is that gives higher AUC than , which in turn gives higher AUC than , in line with the divergences’ properties for sparse training sets. The same trend can be seen with a Gaussian kernel and optimal bandwidth (numbers not reported). The gap between and narrows with larger training sets. In other words, the benefit of increases with sparsity. This can be explained by the risk of , as seen in Figure 5a. Increasing also narrows the gap between and , and eventually (at approximately ), outperforms (numbers not reported). Sim 1 and Sim 3 are less affected because the ratio is already ∞.
The minimum bag-to-bag classifier gives a single sensitivity-specificity outcome, and the KL information outperforms the BH distance. Compared to the ROC curve, as illustrated in Figure 6, the minimum bag-to-bag KL information classifier exceeds the bag-to-class dissimilarities only for very large training sets, typically for 500 or more, then at the expense of extensive computation time.
Sim 5 is an example in which the absolute difference, not the ratio, differentiates the two classes, and has the superior performance. When the extra hierarchy level is added in Sim 6, the performances returned to normal.
The UCSB breast tissue study shows that the simple divergence-based approach can outperform more sophisticated algorithms. is more sensitive than to choice of density estimation method, as shown in Table 2. performs better than with GMM, and both are among the best performing in Table 3. The study is too small to draw conclusions. Table 2 shows how the performance can vary between two common PDF estimation methods that do not assume a particular underlying distribution. Both KDE and GMM are sensitive to chosen parameters or parameter estimation method, bandwidth and number of components, respectively, and no method will fit all data sets. In general, KDE is faster, but more sensitive to bandwidth, whereas GMM is more stable. For bags with very few instances the benefits of GMM cannot be exploited, and KDE is preferred.
The BreakHis study shows that both and perform as good as or better than the other methods, the exception being for , as reported in Table 5. “As good as” refers to the mean being within one standard deviation of the highest mean. Since none of the methods have overall superior performance, we believe that the differences within one standard deviation is not enough to declare a winner. has overall best performance in the sense that it is always within one standard deviation from the highest mean. However, cKL, MI-SVM poly and Non-parametric follow close behind with four out of five. Therefore, we will again avoid declaring a winner. Table 4 demonstrates that the number of components varies between repetitions, but does not influence the accuracy substantially. For reference, we have reported the AUC in Table 6, as this is a common way of reporting performance in the MIL context.
The superior performance of for the KDE (Epan.) in Table 2 can be explained by the Epanechnikov kernel’s zero value, as opposed to the Gaussian kernel which is always positive. will then suffer from its property given the limited training set for each class. With Gaussian kernel and GMMs, improves its performance compared to , as demonstrated in the simulation study. For the BreakHist data, and show similar performance. Although is not within one standard deviation from the best-performing method for the data set, it is within one standard deviation from . The similar performance of and is in line with the simulation study where the superiority of is demonstrated for sparse training sets, but not for all types of data.
6. Discussion
6.1. Point-of-View
The theoretical basis of the bag-to-class divergence approach relies on viewing a bag as a probability distribution, hence fitting into the branch of collective assumptions of the Foulds and Frank taxonomy [13]. The probability distribution estimation can be seen as extracting bag-level information from a set , and hence falls into the BS paradigm of Amores [15]. The probability distribution space is non-vectorial, different from the distance-kernel spaces in [15], and divergences are used for classification.
In practice, the evaluation points of the importance sampling gives a mapping from the set to a single vector, . The mapping concurs with the ES paradigm, and the same applies for the graph-based methods. From that viewpoint, the bag-to-class divergence approach expands the distance branch of Foulds and Frank to include a bag-to-class category in addition to instance-level and bag-level distances. However, the importance sampling is a technicality of the algorithm. We argue that the method belongs to the BS paradigm. When the divergences are used as input to a classifier, the ES paradigm is a better description.
