
Information Quality Assessment for Data Fusion Systems
by
 , , and
, , and
Miguel A. Becerra
1,2,*,† ,
,
Catalina Tobón
2,†,
Andrés Eduardo Castro-Ospina
1,† and
Diego H. Peluffo-Ordóñez
3,4
1
Instituto Tecnológico Metropolitano, Cra. 74d #732, Medellín 050034, Colombia
2
Facultad de Ciencias Básicas, Universidad de Medellín, MATBIOM, Cra. 87 #30-65, Medellín 050010, Colombia
3
Modeling, Simulation and Data Analysis (MSDA) Research Program, Mohammed VI Polytechnic University, Ben Guerir 47963, Morocco
4
Faculty of Engineering, Corporación Universitaria Autónoma de Nariño, Carrera 28 No. 19-24, Pasto 520001, Colombia
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Data 2021, 6(6), 60; https://0-doi-org.brum.beds.ac.uk/10.3390/data6060060
Submission received: 29 April 2021
/
Revised: 3 June 2021
/
Accepted: 3 June 2021
/
Published: 8 June 2021
(This article belongs to the Section Information Systems and Data Management)
Abstract
:This paper provides a comprehensive description of the current literature on data fusion, with an emphasis on Information Quality (IQ) and performance evaluation. This literature review highlights recent studies that reveal existing gaps, the need to find a synergy between data fusion and IQ, several research issues, and the challenges and pitfalls in this field. First, the main models, frameworks, architectures, algorithms, solutions, problems, and requirements are analyzed. Second, a general data fusion engineering process is presented to show how complex it is to design a framework for a specific application. Third, an IQ approach, as well as the different methodologies and frameworks used to assess IQ in information systems are addressed; in addition, data fusion systems are presented along with their related criteria. Furthermore, information on the context in data fusion systems and its IQ assessment are discussed. Subsequently, the issue of data fusion systems’ performance is reviewed. Finally, some key aspects and concluding remarks are outlined, and some future lines of work are gathered.
1. Introduction
The evolution of information has generated an enormous amount of heterogeneous data. This could negatively affect information systems because it requires major efforts from them to appropriately address Information Quality (IQ) problems and to avoid the deterioration of their underlying IQ. In practice, information is collected from multiple and diverse sources (e.g., web-based and human-provided systems) that are naturally multi-sensorial and, therefore, highly conflicting [1]. Indeed, this is why their corresponding acquisition processes involve different time rates and conditions, and various experiments of the target or phenomenon, which results in different data types. These data can broadly be classified into two big classes: hard and soft [2].
Given this scenario, information systems have evolved and improved their efficiency to collect, process, store, analyze, and disseminate information. Nevertheless, designing a unique and generalized framework has become a very complex task [3] because of the new and constantly emerging problems and questions regarding the context, quantity, and quality of data, information, and knowledge [4,5]. Moreover, there is a wide range of issues and matters on how to properly measure information systems’ performance [6,7], which is considered one of the most complex stages during information processing.
In this regard, data fusion has gained much attention and been used in many applications in different fields such as sensor networks [8], fault diagnosis in maintenance [9], internet of things [10], eye movement recognition [11], economic data analysis [12], environmental hazard events [13], acoustic sensor networks [14], target tracking [15], robotics [16], image processing [17], intelligent systems designing, health applications [18], biometrics [19], surveillance [20], and human capital [21] approaches. In this study, the terms “information fusion” and “data fusion” are employed indistinctly for simplicity purposes. Data fusion processes attempt to emulate the natural ability of humans to integrate information obtained from one object using their different senses [4,22]. In addition, they aim to provide a more efficient way to handle heterogeneous data and information (from multiple sources and prior models) to achieve the following goals: (i) improving the reliability of the data/information, (ii) reducing uncertainty, and (iii) increasing IQ.
The concept of data fusion has been widely studied - leading to the emergence of various related patents and scientific publications [23,24,25,26]. Partly, patents are methods aiming to estimate probabilities in distributed sensors [27], portable apparatuses and methods for decision-support for real-time automated multisensor data fusion and analysis [28], as well as systems and methods for asymmetric missile defense [29]. It has been given different names [22] that essentially refer to the same idea but with slight differences in terms of area of application, data type, context, and meaning [30]. Some of these terms include data combination [31], data aggregation [32], multisensor integration [33], multisensor data fusion [34], and information fusion [35]. According to [36], there are more than 25 different definitions for data fusion, which makes it difficult to find a clear distinction between them [3]. Thus, some authors use the term “data fusion” when data are obtained directly from sensors without any processing and the term “information fusion”, when data have been processed [37]. For [37], the definition provided by the Joint Directors of Laboratories (JDL) model is the most commonly employed [38]. It defines data fusion as “a process dealing with the association, correlation, and combination of data and information from single and multiple sources to achieve refined position and identity estimates, and complete and timely assessments of situations and threats, and their significance. The process is characterized by continuous refinements of its estimates and assessments, and the evaluation of the need for additional sources, or modification of the process itself, to achieve improved results” [39].
Currently, data fusion is regarded as an open research field with different unsolved problems. Some of these problems are associated with automated methods to extract meaning from information, the capture of non-numerical data (e.g., statistical data algorithms), the adequate use of uncertain logic declarations, the selection of algorithms and techniques, the assessment of information quality, the analysis and assessment of context information quality, and the evaluation of information fusion systems [4,40,41]. This latter evaluation and its reliability are considered in [42] to be the biggest problems in data fusion systems because there are no standard metrics. Therefore, each author establishes their own metrics, such as those presented in [43,44]. Additionally, in [3] is described data fusion as a challenging task due to the complexity of data, the dependence of the processes on non-measurement variables, and the processing of heterogeneous data sets to use them effectively.
It should be noted that one of the goals of data fusion systems is to improve the quality of information, that is, to generate a gain in information with higher quality using information obtained from multiple sources [45]. For this reason, IQ has been recently studied in the field of information fusion systems, which is considered a challenge because a good IQ in the input does not necessarily guarantee a high IQ in the output [46] and because, without the ability to assess the IQ in any context, it is impossible to establish a status and improvements. Hence, it is crucial to include IQ measures for data fusion systems considering the context as well as IQ metrics of context information. Notwithstanding, IQ has not been widely explored in data fusion due to the complexity of incorporating its assessment into the data fusion process. In addition, the literature reported up to date is limited to a few studies [5,45,46,47,48,49].
In [47], three groups of measures were proposed to evaluate data fusion systems as an alternative to standardizing the evaluation of high level fusion processes, namely, performance measures, measures of merit (derived from quality control), and measures of effectiveness. The concept of effectiveness defines a set of quality criteria that assess efficiency, efficacy, and effectiveness such as information gain, some IQ criteria, and robustness. The functionality of these measures was explained through a brief case of maritime tracking awareness. In [46], the dependencies among IQ criteria, objectives, and the context for decision making were studied. Timeliness, confidence, and credibility were highlighted. The timeliness can allow decision-makers to obtain new observations to improve their decision over time; therefore, it is necessary to balance it with other IQ criteria to achieve good sequential decision-making. The reported results demonstrated the functionality of the method in terms of classification error reduction measure applied in a case study of ship reconnaissance in the military domain. This proposal was taken up in [45] and disseminated in crisis management. They proposed some IQ evaluation ontologies focusing on content, sources, and presentation of information. In addition, they highlighted the need to control quality in the decision-making process and to achieve compact quality measures that relate several IQ criteria. In [5], a comprehensive methodology for assessing IQ in information systems and fusion systems is presented; it is based on quality criteria and transfer functions to assess IQ in subsystems resulting from dividing (with high granularity) data/information processing blocks. The functionality of the model was validated in three case studies. In [48], a low data fusion framework was proposed with a set of IQ criteria distributed over the functional levels of the JDL model and a procedure to apply quality control. The framework was validated on a brain–computer interface case study.
In [49], a survey of data fusion and IQ focused on wireless sensor networks (WSN) was addressed. Noise that affects the WSN was analyzed together with IQ criteria to assess it. Additionally, supervised and unsupervised techniques applied to data fusion were discussed. In [37], a review of data fusion was addressed where different models and techniques of data fusion to carry out the fusion were discussed but without discussing IQ criteria. In our work, unlike other related review works, a broad functional spectrum of data fusion and information quality is analyzed considering the fusion of low- and high-level data-oriented to multiple applications. Though out of the scope of this review, it is important to highlight that there are many works in the area of data profiling that can be used to automatically infer statistics and dependencies among data, with the resulting metadata being an alternative to improving the quality of datasets before and after data fusion processes, as widely discussed in [50,51,52,53].
In this study, all of the aforementioned aspects are outlined, and state-of-the-art publications are systematically and chronologically reviewed within the context of IQ. We define data as a raw sequence of symbols without context; information as contextualized data; context as knowledge applied to the characterization of the situation of an entity; and knowledge as the semantic transformation of the information that has been analyzed, understood, and explained. However, we use “information fusion” and “data fusion” interchangeably unless otherwise specified for understandability purposes.
The rest of this paper is structured as follows. Section 3 presents a general description of the data fusion systems and models and their corresponding taxonomy. Section 4 explains the concept and principles of IQ and data fusion systems’ performance. Section 5 discusses the advantages, disadvantages, limitations, recent developments for bridging gaps and addressing challenges, and future work.
2. Literature Review Process
There are few conceptual studies on data fusion and information quality that attempt to establish relationships between both, which also occurs with context information. Therefore, the objective of this paper is to provide a literature review on data fusion, followed by that on information quality in order to find their connection. For this purpose, we used the following search criteria in Scopus: TITLE-ABS-KEY ((“data fusion” OR “information fusion”) AND (“information quality” OR “quality of information”)) TITLE-ABS-KEY ((“information quality” OR “quality of information”) AND (“methodology” OR “model”)) After fully and independently reading the retrieved papers, we set apart those that included data fusion and information fusion models and information quality methodologies or models and then selected those that discussed both data fusion and IQ.
3. Data Fusion
Currently, data fusion is considered a field of computer science. It is widely used in different processes for a wide range of applications due to its capability to improve information quality. Depending on their architecture as well as on the location and distribution of their design, type of network, and data, among other aspects [38], data fusion systems can be classified as centralized, decentralized, distributed, hierarchical, and hybrid [54]. In the literature, other architectures have also been reported to enhance the performance of data fusion models, as shown in [55].
In this field, multiple models and architectures have been developed to build, in an efficient and structured manner, data fusion systems based on data types and users’ requirements [56]. Their purpose is to reduce data uncertainty to improve the data quality and overcome their faults. Data fusion models locate data and processes at different levels. However, they have become very complex due to the diversity of data, processes, and applications [30].
3.1. Data Fusion Classification
Data fusion can be classified according to abstraction levels, relationships among the data sources, and input–output relations. This classification basically refers to the relationship between data types and processing levels and is described as follows:
(1) Classification based on abstraction levels: In [57], four abstraction levels were proposed. (i) Signal-level fusion: it directs the signals that are acquired from sensors and is employed as a data fusion intermediate stage. (ii) Pixel-level fusion: it is used to improve image processing tasks. (iii) Feature-level fusion: it generates features from signals and images. (iv) Symbol-level fusion: it is also known as the “decision level” and uses symbols that represent decisions. This classification, however, has different limitations, such as the sequence of the levels, referring to signals and images. In [22], a similar but more general classification was introduced based on four levels as follows. (i) Low-level fusion: raw data are fused to obtain data that are more accurate compared to the results obtained with individual sources. (ii) Medium-level fusion or feature-level fusion: features are combined to obtain a map of features to be used in other tasks. (iii) High-level fusion or decision-level fusion: decisions are fused to get a more global or more reliable decision. (iv) Multilevel fusion: some raw data, features, and/or decisions are combined to obtain an output in a particular level.
(2) Classification based on the relationship among the data sources: It consists of three levels. (i) Complementary: two or more data inputs from different parts of the same target are fused to obtain more global and complete information. (ii) Redundant: the same data obtained from different sources are combined to improve data quality. (iii) Cooperative: different data from independent sources are fused to obtain new data or more complex information [58,59].
(3) Classification based on input–output relations: It relates different data types between the input and the output into the fusion systems. These relations are limited by the level of the data, where that of the output must be higher than that of the input. This classification includes six abstraction levels. (i) Data In–Data Out (DAI–DAO): it uses raw data and provides more reliable and/or accurate data. (ii) Data In–Feature Out (DAI–FEO): it can be considered a level where features are extracted from raw data. (iii) Feature In–Feature Out (FEI–FEO): it improves the features and/or extracts new ones. (iv) Feature In–Decision Out (FEI–DEO): it employs features to generate symbolic representations or decisions. (v) Decision In–Decision Out (DEI–DEO): it fuses multiple decisions to obtain more reliable decisions. (vi) Temporal (data/feature/decision) fusion: it integrates different data in various periods and is applied in any level as tracking [55].
3.2. Data Fusion Models
Figure 1 shows the taxonomy of the data fusion models that are currently reported in the literature and used as a reference to build data fusion systems. Such models are classified into three main groups, as follows:
(1) Data-based model, which describes the data on fusion processes and models. In this group, the following fifteen models are included: Joint Directors of Laboratories (JDL), Unified data fusion (jdl) model [60], JDL-user model [60], Visual Data Fusion Model (VDFM) [61], Dasarathy’s or Data–Feature–Decision (DFD) model [55], Data–Information–Knowledge–Wisdom (DIKW) hierarchy [62,63], Distributed Blackboard Data Fusion Architecture (DBDFA) [64], Situation Awareness (SAWAR) [62,65], behavioral knowledge-based data fusion model (also known as Pau’s model—PAU) [66], Waterfall (WF) [56,67,68,69], Multisensor Integration Fusion Model (MSIFM) [59], Rasmussen’s Information Processing Hierarchy (RIPH) [62,63,70], Thomopoulos (Thomo) [54,67,68,71], Transformation of Requirements to Information Processing (TRIP) [60], and Data Fusion Architecture based on Unified Modeling Language (DFA-UML) [72].
(2) Activity-based model, which details the activities conducted by data fusion systems. In this group, the following six models are included: Observe–Orient–Decide–Act (OODA) loop [22], Extended OODA (E-OODA) loop [60], Dynamic OODA (D-OODA) loop [60], Omnibus (OmniB) [69], and Intelligence Cycle (I-Cycle) [30,73].
(3) Role-based model, which defines and explains the relationship among fusion roles. In this group, the following three models are included: Oriented To Object (OTO) model [30], the Object-Centered Information Fusion Model (OCIFM) [60], and the Frankel–Bedworth (FBedw) model [22]. It should be noted that there are other models, such as the Nassar’s model [74] and the Mitchell’s model [54], that although not discussed in this work are also used as references in specific applications.
Figure 2 illustrates the use of the data fusion models presented above in Figure 1 from 1975 to 2021 based on the number of Scopus publications on each model. According to such figure, the most employed one is the JDL model, which has been widely reported in Scopus publications, secondary sources, and patents since 1993. We included the “awareness models” as a single group and found several studies on them. However, it should be noted that these results correspond to papers in which any type of situation awareness model was implemented. The most popular situation awareness model is the Endsley’s model although it was not broadly found in Scopus publications. In addition, some data fusion models incorporate situation awareness in their different stages, such as the JDL model, which applies situation refinement or assessment at level 2. Therefore, the extensive use of the JDL model over time is evident. In [75], a situation awareness model was proposed based on the JDL and Endsley’s models, which captured the different aspects of both.
In this study, we describe the JDL model in detail in order to use it as a reference to compare the data fusion models shown in the taxonomy in Figure 1. It is the most popular functional model even though its functionality may be considered confusing when applied in nonmilitary fields. This model, proposed in [68], originally included four processing levels, which were then adjusted to six [38]. These six levels are presented in Figure 3 and were further discussed in [76]. The JDL model has been widely employed to map applications of different areas such as bioinformatics [77], cyber defense [78], infrastructure [79], and automotive safety [80].
Each of its levels is described below. (i) Level 0—source preprocessing: it establishes the time, type, and identity of the collected data. (ii) Level 1—object refinement (assessment): it performs an iterative data fusion process to track and identify targets and/or their attributes. Therefore, it carries out spatiotemporal alignment, association, correlation, tracking, estimation, clustering, and imperfect data removal, among other tasks, on the data. (iii) Level 2—situation refinement (assessment): it establishes relationships between entities to generate an abstract interpretation based on inferences on a specific context. This helps to understand the status of the perceived elements in a situation. (iv) Level 3—threat refinement (assessment): it uses the relationships detected in level 2 to predict and assess possible threats, vulnerabilities, and opportunities in order to plan responses; it focuses on comprehending how the situation will evolve in the near future. (v) Level 4—process refinement: it manages, tunes, and adjusts the sources. This stage interacts with each level of the system. (vi) Level 5—user refinement: it describes the human in the refinement process and knowledge representation. Finally, the JDL model applies a database management stage that controls the data in the fusion processes.
As mentioned above, we selected the JDL model to establish a correspondence between the different data fusion models. This selection was driven by the fact that this model has been widely used by the information and data fusion community. Additionally, it is very general, which helps to cover the major stages included in the other models. The diversity of data fusion models makes it difficult to choose one for specific applications and data. Table 1 shows the correspondence between the various data fusion models and the JDL model. It is worth mentioning that Table 2 does not hold a comparison among models but only a guide to identify the levels or functional layers of the fusion models. Columns 3–8 correspond to functionalities of levels 0, 1, 2, 3, 4, and 5 of the JDL model, while column 9 corresponds to functionalities that have no similarity with respect to the JDL levels. The procedure to assign each layer, level, or fusion model is depicted with the following example that is based on the SAWAR model: the architecture of the SAWAR model has five main functionalities. The first one corresponds to the perception of elements of a situation. This functionality is closely related to feature extraction, identifications, and tracking; therefore, it is assigned to column 4 (level 1). The second level of the SAWAR model is awareness of the current situation, which is highly related to the functionality of level 2 of the JDL model. The third level is projection, which is very similar to level 3 of the JDL model. The fourth function of the SAWAR model is action taking, which is not very similar by design to level 4 of the JDL model but also gives feedback to the models. making them similar. Finally, the decision level of the SAWAR model cannot be related to any level of the JDL model so it is assigned to column 9.
Table 2 presents the advantages and disadvantages of the aforementioned data fusion models reported by some authors. It is clear that there are many models of this kind. However, some of them may be suitable only for some applications due to their limitations while some others are very complex to understand to apply them in different fields, such as the JDL model. Moreover, some of these models (e.g., situation awareness) focus on high-level fusion, leaving the door open to raw data processing.
3.3. Data Fusion Techniques
After selecting or designing the architecture of the data fusion system, the data type must be determined considering uncertainty in order to choose the appropriate data fusion technique such as probabilistic, soft-computing, and optimization algorithms. These techniques are used in several stages of the JDL model (e.g., characterization, estimation, aggregation, and classification, among others) depending on the intended application. Additionally, the advantages and disadvantages of obtaining a high system performance must be taken into account. A set of methodologies to classify the algorithms used in data fusion and associated with IQ criteria are extensively discussed in [24].
Figure 4 presents a taxonomy of such methodologies. Moreover, their benefits and limitations are emphasized, which should be considered in the engineering process to design and implement data fusion systems.
Out of all of the algorithms used by the methodologies associated with data fusion, we must highlight the optimization algorithm. It uses cost functions in order to minimize or maximize one or multiple parameters, including (i) uncertainty, which is used in the Kalman’s filter [83], and (ii) co-entropy, which is employed, along with the Gaussian kernel, in the Hidden Markov Model (HMM). It has the advantage of rejecting outliers but loses analytical solution [83]. Other techniques (such as Particle Swarm Optimization—PSO) have been widely implemented to optimize different parameters. PSO is considered a superior algorithm in [84], which optimizes the adjustment and the error probability in the data fusion process. This algorithm has a reduced computational cost and optimizes selected sets of solutions to data fusion based on the likelihood method. This method exhibits high complexity in correlating the data due to the loss of certainty and false alarms.
The literature reports a lot of methods to carry out the fusion at different levels of the process. In [37], specialized techniques and algorithms are related to the specific tasks to be performed, as follows: (i) association: Nearest Neighbors, K-Means, Probabilistic data association, Joint Probabilistic Data Association (JPDA), Multiple Hypothesis Test (MHT), Distributed MHT, and Graphical Models; (ii) state estimation: Maximum likelihood and Maximum Posterior, Kalman Filter (KF), Particle Filter, distributed KF, and Covariance Consistency Methods; and (iii) decision fusion: Bayesian Methods, Dempster–Shafer inference, abductive reasoning, and semantic methods. These techniques are used mainly in tracking processes. For its part, in the field of biometric fusion, the Dasarathy model is a remarkable baseline, and according to [26], the techniques applied at each level can be grouped as follows: (i) sensor level: machine learning, Principal Component Analysis (PCA), and PSO, among others; (ii) feature level: PCA, Linear Discriminant Analysis (LDA), Genetic Algorithm, and feature concatenation, among others; and (iii) score level: Bayesian approach, Sum rule, Random Forest, and Copula models, among others. According to the specific application of interest, a wide variety of algorithms based mostly on computational intelligence and statistical techniques are applied in data fusion. For instance, in [23], data fusion is applied to retrieval information from the web and the fusion process itself is focused on score level strategies, such as vote counting.
4. Information Quality
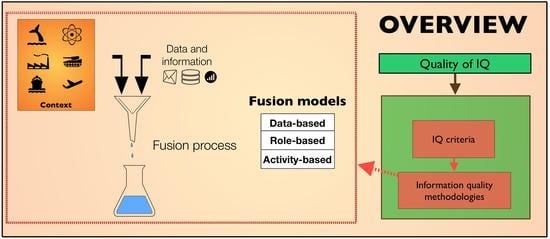
Information Quality (IQ) is a multidisciplinary field [85] that seeks to achieve high quality in making decisions and taking actions [86]. These decisions and actions have been recently applied to improve the data acquisition process and, thus, to enhance the IQ of training databases employed in machine learning (further discussed in [87]) and to develop models such as text mining [88,89]. Many authors have reported different IQ definitions for data and information, which are extensively addressed in [5,86]. Some of these definitions include “fitness for use” [90]; “quality is the degree to which information is meeting user needs according to external, subjective user perceptions” [91]; “meeting or exceeding customer expectations” or “satisfying the needs and preferences of its users” [92]; “quality is the degree to which information has content, form, and time characteristics, which give it value to specific end users” [93]; and “how well the information supports the task” [5]. As can be noted, all of them are “user-centric”, and users can be humans or automated systems [45]. An IQ problem can be defined as the lack of IQ required by users. There are several sources of IQ problems (IQ variance) such as changes in the underlying dynamics of the phenomenon or in its context from the moment information is acquired [86]. Context information in data fusion is further discussed in [4].
The effectiveness of multi-source information systems highly depends on the IQ obtained and processed. Several studies have addressed the multidimensional problem of IQ assessment in information systems by developing frameworks, methodologies, criteria or dimensions, and metrics for general and specific applications. Recently, a method that not only assesses IQ but also detects risky tasks to improve them and, thus, to increase IQ was proposed [94]. In the field of data fusion systems, there are few studies that integrate the IQ criteria as part of general data fusion frameworks, general-purpose functional models, or methodologies [42,45,47,48] even though enhancing it is one of the main goals of data fusion models. It should be noted that a good IQ at the input does not necessarily guarantee a high IQ at the output. Therefore, IQ should be evaluated as part of the refinement process in data fusion systems [45]. According to [45], the information context and its quality are essential to improving the information fusion process. In addition, the authors of such a study consider that, in order to monitor and control IQ, the following issues must be considered: (i) ontology of IQ criteria, (ii) how to achieve a unified quality metric based on IQ criteria, (iii) how to compensate a low IQ and evaluate usability and the quality of IQ, (iv) how to identify the effect of subjectivity on IQ and dependencies on the context, (v) how to assess quality through the capability to adapt to system changes, (vi) how to adequately select quality criteria, and (vii) how to trace IQ assessment throughout the process stages. These issues, which are addressed in [5], are open research challenges.
4.1. Information Quality Criteria
IQ is characterized by different criteria described in [85] as “any component of the IQ concept”. However, we defined them as quality attributes that are measured by means of specific metrics depending on the intended application. Consequently, such criteria must be studied in concert with multiple metrics using the information of the context, the time, and the adaptation assessment, which are necessary for an adequate evaluation [8]. IQ is a multidimensional variable for which the criteria and measures are not necessarily independent among them. Therefore, it may be appropriate to examine the dependence between criteria and metrics to avoid conflicts among variables and adverse effects on IQ assessment.
IQ has been analyzed from different perspectives and represented by multiple criteria, which are found in state-of-the-art literature. Some authors [45,86,91,95,96,97,98] have proposed various categories for grouping IQ criteria, which are presented in Figure 5. Figure 6 illustrates a correlation analysis between IQ criteria, which indicates that some of them provide similar assessments. Each color corresponds to a group of IQ criteria that have similar definitions or have dependencies, for example, accessibility depends on data availability and volatility. Such an analysis was performed based on the definitions reported in Table 3, which were adapted from different publications, mainly [86,91,99,100]. Nevertheless, although the definition of each quality criterion may change depending on the context, we tried to generalize them. Taking as a reference the ISO/IEC 25012 standard, four criteria were not included in Table 3 because they may have the same meaning as other concepts; hence, credibility is included into the concept of believability, currentness into timeliness, understandability into interpretability, and availability into accessibility.
In [91], 16 IQ criteria were proposed and grouped into the following four categories, as presented in Table 4: (i) intrinsic, corresponding to the data’s own attributes; (ii) contextual, denoting the quality defined in the context of the data applied to a task; (iii) representational, referring to the data quality presentation; and (iv) accessibility, concerning the security and accessibility of the data. In [98], 22 IQ criteria were introduced and classified into the following four categories, as shown in Table 5: (i) content, corresponding to the intrinsic attributes of the data; (ii) technical, denoting the attributes established by the source’s software and hardware; (iii) intellectual, referring to the subjective attributes of the data; and (iv) instantiation, concerning criteria related to the presentation of the data.
In [86], a set of criteria were proposed and divided into three groups as follows: (i) intrinsic IQ, including eight criteria and measuring the attributes of information in relation to a reference standard in a given culture; (ii) relational or contextual IQ, encompassing twelve criteria and assessing the attributes that relate information to its context; and (iii) reputational IQ, consisting of only one criterion and evaluates the position of an information in a cultural or activity structure. As can be seen in Table 6, some criteria are included in two groups or categories, which are differentiated by the measurements applied to them [86].
Considering these categories, some relationships can be unveiled, but others are not clear. For instance, we may observe a relationship between the intellectual, contextual, and relational categories; between the intrinsic and content categories; between the representational and instantiation categories; and between the technical and accessibility categories. However, the other categories are difficult to correlate.
The selection of IQ criteria depends on the application, and therefore, several international organizations have established their own set of IQ criteria. For instance, the World Health Organization (WHO) formulated the so-called Health Metrics Network Framework in 2006, which is based on the Data Quality Assessment Framework. Some of these IQ criteria are relevant to the health care sector such as timeliness, periodicity, representativeness, and confidentiality. Treatments and diagnosis depend a lot on the time availability of the measures applied to the patients and the confidentiality thereof. In the environmental sector, the US Environmental Protection Agency applies five IQ criteria as follows: precision, accuracy, representativeness, completeness, and comparability. Such IQ criteria are very relevant to quantitative measures obtained from multiple sensors and forecasting systems. Representativeness helps to improve the process of presentation to the end user. Organizations that apply surveys (such as Eurostat) use accuracy, timeliness, accessibility, clarity, comparability, and coherence. Indeed, for survey settings, accessibility can be a critical matter as the nature of the process of applying surveys must be properly considered. For its part, the economic field has sensitive information; therefore, International Monetary Fund and the Organization for Economic Cooperation and Development uses seven IQ criteria, as follows: relevance, accuracy, timeliness, accessibility, interpretability, coherence, and credibility, which allows for carrying out complex decision-making more properly [102]. All of these aforementioned are examples of the recognized applications of IQ criteria. Notwithstanding, more specific applications may use other criteria not mentioned here. For data fusion, the most used criteria are focused on Intrinsic IQ criteria. At this point, it is worth noting that, despite the fact that multiple applications and studies have used different IQ metrics, most of them have no IQ criterion explicitly associated.
4.2. Information Quality Assessment Frameworks and Methodologies
Developing an IQ assessment for data fusion systems is a new and very complex task. Despite the work conducted in this field, there are not currently uniform metrics and comprehensive evaluation methods for information fusion systems. In addition, there are limited studies that evaluate such systems. The ISO/IEC 25012 standard [101] and several studies into IQ have helped to develop frameworks (defined as “multidimensional structure consisting of general concepts, relations, classifications, and methodologies that could serve as a resource and guide for developing context-specific IQ measurement models” [86]) and methodologies to assess quality in different fields. However, the authors of [103] affirm that there are no patterns to establish dimensions and functions for IQ. Based on the comment made by Stvilia et al. in [86] regarding the limited functionality of IQ frameworks, “most of these frameworks (...) cannot produce robust and systematic models” and “little work had been done to identify and describe the roots of IQ problems”. In this regard, according to our review, we believe that there is not a framework that allows us to contradict their statement.
Remarkably, IQ assessment methodologies are very limited in the field of data fusion. Both IQ assessment methodologies and frameworks have been reported in the literature since 1998. Nevertheless, most evaluations are applied considering information systems as black boxes, which makes it very complex to explain quality to users. Additionally, the main proposed frameworks and methodologies have focused on introducing quality criteria, which is considered insufficient in [5] to assess IQ.
Table 7 shows a set of IQ assessment methodologies and frameworks reported in the literature. Some of them were developed for general applications, and some others were developed for specific applications but without restricting their employment in different fields. To determine the extent to which these methodologies have been used, the number of citations (NC) to each methodology or framework is provided. In addition, such citations are grouped in three periods: 1992–2000 (P1), 2001–2010 (P2), and 2011–2021 (P3). According to our review, over 20 IQ assessment methodologies have been introduced since 1992. The NC to some methodologies could not be quantified because they did not appear in publications in Scopus or the ACM Digital Library. Furthermore, some frameworks or methodologies were not included for different reasons such as because they were not found in our search or because we considered them to be very similar to others.
The most cited frameworks are Data Quality Assessment (DQA) [108], a Methodology for Information Quality Assessment (AIMQ) [107], Total Information Quality Management (TDQM) [104], and Information Quality Assessment Framework (IQAF) [86]. DQA is the most cited one in P2 and P3. From a global analysis, we can observe that DQA is the most commonly used methodology in the entire proposed period. TDQM [104], which is oriented toward the organizational domain, only evaluates output information (analysis of the system as a black box) using all quality criteria at the same time. Moreover, this methodology includes four cycles as follows. (i) Define: criteria is established based on the user’s context. (ii) Measure: an IQ assessment instrument is applied. (iii) Analyze: the IQ measures are analyzed. (iv) Improve: some actions are performed on the systems to enhance IQ. In [100], the Information Quality Assessment for Web Information Systems (IQAWIS) framework evaluates the IQ of web systems based on the quality of an offered service, by means of IQ criteria that are not independent. This is why not all criteria can be employed at the same time. In [85], the Information Quality Assessment Framework (IQAF) is presented. This framework is predictive, reusable, and systematic; in addition, it analyzes changes in the quality of information to establish a generalized evaluation system involving a great number of quality dimensions without focusing on a particular one. Most of these methodologies center on criteria for specific applications with some variants.
Efforts have been made to develop methodologies that can evaluate the quality of the information generated by data fusion systems. These methodologies are shown in Table 8. The most cited one is that introduced by Blasch et al. in [47]. Their framework is limited to proposed criteria, certain metrics, and unified measures but does not provide much detail and description of the methodology. The model presented in the ISO 25012 standard [101] for IQ evaluation is focused on fifteen criteria grouped into three categories as follows. (i) Inherent data quality: it refers to the extent to which the intrinsic quality of data satisfies stated and implicit needs in a specific context. It includes the following criteria: accuracy, completeness, consistency, credibility, and currentness. (ii) System-dependent data quality: it refers to the extent to which the quality of data is reached and preserved into the system in a specific context. It includes the following criteria: availability, portability, and recoverability. (iii) Inherent and system-dependent data quality: it comprises both groups and seven criteria: accessibility, compliance, confidentiality, efficiency, precision, traceability, and understandability. Additionally, such model sets out some recommendations such as to offer a justification when an IQ criterion is excluded and to describe their categorizations.
The context has been recently considered in IQ assessment. In [4], it is defined as a meta-situation that contributes to the situation assessment of data fusion systems because it provides important information. Therefore, recent studies have focused on analyzing the context to include it into the data fusion process [131]. In [4], some methods to evaluate context-based IQ are proposed due to the context’s variability to improve IQ in the data fusion process and to provide end-users with a better assessment of the situation to better orient them in decision making. In [132], context-based IQ is defined as “any inherent information that describes context information and can be used to determine the worth of information for a specific application”.
The context can be characterized following certain models such as the key–value model [133]. Said model represents the context with values and attributes, where IQ can be depicted using a couple of context variable values together with the IQ value. In the ontology-based [134] and logic-based [135] models, which are discussed in [4], context is considered to adjust the parameters of algorithms used for data fusion processing. In the field of data fusion systems, one of the major challenges is to find and explain the relationships between the data context, the fusion process, and the IQ of data fusion inputs, context information, and data fusion outputs and processes. Other challenges include (i) establishing context variables, (ii) eliminating input variables based on quality, (iii) incorporating IQ into data fusion models, (iv) achieving decision-making using information based on its IQ, and (v) delaying decisions until information with a higher IQ is obtained. Context is analyzed in [4] by means of two paradigms: “context of” and “context for”. These two paradigms serve to determine what the context of the situation under study is and how useful it is to know that context. This helps to understand the relationship between context and situation.
Among the methodologies of data fusion with IQ assessment, the three presented in [5,45,47,136] are of special interest, as they included complete methodologies that integrate IQ assessment and a general data fusion model. In [47], a framework to assess the quality in information fusion systems is introduced. Such a framework includes the evaluation of the global quality based on the decomposition of the standard model of data fusion as well as a quality evaluation in two local levels: data fusion and information fusion. This model distinguishes data from information and knowledge and considers data dynamic and able to change with the context dynamics. In [45], the authors proposed a methodology integrating IQ assessment, data fusion, and context information. In [5], a general methodology was presented that enabled the traceability of IQ into all data fusion processing. These methodologies are discussed below.
4.2.1. Methodology Introduced by Todoran et al.
It proposes an IQ evaluation that considers two novel factors. The first one is the granularity of the process (i.e., decomposition of the system/IFS into its elementary processing modules) in order to apply the IQ evaluation and to, consequently, carry out an IQ traceability. The second one is the discrimination between data and information in the information system. Figure 7 summarizes this methodology, which consists of three main stages: (i) defining the elementary modules of the information system and the IQ criteria; (ii) building IQ transfer functions for each process (see Figure 8) based on input and output data/information and IQ criteria and using analytical or nonanalytical functions generated by means of machine learning; and (iii) assessing global IQ, which results in a propagation of local IQ evaluations [5,42]. In our opinion, the greatest limitation of this methodology lies in its ability to define the granularity of a data fusion process as well as to establish the transfer functions and to update them for new input data for each module. This, in turn, makes it difficult to standardize and compare data fusion systems and their performance. The methodology was validated in two simulated environments; the first is an automatic target recognition that uses data obtained from radar and infrared-electro-optical sensors to identify the target as well as the friend or foe provided by the operators. The second is the diagnostic coding support system. Both environments were used to demonstrate the functionality of the methodology. Nonetheless, no performance measures of this methodology are identified in this work. This promising methodology should be tested in a larger number of diverse, real, and simulated environments by taking into account objective performance measures to validate its true usefulness and versatility.