Carbonneau et al. [16] assume underlying instance labels. From a probability distribution viewpoint, this corresponds to posterior probabilities, which are in practice, inaccessible. In Sim 1–Sim 4, the instance labels are inaccessible through observations without previous knowledge about the distributions. In Sim 6, the instance label approach is not useful due to the similarity between the two distributions:
where and are the lognormal and the Gaussian mixture, respectively. Equation (3) is just a special case of Equation (8), where is the random vector . Without knowledge about the distributions, discriminating between training sets following the generative model of Equations (3) and (8) is only possible for a limited number of problems. Even the uncertain objects of Sim 5 are difficult to discriminate from MI objects based solely on the observations in the training set.
6.2. Conclusions and Future Work
Although the bag-to-bag KL information has the minimum misclassification rate, the typical bag sparseness of MI training sets is an obstacle. This is partly solved by bag-to-class dissimilarities and the proposed class-conditional KL information accounts for additional sparsity of bags.
The bag-to-class divergence approach addresses three main challenges of MI learning. (1) Aggregation of instances according to bag label and the additional class-conditioning provide a solution for the bag sparsity problem. (2) The bag-to-bag approach suffers from extensive computation time, solved by the bag-to-class approach. (3) Viewing bags as probability distributions give access to analytical tools from statistics and probability theory, and comparisons of methods can be done on a data-independent level through identification of properties. The properties presented here are not an extensive list, and any extra knowledge should be taken into account whenever available.
A more thorough analysis of the proposed function, , will identify its weaknesses and strengths, and can lead to improved versions as well as alternative class-conditional dissimilarity measures and a more comprehensive tool.
The diversity of data types, assumptions, problem characteristics, sampling sparsity, etc. is far too large for any one approach to be sufficient. The introduction of divergences as an alternative class of dissimilarity functions, and the bag-to-class dissimilarity as an alternative to the bag-to-bag dissimilarity, has added additional tools to the MI toolbox.
Author Contributions
Conceptualization, K.M.; methodology, K.M.; software, K.M.; writing—original draft preparation, K.M.; writing—review and editing, J.Y.H. and F.G.; visualization, K.M.; supervision, J.Y.H. and F.G. All authors have read and agreed to the published version of the manuscript.
Funding
The publication charges for this article have been funded by a grant from the publication fund of UiT The Arctic University of Norway.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MI | multi-instance |
| probability density function | |
| IS | instance space |
| ES | embedded space |
| BS | bag space |
| KL | Kullback–Leibler |
| SVM | support vector machine |
| AIC | Akaike Information Criterion |
| GMM | Gaussian mixture models |
| KDE | kernel density estimation |
| ROC | receiver operating characteristic |
| AUC | area under the ROC curve |
Appendix A
For the sake of readability, we repeat summary versions of the properties here:
Property 1:
Property 2:
Property 3:
Appendix A.1. Non-Symmetric Divergences
We show that the only non-symmetric divergences listed in [53] that fulfil both Property 1 and Property 2 is the KL information. For all other divergences, we show one property that it does not fulfil.
The -divergence, defined as:
does not fulfil Property 2:
The KL information, referred to as Relative information in [53], defined as:
fulfils Property 1:
since and , and Property 2:
The Relative Jensen-Shannon divergence, defined as:
does not fulfil Property 1:
The Relative Arithmetic-Geometric divergence, defined as:
does not fulfil Property 2:
The Relative J-divergence, defined as:
does not fulfil Property 2:
Appendix A.2. Class-Conditional Bag-to-Class Divergence
Class-conditional KL-divergence:
For the class-conditional divergence, there are three PDFs involved, and therefore, we have some additional restrictions. We show that the Equality and Orthogonality properties of f-divergences are fulfilled also by . We were not able to conclude regarding the Monotonicity property.