4.2.2. Methodology Proposed by Rogova (2016)
This methodology proposes a set of quality criteria categories to address the IQ problem in data fusion systems based on human–machine interactions and provides some orientations [45]. Figure 9 presents the elements taken into account by Rogova to evaluate IQ within the framework of the JDL model. Figure 10 summarizes the proposed IQ assessment, which introduces an ontology with the following three main components: IQ source (classified as subjective and objective), IQ content, and IQ presentation. Each component includes an array of well-defined IQ criteria. Furthermore, this IQ assessment considers the quality evaluation of the IQ assessment, which is called “higher-level quality”. This assessment can be performed using the same proposed IQ assessment. Finally, the author highlights the relevance of the context in selecting the criteria and in assessing the quality of the information context in order to obtain good results in decision making, IQ control, and actions. Moreover, IQ presentation to users is regarded as a key factor for successful decision making using data fusion systems. In spite of being an interesting methodology, it still needs more validation in several environments.
4.2.3. Methodology Introduced by Blasch Based on Measures for High-Level Fusion
In [47], the assessment of a data fusion system is analyzed by comparing Low-Level Fusion (LLF) and High-Level Fusion (HLF). Such an analysis is specially focused on the latter because of its complexity, while the former has been widely studied and has standard metrics of quality. The authors propose new measures to assess data fusion systems, including effectiveness, effectiveness force, performance, IQ, and a measure of merit. Additionally, they present some criteria and describe their use. However, we believe that this proposal must be validated in a simulated and real environment in order to identify its advantages and disadvantages.
Note that certain performance criteria are similar to the IQ criteria discussed above (accuracy, repeatability, and consistency, among others). Moreover, some measures were proposed for levels 2 and 3 of the JDL model (e.g., correctness in reasoning, quality of decisions, advice, recommendations, intelligent behavior, resilience, and adaptability in reasoning) were not reported in other works that were analyzed in this review. Additionally, it should be noted that effectiveness is defined as a product of information gain, performance quality, and robustness. The IQ assessment adopted by the authors is the same as that in [91]. The work presented in [47] has shown significant gaps in differentiating IQ from performance in data fusion systems, and its scope includes all information systems.
The next section, discusses performance in data fusion systems in order to contrast IQ with performance measures in such systems.
4.3. Data Fusion System Performance
According to [7], performance is defined as “the degree to which an organization or a work process achieves its goal”. In addition, performance measures must be multifaceted and must consider the amount of resources used to reach the goal, i.e., to achieve high quality versus low cost and high performance. However, establishing a single comprehensive performance measure is complicated because of the different dimensions managed across the fusion process. Moreover, performance measures may also require adaptation to a domain or situation in time, where specific requirements might not be validated in practice. Therefore, evaluating the performance of information fusion systems in real environments is presented by the author as a challenge, since the various metrics used in testing environments cannot be used in real situations, which is an example of false positives. While only some false negatives can be detected without having their total value, false measures are hard to determine for a noncontrolled population, and the systems may show delays in feedback. In view of the above, the author proposes some challenging solutions in this area such as objective measures (independent from reality), performance measures due to correlations between objective assessment and subjective measures, comprehensive measures or a set of metrics involving multiple aspects of behavior, and objective or goal-dependent measures (parameter adjustment based on the domain/situation context of the learning algorithm or user).
Table 9 summarizes the most frequently cited (number of citations (NC)) performance metrics from the 52 publications that were analyzed in [7]. Since the most recent one was a paper from 2009, we complemented the analysis with another 20 selected studies [128,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154] published between 2010 and 2019, as shown in Table 10. According to this latter table, the tendency has not changed and data fusion performance evaluation is still a challenge. This is because the adoption of quality metrics is established from the perspective of researchers for their specific case studies that process different types of data, making it difficult to efficiently determine the reliability of data fusion techniques. Furthermore, the performance measures used in testing environments significantly differ from those employed in real environments [8]. Hence, it is believed that the performance evaluation of information fusion systems should be determined after the decision-making process because there is high dependence on this.
Additionally, the reasons for poor performance should be provided when they are due to bad performance measurements, inaccurate decision making, incorrect fusion, or low quality of input data. In addition, feedback delays in performance measures should be reported. Therefore, it is necessary to verify if the assessment suggestions on testing environments are also useful in practical situations. Moreover, the use of objective measures (which are independent from reality and different from human subjectivity) must be validated. This becomes very complex when users must intervene and some requirements must be fulfilled to select relevant information that is highly dependent on the context as well as objective. Consequently, due to the dependence of some metrics, it is very complicated to define performance indicators that are unified for various possible situations and comprehensive. Comprehensive indicators may lead to a very abstract measurement, and the performance of all of the dimensions may be difficult to describe in detail.
Based on the above, it is difficult to discern between performance metrics and IQ metrics because some IQ metrics are used to evaluate systems’ performance. Despite the classification and discussion provided in [47], the differences between them are not clear. We may find some distinctions between both only in language-related aspects and not in the core of their application, even more if they are assigned to data fusion systems such as the JDL model.
5. Conclusions and Future Work
Data fusion is considered one of the most critical stages in information systems because of its ability to eliminate redundancy, to decrease uncertainty, and to increase the accuracy and efficiency of data. In this study, different types of data fusion architectures were analyzed, covering different factors as well as their advantages and disadvantages. Then, the issue of Information Quality (IQ) assessment was reviewed based on the various methodologies and frameworks that have been introduced for general and specific information systems, including particular proposals for data fusion systems. Finally, the performance of data fusion systems was discussed and contrasted with IQ.
According to the abovementioned, the complexity of data fusion systems is clearly increasing rapidly due to the growing emergence of new types of data and information, including information provided by humans and contextual information. This, in turn, makes data processing more complex but, perhaps, more accurate in different applications. Therefore, new techniques that handle new structures and data types should be developed to obtain high-quality information from multiple sources.
Regarding IQ and performance evaluation in information fusion systems, we suggest that further research should focus on the following: (i) selecting IQ criteria; (ii) presenting IQ to users (which has been discussed in a few works but superficially); (iii) defining the optimal granularity of the processes to evaluate IQ; (iv) unveiling the relationships between quality criteria and determining which criteria adequately define IQ from the perspective of data/information fusion; (v) unifying multiple IQ criteria into one measure; (vi) assessing the evaluated IQ; (vii) measuring the effects of IQ assessment and its cost [85,86]; (viii) developing techniques to manage and enhance IQ in new (structure and unstructured) forms of information [85]; (ix) identifying and describing the roots of IQ problems; (x) designing IQ assessment frameworks that serve to produce robust and systematic models; (xi) creating reusable, systematic, and predictive IQ evaluation frameworks; (xii) constructing models that integrate IQ and the context; (xiii) controlling quality, including that of information of the context based on the relationships between the context, IQ, and fusion processes; and (xiv) establishing adaptive control systems to improve IQ, taking into account changes in the context.
Consequently, we recommend conducting in-depth studies that include other fields, such as studies on cognitive load [155] and multisensorial stimuli [156,157]. This would serve to take advantage of all human senses, considering that the presentation of information affects users’ perception, which may be very relevant for fast decision-making. Finally, as a novel complement to HLF for decision-making, it may be appropriate to include a stage that supports decision-makers. This stage would offer them recommendations about their cognitive load and emotions, among other factors, to prevent decisions from being deeply permeated by primitive urges and to achieve decisions with high reasoning (information properly analyzed by thought), which, in turn, could help to improve every information processing until its application.
Author Contributions
M.A.B.: conceptualization, methodology, validation, formal analysis, investigation, resources, writing—original draft preparation, and writing—review and editing; C.T.: conceptualization, methodology, investigation, and supervision; A.E.C.-O.: conceptualization, methodology, investigation, resources, and writing—review; D.H.P.-O.: methodology, investigation, resources, writing—review and editing, supervision, project administration, and funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by direct funding for publication expenses from the SDAS Research Group (www.sdas-group.com, accessed on 4 June 2021), as stated in its administrative information and policies document.
Acknowledgments
The authors acknowledge/thank the contributions of the research project entitled “Modelo de fusión de datos en lazo cerrado orientado a la calidad de la información” and supported by the SDAS Research Group (www.sdas-group.com, accessed on 4 June 2021).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Xuan, L. Data Fusion in Managing Crowdsourcing Data Analytics Systems. Ph.D. Thesis, National University of Singapore, Singapore, 2013. [Google Scholar]
- Wickramarathne, T.L.; Premaratne, K.; Murthi, M.N.; Scheutz, M.; Kubler, S.; Pravia, M. Belief theoretic methods for soft and hard data fusion. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 2388–2391. [Google Scholar] [CrossRef]
- Lahat, D.; Adaly, T.; Jutten, C. Challenges in multimodal data fusion. In Proceedings of the 2014 22nd European Signal Processing Conference (EUSIPCO) European, Lisbon, Portugal, 1–5 September 2014; pp. 101–105. [Google Scholar]
- Rogova, G.L.; Snidaro, L. Considerations of Context and Quality in Information Fusion. In Proceedings of the 2018 21st International Conference on Information Fusion (FUSION), Cambridge, UK, 10–13 July 2018; pp. 1925–1932. [Google Scholar] [CrossRef]
- Todoran, I.G.; Lecornu, L.; Khenchaf, A.; Caillec, J.M.L. A Methodology to Evaluate Important Dimensions of Information. ACM J. Data Inf. Qual. 2015, 6, 23. [Google Scholar] [CrossRef]
- Blasch, E.P.; Salerno, J.J.; Tadda, G.P. Measuring the worthiness of situation assessment. In Proceedings of the 2011 IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 20–22 July 2011; pp. 87–94. [Google Scholar] [CrossRef]
- van Laere, J. Challenges for IF performance evaluation in practice. In Proceedings of the 12th International Conference on Information Fusion, 2009, FUSION ’09, Seattle, WA, USA, 6–9 July 2009; pp. 866–873. [Google Scholar]
- Cheng, C.T.; Leung, H.; Maupin, P. A Delay-Aware Network Structure for Wireless Sensor Networks With In-Network Data Fusion. IEEE Sens. J. 2013, 13, 1622–1631. [Google Scholar] [CrossRef]
- Shao, H.; Lin, J.; Zhang, L.; Galar, D.; Kumar, U. A novel approach of multisensory fusion to collaborative fault diagnosis in maintenance. Inf. Fusion 2021, 74, 65–76. [Google Scholar] [CrossRef]
- Jan, M.A.; Zakarya, M.; Khan, M.; Mastorakis, S.; Menon, V.G.; Balasubramanian, V.; Rehman, A.U. An AI-enabled lightweight data fusion and load optimization approach for Internet of Things. Future Gener. Comput. Syst. 2021, 122, 40–51. [Google Scholar] [CrossRef]
- Dong, W.; Yang, L.; Gravina, R.; Fortino, G. ANFIS fusion algorithm for eye movement recognition via soft multi-functional electronic skin. Inf. Fusion 2021, 71, 99–108. [Google Scholar] [CrossRef]
- Li, M.; Wang, F.; Jia, X.; Li, W.; Li, T.; Rui, G. Multi-source data fusion for economic data analysis. Neural Comput. Appl. 2021, 33, 4729–4739. [Google Scholar] [CrossRef]
- Xiong, X.; Youngman, B.D.; Economou, T. Data fusion with Gaussian processes for estimation of environmental hazard events. Environmetrics 2021, 32. [Google Scholar] [CrossRef]
- Afifi, H.; Ramaswamy, A.; Karl, H. A Reinforcement Learning QoI/QoS-Aware Approach in Acoustic Sensor Networks. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Smith, D.; Singh, S. Approaches to Multisensor Data Fusion in Target Tracking: A Survey. IEEE Trans. Knowl. Data Eng. 2006, 18, 1696–1710. [Google Scholar] [CrossRef]
- Li, H.; Nashashibi, F.; Yang, M. Split Covariance Intersection Filter: Theory and Its Application to Vehicle Localization. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1860–1871. [Google Scholar] [CrossRef]
- Ardeshir Goshtasby, A.; Nikolov, S. Image fusion: Advances in the state of the art. Inf. Fusion 2007, 8, 114–118. [Google Scholar] [CrossRef]
- Uribe, Y.F.; Alvarez-Uribe, K.C.; Peluffo-Ordoñez, D.H.; Becerra, M.A. Physiological Signals Fusion Oriented to Diagnosis—A Review; Springer: Cham, Switzerland, 2018; pp. 1–15. [Google Scholar] [CrossRef]
- Zapata, J.C.; Duque, C.M.; Rojas-Idarraga, Y.; Gonzalez, M.E.; Guzmán, J.A.; Becerra Botero, M.A. Data fusion applied to biometric identification—A review. In Proceedings of the Colombian Conference on Computing, Cali, Colombia, 19–22 September 2017; Springer: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Arsalaan, A.S.; Nguyen, H.; Coyle, A.; Fida, M. Quality of information with minimum requirements for emergency communications. Ad Hoc Netw. 2021, 111, 102331. [Google Scholar] [CrossRef]
- Londoño-Montoya, E.; Gomez-Bayona, L.; Moreno-López, G.; Duarte, C.; Marín, L.; Becerra, M. Regression fusion framework: An approach for human capital evaluation. In Proceedings of the European Conference on Knowledge Management, ECKM, Barcelona, Spain, 7–8 September 2017; Volume 1. [Google Scholar]
- Abdelgawad, A.; Bayoumi, M. Data Fusion in WSN; Springer: Boston, MA, USA, 2012; pp. 17–35. [Google Scholar] [CrossRef]
- Liu, X.; Dong, X.L.; Ooi, B.C.; Srivastava, D. Online Data Fusion, 2011. Proc. VLDB Endowment. 2011, 11, 932–943. [Google Scholar] [CrossRef]
- Khaleghi, B.; Khamis, A.; Karray, F.O.; Razavi, S.N. Multisensor data fusion: A review of the state-of-the-art. Inf. Fusion 2013, 14, 28–44. [Google Scholar] [CrossRef]
- Yokoya, N.; Grohnfeldt, C.; Chanussot, J. Hyperspectral and Multispectral Data Fusion: A comparative review of the recent literature. IEEE Geosci. Remote Sens. Mag. 2017, 5, 29–56. [Google Scholar] [CrossRef]
- Modak, S.K.S.; Jha, V.K. Multibiometric fusion strategy and its applications: A review. Inf. Fusion 2019, 49, 174–204. [Google Scholar] [CrossRef]
- Olabarrieta, P.; Del, S. Método y Dispositivo de Estimación de la Probabilidad de Error de Medida Para Sistemas Distribuidos de Sensores. Google Patents, No. 073,458, 23 June 2011. [Google Scholar]
- Weller, W.T.; Pepus, G.B. Portable Apparatus and Method for Decision Support for Real Time Automated Multisensor Data Fusion and Analysis. United States Patent Application No. 10,346,725, 9 July 2019. [Google Scholar]
- Hershey, P.C.; Dehnert, R.E.; Williams, J.J.; Wisniewski, D.J. System and Method for Asymmetric Missile Defense. U.S. Patent No. 9,726,460, 8 August 2017. [Google Scholar]
- Rein, K.; Biermann, J. Your high-level information is my low-level data—A new look at terminology for multi-level fusion. In Proceedings of the 2013 16th International Conference on Information Fusion (FUSION), Istanbul, Turkey, 9–12 July 2013; pp. 412–417. [Google Scholar]
- Forzieri, G.; Tanteri, L.; Moser, G.; Catani, F. Mapping natural and urban environments using airborne multi-sensor ADS40-MIVIS-LiDAR synergies. Int. J. Appl. Earth Obs. Geoinf. 2013, 23, 313–323. [Google Scholar] [CrossRef]
- Xiao, S.; Li, B.; Yuan, X. Maximizing precision for energy-efficient data aggregation in wireless sensor networks with lossy links. Ad Hoc Netw. 2015, 26, 103–113. [Google Scholar] [CrossRef]
- Li, Y. Optimal multisensor integrated navigation through information space approach. Phys. Commun. 2014, 13, 44–53. [Google Scholar] [CrossRef]
- Safari, S.; Shabani, F.; Simon, D. Multirate multisensor data fusion for linear systems using Kalman filters and a neural network. Aerosp. Sci. Technol. 2014, 39, 465–471. [Google Scholar] [CrossRef]
- Rodríguez, S.; De Paz, J.; Villarrubia, G.; Zato, C.; Bajo, J.; Corchado, J. Multi-agent information fusion system to manage data from a WSN in a residential home. Inf. Fusion 2015, 23, 43–57. [Google Scholar] [CrossRef] [Green Version]
- Boström, H.; Andler, S.F.; Brohede, M.; Johansson, R.; Karlsson, E.; Laere, J.V.; Niklasson, L.; Nilsson, M.; Persson, A.; Ziemke, T. On the Definition of Information Fusion as a Field of Research. IKI Technical Reports, 2007. Available online: https://www.diva-portal.org/smash/record.jsf?pid=diva2%3A2391&dswid=8841 (accessed on 4 June 2021).