Equality, :
Orthogonality, :
Property 1:
Property 2:
Property 3: , faster than
References
- Cheplygina, V.; de Bruijne, M.; Pluim, J.P. Not-so-supervised: A survey of semi-supervised, multi-instance, and transfer learning in medical image analysis. Med. Image Anal. 2019, 54, 280–296. [Google Scholar] [CrossRef] [Green Version]
- Gelasca, E.D.; Byun, J.; Obara, B.; Manjunath, B.S. Evaluation and Benchmark for Biological Image Segmentation. In Proceedings of the IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 1816–1819. [Google Scholar] [CrossRef] [Green Version]
- Kandemir, M.; Zhang, C.; Hamprecht, F.A. Empowering Multiple Instance Histopathology Cancer Diagnosis by Cell Graphs. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention—MICCAI 2014, Boston, MA, USA, 14–18 September 2014; pp. 228–235. [Google Scholar] [CrossRef]
- Doran, G.; Ray, S. Multiple-Instance Learning from Distributions. J. Mach. Learn. Res. 2016, 17, 1–50. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. Multi-instance clustering with applications to multi-instance prediction. Appl. Intell. 2009, 31, 47–68. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Zhang, M.L.; Huang, S.J.; Li, Y.F. Multi-instance multi-label learning. Artif. Intell. 2012, 176, 2291–2320. [Google Scholar] [CrossRef] [Green Version]
- Tang, P.; Wang, X.; Huang, Z.; Bai, X.; Liu, W. Deep patch learning for weakly supervised object classification and discovery. Pattern Recognit. 2017, 71, 446–459. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Yan, Y.; Tang, P.; Bai, X.; Liu, W. Revisiting multiple instance neural networks. Pattern Recognit. 2018, 74, 15–24. [Google Scholar] [CrossRef] [Green Version]
- Dietterich, T.G.; Lathrop, R.H.; Lozano-Pérez, T. Solving the multiple instance problem with axis-parallel rectangles. Artif. Intell. 1997, 89, 31–71. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.Y. Multiple-instance learning based decision neural networks for image retrieval and classification. Neurocomputing 2016, 171, 826–836. [Google Scholar] [CrossRef]
- Qiao, M.; Liu, L.; Yu, J.; Xu, C.; Tao, D. Diversified dictionaries for multi-instance learning. Pattern Recognit. 2017, 64, 407–416. [Google Scholar] [CrossRef]
- Weidmann, N.; Frank, E.; Pfahringer, B. A Two-Level Learning Method for Generalized Multi-instance Problems. In Proceedings of the European Conference on Machine Learning, Cavtat-Dubrovnik, Croatia, 22–26 September 2003; pp. 468–479. [Google Scholar] [CrossRef] [Green Version]
- Foulds, J.; Frank, E. A review of multi-instance learning assumptions. Knowl. Eng. Rev. 2010, 25, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Cheplygina, V.; Tax, D.M.J.; Loog, M. Multiple Instance Learning with Bag Dissimilarities. Pattern Recognit. 2015, 48, 264–275. [Google Scholar] [CrossRef] [Green Version]
- Amores, J. Multiple Instance Classification: Review, Taxonomy and Comparative Study. Artif. Intell. 2013, 201, 81–105. [Google Scholar] [CrossRef]
- Carbonneau, M.A.; Cheplygina, V.; Granger, E.; Gagnon, G. Multiple Instance Learning: A survey of Problem Characteristics and Applications. Pattern Recognit. 2018, 77, 329–353. [Google Scholar] [CrossRef]
- Maron, O.; Lozano-Pérez, T. A framework for multiple-instance learning. In Advances in Neural Information Processing Systems, Denver, CO, USA, 30 November–5 December 1998; MIT Press: Cambridge, MA, USA, 1998; Volume 10, pp. 570–576. [Google Scholar]
- Xu, X.; Frank, E. Logistic Regression and Boosting for Labeled Bags of Instances; Lecture Notes in Computer Science; Dai, H., Srikant, R., Zhang, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 272–281. [Google Scholar] [CrossRef] [Green Version]
- Tax, D.M.J.; Loog, M.; Duin, R.P.W.; Cheplygina, V.; Lee, W.J. Bag Dissimilarities for Multiple Instance Learning. In Similarity-Based Pattern Recognition; Lecture Notes in Computer Science; Pelillo, M., Hancock, E.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 7005, pp. 222–234. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Sun, Y.Y.; Li, Y.F. Multi-instance Learning by Treating Instances As non-I.I.D. Samples. In Proceedings of the 26th Annual International Conference on Machine Learning—ICML ’09, Montreal, QC, Canada, 14–18 June 2009; pp. 1249–1256. [Google Scholar] [CrossRef] [Green Version]
- Cheplygina, V.; Tax, D.M.J.; Loog, M. Dissimilarity-Based Ensembles for Multiple Instance Learning. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 1379–1391. [Google Scholar] [CrossRef] [Green Version]
- Boiman, O.; Shechtman, E.; Irani, M. In defense of Nearest-Neighbor based image classification. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar] [CrossRef]
- Lee, W.J.; Cheplygina, V.; Tax, D.M.J.; Loog, M.; Duin, R.P.W. Bridging structure and feature representations in graph matching. Int. J. Patten Recognit. Artif. Intell. 2012, 26, 1260005. [Google Scholar] [CrossRef] [Green Version]
- Scott, S.; Zhang, J.; Brown, J. On generalized multiple-instance learning. Int. J. Comput. Intell. Appl. 2005, 5, 21–35. [Google Scholar] [CrossRef] [Green Version]
- Ruiz-Muñoz, J.F.; Castellanos-Dominguez, G.; Orozco-Alzate, M. Enhancing the dissimilarity-based classification of birdsong recordings. Ecol. Inform. 2016, 33, 75–84. [Google Scholar] [CrossRef]
- Sørensen, L.; Loog, M.; Tax, D.M.J.; Lee, W.J.; de Bruijne, M.; Duin, R.P.W. Dissimilarity-Based Multiple Instance Learning. In Structural, Syntactic, and Statistical Pattern Recognition; Hancock, E.R., Wilson, R.C., Windeatt, T., Ulusoy, I., Escolano, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 129–138. [Google Scholar] [CrossRef]
- Schölkopf, B. The Kernel Trick for Distances. In Proceedings of the 13th International Conference on Neural Information Processing Systems, Denver, CO, USA, 27 November–2 December 2000; MIT Press: Cambridge, MA, USA, 2000; pp. 283–289. [Google Scholar]
- Wei, X.S.; Wu, J.; Zhou, Z.H. Scalable Algorithms for Multi-Instance Learning. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 975–987. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Sahu, S.K.; Cheng, R.C.H. A fast distance-based approach for determining the number of components in mixtures. Can. J. Stat. 2003, 31, 3–22. [Google Scholar] [CrossRef]
- Sudharshan, P.; Petitjean, C.; Spanhol, F.; Oliveira, L.E.; Heutte, L.; Honeine, P. Multiple instance learning for histopathological breast cancer image classification. Expert Syst. Appl. 2019, 117, 103–111. [Google Scholar] [CrossRef]
- Zhang, G.; Yin, J.; Li, Z.; Su, X.; Li, G.; Zhang, H. Automated skin biopsy histopathological image annotation using multi-instance representation and learning. BMC Med. Genom. 2013, 6, S10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, W.; Zhang, J.; McKenna, S.J. Multiple instance cancer detection by boosting regularised trees. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Basel, Switzerland, 2015; Volume 9349, pp. 645–652. [Google Scholar] [CrossRef] [Green Version]
- Tomczak, J.M.; Ilse, M.; Welling, M. Deep Learning with Permutation-invariant Operator for Multi-instance Histopathology Classification. arXiv 2017, arXiv:1712.00310. [Google Scholar]
- Mercan, C.; Aksoy, S.; Mercan, E.; Shapiro, L.G.; Weaver, D.L.; Elmore, J.G. Multi-Instance Multi-Label Learning for Multi-Class Classification of Whole Slide Breast Histopathology Images. IEEE Trans. Med. Imaging 2018, 37, 316–325. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Zhu, J.Y.; Chang, E.I.; Lai, M.; Tu, Z. Weakly supervised histopathology cancer image segmentation and classification. Med. Image Anal. 2014, 18, 591–604. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McCann, M.T.; Bhagavatula, R.; Fickus, M.C.; Ozolek, J.A.; Kovaĉević, J. Automated colitis detection from endoscopic biopsies as a tissue screening tool in diagnostic pathology. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 2809–2812. [Google Scholar] [CrossRef] [Green Version]
- Dundar, M.M.; Badve, S.; Raykar, V.C.; Jain, R.K.; Sertel, O.; Gurcan, M.N. A multiple instance learning approach toward optimal classification of pathology slides. In Proceedings of the International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2732–2735. [Google Scholar] [CrossRef]