- Castanedo, F. A Review of Data Fusion Techniques. Sci. World J. 2013. [Google Scholar] [CrossRef]
- Steinberg, A.N.; Bowman, C.L.; White, F.E. Revisions to the JDL Data Fusion. In SPIE Digital Library; SPIE: Orlando, FL, USA, 1999. [Google Scholar] [CrossRef]
- White, F. Data Fusion Lexicon; Data Fusion Subpanel of the Joint Directors of Laboratories: Washington, DC, USA, 1991. [Google Scholar] [CrossRef] [Green Version]
- Dragos, V.; Rein, K. Integration of soft data for information fusion: Pitfalls, challenges and trends. In Proceedings of the 2014 17th International Conference on Information Fusion (FUSION), Salamanca, Spain, 7–10 July 2014; pp. 1–8. [Google Scholar]
- Sidek, O.; Quadri, S. A review of data fusion models and systems. Int. J. Image Data Fusion 2012, 3, 3–21. [Google Scholar] [CrossRef]
- Todoran, I.G.; Lecornu, L.; Khenchaf, A.; Caillec, J.M.L. Information quality evaluation in fusion systems. In Proceedings of the 16th International Conference on Information Fusion, Istanbul, Turkey, 9–12 July 2013. [Google Scholar]
- Clifford, G.; Lopez, D.; Li, Q.; Rezek, I. Signal quality indices and data fusion for determining acceptability of electrocardiograms collected in noisy ambulatory environments. Comput. Cardiol. 2011, 2011, 285–288. [Google Scholar]
- Li, Q.; Mark, R.G.; Clifford, G.D. Robust heart rate estimation from multiple asynchronous noisy sources using signal quality indices and a Kalman filter. Physiol. Meas. 2008, 29, 15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rogova, G.L. Information Quality in Information Fusion and Decision Making with Applications to Crisis Management. In Fusion Methodologies in Crisis Management; Springer International Publishing: Cham, Switzerland, 2016; pp. 65–86. [Google Scholar] [CrossRef]
- Rogova, G.; Hadzagic, M.; St-Hilaire, M.; Florea, M.C.; Valin, P. Context-based information quality for sequential decision making. In Proceedings of the 2013 IEEE International Multi-Disciplinary Conference on Cognitive Methods in Situation Awareness and Decision Support (CogSIMA), San Diego, CA, USA, 25–28 February 2013; pp. 16–21. [Google Scholar] [CrossRef]
- Blasch, E.; Valin, P.; Bosse, E. Measures of effectiveness for high-level fusion. In Proceedings of the 2010 13th International Conference on Information Fusion, Edinburgh, UK, 26–29 July 2010. [Google Scholar]
- Becerra, M.A.; Alvarez-Uribe, K.C.; Peluffo-Ordoñez, D.H. Low Data Fusion Framework Oriented to Information Quality for BCI Systems; Springer: Cham, Switzerland, 2018; pp. 289–300. [Google Scholar] [CrossRef]
- Jesus, G.; Casimiro, A.; Oliveira, A. A Survey on Data Quality for Dependable Monitoring in Wireless Sensor Networks. Sensors 2017, 17, 2010. [Google Scholar] [CrossRef]
- Abedjan, Z.; Golab, L.; Naumann, F. Profiling relational data: A survey. VLDB J. 2015, 24, 557–581. [Google Scholar] [CrossRef] [Green Version]
- Caruccio, L.; Deufemia, V.; Polese, G. Mining relaxed functional dependencies from data. Data Min. Knowl. Discov. 2020, 34, 443–477. [Google Scholar] [CrossRef]
- Caruccio, L.; Deufemia, V.; Naumann, F.; Polese, G. Discovering Relaxed Functional Dependencies based on Multi-attribute Dominance. IEEE Trans. Knowl. Data Eng. 2020, 1. [Google Scholar] [CrossRef]
- Berti-Équille, L.; Harmouch, H.; Naumann, F.; Novelli, N.; Thirumuruganathan, S. Discovery of genuine functional dependencies from relational data with missing values. Proc. VLDB Endow. 2018, 11, 880–892. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, H.B. Introduction. In Data Fusion: Concepts and Ideas; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–14. [Google Scholar] [CrossRef]
- Dasarathy, B. Sensor fusion potential exploitation-innovative architectures and illustrative applications. Proc. IEEE 1997, 85, 24–38. [Google Scholar] [CrossRef]
- Esteban, J.; Starr, A.; Willetts, R.; Hannah, P.; Bryanston-Cross, P. A Review of data fusion models and architectures: Towards engineering guidelines. Neural Comput. Appl. 2005, 14, 273–281. [Google Scholar] [CrossRef] [Green Version]
- Luo, R.; Yih, C.C.; Su, K.L. Multisensor fusion and integration: Approaches, applications, and future research directions. IEEE Sens. J. 2002, 2, 107–119. [Google Scholar] [CrossRef]
- Durrant-Whyte, H.F. Sensor Models and Multisensor Integration. Int. J. Rob. Res. 1988, 7, 97–113. [Google Scholar] [CrossRef]
- Luo, R.; Kay, M. Multisensor integration and fusion in intelligent systems. IEEE Trans. Syst. Man Cybern. 1989, 19, 901–931. [Google Scholar] [CrossRef]
- Foo, P.H.; Ng, G.W. High-level Information Fusion: An Overview. J. Adv. Inf. Fusion 2013, 8, 33–72. [Google Scholar]
- Bossé, E.; Roy, J.; Wark, S. Concepts, Models, and Tools for Information Fusion; Artech House: Norwood, MA, USA, 2007; p. 376. [Google Scholar]
- Elmenreich, W. A Review on System Architectures for Sensor Fusion Applications. In Software Technologies for Embedded and Ubiquitous Systems; Obermaisser, R., Nah, Y., Puschner, P., Rammig, F.J., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; pp. 547–559. [Google Scholar]
- Das, S.K. High-Level Data Fusion; Artech House: Norwood, MA, USA, 2008; p. 373. [Google Scholar]
- Schoess, J.; Castore, G. A Distributed Sensor Architecture For Advanced Aerospace Systems. Int. Soc. Opt. Photonics 1988, 0931, 74. [Google Scholar] [CrossRef]
- Rasmussen, J. Skills, rules, and knowledge; signals, signs, and symbols, and other distinctions in human performance models. IEEE Trans. Syst. Man Cybern. 1983, SMC-13, 257–266. [Google Scholar] [CrossRef]
- Pau, L.F. Sensor data fusion. J. Intell. Robot. Syst. 1988, 1, 103–116. [Google Scholar] [CrossRef]
- Harris, C.J.; Bailey, A.; Dodd, T.J. Multi-Sensor Data Fusion in Defence and Aerospace. Aeronaut. J. 1998, 102, 229–244. [Google Scholar]
- White, F.E. A model for data fusion. In Proceedings of the 1st National Symposium on Sensor Fusion, Naval Training Station, Orlando, FL, USA, 5–8 April 1988; Volume 2. [Google Scholar]
- Bedworth, M.; O’Brien, J. The Omnibus model: A new model of data fusion? IEEE Aerosp. Electron. Syst. Mag. 2000, 15, 30–36. [Google Scholar] [CrossRef] [Green Version]
- Shahbazian, E. Introduction to DF: Models and Processes, Architectures, Techniques and Applications. In Multisensor Fusion; Hyder, A.K., Shahbazian, E., Waltz, E., Eds.; NATO Science Series; Springer: Dordrecht, The Netherlands, 2002; pp. 71–97. [Google Scholar]
- Thomopoulos, S.C.A. Sensor integration and data fusion. J. Robot. Syst. 1990, 7, 337–372. [Google Scholar] [CrossRef]
- Carvalho, H.; Heinzelman, W.; Murphy, A.; Coelho, C. A general data fusion architecture. In Proceedings of the Sixth International Conference of Information Fusion, Cairns, QLD, Australia, 8–11 July 2003. [Google Scholar] [CrossRef] [Green Version]
- Endsley, M.R. Toward a Theory of Situation Awareness in Dynamic Systems. Hum. Factors J. Hum. Factors Ergon. Soc. 1995, 37, 32–64. [Google Scholar] [CrossRef]
- Nassar, M.; Kanaan, G.; Awad, H. Framework for analysis and improvement of data-fusion algorithms. In Proceedings of the 2010 The 2nd IEEE International Conference on Information Management and Engineering (ICIME), Chengdu, China, 16–18 April 2010; pp. 379–382. [Google Scholar] [CrossRef]
- Salerno, J. Information fusion: A high-level architecture overview. In Proceedings of the Fifth International Conference on Information Fusion, FUSION 2002, (IEEE Cat.No.02EX5997), Annapolis, MD, USA, 8–11 July 2002; Volume 1, pp. 680–686. [Google Scholar] [CrossRef]
- Blasch, E.; Plano, S. JDL Level 5 Fusion Model “User Refinement” Issues and Applications in Group Tracking; International Society for Optics and Photonics: Bellingham, WA, USA, 2002; Volume 4729, pp. 270–279. [Google Scholar] [CrossRef]
- Synnergren, J.; Gamalielsson, J.; Olsson, B. Mapping of the JDL data fusion model to bioinformatics. In Proceedings of the 2007 IEEE International Conference on Systems, Man and Cybernetics, Montreal, QC, Canada, 7–10 October 2007; pp. 1506–1511. [Google Scholar] [CrossRef]
- Schreiber-Ehle, S.; Koch, W. The JDL model of data fusion applied to cyber-defence—A review paper. In Proceedings of the 2012 Workshop on Sensor Data Fusion: Trends, Solutions, Applications (SDF), Bonn, Germany, 4–6 September 2012; pp. 116–119. [Google Scholar] [CrossRef]
- Timonen, J.; Laaperi, L.; Rummukainen, L.; Puuska, S.; Vankka, J. Situational awareness and information collection from critical infrastructure. In Proceedings of the 2014 6th International Conference On Cyber Conflict (CyCon 2014), Tallinn, Estonia, 3–6 June 2014; pp. 157–173. [Google Scholar] [CrossRef]
- Polychronopoulos, A.; Amditis, A.; Scheunert, U.; Tatschke, T. Revisiting JDL model for automotive safety applications: The PF2 functional model. In Proceedings of the 2006 9th International Conference on Information Fusion, Florence, Italy, 10–13 July 2006. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, H.L.; Prasad, S.; Pasolli, E.; Jung, J.; Crawford, M. Ensemble Multiple Kernel Active Learning For Classification of Multisource Remote Sensing Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 8, 845–858. [Google Scholar] [CrossRef]
- Das, S.; Grecu, D. COGENT: Cognitive Agent to Amplify Human Perception and Cognition. In Proceedings of the Fourth International Conference on Autonomous Agents, Barcelona, Spain, 3–7 June 2000; AGENTS ’00. ACM: New York, NY, USA, 2000; pp. 443–450. [Google Scholar] [CrossRef]
- Cinar, G.; Principe, J. Adaptive background estimation using an information theoretic cost for hidden state estimation. In Proceedings of the 2011 International Joint Conference on Neural Networks (IJCNN), San Jose, CA, USA, 31 July–5 August 2011; pp. 489–494. [Google Scholar] [CrossRef] [Green Version]
- Sung, W.T.; Tsai, M.H. Data fusion of multi-sensor for IOT precise measurement based on improved PSO algorithms. Comput. Math. Appl. 2012, 64, 1450–1461. [Google Scholar] [CrossRef] [Green Version]
- Madnick, S.E.; Wang, R.Y.; Lee, Y.W.; Zhu, H. Overview and Framework for Data and Information Quality Research. J. Data Inf. Qual. 2009, 1, 1–22. [Google Scholar] [CrossRef]
- Stvilia, B.; Gasser, L.; Twidale, M.B.; Smith, L.C. A framework for information quality assessment. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1720–1733. [Google Scholar] [CrossRef]
- Gu, Y.; Shen, H.; Bai, G.; Wang, T.; Liu, X. QoI-aware incentive for multimedia crowdsensing enabled learning system. Multimed. Syst. 2020, 26, 3–16. [Google Scholar] [CrossRef]
- Demoulin, N.T.M.; Coussement, K. Acceptance of text-mining systems: The signaling role of information quality. Inf. Manag. 2020, 57, 103120. [Google Scholar] [CrossRef]
- Torres, R.; Sidorova, A. Reconceptualizing information quality as effective use in the context of business intelligence and analytics. Int. J. Inf. Manag. 2019, 49, 316–329. [Google Scholar] [CrossRef]
- Juran, J.M.J.M. Juran on Quality by Design: The New Steps for Planning Quality into Goods and Services; Free Press: New York, NY, USA, 1992; p. 538. [Google Scholar]
- Wang, R.Y.; Strong, D.M. Beyond Accuracy: What Data Quality Means to Data Consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Evans, J.R.J.R.; Lindsay, W.M. The Management and Control of Quality; Thomson/South-Western: Nashville, TN, USA, 2005. [Google Scholar]
- O’Brien, J.A.; Marakas, G.M. Introduction to Information Systems; McGraw-Hill/Irwin: New York, NY, USA, 2005; p. 543. [Google Scholar]
- Vaziri, R.; Mohsenzadeh, M.; Habibi, J. TBDQ: A Pragmatic Task-Based Method to Data Quality Assessment and Improvement. PLoS ONE 2016, 11, e0154508. [Google Scholar] [CrossRef] [Green Version]
- Bovee, M.; Srivastava, R.P.; Mak, B. A conceptual framework and belief-function approach to assessing overall information quality. Int. J. Intell. Syst. 2003, 18, 51–74. [Google Scholar] [CrossRef] [Green Version]
- Kahn, B.K.; Strong, D.; Wang, R. Information quality benchmarks: Product and service performance. Commun. ACM 2002, 45, 184–192. [Google Scholar] [CrossRef]
- Helfert, M. Managing and Measuring Data Quality in Data Warehousing. In Proceedings of the World Multiconference on Systemics, Cybernetics and Informatics, Orlando, FL, USA, 22–25 July 2001. [Google Scholar]
- Naumann, F. Quality-Driven Query Answering for Integrated Information Systems; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Ge, M.; Helfert, M.; Jannach, D. Information Quality Assessment: Validating Measurement. In Proceedings of the ECIA 2011 Proceedings, 19th European Conference on Information Systems—ICT and Sustainable Service Development, ECIS 2011, Helsinki, Finland, 9–11 June 2011. [Google Scholar]
- Moges, H.T.; Dejaeger, K.; Lemahieu, W.; Baesens, B. A multidimensional analysis of data quality for credit risk management: New insights and challenges. Inf. Manag. 2013, 50, 43–58. [Google Scholar] [CrossRef]
- ISO. International Standard ISO/IEC 25012:2008 Software Engineering—Software Product Quality Requirements and Evaluation (SQuaRE); Technical Report; International Organization for Standarization: Geneva, Switzerland, 2008. [Google Scholar]
- Kenett, R.S.; Shmueli, G. Information Quality, 1st ed.; John Wiley & Sons, Ltd.: Chichester, UK, 2016. [Google Scholar] [CrossRef]
- Botega, L.C.; de Souza, J.O.; Jorge, F.R.; Coneglian, C.S.; de Campos, M.R.; de Almeida Neris, V.P.; de Araújo, R.B. Methodology for Data and Information Quality Assessment in the Context of Emergency Situational Awareness. Univers. Access Inf. Soc. 2017, 16, 889–902. [Google Scholar] [CrossRef]
- Wang, R.Y. A Product Perspective on Total Data Quality Management. Commun. ACM 1998, 41, 58–65. [Google Scholar] [CrossRef]