- Samsudin, N.A.; Bradley, A.P. Nearest neighbour group-based classification. Pattern Recognit. 2010, 43, 3458–3467. [Google Scholar] [CrossRef]
- Kraus, O.Z.; Ba, J.L.; Frey, B.J. Classifying and segmenting microscopy imageswith deep multiple instance learning. Bioinformatics 2016, 32, i52–i59. [Google Scholar] [CrossRef]
- Hou, L.; Samaras, D.; Kurc, T.M.; Gao, Y.; Davis, J.E.; Saltz, J.H. Efficient Multiple Instance Convolutional Neural Networks for GigapixelResolution Image Classification. arXiv 2015, arXiv:1504.07947. [Google Scholar]
- Jia, Z.; Huang, X.; Chang, E.I.; Xu, Y. Constrained Deep Weak Supervision for Histopathology Image Segmentation. IEEE Trans. Med. Imaging 2017, 36, 2376–2388. [Google Scholar] [CrossRef] [Green Version]
- Jiang, B.; Pei, J.; Tao, Y.; Lin, X. Clustering Uncertain Data Based on Probability Distribution Similarity. IEEE Trans. Knowl. Data Eng. 2013, 25, 751–763. [Google Scholar] [CrossRef]
- Kriegel, H.P.; Pfeifle, M. Density-based Clustering of Uncertain Data. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining KDD ’05, Chicago, IL, USA, 21–24 August 2005; pp. 672–677. [Google Scholar] [CrossRef]
- Ali, S.M.; Silvey, S.D. A General Class of Coefficients of Divergence of One Distribution from Another. J. R. Stat. Soc. Ser. B (Methodol.) 1966, 28, 131–142. [Google Scholar] [CrossRef]
- Csiszár, I. Information-type measures of difference of probability distributions and indirect observations. Studia Scientiarum Mathematicarum Hungarica 1967, 2, 299–318. [Google Scholar]
- Berger, A. On orthogonal probability measures. Proc. Am. Math. Soc. 1953, 4, 800–806. [Google Scholar] [CrossRef]
- Gibbs, A.L.; Su, F.E. On Choosing and Bounding Probability Metrics. Int. Stat. Rev. 2002, 70, 419–435. [Google Scholar] [CrossRef] [Green Version]
- Møllersen, K.; Dhar, S.S.; Godtliebsen, F. On Data-Independent Properties for Density-Based Dissimilarity Measures in Hybrid Clustering. Appl. Math. 2016, 07, 1674–1706. [Google Scholar] [CrossRef] [Green Version]
- Møllersen, K.; Hardeberg, J.Y.; Godtliebsen, F. Divergence-based colour features for melanoma detection. In Proceedings of the 2015 Colour and Visual Computing Symposium (CVCS), Gjøvik, Norway, 25–26 August 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Eguchi, S.; Copas, J. Interpreting Kullback-Leibler Divergence with the Neyman-Pearson Lemma. J. Multivar. Anal. 2006, 97, 2034–2040. [Google Scholar] [CrossRef] [Green Version]
- Kass, R.E.; Raftery, A.E. Bayes Factors. J. Am. Stat. Assoc. 1995, 90, 773–795. [Google Scholar] [CrossRef]
- Taneja, I.J.; Kumar, P. Generalized non-symmetric divergence measures and inequaities. J. Interdiscip. Math. 2006, 9, 581–599. [Google Scholar] [CrossRef]
- McLachlan, G.; Peel, D. Finite Mixture Models; Wiley Series in Probability and Statistics; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2000. [Google Scholar] [CrossRef]
- Sheather, S.J.; Jones, M.C. A Reliable Data-Based Bandwidth Selection Method for Kernel Density Estimation. J. R. Stat. Soc. Ser. B (Methodol.) 1991, 53, 683–690. [Google Scholar] [CrossRef]
- Wei, X.S.; Zhou, Z.H. An empirical study on image bag generators for multi-instance learning. Mach. Learn. 2016, 105, 155–198. [Google Scholar] [CrossRef] [Green Version]
- Andrews, S.; Andrews, S.; Tsochantaridis, I.; Hofmann, T. Support vector machines for multiple-instance learning. Adv. Neural Inf. Process. Syst. 2003, 15, 561–568. [Google Scholar]
- Venkatesan, R.; Chandakkar, P.; Li, B. Simpler Non-Parametric Methods Provide as Good or Better Results to Multiple-Instance Learning. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Sun, M.; Han, T.X.; Liu, M.-C.; Khodayari-Rostamabad, A. Multiple Instance Learning Convolutional Neural Networks for object recognition. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 3270–3275. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Breast tissue images [2]. The image segments are not labeled.