- Jeusfeld, M.A.; Quix, C.; Jarke, M. Design and analysis of quality information for data warehouses. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1998; pp. 349–362. [Google Scholar]
- English, L.P. Improving Data Warehouse and Business Information Quality: Methods for Reducing Costs and Increasing Profits; John Wiley & Sons, Inc.: New York, NY, USA, 1999. [Google Scholar]
- Lee, Y.W.; Strong, D.M.; Kahn, B.K.; Wang, R.Y. AIMQ: A methodology for information quality assessment. Inf. Manag. 2002, 40, 133–146. [Google Scholar] [CrossRef]
- Pipino, L.L.; Lee, Y.W.; Wang, R.Y. Data Quality Assessment. Commun. ACM 2002, 45, 211–218. [Google Scholar] [CrossRef]
- Eppler, M.; Muenzenmayer, P. Measuring information quality in the web context: A survey of state-of-the-art instruments and an application methodology. In Proceedings of the 7th International Conference on Information Quality, MIT Sloan School of Management, Cambridge, MA, USA, 8–10 November 2002; pp. 187–196. [Google Scholar]
- van Solingen, R.; Basili, V.; Caldiera, G.; Rombach, H.D. Goal Question Metric (GQM) Approach. In Encyclopedia of Software Engineering; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2002. [Google Scholar] [CrossRef]
- Falorsi, P.; Pallara, S.; Pavone, A.; Alessandroni, A.; Massella, E.; Scannapieco, M. Improving the quality of toponymic data in the italian public administration. In Proceedings of the ICDT Workshop on Data Quality in Cooperative Information Systems (DQCIS), Siena, Italy, 10–11 January 2003. [Google Scholar]
- Su, Y.; Jin, Z. A Methodology for Information Quality assessment in the Designing and Manufacturing Processes of Mechanical Products. In Proceedings of the 9th International Conference on Information Quality, Cambridge, MA, USA, 5–7 November 2004; pp. 447–465. [Google Scholar]
- Monograph, R.; Wang, E.; Pierce, S.; Madnick, S.; Fisher, C.W.; Loshin, D. Enterprise Knowledge Management—The Data Quality Approach; Series in Data Management Systems; Morgan Kaufmann: Burlington, MA, USA, 2001. [Google Scholar]
- Redman, T.C.; Godfrey, A.B. Data Quality for the Information Age, 1st ed.; Artech House, Inc.: Norwood, MA, USA, 1997. [Google Scholar]
- Scannapieco, M.; Virgillito, A.; Marchetti, C.; Mecella, M.; Baldoni, R. The DaQuinCIS architecture: A platform for exchanging and improving data quality in cooperative information systems. Inf. Syst. 2004, 29, 551–582. [Google Scholar] [CrossRef]
- De Amicis, F.; Batini, C. A methodology for data quality assessment on financial data. Stud. Commun. Sci. SCKM 2004, 4, 115–137. [Google Scholar]
- Long, J.; Seko, C. A cyclic-hierarchical method for database data-quality evaluation and improvement. In Advances in Management Information Systems-Information Quality Monograph (AMISIQ); Routledge: New York, NY, USA, 2005. [Google Scholar]
- Cappiello, C.; Ficiaro, P.; Pernici, B. HIQM: A Methodology for Information Quality Monitoring, Measurement, and Improvement; Springer: Berlin/Heidelberg, Germany, 2006; pp. 339–351. [Google Scholar] [CrossRef]
- Batini, C.; Cabitza, F.; Cappiello, C.; Francalanci, C.; di Milano, P. A Comprehensive Data Quality Methodology for Web and Structured Data. In Proceedings of the 2006 1st International Conference on Digital Information Management, Bangalore, India, 6–8 December 2006; pp. 448–456. [Google Scholar] [CrossRef]
- Alkhattabi, M.; Neagu, D.; Cullen, A. Information quality framework for e-learning systems. Knowl. Manag. E-Learn. 2010, 2, 340–362. [Google Scholar]
- Carlo, B.; Daniele, B.; Federico, C.; Simone, G. A Data Quality Methodology for Heterogeneous Data. Int. J. Database Manag. Syst. 2011, 3, 60–79. [Google Scholar] [CrossRef]
- Heidari, F.; Loucopoulos, P. Quality evaluation framework (QEF): Modeling and evaluating quality of business processes. Int. J. Account. Inf. Syst. 2014, 15, 193–223. [Google Scholar] [CrossRef]
- Chan, K.; Marcus, K.; Scott, L.; Hardy, R. Quality of information approach to improving source selection in tactical networks. In Proceedings of the 2015 18th International Conference on Information Fusion (Fusion), Washington, DC, USA, 6–9 July 2015; pp. 566–573. [Google Scholar]
- Belen Sağlam, R.; Taskaya Temizel, T. A framework for automatic information quality ranking of diabetes websites. Inform. Health Soc. Care 2015, 40, 45–66. [Google Scholar] [CrossRef] [PubMed]
- Vetrò, A.; Canova, L.; Torchiano, M.; Minotas, C.O.; Iemma, R.; Morando, F. Open data quality measurement framework: Definition and application to Open Government Data. Gov. Inf. Q. 2016, 33, 325–337. [Google Scholar] [CrossRef] [Green Version]
- Woodall, P.; Borek, A.; Parlikad, A.K. Evaluation criteria for information quality research. Int. J. Inf. Qual. 2016, 4, 124. [Google Scholar] [CrossRef]
- Kim, S.; Lee, J.G.; Yi, M.Y. Developing information quality assessment framework of presentation slides. J. Inf. Sci. 2017, 43, 742–768. [Google Scholar] [CrossRef]
- Li, Y.; Jha, D.K.; Member, S.; Ray, A.; Wettergren, T.A.; Member, S. Information Fusion of Passive Sensors for Detection of Moving Targets in Dynamic Environments. IEEE Trans. Cybern. 2017, 47, 93–104. [Google Scholar] [CrossRef]
- Stawowy, M.; Olchowik, W.; Rosiński, A.; Dąbrowski, T. The Analysis and Modelling of the Quality of Information Acquired from Weather Station Sensors. Remote Sens. 2021, 13, 693. [Google Scholar] [CrossRef]
- Bouhamed, S.A.; Kallel, I.K.; Yager, R.R.; Bossé, É.; Solaiman, B. An intelligent quality-based approach to fusing multi-source possibilistic information. Inf. Fusion 2020, 55, 68–90. [Google Scholar] [CrossRef]
- Snidaro, L.; García, J.; Llinas, J. Context-based Information Fusion: A survey and discussion. Inf. Fusion 2015, 25, 16–31. [Google Scholar] [CrossRef] [Green Version]
- Krause, M.; Hochstatter, I. Challenges in Modelling and Using Quality of Context (QoC); Springer: Berlin/Heidelberg, Germany, 2005; pp. 324–333. [Google Scholar] [CrossRef]
- Schilit, B.; Adams, N.; Want, R. Context-Aware Computing Applications. In Proceedings of the 1994 First Workshop on Mobile Computing Systems and Applications, Santa Cruz, CA, USA, 8–9 December 1994; pp. 85–90. [Google Scholar] [CrossRef]
- Gómez-Romero, J.; Serrano, M.A.; García, J.; Molina, J.M.; Rogova, G. Context-based multi-level information fusion for harbor surveillance. Inf. Fusion 2015, 21, 173–186. [Google Scholar] [CrossRef] [Green Version]
- Akman, V.; Surav, M. The Use of Situation Theory in Context Modeling. Comput. Intell. 1997, 13, 427–438. [Google Scholar] [CrossRef]
- Rogova, G.; Bosse, E. Information quality in information fusion. In Proceedings of the 2010 13th Conference on Information Fusion (FUSION), Edinburgh, UK, 26–29 July 2010; pp. 1–8. [Google Scholar] [CrossRef]
- Vetrella, A.R.; Fasano, G.; Accardo, D.; Moccia, A. Differential GNSS and Vision-Based Tracking to Improve Navigation Performance in Cooperative Multi-UAV Systems. Sensors 2016, 16, 2164. [Google Scholar] [CrossRef] [PubMed]
- Wu, F.; Huang, Y.; Yuan, Z. Domain-specific sentiment classification via fusing sentiment knowledge from multiple sources. Inf. Fusion 2017, 35, 26–37. [Google Scholar] [CrossRef]
- Oh, S.I.; Kang, H.B. Object Detection and Classification by Decision-Level. Sensors 2017, 17, 207. [Google Scholar] [CrossRef] [Green Version]
- Nakamura, E.F.; Pazzi, R.W. Target Tracking for Sensor Networks: A Survey. ACM Comput. Surv. 2016, 49, 1–31. [Google Scholar]
- Benziane, L.; Hadri, A.E.; Seba, A.; Benallegue, A.; Chitour, Y. Attitude Estimation and Control Using Linearlike Complementary Filters: Theory and Experiment. IEEE Trans. Control Syst. Technol. 2016, 24, 2133–2140. [Google Scholar] [CrossRef] [Green Version]
- Lassoued, K.; Bonnifait, P.; Fantoni, I. Cooperative Localization with Reliable Confidence Domains Between Vehicles Sharing GNSS Pseudoranges Errors with No Base Station. IEEE Intell. Transp. Syst. Mag. 2017, 9, 22–34. [Google Scholar] [CrossRef] [Green Version]
- Farsoni, S.; Bonfè, M.; Astolfi, L. A low-cost high-fidelity ultrasound simulator with the inertial tracking of the probe pose. Control Eng. Pract. 2017, 59, 183–193. [Google Scholar] [CrossRef]
- Cao, N.; Member, S.; Choi, S.; Masazade, E. Sensor Selection for Target Tracking in Wireless Sensor Networks With Uncertainty. IEEE Trans. Signal Process. 2016, 64, 5191–5204. [Google Scholar] [CrossRef] [Green Version]
- El-shenawy, A.K.; Elsaharty, M.A.; Eldin, E. Neuro-Analogical Gate Tuning of Trajectory Data Fusion for a Mecanum-Wheeled Special Needs Chair. PLoS ONE 2017, 12, e0169036. [Google Scholar] [CrossRef]
- Kreibich, O.; Neuzil, J.; Smid, R. Quality-Based Multiple-Sensor Fusion in an Industrial Wireless Sensor Network for MCM. IEEE Trans. Ind. Electron. 2014, 61, 4903–4911. [Google Scholar] [CrossRef]
- Masehian, E.; Jannati, M.; Hekmatfar, T. Cooperative mapping of unknown environments by multiple heterogeneous mobile robots with limited sensing. Robot. Auton. Syst. 2017, 87, 188–218. [Google Scholar] [CrossRef]
- García, J.; Luis, Á.; Molina, J.M. Quality-of-service metrics for evaluating sensor fusion systems without ground truth. In Proceedings of the 2016 19th International Conference on Information Fusion (FUSION), Heidelberg, Germany, 5–8 July 2016. [Google Scholar]
- Shaban, M.; Mahmood, A.; Al-Maadeed, S.A.; Rajpoot, N. An information fusion framework for person localization via body pose in spectator crowds. Inf. Fusion 2019, 51, 178–188. [Google Scholar] [CrossRef]
- Ahmed, K.T.; Ummesafi, S.; Iqbal, A. Content based image retrieval using image features information fusion. Inf. Fusion 2018, 51, 76–99. [Google Scholar] [CrossRef]
- Sun, Y.X.; Song, L.; Liu, Z.G. Belief-based system for fusing multiple classification results with local weights. Opt. Eng. 2018, 58, 1. [Google Scholar] [CrossRef]
- Hartling, S.; Sagan, V.; Sidike, P.; Maimaitijiang, M.; Carron, J.; Hartling, S.; Sagan, V.; Sidike, P.; Maimaitijiang, M.; Carron, J. Urban Tree Species Classification Using a WorldView-2/3 and LiDAR Data Fusion Approach and Deep Learning. Sensors 2019, 19, 1284. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vivone, G.; Addesso, P.; Chanussot, J. A Combiner-Based Full Resolution Quality Assessment Index for Pansharpening. IEEE Geosci. Remote Sens. Lett. 2019, 16, 437–441. [Google Scholar] [CrossRef]
- Koyuncu, M.; Yazici, A.; Civelek, M.; Cosar, A.; Sert, M. Visual and Auditory Data Fusion for Energy-Efficient and Improved Object Recognition in Wireless Multimedia Sensor Networks. IEEE Sens. J. 2019, 19, 1839–1849. [Google Scholar] [CrossRef]
- Klatt, E. The human interface of biomedical informatics. J. Pathol. Inform. 2018, 9, 30. [Google Scholar] [CrossRef] [PubMed]
- Becerra, M.A.; Londoño-Delgado, E.; Pelaez-Becerra, S.M.; Castro-Ospina, A.E.; Mejia-Arboleda, C.; Durango, J.; Peluffo-Ordóñez, D.H. Electroencephalographic Signals and Emotional States for Tactile Pleasantness Classification; Springer: Cham, Switzerland, 2018; pp. 309–316. [Google Scholar] [CrossRef]
- Becerra, M.A.; Londoño-Delgado, E.; Pelaez-Becerra, S.M.; Serna-Guarín, L.; Castro-Ospina, A.E.; Marin-Castrillón, D.; Peluffo-Ordóñez, D.H. Odor Pleasantness Classification from Electroencephalographic Signals and Emotional States; Springer: Cham, Switzerland, 2018; pp. 128–138. [Google Scholar] [CrossRef]
Figure 1.
Taxonomy of data fusion models clustered into three categories: data, activity, and role. The situation awareness model encompasses various models, and even though it was included in the data cluster, it can belong to a specific group depending on the model.
Figure 1.
Taxonomy of data fusion models clustered into three categories: data, activity, and role. The situation awareness model encompasses various models, and even though it was included in the data cluster, it can belong to a specific group depending on the model.

Figure 2.
Number of Scopus publications for each data fusion model per year from 1975 to 2021. The x-axis corresponds to the time window from the appearance of the first data fusion model according to the here-made up-to-date search in Scopus. For each year on the x-axis, the number of citations for each model is shown on the y-axis making distinction with different colors. The first appearance of each model in this graphic is limited to the search in Scopus and does not correspond to the year of publication of the data fusion model. Some models were published earlier than their appearance in Scopus and may also be available in other databases.
Figure 2.
Number of Scopus publications for each data fusion model per year from 1975 to 2021. The x-axis corresponds to the time window from the appearance of the first data fusion model according to the here-made up-to-date search in Scopus. For each year on the x-axis, the number of citations for each model is shown on the y-axis making distinction with different colors. The first appearance of each model in this graphic is limited to the search in Scopus and does not correspond to the year of publication of the data fusion model. Some models were published earlier than their appearance in Scopus and may also be available in other databases.
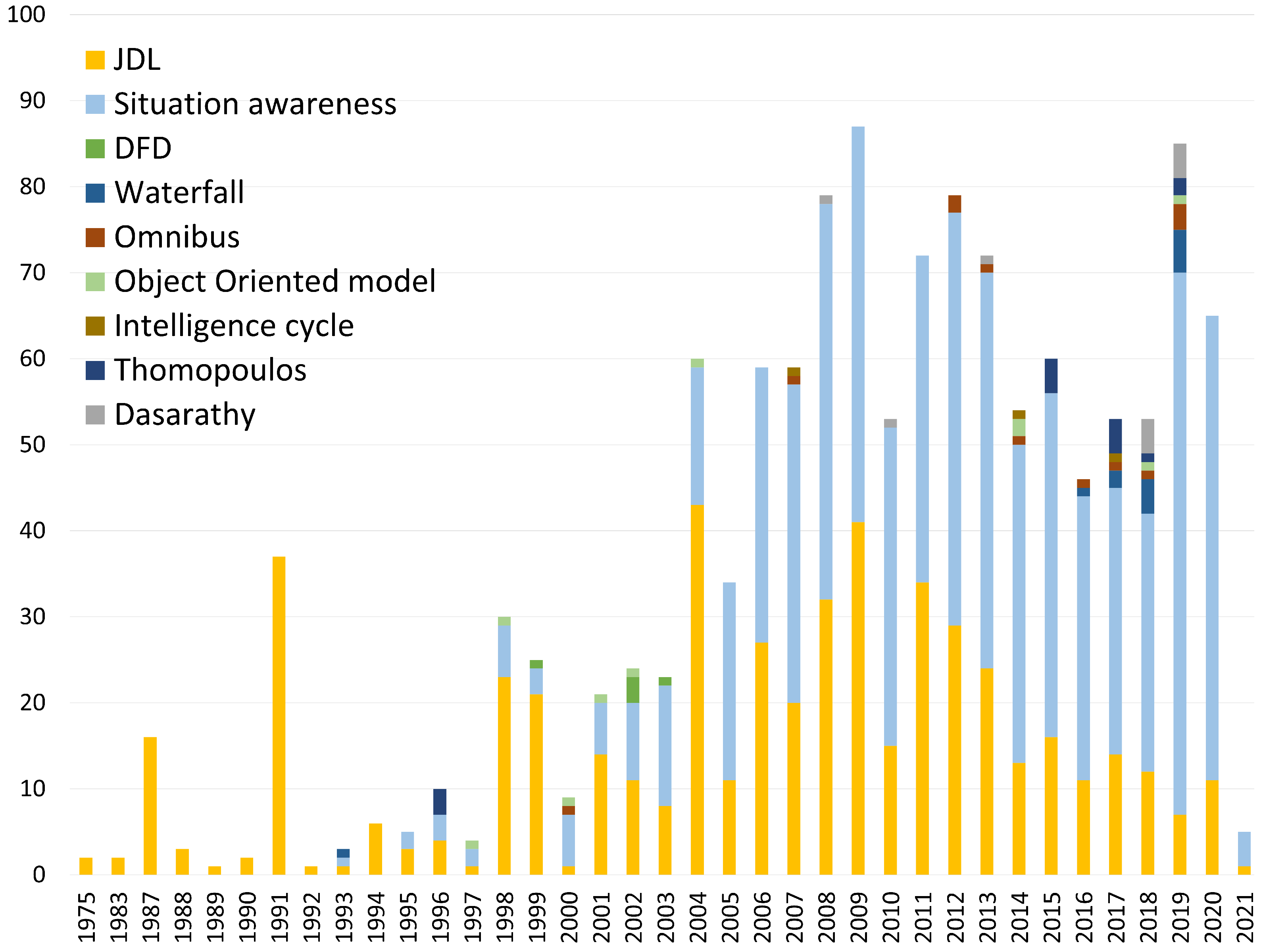
Figure 3.
Joint Directors of Laboratories (JDL) model.

Figure 4.
Taxonomy of the methodologies of information quality-based data fusion techniques.

Figure 5.
Information quality criteria categories proposed by different authors from 1996 to 2016 [45,86,91,95,96,97,98]. Each category includes various criteria.
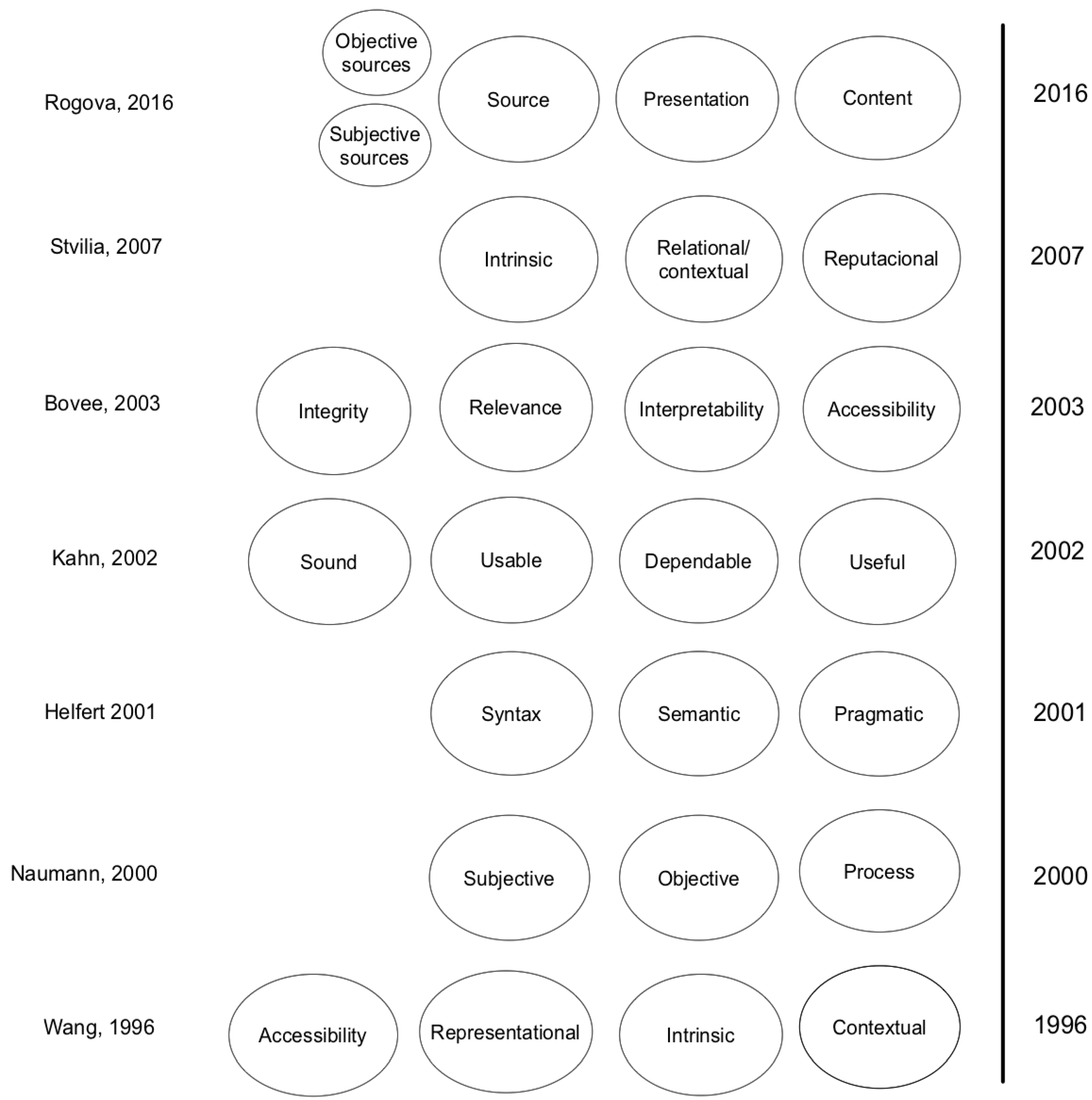
Figure 6.
Correlation between information quality criteria.
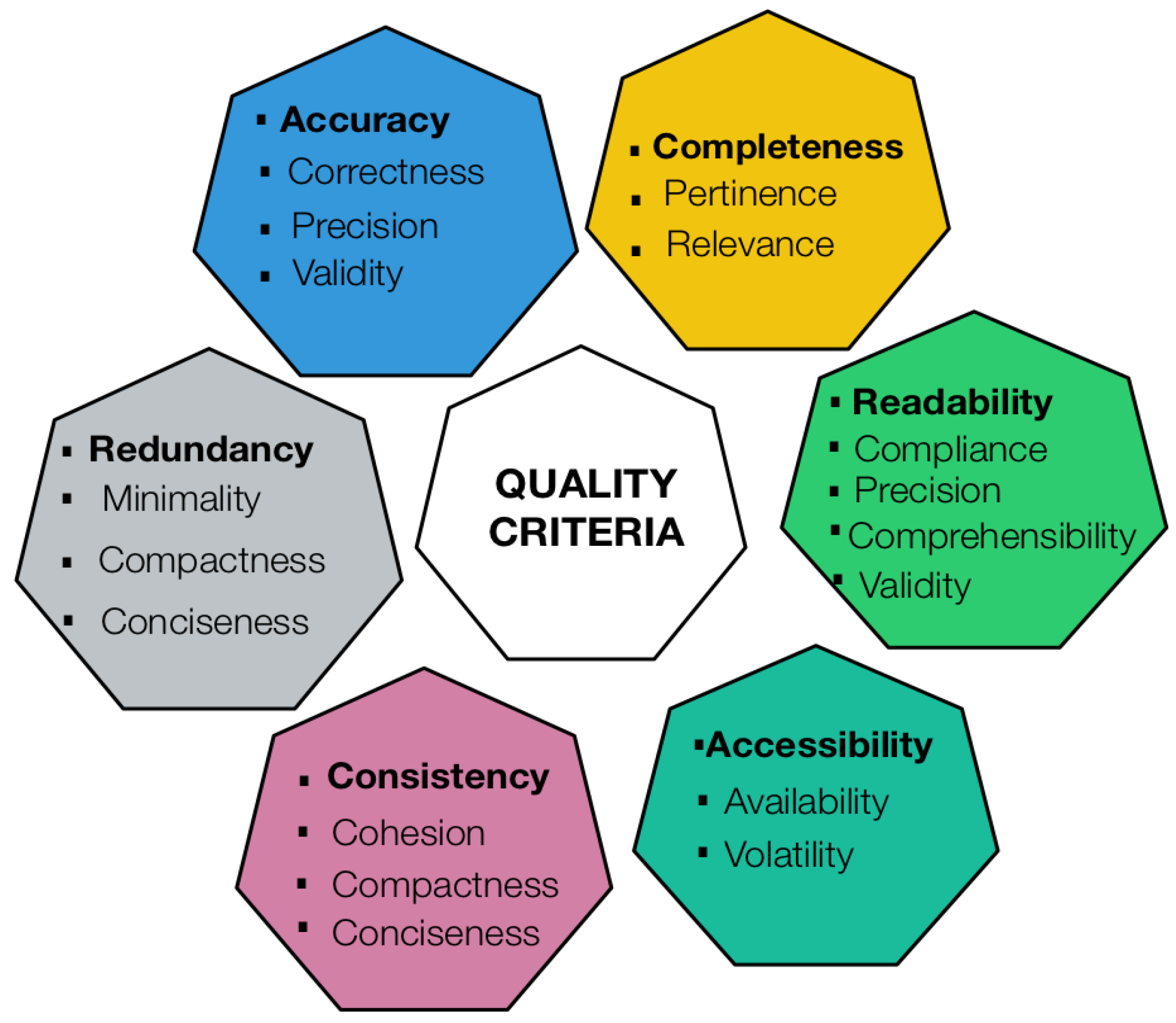
Figure 7.
Methodology introduced/proposed by Todoran et al.
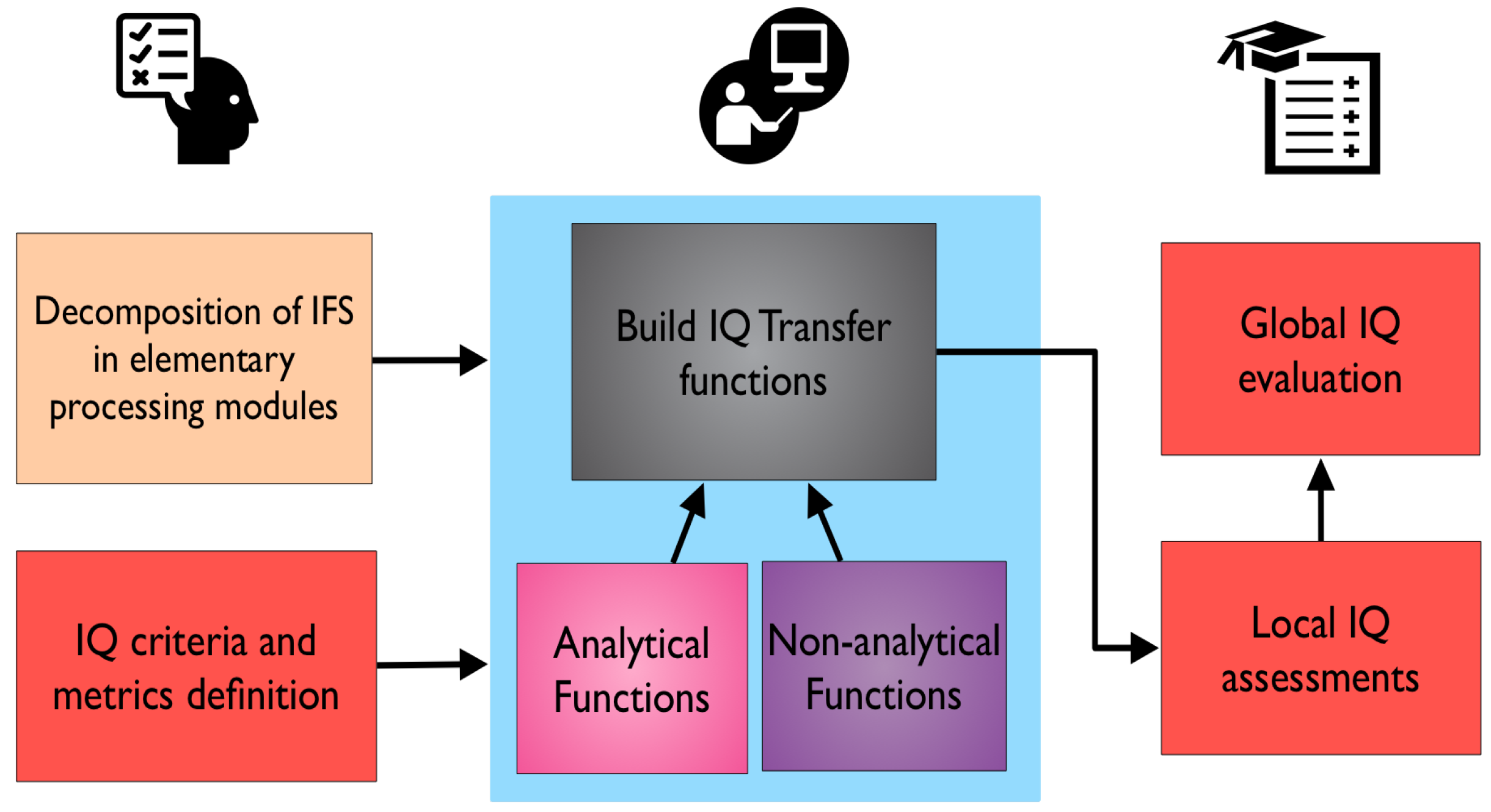
Figure 8.
Block diagram to describe the decomposition of the IFS into elementary modules and the generation of IQ transfer functions for each module. This figure illustrates the decomposition (serial, parallel, or both) of a data fusion system into its elementary modules. In addition, a quality transfer function is obtained for each module by applying analytical or nonanalytical functions using information quality measures and input and output data of each module.
Figure 8.
Block diagram to describe the decomposition of the IFS into elementary modules and the generation of IQ transfer functions for each module. This figure illustrates the decomposition (serial, parallel, or both) of a data fusion system into its elementary modules. In addition, a quality transfer function is obtained for each module by applying analytical or nonanalytical functions using information quality measures and input and output data of each module.

Figure 9.
Components of information quality in the Joint Directors of Laboratories (JDL) model.
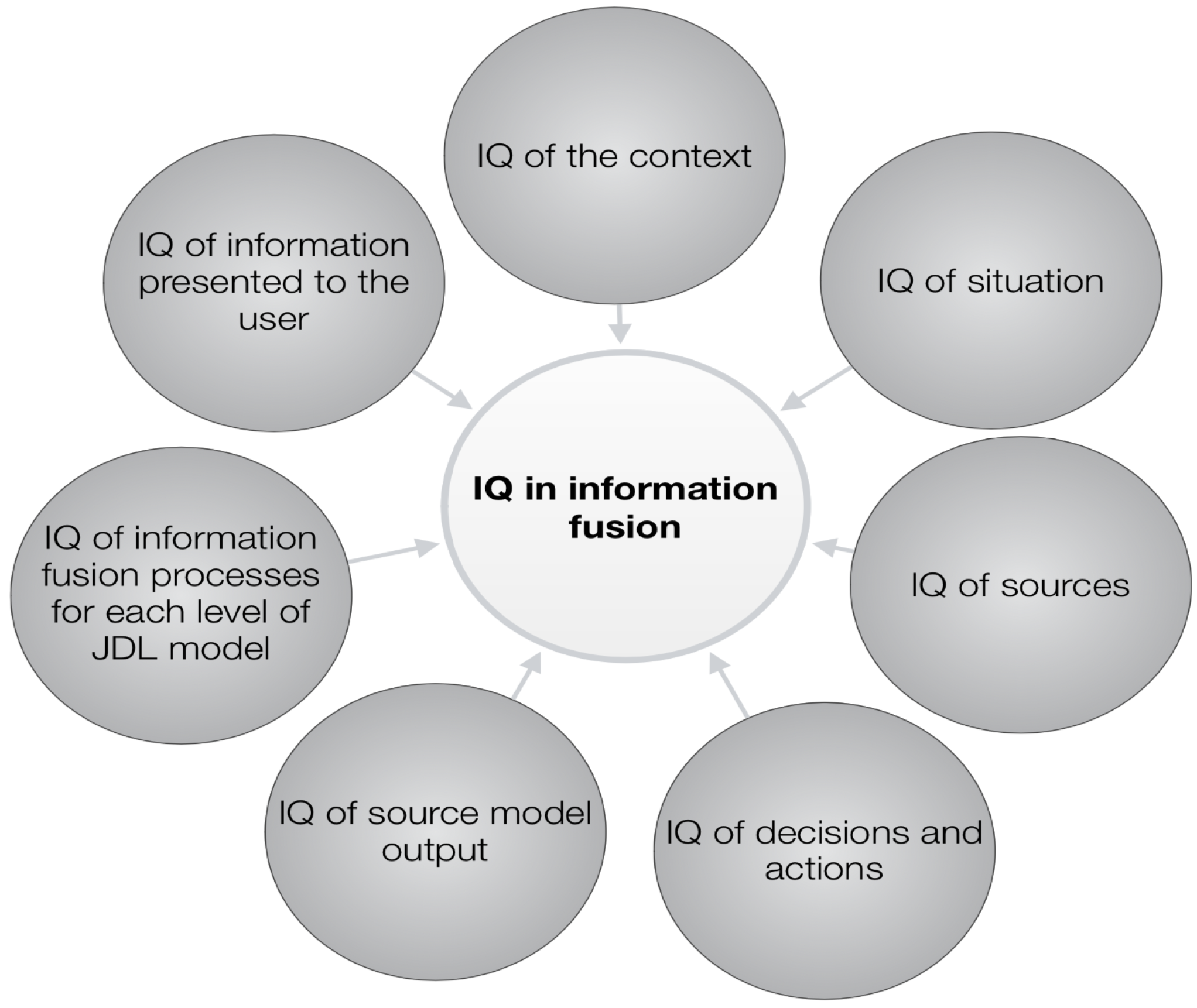
Figure 10.
Summarized Information Quality (IQ) assessment of the methodology proposed in [45]. This assessment includes the relationships between three criteria groups and considers the effects and evaluation of context. In addition, the results of the IQ assessment can be evaluated by IQ criteria that can be taken from the same three groups.
Figure 10.
Summarized Information Quality (IQ) assessment of the methodology proposed in [45]. This assessment includes the relationships between three criteria groups and considers the effects and evaluation of context. In addition, the results of the IQ assessment can be evaluated by IQ criteria that can be taken from the same three groups.