Figure 1.
Breast tissue images [2]. The image segments are not labeled.

Figure 2.
Sea and desert images from Wikimedia Commons.

Figure 3.
Parametric generative model. Bags are realizations of random parameter vectors, sampled according to the respective class distributions. Instances are realizations of feature vectors, sampled according the respective bag distributions. Only the instance sets are observed.
Figure 3.
Parametric generative model. Bags are realizations of random parameter vectors, sampled according to the respective class distributions. Instances are realizations of feature vectors, sampled according the respective bag distributions. Only the instance sets are observed.

Figure 4.
The PDF of a bag with uniform distribution and the PDFs of the two classes.

Figure 5.
(a) One positive bag in the training set gives small variance for the class PDF. (b) Ten positive bags in the training set, and the variance has increased.
Figure 5.
(a) One positive bag in the training set gives small variance for the class PDF. (b) Ten positive bags in the training set, and the variance has increased.

Figure 6.
An example of ROC curves for , and classifiers. The performance increases when the number of positive bags in the training set increases from 1 (dashed line) to 10 (solid line). The sensitivity-specificity pairs for the bag-to-bag KL and BH classifier is displayed for 100 positive and negative bags in the training set for comparison.
Figure 6.
An example of ROC curves for , and classifiers. The performance increases when the number of positive bags in the training set increases from 1 (dashed line) to 10 (solid line). The sensitivity-specificity pairs for the bag-to-bag KL and BH classifier is displayed for 100 positive and negative bags in the training set for comparison.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
AUC for simulated data.
| Bags | : 5 | : 10 | : 25 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Sim: | : | |||||||||
| 1 | 61 | 69 | 85 | 62 | 72 | 89 | 61 | 73 | 92 | |
| 1 | 5 | 63 | 75 | 86 | 64 | 82 | 94 | 68 | 84 | 97 |
| 10 | 69 | 86 | 87 | 73 | 91 | 95 | 75 | 91 | 98 | |
| 1 | 57 | 61 | 75 | 59 | 61 | 78 | 58 | 55 | 75 | |
| 2 | 5 | 59 | 67 | 79 | 60 | 68 | 84 | 62 | 63 | 85 |
| 10 | 64 | 77 | 80 | 66 | 78 | 86 | 68 | 72 | 86 | |
| 1 | 51 | 55 | 71 | 52 | 58 | 73 | 50 | 57 | 74 | |
| 3 | 5 | 53 | 61 | 76 | 53 | 66 | 81 | 52 | 65 | 83 |
| 10 | 58 | 73 | 78 | 58 | 76 | 84 | 57 | 76 | 87 | |
| 1 | 55 | 61 | 70 | 56 | 62 | 73 | 56 | 58 | 69 | |
| 4 | 5 | 56 | 63 | 75 | 57 | 64 | 81 | 59 | 59 | 80 |
| 10 | 60 | 74 | 77 | 62 | 76 | 85 | 63 | 69 | 84 | |
| 1 | 64 | 61 | 62 | 67 | 63 | 66 | 64 | 62 | 67 | |
| 5 | 5 | 73 | 69 | 63 | 74 | 70 | 67 | 75 | 71 | 72 |
| 10 | 74 | 70 | 62 | 75 | 73 | 69 | 76 | 74 | 72 | |
| 1 | 68 | 68 | 67 | 66 | 68 | 68 | 68 | 71 | 68 | |
| 6 | 5 | 65 | 64 | 67 | 68 | 68 | 69 | 70 | 71 | 74 |
| 10 | 66 | 64 | 66 | 70 | 69 | 72 | 72 | 73 | 74 | |
Table 2.