{kind=link}
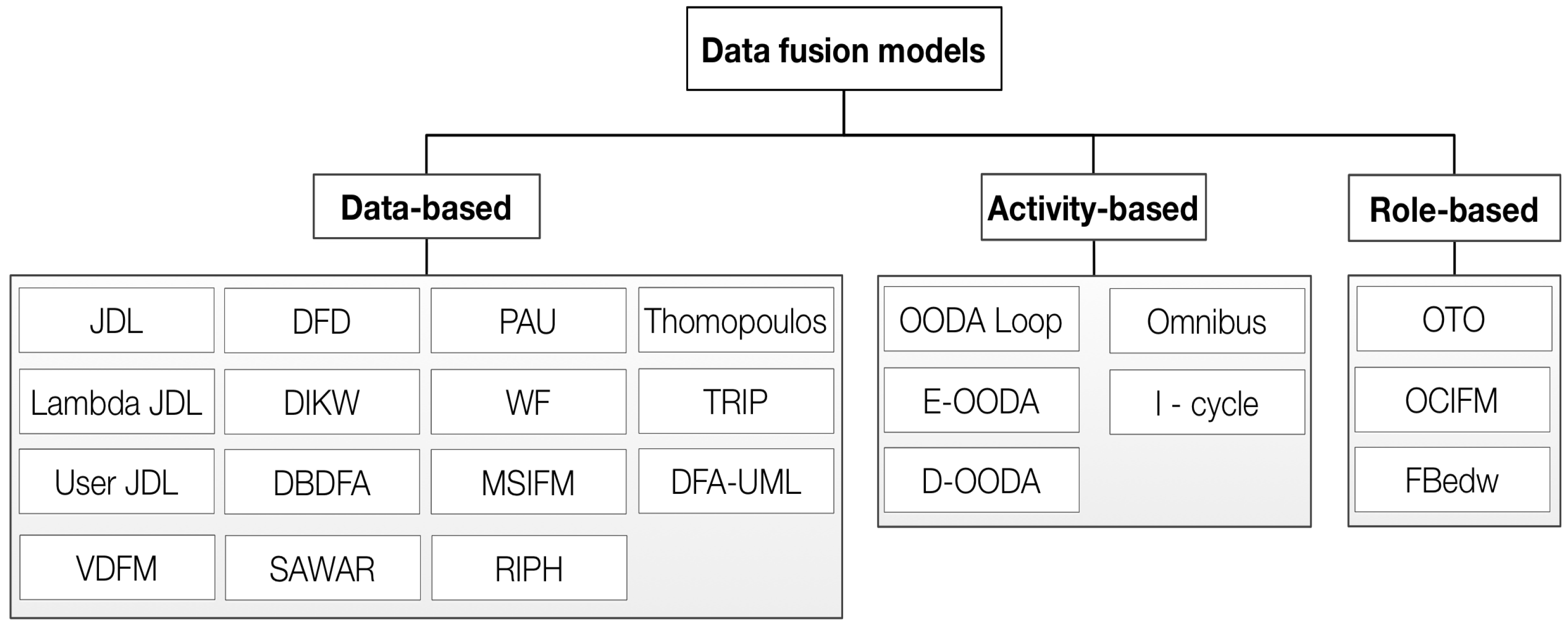{kind=link}
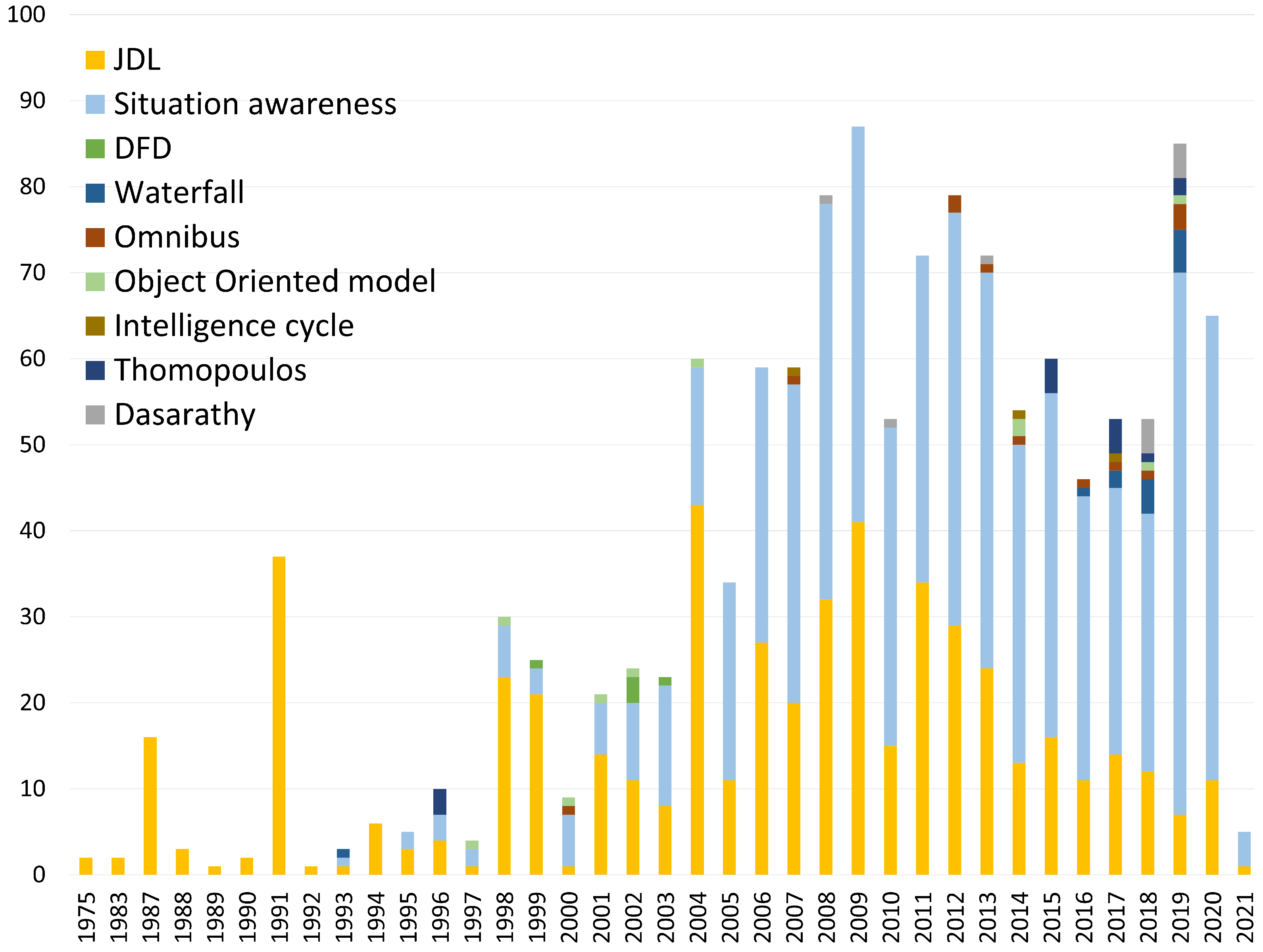{kind=link}
{kind=link}
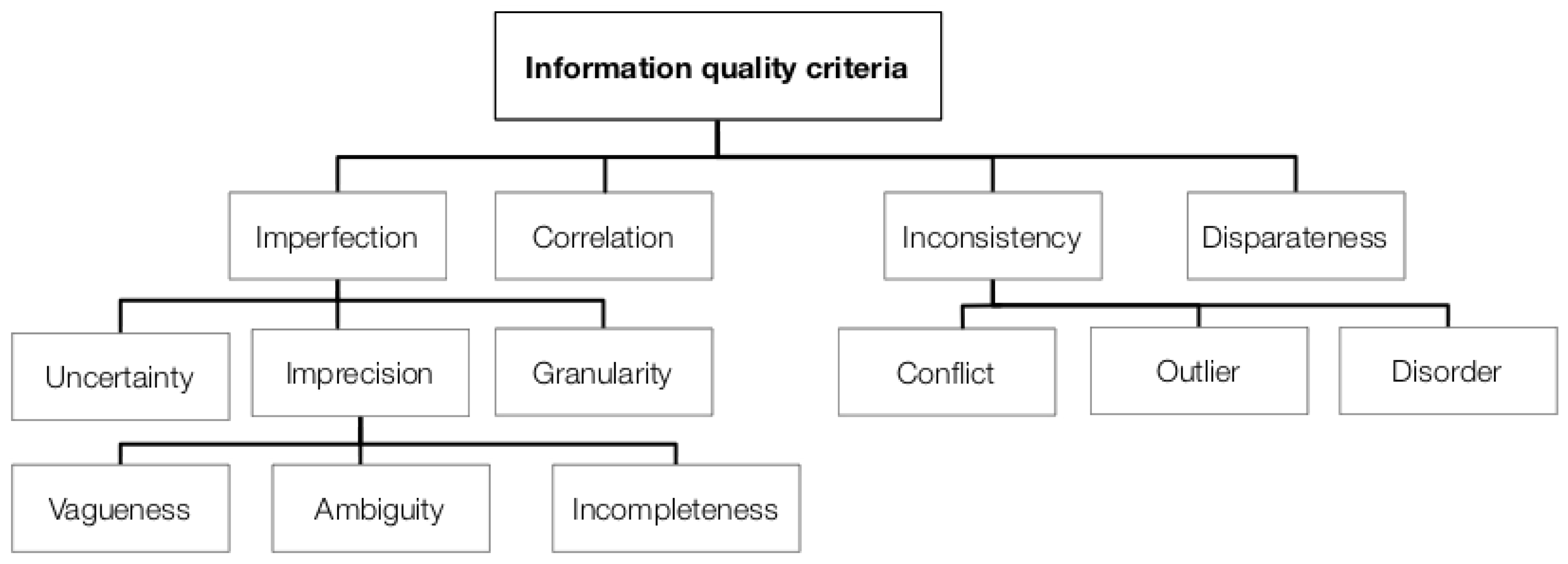{kind=link}
{kind=link}
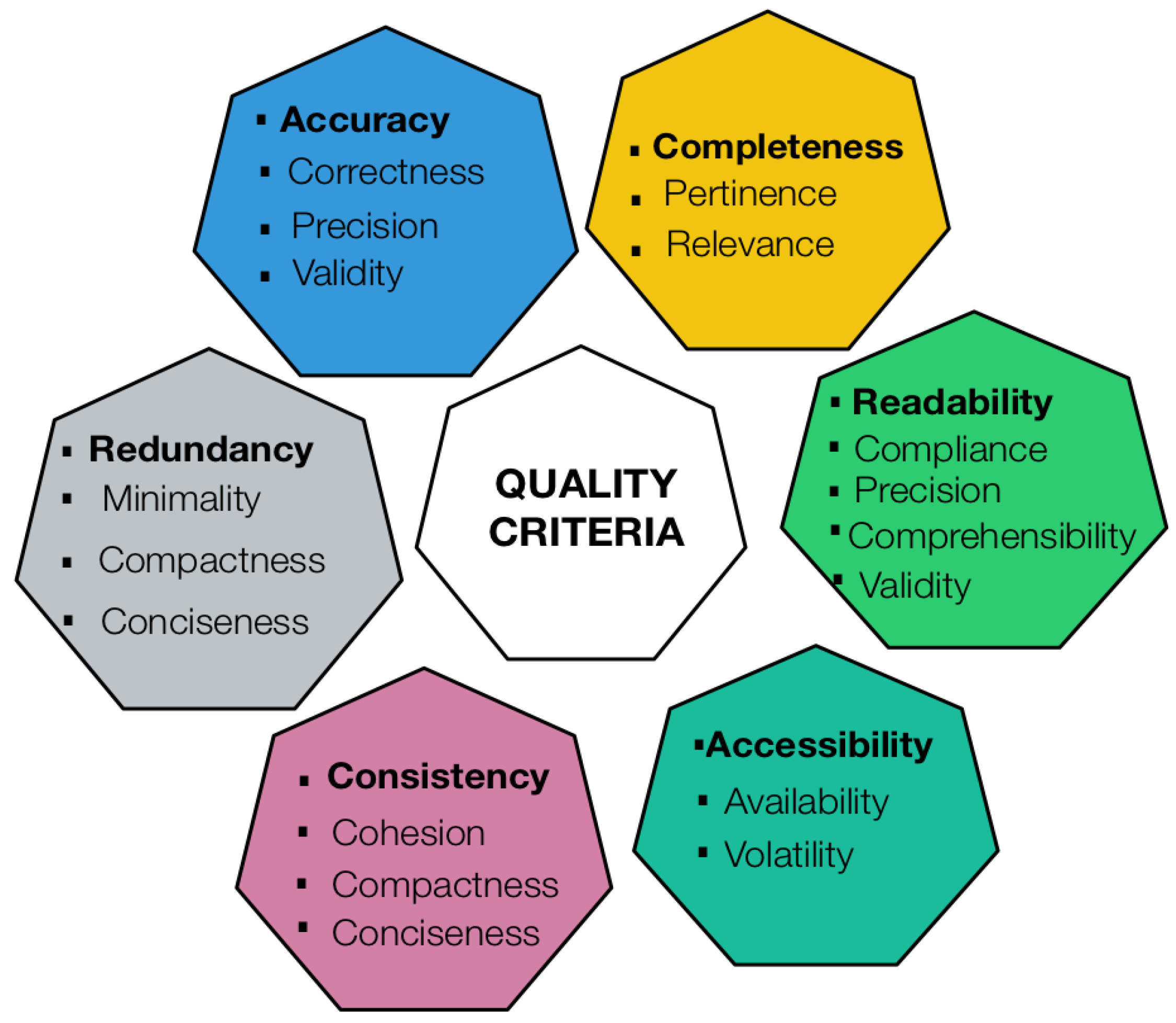{kind=link}
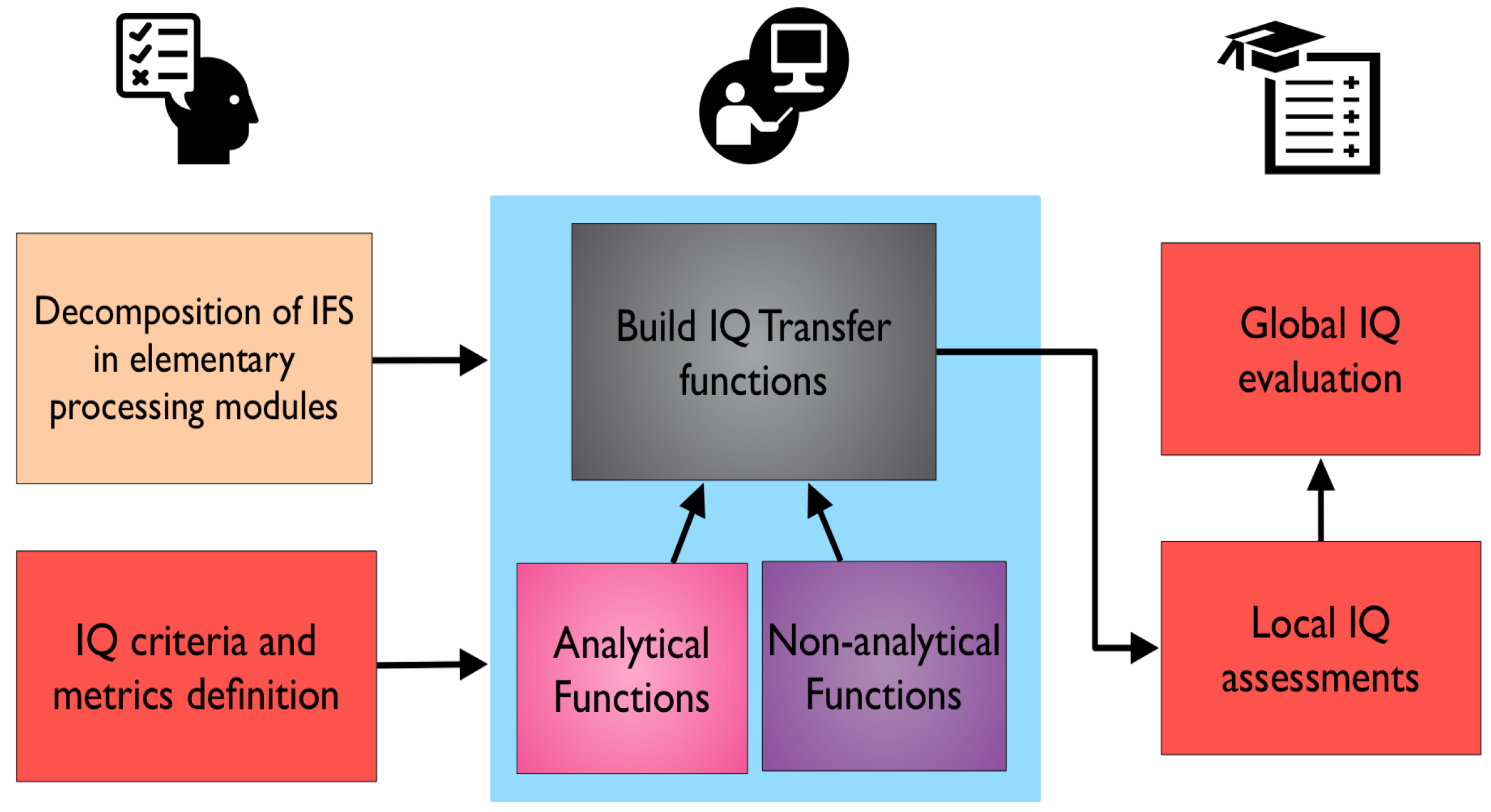{kind=link}
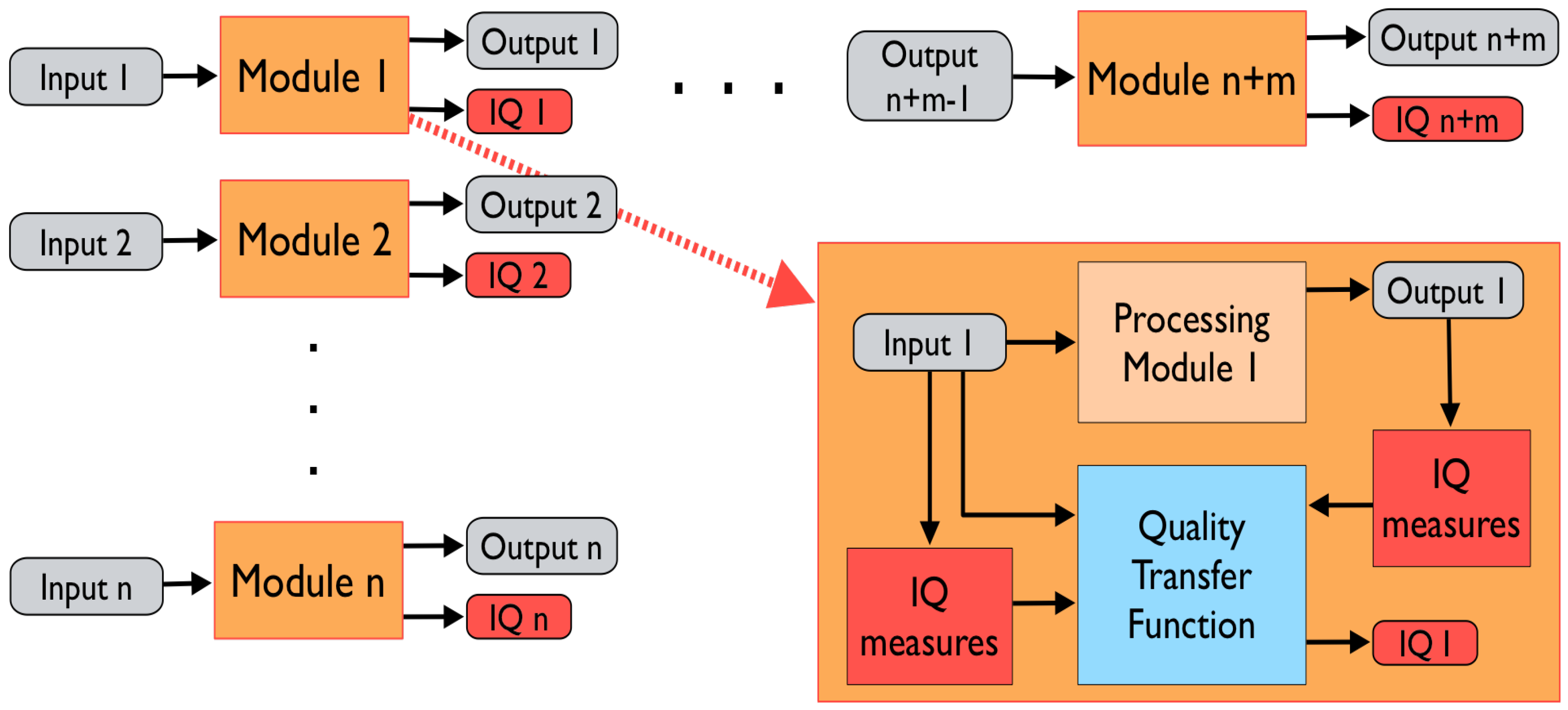{kind=link}
{kind=link}
{kind=link}
Table 1.
Correspondence between data fusion models.
| Model | Description | Level 0 | Level 1 | Level 2 | Level 3 | Level 4 | Level 5 | N/A JDL |
|---|---|---|---|---|---|---|---|---|
| JDL/JDL/User JDL [60] | This is the most popular functional model. It is used in nonmilitary applications. The User JDL model corresponds to level 5. | Level 0 | Level 1 | Level 2 | Level 3 | Level 4 | Level 5 | - |
| VDFM [61] | It is derived from the JDL model and focuses on fusing human information inputs. | Data fusion processes | Data fusion processes/Visual fusion | Concept of interest | Context of concept | Control/Human | Human | - |
| DFD [55] | This functional model describes the abstraction of data. | DAI-DAO, DAI-FEO, FEI-FEO | FEI-DEO, DEI-DEO | N/A | N/A | N/A | N/A | - |
| DIKW [62,63] | This model is represented by a four-level knowledge pyramid. | N/A | Data | Informa- tion | Knowl- edge | N/A | N/A | Wisdom |
| DBDFA [64] | It is focus on confidence to merge sensors | N/A | data fusion | N/A | N/A | N/A | N/A | - |
| SAWAR [62,65] | It focuses on data fusion from a human perspective and considering the context. | State of environment | Perception of elements in current situation | Awareness of current situation | Projection of future states | Perfor- mance of actions | - | Decision |
| PAU [66] | It is based on behavioural knowledge | Sensing | FE, association, DF, Analysis and aggregation | Represen- tation | N/A | N/A | N/A | - |
| WF [56,67,68,69] | This model includes three levels, each with two processes. | Sensing and signal processing. | FE and pattern processing. | Situation assessment and decision making | N/A | Controls | N/A | - |
| MSIFM [59] | It applies two processes: the multi-sensor integration and the fusion which is addressed in hierarchical fusion (HF) centers. | Sensors | HF | N/A | N/A | N/A | N/A | - |
| RIPH [62,63,70] | In this model, the inputs correspond to perceptions (stimulus processing); and the outputs, to actions (motor processing). | N/A | Skill based processing behavior | Rule based processing | knowledge based processing | N/A | N/A | - |
| Thomo- poulos [68,71] | It consists of three modules that fuse data. | N/A | Signal-level fusion. | Evidence-level fusion. | Dynamics-level fusion. | N/A | N/A | - |
| TRIP [60] | This model consists of six levels. In addition, its data processing is hierarchical and bidirectional to meet human information requirements. | Collection evaluation and Collection stage | Object state and information stage | situation stage | Objective stage | N/A | N/A | - |
| DFA-UML [72] | It is based on three functional levels expressed using UML language and it is oriented to data and features. | Data oriented | Task oriented (variable) | Mixture of data and variable | Decide | N/A | N/A | - |
| OODA Loop [22]/E-OODA/D-OODA [60] | It is represented using a four-step feedback system. The E-OODA model proposes a decomposition of each level to give more details. The D-OODA model provides some details to decompose each stage. | Observe | Observe | Orient | Decide | Decide | Act. | - |
| OmniB [69] | It attempts to combine the JDL and I-cycle models. | Observe: sensing and signal processing | Orient: feature extraction and Pattern recognition | Decide: context processing/decision making | Decision fusion | N/A | Act | - |
| I-cycle [30,73] | It follows four sequential stages for information fusion in order to disseminate information demanded by users. | Planning and direction. | Collection | Collation | Evaluation and dissemination | N/A | N/A | - |
| OTO [30] | It has four sequential stages. | Actor | Perceiver | Director | Manager | N/A | N/A | - |
| OCIFM [60] | This model covers the characteristics of the JDL and OmniB models and considers psychological aspects. It is a guide to design IF systems. | Stimuli | Detection and standardization | Behavior/Pragmatic Analysis | Pragmatic analysis | Global goal setting | Global goal setting | Psycho considerations |
| FBedw [22] | It is considered to be an adaptive control system that includes six main stages (sense, perceive, direct, manage, effect and control) applied to local and global processes. | Sense | Perceive | Manage | Effect | Direct | N/A | Control |
Table 2.
Advantages and disadvantages of data fusion models.
| Model | Advantages | Disadvantages/Limitations/Gaps |
|---|---|---|
| JDL/JDL/User JDL [60] | It is a common and general functional model. | It is difficult to set data and applications in a specific level of this model [81] and to reuse it. Also, it is not based on a human perspective. |
| VDFM [61] | It is complementary to the JDL model and focuses on human interaction. | It is only oriented towards high-level fusion and follows a sequence in some processes. |
| DFD [55] | It describes the input and output of data and combines them at any level. However, the level of the output must be higher than or equal to that of the input. In addition, it is considered to be a well-structured model that serves to characterize sensor-oriented data fusion processes. | It loses its fusion power as the processes advance into each level. Additionally, noise spreads at each level. Besides being sensor-oriented, this model is completely hierarchical. |
| DIKW [62,63] | It is similar to the JDL model. | It is hierarchical. |
| DBDFA [64] | It is a very simple model | It is only oriented towards low-level fusion and limited to numerical data obtained from sensors. |
| SAWAR [62,65]. | It expands the level 3 of the JDL model. Situation awareness within a volume of time and space. | It is only oriented towards high-level fusion and follows a sequence in some processes. |
| PAU [66] | It is a general model that is easily interpreted and easy to use. Include low data fusion stages and situation assessment. | It has not feedback to improve the data processing chain. |
| WF [56,67,68,69] | It lacks feedback among levels. | It lacks feedback among levels. |
| MSIFM [59] | It is a very simple model that consider the task to integrate the sensors. | It is limited to sensor fusion. |
| RIPH [62,63,70] | It handles three levels of processing skills and cognitive rules, where there are no regulations and routines to deal with situation levels. The Generic Error Modeling System is an improved version of this model [24,82]. | It does not include a clear definition of each stage and a management technique for the top layer. |
| Thomopoulos [68,71] | It is a very simple model. | It does not generally include a Human–Computer Interaction (HCI) stage and can be developed in several ways. |
| TRIP [60] | It is a general model that is easily interpreted and easy to use. Moreover, it analyzes the human loop. | It may present limitations due to hierarchy matters. |
| DFA- UML [72] | It can be configured based on the measuring environment. The availability of data sources gradually degrades from the point of view of the environment and resources change. Moreover, this model has been tested in different domains. | It is only oriented towards high-level fusion and follows a sequence in some processes. |
| OODA [22]/E-OODA/D-OODA [60] | It can clearly separate the system’s tasks and provide feedback. In addition, it offers a clear view of the system’s tasks. | It does not show the effect of the action stage on the other stages. Additionally, it is not structured in such a way that it can separately identify tasks in the sensor fusion system. |
| OmniB [69] | It shows the processing stages in closed loop and includes a control stage (Act). | It is difficult define the treatment of the data for each level. |
| I-cycle [30,73] | It is a general model. | It does not divide the system’s tasks. Moreover, it is considered an incomplete data fusion model because it lacks some required specific aspects. |
| OTO [30] | It details the different system’s roles. | It does not divide the system’s tasks. |
| OCIFM [60] | It is based on a human perspective and can be a good guide to design dynamic data fusion systems, as it combines the best of the JDL and OmniB models. | It can be a complex model, which may lead to confusion in terms of its application. |
| FBedw [22] | It features a coupling between the local and global processes, considering the objectives and standards that should be achieved. | It lacks formality. |
Table 3.
Definitions of information quality criteria.
| Criteria | Definition |
|---|---|
| Accuracy | It indicates the distance from a reference or ground truth. |
| Precision | It refers to “The degree to which data has attributes that are exact or that provide discrimination in a specific context of use” [101]. |
| Compliance | It corresponds to the extent to which data are adhered to standards, conventions, or regulations [101]. |
| Confidentiality | It denotes the level of security of data to be accessed and interpreted only by authorized users [101]. |
| Portability | It concerns “The degree to which data has attributes that enable it to be installed, replaced or moved from one system to another preserving the existing quality in a specficic context of use” [101]. |
| Recoverability | It refers to “The degree to which data has attributes that enable it to maintain and preserve a specified level of operations and quality, even in the event of failure, in a specific context of use” [101]. |
| Believability | It assesses the reliability of the information object which is linked to its truthfulness and credibility. |
| Objectivity | It evaluates the bias, prejudice, and impartiality of the information object. |
| Reputation | It corresponds to an assessment given by users to the information and its source, based on different properties suitable for the task. |
| Value-Added | It denotes the extent to which information is suitable and advantageous for the task. |
| Efficiency | It assesses the capability of data to quickly provide useful information for the task. |
| Relevancy | It concerns the importance and utility of the information for the task. |
| Timeliness | It is also known as currency and is defined as the age of the information or the degree to which it is up-to-date to execute the task required by the application. |
| Completeness | It evaluates the absence of information and depends on the precision of value and inclusion of its granularity.. |
| Data amount | It refers to the data volume suitable for the task. |
| Interpretability | It defines the level of clear presentation of the information object to fulfill structures of language and symbols specifically required by users or applications. |
| Consistency | It establishes the level of logical and consistent relationships between multiple attributes, values, and elements of an information object to form coherent concepts and meanings, without contradiction, concerning an information object. |
| Conciseness | It determines the level of compactness (abbreviated and complete) of the information. |
| Manipulability | It defines the ease of adaptability of the information object to be aggregated or combined. |
| Accessibility | It refers to the capability to access or not available information. It can be measured based on how fast and easy information is obtained. |
| Security | It corresponds to the level of protection of the information object against damage or fraudulent access. |
| Actionable | It indicates whether data are ready for use. |
| Traceability | It establishes the degree to which the information object is traced to the source. |
| Verifiability | It concerns the level of opportunity to test the correctness of the information object within the context of a particular activity. |
| Cohesiveness | It denotes the level of concentration of the information with respect to a theme. |
| Complexity | It determines the relationship between the connectivity and diversity of an information object. |
| Redundancy | It refers to the repetition of attributes obtained from different sources or processes in a specific context, which serves to define an information object. |
| Naturalness | It corresponds to the extent to which the attributes of the information object approximate to its context. |
| Volatility | It denotes the amount of time during which the information is valid and available for a specific task. |
| Authority | It refers to the level of reputation of the information within the context of a community or culture. |
Table 4.
Quality criteria proposed by Wang and Strong [91].
Table 4.
Quality criteria proposed by Wang and Strong [91].
| Intrinsic | Contextual | Representational | Accessibility |
|---|---|---|---|
| Accuracy | Value-added | Interpretability | Access Security |
| Believability | Relevancy | Ease understanding | |
| Objectivity | Timeliness | Representational consistency | |
| Reputation | Completeness | Representational conciseness | |
| Data Amount | Manipulability |
Table 5.
Quality criteria for web information systems introduced in [98].
Table 5.
Quality criteria for web information systems introduced in [98].
| Content | Technical | Intellectual | Instantiation |
|---|---|---|---|
| Accuracy | Availability | Believability | Data amount |
| Completeness | Latency | Objectivity | Representational Conciseness |
| Customer support | Price | Reputation | Representational Consistency |
| Documentation | Quality of Service (QoS) | Understandbility | |
| Interpretability | Response | Verifiability | |
| Relevancy | Security | ||
| Value-added | Timeliness |
Table 6.
Information quality criteria presented in [86].
Table 6.
Information quality criteria presented in [86].
| Intrinsic | Accuracy/Validity, cohesiveness, complexity, semantic consistency, structural consistency, informativeness/redundancy, naturalness, precision/completeness. |
| Relational/contextual | Accuracy, accessibility, complexity, naturalness, informativeness/redundancy, relevance(aboutness), precision/completeness, security, semantic consistency, structural consistency, verifiability, volatility. |
| Reputational | Authority |
Table 7.
Information quality assessment methodologies. NC: Number of citations, P: period (years), NC-P1: 1992–2000, NC-P2: 2001–2010, NC-P3: 2011–2021. –: Number of citations not determined. Year: correspond to date of the reference.
Table 7.
Information quality assessment methodologies. NC: Number of citations, P: period (years), NC-P1: 1992–2000, NC-P2: 2001–2010, NC-P3: 2011–2021. –: Number of citations not determined. Year: correspond to date of the reference.
| Methodology/Framework | Application | NC-P1 | NC-P2 | NC-P3 | Year |
|---|---|---|---|---|---|
| Total Data Quality Management (TDQM) [104] | Marketing—data consumers | 12 | 225 | 341 | 1998 |
| Data Warehouse Quality (DWQ) methodology [105] | Data warehousing | 3 | 15 | 21 | 1998 |
| Total Information Quality Management (TIQM) [106] | Data warehouse and business | 1 | 43 | 23 | 1999 |
| A Methodology for Information Quality Assessment (AIMQ) [107] | Benchmarking in organizations | 0 | 267 | 673 | 2002 |
| Information Quality Assessment for Web Information Systems (IQAWIS) [98] | Web information systems | 0 | 21 | 65 | 2002 |
| Data Quality Assessment (DQA) [108] | Organizational field | 0 | 273 | 468 | 2002 |
| Information Quality Measurement (IQM) [109] | Web context | 0 | 39 | 93 | 2002 |
| Goal Question Metric (GQM) methodology [110] | Adaptable to different environments | 0 | 0 | 29 | 2002 |
| ISTAT methodology [111] | IQ of Cesus | 0 | 0 | 0 | 2003 |
| Activity-based Measuring and Evaluating of Product Information Quality (AMEQ) methodology [112] | Manufacturing | 0 | 6 | 7 | 2004 |
| Loshin’s methodology or Cost-effect Of Low Data Quality (COLDQ) [113,114] | Cost–benefit of IQ | – | – | – | 2004 |
| Data Quality in Cooperative Information Systems (DaQuinCIS) [115] | Cooperative information systems | 0 | 51 | 34 | 2004 |
| Methodology for the Quality Assessment of Financial Data (QAFD) [116] | Finance applications | – | – | – | 2004 |
| Canadian Institute for Health Information (CIHI) methodology [117] | IQ of Health information | – | – | – | 2005 |
| Hybrid Information Quality Management (HIQM) [118] | General purpose for detecting and correcting errors | 0 | 3 | 9 | 2006 |
| Comprehensive Methodology for Data Quality Management (CDQ) [119] | General purpose | – | – | – | 2007 |
| Information Quality Assessment Framework (IQAF) [86] | General purpose | 0 | 33 | 234 | 2007 |
| IQ assessment framework for e-learning systems [120] | E-learning systems | 0 | 1 | 42 | 2010 |
| Heterogenous Data Quality Methodology (HDQM) [121] | General purpose | 0 | 0 | 38 | 2011 |
| Quality evaluation framework [122] | Business processes | 0 | 0 | 34 | 2014 |
| Analytic hierarchy process (AHP) QoI [123] | Mobile Ad-hoc Networks—wireless sensor networks | 0 | 0 | 6 | 2015 |
| Methodology to evaluate important dimensions of information quality in systems [5] | General purpose | 0 | 0 | 14 | 2015 |
| A framework for automatic information quality ranking [124] | Health—diabetes websites | 0 | 0 | 3 | 2015 |
| Open data quality measurement framework [125] | Government data | 0 | 0 | 119 | 2016 |
| Evaluation criteria for IQ Research [126] | Models, frameworks, and methodologies | 0 | 0 | 0 | 2016 |
| Pragmatic Task-Based Method to Data Quality Assessment and Improvement (TBDQ) [94] | IQ assessment and improvement | 0 | 0 | 4 | 2016 |
| Information Quality Assessment Methodology in the Context of Emergency Situational Awareness (IQESA) [103] | Context of emergency situational awareness | 0 | 0 | 7 | 2017 |
| Framework for information quality assessment of presentation slides [127] | IQ Assessment of presentation slides | 0 | 0 | 1 | 2017 |
| An approach to quality evaluation [128] | Accounting information—linguistic environment | 0 | 0 | 26 | 2017 |
| Methodology to quality evaluation [129] | Weather Station Sensors | 0 | 0 | 0 | 2021 |
Table 8.
Information quality assessment methodologies for data fusion systems.
| Methodology/Framework | Application | NC-P1 | NC-P2 | NC-P3 | Year |
|---|---|---|---|---|---|
| Quality evaluation in Information Fusion Systems (IFS) [47] | Defense | 0 | 0 | 92 | 2010 |
| Information Quality Evaluation in Fusion Systems (IQEFS) [42] | General purpose | 0 | 0 | 10 | 2013 |
| Context-Based Information Quality Conceptual Framework (CIQCF) [46] | Sequential decision making | 0 | 0 | 14 | 2013 |
| Context-Based Information Quality Conceptual Framework (CIQCF) [45] | Decision making in crisis management and human systems | 0 | 0 | 8 | 2016 |
| Low Data Fusion Framework (LDFF) [48] | Brain computer interface | 0 | 0 | 4 | 2018 |
| Intelligent quality-based approach [130] | fusing multi-source possibilistic information | 0 | 0 | 3 | 2020 |
| Dynamic weight allocation method [12] | multisource information fusion | 0 | 0 | 0 | 2021 |
Table 9.
Low data fusion performance metrics—NC.
| Metric | NC | Metric | NC | Metric | NC |
|---|---|---|---|---|---|
| Receiver Operating Characteristic (ROC)/AUC curve/Correctness/False pos., false neg. | 4 | Signal to Noise ratio | 2 | Spatio-Temporal info/Preservation | 1 |
| Accuracy | 5 | Fusion/Relative gain | 2 | Entropy | 2 |
| Response/Execution/Time | 9 | Credibility | 1 | Relevance | 1 |
| Detection rate/False alarm/Detection probability | 7 | Reliability | 1 | Distance/Position/Performance/Probability Error | 10 |
| Purity | 1 | Mutual information | 1 | Computation Cost | 3 |
| Confidence | 1 |
Table 10.
Low data fusion performance metrics 2010–2019.
| Metric | NC | Metric | NC | Metric | NC |
|---|---|---|---|---|---|
| Accuracy | 8 | Time complexity | 1 | Full resolution | 1 |
| delay/Communication cost/Energy consumption | Standard deviation/Attitude error | Confidence | |||
| Computational complexity | 1 | Readiness | 1 | Correct detection probability/ROC | 1 |
| Mean Square Error (MSE) | 4 | F1 score | 2 | False alarm | 2 |
| Sensitivity, false positive, false negative, scenario parameters (length of redundant lines, length of ignored lines, number of ignored lines, number of concave vertices, number of convex vertices, number of disjoint obstacles, length of walls) | 1 | Rate correctly detected. Measure of association and estimation: residual, residual covariance, Kalman gain updated utility state, updated utility uncertainty | 1 | Fusion break rate Rate of fusion tracks Track recombination rate | 1 |
| Intersection over Union (IoU) | 1 | Recall | 3 | Precision | 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Becerra, M.A.; Tobón, C.; Castro-Ospina, A.E.; Peluffo-Ordóñez, D.H. Information Quality Assessment for Data Fusion Systems. Data 2021, 6, 60. https://0-doi-org.brum.beds.ac.uk/10.3390/data6060060
AMA Style
Becerra MA, Tobón C, Castro-Ospina AE, Peluffo-Ordóñez DH. Information Quality Assessment for Data Fusion Systems. Data. 2021; 6(6):60. https://0-doi-org.brum.beds.ac.uk/10.3390/data6060060
Chicago/Turabian StyleBecerra, Miguel A., Catalina Tobón, Andrés Eduardo Castro-Ospina, and Diego H. Peluffo-Ordóñez. 2021. "Information Quality Assessment for Data Fusion Systems" Data 6, no. 6: 60. https://0-doi-org.brum.beds.ac.uk/10.3390/data6060060