AUC We use the following details for the algorithm.
| KDE (Epan.) | KDE (Gauss.) | GMMs | |
|---|---|---|---|
| 90 | 92 | 94 | |
| 82 | 92 | 96 |
Table 3.
AUC for USCB breast tissue images.
| Method | AUC |
|---|---|
| 94 | |
| 96 | |
| DEEPISR-MIL [34] | 90 |
| Li et al. [33] | 93 |
| GPMIL [3] | 86 |
| RGPMIL [3] | 90 |
Table 4.
Number of components.
| Data Set | ||||
|---|---|---|---|---|
| Dimension | 23 | 26 | 25 | 24 |
| Rep 1 | 66 | 55 | 52 | 70 |
| Rep 2 | 58 | 49 | 69 | 71 |
| Rep 3 | 59 | 50 | 50 | 70 |
| Rep 4 | 47 | 49 | 58 | 73 |
| Rep 5 | 63 | 59 | 72 | 74 |
Table 5.
Accuracy and standard deviation. Best results and those within one standard deviation in bold.
Table 5.
Accuracy and standard deviation. Best results and those within one standard deviation in bold.
| Data Set (Magnification) | ||||
|---|---|---|---|---|
| MI-SVM poly [57] | 86.2 (2.8) | 82.8 (4.8) | 81.7 (4.4) | 82.7 (3.8) |
| Non-parametric [58] | 87.8 (5.6) | 85.6 (4.3) | 80.8 (2.8) | 82.9 (4.1) |
| MILCNN [59] | 86.1 (4.2) | 83.8 (3.1) | 80.2 (2.6) | 80.6 (4.6) |
| CNN [31] | 85.6 (4.8) | 83.5 (3.9) | 83.1 (1.9) | 80.8 (3.0) |
| SVM [31] | 79.9 (3.7) | 77.1 (5.5) | 84.2 (1.6) | 81.2 (3.6) |
| rKL | 83.4 (4.1) | 84.9 (4.2) | 88.3 (3.6) | 84.0 (2.8) |
| cKL | 81.5 (3.2) | 85.2 (3.5) | 88.1 (3.6) | 85.0 (3.5) |
Table 6.
AUC and standard deviation.
| Data Set (Magnification) | ||||
|---|---|---|---|---|
| rKL | 91.4 (2.4) | 91.3 (2.2) | 94.4 (1.9) | 91.6 (1.7) |
| cKL | 88.4 (2.6) | 89.7 (1.6) | 91.9 (2.7) | 91.7 (2.4) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Møllersen, K.; Hardeberg, J.Y.; Godtliebsen, F. A Probabilistic Bag-to-Class Approach to Multiple-Instance Learning. Data 2020, 5, 56. https://0-doi-org.brum.beds.ac.uk/10.3390/data5020056
AMA Style
Møllersen K, Hardeberg JY, Godtliebsen F. A Probabilistic Bag-to-Class Approach to Multiple-Instance Learning. Data. 2020; 5(2):56. https://0-doi-org.brum.beds.ac.uk/10.3390/data5020056
Chicago/Turabian StyleMøllersen, Kajsa, Jon Yngve Hardeberg, and Fred Godtliebsen. 2020. "A Probabilistic Bag-to-Class Approach to Multiple-Instance Learning" Data 5, no. 2: 56. https://0-doi-org.brum.beds.ac.uk/10.3390/data5020056